初始化项目,由ModelHub XC社区提供模型
Model: arcee-ai/AFM-4.5B-Base Source: Original Platform
This commit is contained in:
49
.gitattributes
vendored
Normal file
49
.gitattributes
vendored
Normal file
@@ -0,0 +1,49 @@
|
||||
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.model filter=lfs diff=lfs merge=lfs -text
|
||||
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
||||
*.tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
*.db* filter=lfs diff=lfs merge=lfs -text
|
||||
*.ark* filter=lfs diff=lfs merge=lfs -text
|
||||
**/*ckpt*data* filter=lfs diff=lfs merge=lfs -text
|
||||
**/*ckpt*.meta filter=lfs diff=lfs merge=lfs -text
|
||||
**/*ckpt*.index filter=lfs diff=lfs merge=lfs -text
|
||||
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||
*.gguf* filter=lfs diff=lfs merge=lfs -text
|
||||
*.ggml filter=lfs diff=lfs merge=lfs -text
|
||||
*.llamafile* filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
|
||||
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
||||
90
README.md
Normal file
90
README.md
Normal file
@@ -0,0 +1,90 @@
|
||||
---
|
||||
license: apache-2.0
|
||||
language:
|
||||
- en
|
||||
- es
|
||||
- fr
|
||||
- de
|
||||
- it
|
||||
- pt
|
||||
- ru
|
||||
- ar
|
||||
- hi
|
||||
- ko
|
||||
- zh
|
||||
library_name: transformers
|
||||
extra_gated_prompt: Company name is optional, please put NA if you would prefer not to share it.
|
||||
---
|
||||
|
||||
<div align="center">
|
||||
<picture>
|
||||
<img src="https://cdn-uploads.huggingface.co/production/uploads/6435718aaaef013d1aec3b8b/Lj9YVLIKKdImV_jID0A1g.png" width="25%" alt="Arcee AFM 4.5B">
|
||||
</picture>
|
||||
</div>
|
||||
|
||||
# AFM-4.5B-Base
|
||||
|
||||
**AFM-4.5B-Base** is a 4.5 billion parameter instruction-tuned model developed by Arcee.ai, designed for enterprise-grade performance across diverse deployment environments from cloud to edge. The base model was trained on a dataset of 8 trillion tokens, comprising 6.5 trillion tokens of general pretraining data followed by 1.5 trillion tokens of midtraining data with enhanced focus on mathematical reasoning and code generation. Following pretraining, the model underwent supervised fine-tuning on high-quality instruction datasets. The instruction-tuned model was further refined through reinforcement learning on verifiable rewards as well as for human preference. We use a modified version of [TorchTitan](https://arxiv.org/abs/2410.06511) for pretraining, [Axolotl](https://axolotl.ai) for supervised fine-tuning, and a modified version of [Verifiers](https://github.com/willccbb/verifiers) for reinforcement learning.
|
||||
|
||||
The development of AFM-4.5B prioritized data quality as a fundamental requirement for achieving robust model performance. We collaborated with DatologyAI, a company specializing in large-scale data curation. DatologyAI's curation pipeline integrates a suite of proprietary algorithms—model-based quality filtering, embedding-based curation, target distribution-matching, source mixing, and synthetic data. Their expertise enabled the creation of a curated dataset tailored to support strong real-world performance.
|
||||
|
||||
The model architecture follows a standard transformer decoder-only design based on Vaswani et al., incorporating several key modifications for enhanced performance and efficiency. Notable architectural features include grouped query attention for improved inference efficiency and ReLU^2 activation functions instead of SwiGLU to enable sparsification while maintaining or exceeding performance benchmarks.
|
||||
|
||||
The model available in this repo is the base model following merging and context extension.
|
||||
|
||||
***
|
||||
|
||||
<div align="center">
|
||||
<picture>
|
||||
<img src="https://cdn-uploads.huggingface.co/production/uploads/6435718aaaef013d1aec3b8b/sSVjGNHfrJKmQ6w8I18ek.png" style="background-color:ghostwhite;padding:5px;" width="17%" alt="Powered by Datology">
|
||||
</picture>
|
||||
</div>
|
||||
|
||||
## Model Details
|
||||
|
||||
* **Model Architecture:** ArceeForCausalLM
|
||||
* **Parameters:** 4.5B
|
||||
* **Training Tokens:** 8T
|
||||
* **License:** [Apache-2.0](https://huggingface.co/arcee-ai/AFM-4.5B-Base#license)
|
||||
|
||||
***
|
||||
|
||||
## Benchmarks
|
||||
|
||||
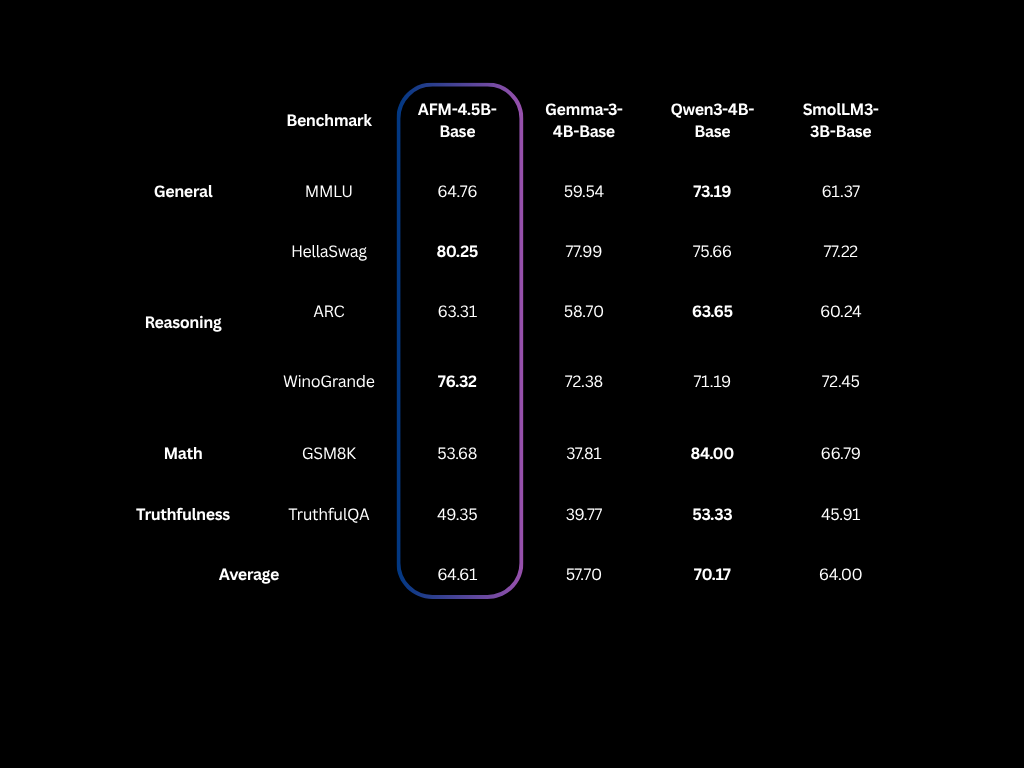
|
||||
|
||||
## How to use with `transformers`
|
||||
|
||||
You can use the model directly with the `transformers` library.
|
||||
|
||||
```python
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
import torch
|
||||
|
||||
model_id = "arcee-ai/AFM-4.5B-Base"
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model_id,
|
||||
torch_dtype=torch.bfloat16,
|
||||
device_map="auto"
|
||||
)
|
||||
|
||||
prompt = "Once upon a time "
|
||||
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(model.device)
|
||||
|
||||
# Generate text
|
||||
outputs = model.generate(
|
||||
input_ids,
|
||||
max_new_tokens=100,
|
||||
do_sample=True,
|
||||
temperature=0.7,
|
||||
top_p=0.95
|
||||
)
|
||||
|
||||
generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
|
||||
print(generated_text)
|
||||
```
|
||||
|
||||
## License
|
||||
|
||||
AFM-4.5B is released under the Apache-2.0 license.
|
||||
36
config.json
Normal file
36
config.json
Normal file
@@ -0,0 +1,36 @@
|
||||
{
|
||||
"architectures": [
|
||||
"ArceeForCausalLM"
|
||||
],
|
||||
"attention_bias": false,
|
||||
"attention_dropout": 0.0,
|
||||
"bos_token_id": 128000,
|
||||
"eos_token_id": 128001,
|
||||
"head_dim": 128,
|
||||
"hidden_act": "relu2",
|
||||
"hidden_size": 2560,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 18432,
|
||||
"max_position_embeddings": 65536,
|
||||
"mlp_bias": false,
|
||||
"model_type": "arcee",
|
||||
"num_attention_heads": 20,
|
||||
"num_hidden_layers": 36,
|
||||
"num_key_value_heads": 4,
|
||||
"rms_norm_eps": 1e-05,
|
||||
"rope_scaling": {
|
||||
"beta_fast": 32.0,
|
||||
"beta_slow": 1.0,
|
||||
"factor": 20.0,
|
||||
"mscale": 1.0,
|
||||
"original_max_position_embeddings": 4096,
|
||||
"rope_type": "yarn",
|
||||
"type": "yarn"
|
||||
},
|
||||
"rope_theta": 10000.0,
|
||||
"tie_word_embeddings": false,
|
||||
"torch_dtype": "bfloat16",
|
||||
"transformers_version": "4.53.2",
|
||||
"use_cache": false,
|
||||
"vocab_size": 128004
|
||||
}
|
||||
1
configuration.json
Normal file
1
configuration.json
Normal file
@@ -0,0 +1 @@
|
||||
{"framework": "pytorch", "task": "text-generation", "allow_remote": true}
|
||||
3
model-00001-of-00002.safetensors
Normal file
3
model-00001-of-00002.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:3571477a89761f392128de1c5b0a636703abe15a1f1d2b9e7823905425f406bc
|
||||
size 4965305552
|
||||
3
model-00002-of-00002.safetensors
Normal file
3
model-00002-of-00002.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:9f505916ba600c03b1c65298a2f2cd658c5a18245e4e6c733adea1661954c59c
|
||||
size 4273097520
|
||||
1
model.safetensors.index.json
Normal file
1
model.safetensors.index.json
Normal file
File diff suppressed because one or more lines are too long
16
special_tokens_map.json
Normal file
16
special_tokens_map.json
Normal file
@@ -0,0 +1,16 @@
|
||||
{
|
||||
"bos_token": {
|
||||
"content": "<|begin_of_text|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"eos_token": {
|
||||
"content": "<|end_of_text|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
}
|
||||
}
|
||||
3
tokenizer.json
Normal file
3
tokenizer.json
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:2f7e8b61d1cb49d927a5f5aaeecdac9cb173cccb3ec1897cb5d7bb08bda54907
|
||||
size 17157913
|
||||
46
tokenizer_config.json
Normal file
46
tokenizer_config.json
Normal file
@@ -0,0 +1,46 @@
|
||||
{
|
||||
"added_tokens_decoder": {
|
||||
"128000": {
|
||||
"content": "<|begin_of_text|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"128001": {
|
||||
"content": "<|end_of_text|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"128002": {
|
||||
"content": "<|im_start|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"128003": {
|
||||
"content": "<|im_end|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
}
|
||||
},
|
||||
"bos_token": "<|begin_of_text|>",
|
||||
"clean_up_tokenization_spaces": true,
|
||||
"eos_token": "<|end_of_text|>",
|
||||
"extra_special_tokens": {},
|
||||
"model_input_names": [
|
||||
"input_ids",
|
||||
"attention_mask"
|
||||
],
|
||||
"model_max_length": 65536,
|
||||
"tokenizer_class": "PreTrainedTokenizerFast"
|
||||
}
|
||||
Reference in New Issue
Block a user