初始化项目,由ModelHub XC社区提供模型
Model: AI-Sweden-Models/Llama-3-8B Source: Original Platform
This commit is contained in:
36
.gitattributes
vendored
Normal file
36
.gitattributes
vendored
Normal file
@@ -0,0 +1,36 @@
|
||||
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||
*.model filter=lfs diff=lfs merge=lfs -text
|
||||
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
l3swe.png filter=lfs diff=lfs merge=lfs -text
|
||||
BIN
13333333.jpg
Normal file
BIN
13333333.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 301 KiB |
119
README.md
Normal file
119
README.md
Normal file
@@ -0,0 +1,119 @@
|
||||
---
|
||||
language:
|
||||
- sv
|
||||
- da
|
||||
- 'no'
|
||||
license: llama3
|
||||
tags:
|
||||
- pytorch
|
||||
- llama
|
||||
- llama-3
|
||||
- ai-sweden
|
||||
base_model: meta-llama/Meta-Llama-3-8B
|
||||
pipeline_tag: text-generation
|
||||
inference:
|
||||
parameters:
|
||||
temperature: 0.6
|
||||
---
|
||||
|
||||
# AI-Sweden-Models/Llama-3-8B
|
||||

|
||||
|
||||
### Intended usage:
|
||||
This is a base model, it can be finetuned to a particular use case.
|
||||
|
||||
[**-----> instruct version here <-----**](https://huggingface.co/AI-Sweden-Models/Llama-3-8B-instruct)
|
||||
|
||||
### Use with transformers
|
||||
|
||||
See the snippet below for usage with Transformers:
|
||||
|
||||
```python
|
||||
import transformers
|
||||
import torch
|
||||
|
||||
model_id = "AI-Sweden-Models/Llama-3-8B"
|
||||
|
||||
pipeline = transformers.pipeline(
|
||||
task="text-generation",
|
||||
model=model_id,
|
||||
model_kwargs={"torch_dtype": torch.bfloat16},
|
||||
device_map="auto"
|
||||
)
|
||||
|
||||
pipeline(
|
||||
text_inputs="Sommar och sol är det bästa jag vet",
|
||||
max_length=128,
|
||||
repetition_penalty=1.03
|
||||
)
|
||||
```
|
||||
```python
|
||||
>>> "Sommar och sol är det bästa jag vet!
|
||||
Och nu när jag har fått lite extra semester så ska jag njuta till max av allt som våren och sommaren har att erbjuda.
|
||||
Jag har redan börjat med att sitta ute på min altan och ta en kopp kaffe och läsa i tidningen, det är så skönt att bara sitta där och njuta av livet.
|
||||
|
||||
Ikväll blir det grillat och det ser jag fram emot!"
|
||||
```
|
||||
## Training information
|
||||
|
||||
`AI-Sweden-Models/Llama-3-8B` is a continuation of the pretraining process from `meta-llama/Meta-Llama-3-8B`.
|
||||
It was trained on a subset from [The Nordic Pile](https://arxiv.org/abs/2303.17183) containing Swedish, Norwegian and Danish. The training is done on all model parameters, it is a full finetune.
|
||||
|
||||
The training dataset consists of 227 105 079 296 tokens. It was trained on the Rattler supercomputer at the Dell Technologies Edge Innovation Center in Austin, Texas. The training used 23 nodes of a duration of 30 days, where one node contained 4X Nvidia A100 GPUs, yielding 92 GPUs.
|
||||
|
||||
## trainer.yaml:
|
||||
```yaml
|
||||
learning_rate: 2e-5
|
||||
warmup_steps: 100
|
||||
lr_scheduler: cosine
|
||||
optimizer: adamw_torch_fused
|
||||
max_grad_norm: 1.0
|
||||
gradient_accumulation_steps: 16
|
||||
micro_batch_size: 1
|
||||
num_epochs: 1
|
||||
sequence_len: 8192
|
||||
```
|
||||
|
||||
## deepspeed_zero2.json:
|
||||
```json
|
||||
{
|
||||
"zero_optimization": {
|
||||
"stage": 2,
|
||||
"offload_optimizer": {
|
||||
"device": "cpu"
|
||||
},
|
||||
"contiguous_gradients": true,
|
||||
"overlap_comm": true
|
||||
},
|
||||
"bf16": {
|
||||
"enabled": "auto"
|
||||
},
|
||||
"fp16": {
|
||||
"enabled": "auto",
|
||||
"auto_cast": false,
|
||||
"loss_scale": 0,
|
||||
"initial_scale_power": 32,
|
||||
"loss_scale_window": 1000,
|
||||
"hysteresis": 2,
|
||||
"min_loss_scale": 1
|
||||
},
|
||||
"gradient_accumulation_steps": "auto",
|
||||
"gradient_clipping": "auto",
|
||||
"train_batch_size": "auto",
|
||||
"train_micro_batch_size_per_gpu": "auto",
|
||||
"wall_clock_breakdown": false
|
||||
}
|
||||
```
|
||||
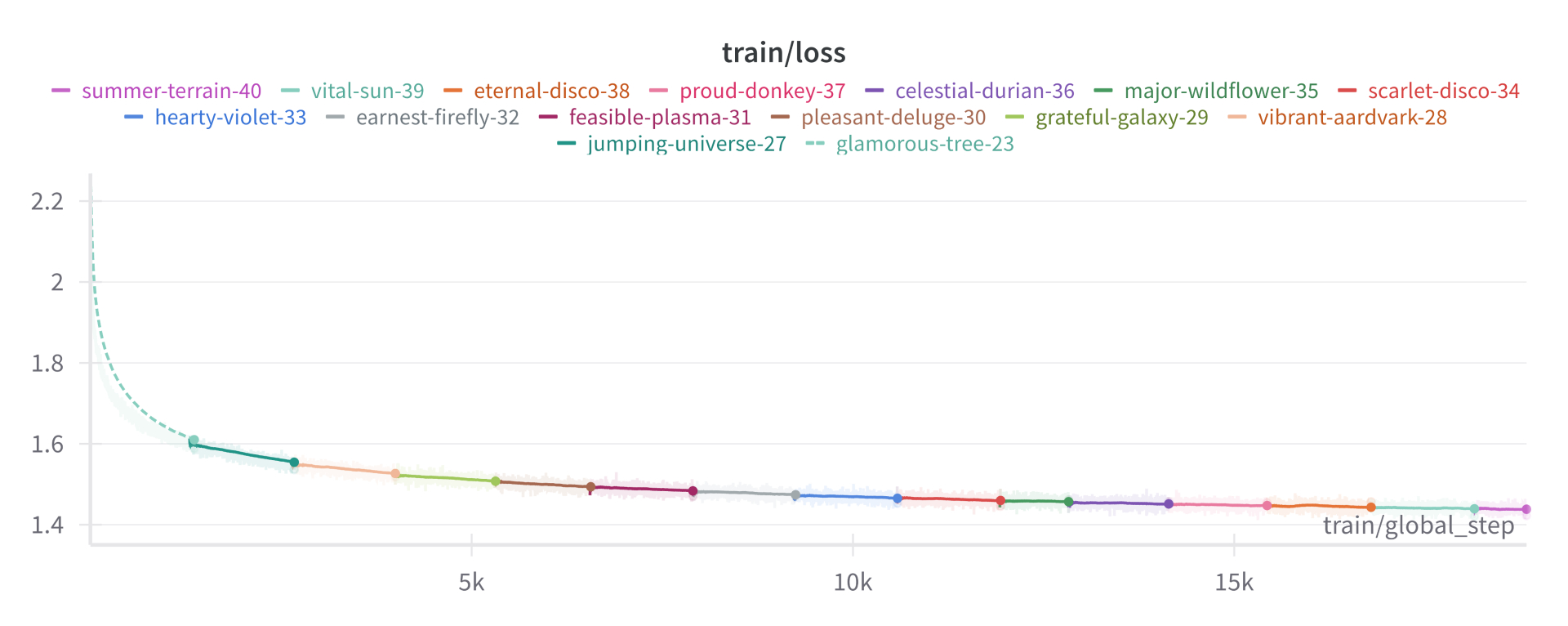
|
||||
|
||||
## Checkpoints
|
||||
* 15/6/2024 (18833) => 1 epoch
|
||||
* 11/6/2024 (16000)
|
||||
* 07/6/2024 (14375)
|
||||
* 03/6/2024 (11525)
|
||||
* 29/5/2024 (8200)
|
||||
* 26/5/2024 (6550)
|
||||
* 24/5/2024 (5325)
|
||||
* 22/5/2024 (3900)
|
||||
* 20/5/2024 (2700)
|
||||
* 13/5/2024 (1500)
|
||||
28
config.json
Normal file
28
config.json
Normal file
@@ -0,0 +1,28 @@
|
||||
{
|
||||
"_name_or_path": ".",
|
||||
"architectures": [
|
||||
"LlamaForCausalLM"
|
||||
],
|
||||
"attention_bias": false,
|
||||
"attention_dropout": 0.0,
|
||||
"bos_token_id": 128000,
|
||||
"eos_token_id": 128001,
|
||||
"hidden_act": "silu",
|
||||
"hidden_size": 4096,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 14336,
|
||||
"max_position_embeddings": 8192,
|
||||
"model_type": "llama",
|
||||
"num_attention_heads": 32,
|
||||
"num_hidden_layers": 32,
|
||||
"num_key_value_heads": 8,
|
||||
"pretraining_tp": 1,
|
||||
"rms_norm_eps": 1e-05,
|
||||
"rope_scaling": null,
|
||||
"rope_theta": 500000.0,
|
||||
"tie_word_embeddings": false,
|
||||
"torch_dtype": "bfloat16",
|
||||
"transformers_version": "4.40.0.dev0",
|
||||
"use_cache": false,
|
||||
"vocab_size": 128256
|
||||
}
|
||||
9
generation_config.json
Normal file
9
generation_config.json
Normal file
@@ -0,0 +1,9 @@
|
||||
{
|
||||
"bos_token_id": 128000,
|
||||
"do_sample": true,
|
||||
"eos_token_id": 128001,
|
||||
"max_length": 4096,
|
||||
"temperature": 0.6,
|
||||
"top_p": 0.9,
|
||||
"transformers_version": "4.40.0.dev0"
|
||||
}
|
||||
3
l3swe.png
Normal file
3
l3swe.png
Normal file
{kind=link}
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:b1a1ae661623ee205c855b3d5922d0ed07b4aa48587a4cfef32066ef623a95d2
|
||||
size 1929130
|
||||
3
model-00001-of-00004.safetensors
Normal file
3
model-00001-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:eda2013e2b54a957aa31cab9652b6df5da013c727fa5e891a7db161571d31028
|
||||
size 4976698672
|
||||
3
model-00002-of-00004.safetensors
Normal file
3
model-00002-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:7f22eb93986e328d5dce7796a312a7a795621945e4fb9e54c6a0e1485799b67f
|
||||
size 4999802720
|
||||
3
model-00003-of-00004.safetensors
Normal file
3
model-00003-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:16aac7ff1199d7d4742b74003e5103efc1b42227634597c522006b7cd806c0a3
|
||||
size 4915916176
|
||||
3
model-00004-of-00004.safetensors
Normal file
3
model-00004-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:1d50648cd92a0b98a9ccf10499d4dfc0c59c28bfb073d242837c71f24458559d
|
||||
size 1168138808
|
||||
298
model.safetensors.index.json
Normal file
298
model.safetensors.index.json
Normal file
@@ -0,0 +1,298 @@
|
||||
{
|
||||
"metadata": {
|
||||
"total_size": 16060522496
|
||||
},
|
||||
"weight_map": {
|
||||
"lm_head.weight": "model-00004-of-00004.safetensors",
|
||||
"model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.20.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.20.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.20.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.20.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.20.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.21.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.21.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.21.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.21.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.21.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.21.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.21.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.21.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.21.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.30.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||
"model.layers.31.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"model.layers.31.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||
"model.layers.31.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.9.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.9.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.9.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.9.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.9.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.9.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.9.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.9.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.norm.weight": "model-00004-of-00004.safetensors"
|
||||
}
|
||||
}
|
||||
23
special_tokens_map.json
Normal file
23
special_tokens_map.json
Normal file
@@ -0,0 +1,23 @@
|
||||
{
|
||||
"bos_token": {
|
||||
"content": "<|begin_of_text|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"eos_token": {
|
||||
"content": "<|end_of_text|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"pad_token": {
|
||||
"content": "<|end_of_text|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
}
|
||||
}
|
||||
410562
tokenizer.json
Normal file
410562
tokenizer.json
Normal file
File diff suppressed because it is too large
Load Diff
2062
tokenizer_config.json
Normal file
2062
tokenizer_config.json
Normal file
File diff suppressed because it is too large
Load Diff
Reference in New Issue
Block a user