初始化项目,由ModelHub XC社区提供模型
Model: TIGER-Lab/Mantis-8B-siglip-llama3 Source: Original Platform
This commit is contained in:
35
.gitattributes
vendored
Normal file
35
.gitattributes
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||
*.model filter=lfs diff=lfs merge=lfs -text
|
||||
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
154
README.md
Normal file
154
README.md
Normal file
@@ -0,0 +1,154 @@
|
||||
---
|
||||
base_model: TIGER-Lab/Mantis-8B-siglip-llama3-pretraind
|
||||
tags:
|
||||
- multimodal
|
||||
- lmm
|
||||
- vlm
|
||||
- llava
|
||||
- siglip
|
||||
- llama3
|
||||
- mantis
|
||||
model-index:
|
||||
- name: Mantis-8B-siglip-llama3
|
||||
results: []
|
||||
license: llama3
|
||||
datasets:
|
||||
- TIGER-Lab/Mantis-Instruct
|
||||
language:
|
||||
- en
|
||||
---
|
||||
|
||||
# 🔥 Mantis (TMLR 2024)
|
||||
|
||||
[Paper](https://arxiv.org/abs/2405.01483) |
|
||||
[Website](https://tiger-ai-lab.github.io/Mantis/) |
|
||||
[Github](https://github.com/TIGER-AI-Lab/Mantis) |
|
||||
[Models](https://huggingface.co/collections/TIGER-Lab/mantis-6619b0834594c878cdb1d6e4) |
|
||||
[Demo](https://huggingface.co/spaces/TIGER-Lab/Mantis) |
|
||||
[Wandb](https://api.wandb.ai/links/dongfu/iydlrqgj)
|
||||
|
||||
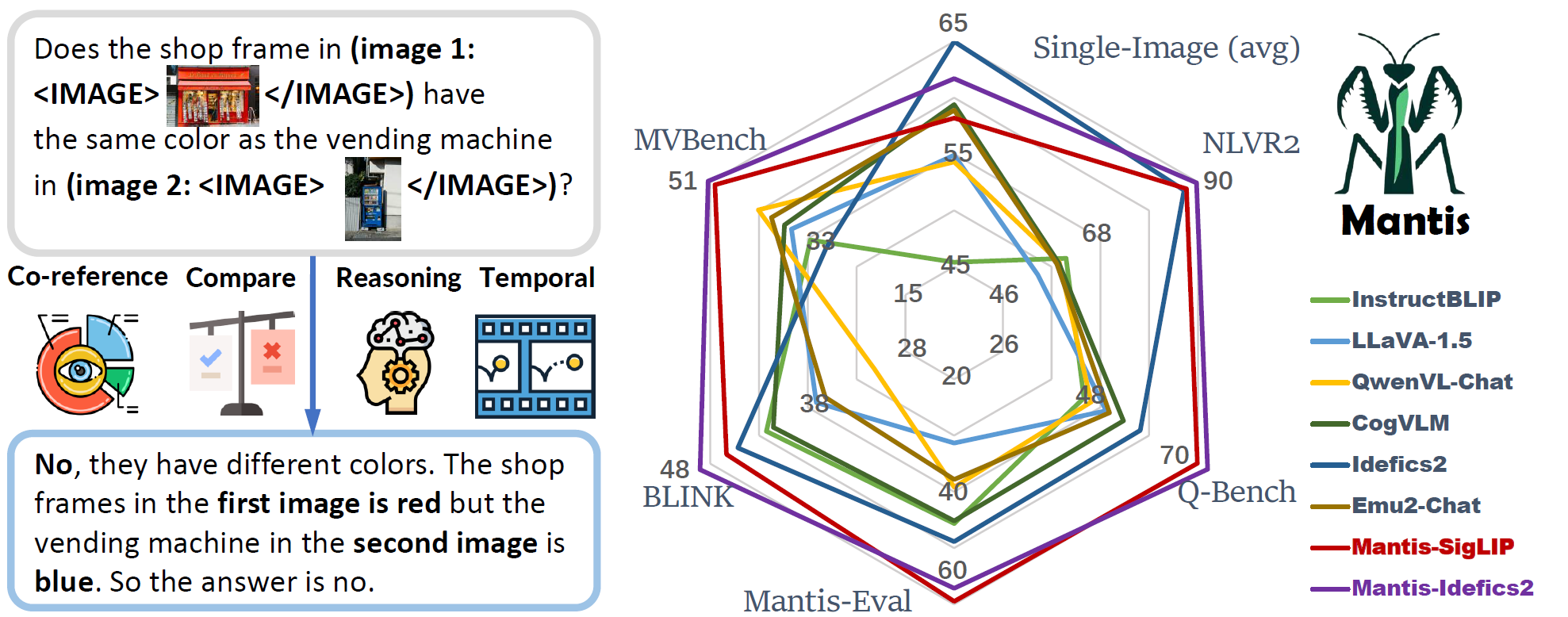
|
||||
|
||||
|
||||
## Summary
|
||||
|
||||
- Mantis is an LLaMA-3 based LMM with **interleaved text and image as inputs**, train on Mantis-Instruct under academic-level resources (i.e. 36 hours on 16xA100-40G).
|
||||
- Mantis is trained to have multi-image skills including co-reference, reasoning, comparing, temporal understanding.
|
||||
- Mantis reaches the state-of-the-art performance on five multi-image benchmarks (NLVR2, Q-Bench, BLINK, MVBench, Mantis-Eval), and also maintain a strong single-image performance on par with CogVLM and Emu2.
|
||||
|
||||
## Multi-Image Performance
|
||||
|
||||
| Models | Size | Format | NLVR2 | Q-Bench | Mantis-Eval | BLINK | MVBench | Avg |
|
||||
|--------------------|:----:|:--------:|:-----:|:-------:|:-----------:|:-----:|:-------:|:----:|
|
||||
| GPT-4V | - | sequence | 88.80 | 76.52 | 62.67 | 51.14 | 43.50 | 64.5 |
|
||||
| Open Source Models | | | | | | | | |
|
||||
| Random | - | - | 48.93 | 40.20 | 23.04 | 38.09 | 27.30 | 35.5 |
|
||||
| Kosmos2 | 1.6B | merge | 49.00 | 35.10 | 30.41 | 37.50 | 21.62 | 34.7 |
|
||||
| LLaVA-v1.5 | 7B | merge | 53.88 | 49.32 | 31.34 | 37.13 | 36.00 | 41.5 |
|
||||
| LLava-V1.6 | 7B | merge | 58.88 | 54.80 | 45.62 | 39.55 | 40.90 | 48.0 |
|
||||
| Qwen-VL-Chat | 7B | merge | 58.72 | 45.90 | 39.17 | 31.17 | 42.15 | 43.4 |
|
||||
| Fuyu | 8B | merge | 51.10 | 49.15 | 27.19 | 36.59 | 30.20 | 38.8 |
|
||||
| BLIP-2 | 13B | merge | 59.42 | 51.20 | 49.77 | 39.45 | 31.40 | 46.2 |
|
||||
| InstructBLIP | 13B | merge | 60.26 | 44.30 | 45.62 | 42.24 | 32.50 | 45.0 |
|
||||
| CogVLM | 17B | merge | 58.58 | 53.20 | 45.16 | 41.54 | 37.30 | 47.2 |
|
||||
| OpenFlamingo | 9B | sequence | 36.41 | 19.60 | 12.44 | 39.18 | 7.90 | 23.1 |
|
||||
| Otter-Image | 9B | sequence | 49.15 | 17.50 | 14.29 | 36.26 | 15.30 | 26.5 |
|
||||
| Idefics1 | 9B | sequence | 54.63 | 30.60 | 28.11 | 24.69 | 26.42 | 32.9 |
|
||||
| VideoLLaVA | 7B | sequence | 56.48 | 45.70 | 35.94 | 38.92 | 44.30 | 44.3 |
|
||||
| Emu2-Chat | 37B | sequence | 58.16 | 50.05 | 37.79 | 36.20 | 39.72 | 44.4 |
|
||||
| Vila | 8B | sequence | 76.45 | 45.70 | 51.15 | 39.30 | 49.40 | 52.4 |
|
||||
| Idefics2 | 8B | sequence | 86.87 | 57.00 | 48.85 | 45.18 | 29.68 | 53.5 |
|
||||
| Mantis-CLIP | 8B | sequence | 84.66 | 66.00 | 55.76 | 47.06 | 48.30 | 60.4 |
|
||||
| Mantis-SIGLIP | 8B | sequence | 87.43 | 69.90 | **59.45** | 46.35 | 50.15 | 62.7 |
|
||||
| Mantis-Flamingo | 9B | sequence | 52.96 | 46.80 | 32.72 | 38.00 | 40.83 | 42.3 |
|
||||
| Mantis-Idefics2 | 8B | sequence | **89.71** | **75.20** | 57.14 | **49.05** | **51.38** | **64.5** |
|
||||
| $\Delta$ over SOTA | - | - | +2.84 | +18.20 | +8.30 | +3.87 | +1.98 | +11.0 |
|
||||
|
||||
## Single-Image Performance
|
||||
|
||||
| Model | Size | TextVQA | VQA | MMB | MMMU | OKVQA | SQA | MathVista | Avg |
|
||||
|-----------------|:----:|:-------:|:----:|:----:|:----:|:-----:|:----:|:---------:|:----:|
|
||||
| OpenFlamingo | 9B | 46.3 | 58.0 | 32.4 | 28.7 | 51.4 | 45.7 | 18.6 | 40.2 |
|
||||
| Idefics1 | 9B | 39.3 | 68.8 | 45.3 | 32.5 | 50.4 | 51.6 | 21.1 | 44.1 |
|
||||
| InstructBLIP | 7B | 33.6 | 75.2 | 38.3 | 30.6 | 45.2 | 70.6 | 24.4 | 45.4 |
|
||||
| Yi-VL | 6B | 44.8 | 72.5 | 68.4 | 39.1 | 51.3 | 71.7 | 29.7 | 53.9 |
|
||||
| Qwen-VL-Chat | 7B | 63.8 | 78.2 | 61.8 | 35.9 | 56.6 | 68.2 | 15.5 | 54.3 |
|
||||
| LLaVA-1.5 | 7B | 58.2 | 76.6 | 64.8 | 35.3 | 53.4 | 70.4 | 25.6 | 54.9 |
|
||||
| Emu2-Chat | 37B | <u>66.6</u> | **84.9** | 63.6 | 36.3 | **64.8** | 65.3 | 30.7 | 58.9 |
|
||||
| CogVLM | 17B | **70.4** | <u>82.3</u> | 65.8 | 32.1 | <u>64.8</u> | 65.6 | 35.0 | 59.4 |
|
||||
| Idefics2 | 8B | 70.4 | 79.1 | <u>75.7</u> | **43.0** | 53.5 | **86.5** | **51.4** | **65.7** |
|
||||
| Mantis-CLIP | 8B | 56.4 | 73.0 | 66.0 | 38.1 | 53.0 | 73.8 | 31.7 | 56.0 |
|
||||
| Mantis-SigLIP | 8B | 59.2 | 74.9 | 68.7 | 40.1 | 55.4 | 74.9 | 34.4 | 58.2 |
|
||||
| Mantis-Idefics2 | 8B | 63.5 | 77.6 | 75.7 | <u>41.1</u> | 52.6 | <u>81.3</u> | <u>40.4</u> | <u>61.7</u> |
|
||||
|
||||
## How to use
|
||||
|
||||
### Installation
|
||||
```bash
|
||||
# This only installs minimum packages (torch, transformers, accelerate) for inference, no redundant packages are installed.
|
||||
pip install git+https://github.com/TIGER-AI-Lab/Mantis.git
|
||||
```
|
||||
|
||||
### Run example inference:
|
||||
```python
|
||||
from mantis.models.mllava import chat_mllava
|
||||
from PIL import Image
|
||||
import torch
|
||||
|
||||
|
||||
image1 = "image1.jpg"
|
||||
image2 = "image2.jpg"
|
||||
images = [Image.open(image1), Image.open(image2)]
|
||||
|
||||
# load processor and model
|
||||
from mantis.models.mllava import MLlavaProcessor, LlavaForConditionalGeneration
|
||||
processor = MLlavaProcessor.from_pretrained("TIGER-Lab/Mantis-8B-siglip-llama3")
|
||||
attn_implementation = None # or "flash_attention_2"
|
||||
model = LlavaForConditionalGeneration.from_pretrained("TIGER-Lab/Mantis-8B-siglip-llama3", device_map="cuda", torch_dtype=torch.bfloat16, attn_implementation=attn_implementation)
|
||||
|
||||
generation_kwargs = {
|
||||
"max_new_tokens": 1024,
|
||||
"num_beams": 1,
|
||||
"do_sample": False
|
||||
}
|
||||
|
||||
# chat
|
||||
text = "Describe the difference of <image> and <image> as much as you can."
|
||||
response, history = chat_mllava(text, images, model, processor, **generation_kwargs)
|
||||
|
||||
print("USER: ", text)
|
||||
print("ASSISTANT: ", response)
|
||||
|
||||
text = "How many wallets are there in image 1 and image 2 respectively?"
|
||||
response, history = chat_mllava(text, images, model, processor, history=history, **generation_kwargs)
|
||||
|
||||
print("USER: ", text)
|
||||
print("ASSISTANT: ", response)
|
||||
|
||||
"""
|
||||
USER: Describe the difference of <image> and <image> as much as you can.
|
||||
ASSISTANT: The second image has more variety in terms of colors and designs. While the first image only shows two brown leather pouches, the second image features four different pouches in various colors and designs, including a purple one with a gold coin, a red one with a gold coin, a black one with a gold coin, and a brown one with a gold coin. This variety makes the second image more visually interesting and dynamic.
|
||||
USER: How many wallets are there in image 1 and image 2 respectively?
|
||||
ASSISTANT: There are two wallets in image 1, and four wallets in image 2.
|
||||
"""
|
||||
```
|
||||
|
||||
### Training
|
||||
See [mantis/train](https://github.com/TIGER-AI-Lab/Mantis/tree/main/mantis/train) for details
|
||||
|
||||
### Evaluation
|
||||
See [mantis/benchmark](https://github.com/TIGER-AI-Lab/Mantis/tree/main/mantis/benchmark) for details
|
||||
|
||||
**Please cite our paper or give a star to out Github repo if you find this model useful**
|
||||
|
||||
## Citation
|
||||
```
|
||||
@article{Jiang2024MANTISIM,
|
||||
title={MANTIS: Interleaved Multi-Image Instruction Tuning},
|
||||
author={Dongfu Jiang and Xuan He and Huaye Zeng and Cong Wei and Max W.F. Ku and Qian Liu and Wenhu Chen},
|
||||
journal={Transactions on Machine Learning Research},
|
||||
year={2024},
|
||||
volume={2024},
|
||||
url={https://openreview.net/forum?id=skLtdUVaJa}
|
||||
}
|
||||
```
|
||||
43
config.json
Normal file
43
config.json
Normal file
@@ -0,0 +1,43 @@
|
||||
{
|
||||
"_name_or_path": "MFuyu/llava_siglip_llama3_8b_pretrain_8192",
|
||||
"architectures": [
|
||||
"LlavaForConditionalGeneration"
|
||||
],
|
||||
"ignore_index": -100,
|
||||
"image_token_index": 128256,
|
||||
"model_type": "llava",
|
||||
"pad_token_id": 128257,
|
||||
"projector_hidden_act": "gelu",
|
||||
"text_config": {
|
||||
"_name_or_path": "meta-llama/Meta-Llama-3-8B-Instruct",
|
||||
"architectures": [
|
||||
"LlamaForCausalLM"
|
||||
],
|
||||
"bos_token_id": 128000,
|
||||
"eos_token_id": 128001,
|
||||
"intermediate_size": 14336,
|
||||
"max_position_embeddings": 8192,
|
||||
"model_type": "llama",
|
||||
"num_key_value_heads": 8,
|
||||
"rms_norm_eps": 1e-05,
|
||||
"rope_theta": 500000.0,
|
||||
"torch_dtype": "bfloat16",
|
||||
"vocab_size": 128258
|
||||
},
|
||||
"torch_dtype": "bfloat16",
|
||||
"transformers_version": "4.39.2",
|
||||
"vision_config": {
|
||||
"hidden_act": "gelu_pytorch_tanh",
|
||||
"hidden_size": 1152,
|
||||
"image_size": 384,
|
||||
"intermediate_size": 4304,
|
||||
"layer_norm_eps": 1e-06,
|
||||
"model_type": "siglip_vision_model",
|
||||
"num_attention_heads": 16,
|
||||
"num_hidden_layers": 27,
|
||||
"patch_size": 14
|
||||
},
|
||||
"vision_feature_layer": -2,
|
||||
"vision_feature_select_strategy": "default",
|
||||
"vocab_size": 128258
|
||||
}
|
||||
1
configuration.json
Normal file
1
configuration.json
Normal file
@@ -0,0 +1 @@
|
||||
{"framework": "pytorch", "task": "text-generation", "allow_remote": true}
|
||||
7
generation_config.json
Normal file
7
generation_config.json
Normal file
@@ -0,0 +1,7 @@
|
||||
{
|
||||
"_from_model_config": true,
|
||||
"bos_token_id": 128000,
|
||||
"eos_token_id": 128001,
|
||||
"pad_token_id": 128257,
|
||||
"transformers_version": "4.39.2"
|
||||
}
|
||||
3
model-00001-of-00004.safetensors
Normal file
3
model-00001-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:1eb2c44b431c009f4f16bef0f55fc037abfad8547a43dcb81607d74db52dc434
|
||||
size 4886330032
|
||||
3
model-00002-of-00004.safetensors
Normal file
3
model-00002-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:d6e54f4adf494c1ba70519af7f66e146fc1a1708eb52e2632f32509a3a3adbbc
|
||||
size 4999820904
|
||||
3
model-00003-of-00004.safetensors
Normal file
3
model-00003-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:b5052d4d2e8de8138be7d119a5efbe2520cf34ff87708bc17da363d59b4da8f7
|
||||
size 4915917680
|
||||
3
model-00004-of-00004.safetensors
Normal file
3
model-00004-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:dca9a32c2e27e1cd1b1b4a675b8e0c4011bfd68c32dae5622b0548b2148d5dfb
|
||||
size 2158046280
|
||||
750
model.safetensors.index.json
Normal file
750
model.safetensors.index.json
Normal file
@@ -0,0 +1,750 @@
|
||||
{
|
||||
"metadata": {
|
||||
"total_size": 16960014464
|
||||
},
|
||||
"weight_map": {
|
||||
"language_model.lm_head.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.10.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.10.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.10.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.10.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.10.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.10.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.14.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.14.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.15.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.15.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.15.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.15.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.15.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.15.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.15.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.15.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.15.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.16.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.16.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.16.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.16.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.16.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.16.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.16.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.16.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.16.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.17.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.17.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.17.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.17.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.17.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.17.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.17.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.17.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.17.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.18.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.18.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.18.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.18.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.18.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.18.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.18.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.18.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.18.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.19.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.19.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.19.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.19.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.19.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.19.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.19.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.19.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.19.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.20.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.20.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.20.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.20.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.20.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.20.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.20.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.20.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.20.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.21.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.21.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.21.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.21.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.21.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.21.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.21.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.21.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.21.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.22.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.22.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.22.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.22.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.22.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.22.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.22.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.23.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.23.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.23.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.23.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.23.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.23.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.24.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.24.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.24.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.24.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.24.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.24.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.24.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.24.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.24.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.25.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.25.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.25.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.25.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.25.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.25.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.25.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.25.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.25.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.26.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.26.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.26.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.26.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.26.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.26.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.26.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.26.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.26.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.27.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.27.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.27.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.27.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.27.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.27.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.27.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.27.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.27.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.28.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.28.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.28.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.28.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.28.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.28.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.28.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.28.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.28.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.29.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.29.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.29.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.29.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.29.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.29.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.29.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.29.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.29.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"language_model.model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.30.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.30.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.30.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.30.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.30.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.30.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.30.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.30.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.30.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.31.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.31.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.31.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.31.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.31.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.31.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.31.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.31.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.31.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
||||
"language_model.model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.5.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.5.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.6.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.6.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.6.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.6.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.6.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.6.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"language_model.model.layers.7.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.7.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.7.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.7.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.7.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.7.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.7.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.7.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.7.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.8.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.8.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.8.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.8.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.8.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.8.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.8.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.8.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.8.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.9.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.9.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.9.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.9.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.9.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.9.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.9.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.9.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.layers.9.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"language_model.model.norm.weight": "model-00004-of-00004.safetensors",
|
||||
"multi_modal_projector.linear_1.bias": "model-00001-of-00004.safetensors",
|
||||
"multi_modal_projector.linear_1.weight": "model-00001-of-00004.safetensors",
|
||||
"multi_modal_projector.linear_2.bias": "model-00001-of-00004.safetensors",
|
||||
"multi_modal_projector.linear_2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.embeddings.patch_embedding.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.embeddings.patch_embedding.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.embeddings.position_embedding.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.10.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.11.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.12.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.13.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.14.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.15.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.16.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.17.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.18.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.19.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.20.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.21.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.22.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.23.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.24.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.25.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.26.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.7.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.8.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.encoder.layers.9.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.head.attention.in_proj_bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.head.attention.in_proj_weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.head.attention.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.head.attention.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.head.layernorm.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.head.layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.head.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.head.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.head.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.head.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.head.probe": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.post_layernorm.bias": "model-00001-of-00004.safetensors",
|
||||
"vision_tower.vision_model.post_layernorm.weight": "model-00001-of-00004.safetensors"
|
||||
}
|
||||
}
|
||||
37
preprocessor_config.json
Normal file
37
preprocessor_config.json
Normal file
@@ -0,0 +1,37 @@
|
||||
{
|
||||
"_valid_processor_keys": [
|
||||
"images",
|
||||
"do_resize",
|
||||
"size",
|
||||
"resample",
|
||||
"do_rescale",
|
||||
"rescale_factor",
|
||||
"do_normalize",
|
||||
"image_mean",
|
||||
"image_std",
|
||||
"return_tensors",
|
||||
"data_format",
|
||||
"input_data_format"
|
||||
],
|
||||
"do_normalize": true,
|
||||
"do_rescale": true,
|
||||
"do_resize": true,
|
||||
"image_mean": [
|
||||
0.5,
|
||||
0.5,
|
||||
0.5
|
||||
],
|
||||
"image_processor_type": "SiglipImageProcessor",
|
||||
"image_std": [
|
||||
0.5,
|
||||
0.5,
|
||||
0.5
|
||||
],
|
||||
"processor_class": "MLlavaProcessor",
|
||||
"resample": 3,
|
||||
"rescale_factor": 0.00392156862745098,
|
||||
"size": {
|
||||
"height": 384,
|
||||
"width": 384
|
||||
}
|
||||
}
|
||||
21
special_tokens_map.json
Normal file
21
special_tokens_map.json
Normal file
@@ -0,0 +1,21 @@
|
||||
{
|
||||
"additional_special_tokens": [
|
||||
"<image>",
|
||||
"<|pad|>"
|
||||
],
|
||||
"bos_token": {
|
||||
"content": "<|begin_of_text|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"eos_token": {
|
||||
"content": "<|end_of_text|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"unk_token": "<unk>"
|
||||
}
|
||||
410578
tokenizer.json
Normal file
410578
tokenizer.json
Normal file
File diff suppressed because it is too large
Load Diff
2095
tokenizer_config.json
Normal file
2095
tokenizer_config.json
Normal file
File diff suppressed because it is too large
Load Diff
3
training_args.bin
Normal file
3
training_args.bin
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:24089c5ab7a2f2796b48c8aaf15f9207f76287e9c8c6cfe7ce31731e3fbb330c
|
||||
size 6392
|
||||
Reference in New Issue
Block a user