初始化项目,由ModelHub XC社区提供模型
Model: TIGER-Lab/StructLM-7B-Mistral Source: Original Platform
This commit is contained in:
35
.gitattributes
vendored
Normal file
35
.gitattributes
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||
*.model filter=lfs diff=lfs merge=lfs -text
|
||||
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
119
README.md
Normal file
119
README.md
Normal file
@@ -0,0 +1,119 @@
|
||||
---
|
||||
license: mit
|
||||
datasets:
|
||||
- TIGER-Lab/SKGInstruct
|
||||
language:
|
||||
- en
|
||||
---
|
||||
# 🏗️ StructLM: Towards Building Generalist Models for Structured Knowledge Grounding
|
||||
|
||||
|
||||
|
||||
Project Page: [https://tiger-ai-lab.github.io/StructLM/](https://tiger-ai-lab.github.io/StructLM/)
|
||||
|
||||
Paper: [https://arxiv.org/pdf/2402.16671.pdf](https://arxiv.org/pdf/2402.16671.pdf)
|
||||
|
||||
Code: [https://github.com/TIGER-AI-Lab/StructLM](https://github.com/TIGER-AI-Lab/StructLM)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## Introduction
|
||||
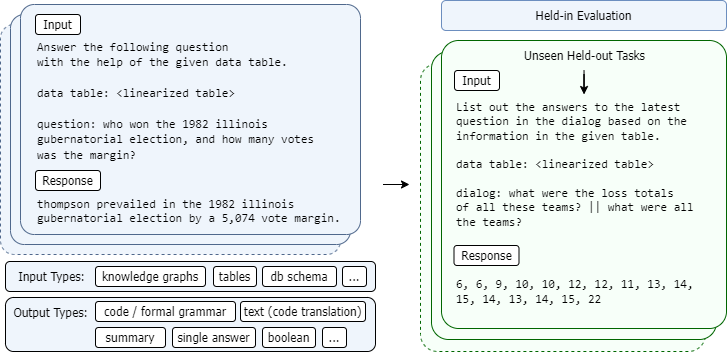
StructLM, is a series of open-source large language models (LLMs) finetuned for structured knowledge grounding (SKG) tasks.
|
||||
|
||||
This model is trained using Mistral as the base model, instead of CodeLlama.
|
||||
|
||||
## Training Data
|
||||
This model is trained on 🤗 [SKGInstruct-skg-only Dataset](https://huggingface.co/datasets/TIGER-Lab/SKGInstruct-skg-only). Check out the dataset card for more details.
|
||||
|
||||
## Training Procedure
|
||||
This models is fine-tuned with Mistral-v0.2 models as base models. Each model is trained for 3 epochs, and the best checkpoint is selected.
|
||||
|
||||
## Evaluation
|
||||
Reference our project page for evaluation results on 7B-M
|
||||
|
||||
## Usage
|
||||
You can use the models through Huggingface's Transformers library.
|
||||
Check our Github repo for the evaluation code: [https://github.com/TIGER-AI-Lab/StructLM](https://github.com/TIGER-AI-Lab/StructLM)
|
||||
|
||||
|
||||
## Prompt Format
|
||||
|
||||
**For this 7B model, the prompt format is**
|
||||
```
|
||||
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
|
||||
|
||||
|
||||
### Instruction:
|
||||
{instruction}
|
||||
|
||||
{input}
|
||||
|
||||
{question}
|
||||
|
||||
### Response:
|
||||
|
||||
```
|
||||
|
||||
To see concrete examples of this linearization, you can directly reference the 🤗 [SKGInstruct Dataset](https://huggingface.co/datasets/TIGER-Lab/SKGInstruct) (coming soon).
|
||||
We will provide code for linearizing this data shortly.
|
||||
|
||||
|
||||
A few examples:
|
||||
|
||||
**Tabular data**
|
||||
```
|
||||
col : day | kilometers row 1 : tuesday | 0 row 2 : wednesday | 0 row 3 : thursday | 4 row 4 : friday | 0 row 5 : saturday | 0
|
||||
```
|
||||
|
||||
**Knowledge triples (dart)**
|
||||
```
|
||||
Hawaii Five-O : notes : Episode: The Flight of the Jewels | [TABLECONTEXT] : [title] : Jeff Daniels | [TABLECONTEXT] : title : Hawaii Five-O
|
||||
```
|
||||
|
||||
**Knowledge graph schema (grailqa)**
|
||||
```
|
||||
top antiquark: m.094nrqp | physics.particle_antiparticle.self_antiparticle physics.particle_family physics.particle.antiparticle physics.particle_family.subclasses physics.subatomic_particle_generation physics.particle_family.particles physics.particle common.image.appears_in_topic_gallery physics.subatomic_particle_generation.particles physics.particle.family physics.particle_family.parent_class physics.particle_antiparticle physics.particle_antiparticle.particle physics.particle.generation
|
||||
```
|
||||
|
||||
**Example input**
|
||||
|
||||
```
|
||||
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
|
||||
|
||||
|
||||
### Instruction:
|
||||
Use the information in the following table to solve the problem, choose between the choices if they are provided. table:
|
||||
|
||||
col : day | kilometers row 1 : tuesday | 0 row 2 : wednesday | 0 row 3 : thursday | 4 row 4 : friday | 0 row 5 : saturday | 0
|
||||
|
||||
question:
|
||||
|
||||
Allie kept track of how many kilometers she walked during the past 5 days. What is the range of the numbers? [/INST]
|
||||
|
||||
### Response:
|
||||
|
||||
```
|
||||
|
||||
|
||||
## Intended Uses
|
||||
These models are trained for research purposes. They are designed to be proficient in interpreting linearized structured input. Downstream uses can potentially include various applications requiring the interpretation of structured data.
|
||||
|
||||
## Limitations
|
||||
While we've tried to build an SKG-specialized model capable of generalizing, we have shown that this is a challenging domain, and it may lack performance characteristics that allow it to be directly used in chat or other applications.
|
||||
|
||||
|
||||
## Citation
|
||||
If you use the models, data, or code from this project, please cite the original paper:
|
||||
|
||||
```
|
||||
@misc{zhuang2024structlm,
|
||||
title={StructLM: Towards Building Generalist Models for Structured Knowledge Grounding},
|
||||
author={Alex Zhuang and Ge Zhang and Tianyu Zheng and Xinrun Du and Junjie Wang and Weiming Ren and Stephen W. Huang and Jie Fu and Xiang Yue and Wenhu Chen},
|
||||
year={2024},
|
||||
eprint={2402.16671},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CL}
|
||||
}
|
||||
```
|
||||
3
added_tokens.json
Normal file
3
added_tokens.json
Normal file
@@ -0,0 +1,3 @@
|
||||
{
|
||||
"[PAD]": 32000
|
||||
}
|
||||
26
config.json
Normal file
26
config.json
Normal file
@@ -0,0 +1,26 @@
|
||||
{
|
||||
"_name_or_path": "/ML-A800/models/Mistral-7B-v0.2-hf",
|
||||
"architectures": [
|
||||
"MistralForCausalLM"
|
||||
],
|
||||
"attention_dropout": 0.0,
|
||||
"bos_token_id": 1,
|
||||
"eos_token_id": 2,
|
||||
"hidden_act": "silu",
|
||||
"hidden_size": 4096,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 14336,
|
||||
"max_position_embeddings": 32768,
|
||||
"model_type": "mistral",
|
||||
"num_attention_heads": 32,
|
||||
"num_hidden_layers": 32,
|
||||
"num_key_value_heads": 8,
|
||||
"rms_norm_eps": 1e-05,
|
||||
"rope_theta": 1000000.0,
|
||||
"sliding_window": 32768,
|
||||
"tie_word_embeddings": false,
|
||||
"torch_dtype": "bfloat16",
|
||||
"transformers_version": "4.38.0",
|
||||
"use_cache": false,
|
||||
"vocab_size": 32001
|
||||
}
|
||||
1
configuration.json
Normal file
1
configuration.json
Normal file
@@ -0,0 +1 @@
|
||||
{"framework": "pytorch", "task": "text-generation", "allow_remote": true}
|
||||
6
generation_config.json
Normal file
6
generation_config.json
Normal file
@@ -0,0 +1,6 @@
|
||||
{
|
||||
"_from_model_config": true,
|
||||
"bos_token_id": 1,
|
||||
"eos_token_id": 2,
|
||||
"transformers_version": "4.38.0"
|
||||
}
|
||||
3
model-00001-of-00003.safetensors
Normal file
3
model-00001-of-00003.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:0a72bcc8902f4dd77f2fc5c410666dd98e2d29e7e4bca1aa34b594f71499ccdc
|
||||
size 4943170528
|
||||
3
model-00002-of-00003.safetensors
Normal file
3
model-00002-of-00003.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:0603773a384d5f556db0787c39549e37b63926a64fa93b4aabb1a9a2e48d98a1
|
||||
size 4999819336
|
||||
3
model-00003-of-00003.safetensors
Normal file
3
model-00003-of-00003.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:3b174d7a5f2802d92a6f9b97fd6f1b761fa097fd69ebb00bcf5fbe6796de2628
|
||||
size 4540524536
|
||||
298
model.safetensors.index.json
Normal file
298
model.safetensors.index.json
Normal file
@@ -0,0 +1,298 @@
|
||||
{
|
||||
"metadata": {
|
||||
"total_size": 14483480576
|
||||
},
|
||||
"weight_map": {
|
||||
"lm_head.weight": "model-00003-of-00003.safetensors",
|
||||
"model.embed_tokens.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.0.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.1.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.10.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.10.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.10.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.10.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.10.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.10.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.10.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.11.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.12.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.13.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.14.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.15.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.16.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.17.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.18.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.19.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.2.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.20.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.20.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.20.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.20.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.20.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.21.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.21.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.21.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.21.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.21.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.21.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.21.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.21.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.21.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.22.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.22.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.22.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.22.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.22.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
||||
"model.layers.23.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.24.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.25.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.26.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.27.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.28.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.29.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.3.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.30.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.30.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.30.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.31.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.31.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.31.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.31.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.31.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.31.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.31.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.31.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.31.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
||||
"model.layers.4.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.5.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.6.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.7.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.8.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.9.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.9.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.9.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
||||
"model.norm.weight": "model-00003-of-00003.safetensors"
|
||||
}
|
||||
}
|
||||
30
special_tokens_map.json
Normal file
30
special_tokens_map.json
Normal file
@@ -0,0 +1,30 @@
|
||||
{
|
||||
"bos_token": {
|
||||
"content": "<s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"eos_token": {
|
||||
"content": "</s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"pad_token": {
|
||||
"content": "[PAD]",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"unk_token": {
|
||||
"content": "<unk>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
}
|
||||
}
|
||||
BIN
tokenizer.model
(Stored with Git LFS)
Normal file
BIN
tokenizer.model
(Stored with Git LFS)
Normal file
Binary file not shown.
51
tokenizer_config.json
Normal file
51
tokenizer_config.json
Normal file
@@ -0,0 +1,51 @@
|
||||
{
|
||||
"add_bos_token": true,
|
||||
"add_eos_token": false,
|
||||
"add_prefix_space": true,
|
||||
"added_tokens_decoder": {
|
||||
"0": {
|
||||
"content": "<unk>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"1": {
|
||||
"content": "<s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"2": {
|
||||
"content": "</s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"32000": {
|
||||
"content": "[PAD]",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
}
|
||||
},
|
||||
"bos_token": "<s>",
|
||||
"clean_up_tokenization_spaces": false,
|
||||
"eos_token": "</s>",
|
||||
"legacy": true,
|
||||
"model_max_length": 3072,
|
||||
"pad_token": "[PAD]",
|
||||
"padding_side": "right",
|
||||
"sp_model_kwargs": {},
|
||||
"spaces_between_special_tokens": false,
|
||||
"tokenizer_class": "LlamaTokenizer",
|
||||
"unk_token": "<unk>",
|
||||
"use_default_system_prompt": false
|
||||
}
|
||||
74034
trainer_state.json
Normal file
74034
trainer_state.json
Normal file
File diff suppressed because it is too large
Load Diff
3
training_args.bin
Normal file
3
training_args.bin
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:f659fdf57347db27e4f907b93e3a8624adcc62a797f0c126b73201cb6799efb6
|
||||
size 5240
|
||||
Reference in New Issue
Block a user