license, base_model, library_name, pipeline_tag, tags
| license | base_model | library_name | pipeline_tag | tags | ||||
|---|---|---|---|---|---|---|---|---|
| apache-2.0 |
|
transformers | text-generation |
|
Model Card for DAPO w/ Prompt Augmentation
If you are using the model, a star to our github repo would be really appreciated! 😊
This is the step 2720 checkpoint when training Qwen2.5-Math-1.5B on MATH Level-3-to-5 Dataset using DAPO (no dynamic sampling) with prompt augmentation. The training procedure is outlined in the paper Prompt Augmentation Scales up GRPO Training on Mathematical Reasoning.
Model Sources
- Repository 🤖: https://github.com/wenquanlu/prompt-augmentation-GRPO
- Paper 📝: Prompt Augmentation Scales up GRPO Training on Mathematical Reasoning
Uses
This model is intended for mathematical reasoning tasks. It leverages prompt augmentation to generate reasoning traces under diverse templates, increasing rollout diversity and stability during RL training.
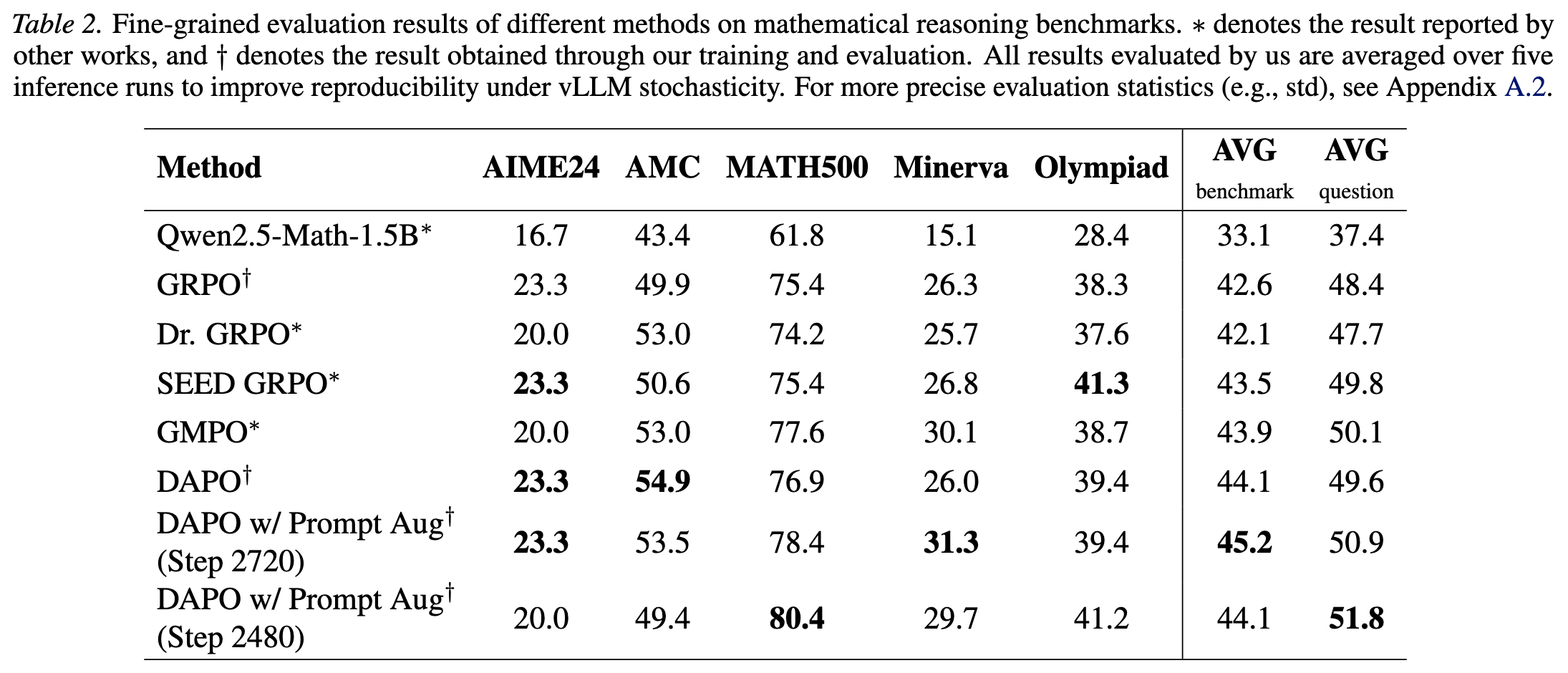
Results
Citation
@misc{lu2026promptaugmentationscalesgrpo,
title={Prompt Augmentation Scales up GRPO Training on Mathematical Reasoning},
author={Wenquan Lu and Hai Huang and Randall Balestriero},
journal={arXiv preprint arXiv:2602.03190},
year={2026},
}