2.3 KiB
2.3 KiB
license, language, base_model, pipeline_tag, library_name, tags
| license | language | base_model | pipeline_tag | library_name | tags | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| apache-2.0 |
|
|
text-generation | transformers |
|
Supertron1-4B: A Capable, Efficient Instruction-Tuned Language Model
Model Description
Supertron1-4B is an instruction-tuned language model built on top of Qwen3-4B. Designed to be a reliable, efficient daily driver, it delivers strong performance across math, coding, reasoning, and general conversation while remaining fast and lightweight enough to run on consumer hardware.
- Developed by: Surpem
- Model type: Causal Language Model
- Architecture: Dense Transformer, 4B parameters
- Fine-tuned from: Qwen/Qwen3-4B
- License: Apache 2.0
Results
Supertron1-4B holds its own against models in the 4–8B class and surpasses Mistral 7B on all four core benchmarks despite having nearly half the parameters.
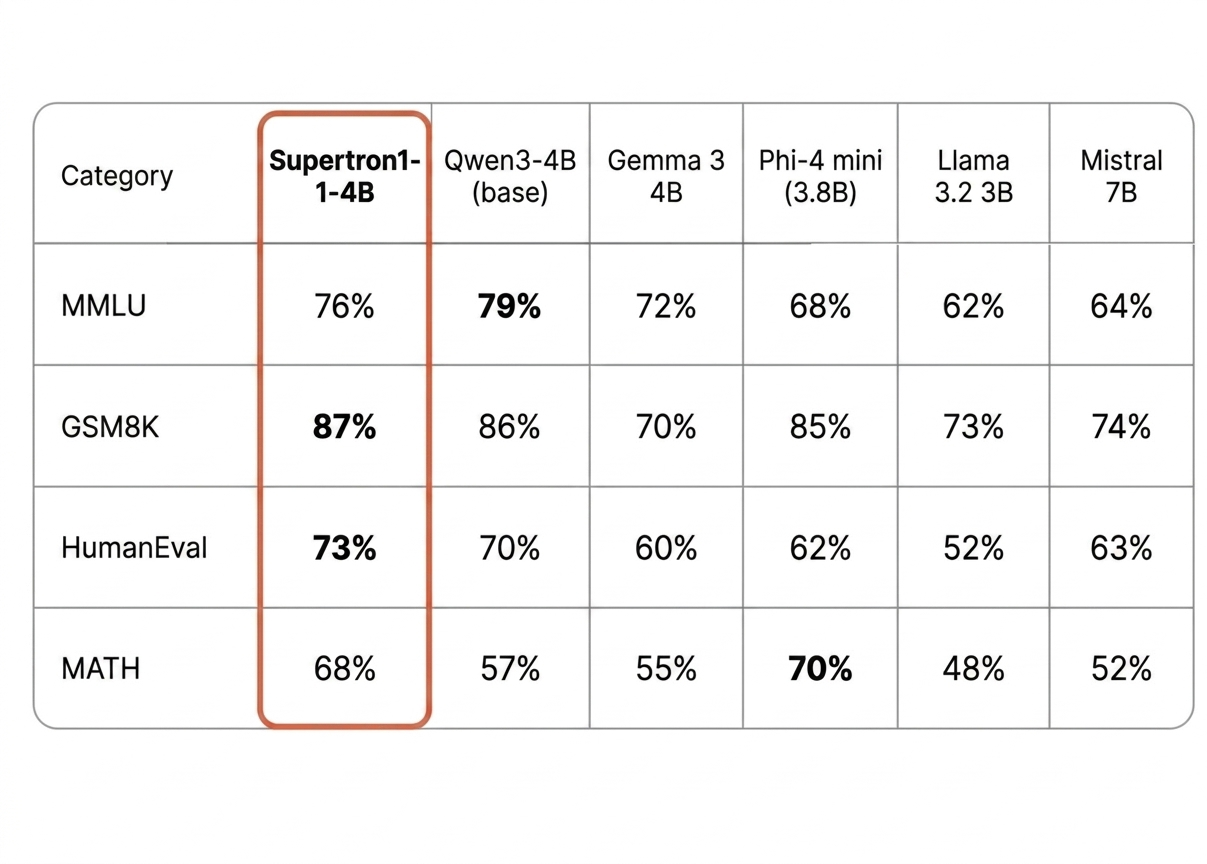
Key takeaways:
- Beats Mistral 7B on every benchmark at 4B parameters
- Strong GSM8K and HumanEval performance from math and coding focused tuning
- Competitive with Phi-4 mini on a fraction of the compute
Get Started
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "surpem/supertron1-4b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
messages = [
{"role": "user", "content": "Explain the difference between LoRA and full fine-tuning."}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=512)
print(tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:], skip_special_tokens=True))
Citation
@misc{surpem2026supertron1,
title={Supertron1-4B — Efficient Instruction-Tuned Language Model},
author={Surpem},
year={2026},
url={https://huggingface.co/surpem/supertron1-4b},
}