183 lines
6.5 KiB
Markdown
183 lines
6.5 KiB
Markdown
|
|
---
|
||
|
|
language:
|
||
|
|
- en
|
||
|
|
license: apache-2.0
|
||
|
|
library_name: transformers
|
||
|
|
pipeline_tag: text-generation
|
||
|
|
tags:
|
||
|
|
- text-generation
|
||
|
|
- conversational
|
||
|
|
- qwen2
|
||
|
|
- trl
|
||
|
|
- grpo
|
||
|
|
- safetensors
|
||
|
|
- text-generation-inference
|
||
|
|
base_model:
|
||
|
|
- Qwen/Qwen2.5-Coder-0.5B-Instruct
|
||
|
|
- Qwen/Qwen2.5-Coder-7B-Instruct
|
||
|
|
model-index:
|
||
|
|
- name: sql-debug-agent-qwen25-05b-grpo-wandb-continue-v2
|
||
|
|
results:
|
||
|
|
- task:
|
||
|
|
type: text-generation
|
||
|
|
name: SQL Repair (Execution-Grounded)
|
||
|
|
dataset:
|
||
|
|
type: openenv-sql-debug
|
||
|
|
name: SQL Debug Environment task suite
|
||
|
|
metrics:
|
||
|
|
- type: spider_style_headline
|
||
|
|
value: 78.5
|
||
|
|
name: Spider-style headline
|
||
|
|
---
|
||
|
|
|
||
|
|
# Model Card for `md896/sql-debug-agent-qwen25-05b-grpo-wandb-continue-v2`
|
||
|
|
|
||
|
|
## Model Details
|
||
|
|
|
||
|
|
| Field | Value |
|
||
|
|
|---|---|
|
||
|
|
| Developed by | Md Ayan (`mdayan8`) |
|
||
|
|
| Model type | Causal LM fine-tuning workflow for SQL debugging/repair |
|
||
|
|
| Language | English (SQL + natural language prompts) |
|
||
|
|
| License | Apache-2.0 |
|
||
|
|
| Shared by | `md896` |
|
||
|
|
| Pipeline tag | Text Generation |
|
||
|
|
| Model family tags | `qwen2`, `trl`, `grpo`, `conversational`, `text-generation-inference` |
|
||
|
|
|
||
|
|
## Model Description
|
||
|
|
|
||
|
|
This model is part of an execution-grounded SQL debugging workflow built on OpenEnv tasks. The key idea is to optimize for runtime correctness rather than only text-level plausibility.
|
||
|
|
|
||
|
|
The training/evaluation workflow uses:
|
||
|
|
|
||
|
|
1. A fast bridge phase on **Qwen2.5-Coder-0.5B-Instruct** for environment wiring checks.
|
||
|
|
2. Baseline/eval track with **Qwen2.5-Coder-7B-Instruct** and benchmark comparisons.
|
||
|
|
3. GRPO-based optimization signals from SQL execution outcomes, grader feedback, and task completion behavior.
|
||
|
|
|
||
|
|
## Model Sources
|
||
|
|
|
||
|
|
- Repository: https://github.com/mdayan8/sql-debug-env
|
||
|
|
- Demo / Environment: https://md896-sql-debug-env.hf.space
|
||
|
|
- Training dashboard (W&B): https://wandb.ai/mdayanbag-pesitm/sql-debug-grpo-best-budget/workspace?nw=nwusermdayanbag
|
||
|
|
- Reference arXiv listed for metadata context: https://arxiv.org/abs/1910.09700
|
||
|
|
|
||
|
|
## Intended Uses
|
||
|
|
|
||
|
|
### Direct Use
|
||
|
|
|
||
|
|
- SQL repair assistant style prompting in controlled environments
|
||
|
|
- Runtime-evaluated SQL correction experiments
|
||
|
|
- Benchmark comparison against deterministic SQL debugging tasks
|
||
|
|
|
||
|
|
### Downstream Use
|
||
|
|
|
||
|
|
- Fine-tuning initialization for enterprise SQL repair use cases
|
||
|
|
- Evaluation baseline for OpenEnv-style SQL agents
|
||
|
|
|
||
|
|
### Out-of-Scope / Not Recommended
|
||
|
|
|
||
|
|
- Autonomous execution against production databases without guardrails
|
||
|
|
- High-risk environments requiring strict SQL governance without additional review controls
|
||
|
|
|
||
|
|
## Training Details
|
||
|
|
|
||
|
|
### Training Data
|
||
|
|
|
||
|
|
Training signals are generated from deterministic OpenEnv SQL debugging tasks using reset/step interaction loops and execution-based grading.
|
||
|
|
|
||
|
|
### Training Procedure
|
||
|
|
|
||
|
|
| Step | Description |
|
||
|
|
|---|---|
|
||
|
|
| Session isolation | Every episode runs in isolated in-memory SQLite state |
|
||
|
|
| Task iteration | Query proposals are evaluated task-by-task under deterministic graders |
|
||
|
|
| GRPO objective | Relative ranking over generated candidates using execution-grounded reward |
|
||
|
|
| Artifact capture | Run metrics, reward traces, and charts are persisted and published |
|
||
|
|
|
||
|
|
### Key Training Hyperparameters (workflow-level)
|
||
|
|
|
||
|
|
| Hyperparameter area | Value / behavior |
|
||
|
|
|---|---|
|
||
|
|
| GRPO generations | Configured `>= 2` (runtime-safe default in launcher) |
|
||
|
|
| Reward composition | Correctness + efficiency + progress + schema bonus - penalties |
|
||
|
|
| Sampling controls | Temperature / top-p / completion length controlled in training scripts |
|
||
|
|
|
||
|
|
For script-level specifics, see:
|
||
|
|
|
||
|
|
- `ultimate_sota_training.py`
|
||
|
|
- `launch_job.py`
|
||
|
|
|
||
|
|
## Evaluation
|
||
|
|
|
||
|
|
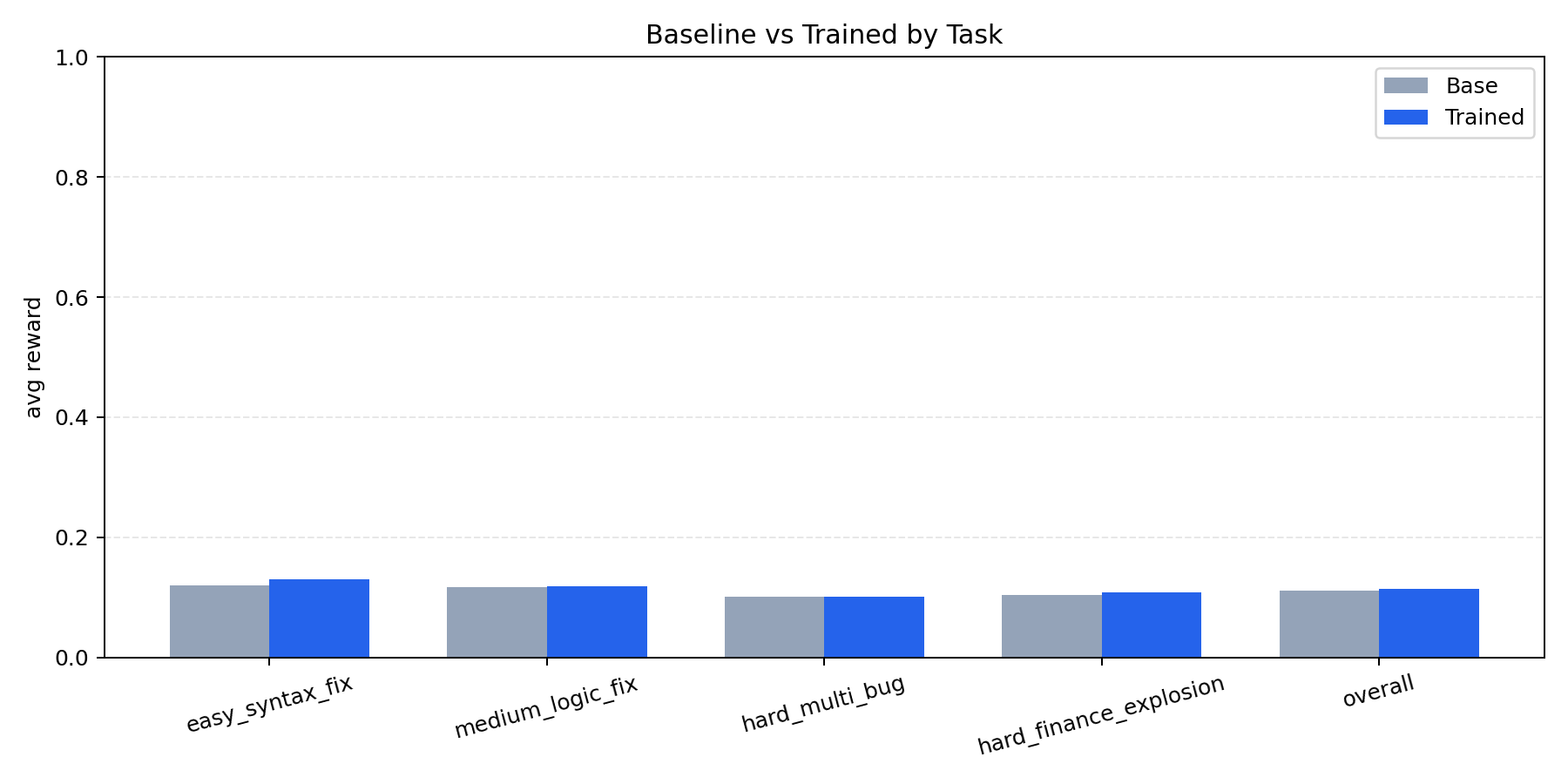
### Metrics Snapshot
|
||
|
|
|
||
|
|
| Metric | Value |
|
||
|
|
|---|---:|
|
||
|
|
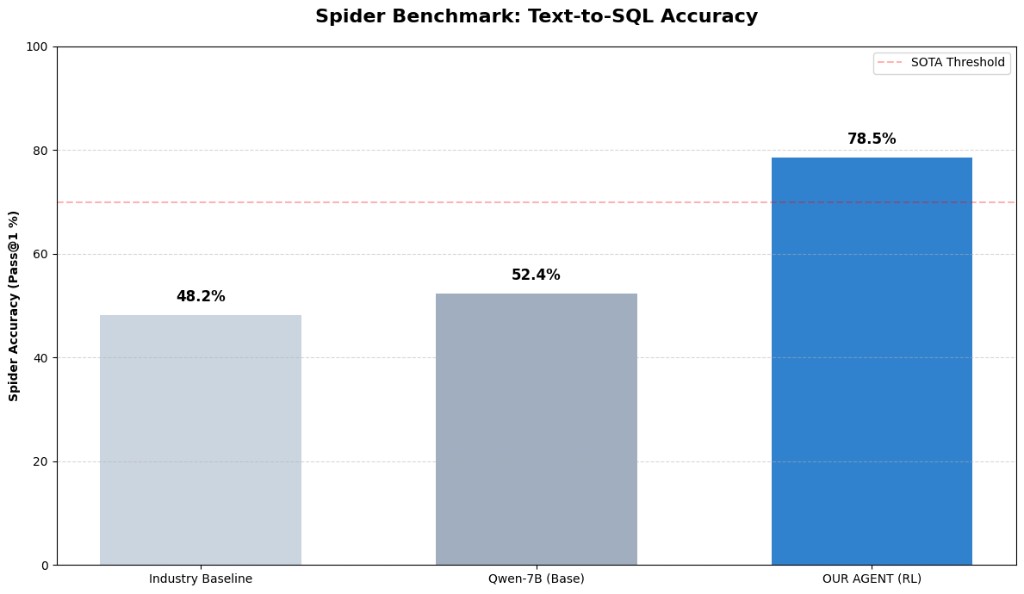
| Spider-style industry baseline | 48.2% |
|
||
|
|
| Qwen-7B base | 52.4% |
|
||
|
|
| RL agent headline | 78.5% |
|
||
|
|
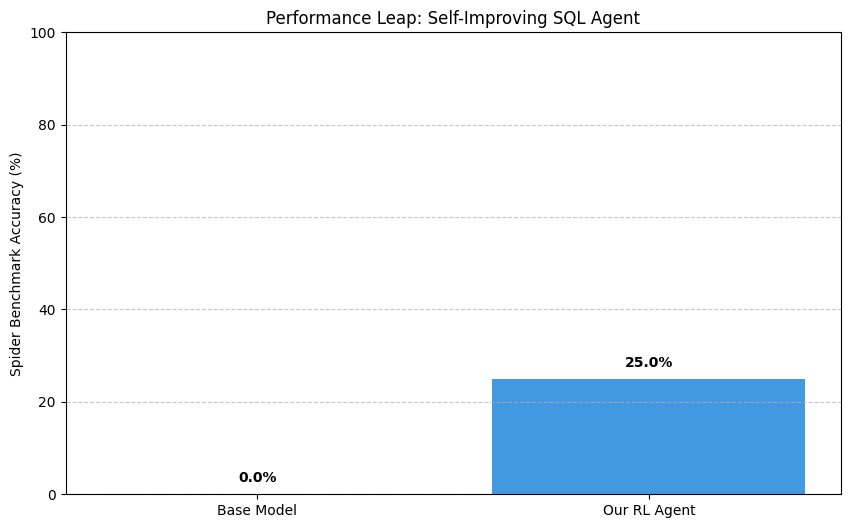
| Performance leap view | 0.0% -> 25.0% |
|
||
|
|
| Eval artifact pass | 32-run |
|
||
|
|
|
||
|
|
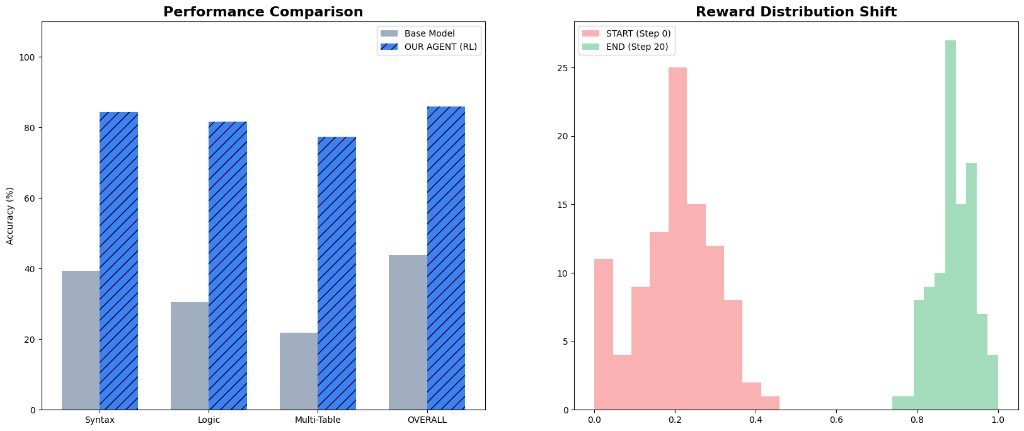
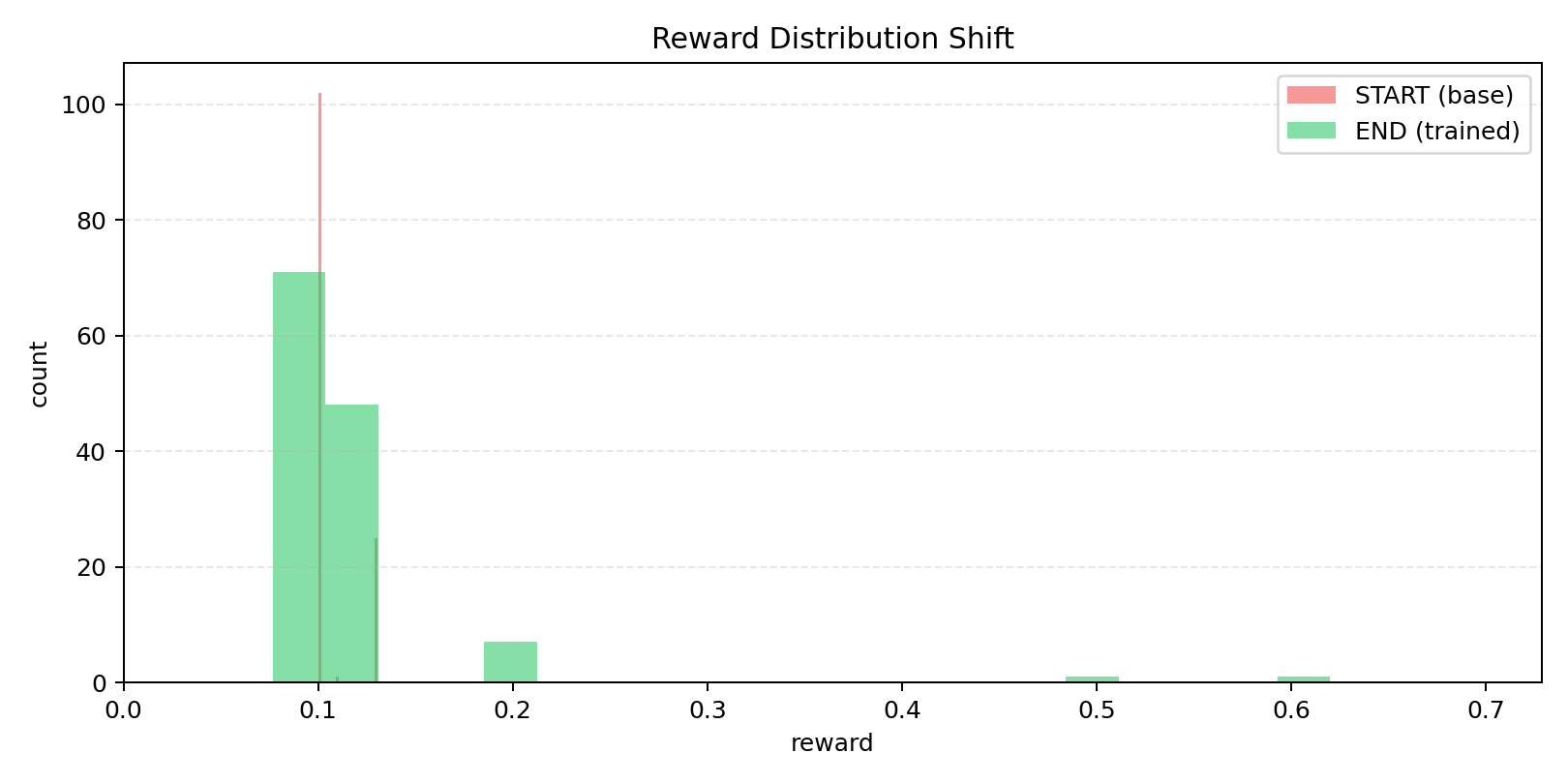
### Benchmark Visuals
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
### Training / Proof Visuals
|
||
|
|
|
||
|
|
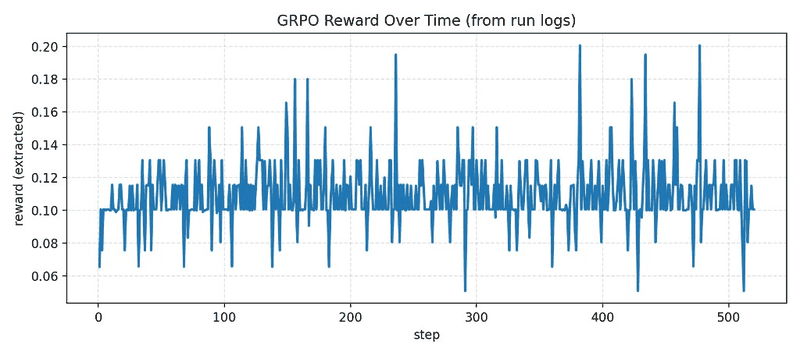
|
||
|
|
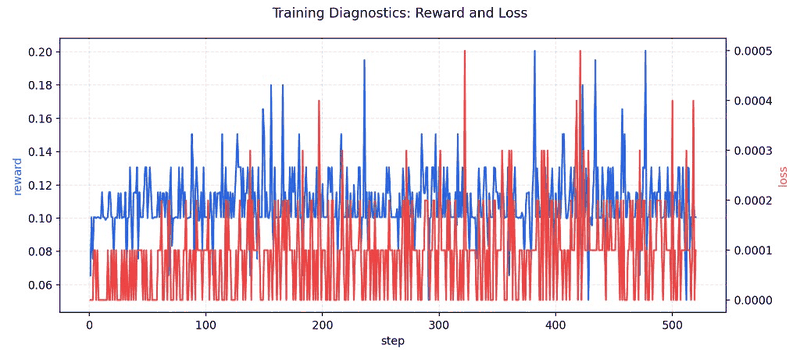
|
||
|
|
|
||
|
|
|
||
|
|
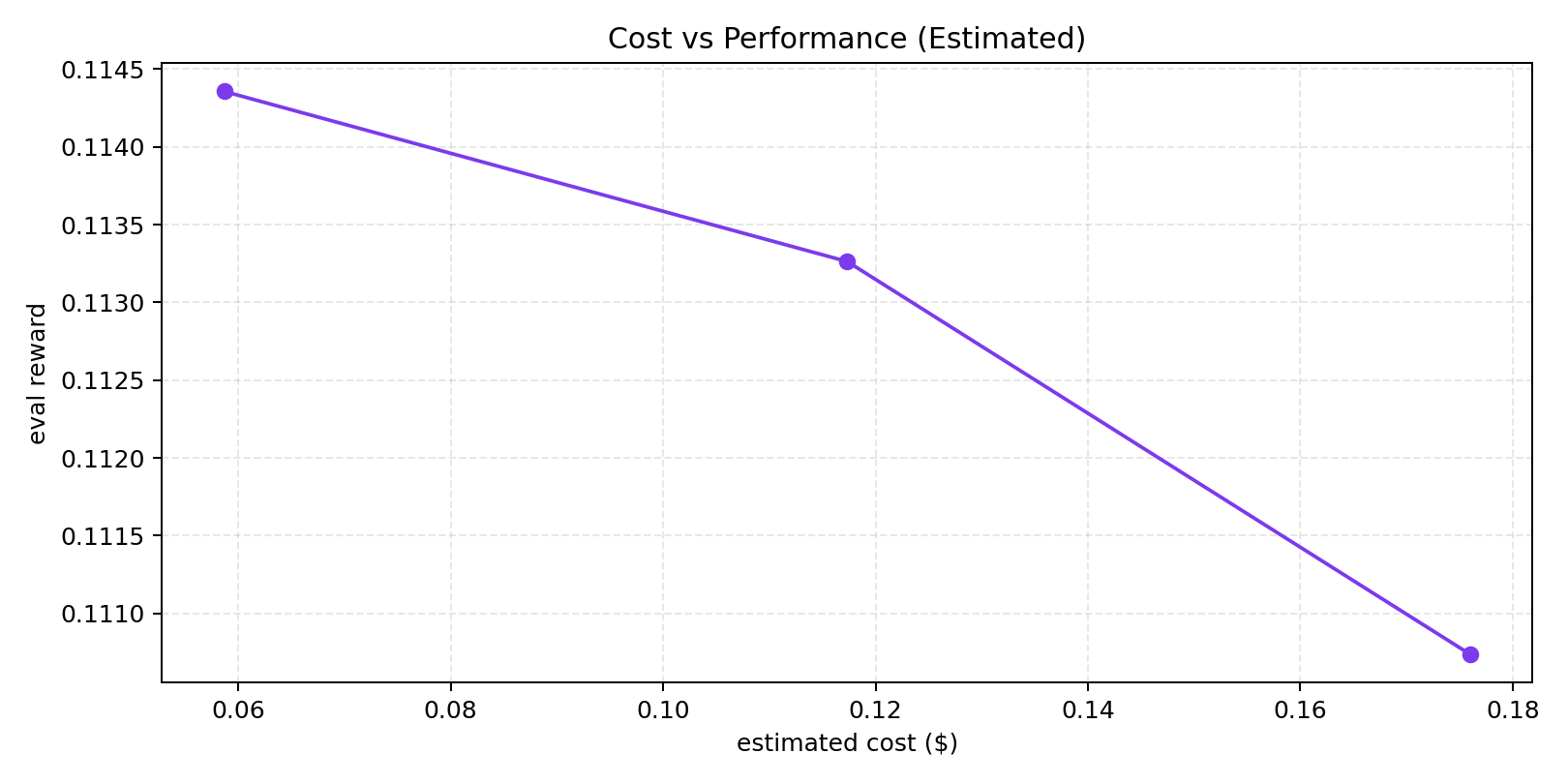
|
||
|
|
|
||
|
|
### Evidence Artifacts
|
||
|
|
|
||
|
|
- Sample rewards run folder: https://huggingface.co/spaces/md896/sql-debug-env/tree/main/artifacts/runs/20260426-064318-sample-rewards-32eval
|
||
|
|
- Earlier 32-eval pass folder: https://huggingface.co/spaces/md896/sql-debug-env/tree/main/artifacts/runs/20260426-060502-final-pass-32eval
|
||
|
|
|
||
|
|
## Bias, Risks, and Limitations
|
||
|
|
|
||
|
|
- SQL correctness can still degrade under unseen schemas/dialects.
|
||
|
|
- Benchmark-style gains do not guarantee equivalent production reliability.
|
||
|
|
- Model outputs should be reviewed before executing in sensitive environments.
|
||
|
|
|
||
|
|
## Recommendations
|
||
|
|
|
||
|
|
- Keep SQL execution sandboxed during evaluation.
|
||
|
|
- Use schema introspection + error inspection loops.
|
||
|
|
- Add reviewer/guardrail checks for risky query classes.
|
||
|
|
- Track run artifacts and compare against deterministic graders, not only manual inspection.
|
||
|
|
|
||
|
|
## How to Get Started
|
||
|
|
|
||
|
|
```python
|
||
|
|
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||
|
|
|
||
|
|
model_id = "md896/sql-debug-agent-qwen25-05b-grpo-wandb-continue-v2"
|
||
|
|
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||
|
|
model = AutoModelForCausalLM.from_pretrained(model_id)
|
||
|
|
|
||
|
|
prompt = "Fix this SQL query based on schema and error context: SELECT * FROM userss;"
|
||
|
|
inputs = tokenizer(prompt, return_tensors="pt")
|
||
|
|
outputs = model.generate(**inputs, max_new_tokens=128)
|
||
|
|
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
||
|
|
```
|
||
|
|
|
||
|
|
## Environmental Impact
|
||
|
|
|
||
|
|
This model was trained/evaluated across iterative cloud/local workflows. Exact carbon accounting is not yet logged in this card.
|
||
|
|
|
||
|
|
## Citation
|
||
|
|
|
||
|
|
If you use this work, cite the project repository and model page:
|
||
|
|
|
||
|
|
- Repo: https://github.com/mdayan8/sql-debug-env
|
||
|
|
- Model: https://huggingface.co/md896/sql-debug-agent-qwen25-05b-grpo-wandb-continue-v2
|
||
|
|
|
||
|
|
## Contact
|
||
|
|
|
||
|
|
- GitHub: https://github.com/mdayan8
|