3.2 KiB
license, license_name, license_link, base_model, library_name, tags, pipeline_tag, language
| license | license_name | license_link | base_model | library_name | tags | pipeline_tag | language | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| other | lfm1.0 | https://www.liquid.ai/legal/lfm-license |
|
transformers |
|
text-generation |
|
LFM2-2.6B-mr-tictactoe
A 2.6B parameter model that plays near-perfect Tic Tac Toe, outperforming openai/gpt-5-mini on this task.
Built from LiquidAI/LFM2-2.6B through a full training pipeline: Supervised Fine-Tuning on synthetic data, followed by two rounds of Reinforcement Learning (CISPO) in a verifiable Tic Tac Toe environment.
This model was developed as part of 🎓 LLM RL Environments Lil Course, a hands-on course on building RL environments for Language Models, where models learn from rewards, not examples. It walks through the full process of turning a small open model into a specialist that outperforms a large proprietary one on a specific task (Tic Tac Toe).
🤗🕹️ Play against Mr. Tic Tac Toe
Training pipeline
| Step | Model | Method |
|---|---|---|
| 1. SFT warm-up | anakin87/LFM2-2.6B-ttt-sft | SFT on 174 synthetic games from gpt-5-mini |
| 2. RL round 1 | anakin87/LFM2-2.6B-ttt-rl + merged | CISPO, 600 steps, opponents at 20-70% random |
| 3. RL round 2 | anakin87/LFM2-2.6B-ttt-rl-2 + this model | CISPO, 400 steps, opponents at 0-25% random, temp 1.25 |
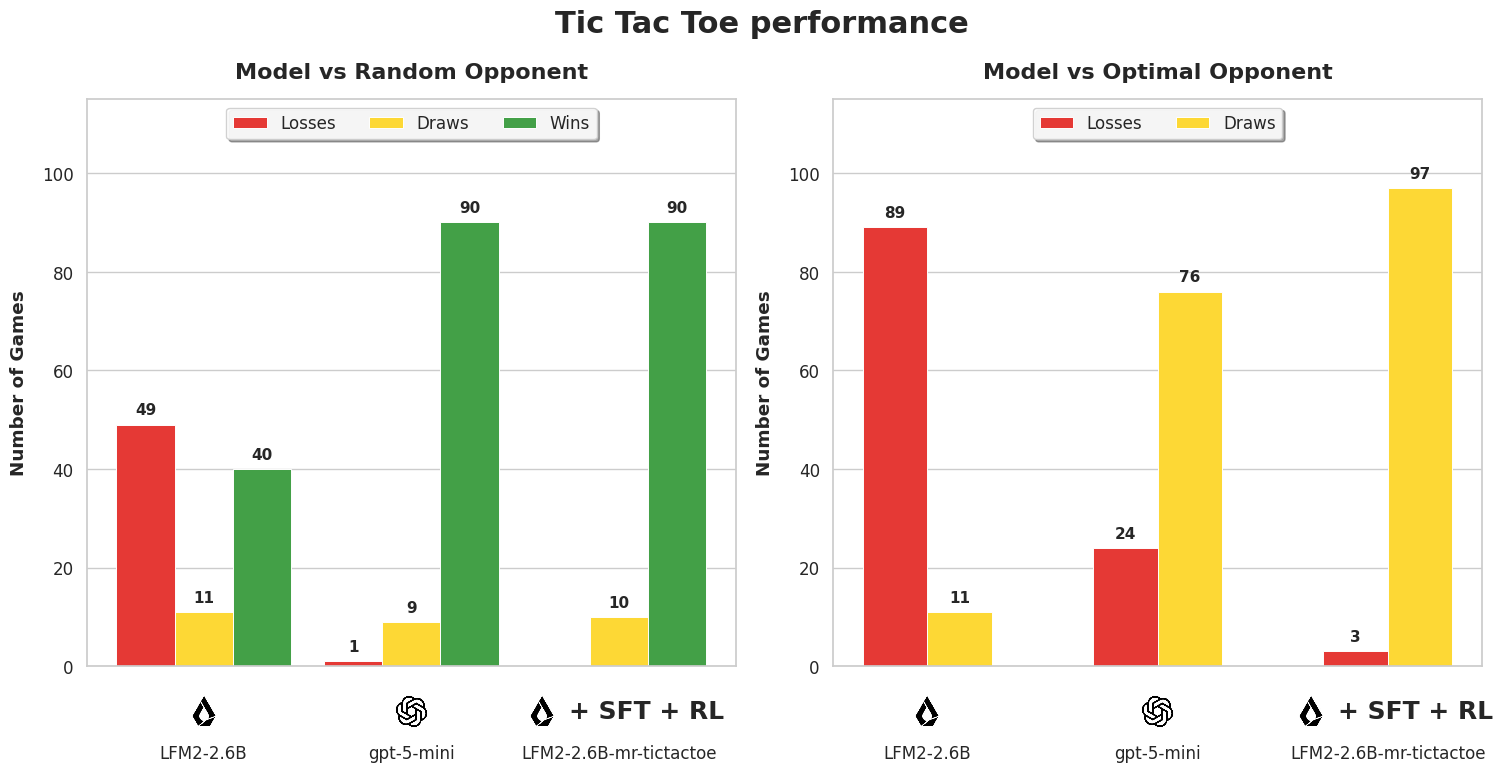
Evaluation
100 games per setting. The model plays as X (first mover) against a Minimax-based opponent.
| Model vs random opponent | % Wins | % Draws | % Losses | % Follows format | % Games w invalid moves |
|---|---|---|---|---|---|
| openai/gpt-5-mini | 90 | 9 | 1 | 100 | 0 |
| LiquidAI/LFM2-2.6B | 40 | 11 | 49 | 27.8 | 40 |
| anakin87/LFM2-2.6B-mr-tictactoe | 90 | 10 | 0 | 100 | 0 |
| Model vs optimal opponent | % Wins | % Draws | % Losses | % Follows format | % Games w invalid moves |
| openai/gpt-5-mini | 0 | 76 | 24 | 100 | 0 |
| LiquidAI/LFM2-2.6B | 0 | 11 | 89 | 24.7 | 43 |
| anakin87/LFM2-2.6B-mr-tictactoe | 0 | 97 | 3 | 99.8 | 0 |
Training details
- Algorithm: CISPO (two rounds), using Verifiers RLTrainer
- Environment: anakin87/tictactoe (Verifiers environment)
- LoRA rank: 8
- Hardware: 2x NVIDIA RTX Pro 6000 (round 1), 2x NVIDIA H200 (round 2)
- Training time: ~8 hours per round
- W&B project: LFM2-2.6B Tic Tac Toe