初始化项目,由ModelHub XC社区提供模型
Model: nectec/Pathumma-llm-text-1.0.0 Source: Original Platform
This commit is contained in:
36
.gitattributes
vendored
Normal file
36
.gitattributes
vendored
Normal file
@@ -0,0 +1,36 @@
|
||||
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||
*.model filter=lfs diff=lfs merge=lfs -text
|
||||
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
Pathumma-llm-it-7b-Q4_K_M.gguf filter=lfs diff=lfs merge=lfs -text
|
||||
3
Pathumma-llm-it-7b-Q4_K_M.gguf
Normal file
3
Pathumma-llm-it-7b-Q4_K_M.gguf
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:40b4b5c1c4fbd5b4bd5505e2d8fcb0fa59a761e420c30d3227c8d46efff80ccc
|
||||
size 4683073344
|
||||
181
README.md
Normal file
181
README.md
Normal file
@@ -0,0 +1,181 @@
|
||||
---
|
||||
license: apache-2.0
|
||||
language:
|
||||
- th
|
||||
- zh
|
||||
- en
|
||||
metrics:
|
||||
- accuracy
|
||||
base_model:
|
||||
- nectec/OpenThaiLLM-Prebuilt-7B
|
||||
base_model_relation: finetune
|
||||
pipeline_tag: text-generation
|
||||
tags:
|
||||
- chemistry
|
||||
- biology
|
||||
- finance
|
||||
- legal
|
||||
- code
|
||||
- medical
|
||||
- text-generation-inference
|
||||
---
|
||||

|
||||
# **PathummaLLM-text-1.0.0-7B: Thai & China & English Large Language Model Instruct**
|
||||
**PathummaLLM-text-1.0.0-7B** is a Thai 🇹🇭 & China 🇨🇳 & English 🇬🇧 large language model with 7 billion parameters, and it is Instruction finetune based on OpenThaiLLM-Prebuilt.
|
||||
It demonstrates competitive performance with Openthaigpt1.5-7b-instruct, and its optimized for application use cases, Retrieval-Augmented Generation (RAG),
|
||||
constrained generation, and reasoning tasks.
|
||||
|
||||
## **Model Detail**
|
||||
For release notes, please see our [blog](https://medium.com/@superkingbasskb/pathummallm-v-1-0-0-release-6a098ddfe276).<br>
|
||||
The detail about Text LLM part in this [blog](https://medium.com/@superkingbasskb/pathummallm-text-v-1-0-0-release-1fd41344b061).
|
||||
|
||||
## **Datasets ratio**
|
||||
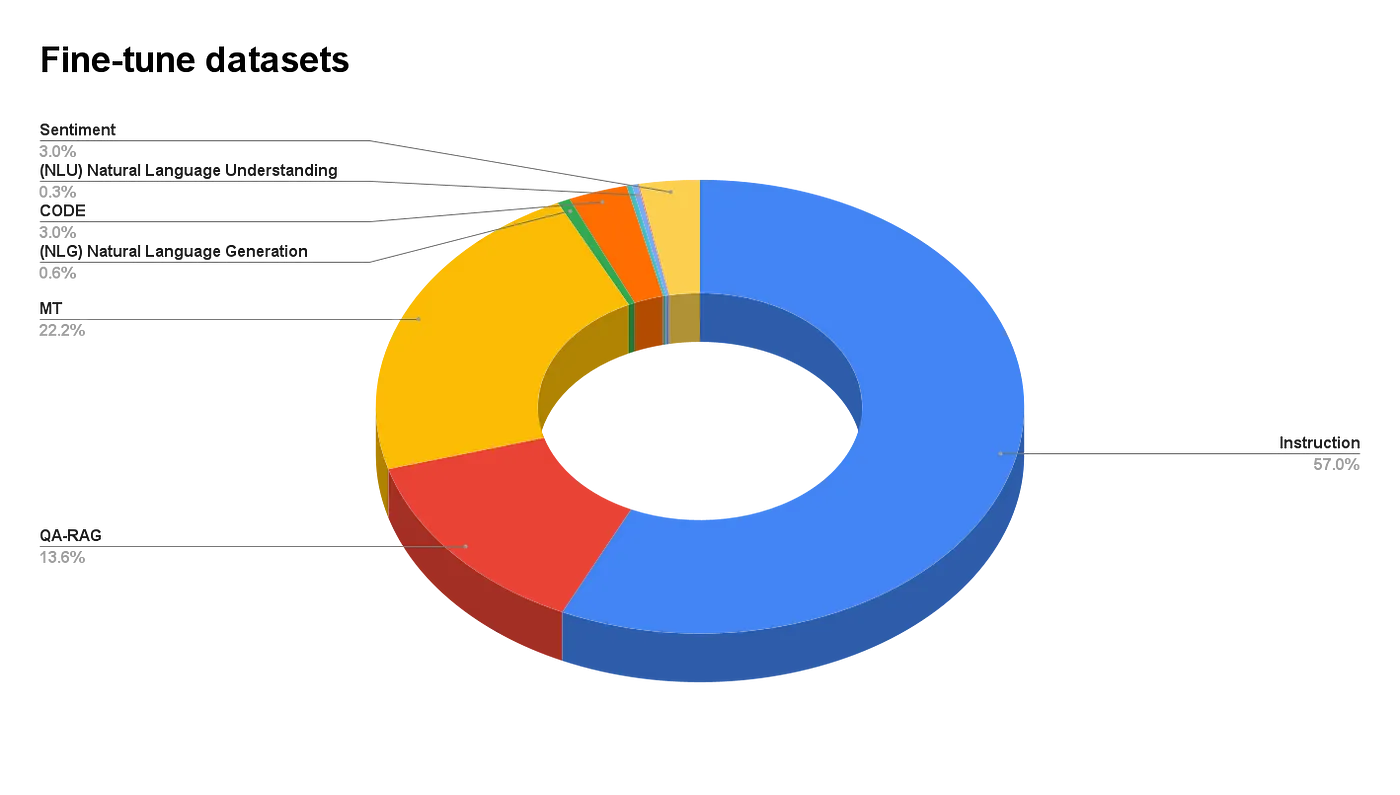
|
||||
|
||||
## **Requirements**
|
||||
The code of Qwen2.5 has been in the latest Hugging face `transformers` and we advise you to use the latest version of `transformers`.
|
||||
|
||||
With `transformers<4.37.0`, you will encounter the following error:
|
||||
```
|
||||
KeyError: 'qwen2'
|
||||
```
|
||||
## **Support Community**
|
||||
|
||||
**https://discord.gg/3WJwJjZt7r**
|
||||
|
||||
## **Implementation**
|
||||
|
||||
Here is a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate content.
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
device = "cuda" # the device to load the model onto
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
"nectec/Pathumma-llm-text-1.0.0",
|
||||
torch_dtype="auto",
|
||||
device_map="auto"
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained("nectec/Pathumma-llm-text-1.0.0")
|
||||
|
||||
prompt = "บริษัท A มีต้นทุนคงที่ 100,000 บาท และต้นทุนผันแปรต่อหน่วย 50 บาท ขายสินค้าได้ในราคา 150 บาทต่อหน่วย ต้องขายสินค้าอย่างน้อยกี่หน่วยเพื่อให้ถึงจุดคุ้มทุน?"
|
||||
messages = [
|
||||
{"role": "system", "content": "You are Pathumma LLM, created by NECTEC. Your are a helpful assistant."},
|
||||
{"role": "user", "content": prompt}
|
||||
]
|
||||
text = tokenizer.apply_chat_template(
|
||||
messages,
|
||||
tokenize=False,
|
||||
add_generation_prompt=True
|
||||
)
|
||||
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
|
||||
|
||||
generated_ids = model.generate(
|
||||
model_inputs.input_ids,
|
||||
max_new_tokens=4096,
|
||||
repetition_penalty=1.1,
|
||||
temperature = 0.4
|
||||
)
|
||||
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
print(response)
|
||||
```
|
||||
## **Implementation for GGUF**
|
||||
|
||||
```python
|
||||
%pip install --quiet https://github.com/abetlen/llama-cpp-python/releases/download/v0.2.90-cu124/llama_cpp_python-0.2.90-cp310-cp310-linux_x86_64.whl
|
||||
import transformers
|
||||
import torch
|
||||
from llama_cpp import Llama
|
||||
import os
|
||||
import requests
|
||||
|
||||
local_dir = "your local dir"
|
||||
directory_path = r'{local_dir}/Pathumma-llm-text-1.0.0'
|
||||
if not os.path.exists(directory_path):
|
||||
os.mkdir(directory_path)
|
||||
|
||||
if not os.path.exists(f'{local_dir}/Pathumma-llm-text-1.0.0/Pathumma-llm-it-7b-Q4_K_M.gguf'):
|
||||
!wget -O f'{local_dir}/Pathumma-llm-text-1.0.0/Pathumma-llm-it-7b-Q4_K_M.gguf' "https://huggingface.co/nectec/Pathumma-llm-text-1.0.0/resolve/main/Pathumma-llm-it-7b-Q4_K_M.gguf?download=true"
|
||||
|
||||
# Initialize the Llama model
|
||||
llm = Llama(model_path=f'{local_dir}/Pathumma-llm-text-1.0.0/Pathumma-llm-it-7b-Q4_K_M.gguf', n_gpu_layers=-1, n_ctx=8192,verbose=False)
|
||||
tokenizer = transformers.AutoTokenizer.from_pretrained("nectec/Pathumma-llm-text-1.0.0")
|
||||
|
||||
memory = [{'content': 'You are Pathumma LLM, created by NECTEC (National Electronics and Computer Technology Center). Your are a helpful assistant.', 'role': 'system'},]
|
||||
|
||||
def generate(instuction,memory=memory):
|
||||
memory.append({'content': instuction, 'role': 'user'})
|
||||
p = tokenizer.apply_chat_template(
|
||||
memory,
|
||||
tokenize=False,
|
||||
add_generation_prompt=True
|
||||
)
|
||||
response = llm(
|
||||
p,
|
||||
max_tokens=2048,
|
||||
temperature=0.2,
|
||||
top_p=0.95,
|
||||
repeat_penalty=1.1,
|
||||
top_k=40,
|
||||
min_p=0.05,
|
||||
stop=["<|im_end|>"]
|
||||
)
|
||||
output = response['choices'][0]['text']
|
||||
memory.append({'content': output, 'role': 'assistant'})
|
||||
return output
|
||||
|
||||
print(generate("คุณคือใคร"))
|
||||
```
|
||||
|
||||
## **Evaluation Performance**
|
||||
| Model | m3exam | thaiexam | xcopa | belebele | xnli | thaisentiment | XL sum | flores200 eng > th | flores200 th > eng | iapp | AVG(NLU) | AVG(MC) | AVG(NLG) |
|
||||
| :--- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
||||
| Pathumma-llm-text-1.0.0 | **55.02** | 51.32 | 83 | 77.77 | **40.11** | 41.29 | 16.9286253 | 26.54 | **51.88** | 41.28 | 60.54 | **53.17** | 34.16 |
|
||||
| Openthaigpt1.5-7b-instruct | 54.01 | **52.04** | **85.4** | **79.44** | 39.7 | **50.24** | 18.11 | 29.09 | 29.58 | 32.49 | **63.70** | 53.03 | 27.32 |
|
||||
| SeaLLMs-v3-7B-Chat | 51.43 | 51.33 | 83.4 | 78.22 | 34.05 | 39.57 | 20.27 | **32.91** | 28.8 | 48.12 | 58.81 | 51.38 | 32.53 |
|
||||
| llama-3-typhoon-v1.5-8B | 43.82 | 41.95 | 81.6 | 71.89 | 33.35 | 38.45 | 16.66 | 31.94 | 28.86 | 54.78 | 56.32 | 42.89 | 33.06 |
|
||||
| Meta-Llama-3.1-8B-Instruct | 45.11 | 43.89 | 73.4 | 74.89 | 33.49 | 45.45 | **21.61** | 30.45 | 32.28 | **68.57** | 56.81 | 44.50 | **38.23** |
|
||||
|
||||
## **Contributor Contract**
|
||||
|
||||
**LLM Team**
|
||||
Pakawat Phasook (pakawat.phas@kmutt.ac.th)<br>
|
||||
Jessada Pranee (jessada.pran@kmutt.ac.th)<br>
|
||||
Arnon Saeoung (anon.saeoueng@gmail.com)<br>
|
||||
Kun Kerdthaisong (kun.ker@dome.tu.ac.th)<br>
|
||||
Kittisak Sukhantharat (kittisak.suk@stu.nida.ac.th)<br>
|
||||
Piyawat Chuangkrud (piyawat@it.kmitl.ac.th)<br>
|
||||
Chaianun Damrongrat (chaianun.damrongrat@nectec.or.th)<br>
|
||||
Sarawoot Kongyoung (sarawoot.kongyoung@nectec.or.th)
|
||||
|
||||
**Audio Team**
|
||||
Pattara Tipaksorn (pattara.tip@ncr.nstda.or.th)<br>
|
||||
Wayupuk Sommuang (wayupuk.som@dome.tu.ac.th)<br>
|
||||
Oatsada Chatthong (atsada.cha@dome.tu.ac.th)<br>
|
||||
Kwanchiva Thangthai (kwanchiva.thangthai@nectec.or.th)
|
||||
|
||||
**Vision Team**
|
||||
Thirawarit Pitiphiphat (60010474@kmitl.ac.th)<br>
|
||||
Peerapas Ngokpon (jamesselmon78169@gmail.com)<br>
|
||||
Theerasit Issaranon (theerasit.issaranon@nectec.or.th)
|
||||
|
||||
## **Citation**
|
||||
|
||||
If you find our work helpful, feel free to give us a cite.
|
||||
|
||||
```
|
||||
@misc{qwen2.5,
|
||||
title = {Qwen2.5: A Party of Foundation Models},
|
||||
url = {https://qwenlm.github.io/blog/qwen2.5/},
|
||||
author = {Qwen Team},
|
||||
month = {September},
|
||||
year = {2024}
|
||||
}
|
||||
|
||||
@article{qwen2,
|
||||
title={Qwen2 Technical Report},
|
||||
author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan},
|
||||
journal={arXiv preprint arXiv:2407.10671},
|
||||
year={2024}
|
||||
}
|
||||
|
||||
24
added_tokens.json
Normal file
24
added_tokens.json
Normal file
@@ -0,0 +1,24 @@
|
||||
{
|
||||
"</tool_call>": 151658,
|
||||
"<tool_call>": 151657,
|
||||
"<|box_end|>": 151649,
|
||||
"<|box_start|>": 151648,
|
||||
"<|endoftext|>": 151643,
|
||||
"<|file_sep|>": 151664,
|
||||
"<|fim_middle|>": 151660,
|
||||
"<|fim_pad|>": 151662,
|
||||
"<|fim_prefix|>": 151659,
|
||||
"<|fim_suffix|>": 151661,
|
||||
"<|im_end|>": 151645,
|
||||
"<|im_start|>": 151644,
|
||||
"<|image_pad|>": 151655,
|
||||
"<|object_ref_end|>": 151647,
|
||||
"<|object_ref_start|>": 151646,
|
||||
"<|quad_end|>": 151651,
|
||||
"<|quad_start|>": 151650,
|
||||
"<|repo_name|>": 151663,
|
||||
"<|video_pad|>": 151656,
|
||||
"<|vision_end|>": 151653,
|
||||
"<|vision_pad|>": 151654,
|
||||
"<|vision_start|>": 151652
|
||||
}
|
||||
29
config.json
Normal file
29
config.json
Normal file
@@ -0,0 +1,29 @@
|
||||
{
|
||||
"_name_or_path": "/scratch/lt200258-aithai/experiments/model/qwen2.5-7B-16-10-100M",
|
||||
"architectures": [
|
||||
"Qwen2ForCausalLM"
|
||||
],
|
||||
"attention_dropout": 0.0,
|
||||
"bos_token_id": 151643,
|
||||
"eos_token_id": 151645,
|
||||
"hidden_act": "silu",
|
||||
"hidden_size": 3584,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 18944,
|
||||
"max_position_embeddings": 131072,
|
||||
"max_window_layers": 28,
|
||||
"model_type": "qwen2",
|
||||
"num_attention_heads": 28,
|
||||
"num_hidden_layers": 28,
|
||||
"num_key_value_heads": 4,
|
||||
"rms_norm_eps": 1e-06,
|
||||
"rope_theta": 1000000.0,
|
||||
"sliding_window": null,
|
||||
"tie_word_embeddings": false,
|
||||
"torch_dtype": "bfloat16",
|
||||
"transformers_version": "4.43.1",
|
||||
"use_cache": true,
|
||||
"use_mrope": false,
|
||||
"use_sliding_window": false,
|
||||
"vocab_size": 152064
|
||||
}
|
||||
6
generation_config.json
Normal file
6
generation_config.json
Normal file
@@ -0,0 +1,6 @@
|
||||
{
|
||||
"bos_token_id": 151643,
|
||||
"eos_token_id": 151643,
|
||||
"max_new_tokens": 2048,
|
||||
"transformers_version": "4.43.1"
|
||||
}
|
||||
151388
merges.txt
Normal file
151388
merges.txt
Normal file
File diff suppressed because it is too large
Load Diff
3
model-00001-of-00007.safetensors
Normal file
3
model-00001-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:a07699cb765163a68214f2b84a50a25584044fb6099d2005d20ead2152743c43
|
||||
size 4976687216
|
||||
3
model-00002-of-00007.safetensors
Normal file
3
model-00002-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:2ef43e13a4f5c58de20caae06017169dd32ce1c2a4114af15be08073c07deafd
|
||||
size 4778622352
|
||||
3
model-00003-of-00007.safetensors
Normal file
3
model-00003-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:1ecef61abefad6933732eaaef46b81e27eb2267d8c7286d0854fb7382ae1c518
|
||||
size 4932743960
|
||||
3
model-00004-of-00007.safetensors
Normal file
3
model-00004-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:e6a603c52f7b30be5c0bb71c44ff47c99552939f20fe500f1b65b1bf3b269c54
|
||||
size 4932743992
|
||||
3
model-00005-of-00007.safetensors
Normal file
3
model-00005-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:4089887998f1534d8d579072851470a78621ca80e11b6005030b84111c5a5947
|
||||
size 4998852296
|
||||
3
model-00006-of-00007.safetensors
Normal file
3
model-00006-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:bfd006dc7b553c828632605b04bc4ab6c2ced406f4eef1b7f4df3de54cf9328e
|
||||
size 3662865184
|
||||
3
model-00007-of-00007.safetensors
Normal file
3
model-00007-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:4691f6c8fcaae4ab9d9fc5354f0c908c969a691cde85c6bf32889855264b0255
|
||||
size 2179989632
|
||||
346
model.safetensors.index.json
Normal file
346
model.safetensors.index.json
Normal file
@@ -0,0 +1,346 @@
|
||||
{
|
||||
"metadata": {
|
||||
"total_size": 30462466048
|
||||
},
|
||||
"weight_map": {
|
||||
"lm_head.weight": "model-00007-of-00007.safetensors",
|
||||
"model.embed_tokens.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.10.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.10.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.10.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.10.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.10.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.11.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.11.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.11.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.11.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.11.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.13.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.13.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.13.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.14.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.14.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.14.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.14.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.15.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.15.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.15.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.15.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.15.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.16.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.16.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.16.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.16.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.16.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.17.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.17.mlp.down_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.17.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.17.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.17.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.18.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.18.mlp.gate_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.mlp.up_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.19.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.19.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.19.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.19.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.2.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.20.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.20.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.20.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.20.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.20.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.21.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.21.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.21.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.21.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.21.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.22.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.22.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.22.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.22.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.22.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.23.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.23.mlp.down_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.23.mlp.gate_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.23.mlp.up_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.23.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.24.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.24.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.24.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.24.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.24.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.25.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.25.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.25.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.25.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.25.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.26.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.26.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.26.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.26.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.26.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.27.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.27.mlp.down_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.27.mlp.gate_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.27.mlp.up_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.27.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.3.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.3.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.3.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.3.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.3.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.4.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.4.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.4.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.4.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.4.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.mlp.down_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.mlp.gate_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.mlp.up_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.8.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.8.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.8.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.8.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.9.mlp.down_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.9.mlp.gate_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.9.mlp.up_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.9.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.norm.weight": "model-00006-of-00007.safetensors"
|
||||
}
|
||||
}
|
||||
3
pytorch_model.bin
Normal file
3
pytorch_model.bin
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:06e0b4d336d5a5b19e14b006a25d1918bd08b79a5b2c734245a77515de17902d
|
||||
size 30462579142
|
||||
38
special_tokens_map.json
Normal file
38
special_tokens_map.json
Normal file
@@ -0,0 +1,38 @@
|
||||
{
|
||||
"additional_special_tokens": [
|
||||
"<|im_start|>",
|
||||
"<|im_end|>",
|
||||
"<|object_ref_start|>",
|
||||
"<|object_ref_end|>",
|
||||
"<|box_start|>",
|
||||
"<|box_end|>",
|
||||
"<|quad_start|>",
|
||||
"<|quad_end|>",
|
||||
"<|vision_start|>",
|
||||
"<|vision_end|>",
|
||||
"<|vision_pad|>",
|
||||
"<|image_pad|>",
|
||||
"<|video_pad|>"
|
||||
],
|
||||
"bos_token": {
|
||||
"content": "<|im_start|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"eos_token": {
|
||||
"content": "<|im_end|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"pad_token": {
|
||||
"content": "<|endoftext|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
}
|
||||
}
|
||||
208
tokenizer_config.json
Normal file
208
tokenizer_config.json
Normal file
@@ -0,0 +1,208 @@
|
||||
{
|
||||
"add_bos_token": false,
|
||||
"add_prefix_space": false,
|
||||
"added_tokens_decoder": {
|
||||
"151643": {
|
||||
"content": "<|endoftext|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151644": {
|
||||
"content": "<|im_start|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151645": {
|
||||
"content": "<|im_end|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151646": {
|
||||
"content": "<|object_ref_start|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151647": {
|
||||
"content": "<|object_ref_end|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151648": {
|
||||
"content": "<|box_start|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151649": {
|
||||
"content": "<|box_end|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151650": {
|
||||
"content": "<|quad_start|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151651": {
|
||||
"content": "<|quad_end|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151652": {
|
||||
"content": "<|vision_start|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151653": {
|
||||
"content": "<|vision_end|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151654": {
|
||||
"content": "<|vision_pad|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151655": {
|
||||
"content": "<|image_pad|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151656": {
|
||||
"content": "<|video_pad|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151657": {
|
||||
"content": "<tool_call>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151658": {
|
||||
"content": "</tool_call>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151659": {
|
||||
"content": "<|fim_prefix|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151660": {
|
||||
"content": "<|fim_middle|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151661": {
|
||||
"content": "<|fim_suffix|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151662": {
|
||||
"content": "<|fim_pad|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151663": {
|
||||
"content": "<|repo_name|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151664": {
|
||||
"content": "<|file_sep|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
}
|
||||
},
|
||||
"additional_special_tokens": [
|
||||
"<|im_start|>",
|
||||
"<|im_end|>",
|
||||
"<|object_ref_start|>",
|
||||
"<|object_ref_end|>",
|
||||
"<|box_start|>",
|
||||
"<|box_end|>",
|
||||
"<|quad_start|>",
|
||||
"<|quad_end|>",
|
||||
"<|vision_start|>",
|
||||
"<|vision_end|>",
|
||||
"<|vision_pad|>",
|
||||
"<|image_pad|>",
|
||||
"<|video_pad|>"
|
||||
],
|
||||
"bos_token": "<|im_start|>",
|
||||
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are a helpful assistant.' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
|
||||
"clean_up_tokenization_spaces": false,
|
||||
"eos_token": "<|im_end|>",
|
||||
"errors": "replace",
|
||||
"model_max_length": 8192,
|
||||
"pad_token": "<|endoftext|>",
|
||||
"padding_side": "right",
|
||||
"split_special_tokens": false,
|
||||
"tokenizer_class": "Qwen2Tokenizer",
|
||||
"unk_token": null
|
||||
}
|
||||
151645
vocab.json
Normal file
151645
vocab.json
Normal file
File diff suppressed because it is too large
Load Diff
Reference in New Issue
Block a user