初始化项目,由ModelHub XC社区提供模型
Model: datajuicer/LLaMA-1B-dj-refine-150B Source: Original Platform
This commit is contained in:
35
.gitattributes
vendored
Normal file
35
.gitattributes
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||
*.model filter=lfs diff=lfs merge=lfs -text
|
||||
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
35
README.md
Normal file
35
README.md
Normal file
@@ -0,0 +1,35 @@
|
||||
---
|
||||
license: apache-2.0
|
||||
datasets:
|
||||
- datajuicer/redpajama-wiki-refined-by-data-juicer
|
||||
- datajuicer/redpajama-arxiv-refined-by-data-juicer
|
||||
- datajuicer/redpajama-c4-refined-by-data-juicer
|
||||
- datajuicer/redpajama-book-refined-by-data-juicer
|
||||
- datajuicer/redpajama-cc-2019-30-refined-by-data-juicer
|
||||
- datajuicer/redpajama-cc-2020-05-refined-by-data-juicer
|
||||
- datajuicer/redpajama-cc-2021-04-refined-by-data-juicer
|
||||
- datajuicer/redpajama-cc-2022-05-refined-by-data-juicer
|
||||
- datajuicer/redpajama-cc-2023-06-refined-by-data-juicer
|
||||
- datajuicer/redpajama-pile-stackexchange-refined-by-data-juicer
|
||||
- datajuicer/redpajama-stack-code-refined-by-data-juicer
|
||||
- datajuicer/the-pile-nih-refined-by-data-juicer
|
||||
- datajuicer/the-pile-europarl-refined-by-data-juicer
|
||||
- datajuicer/the-pile-philpaper-refined-by-data-juicer
|
||||
- datajuicer/the-pile-pubmed-abstracts-refined-by-data-juicer
|
||||
- datajuicer/the-pile-pubmed-central-refined-by-data-juicer
|
||||
- datajuicer/the-pile-freelaw-refined-by-data-juicer
|
||||
- datajuicer/the-pile-hackernews-refined-by-data-juicer
|
||||
- datajuicer/the-pile-uspto-refined-by-data-juicer
|
||||
---
|
||||
## News
|
||||
Our first data-centric LLM competition begins! Please visit the competition's official websites, **FT-Data Ranker** ([1B Track](https://tianchi.aliyun.com/competition/entrance/532157), [7B Track](https://tianchi.aliyun.com/competition/entrance/532158)), for more information.
|
||||
## Introduction
|
||||
This is a reference LLM from [Data-Juicer](https://github.com/alibaba/data-juicer).
|
||||
|
||||
The model architecture is LLaMA-1.3B and we adopt the [OpenLLaMA](https://github.com/openlm-research/open_llama) implementation.
|
||||
The model is pre-trained on 150B tokens of Data-Juicer's refined RedPajama and Pile.
|
||||
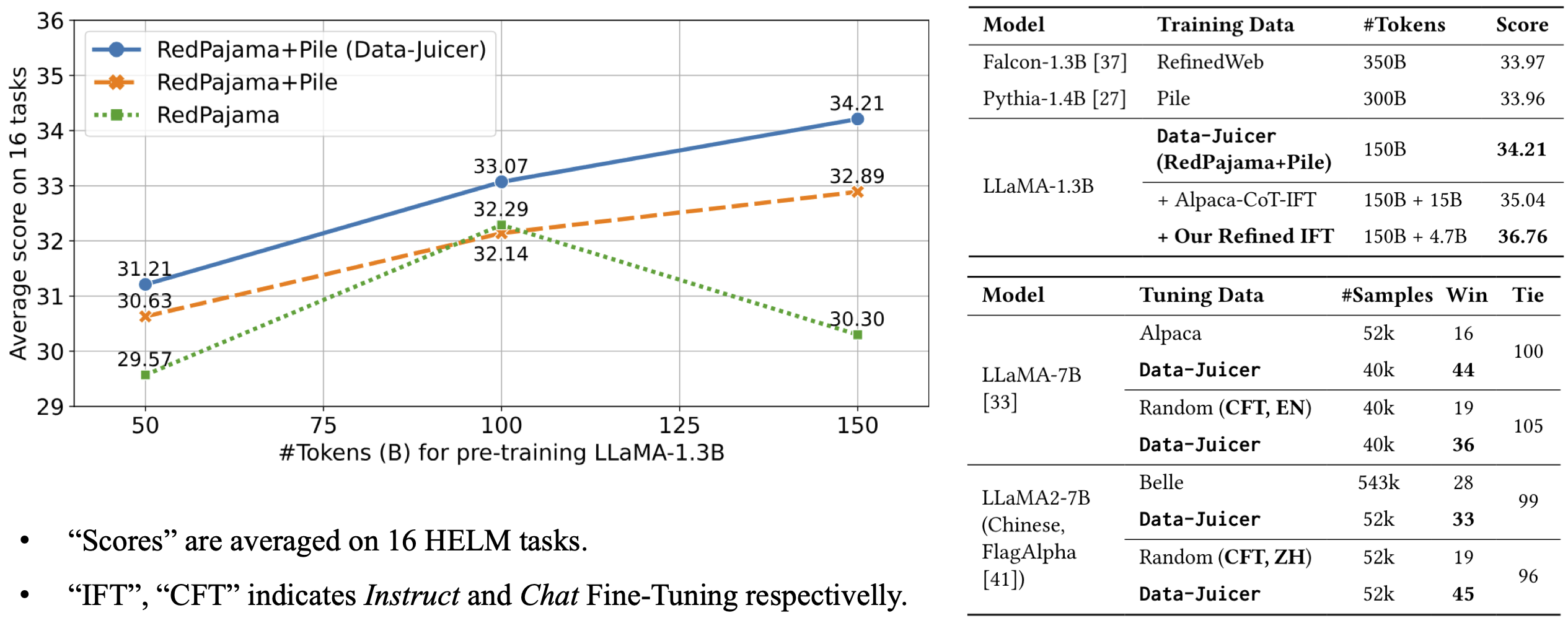
It achieves an average score of 34.21 over 16 HELM tasks, beating Falcon-1.3B (trained on 350B tokens from RefinedWeb), Pythia-1.4B (trained on 300B tokens from original Pile) and Open-LLaMA-1.3B (trained on 150B tokens from original RedPajama and Pile).
|
||||
|
||||
For more details, please refer to our [paper](https://arxiv.org/abs/2309.02033).
|
||||
|
||||
|
||||
7
added_tokens.json
Normal file
7
added_tokens.json
Normal file
@@ -0,0 +1,7 @@
|
||||
{
|
||||
"<CLS>": 32000,
|
||||
"<EOD>": 32002,
|
||||
"<MASK>": 32003,
|
||||
"<PAD>": 32004,
|
||||
"<SEP>": 32001
|
||||
}
|
||||
28
config.json
Normal file
28
config.json
Normal file
@@ -0,0 +1,28 @@
|
||||
{
|
||||
"architectures": [
|
||||
"LlamaForCausalLM"
|
||||
],
|
||||
"attention_bias": false,
|
||||
"bos_token_id": 1,
|
||||
"eos_token_id": 2,
|
||||
"hidden_act": "silu",
|
||||
"hidden_size": 2048,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 5504,
|
||||
"max_position_embeddings": 2048,
|
||||
"max_sequence_length": 2048,
|
||||
"model_type": "llama",
|
||||
"num_attention_heads": 16,
|
||||
"num_hidden_layers": 24,
|
||||
"num_key_value_heads": 16,
|
||||
"pad_token_id": 32004,
|
||||
"pretraining_tp": 1,
|
||||
"rms_norm_eps": 1e-06,
|
||||
"rope_scaling": null,
|
||||
"rope_theta": 10000.0,
|
||||
"tie_word_embeddings": false,
|
||||
"torch_dtype": "float32",
|
||||
"transformers_version": "4.34.1",
|
||||
"use_cache": true,
|
||||
"vocab_size": 32128
|
||||
}
|
||||
7
generation_config.json
Normal file
7
generation_config.json
Normal file
@@ -0,0 +1,7 @@
|
||||
{
|
||||
"_from_model_config": true,
|
||||
"bos_token_id": 1,
|
||||
"eos_token_id": 2,
|
||||
"pad_token_id": 32004,
|
||||
"transformers_version": "4.34.1"
|
||||
}
|
||||
3
pytorch_model.bin
Normal file
3
pytorch_model.bin
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:77f45debb9b8ca613ed4184024f8d6f59dcd70d93b44f9c5f1c5853f22587459
|
||||
size 5383861709
|
||||
36
special_tokens_map.json
Normal file
36
special_tokens_map.json
Normal file
@@ -0,0 +1,36 @@
|
||||
{
|
||||
"additional_special_tokens": [
|
||||
"<EOD>"
|
||||
],
|
||||
"bos_token": {
|
||||
"content": "<s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"cls_token": "<CLS>",
|
||||
"eos_token": {
|
||||
"content": "</s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"mask_token": "<MASK>",
|
||||
"pad_token": {
|
||||
"content": "<PAD>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"sep_token": "<SEP>",
|
||||
"unk_token": {
|
||||
"content": "<unk>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
}
|
||||
}
|
||||
93436
tokenizer.json
Normal file
93436
tokenizer.json
Normal file
File diff suppressed because it is too large
Load Diff
3
tokenizer.model
Normal file
3
tokenizer.model
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:9e556afd44213b6bd1be2b850ebbbd98f5481437a8021afaf58ee7fb1818d347
|
||||
size 499723
|
||||
87
tokenizer_config.json
Normal file
87
tokenizer_config.json
Normal file
@@ -0,0 +1,87 @@
|
||||
{
|
||||
"add_bos_token": true,
|
||||
"add_eos_token": false,
|
||||
"added_tokens_decoder": {
|
||||
"0": {
|
||||
"content": "<unk>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"1": {
|
||||
"content": "<s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"2": {
|
||||
"content": "</s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"32000": {
|
||||
"content": "<CLS>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"32001": {
|
||||
"content": "<SEP>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"32002": {
|
||||
"content": "<EOD>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"32003": {
|
||||
"content": "<MASK>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"32004": {
|
||||
"content": "<PAD>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
}
|
||||
},
|
||||
"additional_special_tokens": [
|
||||
"<EOD>"
|
||||
],
|
||||
"bos_token": "<s>",
|
||||
"clean_up_tokenization_spaces": false,
|
||||
"cls_token": "<CLS>",
|
||||
"eos_token": "</s>",
|
||||
"legacy": true,
|
||||
"mask_token": "<MASK>",
|
||||
"model_max_length": 2048,
|
||||
"pad_token": "<PAD>",
|
||||
"sep_token": "<SEP>",
|
||||
"sp_model_kwargs": {},
|
||||
"spaces_between_special_tokens": false,
|
||||
"tokenizer_class": "LlamaTokenizer",
|
||||
"unk_token": "<unk>",
|
||||
"use_default_system_prompt": true
|
||||
}
|
||||
Reference in New Issue
Block a user