初始化项目,由ModelHub XC社区提供模型
Model: NousResearch/Yarn-Solar-10b-64k Source: Original Platform
This commit is contained in:
40
.gitattributes
vendored
Normal file
40
.gitattributes
vendored
Normal file
@@ -0,0 +1,40 @@
|
||||
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||
*.model filter=lfs diff=lfs merge=lfs -text
|
||||
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
pytorch_model-00001-of-00005.bin filter=lfs diff=lfs merge=lfs -text
|
||||
pytorch_model-00002-of-00005.bin filter=lfs diff=lfs merge=lfs -text
|
||||
pytorch_model-00003-of-00005.bin filter=lfs diff=lfs merge=lfs -text
|
||||
pytorch_model-00004-of-00005.bin filter=lfs diff=lfs merge=lfs -text
|
||||
pytorch_model-00005-of-00005.bin filter=lfs diff=lfs merge=lfs -text
|
||||
68
README.md
Normal file
68
README.md
Normal file
@@ -0,0 +1,68 @@
|
||||
---
|
||||
datasets:
|
||||
- emozilla/yarn-train-tokenized-32k-mistral
|
||||
metrics:
|
||||
- perplexity
|
||||
library_name: transformers
|
||||
license: apache-2.0
|
||||
language:
|
||||
- en
|
||||
---
|
||||
|
||||
# Model Card: Yarn-Solar-10b-64k
|
||||
|
||||
[Preprint (arXiv)](https://arxiv.org/abs/2309.00071)
|
||||
[GitHub](https://github.com/jquesnelle/yarn)
|
||||
|
||||
|
||||
## Model Description
|
||||
|
||||
Yarn-Solar-10b-64k is a state-of-the-art language model for long context, further pretrained on two billion long context tokens using the YaRN extension method.
|
||||
It is an extension of [SOLAR-10.7B-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-v1.0) and supports a 64k token context window.
|
||||
|
||||
To use, pass `trust_remote_code=True` when loading the model, for example
|
||||
|
||||
```python
|
||||
model = AutoModelForCausalLM.from_pretrained("NousResearch/Yarn-Solar-10b-64k",
|
||||
attn_implementation="flash_attention_2",
|
||||
torch_dtype=torch.bfloat16,
|
||||
device_map="auto",
|
||||
trust_remote_code=True)
|
||||
```
|
||||
|
||||
In addition you will need to use the latest version of `transformers`
|
||||
```sh
|
||||
pip install git+https://github.com/huggingface/transformers
|
||||
```
|
||||
|
||||
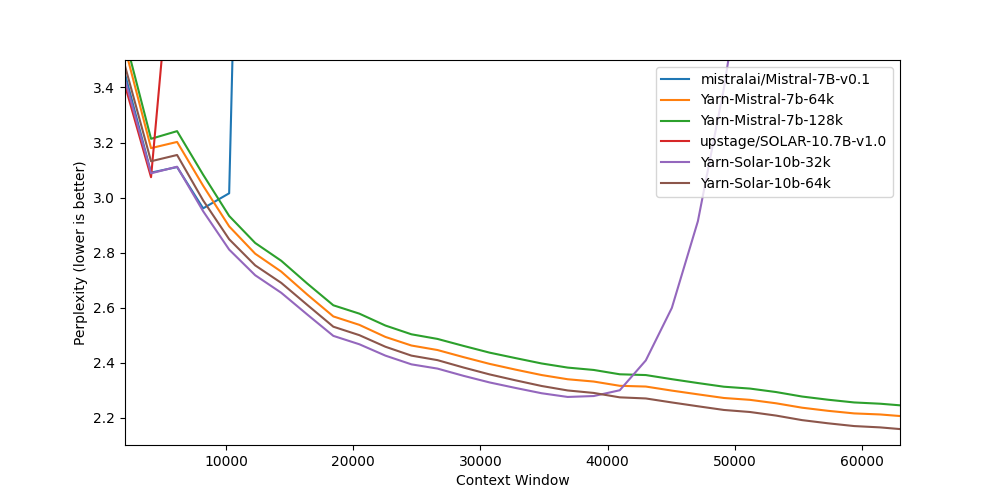
## Benchmarks
|
||||
|
||||
Long context benchmarks:
|
||||
| Model | Context Window | 4k PPL | 8k PPL | 16k PPL | 32k PPL | 64k PPL |
|
||||
|-------|---------------:|------:|----------:|-----:|-----:|------------:|
|
||||
| [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | 8k | 3.09 | 2.96 | - | - | - |
|
||||
| [Yarn-Mistral-7b-64k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-64k) | 64k | 3.18 | 3.04 | 2.65 | 2.44 | 2.20 |
|
||||
| [Yarn-Mistral-7b-128k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k) | 128k | 3.21 | 3.08 | 2.68 | 2.47 | 2.24 |
|
||||
| [SOLAR-10.7B-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-v1.0) | 4k | 3.07 | - | - | - | - |
|
||||
| [Yarn-Solar-10b-32k](https://huggingface.co/NousResearch/Yarn-Solar-10b-32k) | 32k | 3.09 | 2.95 | 2.57 | 2.31 | - |
|
||||
| **[Yarn-Solar-10b-64k](https://huggingface.co/NousResearch/Yarn-Solar-10b-64k)** | **64k** | **3.13** | **2.99** | **2.61** | **2.34** | **2.15** |
|
||||
|
||||
Short context benchmarks showing that quality degradation is minimal:
|
||||
| Model | Context Window | ARC-c | Hellaswag | MMLU | Truthful QA |
|
||||
|-------|---------------:|------:|----------:|-----:|------------:|
|
||||
| [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | 8k | 59.98 | 83.31 | 64.16 | 42.15 |
|
||||
| [Yarn-Mistral-7b-64k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-64k) | 64k | 59.38 | 81.21 | 61.32 | 42.50 |
|
||||
| [Yarn-Mistral-7b-128k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k) | 128k | 58.87 | 80.58 | 60.64 | 42.46 |
|
||||
| [SOLAR-10.7B-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-v1.0) | 4k | 61.95 | 84.60 | 65.48 | 45.04 |
|
||||
| [Yarn-Solar-10b-32k](https://huggingface.co/NousResearch/Yarn-Solar-10b-32k) | 32k | 59.64 | 83.65 | 64.36 | 44.82 |
|
||||
| **[Yarn-Solar-10b-64k](https://huggingface.co/NousResearch/Yarn-Solar-10b-64k)** | **64k** | **59.21** | **83.08** | **63.57** | **45.70** |
|
||||
|
||||
## Collaborators
|
||||
|
||||
- [bloc97](https://github.com/bloc97): Methods, paper and evals
|
||||
- [@theemozilla](https://twitter.com/theemozilla): Methods, paper, model training, and evals
|
||||
- [@EnricoShippole](https://twitter.com/EnricoShippole): Model training
|
||||
- [honglu2875](https://github.com/honglu2875): Paper and evals
|
||||
|
||||
The authors would like to thank LAION AI for their support of compute for this model.
|
||||
It was trained on the [JUWELS](https://www.fz-juelich.de/en/ias/jsc/systems/supercomputers/juwels) supercomputer.
|
||||
36
config.json
Normal file
36
config.json
Normal file
@@ -0,0 +1,36 @@
|
||||
{
|
||||
"_name_or_path": "upstage/SOLAR-10.7B-v1.0",
|
||||
"architectures": [
|
||||
"LlamaForCausalLM"
|
||||
],
|
||||
"attention_bias": false,
|
||||
"auto_map": {
|
||||
"AutoConfig": "configuration_llama.LlamaConfig",
|
||||
"AutoModelForCausalLM": "modeling_llama_yarn.LlamaForCausalLM"
|
||||
},
|
||||
"bos_token_id": 1,
|
||||
"eos_token_id": 2,
|
||||
"hidden_act": "silu",
|
||||
"hidden_size": 4096,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 14336,
|
||||
"max_position_embeddings": 65536,
|
||||
"model_type": "llama",
|
||||
"num_attention_heads": 32,
|
||||
"num_hidden_layers": 48,
|
||||
"num_key_value_heads": 8,
|
||||
"pad_token_id": 0,
|
||||
"pretraining_tp": 1,
|
||||
"rms_norm_eps": 1e-05,
|
||||
"rope_scaling": {
|
||||
"factor": 16.0,
|
||||
"original_max_position_embeddings": 4096,
|
||||
"type": "yarn"
|
||||
},
|
||||
"rope_theta": 10000.0,
|
||||
"tie_word_embeddings": false,
|
||||
"torch_dtype": "bfloat16",
|
||||
"transformers_version": "4.35.2",
|
||||
"use_cache": true,
|
||||
"vocab_size": 32000
|
||||
}
|
||||
1
configuration.json
Normal file
1
configuration.json
Normal file
@@ -0,0 +1 @@
|
||||
{"framework": "pytorch", "task": "text-generation", "allow_remote": true}
|
||||
188
configuration_llama.py
Normal file
188
configuration_llama.py
Normal file
@@ -0,0 +1,188 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 EleutherAI and the HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
||||
# and OPT implementations in this library. It has been modified from its
|
||||
# original forms to accommodate minor architectural differences compared
|
||||
# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" LLaMA model configuration"""
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
from transformers.utils import logging
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
LLAMA_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
|
||||
|
||||
|
||||
class LlamaConfig(PretrainedConfig):
|
||||
r"""
|
||||
This is the configuration class to store the configuration of a [`LlamaModel`]. It is used to instantiate an LLaMA
|
||||
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
|
||||
defaults will yield a similar configuration to that of the LLaMA-7B.
|
||||
|
||||
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
||||
documentation from [`PretrainedConfig`] for more information.
|
||||
|
||||
|
||||
Args:
|
||||
vocab_size (`int`, *optional*, defaults to 32000):
|
||||
Vocabulary size of the LLaMA model. Defines the number of different tokens that can be represented by the
|
||||
`inputs_ids` passed when calling [`LlamaModel`]
|
||||
hidden_size (`int`, *optional*, defaults to 4096):
|
||||
Dimension of the hidden representations.
|
||||
intermediate_size (`int`, *optional*, defaults to 11008):
|
||||
Dimension of the MLP representations.
|
||||
num_hidden_layers (`int`, *optional*, defaults to 32):
|
||||
Number of hidden layers in the Transformer encoder.
|
||||
num_attention_heads (`int`, *optional*, defaults to 32):
|
||||
Number of attention heads for each attention layer in the Transformer encoder.
|
||||
num_key_value_heads (`int`, *optional*):
|
||||
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
||||
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
||||
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
||||
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
||||
by meanpooling all the original heads within that group. For more details checkout [this
|
||||
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
|
||||
`num_attention_heads`.
|
||||
pretraining_tp (`int`, *optional*, defaults to `1`):
|
||||
Experimental feature. Tensor parallelism rank used during pretraining. Please refer to [this
|
||||
document](https://huggingface.co/docs/transformers/parallelism) to understand more about it. This value is
|
||||
necessary to ensure exact reproducibility of the pretraining results. Please refer to [this
|
||||
issue](https://github.com/pytorch/pytorch/issues/76232).
|
||||
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
||||
The non-linear activation function (function or string) in the decoder.
|
||||
max_position_embeddings (`int`, *optional*, defaults to 2048):
|
||||
The maximum sequence length that this model might ever be used with. Typically set this to something large
|
||||
just in case (e.g., 512 or 1024 or 2048).
|
||||
initializer_range (`float`, *optional*, defaults to 0.02):
|
||||
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
||||
rms_norm_eps (`float`, *optional*, defaults to 1e-12):
|
||||
The epsilon used by the rms normalization layers.
|
||||
use_cache (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
||||
relevant if `config.is_decoder=True`.
|
||||
tie_word_embeddings(`bool`, *optional*, defaults to `False`):
|
||||
Whether to tie weight embeddings
|
||||
rope_scaling (`Dict`, *optional*):
|
||||
Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports three scaling
|
||||
strategies: linear and dynamic. Their scaling factor must be an float greater than 1. The expected format
|
||||
is `{"type": strategy name, "factor": scaling factor}`. When using this flag, don't update
|
||||
`max_position_embeddings` to the expected new maximum. See the following thread for more information on how
|
||||
these scaling strategies behave:
|
||||
https://www.reddit.com/r/LocalLLaMA/comments/14mrgpr/dynamically_scaled_rope_further_increases/. This is an
|
||||
experimental feature, subject to breaking API changes in future versions.
|
||||
attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):
|
||||
Whether to use a bias in the query, key, value and output projection layers during self-attention.
|
||||
attention_dropout (`float`, *optional*, defaults to 0.0):
|
||||
The dropout ratio for the attention probabilities.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from transformers import LlamaModel, LlamaConfig
|
||||
|
||||
>>> # Initializing a LLaMA llama-7b style configuration
|
||||
>>> configuration = LlamaConfig()
|
||||
|
||||
>>> # Initializing a model from the llama-7b style configuration
|
||||
>>> model = LlamaModel(configuration)
|
||||
|
||||
>>> # Accessing the model configuration
|
||||
>>> configuration = model.config
|
||||
```"""
|
||||
model_type = "llama"
|
||||
keys_to_ignore_at_inference = ["past_key_values"]
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size=32000,
|
||||
hidden_size=4096,
|
||||
intermediate_size=11008,
|
||||
num_hidden_layers=32,
|
||||
num_attention_heads=32,
|
||||
num_key_value_heads=None,
|
||||
hidden_act="silu",
|
||||
max_position_embeddings=2048,
|
||||
initializer_range=0.02,
|
||||
rms_norm_eps=1e-6,
|
||||
use_cache=True,
|
||||
pad_token_id=0,
|
||||
bos_token_id=1,
|
||||
eos_token_id=2,
|
||||
pretraining_tp=1,
|
||||
tie_word_embeddings=False,
|
||||
rope_theta=10000,
|
||||
rope_scaling=None,
|
||||
attention_bias=False,
|
||||
attention_dropout=0.0,
|
||||
**kwargs,
|
||||
):
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.hidden_size = hidden_size
|
||||
self.intermediate_size = intermediate_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_attention_heads = num_attention_heads
|
||||
|
||||
# for backward compatibility
|
||||
if num_key_value_heads is None:
|
||||
num_key_value_heads = num_attention_heads
|
||||
|
||||
self.num_key_value_heads = num_key_value_heads
|
||||
self.hidden_act = hidden_act
|
||||
self.initializer_range = initializer_range
|
||||
self.rms_norm_eps = rms_norm_eps
|
||||
self.pretraining_tp = pretraining_tp
|
||||
self.use_cache = use_cache
|
||||
self.rope_theta = rope_theta
|
||||
self.rope_scaling = rope_scaling
|
||||
self._rope_scaling_validation()
|
||||
self.attention_bias = attention_bias
|
||||
self.attention_dropout = attention_dropout
|
||||
|
||||
super().__init__(
|
||||
pad_token_id=pad_token_id,
|
||||
bos_token_id=bos_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
tie_word_embeddings=tie_word_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
def _rope_scaling_validation(self):
|
||||
"""
|
||||
Validate the `rope_scaling` configuration.
|
||||
"""
|
||||
if self.rope_scaling is None:
|
||||
return
|
||||
|
||||
if not isinstance(self.rope_scaling, dict):
|
||||
raise ValueError(
|
||||
"`rope_scaling` must be a dictionary, "
|
||||
f"got {self.rope_scaling}"
|
||||
)
|
||||
rope_scaling_type = self.rope_scaling.get("type", None)
|
||||
rope_scaling_factor = self.rope_scaling.get("factor", None)
|
||||
if rope_scaling_type is None or rope_scaling_type not in ["linear", "dynamic", "yarn", "dynamic-yarn"]:
|
||||
raise ValueError(
|
||||
f"`rope_scaling`'s name field must be one of ['linear', 'dynamic', 'yarn', 'dynamic-yarn'], got {rope_scaling_type}"
|
||||
)
|
||||
if rope_scaling_factor is None or not isinstance(rope_scaling_factor, float) or rope_scaling_factor <= 1.0:
|
||||
raise ValueError(f"`rope_scaling`'s factor field must be an float > 1, got {rope_scaling_factor}")
|
||||
if rope_scaling_type == "yarn" or rope_scaling_type == "dynamic-yarn":
|
||||
original_max_position_embeddings = self.rope_scaling.get("original_max_position_embeddings", None)
|
||||
if original_max_position_embeddings is None or not isinstance(original_max_position_embeddings, int):
|
||||
raise ValueError(f"`rope_scaling.original_max_position_embeddings` must be set to an int when using yarn, and dynamic-yarn")
|
||||
8
generation_config.json
Normal file
8
generation_config.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"_from_model_config": true,
|
||||
"bos_token_id": 1,
|
||||
"eos_token_id": 2,
|
||||
"pad_token_id": 0,
|
||||
"transformers_version": "4.35.2",
|
||||
"use_cache": false
|
||||
}
|
||||
1577
modeling_llama_yarn.py
Normal file
1577
modeling_llama_yarn.py
Normal file
File diff suppressed because it is too large
Load Diff
3
pytorch_model-00001-of-00005.bin
Normal file
3
pytorch_model-00001-of-00005.bin
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:c1fa662dbcf2ce650cb50c33418107ad3e54a5d664b84ea02c33170e3244b69a
|
||||
size 4943186400
|
||||
3
pytorch_model-00002-of-00005.bin
Normal file
3
pytorch_model-00002-of-00005.bin
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:19178308c43fb80f74693cac2a41167a8e8c8669d3e71c9214a3306c4ead6296
|
||||
size 4999845640
|
||||
3
pytorch_model-00003-of-00005.bin
Normal file
3
pytorch_model-00003-of-00005.bin
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:d651a87c23df1c3ea0d9445687e93a2ee371bd9f63c283184df1314e7add285a
|
||||
size 4915940938
|
||||
3
pytorch_model-00004-of-00005.bin
Normal file
3
pytorch_model-00004-of-00005.bin
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:c9f916858eee987e82b063f2375a8fe8cae18a9a55ca438e19ca2e6f74e30bf7
|
||||
size 4915940938
|
||||
3
pytorch_model-00005-of-00005.bin
Normal file
3
pytorch_model-00005-of-00005.bin
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:f670676a18f51664e3a453388db23301b245aedc0f54be3ab53267c99a353cdb
|
||||
size 1688292906
|
||||
442
pytorch_model.bin.index.json
Normal file
442
pytorch_model.bin.index.json
Normal file
@@ -0,0 +1,442 @@
|
||||
{
|
||||
"metadata": {
|
||||
"total_size": 21463048192
|
||||
},
|
||||
"weight_map": {
|
||||
"lm_head.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.embed_tokens.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.0.input_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.0.mlp.down_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.0.mlp.gate_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.0.mlp.up_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.0.post_attention_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.0.self_attn.k_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.0.self_attn.o_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.0.self_attn.q_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.0.self_attn.v_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.1.input_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.1.mlp.down_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.1.mlp.gate_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.1.mlp.up_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.1.post_attention_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.1.self_attn.k_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.1.self_attn.o_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.1.self_attn.q_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.1.self_attn.v_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.10.input_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.10.mlp.down_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.10.mlp.gate_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.10.mlp.up_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.10.post_attention_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.10.self_attn.k_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.10.self_attn.o_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.10.self_attn.q_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.10.self_attn.v_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.11.input_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.11.mlp.down_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.11.mlp.gate_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.11.mlp.up_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.11.post_attention_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.11.self_attn.k_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.11.self_attn.o_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.11.self_attn.q_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.11.self_attn.v_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.12.input_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.12.mlp.down_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.12.mlp.gate_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.12.mlp.up_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.12.post_attention_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.12.self_attn.k_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.12.self_attn.o_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.12.self_attn.q_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.12.self_attn.v_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.13.input_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.13.mlp.down_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.13.mlp.gate_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.13.mlp.up_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.13.post_attention_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.13.self_attn.k_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.13.self_attn.o_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.13.self_attn.q_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.13.self_attn.v_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.14.input_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.14.mlp.down_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.14.mlp.gate_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.14.mlp.up_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.14.post_attention_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.14.self_attn.k_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.14.self_attn.o_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.14.self_attn.q_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.14.self_attn.v_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.15.input_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.15.mlp.down_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.15.mlp.gate_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.15.mlp.up_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.15.post_attention_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.15.self_attn.k_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.15.self_attn.o_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.15.self_attn.q_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.15.self_attn.v_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.16.input_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.16.mlp.down_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.16.mlp.gate_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.16.mlp.up_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.16.post_attention_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.16.self_attn.k_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.16.self_attn.o_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.16.self_attn.q_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.16.self_attn.v_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.17.input_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.17.mlp.down_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.17.mlp.gate_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.17.mlp.up_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.17.post_attention_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.17.self_attn.k_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.17.self_attn.o_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.17.self_attn.q_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.17.self_attn.v_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.18.input_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.18.mlp.down_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.18.mlp.gate_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.18.mlp.up_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.18.post_attention_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.18.self_attn.k_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.18.self_attn.o_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.18.self_attn.q_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.18.self_attn.v_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.19.input_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.19.mlp.down_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.19.mlp.gate_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.19.mlp.up_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.19.post_attention_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.19.self_attn.k_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.19.self_attn.o_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.19.self_attn.q_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.19.self_attn.v_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.2.input_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.2.mlp.down_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.2.mlp.gate_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.2.mlp.up_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.2.post_attention_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.2.self_attn.k_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.2.self_attn.o_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.2.self_attn.q_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.2.self_attn.v_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.20.input_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.20.mlp.down_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.20.mlp.gate_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.20.mlp.up_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.20.post_attention_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.20.self_attn.k_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.20.self_attn.o_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.20.self_attn.q_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.20.self_attn.v_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.21.input_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.21.mlp.down_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.21.mlp.gate_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.21.mlp.up_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.21.post_attention_layernorm.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.21.self_attn.k_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.21.self_attn.o_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.21.self_attn.q_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.21.self_attn.v_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.22.input_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.22.mlp.down_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.22.mlp.gate_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.22.mlp.up_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.22.post_attention_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.22.self_attn.k_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.22.self_attn.o_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.22.self_attn.q_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.22.self_attn.v_proj.weight": "pytorch_model-00002-of-00005.bin",
|
||||
"model.layers.23.input_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.23.mlp.down_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.23.mlp.gate_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.23.mlp.up_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.23.post_attention_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.23.self_attn.k_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.23.self_attn.o_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.23.self_attn.q_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.23.self_attn.v_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.24.input_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.24.mlp.down_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.24.mlp.gate_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.24.mlp.up_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.24.post_attention_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.24.self_attn.k_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.24.self_attn.o_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.24.self_attn.q_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.24.self_attn.v_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.25.input_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.25.mlp.down_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.25.mlp.gate_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.25.mlp.up_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.25.post_attention_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.25.self_attn.k_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.25.self_attn.o_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.25.self_attn.q_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.25.self_attn.v_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.26.input_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.26.mlp.down_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.26.mlp.gate_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.26.mlp.up_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.26.post_attention_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.26.self_attn.k_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.26.self_attn.o_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.26.self_attn.q_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.26.self_attn.v_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.27.input_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.27.mlp.down_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.27.mlp.gate_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.27.mlp.up_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.27.post_attention_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.27.self_attn.k_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.27.self_attn.o_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.27.self_attn.q_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.27.self_attn.v_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.28.input_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.28.mlp.down_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.28.mlp.gate_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.28.mlp.up_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.28.post_attention_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.28.self_attn.k_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.28.self_attn.o_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.28.self_attn.q_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.28.self_attn.v_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.29.input_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.29.mlp.down_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.29.mlp.gate_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.29.mlp.up_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.29.post_attention_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.29.self_attn.k_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.29.self_attn.o_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.29.self_attn.q_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.29.self_attn.v_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.3.input_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.3.mlp.down_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.3.mlp.gate_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.3.mlp.up_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.3.post_attention_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.3.self_attn.k_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.3.self_attn.o_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.3.self_attn.q_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.3.self_attn.v_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.30.input_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.30.mlp.down_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.30.mlp.gate_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.30.mlp.up_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.30.post_attention_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.30.self_attn.k_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.30.self_attn.o_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.30.self_attn.q_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.30.self_attn.v_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.31.input_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.31.mlp.down_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.31.mlp.gate_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.31.mlp.up_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.31.post_attention_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.31.self_attn.k_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.31.self_attn.o_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.31.self_attn.q_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.31.self_attn.v_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.32.input_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.32.mlp.down_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.32.mlp.gate_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.32.mlp.up_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.32.post_attention_layernorm.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.32.self_attn.k_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.32.self_attn.o_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.32.self_attn.q_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.32.self_attn.v_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.33.input_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.33.mlp.down_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.33.mlp.gate_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.33.mlp.up_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.33.post_attention_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.33.self_attn.k_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.33.self_attn.o_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.33.self_attn.q_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.33.self_attn.v_proj.weight": "pytorch_model-00003-of-00005.bin",
|
||||
"model.layers.34.input_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.34.mlp.down_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.34.mlp.gate_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.34.mlp.up_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.34.post_attention_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.34.self_attn.k_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.34.self_attn.o_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.34.self_attn.q_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.34.self_attn.v_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.35.input_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.35.mlp.down_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.35.mlp.gate_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.35.mlp.up_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.35.post_attention_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.35.self_attn.k_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.35.self_attn.o_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.35.self_attn.q_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.35.self_attn.v_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.36.input_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.36.mlp.down_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.36.mlp.gate_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.36.mlp.up_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.36.post_attention_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.36.self_attn.k_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.36.self_attn.o_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.36.self_attn.q_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.36.self_attn.v_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.37.input_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.37.mlp.down_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.37.mlp.gate_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.37.mlp.up_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.37.post_attention_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.37.self_attn.k_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.37.self_attn.o_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.37.self_attn.q_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.37.self_attn.v_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.38.input_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.38.mlp.down_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.38.mlp.gate_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.38.mlp.up_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.38.post_attention_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.38.self_attn.k_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.38.self_attn.o_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.38.self_attn.q_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.38.self_attn.v_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.39.input_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.39.mlp.down_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.39.mlp.gate_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.39.mlp.up_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.39.post_attention_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.39.self_attn.k_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.39.self_attn.o_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.39.self_attn.q_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.39.self_attn.v_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.4.input_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.4.mlp.down_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.4.mlp.gate_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.4.mlp.up_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.4.post_attention_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.4.self_attn.k_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.4.self_attn.o_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.4.self_attn.q_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.4.self_attn.v_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.40.input_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.40.mlp.down_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.40.mlp.gate_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.40.mlp.up_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.40.post_attention_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.40.self_attn.k_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.40.self_attn.o_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.40.self_attn.q_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.40.self_attn.v_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.41.input_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.41.mlp.down_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.41.mlp.gate_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.41.mlp.up_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.41.post_attention_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.41.self_attn.k_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.41.self_attn.o_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.41.self_attn.q_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.41.self_attn.v_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.42.input_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.42.mlp.down_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.42.mlp.gate_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.42.mlp.up_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.42.post_attention_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.42.self_attn.k_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.42.self_attn.o_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.42.self_attn.q_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.42.self_attn.v_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.43.input_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.43.mlp.down_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.43.mlp.gate_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.43.mlp.up_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.43.post_attention_layernorm.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.43.self_attn.k_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.43.self_attn.o_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.43.self_attn.q_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.43.self_attn.v_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.44.input_layernorm.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.44.mlp.down_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.44.mlp.gate_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.44.mlp.up_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.44.post_attention_layernorm.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.44.self_attn.k_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.44.self_attn.o_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.44.self_attn.q_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.44.self_attn.v_proj.weight": "pytorch_model-00004-of-00005.bin",
|
||||
"model.layers.45.input_layernorm.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.45.mlp.down_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.45.mlp.gate_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.45.mlp.up_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.45.post_attention_layernorm.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.45.self_attn.k_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.45.self_attn.o_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.45.self_attn.q_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.45.self_attn.v_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.46.input_layernorm.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.46.mlp.down_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.46.mlp.gate_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.46.mlp.up_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.46.post_attention_layernorm.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.46.self_attn.k_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.46.self_attn.o_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.46.self_attn.q_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.46.self_attn.v_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.47.input_layernorm.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.47.mlp.down_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.47.mlp.gate_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.47.mlp.up_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.47.post_attention_layernorm.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.47.self_attn.k_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.47.self_attn.o_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.47.self_attn.q_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.47.self_attn.v_proj.weight": "pytorch_model-00005-of-00005.bin",
|
||||
"model.layers.5.input_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.5.mlp.down_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.5.mlp.gate_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.5.mlp.up_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.5.post_attention_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.5.self_attn.k_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.5.self_attn.o_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.5.self_attn.q_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.5.self_attn.v_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.6.input_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.6.mlp.down_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.6.mlp.gate_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.6.mlp.up_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.6.post_attention_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.6.self_attn.k_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.6.self_attn.o_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.6.self_attn.q_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.6.self_attn.v_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.7.input_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.7.mlp.down_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.7.mlp.gate_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.7.mlp.up_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.7.post_attention_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.7.self_attn.k_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.7.self_attn.o_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.7.self_attn.q_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.7.self_attn.v_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.8.input_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.8.mlp.down_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.8.mlp.gate_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.8.mlp.up_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.8.post_attention_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.8.self_attn.k_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.8.self_attn.o_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.8.self_attn.q_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.8.self_attn.v_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.9.input_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.9.mlp.down_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.9.mlp.gate_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.9.mlp.up_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.9.post_attention_layernorm.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.9.self_attn.k_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.9.self_attn.o_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.9.self_attn.q_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.layers.9.self_attn.v_proj.weight": "pytorch_model-00001-of-00005.bin",
|
||||
"model.norm.weight": "pytorch_model-00005-of-00005.bin"
|
||||
}
|
||||
}
|
||||
23
special_tokens_map.json
Normal file
23
special_tokens_map.json
Normal file
@@ -0,0 +1,23 @@
|
||||
{
|
||||
"bos_token": {
|
||||
"content": "<s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"eos_token": {
|
||||
"content": "</s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"unk_token": {
|
||||
"content": "<unk>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
}
|
||||
}
|
||||
91122
tokenizer.json
Normal file
91122
tokenizer.json
Normal file
File diff suppressed because it is too large
Load Diff
BIN
tokenizer.model
(Stored with Git LFS)
Normal file
BIN
tokenizer.model
(Stored with Git LFS)
Normal file
Binary file not shown.
40
tokenizer_config.json
Normal file
40
tokenizer_config.json
Normal file
@@ -0,0 +1,40 @@
|
||||
{
|
||||
"added_tokens_decoder": {
|
||||
"0": {
|
||||
"content": "<unk>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"1": {
|
||||
"content": "<s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"2": {
|
||||
"content": "</s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
}
|
||||
},
|
||||
"additional_special_tokens": [],
|
||||
"bos_token": "<s>",
|
||||
"clean_up_tokenization_spaces": false,
|
||||
"eos_token": "</s>",
|
||||
"legacy": true,
|
||||
"model_max_length": 1000000000000000019884624838656,
|
||||
"pad_token": null,
|
||||
"sp_model_kwargs": {},
|
||||
"spaces_between_special_tokens": false,
|
||||
"tokenizer_class": "LlamaTokenizer",
|
||||
"unk_token": "<unk>",
|
||||
"use_default_system_prompt": true
|
||||
}
|
||||
Reference in New Issue
Block a user