初始化项目,由ModelHub XC社区提供模型
Model: Qwen/Qwen3-VL-4B-Thinking Source: Original Platform
This commit is contained in:
53
.gitattributes
vendored
Normal file
53
.gitattributes
vendored
Normal file
@@ -0,0 +1,53 @@
|
||||
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.model filter=lfs diff=lfs merge=lfs -text
|
||||
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
||||
*.tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
*.db* filter=lfs diff=lfs merge=lfs -text
|
||||
*.ark* filter=lfs diff=lfs merge=lfs -text
|
||||
**/*ckpt*data* filter=lfs diff=lfs merge=lfs -text
|
||||
**/*ckpt*.meta filter=lfs diff=lfs merge=lfs -text
|
||||
**/*ckpt*.index filter=lfs diff=lfs merge=lfs -text
|
||||
|
||||
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||
*.gguf* filter=lfs diff=lfs merge=lfs -text
|
||||
*.ggml filter=lfs diff=lfs merge=lfs -text
|
||||
*.llamafile* filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
|
||||
vocab.json filter=lfs diff=lfs merge=lfs -text
|
||||
model-00002-of-00002.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
merges.txt filter=lfs diff=lfs merge=lfs -text
|
||||
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
||||
model-00001-of-00002.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
192
README.md
Normal file
192
README.md
Normal file
@@ -0,0 +1,192 @@
|
||||
---
|
||||
license: apache-2.0
|
||||
pipeline_tag: image-text-to-text
|
||||
library_name: transformers
|
||||
---
|
||||
<a href="https://chat.qwenlm.ai/" target="_blank" style="margin: 2px;">
|
||||
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
|
||||
</a>
|
||||
|
||||
# Qwen3-VL-4B-Thinking
|
||||
|
||||
|
||||
Meet Qwen3-VL — the most powerful vision-language model in the Qwen series to date.
|
||||
|
||||
This generation delivers comprehensive upgrades across the board: superior text understanding & generation, deeper visual perception & reasoning, extended context length, enhanced spatial and video dynamics comprehension, and stronger agent interaction capabilities.
|
||||
|
||||
Available in Dense and MoE architectures that scale from edge to cloud, with Instruct and reasoning‑enhanced Thinking editions for flexible, on‑demand deployment.
|
||||
|
||||
|
||||
#### Key Enhancements:
|
||||
|
||||
* **Visual Agent**: Operates PC/mobile GUIs—recognizes elements, understands functions, invokes tools, completes tasks.
|
||||
|
||||
* **Visual Coding Boost**: Generates Draw.io/HTML/CSS/JS from images/videos.
|
||||
|
||||
* **Advanced Spatial Perception**: Judges object positions, viewpoints, and occlusions; provides stronger 2D grounding and enables 3D grounding for spatial reasoning and embodied AI.
|
||||
|
||||
* **Long Context & Video Understanding**: Native 256K context, expandable to 1M; handles books and hours-long video with full recall and second-level indexing.
|
||||
|
||||
* **Enhanced Multimodal Reasoning**: Excels in STEM/Math—causal analysis and logical, evidence-based answers.
|
||||
|
||||
* **Upgraded Visual Recognition**: Broader, higher-quality pretraining is able to “recognize everything”—celebrities, anime, products, landmarks, flora/fauna, etc.
|
||||
|
||||
* **Expanded OCR**: Supports 32 languages (up from 19); robust in low light, blur, and tilt; better with rare/ancient characters and jargon; improved long-document structure parsing.
|
||||
|
||||
* **Text Understanding on par with pure LLMs**: Seamless text–vision fusion for lossless, unified comprehension.
|
||||
|
||||
|
||||
#### Model Architecture Updates:
|
||||
|
||||
<p align="center">
|
||||
<img src="https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3-VL/qwen3vl_arc.jpg" width="80%"/>
|
||||
<p>
|
||||
|
||||
|
||||
1. **Interleaved-MRoPE**: Full‑frequency allocation over time, width, and height via robust positional embeddings, enhancing long‑horizon video reasoning.
|
||||
|
||||
2. **DeepStack**: Fuses multi‑level ViT features to capture fine‑grained details and sharpen image–text alignment.
|
||||
|
||||
3. **Text–Timestamp Alignment:** Moves beyond T‑RoPE to precise, timestamp‑grounded event localization for stronger video temporal modeling.
|
||||
|
||||
|
||||
This is the weight repository for Qwen3-VL-4B-Thinking.
|
||||
|
||||
|
||||
---
|
||||
|
||||
## Model Performance
|
||||
|
||||
**Multimodal performance**
|
||||
|
||||

|
||||
|
||||
**Pure text performance**
|
||||
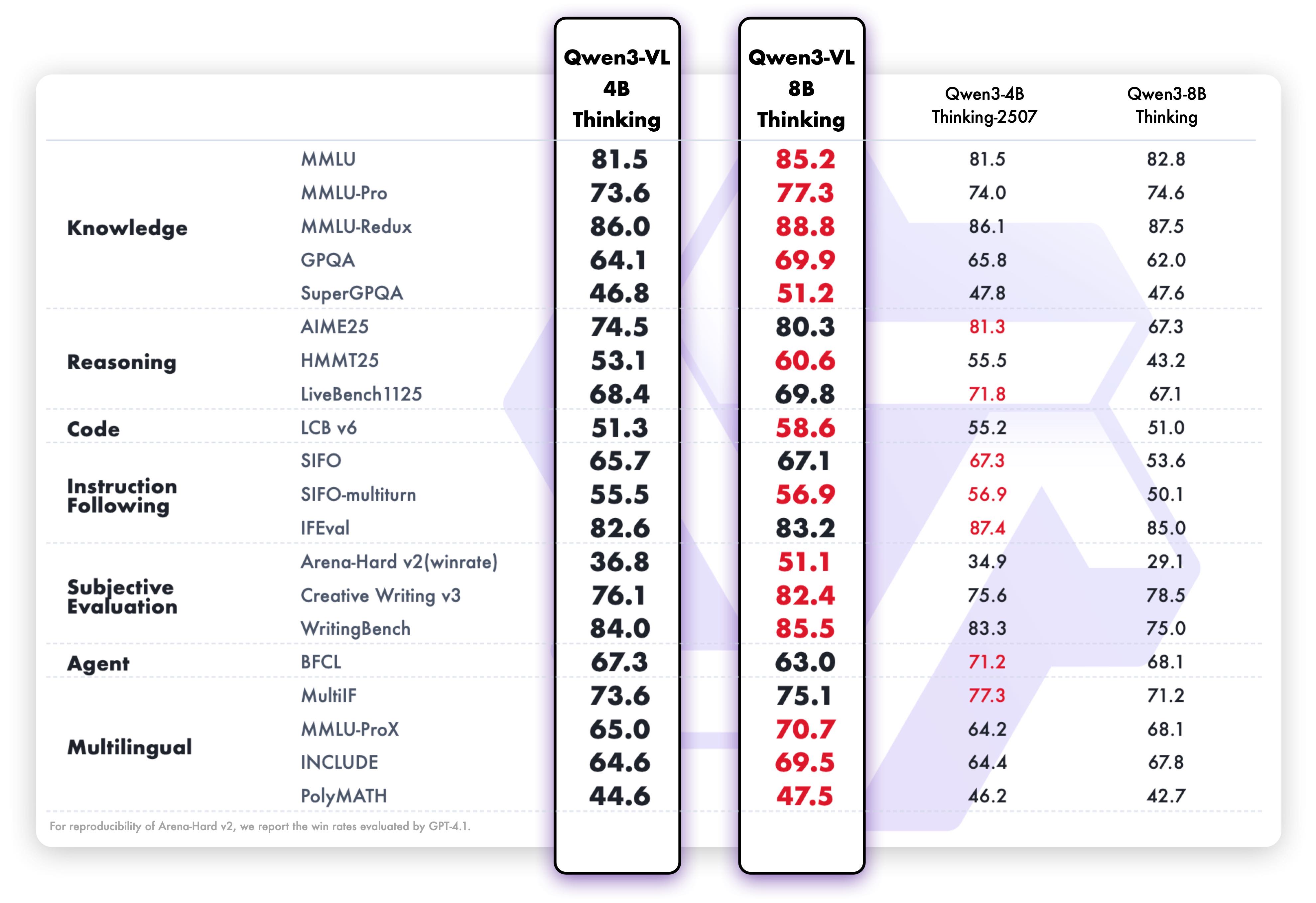
|
||||
|
||||
## Quickstart
|
||||
|
||||
Below, we provide simple examples to show how to use Qwen3-VL with 🤖 ModelScope and 🤗 Transformers.
|
||||
|
||||
The code of Qwen3-VL has been in the latest Hugging face transformers and we advise you to build from source with command:
|
||||
```
|
||||
pip install git+https://github.com/huggingface/transformers
|
||||
# pip install transformers==4.57.0 # currently, V4.57.0 is not released
|
||||
```
|
||||
|
||||
### Using 🤗 Transformers to Chat
|
||||
|
||||
Here we show a code snippet to show you how to use the chat model with `transformers`:
|
||||
|
||||
```python
|
||||
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
|
||||
|
||||
# default: Load the model on the available device(s)
|
||||
model = Qwen3VLForConditionalGeneration.from_pretrained(
|
||||
"Qwen/Qwen3-VL-4B-Thinking", dtype="auto", device_map="auto"
|
||||
)
|
||||
|
||||
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
|
||||
# model = Qwen3VLForConditionalGeneration.from_pretrained(
|
||||
# "Qwen/Qwen3-VL-4B-Thinking",
|
||||
# dtype=torch.bfloat16,
|
||||
# attn_implementation="flash_attention_2",
|
||||
# device_map="auto",
|
||||
# )
|
||||
|
||||
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-4B-Thinking")
|
||||
|
||||
messages = [
|
||||
{
|
||||
"role": "user",
|
||||
"content": [
|
||||
{
|
||||
"type": "image",
|
||||
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
|
||||
},
|
||||
{"type": "text", "text": "Describe this image."},
|
||||
],
|
||||
}
|
||||
]
|
||||
|
||||
# Preparation for inference
|
||||
inputs = processor.apply_chat_template(
|
||||
messages,
|
||||
tokenize=True,
|
||||
add_generation_prompt=True,
|
||||
return_dict=True,
|
||||
return_tensors="pt"
|
||||
)
|
||||
inputs = inputs.to(model.device)
|
||||
|
||||
# Inference: Generation of the output
|
||||
generated_ids = model.generate(**inputs, max_new_tokens=128)
|
||||
generated_ids_trimmed = [
|
||||
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
||||
]
|
||||
output_text = processor.batch_decode(
|
||||
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
||||
)
|
||||
print(output_text)
|
||||
```
|
||||
|
||||
### Generation Hyperparameters
|
||||
#### VL
|
||||
```bash
|
||||
export greedy='false'
|
||||
export top_p=0.95
|
||||
export top_k=20
|
||||
export repetition_penalty=1.0
|
||||
export presence_penalty=0.0
|
||||
export temperature=1.0
|
||||
export out_seq_length=40960
|
||||
```
|
||||
|
||||
#### Text
|
||||
```bash
|
||||
export greedy='false'
|
||||
export top_p=0.95
|
||||
export top_k=20
|
||||
export repetition_penalty=1.0
|
||||
export presence_penalty=1.5
|
||||
export temperature=1.0
|
||||
export out_seq_length=32768 (for aime, lcb, and gpqa, it is recommended to set to 81920)
|
||||
```
|
||||
|
||||
|
||||
## Citation
|
||||
|
||||
If you find our work helpful, feel free to give us a cite.
|
||||
|
||||
```
|
||||
@misc{qwen3technicalreport,
|
||||
title={Qwen3 Technical Report},
|
||||
author={Qwen Team},
|
||||
year={2025},
|
||||
eprint={2505.09388},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CL},
|
||||
url={https://arxiv.org/abs/2505.09388},
|
||||
}
|
||||
|
||||
@article{Qwen2.5-VL,
|
||||
title={Qwen2.5-VL Technical Report},
|
||||
author={Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Zesen and Zhang, Hang and Yang, Zhibo and Xu, Haiyang and Lin, Junyang},
|
||||
journal={arXiv preprint arXiv:2502.13923},
|
||||
year={2025}
|
||||
}
|
||||
|
||||
@article{Qwen2VL,
|
||||
title={Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution},
|
||||
author={Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang},
|
||||
journal={arXiv preprint arXiv:2409.12191},
|
||||
year={2024}
|
||||
}
|
||||
|
||||
@article{Qwen-VL,
|
||||
title={Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond},
|
||||
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
|
||||
journal={arXiv preprint arXiv:2308.12966},
|
||||
year={2023}
|
||||
}
|
||||
```
|
||||
3
chat_template.json
Normal file
3
chat_template.json
Normal file
File diff suppressed because one or more lines are too long
63
config.json
Normal file
63
config.json
Normal file
@@ -0,0 +1,63 @@
|
||||
{
|
||||
"architectures": [
|
||||
"Qwen3VLForConditionalGeneration"
|
||||
],
|
||||
"image_token_id": 151655,
|
||||
"model_type": "qwen3_vl",
|
||||
"text_config": {
|
||||
"attention_bias": false,
|
||||
"attention_dropout": 0.0,
|
||||
"bos_token_id": 151643,
|
||||
"dtype": "bfloat16",
|
||||
"eos_token_id": 151645,
|
||||
"head_dim": 128,
|
||||
"hidden_act": "silu",
|
||||
"hidden_size": 2560,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 9728,
|
||||
"max_position_embeddings": 262144,
|
||||
"model_type": "qwen3_vl_text",
|
||||
"num_attention_heads": 32,
|
||||
"num_hidden_layers": 36,
|
||||
"num_key_value_heads": 8,
|
||||
"rms_norm_eps": 1e-06,
|
||||
"rope_scaling": {
|
||||
"mrope_interleaved": true,
|
||||
"mrope_section": [
|
||||
24,
|
||||
20,
|
||||
20
|
||||
],
|
||||
"rope_type": "default"
|
||||
},
|
||||
"rope_theta": 5000000,
|
||||
"tie_word_embeddings": true,
|
||||
"use_cache": true,
|
||||
"vocab_size": 151936
|
||||
},
|
||||
"tie_word_embeddings": true,
|
||||
"transformers_version": "4.57.0.dev0",
|
||||
"video_token_id": 151656,
|
||||
"vision_config": {
|
||||
"deepstack_visual_indexes": [
|
||||
5,
|
||||
11,
|
||||
17
|
||||
],
|
||||
"depth": 24,
|
||||
"hidden_act": "gelu_pytorch_tanh",
|
||||
"hidden_size": 1024,
|
||||
"in_channels": 3,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 4096,
|
||||
"model_type": "qwen3_vl",
|
||||
"num_heads": 16,
|
||||
"num_position_embeddings": 2304,
|
||||
"out_hidden_size": 2560,
|
||||
"patch_size": 16,
|
||||
"spatial_merge_size": 2,
|
||||
"temporal_patch_size": 2
|
||||
},
|
||||
"vision_end_token_id": 151653,
|
||||
"vision_start_token_id": 151652
|
||||
}
|
||||
1
configuration.json
Normal file
1
configuration.json
Normal file
@@ -0,0 +1 @@
|
||||
{"framework": "pytorch", "task": "text-generation", "allow_remote": true}
|
||||
14
generation_config.json
Normal file
14
generation_config.json
Normal file
@@ -0,0 +1,14 @@
|
||||
{
|
||||
"bos_token_id": 151643,
|
||||
"pad_token_id": 151643,
|
||||
"do_sample": true,
|
||||
"eos_token_id": [
|
||||
151645,
|
||||
151643
|
||||
],
|
||||
"top_k": 20,
|
||||
"top_p": 0.95,
|
||||
"repetition_penalty": 1.0,
|
||||
"temperature": 1.0,
|
||||
"transformers_version": "4.56.0"
|
||||
}
|
||||
3
merges.txt
Normal file
3
merges.txt
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:599bab54075088774b1733fde865d5bd747cbcc7a547c5bc12610e874e26f5e3
|
||||
size 1671839
|
||||
3
model-00001-of-00002.safetensors
Normal file
3
model-00001-of-00002.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:02cab5e606c91e5ede7b1a70c49fa5abc58c77692362ee3be2e6656fd1327793
|
||||
size 4967229296
|
||||
3
model-00002-of-00002.safetensors
Normal file
3
model-00002-of-00002.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:000ef17ec19fdd0531d825080c896c86025bc93036de1f34e3d133fa71c2cccf
|
||||
size 3908490048
|
||||
720
model.safetensors.index.json
Normal file
720
model.safetensors.index.json
Normal file
@@ -0,0 +1,720 @@
|
||||
{
|
||||
"metadata": {
|
||||
"total_size": 8875631616
|
||||
},
|
||||
"weight_map": {
|
||||
"model.language_model.embed_tokens.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.0.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.0.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.0.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.0.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.0.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.0.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.0.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.0.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.0.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.0.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.0.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.1.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.1.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.1.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.1.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.1.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.1.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.1.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.1.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.1.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.1.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.1.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.10.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.10.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.10.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.10.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.10.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.10.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.10.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.10.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.10.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.10.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.10.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.11.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.11.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.11.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.11.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.11.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.11.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.11.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.11.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.11.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.11.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.11.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.12.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.12.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.12.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.12.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.12.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.12.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.12.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.12.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.12.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.12.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.12.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.13.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.13.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.13.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.13.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.13.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.13.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.13.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.13.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.13.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.13.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.13.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.14.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.14.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.14.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.14.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.14.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.14.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.14.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.14.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.14.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.14.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.14.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.15.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.15.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.15.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.15.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.15.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.15.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.15.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.15.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.15.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.15.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.15.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.16.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.16.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.16.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.16.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.16.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.16.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.16.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.16.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.16.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.16.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.16.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.17.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.17.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.17.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.17.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.17.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.17.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.17.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.17.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.17.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.17.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.17.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.18.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.18.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.18.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.18.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.18.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.18.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.18.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.18.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.18.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.18.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.18.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.19.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.19.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.19.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.19.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.19.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.19.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.19.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.19.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.19.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.19.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.19.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.2.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.2.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.2.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.2.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.2.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.2.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.2.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.2.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.2.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.2.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.2.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.20.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.20.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.20.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.20.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.20.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.20.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.20.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.20.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.20.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.20.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.20.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.21.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.21.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.21.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.21.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.21.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.21.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.21.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.21.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.21.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.21.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.21.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.22.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.22.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.22.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.22.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.22.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.22.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.22.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.22.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.22.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.22.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.22.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.23.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.23.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.23.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.23.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.23.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.23.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.23.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.23.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.23.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.23.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.23.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.24.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.24.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.24.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.24.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.24.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.24.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.24.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.24.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.24.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.24.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.24.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.25.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.25.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.25.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.25.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.25.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.25.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.25.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.25.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.25.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.25.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.25.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.26.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.26.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.26.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.26.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.26.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.26.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.26.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.26.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.26.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.26.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.26.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.27.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.27.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.27.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.27.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.27.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.27.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.27.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.27.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.27.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.27.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.27.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.28.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.28.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.28.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.28.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.28.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.28.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.28.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.28.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.28.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.28.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.28.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.29.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.29.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.29.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.29.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.29.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.29.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.29.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.29.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.29.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.29.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.29.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.3.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.3.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.3.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.3.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.3.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.3.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.3.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.3.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.3.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.3.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.3.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.30.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.30.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.30.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.30.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.30.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.30.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.30.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.30.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.30.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.30.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.30.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.31.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.31.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.31.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.31.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.31.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.31.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.31.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.31.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.31.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.31.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.31.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.32.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.32.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.32.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.32.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.32.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.32.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.32.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.32.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.32.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.32.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.32.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.33.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.33.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.33.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.33.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.33.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.33.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.33.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.33.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.33.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.33.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.33.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.34.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.34.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.34.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.34.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.34.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.34.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.34.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.34.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.34.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.34.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.34.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.35.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.35.mlp.down_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.35.mlp.gate_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.35.mlp.up_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.35.post_attention_layernorm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.35.self_attn.k_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.35.self_attn.k_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.35.self_attn.o_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.35.self_attn.q_norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.35.self_attn.q_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.35.self_attn.v_proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.language_model.layers.4.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.4.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.4.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.4.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.4.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.4.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.4.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.4.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.4.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.4.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.4.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.5.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.5.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.5.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.5.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.5.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.5.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.5.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.5.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.5.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.5.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.5.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.6.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.6.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.6.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.6.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.6.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.6.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.6.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.6.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.6.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.6.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.6.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.7.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.7.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.7.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.7.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.7.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.7.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.7.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.7.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.7.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.7.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.7.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.8.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.8.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.8.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.8.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.8.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.8.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.8.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.8.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.8.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.8.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.8.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.9.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.9.mlp.down_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.9.mlp.gate_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.9.mlp.up_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.9.post_attention_layernorm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.9.self_attn.k_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.9.self_attn.k_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.9.self_attn.o_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.9.self_attn.q_norm.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.9.self_attn.q_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.layers.9.self_attn.v_proj.weight": "model-00001-of-00002.safetensors",
|
||||
"model.language_model.norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.0.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.0.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.0.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.0.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.0.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.0.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.0.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.0.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.0.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.0.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.0.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.0.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.1.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.1.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.1.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.1.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.1.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.1.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.1.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.1.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.1.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.1.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.1.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.1.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.10.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.10.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.10.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.10.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.10.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.10.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.10.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.10.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.10.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.10.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.10.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.10.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.11.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.11.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.11.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.11.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.11.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.11.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.11.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.11.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.11.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.11.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.11.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.11.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.12.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.12.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.12.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.12.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.12.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.12.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.12.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.12.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.12.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.12.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.12.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.12.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.13.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.13.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.13.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.13.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.13.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.13.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.13.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.13.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.13.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.13.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.13.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.13.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.14.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.14.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.14.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.14.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.14.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.14.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.14.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.14.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.14.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.14.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.14.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.14.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.15.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.15.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.15.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.15.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.15.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.15.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.15.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.15.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.15.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.15.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.15.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.15.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.16.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.16.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.16.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.16.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.16.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.16.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.16.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.16.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.16.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.16.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.16.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.16.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.17.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.17.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.17.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.17.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.17.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.17.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.17.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.17.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.17.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.17.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.17.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.17.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.18.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.18.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.18.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.18.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.18.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.18.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.18.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.18.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.18.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.18.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.18.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.18.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.19.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.19.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.19.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.19.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.19.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.19.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.19.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.19.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.19.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.19.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.19.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.19.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.2.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.2.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.2.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.2.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.2.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.2.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.2.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.2.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.2.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.2.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.2.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.2.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.20.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.20.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.20.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.20.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.20.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.20.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.20.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.20.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.20.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.20.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.20.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.20.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.21.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.21.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.21.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.21.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.21.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.21.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.21.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.21.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.21.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.21.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.21.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.21.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.22.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.22.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.22.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.22.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.22.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.22.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.22.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.22.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.22.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.22.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.22.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.22.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.23.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.23.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.23.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.23.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.23.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.23.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.23.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.23.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.23.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.23.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.23.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.23.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.3.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.3.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.3.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.3.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.3.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.3.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.3.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.3.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.3.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.3.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.3.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.3.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.4.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.4.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.4.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.4.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.4.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.4.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.4.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.4.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.4.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.4.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.4.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.4.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.5.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.5.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.5.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.5.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.5.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.5.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.5.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.5.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.5.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.5.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.5.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.5.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.6.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.6.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.6.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.6.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.6.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.6.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.6.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.6.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.6.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.6.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.6.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.6.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.7.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.7.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.7.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.7.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.7.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.7.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.7.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.7.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.7.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.7.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.7.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.7.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.8.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.8.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.8.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.8.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.8.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.8.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.8.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.8.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.8.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.8.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.8.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.8.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.9.attn.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.9.attn.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.9.attn.qkv.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.9.attn.qkv.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.9.mlp.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.9.mlp.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.9.mlp.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.9.mlp.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.9.norm1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.9.norm1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.9.norm2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.blocks.9.norm2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.0.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.0.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.0.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.0.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.0.norm.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.0.norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.1.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.1.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.1.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.1.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.1.norm.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.1.norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.2.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.2.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.2.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.2.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.2.norm.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.deepstack_merger_list.2.norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.merger.linear_fc1.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.merger.linear_fc1.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.merger.linear_fc2.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.merger.linear_fc2.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.merger.norm.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.merger.norm.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.patch_embed.proj.bias": "model-00002-of-00002.safetensors",
|
||||
"model.visual.patch_embed.proj.weight": "model-00002-of-00002.safetensors",
|
||||
"model.visual.pos_embed.weight": "model-00002-of-00002.safetensors"
|
||||
}
|
||||
}
|
||||
21
preprocessor_config.json
Normal file
21
preprocessor_config.json
Normal file
@@ -0,0 +1,21 @@
|
||||
{
|
||||
"size": {
|
||||
"longest_edge": 16777216,
|
||||
"shortest_edge": 65536
|
||||
},
|
||||
"patch_size": 16,
|
||||
"temporal_patch_size": 2,
|
||||
"merge_size": 2,
|
||||
"image_mean": [
|
||||
0.5,
|
||||
0.5,
|
||||
0.5
|
||||
],
|
||||
"image_std": [
|
||||
0.5,
|
||||
0.5,
|
||||
0.5
|
||||
],
|
||||
"processor_class": "Qwen3VLProcessor",
|
||||
"image_processor_type": "Qwen2VLImageProcessorFast"
|
||||
}
|
||||
3
tokenizer.json
Normal file
3
tokenizer.json
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:a5d85b6dcc535e6b93115a9ef287e6132fdbf30270da6218194ba742261173c7
|
||||
size 7032403
|
||||
239
tokenizer_config.json
Normal file
239
tokenizer_config.json
Normal file
File diff suppressed because one or more lines are too long
21
video_preprocessor_config.json
Normal file
21
video_preprocessor_config.json
Normal file
@@ -0,0 +1,21 @@
|
||||
{
|
||||
"size": {
|
||||
"longest_edge": 25165824,
|
||||
"shortest_edge": 4096
|
||||
},
|
||||
"patch_size": 16,
|
||||
"temporal_patch_size": 2,
|
||||
"merge_size": 2,
|
||||
"image_mean": [
|
||||
0.5,
|
||||
0.5,
|
||||
0.5
|
||||
],
|
||||
"image_std": [
|
||||
0.5,
|
||||
0.5,
|
||||
0.5
|
||||
],
|
||||
"processor_class": "Qwen3VLProcessor",
|
||||
"video_processor_type": "Qwen3VLVideoProcessor"
|
||||
}
|
||||
BIN
vocab.json
(Stored with Git LFS)
Normal file
BIN
vocab.json
(Stored with Git LFS)
Normal file
Binary file not shown.
Reference in New Issue
Block a user