{kind=link}
{kind=link}
language, license, tags, base_model, pipeline_tag, inference
| language | license | tags | base_model | pipeline_tag | inference | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
llama3 |
|
meta-llama/Meta-Llama-3-8B | text-generation |
|
AI-Sweden-Models/Llama-3-8B

Intended usage:
This is a base model, it can be finetuned to a particular use case.
-----> instruct version here <-----
Use with transformers
See the snippet below for usage with Transformers:
import transformers
import torch
model_id = "AI-Sweden-Models/Llama-3-8B"
pipeline = transformers.pipeline(
task="text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto"
)
pipeline(
text_inputs="Sommar och sol är det bästa jag vet",
max_length=128,
repetition_penalty=1.03
)
>>> "Sommar och sol är det bästa jag vet!
Och nu när jag har fått lite extra semester så ska jag njuta till max av allt som våren och sommaren har att erbjuda.
Jag har redan börjat med att sitta ute på min altan och ta en kopp kaffe och läsa i tidningen, det är så skönt att bara sitta där och njuta av livet.
Ikväll blir det grillat och det ser jag fram emot!"
Training information
AI-Sweden-Models/Llama-3-8B is a continuation of the pretraining process from meta-llama/Meta-Llama-3-8B.
It was trained on a subset from The Nordic Pile containing Swedish, Norwegian and Danish. The training is done on all model parameters, it is a full finetune.
The training dataset consists of 227 105 079 296 tokens. It was trained on the Rattler supercomputer at the Dell Technologies Edge Innovation Center in Austin, Texas. The training used 23 nodes of a duration of 30 days, where one node contained 4X Nvidia A100 GPUs, yielding 92 GPUs.
trainer.yaml:
learning_rate: 2e-5
warmup_steps: 100
lr_scheduler: cosine
optimizer: adamw_torch_fused
max_grad_norm: 1.0
gradient_accumulation_steps: 16
micro_batch_size: 1
num_epochs: 1
sequence_len: 8192
deepspeed_zero2.json:
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu"
},
"contiguous_gradients": true,
"overlap_comm": true
},
"bf16": {
"enabled": "auto"
},
"fp16": {
"enabled": "auto",
"auto_cast": false,
"loss_scale": 0,
"initial_scale_power": 32,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
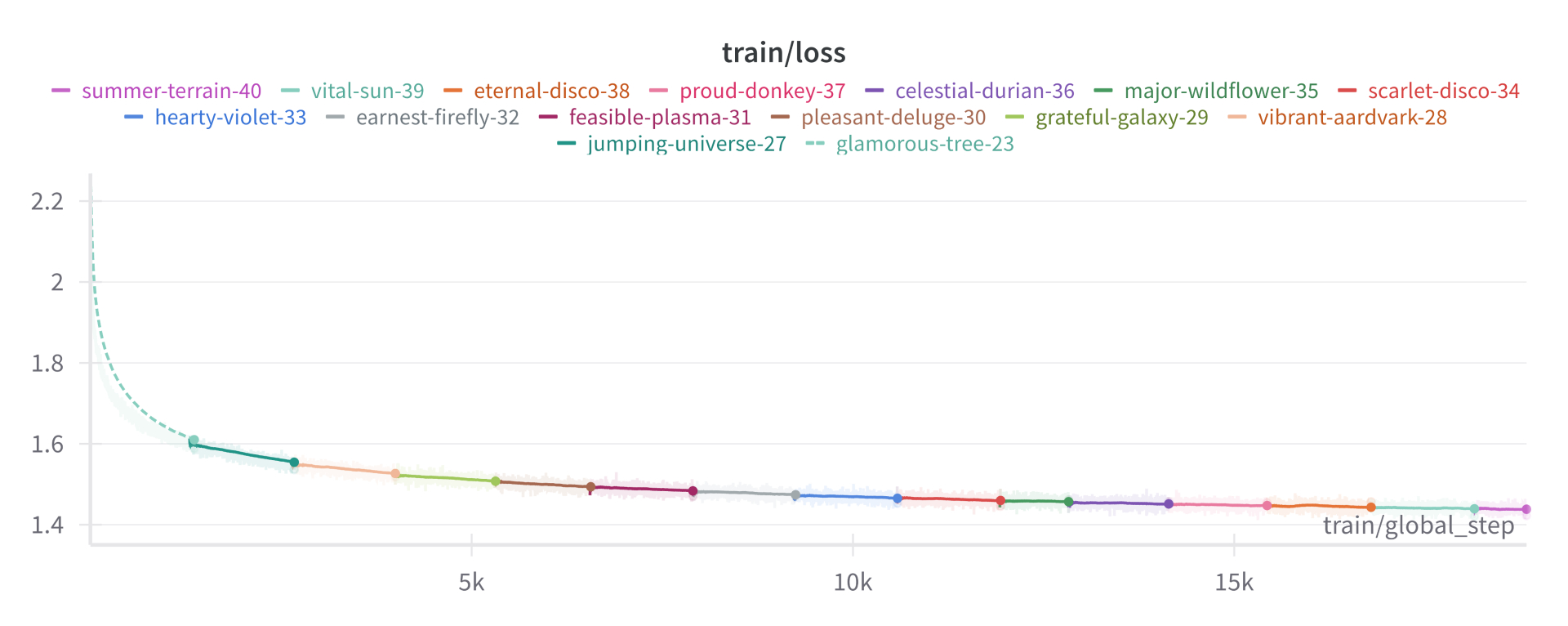
Checkpoints
- 15/6/2024 (18833) => 1 epoch
- 11/6/2024 (16000)
- 07/6/2024 (14375)
- 03/6/2024 (11525)
- 29/5/2024 (8200)
- 26/5/2024 (6550)
- 24/5/2024 (5325)
- 22/5/2024 (3900)
- 20/5/2024 (2700)
- 13/5/2024 (1500)