add pkgs
This commit is contained in:
102
LICENSE.CHN.TXT
Normal file
102
LICENSE.CHN.TXT
Normal file
@@ -0,0 +1,102 @@
|
||||
软件许可协议
|
||||
|
||||
重要须知:本《许可协议》(以下称《协议》)是您(使用本软件的用户)与我公司(昆仑
|
||||
芯(北京)科技有限公司)之间有关本软件产品的法律协议。本“软件产品”包括计算机软件
|
||||
,并可能包括相关媒体、印刷材料和“联机”或电子文档(“软件产品”)。本“软件产品”还
|
||||
包括提供给您的原“软件产品”的任何更新和补充资料。任何与本“软件产品”一同提供给您
|
||||
的相关的软件产品是根据本许可协议中的条款而授予您。如您不同意本《协议》中的条款,
|
||||
请不要安装或使用本软件产品及其相关服务。您一旦安装、使用、复制、下载或以其它方式
|
||||
使用的行为将视为对本协议的接受,并同意接受本协议各项条款的约束。未经我方公司授权
|
||||
,任何拷贝、销售、转让、出租、修改本“软件”的行为均被认为是侵权行为。
|
||||
|
||||
本“软件产品”之著作权及其它知识产权等相关权利或利益(包括但不限于现已取得或未来可
|
||||
取得之著作权、专利权、商标权、营业秘密等)皆为我方公司所有。本“软件产品”受中华人
|
||||
民共和国著作权法及所适用的国际著作权条约和其它知识产权法及条约的保护。
|
||||
|
||||
第一条 许可证的授予。
|
||||
本《协议》授予您下列权利:
|
||||
1、应用软件。您可在单一一台计算机上安装、使用、访问、显示、运行或以其它方式
|
||||
互相作用于(“运行”)本“软件产品”的一份副本。运行“软件产品”的计算机
|
||||
的用户可以制作另一份副本,仅供在其在安装到公司其他电脑管理注册后的
|
||||
同一项目之用。
|
||||
2、储存/网络用途。您还可以在您的计算机上运行“软件产品”,您必须为增加的每个
|
||||
项目获得一份许可证。
|
||||
3、保留权利。未明示授予的一切其它权利均为我公司及其供应商所有。
|
||||
4、如果您是从我公司或其授权被许可人之处获得本软件,那么只要您遵守本协议的所
|
||||
有条款,就可以按其文档描述的方式和目的使用软件。如果软件的设计是为与我公司
|
||||
发布的另一应用程序软件产品(“主程序”)一起使用,并且您拥有我公司提供之使用
|
||||
主程序的有效许可,则我公司授予您与主程序一起使用本软件的非排他性许可。用户
|
||||
仅获得本软件产品的非排他性使用权。
|
||||
|
||||
第二条 限制和义务。
|
||||
1、组件的分隔。本“软件产品”是作为单一产品而被授予使用许可的。您不得将其组成
|
||||
部分分开在多台计算机上使用。
|
||||
2、组件的修改。您不得对许可软件进行任何更改、添加,或基于本软件创作衍生作品。
|
||||
3、不得进行逆向工程。不得全部或部分地翻译、分解、反向编译、反汇编、反向工程
|
||||
或其他试图从许可软件导出程序源代码的行为。
|
||||
4、本《协议》不授予您有关任何本软件产品商标或服务商标的任何权利。不得除掉、
|
||||
掩盖或更改许可软件上有关许可软件著作权或商标的标志。
|
||||
5、不得将许可软件向第三方提供、销售、出租、出借、转让或提供分许可、转许可、
|
||||
通过信息网络传播或以其他形式供他人利用。
|
||||
6、不得限制、破坏或绕过许可软件附带的加密附件或我方提供的其他确保许可软件正
|
||||
确使用的限制性措施。
|
||||
7、支持服务。我公司可能为您提供与“软件产品”有关的支持服务(“支持服务”)。支
|
||||
持服务的使用受用户手册、“联机”文档和/或其它提供的材料中所述的各项政策和计划
|
||||
的制约。提供给您作为支持服务的一部分的任何附加软件代码应被视为本“软件产品”
|
||||
的一部分,并须符合本《协议》中的各项条款和条件。
|
||||
8、终止。如您未遵守本《协议》的各项条款和条件,在不损害其它权利的情况下,我
|
||||
公司可终止本《协议》。如此类情况发生,您必须销毁“软件产品”的所有副本及其所
|
||||
有组成部分。
|
||||
|
||||
第三条 知识产权。
|
||||
1、本“软件产品”(包括但不限于本“软件产品”中所含的任何图像、照片、动画、录像
|
||||
、录音、音乐、文字和附加程序)、随附的印刷材料、及本“软件产品”的任何副本的
|
||||
产权和著作权,均由我公司及其供应商拥有。
|
||||
2、禁止被许可方向任何第三方授予本许可产品全部或部分权力、许可、利益或特权。
|
||||
|
||||
第四条 免责声明。
|
||||
1、本“软件产品”以“现状”方式提供,我公司不保证本软件产品能够或不能够完全满足
|
||||
用户需求,在用户手册、帮助文件、使用说明书等软件文档中的介绍性内容仅供用户
|
||||
参考,不得理解为对用户所做的任何承诺。我公司保留对软件版本进行升级,对功能
|
||||
、内容、结构、界面、运行方式等进行修改或自动更新的权利。
|
||||
2、我公司不对软件进行任何明示或默示担保,包括但不限于适用于特定用途、适销性
|
||||
、可销售品质或不侵犯第三方权利的默示担保。前述责任排除和限制在适用法律的最
|
||||
大允许范围内有效,即使补救措施未能有效发挥作用。
|
||||
|
||||
第五条 责任限制。
|
||||
1、除法律规定不得排除或限制的任何赔偿外,我公司、其关联公司及供应商在任何情
|
||||
况下都不对任何损失、损害、索赔或费用,包括任何间接、相应而生、附带的损失或
|
||||
任何失去的利润或储蓄,或因业务中断、人身伤害或不履行照顾责任或第三方索赔而
|
||||
引致的任何损害承担任何责任,即使我公司代表已被告知出现这种损失、损害、索赔
|
||||
或费用的可能性。无论任何情况下,依照本协议或与本协议有关的我公司、其关联公
|
||||
司以及供应商所承担的集合责任或以其他方式规定的责任均限于购买本软件所支付的
|
||||
款项(如果有)。即使在实质性或严重违反本协议或违反本协议的实质性或重要条款
|
||||
的情况下,本限制仍将适用。我公司代表其关联公司和供应商否认、排除和限制义务
|
||||
、担保和责任,但不在其他方面或为其他目的代表其行事。
|
||||
2、在您所在地的相关法律允许的情况下,前述限制和排除方能适用。本责任限制在某
|
||||
些国家可能无效。您可能依据消费者保护法和其他法律享有不得放弃的权利。我公司
|
||||
不在适用法律允许的范围外限制您所享有的担保或赔偿。
|
||||
|
||||
第六条 出口规则。
|
||||
1、您应遵守所有适用的出口法律、限制或规定。如果本软件按照中国、美国及其他所
|
||||
适用的出口法规被视为出口管制品,您须声明并保证您不是贸易禁运国或受限制国的
|
||||
公民,或没有居住在这些国家,并且您接收本软件不受中国、美国及其他所适用的出
|
||||
口法规的禁止。
|
||||
2、我方不对您承担由于您不遵守出口管制法律、制裁、限制措施和禁运以及本协议约
|
||||
定义务的行为而导致的任何责任。我方保留随时就本条约定对您及其使用相关方审计
|
||||
的权利。如您违反本条约定,我方有权随时不经通知终止本协议,并对给我方造成的
|
||||
一切损失承担责任(包括但不限于经济损失、名誉损失),且应采取充分、必要、有
|
||||
效的措施消除给我方造成的不利影响。
|
||||
|
||||
第七条 其它。
|
||||
1、本协议受中华人民共和国法律的管辖。我公司在法律范围内对本协议享有最终解释
|
||||
权。
|
||||
2、如果不遵守本协议中的条款,您使用本软件的权利将会立即终止。如果发现本协议
|
||||
中有任何规定无法执行,则仅该条规定(且以尽可能小的范围进行释义)将被视为无
|
||||
法执行,而本协议其余部分仍将根据其条款保持有效且应予以执行。第三条、第五条
|
||||
和第六条在本协议终止后继续有效。本协议不会损害用户方的法定权利。本协议是我
|
||||
公司与您之间有关本软件的完整协议,它将取代先前任何与本软件相关的陈述、讨论
|
||||
、承诺、通信或宣传。
|
||||
3、如用户对我公司的解释或修改有异议,应当立即停止使用本软件产品。用户继续使
|
||||
用本软件产品的行为将被视为对我方公司的解释或修改的接受。
|
||||
4、本协议用中英文两种版本书写,如有歧义,以中文版为准。
|
||||
196
LICENSE.ENG.TXT
Normal file
196
LICENSE.ENG.TXT
Normal file
@@ -0,0 +1,196 @@
|
||||
IMPORTANTNOTE: This License Agreement (hereinafter referred to as
|
||||
the "Agreement") is the legal agreement between you (end-user of
|
||||
this software) and our company(Kunlunxin (Beijing) Technology Co.,
|
||||
Ltd.) concerning the Software. This "Software Product" includes computer
|
||||
software and may include relatedmedia, printed material, and "online" or
|
||||
electronic documentation(the "Software Product"). This "Software Product"
|
||||
also includes any updates and supplements to your original "Software
|
||||
Product". Any associated softwareproducts provided to you with this
|
||||
Software Product is granted to you inaccordance with the terms of this
|
||||
License Agreement. If you do not agree to the terms of this Agreement,
|
||||
please do not install or use the Software Product and its associated
|
||||
services. Your installation, use, copying, downloading or other use will
|
||||
be deemed an acceptance of this Agreement and you agree to be bound by
|
||||
the terms of this Agreement. Any act of copying, selling, transferring,
|
||||
rentingor modifying the Software without our authorization is considered
|
||||
an infringement.
|
||||
|
||||
The copyright and other intellectual property rights or interests of the
|
||||
"Software Product" (including but not limited to the copyrights, patent
|
||||
rights, trademark rights, trade secrets, etc. that have been or may be
|
||||
obtained in the future) are owned by our company. This Software Product
|
||||
is protected by the Copyright Law of the People's Republic of China
|
||||
and applicable international copyright treaties and other intellectual
|
||||
property laws and treaties.
|
||||
|
||||
Article 1 Grant of License.
|
||||
This Agreement grants you the followingrights:
|
||||
1. Application software. You may install,use, access, display,
|
||||
run or otherwise interact ("run") with a copy of the Software
|
||||
Product on a single computer. The user of the computer running
|
||||
the Software Product may make another copy only for the same
|
||||
project after it has been installed on another company computer.
|
||||
|
||||
2. Storage/network use. You can also run Software Products on
|
||||
your computer, and you must obtain a license for each item added.
|
||||
|
||||
3. Rights reserved. All other rights not expressly granted are
|
||||
the property of us and our suppliers.
|
||||
|
||||
4. If you obtained the Software from our company or its authorized
|
||||
licensee, you may use the Software in the manner and for the
|
||||
purpose described in its documentation, as long as you comply
|
||||
with all the terms of this Agreement. If the Software is designed
|
||||
to be used with another application software product (the "Main
|
||||
Program") released by us and you have a valid license to use
|
||||
the Main Program, we grant you a non-exclusive license to use
|
||||
the Software with the Main Program. Users are only entitled to
|
||||
non-exclusive use of this software product.
|
||||
|
||||
Article 2 Restrictions and Obligations.
|
||||
1. Separation of components. This Software Product is licensed
|
||||
as a single product. You must not use its components separately
|
||||
on more than one computer.
|
||||
|
||||
2. Modification of components. You may not make any changes or
|
||||
additions to the licensed software, or create derivatives based
|
||||
on the software.
|
||||
|
||||
3. Reverse engineering is not allowed. Do not translate,
|
||||
disassemble, decompile,disassemble, reverse engineer, or
|
||||
otherwise attempt to export the program source code from the
|
||||
Licensed Software, in whole or in part.
|
||||
|
||||
4. This Agreement does not grant you any rights with respect
|
||||
to any trademarks or service marks of the Software Product. No
|
||||
marks relating to the copyright or trademark of the licensed
|
||||
software shall be removed, covered up or altered.
|
||||
|
||||
5. The licensed software shall not be provided, sold, leased,
|
||||
lent, transferred or sub-licensed, transmitted through information
|
||||
network or used by others in other forms.
|
||||
|
||||
6. Do not restrict, destroy or bypass the encrypted attachments
|
||||
attached to the Licensed Software or other restrictive measures
|
||||
provided by us to ensure the proper use of the Licensed Software.
|
||||
|
||||
7. Supporting services. We may provide you with support services
|
||||
related to the Software Product ("Support Services"). The use
|
||||
of Support Services is governed by the policies and programs
|
||||
described in the User Manual, the Online documentation, and/or
|
||||
other materials provided. Any additional software code provided
|
||||
to you as part of the Support Services shall be regarded as a
|
||||
part of this Software Product and must comply with the terms
|
||||
and conditions of this Agreement.
|
||||
|
||||
8. Termination. Without prejudice to any other rights, we may
|
||||
terminate this Agreement if you fail to comply with the terms and
|
||||
conditions of this Agreement. If this happens, you must destroy
|
||||
all copies of the Software Product and all of its components.
|
||||
|
||||
Article 3 Intellectual Property Rights.
|
||||
1. The property rights and copyrights of the Software Product
|
||||
(including but not limited to any images, photos, animations,
|
||||
video recordings, audio recordings, music, texts and additional
|
||||
programs included in the Software Product), the accompanying
|
||||
printed materials, and any copies of the Software Product are
|
||||
owned by our company and its suppliers.
|
||||
|
||||
2. Licensee is prohibited from granting all or part of the rights,
|
||||
licenses,benefits or privileges of the Licensed Products to any
|
||||
third party.
|
||||
|
||||
Article 4 Disclaimer.
|
||||
1. The "software product" is provided in the "as-is" mode. Our
|
||||
company does not guarantee that the software product can or cannot
|
||||
fully meet the user's requirements. The introductory contents
|
||||
in the user manual, help documents, operating instructions and
|
||||
other software documents are only for user's reference, and
|
||||
shall not be construed as any commitment made to the user. Our
|
||||
company reserves the right to upgrade the software version,
|
||||
modify or automatically update the function, content, structure,
|
||||
interface and operation mode.
|
||||
|
||||
2. Our company does not make any express or implied warranty on the
|
||||
software,including but not limited to the implied warranty that
|
||||
the software is suitablefor specific purpose, merchantability,
|
||||
marketable quality or does not infringethe rights of third
|
||||
parties. The foregoing exclusions and limitations ofliability
|
||||
shall be effective to the fullest extent permitted by applicable
|
||||
law,even if remedies do not function effectively.
|
||||
|
||||
Article 5 Limitation of Liability.
|
||||
1. Except for any indemnity which shall not be excluded or
|
||||
limited by law, we, its affiliates and suppliers shall under no
|
||||
circumstances be liable for any loss,damage, claim or expense,
|
||||
including any indirect, consequential, incidental loss or any
|
||||
lost profits or savings, or any damages arising frombusiness
|
||||
interruption personal injury or non-performance of the duty of
|
||||
care or 3rd party claims, even though our representative has
|
||||
been informed of the possibility of such loss, damage, claims
|
||||
or expenses. In any event, the aggregate liability or otherwise
|
||||
imposed upon us, its affiliates and supplier spursuant to or in
|
||||
connection with this Agreement shall be limited to the amount(if
|
||||
any) paid for the purchase of the Software. This restriction shall
|
||||
apply even in the event of a material or substantial breach of
|
||||
this Agreement or abreach of a material or significant provision
|
||||
of this Agreement. We disclaim,exclude and limit our obligations,
|
||||
warranties and liabilities on behalf of our affiliatesand
|
||||
suppliers, but do not act otherwise or for any other purpose.
|
||||
|
||||
2. The foregoing limitations and exclusions shall apply to the
|
||||
extent permitted by the relevant laws of your location. This
|
||||
limitation of liability may be void in certain countries. You may
|
||||
have rights that may not be waived under consumer protection laws
|
||||
and other laws. We do not limit your warranties or indemnities
|
||||
to the extent permitted by applicable law.
|
||||
|
||||
Article 6 Export Rules.
|
||||
1. You shall comply with all applicable export laws, restrictions
|
||||
or regulations. If the Software is considered export-controlled
|
||||
in accordance with China, the United States and other applicable
|
||||
export regulations, you must represent and warrant that you
|
||||
are not a citizen of, or resident in, a trade embargoed or
|
||||
restricted country,and that your accept the Software is not
|
||||
prohibited by export laws and regulations of China, the United
|
||||
States and other applicable laws and regulations.
|
||||
|
||||
2. We shall not be liable to you for any liability arising
|
||||
from your non-compliance with export control laws, sanctions,
|
||||
restrictions and embargoes, as well as your obligations under
|
||||
this Agreement. We reserve the right to audit you and the parties
|
||||
involved in your use of this Agreement at any time. In the event
|
||||
that you violate this agreement, we have the right to terminate
|
||||
this Agreement at any time without notice, and you shall bear
|
||||
the responsibility for all losses (including but not limited
|
||||
to economic loss and reputation loss) caused to us, and take
|
||||
sufficient, necessary and effective measures to eliminate the
|
||||
adverse effects caused to us.
|
||||
|
||||
Article 7 Others.
|
||||
1. This Agreement shall be governed by the laws of the People's
|
||||
Republic of China. We have the right of final interpretation of
|
||||
this Agreement within the scope of law.
|
||||
|
||||
2. If you do not comply with the terms of this Agreement,
|
||||
your right to use the Software will terminate immediately. If
|
||||
any provision of this Agreement is found unenforceable, only
|
||||
that provision (and shall be construed to the minimum extent
|
||||
possible) shall be deemed unenforceable, and the remainder of this
|
||||
Agreement shall remain in force and effect in accordance with its
|
||||
terms. Articles 3, 5 and 6 shall survive after the termination
|
||||
of this Agreement. This Agreement shall not prejudice the legal
|
||||
rights of the User. This Agreement is the entire agreement
|
||||
between us and you with respect to the Software and supersedes
|
||||
any prior representations, discussions, promises, communications
|
||||
or publicity relating to the Software.
|
||||
|
||||
3. If the user disagrees with the interpretation or modification
|
||||
of our company, the user shall immediately stop using the
|
||||
software product. User's continued use of the Software Product
|
||||
shall be deemed as acceptance of our Company's interpretation
|
||||
or modification.
|
||||
|
||||
4. This Agreement is written in both Chinese and English. In
|
||||
case of any ambiguity, the Chinese version shall prevail.
|
||||
|
||||
81
README.md
81
README.md
@@ -1,2 +1,81 @@
|
||||
# r200_8f_xtrt_llm
|
||||
=============
|
||||
版本号:v0.5.3
|
||||
发布时间:2024.02.01
|
||||
|
||||
v0.5.3 版产品特性:
|
||||
- 完善 Continuous Batching功能,并在外部客户场景验证了性能与精度正确性
|
||||
- 新增 Paged Attention功能
|
||||
- 新增 pipeline parallel模式,已验证 llama系列模型
|
||||
- 进一步优化llama、baichuan、chatglm模型性能。包括:优化显存分配方案,进一步提高最大batch_size;使用FA减小内存占用等方案。
|
||||
- 极大提高了编译模型的速度
|
||||
- 新增 smooth quant功能,已在 llama系列、qwen系列、bloom 等开源模型上验证了正确性
|
||||
- 验证了 QWen-72b模型的精度正确性,支持float16、int8以及分布式功能
|
||||
|
||||
v0.5.3 bug fix:
|
||||
- llama系列模型,在定长、多batch下的精度问题
|
||||
- 变长的精度问题
|
||||
|
||||
v0.5.3 已知问题:
|
||||
- 不支持 float32模型精度,需要自行转到 float16
|
||||
|
||||
下版本规划:
|
||||
- 初版 cpp runtime
|
||||
- 进一步强化重点客户关注的通用Feature
|
||||
|
||||
发版链接和Docker
|
||||
- [XTRT-LLM产出](https://klx-sdk-release-public.su.bcebos.com/xtrt_llm/release/v0.5.3/output.tar.gz)
|
||||
- Ubuntu Docker: docker pull iregistry.baidu-int.com/isa/xtcl_ubuntu2004:v4.3
|
||||
|
||||
|
||||
=============
|
||||
版本号:v0.5.2.2
|
||||
发布时间:2024.01.26
|
||||
|
||||
v0.5.2.2版产品特性
|
||||
- 统一了XTRT和XPyTorch的底层依赖模块
|
||||
- 修复了若干已知问题
|
||||
|
||||
发版链接和Docker
|
||||
- [XTRT-LLM产出](https://klx-sdk-release-public.su.bcebos.com/xtrt_llm/release/v0.5.2.2/output.tar.gz)
|
||||
- Ubuntu Docker: docker pull iregistry.baidu-int.com/isa/xtcl_ubuntu2004:v4.3
|
||||
|
||||
|
||||
=============
|
||||
版本号:v0.5.2
|
||||
发布时间:2023.12.28
|
||||
|
||||
v0.5.2版产品特性
|
||||
- 验证了Baichuan2-7B, Baichuan2-13B模型的正确性,支持FP16和INT8分布式功能,支持了Baichuan-13B的分布式运行
|
||||
- 验证了Qwen-7B, Qwen-14B模型的正确性,支持FP16和INT8分布式功能
|
||||
- 验证了ChatGLM-6B模型的正确性,支持FP16和INT8功能
|
||||
- 验证了Bloom模型的正确性,支持FP16和INT8分布式功能
|
||||
- 验证了GPT-Neox-20B模型的正确性,支持FP16和INT8分布式功能
|
||||
- 增加运行时Memory Cache和分桶算法,提升首字延迟性能
|
||||
- 框架层面增加服务调度功能,完成Continuous Batching的初版Demo
|
||||
|
||||
下版本规划
|
||||
- 完整支持Continuous Batching,Remove Padding功能
|
||||
- 接入外部客户的大模型验证,交付等实际项目,开发重点客户关注的通用Feature
|
||||
- 模型适配KL3
|
||||
|
||||
|
||||
=============
|
||||
版本号:v0.5.1
|
||||
发布时间:2023.12.7
|
||||
|
||||
使用场景
|
||||
XTRT-LLM在如下场景下为前场同学提供帮助与支持
|
||||
- 如客户当前使用TensorRT-LLM进行GPU模型的推理与部署,XTRT-LLM可快速完成迁移与适配,提供高性能版本的XPU推理能力,降低客户对接成本
|
||||
- 如客户指定开源LLM进行POC和性能PK,对于XTRT-LLM已经验证支持的模型,可直接加载Huggingface上的公版权重,进行高性能版本的模型推理
|
||||
|
||||
v0.5.1版产品特性
|
||||
- 实现并对齐了Nvidia TensorRT-LLM v0.5版本的基础数据结构,完成了核心功能的验证,兼容TensorRT-LLM的Python前端组网
|
||||
- 验证了LLama-7B, LLama-13B, LLama-65B和LLama2-70B全系模型的正确性,支持FP16和INT8分布式功能
|
||||
- 验证了Baichuan-7B, Baichuan-13B模型的正确性,支持FP16和INT8功能
|
||||
- 验证了ChatGLM2-6B, ChatGLM3-6B模型的正确性,支持FP16和INT8功能
|
||||
- 验证了GPT-J模型的正确性,支持FP16和INT8功能
|
||||
|
||||
下版本规划
|
||||
- 整体支持10+个大模型,进一步优化模型性能,下一版仍以月粒度发版
|
||||
- 逐步接入外部客户的大模型验证,交付等实际项目,并开发客户关注的Feature
|
||||
- 模型适配KL3
|
||||
|
||||
96
doc/UserGuide.md
Normal file
96
doc/UserGuide.md
Normal file
@@ -0,0 +1,96 @@
|
||||
# 昆仑芯XTRT-LLM使用指南
|
||||
|
||||
## 产品整体定位
|
||||
|
||||
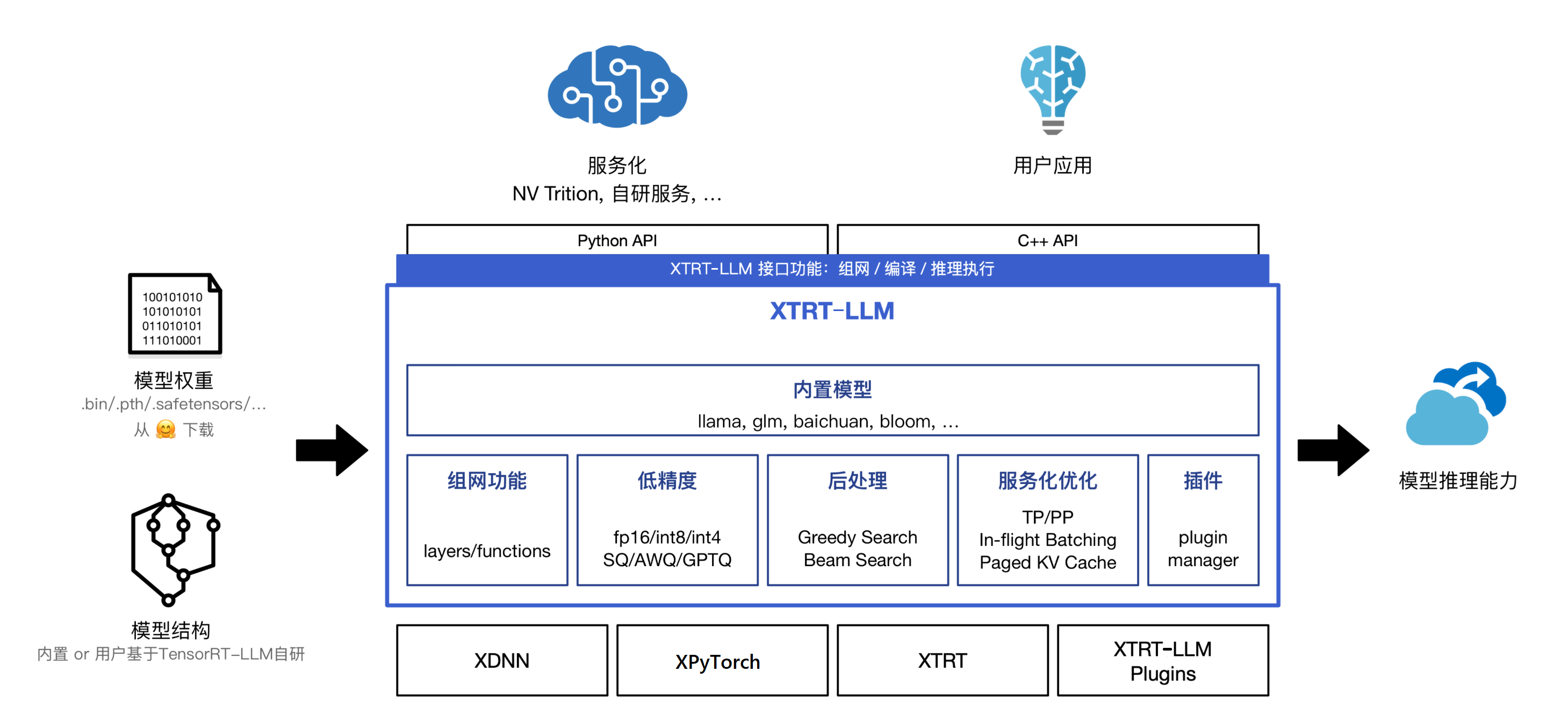
XTRT—LLM产品定位是快速对齐Nvidia的大模型产品,在不改或者少改几行代码的情况下,能够做到完全兼容现有TensorRT-LLM产品;以模块化、Python组网的方式来支持大模型的推理。保证用户在使用上不会感知底层运行时的不同,只需关注模型结构和对应的算法本身,通过简单配置就可以实现单卡和单机多卡分布式两种推理运行方式,也符合算法工程师普遍的使用习惯。下图是`XTRT-LLM整体架构图`:
|
||||
|
||||
|
||||
|
||||
## 使用场景
|
||||
XTRT-LLM可提供以下场景的支持:
|
||||
- 在已经使用TensorRT-LLM进行GPU模型的推理与部署的情况下,XTRT-LLM可支持用户快速完成模型的迁移与适配,提供高性能版本的XPU推理能力,降低对接成本。
|
||||
- 在指定开源LLM进行部署和性能测试情况下,对于XTRT-LLM已经验证支持的模型,可直接加载Huggingface上的公版权重,进行高性能版本的模型推理。
|
||||
|
||||
## 环境搭建与Demo
|
||||
XTRT-LLM的环境搭建需要下载对应的Docker环境以及XTRT-LLM的产出来搭建大模型的运行环境。大模型的运行需要有编译和运行两个阶段。每个模型的具体运行会略有差异,详细的模型运行步骤可以参考对应模型目录下的README.md文件,这里以LLama-7B模型的单卡运行举例
|
||||
|
||||
### 环境搭建
|
||||
- 下载Docker image并启动Docker
|
||||
|
||||
```bash
|
||||
# 下载Docker image
|
||||
docker pull iregistry.baidu-int.com/isa/xtcl_ubuntu2004:v4.3
|
||||
|
||||
# 启动Docker
|
||||
sudo docker run -it
|
||||
--net=host
|
||||
--cap-add=SYS_PTRACE
|
||||
--device=/dev/xpu0:/dev/xpu0 --device=/dev/xpu1:/dev/xpu1 #根据实际的昆仑芯卡设备数选择--device映射的数目**
|
||||
--device=/dev/xpu2:/dev/xpu2 --device=/dev/xpu3:/dev/xpu3
|
||||
--device=/dev/xpu4:/dev/xpu4 --device=/dev/xpu5:/dev/xpu5
|
||||
--device=/dev/xpu6:/dev/xpu6 --device=/dev/xpu7:/dev/xpu7
|
||||
--device=/dev/xpuctrl:/dev/xpuctrl
|
||||
--name xtrt_llm
|
||||
-v /宿主机路径:/容器路径
|
||||
-w /容器工作路径
|
||||
iregistry.baidu-int.com/isa/xtcl_ubuntu2004:v4.3 /bin/bash
|
||||
```
|
||||
|
||||
- 下载XTRT-LLM产出包并解压
|
||||
|
||||
```bash
|
||||
# 去除代理
|
||||
unset http_proxy https_proxy
|
||||
# 下载产出包
|
||||
wget https://klx-sdk-release-public.su.bcebos.com/xtrt_llm/release/v0.5.3/output.tar.gz && tar -zxf output.tar.gz
|
||||
cd output/
|
||||
```
|
||||
|
||||
- 设置代理
|
||||
|
||||
根据实际网络场景,设置`scripts/install_release.sh`脚本中代理配置
|
||||
```bash
|
||||
set_proxy() {
|
||||
export http_proxy=xxx
|
||||
export https_proxy=xxx
|
||||
}
|
||||
```
|
||||
|
||||
- 切换到运行环境
|
||||
|
||||
```bash
|
||||
source /home/pt201/bin/activate
|
||||
bash scripts/install_release.sh
|
||||
source scripts/set_release_env.sh
|
||||
```
|
||||
|
||||
### 运行模型
|
||||
|
||||
- 下载模型权重
|
||||
|
||||
以llama-7b为例
|
||||
```bash
|
||||
cd examples/llama
|
||||
bash ../../scripts/download_model.sh llama-7b
|
||||
# bash ../../scripts/download_model.sh <模型名称>
|
||||
# 当前支持的模型有: llama-7b, llama-13b, llama-65b, llama2-70b, chatglm-6b, chatglm2-6b, chatglm3-6b, baichuan-7b, baichuan-13b, baichuan2-7b, baichuan2-13b, bloom, gpt-neox-20b, qwen-7b, qwen-14b, qwen-72b and gptj-6b
|
||||
```
|
||||
下载的模型权重默认存放在 `examples` 目录下各模型对应的文件夹下的`downloads`,例如`examples/llama/downloads`
|
||||
|
||||
- 编译模型
|
||||
|
||||
模型具体的build命令请参考 `examples` 目录下各模型对应的`README.md`或`README_CN.md`
|
||||
根据需要添加build.py中的配置参数,该过程需要几分钟的时间,每次修改参数都需要重新执行编译过程。
|
||||
```bash
|
||||
python3 build.py --model_dir ./downloads/llama-7b-hf/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/llama-7b-hf/trt_engines/fp16/1-XPU/
|
||||
```
|
||||
|
||||
- 运行模型
|
||||
|
||||
模型具体的run命令请参考 `examples` 目录下各模型对应的`README.md`或`README_CN.md`
|
||||
```bash
|
||||
python3 run.py --engine_dir ./downloads/llama-7b-hf/trt_engines/fp16/1-XPU/ --max_output_len 128 --tokenizer_dir ./downloads/llama-7b-hf/
|
||||
```
|
||||
0
examples/__init__.py
Normal file
0
examples/__init__.py
Normal file
BIN
examples/__pycache__/utils.cpython-38.pyc
Normal file
BIN
examples/__pycache__/utils.cpython-38.pyc
Normal file
Binary file not shown.
146
examples/baichuan/README.md
Normal file
146
examples/baichuan/README.md
Normal file
@@ -0,0 +1,146 @@
|
||||
# Baichuan
|
||||
|
||||
This document shows how to build and run a Baichuan models (including `v1_7b`/`v1_13b`/`v2_7b`/`v2_13b`) in XTRT-LLM on both single XPU and single node multi-XPU.
|
||||
|
||||
## Overview
|
||||
|
||||
The XTRT-LLM Baichuan example code is located in [`examples/baichuan`](./). There are several main files in that folder:
|
||||
|
||||
* [`build.py`](./build.py) to build the XTRT engine(s) needed to run the Baichuan model,
|
||||
* [`run.py`](./run.py) to run the inference on an input text,
|
||||
|
||||
These scripts accept an argument named model_version, whose value should be `v1_7b`/`v1_13b`/`v2_7b`/`v2_13b` and the default value is `v1_13b`.
|
||||
|
||||
## Support Matrix
|
||||
* FP16
|
||||
* INT4 & INT8 Weight-Only
|
||||
|
||||
## Usage
|
||||
|
||||
The XTRT-LLM Baichuan example code locates at [examples/baichuan](./). It takes HF weights as input, and builds the corresponding XTRT engines. The number of XTRT engines depends on the number of XPUs used to run inference.
|
||||
|
||||
### Build XTRT engine(s)
|
||||
|
||||
Need to specify the HF Baichuan checkpoint path. For `v1_13b`, you should use whether [./downloads/baichuan-13b](./downloads/baichuan-13b) or [baichuan-inc/Baichuan-13B-Base](https://huggingface.co/baichuan-inc/Baichuan-13B-Base). For `v2_13b`, you should use whether [baichuan-inc/Baichuan2-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat) or [baichuan-inc/Baichuan2-13B-Base](https://huggingface.co/baichuan-inc/Baichuan2-13B-Base). More Baichuan models could be found on [baichuan-inc](https://huggingface.co/baichuan-inc).
|
||||
|
||||
XTRT-LLM Baichuan builds XTRT engine(s) from HF checkpoint. If no checkpoint directory is specified, XTRT-LLM will build engine(s) with dummy weights.
|
||||
|
||||
Normally `build.py` only requires single XPU, but if you've already got all the XPUs needed while inferencing, you could enable parallelly building to make the engine building process faster by adding `--parallel_build` argument. Please note that currently `parallel_build` feature only supports single node.
|
||||
|
||||
Here're some examples that take `v1_13b` as example(`v1_7b`, `v2_7b`, `v2_13b` are supported):
|
||||
|
||||
```bash
|
||||
|
||||
# Build the Baichuan V1 13B model using a single XPU and FP16.
|
||||
python build.py --model_version v1_13b \
|
||||
--model_dir ./downloads/baichuan-13b \
|
||||
--dtype float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/baichuan-13b/fp16/tp1
|
||||
|
||||
# Build the Baichuan V1 13B model using a single XPU and apply INT8 weight-only quantization.
|
||||
python build.py --model_version v1_13b \
|
||||
--model_dir ./downloads/baichuan-13b \
|
||||
--dtype float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_weight_only \
|
||||
--output_dir ./downloads/baichuan-13b/int8/tp1
|
||||
|
||||
# Build the Baichuan V1 13B model using a single GPU and apply INT4 weight-only quantization.
|
||||
python build.py --model_version v1_13b \
|
||||
--model_dir baichuan-inc/Baichuan-13B-Chat \
|
||||
--dtype float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_weight_only \
|
||||
--weight_only_precision int4 \
|
||||
--output_dir ./tmp/baichuan_v1_13b/trt_engines/int4_weight_only/1-gpu/
|
||||
|
||||
# Build Baichuan V1 13B using 2-way tensor parallelism and FP16.
|
||||
python build.py --model_version v1_13b \
|
||||
--model_dir ./downloads/baichuan-13b \
|
||||
--dtype float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/baichuan-13b/fp16/tp2 \
|
||||
--parallel_build \
|
||||
--world_size 2
|
||||
|
||||
# Build Baichuan V1 13B using 2-way tensor parallelism and apply INT8 weight-only quantization.
|
||||
python build.py --model_version v1_13b \
|
||||
--model_dir ./downloads/baichuan-13b \
|
||||
--dtype float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_weight_only \
|
||||
--output_dir ./downloads/baichuan-13b/int8/tp2 \
|
||||
--parallel_build \
|
||||
--world_size 2
|
||||
|
||||
|
||||
```
|
||||
### Run
|
||||
|
||||
Before running the examples, make sure set the environment variables:
|
||||
|
||||
```bash
|
||||
export PYTORCH_NO_XPU_MEMORY_CACHING=0 # disable XPytorch cache XPU memory.
|
||||
export XMLIR_D_XPU_L3_SIZE=0 # disable XPytorch use L3.
|
||||
```
|
||||
|
||||
If you are runing with multiple XPUs and no L3 space, you can set `BKCL_CCIX_BUFFER_GM=1` to disable L3.
|
||||
|
||||
To run a XTRT-LLM Baichuan model using the engines generated by `build.py`. Here're some examples:
|
||||
|
||||
```bash
|
||||
# Generate summarization for a given input text
|
||||
python summarize.py --model_version v2_13b \
|
||||
--hf_model_location ./downloads/baichuan2-13b \
|
||||
--engine_dir ./downloads/baichuan2-13b/fp16/tp1/ \
|
||||
--log_level info
|
||||
|
||||
# With fp16 inference
|
||||
python run.py --model_version v1_13b \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/baichuan-13b \
|
||||
--log_level=info \
|
||||
--engine_dir=./downloads/baichuan-13b/fp16/tp1
|
||||
|
||||
# With INT8 weight-only quantization inference
|
||||
python run.py --model_version v1_13b \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir=./downloads/baichuan-13b \
|
||||
--log_level=info \
|
||||
--engine_dir=./downloads/baichuan-13b/int8/tp1
|
||||
|
||||
# With INT4 weight-only quantization inference
|
||||
python run.py --model_version v1_13b \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir=baichuan-inc/Baichuan-13B-Chat \
|
||||
--engine_dir=./tmp/baichuan_v1_13b/trt_engines/int4_weight_only/1-gpu/
|
||||
|
||||
# with fp16 and 2-way tensor parallelism inference
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python run.py --model_version v1_13b \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir=./downloads/baichuan-13b \
|
||||
--log_level=info \
|
||||
--engine_dir=./downloads/baichuan-13b/fp16/tp2
|
||||
|
||||
# with INT8 weight-only and 2-way tensor parallelism inference
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python run.py --model_version v1_13b \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir=./downloads/baichuan-13b \
|
||||
--log_level=info \
|
||||
--engine_dir=./downloads/baichuan-13b/int8/tp2
|
||||
|
||||
```
|
||||
|
||||
### Known Issues
|
||||
|
||||
* The implementation of the Baichuan-7B model with INT8 Weight-Only and Tensor
|
||||
Parallelism greater than 2 might have accuracy issues. It is under
|
||||
investigation.
|
||||
127
examples/baichuan/README_CN.md
Normal file
127
examples/baichuan/README_CN.md
Normal file
@@ -0,0 +1,127 @@
|
||||
# Baichuan
|
||||
|
||||
本文档介绍了如何使用昆仑芯XTRT-LLM在单XPU和单节点多XPU上构建和运行百川(Baichuan)模型(包括`v1_7b`/`v1_13b`/`v2_7b`/`v2_13b`)。
|
||||
|
||||
## 概述
|
||||
|
||||
XTRT-LLM Baichuan示例代码位于 [`examples/baichuan`](./). 此文件夹中有以下几个主要文件:
|
||||
|
||||
* [`build.py`](./build.py) 构建运行Baichuan模型所需的XTRT引擎
|
||||
* [`run.py`](./run.py) 基于输入的文字进行推理
|
||||
|
||||
这些脚本接收一个名为model_version的参数,其值应为 `v1_7b`/`v1_13b`/`v2_7b`/`v2_13b` ,其默认值为 `v1_13b`。
|
||||
|
||||
## 支持的矩阵
|
||||
|
||||
* FP16
|
||||
* INT8 Weight-Only
|
||||
|
||||
## 使用说明
|
||||
|
||||
XTRT-LLM Baichuan示例代码位于 [`examples/baichuan`](./)。它使用HF权重作为输入,并且构建对应的XTRT引擎。XTRT引擎的数量取决于为了运行推理而使用的XPU个数。
|
||||
|
||||
### 构建XTRT引擎
|
||||
|
||||
需要明确HF Baichuan checkpoint的路径。对于`v1_13b`,应该使用 [./downloads/baichuan-13b](./downloads/baichuan-13b) 或者 [baichuan-inc/Baichuan-13B-Base](https://huggingface.co/baichuan-inc/Baichuan-13B-Base).对于`v2_13b`,应该使用 [baichuan-inc/Baichuan2-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat)或者 [baichuan-inc/Baichuan2-13B-Base](https://huggingface.co/baichuan-inc/Baichuan2-13B-Base)。更多的Baichuan模型可见 [baichuan-inc](https://huggingface.co/baichuan-inc)。
|
||||
|
||||
XTRT-LLM Baichuan从HF checkpoint构建XTRT引擎。如果未指定checkpoint目录,XTRT-LLM将使用伪权重构建引擎。
|
||||
|
||||
通常`build.py`只需要一个XPU,但如果您在推理时已经获得了所需的所有XPU,则可以通过添加`--parallel_build`参数来启用并行构建,从而加快引擎构建过程。请注意,当前并行构建功能仅支持单个节点。
|
||||
|
||||
以下是一些以`v1_13b`为例的示例(亦支持`v1_7b`、`v2_7b`和`v2_13b`):
|
||||
|
||||
```bash
|
||||
# Build the Baichuan V1 13B model using a single XPU and FP16.
|
||||
python build.py --model_version v1_13b \
|
||||
--model_dir ./downloads/baichuan-13b \
|
||||
--dtype float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/baichuan-13b/fp16/tp1
|
||||
|
||||
# Build the Baichuan V1 13B model using a single XPU and apply INT8 weight-only quantization.
|
||||
python build.py --model_version v1_13b \
|
||||
--model_dir ./downloads/baichuan-13b \
|
||||
--dtype float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_weight_only \
|
||||
--output_dir ./downloads/baichuan-13b/int8/tp1
|
||||
|
||||
# Build Baichuan V1 13B using 2-way tensor parallelism and FP16.
|
||||
python build.py --model_version v1_13b \
|
||||
--model_dir ./downloads/baichuan-13b \
|
||||
--dtype float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/baichuan-13b/fp16/tp2 \
|
||||
--parallel_build \
|
||||
--world_size 2
|
||||
|
||||
# Build Baichuan V1 13B using 2-way tensor parallelism and apply INT8 weight-only quantization.
|
||||
python build.py --model_version v1_13b \
|
||||
--model_dir ./downloads/baichuan-13b \
|
||||
--dtype float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_weight_only \
|
||||
--output_dir ./downloads/baichuan-13b/int8/tp2 \
|
||||
--parallel_build \
|
||||
--world_size 2
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 运行
|
||||
|
||||
在运行示例之前,请确保设置环境变量:
|
||||
|
||||
```bash
|
||||
export PYTORCH_NO_XPU_MEMORY_CACHING=0 # disable XPytorch cache XPU memory.
|
||||
export XMLIR_D_XPU_L3_SIZE=0 # disable XPytorch use L3.
|
||||
```
|
||||
|
||||
如果使用多个XPU且没有L3空间运行,则可以通过设置`BKCL_CCIX_BUFFER_GM=1`以禁用L3。
|
||||
|
||||
使用`build.py`生成的引擎运行XTRT-LLM Baichuan模型:
|
||||
|
||||
```bash
|
||||
# With fp16 inference
|
||||
python run.py --model_version v1_13b \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/baichuan-13b \
|
||||
--log_level=info \
|
||||
--engine_dir=./downloads/baichuan-13b/fp16/tp1
|
||||
|
||||
# With INT8 weight-only quantization inference
|
||||
python run.py --model_version v1_13b \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir=./downloads/baichuan-13b \
|
||||
--log_level=info \
|
||||
--engine_dir=./downloads/baichuan-13b/int8/tp1
|
||||
|
||||
# with fp16 and 2-way tensor parallelism inference
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python run.py --model_version v1_13b \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir=./downloads/baichuan-13b \
|
||||
--log_level=info \
|
||||
--engine_dir=./downloads/baichuan-13b/fp16/tp2
|
||||
|
||||
# with INT8 weight-only and 2-way tensor parallelism inference
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python run.py --model_version v1_13b \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir=./downloads/baichuan-13b \
|
||||
--log_level=info \
|
||||
--engine_dir=./downloads/baichuan-13b/int8/tp2
|
||||
|
||||
```
|
||||
|
||||
### 已知问题
|
||||
|
||||
- 采用仅使用INT8权重和大于2的Tensor Parallelism的Baichuan-7B模型的实现可能存在精度问题。此问题正在调查中。
|
||||
|
||||
|
||||
|
||||
491
examples/baichuan/build.py
Normal file
491
examples/baichuan/build.py
Normal file
@@ -0,0 +1,491 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import os
|
||||
import time
|
||||
|
||||
import onnx
|
||||
import torch.multiprocessing as mp
|
||||
import tvm as trt
|
||||
from onnx import TensorProto, helper
|
||||
from transformers import AutoConfig, AutoModelForCausalLM
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm._utils import str_dtype_to_xtrt
|
||||
from xtrt_llm.builder import Builder
|
||||
from xtrt_llm.layers.attention import PositionEmbeddingType
|
||||
from xtrt_llm.logger import logger
|
||||
from xtrt_llm.mapping import Mapping
|
||||
from xtrt_llm.models import BaichuanForCausalLM, weight_only_quantize
|
||||
from xtrt_llm.network import net_guard
|
||||
from xtrt_llm.plugin.plugin import ContextFMHAType
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
from weight import load_from_hf_baichuan # isort:skip
|
||||
|
||||
# 2 routines: get_engine_name, serialize_engine
|
||||
# are direct copy from gpt example, TODO: put in utils?
|
||||
|
||||
|
||||
def trt_dtype_to_onnx(dtype):
|
||||
if dtype == trt.float16:
|
||||
return TensorProto.DataType.FLOAT16
|
||||
elif dtype == trt.float32:
|
||||
return TensorProto.DataType.FLOAT
|
||||
elif dtype == trt.int32:
|
||||
return TensorProto.DataType.INT32
|
||||
else:
|
||||
raise TypeError("%s is not supported" % dtype)
|
||||
|
||||
|
||||
def to_onnx(network, path):
|
||||
inputs = []
|
||||
for i in range(network.num_inputs):
|
||||
network_input = network.get_input(i)
|
||||
inputs.append(
|
||||
helper.make_tensor_value_info(
|
||||
network_input.name, trt_dtype_to_onnx(network_input.dtype),
|
||||
list(network_input.shape)))
|
||||
|
||||
outputs = []
|
||||
for i in range(network.num_outputs):
|
||||
network_output = network.get_output(i)
|
||||
outputs.append(
|
||||
helper.make_tensor_value_info(
|
||||
network_output.name, trt_dtype_to_onnx(network_output.dtype),
|
||||
list(network_output.shape)))
|
||||
|
||||
nodes = []
|
||||
for i in range(network.num_layers):
|
||||
layer = network.get_layer(i)
|
||||
layer_inputs = []
|
||||
for j in range(layer.num_inputs):
|
||||
ipt = layer.get_input(j)
|
||||
if ipt is not None:
|
||||
layer_inputs.append(layer.get_input(j).name)
|
||||
layer_outputs = [
|
||||
layer.get_output(j).name for j in range(layer.num_outputs)
|
||||
]
|
||||
nodes.append(
|
||||
helper.make_node(str(layer.type),
|
||||
name=layer.name,
|
||||
inputs=layer_inputs,
|
||||
outputs=layer_outputs,
|
||||
domain="com.nvidia"))
|
||||
|
||||
onnx_model = helper.make_model(helper.make_graph(nodes,
|
||||
'attention',
|
||||
inputs,
|
||||
outputs,
|
||||
initializer=None),
|
||||
producer_name='NVIDIA')
|
||||
onnx.save(onnx_model, path)
|
||||
|
||||
|
||||
def get_engine_name(model, dtype, tp_size, rank):
|
||||
return '{}_{}_tp{}_rank{}.engine'.format(model, dtype, tp_size, rank)
|
||||
|
||||
|
||||
def serialize_engine(engine, path):
|
||||
logger.info(f'Serializing engine to {path}...')
|
||||
tik = time.time()
|
||||
# import pdb;pdb.set_trace()
|
||||
engine.serialize(path)
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Engine serialized. Total time: {t}')
|
||||
|
||||
|
||||
def parse_arguments():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--world_size',
|
||||
type=int,
|
||||
default=1,
|
||||
help='world size, only support tensor parallelism now')
|
||||
parser.add_argument('--model_dir',
|
||||
type=str,
|
||||
default='baichuan-inc/Baichuan-13B-Chat')
|
||||
parser.add_argument('--model_version',
|
||||
type=str,
|
||||
default='v1_13b',
|
||||
choices=['v1_7b', 'v1_13b', 'v2_7b', 'v2_13b'])
|
||||
parser.add_argument('--dtype',
|
||||
type=str,
|
||||
default='float16',
|
||||
choices=['float32', 'bfloat16', 'float16'])
|
||||
parser.add_argument(
|
||||
'--opt_memory_use',
|
||||
default=True,
|
||||
action="store_true",
|
||||
help='Whether to use Host memory optimization for building engine')
|
||||
parser.add_argument(
|
||||
'--timing_cache',
|
||||
type=str,
|
||||
default='model.cache',
|
||||
help=
|
||||
'The path of to read timing cache from, will be ignored if the file does not exist'
|
||||
)
|
||||
parser.add_argument('--log_level', type=str, default='info')
|
||||
parser.add_argument('--pp_size', type=int, default=1)
|
||||
parser.add_argument('--vocab_size', type=int, default=64000)
|
||||
parser.add_argument('--n_layer', type=int, default=40)
|
||||
parser.add_argument('--n_positions', type=int, default=4096)
|
||||
parser.add_argument('--n_embd', type=int, default=5120)
|
||||
parser.add_argument('--n_head', type=int, default=40)
|
||||
parser.add_argument('--inter_size', type=int, default=13696)
|
||||
parser.add_argument('--hidden_act', type=str, default='silu')
|
||||
parser.add_argument('--max_batch_size', type=int, default=1)
|
||||
parser.add_argument('--max_input_len', type=int, default=1024)
|
||||
parser.add_argument('--max_output_len', type=int, default=1024)
|
||||
parser.add_argument('--max_beam_width', type=int, default=1)
|
||||
parser.add_argument('--use_gpt_attention_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=True,
|
||||
choices=['float16', 'bfloat16', 'float32'])
|
||||
parser.add_argument('--use_gemm_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
choices=['float16', 'bfloat16', 'float32'])
|
||||
parser.add_argument('--enable_context_fmha',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--enable_context_fmha_fp32_acc',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--parallel_build', default=False, action='store_true')
|
||||
parser.add_argument('--visualize', default=False, action='store_true')
|
||||
parser.add_argument('--enable_debug_output',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--gpus_per_node', type=int, default=8)
|
||||
parser.add_argument(
|
||||
'--output_dir',
|
||||
type=str,
|
||||
default='baichuan_outputs',
|
||||
help=
|
||||
'The path to save the serialized engine files, timing cache file and model configs'
|
||||
)
|
||||
parser.add_argument('--remove_input_padding',
|
||||
default=False,
|
||||
action='store_true')
|
||||
|
||||
parser.add_argument(
|
||||
'--use_weight_only',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help='Quantize weights for the various GEMMs to INT4/INT8.'
|
||||
'See --weight_only_precision to set the precision')
|
||||
|
||||
parser.add_argument(
|
||||
'--weight_only_precision',
|
||||
const='int8',
|
||||
type=str,
|
||||
nargs='?',
|
||||
default='int8',
|
||||
choices=['int8', 'int4'],
|
||||
help=
|
||||
'Define the precision for the weights when using weight-only quantization.'
|
||||
'You must also use --use_weight_only for that argument to have an impact.'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_inflight_batching',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Activates inflight batching mode of gptAttentionPlugin.")
|
||||
parser.add_argument(
|
||||
'--paged_kv_cache',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help=
|
||||
'By default we use contiguous KV cache. By setting this flag you enable paged KV cache'
|
||||
)
|
||||
parser.add_argument('--tokens_per_block',
|
||||
type=int,
|
||||
default=64,
|
||||
help='Number of tokens per block in paged KV cache')
|
||||
parser.add_argument(
|
||||
'--max_num_tokens',
|
||||
type=int,
|
||||
default=None,
|
||||
help='Define the max number of tokens supported by the engine')
|
||||
parser.add_argument('--gather_all_token_logits',
|
||||
action='store_true',
|
||||
default=False)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
if args.use_weight_only:
|
||||
args.quant_mode = QuantMode.use_weight_only(
|
||||
args.weight_only_precision == 'int4')
|
||||
else:
|
||||
args.quant_mode = QuantMode(0)
|
||||
|
||||
if args.use_inflight_batching:
|
||||
if not args.use_gpt_attention_plugin:
|
||||
args.use_gpt_attention_plugin = 'float16'
|
||||
logger.info(
|
||||
f"Using GPT attention plugin for inflight batching mode. Setting to default '{args.use_gpt_attention_plugin}'"
|
||||
)
|
||||
if not args.remove_input_padding:
|
||||
args.remove_input_padding = True
|
||||
logger.info(
|
||||
"Using remove input padding for inflight batching mode.")
|
||||
if not args.paged_kv_cache:
|
||||
args.paged_kv_cache = True
|
||||
logger.info("Using paged KV cache for inflight batching mode.")
|
||||
|
||||
if args.max_num_tokens is not None:
|
||||
assert args.enable_context_fmha
|
||||
|
||||
if args.model_dir is not None:
|
||||
hf_config = AutoConfig.from_pretrained(args.model_dir,
|
||||
trust_remote_code=True)
|
||||
# override the inter_size for Baichuan
|
||||
args.inter_size = hf_config.intermediate_size
|
||||
args.n_embd = hf_config.hidden_size
|
||||
args.n_head = hf_config.num_attention_heads
|
||||
args.n_layer = hf_config.num_hidden_layers
|
||||
if args.model_version == 'v1_7b' or args.model_version == 'v2_7b':
|
||||
args.n_positions = hf_config.max_position_embeddings
|
||||
else:
|
||||
args.n_positions = hf_config.model_max_length
|
||||
args.vocab_size = hf_config.vocab_size
|
||||
args.hidden_act = hf_config.hidden_act
|
||||
else:
|
||||
# default values are based on v1_13b, change them based on model_version
|
||||
if args.model_version == 'v1_7b':
|
||||
args.inter_size = 11008
|
||||
args.n_embd = 4096
|
||||
args.n_head = 32
|
||||
args.n_layer = 32
|
||||
args.n_positions = 4096
|
||||
args.vocab_size = 64000
|
||||
args.hidden_act = 'silu'
|
||||
elif args.model_version == 'v2_7b':
|
||||
args.inter_size = 11008
|
||||
args.n_embd = 4096
|
||||
args.n_head = 32
|
||||
args.n_layer = 32
|
||||
args.n_positions = 4096
|
||||
args.vocab_size = 125696
|
||||
args.hidden_act = 'silu'
|
||||
elif args.model_version == 'v2_13b':
|
||||
args.inter_size = 13696
|
||||
args.n_embd = 5120
|
||||
args.n_head = 40
|
||||
args.n_layer = 40
|
||||
args.n_positions = 4096
|
||||
args.vocab_size = 125696
|
||||
args.hidden_act = 'silu'
|
||||
|
||||
if args.dtype == 'bfloat16':
|
||||
assert args.use_gemm_plugin, "Please use gemm plugin when dtype is bfloat16"
|
||||
|
||||
return args
|
||||
|
||||
|
||||
def build_rank_engine(builder: Builder,
|
||||
builder_config: xtrt_llm.builder.BuilderConfig,
|
||||
engine_name, rank, args):
|
||||
'''
|
||||
@brief: Build the engine on the given rank.
|
||||
@param rank: The rank to build the engine.
|
||||
@param args: The cmd line arguments.
|
||||
@return: The built engine.
|
||||
'''
|
||||
kv_dtype = str_dtype_to_xtrt(args.dtype)
|
||||
if args.model_version == 'v1_7b' or args.model_version == 'v2_7b':
|
||||
position_embedding_type = PositionEmbeddingType.rope_gpt_neox
|
||||
else:
|
||||
position_embedding_type = PositionEmbeddingType.alibi
|
||||
|
||||
# Initialize Module
|
||||
xtrt_llm_baichuan = BaichuanForCausalLM(
|
||||
num_layers=args.n_layer,
|
||||
num_heads=args.n_head,
|
||||
hidden_size=args.n_embd,
|
||||
vocab_size=args.vocab_size,
|
||||
hidden_act=args.hidden_act,
|
||||
max_position_embeddings=args.n_positions,
|
||||
position_embedding_type=position_embedding_type,
|
||||
dtype=kv_dtype,
|
||||
mlp_hidden_size=args.inter_size,
|
||||
mapping=Mapping(world_size=args.world_size,
|
||||
rank=rank,
|
||||
tp_size=args.world_size),
|
||||
gather_all_token_logits=args.gather_all_token_logits)
|
||||
if args.use_weight_only and args.weight_only_precision == 'int8' and 0:
|
||||
xtrt_llm_baichuan = weight_only_quantize(xtrt_llm_baichuan,
|
||||
QuantMode.use_weight_only())
|
||||
elif args.use_weight_only and args.weight_only_precision == 'int4' and 0:
|
||||
xtrt_llm_baichuan = weight_only_quantize(
|
||||
xtrt_llm_baichuan, QuantMode.use_weight_only(use_int4_weights=True))
|
||||
if args.model_dir is not None:
|
||||
logger.info(
|
||||
f'Loading HF Baichuan {args.model_version} ... from {args.model_dir}'
|
||||
)
|
||||
tik = time.time()
|
||||
hf_baichuan = AutoModelForCausalLM.from_pretrained(
|
||||
args.model_dir,
|
||||
device_map={
|
||||
"model": "cpu",
|
||||
"lm_head": "cpu"
|
||||
}, # Load to CPU memory
|
||||
torch_dtype="auto",
|
||||
trust_remote_code=True)
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'HF Baichuan {args.model_version} loaded. Total time: {t}')
|
||||
load_from_hf_baichuan(xtrt_llm_baichuan,
|
||||
hf_baichuan,
|
||||
args.model_version,
|
||||
rank,
|
||||
args.world_size,
|
||||
dtype=args.dtype)
|
||||
del hf_baichuan
|
||||
|
||||
# Module -> Network
|
||||
network = builder.create_network()
|
||||
network.trt_network.name = engine_name
|
||||
if args.use_gpt_attention_plugin:
|
||||
network.plugin_config.set_gpt_attention_plugin(
|
||||
dtype=args.use_gpt_attention_plugin)
|
||||
if args.use_gemm_plugin:
|
||||
network.plugin_config.set_gemm_plugin(dtype=args.use_gemm_plugin)
|
||||
assert not (args.enable_context_fmha and args.enable_context_fmha_fp32_acc)
|
||||
if args.enable_context_fmha:
|
||||
network.plugin_config.set_context_fmha(ContextFMHAType.enabled)
|
||||
if args.enable_context_fmha_fp32_acc:
|
||||
network.plugin_config.set_context_fmha(
|
||||
ContextFMHAType.enabled_with_fp32_acc)
|
||||
if args.use_weight_only:
|
||||
network.plugin_config.set_weight_only_quant_matmul_plugin(
|
||||
dtype='float16')
|
||||
builder_config.trt_builder_config.use_weight_only = args.weight_only_precision
|
||||
if args.world_size > 1:
|
||||
network.plugin_config.set_nccl_plugin(args.dtype)
|
||||
if args.remove_input_padding:
|
||||
network.plugin_config.enable_remove_input_padding()
|
||||
if args.paged_kv_cache:
|
||||
network.plugin_config.enable_paged_kv_cache(args.tokens_per_block)
|
||||
|
||||
with net_guard(network):
|
||||
# Prepare
|
||||
network.set_named_parameters(xtrt_llm_baichuan.named_parameters())
|
||||
|
||||
# Forward
|
||||
inputs = xtrt_llm_baichuan.prepare_inputs(args.max_batch_size,
|
||||
args.max_input_len,
|
||||
args.max_output_len, True,
|
||||
args.max_beam_width,
|
||||
args.max_num_tokens)
|
||||
xtrt_llm_baichuan(*inputs)
|
||||
if args.enable_debug_output:
|
||||
# mark intermediate nodes' outputs
|
||||
for k, v in xtrt_llm_baichuan.named_network_outputs():
|
||||
v = v.trt_tensor
|
||||
v.name = k
|
||||
network.trt_network.mark_output(v)
|
||||
v.dtype = kv_dtype
|
||||
if args.visualize:
|
||||
model_path = os.path.join(args.output_dir, 'test.onnx')
|
||||
to_onnx(network.trt_network, model_path)
|
||||
|
||||
engine = None
|
||||
|
||||
# Network -> Engine
|
||||
engine = builder.build_engine(network, builder_config, compiler="gr")
|
||||
if rank == 0:
|
||||
config_path = os.path.join(args.output_dir, 'config.json')
|
||||
builder.save_config(builder_config, config_path)
|
||||
if args.opt_memory_use:
|
||||
return engine, network
|
||||
return engine
|
||||
|
||||
|
||||
def build(rank, args):
|
||||
# torch.cuda.set_device(rank % args.gpus_per_node)
|
||||
xtrt_llm.logger.set_level(args.log_level)
|
||||
if not os.path.exists(args.output_dir):
|
||||
os.makedirs(args.output_dir)
|
||||
|
||||
# when doing serializing build, all ranks share one engine
|
||||
builder = Builder()
|
||||
|
||||
cache = None
|
||||
model_name = 'baichuan'
|
||||
for cur_rank in range(args.world_size):
|
||||
# skip other ranks if parallel_build is enabled
|
||||
if args.parallel_build and cur_rank != rank:
|
||||
continue
|
||||
builder_config = builder.create_builder_config(
|
||||
name=model_name,
|
||||
precision=args.dtype,
|
||||
timing_cache=args.timing_cache if cache is None else cache,
|
||||
tensor_parallel=args.world_size, # TP only
|
||||
parallel_build=args.parallel_build,
|
||||
pipeline_parallel=args.pp_size,
|
||||
num_layers=args.n_layer,
|
||||
num_heads=args.n_head,
|
||||
hidden_size=args.n_embd,
|
||||
inter_size=args.inter_size,
|
||||
vocab_size=args.vocab_size,
|
||||
hidden_act=args.hidden_act,
|
||||
max_position_embeddings=args.n_positions,
|
||||
max_batch_size=args.max_batch_size,
|
||||
max_input_len=args.max_input_len,
|
||||
max_output_len=args.max_output_len,
|
||||
max_num_tokens=args.max_num_tokens,
|
||||
int8=args.quant_mode.has_act_and_weight_quant(),
|
||||
quant_mode=args.quant_mode,
|
||||
fusion_pattern_list=["remove_dup_mask"],
|
||||
gather_all_token_logits=args.gather_all_token_logits,
|
||||
)
|
||||
guard = xtrt_llm.fusion_patterns.FuseonPatternGuard()
|
||||
print(guard)
|
||||
engine_name = get_engine_name(model_name, args.dtype, args.world_size,
|
||||
cur_rank)
|
||||
if args.opt_memory_use:
|
||||
engine, network = build_rank_engine(builder, builder_config,
|
||||
engine_name, cur_rank, args)
|
||||
else:
|
||||
engine = build_rank_engine(builder, builder_config, engine_name,
|
||||
cur_rank, args)
|
||||
assert engine is not None, f'Failed to build engine for rank {cur_rank}'
|
||||
|
||||
serialize_engine(engine, os.path.join(args.output_dir, engine_name))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = parse_arguments()
|
||||
logger.set_level(args.log_level)
|
||||
tik = time.time()
|
||||
if args.parallel_build and args.world_size > 1:
|
||||
logger.warning(
|
||||
f'Parallelly build TensorRT engines. Please make sure that all of the {args.world_size} GPUs are totally free.'
|
||||
)
|
||||
mp.spawn(build, nprocs=args.world_size, args=(args, ))
|
||||
else:
|
||||
args.parallel_build = False
|
||||
logger.info('Serially build TensorRT engines.')
|
||||
build(0, args)
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Total time of building all {args.world_size} engines: {t}')
|
||||
99
examples/baichuan/build.sh
Executable file
99
examples/baichuan/build.sh
Executable file
@@ -0,0 +1,99 @@
|
||||
build_baichuan() {
|
||||
get_path
|
||||
|
||||
cmd="XTCL_BUILD_DEBUG=1 python3 build.py ${tp_cmd} --model_version $model_name \
|
||||
--model_dir ${model_home}/downloads/baichuan${model_version_num}-${model_size} \
|
||||
--dtype float16 ${int8_cmd} \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ${model_home}/engine/baichuan${model_version_num}-${model_size}/${precision}/${tp}"
|
||||
echo "******************** cmd *********************"
|
||||
echo $cmd
|
||||
eval ${cmd} |& tee ${log_file}
|
||||
}
|
||||
|
||||
get_path(){
|
||||
model_home=/home/workspace
|
||||
model_version=$(echo $model_name | cut -d "_" -f 1)
|
||||
model_size=$(echo $model_name | cut -d "_" -f 2)
|
||||
precision=$(echo $model_name | cut -d "_" -f 3)
|
||||
tp=$(echo $model_name | cut -d "_" -f 4)
|
||||
model_name=${model_version}_${model_size}
|
||||
model_version_num=$(echo $model_version | grep -o '[0-9]\+')
|
||||
|
||||
if [[ "$model_version_num" == "1" ]]; then
|
||||
model_version_num=""
|
||||
fi
|
||||
|
||||
mpi_num=$(echo $tp | cut -d "p" -f 2)
|
||||
if (( $mpi_num > 1 )); then
|
||||
mpi_cmd="mpirun --allow-run-as-root -n $mpi_num"
|
||||
tp_cmd="--parallel_build --world_size $mpi_num"
|
||||
else
|
||||
mpi_cmd=""
|
||||
tp_cmd=""
|
||||
fi
|
||||
|
||||
if [[ "$precision" == "int8" ]]; then
|
||||
int8_cmd="--use_weight_only"
|
||||
else
|
||||
int8_cmd=""
|
||||
fi
|
||||
|
||||
echo "------------------------------------------------------"
|
||||
log_file=./logs/relay_${model_name}_"$(date '+%Y-%m-%d-%H:%M:%S')".log
|
||||
echo "log file -> ${log_file} "
|
||||
|
||||
echo -e "\033[1;31m" # 设置红色字体
|
||||
echo "Model version Model size Precision TP"
|
||||
echo -e "\033[0m" # 重置字体颜色
|
||||
echo "------------------------------------------------------"
|
||||
echo -e "\033[0;32m"
|
||||
echo "$model_version" " " "$model_size" " " "$precision" " " "$tp"
|
||||
echo ""
|
||||
}
|
||||
|
||||
|
||||
if [ "$#" -ne 1 ]; then
|
||||
echo "Usage: $0 -m=<model_name>"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
model_name="$1"
|
||||
|
||||
case $model_name in
|
||||
"v1_13b_fp16_tp1")
|
||||
build_baichuan
|
||||
;;
|
||||
"v1_13b_int8_tp1")
|
||||
build_baichuan
|
||||
;;
|
||||
"v1_13b_fp16_tp2")
|
||||
build_baichuan
|
||||
;;
|
||||
"v1_13b_int8_tp2")
|
||||
build_baichuan
|
||||
;;
|
||||
"v1_7b_fp16_tp1")
|
||||
build_baichuan
|
||||
;;
|
||||
"v1_7b_int8_tp1")
|
||||
build_baichuan
|
||||
;;
|
||||
"v2_13b_fp16_tp1")
|
||||
build_baichuan
|
||||
;;
|
||||
"v2_13b_int8_tp1")
|
||||
build_baichuan
|
||||
;;
|
||||
"v2_13b_fp16_tp2")
|
||||
build_baichuan
|
||||
;;
|
||||
"v2_13b_int8_tp2")
|
||||
build_baichuan
|
||||
;;
|
||||
*)
|
||||
echo "Unknown model name: $model_name"
|
||||
exit 1
|
||||
;;
|
||||
esac
|
||||
5
examples/baichuan/requirements.txt
Normal file
5
examples/baichuan/requirements.txt
Normal file
@@ -0,0 +1,5 @@
|
||||
datasets~=2.3.2
|
||||
rouge_score~=0.1.2
|
||||
sentencepiece~=0.1.99
|
||||
cpm-kernels~=1.0.11
|
||||
transformers_stream_generator~=0.0.4
|
||||
283
examples/baichuan/run.py
Normal file
283
examples/baichuan/run.py
Normal file
@@ -0,0 +1,283 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import csv
|
||||
import json
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from transformers import AutoTokenizer
|
||||
from tvm.contrib.profiling import Profiler
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm.runtime import ModelConfig, SamplingConfig
|
||||
|
||||
from build import get_engine_name # isort:skip
|
||||
|
||||
EOS_TOKEN = 2
|
||||
PAD_TOKEN = 0
|
||||
|
||||
|
||||
def parse_arguments():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--max_output_len', type=int, required=True)
|
||||
parser.add_argument('--log_level', type=str, default='error')
|
||||
parser.add_argument('--model_version',
|
||||
type=str,
|
||||
default='v1_13b',
|
||||
choices=['v1_7b', 'v1_13b', 'v2_7b', 'v2_13b'])
|
||||
parser.add_argument('--engine_dir', type=str, default='baichuan_outputs')
|
||||
parser.add_argument('--tokenizer_dir',
|
||||
type=str,
|
||||
default="baichuan-inc/Baichuan-13B-Chat",
|
||||
help="Directory containing the tokenizer.model.")
|
||||
parser.add_argument('--input_text', type=str, default="解释一下“温故而知新”")
|
||||
parser.add_argument(
|
||||
'--input_tokens',
|
||||
dest='input_file',
|
||||
type=str,
|
||||
help=
|
||||
'CSV or Numpy file containing tokenized input. Alternative to text input.',
|
||||
default=None)
|
||||
parser.add_argument('--output_csv',
|
||||
type=str,
|
||||
help='CSV file where the tokenized output is stored.',
|
||||
default=None)
|
||||
parser.add_argument('--output_npy',
|
||||
type=str,
|
||||
help='Numpy file where the tokenized output is stored.',
|
||||
default=None)
|
||||
parser.add_argument('--num_beams',
|
||||
type=int,
|
||||
help="Use beam search if num_beams >1",
|
||||
default=1)
|
||||
parser.add_argument(
|
||||
'--performance_test_scale',
|
||||
type=str,
|
||||
help=
|
||||
"Scale for performance test. e.g., 8x1024x64 (batch_size, input_text_length, max_output_length)",
|
||||
default="")
|
||||
return parser.parse_args()
|
||||
|
||||
|
||||
def generate(
|
||||
max_output_len: int,
|
||||
log_level: str = 'error',
|
||||
model_version: str = 'v1_13b',
|
||||
engine_dir: str = 'baichuan_outputs',
|
||||
input_text: str = "解释一下“温故而知新”",
|
||||
input_file: str = None,
|
||||
output_csv: str = None,
|
||||
output_npy: str = None,
|
||||
tokenizer_dir: str = None,
|
||||
num_beams: int = 1,
|
||||
performance_test_scale: str = "",
|
||||
):
|
||||
xtrt_llm.logger.set_level(log_level)
|
||||
|
||||
config_path = os.path.join(engine_dir, 'config.json')
|
||||
with open(config_path, 'r') as f:
|
||||
config = json.load(f)
|
||||
use_gpt_attention_plugin = config['plugin_config']['gpt_attention_plugin']
|
||||
remove_input_padding = config['plugin_config']['remove_input_padding']
|
||||
paged_kv_cache = config['plugin_config']['paged_kv_cache']
|
||||
tokens_per_block = config['plugin_config']['tokens_per_block']
|
||||
dtype = config['builder_config']['precision']
|
||||
world_size = config['builder_config']['tensor_parallel']
|
||||
# assert world_size == xtrt_llm.mpi_world_size(), \
|
||||
# f'Engine world size ({world_size}) != Runtime world size ({xtrt_llm.mpi_world_size()})'
|
||||
num_heads = config['builder_config']['num_heads'] // world_size
|
||||
hidden_size = config['builder_config']['hidden_size'] // world_size
|
||||
vocab_size = config['builder_config']['vocab_size']
|
||||
num_layers = config['builder_config']['num_layers']
|
||||
builder_config = config['builder_config']
|
||||
gather_all_token_logits = builder_config.get('gather_all_token_logits',
|
||||
False)
|
||||
|
||||
runtime_rank = xtrt_llm.mpi_rank()
|
||||
if world_size > 1:
|
||||
os.environ["XCCL_GROUP_ID"] = str(runtime_rank // world_size)
|
||||
os.environ["XCCL_NRANKS"] = str(world_size)
|
||||
os.environ["XCCL_CUR_RANK"] = str(runtime_rank % world_size)
|
||||
os.environ["XCCL_DEVICE_ID"] = str(runtime_rank)
|
||||
os.environ["MP_RUN"] = str(1)
|
||||
runtime_mapping = xtrt_llm.Mapping(world_size,
|
||||
runtime_rank,
|
||||
tp_size=world_size)
|
||||
torch.cuda.set_device(runtime_rank % runtime_mapping.gpus_per_node)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(tokenizer_dir,
|
||||
use_fast=False,
|
||||
trust_remote_code=True)
|
||||
|
||||
model_config = ModelConfig(num_heads=num_heads,
|
||||
num_kv_heads=num_heads,
|
||||
hidden_size=hidden_size,
|
||||
vocab_size=vocab_size,
|
||||
num_layers=num_layers,
|
||||
gpt_attention_plugin=use_gpt_attention_plugin,
|
||||
paged_kv_cache=paged_kv_cache,
|
||||
tokens_per_block=tokens_per_block,
|
||||
remove_input_padding=remove_input_padding,
|
||||
dtype=dtype,
|
||||
gather_all_token_logits=gather_all_token_logits)
|
||||
|
||||
repetition_penalty = 1.1
|
||||
temperature = 0.3
|
||||
top_k = 5
|
||||
top_p = 0.85
|
||||
if args.model_version == 'v1_7b':
|
||||
temperature = 1
|
||||
top_k = 1
|
||||
top_p = 0
|
||||
elif args.model_version == 'v2_7b' or args.model_version == 'v2_13b':
|
||||
repetition_penalty = 1.05
|
||||
sampling_config = SamplingConfig(end_id=EOS_TOKEN,
|
||||
pad_id=PAD_TOKEN,
|
||||
num_beams=num_beams,
|
||||
repetition_penalty=repetition_penalty,
|
||||
temperature=temperature,
|
||||
top_k=top_k,
|
||||
top_p=top_p)
|
||||
|
||||
engine_name = get_engine_name('baichuan', dtype, world_size, runtime_rank)
|
||||
serialize_path = os.path.join(engine_dir, engine_name)
|
||||
decoder = xtrt_llm.runtime.GenerationSession(model_config, serialize_path,
|
||||
runtime_mapping)
|
||||
|
||||
input_tokens = []
|
||||
if input_file is None:
|
||||
input_tokens.append(
|
||||
tokenizer.encode(input_text, add_special_tokens=False))
|
||||
else:
|
||||
if input_file.endswith('.csv'):
|
||||
with open(input_file, 'r') as csv_file:
|
||||
csv_reader = csv.reader(csv_file, delimiter=',')
|
||||
for line in csv_reader:
|
||||
input_tokens.append(np.array(line, dtype='int32'))
|
||||
elif input_file.endswith('.npy'):
|
||||
inputs = np.load(input_file)
|
||||
for row in inputs:
|
||||
row = row[row != EOS_TOKEN]
|
||||
input_tokens.append(row)
|
||||
else:
|
||||
print('Input file format not supported.')
|
||||
raise SystemExit
|
||||
|
||||
input_ids = None
|
||||
input_lengths = None
|
||||
if input_file is None:
|
||||
input_ids = torch.tensor(input_tokens, dtype=torch.int32, device='cuda')
|
||||
input_lengths = torch.tensor([input_ids.size(1)],
|
||||
dtype=torch.int32,
|
||||
device='cuda')
|
||||
else:
|
||||
input_lengths = torch.tensor([len(x) for x in input_tokens],
|
||||
dtype=torch.int32,
|
||||
device='cuda')
|
||||
if remove_input_padding:
|
||||
input_ids = np.concatenate(input_tokens)
|
||||
input_ids = torch.tensor(input_ids,
|
||||
dtype=torch.int32,
|
||||
device='cuda').unsqueeze(0)
|
||||
else:
|
||||
input_ids = torch.nested.to_padded_tensor(
|
||||
torch.nested.nested_tensor(input_tokens, dtype=torch.int32),
|
||||
EOS_TOKEN).cuda()
|
||||
|
||||
if performance_test_scale != "":
|
||||
performance_test_scale_list = performance_test_scale.split("E")
|
||||
warmup_epochs = 3
|
||||
for scale in performance_test_scale_list:
|
||||
for i in range(warmup_epochs):
|
||||
xtrt_llm.logger.info(
|
||||
f"Running performance test with scale {scale}")
|
||||
bs, seqlen, max_output_len = [int(x) for x in scale.split("x")]
|
||||
try:
|
||||
_input_ids = torch.from_numpy(
|
||||
np.zeros((bs, seqlen)).astype("int32")).cuda()
|
||||
_input_lengths = torch.from_numpy(
|
||||
np.full((bs, ), seqlen).astype("int32")).cuda()
|
||||
max_input_length = torch.max(_input_lengths).item()
|
||||
|
||||
decoder.setup(_input_lengths.size(0), max_input_length,
|
||||
max_output_len, num_beams)
|
||||
with Profiler(f'{bs}_{seqlen}_{max_output_len}_decode',
|
||||
show_report=True):
|
||||
output_ids = decoder.decode(
|
||||
_input_ids,
|
||||
_input_lengths,
|
||||
sampling_config,
|
||||
stop_words_list=[tokenizer.eos_token_id])
|
||||
except Exception as e:
|
||||
xtrt_llm.logger.info(
|
||||
f"Error occurs in performance test: {e}.")
|
||||
exit(0)
|
||||
|
||||
max_input_length = torch.max(input_lengths).item()
|
||||
decoder.setup(input_lengths.size(0),
|
||||
max_input_length,
|
||||
max_output_len,
|
||||
beam_width=num_beams)
|
||||
|
||||
output_ids = decoder.decode(input_ids,
|
||||
input_lengths,
|
||||
sampling_config,
|
||||
stop_words_list=[tokenizer.eos_token_id])
|
||||
torch.cuda.synchronize()
|
||||
|
||||
if runtime_rank == 0:
|
||||
if output_csv is None and output_npy is None:
|
||||
for b in range(input_lengths.size(0)):
|
||||
inputs = input_tokens[b]
|
||||
input_text = tokenizer.decode(inputs)
|
||||
print(f'Input: \"{input_text}\"')
|
||||
if num_beams <= 1:
|
||||
output_begin = max_input_length
|
||||
outputs = output_ids[b][0][output_begin:].tolist()
|
||||
output_text = tokenizer.decode(outputs)
|
||||
print(f'Output: \"{output_text}\"')
|
||||
else:
|
||||
for beam in range(num_beams):
|
||||
output_begin = input_lengths[b]
|
||||
output_end = input_lengths[b] + max_output_len
|
||||
outputs = output_ids[b][beam][
|
||||
output_begin:output_end].tolist()
|
||||
output_text = tokenizer.decode(outputs)
|
||||
print(f'Output: \"{output_text}\"')
|
||||
|
||||
output_ids = output_ids.reshape((-1, output_ids.size(2)))
|
||||
|
||||
if output_csv is not None:
|
||||
output_file = Path(output_csv)
|
||||
output_file.parent.mkdir(exist_ok=True, parents=True)
|
||||
outputs = output_ids.tolist()
|
||||
with open(output_file, 'w') as csv_file:
|
||||
writer = csv.writer(csv_file, delimiter=',')
|
||||
writer.writerows(outputs)
|
||||
|
||||
if output_npy is not None:
|
||||
output_file = Path(output_npy)
|
||||
output_file.parent.mkdir(exist_ok=True, parents=True)
|
||||
outputs = np.array(output_ids.cpu().contiguous(), dtype='int32')
|
||||
np.save(output_file, outputs)
|
||||
return
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = parse_arguments()
|
||||
generate(**vars(args))
|
||||
108
examples/baichuan/run.sh
Executable file
108
examples/baichuan/run.sh
Executable file
@@ -0,0 +1,108 @@
|
||||
get_path(){
|
||||
model_home=/home/workspace
|
||||
model_version=$(echo $model_name | cut -d "_" -f 1)
|
||||
model_size=$(echo $model_name | cut -d "_" -f 2)
|
||||
precision=$(echo $model_name | cut -d "_" -f 3)
|
||||
tp=$(echo $model_name | cut -d "_" -f 4)
|
||||
model_name=${model_version}_${model_size}
|
||||
model_version_num=$(echo $model_version | grep -o '[0-9]\+')
|
||||
|
||||
if [[ "$model_version_num" == "1" ]]; then
|
||||
model_version_num=""
|
||||
fi
|
||||
|
||||
|
||||
mpi_num=$(echo $tp | cut -d "p" -f 2)
|
||||
if (( $mpi_num > 1 )); then
|
||||
mpi_cmd="mpirun --allow-run-as-root -n $mpi_num"
|
||||
# mpi_cmd="mpirun -n $mpi_num"
|
||||
else
|
||||
mpi_cmd=""
|
||||
fi
|
||||
|
||||
echo -e "\033[1;31m" # 设置红色字体
|
||||
echo "Model version Model size Precision TP"
|
||||
echo -e "\033[0m" # 重置字体颜色
|
||||
echo "------------------------------------------------------"
|
||||
echo -e "\033[0;32m"
|
||||
echo "$model_version" " " "$model_size" " " "$precision" " " "$tp"
|
||||
echo ""
|
||||
}
|
||||
|
||||
run_baichuan(){
|
||||
get_path
|
||||
|
||||
engine_dir=${model_home}/engine/baichuan${model_version_num}-${model_size}/${precision}/${tp}
|
||||
tokenizer_dir=${model_home}/downloads/baichuan${model_version_num}-${model_size}
|
||||
|
||||
env_cmd="PYTORCH_NO_XPU_MEMORY_CACHING=0 XMLIR_D_XPU_L3_SIZE=0 "
|
||||
required_cmd="--engine_dir=$engine_dir --tokenizer_dir=$tokenizer_dir"
|
||||
options="--max_output_len=128 --log_level=info"
|
||||
# inputs="--input_text='世界前五的高峰是?'"
|
||||
|
||||
prof_cmd="--performance_test_scale=\
|
||||
1x512x512E1x1024x1024E1x2048x64E1x2048x2048E\
|
||||
2x512x512E2x1024x1024E2x2048x64E2x2048x2048E\
|
||||
4x512x512E4x1024x1024E4x2048x64E4x2048x2048E\
|
||||
8x512x512E8x1024x1024E8x2048x64E8x2048x2048E\
|
||||
16x2048x2048E\
|
||||
32x128x2048E32x2048x128E\
|
||||
64x128x128E"
|
||||
prof_cmd="--performance_test_scale=20x1024x1024E32x1024x1024E48x1024x1024"
|
||||
cmd="${env_cmd} $mpi_cmd python3 run.py ${required_cmd} ${options} ${inputs} ${prof_cmd}"
|
||||
|
||||
echo "==================== cmd ======================"
|
||||
echo $cmd
|
||||
eval $cmd
|
||||
|
||||
}
|
||||
|
||||
if [ "$#" -ne 2 ]; then
|
||||
echo "Usage: $0 -m=<model_name> -d=<device_id>"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
model_name="$1"
|
||||
# device_id="$2"
|
||||
log_file=./logs/${model_name}_"$(date '+%Y-%m-%d-%H:%M:%S')".log
|
||||
export XPU_VISIBLE_DEVICES=$2
|
||||
# export XPU_VISIBLE_DEVICES=0,1
|
||||
|
||||
|
||||
|
||||
case $model_name in
|
||||
"v1_13b_fp16_tp1")
|
||||
run_baichuan |& tee $log_file 2>&1 &
|
||||
;;
|
||||
"v1_13b_int8_tp1")
|
||||
run_baichuan |& tee $log_file 2>&1 &
|
||||
;;
|
||||
"v1_13b_fp16_tp2")
|
||||
run_baichuan |& tee $log_file 2>&1 &
|
||||
;;
|
||||
"v1_13b_int8_tp2")
|
||||
run_baichuan |& tee $log_file 2>&1 &
|
||||
;;
|
||||
"v1_7b_fp16_tp1")
|
||||
run_baichuan |& tee $log_file 2>&1 &
|
||||
;;
|
||||
"v1_7b_int8_tp1")
|
||||
run_baichuan |& tee $log_file 2>&1 &
|
||||
;;
|
||||
"v2_13b_fp16_tp1")
|
||||
run_baichuan |& tee $log_file 2>&1 &
|
||||
;;
|
||||
"v2_13b_int8_tp1")
|
||||
run_baichuan |& tee $log_file 2>&1 &
|
||||
;;
|
||||
"v2_13b_fp16_tp2")
|
||||
run_baichuan
|
||||
;;
|
||||
"v2_13b_int8_tp2")
|
||||
run_baichuan |& tee $log_file 2>&1 &
|
||||
;;
|
||||
*)
|
||||
echo "Unknown model name: $model_name"
|
||||
exit 1
|
||||
;;
|
||||
esac
|
||||
392
examples/baichuan/summarize.py
Normal file
392
examples/baichuan/summarize.py
Normal file
@@ -0,0 +1,392 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import copy
|
||||
import json
|
||||
import os
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from datasets import load_dataset, load_metric
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
import xtrt_llm
|
||||
import xtrt_llm.profiler as profiler
|
||||
from xtrt_llm.logger import logger
|
||||
|
||||
from build import get_engine_name # isort:skip
|
||||
|
||||
|
||||
def TRTBaichuan(args, config):
|
||||
dtype = config['builder_config']['precision']
|
||||
world_size = config['builder_config']['tensor_parallel']
|
||||
assert world_size == xtrt_llm.mpi_world_size(), \
|
||||
f'Engine world size ({world_size}) != Runtime world size ({xtrt_llm.mpi_world_size()})'
|
||||
|
||||
world_size = config['builder_config']['tensor_parallel']
|
||||
num_heads = config['builder_config']['num_heads'] // world_size
|
||||
hidden_size = config['builder_config']['hidden_size'] // world_size
|
||||
vocab_size = config['builder_config']['vocab_size']
|
||||
num_layers = config['builder_config']['num_layers']
|
||||
use_gpt_attention_plugin = bool(
|
||||
config['plugin_config']['gpt_attention_plugin'])
|
||||
remove_input_padding = config['plugin_config']['remove_input_padding']
|
||||
paged_kv_cache = config['plugin_config']['paged_kv_cache']
|
||||
tokens_per_block = config['plugin_config']['tokens_per_block']
|
||||
|
||||
model_config = xtrt_llm.runtime.ModelConfig(
|
||||
vocab_size=vocab_size,
|
||||
num_layers=num_layers,
|
||||
num_heads=num_heads,
|
||||
num_kv_heads=num_heads,
|
||||
hidden_size=hidden_size,
|
||||
gpt_attention_plugin=use_gpt_attention_plugin,
|
||||
tokens_per_block=tokens_per_block,
|
||||
remove_input_padding=remove_input_padding,
|
||||
paged_kv_cache=paged_kv_cache,
|
||||
dtype=dtype)
|
||||
|
||||
runtime_rank = xtrt_llm.mpi_rank()
|
||||
runtime_mapping = xtrt_llm.Mapping(world_size,
|
||||
runtime_rank,
|
||||
tp_size=world_size)
|
||||
if world_size > 1:
|
||||
os.environ["XCCL_GROUP_ID"] = str(runtime_rank // world_size)
|
||||
os.environ["XCCL_NRANKS"] = str(world_size)
|
||||
os.environ["XCCL_CUR_RANK"] = str(runtime_rank % world_size)
|
||||
os.environ["XCCL_DEVICE_ID"] = str(runtime_rank)
|
||||
os.environ["MP_RUN"] = str(1)
|
||||
torch.cuda.set_device(runtime_rank % runtime_mapping.gpus_per_node)
|
||||
|
||||
engine_name = get_engine_name('baichuan', dtype, world_size, runtime_rank)
|
||||
serialize_path = os.path.join(args.engine_dir, engine_name)
|
||||
|
||||
xtrt_llm.logger.set_level(args.log_level)
|
||||
|
||||
profiler.start('load xtrt_llm engine')
|
||||
# with open(serialize_path, 'rb') as f:
|
||||
# engine_buffer = f.read()
|
||||
decoder = xtrt_llm.runtime.GenerationSession(model_config, serialize_path,
|
||||
runtime_mapping)
|
||||
profiler.stop('load xtrt_llm engine')
|
||||
xtrt_llm.logger.info(
|
||||
f'Load engine takes: {profiler.elapsed_time_in_sec("load xtrt_llm engine")} sec'
|
||||
)
|
||||
return decoder
|
||||
|
||||
|
||||
def main(args):
|
||||
runtime_rank = xtrt_llm.mpi_rank()
|
||||
logger.set_level(args.log_level)
|
||||
|
||||
test_hf = args.test_hf and runtime_rank == 0 # only run hf on rank 0
|
||||
test_trt_llm = args.test_trt_llm
|
||||
hf_model_location = args.hf_model_location
|
||||
profiler.start('load tokenizer')
|
||||
tokenizer = AutoTokenizer.from_pretrained(hf_model_location,
|
||||
use_fast=False,
|
||||
trust_remote_code=True)
|
||||
profiler.stop('load tokenizer')
|
||||
xtrt_llm.logger.info(
|
||||
f'Load tokenizer takes: {profiler.elapsed_time_in_sec("load tokenizer")} sec'
|
||||
)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
dataset_cnn = load_dataset("ccdv/cnn_dailymail",
|
||||
'3.0.0',
|
||||
cache_dir=args.dataset_path)
|
||||
|
||||
max_batch_size = args.batch_size
|
||||
|
||||
# runtime parameters
|
||||
# repetition_penalty = 1
|
||||
top_k = args.top_k
|
||||
output_len = 100
|
||||
test_token_num = 923
|
||||
# top_p = 0.0
|
||||
# random_seed = 5
|
||||
temperature = 1
|
||||
num_beams = args.num_beams
|
||||
|
||||
pad_id = tokenizer.encode(tokenizer.pad_token, add_special_tokens=False)[0]
|
||||
end_id = tokenizer.encode(tokenizer.eos_token, add_special_tokens=False)[0]
|
||||
|
||||
if test_trt_llm:
|
||||
config_path = os.path.join(args.engine_dir, 'config.json')
|
||||
with open(config_path, 'r') as f:
|
||||
config = json.load(f)
|
||||
|
||||
xtrt_llm_baichuan = TRTBaichuan(args, config)
|
||||
|
||||
if test_hf:
|
||||
profiler.start('load HF model')
|
||||
model = AutoModelForCausalLM.from_pretrained(hf_model_location,
|
||||
trust_remote_code=True)
|
||||
profiler.stop('load HF model')
|
||||
xtrt_llm.logger.info(
|
||||
f'Load HF model takes: {profiler.elapsed_time_in_sec("load HF model")} sec'
|
||||
)
|
||||
if args.data_type == 'fp16':
|
||||
model.half()
|
||||
model.cuda()
|
||||
|
||||
def summarize_xtrt_llm(datapoint):
|
||||
batch_size = len(datapoint['article'])
|
||||
|
||||
line = copy.copy(datapoint['article'])
|
||||
line_encoded = []
|
||||
input_lengths = []
|
||||
for i in range(batch_size):
|
||||
line[i] = line[i] + ' TL;DR: '
|
||||
|
||||
line[i] = line[i].strip()
|
||||
line[i] = line[i].replace(" n't", "n't")
|
||||
|
||||
input_id = tokenizer.encode(line[i],
|
||||
return_tensors='pt').type(torch.int32)
|
||||
input_id = input_id[:, -test_token_num:]
|
||||
|
||||
line_encoded.append(input_id)
|
||||
input_lengths.append(input_id.shape[-1])
|
||||
|
||||
# do padding, should move outside the profiling to prevent the overhead
|
||||
max_length = max(input_lengths)
|
||||
if xtrt_llm_baichuan.remove_input_padding:
|
||||
line_encoded = [
|
||||
torch.tensor(t, dtype=torch.int32).cuda() for t in line_encoded
|
||||
]
|
||||
else:
|
||||
# do padding, should move outside the profiling to prevent the overhead
|
||||
for i in range(batch_size):
|
||||
pad_size = max_length - input_lengths[i]
|
||||
|
||||
pad = torch.ones([1, pad_size]).type(torch.int32) * pad_id
|
||||
line_encoded[i] = torch.cat(
|
||||
[torch.tensor(line_encoded[i], dtype=torch.int32), pad],
|
||||
axis=-1)
|
||||
|
||||
line_encoded = torch.cat(line_encoded, axis=0).cuda()
|
||||
input_lengths = torch.tensor(input_lengths,
|
||||
dtype=torch.int32).cuda()
|
||||
|
||||
sampling_config = xtrt_llm.runtime.SamplingConfig(end_id=end_id,
|
||||
pad_id=pad_id,
|
||||
top_k=top_k,
|
||||
num_beams=num_beams)
|
||||
|
||||
with torch.no_grad():
|
||||
xtrt_llm_baichuan.setup(batch_size,
|
||||
max_context_length=max_length,
|
||||
max_new_tokens=output_len,
|
||||
beam_width=num_beams)
|
||||
if xtrt_llm_baichuan.remove_input_padding:
|
||||
output_ids = xtrt_llm_baichuan.decode_batch(
|
||||
line_encoded, sampling_config)
|
||||
else:
|
||||
output_ids = xtrt_llm_baichuan.decode(
|
||||
line_encoded,
|
||||
input_lengths,
|
||||
sampling_config,
|
||||
)
|
||||
|
||||
torch.cuda.synchronize()
|
||||
|
||||
# Extract a list of tensors of shape beam_width x output_ids.
|
||||
if xtrt_llm_baichuan.mapping.is_first_pp_rank():
|
||||
output_beams_list = [
|
||||
tokenizer.batch_decode(output_ids[batch_idx, :,
|
||||
input_lengths[batch_idx]:],
|
||||
skip_special_tokens=True)
|
||||
for batch_idx in range(batch_size)
|
||||
]
|
||||
return output_beams_list, output_ids[:, :, max_length:].tolist()
|
||||
return [], []
|
||||
|
||||
def summarize_hf(datapoint):
|
||||
batch_size = len(datapoint['article'])
|
||||
if batch_size > 1:
|
||||
logger.warning(
|
||||
f"HF does not support batch_size > 1 to verify correctness due to padding. Current batch size is {batch_size}"
|
||||
)
|
||||
|
||||
line = copy.copy(datapoint['article'])
|
||||
for i in range(batch_size):
|
||||
line[i] = line[i] + ' TL;DR: '
|
||||
|
||||
line[i] = line[i].strip()
|
||||
line[i] = line[i].replace(" n't", "n't")
|
||||
|
||||
line_encoded = tokenizer(line,
|
||||
return_tensors='pt',
|
||||
padding=True,
|
||||
truncation=True)["input_ids"].type(torch.int64)
|
||||
|
||||
line_encoded = line_encoded[:, -test_token_num:]
|
||||
line_encoded = line_encoded.cuda()
|
||||
|
||||
with torch.no_grad():
|
||||
output = model.generate(line_encoded,
|
||||
max_new_tokens=output_len,
|
||||
top_k=top_k,
|
||||
temperature=temperature,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
num_beams=num_beams,
|
||||
num_return_sequences=num_beams,
|
||||
early_stopping=True)
|
||||
|
||||
tokens_list = output[:, len(line_encoded[0]):].tolist()
|
||||
output = output.reshape([batch_size, num_beams, -1])
|
||||
output_lines_list = [
|
||||
tokenizer.batch_decode(output[:, i, len(line_encoded[0]):],
|
||||
skip_special_tokens=True)
|
||||
for i in range(num_beams)
|
||||
]
|
||||
|
||||
return output_lines_list, tokens_list
|
||||
|
||||
if test_trt_llm:
|
||||
datapoint = dataset_cnn['test'][0:1]
|
||||
summary, _ = summarize_xtrt_llm(datapoint)
|
||||
if runtime_rank == 0:
|
||||
logger.info(
|
||||
"---------------------------------------------------------")
|
||||
logger.info("XTRT-LLM Generated : ")
|
||||
logger.info(f" Article : {datapoint['article']}")
|
||||
logger.info(f"\n Highlights : {datapoint['highlights']}")
|
||||
logger.info(f"\n Summary : {summary}")
|
||||
logger.info(
|
||||
"---------------------------------------------------------")
|
||||
|
||||
if test_hf:
|
||||
datapoint = dataset_cnn['test'][0:1]
|
||||
summary, _ = summarize_hf(datapoint)
|
||||
logger.info("---------------------------------------------------------")
|
||||
logger.info("HF Generated : ")
|
||||
logger.info(f" Article : {datapoint['article']}")
|
||||
logger.info(f"\n Highlights : {datapoint['highlights']}")
|
||||
logger.info(f"\n Summary : {summary}")
|
||||
logger.info("---------------------------------------------------------")
|
||||
|
||||
metric_xtrt_llm = [load_metric("rouge") for _ in range(num_beams)]
|
||||
metric_hf = [load_metric("rouge") for _ in range(num_beams)]
|
||||
for i in range(num_beams):
|
||||
metric_xtrt_llm[i].seed = 0
|
||||
metric_hf[i].seed = 0
|
||||
|
||||
ite_count = 0
|
||||
data_point_idx = 0
|
||||
while (data_point_idx < len(dataset_cnn['test'])) and (ite_count <
|
||||
args.max_ite):
|
||||
if runtime_rank == 0:
|
||||
logger.debug(
|
||||
f"run data_point {data_point_idx} ~ {data_point_idx + max_batch_size}"
|
||||
)
|
||||
datapoint = dataset_cnn['test'][data_point_idx:(data_point_idx +
|
||||
max_batch_size)]
|
||||
|
||||
if test_trt_llm:
|
||||
profiler.start('xtrt_llm')
|
||||
summary_xtrt_llm, tokens_xtrt_llm = summarize_xtrt_llm(datapoint)
|
||||
profiler.stop('xtrt_llm')
|
||||
|
||||
if test_hf:
|
||||
profiler.start('hf')
|
||||
summary_hf, tokens_hf = summarize_hf(datapoint)
|
||||
profiler.stop('hf')
|
||||
|
||||
if runtime_rank == 0:
|
||||
if test_trt_llm:
|
||||
for batch_idx in range(len(summary_xtrt_llm)):
|
||||
for beam_idx in range(num_beams):
|
||||
metric_xtrt_llm[beam_idx].add_batch(
|
||||
predictions=[summary_xtrt_llm[batch_idx][beam_idx]],
|
||||
references=[datapoint['highlights'][batch_idx]])
|
||||
if test_hf:
|
||||
for beam_idx in range(num_beams):
|
||||
for batch_idx in range(len(summary_hf[beam_idx])):
|
||||
metric_hf[beam_idx].add_batch(
|
||||
predictions=[summary_hf[beam_idx][batch_idx]],
|
||||
references=[datapoint['highlights'][batch_idx]])
|
||||
|
||||
logger.debug('-' * 100)
|
||||
logger.debug(f"Article : {datapoint['article']}")
|
||||
if test_trt_llm:
|
||||
logger.debug(f'XTRT-LLM Summary: {summary_xtrt_llm}')
|
||||
if test_hf:
|
||||
logger.debug(f'HF Summary: {summary_hf}')
|
||||
logger.debug(f"highlights : {datapoint['highlights']}")
|
||||
|
||||
data_point_idx += max_batch_size
|
||||
ite_count += 1
|
||||
|
||||
if runtime_rank == 0:
|
||||
if test_trt_llm:
|
||||
np.random.seed(0) # rouge score use sampling to compute the score
|
||||
logger.info(
|
||||
f'XTRT-LLM (total latency: {profiler.elapsed_time_in_sec("xtrt_llm")} sec)'
|
||||
)
|
||||
for beam_idx in range(num_beams):
|
||||
logger.info(f"XTRT-LLM beam {beam_idx} result")
|
||||
computed_metrics_xtrt_llm = metric_xtrt_llm[beam_idx].compute()
|
||||
for key in computed_metrics_xtrt_llm.keys():
|
||||
logger.info(
|
||||
f' {key} : {computed_metrics_xtrt_llm[key].mid[2]*100}'
|
||||
)
|
||||
|
||||
if args.check_accuracy and beam_idx == 0:
|
||||
assert computed_metrics_xtrt_llm['rouge1'].mid[
|
||||
2] * 100 > args.xtrt_llm_rouge1_threshold
|
||||
if test_hf:
|
||||
np.random.seed(0) # rouge score use sampling to compute the score
|
||||
logger.info(
|
||||
f'Hugging Face (total latency: {profiler.elapsed_time_in_sec("hf")} sec)'
|
||||
)
|
||||
for beam_idx in range(num_beams):
|
||||
logger.info(f"HF beam {beam_idx} result")
|
||||
computed_metrics_hf = metric_hf[beam_idx].compute()
|
||||
for key in computed_metrics_hf.keys():
|
||||
logger.info(
|
||||
f' {key} : {computed_metrics_hf[key].mid[2]*100}')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--model_version',
|
||||
type=str,
|
||||
default='v1_13b',
|
||||
choices=['v1_7b', 'v1_13b', 'v2_7b', 'v2_13b'])
|
||||
parser.add_argument('--hf_model_location',
|
||||
type=str,
|
||||
default='baichuan-inc/Baichuan-13B-Chat')
|
||||
parser.add_argument('--test_hf', action='store_true')
|
||||
parser.add_argument('--test_trt_llm', action='store_true')
|
||||
parser.add_argument('--data_type',
|
||||
type=str,
|
||||
choices=['fp32', 'fp16'],
|
||||
default='fp16')
|
||||
parser.add_argument('--dataset_path', type=str, default='')
|
||||
parser.add_argument('--log_level', type=str, default='info')
|
||||
parser.add_argument('--engine_dir', type=str, default='baichuan_outputs')
|
||||
parser.add_argument('--batch_size', type=int, default=1)
|
||||
parser.add_argument('--max_ite', type=int, default=20)
|
||||
parser.add_argument('--check_accuracy', action='store_true')
|
||||
parser.add_argument('--xtrt_llm_rouge1_threshold', type=float, default=15.0)
|
||||
parser.add_argument('--num_beams', type=int, default=1)
|
||||
parser.add_argument('--top_k', type=int, default=1)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
main(args)
|
||||
173
examples/baichuan/weight.py
Normal file
173
examples/baichuan/weight.py
Normal file
@@ -0,0 +1,173 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import time
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm._utils import str_dtype_to_torch, torch_to_numpy
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
|
||||
def extract_layer_idx(name):
|
||||
ss = name.split('.')
|
||||
for s in ss:
|
||||
if s.isdigit():
|
||||
return s
|
||||
return None
|
||||
|
||||
|
||||
def split(v, tp_size, idx, dim=0):
|
||||
if tp_size == 1:
|
||||
return v
|
||||
if len(v.shape) == 1:
|
||||
return np.ascontiguousarray(np.split(v, tp_size)[idx])
|
||||
else:
|
||||
return np.ascontiguousarray(np.split(v, tp_size, axis=dim)[idx])
|
||||
|
||||
|
||||
def load_from_hf_baichuan(xtrt_llm_baichuan,
|
||||
hf_baichuan,
|
||||
model_version,
|
||||
rank=0,
|
||||
tensor_parallel=1,
|
||||
dtype="float32"):
|
||||
assert model_version is not None
|
||||
xtrt_llm.logger.info(f'Loading weights from HF Baichuan {model_version}...')
|
||||
tik = time.time()
|
||||
|
||||
quant_mode = getattr(xtrt_llm_baichuan, 'quant_mode', QuantMode(0))
|
||||
if quant_mode.is_int8_weight_only():
|
||||
plugin_weight_only_quant_type = torch.int8
|
||||
elif quant_mode.is_int4_weight_only():
|
||||
plugin_weight_only_quant_type = torch.quint4x2
|
||||
use_weight_only = quant_mode.is_weight_only()
|
||||
|
||||
model_params = dict(hf_baichuan.named_parameters())
|
||||
for k, v in model_params.items():
|
||||
torch_dtype = str_dtype_to_torch(dtype)
|
||||
v = torch_to_numpy(v.to(torch_dtype).detach().cpu())
|
||||
if 'model.embed_tokens.weight' in k:
|
||||
xtrt_llm_baichuan.vocab_embedding.weight.value = v
|
||||
elif 'model.norm.weight' in k:
|
||||
xtrt_llm_baichuan.ln_f.weight.value = v
|
||||
elif 'lm_head.weight' in k:
|
||||
if model_version.startswith('v2'):
|
||||
# baichuan v2 models use NormHead
|
||||
xtrt_llm.logger.info(
|
||||
f'Normalizing lm_head.weight for {model_version}')
|
||||
original_v = model_params[k]
|
||||
v = torch_to_numpy(
|
||||
torch.nn.functional.normalize(original_v).to(
|
||||
torch_dtype).detach().cpu())
|
||||
xtrt_llm_baichuan.lm_head.weight.value = np.ascontiguousarray(
|
||||
split(v, tensor_parallel, rank))
|
||||
else:
|
||||
layer_idx = extract_layer_idx(k)
|
||||
if layer_idx is None:
|
||||
continue
|
||||
idx = int(layer_idx)
|
||||
if idx >= xtrt_llm_baichuan._num_layers:
|
||||
continue
|
||||
if 'input_layernorm.weight' in k:
|
||||
xtrt_llm_baichuan.layers[idx].input_layernorm.weight.value = v
|
||||
elif 'post_attention_layernorm.weight' in k:
|
||||
dst = xtrt_llm_baichuan.layers[idx].post_layernorm.weight
|
||||
dst.value = v
|
||||
elif 'self_attn.W_pack.weight' in k:
|
||||
dst = xtrt_llm_baichuan.layers[idx].attention.qkv.weight
|
||||
q_emb = v.shape[0] // 3
|
||||
model_emb = v.shape[1]
|
||||
v = v.reshape(3, q_emb, model_emb)
|
||||
split_v = split(v, tensor_parallel, rank, dim=1)
|
||||
split_v = split_v.reshape(3 * (q_emb // tensor_parallel),
|
||||
model_emb)
|
||||
if use_weight_only:
|
||||
v = np.ascontiguousarray(split_v.transpose())
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(v), plugin_weight_only_quant_type)
|
||||
# workaround for trt not supporting int8 inputs in plugins currently
|
||||
dst.value = processed_torch_weights.view(
|
||||
dtype=torch.float32).numpy()
|
||||
scales = xtrt_llm_baichuan.layers[
|
||||
idx].attention.qkv.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
dst.value = np.ascontiguousarray(split_v)
|
||||
elif 'self_attn.o_proj.weight' in k:
|
||||
dst = xtrt_llm_baichuan.layers[idx].attention.dense.weight
|
||||
split_v = split(v, tensor_parallel, rank, dim=1)
|
||||
if use_weight_only:
|
||||
v = np.ascontiguousarray(split_v.transpose())
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(v), plugin_weight_only_quant_type)
|
||||
# workaround for trt not supporting int8 inputs in plugins currently
|
||||
dst.value = processed_torch_weights.view(
|
||||
dtype=torch.float32).numpy()
|
||||
scales = xtrt_llm_baichuan.layers[
|
||||
idx].attention.dense.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
dst.value = np.ascontiguousarray(split_v)
|
||||
elif 'mlp.up_proj.weight' in k:
|
||||
dst = xtrt_llm_baichuan.layers[idx].mlp.gate.weight
|
||||
split_v = split(v, tensor_parallel, rank, dim=0)
|
||||
if use_weight_only:
|
||||
v = np.ascontiguousarray(split_v.transpose())
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(v), plugin_weight_only_quant_type)
|
||||
# workaround for trt not supporting int8 inputs in plugins currently
|
||||
dst.value = processed_torch_weights.view(
|
||||
dtype=torch.float32).numpy()
|
||||
scales = xtrt_llm_baichuan.layers[
|
||||
idx].mlp.gate.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
dst.value = np.ascontiguousarray(split_v)
|
||||
elif 'mlp.down_proj.weight' in k:
|
||||
dst = xtrt_llm_baichuan.layers[idx].mlp.proj.weight
|
||||
split_v = split(v, tensor_parallel, rank, dim=1)
|
||||
if use_weight_only:
|
||||
v = np.ascontiguousarray(split_v.transpose())
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(v), plugin_weight_only_quant_type)
|
||||
# workaround for trt not supporting int8 inputs in plugins currently
|
||||
dst.value = processed_torch_weights.view(
|
||||
dtype=torch.float32).numpy()
|
||||
scales = xtrt_llm_baichuan.layers[
|
||||
idx].mlp.proj.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
dst.value = np.ascontiguousarray(split_v)
|
||||
elif 'mlp.gate_proj.weight' in k:
|
||||
dst = xtrt_llm_baichuan.layers[idx].mlp.fc.weight
|
||||
split_v = split(v, tensor_parallel, rank, dim=0)
|
||||
if use_weight_only:
|
||||
v = np.ascontiguousarray(split_v.transpose())
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(v), plugin_weight_only_quant_type)
|
||||
# workaround for trt not supporting int8 inputs in plugins currently
|
||||
dst.value = processed_torch_weights.view(
|
||||
dtype=torch.float32).numpy()
|
||||
scales = xtrt_llm_baichuan.layers[
|
||||
idx].mlp.fc.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
dst.value = np.ascontiguousarray(split_v)
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
xtrt_llm.logger.info(f'Weights loaded. Total time: {t}')
|
||||
2
examples/bloom/.gitignore
vendored
Normal file
2
examples/bloom/.gitignore
vendored
Normal file
@@ -0,0 +1,2 @@
|
||||
__pycache__/
|
||||
bloom/
|
||||
131
examples/bloom/README.md
Normal file
131
examples/bloom/README.md
Normal file
@@ -0,0 +1,131 @@
|
||||
# BLOOM
|
||||
|
||||
This document shows how to build and run a BLOOM model in XTRT-LLM on both single XPU and single node multi-XPU.
|
||||
|
||||
## Overview
|
||||
|
||||
The XTRT-LLM BLOOM example code is located in [`examples/bloom`](./). There are several main files in that folder:
|
||||
|
||||
* [`build.py`](./build.py) to build the XTRT engine(s) needed to run the BLOOM model,
|
||||
* [`run.py`](./run.py) to run the inference on an input text,
|
||||
* [`summarize.py`](./summarize.py) to summarize the articles in the [cnn_dailymail](https://huggingface.co/datasets/cnn_dailymail) dataset using the model.
|
||||
|
||||
## Support Matrix
|
||||
* FP16
|
||||
* INT8 & INT4 Weight-Only
|
||||
* Tensor Parallel
|
||||
|
||||
## Usage
|
||||
|
||||
The XTRT-LLM BLOOM example code locates at [examples/bloom](./). It takes HF weights as input, and builds the corresponding XTRT engines. The number of XTRT engines depends on the number of XPUs used to run inference.
|
||||
|
||||
### Build XTRT engine(s)
|
||||
|
||||
Need to prepare the HF BLOOM checkpoint first by following the guides here https://huggingface.co/docs/transformers/main/en/model_doc/bloom.
|
||||
|
||||
e.g. To install BLOOM-560M
|
||||
|
||||
```bash
|
||||
# Setup git-lfs
|
||||
git lfs install
|
||||
rm -rf ./downloads/bloom/560M/
|
||||
mkdir -p ./downloads/bloom/560M/ && git clone https://huggingface.co/bigscience/bloom-560m ./downloads/bloom/560M/
|
||||
```
|
||||
|
||||
XTRT-LLM BLOOM builds XTRT engine(s) from HF checkpoint.
|
||||
|
||||
Normally `build.py` only requires single XPU, but if you've already got all the XPUs needed for inference, you could enable parallel building to make the engine building process faster by adding `--parallel_build` argument. Please note that currently `parallel_build` feature only supports single node.
|
||||
|
||||
Here're some examples:
|
||||
|
||||
```bash
|
||||
# Build a single-XPU float16 engine from HF weights.
|
||||
# Try use_gemm_plugin to prevent accuracy issue. TODO check this holds for BLOOM
|
||||
|
||||
# Single XPU on BLOOM 560M
|
||||
python build.py --model_dir ./downloads/bloom/560M/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/bloom/560M/trt_engines/fp16/1-XPU/
|
||||
|
||||
# Build the BLOOM 560M using a single XPU and apply INT8 weight-only quantization.
|
||||
python build.py --model_dir ./downloads/bloom/560M/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_weight_only \
|
||||
--weight_only_precision int8 \
|
||||
--output_dir ./downloads/bloom/560M/trt_engines/int8_weight_only/1-XPU/
|
||||
|
||||
# Use 2-way tensor parallelism on BLOOM 560M
|
||||
python build.py --model_dir ./downloads/bloom/560M/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/bloom/560M/trt_engines/fp16/2-XPU/ \
|
||||
--world_size 2
|
||||
```
|
||||
|
||||
#### SmoothQuant
|
||||
|
||||
Unlike the FP16 build where the HF weights are processed and loaded into the XTRT-LLM directly, the SmoothQuant needs to load INT8 weights which should be pre-processed before building an engine.
|
||||
|
||||
Example:
|
||||
```bash
|
||||
python3 hf_bloom_convert.py -i ./downloads/bloom/560M/ -o ./downloads/bloom-smooth/560M --smoothquant 0.5 --tensor-parallelism 1 --storage-type float16
|
||||
```
|
||||
Note `hf_bloom_convert.py` run with pytorch, and
|
||||
1. `torch-cpu` has better accuracy than XPyTorch generally.
|
||||
2. XPyTorch often use more than 32GB GM, thus more XPU are necessary to finish it.
|
||||
3. add `-p=1` if run with XPyTorch.
|
||||
|
||||
[`build.py`](./build.py) add new options for the support of INT8 inference of SmoothQuant models.
|
||||
|
||||
`--use_smooth_quant` is the starting point of INT8 inference. By default, it
|
||||
will run the model in the _per-tensor_ mode.
|
||||
|
||||
`--per-token` and `--per-channel` are not supported yet.
|
||||
|
||||
Examples of build invocations:
|
||||
|
||||
```bash
|
||||
# Build model for SmoothQuant in the _per_tensor_ mode.
|
||||
python3 build.py --bin_model_dir=./downloads/bloom-smooth/560M/1-XPU \
|
||||
--use_smooth_quant \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/bloom-smooth/560M/trt_engines/fp16/1-XPU/
|
||||
```
|
||||
|
||||
Note that GPT attention plugin is required to be enabled for SmoothQuant for now.
|
||||
|
||||
|
||||
Note we use `--bin_model_dir` instead of `--model_dir` since SmoothQuant model needs INT8 weights and various scales from the binary files.
|
||||
|
||||
### Run
|
||||
|
||||
```bash
|
||||
python ../summarize.py --test_trt_llm \
|
||||
--hf_model_dir ./downloads/bloom/560M/ \
|
||||
--data_type fp16 \
|
||||
--engine_dir ./downloads/bloom/560M/trt_engines/fp16/1-XPU/
|
||||
|
||||
python ../summarize.py --test_trt_llm \
|
||||
--hf_model_dir ./downloads/bloom/560M/ \
|
||||
--data_type fp16 \
|
||||
--engine_dir ./downloads/bloom/560M/trt_engines/int8_weight_only/1-XPU/
|
||||
|
||||
python run.py --tokenizer_dir ./downloads/bloom/560M/ \
|
||||
--max_output_len=50 \
|
||||
--engine_dir ./downloads/bloom/560M/trt_engines/fp16/1-XPU/
|
||||
|
||||
python run.py --tokenizer_dir ./downloads/bloom/560M/ \
|
||||
--max_output_len=50 \
|
||||
--engine_dir ./downloads/bloom/560M/trt_engines/int8_weight_only/1-XPU/
|
||||
|
||||
python run.py --tokenizer_dir ./downloads/bloom/560M/ \
|
||||
--max_output_len=50 \
|
||||
--engine_dir ./downloads/bloom-smooth/560M/trt_engines/fp16/1-XPU/
|
||||
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python run.py --tokenizer_dir ./downloads/bloom/560M/ \
|
||||
--max_output_len=50 \
|
||||
--engine_dir ./downloads/bloom/560M/trt_engines/fp16/2-XPU/
|
||||
```
|
||||
132
examples/bloom/README_CN.md
Normal file
132
examples/bloom/README_CN.md
Normal file
@@ -0,0 +1,132 @@
|
||||
# BLOOM
|
||||
|
||||
本文档介绍了如何使用昆仑芯XTRT-LLM在单XPU和单节点多XPU上使用昆仑芯XTRT-LLM构建和运行BLOOM模型。
|
||||
|
||||
## 概述
|
||||
|
||||
XTRT-LLM BLOOM示例代码位于 [`examples/bloom`](./). 此文件夹中有以下几个主要文件:
|
||||
|
||||
* [`build.py`](./build.py) 构建运行BLOOM模型所需的XTRT引擎
|
||||
* [`run.py`](./run.py) 基于输入的文字进行推理
|
||||
* [`summarize.py`](./summarize.py) 使用此模型对[cnn_dailymail](https://huggingface.co/datasets/cnn_dailymail) 数据集中的文章进行总结
|
||||
|
||||
## 支持的矩阵
|
||||
|
||||
* FP16
|
||||
* INT8 Weight-Only
|
||||
* Tensor Parallel
|
||||
|
||||
## 使用说明
|
||||
|
||||
XTRT-LLM BLOOM示例代码位于[examples/bloom](./)。它使用HF权重作为输入,并且构建对应的XTRT引擎。XTRT引擎的数量取决于为了运行推理而是用的XPU个数。
|
||||
|
||||
### 构建XTRT引擎
|
||||
|
||||
需要先按照下面的指南准备HF BLOOM checkpoint:https://huggingface.co/docs/transformers/main/en/model_doc/bloom。
|
||||
|
||||
举例:安装BLOOM-560M
|
||||
|
||||
```bash
|
||||
# Setup git-lfs
|
||||
git lfs install
|
||||
rm -rf ./downloads/bloom/560M/
|
||||
mkdir -p ./downloads/bloom/560M/ && git clone https://huggingface.co/bigscience/bloom-560m ./downloads/bloom/560M/
|
||||
```
|
||||
|
||||
XTRT-LLM BLOOM从HF checkpoint构建XTRT引擎。
|
||||
|
||||
通常 `build.py`只需要单个XPU,但如果您已经获得了推理所需的所有XPU,则可以通过添加 `--parallel_build` 参数来启用并行构建,从而加快引擎构建过程。请注意,目前`parallel_build`仅支持单个节点XPU。
|
||||
|
||||
以下为示例:
|
||||
|
||||
```bash
|
||||
# Build a single-XPU float16 engine from HF weights.
|
||||
# Try use_gemm_plugin to prevent accuracy issue. TODO check this holds for BLOOM
|
||||
|
||||
# Single XPU on BLOOM 560M
|
||||
python build.py --model_dir ./downloads/bloom/560M/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/bloom/560M/trt_engines/fp16/1-XPU/
|
||||
|
||||
# Build the BLOOM 560M using a single XPU and apply INT8 weight-only quantization.
|
||||
python build.py --model_dir ./downloads/bloom/560M/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_weight_only \
|
||||
--weight_only_precision int8 \
|
||||
--output_dir ./downloads/bloom/560M/trt_engines/int8_weight_only/1-XPU/
|
||||
|
||||
# Use 2-way tensor parallelism on BLOOM 560M
|
||||
python build.py --model_dir ./downloads/bloom/560M/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/bloom/560M/trt_engines/fp16/2-XPU/ \
|
||||
--world_size 2
|
||||
```
|
||||
|
||||
#### SmoothQuant
|
||||
|
||||
|
||||
与FP16的HF权重可以直接被处理并加载到XTRT-LLM不同,SmoothQuant需要加载INT8权重,而INT8权重在构建引擎之前需要进行预处理。
|
||||
|
||||
示例:
|
||||
```bash
|
||||
python3 hf_bloom_convert.py -i ./downloads/bloom/560M/ -o ./downloads/bloom-smooth/560M --smoothquant 0.5 --tensor-parallelism 1 --storage-type float16
|
||||
```
|
||||
|
||||
注意:使用PyTorch运行`hf_bloom_convert.py`,并且
|
||||
|
||||
1. 'torch-cpu' 通常比XPyTorch精度更高
|
||||
2. XPyTorch 通常使用超过32GB的GM,因此需要更多的XPU来完成它
|
||||
3. 使用XPyTorch运行时,请添加`-p=1`
|
||||
|
||||
`build.py`增加了新的选项来支持SmoothQuant模型的INT8推理。
|
||||
|
||||
`--use_smooth_quant` 是INT8推理的起点。默认情况下,它将以`--per-token`模式运行模型。
|
||||
`--per-token`和`--per-channel`目前还不支持。
|
||||
|
||||
构建调用示例:
|
||||
|
||||
```bash
|
||||
# Build model for SmoothQuant in the _per_tensor_ mode.
|
||||
python3 build.py --bin_model_dir=./downloads/bloom-smooth/560M/1-XPU \
|
||||
--use_smooth_quant \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/bloom-smooth/560M/trt_engines/fp16/1-XPU/
|
||||
```
|
||||
|
||||
注意:目前,SmoothQuant需要启用GPT attention插件。
|
||||
|
||||
注意:我们使用`--bin_model_dir`而不是`--model_dir`,因为SmoothQuant模型需要INT8权重和二进制文件中的各种scales。
|
||||
|
||||
### 运行
|
||||
|
||||
```bash
|
||||
python ../summarize.py --test_trt_llm \
|
||||
--hf_model_dir ./downloads/bloom/560M/ \
|
||||
--data_type fp16 \
|
||||
--engine_dir ./downloads/bloom/560M/trt_engines/fp16/1-XPU/
|
||||
|
||||
python ../summarize.py --test_trt_llm \
|
||||
--hf_model_dir ./downloads/bloom/560M/ \
|
||||
--data_type fp16 \
|
||||
--engine_dir ./downloads/bloom/560M/trt_engines/int8_weight_only/1-XPU/
|
||||
|
||||
python run.py --tokenizer_dir ./downloads/bloom/560M/ \
|
||||
--max_output_len=50 \
|
||||
--engine_dir ./downloads/bloom/560M/trt_engines/fp16/1-XPU/
|
||||
|
||||
python run.py --tokenizer_dir ./downloads/bloom/560M/ \
|
||||
--max_output_len=50 \
|
||||
--engine_dir ./downloads/bloom/560M/trt_engines/int8_weight_only/1-XPU/
|
||||
|
||||
python run.py --tokenizer_dir ./downloads/bloom/560M/ \
|
||||
--max_output_len=50 \
|
||||
--engine_dir ./downloads/bloom-smooth/560M/trt_engines/fp16/1-XPU/
|
||||
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python run.py --tokenizer_dir ./downloads/bloom/560M/ \
|
||||
--max_output_len=50 \
|
||||
--engine_dir ./downloads/bloom/560M/trt_engines/fp16/2-XPU/
|
||||
```
|
||||
521
examples/bloom/build.py
Normal file
521
examples/bloom/build.py
Normal file
@@ -0,0 +1,521 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import os
|
||||
import time
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
import torch.multiprocessing as mp
|
||||
from transformers import BloomConfig, BloomForCausalLM
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm._utils import str_dtype_to_xtrt
|
||||
from xtrt_llm.builder import Builder
|
||||
from xtrt_llm.logger import logger
|
||||
from xtrt_llm.mapping import Mapping
|
||||
from xtrt_llm.models import smooth_quantize, weight_only_quantize
|
||||
from xtrt_llm.network import net_guard
|
||||
from xtrt_llm.plugin.plugin import ContextFMHAType
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
from weight import load_from_hf_bloom, load_from_bin, parse_config, check_embedding_share # isort:skip
|
||||
|
||||
MODEL_NAME = "bloom"
|
||||
|
||||
import onnx
|
||||
import tvm.tensorrt as trt
|
||||
from onnx import TensorProto, helper
|
||||
|
||||
|
||||
def trt_dtype_to_onnx(dtype):
|
||||
if dtype == trt.float16:
|
||||
return TensorProto.DataType.FLOAT16
|
||||
elif dtype == trt.float32:
|
||||
return TensorProto.DataType.FLOAT
|
||||
elif dtype == trt.int32:
|
||||
return TensorProto.DataType.INT32
|
||||
else:
|
||||
raise TypeError("%s is not supported" % dtype)
|
||||
|
||||
|
||||
def to_onnx(network, path):
|
||||
inputs = []
|
||||
for i in range(network.num_inputs):
|
||||
network_input = network.get_input(i)
|
||||
inputs.append(
|
||||
helper.make_tensor_value_info(
|
||||
network_input.name, trt_dtype_to_onnx(network_input.dtype),
|
||||
list(network_input.shape)))
|
||||
|
||||
outputs = []
|
||||
for i in range(network.num_outputs):
|
||||
network_output = network.get_output(i)
|
||||
outputs.append(
|
||||
helper.make_tensor_value_info(
|
||||
network_output.name, trt_dtype_to_onnx(network_output.dtype),
|
||||
list(network_output.shape)))
|
||||
|
||||
nodes = []
|
||||
for i in range(network.num_layers):
|
||||
layer = network.get_layer(i)
|
||||
layer_inputs = []
|
||||
for j in range(layer.num_inputs):
|
||||
ipt = layer.get_input(j)
|
||||
if ipt is not None:
|
||||
layer_inputs.append(layer.get_input(j).name)
|
||||
layer_outputs = [
|
||||
layer.get_output(j).name for j in range(layer.num_outputs)
|
||||
]
|
||||
nodes.append(
|
||||
helper.make_node(str(layer.type),
|
||||
name=layer.name,
|
||||
inputs=layer_inputs,
|
||||
outputs=layer_outputs,
|
||||
domain="com.nvidia"))
|
||||
|
||||
onnx_model = helper.make_model(helper.make_graph(nodes,
|
||||
'attention',
|
||||
inputs,
|
||||
outputs,
|
||||
initializer=None),
|
||||
producer_name='NVIDIA')
|
||||
onnx.save(onnx_model, path)
|
||||
|
||||
|
||||
def get_engine_name(model, dtype, tp_size, rank):
|
||||
return '{}_{}_tp{}_rank{}.engine'.format(model, dtype, tp_size, rank)
|
||||
|
||||
|
||||
def serialize_engine(engine, path):
|
||||
logger.info(f'Serializing engine to {path}...')
|
||||
tik = time.time()
|
||||
engine.serialize(path)
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Engine serialized. Total time: {t}')
|
||||
|
||||
|
||||
def parse_arguments():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--world_size',
|
||||
type=int,
|
||||
default=1,
|
||||
help='world size, only support tensor parallelism now')
|
||||
parser.add_argument('--model_dir', type=str, default=None)
|
||||
parser.add_argument('--bin_model_dir', type=str, default=None)
|
||||
parser.add_argument('--dtype',
|
||||
type=str,
|
||||
default='float16',
|
||||
choices=['float32', 'float16'])
|
||||
parser.add_argument(
|
||||
'--timing_cache',
|
||||
type=str,
|
||||
default='model.cache',
|
||||
help=
|
||||
'The path of to read timing cache from, will be ignored if the file does not exist'
|
||||
)
|
||||
parser.add_argument('--log_level', type=str, default='info')
|
||||
parser.add_argument('--vocab_size', type=int, default=250680)
|
||||
parser.add_argument('--n_layer', type=int, default=32)
|
||||
parser.add_argument('--n_positions', type=int, default=2048)
|
||||
parser.add_argument('--n_embd', type=int, default=4096)
|
||||
parser.add_argument('--n_head', type=int, default=32)
|
||||
parser.add_argument('--mlp_hidden_size', type=int, default=None)
|
||||
parser.add_argument('--max_batch_size', type=int, default=8)
|
||||
parser.add_argument('--max_input_len', type=int, default=1024)
|
||||
parser.add_argument('--max_output_len', type=int, default=1024)
|
||||
parser.add_argument('--max_beam_width', type=int, default=1)
|
||||
parser.add_argument('--use_gpt_attention_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
choices=['float16', 'float32'])
|
||||
parser.add_argument('--use_gemm_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
choices=['float16', 'float32'])
|
||||
parser.add_argument('--enable_context_fmha',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--enable_context_fmha_fp32_acc',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument(
|
||||
'--use_layernorm_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
choices=['float16', 'float32'],
|
||||
help=
|
||||
"Activates layernorm plugin. You can specify the plugin dtype or leave blank to use the model dtype."
|
||||
)
|
||||
parser.add_argument('--parallel_build', default=False, action='store_true')
|
||||
parser.add_argument('--visualize', default=False, action='store_true')
|
||||
parser.add_argument('--enable_debug_output',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--gpus_per_node', type=int, default=8)
|
||||
parser.add_argument(
|
||||
'--output_dir',
|
||||
type=str,
|
||||
default='bloom_outputs',
|
||||
help=
|
||||
'The path to save the serialized engine files, timing cache file and model configs'
|
||||
)
|
||||
# Arguments related to the quantization of the model.
|
||||
parser.add_argument(
|
||||
'--use_smooth_quant',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'Use the SmoothQuant method to quantize activations and weights for the various GEMMs.'
|
||||
'See --per_channel and --per_token for finer-grained quantization options.'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_weight_only',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help='Quantize weights for the various GEMMs to INT4/INT8.'
|
||||
'See --weight_only_precision to set the precision')
|
||||
parser.add_argument(
|
||||
'--weight_only_precision',
|
||||
const='int8',
|
||||
type=str,
|
||||
nargs='?',
|
||||
default='int8',
|
||||
choices=['int8', 'int4'],
|
||||
help=
|
||||
'Define the precision for the weights when using weight-only quantization.'
|
||||
'You must also use --use_weight_only for that argument to have an impact.'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--per_channel',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use a single static scaling factor for the GEMM\'s result. '
|
||||
'per_channel instead uses a different static scaling factor for each channel. '
|
||||
'The latter is usually more accurate, but a little slower.')
|
||||
parser.add_argument(
|
||||
'--per_token',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use a single static scaling factor to scale activations in the int8 range. '
|
||||
'per_token chooses at run time, and for each token, a custom scaling factor. '
|
||||
'The latter is usually more accurate, but a little slower.')
|
||||
parser.add_argument(
|
||||
'--int8_kv_cache',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use dtype for KV cache. int8_kv_cache chooses int8 quantization for KV'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_parallel_embedding',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help=
|
||||
'By default embedding parallelism is disabled. By setting this flag, embedding parallelism is enabled'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--embedding_sharding_dim',
|
||||
type=int,
|
||||
default=0,
|
||||
choices=[0, 1],
|
||||
help=
|
||||
'By default the embedding lookup table is sharded along vocab dimension (embedding_sharding_dim=0). '
|
||||
'To shard it along hidden dimension, set embedding_sharding_dim=1'
|
||||
'Note: embedding sharing is only enabled when embedding_sharding_dim = 0'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_embedding_sharing',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help=
|
||||
'Try to reduce the engine size by sharing the embedding lookup table between two layers.'
|
||||
'Note: the flag might not take effect when the criteria are not met.')
|
||||
parser.add_argument(
|
||||
'--use_lookup_plugin',
|
||||
nargs='?',
|
||||
const=None,
|
||||
default=False,
|
||||
choices=['float16', 'float32', 'bfloat16'],
|
||||
help="Activates the lookup plugin which enables embedding sharing.")
|
||||
|
||||
args = parser.parse_args()
|
||||
logger.set_level(args.log_level)
|
||||
|
||||
if args.model_dir is not None:
|
||||
hf_config = BloomConfig.from_pretrained(args.model_dir)
|
||||
args.n_embd = hf_config.hidden_size
|
||||
args.n_head = hf_config.num_attention_heads
|
||||
args.n_layer = hf_config.num_hidden_layers
|
||||
args.vocab_size = hf_config.vocab_size
|
||||
elif args.bin_model_dir is not None:
|
||||
logger.info(f"Setting model configuration from {args.bin_model_dir}.")
|
||||
n_embd, n_head, n_layer, vocab_size, _, rotary_pct, bias, inter_size, multi_query_mode, dtype, prompt_num_tasks, prompt_max_vocab_size = parse_config(
|
||||
Path(args.bin_model_dir) / "config.ini")
|
||||
args.n_embd = n_embd
|
||||
args.n_head = n_head
|
||||
args.n_layer = n_layer
|
||||
args.vocab_size = vocab_size
|
||||
|
||||
assert not (
|
||||
args.use_smooth_quant and args.use_weight_only
|
||||
), "You cannot enable both SmoothQuant and INT8 weight-only together."
|
||||
|
||||
if args.use_smooth_quant:
|
||||
args.quant_mode = QuantMode.use_smooth_quant(args.per_token,
|
||||
args.per_channel)
|
||||
elif args.use_weight_only:
|
||||
args.quant_mode = QuantMode.use_weight_only(
|
||||
args.weight_only_precision == 'int4')
|
||||
else:
|
||||
args.quant_mode = QuantMode(0)
|
||||
|
||||
if args.int8_kv_cache:
|
||||
args.quant_mode = args.quant_mode.set_int8_kv_cache()
|
||||
|
||||
return args
|
||||
|
||||
|
||||
def build_rank_engine(builder: Builder,
|
||||
builder_config: xtrt_llm.builder.BuilderConfig,
|
||||
engine_name, rank, args):
|
||||
'''
|
||||
@brief: Build the engine on the given rank.
|
||||
@param rank: The rank to build the engine.
|
||||
@param args: The cmd line arguments.
|
||||
@return: The built engine.
|
||||
'''
|
||||
kv_dtype = str_dtype_to_xtrt(args.dtype)
|
||||
|
||||
# Share_embedding_table can be set True only when:
|
||||
# 1) the weight for lm_head() does not exist while other weights exist
|
||||
# 2) For multiple-processes, use_parallel_embedding=True and embedding_sharding_dim == 0.
|
||||
# Besides, for TensorRT 9.0, we can observe the engine size reduction when the lookup and gemm plugin are enabled.
|
||||
share_embedding_table = False
|
||||
if args.use_embedding_sharing:
|
||||
if args.world_size > 1:
|
||||
if args.model_dir is not None and args.embedding_sharding_dim == 0 and args.use_parallel_embedding:
|
||||
share_embedding_table = check_embedding_share(args.model_dir)
|
||||
else:
|
||||
if args.model_dir is not None:
|
||||
share_embedding_table = check_embedding_share(args.model_dir)
|
||||
|
||||
if not share_embedding_table:
|
||||
logger.warning(f'Cannot share the embedding lookup table.')
|
||||
|
||||
if share_embedding_table:
|
||||
logger.info(
|
||||
'Engine will share embedding and language modeling weights.')
|
||||
|
||||
# Initialize Module
|
||||
xtrt_llm_bloom = xtrt_llm.models.BloomForCausalLM(
|
||||
num_layers=args.n_layer,
|
||||
num_heads=args.n_head,
|
||||
hidden_size=args.n_embd,
|
||||
vocab_size=args.vocab_size,
|
||||
max_position_embeddings=args.n_positions,
|
||||
dtype=kv_dtype,
|
||||
mapping=Mapping(world_size=args.world_size,
|
||||
rank=rank,
|
||||
tp_size=args.world_size), # TP only
|
||||
use_parallel_embedding=args.use_parallel_embedding,
|
||||
embedding_sharding_dim=args.embedding_sharding_dim,
|
||||
share_embedding_table=share_embedding_table,
|
||||
quant_mode=args.quant_mode)
|
||||
if args.use_smooth_quant:
|
||||
xtrt_llm_bloom = smooth_quantize(xtrt_llm_bloom, args.quant_mode)
|
||||
elif args.use_weight_only and 0:
|
||||
xtrt_llm_bloom = weight_only_quantize(xtrt_llm_bloom, args.quant_mode)
|
||||
|
||||
if args.model_dir is not None:
|
||||
logger.info(f'Loading HF BLOOM ... from {args.model_dir}')
|
||||
tik = time.time()
|
||||
hf_bloom = BloomForCausalLM.from_pretrained(args.model_dir,
|
||||
torch_dtype="auto")
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'HF BLOOM loaded. Total time: {t}')
|
||||
print(hf_bloom)
|
||||
load_from_hf_bloom(xtrt_llm_bloom,
|
||||
hf_bloom,
|
||||
rank,
|
||||
args.world_size,
|
||||
fp16=(args.dtype == 'float16'),
|
||||
use_parallel_embedding=args.use_parallel_embedding,
|
||||
sharding_dim=args.embedding_sharding_dim,
|
||||
share_embedding_table=share_embedding_table)
|
||||
elif args.bin_model_dir is not None:
|
||||
load_from_bin(xtrt_llm_bloom,
|
||||
args.bin_model_dir,
|
||||
rank,
|
||||
args.world_size,
|
||||
args.dtype,
|
||||
use_parallel_embedding=args.use_parallel_embedding,
|
||||
sharding_dim=args.embedding_sharding_dim,
|
||||
share_embedding_table=share_embedding_table)
|
||||
|
||||
# Module -> Network
|
||||
network = builder.create_network()
|
||||
network.trt_network.name = engine_name
|
||||
if args.use_gpt_attention_plugin:
|
||||
network.plugin_config.set_gpt_attention_plugin(
|
||||
dtype=args.use_gpt_attention_plugin)
|
||||
if args.use_gemm_plugin:
|
||||
network.plugin_config.set_gemm_plugin(dtype=args.use_gemm_plugin)
|
||||
if args.use_layernorm_plugin:
|
||||
network.plugin_config.set_layernorm_plugin(
|
||||
dtype=args.use_layernorm_plugin)
|
||||
if args.use_lookup_plugin:
|
||||
# Use the plugin for the embedding parallelism
|
||||
network.plugin_config.set_lookup_plugin(dtype=args.dtype)
|
||||
assert not (args.enable_context_fmha and args.enable_context_fmha_fp32_acc)
|
||||
if args.enable_context_fmha:
|
||||
network.plugin_config.set_context_fmha(ContextFMHAType.enabled)
|
||||
if args.enable_context_fmha_fp32_acc:
|
||||
network.plugin_config.set_context_fmha(
|
||||
ContextFMHAType.enabled_with_fp32_acc)
|
||||
# Quantization plugins.
|
||||
if args.use_smooth_quant:
|
||||
network.plugin_config.set_smooth_quant_gemm_plugin(dtype=args.dtype)
|
||||
network.plugin_config.set_layernorm_quantization_plugin(
|
||||
dtype=args.dtype)
|
||||
|
||||
network.plugin_config.set_quantize_tensor_plugin()
|
||||
network.plugin_config.set_quantize_per_token_plugin()
|
||||
elif args.use_weight_only:
|
||||
network.plugin_config.set_weight_only_quant_matmul_plugin(
|
||||
dtype=args.dtype)
|
||||
if args.quant_mode.is_weight_only():
|
||||
builder_config.trt_builder_config.use_weight_only = args.weight_only_precision
|
||||
if args.world_size > 1:
|
||||
network.plugin_config.set_nccl_plugin(args.dtype)
|
||||
with net_guard(network):
|
||||
# Prepare
|
||||
network.set_named_parameters(xtrt_llm_bloom.named_parameters())
|
||||
|
||||
# Forward
|
||||
inputs = xtrt_llm_bloom.prepare_inputs(args.max_batch_size,
|
||||
args.max_input_len,
|
||||
args.max_output_len, True,
|
||||
args.max_beam_width)
|
||||
xtrt_llm_bloom(*inputs)
|
||||
if args.enable_debug_output:
|
||||
# mark intermediate nodes' outputs
|
||||
for k, v in xtrt_llm_bloom.named_network_outputs():
|
||||
v = v.trt_tensor
|
||||
v.name = k
|
||||
network.trt_network.mark_output(v)
|
||||
v.dtype = kv_dtype
|
||||
if args.visualize:
|
||||
model_path = os.path.join(args.output_dir, 'test.onnx')
|
||||
to_onnx(network.trt_network, model_path)
|
||||
|
||||
# xtrt_llm.graph_rewriting.optimize(network)
|
||||
|
||||
engine = None
|
||||
|
||||
# Network -> Engine
|
||||
engine = builder.build_engine(network, builder_config)
|
||||
if rank == 0:
|
||||
config_path = os.path.join(args.output_dir, 'config.json')
|
||||
builder.save_config(builder_config, config_path)
|
||||
return engine
|
||||
|
||||
|
||||
def build(rank, args):
|
||||
torch.cuda.set_device(rank % args.gpus_per_node)
|
||||
xtrt_llm.logger.set_level(args.log_level)
|
||||
if not os.path.exists(args.output_dir):
|
||||
os.makedirs(args.output_dir)
|
||||
|
||||
# when doing serializing build, all ranks share one engine
|
||||
builder = Builder()
|
||||
|
||||
cache = None
|
||||
for cur_rank in range(args.world_size):
|
||||
# skip other ranks if parallel_build is enabled
|
||||
if args.parallel_build and cur_rank != rank:
|
||||
continue
|
||||
# NOTE: when only int8 kv cache is used together with paged kv cache no int8 tensors are exposed to TRT
|
||||
int8_trt_flag = args.quant_mode.has_act_and_weight_quant(
|
||||
) or args.quant_mode.has_int8_kv_cache()
|
||||
builder_config = builder.create_builder_config(
|
||||
name=MODEL_NAME,
|
||||
precision=args.dtype,
|
||||
timing_cache=args.timing_cache if cache is None else cache,
|
||||
tensor_parallel=args.world_size, # TP only
|
||||
parallel_build=args.parallel_build,
|
||||
num_layers=args.n_layer,
|
||||
num_heads=args.n_head,
|
||||
hidden_size=args.n_embd,
|
||||
inter_size=args.mlp_hidden_size,
|
||||
vocab_size=args.vocab_size,
|
||||
max_position_embeddings=args.n_positions,
|
||||
max_batch_size=args.max_batch_size,
|
||||
max_input_len=args.max_input_len,
|
||||
max_output_len=args.max_output_len,
|
||||
int8=(args.quant_mode.has_act_and_weight_quant()
|
||||
or args.quant_mode.has_int8_kv_cache()),
|
||||
fusion_pattern_list=["remove_dup_mask"],
|
||||
quant_mode=args.quant_mode)
|
||||
guard = xtrt_llm.fusion_patterns.FuseonPatternGuard()
|
||||
print(guard)
|
||||
builder_config.trt_builder_config.builder_optimization_level = 1
|
||||
engine_name = get_engine_name(MODEL_NAME, args.dtype, args.world_size,
|
||||
cur_rank)
|
||||
engine = build_rank_engine(builder, builder_config, engine_name,
|
||||
cur_rank, args)
|
||||
assert engine is not None, f'Failed to build engine for rank {cur_rank}'
|
||||
|
||||
if cur_rank == 0:
|
||||
# Use in-memory timing cache for multiple builder passes.
|
||||
if not args.parallel_build:
|
||||
cache = builder_config.trt_builder_config.get_timing_cache()
|
||||
|
||||
serialize_engine(engine, os.path.join(args.output_dir, engine_name))
|
||||
|
||||
# if rank == 0:
|
||||
# ok = builder.save_timing_cache(
|
||||
# builder_config, os.path.join(args.output_dir, "model.cache"))
|
||||
# assert ok, "Failed to save timing cache."
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = parse_arguments()
|
||||
logger.set_level(args.log_level)
|
||||
tik = time.time()
|
||||
if args.parallel_build and args.world_size > 1 and \
|
||||
torch.cuda.device_count() >= args.world_size:
|
||||
logger.warning(
|
||||
f'Parallelly build TensorRT engines. Please make sure that all of the {args.world_size} GPUs are totally free.'
|
||||
)
|
||||
mp.spawn(build, nprocs=args.world_size, args=(args, ))
|
||||
else:
|
||||
args.parallel_build = False
|
||||
logger.info('Serially build TensorRT engines.')
|
||||
build(0, args)
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Total time of building all {args.world_size} engines: {t}')
|
||||
283
examples/bloom/convert.py
Normal file
283
examples/bloom/convert.py
Normal file
@@ -0,0 +1,283 @@
|
||||
"""
|
||||
Utilities for exporting a model to our custom format.
|
||||
"""
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
from xtrt_llm._utils import torch_to_numpy
|
||||
|
||||
|
||||
def cpu_map_location(storage, loc):
|
||||
return storage.cpu()
|
||||
|
||||
|
||||
def gpu_map_location(storage, loc):
|
||||
if loc.startswith("cuda"):
|
||||
training_gpu_idx = int(loc.split(":")[1])
|
||||
inference_gpu_idx = training_gpu_idx % torch.cuda.device_count()
|
||||
return storage.cuda(inference_gpu_idx)
|
||||
elif loc.startswith("cpu"):
|
||||
return storage.cpu()
|
||||
else:
|
||||
raise ValueError(f"Not handled {loc}")
|
||||
|
||||
|
||||
def save_val(val, dir, key, tp_num=None):
|
||||
suffix = "bin" if tp_num is None else f"{tp_num}.bin"
|
||||
val.tofile(dir / f"model.{key}.{suffix}")
|
||||
|
||||
|
||||
def save_split(split_vals, dir, key, i, split_factor):
|
||||
for j, val in enumerate(split_vals):
|
||||
save_val(val, dir, key, i * split_factor + j)
|
||||
|
||||
|
||||
def generate_int8(weights, act_range, is_qkv=False, multi_query_mode=False):
|
||||
"""
|
||||
This function has two purposes:
|
||||
- compute quantized weights, scaled either per-tensor or per-column
|
||||
- compute scaling factors
|
||||
|
||||
Depending on the GEMM API (CUTLASS/CUBLAS) the required scaling factors differ.
|
||||
CUTLASS uses two sets of scaling factors. One for the activation X, one for the weight W.
|
||||
CUBLAS only has one (we can't do per-row scaling). So we must provide pre-multiplied scaling factor.
|
||||
|
||||
Here is the list of what we need (T means per-tensor, C per-column):
|
||||
- scale_x_orig_quant puts fp activation into the quantized range (i.e. [-128, 127], for int8). Used before the GEMM. (T)
|
||||
- scale_y_quant_orig puts quantized activation into the fp range. Used if the GEMM outputs int8. (T)
|
||||
- scale_w_quant_orig puts weights from quant range to fp range (used with CUTLASS) (T, C)
|
||||
- scale_y_accum_quant puts the GEMM result (XW) from accumulation range (int32)
|
||||
to quant range (int8) (used for CUBLAS) (T, C)
|
||||
|
||||
Note that we don't do anything special about row-parallel GEMM. Theoretically, we could have per-GPU scaling factors too,
|
||||
but then the model would change depending on the number of GPUs used.
|
||||
|
||||
For QKV projection, the behavior is special. Even if we have a single matrix to perform QKV projection, we consider it
|
||||
as three different matrices: Q, K, and V. So per-tensor actually means one scaling factor for each Q, K and V.
|
||||
"""
|
||||
|
||||
# compute weight scaling factors for fp->int8 and int8->fp
|
||||
if is_qkv and not multi_query_mode:
|
||||
scale_w_orig_quant_t = 127. / act_range["w"].reshape(3, -1).max(
|
||||
dim=-1, keepdims=True)[0].cpu().numpy()
|
||||
scale_w_orig_quant_c = 127. / act_range["w"].reshape(3,
|
||||
-1).cpu().numpy()
|
||||
elif is_qkv and multi_query_mode:
|
||||
raise ValueError(
|
||||
f"Multi-query w/ int8 quant has not been supported yet")
|
||||
else:
|
||||
scale_w_orig_quant_t = 127. / act_range["w"].max().cpu().numpy()
|
||||
scale_w_orig_quant_c = 127. / act_range["w"].cpu().numpy()
|
||||
scale_w_quant_orig_t = 1.0 / scale_w_orig_quant_t
|
||||
scale_w_quant_orig_c = 1.0 / scale_w_orig_quant_c
|
||||
|
||||
# compute the rest of needed scaling factors
|
||||
scale_x_orig_quant_t = np.array(127. / act_range["x"].max().item())
|
||||
scale_y_orig_quant_t = np.array(127. / act_range["y"].max().item())
|
||||
scale_y_quant_orig_t = np.array(act_range["y"].max().item() / 127.)
|
||||
scale_y_accum_quant_t = scale_y_orig_quant_t / (scale_x_orig_quant_t *
|
||||
scale_w_orig_quant_t)
|
||||
scale_y_accum_quant_c = scale_y_orig_quant_t / (scale_x_orig_quant_t *
|
||||
scale_w_orig_quant_c)
|
||||
if is_qkv:
|
||||
scale_y_accum_quant_t = np.broadcast_to(scale_y_accum_quant_t,
|
||||
scale_w_orig_quant_c.shape)
|
||||
scale_w_quant_orig_t = np.broadcast_to(scale_w_quant_orig_t,
|
||||
scale_w_orig_quant_c.shape)
|
||||
|
||||
to_i8 = lambda x: x.round().clip(-127, 127).astype(np.int8)
|
||||
return {
|
||||
"weight.int8": to_i8(weights * scale_w_orig_quant_t),
|
||||
"weight.int8.col": to_i8(weights * scale_w_orig_quant_c),
|
||||
"scale_x_orig_quant": scale_x_orig_quant_t.astype(np.float32),
|
||||
"scale_w_quant_orig": scale_w_quant_orig_t.astype(np.float32),
|
||||
"scale_w_quant_orig.col": scale_w_quant_orig_c.astype(np.float32),
|
||||
"scale_y_accum_quant": scale_y_accum_quant_t.astype(np.float32),
|
||||
"scale_y_accum_quant.col": scale_y_accum_quant_c.astype(np.float32),
|
||||
"scale_y_quant_orig": scale_y_quant_orig_t.astype(np.float32),
|
||||
}
|
||||
|
||||
|
||||
def write_int8(vals,
|
||||
dir,
|
||||
base_key,
|
||||
split_dim,
|
||||
tp_rank,
|
||||
split_factor,
|
||||
kv_cache_only=False):
|
||||
if not kv_cache_only:
|
||||
save_split(np.split(vals["weight.int8"], split_factor, axis=split_dim),
|
||||
dir, f"{base_key}.weight.int8", tp_rank, split_factor)
|
||||
save_split(
|
||||
np.split(vals["weight.int8.col"], split_factor, axis=split_dim),
|
||||
dir, f"{base_key}.weight.int8.col", tp_rank, split_factor)
|
||||
|
||||
saved_keys_once = ["scale_y_quant_orig"]
|
||||
if not kv_cache_only:
|
||||
saved_keys_once += [
|
||||
"scale_x_orig_quant", "scale_w_quant_orig", "scale_y_accum_quant"
|
||||
]
|
||||
# per-column scaling factors are loaded per-gpu for ColumnParallel GEMMs (QKV, FC1)
|
||||
if not kv_cache_only:
|
||||
if split_dim == -1:
|
||||
save_split(
|
||||
np.split(vals["scale_w_quant_orig.col"],
|
||||
split_factor,
|
||||
axis=split_dim), dir,
|
||||
f"{base_key}.scale_w_quant_orig.col", tp_rank, split_factor)
|
||||
save_split(
|
||||
np.split(vals["scale_y_accum_quant.col"],
|
||||
split_factor,
|
||||
axis=split_dim), dir,
|
||||
f"{base_key}.scale_y_accum_quant.col", tp_rank, split_factor)
|
||||
else:
|
||||
saved_keys_once += [
|
||||
"scale_w_quant_orig.col", "scale_y_accum_quant.col"
|
||||
]
|
||||
|
||||
if tp_rank == 0:
|
||||
for save_key in saved_keys_once:
|
||||
save_val(vals[save_key], dir, f"{base_key}.{save_key}")
|
||||
|
||||
|
||||
# Note: in multi_query_mode, only query heads are split between multiple GPUs, while key/value head
|
||||
# are not split as there is only one head per key/value.
|
||||
@torch.no_grad()
|
||||
def split_and_save_weight(tp_rank, saved_dir, split_factor, key, vals,
|
||||
storage_type, act_range, config):
|
||||
use_attention_nemo_shape = config.get("use_attention_nemo_shape", False)
|
||||
split_gated_activation = config.get("split_gated_activation", False)
|
||||
num_attention_heads = config.get("num_attention_heads", 0)
|
||||
tp_size = config.get("tp_size", 1)
|
||||
int8_outputs = config.get("int8_outputs", None)
|
||||
multi_query_mode = config.get("multi_query_mode", False)
|
||||
local_dim = config.get("local_dim", None)
|
||||
|
||||
save_int8 = int8_outputs == "all" or int8_outputs == "kv_cache_only"
|
||||
|
||||
if not isinstance(vals, list):
|
||||
vals = [vals]
|
||||
|
||||
if config.get("transpose_weights", False) and vals[0].ndim == 2:
|
||||
vals = [val.T for val in vals]
|
||||
if "layernorm.weight" in key and config.get("apply_layernorm_1p", False):
|
||||
vals = [val + 1.0 for val in vals]
|
||||
vals = [torch_to_numpy(val.cpu().to(storage_type)) for val in vals]
|
||||
|
||||
if "input_layernorm.weight" in key or "input_layernorm.bias" in key or \
|
||||
"attention.dense.bias" in key or "post_attention_layernorm.weight" in key or \
|
||||
"post_attention_layernorm.bias" in key or "mlp.dense_4h_to_h.bias" in key or \
|
||||
"final_layernorm.weight" in key or "final_layernorm.bias" in key or \
|
||||
"word_embeddings_layernorm.weight" in key or "word_embeddings_layernorm.bias" in key:
|
||||
|
||||
# shared weights, only need to convert the weights of rank 0
|
||||
if tp_rank == 0:
|
||||
save_val(vals[0], saved_dir, key)
|
||||
|
||||
elif "attention.dense.weight" in key or "mlp.dense_4h_to_h.weight" in key:
|
||||
cat_dim = 0
|
||||
val = np.concatenate(vals, axis=cat_dim)
|
||||
split_vals = np.split(val, split_factor, axis=cat_dim)
|
||||
save_split(split_vals, saved_dir, key, tp_rank, split_factor)
|
||||
if act_range is not None and int8_outputs == "all":
|
||||
base_key = key.replace(".weight", "")
|
||||
vals_i8 = generate_int8(val,
|
||||
act_range,
|
||||
multi_query_mode=multi_query_mode)
|
||||
write_int8(vals_i8, saved_dir, base_key, cat_dim, tp_rank,
|
||||
split_factor)
|
||||
|
||||
elif "mlp.dense_h_to_4h.weight" in key or "mlp.dense_h_to_4h.bias" in key:
|
||||
if split_gated_activation:
|
||||
splits = [np.split(val, 2, axis=-1) for val in vals]
|
||||
vals, gates = list(zip(*splits))
|
||||
cat_dim = -1
|
||||
val = np.concatenate(vals, axis=cat_dim)
|
||||
split_vals = np.split(val, split_factor, axis=cat_dim)
|
||||
save_split(split_vals, saved_dir, key, tp_rank, split_factor)
|
||||
if act_range is not None and int8_outputs == "all":
|
||||
base_key = key.replace(".weight", "")
|
||||
vals_i8 = generate_int8(val,
|
||||
act_range,
|
||||
multi_query_mode=multi_query_mode)
|
||||
write_int8(vals_i8, saved_dir, base_key, cat_dim, tp_rank,
|
||||
split_factor)
|
||||
|
||||
if split_gated_activation:
|
||||
assert not save_int8
|
||||
prefix, dot, suffix = key.rpartition(".")
|
||||
key = prefix + ".gate" + dot + suffix
|
||||
|
||||
gate = np.concatenate(gates, axis=cat_dim)
|
||||
split_vals = np.split(gate, split_factor, axis=cat_dim)
|
||||
save_split(split_vals, saved_dir, key, tp_rank, split_factor)
|
||||
|
||||
elif "attention.query_key_value.bias" in key:
|
||||
if local_dim is None:
|
||||
local_dim = vals[0].shape[-1] // 3
|
||||
|
||||
if multi_query_mode:
|
||||
val = vals[0]
|
||||
# out_feature = local_dim + 2 * head_size; assumes local_dim equals to hidden_dim
|
||||
b_q, b_kv = np.split(val, [local_dim], axis=-1)
|
||||
b_q_split = np.split(b_q, split_factor, axis=-1)
|
||||
split_vals = [np.concatenate((i, b_kv), axis=-1) for i in b_q_split]
|
||||
else:
|
||||
if use_attention_nemo_shape:
|
||||
head_num = num_attention_heads // tp_size
|
||||
size_per_head = local_dim // num_attention_heads
|
||||
nemo_shape = (head_num, 3, size_per_head)
|
||||
vals = [val.reshape(nemo_shape) for val in vals]
|
||||
vals = [val.transpose(1, 0, 2) for val in vals]
|
||||
|
||||
vals = [val.reshape(3, local_dim) for val in vals]
|
||||
val = np.concatenate(vals, axis=-1)
|
||||
split_vals = np.split(val, split_factor, axis=-1)
|
||||
save_split(split_vals, saved_dir, key, tp_rank, split_factor)
|
||||
|
||||
elif "attention.query_key_value.weight" in key:
|
||||
hidden_dim = vals[0].shape[0]
|
||||
if local_dim is None:
|
||||
local_dim = vals[0].shape[-1] // 3
|
||||
if multi_query_mode:
|
||||
val = vals[0]
|
||||
# out_feature = local_dim + 2 * head_size; assumes local_dim equals to hidden_dim
|
||||
head_size = (val.shape[-1] - local_dim) // 2
|
||||
val = val.reshape(hidden_dim, local_dim + 2 * head_size)
|
||||
w_q, w_kv = np.split(val, [local_dim], axis=-1)
|
||||
w_q_split = np.split(w_q, split_factor, axis=-1)
|
||||
split_vals = [np.concatenate((i, w_kv), axis=-1) for i in w_q_split]
|
||||
else:
|
||||
if use_attention_nemo_shape:
|
||||
head_num = num_attention_heads // tp_size
|
||||
size_per_head = hidden_dim // num_attention_heads
|
||||
vals = [
|
||||
val.reshape(hidden_dim, head_num, 3, size_per_head)
|
||||
for val in vals
|
||||
]
|
||||
vals = [val.transpose(0, 2, 1, 3) for val in vals]
|
||||
|
||||
vals = [val.reshape(hidden_dim, 3, local_dim) for val in vals]
|
||||
cat_dim = -1
|
||||
val = np.concatenate(vals, axis=cat_dim)
|
||||
split_vals = np.split(val, split_factor, axis=cat_dim)
|
||||
save_split(split_vals, saved_dir, key, tp_rank, split_factor)
|
||||
if save_int8:
|
||||
base_key = key.replace(".weight", "")
|
||||
vals_i8 = generate_int8(val,
|
||||
act_range,
|
||||
is_qkv=True,
|
||||
multi_query_mode=multi_query_mode)
|
||||
write_int8(vals_i8,
|
||||
saved_dir,
|
||||
base_key,
|
||||
cat_dim,
|
||||
tp_rank,
|
||||
split_factor,
|
||||
kv_cache_only=int8_outputs == "kv_cache_only")
|
||||
elif "attention.dense.smoother" in key or "mlp.dense_4h_to_h.smoother" in key:
|
||||
split_vals = np.split(vals[0], split_factor, axis=0)
|
||||
save_split(split_vals, saved_dir, key, tp_rank, split_factor)
|
||||
else:
|
||||
print(f"[WARNING] {key} not handled by converter")
|
||||
363
examples/bloom/hf_bloom_convert.py
Normal file
363
examples/bloom/hf_bloom_convert.py
Normal file
@@ -0,0 +1,363 @@
|
||||
'''
|
||||
Convert huggingface Bloom model. Use https://huggingface.co/bigscience/bloom as demo.
|
||||
'''
|
||||
import argparse
|
||||
import configparser
|
||||
import dataclasses
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
import torch.multiprocessing as multiprocessing
|
||||
from convert import split_and_save_weight
|
||||
from smoothquant import capture_activation_range, smooth_gemm
|
||||
from tqdm import tqdm
|
||||
from transformers import BloomForCausalLM, BloomTokenizerFast
|
||||
from transformers.models.bloom.modeling_bloom import BloomBlock
|
||||
|
||||
from xtrt_llm._utils import str_dtype_to_torch, torch_to_numpy
|
||||
|
||||
|
||||
@dataclasses.dataclass(frozen=True)
|
||||
class ProgArgs:
|
||||
out_dir: str
|
||||
in_file: str
|
||||
tensor_parallelism: int = 1
|
||||
processes: int = 4
|
||||
calibrate_kv_cache: bool = False
|
||||
smoothquant: float = None
|
||||
model: str = "bloom"
|
||||
storage_type: str = "fp32"
|
||||
dataset_cache_dir: str = None
|
||||
load_model_on_cpu: bool = False
|
||||
convert_model_on_cpu: bool = False
|
||||
|
||||
@staticmethod
|
||||
def parse(args=None) -> 'ProgArgs':
|
||||
parser = argparse.ArgumentParser(
|
||||
formatter_class=argparse.RawTextHelpFormatter)
|
||||
parser.add_argument('--out-dir',
|
||||
'-o',
|
||||
type=str,
|
||||
help='file name of output directory',
|
||||
required=True)
|
||||
parser.add_argument('--in-file',
|
||||
'-i',
|
||||
type=str,
|
||||
help='file name of input checkpoint file',
|
||||
required=True)
|
||||
parser.add_argument('--tensor-parallelism',
|
||||
'-tp',
|
||||
type=int,
|
||||
help='Requested tensor parallelism for inference',
|
||||
default=1)
|
||||
parser.add_argument(
|
||||
"--processes",
|
||||
"-p",
|
||||
type=int,
|
||||
help=
|
||||
"How many processes to spawn for conversion (default: 4). Set it to a lower value to reduce RAM usage.",
|
||||
default=4)
|
||||
parser.add_argument(
|
||||
"--calibrate-kv-cache",
|
||||
"-kv",
|
||||
action="store_true",
|
||||
help=
|
||||
"Generate scaling factors for KV cache. Used for storing KV cache in int8."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--smoothquant",
|
||||
"-sq",
|
||||
type=float,
|
||||
default=None,
|
||||
help="Set the α parameter (see https://arxiv.org/pdf/2211.10438.pdf)"
|
||||
" to Smoothquant the model, and output int8 weights."
|
||||
" A good first try is 0.5. Must be in [0, 1]")
|
||||
parser.add_argument(
|
||||
"--model",
|
||||
default="bloom",
|
||||
type=str,
|
||||
help="Specify Bloom variants to convert checkpoints correctly",
|
||||
choices=["bloom"])
|
||||
parser.add_argument("--storage-type",
|
||||
"-t",
|
||||
type=str,
|
||||
default="float32",
|
||||
choices=["float32", "float16", "bfloat16"])
|
||||
parser.add_argument("--dataset-cache-dir",
|
||||
type=str,
|
||||
default=None,
|
||||
help="cache dir to load the hugging face dataset")
|
||||
parser.add_argument("--load-model-on-cpu", action="store_true")
|
||||
parser.add_argument("--convert-model-on-cpu", action="store_true")
|
||||
return ProgArgs(**vars(parser.parse_args(args)))
|
||||
|
||||
|
||||
def reorder_torch_qkv_weight_or_bias(v, model, is_bias=False):
|
||||
""" Reorder the qkv weight.
|
||||
|
||||
Note that the shape of the fused QKV weights in HF is different from the
|
||||
shape that XTRT-LLM requires.
|
||||
HF: (num_heads x 3 x head_dim, hidden_size)
|
||||
XTRT-LLM: (3 x num_heads x head_dim, hidden_size)
|
||||
This is unlike to the other models in HF e.g. GPT where they have the
|
||||
same shape with XTRT-LLM, i.e., (3 x num_heads x head_dim, hidden_size). We reshape the qkv
|
||||
weight: (3 x num_heads x head_dim, hidden).
|
||||
bias : (3 x num_heads x head_dim).
|
||||
"""
|
||||
|
||||
n_head = model.transformer.num_heads
|
||||
hidden_size = model.transformer.embed_dim
|
||||
head_dim = hidden_size // n_head
|
||||
|
||||
# (3 x hidden, ...) view as (num_heads, 3, head_dim, ...)
|
||||
v = v.reshape(n_head, 3, head_dim, -1)
|
||||
# permute to (3, num_heads, head_dim, ...)
|
||||
v = v.permute((1, 0, 2, 3))
|
||||
# final shape: weight=(3 x hidden, hidden) or bias=(3 x hidden)
|
||||
if is_bias:
|
||||
return v.reshape(3 * hidden_size)
|
||||
return v.reshape(3 * hidden_size, hidden_size)
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def smooth_bloom_model(model, scales, alpha, bloom_qkv_param, bloom_smoother):
|
||||
# Smooth the activation and weights with smoother = $\diag{s}$
|
||||
for name, module in model.named_modules():
|
||||
if not isinstance(module, BloomBlock):
|
||||
continue
|
||||
|
||||
# reorder qkv weight/bias and scales
|
||||
param = module.self_attention.query_key_value.weight
|
||||
param = reorder_torch_qkv_weight_or_bias(param, model, is_bias=False)
|
||||
|
||||
layer_name = name + ".self_attention.query_key_value"
|
||||
act_range_qkv = scales.get(layer_name)
|
||||
# (n_head x 3 x head_dim) -> (3 x n_head x head_dim)
|
||||
act_range_qkv['w'] = reorder_torch_qkv_weight_or_bias(
|
||||
act_range_qkv['w'], model, is_bias=True)
|
||||
act_range_qkv['y'] = reorder_torch_qkv_weight_or_bias(
|
||||
act_range_qkv['y'], model, is_bias=True)
|
||||
scales[layer_name] = act_range_qkv
|
||||
|
||||
# qkv_proj
|
||||
smoother = smooth_gemm(param, scales[layer_name]["x"],
|
||||
module.input_layernorm.weight,
|
||||
module.input_layernorm.bias, alpha)
|
||||
scales[layer_name]["x"] = scales[layer_name]["x"] / smoother
|
||||
scales[layer_name]["w"] = param.abs().max(dim=1)[0]
|
||||
bloom_qkv_param[layer_name] = param
|
||||
|
||||
# dense
|
||||
# enabled for better accuracy with perf overhead of quantiztion
|
||||
layer_name = name + ".self_attention.dense"
|
||||
smoother = smooth_gemm(module.self_attention.dense.weight,
|
||||
scales[layer_name]["x"], None, None, alpha)
|
||||
bloom_smoother[layer_name] = smoother
|
||||
|
||||
scales[layer_name]["x"] = scales[layer_name]["x"] / smoother
|
||||
scales[layer_name]["w"] = module.self_attention.dense.weight.abs().max(
|
||||
dim=1)[0]
|
||||
|
||||
# fc1
|
||||
layer_name = name + ".mlp.dense_h_to_4h"
|
||||
smoother = smooth_gemm(module.mlp.dense_h_to_4h.weight,
|
||||
scales[layer_name]["x"],
|
||||
module.post_attention_layernorm.weight,
|
||||
module.post_attention_layernorm.bias, alpha)
|
||||
scales[layer_name]["x"] = scales[layer_name]["x"] / smoother
|
||||
scales[layer_name]["w"] = module.mlp.dense_h_to_4h.weight.abs().max(
|
||||
dim=1)[0]
|
||||
|
||||
# fc2
|
||||
# enabled for better accuracy with perf overhead of quantiztion
|
||||
layer_name = name + ".mlp.dense_4h_to_h"
|
||||
smoother = smooth_gemm(module.mlp.dense_4h_to_h.weight,
|
||||
scales[layer_name]["x"], None, None, alpha)
|
||||
bloom_smoother[layer_name] = smoother
|
||||
scales[layer_name]["x"] = scales[layer_name]["x"] / smoother
|
||||
scales[layer_name]["w"] = module.mlp.dense_4h_to_h.weight.abs().max(
|
||||
dim=1)[0]
|
||||
|
||||
|
||||
# Bloom uses nn.Linear for these following ops whose weight matrix is transposed compared to transformer.Conv1D
|
||||
def transpose_weights(hf_name, param):
|
||||
weight_to_transpose = [
|
||||
"self_attention.query_key_value", "self_attention.dense",
|
||||
"mlp.dense_h_to_4h", "mlp.dense_4h_to_h"
|
||||
]
|
||||
if any([k in hf_name for k in weight_to_transpose]):
|
||||
if len(param.shape) == 2:
|
||||
param = param.transpose(0, 1)
|
||||
return param
|
||||
|
||||
|
||||
def bloom_to_trt_llm_name(orig_name):
|
||||
global_weights = {
|
||||
"transformer.word_embeddings.weight": "model.wpe",
|
||||
"transformer.word_embeddings_layernorm.bias":
|
||||
"model.word_embeddings_layernorm.bias",
|
||||
"transformer.word_embeddings_layernorm.weight":
|
||||
"model.word_embeddings_layernorm.weight",
|
||||
"transformer.ln_f.bias": "model.final_layernorm.bias",
|
||||
"transformer.ln_f.weight": "model.final_layernorm.weight",
|
||||
"lm_head.weight": "model.lm_head.weight"
|
||||
}
|
||||
|
||||
if orig_name in global_weights:
|
||||
return global_weights[orig_name]
|
||||
|
||||
_, _, layer_id, *weight_name = orig_name.split(".")
|
||||
layer_id = int(layer_id)
|
||||
weight_name = "transformer." + ".".join(weight_name)
|
||||
|
||||
per_layer_weights = {
|
||||
"transformer.input_layernorm.bias": "input_layernorm.bias",
|
||||
"transformer.input_layernorm.weight": "input_layernorm.weight",
|
||||
"transformer.self_attention.query_key_value.bias":
|
||||
"attention.query_key_value.bias",
|
||||
"transformer.self_attention.query_key_value.weight":
|
||||
"attention.query_key_value.weight",
|
||||
"transformer.self_attention.dense.bias": "attention.dense.bias",
|
||||
"transformer.self_attention.dense.weight": "attention.dense.weight",
|
||||
"transformer.post_attention_layernorm.bias":
|
||||
"post_attention_layernorm.bias",
|
||||
"transformer.post_attention_layernorm.weight":
|
||||
"post_attention_layernorm.weight",
|
||||
"transformer.mlp.dense_h_to_4h.bias": "mlp.dense_h_to_4h.bias",
|
||||
"transformer.mlp.dense_h_to_4h.weight": "mlp.dense_h_to_4h.weight",
|
||||
"transformer.mlp.dense_4h_to_h.bias": "mlp.dense_4h_to_h.bias",
|
||||
"transformer.mlp.dense_4h_to_h.weight": "mlp.dense_4h_to_h.weight",
|
||||
}
|
||||
return f"layers.{layer_id}.{per_layer_weights[weight_name]}"
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def hf_bloom_converter(args: ProgArgs):
|
||||
infer_tp = args.tensor_parallelism
|
||||
multi_query_mode = True if args.model in ["santacoder", "starcoder"
|
||||
] else False
|
||||
saved_dir = Path(args.out_dir) / f"{infer_tp}-XPU"
|
||||
saved_dir.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# load position_embedding from rank 0
|
||||
model = BloomForCausalLM.from_pretrained(args.in_file,
|
||||
torch_dtype="auto",
|
||||
device_map="auto",
|
||||
trust_remote_code=True)
|
||||
if args.load_model_on_cpu:
|
||||
model = model.float()
|
||||
model = model.cpu()
|
||||
torch.cuda.empty_cache()
|
||||
act_range = {}
|
||||
bloom_qkv_param = {}
|
||||
# smoother for inputs of self_attention.dense and mlp.dense_4h_to_h
|
||||
bloom_smoother = {}
|
||||
|
||||
if args.smoothquant is not None or args.calibrate_kv_cache:
|
||||
os.environ["TOKENIZERS_PARALLELISM"] = os.environ.get(
|
||||
"TOKENIZERS_PARALLELISM", "false")
|
||||
from datasets import load_dataset
|
||||
dataset = load_dataset("lambada",
|
||||
split="validation",
|
||||
cache_dir=args.dataset_cache_dir)
|
||||
act_range = capture_activation_range(
|
||||
model, BloomTokenizerFast.from_pretrained(args.in_file), dataset)
|
||||
if args.smoothquant is not None:
|
||||
smooth_bloom_model(model, act_range, args.smoothquant,
|
||||
bloom_qkv_param, bloom_smoother)
|
||||
|
||||
config = configparser.ConfigParser()
|
||||
config["bloom"] = {}
|
||||
for key in vars(args):
|
||||
config["bloom"][key] = f"{vars(args)[key]}"
|
||||
for k, v in vars(model.config).items():
|
||||
config["bloom"][k] = f"{v}"
|
||||
config["bloom"]["storage_dtype"] = args.storage_type
|
||||
config["bloom"]["multi_query_mode"] = str(multi_query_mode)
|
||||
with open(saved_dir / "config.ini", 'w') as configfile:
|
||||
config.write(configfile)
|
||||
|
||||
storage_type = str_dtype_to_torch(args.storage_type)
|
||||
|
||||
global_trt_llm_weights = [
|
||||
"model.wpe", "model.word_embeddings_layernorm.bias",
|
||||
"model.word_embeddings_layernorm.weight", "model.final_layernorm.bias",
|
||||
"model.final_layernorm.weight", "model.lm_head.weight"
|
||||
]
|
||||
|
||||
int8_outputs = None
|
||||
if args.calibrate_kv_cache:
|
||||
int8_outputs = "kv_cache_only"
|
||||
if args.smoothquant is not None:
|
||||
int8_outputs = "all"
|
||||
|
||||
starmap_args = []
|
||||
for name, param in model.named_parameters():
|
||||
if "weight" not in name and "bias" not in name:
|
||||
continue
|
||||
trt_llm_name = bloom_to_trt_llm_name(name)
|
||||
|
||||
if args.convert_model_on_cpu:
|
||||
param = param.cpu()
|
||||
if name.replace(".weight", "") in bloom_smoother.keys():
|
||||
smoother = bloom_smoother[name.replace(".weight", "")]
|
||||
starmap_args.append(
|
||||
(0, saved_dir, infer_tp,
|
||||
f"{trt_llm_name}.smoother".replace(".weight", ""),
|
||||
smoother.to(torch.float32), torch.float32, None, {
|
||||
"int8_outputs": int8_outputs,
|
||||
"multi_query_mode": multi_query_mode,
|
||||
"local_dim": None,
|
||||
}))
|
||||
|
||||
# reorder qkv weight and bias
|
||||
if "attention.query_key_value.weight" in trt_llm_name:
|
||||
if args.smoothquant is not None:
|
||||
param = bloom_qkv_param.get(name.replace(".weight", ""))
|
||||
else:
|
||||
param = reorder_torch_qkv_weight_or_bias(param,
|
||||
model,
|
||||
is_bias=False)
|
||||
if "attention.query_key_value.bias" in trt_llm_name:
|
||||
param = reorder_torch_qkv_weight_or_bias(param, model, is_bias=True)
|
||||
|
||||
param = transpose_weights(name, param)
|
||||
|
||||
if trt_llm_name in global_trt_llm_weights:
|
||||
torch_to_numpy(param.to(storage_type).cpu()).tofile(
|
||||
saved_dir / f"{trt_llm_name}.bin")
|
||||
else:
|
||||
# Needed by QKV projection weight split. With multi_query_mode one does not simply take
|
||||
# out_dim and divide it by 3 to get local_dim becuase out_dim = local_dim + 2 * head_size
|
||||
local_dim = model.transformer.h[
|
||||
0].attn.embed_dim if multi_query_mode else None
|
||||
starmap_args.append(
|
||||
(0, saved_dir, infer_tp, trt_llm_name, param.to(storage_type),
|
||||
storage_type, act_range.get(name.replace(".weight", "")), {
|
||||
"int8_outputs": int8_outputs,
|
||||
"multi_query_mode": multi_query_mode,
|
||||
"local_dim": local_dim
|
||||
}))
|
||||
|
||||
starmap_args = tqdm(starmap_args, desc="saving weights")
|
||||
if args.processes > 1:
|
||||
with multiprocessing.Pool(args.processes) as pool:
|
||||
pool.starmap(split_and_save_weight, starmap_args)
|
||||
else:
|
||||
# simpler for debug situations
|
||||
for starmap_arg in starmap_args:
|
||||
split_and_save_weight(*starmap_arg)
|
||||
|
||||
|
||||
def run_conversion(args: ProgArgs):
|
||||
print("\n=============== Arguments ===============")
|
||||
for key, value in vars(args).items():
|
||||
print(f"{key}: {value}")
|
||||
print("========================================")
|
||||
hf_bloom_converter(args)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
torch.multiprocessing.set_start_method("spawn")
|
||||
run_conversion(ProgArgs.parse())
|
||||
3
examples/bloom/requirements.txt
Normal file
3
examples/bloom/requirements.txt
Normal file
@@ -0,0 +1,3 @@
|
||||
datasets~=2.3.2
|
||||
rouge_score~=0.1.2
|
||||
sentencepiece~=0.1.99
|
||||
130
examples/bloom/run.py
Normal file
130
examples/bloom/run.py
Normal file
@@ -0,0 +1,130 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
|
||||
import torch
|
||||
from transformers import BloomTokenizerFast
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm.runtime import ModelConfig, SamplingConfig
|
||||
import numpy as np
|
||||
|
||||
from build import get_engine_name # isort:skip
|
||||
|
||||
EOS_TOKEN = 2
|
||||
PAD_TOKEN = 3
|
||||
|
||||
|
||||
def parse_arguments():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--max_output_len', type=int, required=True)
|
||||
parser.add_argument('--log_level', type=str, default='error')
|
||||
parser.add_argument('--engine_dir', type=str, default='bloom_outputs')
|
||||
parser.add_argument('--tokenizer_dir',
|
||||
type=str,
|
||||
default=".",
|
||||
help="Directory containing the tokenizer.model.")
|
||||
parser.add_argument('--input_text',
|
||||
type=str,
|
||||
default='Born in north-east France, Soyer trained as a')
|
||||
parser.add_argument(
|
||||
'--performance_test_scale',
|
||||
type=str,
|
||||
help=
|
||||
"Scale for performance test. e.g., 8x1024x64 (batch_size, input_text_length, max_output_length)",
|
||||
default="")
|
||||
return parser.parse_args()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = parse_arguments()
|
||||
xtrt_llm.logger.set_level(args.log_level)
|
||||
|
||||
config_path = os.path.join(args.engine_dir, 'config.json')
|
||||
with open(config_path, 'r') as f:
|
||||
config = json.load(f)
|
||||
use_gpt_attention_plugin = config['plugin_config']['gpt_attention_plugin']
|
||||
dtype = config['builder_config']['precision']
|
||||
world_size = config['builder_config']['tensor_parallel']
|
||||
assert world_size == xtrt_llm.mpi_world_size(), \
|
||||
f'Engine world size ({world_size}) != Runtime world size ({xtrt_llm.mpi_world_size()})'
|
||||
num_heads = config['builder_config']['num_heads'] // world_size
|
||||
hidden_size = config['builder_config']['hidden_size'] // world_size
|
||||
vocab_size = config['builder_config']['vocab_size']
|
||||
num_layers = config['builder_config']['num_layers']
|
||||
|
||||
runtime_rank = xtrt_llm.mpi_rank()
|
||||
if world_size > 1:
|
||||
os.environ["XCCL_GROUP_ID"] = str(runtime_rank // world_size)
|
||||
os.environ["XCCL_NRANKS"] = str(world_size)
|
||||
os.environ["XCCL_CUR_RANK"] = str(runtime_rank % world_size)
|
||||
os.environ["XCCL_DEVICE_ID"] = str(runtime_rank)
|
||||
os.environ["MP_RUN"] = str(1)
|
||||
runtime_mapping = xtrt_llm.Mapping(world_size,
|
||||
runtime_rank,
|
||||
tp_size=world_size)
|
||||
torch.cuda.set_device(runtime_rank % runtime_mapping.gpus_per_node)
|
||||
|
||||
engine_name = get_engine_name('bloom', dtype, world_size, runtime_rank)
|
||||
serialize_path = os.path.join(args.engine_dir, engine_name)
|
||||
|
||||
tokenizer = BloomTokenizerFast.from_pretrained(args.tokenizer_dir)
|
||||
input_ids = torch.tensor(tokenizer.encode(args.input_text),
|
||||
dtype=torch.int32).cuda().unsqueeze(0)
|
||||
|
||||
model_config = ModelConfig(num_heads=num_heads,
|
||||
num_kv_heads=num_heads,
|
||||
hidden_size=hidden_size,
|
||||
vocab_size=vocab_size,
|
||||
num_layers=num_layers,
|
||||
gpt_attention_plugin=use_gpt_attention_plugin,
|
||||
dtype=dtype)
|
||||
sampling_config = SamplingConfig(end_id=EOS_TOKEN, pad_id=PAD_TOKEN)
|
||||
input_lengths = torch.tensor(
|
||||
[input_ids.size(1) for _ in range(input_ids.size(0))]).int().cuda()
|
||||
|
||||
# with open(serialize_path, 'rb') as f:
|
||||
# engine_buffer = f.read()
|
||||
decoder = xtrt_llm.runtime.GenerationSession(model_config,
|
||||
serialize_path,
|
||||
runtime_mapping)
|
||||
if args.performance_test_scale != "":
|
||||
performance_test_scale_list = args.performance_test_scale.split("E")
|
||||
for scale in performance_test_scale_list:
|
||||
xtrt_llm.logger.info(f"Running performance test with scale {scale}")
|
||||
bs, seqlen, _max_output_len = [int(x) for x in scale.split("x")]
|
||||
_input_ids = torch.from_numpy(
|
||||
np.zeros((bs, seqlen)).astype("int32")).cuda()
|
||||
_input_lengths = torch.from_numpy(
|
||||
np.full((bs, ), seqlen).astype("int32")).cuda()
|
||||
_max_input_length = torch.max(_input_lengths).item()
|
||||
decoder.setup(_input_lengths.size(0), _max_input_length,
|
||||
_max_output_len)
|
||||
_output_gen_ids = decoder.decode(_input_ids,
|
||||
_input_lengths,
|
||||
sampling_config)
|
||||
decoder.setup(input_ids.size(0),
|
||||
max_context_length=input_ids.size(1),
|
||||
max_new_tokens=args.max_output_len)
|
||||
output_ids = decoder.decode(input_ids, input_lengths, sampling_config)
|
||||
torch.cuda.synchronize()
|
||||
|
||||
output_ids = output_ids.tolist()[0][0][input_ids.size(1):]
|
||||
output_text = tokenizer.decode(output_ids)
|
||||
print(f'Input: \"{args.input_text}\"')
|
||||
print(f'Output Ids: \"{output_ids}\"')
|
||||
print(f'Output: \"{output_text}\"')
|
||||
141
examples/bloom/smoothquant.py
Normal file
141
examples/bloom/smoothquant.py
Normal file
@@ -0,0 +1,141 @@
|
||||
'''
|
||||
Utilities for SmoothQuant models
|
||||
'''
|
||||
|
||||
import functools
|
||||
from collections import defaultdict
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from tqdm import tqdm
|
||||
from transformers.pytorch_utils import Conv1D
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def apply_smoothing(scales,
|
||||
gemm_weights,
|
||||
layernorm_weights=None,
|
||||
layernorm_bias=None,
|
||||
dtype=torch.float32,
|
||||
layernorm_1p=False):
|
||||
if not isinstance(gemm_weights, list):
|
||||
gemm_weights = [gemm_weights]
|
||||
|
||||
if layernorm_weights is not None:
|
||||
assert layernorm_weights.numel() == scales.numel()
|
||||
layernorm_weights.div_(scales).to(dtype)
|
||||
if layernorm_bias is not None:
|
||||
assert layernorm_bias.numel() == scales.numel()
|
||||
layernorm_bias.div_(scales).to(dtype)
|
||||
if layernorm_1p:
|
||||
layernorm_weights += (1 / scales) - 1
|
||||
|
||||
for gemm in gemm_weights:
|
||||
gemm.mul_(scales.view(1, -1)).to(dtype)
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def smooth_gemm(gemm_weights,
|
||||
act_scales,
|
||||
layernorm_weights=None,
|
||||
layernorm_bias=None,
|
||||
alpha=0.5,
|
||||
weight_scales=None):
|
||||
if not isinstance(gemm_weights, list):
|
||||
gemm_weights = [gemm_weights]
|
||||
orig_dtype = gemm_weights[0].dtype
|
||||
|
||||
for gemm in gemm_weights:
|
||||
# gemm_weights are expected to be transposed
|
||||
assert gemm.shape[1] == act_scales.numel()
|
||||
|
||||
if weight_scales is None:
|
||||
weight_scales = torch.cat(
|
||||
[gemm.abs().max(dim=0, keepdim=True)[0] for gemm in gemm_weights],
|
||||
dim=0)
|
||||
weight_scales = weight_scales.max(dim=0)[0]
|
||||
weight_scales.to(float).clamp(min=1e-5)
|
||||
scales = (act_scales.to(gemm_weights[0].device).to(float).pow(alpha) /
|
||||
weight_scales.pow(1 - alpha)).clamp(min=1e-5)
|
||||
|
||||
apply_smoothing(scales, gemm_weights, layernorm_weights, layernorm_bias,
|
||||
orig_dtype)
|
||||
|
||||
return scales
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def smooth_ln_fcs(ln, fcs, act_scales, alpha=0.5):
|
||||
if not isinstance(fcs, list):
|
||||
fcs = [fcs]
|
||||
for fc in fcs:
|
||||
assert isinstance(fc, nn.Linear)
|
||||
assert ln.weight.numel() == fc.in_features == act_scales.numel()
|
||||
|
||||
device, dtype = fcs[0].weight.device, fcs[0].weight.dtype
|
||||
act_scales = act_scales.to(device=device, dtype=dtype)
|
||||
weight_scales = torch.cat(
|
||||
[fc.weight.abs().max(dim=0, keepdim=True)[0] for fc in fcs], dim=0)
|
||||
weight_scales = weight_scales.max(dim=0)[0].clamp(min=1e-5)
|
||||
|
||||
scales = (act_scales.pow(alpha) /
|
||||
weight_scales.pow(1 - alpha)).clamp(min=1e-5).to(device).to(dtype)
|
||||
|
||||
if ln is not None:
|
||||
ln.weight.div_(scales)
|
||||
ln.bias.div_(scales)
|
||||
|
||||
for fc in fcs:
|
||||
fc.weight.mul_(scales.view(1, -1))
|
||||
return scales
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def capture_activation_range(model,
|
||||
tokenizer,
|
||||
dataset,
|
||||
num_samples=512,
|
||||
seq_len=512):
|
||||
model.eval()
|
||||
device = next(model.parameters()).device
|
||||
act_scales = defaultdict(lambda: {"x": None, "y": None, "w": None})
|
||||
|
||||
def stat_tensor(name, tensor, act_scales, key):
|
||||
hidden_dim = tensor.shape[-1]
|
||||
tensor = tensor.view(-1, hidden_dim).abs().detach()
|
||||
comming_max = torch.max(tensor, dim=0)[0].float()
|
||||
|
||||
if act_scales[name][key] is None:
|
||||
act_scales[name][key] = comming_max
|
||||
else:
|
||||
act_scales[name][key] = torch.max(act_scales[name][key],
|
||||
comming_max)
|
||||
|
||||
def stat_input_hook(m, x, y, name):
|
||||
if isinstance(x, tuple):
|
||||
x = x[0]
|
||||
stat_tensor(name, x, act_scales, "x")
|
||||
stat_tensor(name, y, act_scales, "y")
|
||||
|
||||
if act_scales[name]["w"] is None:
|
||||
act_scales[name]["w"] = m.weight.abs().clip(1e-8,
|
||||
None).max(dim=1)[0]
|
||||
|
||||
hooks = []
|
||||
for name, m in model.named_modules():
|
||||
if isinstance(m, nn.Linear) or isinstance(m, Conv1D):
|
||||
hooks.append(
|
||||
m.register_forward_hook(
|
||||
functools.partial(stat_input_hook, name=name)))
|
||||
|
||||
for i in tqdm(range(num_samples), desc="calibrating model"):
|
||||
input_ids = tokenizer(dataset[i]["text"],
|
||||
return_tensors="pt",
|
||||
max_length=seq_len,
|
||||
truncation=True).input_ids.to(device)
|
||||
model(input_ids)
|
||||
|
||||
for h in hooks:
|
||||
h.remove()
|
||||
|
||||
return act_scales
|
||||
372
examples/bloom/summarize.py
Normal file
372
examples/bloom/summarize.py
Normal file
@@ -0,0 +1,372 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# TODO Just a copy paste, needs work
|
||||
|
||||
import argparse
|
||||
import copy
|
||||
import json
|
||||
import os
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from datasets import load_dataset, load_metric
|
||||
from transformers import AutoModelForCausalLM, BloomTokenizerFast
|
||||
|
||||
import xtrt_llm as tensorrt_llm
|
||||
import xtrt_llm.profiler as profiler
|
||||
from xtrt_llm.logger import logger
|
||||
|
||||
from build import get_engine_name # isort:skip
|
||||
|
||||
|
||||
def TRTBloom(args, config):
|
||||
dtype = config['builder_config']['precision']
|
||||
world_size = config['builder_config']['tensor_parallel']
|
||||
assert world_size == tensorrt_llm.mpi_world_size(), \
|
||||
f'Engine world size ({world_size}) != Runtime world size ({tensorrt_llm.mpi_world_size()})'
|
||||
|
||||
world_size = config['builder_config']['tensor_parallel']
|
||||
num_heads = config['builder_config']['num_heads'] // world_size
|
||||
hidden_size = config['builder_config']['hidden_size'] // world_size
|
||||
vocab_size = config['builder_config']['vocab_size']
|
||||
num_layers = config['builder_config']['num_layers']
|
||||
use_gpt_attention_plugin = bool(
|
||||
config['plugin_config']['gpt_attention_plugin'])
|
||||
|
||||
model_config = tensorrt_llm.runtime.ModelConfig(
|
||||
vocab_size=vocab_size,
|
||||
num_layers=num_layers,
|
||||
num_heads=num_heads,
|
||||
num_kv_heads=num_heads,
|
||||
hidden_size=hidden_size,
|
||||
gpt_attention_plugin=use_gpt_attention_plugin,
|
||||
dtype=dtype)
|
||||
|
||||
runtime_rank = tensorrt_llm.mpi_rank()
|
||||
runtime_mapping = tensorrt_llm.Mapping(world_size,
|
||||
runtime_rank,
|
||||
tp_size=world_size)
|
||||
torch.cuda.set_device(runtime_rank % runtime_mapping.gpus_per_node)
|
||||
|
||||
engine_name = get_engine_name('bloom', dtype, world_size, runtime_rank)
|
||||
serialize_path = os.path.join(args.engine_dir, engine_name)
|
||||
|
||||
tensorrt_llm.logger.set_level(args.log_level)
|
||||
|
||||
profiler.start('load tensorrt_llm engine')
|
||||
'''
|
||||
with open(serialize_path, 'rb') as f:
|
||||
engine_buffer = f.read()
|
||||
'''
|
||||
decoder = tensorrt_llm.runtime.GenerationSession(model_config,
|
||||
serialize_path,
|
||||
runtime_mapping)
|
||||
profiler.stop('load tensorrt_llm engine')
|
||||
tensorrt_llm.logger.info(
|
||||
f'Load engine takes: {profiler.elapsed_time_in_sec("load tensorrt_llm engine")} sec'
|
||||
)
|
||||
return decoder
|
||||
|
||||
|
||||
def main(args):
|
||||
runtime_rank = tensorrt_llm.mpi_rank()
|
||||
logger.set_level(args.log_level)
|
||||
|
||||
test_hf = args.test_hf and runtime_rank == 0 # only run hf on rank 0
|
||||
test_trt_llm = args.test_trt_llm
|
||||
hf_model_location = args.hf_model_location
|
||||
profiler.start('load tokenizer')
|
||||
tokenizer = BloomTokenizerFast.from_pretrained(hf_model_location,
|
||||
padding_side='left')
|
||||
profiler.stop('load tokenizer')
|
||||
tensorrt_llm.logger.info(
|
||||
f'Load tokenizer takes: {profiler.elapsed_time_in_sec("load tokenizer")} sec'
|
||||
)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
dataset_cnn = load_dataset("ccdv/cnn_dailymail",
|
||||
'3.0.0',
|
||||
cache_dir=args.dataset_path)
|
||||
|
||||
max_batch_size = args.batch_size
|
||||
|
||||
# runtime parameters
|
||||
# repetition_penalty = 1
|
||||
top_k = args.top_k
|
||||
output_len = 100
|
||||
test_token_num = 923
|
||||
# top_p = 0.0
|
||||
# random_seed = 5
|
||||
temperature = 1
|
||||
num_beams = args.num_beams
|
||||
|
||||
pad_id = tokenizer.encode(tokenizer.pad_token, add_special_tokens=False)[0]
|
||||
end_id = tokenizer.encode(tokenizer.eos_token, add_special_tokens=False)[0]
|
||||
|
||||
if test_trt_llm:
|
||||
config_path = os.path.join(args.engine_dir, 'config.json')
|
||||
with open(config_path, 'r') as f:
|
||||
config = json.load(f)
|
||||
|
||||
tensorrt_llm_bloom = TRTBloom(args, config)
|
||||
|
||||
if test_hf:
|
||||
profiler.start('load HF model')
|
||||
model = AutoModelForCausalLM.from_pretrained(hf_model_location)
|
||||
profiler.stop('load HF model')
|
||||
tensorrt_llm.logger.info(
|
||||
f'Load HF model takes: {profiler.elapsed_time_in_sec("load HF model")} sec'
|
||||
)
|
||||
if args.data_type == 'fp16':
|
||||
model.half()
|
||||
model.cuda()
|
||||
|
||||
def summarize_tensorrt_llm(datapoint):
|
||||
batch_size = len(datapoint['article'])
|
||||
|
||||
line = copy.copy(datapoint['article'])
|
||||
line_encoded = []
|
||||
input_lengths = []
|
||||
for i in range(batch_size):
|
||||
line[i] = line[i] + ' TL;DR: '
|
||||
|
||||
line[i] = line[i].strip()
|
||||
line[i] = line[i].replace(" n't", "n't")
|
||||
|
||||
input_id = tokenizer.encode(line[i],
|
||||
return_tensors='pt').type(torch.int32)
|
||||
input_id = input_id[:, -test_token_num:]
|
||||
|
||||
line_encoded.append(input_id)
|
||||
input_lengths.append(input_id.shape[-1])
|
||||
|
||||
# do padding, should move outside the profiling to prevent the overhead
|
||||
max_length = max(input_lengths)
|
||||
for i in range(batch_size):
|
||||
pad_size = max_length - input_lengths[i]
|
||||
|
||||
pad = torch.ones([1, pad_size]).type(torch.int32) * pad_id
|
||||
line_encoded[i] = torch.cat(
|
||||
[torch.tensor(line_encoded[i], dtype=torch.int32), pad],
|
||||
axis=-1)
|
||||
|
||||
line_encoded = torch.cat(line_encoded, axis=0).cuda()
|
||||
input_lengths = torch.tensor(input_lengths, dtype=torch.int32).cuda()
|
||||
|
||||
sampling_config = tensorrt_llm.runtime.SamplingConfig(
|
||||
end_id=end_id, pad_id=pad_id, top_k=top_k, num_beams=num_beams)
|
||||
|
||||
with torch.no_grad():
|
||||
tensorrt_llm_bloom.setup(line_encoded.size(0),
|
||||
max_context_length=line_encoded.size(1),
|
||||
max_new_tokens=output_len,
|
||||
beam_width=num_beams)
|
||||
|
||||
output_ids = tensorrt_llm_bloom.decode(
|
||||
line_encoded,
|
||||
input_lengths,
|
||||
sampling_config,
|
||||
)
|
||||
|
||||
torch.cuda.synchronize()
|
||||
|
||||
# Extract a list of tensors of shape beam_width x output_ids.
|
||||
if tensorrt_llm_bloom.mapping.is_first_pp_rank():
|
||||
output_beams_list = [
|
||||
tokenizer.batch_decode(output_ids[batch_idx, :,
|
||||
input_lengths[batch_idx]:],
|
||||
skip_special_tokens=True)
|
||||
for batch_idx in range(batch_size)
|
||||
]
|
||||
return output_beams_list, output_ids[:, :, max_length:].tolist()
|
||||
return [], []
|
||||
|
||||
def summarize_hf(datapoint):
|
||||
batch_size = len(datapoint['article'])
|
||||
if batch_size > 1:
|
||||
logger.warning(
|
||||
f"HF does not support batch_size > 1 to verify correctness due to padding. Current batch size is {batch_size}"
|
||||
)
|
||||
|
||||
line = copy.copy(datapoint['article'])
|
||||
for i in range(batch_size):
|
||||
line[i] = line[i] + ' TL;DR: '
|
||||
|
||||
line[i] = line[i].strip()
|
||||
line[i] = line[i].replace(" n't", "n't")
|
||||
|
||||
line_encoded = tokenizer(line,
|
||||
return_tensors='pt',
|
||||
padding=True,
|
||||
truncation=True)["input_ids"].type(torch.int64)
|
||||
|
||||
line_encoded = line_encoded[:, -test_token_num:]
|
||||
line_encoded = line_encoded.cuda()
|
||||
|
||||
with torch.no_grad():
|
||||
output = model.generate(line_encoded,
|
||||
max_length=len(line_encoded[0]) +
|
||||
output_len,
|
||||
top_k=top_k,
|
||||
temperature=temperature,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
num_beams=num_beams,
|
||||
num_return_sequences=num_beams,
|
||||
early_stopping=True)
|
||||
|
||||
tokens_list = output[:, len(line_encoded[0]):].tolist()
|
||||
output = output.reshape([batch_size, num_beams, -1])
|
||||
output_lines_list = [
|
||||
tokenizer.batch_decode(output[:, i, len(line_encoded[0]):],
|
||||
skip_special_tokens=True)
|
||||
for i in range(num_beams)
|
||||
]
|
||||
|
||||
return output_lines_list, tokens_list
|
||||
|
||||
if test_trt_llm:
|
||||
datapoint = dataset_cnn['test'][0:1]
|
||||
summary, _ = summarize_tensorrt_llm(datapoint)
|
||||
if runtime_rank == 0:
|
||||
logger.info(
|
||||
"---------------------------------------------------------")
|
||||
logger.info("XTRT-LLM Generated : ")
|
||||
logger.info(f" Article : {datapoint['article']}")
|
||||
logger.info(f"\n Highlights : {datapoint['highlights']}")
|
||||
logger.info(f"\n Summary : {summary}")
|
||||
logger.info(
|
||||
"---------------------------------------------------------")
|
||||
|
||||
if test_hf:
|
||||
datapoint = dataset_cnn['test'][0:1]
|
||||
summary, _ = summarize_hf(datapoint)
|
||||
logger.info("---------------------------------------------------------")
|
||||
logger.info("HF Generated : ")
|
||||
logger.info(f" Article : {datapoint['article']}")
|
||||
logger.info(f"\n Highlights : {datapoint['highlights']}")
|
||||
logger.info(f"\n Summary : {summary}")
|
||||
logger.info("---------------------------------------------------------")
|
||||
|
||||
metric_tensorrt_llm = [load_metric("rouge") for _ in range(num_beams)]
|
||||
metric_hf = [load_metric("rouge") for _ in range(num_beams)]
|
||||
for i in range(num_beams):
|
||||
metric_tensorrt_llm[i].seed = 0
|
||||
metric_hf[i].seed = 0
|
||||
|
||||
ite_count = 0
|
||||
data_point_idx = 0
|
||||
while (data_point_idx < len(dataset_cnn['test'])) and (ite_count <
|
||||
args.max_ite):
|
||||
if runtime_rank == 0:
|
||||
logger.debug(
|
||||
f"run data_point {data_point_idx} ~ {data_point_idx + max_batch_size}"
|
||||
)
|
||||
datapoint = dataset_cnn['test'][data_point_idx:(data_point_idx +
|
||||
max_batch_size)]
|
||||
|
||||
if test_trt_llm:
|
||||
profiler.start('tensorrt_llm')
|
||||
summary_tensorrt_llm, tokens_tensorrt_llm = summarize_tensorrt_llm(
|
||||
datapoint)
|
||||
profiler.stop('tensorrt_llm')
|
||||
|
||||
if test_hf:
|
||||
profiler.start('hf')
|
||||
summary_hf, tokens_hf = summarize_hf(datapoint)
|
||||
profiler.stop('hf')
|
||||
|
||||
if runtime_rank == 0:
|
||||
if test_trt_llm:
|
||||
for batch_idx in range(len(summary_tensorrt_llm)):
|
||||
for beam_idx in range(num_beams):
|
||||
metric_tensorrt_llm[beam_idx].add_batch(
|
||||
predictions=[
|
||||
summary_tensorrt_llm[batch_idx][beam_idx]
|
||||
],
|
||||
references=[datapoint['highlights'][batch_idx]])
|
||||
if test_hf:
|
||||
for beam_idx in range(num_beams):
|
||||
for batch_idx in range(len(summary_hf[beam_idx])):
|
||||
metric_hf[beam_idx].add_batch(
|
||||
predictions=[summary_hf[beam_idx][batch_idx]],
|
||||
references=[datapoint['highlights'][batch_idx]])
|
||||
|
||||
logger.debug('-' * 100)
|
||||
logger.debug(f"Article : {datapoint['article']}")
|
||||
if test_trt_llm:
|
||||
logger.debug(f'XTRT-LLM Summary: {summary_tensorrt_llm}')
|
||||
if test_hf:
|
||||
logger.debug(f'HF Summary: {summary_hf}')
|
||||
logger.debug(f"highlights : {datapoint['highlights']}")
|
||||
|
||||
data_point_idx += max_batch_size
|
||||
ite_count += 1
|
||||
|
||||
if runtime_rank == 0:
|
||||
if test_trt_llm:
|
||||
np.random.seed(0) # rouge score use sampling to compute the score
|
||||
logger.info(
|
||||
f'XTRT-LLM (total latency: {profiler.elapsed_time_in_sec("tensorrt_llm")} sec)'
|
||||
)
|
||||
for beam_idx in range(num_beams):
|
||||
logger.info(f"XTRT-LLM beam {beam_idx} result")
|
||||
computed_metrics_tensorrt_llm = metric_tensorrt_llm[
|
||||
beam_idx].compute()
|
||||
for key in computed_metrics_tensorrt_llm.keys():
|
||||
logger.info(
|
||||
f' {key} : {computed_metrics_tensorrt_llm[key].mid[2]*100}'
|
||||
)
|
||||
|
||||
if args.check_accuracy and beam_idx == 0:
|
||||
assert computed_metrics_tensorrt_llm['rouge1'].mid[
|
||||
2] * 100 > args.tensorrt_llm_rouge1_threshold
|
||||
if test_hf:
|
||||
np.random.seed(0) # rouge score use sampling to compute the score
|
||||
logger.info(
|
||||
f'Hugging Face (total latency: {profiler.elapsed_time_in_sec("hf")} sec)'
|
||||
)
|
||||
for beam_idx in range(num_beams):
|
||||
logger.info(f"HF beam {beam_idx} result")
|
||||
computed_metrics_hf = metric_hf[beam_idx].compute()
|
||||
for key in computed_metrics_hf.keys():
|
||||
logger.info(
|
||||
f' {key} : {computed_metrics_hf[key].mid[2]*100}')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--hf_model_location', type=str, default='./bloom/560M')
|
||||
parser.add_argument('--test_hf', action='store_true')
|
||||
parser.add_argument('--test_trt_llm', action='store_true')
|
||||
parser.add_argument('--data_type',
|
||||
type=str,
|
||||
choices=['fp32', 'fp16'],
|
||||
default='fp16')
|
||||
parser.add_argument('--dataset_path', type=str, default='')
|
||||
parser.add_argument('--log_level', type=str, default='info')
|
||||
parser.add_argument('--engine_dir', type=str, default='bloom_outputs')
|
||||
parser.add_argument('--batch_size', type=int, default=1)
|
||||
parser.add_argument('--max_ite', type=int, default=20)
|
||||
parser.add_argument('--check_accuracy', action='store_true')
|
||||
parser.add_argument('--tensorrt_llm_rouge1_threshold',
|
||||
type=float,
|
||||
default=15.0)
|
||||
parser.add_argument('--num_beams', type=int, default=1)
|
||||
parser.add_argument('--top_k', type=int, default=1)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
main(args)
|
||||
549
examples/bloom/weight.py
Normal file
549
examples/bloom/weight.py
Normal file
@@ -0,0 +1,549 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import configparser
|
||||
import time
|
||||
from pathlib import Path
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm._utils import str_dtype_to_np
|
||||
from xtrt_llm.models import BloomForCausalLM
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
|
||||
def split(v, tp_size, idx, dim=0):
|
||||
if tp_size == 1:
|
||||
return v
|
||||
if len(v.shape) == 1:
|
||||
return np.ascontiguousarray(np.split(v, tp_size)[idx])
|
||||
else:
|
||||
return np.ascontiguousarray(np.split(v, tp_size, axis=dim)[idx])
|
||||
|
||||
|
||||
def reorder_qkv_weight_or_bias(v, n_head, n_hidden, is_bias=False):
|
||||
""" Reorder the qkv weight.
|
||||
|
||||
Note that the shape of the fused QKV weights in HF is different from the
|
||||
shape that XTRT-LLM requires.
|
||||
HF: (num_heads x 3 x head_dim, hidden_size)
|
||||
XTRT-LLM: (3 x num_heads x head_dim, hidden_size)
|
||||
This is unlike to the other models in HF e.g. GPT where they have the
|
||||
same shape with XTRT-LLM, i.e., (3 x num_heads x head_dim, hidden_size). Also,
|
||||
to split across attention heads in tensor parallel, we reshape the qkv
|
||||
weight: (3, num_heads x head_dim, hidden).
|
||||
bias : (3, num_heads x head_dim).
|
||||
"""
|
||||
|
||||
head_dim = n_hidden // n_head
|
||||
|
||||
# (3 x hidden, ...) view as (num_heads, 3, head_dim, ...)
|
||||
v = v.reshape(n_head, 3, head_dim, -1)
|
||||
# permute to (3, num_heads, head_dim, ...)
|
||||
v = v.transpose((1, 0, 2, 3))
|
||||
# final shape: weight=(3, hidden, hidden) or bias=(3, hidden)
|
||||
if is_bias:
|
||||
return v.reshape(3, n_hidden)
|
||||
return v.reshape(3, n_hidden, n_hidden)
|
||||
|
||||
|
||||
def split_qkv_tp(xtrt_llm_bloom, v, tensor_parallel, rank):
|
||||
"""
|
||||
Splits the QKV matrix according to tensor parallelism
|
||||
"""
|
||||
n_heads = xtrt_llm_bloom._num_heads
|
||||
hidden_size = xtrt_llm_bloom._hidden_size
|
||||
v = reorder_qkv_weight_or_bias(v, n_heads, hidden_size, is_bias=False)
|
||||
split_v = split(v, tensor_parallel, rank, dim=1)
|
||||
split_v = split_v.reshape(3 * (hidden_size // tensor_parallel), hidden_size)
|
||||
|
||||
return np.ascontiguousarray(split_v)
|
||||
|
||||
|
||||
def split_qkv_bias_tp(xtrt_llm_bloom, v, tensor_parallel, rank):
|
||||
"""
|
||||
Splits the QKV bias according to tensor parallelism
|
||||
"""
|
||||
layer = xtrt_llm_bloom.layers[0]
|
||||
n_heads = layer.num_attention_heads
|
||||
hidden_size = layer.hidden_size
|
||||
v = reorder_qkv_weight_or_bias(v, n_heads, hidden_size, is_bias=True)
|
||||
split_v = split(v, tensor_parallel, rank, dim=1)
|
||||
split_v = split_v.reshape(3 * (hidden_size // tensor_parallel))
|
||||
return np.ascontiguousarray(split_v)
|
||||
|
||||
|
||||
def split_matrix_tp(v, tensor_parallel, rank, dim):
|
||||
return np.ascontiguousarray(split(v, tensor_parallel, rank, dim=dim))
|
||||
|
||||
|
||||
def get_weight(config, prefix, dtype):
|
||||
return config[prefix + '.weight'].to(dtype).detach().cpu().numpy()
|
||||
|
||||
|
||||
def get_bias(config, prefix, dtype):
|
||||
return config[prefix + '.bias'].to(dtype).detach().cpu().numpy()
|
||||
|
||||
|
||||
def get_weight_and_bias(config, prefix, dtype):
|
||||
return get_weight(config, prefix, dtype), get_bias(config, prefix, dtype)
|
||||
|
||||
|
||||
def set_layer_weight(layer, val, quant_mode):
|
||||
if quant_mode.is_int8_weight_only():
|
||||
plugin_weight_only_quant_type = torch.int8
|
||||
elif quant_mode.is_int4_weight_only():
|
||||
plugin_weight_only_quant_type = torch.quint4x2
|
||||
# use_weight_only = quant_mode.is_weight_only()
|
||||
use_weight_only = 0
|
||||
|
||||
if use_weight_only:
|
||||
v = np.ascontiguousarray(val.transpose())
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(v), plugin_weight_only_quant_type)
|
||||
# workaround for trt not supporting int8 inputs in plugins currently
|
||||
layer.weight.value = processed_torch_weights.view(
|
||||
dtype=torch.float32).numpy()
|
||||
layer.per_channel_scale.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
layer.weight.value = np.ascontiguousarray(val)
|
||||
|
||||
|
||||
def check_embedding_share(dir_path):
|
||||
share_embedding_table = False
|
||||
if Path(dir_path).exists():
|
||||
share_embedding_table = True
|
||||
return share_embedding_table
|
||||
|
||||
|
||||
def load_from_hf_bloom(xtrt_llm_bloom,
|
||||
hf_bloom,
|
||||
rank=0,
|
||||
tensor_parallel=1,
|
||||
fp16=False,
|
||||
use_parallel_embedding=False,
|
||||
sharding_dim=0,
|
||||
share_embedding_table=False):
|
||||
xtrt_llm.logger.info('Loading weights from HF BLOOM...')
|
||||
tik = time.time()
|
||||
|
||||
quant_mode = getattr(xtrt_llm_bloom, 'quant_mode', QuantMode(0))
|
||||
|
||||
model_params = dict(hf_bloom.named_parameters())
|
||||
dtype = torch.float16 if fp16 else torch.float32
|
||||
for l in range(hf_bloom.config.num_hidden_layers):
|
||||
prefix = f'transformer.h.{l}.'
|
||||
|
||||
qkv_weight, qkv_bias = get_weight_and_bias(
|
||||
model_params, prefix + 'self_attention.query_key_value', dtype)
|
||||
split_v = split_qkv_tp(xtrt_llm_bloom, qkv_weight, tensor_parallel,
|
||||
rank)
|
||||
set_layer_weight(xtrt_llm_bloom.layers[l].attention.qkv, split_v,
|
||||
quant_mode)
|
||||
xtrt_llm_bloom.layers[
|
||||
l].attention.qkv.bias.value = split_qkv_bias_tp(
|
||||
xtrt_llm_bloom, qkv_bias, tensor_parallel, rank)
|
||||
|
||||
attn_dense_weight, attn_dense_bias = get_weight_and_bias(
|
||||
model_params, prefix + 'self_attention.dense', dtype)
|
||||
split_v = split_matrix_tp(attn_dense_weight,
|
||||
tensor_parallel,
|
||||
rank,
|
||||
dim=1)
|
||||
set_layer_weight(xtrt_llm_bloom.layers[l].attention.dense, split_v,
|
||||
quant_mode)
|
||||
xtrt_llm_bloom.layers[
|
||||
l].attention.dense.bias.value = attn_dense_bias
|
||||
|
||||
mlp_fc_weight, mlp_fc_bias = get_weight_and_bias(
|
||||
model_params, prefix + 'mlp.dense_h_to_4h', dtype)
|
||||
split_v = split_matrix_tp(mlp_fc_weight, tensor_parallel, rank, dim=0)
|
||||
set_layer_weight(xtrt_llm_bloom.layers[l].mlp.fc, split_v,
|
||||
quant_mode)
|
||||
xtrt_llm_bloom.layers[l].mlp.fc.bias.value = split_matrix_tp(
|
||||
mlp_fc_bias, tensor_parallel, rank, dim=0)
|
||||
|
||||
mlp_proj_weight, mlp_proj_bias = get_weight_and_bias(
|
||||
model_params, prefix + 'mlp.dense_4h_to_h', dtype)
|
||||
split_v = split_matrix_tp(mlp_proj_weight, tensor_parallel, rank, dim=1)
|
||||
set_layer_weight(xtrt_llm_bloom.layers[l].mlp.proj, split_v,
|
||||
quant_mode)
|
||||
xtrt_llm_bloom.layers[l].mlp.proj.bias.value = mlp_proj_bias
|
||||
|
||||
# Layer norms do not use tensor parallelism
|
||||
input_ln_weight, input_ln_bias = get_weight_and_bias(
|
||||
model_params, prefix + 'input_layernorm', dtype)
|
||||
xtrt_llm_bloom.layers[
|
||||
l].input_layernorm.weight.value = input_ln_weight
|
||||
xtrt_llm_bloom.layers[l].input_layernorm.bias.value = input_ln_bias
|
||||
|
||||
post_ln_weight, post_ln_bias = get_weight_and_bias(
|
||||
model_params, prefix + 'post_attention_layernorm', dtype)
|
||||
xtrt_llm_bloom.layers[
|
||||
l].post_layernorm.weight.value = post_ln_weight
|
||||
xtrt_llm_bloom.layers[l].post_layernorm.bias.value = post_ln_bias
|
||||
|
||||
embed_w = get_weight(model_params, 'transformer.word_embeddings', dtype)
|
||||
if not share_embedding_table:
|
||||
xtrt_llm_bloom.lm_head.weight.value = split_matrix_tp(
|
||||
embed_w.copy(), tensor_parallel, rank, dim=0)
|
||||
|
||||
if not use_parallel_embedding:
|
||||
xtrt_llm_bloom.embedding.weight.value = embed_w
|
||||
else:
|
||||
assert hf_bloom.config.vocab_size % tensor_parallel == 0
|
||||
xtrt_llm_bloom.embedding.weight.value = split_matrix_tp(
|
||||
embed_w, tensor_parallel, rank, dim=sharding_dim)
|
||||
|
||||
embed_f_w, embed_f_b = get_weight_and_bias(
|
||||
model_params, 'transformer.word_embeddings_layernorm', dtype)
|
||||
xtrt_llm_bloom.ln_embed.weight.value = embed_f_w
|
||||
xtrt_llm_bloom.ln_embed.bias.value = embed_f_b
|
||||
|
||||
ln_f_w, ln_f_b = get_weight_and_bias(model_params, 'transformer.ln_f',
|
||||
dtype)
|
||||
xtrt_llm_bloom.ln_f.weight.value = ln_f_w
|
||||
xtrt_llm_bloom.ln_f.bias.value = ln_f_b
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
xtrt_llm.logger.info(f'Weights loaded. Total time: {t}')
|
||||
|
||||
|
||||
def gen_suffix(rank, use_smooth_quant, quant_per_channel):
|
||||
suffix = f"{rank}.bin"
|
||||
if use_smooth_quant:
|
||||
sq_prefix = "int8."
|
||||
if quant_per_channel:
|
||||
sq_prefix += "col."
|
||||
suffix = sq_prefix + suffix
|
||||
return suffix
|
||||
|
||||
|
||||
def extract_layer_idx(name):
|
||||
ss = name.split('.')
|
||||
for s in ss:
|
||||
if s.isdigit():
|
||||
return s
|
||||
return None
|
||||
|
||||
|
||||
def parse_config(ini_file):
|
||||
bloom_config = configparser.ConfigParser()
|
||||
bloom_config.read(ini_file)
|
||||
|
||||
n_embd = bloom_config.getint('bloom', 'hidden_size')
|
||||
n_head = bloom_config.getint('bloom', 'n_head')
|
||||
n_layer = bloom_config.getint('bloom', 'n_layer')
|
||||
vocab_size = bloom_config.getint('bloom', 'vocab_size')
|
||||
do_layer_norm_before = bloom_config.getboolean('bloom',
|
||||
'do_layer_norm_before',
|
||||
fallback=True)
|
||||
rotary_pct = bloom_config.getfloat('bloom', 'rotary_pct', fallback=0.0)
|
||||
bias = bloom_config.getboolean('bloom', 'bias', fallback=True)
|
||||
inter_size = bloom_config.getint('bloom',
|
||||
'intermediate_size',
|
||||
fallback=None)
|
||||
dtype = bloom_config.get('bloom', 'storage_dtype', fallback='float32')
|
||||
|
||||
if inter_size is None:
|
||||
inter_size = 4 * n_embd
|
||||
|
||||
multi_query_mode = bloom_config.getboolean('bloom',
|
||||
'multi_query_mode',
|
||||
fallback=False)
|
||||
prompt_num_tasks = bloom_config.getint('bloom',
|
||||
'prompt_num_tasks',
|
||||
fallback=0)
|
||||
prompt_max_vocab_size = bloom_config.getint('bloom',
|
||||
'prompt_max_vocab_size',
|
||||
fallback=0)
|
||||
return n_embd, n_head, n_layer, vocab_size, do_layer_norm_before, rotary_pct, bias, inter_size, multi_query_mode, dtype, prompt_num_tasks, prompt_max_vocab_size
|
||||
|
||||
|
||||
def load_from_bin(xtrt_llm_bloom: BloomForCausalLM,
|
||||
dir_path,
|
||||
rank=0,
|
||||
tensor_parallel=1,
|
||||
dtype='float32',
|
||||
use_parallel_embedding=False,
|
||||
sharding_dim=0,
|
||||
share_embedding_table=False):
|
||||
xtrt_llm.logger.info('Loading weights from bin...')
|
||||
tik = time.time()
|
||||
|
||||
quant_mode = getattr(xtrt_llm_bloom, 'quant_mode', QuantMode(0))
|
||||
if quant_mode.is_int8_weight_only():
|
||||
torch.int8
|
||||
elif quant_mode.is_int4_weight_only():
|
||||
torch.quint4x2
|
||||
n_embd, n_head, n_layer, vocab_size, do_layer_norm_before, rotary_pct, bias, inter_size, multi_query_mode, *_ = parse_config(
|
||||
Path(dir_path) / 'config.ini')
|
||||
np_dtype = str_dtype_to_np(dtype)
|
||||
|
||||
def fromfile(dir_path, name, shape=None, dtype=None):
|
||||
dtype = np_dtype if dtype is None else dtype
|
||||
p = dir_path + '/' + name
|
||||
if Path(p).exists():
|
||||
t = np.fromfile(p, dtype=dtype)
|
||||
if shape is not None:
|
||||
t = t.reshape(shape)
|
||||
return t
|
||||
return None
|
||||
|
||||
def set_smoothquant_scale_factors(module,
|
||||
pre_scale_weight,
|
||||
dir_path,
|
||||
basename,
|
||||
shape,
|
||||
per_tok_dyn,
|
||||
per_channel,
|
||||
is_qkv=False,
|
||||
rank=None):
|
||||
suffix = "bin"
|
||||
if per_channel:
|
||||
if rank is not None:
|
||||
suffix = f"{rank}." + suffix
|
||||
suffix = "col." + suffix
|
||||
|
||||
col_shape = shape if (per_channel or is_qkv) else [1, 1]
|
||||
if per_tok_dyn:
|
||||
if pre_scale_weight is not None:
|
||||
pre_scale_weight.value = np.array([1.0], dtype=np.float32)
|
||||
t = fromfile(dir_path, f"{basename}scale_w_quant_orig.{suffix}",
|
||||
col_shape, np.float32)
|
||||
module.per_channel_scale.value = t
|
||||
else:
|
||||
t = fromfile(dir_path, f"{basename}scale_x_orig_quant.bin", [1],
|
||||
np.float32)
|
||||
pre_scale_weight.value = t
|
||||
t = fromfile(dir_path, f"{basename}scale_y_accum_quant.{suffix}",
|
||||
col_shape, np.float32)
|
||||
module.per_channel_scale.value = t
|
||||
t = fromfile(dir_path, f"{basename}scale_y_quant_orig.bin", [1, 1],
|
||||
np.float32)
|
||||
module.act_scale.value = t
|
||||
|
||||
def set_smoother(module, dir_path, base_name, shape, rank):
|
||||
suffix = f"{rank}.bin"
|
||||
t = fromfile(dir_path, f"{base_name}.smoother.{suffix}", shape,
|
||||
np.float32)
|
||||
module.smoother.value = t
|
||||
|
||||
# Determine the quantization mode.
|
||||
quant_mode = getattr(xtrt_llm_bloom, "quant_mode", QuantMode(0))
|
||||
# Do we use SmoothQuant?
|
||||
use_smooth_quant = quant_mode.has_act_and_weight_quant()
|
||||
# Do we use quantization per token?
|
||||
quant_per_token_dyn = quant_mode.has_per_token_dynamic_scaling()
|
||||
# Do we use quantization per channel?
|
||||
quant_per_channel = quant_mode.has_per_channel_scaling()
|
||||
|
||||
# Do we use INT4/INT8 weight-only?
|
||||
quant_mode.is_weight_only()
|
||||
|
||||
# Int8 KV cache
|
||||
use_int8_kv_cache = quant_mode.has_int8_kv_cache()
|
||||
|
||||
'''
|
||||
def sq_trick(x):
|
||||
return x.view(np.float32) if use_smooth_quant else x
|
||||
'''
|
||||
|
||||
# Debug
|
||||
suffix = gen_suffix(rank, use_smooth_quant, quant_per_channel)
|
||||
# The type of weights.
|
||||
w_type = np_dtype if not use_smooth_quant else np.int8
|
||||
|
||||
vocab_embedding_weight = (fromfile(dir_path, 'model.wpe.bin',
|
||||
[vocab_size, n_embd]))
|
||||
embed_w = np.ascontiguousarray(
|
||||
split(vocab_embedding_weight.copy(), tensor_parallel, rank))
|
||||
if not share_embedding_table:
|
||||
xtrt_llm_bloom.lm_head.weight.value = embed_w
|
||||
|
||||
if not use_parallel_embedding:
|
||||
xtrt_llm_bloom.embedding.weight.value = np.ascontiguousarray(
|
||||
vocab_embedding_weight)
|
||||
else:
|
||||
assert vocab_size % tensor_parallel == 0
|
||||
xtrt_llm_bloom.embedding.weight.value = np.ascontiguousarray(
|
||||
split(vocab_embedding_weight,
|
||||
tensor_parallel,
|
||||
rank,
|
||||
dim=sharding_dim))
|
||||
|
||||
xtrt_llm_bloom.ln_embed.bias.value = (fromfile(
|
||||
dir_path, 'model.word_embeddings_layernorm.bias.bin'))
|
||||
xtrt_llm_bloom.ln_embed.weight.value = (fromfile(
|
||||
dir_path, 'model.word_embeddings_layernorm.weight.bin'))
|
||||
|
||||
xtrt_llm_bloom.ln_f.bias.value = (fromfile(
|
||||
dir_path, 'model.final_layernorm.bias.bin'))
|
||||
xtrt_llm_bloom.ln_f.weight.value = (fromfile(
|
||||
dir_path, 'model.final_layernorm.weight.bin'))
|
||||
|
||||
for i in range(n_layer):
|
||||
c_attn_out_dim = (3 * n_embd //
|
||||
tensor_parallel) if not multi_query_mode else (
|
||||
n_embd // tensor_parallel +
|
||||
(n_embd // n_head) * 2)
|
||||
xtrt_llm_bloom.layers[i].input_layernorm.weight.value = (fromfile(
|
||||
dir_path, 'model.layers.' + str(i) + '.input_layernorm.weight.bin'))
|
||||
xtrt_llm_bloom.layers[i].input_layernorm.bias.value = (fromfile(
|
||||
dir_path, 'model.layers.' + str(i) + '.input_layernorm.bias.bin'))
|
||||
|
||||
t = fromfile(
|
||||
dir_path, 'model.layers.' + str(i) +
|
||||
'.attention.query_key_value.weight.' + suffix,
|
||||
[n_embd, c_attn_out_dim], w_type)
|
||||
if t is not None:
|
||||
layer = xtrt_llm_bloom.layers[i].attention.qkv
|
||||
if use_smooth_quant:
|
||||
'''
|
||||
layer.weight.value = sq_trick(
|
||||
np.ascontiguousarray(np.transpose(t, [1, 0])))
|
||||
'''
|
||||
layer.weight.value = np.ascontiguousarray(np.transpose(t, [1, 0]))
|
||||
set_smoothquant_scale_factors(
|
||||
layer,
|
||||
xtrt_llm_bloom.layers[i].input_layernorm.scale_to_int,
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.attention.query_key_value.',
|
||||
[1, c_attn_out_dim],
|
||||
quant_per_token_dyn,
|
||||
quant_per_channel,
|
||||
rank=rank,
|
||||
is_qkv=True)
|
||||
else:
|
||||
set_layer_weight(layer, np.transpose(t, [1, 0]), quant_mode)
|
||||
if bias:
|
||||
t = fromfile(
|
||||
dir_path, 'model.layers.' + str(i) +
|
||||
'.attention.query_key_value.bias.' + str(rank) + '.bin')
|
||||
if t is not None:
|
||||
layer.bias.value = np.ascontiguousarray(t)
|
||||
|
||||
t = fromfile(
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.attention.dense.weight.' + suffix,
|
||||
[n_embd // tensor_parallel, n_embd], w_type)
|
||||
layer = xtrt_llm_bloom.layers[i].attention.dense
|
||||
if use_smooth_quant:
|
||||
'''
|
||||
layer.weight.value = sq_trick(
|
||||
np.ascontiguousarray(np.transpose(t, [1, 0])))
|
||||
'''
|
||||
layer.weight.value = np.ascontiguousarray(np.transpose(t, [1, 0]))
|
||||
dense_scale = getattr(xtrt_llm_bloom.layers[i].attention,
|
||||
"quantization_scaling_factor", None)
|
||||
set_smoothquant_scale_factors(
|
||||
layer, dense_scale, dir_path,
|
||||
'model.layers.' + str(i) + '.attention.dense.', [1, n_embd],
|
||||
quant_per_token_dyn, quant_per_channel)
|
||||
# set it to ones if dense layer is not applied smooth quant
|
||||
# layer.smoother.value = np.ones(
|
||||
# [1, n_embd // tensor_parallel], dtype=np.float32)
|
||||
# set it to the real smoother if dense layer is applied smooth quant
|
||||
set_smoother(layer, dir_path,
|
||||
'model.layers.' + str(i) + '.attention.dense',
|
||||
[1, n_embd // tensor_parallel], rank)
|
||||
else:
|
||||
set_layer_weight(layer, np.transpose(t, [1, 0]), quant_mode)
|
||||
if bias:
|
||||
layer.bias.value = fromfile(
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.attention.dense.bias.bin')
|
||||
|
||||
dst = xtrt_llm_bloom.layers[i].post_layernorm.weight
|
||||
dst.value = fromfile(
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.post_attention_layernorm.weight.bin')
|
||||
dst = xtrt_llm_bloom.layers[i].post_layernorm.bias
|
||||
dst.value = fromfile(
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.post_attention_layernorm.bias.bin')
|
||||
|
||||
t = fromfile(
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.mlp.dense_h_to_4h.weight.' + suffix,
|
||||
[n_embd, inter_size // tensor_parallel], w_type)
|
||||
layer = xtrt_llm_bloom.layers[i].mlp.fc
|
||||
if use_smooth_quant:
|
||||
'''
|
||||
layer.weight.value = sq_trick(
|
||||
np.ascontiguousarray(np.transpose(t, [1, 0])))
|
||||
'''
|
||||
layer.weight.value = np.ascontiguousarray(np.transpose(t, [1, 0]))
|
||||
set_smoothquant_scale_factors(
|
||||
layer,
|
||||
xtrt_llm_bloom.layers[i].post_layernorm.scale_to_int,
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.mlp.dense_h_to_4h.',
|
||||
[1, inter_size // tensor_parallel],
|
||||
quant_per_token_dyn,
|
||||
quant_per_channel,
|
||||
rank=rank)
|
||||
else:
|
||||
set_layer_weight(layer, np.transpose(t, [1, 0]), quant_mode)
|
||||
if bias:
|
||||
layer.bias.value = fromfile(
|
||||
dir_path, 'model.layers.' + str(i) +
|
||||
'.mlp.dense_h_to_4h.bias.' + str(rank) + '.bin')
|
||||
|
||||
t = fromfile(
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.mlp.dense_4h_to_h.weight.' + suffix,
|
||||
[inter_size // tensor_parallel, n_embd], w_type)
|
||||
layer = xtrt_llm_bloom.layers[i].mlp.proj
|
||||
if use_smooth_quant:
|
||||
'''
|
||||
layer.weight.value = sq_trick(
|
||||
np.ascontiguousarray(np.transpose(t, [1, 0])))
|
||||
'''
|
||||
layer.weight.value = np.ascontiguousarray(np.transpose(t, [1, 0]))
|
||||
proj_scale = getattr(xtrt_llm_bloom.layers[i].mlp,
|
||||
"quantization_scaling_factor", None)
|
||||
set_smoothquant_scale_factors(
|
||||
layer, proj_scale, dir_path,
|
||||
'model.layers.' + str(i) + '.mlp.dense_4h_to_h.', [1, n_embd],
|
||||
quant_per_token_dyn, quant_per_channel)
|
||||
# set it to ones if proj layer is not applied smooth quant
|
||||
# layer.smoother.value = np.ones(
|
||||
# [1, inter_size // tensor_parallel], dtype=np.float32)
|
||||
# set it to the real smoother if proj layer is applied smooth quant
|
||||
set_smoother(layer, dir_path,
|
||||
'model.layers.' + str(i) + '.mlp.dense_4h_to_h',
|
||||
[1, inter_size // tensor_parallel], rank)
|
||||
else:
|
||||
set_layer_weight(layer, np.transpose(t, [1, 0]), quant_mode)
|
||||
if bias:
|
||||
layer.bias.value = fromfile(
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.mlp.dense_4h_to_h.bias.bin')
|
||||
|
||||
if use_int8_kv_cache:
|
||||
t = fromfile(
|
||||
dir_path, 'model.layers.' + str(i) +
|
||||
'.attention.query_key_value.scale_y_quant_orig.bin', [1],
|
||||
np.float32)
|
||||
xtrt_llm_bloom.layers[
|
||||
i].attention.kv_orig_quant_scale.value = 1.0 / t
|
||||
xtrt_llm_bloom.layers[i].attention.kv_quant_orig_scale.value = t
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
xtrt_llm.logger.info(f'Weights loaded. Total time: {t}')
|
||||
8
examples/chatglm/.gitignore
vendored
Normal file
8
examples/chatglm/.gitignore
vendored
Normal file
@@ -0,0 +1,8 @@
|
||||
__pycache__/
|
||||
.vscode/
|
||||
awq/
|
||||
chatglm*_6b*/
|
||||
dataset/
|
||||
glm_10b/
|
||||
output_*/
|
||||
model.cache
|
||||
166
examples/chatglm/README.md
Normal file
166
examples/chatglm/README.md
Normal file
@@ -0,0 +1,166 @@
|
||||
# ChatGLM
|
||||
|
||||
This document explains how to build the [ChatGLM-6B](https://huggingface.co/THUDM/chatglm-6b), [ChatGLM2-6B](https://huggingface.co/THUDM/chatglm2-6b), [ChatGLM2-6B-32k](https://huggingface.co/THUDM/chatglm2-6b-32k), [ChatGLM3-6B](https://huggingface.co/THUDM/chatglm3-6b), [ChatGLM3-6B-Base](https://huggingface.co/THUDM/chatglm3-6b-base), [ChatGLM3-6B-32k](https://huggingface.co/THUDM/chatglm3-6b-32k) models using XTRT-LLM and run on a single XPU, a single node with multiple XPUs or multiple nodes with multiple XPUs.
|
||||
|
||||
## Overview
|
||||
|
||||
The XTRT-LLM ChatGLM implementation can be found in [`xtrt_llm/models/chatglm/model.py`](../../xtrt_llm/models/chatglm/model.py).
|
||||
The XTRT-LLM ChatGLM example code is located in [`examples/chatglm`](./). There are two main files:
|
||||
|
||||
* [`build.py`](./build.py) to build the [XTRT](https://console.cloud.baidu-int.com/devops/icode/repos/baidu/xpu/xmir/tree/master) engine(s) needed to run the ChatGLM model.
|
||||
* [`run.py`](./run.py) to run the inference on an input text.
|
||||
|
||||
## Support Matrix
|
||||
|
||||
| Model Name | FP16 | FMHA | WO | AWQ | SQ | TP | PP | ST | C++ Runtime | benchmark | IFB |
|
||||
| :--------------: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---------: | :-------: | :---: |
|
||||
| chatglm_6b | Y | Y | Y | | | Y | | | | | |
|
||||
| chatglm2_6b | Y | Y | Y | | | Y | | | | | |
|
||||
| chatglm2-6b_32k | Y | Y | Y | | | Y | | | | | |
|
||||
| chatglm3_6b | Y | Y | Y | | | Y | | | | | |
|
||||
| chatglm3_6b_base | Y | Y | Y | | | Y | | | | | |
|
||||
| chatglm3_6b_32k | Y | Y | Y | | | Y | | | | | |
|
||||
| glm_10b | Y | Y | Y | | | Y | | | | | |
|
||||
|
||||
* Model Name: the name of the model, the same as the name on HuggingFace
|
||||
* FMHA: Fused MultiHead Attention (see introduction below)
|
||||
* WO: Weight Only Quantization (int8 / int4)
|
||||
* AWQ: Activation Aware Weight Quantization
|
||||
* SQ: Smooth Quantization
|
||||
* ST: Strongly Typed
|
||||
* TP: Tensor Parallel
|
||||
* PP: Pipeline Parallel
|
||||
* IFB: In-flight Batching (see introduction below)
|
||||
|
||||
## Usage
|
||||
|
||||
The next section describe how to build the engine and run the inference demo.
|
||||
|
||||
### 1. Download repo and weights from HuggingFace Transformers
|
||||
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
apt-get update
|
||||
apt-get install git-lfs
|
||||
rm -rf chatglm*
|
||||
|
||||
# clone one or more models we want to build
|
||||
git clone https://huggingface.co/THUDM/chatglm-6b chatglm_6b
|
||||
git clone https://huggingface.co/THUDM/chatglm2-6b chatglm2_6b
|
||||
git clone https://huggingface.co/THUDM/chatglm2-6b-32k chatglm2_6b_32k
|
||||
git clone https://huggingface.co/THUDM/chatglm3-6b chatglm3_6b
|
||||
git clone https://huggingface.co/THUDM/chatglm3-6b-base chatglm3_6b_base
|
||||
git clone https://huggingface.co/THUDM/chatglm3-6b-32k chatglm3_6b_32k
|
||||
git clone https://huggingface.co/THUDM/glm-10b glm_10b
|
||||
```
|
||||
|
||||
### 2. Build XTRT engine(s)
|
||||
|
||||
* This ChatGLM example in XTRT-LLM builds XTRT engine(s) using HF checkpoint directly (rather than using FT checkpoints such as GPT example).
|
||||
* If no checkpoint directory is specified, XTRT-LLM will build engine(s) using dummy weights.
|
||||
* The [`build.py`](./build.py) script requires a single XPU to build the XTRT engine(s).
|
||||
* You can enable parallel builds to accelerate the engine building process if you have more than one XPU in your system (of the same model).
|
||||
* For parallel building, add the `--parallel_build` argument to the build command (this feature cannot take advantage of more than a single node).
|
||||
* The number of XTRT engines depends on the number of XPUs that will be used to run inference.
|
||||
* argument [--model_name/-m] is required, which can be one of "chatglm_6b", "chatglm2_6b", "chatglm2_6b_32k", "chatglm3_6b", "chatglm3_6b_base", "chatglm3_6b_32k" or "glm-10b" (use "_" rather than "-") for ChatGLM-6B, ChatGLM2-6B, ChatGLM2-6B-32K ChatGLM3-6B, ChatGLM3-6B-Base, ChatGLM3-6B-32K or GLM-10B model respectively.
|
||||
|
||||
#### Examples of build invocations
|
||||
|
||||
```bash
|
||||
# Build a default engine of ChatGLM3-6B on single XPU with FP16, GPT Attention plugin, Gemm plugin, RMS Normolization plugin
|
||||
python3 build.py -m chatglm3_6b
|
||||
|
||||
# Build a engine on single XPU with FMHA kernels (see introduction below), other configurations are the same as default example
|
||||
python3 build.py -m chatglm3_6b --enable_context_fmha # or --enable_context_fmha_fp32_acc
|
||||
|
||||
# Build a engine on single XPU with int8/int4 Weight-Only quantization, other configurations are the same as default example
|
||||
python3 build.py -m chatglm3_6b --use_weight_only # or --use_weight_only --weight_only_precision int4
|
||||
|
||||
# Build a engine on single XPU with int8_kv_cache and remove_input_padding, other configurations are the same as default example
|
||||
python3 build.py -m chatglm3_6b --paged_kv_cache --remove_input_padding
|
||||
|
||||
# Build a engine on two XPU, other configurations are the same as default example
|
||||
python3 build.py -m chatglm3_6b --world_size 2
|
||||
|
||||
# Build a engine of Chatglm-6B on single XPU, other configurations are the same as default example
|
||||
python3 build.py -m chatglm_6b
|
||||
|
||||
# Build a engine of Chatglm2-6B on single XPU, other configurations are the same as default example
|
||||
python3 build.py -m chatglm2_6b
|
||||
|
||||
# Build a engine of ChatGLM2-6B-32k on single XPU, other configurations are the same as default example
|
||||
python3 build.py -m chatglm2_6b-32k
|
||||
|
||||
# Build a engine of ChatGLM3-6B-Base on single XPU, other configurations are the same as default example
|
||||
python3 build.py -m chatglm3_6b_base
|
||||
|
||||
# Build a engine of ChatGLM3-6B-32k on single XPU, other configurations are the same as default example
|
||||
python3 build.py -m chatglm3_6b-32k
|
||||
|
||||
# Build a engine of GLM-10B on single XPU, other configurations are the same as default example
|
||||
python3 build.py -m glm_10b
|
||||
```
|
||||
|
||||
#### Enabled plugins
|
||||
|
||||
* Use `--use_gpt_attention_plugin <DataType>` to configure GPT Attention plugin (default as float16)
|
||||
* Use `--use_gemm_plugin <DataType>` to configure GEMM plugin (default as float16)
|
||||
* Use `--use_layernorm_plugin <DataType>` (for ChatGLM-6B and GLM-10B models) to configure layernorm normolization plugin (default as float16)
|
||||
* Use `--use_rmsnorm_plugin <DataType>` (for ChatGLM2-6B\* and ChatGLM3-6B\* models) to configure RMS normolization plugin (default as float16)
|
||||
|
||||
|
||||
#### Weight Only quantization
|
||||
|
||||
* Use `--use_weight_only` to enable INT8-Weight-Only quantization, this will siginficantly lower the latency and memory footprint.
|
||||
|
||||
* Furthermore, use `--weight_only_precision int8` or `--weight_only_precision int4` to configure the data type of the weights.
|
||||
|
||||
#### In-flight batching
|
||||
|
||||
* The engine must be built accordingly if [in-flight batching in C++ runtime](../../docs/in_flight_batching.md) will be used.
|
||||
|
||||
* Use `--use_inflight_batching` to enable In-flight Batching.
|
||||
|
||||
* Switch `--use_gpt_attention_plugin=float16`, `--paged_kv_cache`, `--remove_input_padding` will be set when using In-flight Batching.
|
||||
|
||||
* It is possible to use `--use_gpt_attention_plugin float32` In-flight Batching.
|
||||
|
||||
* The size of the block in paged KV cache can be conteoled additionally by using `--tokens_per_block=N`.
|
||||
|
||||
### 3. Run
|
||||
|
||||
#### Single node, single XPU
|
||||
|
||||
```bash
|
||||
# Run the default engine of ChatGLM3-6B on single XPU, other model name is available if built.
|
||||
python3 run.py -m chatglm3_6b
|
||||
# Run the default engine of ChatGLM3-6B on single XPU, using streaming output, other model name is available if built.
|
||||
# In this case only the first sample in the first batch is shown,
|
||||
# But actually all output of all batches are available.
|
||||
python3 run.py -m chatglm3_6b --streaming
|
||||
# Run the default engine of GLM3-10B on single XPU, other model name is available if built.
|
||||
# Token "[MASK]" or "[sMASK]" or "[gMASK]" must be included inside the prompt as the original model commanded.
|
||||
python3 run.py -m chatglm3_6b --input_text "Peking University is [MASK] than Tsinghua Univercity."
|
||||
```
|
||||
|
||||
#### Single node, multi XPU
|
||||
|
||||
```bash
|
||||
# Run the Tensor Parallel 2 engine of ChatGLM3-6B on two XPU, other model name is available if built.
|
||||
mpirun -n 2 python run.py -m chatglm3_6b
|
||||
```
|
||||
|
||||
* `--allow-run-as-root` might be needed if using `mpirun` as root.
|
||||
|
||||
#### Run comparison of performance and accuracy
|
||||
|
||||
```bash
|
||||
# Run the summarization of ChatGLM3-6B task, other model name is available if built.
|
||||
python3 ../summarize.py --test_trt_llm --tokenizer_dir chatglm3_6b --max_input_length 2048
|
||||
```
|
||||
|
||||
### 4. Note
|
||||
|
||||
* [`vllm_test/test_llm_engine.py`](../../vllm_test/test_llm_engine.py) should be run instead of run.py when `--paged_kv_cache` is set.
|
||||
* Accuray of multi-batch chatglm2/3 is not available in padding mode.
|
||||
* `--remove_input_padding` is not available in chatglm_6b.
|
||||
789
examples/chatglm/build.py
Normal file
789
examples/chatglm/build.py
Normal file
@@ -0,0 +1,789 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import json
|
||||
import time
|
||||
from pathlib import Path
|
||||
from typing import List
|
||||
|
||||
# isort: off
|
||||
import torch
|
||||
import torch.multiprocessing as mp
|
||||
import tvm.tensorrt as trt
|
||||
# isort: on
|
||||
from visualize import to_onnx
|
||||
from weight import get_scaling_factors, load_from_hf
|
||||
|
||||
import xtrt_llm as tensorrt_llm
|
||||
from xtrt_llm._utils import str_dtype_to_trt
|
||||
from xtrt_llm.builder import Builder
|
||||
from xtrt_llm.logger import logger
|
||||
from xtrt_llm.mapping import Mapping
|
||||
from xtrt_llm.models import ChatGLMHeadModel, quantize_model
|
||||
from xtrt_llm.network import net_guard
|
||||
from xtrt_llm.plugin.plugin import ContextFMHAType
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
|
||||
def get_engine_name(model, dtype, tp_size, pp_size, rank):
|
||||
if pp_size == 1:
|
||||
return '{}_{}_tp{}_rank{}.engine'.format(model, dtype, tp_size, rank)
|
||||
return '{}_{}_tp{}_pp{}_rank{}.engine'.format(model, dtype, tp_size,
|
||||
pp_size, rank)
|
||||
|
||||
|
||||
def find_engines(dir: Path,
|
||||
model_name: str = "*",
|
||||
dtype: str = "*",
|
||||
tp_size: str = "*",
|
||||
rank: str = "*") -> List[Path]:
|
||||
template = f"{model_name}_{dtype}_tp{tp_size}_rank{rank}.engine"
|
||||
return [f"{str(dir)}/{template}"]
|
||||
return list(dir.glob(template))
|
||||
|
||||
|
||||
def serialize_engine(engine, path):
|
||||
logger.info(f'Serializing engine to {path}...')
|
||||
tik = time.time()
|
||||
'''
|
||||
with open(path, 'wb') as f:
|
||||
f.write(bytearray(engine))
|
||||
'''
|
||||
engine.serialize(str(path))
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Engine serialized. Total time: {t}')
|
||||
|
||||
|
||||
def truncate_input_output_len(
|
||||
max_input_len,
|
||||
max_output_len,
|
||||
max_seq_length_from_config,
|
||||
is_fixed_max_position_length=False,
|
||||
):
|
||||
max_seq_length = max_seq_length_from_config
|
||||
if max_input_len >= max_seq_length_from_config:
|
||||
print("Truncate max_input_len as %d" % (max_seq_length_from_config - 1))
|
||||
max_input_len = max_seq_length_from_config - 1
|
||||
max_output_len = 1
|
||||
elif max_input_len + max_output_len > max_seq_length_from_config:
|
||||
print("Truncate max_output_len as %d" %
|
||||
(max_seq_length_from_config - max_input_len))
|
||||
max_output_len = max_seq_length_from_config - max_input_len
|
||||
elif not is_fixed_max_position_length:
|
||||
max_seq_length = max_input_len + max_output_len
|
||||
return max_input_len, max_output_len, max_seq_length
|
||||
|
||||
|
||||
def parse_arguments(args):
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
'--model_name',
|
||||
'-m',
|
||||
type=str,
|
||||
required=True,
|
||||
choices=[
|
||||
"chatglm_6b", "chatglm2_6b", "chatglm2_6b_32k", "chatglm3_6b",
|
||||
"chatglm3_6b_base", "chatglm3_6b_32k", "glm_10b"
|
||||
],
|
||||
help=
|
||||
'the name of the model, use "_" rather than "-" to connect the name parts'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--world_size',
|
||||
type=int,
|
||||
default=1,
|
||||
help='world size, only support tensor parallelism now',
|
||||
)
|
||||
parser.add_argument('--tp_size', type=int, default=1)
|
||||
parser.add_argument('--pp_size', type=int, default=1)
|
||||
parser.add_argument('--model_dir', type=Path, default=None)
|
||||
parser.add_argument('--quant_ckpt_path', type=str, default="awq/")
|
||||
parser.add_argument(
|
||||
'--dtype',
|
||||
type=str,
|
||||
default='float16',
|
||||
choices=['float32', 'float16', 'bfloat16'],
|
||||
)
|
||||
parser.add_argument(
|
||||
'--logits_dtype',
|
||||
type=str,
|
||||
default='float32',
|
||||
choices=['float16', 'float32'],
|
||||
)
|
||||
parser.add_argument(
|
||||
'--timing_cache',
|
||||
type=str,
|
||||
default='model.cache',
|
||||
help=
|
||||
'The path of to read timing cache from, will be ignored if the file does not exist'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--log_level',
|
||||
type=str,
|
||||
default='info',
|
||||
choices=['verbose', 'info', 'warning', 'error', 'internal_error'],
|
||||
)
|
||||
parser.add_argument('--max_batch_size', type=int, default=8)
|
||||
parser.add_argument('--max_input_len', type=int, default=1024)
|
||||
parser.add_argument('--max_output_len', type=int, default=1024)
|
||||
parser.add_argument('--max_beam_width', type=int, default=1)
|
||||
parser.add_argument(
|
||||
'--use_gpt_attention_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
default='float16',
|
||||
choices=['float32', 'float16', 'bfloat16', False],
|
||||
help=
|
||||
"Activates attention plugin. You can specify the plugin dtype or leave blank to use the model dtype."
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_gemm_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default='float16',
|
||||
choices=['float32', 'float16', 'bfloat16', False],
|
||||
help=
|
||||
"Activates GEMM plugin. You can specify the plugin dtype or leave blank to use the model dtype."
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_layernorm_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default='float16',
|
||||
choices=['float32', 'float16', 'bfloat16', False],
|
||||
help=
|
||||
"Activates layernorm plugin for ChatGLM-6B / GLM-10B models. You can specify the plugin dtype or leave blank to use the model dtype."
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_rmsnorm_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default='float16',
|
||||
choices=['float32', 'float16', 'bfloat16', False],
|
||||
help=
|
||||
"Activates rmsnorm plugin for ChatGLM2-6B* / ChatGLM3-6B* models. You can specify the plugin dtype or leave blank to use the model dtype."
|
||||
)
|
||||
parser.add_argument('--gather_all_token_logits',
|
||||
action='store_true',
|
||||
default=False)
|
||||
parser.add_argument('--parallel_build', default=False, action='store_true')
|
||||
parser.add_argument(
|
||||
'--enable_context_fmha',
|
||||
default=False,
|
||||
action='store_true',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--enable_context_fmha_fp32_acc',
|
||||
default=False,
|
||||
action='store_true',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--multi_block_mode',
|
||||
default=False,
|
||||
action='store_true',
|
||||
help=
|
||||
'Split long kv sequence into multiple blocks (applied to generation MHA kernels). \
|
||||
It is beneifical when batchxnum_heads cannot fully utilize XPU.'
|
||||
)
|
||||
parser.add_argument('--visualize', default=False, action='store_true')
|
||||
parser.add_argument(
|
||||
'--enable_debug_output',
|
||||
default=False,
|
||||
action='store_true',
|
||||
)
|
||||
parser.add_argument('--gpus_per_node', type=int, default=8)
|
||||
parser.add_argument('--builder_opt', type=int, default=None)
|
||||
parser.add_argument(
|
||||
'--output_dir',
|
||||
type=Path,
|
||||
default=None,
|
||||
help=
|
||||
'The path to save the serialized engine files, timing cache file and model configs'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--strongly_typed',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'This option is introduced with trt 9.1.0.1+ and will reduce the building time significantly for fp8.'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--remove_input_padding',
|
||||
default=False,
|
||||
action='store_true',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--paged_kv_cache',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help=
|
||||
'By default we use contiguous KV cache. By setting this flag you enable paged KV cache'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_inflight_batching',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Activates inflight batching mode of gptAttentionPlugin.",
|
||||
)
|
||||
|
||||
# Arguments related to the quantization of the model.
|
||||
parser.add_argument(
|
||||
'--use_smooth_quant',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'Use the SmoothQuant method to quantize activations and weights for the various GEMMs.'
|
||||
'See --per_channel and --per_token for finer-grained quantization options.'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_weight_only',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help='Quantize weights for the various GEMMs to INT4/INT8.'
|
||||
'See --weight_only_precision to set the precision',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--weight_only_precision',
|
||||
const='int8',
|
||||
type=str,
|
||||
nargs='?',
|
||||
default='int8',
|
||||
choices=['int8', 'int4', 'int4_awq'],
|
||||
help=
|
||||
'Define the precision for the weights when using weight-only quantization.'
|
||||
'You must also use --use_weight_only for that argument to have an impact.',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--per_channel',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use a single static scaling factor for the GEMM\'s result. '
|
||||
'per_channel instead uses a different static scaling factor for each channel. '
|
||||
'The latter is usually more accurate, but a little slower.',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--per_token',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use a single static scaling factor to scale activations in the int8 range. '
|
||||
'per_token chooses at run time, and for each token, a custom scaling factor. '
|
||||
'The latter is usually more accurate, but a little slower.',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--per_group',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use a single static scaling factor to scale weights in the int4 range. '
|
||||
'per_group chooses at run time, and for each group, a custom scaling factor. '
|
||||
'The flag is built for GPTQ/AWQ quantization.',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--group_size',
|
||||
type=int,
|
||||
default=128,
|
||||
help='Group size used in GPTQ/AWQ quantization.',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--int8_kv_cache',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use dtype for KV cache. int8_kv_cache chooses int8 quantization for KV'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--random_seed',
|
||||
type=int,
|
||||
default=None,
|
||||
help=
|
||||
'Seed to use when initializing the random number generator for torch.',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--tokens_per_block',
|
||||
type=int,
|
||||
default=64,
|
||||
help='Number of tokens per block in paged KV cache',
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
'--enable_fp8',
|
||||
default=False,
|
||||
action='store_true',
|
||||
help='Use FP8 Linear layer for Attention QKV/Dense and MLP.',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--fp8_kv_cache',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use dtype for KV cache. fp8_kv_cache chooses fp8 quantization for KV'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--max_num_tokens',
|
||||
type=int,
|
||||
default=None,
|
||||
help='Define the max number of tokens supported by the engine',
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_custom_all_reduce',
|
||||
action='store_true',
|
||||
help=
|
||||
'Activates latency-optimized algorithm for all-reduce instead of NCCL.',
|
||||
)
|
||||
args = parser.parse_args(args)
|
||||
|
||||
logger.set_level(args.log_level)
|
||||
|
||||
plugins_args = [
|
||||
'use_gpt_attention_plugin',
|
||||
'use_gemm_plugin',
|
||||
'use_layernorm_plugin',
|
||||
'use_rmsnorm_plugin',
|
||||
]
|
||||
for plugin_arg in plugins_args:
|
||||
if getattr(args, plugin_arg) is None:
|
||||
logger.info(
|
||||
f"{plugin_arg} set, without specifying a value. Using {args.dtype} automatically."
|
||||
)
|
||||
setattr(args, plugin_arg, args.dtype)
|
||||
|
||||
assert args.world_size == args.tp_size * args.pp_size # only TP is supported now
|
||||
|
||||
if args.model_dir is None:
|
||||
args.model_dir = Path(args.model_name)
|
||||
if args.output_dir is None:
|
||||
args.output_dir = Path("output_" + args.model_name)
|
||||
with open(args.model_dir / "config.json", "r") as f:
|
||||
js = json.loads(f.read())
|
||||
|
||||
if args.model_name in ["chatglm_6b", "glm_10b"]:
|
||||
assert args.max_input_len < js["max_sequence_length"]
|
||||
|
||||
if args.model_name in ["chatglm_6b"]:
|
||||
args.apply_query_key_layer_scaling = False
|
||||
args.apply_residual_connection_post_layernorm = False
|
||||
args.ffn_hidden_size = js["inner_hidden_size"]
|
||||
args.hidden_act = 'gelu'
|
||||
args.hidden_size = js["hidden_size"]
|
||||
args.linear_bias = True
|
||||
args.max_input_len, args.max_output_len, args.max_seq_length = truncate_input_output_len(
|
||||
args.max_input_len,
|
||||
args.max_output_len,
|
||||
js["max_sequence_length"],
|
||||
)
|
||||
args.multi_query_mode = False
|
||||
args.norm_epsilon = js["layernorm_epsilon"]
|
||||
args.num_heads = js["num_attention_heads"]
|
||||
args.num_kv_heads = js["num_attention_heads"]
|
||||
args.num_layers = js["num_layers"]
|
||||
args.qkv_bias = True
|
||||
args.rmsnorm = False
|
||||
args.rotary_embedding_scaling = 1.0
|
||||
args.use_cache = js["use_cache"]
|
||||
args.vocab_size = js["vocab_size"]
|
||||
elif args.model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
args.apply_query_key_layer_scaling = False
|
||||
args.apply_residual_connection_post_layernorm = js[
|
||||
"apply_residual_connection_post_layernorm"]
|
||||
args.ffn_hidden_size = js["ffn_hidden_size"]
|
||||
args.hidden_act = 'swiglu'
|
||||
args.hidden_size = js["hidden_size"]
|
||||
args.linear_bias = js["add_bias_linear"]
|
||||
args.max_input_len, args.max_output_len, args.max_seq_length = truncate_input_output_len(
|
||||
args.max_input_len,
|
||||
args.max_output_len,
|
||||
js["seq_length"],
|
||||
)
|
||||
args.multi_query_mode = js["multi_query_attention"]
|
||||
args.norm_epsilon = js["layernorm_epsilon"]
|
||||
args.num_heads = js["num_attention_heads"]
|
||||
args.num_kv_heads = js["multi_query_group_num"]
|
||||
args.num_layers = js["num_layers"]
|
||||
args.qkv_bias = js["add_qkv_bias"]
|
||||
args.rmsnorm = js["rmsnorm"]
|
||||
if args.model_name in ["chatglm2_6b_32k", "chatglm3_6b_32k"]:
|
||||
args.rotary_embedding_scaling = js["rope_ratio"]
|
||||
else:
|
||||
args.rotary_embedding_scaling = 1.0
|
||||
args.use_cache = js["use_cache"]
|
||||
args.vocab_size = js["padded_vocab_size"]
|
||||
elif args.model_name in ["glm_10b"]:
|
||||
args.apply_query_key_layer_scaling = False
|
||||
args.apply_residual_connection_post_layernorm = False
|
||||
args.ffn_hidden_size = 4 * js["hidden_size"]
|
||||
args.hidden_act = 'gelu'
|
||||
args.hidden_size = js["hidden_size"]
|
||||
args.linear_bias = True
|
||||
args.max_input_len, args.max_output_len, args.max_seq_length = truncate_input_output_len(
|
||||
args.max_input_len,
|
||||
args.max_output_len,
|
||||
js["max_sequence_length"],
|
||||
True,
|
||||
)
|
||||
args.multi_query_mode = False
|
||||
args.norm_epsilon = 1.0e-5
|
||||
args.num_heads = js["num_attention_heads"]
|
||||
args.num_kv_heads = js["num_attention_heads"]
|
||||
args.num_layers = js["num_layers"]
|
||||
args.qkv_bias = True
|
||||
args.rmsnorm = False
|
||||
args.rotary_embedding_scaling = 1.0
|
||||
args.use_cache = True
|
||||
args.vocab_size = js["vocab_size"]
|
||||
|
||||
if args.use_inflight_batching:
|
||||
if not args.use_gpt_attention_plugin:
|
||||
args.use_gpt_attention_plugin = 'float16'
|
||||
logger.info(
|
||||
f"Using GPT attention plugin for inflight batching mode. Setting to default '{args.use_gpt_attention_plugin}'"
|
||||
)
|
||||
if not args.remove_input_padding:
|
||||
args.remove_input_padding = True
|
||||
logger.info(
|
||||
"Using remove input padding for inflight batching mode.")
|
||||
if not args.paged_kv_cache:
|
||||
args.paged_kv_cache = True
|
||||
logger.info("Using paged KV cache for inflight batching mode.")
|
||||
|
||||
assert not (
|
||||
args.use_smooth_quant and args.use_weight_only
|
||||
), "You cannot enable both SmoothQuant and INT8 weight-only together."
|
||||
|
||||
if args.use_smooth_quant:
|
||||
args.quant_mode = QuantMode.use_smooth_quant(args.per_token,
|
||||
args.per_channel)
|
||||
elif args.use_weight_only:
|
||||
args.quant_mode = QuantMode.use_weight_only(
|
||||
args.weight_only_precision == 'int4')
|
||||
else:
|
||||
args.quant_mode = QuantMode(0)
|
||||
|
||||
if args.int8_kv_cache:
|
||||
args.quant_mode = args.quant_mode.set_int8_kv_cache()
|
||||
|
||||
elif args.fp8_kv_cache:
|
||||
args.quant_mode = args.quant_mode.set_fp8_kv_cache()
|
||||
if args.enable_fp8:
|
||||
args.quant_mode = args.quant_mode.set_fp8_qdq()
|
||||
|
||||
if args.max_num_tokens is not None:
|
||||
assert args.enable_context_fmha
|
||||
|
||||
logger.info(' Build Arguments '.center(100, '='))
|
||||
for k, v in vars(args).items():
|
||||
logger.info(f' - {k.ljust(30, ".")}: {v}')
|
||||
logger.info('=' * 100)
|
||||
|
||||
return args
|
||||
|
||||
|
||||
def build_rank_engine(
|
||||
builder: Builder,
|
||||
builder_config: tensorrt_llm.builder.BuilderConfig,
|
||||
engine_name: str,
|
||||
rank: int,
|
||||
args: argparse.Namespace,
|
||||
) -> trt.ICudaEngine:
|
||||
'''
|
||||
@brief: Build the engine on the given rank.
|
||||
@param rank: The rank to build the engine.
|
||||
@param args: The cmd line arguments.
|
||||
@return: The built engine.
|
||||
'''
|
||||
# Initialize Module
|
||||
args.mapping = Mapping(
|
||||
world_size=args.world_size,
|
||||
rank=rank,
|
||||
tp_size=args.tp_size,
|
||||
)
|
||||
assert args.num_layers % args.pp_size == 0, \
|
||||
f"num_layers {args.n_layer} must be a multiple of pipeline "\
|
||||
f"parallelism size {args.pp_size}"
|
||||
trtllm_model = ChatGLMHeadModel(
|
||||
apply_query_key_layer_scaling=args.apply_query_key_layer_scaling,
|
||||
apply_residual_connection_post_layernorm=args.
|
||||
apply_residual_connection_post_layernorm,
|
||||
dtype=args.dtype,
|
||||
enable_debug_output=args.enable_debug_output,
|
||||
ffn_hidden_size=args.ffn_hidden_size,
|
||||
hidden_act=args.hidden_act,
|
||||
hidden_size=args.hidden_size,
|
||||
linear_bias=args.linear_bias,
|
||||
logits_dtype=args.logits_dtype,
|
||||
mapping=args.mapping,
|
||||
max_input_len=args.max_input_len,
|
||||
max_output_len=args.max_output_len,
|
||||
max_seq_length=args.max_seq_length,
|
||||
model_name=args.model_name,
|
||||
norm_epsilon=args.norm_epsilon,
|
||||
num_heads=args.num_heads,
|
||||
num_kv_heads=args.num_kv_heads,
|
||||
num_layers=args.num_layers,
|
||||
qkv_bias=args.qkv_bias,
|
||||
quant_mode=args.quant_mode,
|
||||
rmsnorm=args.rmsnorm,
|
||||
rotary_embedding_scaling=args.rotary_embedding_scaling,
|
||||
tokens_per_block=args.tokens_per_block,
|
||||
use_cache=args.use_cache,
|
||||
vocab_size=args.vocab_size,
|
||||
)
|
||||
'''
|
||||
if args.use_smooth_quant or args.use_weight_only:
|
||||
'''
|
||||
if args.use_smooth_quant:
|
||||
trtllm_model = quantize_model(trtllm_model, args.quant_mode)
|
||||
elif args.enable_fp8 or args.fp8_kv_cache:
|
||||
logger.info(f'Loading scaling factors from '
|
||||
f'{args.quantized_fp8_model_path}')
|
||||
quant_scales = get_scaling_factors(args.quantized_fp8_model_path,
|
||||
num_layers=args.n_layer,
|
||||
quant_mode=args.quant_mode)
|
||||
trtllm_model = quantize_model(trtllm_model,
|
||||
quant_mode=args.quant_mode,
|
||||
quant_scales=quant_scales)
|
||||
elif args.use_weight_only:
|
||||
builder_config.trt_builder_config.use_weight_only = args.weight_only_precision
|
||||
|
||||
trtllm_model = load_from_hf(
|
||||
trtllm_model,
|
||||
args.model_dir,
|
||||
mapping=args.mapping,
|
||||
dtype=args.dtype,
|
||||
model_name=args.model_name,
|
||||
)
|
||||
|
||||
# Module -> Network
|
||||
network = builder.create_network()
|
||||
network.trt_network.name = engine_name
|
||||
if args.use_gpt_attention_plugin:
|
||||
network.plugin_config.set_gpt_attention_plugin(
|
||||
dtype=args.use_gpt_attention_plugin)
|
||||
if args.use_gemm_plugin:
|
||||
if not args.enable_fp8:
|
||||
network.plugin_config.set_gemm_plugin(dtype=args.use_gemm_plugin)
|
||||
else:
|
||||
logger.info(
|
||||
"Gemm plugin does not support FP8. Disabled Gemm plugin.")
|
||||
if args.use_rmsnorm_plugin:
|
||||
network.plugin_config.set_rmsnorm_plugin(dtype=args.use_rmsnorm_plugin)
|
||||
|
||||
# Quantization plugins.
|
||||
if args.use_smooth_quant:
|
||||
network.plugin_config.set_smooth_quant_gemm_plugin(dtype=args.dtype)
|
||||
network.plugin_config.set_rmsnorm_quantization_plugin(dtype=args.dtype)
|
||||
network.plugin_config.set_quantize_tensor_plugin()
|
||||
network.plugin_config.set_quantize_per_token_plugin()
|
||||
assert not (args.enable_context_fmha and args.enable_context_fmha_fp32_acc)
|
||||
if args.enable_context_fmha:
|
||||
network.plugin_config.set_context_fmha(ContextFMHAType.enabled)
|
||||
if args.enable_context_fmha_fp32_acc:
|
||||
network.plugin_config.set_context_fmha(
|
||||
ContextFMHAType.enabled_with_fp32_acc)
|
||||
if args.multi_block_mode:
|
||||
network.plugin_config.enable_mmha_multi_block_mode()
|
||||
if args.use_weight_only:
|
||||
if args.per_group:
|
||||
network.plugin_config.set_weight_only_groupwise_quant_matmul_plugin(
|
||||
dtype='float16')
|
||||
else:
|
||||
network.plugin_config.set_weight_only_quant_matmul_plugin(
|
||||
dtype='float16')
|
||||
if args.world_size > 1:
|
||||
network.plugin_config.set_nccl_plugin(args.dtype,
|
||||
args.use_custom_all_reduce)
|
||||
if args.remove_input_padding:
|
||||
network.plugin_config.enable_remove_input_padding()
|
||||
if args.paged_kv_cache:
|
||||
network.plugin_config.enable_paged_kv_cache(args.tokens_per_block)
|
||||
|
||||
with net_guard(network):
|
||||
# Prepare
|
||||
network.set_named_parameters(trtllm_model.named_parameters())
|
||||
|
||||
# Forward
|
||||
inputs = trtllm_model.prepare_inputs(
|
||||
max_batch_size=args.max_batch_size,
|
||||
max_input_len=args.max_input_len,
|
||||
max_new_tokens=args.max_output_len,
|
||||
use_cache=True,
|
||||
max_beam_width=args.max_beam_width,
|
||||
)
|
||||
trtllm_model(*inputs)
|
||||
if args.enable_debug_output:
|
||||
# mark intermediate nodes' outputs
|
||||
for k, v in trtllm_model.named_network_outputs():
|
||||
v = v.trt_tensor
|
||||
v.name = k
|
||||
network.trt_network.mark_output(v)
|
||||
v.dtype = str_dtype_to_trt(args.dtype)
|
||||
if args.visualize:
|
||||
model_path = args.output_dir / 'test.onnx'
|
||||
to_onnx(network.trt_network, model_path)
|
||||
'''
|
||||
tensorrt_llm.graph_rewriting.optimize(network)
|
||||
'''
|
||||
|
||||
# Network -> Engine
|
||||
engine = None
|
||||
engine = builder.build_engine(network, builder_config)
|
||||
if rank == 0:
|
||||
config_path = args.output_dir / 'config.json'
|
||||
builder.save_config(builder_config, config_path)
|
||||
|
||||
return engine
|
||||
|
||||
|
||||
def build(rank, args):
|
||||
torch.cuda.set_device(rank % args.gpus_per_node)
|
||||
logger.set_level(args.log_level)
|
||||
args.output_dir.mkdir(parents=True, exist_ok=True)
|
||||
timing_cache_file = args.output_dir / "model.cache"
|
||||
timing_cache = timing_cache_file
|
||||
|
||||
builder = Builder()
|
||||
|
||||
for cur_rank in range(args.world_size):
|
||||
# skip other ranks if parallel_build is enabled
|
||||
if args.parallel_build and cur_rank != rank:
|
||||
continue
|
||||
# NOTE: when only int8 kv cache is used together with paged kv cache no int8 tensors are exposed to TRT
|
||||
int8_trt_flag = args.quant_mode.has_act_or_weight_quant() or (
|
||||
not args.paged_kv_cache and args.quant_mode.has_int8_kv_cache())
|
||||
builder_config = builder.create_builder_config(
|
||||
precision=args.dtype,
|
||||
timing_cache=timing_cache,
|
||||
tensor_parallel=args.tp_size,
|
||||
pipeline_parallel=args.pp_size,
|
||||
int8=int8_trt_flag,
|
||||
fp8=args.enable_fp8,
|
||||
strongly_typed=args.strongly_typed,
|
||||
opt_level=args.builder_opt,
|
||||
hardware_compatibility=None,
|
||||
apply_query_key_layer_scaling=args.apply_query_key_layer_scaling,
|
||||
gather_all_token_logits=args.gather_all_token_logits,
|
||||
hidden_act=args.hidden_act,
|
||||
hidden_size=args.hidden_size,
|
||||
max_batch_size=args.max_batch_size,
|
||||
max_beam_width=args.max_beam_width,
|
||||
max_input_len=args.max_input_len,
|
||||
max_num_tokens=args.max_output_len + args.max_input_len,
|
||||
max_output_len=args.max_output_len,
|
||||
max_position_embeddings=args.max_seq_length,
|
||||
multi_query_mode=args.multi_query_mode,
|
||||
name=args.model_name,
|
||||
num_heads=args.num_heads,
|
||||
num_kv_heads=args.num_kv_heads,
|
||||
inter_size = args.ffn_hidden_size,
|
||||
num_layers=args.num_layers,
|
||||
paged_kv_cache=args.paged_kv_cache,
|
||||
parallel_build=args.parallel_build,
|
||||
quant_mode=args.quant_mode,
|
||||
remove_input_padding=args.remove_input_padding,
|
||||
vocab_size=args.vocab_size,
|
||||
fusion_pattern_list=["remove_dup_mask"],
|
||||
)
|
||||
guard = tensorrt_llm.fusion_patterns.FuseonPatternGuard()
|
||||
print(guard)
|
||||
|
||||
engine_name = get_engine_name(
|
||||
args.model_name,
|
||||
args.dtype,
|
||||
args.world_size,
|
||||
args.pp_size,
|
||||
cur_rank,
|
||||
)
|
||||
engine = build_rank_engine(
|
||||
builder,
|
||||
builder_config,
|
||||
engine_name,
|
||||
cur_rank,
|
||||
args,
|
||||
)
|
||||
assert engine is not None, f'Failed to build engine for rank {cur_rank}'
|
||||
'''
|
||||
local_num_kv_heads = (args.num_kv_heads + args.world_size -
|
||||
1) // args.world_size
|
||||
kv_dtype = str_dtype_to_trt(args.dtype)
|
||||
if args.quant_mode.has_int8_kv_cache():
|
||||
kv_dtype = str_dtype_to_trt('int8')
|
||||
elif args.quant_mode.has_fp8_kv_cache():
|
||||
kv_dtype = str_dtype_to_trt('fp8')
|
||||
check_gpt_mem_usage(
|
||||
engine=engine,
|
||||
kv_dtype=kv_dtype,
|
||||
use_gpt_attention_plugin=args.use_gpt_attention_plugin,
|
||||
paged_kv_cache=args.paged_kv_cache,
|
||||
max_batch_size=args.max_batch_size,
|
||||
max_beam_width=args.max_beam_width,
|
||||
max_input_len=args.max_input_len,
|
||||
max_output_len=args.max_output_len,
|
||||
local_num_kv_heads=local_num_kv_heads,
|
||||
head_size=args.hidden_size // args.num_heads,
|
||||
num_layers=args.num_layers)
|
||||
'''
|
||||
|
||||
if cur_rank == 0:
|
||||
# Use in-memory timing cache for multiple builder passes.
|
||||
if not args.parallel_build:
|
||||
timing_cache = builder_config.trt_builder_config.get_timing_cache(
|
||||
)
|
||||
|
||||
serialize_engine(engine, args.output_dir / engine_name)
|
||||
del engine
|
||||
'''
|
||||
if rank == 0:
|
||||
ok = builder.save_timing_cache(builder_config, timing_cache_file)
|
||||
assert ok, "Failed to save timing cache."
|
||||
'''
|
||||
|
||||
|
||||
def run_build(args=None):
|
||||
args = parse_arguments(args)
|
||||
|
||||
if args.random_seed is not None:
|
||||
torch.manual_seed(args.random_seed)
|
||||
|
||||
logger.set_level(args.log_level)
|
||||
tik = time.time()
|
||||
if args.parallel_build and args.world_size > 1 and \
|
||||
torch.cuda.device_count() >= args.world_size:
|
||||
logger.warning(
|
||||
f'Parallelly build XTRT engines. Please make sure that all of the {args.world_size} XPUs are totally free.'
|
||||
)
|
||||
mp.spawn(build, nprocs=args.world_size, args=(args, ))
|
||||
else:
|
||||
args.parallel_build = False
|
||||
logger.info('Serially build XTRT engines.')
|
||||
build(0, args)
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Total time of building all {args.world_size} engines: {t}')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
run_build()
|
||||
40
examples/chatglm/process.py
Normal file
40
examples/chatglm/process.py
Normal file
@@ -0,0 +1,40 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import re
|
||||
|
||||
|
||||
def process_response_chatglm_6b(responseList):
|
||||
# from chatglm-6b/modeling_chatflm.py
|
||||
for i, response in enumerate(responseList):
|
||||
response = response.strip()
|
||||
punkts = [
|
||||
[",", ","],
|
||||
["!", "!"],
|
||||
[":", ":"],
|
||||
[";", ";"],
|
||||
["\?", "?"],
|
||||
]
|
||||
for item in punkts:
|
||||
response = re.sub(r"([\u4e00-\u9fff])%s" % item[0],
|
||||
r"\1%s" % item[1], response)
|
||||
response = re.sub(r"%s([\u4e00-\u9fff])" % item[0],
|
||||
r"%s\1" % item[1], response)
|
||||
|
||||
responseList[i] = response
|
||||
return responseList
|
||||
|
||||
|
||||
def process_response(responseList):
|
||||
return responseList
|
||||
157
examples/chatglm/quantize.py
Normal file
157
examples/chatglm/quantize.py
Normal file
@@ -0,0 +1,157 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""
|
||||
Adapted from examples/quantization/hf_ptq.py
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import random
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from tensorrt_llm._utils import str_dtype_to_torch
|
||||
from tensorrt_llm.logger import logger
|
||||
from tensorrt_llm.models.quantized.ammo import quantize_and_export
|
||||
from torch.utils.data import DataLoader
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
|
||||
def get_calib_dataloader(data="cnn_dailymail",
|
||||
tokenizer=None,
|
||||
batch_size=1,
|
||||
calib_size=512,
|
||||
block_size=512,
|
||||
cache_dir=None):
|
||||
print("Loading calibration dataset")
|
||||
if data == "pileval":
|
||||
dataset = load_dataset(
|
||||
"json",
|
||||
data_files="https://the-eye.eu/public/AI/pile/val.jsonl.zst",
|
||||
split="train",
|
||||
cache_dir=cache_dir)
|
||||
dataset = dataset["text"][:calib_size]
|
||||
elif data == "cnn_dailymail":
|
||||
dataset = load_dataset("cnn_dailymail",
|
||||
name="3.0.0",
|
||||
split="train",
|
||||
cache_dir=cache_dir)
|
||||
dataset = dataset["article"][:calib_size]
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
batch_encoded = tokenizer.batch_encode_plus(dataset,
|
||||
return_tensors="pt",
|
||||
padding=True,
|
||||
max_length=block_size)
|
||||
batch_encoded = batch_encoded["input_ids"]
|
||||
batch_encoded = batch_encoded.cuda()
|
||||
|
||||
calib_dataloader = DataLoader(batch_encoded,
|
||||
batch_size=batch_size,
|
||||
shuffle=False)
|
||||
|
||||
return calib_dataloader
|
||||
|
||||
|
||||
def get_tokenizer(ckpt_path, **kwargs):
|
||||
logger.info(f"Loading tokenizer from {ckpt_path}")
|
||||
tokenizer = AutoTokenizer.from_pretrained(ckpt_path,
|
||||
trust_remote_code=True,
|
||||
padding_side="left",
|
||||
**kwargs)
|
||||
if tokenizer.pad_token is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
return tokenizer
|
||||
|
||||
|
||||
def get_model(ckpt_path, dtype="float16", cache_dir=None):
|
||||
logger.info(f"Loading model from {ckpt_path}")
|
||||
torch_dtype = str_dtype_to_torch(dtype)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
ckpt_path,
|
||||
device_map="auto",
|
||||
cache_dir=cache_dir,
|
||||
trust_remote_code=True,
|
||||
torch_dtype=torch_dtype,
|
||||
)
|
||||
model.eval()
|
||||
model = model.to(memory_format=torch.channels_last)
|
||||
return model
|
||||
|
||||
|
||||
def parse_arguments(args):
|
||||
parser = argparse.ArgumentParser(description=__doc__)
|
||||
parser.add_argument(
|
||||
'--model_name',
|
||||
'-m',
|
||||
type=str,
|
||||
required=True,
|
||||
choices=[
|
||||
"chatglm_6b", "chatglm2_6b", "chatglm2_6b_32k", "chatglm3_6b",
|
||||
"chatglm3_6b_base", "chatglm3_6b_32k", "glm_10b"
|
||||
],
|
||||
help=
|
||||
'the name of the model, use "_" rather than "-" to connect the name parts'
|
||||
)
|
||||
parser.add_argument("--dtype", help="Model data type.", default="float16")
|
||||
parser.add_argument(
|
||||
"--qformat",
|
||||
type=str,
|
||||
choices=['fp8', 'int4_awq'],
|
||||
default='int4_awq',
|
||||
help='Quantization format. Currently only fp8 is supported. '
|
||||
'For int8 smoothquant, use smoothquant.py instead. ')
|
||||
parser.add_argument("--calib_size",
|
||||
type=int,
|
||||
default=32,
|
||||
help="Number of samples for calibration.")
|
||||
parser.add_argument('--model_dir', type=str, default=None)
|
||||
parser.add_argument("--export_path", default="awq")
|
||||
parser.add_argument("--cache_dir",
|
||||
type=str,
|
||||
default="dataset/",
|
||||
help="Directory of dataset cache.")
|
||||
parser.add_argument('--seed', type=int, default=None, help='Random seed')
|
||||
args = parser.parse_args()
|
||||
return args
|
||||
|
||||
|
||||
def main(args=None):
|
||||
if not torch.cuda.is_available():
|
||||
raise EnvironmentError("GPU is required for inference.")
|
||||
|
||||
args = parse_arguments(args)
|
||||
|
||||
if args.model_dir is None:
|
||||
args.model_dir = args.model_name
|
||||
if args.seed is not None:
|
||||
random.seed(args.seed)
|
||||
np.random.seed(args.seed)
|
||||
|
||||
tokenizer = get_tokenizer(args.model_dir, cache_dir=args.cache_dir)
|
||||
model = get_model(args.model_dir, args.dtype, cache_dir=args.cache_dir)
|
||||
|
||||
calib_dataloader = get_calib_dataloader(tokenizer=tokenizer,
|
||||
calib_size=args.calib_size,
|
||||
cache_dir=args.cache_dir)
|
||||
model = quantize_and_export(model,
|
||||
qformat=args.qformat,
|
||||
calib_dataloader=calib_dataloader,
|
||||
export_path=args.export_path)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
5
examples/chatglm/requirements.txt
Normal file
5
examples/chatglm/requirements.txt
Normal file
@@ -0,0 +1,5 @@
|
||||
datasets~=2.14.5
|
||||
evaluate~=0.4.1
|
||||
protobuf
|
||||
rouge_score~=0.1.2
|
||||
sentencepiece
|
||||
371
examples/chatglm/run.py
Normal file
371
examples/chatglm/run.py
Normal file
@@ -0,0 +1,371 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import json
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
import transformers
|
||||
|
||||
import xtrt_llm
|
||||
import xtrt_llm as tensorrt_llm
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
from xtrt_llm.runtime import (ChatGLMGenerationSession, GenerationSession,
|
||||
ModelConfig, SamplingConfig)
|
||||
|
||||
from build import find_engines # isort:skip
|
||||
|
||||
|
||||
def parse_arguments(args=None):
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
'--model_name',
|
||||
'-m',
|
||||
type=str,
|
||||
required=True,
|
||||
choices=[
|
||||
"chatglm_6b", "chatglm2_6b", "chatglm2_6b_32k", "chatglm3_6b",
|
||||
"chatglm3_6b_base", "chatglm3_6b_32k", "glm_10b"
|
||||
],
|
||||
help=
|
||||
'the name of the model, use "_" rather than "-" to connect the name parts'
|
||||
)
|
||||
parser.add_argument('--max_output_len', type=int, default=1024)
|
||||
parser.add_argument('--log_level', type=str, default='error')
|
||||
parser.add_argument('--engine_dir', type=str, default=None)
|
||||
parser.add_argument('--beam_width', type=int, default=1)
|
||||
parser.add_argument('--streaming', default=False, action='store_true')
|
||||
parser.add_argument(
|
||||
'--input_text',
|
||||
type=str,
|
||||
nargs='*',
|
||||
default=[
|
||||
"What's new between ChatGLM3-6B and ChatGLM2-6B?",
|
||||
"Could you introduce NVIDIA Corporation for me?",
|
||||
],
|
||||
)
|
||||
parser.add_argument(
|
||||
'--input_tokens',
|
||||
type=str,
|
||||
help=
|
||||
'CSV or Numpy file containing tokenized input. Alternative to text input.',
|
||||
default=None,
|
||||
)
|
||||
parser.add_argument(
|
||||
'--tokenizer_dir',
|
||||
type=str,
|
||||
default=None,
|
||||
help='Directory containing the tokenizer model.',
|
||||
)
|
||||
parser.add_argument('--temperature', type=float, default=1.0)
|
||||
parser.add_argument('--top_k', type=int, default=1)
|
||||
parser.add_argument('--top_p', type=float, default=0.0)
|
||||
parser.add_argument('--random_seed', type=int, default=1)
|
||||
parser.add_argument(
|
||||
'--performance_test_scale',
|
||||
type=str,
|
||||
help=
|
||||
"Scale for performance test. e.g., 8x1024x64 (batch_size, input_text_length, max_output_length)",
|
||||
default="")
|
||||
|
||||
args = parser.parse_args(args)
|
||||
|
||||
if args.engine_dir is None:
|
||||
args.engine_dir = Path("output_" + args.model_name)
|
||||
|
||||
return args
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = parse_arguments()
|
||||
tensorrt_llm.logger.set_level(args.log_level)
|
||||
|
||||
config_path = Path(args.engine_dir) / 'config.json'
|
||||
with open(config_path, 'r') as f:
|
||||
config = json.load(f)
|
||||
|
||||
dtype = config['builder_config']['precision']
|
||||
max_batch_size = config['builder_config']['max_batch_size']
|
||||
max_input_len = config['builder_config']['max_input_len']
|
||||
max_output_len = config['builder_config']['max_output_len']
|
||||
max_beam_width = config['builder_config']['max_beam_width']
|
||||
remove_input_padding = config['builder_config']['remove_input_padding']
|
||||
use_gpt_attention_plugin = config['plugin_config']['gpt_attention_plugin']
|
||||
tp_size = config['builder_config']['tensor_parallel']
|
||||
pp_size = config['builder_config']['pipeline_parallel']
|
||||
world_size = tp_size * pp_size
|
||||
assert world_size == tensorrt_llm.mpi_world_size(), \
|
||||
f'Engine world size ({tp_size} * {pp_size}) != Runtime world size ({tensorrt_llm.mpi_world_size()})'
|
||||
|
||||
if args.model_name not in ("chatglm_6b", "glm_10b") and len(
|
||||
args.input_text) > 1 and not remove_input_padding:
|
||||
print(
|
||||
"Accuracy of multi-batch chatglm2/3 is not available in padding mode!"
|
||||
)
|
||||
args.input_text = args.input_text[:1]
|
||||
|
||||
if args.max_output_len > max_output_len:
|
||||
print("Truncate max_output_len as %d" % max_output_len)
|
||||
max_output_len = min(max_output_len, args.max_output_len)
|
||||
if args.beam_width > max_beam_width:
|
||||
print("Truncate beam_width as %d" % max_beam_width)
|
||||
beam_width = min(max_beam_width, args.beam_width)
|
||||
|
||||
runtime_rank = tensorrt_llm.mpi_rank()
|
||||
runtime_mapping = tensorrt_llm.Mapping(
|
||||
world_size,
|
||||
runtime_rank,
|
||||
tp_size=world_size,
|
||||
)
|
||||
torch.cuda.set_device(runtime_rank % runtime_mapping.gpus_per_node)
|
||||
if world_size > 1:
|
||||
import os
|
||||
os.environ["XCCL_GROUP_ID"] = str(runtime_rank // world_size)
|
||||
os.environ["XCCL_NRANKS"] = str(world_size)
|
||||
os.environ["XCCL_CUR_RANK"] = str(runtime_rank % world_size)
|
||||
os.environ["XCCL_DEVICE_ID"] = str(runtime_rank)
|
||||
os.environ["MP_RUN"] = str(1)
|
||||
serialize_path = find_engines(
|
||||
Path(args.engine_dir),
|
||||
model_name=args.model_name,
|
||||
dtype=dtype,
|
||||
tp_size=world_size,
|
||||
rank=runtime_rank,
|
||||
)[0]
|
||||
|
||||
if args.tokenizer_dir is None:
|
||||
args.tokenizer_dir = args.model_name
|
||||
tokenizer = transformers.AutoTokenizer.from_pretrained(
|
||||
args.tokenizer_dir, trust_remote_code=True)
|
||||
end_id = tokenizer.eos_token_id
|
||||
pad_id = tokenizer.pad_token_id
|
||||
if args.model_name in ["glm_10b"]:
|
||||
sop_id = tokenizer.sop_token_id
|
||||
eop_id = tokenizer.eop_token_id
|
||||
input_ids = None
|
||||
input_text = None
|
||||
if args.input_tokens is None:
|
||||
input_text = args.input_text
|
||||
batch_size = len(input_text)
|
||||
if batch_size > max_batch_size:
|
||||
print("Truncate batch_size as %d" % max_batch_size)
|
||||
batch_size = max_batch_size
|
||||
input_text = input_text[:max_batch_size]
|
||||
tokenized = tokenizer(input_text,
|
||||
return_tensors="pt",
|
||||
padding=True,
|
||||
return_length=True)
|
||||
input_ids = tokenized['input_ids'].int()
|
||||
input_lengths = tokenized['length'].int()
|
||||
max_input_len_real = torch.max(input_lengths)
|
||||
if max_input_len_real > max_input_len:
|
||||
print("Truncate input_length as %d" % max_input_len)
|
||||
input_ids = input_ids[:, :max_input_len]
|
||||
input_lengths = torch.where(input_lengths > max_input_len,
|
||||
max_input_len, input_lengths)
|
||||
else:
|
||||
max_input_len = max_input_len_real
|
||||
if args.model_name in ["glm_10b"]:
|
||||
input_ids = torch.cat(
|
||||
(input_ids, input_ids.new_full((batch_size, 1), sop_id)),
|
||||
dim=-1,
|
||||
)
|
||||
input_lengths += 1
|
||||
max_input_len_real += 1
|
||||
|
||||
else:
|
||||
input_ids = []
|
||||
with open(args.input_tokens) as f_in:
|
||||
for line in f_in:
|
||||
for e in line.strip().split(','):
|
||||
input_ids.append(int(e))
|
||||
input_text = "<ids from file>"
|
||||
input_ids = torch.tensor(input_ids,
|
||||
dtype=torch.int32).cuda().unsqueeze(0)
|
||||
|
||||
if remove_input_padding:
|
||||
input_ids_no_padding = torch.zeros(1,
|
||||
torch.sum(input_lengths),
|
||||
dtype=torch.int32)
|
||||
lengths_acc = torch.cumsum(
|
||||
torch.cat([torch.IntTensor([0]), input_lengths]),
|
||||
dim=0,
|
||||
)
|
||||
for i in range(len(input_ids)):
|
||||
input_ids_no_padding[
|
||||
0, lengths_acc[i]:lengths_acc[i + 1]] = torch.IntTensor(
|
||||
input_ids[i,
|
||||
max_input_len - input_lengths[i]:max_input_len])
|
||||
|
||||
input_ids = input_ids_no_padding
|
||||
|
||||
elif use_gpt_attention_plugin:
|
||||
# when using gpt attention plugin, inputs needs to align at the head
|
||||
input_ids_padding_right = torch.zeros_like(input_ids) + end_id
|
||||
for i, sample in enumerate(input_ids):
|
||||
nPadding = 0
|
||||
for token in sample:
|
||||
if token == pad_id:
|
||||
nPadding += 1
|
||||
else:
|
||||
break
|
||||
input_ids_padding_right[
|
||||
i, :len(sample[nPadding:])] = sample[nPadding:]
|
||||
input_ids = input_ids_padding_right
|
||||
|
||||
model_config = ModelConfig(
|
||||
vocab_size=config['builder_config']['vocab_size'],
|
||||
num_layers=config['builder_config']['num_layers'],
|
||||
num_heads=config['builder_config']['num_heads'] // tp_size,
|
||||
num_kv_heads=(config['builder_config']['num_kv_heads'] + tp_size - 1) //
|
||||
tp_size,
|
||||
hidden_size=config['builder_config']['hidden_size'] // tp_size,
|
||||
gpt_attention_plugin=use_gpt_attention_plugin,
|
||||
remove_input_padding=config['builder_config']['remove_input_padding'],
|
||||
model_name=args.model_name,
|
||||
paged_kv_cache=config['builder_config']['paged_kv_cache'],
|
||||
quant_mode=QuantMode(config['builder_config']['quant_mode']),
|
||||
dtype=dtype,
|
||||
)
|
||||
|
||||
sampling_config = SamplingConfig(
|
||||
end_id=eop_id if args.model_name in ["glm_10b"] else end_id,
|
||||
pad_id=pad_id,
|
||||
num_beams=beam_width,
|
||||
temperature=args.temperature,
|
||||
top_k=args.top_k,
|
||||
top_p=args.top_p,
|
||||
)
|
||||
sampling_config.random_seed = args.random_seed
|
||||
'''
|
||||
with open(serialize_path, 'rb') as f:
|
||||
engine_buffer = f.read()
|
||||
'''
|
||||
engine_buffer = serialize_path
|
||||
|
||||
if args.model_name in ["chatglm_6b", "glm_10b"]:
|
||||
session = ChatGLMGenerationSession
|
||||
elif args.model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
session = GenerationSession
|
||||
decoder = session(
|
||||
model_config,
|
||||
engine_buffer,
|
||||
runtime_mapping,
|
||||
)
|
||||
|
||||
decoder.setup(
|
||||
len(input_text),
|
||||
max_input_len,
|
||||
max_output_len,
|
||||
beam_width,
|
||||
)
|
||||
output = decoder.decode(
|
||||
input_ids.contiguous().cuda(),
|
||||
input_lengths.contiguous().cuda(),
|
||||
sampling_config,
|
||||
output_sequence_lengths=True,
|
||||
return_dict=True,
|
||||
streaming=args.streaming,
|
||||
stop_words_list=None if args.model_name in ["chatglm_6b", "glm_10b"]
|
||||
else [tokenizer.eos_token_id],
|
||||
)
|
||||
if args.performance_test_scale != "":
|
||||
import time
|
||||
|
||||
import numpy as np
|
||||
for scale in args.performance_test_scale.split("E"):
|
||||
xtrt_llm.logger.info(f"Running performance test with scale {scale}")
|
||||
bs, seqlen, _max_output_len = [int(x) for x in scale.split("x")]
|
||||
_input_ids = torch.from_numpy(
|
||||
np.zeros((bs, seqlen)).astype("int32")).cuda()
|
||||
_input_lengths = torch.from_numpy(
|
||||
np.full((bs, ), seqlen).astype("int32")).cuda()
|
||||
_max_input_length = torch.max(_input_lengths).item()
|
||||
if model_config.remove_input_padding:
|
||||
_input_ids = _input_ids.view((1, -1)).contiguous()
|
||||
|
||||
_t_begin = time.time()
|
||||
decoder.setup(_input_lengths.size(0), _max_input_length,
|
||||
_max_output_len, beam_width)
|
||||
_output_gen_ids = decoder.decode(_input_ids,
|
||||
_input_lengths,
|
||||
sampling_config,
|
||||
streaming=streaming)
|
||||
_t_end = time.time()
|
||||
xtrt_llm.logger.info(
|
||||
f"Total latency: {(_t_end - _t_begin) * 1000:.3f} ms")
|
||||
xtrt_llm.logger.info(
|
||||
f"Throughput: {bs * _max_output_len / (_t_end - _t_begin):.3f} tokens/sec"
|
||||
)
|
||||
exit(0)
|
||||
|
||||
if runtime_rank == 0:
|
||||
if args.model_name in ["chatglm_6b"]:
|
||||
from process import process_response_chatglm_6b as process_response
|
||||
elif args.model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
"glm_10b",
|
||||
]:
|
||||
from process import process_response
|
||||
|
||||
if args.streaming: # streaming output
|
||||
print("#" * 80)
|
||||
# only the first sample in the first batch is shown,
|
||||
# but actually all output of all batches are available
|
||||
print(f"Input idx: {0:2d} ---> len={input_lengths[0]}")
|
||||
print(f'Input: \"{input_text[0]}\""')
|
||||
for output_item in output:
|
||||
output_id = output_item["output_ids"]
|
||||
output_sequence_lengths = output_item["sequence_lengths"]
|
||||
output_id = output_id[0, 0, output_sequence_lengths[0, 0] - 1]
|
||||
output_word = tokenizer.convert_ids_to_tokens(int(output_id))
|
||||
output_word = output_word.replace("▁", " ") # For English
|
||||
output_word = tokenizer.convert_tokens_to_string(output_word)
|
||||
print(output_word, end="", flush=True)
|
||||
print("\n" + "#" * 80)
|
||||
else: # regular output
|
||||
torch.cuda.synchronize()
|
||||
output_ids = output["output_ids"]
|
||||
output_lengths = output["sequence_lengths"]
|
||||
print("#" * 80)
|
||||
for i in range(batch_size):
|
||||
print(f'Input idx: {i:2d} ---> len={input_lengths[i]}')
|
||||
print(f'Input: \"{input_text[i]}\"')
|
||||
print(f"Output idx: {i:2d} --->")
|
||||
output_ids_one_batch = output_ids[i, :, input_lengths[i]:]
|
||||
output_lengths_one_batch = output_lengths[i] - input_lengths[
|
||||
i] + 1
|
||||
output_token_list = tokenizer.batch_decode(
|
||||
output_ids_one_batch, skip_special_tokens=True)
|
||||
output_token_list = process_response(output_token_list)
|
||||
for j, (length, simple_output) in enumerate(
|
||||
zip(output_lengths_one_batch, output_token_list)):
|
||||
print("Beam %2d ---> len=%d" %(j, length))
|
||||
print(f'Output: \"{simple_output}\"')
|
||||
print("#" * 80)
|
||||
|
||||
del decoder
|
||||
|
||||
print(f"Finished from worker {runtime_rank}")
|
||||
128
examples/chatglm/run.sh
Normal file
128
examples/chatglm/run.sh
Normal file
@@ -0,0 +1,128 @@
|
||||
XMLIR_D_XPU_L3_SIZE=0 python3 run.py -m chatglm2_6b --engine_dir engine_outputs --tokenizer_dir downloads/chatglm2-6b --input_text="中华人民共和国主席令
|
||||
(第八十三号)
|
||||
《中华人民共和国刑法》已由中华人民共和国第八届全国人民代表大会第五次会议于1997年3月14日修订,现将修订后的《中华人民共和国刑法》公布,自1997年10月1日起施行。
|
||||
1997年3月14日
|
||||
中华人民共和国刑法
|
||||
(1979年7月1日第五届全国人民代表大会第二次会议通过,
|
||||
1997年3月14日第八届全国人民代表大会第五次会议修订)
|
||||
第一编 总 则
|
||||
第一章 刑法的任务、基本原则和适用范围
|
||||
第一条 为了惩罚犯罪,保护人民,根据宪法,结合我国同犯罪作斗争的具体经验及实际情况,制定本法。
|
||||
第二条 中华人民共和国刑法的任务,是用刑罚同一切犯罪行为作斗争,以保卫国家安全,保卫人民民主专政的政权和社会主义制度,保护国有财产和劳动群众集体所有的财产,保护公民私人所有的财产,保护公民的人身权利、民主权利和其他权利,维护社会秩序、经济秩序,保障社会主义建设事业的顺利进行。
|
||||
第三条 法律明文规定为犯罪行为的,依照法律定罪处刑;法律没有明文规定为犯罪行为的,不得定罪处刑。
|
||||
第四条 对任何人犯罪,在适用法律上一律平等。不允许任何人有超越法律的特权。
|
||||
第五条 刑罚的轻重,应当与犯罪分子所犯罪行和承担的刑事责任相适应。
|
||||
第六条 凡在中华人民共和国领域内犯罪的,除法律有特别规定的以外,都适用本法。
|
||||
凡在中华人民共和国船舶或者航空器内犯罪的,也适用本法。
|
||||
犯罪的行为或者结果有一项发生在中华人民共和国领域内的,就认为是在中华人民共和国领域内犯罪。
|
||||
第七条 中华人民共和国公民在中华人民共和国领域外犯本法规定之罪的,适用本法,但是按本法规定的最高刑为三年以下有期徒刑的,可以不予追究。
|
||||
中华人民共和国国家工作人员和军人在中华人民共和国领域外犯本法规定之罪的,适用本法。
|
||||
第八条 外国人在中华人民共和国领域外对中华人民共和国国家或者公民犯罪,而按本法规定的最低刑为三年以上有期徒刑的,可以适用本法,但是按照犯罪地的法律不受处罚的除外。
|
||||
第九条 对于中华人民共和国缔结或者参加的国际条约所规定的罪行,中华人民共和国在所承担条约义务的范围内行使刑事管辖权的,适用本法。
|
||||
第十条 凡在中华人民共和国领域外犯罪,依照本法应当负刑事责任的,虽然经过外国审判,仍然可以依照本法追究,但是在外国已经受过刑罚处罚的,可以免除或者减轻处罚。
|
||||
第十一条 享有外交特权和豁免权的外国人的刑事责任,通过外交途径解决。
|
||||
第十二条 中华人民共和国成立以后本法施行以前的行为,如果当时的法律不认为是犯罪的,适用当时的法律;如果当时的法律认为是犯罪的,依照本法总则第四章第八节的规定应当追诉的,按照当时的法律追究刑事责任,但是如果本法不认为是犯罪或者处刑较轻的,适用本法。
|
||||
本法施行以前,依照当时的法律已经作出的生效判决,继续有效。
|
||||
第二章 犯罪
|
||||
第一节 犯罪和刑事责任
|
||||
第十三条 一切危害国家主权、领土完整和安全,分裂国家、颠覆人民民主专政的政权和推翻社会主义制度,破坏社会秩序和经济秩序,侵犯国有财产或者劳动群众集体所有的财产,侵犯公民私人所有的财产,侵犯公民的人身权利、民主权利和其他权利,以及其他危害社会的行为,依照法律应当受刑罚处罚的,都是犯罪,但是情节显著轻微危害不大的,不认为是犯罪。
|
||||
第十四条 明知自己的行为会发生危害社会的结果,并且希望或者放任这种结果发生,因而构成犯罪的,是故意犯罪。
|
||||
故意犯罪,应当负刑事责任。
|
||||
第十五条 应当预见自己的行为可能发生危害社会的结果,因为疏忽大意而没有预见,或者已经预见而轻信能够避免,以致发生这种结果的,是过失犯罪。
|
||||
过失犯罪,法律有规定的才负刑事责任。
|
||||
第十六条 行为在客观上虽然造成了损害结果,但是不是出于故意或者过失,而是由于不能抗拒或者不能预见的原因所引起的,不是犯罪。
|
||||
第十七条 已满十六周岁的人犯罪,应当负刑事责任。
|
||||
已满十四周岁不满十六周岁的人,犯故意杀人、故意伤害致人重伤或者死亡、强奸、抢劫、贩卖毒品、放火、爆炸、投毒罪的,应当负刑事责任。
|
||||
已满十四周岁不满十八周岁的人犯罪,应当从轻或者减轻处罚。
|
||||
因不满十六周岁不予刑事处罚的,责令他的家长或者监护人加以管教;在必要的时候,也可以由政府收容教养。
|
||||
第十八条 精神病人在不能辨认或者不能控制自己行为的时候造成危害结果,经法定程序鉴定确认的,不负刑事责任,但是应当责令他的家属或者监护人严加看管和医疗;在必要的时候,由政府强制医疗。
|
||||
间歇性的精神病人在精神正常的时候犯罪,应当负刑事责任。
|
||||
尚未完全丧失辨认或者控制自己行为能力的精神病人犯罪的,应当负刑事责任,但是可以从轻或者减轻处罚。
|
||||
醉酒的人犯罪,应当负刑事责任。
|
||||
第十九条 又聋又哑的人或者盲人犯罪,可以从轻、减轻或者免除处罚。
|
||||
第二十条 为了使国家、公共利益、本人或者他人的人身、财产和其他权利免受正在进行的不法侵害,而采取的制止不法侵害的行为,对不法侵害人造成损害的,属于正当防卫,不负刑事责任。
|
||||
正当防卫明显超过必要限度造成重大损害的,应当负刑事责任,但是应当减轻或者免除处罚。
|
||||
对正在进行行凶、杀人、抢劫、强奸、绑架以及其他严重危及人身安全的暴力犯罪,采取防卫行为,造成不法侵害人伤亡的,不属于防卫过当,不负刑事责任。
|
||||
第二十一条 为了使国家、公共利益、本人或者他人的人身、财产和其他权利免受正在发生的危险,不得已采取的紧急避险行为,造成损害的,不负刑事责任。
|
||||
紧急避险超过必要限度造成不应有的损害的,应当负刑事责任,但是应当减轻或者免除处罚。
|
||||
第一款中关于避免本人危险的规定,不适用于职务上、业务上负有特定责任的人。
|
||||
第二节 犯罪的预备、未遂和中止
|
||||
第二十二条 为了犯罪,准备工具、制造条件的,是犯罪预备。
|
||||
对于预备犯,可以比照既遂犯从轻、减轻处罚或者免除处罚。
|
||||
第二十三条 已经着手实行犯罪,由于犯罪分子意志以外的原因而未得逞的,是犯罪未遂。
|
||||
对于未遂犯,可以比照既遂犯从轻或者减轻处罚。
|
||||
第二十四条 在犯罪过程中,自动放弃犯罪或者自动有效地防止犯罪结果发生的,是犯罪中止。
|
||||
对于中止犯,没有造成损害的,应当免除处罚;造成损害的,应当减轻处罚。
|
||||
第三节 共同犯罪
|
||||
第二十五条 共同犯罪是指二人以上共同故意犯罪。
|
||||
二人以上共同过失犯罪,不以共同犯罪论处;应当负刑事责任的,按照他们所犯的罪分别处罚。
|
||||
第二十六条 组织、领导犯罪集团进行犯罪活动的或者在共同犯罪中起主要作用的,是主犯。
|
||||
三人以上为共同实施犯罪而组成的较为固定的犯罪组织,是犯罪集团。
|
||||
对组织、领导犯罪集团的首要分子,按照集团所犯的全部罪行处罚。
|
||||
对于第三款规定以外的主犯,应当按照其所参与的或者组织、指挥的全部犯罪处罚。
|
||||
第二十七条 在共同犯罪中起次要或者辅助作用的,是从犯。
|
||||
对于从犯,应当从轻、减轻处罚或者免除处罚。
|
||||
第二十八条 对于被胁迫参加犯罪的,应当按照他的犯罪情节减轻处罚或者免除处罚。
|
||||
第二十九条 教唆他人犯罪的,应当按照他在共同犯罪中所起的作用处罚。教唆不满十八周岁的人犯罪的,应当从重处罚。
|
||||
如果被教唆的人没有犯被教唆的罪,对于教唆犯,可以从轻或者减轻处罚。
|
||||
第四节 单位犯罪
|
||||
第三十条 公司、企业、事业单位、机关、团体实施的危害社会的行为,法律规定为单位犯罪的,应当负刑事责任。
|
||||
第三十一条 单位犯罪的,对单位判处罚金,并对其直接负责的主管人员和其他直接责任人员判处刑罚。本法分则和其他法律另有规定的,依照规定。
|
||||
第三章 刑罚
|
||||
第一节 刑罚的种类
|
||||
第三十二条 刑罚分为主刑和附加刑。
|
||||
第三十三条 主刑的种类如下:
|
||||
(一)管制;
|
||||
(二)拘役;
|
||||
(三)有期徒刑;
|
||||
(四)无期徒刑;
|
||||
(五)死刑。
|
||||
第三十四条 附加刑的种类如下:
|
||||
(一)罚金;
|
||||
(二)剥夺政治权利;
|
||||
(三)没收财产。
|
||||
附加刑也可以独立适用。
|
||||
第三十五条 对于犯罪的外国人,可以独立适用或者附加适用驱逐出境。
|
||||
第三十六条 由于犯罪行为而使被害人遭受经济损失的,对犯罪分子除依法给予刑事处罚外,并应根据情况判处赔偿经济损失。
|
||||
承担民事赔偿责任的犯罪分子,同时被判处罚金,其财产不足以全部支付的,或者被判处没收财产的,应当先承担对被害人的民事赔偿责任。
|
||||
第三十七条 对于犯罪情节轻微不需要判处刑罚的,可以免予刑事处罚,但是可以根据案件的不同情况,予以训诫或者责令具结悔过、赔礼道歉、赔偿损失,或者由主管部门予以行政处罚或者行政处分。
|
||||
第二节 管制
|
||||
第三十八条 管制的期限,为三个月以上二年以下。
|
||||
被判处管制的犯罪分子,由公安机关执行。
|
||||
第三十九条 被判处管制的犯罪分子,在执行期间,应当遵守下列规定:
|
||||
(一)遵守法律、行政法规,服从监督;
|
||||
(二)未经执行机关批准,不得行使言论、出版、集会、结社、游行、示威自由的权利;
|
||||
(三)按照执行机关规定报告自己的活动情况;
|
||||
(四)遵守执行机关关于会客的规定;
|
||||
(五)离开所居住的市、县或者迁居,应当报经执行机关批准。
|
||||
对于被判处管制的犯罪分子,在劳动中应当同工同酬。
|
||||
第四十条 被判处管制的犯罪分子,管制期满,执行机关应即向本人和其所在单位或者居住地的群众宣布解除管制。
|
||||
第四十一条 管制的刑期,从判决执行之日起计算;判决执行以前先行羁押的,羁押一日折抵刑期二日。
|
||||
第三节 拘役
|
||||
第四十二条 拘役的期限,为一个月以上六个月以下。
|
||||
第四十三条 被判处拘役的犯罪分子,由公安机关就近执行。
|
||||
在执行期间,被判处拘役的犯罪分子每月可以回家一天至两天;参加劳动的,可以酌量发给报酬。
|
||||
第四十四条 拘役的刑期,从判决执行之日起计算;判决执行以前先行羁押的,羁押一日折抵刑期一日。
|
||||
第四节 有期徒刑、无期徒刑
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
第四十五条 有期徒刑的期限,除本法第五十条、第六十九条规定外,为六个月以上十五年以下。
|
||||
|
||||
问:杀人、抢劫、强奸的犯什么罪?
|
||||
答:"
|
||||
155
examples/chatglm/smoothquant.py
Normal file
155
examples/chatglm/smoothquant.py
Normal file
@@ -0,0 +1,155 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
'''
|
||||
Utilities for SmoothQuant models
|
||||
'''
|
||||
|
||||
import functools
|
||||
from collections import defaultdict
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from tqdm import tqdm
|
||||
from transformers.pytorch_utils import Conv1D
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def apply_smoothing(scales,
|
||||
gemm_weights,
|
||||
layernorm_weights=None,
|
||||
layernorm_bias=None,
|
||||
dtype=torch.float32,
|
||||
layernorm_1p=False):
|
||||
if not isinstance(gemm_weights, list):
|
||||
gemm_weights = [gemm_weights]
|
||||
|
||||
if layernorm_weights is not None:
|
||||
assert layernorm_weights.numel() == scales.numel()
|
||||
layernorm_weights.div_(scales).to(dtype)
|
||||
if layernorm_bias is not None:
|
||||
assert layernorm_bias.numel() == scales.numel()
|
||||
layernorm_bias.div_(scales).to(dtype)
|
||||
if layernorm_1p:
|
||||
layernorm_weights += (1 / scales) - 1
|
||||
|
||||
for gemm in gemm_weights:
|
||||
gemm.mul_(scales.view(1, -1)).to(dtype)
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def smooth_gemm(gemm_weights,
|
||||
act_scales,
|
||||
layernorm_weights=None,
|
||||
layernorm_bias=None,
|
||||
alpha=0.5,
|
||||
weight_scales=None):
|
||||
if not isinstance(gemm_weights, list):
|
||||
gemm_weights = [gemm_weights]
|
||||
orig_dtype = gemm_weights[0].dtype
|
||||
|
||||
for gemm in gemm_weights:
|
||||
# gemm_weights are expected to be transposed
|
||||
assert gemm.shape[1] == act_scales.numel()
|
||||
|
||||
if weight_scales is None:
|
||||
weight_scales = torch.cat(
|
||||
[gemm.abs().max(dim=0, keepdim=True)[0] for gemm in gemm_weights],
|
||||
dim=0)
|
||||
weight_scales = weight_scales.max(dim=0)[0]
|
||||
weight_scales.to(float).clamp(min=1e-5)
|
||||
scales = (act_scales.to(gemm_weights[0].device).to(float).pow(alpha) /
|
||||
weight_scales.pow(1 - alpha)).clamp(min=1e-5)
|
||||
|
||||
apply_smoothing(scales, gemm_weights, layernorm_weights, layernorm_bias,
|
||||
orig_dtype)
|
||||
|
||||
return scales
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def smooth_ln_fcs(ln, fcs, act_scales, alpha=0.5):
|
||||
if not isinstance(fcs, list):
|
||||
fcs = [fcs]
|
||||
for fc in fcs:
|
||||
assert isinstance(fc, nn.Linear)
|
||||
assert ln.weight.numel() == fc.in_features == act_scales.numel()
|
||||
|
||||
device, dtype = fcs[0].weight.device, fcs[0].weight.dtype
|
||||
act_scales = act_scales.to(device=device, dtype=dtype)
|
||||
weight_scales = torch.cat(
|
||||
[fc.weight.abs().max(dim=0, keepdim=True)[0] for fc in fcs], dim=0)
|
||||
weight_scales = weight_scales.max(dim=0)[0].clamp(min=1e-5)
|
||||
|
||||
scales = (act_scales.pow(alpha) /
|
||||
weight_scales.pow(1 - alpha)).clamp(min=1e-5).to(device).to(dtype)
|
||||
|
||||
if ln is not None:
|
||||
ln.weight.div_(scales)
|
||||
ln.bias.div_(scales)
|
||||
|
||||
for fc in fcs:
|
||||
fc.weight.mul_(scales.view(1, -1))
|
||||
return scales
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def capture_activation_range(model,
|
||||
tokenizer,
|
||||
dataset,
|
||||
num_samples=512,
|
||||
seq_len=512):
|
||||
model.eval()
|
||||
device = next(model.parameters()).device
|
||||
act_scales = defaultdict(lambda: {"x": None, "y": None, "w": None})
|
||||
|
||||
def stat_tensor(name, tensor, act_scales, key):
|
||||
hidden_dim = tensor.shape[-1]
|
||||
tensor = tensor.view(-1, hidden_dim).abs().detach()
|
||||
comming_max = torch.max(tensor, dim=0)[0].float()
|
||||
|
||||
if act_scales[name][key] is None:
|
||||
act_scales[name][key] = comming_max
|
||||
else:
|
||||
act_scales[name][key] = torch.max(act_scales[name][key],
|
||||
comming_max)
|
||||
|
||||
def stat_input_hook(m, x, y, name):
|
||||
if isinstance(x, tuple):
|
||||
x = x[0]
|
||||
stat_tensor(name, x, act_scales, "x")
|
||||
stat_tensor(name, y, act_scales, "y")
|
||||
|
||||
if act_scales[name]["w"] is None:
|
||||
act_scales[name]["w"] = m.weight.abs().clip(1e-8,
|
||||
None).max(dim=0)[0]
|
||||
|
||||
hooks = []
|
||||
for name, m in model.named_modules():
|
||||
if isinstance(m, nn.Linear) or isinstance(m, Conv1D):
|
||||
hooks.append(
|
||||
m.register_forward_hook(
|
||||
functools.partial(stat_input_hook, name=name)))
|
||||
|
||||
for i in tqdm(range(num_samples), desc="calibrating model"):
|
||||
input_ids = tokenizer(dataset[i]["text"],
|
||||
return_tensors="pt",
|
||||
max_length=seq_len,
|
||||
truncation=True).input_ids.to(device)
|
||||
model(input_ids)
|
||||
|
||||
for h in hooks:
|
||||
h.remove()
|
||||
|
||||
return act_scales
|
||||
73
examples/chatglm/visualize.py
Normal file
73
examples/chatglm/visualize.py
Normal file
@@ -0,0 +1,73 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import onnx
|
||||
import tvm.tensorrt as trt
|
||||
from onnx import TensorProto, helper
|
||||
|
||||
|
||||
def trt_dtype_to_onnx(dtype):
|
||||
if dtype == trt.float16:
|
||||
return TensorProto.DataType.FLOAT16
|
||||
elif dtype == trt.float32:
|
||||
return TensorProto.DataType.FLOAT
|
||||
elif dtype == trt.int32:
|
||||
return TensorProto.DataType.INT32
|
||||
else:
|
||||
raise TypeError("%s is not supported" % dtype)
|
||||
|
||||
|
||||
def to_onnx(network, path):
|
||||
inputs = []
|
||||
for i in range(network.num_inputs):
|
||||
network_input = network.get_input(i)
|
||||
inputs.append(
|
||||
helper.make_tensor_value_info(
|
||||
network_input.name, trt_dtype_to_onnx(network_input.dtype),
|
||||
list(network_input.shape)))
|
||||
|
||||
outputs = []
|
||||
for i in range(network.num_outputs):
|
||||
network_output = network.get_output(i)
|
||||
outputs.append(
|
||||
helper.make_tensor_value_info(
|
||||
network_output.name, trt_dtype_to_onnx(network_output.dtype),
|
||||
list(network_output.shape)))
|
||||
|
||||
nodes = []
|
||||
for i in range(network.num_layers):
|
||||
layer = network.get_layer(i)
|
||||
layer_inputs = []
|
||||
for j in range(layer.num_inputs):
|
||||
ipt = layer.get_input(j)
|
||||
if ipt is not None:
|
||||
layer_inputs.append(layer.get_input(j).name)
|
||||
layer_outputs = [
|
||||
layer.get_output(j).name for j in range(layer.num_outputs)
|
||||
]
|
||||
nodes.append(
|
||||
helper.make_node(str(layer.type),
|
||||
name=layer.name,
|
||||
inputs=layer_inputs,
|
||||
outputs=layer_outputs,
|
||||
domain="com.nvidia"))
|
||||
|
||||
onnx_model = helper.make_model(helper.make_graph(nodes,
|
||||
'attention',
|
||||
inputs,
|
||||
outputs,
|
||||
initializer=None),
|
||||
producer_name='NVIDIA')
|
||||
onnx.save(onnx_model, path)
|
||||
590
examples/chatglm/weight.py
Normal file
590
examples/chatglm/weight.py
Normal file
@@ -0,0 +1,590 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import time
|
||||
from pathlib import Path
|
||||
from typing import Dict, List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
import transformers
|
||||
|
||||
import xtrt_llm as tensorrt_llm
|
||||
import xtrt_llm.logger as logger
|
||||
from xtrt_llm._utils import str_dtype_to_torch, torch_to_numpy
|
||||
from xtrt_llm.mapping import Mapping
|
||||
from xtrt_llm.models.quantized.quant import get_dummy_quant_scales
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
|
||||
def split(weight: np.ndarray, tp_size: int, rank: int = 0, dim: int = 0):
|
||||
if tp_size == 1:
|
||||
return weight
|
||||
elif weight.ndim == 1:
|
||||
return np.ascontiguousarray(np.split(weight, tp_size)[rank].copy())
|
||||
return np.ascontiguousarray(
|
||||
np.split(weight, tp_size, axis=dim)[rank].copy())
|
||||
|
||||
|
||||
def split_matrix(weight: np.ndarray, tp_size: int, rank: int, dim: int):
|
||||
return np.ascontiguousarray(split(weight, tp_size, rank, dim=dim))
|
||||
|
||||
|
||||
def tile_kv_weight_bias(v, kv_num_head, tp_size):
|
||||
head_size = v.shape[0] // kv_num_head
|
||||
reps = tp_size // kv_num_head
|
||||
if v.ndim == 1:
|
||||
v = v.reshape(kv_num_head, head_size)[:, None, :]
|
||||
v = v.expand(kv_num_head, reps, head_size).reshape(-1).clone()
|
||||
else:
|
||||
hidden_size = v.shape[1]
|
||||
v = v.reshape(kv_num_head, head_size, hidden_size)[:, None, :, :]
|
||||
v = v.expand(kv_num_head, reps, head_size,
|
||||
hidden_size).reshape(-1, hidden_size).clone()
|
||||
return v
|
||||
|
||||
|
||||
def split_qkv(v, tp_size, rank, hidden_size, num_heads, num_kv_heads):
|
||||
head_size = hidden_size // num_heads
|
||||
if tp_size == 1:
|
||||
return v
|
||||
|
||||
assert v.shape[0] == hidden_size + head_size * num_kv_heads * 2
|
||||
query = v[:hidden_size]
|
||||
key = v[hidden_size:hidden_size + head_size * num_kv_heads]
|
||||
value = v[hidden_size + head_size * num_kv_heads:hidden_size +
|
||||
head_size * num_kv_heads * 2]
|
||||
|
||||
if num_kv_heads < tp_size:
|
||||
key = tile_kv_weight_bias(key, num_kv_heads, tp_size)
|
||||
value = tile_kv_weight_bias(value, num_kv_heads, tp_size)
|
||||
assert (key.shape[0] % (tp_size * head_size)) == 0
|
||||
assert (value.shape[0] % (tp_size * head_size)) == 0
|
||||
|
||||
q_tmp = torch.chunk(query, tp_size, dim=0)[rank]
|
||||
k_tmp = torch.chunk(key, tp_size, dim=0)[rank]
|
||||
v_tmp = torch.chunk(value, tp_size, dim=0)[rank]
|
||||
return torch.concatenate([q_tmp, k_tmp, v_tmp], dim=0).contiguous()
|
||||
|
||||
|
||||
def load_quant_weight(src, value_dst, scale_dst, plugin_weight_only_quant_type):
|
||||
v = torch.transpose(src, dim0=0, dim1=1).contiguous()
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
v, plugin_weight_only_quant_type)
|
||||
value_dst.value = torch_to_numpy(processed_torch_weights)
|
||||
scale_dst.value = torch_to_numpy(torch_weight_scales)
|
||||
|
||||
|
||||
def load_from_hf(
|
||||
trt_model,
|
||||
hf_model_dir,
|
||||
mapping=Mapping(),
|
||||
dtype="float32",
|
||||
model_name=None,
|
||||
multi_query_mode=False,
|
||||
):
|
||||
|
||||
assert model_name is not None, "Model name must be set"
|
||||
|
||||
tensorrt_llm.logger.info("Loading weights from HF")
|
||||
|
||||
if not Path(hf_model_dir).exists():
|
||||
tensorrt_llm.logger.info(
|
||||
"No weight file found from %s, use random weights" % hf_model_dir)
|
||||
return trt_model
|
||||
|
||||
tik = time.time()
|
||||
|
||||
hf_model = transformers.AutoModel.from_pretrained(hf_model_dir,
|
||||
trust_remote_code=True)
|
||||
hidden_size = hf_model.config.hidden_size
|
||||
num_heads = hf_model.config.num_attention_heads
|
||||
num_layers = hf_model.config.num_layers
|
||||
|
||||
torch_type = str_dtype_to_torch(dtype)
|
||||
quant_mode = getattr(trt_model, 'quant_mode', QuantMode(0))
|
||||
if quant_mode.is_int8_weight_only():
|
||||
plugin_weight_only_quant_type = torch.int8
|
||||
elif quant_mode.is_int4_weight_only():
|
||||
plugin_weight_only_quant_type = torch.quint4x2
|
||||
use_weight_only = quant_mode.is_weight_only()
|
||||
|
||||
layers_per_pipeline_stage = num_layers // mapping.pp_size
|
||||
layers_range = list(
|
||||
range(mapping.pp_rank * layers_per_pipeline_stage,
|
||||
(mapping.pp_rank + 1) * layers_per_pipeline_stage))
|
||||
feed_weight_count = 0
|
||||
|
||||
if model_name in ["chatglm_6b", "glm_10b"]:
|
||||
num_kv_heads = hf_model.config.num_attention_heads
|
||||
elif model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
num_kv_heads = hf_model.config.multi_query_group_num
|
||||
|
||||
if mapping.is_first_pp_rank():
|
||||
# Embedding
|
||||
if model_name in ["chatglm_6b"]:
|
||||
weight = hf_model.transformer.word_embeddings.weight.to(
|
||||
torch_type).detach()
|
||||
trt_model.embedding.weight.value = torch_to_numpy(weight)
|
||||
feed_weight_count += 1
|
||||
elif model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
weight = hf_model.transformer.embedding.word_embeddings.weight.to(
|
||||
torch_type).detach()
|
||||
trt_model.embedding.weight.value = torch_to_numpy(weight)
|
||||
feed_weight_count += 1
|
||||
elif model_name in ["glm_10b"]:
|
||||
weight = hf_model.word_embeddings.weight.to(torch_type).detach()
|
||||
trt_model.embedding.weight.value = torch_to_numpy(weight)
|
||||
weight = hf_model.transformer.position_embeddings.weight.to(
|
||||
torch_type).detach()
|
||||
trt_model.position_embeddings.weight.value = torch_to_numpy(weight)
|
||||
weight = hf_model.transformer.block_position_embeddings.weight.to(
|
||||
torch_type).detach()
|
||||
trt_model.block_embeddings.weight.value = torch_to_numpy(weight)
|
||||
feed_weight_count += 3
|
||||
|
||||
if mapping.is_last_pp_rank():
|
||||
# Final normalization
|
||||
if model_name in ["chatglm_6b"]:
|
||||
weight = hf_model.transformer.final_layernorm.weight.to(
|
||||
torch_type).detach()
|
||||
trt_model.final_norm.weight.value = torch_to_numpy(weight)
|
||||
bias = hf_model.transformer.final_layernorm.bias.to(
|
||||
torch_type).detach()
|
||||
trt_model.final_norm.bias.value = torch_to_numpy(bias)
|
||||
feed_weight_count += 2
|
||||
elif model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
weight = hf_model.transformer.encoder.final_layernorm.weight.to(
|
||||
torch_type).detach()
|
||||
trt_model.final_norm.weight.value = torch_to_numpy(weight)
|
||||
feed_weight_count += 1
|
||||
elif model_name in ["glm_10b"]:
|
||||
weight = hf_model.transformer.final_layernorm.weight.to(
|
||||
torch_type).detach()
|
||||
trt_model.final_norm.weight.value = torch_to_numpy(weight)
|
||||
bias = hf_model.transformer.final_layernorm.bias.to(
|
||||
torch_type).detach()
|
||||
trt_model.final_norm.bias.value = torch_to_numpy(bias)
|
||||
feed_weight_count += 2
|
||||
|
||||
# Final LM
|
||||
if model_name in ["chatglm_6b"]:
|
||||
weight = hf_model.lm_head.weight.to(torch_type).detach()
|
||||
if weight.shape[0] % mapping.tp_size != 0:
|
||||
pad_width = trt_model.lm_head.out_features * mapping.tp_size - weight.shape[
|
||||
0]
|
||||
weight = F.pad(weight, (0, 0, 0, pad_width))
|
||||
split_weight = torch.chunk(weight, mapping.tp_size,
|
||||
dim=0)[mapping.rank]
|
||||
trt_model.lm_head.weight.value = torch_to_numpy(split_weight)
|
||||
feed_weight_count += 1
|
||||
elif model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
weight = hf_model.transformer.output_layer.weight.to(
|
||||
torch_type).detach()
|
||||
if weight.shape[0] % mapping.tp_size != 0:
|
||||
pad_width = trt_model.lm_head.out_features * mapping.tp_size - weight.shape[
|
||||
0]
|
||||
weight = F.pad(weight, (0, 0, 0, pad_width))
|
||||
split_weight = torch.chunk(weight, mapping.tp_size,
|
||||
dim=0)[mapping.rank]
|
||||
trt_model.lm_head.weight.value = torch_to_numpy(split_weight)
|
||||
feed_weight_count += 1
|
||||
elif model_name in ["glm_10b"]:
|
||||
weight = hf_model.word_embeddings.weight.to(torch_type).detach()
|
||||
if weight.shape[0] % mapping.tp_size != 0:
|
||||
pad_width = trt_model.lm_head.out_features * mapping.tp_size - weight.shape[
|
||||
0]
|
||||
weight = F.pad(weight, (0, 0, 0, pad_width))
|
||||
split_weight = torch.chunk(weight, mapping.tp_size,
|
||||
dim=0)[mapping.rank]
|
||||
trt_model.lm_head.weight.value = torch_to_numpy(split_weight)
|
||||
feed_weight_count += 1
|
||||
|
||||
# Weight per layer
|
||||
for layer_idx in range(num_layers):
|
||||
if layer_idx not in layers_range:
|
||||
continue
|
||||
i = int(layer_idx) - mapping.pp_rank * layers_per_pipeline_stage
|
||||
if i >= num_layers:
|
||||
continue
|
||||
|
||||
# Pre normalization
|
||||
if model_name in ["chatglm_6b"]:
|
||||
weight = hf_model.transformer.layers[i].input_layernorm.weight.to(
|
||||
torch_type).detach()
|
||||
trt_model.layers[i].pre_norm.weight.value = torch_to_numpy(weight)
|
||||
bias = hf_model.transformer.layers[i].input_layernorm.bias.to(
|
||||
torch_type).detach()
|
||||
trt_model.layers[i].pre_norm.bias.value = torch_to_numpy(bias)
|
||||
feed_weight_count += 2
|
||||
elif model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
weight = hf_model.transformer.encoder.layers[
|
||||
i].input_layernorm.weight.to(torch_type).detach()
|
||||
trt_model.layers[i].pre_norm.weight.value = torch_to_numpy(weight)
|
||||
feed_weight_count += 1
|
||||
elif model_name in ["glm_10b"]:
|
||||
weight = hf_model.transformer.layers[i].input_layernorm.weight.to(
|
||||
torch_type).detach()
|
||||
trt_model.layers[i].pre_norm.weight.value = torch_to_numpy(weight)
|
||||
bias = hf_model.transformer.layers[i].input_layernorm.bias.to(
|
||||
torch_type).detach()
|
||||
trt_model.layers[i].pre_norm.bias.value = torch_to_numpy(bias)
|
||||
feed_weight_count += 2
|
||||
|
||||
# QKV multiplication weight
|
||||
if model_name in ["chatglm_6b"]:
|
||||
weight = hf_model.transformer.layers[
|
||||
i].attention.query_key_value.weight.to(torch_type).detach()
|
||||
elif model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
weight = hf_model.transformer.encoder.layers[
|
||||
i].self_attention.query_key_value.weight.to(
|
||||
torch_type).detach()
|
||||
elif model_name in ["glm_10b"]:
|
||||
weight = hf_model.transformer.layers[
|
||||
i].attention.query_key_value.weight.to(torch_type).detach()
|
||||
|
||||
split_weight = split_qkv(weight, mapping.tp_size, mapping.tp_rank,
|
||||
hidden_size, num_heads, num_kv_heads)
|
||||
dst = trt_model.layers[i].attention.qkv
|
||||
if use_weight_only:
|
||||
load_quant_weight(
|
||||
src=split_weight,
|
||||
value_dst=dst.weight,
|
||||
scale_dst=dst.per_channel_scale,
|
||||
plugin_weight_only_quant_type=plugin_weight_only_quant_type)
|
||||
else:
|
||||
dst.weight.value = torch_to_numpy(split_weight)
|
||||
feed_weight_count += 1
|
||||
|
||||
# QKV multiplication bias
|
||||
if model_name in ["chatglm_6b"]:
|
||||
bias = hf_model.transformer.layers[
|
||||
i].attention.query_key_value.bias.to(torch_type).detach()
|
||||
elif model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
bias = hf_model.transformer.encoder.layers[
|
||||
i].self_attention.query_key_value.bias.to(torch_type).detach()
|
||||
elif model_name in ["glm_10b"]:
|
||||
bias = hf_model.transformer.layers[
|
||||
i].attention.query_key_value.bias.to(torch_type).detach()
|
||||
|
||||
split_bias = split_qkv(bias, mapping.tp_size, mapping.tp_rank,
|
||||
hidden_size, num_heads, num_kv_heads)
|
||||
trt_model.layers[i].attention.qkv.bias.value = torch_to_numpy(
|
||||
split_bias)
|
||||
feed_weight_count += 1
|
||||
|
||||
# Dense multiplication weight
|
||||
if model_name in ["chatglm_6b"]:
|
||||
weight = hf_model.transformer.layers[i].attention.dense.weight.to(
|
||||
torch_type).detach()
|
||||
elif model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
weight = hf_model.transformer.encoder.layers[
|
||||
i].self_attention.dense.weight.to(torch_type).detach()
|
||||
elif model_name in ["glm_10b"]:
|
||||
weight = hf_model.transformer.layers[i].attention.dense.weight.to(
|
||||
torch_type).detach()
|
||||
|
||||
split_weight = torch.chunk(weight, mapping.tp_size, dim=1)[mapping.rank]
|
||||
dst = trt_model.layers[i].attention.dense
|
||||
if use_weight_only:
|
||||
load_quant_weight(
|
||||
src=split_weight,
|
||||
value_dst=dst.weight,
|
||||
scale_dst=dst.per_channel_scale,
|
||||
plugin_weight_only_quant_type=plugin_weight_only_quant_type)
|
||||
else:
|
||||
dst.weight.value = np.ascontiguousarray(
|
||||
torch_to_numpy(split_weight))
|
||||
feed_weight_count += 1
|
||||
|
||||
# Dense multiplication bias, only GLM-10B
|
||||
if model_name in ["glm_10b", "chatglm_6b"]:
|
||||
bias = hf_model.transformer.layers[i].attention.dense.bias.to(
|
||||
torch_type).detach()
|
||||
split_bias = split_qkv(bias, mapping.tp_size, mapping.tp_rank,
|
||||
hidden_size, num_heads, num_kv_heads)
|
||||
trt_model.layers[i].attention.dense.bias.value = torch_to_numpy(
|
||||
split_bias)
|
||||
feed_weight_count += 1
|
||||
|
||||
# Post normalization
|
||||
if model_name in ["chatglm_6b"]:
|
||||
weight = hf_model.transformer.layers[
|
||||
i].post_attention_layernorm.weight.to(torch_type).detach()
|
||||
trt_model.layers[i].post_norm.weight.value = torch_to_numpy(weight)
|
||||
bias = hf_model.transformer.layers[
|
||||
i].post_attention_layernorm.bias.to(torch_type).detach()
|
||||
trt_model.layers[i].post_norm.bias.value = torch_to_numpy(bias)
|
||||
feed_weight_count += 2
|
||||
elif model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
weight = hf_model.transformer.encoder.layers[
|
||||
i].post_attention_layernorm.weight.to(torch_type).detach()
|
||||
trt_model.layers[i].post_norm.weight.value = torch_to_numpy(weight)
|
||||
feed_weight_count += 1
|
||||
elif model_name in ["glm_10b"]:
|
||||
weight = hf_model.transformer.layers[
|
||||
i].post_attention_layernorm.weight.to(torch_type).detach()
|
||||
trt_model.layers[i].post_norm.weight.value = torch_to_numpy(weight)
|
||||
bias = hf_model.transformer.layers[
|
||||
i].post_attention_layernorm.bias.to(torch_type).detach()
|
||||
trt_model.layers[i].post_norm.bias.value = torch_to_numpy(bias)
|
||||
feed_weight_count += 2
|
||||
|
||||
# Multilayer perceptron h -> 4h weight
|
||||
if model_name in ["chatglm_6b"]:
|
||||
weight = hf_model.transformer.layers[i].mlp.dense_h_to_4h.weight.to(
|
||||
torch_type).detach()
|
||||
split_weight = torch.chunk(weight, mapping.tp_size,
|
||||
dim=0)[mapping.rank]
|
||||
elif model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
weight = hf_model.transformer.encoder.layers[
|
||||
i].mlp.dense_h_to_4h.weight.to(torch_type).detach()
|
||||
split_weight = torch.chunk(weight, 2 * mapping.tp_size, dim=0)
|
||||
# swap first and second half weight in columns to adapt trt_llm Swiglu
|
||||
split_weight = torch.cat(
|
||||
[
|
||||
split_weight[mapping.rank + mapping.tp_size],
|
||||
split_weight[mapping.rank],
|
||||
],
|
||||
dim=0,
|
||||
)
|
||||
elif model_name in ["glm_10b"]:
|
||||
weight = hf_model.transformer.layers[i].mlp.dense_h_to_4h.weight.to(
|
||||
torch_type).detach()
|
||||
split_weight = torch.chunk(weight, mapping.tp_size,
|
||||
dim=0)[mapping.rank]
|
||||
|
||||
dst = trt_model.layers[i].mlp.fc
|
||||
if use_weight_only:
|
||||
load_quant_weight(
|
||||
src=split_weight,
|
||||
value_dst=dst.weight,
|
||||
scale_dst=dst.per_channel_scale,
|
||||
plugin_weight_only_quant_type=plugin_weight_only_quant_type)
|
||||
else:
|
||||
dst.weight.value = torch_to_numpy(split_weight)
|
||||
feed_weight_count += 1
|
||||
|
||||
# Multilayer perceptron h -> 4h bias, only GLM-10B
|
||||
if model_name in ["glm_10b", "chatglm_6b"]:
|
||||
bias = hf_model.transformer.layers[i].mlp.dense_h_to_4h.bias.to(
|
||||
torch_type).detach()
|
||||
split_bias = split_qkv(bias, mapping.tp_size, mapping.tp_rank,
|
||||
hidden_size, num_heads, num_kv_heads)
|
||||
trt_model.layers[i].mlp.fc.bias.value = torch_to_numpy(split_bias)
|
||||
feed_weight_count += 1
|
||||
|
||||
# Multilayer perceptron 4h -> h weight
|
||||
if model_name in ["chatglm_6b"]:
|
||||
weight = hf_model.transformer.layers[i].mlp.dense_4h_to_h.weight.to(
|
||||
torch_type).detach()
|
||||
elif model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
weight = hf_model.transformer.encoder.layers[
|
||||
i].mlp.dense_4h_to_h.weight.to(torch_type).detach()
|
||||
elif model_name in ["glm_10b"]:
|
||||
weight = hf_model.transformer.layers[i].mlp.dense_4h_to_h.weight.to(
|
||||
torch_type).detach()
|
||||
|
||||
split_weight = torch.chunk(weight, mapping.tp_size, dim=1)[mapping.rank]
|
||||
dst = trt_model.layers[i].mlp.proj
|
||||
if use_weight_only:
|
||||
load_quant_weight(
|
||||
src=split_weight,
|
||||
value_dst=dst.weight,
|
||||
scale_dst=dst.per_channel_scale,
|
||||
plugin_weight_only_quant_type=plugin_weight_only_quant_type)
|
||||
else:
|
||||
dst.weight.value = np.ascontiguousarray(
|
||||
torch_to_numpy(split_weight))
|
||||
feed_weight_count += 1
|
||||
|
||||
# Multilayer perceptron 4h -> h bias, only GLM-10B
|
||||
if model_name in ["glm_10b", "chatglm_6b"]:
|
||||
bias = hf_model.transformer.layers[i].mlp.dense_4h_to_h.bias.to(
|
||||
torch_type).detach()
|
||||
split_bias = split_qkv(bias, mapping.tp_size, mapping.tp_rank,
|
||||
hidden_size, num_heads, num_kv_heads)
|
||||
trt_model.layers[i].mlp.proj.bias.value = torch_to_numpy(split_bias)
|
||||
feed_weight_count += 1
|
||||
|
||||
del hf_model
|
||||
tok = time.time()
|
||||
|
||||
# Final check
|
||||
if model_name in ["chatglm_6b"]:
|
||||
weight_count = 4 + num_layers * 9
|
||||
elif model_name in [
|
||||
"chatglm2_6b",
|
||||
"chatglm2_6b_32k",
|
||||
"chatglm3_6b",
|
||||
"chatglm3_6b_base",
|
||||
"chatglm3_6b_32k",
|
||||
]:
|
||||
weight_count = 3 + num_layers * 7
|
||||
elif model_name in ["glm_10b"]:
|
||||
weight_count = 6 + num_layers * 12
|
||||
if feed_weight_count < weight_count:
|
||||
tensorrt_llm.logger.error("%d weights not loaded from HF" %
|
||||
(weight_count - feed_weight_count))
|
||||
return None
|
||||
tensorrt_llm.logger.info("Loading weights finish in %.2fs" % (tok - tik))
|
||||
return trt_model
|
||||
|
||||
|
||||
def get_scaling_factors(
|
||||
model_path: Union[str, Path],
|
||||
num_layers: int,
|
||||
quant_mode: Optional[QuantMode] = None,
|
||||
) -> Optional[Dict[str, List[int]]]:
|
||||
""" Get the scaling factors for Falcon model
|
||||
|
||||
Returns a dictionary of scaling factors for the selected layers of the
|
||||
Falcon model.
|
||||
|
||||
Args:
|
||||
model_path (str): Path to the quantized Falcon model
|
||||
layers (list): List of layers to get the scaling factors for. If None,
|
||||
all layers are selected.
|
||||
|
||||
Returns:
|
||||
dict: Dictionary of scaling factors for the selected layers of the
|
||||
Falcon model.
|
||||
|
||||
example:
|
||||
|
||||
{
|
||||
'qkv_act': qkv_act_scale,
|
||||
'qkv_weights': qkv_weights_scale,
|
||||
'qkv_out' : qkv_outputs_scale,
|
||||
'dense_act': dense_act_scale,
|
||||
'dense_weights': dense_weights_scale,
|
||||
'fc_act': fc_act_scale,
|
||||
'fc_weights': fc_weights_scale,
|
||||
'proj_act': proj_act_scale,
|
||||
'proj_weights': proj_weights_scale,
|
||||
}
|
||||
"""
|
||||
|
||||
if model_path is None:
|
||||
logger.warning(f"--quantized_fp8_model_path not specified. "
|
||||
f"Initialize quantization scales automatically.")
|
||||
return get_dummy_quant_scales(num_layers)
|
||||
weight_dict = np.load(model_path)
|
||||
|
||||
# yapf: disable
|
||||
scaling_factor = {
|
||||
'qkv_act': [],
|
||||
'qkv_weights': [],
|
||||
'qkv_output': [],
|
||||
'dense_act': [],
|
||||
'dense_weights': [],
|
||||
'fc_act': [],
|
||||
'fc_weights': [],
|
||||
'proj_act': [],
|
||||
'proj_weights': [],
|
||||
}
|
||||
|
||||
for layer in range(num_layers):
|
||||
scaling_factor['qkv_act'].append(max(
|
||||
weight_dict[f'_np:layers:{layer}:attention:qkv:q:activation_scaling_factor'].item(),
|
||||
weight_dict[f'_np:layers:{layer}:attention:qkv:k:activation_scaling_factor'].item(),
|
||||
weight_dict[f'_np:layers:{layer}:attention:qkv:v:activation_scaling_factor'].item()
|
||||
))
|
||||
scaling_factor['qkv_weights'].append(max(
|
||||
weight_dict[f'_np:layers:{layer}:attention:qkv:q:weights_scaling_factor'].item(),
|
||||
weight_dict[f'_np:layers:{layer}:attention:qkv:k:weights_scaling_factor'].item(),
|
||||
weight_dict[f'_np:layers:{layer}:attention:qkv:v:weights_scaling_factor'].item()
|
||||
))
|
||||
if quant_mode is not None and quant_mode.has_fp8_kv_cache():
|
||||
# Not calibrarting KV cache.
|
||||
scaling_factor['qkv_output'].append(1.0)
|
||||
scaling_factor['dense_act'].append(weight_dict[f'_np:layers:{layer}:attention:dense:activation_scaling_factor'].item())
|
||||
scaling_factor['dense_weights'].append(weight_dict[f'_np:layers:{layer}:attention:dense:weights_scaling_factor'].item())
|
||||
scaling_factor['fc_act'].append(weight_dict[f'_np:layers:{layer}:mlp:fc:activation_scaling_factor'].item())
|
||||
scaling_factor['fc_weights'].append(weight_dict[f'_np:layers:{layer}:mlp:fc:weights_scaling_factor'].item())
|
||||
scaling_factor['proj_act'].append(weight_dict[f'_np:layers:{layer}:mlp:proj:activation_scaling_factor'].item())
|
||||
scaling_factor['proj_weights'].append(weight_dict[f'_np:layers:{layer}:mlp:proj:weights_scaling_factor'].item())
|
||||
# yapf: enable
|
||||
for k, v in scaling_factor.items():
|
||||
assert len(v) == num_layers, \
|
||||
f'Expect scaling factor {k} of length {num_layers}, got {len(v)}'
|
||||
|
||||
return scaling_factor
|
||||
5
examples/gptj/.gitignore
vendored
Normal file
5
examples/gptj/.gitignore
vendored
Normal file
@@ -0,0 +1,5 @@
|
||||
__pycache__/
|
||||
gptj_model/
|
||||
*.log
|
||||
*.txt
|
||||
*.json
|
||||
77
examples/gptj/README.md
Normal file
77
examples/gptj/README.md
Normal file
@@ -0,0 +1,77 @@
|
||||
# GPT-J
|
||||
|
||||
This document explains how to build the [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6b) model using XTRT-LLM and run on a single XPU.
|
||||
|
||||
## Overview
|
||||
|
||||
The XTRT-LLM GPT-J example
|
||||
code is located in [`examples/gptj`](./). There are several main files in that folder:
|
||||
|
||||
* [`build.py`](./build.py) to build the [XTRT] engine(s) needed to run the GPT-J model,
|
||||
* [`run.py`](./run.py) to run the inference on an input text,
|
||||
|
||||
## Support Matrix
|
||||
* FP16
|
||||
|
||||
## Usage
|
||||
|
||||
### 1. Download weights from HuggingFace (HF) Transformers
|
||||
|
||||
```bash
|
||||
# 1. Weights & config
|
||||
git clone https://huggingface.co/EleutherAI/gpt-j-6b ./downloads/gptj-6b
|
||||
pushd ./downloads/gptj-6b && \
|
||||
rm -f pytorch_model.bin && \
|
||||
wget https://huggingface.co/EleutherAI/gpt-j-6b/resolve/main/pytorch_model.bin && \
|
||||
popd
|
||||
|
||||
# 2. Vocab and merge table
|
||||
wget https://huggingface.co/EleutherAI/gpt-j-6b/resolve/main/vocab.json
|
||||
wget https://huggingface.co/EleutherAI/gpt-j-6b/resolve/main/merges.txt
|
||||
```
|
||||
|
||||
### 2. Build XTRT engine(s)
|
||||
|
||||
XTRT-LLM builds XTRT engine(s) using a HF checkpoint. If no checkpoint directory is specified, XTRT-LLM will build engine(s) using
|
||||
dummy weights.
|
||||
|
||||
Examples of build invocations:
|
||||
|
||||
```bash
|
||||
# Build a float16 engine using HF weights.
|
||||
# Enable several XTRT-LLM plugins to increase runtime performance. It also helps with build time.
|
||||
|
||||
python3 build.py --dtype=float16 \
|
||||
--log_level=verbose \
|
||||
--enable_context_fmha \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--max_batch_size=32 \
|
||||
--max_input_len=1919 \
|
||||
--max_output_len=128 \
|
||||
--output_dir=./downloads/gptj-6b/trt_engines/fp16/1-XPU/ \
|
||||
--model_dir=./downloads/gptj-6b 2>&1 | tee build.log
|
||||
|
||||
# Build a float16 engine using dummy weights, useful for performance tests.
|
||||
# Enable several XTRT-LLM plugins to increase runtime performance. It also helps with build time.
|
||||
|
||||
python3 build.py --dtype=float16 \
|
||||
--log_level=verbose \
|
||||
--enable_context_fmha \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--max_batch_size=32 \
|
||||
--max_input_len=1919 \
|
||||
--max_output_len=128 \
|
||||
--output_dir=./downloads/gptj-6b/trt_engines/gptj_engine_dummy_weights 2>&1 | tee build.log
|
||||
```
|
||||
|
||||
### 3. Run
|
||||
|
||||
To run a XTRT-LLM GPT-J model:
|
||||
|
||||
```bash
|
||||
python3 run.py --max_output_len=50 \
|
||||
--engine_dir=./downloads/gptj-6b/trt_engines/fp16/1-XPU/ \
|
||||
--hf_model_location=./downloads/gptj-6b
|
||||
```
|
||||
76
examples/gptj/README_CN.md
Normal file
76
examples/gptj/README_CN.md
Normal file
@@ -0,0 +1,76 @@
|
||||
# GPT-J
|
||||
|
||||
本文档介绍了如何使用昆仑芯XTRT-LLM在单XPU上构建和运行[GPT-J](https://huggingface.co/EleutherAI/gpt-j-6b)模型。
|
||||
|
||||
## 概述
|
||||
|
||||
XTRT-LLM GPT-J 示例代码位于 [`examples/gptj`](./)。 此文件夹中有以下几个主要文件:
|
||||
|
||||
* [`build.py`](./build.py) 构建运行GPT-J模型所需的XTRT引擎
|
||||
* [`run.py`](./run.py) 基于输入的文字进行推理
|
||||
|
||||
## 支持的矩阵
|
||||
|
||||
* FP16
|
||||
|
||||
## 使用说明
|
||||
|
||||
### 1.从HuggingFace(HF) Transformers下载权重
|
||||
|
||||
```bash
|
||||
# 1. Weights & config
|
||||
git clone https://huggingface.co/EleutherAI/gpt-j-6b ./downloads/gptj-6b
|
||||
pushd ./downloads/gptj-6b && \
|
||||
rm -f pytorch_model.bin && \
|
||||
wget https://huggingface.co/EleutherAI/gpt-j-6b/resolve/main/pytorch_model.bin && \
|
||||
popd
|
||||
|
||||
# 2. Vocab and merge table
|
||||
wget https://huggingface.co/EleutherAI/gpt-j-6b/resolve/main/vocab.json
|
||||
wget https://huggingface.co/EleutherAI/gpt-j-6b/resolve/main/merges.txt
|
||||
```
|
||||
|
||||
### 2. 构建XTRT引擎
|
||||
|
||||
XTRT-LLM从HF checkpoint构建XTRT引擎。如果未指定checkpoint目录,XTRT-LLM将使用伪权重构建引擎。
|
||||
|
||||
构建调用示例:
|
||||
|
||||
```bash
|
||||
# Build a float16 engine using HF weights.
|
||||
# Enable several XTRT-LLM plugins to increase runtime performance. It also helps with build time.
|
||||
|
||||
python3 build.py --dtype=float16 \
|
||||
--log_level=verbose \
|
||||
--enable_context_fmha \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--max_batch_size=32 \
|
||||
--max_input_len=1919 \
|
||||
--max_output_len=128 \
|
||||
--output_dir=./downloads/gptj-6b/trt_engines/fp16/1-XPU/ \
|
||||
--model_dir=./downloads/gptj-6b 2>&1 | tee build.log
|
||||
|
||||
# Build a float16 engine using dummy weights, useful for performance tests.
|
||||
# Enable several XTRT-LLM plugins to increase runtime performance. It also helps with build time.
|
||||
|
||||
python3 build.py --dtype=float16 \
|
||||
--log_level=verbose \
|
||||
--enable_context_fmha \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--max_batch_size=32 \
|
||||
--max_input_len=1919 \
|
||||
--max_output_len=128 \
|
||||
--output_dir=./downloads/gptj-6b/trt_engines/gptj_engine_dummy_weights 2>&1 | tee build.log
|
||||
```
|
||||
|
||||
### 3. 运行
|
||||
|
||||
要运行XTRT-LLM GPT-J模型,请执行以下操作:
|
||||
|
||||
```bash
|
||||
python3 run.py --max_output_len=50 \
|
||||
--engine_dir=./downloads/gptj-6b/trt_engines/fp16/1-XPU/ \
|
||||
--hf_model_location=./downloads/gptj-6b
|
||||
```
|
||||
489
examples/gptj/build.py
Normal file
489
examples/gptj/build.py
Normal file
@@ -0,0 +1,489 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import time
|
||||
|
||||
import tvm.tensorrt as trt
|
||||
import torch
|
||||
import torch.multiprocessing as mp
|
||||
from transformers import AutoModelForCausalLM
|
||||
from weight import get_scaling_factors, load_from_awq_gpt_j, load_from_hf_gpt_j
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm.builder import Builder
|
||||
from xtrt_llm.logger import logger
|
||||
from xtrt_llm.mapping import Mapping
|
||||
from xtrt_llm.models import (weight_only_groupwise_quantize,
|
||||
weight_only_quantize)
|
||||
from xtrt_llm.network import net_guard
|
||||
from xtrt_llm.plugin.plugin import ContextFMHAType
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
MODEL_NAME = "gptj"
|
||||
hf_gpt = None
|
||||
awq_gptj_config = None
|
||||
|
||||
|
||||
def get_engine_name(model, dtype, tp_size, rank):
|
||||
return '{}_{}_tp{}_rank{}.engine'.format(model, dtype, tp_size, rank)
|
||||
|
||||
|
||||
def serialize_engine(engine, path):
|
||||
logger.info(f'Serializing engine to {path}...')
|
||||
tik = time.time()
|
||||
engine.serialize(path)
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Engine serialized. Total time: {t}')
|
||||
|
||||
|
||||
def parse_arguments(args):
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--world_size',
|
||||
type=int,
|
||||
default=1,
|
||||
help='world size, only support tensor parallelism now')
|
||||
parser.add_argument(
|
||||
'--model_dir',
|
||||
type=str,
|
||||
default=None,
|
||||
help='The path to HF GPT-J model / checkpoints to read weights from')
|
||||
parser.add_argument('--dtype',
|
||||
type=str,
|
||||
default='float16',
|
||||
choices=['float16', 'float32'])
|
||||
parser.add_argument('--logits_dtype',
|
||||
type=str,
|
||||
default='float32',
|
||||
choices=['float16', 'float32'])
|
||||
parser.add_argument(
|
||||
'--timing_cache',
|
||||
type=str,
|
||||
default='model.cache',
|
||||
help=
|
||||
'The path of to read timing cache from, will be ignored if the file does not exist'
|
||||
)
|
||||
parser.add_argument('--log_level', type=str, default='info')
|
||||
parser.add_argument('--vocab_size', type=int, default=50401)
|
||||
parser.add_argument('--n_layer', type=int, default=28)
|
||||
parser.add_argument('--n_positions', type=int, default=2048)
|
||||
parser.add_argument('--n_embd', type=int, default=4096)
|
||||
parser.add_argument('--n_head', type=int, default=16)
|
||||
parser.add_argument('--hidden_act', type=str, default='gelu')
|
||||
parser.add_argument('--rotary_dim', type=int, default=64)
|
||||
parser.add_argument('--max_batch_size', type=int, default=256)
|
||||
parser.add_argument('--max_input_len', type=int, default=200)
|
||||
parser.add_argument('--max_output_len', type=int, default=200)
|
||||
parser.add_argument('--max_beam_width', type=int, default=1)
|
||||
parser.add_argument('--use_gpt_attention_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
choices=['float16', 'float32'])
|
||||
parser.add_argument('--use_gemm_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
choices=['float16', 'float32'])
|
||||
parser.add_argument('--use_weight_only_quant_matmul_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
choices=['float16'])
|
||||
parser.add_argument('--use_layernorm_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
choices=['float16', 'float32'])
|
||||
parser.add_argument('--parallel_build', default=False, action='store_true')
|
||||
parser.add_argument('--enable_context_fmha',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--enable_context_fmha_fp32_acc',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--gpus_per_node', type=int, default=8)
|
||||
parser.add_argument(
|
||||
'--output_dir',
|
||||
type=str,
|
||||
default='gpt_outputs',
|
||||
help=
|
||||
'The path to save the serialized engine files, timing cache file and model configs'
|
||||
)
|
||||
parser.add_argument('--remove_input_padding',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--enable_fp8', default=False, action='store_true')
|
||||
parser.add_argument(
|
||||
'--quantized_fp8_model_path',
|
||||
type=str,
|
||||
default=None,
|
||||
help='Path of a quantized model checkpoint that in .npz format')
|
||||
parser.add_argument(
|
||||
'--fp8_kv_cache',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use dtype for KV cache. fp8_kv_cache chooses fp8 quantization for KV'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_inflight_batching',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Activates inflight batching mode of gptAttentionPlugin.")
|
||||
parser.add_argument(
|
||||
'--enable_two_optimization_profiles',
|
||||
default=False,
|
||||
action='store_true',
|
||||
help=
|
||||
"Enables two optimization profiles during engine build, for context and generate phases. By default (and for inflight batching too), only 1 opt profile."
|
||||
)
|
||||
parser.add_argument(
|
||||
'--paged_kv_cache',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help=
|
||||
'By default we use contiguous KV cache. By setting this flag you enable paged KV cache'
|
||||
)
|
||||
parser.add_argument('--tokens_per_block',
|
||||
type=int,
|
||||
default=64,
|
||||
help='Number of tokens per block in paged KV cache')
|
||||
parser.add_argument(
|
||||
'--max_num_tokens',
|
||||
type=int,
|
||||
default=None,
|
||||
help='Define the max number of tokens supported by the engine')
|
||||
parser.add_argument(
|
||||
'--per_group',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use a single static scaling factor to scale weights in the int4 range. '
|
||||
'per_group chooses at run time, and for each group, a custom scaling factor. '
|
||||
'The falg is built for GPTQ/AWQ quantization.')
|
||||
parser.add_argument(
|
||||
'--use_weight_only',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help='Quantize weights for the various GEMMs to INT4/INT8.'
|
||||
'See --weight_only_precision to set the precision')
|
||||
parser.add_argument(
|
||||
'--weight_only_precision',
|
||||
const='int8',
|
||||
type=str,
|
||||
nargs='?',
|
||||
default='int8',
|
||||
choices=['int8', 'int4'],
|
||||
help=
|
||||
'Define the precision for the weights when using weight-only quantization.'
|
||||
'You must also use --use_weight_only for that argument to have an impact.'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--strongly_typed',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'This option is introduced with trt 9.1.0.1+ and will reduce the building time significantly for fp8.'
|
||||
)
|
||||
args = parser.parse_args(args)
|
||||
|
||||
logger.set_level(args.log_level)
|
||||
|
||||
if not args.remove_input_padding:
|
||||
if args.use_gpt_attention_plugin:
|
||||
logger.warning(
|
||||
f"It is recommended to specify --remove_input_padding when using GPT attention plugin"
|
||||
)
|
||||
|
||||
if args.model_dir is not None:
|
||||
global hf_gpt
|
||||
if args.use_weight_only and args.weight_only_precision == 'int4' and args.per_group:
|
||||
logger.info(f'Loading AWQ GPTJ model from {args.model_dir}...')
|
||||
global awq_gptj_config
|
||||
with open(args.model_dir + "/config.json",
|
||||
encoding='utf-8') as config_file:
|
||||
awq_gptj_config = json.load(config_file)
|
||||
args.n_embd = awq_gptj_config['n_embd']
|
||||
args.n_head = awq_gptj_config['n_head']
|
||||
args.n_layer = awq_gptj_config['n_layer']
|
||||
args.n_positions = awq_gptj_config['n_positions']
|
||||
args.vocab_size = awq_gptj_config['vocab_size']
|
||||
if args.vocab_size % 64 != 0:
|
||||
args.vocab_size = int(
|
||||
(awq_gptj_config['vocab_size'] + 63) / 64) * 64
|
||||
print(
|
||||
"vocab_size is {}, to use awq we pad it to {}.".format(
|
||||
awq_gptj_config['vocab_size'], args.vocab_size))
|
||||
hf_gpt = torch.load(args.model_dir + "/gptj_quantized.pth")
|
||||
else:
|
||||
logger.info(f'Loading HF GPTJ model from {args.model_dir}...')
|
||||
hf_gpt = AutoModelForCausalLM.from_pretrained(args.model_dir)
|
||||
args.n_embd = hf_gpt.config.n_embd
|
||||
args.n_head = hf_gpt.config.n_head
|
||||
args.n_layer = hf_gpt.config.n_layer
|
||||
args.n_positions = hf_gpt.config.n_positions
|
||||
args.vocab_size = hf_gpt.config.vocab_size
|
||||
|
||||
assert not (args.use_weight_only and args.weight_only_precision
|
||||
== 'int8'), "Not support int8 weight only."
|
||||
|
||||
assert not (args.use_weight_only and args.weight_only_precision == 'int4'
|
||||
and args.per_group
|
||||
== False), "We only support AWQ for int4 weight only."
|
||||
|
||||
if args.use_weight_only:
|
||||
args.quant_mode = QuantMode.use_weight_only(
|
||||
args.weight_only_precision == 'int4')
|
||||
else:
|
||||
args.quant_mode = QuantMode(0)
|
||||
|
||||
if args.fp8_kv_cache:
|
||||
assert (
|
||||
args.use_gpt_attention_plugin
|
||||
), "You have to use GPT attention plugin when fp8 KV cache is set"
|
||||
args.quant_mode = args.quant_mode.set_fp8_kv_cache()
|
||||
|
||||
if args.enable_fp8:
|
||||
args.quant_mode = args.quant_mode.set_fp8_qdq()
|
||||
|
||||
if args.use_inflight_batching:
|
||||
if not args.use_gpt_attention_plugin:
|
||||
args.use_gpt_attention_plugin = 'float16'
|
||||
logger.info(
|
||||
f"Using GPT attention plugin for inflight batching mode. Setting to default '{args.use_gpt_attention_plugin}'"
|
||||
)
|
||||
if not args.remove_input_padding:
|
||||
args.remove_input_padding = True
|
||||
logger.info(
|
||||
"Using remove input padding for inflight batching mode.")
|
||||
if not args.paged_kv_cache:
|
||||
args.paged_kv_cache = True
|
||||
logger.info("Using paged KV cache for inflight batching mode.")
|
||||
|
||||
if args.max_num_tokens is not None:
|
||||
assert args.enable_context_fmha
|
||||
|
||||
if args.remove_input_padding or args.use_inflight_batching or args.paged_kv_cache:
|
||||
assert (
|
||||
not args.enable_two_optimization_profiles
|
||||
), "Only 1 opt profile supported for inflight batching and paged kv cache."
|
||||
|
||||
return args
|
||||
|
||||
|
||||
def build_rank_engine(builder: Builder,
|
||||
builder_config: xtrt_llm.builder.BuilderConfig,
|
||||
engine_name, rank, args):
|
||||
'''
|
||||
@brief: Build the engine on the given rank.
|
||||
@param rank: The rank to build the engine.
|
||||
@param args: The cmd line arguments.
|
||||
@return: The built engine.
|
||||
'''
|
||||
kv_dtype = trt.float16 if args.dtype == 'float16' else trt.float32
|
||||
|
||||
# Initialize Module
|
||||
xtrt_llm_gpt = xtrt_llm.models.GPTJForCausalLM(
|
||||
num_layers=args.n_layer,
|
||||
num_heads=args.n_head,
|
||||
hidden_size=args.n_embd,
|
||||
vocab_size=args.vocab_size,
|
||||
hidden_act=args.hidden_act,
|
||||
max_position_embeddings=args.n_positions,
|
||||
rotary_dim=args.rotary_dim,
|
||||
dtype=kv_dtype,
|
||||
logits_dtype=args.logits_dtype,
|
||||
mapping=Mapping(world_size=args.world_size,
|
||||
rank=rank,
|
||||
tp_size=args.world_size), # TP only
|
||||
quant_mode=args.quant_mode)
|
||||
if args.use_weight_only_quant_matmul_plugin:
|
||||
xtrt_llm_gpt = weight_only_quantize(xtrt_llm_gpt)
|
||||
if args.use_weight_only and args.weight_only_precision == 'int4':
|
||||
if args.per_group:
|
||||
xtrt_llm_gpt = weight_only_groupwise_quantize(
|
||||
model=xtrt_llm_gpt,
|
||||
quant_mode=QuantMode.from_description(
|
||||
quantize_weights=True,
|
||||
quantize_activations=False,
|
||||
per_token=False,
|
||||
per_channel=False,
|
||||
per_group=True,
|
||||
use_int4_weights=True),
|
||||
group_size=128,
|
||||
zero=False,
|
||||
pre_quant_scale=True,
|
||||
exclude_modules=[],
|
||||
)
|
||||
if args.model_dir is not None:
|
||||
assert hf_gpt is not None, f'Could not load weights from hf_gpt model as it is not loaded yet.'
|
||||
if args.enable_fp8:
|
||||
gptj_scaling_factors = get_scaling_factors(
|
||||
args.quantized_fp8_model_path, args.n_layer, args.quant_mode)
|
||||
else:
|
||||
gptj_scaling_factors = None
|
||||
if args.use_weight_only and args.weight_only_precision == 'int4' and args.per_group:
|
||||
load_from_awq_gpt_j(xtrt_llm_gpt,
|
||||
awq_gpt_j=hf_gpt,
|
||||
config=awq_gptj_config,
|
||||
dtype=args.dtype)
|
||||
else:
|
||||
load_from_hf_gpt_j(xtrt_llm_gpt,
|
||||
hf_gpt,
|
||||
args.dtype,
|
||||
scaling_factors=gptj_scaling_factors)
|
||||
|
||||
# Module -> Network
|
||||
network = builder.create_network()
|
||||
network.trt_network.name = engine_name
|
||||
if args.use_gpt_attention_plugin:
|
||||
network.plugin_config.set_gpt_attention_plugin(
|
||||
dtype=args.use_gpt_attention_plugin)
|
||||
if args.use_gemm_plugin:
|
||||
network.plugin_config.set_gemm_plugin(dtype=args.use_gemm_plugin)
|
||||
if args.use_layernorm_plugin:
|
||||
network.plugin_config.set_layernorm_plugin(
|
||||
dtype=args.use_layernorm_plugin)
|
||||
assert not (args.enable_context_fmha and args.enable_context_fmha_fp32_acc)
|
||||
if args.enable_context_fmha:
|
||||
network.plugin_config.set_context_fmha(ContextFMHAType.enabled)
|
||||
if args.enable_context_fmha_fp32_acc:
|
||||
network.plugin_config.set_context_fmha(
|
||||
ContextFMHAType.enabled_with_fp32_acc)
|
||||
if args.use_weight_only_quant_matmul_plugin:
|
||||
network.plugin_config.set_weight_only_quant_matmul_plugin(
|
||||
dtype=args.use_weight_only_quant_matmul_plugin)
|
||||
if args.use_weight_only:
|
||||
if args.per_group:
|
||||
network.plugin_config.set_weight_only_groupwise_quant_matmul_plugin(
|
||||
dtype='float16')
|
||||
if args.world_size > 1:
|
||||
network.plugin_config.set_nccl_plugin(args.dtype)
|
||||
if args.remove_input_padding:
|
||||
network.plugin_config.enable_remove_input_padding()
|
||||
if args.paged_kv_cache:
|
||||
network.plugin_config.enable_paged_kv_cache(args.tokens_per_block)
|
||||
|
||||
with net_guard(network):
|
||||
# Prepare
|
||||
network.set_named_parameters(xtrt_llm_gpt.named_parameters())
|
||||
|
||||
# Forward
|
||||
inputs = xtrt_llm_gpt.prepare_inputs(
|
||||
args.max_batch_size,
|
||||
args.max_input_len,
|
||||
args.max_output_len,
|
||||
True,
|
||||
args.max_beam_width,
|
||||
max_num_tokens=args.max_num_tokens,
|
||||
enable_two_optimization_profiles=args.
|
||||
enable_two_optimization_profiles)
|
||||
xtrt_llm_gpt(*inputs)
|
||||
|
||||
# xtrt_llm.graph_rewriting.optimize(network)
|
||||
|
||||
engine = None
|
||||
|
||||
# Network -> Engine
|
||||
engine = builder.build_engine(network, builder_config, compiler="gr")
|
||||
if rank == 0:
|
||||
config_path = os.path.join(args.output_dir, 'config.json')
|
||||
builder.save_config(builder_config, config_path)
|
||||
return engine
|
||||
|
||||
|
||||
def build(rank, args):
|
||||
# torch.cuda.set_device(rank % args.gpus_per_node)
|
||||
xtrt_llm.logger.set_level(args.log_level)
|
||||
if not os.path.exists(args.output_dir):
|
||||
os.makedirs(args.output_dir)
|
||||
|
||||
# when doing serializing build, all ranks share one engine
|
||||
builder = Builder()
|
||||
|
||||
cache = None
|
||||
for cur_rank in range(args.world_size):
|
||||
# skip other ranks if parallel_build is enabled
|
||||
if args.parallel_build and cur_rank != rank:
|
||||
continue
|
||||
|
||||
builder_config = builder.create_builder_config(
|
||||
name=MODEL_NAME,
|
||||
precision=args.dtype,
|
||||
timing_cache=args.timing_cache if cache is None else cache,
|
||||
tensor_parallel=args.world_size, # TP only
|
||||
parallel_build=args.parallel_build,
|
||||
num_layers=args.n_layer,
|
||||
num_heads=args.n_head,
|
||||
hidden_size=args.n_embd,
|
||||
inter_size=args.n_embd * 4,
|
||||
vocab_size=args.vocab_size,
|
||||
hidden_act=args.hidden_act,
|
||||
max_position_embeddings=args.n_positions,
|
||||
max_batch_size=args.max_batch_size,
|
||||
max_input_len=args.max_input_len,
|
||||
max_output_len=args.max_output_len,
|
||||
max_num_tokens=args.max_num_tokens,
|
||||
fp8=args.enable_fp8,
|
||||
quant_mode=args.quant_mode,
|
||||
strongly_typed=args.strongly_typed)
|
||||
|
||||
engine_name = get_engine_name(MODEL_NAME, args.dtype, args.world_size,
|
||||
cur_rank)
|
||||
engine = build_rank_engine(builder, builder_config, engine_name,
|
||||
cur_rank, args)
|
||||
assert engine is not None, f'Failed to build engine for rank {cur_rank}'
|
||||
|
||||
# if cur_rank == 0:
|
||||
# # Use in-memory timing cache for multiple builder passes.
|
||||
# if not args.parallel_build:
|
||||
# cache = builder_config.xtrt_builder_config.get_timing_cache()
|
||||
|
||||
serialize_engine(engine, os.path.join(args.output_dir, engine_name))
|
||||
|
||||
# if rank == 0:
|
||||
# ok = builder.save_timing_cache(
|
||||
# builder_config, os.path.join(args.output_dir, "model.cache"))
|
||||
# assert ok, "Failed to save timing cache."
|
||||
|
||||
|
||||
def run_build(args=None):
|
||||
args = parse_arguments(args)
|
||||
tik = time.time()
|
||||
if args.parallel_build and args.world_size > 1 and \
|
||||
torch.cuda.device_count() >= args.world_size:
|
||||
logger.warning(
|
||||
f'Parallelly build TensorRT engines. Please make sure that all of the {args.world_size} GPUs are totally free.'
|
||||
)
|
||||
mp.spawn(build, nprocs=args.world_size, args=(args, ))
|
||||
else:
|
||||
args.parallel_build = False
|
||||
logger.info('Serially build TensorRT engines.')
|
||||
build(0, args)
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Total time of building all {args.world_size} engines: {t}')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
run_build()
|
||||
137
examples/gptj/quantize.py
Normal file
137
examples/gptj/quantize.py
Normal file
@@ -0,0 +1,137 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""
|
||||
Adapted from examples/quantization/hf_ptq.py
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import random
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from torch.utils.data import DataLoader
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
from xtrt_llm._utils import str_dtype_to_torch
|
||||
from xtrt_llm.logger import logger
|
||||
from xtrt_llm.models.quantized.ammo import quantize_and_export
|
||||
|
||||
|
||||
def get_calib_dataloader(data="cnn_dailymail",
|
||||
tokenizer=None,
|
||||
batch_size=1,
|
||||
calib_size=512,
|
||||
block_size=512):
|
||||
print("Loading calibration dataset")
|
||||
if data == "pileval":
|
||||
dataset = load_dataset(
|
||||
"json",
|
||||
data_files="https://the-eye.eu/public/AI/pile/val.jsonl.zst",
|
||||
split="train")
|
||||
dataset = dataset["text"][:calib_size]
|
||||
elif data == "cnn_dailymail":
|
||||
dataset = load_dataset("cnn_dailymail", name="3.0.0", split="train")
|
||||
dataset = dataset["article"][:calib_size]
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
# NOTE truncate dataset to n_positions for RoPE in GPT-J
|
||||
batch_encoded = tokenizer.batch_encode_plus(
|
||||
dataset,
|
||||
return_tensors="pt",
|
||||
padding=True,
|
||||
truncation=True,
|
||||
max_length=block_size,
|
||||
)
|
||||
batch_encoded = batch_encoded["input_ids"]
|
||||
batch_encoded = batch_encoded.cuda()
|
||||
|
||||
calib_dataloader = DataLoader(batch_encoded,
|
||||
batch_size=batch_size,
|
||||
shuffle=False)
|
||||
|
||||
return calib_dataloader
|
||||
|
||||
|
||||
def get_tokenizer(ckpt_path, **kwargs):
|
||||
logger.info(f"Loading tokenizer from {ckpt_path}")
|
||||
tokenizer = AutoTokenizer.from_pretrained(ckpt_path,
|
||||
padding_side="left",
|
||||
**kwargs)
|
||||
if tokenizer.pad_token is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
return tokenizer
|
||||
|
||||
|
||||
def get_model(ckpt_path, dtype="float16"):
|
||||
logger.info(f"Loading model from {ckpt_path}")
|
||||
torch_dtype = str_dtype_to_torch(dtype)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
ckpt_path,
|
||||
device_map="auto",
|
||||
trust_remote_code=True,
|
||||
torch_dtype=torch_dtype,
|
||||
)
|
||||
model.eval()
|
||||
model = model.to(memory_format=torch.channels_last)
|
||||
return model
|
||||
|
||||
|
||||
def get_args():
|
||||
parser = argparse.ArgumentParser(description=__doc__)
|
||||
parser.add_argument("--model_dir",
|
||||
type=str,
|
||||
required=True,
|
||||
help="Directory of a HF model checkpoint")
|
||||
parser.add_argument("--dtype", help="Model data type.", default="float16")
|
||||
parser.add_argument("--qformat",
|
||||
type=str,
|
||||
choices=['fp8'],
|
||||
default='fp8',
|
||||
help='Quantization format.')
|
||||
parser.add_argument("--calib_size",
|
||||
type=int,
|
||||
default=512,
|
||||
help="Number of samples for calibration.")
|
||||
parser.add_argument("--export_path", default="exported_model")
|
||||
parser.add_argument('--seed', type=int, default=None, help='Random seed')
|
||||
args = parser.parse_args()
|
||||
return args
|
||||
|
||||
|
||||
def main():
|
||||
if not torch.cuda.is_available():
|
||||
raise EnvironmentError("GPU is required for inference.")
|
||||
|
||||
args = get_args()
|
||||
|
||||
if args.seed is not None:
|
||||
random.seed(args.seed)
|
||||
np.random.seed(args.seed)
|
||||
|
||||
tokenizer = get_tokenizer(args.model_dir)
|
||||
model = get_model(args.model_dir, args.dtype)
|
||||
|
||||
calib_dataloader = get_calib_dataloader(tokenizer=tokenizer,
|
||||
calib_size=args.calib_size)
|
||||
model = quantize_and_export(model,
|
||||
qformat=args.qformat,
|
||||
calib_dataloader=calib_dataloader,
|
||||
export_path=args.export_path)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
284
examples/gptj/run.py
Normal file
284
examples/gptj/run.py
Normal file
@@ -0,0 +1,284 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import csv
|
||||
import json
|
||||
from pathlib import Path
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from utils import token_encoder
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
from xtrt_llm.runtime import ModelConfig, SamplingConfig
|
||||
|
||||
from build import get_engine_name # isort:skip
|
||||
|
||||
# GPT3 Related variables
|
||||
# Reference : https://github.com/NVIDIA/FasterTransformer/blob/main/sample/pytorch/gpt_sample.py
|
||||
MERGES_FILE = "merges.txt"
|
||||
VOCAB_FILE = "vocab.json"
|
||||
|
||||
PAD_ID = 50256
|
||||
START_ID = 50256
|
||||
END_ID = 50256
|
||||
|
||||
|
||||
def read_config(config_path: Path):
|
||||
with open(config_path, 'r') as f:
|
||||
config = json.load(f)
|
||||
use_gpt_attention_plugin = config['plugin_config']['gpt_attention_plugin']
|
||||
remove_input_padding = config['plugin_config']['remove_input_padding']
|
||||
world_size = config['builder_config']['tensor_parallel']
|
||||
assert world_size == xtrt_llm.mpi_world_size(), \
|
||||
f'Engine world size ({world_size}) != Runtime world size ({xtrt_llm.mpi_world_size()})'
|
||||
num_heads = config['builder_config']['num_heads'] // world_size
|
||||
hidden_size = config['builder_config']['hidden_size'] // world_size
|
||||
vocab_size = config['builder_config']['vocab_size']
|
||||
num_layers = config['builder_config']['num_layers']
|
||||
quant_mode = QuantMode(config['builder_config']['quant_mode'])
|
||||
paged_kv_cache = config['plugin_config']['paged_kv_cache']
|
||||
tokens_per_block = config['plugin_config']['tokens_per_block']
|
||||
dtype = config['builder_config']['precision']
|
||||
|
||||
model_config = ModelConfig(num_heads=num_heads,
|
||||
num_kv_heads=num_heads,
|
||||
hidden_size=hidden_size,
|
||||
vocab_size=vocab_size,
|
||||
num_layers=num_layers,
|
||||
gpt_attention_plugin=use_gpt_attention_plugin,
|
||||
remove_input_padding=remove_input_padding,
|
||||
paged_kv_cache=paged_kv_cache,
|
||||
tokens_per_block=tokens_per_block,
|
||||
quant_mode=quant_mode,
|
||||
dtype=dtype)
|
||||
|
||||
max_input_len = config['builder_config']['max_input_len']
|
||||
|
||||
return model_config, world_size, dtype, max_input_len
|
||||
|
||||
|
||||
def parse_input(input_text: str, input_file: str, tokenizer, pad_id: int,
|
||||
remove_input_padding: bool):
|
||||
input_tokens = []
|
||||
if input_file is None:
|
||||
input_tokens.append(tokenizer.encode(input_text))
|
||||
else:
|
||||
if input_file.endswith('.csv'):
|
||||
with open(input_file, 'r') as csv_file:
|
||||
csv_reader = csv.reader(csv_file, delimiter=',')
|
||||
for line in csv_reader:
|
||||
input_tokens.append(np.array(line, dtype='int32'))
|
||||
elif input_file.endswith('.npy'):
|
||||
inputs = np.load(input_file)
|
||||
for row in inputs:
|
||||
row = row[row != pad_id]
|
||||
input_tokens.append(row)
|
||||
else:
|
||||
print('Input file format not supported.')
|
||||
raise SystemExit
|
||||
|
||||
input_ids = None
|
||||
input_lengths = torch.tensor([len(x) for x in input_tokens],
|
||||
dtype=torch.int32).cuda()
|
||||
if remove_input_padding:
|
||||
input_ids = np.concatenate(input_tokens)
|
||||
input_ids = torch.tensor(input_ids, dtype=torch.int32,
|
||||
device='cuda').unsqueeze(0)
|
||||
else:
|
||||
input_ids = torch.nested.to_padded_tensor(
|
||||
torch.nested.nested_tensor(input_tokens, dtype=torch.int32),
|
||||
pad_id).cuda()
|
||||
|
||||
return input_ids, input_lengths
|
||||
|
||||
|
||||
def print_output(output_ids, cum_log_probs, input_lengths, sequence_lengths,
|
||||
tokenizer, output_csv, output_npy):
|
||||
|
||||
num_beams = output_ids.size(1)
|
||||
if output_csv is None and output_npy is None:
|
||||
for b in range(input_lengths.size(0)):
|
||||
inputs = output_ids[b][0][:input_lengths[b]].tolist()
|
||||
input_text = tokenizer.decode(inputs)
|
||||
print(f'Input idx: {b}')
|
||||
print(f'Input: \"{input_text}\"')
|
||||
for beam in range(num_beams):
|
||||
output_begin = input_lengths[b]
|
||||
output_end = sequence_lengths[b][beam]
|
||||
outputs = output_ids[b][beam][output_begin:output_end].tolist()
|
||||
output_text = tokenizer.decode(outputs)
|
||||
if num_beams > 1:
|
||||
cum_log_prob = cum_log_probs[b][beam]
|
||||
print(f'Output idx: {b}, beam {beam} (cum_log_prob: {cum_log_prob})')
|
||||
print(f'Output: \"{output_text}\"')
|
||||
else:
|
||||
print(f'Output idx:{b}')
|
||||
print(f'Output: \"{output_text}\"')
|
||||
|
||||
output_ids = output_ids.reshape((-1, output_ids.size(2)))
|
||||
|
||||
if output_csv is not None:
|
||||
output_file = Path(output_csv)
|
||||
output_file.parent.mkdir(exist_ok=True, parents=True)
|
||||
outputs = output_ids.tolist()
|
||||
with open(output_file, 'w') as csv_file:
|
||||
writer = csv.writer(csv_file, delimiter=',')
|
||||
writer.writerows(outputs)
|
||||
|
||||
if output_npy is not None:
|
||||
output_file = Path(output_npy)
|
||||
output_file.parent.mkdir(exist_ok=True, parents=True)
|
||||
outputs = np.array(output_ids.cpu().contiguous(), dtype='int32')
|
||||
np.save(output_file, outputs)
|
||||
|
||||
|
||||
def parse_arguments():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--max_output_len', type=int, required=True)
|
||||
parser.add_argument('--log_level', type=str, default='error')
|
||||
parser.add_argument('--engine_dir', type=str, default='gpt_outputs')
|
||||
parser.add_argument('--num_beams', type=int, default=1)
|
||||
parser.add_argument('--min_length', type=int, default=1)
|
||||
parser.add_argument('--input_text',
|
||||
type=str,
|
||||
default='Born in north-east France, Soyer trained as a')
|
||||
parser.add_argument(
|
||||
'--input_tokens',
|
||||
dest='input_file',
|
||||
type=str,
|
||||
help=
|
||||
'CSV or Numpy file containing tokenized input. Alternative to text input.',
|
||||
default=None)
|
||||
parser.add_argument('--output_csv',
|
||||
type=str,
|
||||
help='CSV file where the tokenized output is stored.',
|
||||
default=None)
|
||||
parser.add_argument('--output_npy',
|
||||
type=str,
|
||||
help='Numpy file where the tokenized output is stored.',
|
||||
default=None)
|
||||
parser.add_argument(
|
||||
'--hf_model_location',
|
||||
type=str,
|
||||
default="gptj_model",
|
||||
help=
|
||||
'The hugging face model location stores the merges.txt and vocab.json to create tokenizer'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--performance_test_scale',
|
||||
type=str,
|
||||
help=
|
||||
"Scale for performance test. e.g., 8x1024x64 (batch_size, input_text_length, max_output_length)",
|
||||
default="")
|
||||
return parser.parse_args()
|
||||
|
||||
|
||||
def generate(
|
||||
max_output_len: int,
|
||||
log_level: str = 'error',
|
||||
engine_dir: str = 'gpt_outputs',
|
||||
input_text: str = 'Born in north-east France, Soyer trained as a',
|
||||
input_file: str = None,
|
||||
output_csv: str = None,
|
||||
output_npy: str = None,
|
||||
hf_model_location: str = 'gptj',
|
||||
num_beams: int = 1,
|
||||
min_length: int = 1,
|
||||
performance_test_scale: str = "",
|
||||
):
|
||||
xtrt_llm.logger.set_level(log_level)
|
||||
|
||||
engine_dir = Path(engine_dir)
|
||||
config_path = engine_dir / 'config.json'
|
||||
model_config, world_size, dtype, max_input_len = read_config(config_path)
|
||||
|
||||
runtime_rank = xtrt_llm.mpi_rank()
|
||||
runtime_mapping = xtrt_llm.Mapping(world_size,
|
||||
runtime_rank,
|
||||
tp_size=world_size)
|
||||
torch.cuda.set_device(runtime_rank % runtime_mapping.gpus_per_node)
|
||||
|
||||
vocab_file = Path(hf_model_location) / VOCAB_FILE
|
||||
merges_file = Path(hf_model_location) / MERGES_FILE
|
||||
assert vocab_file.is_file(), f"{vocab_file} does not exist"
|
||||
assert merges_file.is_file(), f"{merges_file} does not exist"
|
||||
tokenizer = token_encoder.get_encoder(vocab_file, merges_file)
|
||||
|
||||
sampling_config = SamplingConfig(end_id=END_ID,
|
||||
pad_id=PAD_ID,
|
||||
num_beams=num_beams,
|
||||
min_length=min_length)
|
||||
|
||||
engine_name = get_engine_name('gptj', dtype, world_size, runtime_rank)
|
||||
# serialize_path = Path(engine_dir) / engine_name
|
||||
serialize_path = str(engine_dir) + "/" + engine_name
|
||||
# with open(serialize_path, 'rb') as f:
|
||||
# engine_buffer = f.read()
|
||||
decoder = xtrt_llm.runtime.GenerationSession(model_config,
|
||||
serialize_path,
|
||||
runtime_mapping,
|
||||
debug_mode=False,
|
||||
debug_tensors_to_save=None)
|
||||
|
||||
input_ids, input_lengths = parse_input(input_text, input_file, tokenizer,
|
||||
PAD_ID,
|
||||
model_config.remove_input_padding)
|
||||
|
||||
if performance_test_scale != "":
|
||||
performance_test_scale_list = performance_test_scale.split("E")
|
||||
for scale in performance_test_scale_list:
|
||||
xtrt_llm.logger.info(f"Running performance test with scale {scale}")
|
||||
bs, seqlen, _max_output_len = [int(x) for x in scale.split("x")]
|
||||
_input_ids = torch.from_numpy(
|
||||
np.zeros((bs, seqlen)).astype("int32")).cuda()
|
||||
_input_lengths = torch.from_numpy(
|
||||
np.full((bs, ), seqlen).astype("int32")).cuda()
|
||||
_max_input_length = torch.max(_input_lengths).item()
|
||||
|
||||
decoder.setup(_input_lengths.size(0), _max_input_length,
|
||||
_max_output_len, num_beams)
|
||||
_output_gen_ids = decoder.decode(_input_ids,
|
||||
_input_lengths,
|
||||
sampling_config,
|
||||
output_sequence_lengths=True,
|
||||
return_dict=True)
|
||||
|
||||
max_input_length = torch.max(input_lengths).item()
|
||||
decoder.setup(input_lengths.size(0),
|
||||
max_input_length,
|
||||
max_output_len,
|
||||
beam_width=num_beams)
|
||||
|
||||
outputs = decoder.decode(input_ids,
|
||||
input_lengths,
|
||||
sampling_config,
|
||||
output_sequence_lengths=True,
|
||||
return_dict=True)
|
||||
output_ids = outputs['output_ids']
|
||||
sequence_lengths = outputs['sequence_lengths']
|
||||
torch.cuda.synchronize()
|
||||
|
||||
cum_log_probs = decoder.cum_log_probs if num_beams > 1 else None
|
||||
|
||||
if runtime_rank == 0:
|
||||
print_output(output_ids, cum_log_probs, input_lengths, sequence_lengths,
|
||||
tokenizer, output_csv, output_npy)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = parse_arguments()
|
||||
generate(**vars(args))
|
||||
8
examples/gptj/run.sh
Normal file
8
examples/gptj/run.sh
Normal file
@@ -0,0 +1,8 @@
|
||||
XMLIR_D_XPU_L3_SIZE=0 \
|
||||
python3 run.py \
|
||||
--engine_dir=./downloads/gptj-6b/trt_engines/fp16/1-XPU/ \
|
||||
--hf_model_location=./downloads/gptj-6b \
|
||||
--max_output_len=2048 \
|
||||
--performance_test_scale=1x512x512E1x1024x1024E1x2000x64E1x2048x2048E2x512x512E2x1024x1024E2x2000x64E2x2048x2048E4x512x512E\
|
||||
4x1024x1024E4x2000x64E4x2048x2048E8x512x512E8x1024x1024E8x2000x64 \
|
||||
--log_level=info
|
||||
409
examples/gptj/summarize.py
Normal file
409
examples/gptj/summarize.py
Normal file
@@ -0,0 +1,409 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import copy
|
||||
import json
|
||||
import os
|
||||
import random
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from datasets import load_dataset, load_metric
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
import xtrt_llm
|
||||
import xtrt_llm.profiler as profiler
|
||||
from xtrt_llm.logger import logger
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
from build import get_engine_name # isort:skip
|
||||
|
||||
|
||||
def TRTGPTJ(args, config):
|
||||
dtype = config['builder_config']['precision']
|
||||
world_size = config['builder_config']['tensor_parallel']
|
||||
assert world_size == xtrt_llm.mpi_world_size(), \
|
||||
f'Engine world size ({world_size}) != Runtime world size ({xtrt_llm.mpi_world_size()})'
|
||||
|
||||
world_size = config['builder_config']['tensor_parallel']
|
||||
num_heads = config['builder_config']['num_heads'] // world_size
|
||||
hidden_size = config['builder_config']['hidden_size'] // world_size
|
||||
vocab_size = config['builder_config']['vocab_size']
|
||||
num_layers = config['builder_config']['num_layers']
|
||||
use_gpt_attention_plugin = bool(
|
||||
config['plugin_config']['gpt_attention_plugin'])
|
||||
remove_input_padding = config['plugin_config']['remove_input_padding']
|
||||
quant_mode = QuantMode(config['builder_config'].get('quant_mode', 0))
|
||||
paged_kv_cache = config['plugin_config']['paged_kv_cache']
|
||||
tokens_per_block = config['plugin_config']['tokens_per_block']
|
||||
|
||||
model_config = xtrt_llm.runtime.ModelConfig(
|
||||
vocab_size=vocab_size,
|
||||
num_layers=num_layers,
|
||||
num_heads=num_heads,
|
||||
num_kv_heads=num_heads,
|
||||
hidden_size=hidden_size,
|
||||
gpt_attention_plugin=use_gpt_attention_plugin,
|
||||
remove_input_padding=remove_input_padding,
|
||||
paged_kv_cache=paged_kv_cache,
|
||||
tokens_per_block=tokens_per_block,
|
||||
quant_mode=quant_mode,
|
||||
dtype=dtype)
|
||||
|
||||
runtime_rank = xtrt_llm.mpi_rank()
|
||||
runtime_mapping = xtrt_llm.Mapping(world_size,
|
||||
runtime_rank,
|
||||
tp_size=world_size)
|
||||
torch.cuda.set_device(runtime_rank % runtime_mapping.gpus_per_node)
|
||||
|
||||
engine_name = get_engine_name('gptj', dtype, world_size, runtime_rank)
|
||||
serialize_path = os.path.join(args.engine_dir, engine_name)
|
||||
|
||||
xtrt_llm.logger.set_level(args.log_level)
|
||||
|
||||
with open(serialize_path, 'rb') as f:
|
||||
engine_buffer = f.read()
|
||||
decoder = xtrt_llm.runtime.GenerationSession(model_config,
|
||||
engine_buffer,
|
||||
runtime_mapping)
|
||||
|
||||
return decoder
|
||||
|
||||
|
||||
def main(args):
|
||||
runtime_rank = xtrt_llm.mpi_rank()
|
||||
logger.set_level(args.log_level)
|
||||
|
||||
test_hf = args.test_hf and runtime_rank == 0 # only run hf on rank 0
|
||||
test_trt_llm = args.test_trt_llm
|
||||
model_dir = args.model_dir
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_dir,
|
||||
padding_side='left',
|
||||
model_max_length=2048,
|
||||
truncation=True)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
dataset_cnn = load_dataset("ccdv/cnn_dailymail",
|
||||
'3.0.0',
|
||||
cache_dir=args.dataset_path)
|
||||
|
||||
config_path = os.path.join(args.engine_dir, 'config.json')
|
||||
with open(config_path, 'r') as f:
|
||||
config = json.load(f)
|
||||
|
||||
max_batch_size = args.batch_size
|
||||
|
||||
# runtime parameters
|
||||
# repetition_penalty = 1
|
||||
top_k = args.top_k
|
||||
output_len = args.output_len
|
||||
test_token_num = 923
|
||||
# top_p = 0.0
|
||||
# random_seed = 5
|
||||
temperature = 1
|
||||
num_beams = args.num_beams
|
||||
|
||||
pad_id = tokenizer.encode(tokenizer.pad_token, add_special_tokens=False)[0]
|
||||
end_id = tokenizer.encode(tokenizer.eos_token, add_special_tokens=False)[0]
|
||||
|
||||
if test_trt_llm:
|
||||
xtrt_llm_gpt = TRTGPTJ(args, config)
|
||||
|
||||
if test_hf:
|
||||
model = AutoModelForCausalLM.from_pretrained(model_dir)
|
||||
model.cuda()
|
||||
if args.data_type == 'fp16':
|
||||
model.half()
|
||||
|
||||
def summarize_xtrt_llm(datapoint):
|
||||
batch_size = len(datapoint['article'])
|
||||
|
||||
line = copy.copy(datapoint['article'])
|
||||
line_encoded = []
|
||||
input_lengths = []
|
||||
for i in range(batch_size):
|
||||
line[i] = line[i] + ' TL;DR: '
|
||||
|
||||
line[i] = line[i].strip()
|
||||
line[i] = line[i].replace(" n't", "n't")
|
||||
|
||||
input_id = tokenizer.encode(line[i],
|
||||
return_tensors='pt').type(torch.int32)
|
||||
input_id = input_id[:, -test_token_num:]
|
||||
|
||||
line_encoded.append(input_id)
|
||||
input_lengths.append(input_id.shape[-1])
|
||||
|
||||
# do padding, should move outside the profiling to prevent the overhead
|
||||
max_length = max(input_lengths)
|
||||
if xtrt_llm_gpt.remove_input_padding:
|
||||
line_encoded = [
|
||||
torch.tensor(t, dtype=torch.int32).cuda() for t in line_encoded
|
||||
]
|
||||
else:
|
||||
# do padding, should move outside the profiling to prevent the overhead
|
||||
for i in range(batch_size):
|
||||
pad_size = max_length - input_lengths[i]
|
||||
|
||||
pad = torch.ones([1, pad_size]).type(torch.int32) * pad_id
|
||||
line_encoded[i] = torch.cat(
|
||||
[torch.tensor(line_encoded[i], dtype=torch.int32), pad],
|
||||
axis=-1)
|
||||
|
||||
line_encoded = torch.cat(line_encoded, axis=0).cuda()
|
||||
input_lengths = torch.tensor(input_lengths,
|
||||
dtype=torch.int32).cuda()
|
||||
|
||||
sampling_config = xtrt_llm.runtime.SamplingConfig(
|
||||
end_id=end_id, pad_id=pad_id, top_k=top_k, num_beams=num_beams)
|
||||
|
||||
with torch.no_grad():
|
||||
xtrt_llm_gpt.setup(batch_size,
|
||||
max_context_length=max_length,
|
||||
max_new_tokens=output_len,
|
||||
beam_width=num_beams)
|
||||
|
||||
if xtrt_llm_gpt.remove_input_padding:
|
||||
output_ids = xtrt_llm_gpt.decode_batch(
|
||||
line_encoded, sampling_config)
|
||||
else:
|
||||
output_ids = xtrt_llm_gpt.decode(
|
||||
line_encoded,
|
||||
input_lengths,
|
||||
sampling_config,
|
||||
)
|
||||
|
||||
torch.cuda.synchronize()
|
||||
|
||||
# Extract a list of tensors of shape beam_width x output_ids.
|
||||
output_beams_list, output_ids_list = [], []
|
||||
if xtrt_llm_gpt.mapping.is_first_pp_rank():
|
||||
output_beams_list = [
|
||||
tokenizer.batch_decode(output_ids[batch_idx, :,
|
||||
input_lengths[batch_idx]:],
|
||||
skip_special_tokens=True)
|
||||
for batch_idx in range(batch_size)
|
||||
]
|
||||
output_ids_list = [
|
||||
output_ids[batch_idx, :, input_lengths[batch_idx]:]
|
||||
for batch_idx in range(batch_size)
|
||||
]
|
||||
return output_beams_list, output_ids_list
|
||||
|
||||
def summarize_hf(datapoint):
|
||||
batch_size = len(datapoint['article'])
|
||||
if batch_size > 1:
|
||||
logger.warning(
|
||||
f"HF does not support batch_size > 1 to verify correctness due to padding. Current batch size is {batch_size}"
|
||||
)
|
||||
|
||||
line = copy.copy(datapoint['article'])
|
||||
for i in range(batch_size):
|
||||
line[i] = line[i] + ' TL;DR: '
|
||||
|
||||
line[i] = line[i].strip()
|
||||
line[i] = line[i].replace(" n't", "n't")
|
||||
|
||||
line_encoded = tokenizer(line,
|
||||
return_tensors='pt',
|
||||
padding=True,
|
||||
truncation=True)["input_ids"].type(torch.int64)
|
||||
|
||||
line_encoded = line_encoded[:, -test_token_num:]
|
||||
line_encoded = line_encoded.cuda()
|
||||
|
||||
with torch.no_grad():
|
||||
output = model.generate(line_encoded,
|
||||
max_length=len(line_encoded[0]) +
|
||||
output_len,
|
||||
top_k=top_k,
|
||||
temperature=temperature,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
num_beams=num_beams,
|
||||
num_return_sequences=num_beams,
|
||||
early_stopping=True)
|
||||
|
||||
tokens_list = output[:, len(line_encoded[0]):].tolist()
|
||||
output = output.reshape([batch_size, num_beams, -1])
|
||||
output_lines_list = [
|
||||
tokenizer.batch_decode(output[:, i, len(line_encoded[0]):],
|
||||
skip_special_tokens=True)
|
||||
for i in range(num_beams)
|
||||
]
|
||||
|
||||
return output_lines_list, tokens_list
|
||||
|
||||
if test_trt_llm:
|
||||
datapoint = dataset_cnn['test'][0:1]
|
||||
summary, _ = summarize_xtrt_llm(datapoint)
|
||||
if runtime_rank == 0:
|
||||
logger.info(
|
||||
"---------------------------------------------------------")
|
||||
logger.info("XTRT-LLM Generated : ")
|
||||
logger.info(f" Article : {datapoint['article']}")
|
||||
logger.info(f"\n Highlights : {datapoint['highlights']}")
|
||||
logger.info(f"\n Summary : {summary}")
|
||||
logger.info(
|
||||
"---------------------------------------------------------")
|
||||
|
||||
if test_hf:
|
||||
datapoint = dataset_cnn['test'][0:1]
|
||||
summary, _ = summarize_hf(datapoint)
|
||||
logger.info("---------------------------------------------------------")
|
||||
logger.info("HF Generated : ")
|
||||
logger.info(f" Article : {datapoint['article']}")
|
||||
logger.info(f"\n Highlights : {datapoint['highlights']}")
|
||||
logger.info(f"\n Summary : {summary}")
|
||||
logger.info("---------------------------------------------------------")
|
||||
|
||||
xtrt_llm_result = [[] for _ in range(num_beams)]
|
||||
hf_result = [[] for _ in range(num_beams)]
|
||||
ite_count = 0
|
||||
data_point_idx = 0
|
||||
|
||||
# Support running the set with different order to verify correctness
|
||||
test_idx = list(
|
||||
range(min(len(dataset_cnn['test']), max_batch_size * args.max_ite)))
|
||||
random.seed(args.random_seed)
|
||||
random.shuffle(test_idx)
|
||||
while (data_point_idx < len(dataset_cnn['test'])) and (ite_count <
|
||||
args.max_ite):
|
||||
if runtime_rank == 0:
|
||||
logger.debug(
|
||||
f"run data_point {data_point_idx} ~ {data_point_idx + max_batch_size}"
|
||||
)
|
||||
datapoint = dataset_cnn['test'][test_idx[data_point_idx:(
|
||||
data_point_idx + max_batch_size)]]
|
||||
|
||||
if test_trt_llm:
|
||||
profiler.start('xtrt_llm')
|
||||
summary_xtrt_llm, tokens_xtrt_llm = summarize_xtrt_llm(
|
||||
datapoint)
|
||||
profiler.stop('xtrt_llm')
|
||||
|
||||
if test_hf:
|
||||
profiler.start('hf')
|
||||
summary_hf, tokens_hf = summarize_hf(datapoint)
|
||||
profiler.stop('hf')
|
||||
|
||||
if runtime_rank == 0:
|
||||
if test_trt_llm:
|
||||
for batch_idx in range(len(summary_xtrt_llm)):
|
||||
for beam_idx in range(num_beams):
|
||||
xtrt_llm_result[beam_idx].append(
|
||||
tuple([
|
||||
datapoint['id'][batch_idx],
|
||||
summary_xtrt_llm[batch_idx][beam_idx],
|
||||
datapoint['highlights'][batch_idx]
|
||||
]))
|
||||
if test_hf:
|
||||
for beam_idx in range(num_beams):
|
||||
for batch_idx in range(len(summary_hf[beam_idx])):
|
||||
hf_result[beam_idx].append(
|
||||
tuple([
|
||||
datapoint['id'][batch_idx],
|
||||
summary_hf[beam_idx][batch_idx],
|
||||
datapoint['highlights'][batch_idx]
|
||||
]))
|
||||
|
||||
logger.debug('-' * 100)
|
||||
logger.debug(f"Article : {datapoint['article']}")
|
||||
if test_trt_llm:
|
||||
logger.debug(f'XTRT-LLM Summary: {summary_xtrt_llm}')
|
||||
if test_hf:
|
||||
logger.debug(f'HF Summary: {summary_hf}')
|
||||
logger.debug(f"highlights : {datapoint['highlights']}")
|
||||
|
||||
data_point_idx += max_batch_size
|
||||
ite_count += 1
|
||||
|
||||
if runtime_rank == 0:
|
||||
if test_trt_llm:
|
||||
np.random.seed(0) # rouge score use sampling to compute the score
|
||||
logger.info(
|
||||
f'XTRT-LLM (total latency: {profiler.elapsed_time_in_sec("xtrt_llm")} sec)'
|
||||
)
|
||||
for beam_idx in range(num_beams):
|
||||
# Because 'rouge' uses sampling to compute the scores, the scores
|
||||
# would be different when the results are same with different order.
|
||||
# So, sorting them first to prevent this issue.
|
||||
metric_xtrt_llm = load_metric("rouge")
|
||||
metric_xtrt_llm.seed = 0
|
||||
beams_results = sorted(xtrt_llm_result[beam_idx])
|
||||
|
||||
for j in range(len(beams_results)):
|
||||
metric_xtrt_llm.add_batch(
|
||||
predictions=[beams_results[j][1]],
|
||||
references=[beams_results[j][2]])
|
||||
|
||||
logger.info(f"XTRT-LLM beam {beam_idx} result")
|
||||
computed_metrics_xtrt_llm = metric_xtrt_llm.compute()
|
||||
for key in computed_metrics_xtrt_llm.keys():
|
||||
logger.info(
|
||||
f' {key} : {computed_metrics_xtrt_llm[key].mid[2]*100}'
|
||||
)
|
||||
|
||||
if args.check_accuracy and beam_idx == 0:
|
||||
assert computed_metrics_xtrt_llm['rouge1'].mid[
|
||||
2] * 100 > args.xtrt_llm_rouge1_threshold
|
||||
if test_hf:
|
||||
np.random.seed(0) # rouge score use sampling to compute the score
|
||||
logger.info(
|
||||
f'Hugging Face (total latency: {profiler.elapsed_time_in_sec("hf")} sec)'
|
||||
)
|
||||
for beam_idx in range(num_beams):
|
||||
metric_tensorrt_hf = load_metric("rouge")
|
||||
metric_tensorrt_hf.seed = 0
|
||||
beams_results = sorted(hf_result[beam_idx])
|
||||
|
||||
for j in range(len(beams_results)):
|
||||
metric_tensorrt_hf.add_batch(
|
||||
predictions=[beams_results[j][1]],
|
||||
references=[beams_results[j][2]])
|
||||
logger.info(f"HF beam {beam_idx} result")
|
||||
computed_metrics_hf = metric_tensorrt_hf.compute()
|
||||
for key in computed_metrics_hf.keys():
|
||||
logger.info(
|
||||
f' {key} : {computed_metrics_hf[key].mid[2]*100}')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--model_dir', type=str, default='EleutherAI/gpt-j-6B')
|
||||
parser.add_argument('--test_hf', action='store_true')
|
||||
parser.add_argument('--test_trt_llm', action='store_true')
|
||||
parser.add_argument('--data_type',
|
||||
type=str,
|
||||
choices=['fp32', 'fp16'],
|
||||
default='fp32')
|
||||
parser.add_argument('--dataset_path', type=str, default='')
|
||||
parser.add_argument('--log_level', type=str, default='info')
|
||||
parser.add_argument('--engine_dir', type=str, default='gptj_engine')
|
||||
parser.add_argument('--batch_size', type=int, default=1)
|
||||
parser.add_argument('--max_ite', type=int, default=20)
|
||||
parser.add_argument('--output_len', type=int, default=100)
|
||||
parser.add_argument('--check_accuracy', action='store_true')
|
||||
parser.add_argument('--xtrt_llm_rouge1_threshold',
|
||||
type=float,
|
||||
default=15.0)
|
||||
parser.add_argument('--num_beams', type=int, default=1)
|
||||
parser.add_argument('--top_k', type=int, default=1)
|
||||
parser.add_argument('--random_seed', type=int, default=0)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
main(args)
|
||||
14
examples/gptj/utils/__init__.py
Normal file
14
examples/gptj/utils/__init__.py
Normal file
@@ -0,0 +1,14 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
178
examples/gptj/utils/token_encoder.py
Normal file
178
examples/gptj/utils/token_encoder.py
Normal file
@@ -0,0 +1,178 @@
|
||||
"""Byte pair encoding utilities"""
|
||||
|
||||
# Modified MIT License
|
||||
|
||||
# Software Copyright (c) 2019 OpenAI
|
||||
|
||||
# We don’t claim ownership of the content you create with GPT-2, so it is yours to do with as you please.
|
||||
# We only ask that you use GPT-2 responsibly and clearly indicate your content was created using GPT-2.
|
||||
|
||||
# Permission is hereby granted, free of charge, to any person obtaining a copy of this software and
|
||||
# associated documentation files (the "Software"), to deal in the Software without restriction,
|
||||
# including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense,
|
||||
# and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so,
|
||||
# subject to the following conditions:
|
||||
|
||||
# The above copyright notice and this permission notice shall be included
|
||||
# in all copies or substantial portions of the Software.
|
||||
# The above copyright notice and this permission notice need not be included
|
||||
# with content created by the Software.
|
||||
|
||||
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
|
||||
# INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS
|
||||
# BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
|
||||
# TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE
|
||||
# OR OTHER DEALINGS IN THE SOFTWARE.
|
||||
# Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import json
|
||||
from functools import lru_cache
|
||||
|
||||
import regex as re
|
||||
|
||||
|
||||
@lru_cache()
|
||||
def bytes_to_unicode():
|
||||
"""
|
||||
Returns list of utf-8 byte and a corresponding list of unicode strings.
|
||||
The reversible bpe codes work on unicode strings.
|
||||
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
|
||||
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
|
||||
This is a significant percentage of your normal, say, 32K bpe vocab.
|
||||
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
|
||||
And avoids mapping to whitespace/control characters the bpe code barfs on.
|
||||
"""
|
||||
bs = list(range(ord("!"),
|
||||
ord("~") + 1)) + list(range(
|
||||
ord("¡"),
|
||||
ord("¬") + 1)) + list(range(ord("®"),
|
||||
ord("ÿ") + 1))
|
||||
cs = bs[:]
|
||||
n = 0
|
||||
for b in range(2**8):
|
||||
if b not in bs:
|
||||
bs.append(b)
|
||||
cs.append(2**8 + n)
|
||||
n += 1
|
||||
cs = [chr(n) for n in cs]
|
||||
return dict(zip(bs, cs))
|
||||
|
||||
|
||||
def get_pairs(word):
|
||||
"""Return set of symbol pairs in a word.
|
||||
|
||||
Word is represented as tuple of symbols (symbols being variable-length strings).
|
||||
"""
|
||||
pairs = set()
|
||||
prev_char = word[0]
|
||||
for char in word[1:]:
|
||||
pairs.add((prev_char, char))
|
||||
prev_char = char
|
||||
return pairs
|
||||
|
||||
|
||||
class Encoder:
|
||||
|
||||
def __init__(self, encoder, bpe_merges, errors='replace'):
|
||||
self.encoder = encoder
|
||||
self.decoder = {v: k for k, v in self.encoder.items()}
|
||||
self.errors = errors # how to handle errors in decoding
|
||||
self.byte_encoder = bytes_to_unicode()
|
||||
self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
|
||||
self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges))))
|
||||
self.cache = {}
|
||||
|
||||
# Should have added re.IGNORECASE so BPE merges can happen for capitalized versions of contractions
|
||||
self.pat = re.compile(
|
||||
r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
|
||||
)
|
||||
|
||||
def bpe(self, token):
|
||||
if token in self.cache:
|
||||
return self.cache[token]
|
||||
word = tuple(token)
|
||||
pairs = get_pairs(word)
|
||||
|
||||
if not pairs:
|
||||
return token
|
||||
|
||||
while True:
|
||||
bigram = min(
|
||||
pairs, key=lambda pair: self.bpe_ranks.get(pair, float('inf')))
|
||||
if bigram not in self.bpe_ranks:
|
||||
break
|
||||
first, second = bigram
|
||||
new_word = []
|
||||
i = 0
|
||||
while i < len(word):
|
||||
try:
|
||||
j = word.index(first, i)
|
||||
new_word.extend(word[i:j])
|
||||
i = j
|
||||
except:
|
||||
new_word.extend(word[i:])
|
||||
break
|
||||
|
||||
if word[i] == first and i < len(word) - 1 and word[i +
|
||||
1] == second:
|
||||
new_word.append(first + second)
|
||||
i += 2
|
||||
else:
|
||||
new_word.append(word[i])
|
||||
i += 1
|
||||
new_word = tuple(new_word)
|
||||
word = new_word
|
||||
if len(word) == 1:
|
||||
break
|
||||
else:
|
||||
pairs = get_pairs(word)
|
||||
word = ' '.join(word)
|
||||
self.cache[token] = word
|
||||
return word
|
||||
|
||||
def encode(self, text):
|
||||
bpe_tokens = []
|
||||
for token in re.findall(self.pat, text):
|
||||
token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
|
||||
bpe_tokens.extend(self.encoder[bpe_token]
|
||||
for bpe_token in self.bpe(token).split(' '))
|
||||
return bpe_tokens
|
||||
|
||||
def decode(self, tokens):
|
||||
text = ''.join([self.decoder[token] for token in tokens])
|
||||
text = bytearray([self.byte_decoder[c]
|
||||
for c in text]).decode('utf-8', errors=self.errors)
|
||||
return text
|
||||
|
||||
def batch_decode(self, output):
|
||||
ret = []
|
||||
for tokens in output:
|
||||
ret.append(self.decode(tokens))
|
||||
return ret
|
||||
|
||||
|
||||
def get_encoder(vocab_file, bpe_file):
|
||||
with open(vocab_file, 'r', encoding="utf-8") as f:
|
||||
encoder = json.load(f)
|
||||
with open(bpe_file, 'r', encoding="utf-8") as f:
|
||||
bpe_data = f.read()
|
||||
bpe_merges = [
|
||||
tuple(merge_str.split()) for merge_str in bpe_data.split('\n')[1:-1]
|
||||
]
|
||||
return Encoder(
|
||||
encoder=encoder,
|
||||
bpe_merges=bpe_merges,
|
||||
)
|
||||
455
examples/gptj/weight.py
Normal file
455
examples/gptj/weight.py
Normal file
@@ -0,0 +1,455 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import time
|
||||
from operator import attrgetter
|
||||
from pathlib import Path
|
||||
from typing import Dict, List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
import xtrt_llm
|
||||
import xtrt_llm.logger as logger
|
||||
from xtrt_llm._utils import str_dtype_to_torch
|
||||
from xtrt_llm.models import GPTJForCausalLM
|
||||
from xtrt_llm.models.quantized.quant import get_dummy_quant_scales
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
|
||||
def get_scaling_factors(
|
||||
model_path: Union[str, Path],
|
||||
num_layers: int,
|
||||
quant_mode: Optional[QuantMode] = None,
|
||||
) -> Optional[Dict[str, List[int]]]:
|
||||
""" Get the scaling factors for GPT-J model
|
||||
|
||||
Returns a dictionary of scaling factors for the selected layers of the
|
||||
GPT-J model.
|
||||
|
||||
Args:
|
||||
model_path (str): Path to the quantized GPT-J model
|
||||
layers (list): List of layers to get the scaling factors for. If None,
|
||||
all layers are selected.
|
||||
|
||||
Returns:
|
||||
dict: Dictionary of scaling factors for the selected layers of the
|
||||
GPT-J model.
|
||||
|
||||
example:
|
||||
|
||||
{
|
||||
'qkv_act': qkv_act_scale,
|
||||
'qkv_weights': qkv_weights_scale,
|
||||
'qkv_output' : qkv_outputs_scale,
|
||||
'dense_act': dense_act_scale,
|
||||
'dense_weights': dense_weights_scale,
|
||||
'fc_act': fc_act_scale,
|
||||
'fc_weights': fc_weights_scale,
|
||||
'proj_act': proj_act_scale,
|
||||
'proj_weights': proj_weights_scale,
|
||||
}
|
||||
"""
|
||||
|
||||
if model_path is None:
|
||||
logger.warning(f"--quantized_fp8_model_path not specified. "
|
||||
f"Initialize quantization scales automatically.")
|
||||
return get_dummy_quant_scales(num_layers)
|
||||
weight_dict = np.load(model_path)
|
||||
|
||||
# yapf: disable
|
||||
scaling_factor = {
|
||||
'qkv_act': [],
|
||||
'qkv_weights': [],
|
||||
'qkv_output': [],
|
||||
'dense_act': [],
|
||||
'dense_weights': [],
|
||||
'fc_act': [],
|
||||
'fc_weights': [],
|
||||
'proj_act': [],
|
||||
'proj_weights': [],
|
||||
}
|
||||
|
||||
for layer in range(num_layers):
|
||||
scaling_factor['qkv_act'].append(max(
|
||||
weight_dict[f'_np:layers:{layer}:attention:qkv:q:activation_scaling_factor'].item(),
|
||||
weight_dict[f'_np:layers:{layer}:attention:qkv:k:activation_scaling_factor'].item(),
|
||||
weight_dict[f'_np:layers:{layer}:attention:qkv:v:activation_scaling_factor'].item()
|
||||
))
|
||||
scaling_factor['qkv_weights'].append(max(
|
||||
weight_dict[f'_np:layers:{layer}:attention:qkv:q:weights_scaling_factor'].item(),
|
||||
weight_dict[f'_np:layers:{layer}:attention:qkv:k:weights_scaling_factor'].item(),
|
||||
weight_dict[f'_np:layers:{layer}:attention:qkv:v:weights_scaling_factor'].item()
|
||||
))
|
||||
if quant_mode is not None and quant_mode.has_fp8_kv_cache():
|
||||
# Not calibrarting KV cache.
|
||||
scaling_factor['qkv_output'].append(1.0)
|
||||
scaling_factor['dense_act'].append(weight_dict[f'_np:layers:{layer}:attention:dense:activation_scaling_factor'].item())
|
||||
scaling_factor['dense_weights'].append(weight_dict[f'_np:layers:{layer}:attention:dense:weights_scaling_factor'].item())
|
||||
scaling_factor['fc_act'].append(weight_dict[f'_np:layers:{layer}:mlp:fc:activation_scaling_factor'].item())
|
||||
scaling_factor['fc_weights'].append(weight_dict[f'_np:layers:{layer}:mlp:fc:weights_scaling_factor'].item())
|
||||
scaling_factor['proj_act'].append(weight_dict[f'_np:layers:{layer}:mlp:proj:activation_scaling_factor'].item())
|
||||
scaling_factor['proj_weights'].append(weight_dict[f'_np:layers:{layer}:mlp:proj:weights_scaling_factor'].item())
|
||||
# yapf: enable
|
||||
for k, v in scaling_factor.items():
|
||||
assert len(v) == num_layers, \
|
||||
f'Expect scaling factor {k} of length {num_layers}, got {len(v)}'
|
||||
|
||||
return scaling_factor
|
||||
|
||||
|
||||
def load_from_hf_gpt_j(xtrt_llm_gpt_j: GPTJForCausalLM,
|
||||
hf_gpt_j,
|
||||
dtype="float32",
|
||||
scaling_factors=None):
|
||||
|
||||
hf_model_gptj_block_names = [
|
||||
"ln_1.weight",
|
||||
"ln_1.bias",
|
||||
"mlp.fc_in.weight",
|
||||
"mlp.fc_in.bias",
|
||||
"mlp.fc_out.weight",
|
||||
"mlp.fc_out.bias",
|
||||
]
|
||||
|
||||
xtrt_llm_model_gptj_block_names = [
|
||||
"input_layernorm.weight",
|
||||
"input_layernorm.bias",
|
||||
"mlp.fc.weight",
|
||||
"mlp.fc.bias",
|
||||
"mlp.proj.weight",
|
||||
"mlp.proj.bias",
|
||||
]
|
||||
|
||||
quant_mode = getattr(xtrt_llm_gpt_j, 'quant_mode', QuantMode(0))
|
||||
|
||||
xtrt_llm.logger.info('Loading weights from HF GPT-J...')
|
||||
tik = time.time()
|
||||
|
||||
torch_dtype = str_dtype_to_torch(dtype)
|
||||
hf_gpt_j_state_dict = hf_gpt_j.state_dict()
|
||||
|
||||
v = hf_gpt_j_state_dict.get('transformer.wte.weight')
|
||||
xtrt_llm_gpt_j.embedding.weight.value = v.to(torch_dtype).cpu().numpy()
|
||||
|
||||
n_layer = hf_gpt_j.config.n_layer
|
||||
|
||||
for layer_idx in range(n_layer):
|
||||
prefix = "transformer.h." + str(layer_idx) + "."
|
||||
for idx, hf_attr in enumerate(hf_model_gptj_block_names):
|
||||
v = hf_gpt_j_state_dict.get(prefix + hf_attr)
|
||||
layer = attrgetter(xtrt_llm_model_gptj_block_names[idx])(
|
||||
xtrt_llm_gpt_j.layers[layer_idx])
|
||||
if idx == 2 and scaling_factors:
|
||||
xtrt_llm_gpt_j.layers[
|
||||
layer_idx].mlp.fc.activation_scaling_factor.value = np.array(
|
||||
[scaling_factors['fc_act'][layer_idx]],
|
||||
dtype=np.float32)
|
||||
|
||||
xtrt_llm_gpt_j.layers[
|
||||
layer_idx].mlp.fc.weights_scaling_factor.value = np.array(
|
||||
[scaling_factors['fc_weights'][layer_idx]],
|
||||
dtype=np.float32)
|
||||
|
||||
elif idx == 4 and scaling_factors:
|
||||
xtrt_llm_gpt_j.layers[
|
||||
layer_idx].mlp.proj.activation_scaling_factor.value = np.array(
|
||||
[scaling_factors['proj_act'][layer_idx]],
|
||||
dtype=np.float32)
|
||||
|
||||
xtrt_llm_gpt_j.layers[
|
||||
layer_idx].mlp.proj.weights_scaling_factor.value = np.array(
|
||||
[scaling_factors['proj_weights'][layer_idx]],
|
||||
dtype=np.float32)
|
||||
setattr(layer, 'value', v.to(torch_dtype).cpu().numpy())
|
||||
|
||||
# Attention QKV Linear
|
||||
# concatenate the Q, K, V layers weights.
|
||||
q_weights = hf_gpt_j_state_dict.get(prefix + "attn.q_proj.weight")
|
||||
k_weights = hf_gpt_j_state_dict.get(prefix + "attn.k_proj.weight")
|
||||
v_weights = hf_gpt_j_state_dict.get(prefix + "attn.v_proj.weight")
|
||||
qkv_weights = torch.cat((q_weights, k_weights, v_weights))
|
||||
layer = attrgetter("attention.qkv.weight")(
|
||||
xtrt_llm_gpt_j.layers[layer_idx])
|
||||
setattr(layer, "value", qkv_weights.to(torch_dtype).cpu().numpy())
|
||||
if scaling_factors:
|
||||
xtrt_llm_gpt_j.layers[
|
||||
layer_idx].attention.qkv.activation_scaling_factor.value = np.array(
|
||||
[scaling_factors['qkv_act'][layer_idx]], dtype=np.float32)
|
||||
xtrt_llm_gpt_j.layers[
|
||||
layer_idx].attention.qkv.weights_scaling_factor.value = np.array(
|
||||
[scaling_factors['qkv_weights'][layer_idx]],
|
||||
dtype=np.float32)
|
||||
|
||||
if quant_mode.has_fp8_kv_cache():
|
||||
if scaling_factors:
|
||||
xtrt_llm_gpt_j.layers[
|
||||
layer_idx].attention.kv_orig_quant_scale.value = np.array(
|
||||
[scaling_factors['qkv_output'][layer_idx]],
|
||||
dtype=np.float32)
|
||||
xtrt_llm_gpt_j.layers[
|
||||
layer_idx].attention.kv_quant_orig_scale.value = np.array(
|
||||
[1.0 / scaling_factors['qkv_output'][layer_idx]],
|
||||
dtype=np.float32)
|
||||
|
||||
# Attention Dense (out_proj) Linear
|
||||
v = hf_gpt_j_state_dict.get(prefix + "attn.out_proj.weight")
|
||||
layer = attrgetter("attention.dense.weight")(
|
||||
xtrt_llm_gpt_j.layers[layer_idx])
|
||||
setattr(layer, "value", v.to(torch_dtype).cpu().numpy())
|
||||
if scaling_factors:
|
||||
xtrt_llm_gpt_j.layers[
|
||||
layer_idx].attention.dense.activation_scaling_factor.value = np.array(
|
||||
[scaling_factors['dense_act'][layer_idx]], dtype=np.float32)
|
||||
xtrt_llm_gpt_j.layers[
|
||||
layer_idx].attention.dense.weights_scaling_factor.value = np.array(
|
||||
[scaling_factors['dense_weights'][layer_idx]],
|
||||
dtype=np.float32)
|
||||
|
||||
v = hf_gpt_j_state_dict.get('transformer.ln_f.weight')
|
||||
xtrt_llm_gpt_j.ln_f.weight.value = v.to(torch_dtype).cpu().numpy()
|
||||
|
||||
v = hf_gpt_j_state_dict.get('transformer.ln_f.bias')
|
||||
xtrt_llm_gpt_j.ln_f.bias.value = v.to(torch_dtype).cpu().numpy()
|
||||
|
||||
v = hf_gpt_j_state_dict.get('lm_head.weight')
|
||||
xtrt_llm_gpt_j.lm_head.weight.value = v.to(torch_dtype).cpu().numpy()
|
||||
|
||||
v = hf_gpt_j_state_dict.get('lm_head.bias')
|
||||
xtrt_llm_gpt_j.lm_head.bias.value = v.to(torch_dtype).cpu().numpy()
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
xtrt_llm.logger.info(f'Weights loaded. Total time: {t}')
|
||||
|
||||
|
||||
def AWQ_quantize_pack_preprocess(weight, scale, group_size, packer,
|
||||
preprocessor):
|
||||
scale = scale.repeat_interleave(group_size, dim=0)
|
||||
weight = weight / scale
|
||||
weight = torch.round(weight).char()
|
||||
weight = torch.where(weight > 7, 7, weight)
|
||||
qweight_int8 = torch.where(weight < -8, -8, weight)
|
||||
int4_weight = packer(qweight_int8.cpu())
|
||||
int4_weight = preprocessor(int4_weight, torch.quint4x2)
|
||||
return int4_weight.view(torch.float32).cpu().numpy()
|
||||
|
||||
|
||||
def process_and_assign_weight(awq_gpt_j, mPrefix, mOp, group_size, packer,
|
||||
preprocessor, torch_dtype):
|
||||
weight = awq_gpt_j[mPrefix + ".weight"].T.contiguous()
|
||||
[k, n] = weight.shape
|
||||
amax = awq_gpt_j[mPrefix + ".weight_quantizer._amax"].reshape(
|
||||
(n, int(k / group_size))).T.contiguous()
|
||||
pre_quant_scale = awq_gpt_j[mPrefix +
|
||||
".input_quantizer._pre_quant_scale"].reshape(
|
||||
(1, k))
|
||||
scale = amax / 8.0
|
||||
mOp.qweight.value = AWQ_quantize_pack_preprocess(weight, scale, group_size,
|
||||
packer, preprocessor)
|
||||
mOp.scale.value = scale.to(torch_dtype).cpu().numpy()
|
||||
mOp.pre_quant_scale.value = pre_quant_scale.to(torch_dtype).cpu().numpy()
|
||||
|
||||
|
||||
def deSmooth(weight, pre_quant_scale):
|
||||
[k, n] = weight.shape
|
||||
pre_quant_scale = pre_quant_scale.repeat((n, 1)).transpose(1,
|
||||
0).contiguous()
|
||||
weight = weight * pre_quant_scale
|
||||
return weight
|
||||
|
||||
|
||||
def reSmooth(weight, pre_quant_scale):
|
||||
[k, n] = weight.shape
|
||||
pre_quant_scale = pre_quant_scale.repeat((n, 1)).transpose(1,
|
||||
0).contiguous()
|
||||
weight = weight / pre_quant_scale
|
||||
return weight
|
||||
|
||||
|
||||
def get_scale(weight, group_size):
|
||||
weight = weight.T.contiguous()
|
||||
[n, k] = weight.shape
|
||||
weight = weight.reshape(n, int(k / group_size), group_size)
|
||||
weight = torch.abs(weight.reshape(-1, group_size))
|
||||
amax, idx = weight.max(1)
|
||||
amax = amax.reshape(n, int(k / group_size)).T.contiguous()
|
||||
return amax / 8
|
||||
|
||||
|
||||
def reSmooth_and_get_scale(weight, pre_quant_scale, avg_pre_quant_scale,
|
||||
group_size):
|
||||
weight = deSmooth(weight, pre_quant_scale)
|
||||
weight = reSmooth(weight, avg_pre_quant_scale)
|
||||
scale = get_scale(weight, group_size)
|
||||
return weight, scale
|
||||
|
||||
|
||||
def process_and_assign_qkv_weight(awq_gpt_j, prefix, mOp, group_size, packer,
|
||||
preprocessor, torch_dtype):
|
||||
q_weight = awq_gpt_j[prefix + "attn.q_proj.weight"].T.contiguous()
|
||||
k_weight = awq_gpt_j[prefix + "attn.k_proj.weight"].T.contiguous()
|
||||
v_weight = awq_gpt_j[prefix + "attn.v_proj.weight"].T.contiguous()
|
||||
[k, n] = q_weight.shape
|
||||
|
||||
q_pre_quant_scale = awq_gpt_j[
|
||||
prefix + "attn.q_proj.input_quantizer._pre_quant_scale"].reshape((1, k))
|
||||
k_pre_quant_scale = awq_gpt_j[
|
||||
prefix + "attn.k_proj.input_quantizer._pre_quant_scale"].reshape((1, k))
|
||||
v_pre_quant_scale = awq_gpt_j[
|
||||
prefix + "attn.v_proj.input_quantizer._pre_quant_scale"].reshape((1, k))
|
||||
|
||||
qkv_pre_quant_scale = (q_pre_quant_scale + k_pre_quant_scale +
|
||||
v_pre_quant_scale) / 3.0
|
||||
q_weight, q_scale = reSmooth_and_get_scale(q_weight, q_pre_quant_scale,
|
||||
qkv_pre_quant_scale, group_size)
|
||||
k_weight, k_scale = reSmooth_and_get_scale(k_weight, k_pre_quant_scale,
|
||||
qkv_pre_quant_scale, group_size)
|
||||
v_weight, v_scale = reSmooth_and_get_scale(v_weight, v_pre_quant_scale,
|
||||
qkv_pre_quant_scale, group_size)
|
||||
|
||||
qkv_weights = torch.cat((q_weight, k_weight, v_weight), dim=1)
|
||||
qkv_scale = torch.cat((q_scale, k_scale, v_scale), dim=1)
|
||||
mOp.pre_quant_scale.value = qkv_pre_quant_scale.to(
|
||||
torch_dtype).cpu().numpy()
|
||||
mOp.qweight.value = AWQ_quantize_pack_preprocess(qkv_weights, qkv_scale,
|
||||
group_size, packer,
|
||||
preprocessor)
|
||||
mOp.scale.value = qkv_scale.to(torch_dtype).cpu().numpy()
|
||||
|
||||
|
||||
def load_from_awq_gpt_j(xtrt_llm_gpt_j: GPTJForCausalLM,
|
||||
awq_gpt_j,
|
||||
config,
|
||||
dtype="float16",
|
||||
group_size=128):
|
||||
|
||||
awq_gptj_block_names = [
|
||||
"ln_1.weight",
|
||||
"ln_1.bias",
|
||||
"mlp.fc_in.bias",
|
||||
"mlp.fc_out.bias",
|
||||
]
|
||||
|
||||
xtrt_llm_model_gptj_block_names = [
|
||||
"input_layernorm.weight",
|
||||
"input_layernorm.bias",
|
||||
"mlp.fc.bias",
|
||||
"mlp.proj.bias",
|
||||
]
|
||||
|
||||
getattr(xtrt_llm_gpt_j, 'quant_mode', QuantMode(0))
|
||||
|
||||
packer = torch.ops.fastertransformer.pack_int8_tensor_to_packed_int4
|
||||
preprocessor = torch.ops.fastertransformer.preprocess_weights_for_mixed_gemm
|
||||
|
||||
xtrt_llm.logger.info('Loading weights from AWQ GPT-J...')
|
||||
tik = time.time()
|
||||
|
||||
torch_dtype = str_dtype_to_torch(dtype)
|
||||
|
||||
#check if we need to pad vocab
|
||||
v = awq_gpt_j.get('transformer.wte.weight')
|
||||
[vocab_size, k] = v.shape
|
||||
pad_vocab = False
|
||||
pad_vocab_size = vocab_size
|
||||
if vocab_size % 64 != 0:
|
||||
pad_vocab = True
|
||||
pad_vocab_size = int((vocab_size + 63) / 64) * 64
|
||||
if pad_vocab:
|
||||
new_v = torch.zeros([pad_vocab_size, k])
|
||||
new_v[:vocab_size, :] = v
|
||||
v = new_v
|
||||
xtrt_llm_gpt_j.embedding.weight.value = v.to(torch_dtype).cpu().numpy()
|
||||
|
||||
n_layer = config["n_layer"]
|
||||
|
||||
for layer_idx in range(n_layer):
|
||||
prefix = "transformer.h." + str(layer_idx) + "."
|
||||
xtrt_llm.logger.info(f'Process weights in layer: {layer_idx}')
|
||||
for idx, awq_attr in enumerate(awq_gptj_block_names):
|
||||
v = awq_gpt_j[prefix + awq_attr]
|
||||
layer = attrgetter(xtrt_llm_model_gptj_block_names[idx])(
|
||||
xtrt_llm_gpt_j.layers[layer_idx])
|
||||
setattr(layer, 'value', v.to(torch_dtype).cpu().numpy())
|
||||
|
||||
# Attention QKV Linear
|
||||
# concatenate the Q, K, V layers weights.
|
||||
process_and_assign_qkv_weight(
|
||||
awq_gpt_j, prefix,
|
||||
xtrt_llm_gpt_j.layers[layer_idx].attention.qkv, group_size,
|
||||
packer, preprocessor, torch_dtype)
|
||||
|
||||
# Attention Dense (out_proj) Linear
|
||||
mPrefix = prefix + "attn.out_proj"
|
||||
mOp = xtrt_llm_gpt_j.layers[layer_idx].attention.dense
|
||||
process_and_assign_weight(awq_gpt_j, mPrefix, mOp, group_size, packer,
|
||||
preprocessor, torch_dtype)
|
||||
|
||||
# MLP Dense (mlp.fc) Linear
|
||||
mPrefix = prefix + "mlp.fc_in"
|
||||
mOp = xtrt_llm_gpt_j.layers[layer_idx].mlp.fc
|
||||
process_and_assign_weight(awq_gpt_j, mPrefix, mOp, group_size, packer,
|
||||
preprocessor, torch_dtype)
|
||||
|
||||
# MLP Desne (mlp.proj) Linear
|
||||
mPrefix = prefix + "mlp.fc_out"
|
||||
mOp = xtrt_llm_gpt_j.layers[layer_idx].mlp.proj
|
||||
process_and_assign_weight(awq_gpt_j, mPrefix, mOp, group_size, packer,
|
||||
preprocessor, torch_dtype)
|
||||
|
||||
v = awq_gpt_j['transformer.ln_f.weight']
|
||||
xtrt_llm_gpt_j.ln_f.weight.value = v.to(torch_dtype).cpu().numpy()
|
||||
|
||||
v = awq_gpt_j['transformer.ln_f.bias']
|
||||
xtrt_llm_gpt_j.ln_f.bias.value = v.to(torch_dtype).cpu().numpy()
|
||||
|
||||
#lm_head
|
||||
if pad_vocab:
|
||||
weight = awq_gpt_j['lm_head.weight']
|
||||
[vocab_size, k] = weight.shape
|
||||
new_weight = torch.zeros([pad_vocab_size, k])
|
||||
new_weight[:vocab_size, :] = weight
|
||||
new_weight = new_weight.T.contiguous()
|
||||
amax = awq_gpt_j['lm_head.weight_quantizer._amax'].reshape(
|
||||
[vocab_size, int(k / group_size)])
|
||||
new_amax = torch.ones([pad_vocab_size, int(k / group_size)])
|
||||
new_amax[:vocab_size, :] = amax
|
||||
new_amax = new_amax.T.contiguous()
|
||||
new_scale = new_amax / 8
|
||||
xtrt_llm_gpt_j.lm_head.qweight.value = AWQ_quantize_pack_preprocess(
|
||||
new_weight, new_scale, group_size, packer, preprocessor)
|
||||
xtrt_llm_gpt_j.lm_head.scale.value = new_scale.to(
|
||||
torch_dtype).cpu().numpy()
|
||||
xtrt_llm_gpt_j.lm_head.pre_quant_scale.value = awq_gpt_j[
|
||||
'lm_head.input_quantizer._pre_quant_scale'].to(
|
||||
torch_dtype).cpu().numpy()
|
||||
|
||||
bias = awq_gpt_j['lm_head.bias']
|
||||
new_bias = torch.zeros([pad_vocab_size])
|
||||
new_bias[:vocab_size] = bias
|
||||
xtrt_llm_gpt_j.lm_head.bias.value = new_bias.to(
|
||||
torch_dtype).cpu().numpy()
|
||||
else:
|
||||
mPrefix = "lm_head"
|
||||
mOp = xtrt_llm_gpt_j.lm_head
|
||||
process_and_assign_weight(awq_gpt_j, mPrefix, mOp, group_size, packer,
|
||||
preprocessor, torch_dtype)
|
||||
|
||||
v = awq_gpt_j['lm_head.bias']
|
||||
xtrt_llm_gpt_j.lm_head.bias.value = v.to(torch_dtype).cpu().numpy()
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
xtrt_llm.logger.info(f'Weights loaded. Total time: {t}')
|
||||
3
examples/gptneox/.gitignore
vendored
Normal file
3
examples/gptneox/.gitignore
vendored
Normal file
@@ -0,0 +1,3 @@
|
||||
__pycache__/
|
||||
gptneox_model/
|
||||
*.log
|
||||
93
examples/gptneox/README.md
Normal file
93
examples/gptneox/README.md
Normal file
@@ -0,0 +1,93 @@
|
||||
# GPT-NeoX
|
||||
|
||||
This document explains how to build the [GPT-NeoX](https://huggingface.co/EleutherAI/gpt-neox-20b) model using XTRT-LLM and run on single node multi-XPU.
|
||||
|
||||
## Overview
|
||||
|
||||
The XTRT-LLM GPT-NeoX example code is located in [`examples/gptneox`](./). There are several main files in that folder:
|
||||
|
||||
* [`build.py`](./build.py) to build the XTRT engine(s) needed to run the GPT-NeoX model,
|
||||
* [`run.py`](./run.py) to run the inference on an input text,
|
||||
|
||||
|
||||
## Support Matrix
|
||||
* FP16
|
||||
* INT8 Weight-Only
|
||||
* Tensor Parallel
|
||||
|
||||
## Usage
|
||||
|
||||
### 1. Download weights from HuggingFace (HF) Transformers
|
||||
|
||||
```bash
|
||||
# Weights & config
|
||||
sh get_weights.sh
|
||||
```
|
||||
|
||||
### 2. Build XTRT engine(s)
|
||||
|
||||
XTRT-LLM builds XTRT engine(s) using a HF checkpoint. If no checkpoint directory is specified, XTRT-LLM will build engine(s) using dummy weights.
|
||||
|
||||
Examples of build invocations:
|
||||
|
||||
```bash
|
||||
# Build a float16 engine using 2-way tensor parallelism and HF weights.
|
||||
# Enable several XTRT-LLM plugins to increase runtime performance. It also helps with build time.
|
||||
python3 build.py --dtype=float16 \
|
||||
--log_level=verbose \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_layernorm_plugin float16 \
|
||||
--max_batch_size=16 \
|
||||
--max_input_len=1024 \
|
||||
--max_output_len=1024 \
|
||||
--world_size=2 \
|
||||
--output_dir=./downloads/gptneox_model/trt_engines/fp16/2-XPU/ \
|
||||
--model_dir=./downloads/gptneox_model 2>&1 | tee build_tp2.log
|
||||
|
||||
# Build a engine using 2-way tensor parallelism and HF weights. Apply INT8 weight-only quantization.
|
||||
# Enable several XTRT-LLM plugins to increase runtime performance. It also helps with build time.
|
||||
python3 build.py --dtype=float16 \
|
||||
--log_level=verbose \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_layernorm_plugin float16 \
|
||||
--max_batch_size=16 \
|
||||
--max_input_len=1024 \
|
||||
--max_output_len=1024 \
|
||||
--world_size=2 \
|
||||
--use_weight_only \
|
||||
--output_dir=./downloads/gptneox_model/trt_engines/in8/2-XPU/ \
|
||||
--model_dir=./downloads/gptneox_model 2>&1 | tee build_tp2.log
|
||||
```
|
||||
|
||||
### 3. Run
|
||||
|
||||
Before running the examples, make sure set the environment variables:
|
||||
```bash
|
||||
export PYTORCH_NO_XPU_MEMORY_CACHING=0 # disable XPytorch cache XPU memory.
|
||||
export XMLIR_D_XPU_L3_SIZE=0 # disable XPytorch use L3.
|
||||
```
|
||||
|
||||
If NOT using R480-X8, make sure set the environment variables:
|
||||
```bash
|
||||
export BKCL_PCIE_RING=1
|
||||
```
|
||||
|
||||
To run a XTRT-LLM GPT-NeoX model using the engines generated by `build.py`:
|
||||
|
||||
```bash
|
||||
# For 2-way tensor parallelism, FP16
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python3 run.py \
|
||||
--max_output_len=50 \
|
||||
--engine_dir=./downloads/gptneox_model/trt_engines/fp16/2-XPU/ \
|
||||
--tokenizer_dir=./downloads/gptneox_model
|
||||
|
||||
# For 2-way tensor parallelism, INT8
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python3 run.py \
|
||||
--max_output_len=50 \
|
||||
--engine_dir=./downloads/gptneox_model/trt_engines/in8/2-XPU/ \
|
||||
--tokenizer_dir=./downloads/gptneox_model
|
||||
```
|
||||
95
examples/gptneox/README_CN.md
Normal file
95
examples/gptneox/README_CN.md
Normal file
@@ -0,0 +1,95 @@
|
||||
# GPT-NeoX
|
||||
|
||||
本文档介绍了如何使用昆仑芯XTRT-LLM在单节点多XPU上构建和运行[GPT-NeoX](https://huggingface.co/EleutherAI/gpt-neox-20b) 模型。
|
||||
|
||||
## 概述
|
||||
|
||||
XTRT-LLM GPT-NeoX 示例代码位于 [`examples/gptneox`](./)。 此文件夹中有以下几个主要文件:
|
||||
|
||||
* [`build.py`](./build.py) 构建运行GPT-NeoX模型所需的XTRT引擎
|
||||
* [`run.py`](./run.py) 基于输入的文字进行推理
|
||||
|
||||
## 支持的矩阵
|
||||
|
||||
* FP16
|
||||
* INT8 Weight-Only
|
||||
* Tensor Parallel
|
||||
|
||||
## 使用说明
|
||||
|
||||
### 1.从HuggingFace(HF) Transformers下载权重
|
||||
|
||||
```bash
|
||||
# Weights & config
|
||||
sh get_weights.sh
|
||||
```
|
||||
|
||||
### 2. 构建XTRT引擎
|
||||
|
||||
XTRT-LLM从HF checkpoint构建XTRT引擎。如果未指定checkpoint目录,XTRT-LLM将使用伪权重构建引擎。
|
||||
|
||||
构建调用示例:
|
||||
|
||||
```bash
|
||||
# Build a float16 engine using 2-way tensor parallelism and HF weights.
|
||||
# Enable several XTRT-LLM plugins to increase runtime performance. It also helps with build time.
|
||||
python3 build.py --dtype=float16 \
|
||||
--log_level=verbose \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_layernorm_plugin float16 \
|
||||
--max_batch_size=16 \
|
||||
--max_input_len=1024 \
|
||||
--max_output_len=1024 \
|
||||
--world_size=2 \
|
||||
--output_dir=./downloads/gptneox_model/trt_engines/fp16/2-XPU/ \
|
||||
--model_dir=./downloads/gptneox_model 2>&1 | tee build_tp2.log
|
||||
|
||||
# Build a engine using 2-way tensor parallelism and HF weights. Apply INT8 weight-only quantization.
|
||||
# Enable several XTRT-LLM plugins to increase runtime performance. It also helps with build time.
|
||||
python3 build.py --dtype=float16 \
|
||||
--log_level=verbose \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_gemm_plugin float16 \
|
||||
--use_layernorm_plugin float16 \
|
||||
--max_batch_size=16 \
|
||||
--max_input_len=1024 \
|
||||
--max_output_len=1024 \
|
||||
--world_size=2 \
|
||||
--use_weight_only \
|
||||
--output_dir=./downloads/gptneox_model/trt_engines/in8/2-XPU/ \
|
||||
--model_dir=./downloads/gptneox_model 2>&1 | tee build_tp2.log
|
||||
```
|
||||
|
||||
### 3. 运行
|
||||
|
||||
在运行示例之前,请确保设置环境变量:
|
||||
|
||||
```bash
|
||||
export PYTORCH_NO_XPU_MEMORY_CACHING=0 # disable XPytorch cache XPU memory.
|
||||
export XMLIR_D_XPU_L3_SIZE=0 # disable XPytorch use L3.
|
||||
```
|
||||
|
||||
如果不使用昆仑芯R480-X8产品,请确保设置环境变量如下:
|
||||
|
||||
```bash
|
||||
export BKCL_PCIE_RING=1
|
||||
```
|
||||
|
||||
要使用`build.py`生成的引擎运行XTRT-LLM GPT-NeoX模型,请执行以下操作:
|
||||
|
||||
```bash
|
||||
# For 2-way tensor parallelism, FP16
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python3 run.py \
|
||||
--max_output_len=50 \
|
||||
--engine_dir=./downloads/gptneox_model/trt_engines/fp16/2-XPU/ \
|
||||
--tokenizer_dir=./downloads/gptneox_model
|
||||
|
||||
# For 2-way tensor parallelism, INT8
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python3 run.py \
|
||||
--max_output_len=50 \
|
||||
--engine_dir=./downloads/gptneox_model/trt_engines/in8/2-XPU/ \
|
||||
--tokenizer_dir=./downloads/gptneox_model
|
||||
```
|
||||
442
examples/gptneox/build.py
Normal file
442
examples/gptneox/build.py
Normal file
@@ -0,0 +1,442 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import time
|
||||
|
||||
#import tensorrt as trt
|
||||
import torch
|
||||
import torch.multiprocessing as mp
|
||||
from safetensors import safe_open
|
||||
from transformers import AutoModelForCausalLM, GPTNeoXConfig
|
||||
from weight import load_from_hf_gpt_neox
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm._utils import str_dtype_to_xtrt
|
||||
from xtrt_llm.builder import Builder
|
||||
from xtrt_llm.logger import logger
|
||||
from xtrt_llm.mapping import Mapping
|
||||
from xtrt_llm.models import weight_only_groupwise_quantize, weight_only_quantize
|
||||
from xtrt_llm.network import net_guard
|
||||
from xtrt_llm.plugin.plugin import ContextFMHAType
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
MODEL_NAME = "gptneox"
|
||||
hf_gpt = None
|
||||
|
||||
|
||||
class StateDict():
|
||||
|
||||
def __init__(self, quant_ckpt_dir):
|
||||
self.model_state_dict = safe_open(quant_ckpt_dir,
|
||||
framework="pt",
|
||||
device=0)
|
||||
|
||||
def get(self, k):
|
||||
return self.model_state_dict.get_tensor(k).cpu()
|
||||
|
||||
|
||||
class GPTQModel():
|
||||
|
||||
def __init__(self, model_dir, quant_ckpt_dir):
|
||||
with open(model_dir + '/config.json', 'r') as f:
|
||||
model_config = json.load(f)
|
||||
self.config = GPTNeoXConfig()
|
||||
self.config.vocab_size = model_config['vocab_size']
|
||||
self.config.hidden_size = model_config['hidden_size']
|
||||
self.config.num_hidden_layers = model_config['num_hidden_layers']
|
||||
self.config.num_attention_heads = model_config[
|
||||
'num_attention_heads']
|
||||
self.config.intermediate_size = model_config['intermediate_size']
|
||||
self.config.hidden_act = model_config['hidden_act']
|
||||
self.config.rotary_pct = model_config['rotary_pct']
|
||||
self.config.rotary_emb_base = model_config['rotary_emb_base']
|
||||
self.config.max_position_embeddings = model_config[
|
||||
'max_position_embeddings']
|
||||
self.config.initializer_range = model_config['initializer_range']
|
||||
self.config.layer_norm_eps = model_config['layer_norm_eps']
|
||||
self.config.use_cache = model_config['use_cache']
|
||||
self.config.bos_token_id = model_config['bos_token_id']
|
||||
self.config.eos_token_id = model_config['eos_token_id']
|
||||
self.config.tie_word_embeddings = model_config[
|
||||
'tie_word_embeddings']
|
||||
self.model_state_dict = StateDict(quant_ckpt_dir)
|
||||
|
||||
def state_dict(self):
|
||||
return self.model_state_dict
|
||||
|
||||
|
||||
def get_engine_name(model, dtype, tp_size, rank):
|
||||
return '{}_{}_tp{}_rank{}.engine'.format(model, dtype, tp_size, rank)
|
||||
|
||||
|
||||
def serialize_engine(engine, path):
|
||||
logger.info(f'Serializing engine to {path}...')
|
||||
tik = time.time()
|
||||
engine.serialize(path)
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Engine serialized. Total time: {t}')
|
||||
|
||||
|
||||
def parse_arguments():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--world_size',
|
||||
type=int,
|
||||
default=1,
|
||||
help='world size, only support tensor parallelism now')
|
||||
parser.add_argument(
|
||||
'--model_dir',
|
||||
type=str,
|
||||
default=None,
|
||||
help='The path to HF GPT-NeoX model / checkpoints to read weights from')
|
||||
parser.add_argument('--dtype',
|
||||
type=str,
|
||||
default='float16',
|
||||
choices=['float16', 'float32'])
|
||||
parser.add_argument(
|
||||
'--timing_cache',
|
||||
type=str,
|
||||
default='model.cache',
|
||||
help=
|
||||
'The path of to read timing cache from, will be ignored if the file does not exist'
|
||||
)
|
||||
parser.add_argument('--log_level', type=str, default='info')
|
||||
parser.add_argument('--vocab_size', type=int, default=50432)
|
||||
parser.add_argument('--n_layer', type=int, default=44)
|
||||
parser.add_argument('--n_positions', type=int, default=2048)
|
||||
parser.add_argument('--n_embd', type=int, default=6144)
|
||||
parser.add_argument('--n_head', type=int, default=64)
|
||||
parser.add_argument('--hidden_act', type=str, default='gelu')
|
||||
parser.add_argument(
|
||||
'--rotary_pct',
|
||||
type=float,
|
||||
default=0.25,
|
||||
help="Percentage of hidden dimensions to allocate to rotary embeddings."
|
||||
)
|
||||
parser.add_argument('--max_batch_size', type=int, default=64)
|
||||
parser.add_argument('--max_input_len', type=int, default=1024)
|
||||
parser.add_argument('--max_output_len', type=int, default=1024)
|
||||
parser.add_argument('--max_beam_width', type=int, default=1)
|
||||
parser.add_argument('--use_gpt_attention_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
choices=['float16', 'float32'])
|
||||
parser.add_argument('--use_gemm_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
choices=['float16', 'float32'])
|
||||
parser.add_argument('--use_weight_only_quant_matmul_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
choices=['float16'])
|
||||
parser.add_argument('--use_weight_only_groupwise_quant_matmul_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
choices=['float16'])
|
||||
parser.add_argument(
|
||||
'--groupwise_quant_safetensors_path',
|
||||
type=str,
|
||||
default=None,
|
||||
help=
|
||||
"The path to groupwise quantized GPT-NeoX model / checkpoints to read weights from."
|
||||
)
|
||||
parser.add_argument('--use_layernorm_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
choices=['float16', 'float32'])
|
||||
parser.add_argument('--parallel_build', default=False, action='store_true')
|
||||
parser.add_argument('--enable_context_fmha',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--enable_context_fmha_fp32_acc',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--gpus_per_node', type=int, default=8)
|
||||
parser.add_argument(
|
||||
'--output_dir',
|
||||
type=str,
|
||||
default='gpt_outputs',
|
||||
help=
|
||||
'The path to save the serialized engine files, timing cache file and model configs'
|
||||
)
|
||||
parser.add_argument('--remove_input_padding',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument(
|
||||
'--use_parallel_embedding',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help=
|
||||
'By default embedding parallelism is disabled. By setting this flag, embedding parallelism is enabled'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--embedding_sharding_dim',
|
||||
type=int,
|
||||
default=1, # Meta does TP on hidden dim
|
||||
choices=[0, 1],
|
||||
help=
|
||||
'By default the embedding lookup table is sharded along vocab dimension (--embedding_sharding_dim=0). '
|
||||
'To shard it along hidden dimension, set --embedding_sharding_dim=1'
|
||||
'Note: embedding sharing is only enabled when --embedding_sharding_dim=0'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_weight_only',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help='Quantize weights for the various GEMMs to INT4/INT8.'
|
||||
'See --weight_only_precision to set the precision')
|
||||
parser.add_argument(
|
||||
'--weight_only_precision',
|
||||
const='int8',
|
||||
type=str,
|
||||
nargs='?',
|
||||
default='int8',
|
||||
choices=['int8', 'int4'],
|
||||
help=
|
||||
'Define the precision for the weights when using weight-only quantization.'
|
||||
'You must also use --use_weight_only for that argument to have an impact.'
|
||||
)
|
||||
parser.add_argument('--inter_size', type=int, default=None)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
xtrt_llm.logger.set_level(args.log_level)
|
||||
|
||||
if args.model_dir is not None:
|
||||
global hf_gpt
|
||||
if not args.use_weight_only_groupwise_quant_matmul_plugin:
|
||||
logger.info(f'Loading HF GPT-NeoX model from {args.model_dir}...')
|
||||
hf_gpt = AutoModelForCausalLM.from_pretrained(args.model_dir)
|
||||
args.n_embd = hf_gpt.config.hidden_size
|
||||
args.n_head = hf_gpt.config.num_attention_heads
|
||||
args.n_layer = hf_gpt.config.num_hidden_layers
|
||||
args.n_positions = hf_gpt.config.max_position_embeddings
|
||||
args.vocab_size = hf_gpt.config.vocab_size
|
||||
args.rotary_pct = hf_gpt.config.rotary_pct
|
||||
else:
|
||||
assert (
|
||||
args.groupwise_quant_safetensors_path is not None
|
||||
), f'Please set the path to the groupwise quantized GPT-NeoX checkpoints with --groupwise_quant_safetensors_path'
|
||||
logger.info(
|
||||
f'Loading GPTQ quantized HF GPT-NeoX model from {args.groupwise_quant_safetensors_path}...'
|
||||
)
|
||||
hf_gpt = GPTQModel(args.model_dir,
|
||||
args.groupwise_quant_safetensors_path)
|
||||
args.n_embd = hf_gpt.config.hidden_size
|
||||
args.n_head = hf_gpt.config.num_attention_heads
|
||||
args.n_layer = hf_gpt.config.num_hidden_layers
|
||||
args.n_positions = hf_gpt.config.max_position_embeddings
|
||||
args.vocab_size = hf_gpt.config.vocab_size
|
||||
args.rotary_pct = hf_gpt.config.rotary_pct
|
||||
args.inter_size = hf_gpt.config.intermediate_size
|
||||
|
||||
if args.use_weight_only:
|
||||
args.quant_mode = QuantMode.use_weight_only(
|
||||
args.weight_only_precision == 'int4')
|
||||
else:
|
||||
args.quant_mode = QuantMode(0)
|
||||
|
||||
return args
|
||||
|
||||
|
||||
def build_rank_engine(builder: Builder,
|
||||
builder_config: xtrt_llm.builder.BuilderConfig,
|
||||
engine_name, rank, args):
|
||||
'''
|
||||
@brief: Build the engine on the given rank.
|
||||
@param rank: The rank to build the engine.
|
||||
@param args: The cmd line arguments.
|
||||
@return: The built engine.
|
||||
'''
|
||||
kv_dtype = str_dtype_to_xtrt(args.dtype)
|
||||
rotary_dim = int((args.n_embd // args.n_head) * args.rotary_pct)
|
||||
|
||||
# Initialize Module
|
||||
xtrt_llm_gpt = xtrt_llm.models.GPTNeoXForCausalLM(
|
||||
num_layers=args.n_layer,
|
||||
num_heads=args.n_head,
|
||||
hidden_size=args.n_embd,
|
||||
vocab_size=args.vocab_size,
|
||||
hidden_act=args.hidden_act,
|
||||
max_position_embeddings=args.n_positions,
|
||||
rotary_dim=rotary_dim,
|
||||
dtype=kv_dtype,
|
||||
mapping=Mapping(world_size=args.world_size,
|
||||
rank=rank,
|
||||
tp_size=args.world_size), # TP only
|
||||
apply_query_key_layer_scaling=builder_config.
|
||||
apply_query_key_layer_scaling,
|
||||
use_parallel_embedding=args.use_parallel_embedding,
|
||||
embedding_sharding_dim=args.embedding_sharding_dim)
|
||||
|
||||
if args.use_weight_only_quant_matmul_plugin:
|
||||
xtrt_llm_gpt = weight_only_quantize(xtrt_llm_gpt)
|
||||
|
||||
if args.use_weight_only_groupwise_quant_matmul_plugin:
|
||||
xtrt_llm_gpt = weight_only_groupwise_quantize(model=xtrt_llm_gpt,
|
||||
quant_mode=QuantMode(0),
|
||||
group_size=128,
|
||||
zero=True)
|
||||
|
||||
if args.model_dir is not None:
|
||||
assert hf_gpt is not None, f'Could not load weights from hf_gpt model as it is not loaded yet.'
|
||||
|
||||
if args.world_size > 1:
|
||||
assert (
|
||||
args.n_embd % args.world_size == 0
|
||||
), f'Embedding size/hidden size must be divisible by world size.'
|
||||
assert (
|
||||
args.n_head % args.world_size == 0
|
||||
), f'Number of attention heads must be divisible by world size.'
|
||||
|
||||
load_from_hf_gpt_neox(
|
||||
xtrt_llm_gpt, hf_gpt, args.dtype, rank, args.world_size,
|
||||
args.use_weight_only_groupwise_quant_matmul_plugin)
|
||||
|
||||
# Module -> Network
|
||||
network = builder.create_network()
|
||||
network.trt_network.name = engine_name
|
||||
if args.use_gpt_attention_plugin:
|
||||
network.plugin_config.set_gpt_attention_plugin(
|
||||
dtype=args.use_gpt_attention_plugin)
|
||||
if args.use_gemm_plugin:
|
||||
network.plugin_config.set_gemm_plugin(dtype=args.use_gemm_plugin)
|
||||
if args.use_layernorm_plugin:
|
||||
network.plugin_config.set_layernorm_plugin(
|
||||
dtype=args.use_layernorm_plugin)
|
||||
assert not (args.enable_context_fmha and args.enable_context_fmha_fp32_acc)
|
||||
if args.enable_context_fmha:
|
||||
network.plugin_config.set_context_fmha(ContextFMHAType.enabled)
|
||||
if args.enable_context_fmha_fp32_acc:
|
||||
network.plugin_config.set_context_fmha(
|
||||
ContextFMHAType.enabled_with_fp32_acc)
|
||||
if args.use_weight_only_quant_matmul_plugin:
|
||||
network.plugin_config.set_weight_only_quant_matmul_plugin(
|
||||
dtype=args.use_weight_only_quant_matmul_plugin)
|
||||
if args.use_weight_only_groupwise_quant_matmul_plugin:
|
||||
network.plugin_config.set_weight_only_groupwise_quant_matmul_plugin(
|
||||
dtype=args.use_weight_only_groupwise_quant_matmul_plugin)
|
||||
if args.quant_mode.is_weight_only():
|
||||
builder_config.trt_builder_config.use_weight_only = args.weight_only_precision
|
||||
|
||||
if args.world_size > 1:
|
||||
network.plugin_config.set_nccl_plugin(args.dtype)
|
||||
if args.remove_input_padding:
|
||||
network.plugin_config.enable_remove_input_padding()
|
||||
with net_guard(network):
|
||||
# Prepare
|
||||
network.set_named_parameters(xtrt_llm_gpt.named_parameters())
|
||||
|
||||
# Forward
|
||||
inputs = xtrt_llm_gpt.prepare_inputs(args.max_batch_size,
|
||||
args.max_input_len,
|
||||
args.max_output_len, True,
|
||||
args.max_beam_width)
|
||||
xtrt_llm_gpt(*inputs)
|
||||
|
||||
#xtrt_llm.graph_rewriting.optimize(network)
|
||||
|
||||
engine = None
|
||||
|
||||
# Network -> Engine
|
||||
engine = builder.build_engine(network, builder_config, compiler="gr")
|
||||
if rank == 0:
|
||||
config_path = os.path.join(args.output_dir, 'config.json')
|
||||
builder.save_config(builder_config, config_path)
|
||||
return engine
|
||||
|
||||
|
||||
def build(rank, args):
|
||||
#torch.cuda.set_device(rank % args.gpus_per_node)
|
||||
xtrt_llm.logger.set_level(args.log_level)
|
||||
if not os.path.exists(args.output_dir):
|
||||
os.makedirs(args.output_dir)
|
||||
|
||||
# when doing serializing build, all ranks share one engine
|
||||
apply_query_key_layer_scaling = False
|
||||
builder = Builder()
|
||||
|
||||
cache = None
|
||||
for cur_rank in range(args.world_size):
|
||||
# skip other ranks if parallel_build is enabled
|
||||
if args.parallel_build and cur_rank != rank:
|
||||
continue
|
||||
builder_config = builder.create_builder_config(
|
||||
name=MODEL_NAME,
|
||||
precision=args.dtype,
|
||||
timing_cache=args.timing_cache if cache is None else cache,
|
||||
tensor_parallel=args.world_size, # TP only
|
||||
parallel_build=args.parallel_build,
|
||||
num_layers=args.n_layer,
|
||||
num_heads=args.n_head,
|
||||
inter_size=args.inter_size,
|
||||
hidden_size=args.n_embd,
|
||||
vocab_size=args.vocab_size,
|
||||
hidden_act=args.hidden_act,
|
||||
max_position_embeddings=args.n_positions,
|
||||
apply_query_key_layer_scaling=apply_query_key_layer_scaling,
|
||||
max_batch_size=args.max_batch_size,
|
||||
max_input_len=args.max_input_len,
|
||||
max_output_len=args.max_output_len,
|
||||
fusion_pattern_list=["remove_dup_mask"])
|
||||
|
||||
engine_name = get_engine_name(MODEL_NAME, args.dtype, args.world_size,
|
||||
cur_rank)
|
||||
engine = build_rank_engine(builder, builder_config, engine_name,
|
||||
cur_rank, args)
|
||||
assert engine is not None, f'Failed to build engine for rank {cur_rank}'
|
||||
|
||||
# if cur_rank == 0:
|
||||
# # Use in-memory timing cache for multiple builder passes.
|
||||
# if not args.parallel_build:
|
||||
# cache = builder_config.trt_builder_config.get_timing_cache()
|
||||
|
||||
serialize_engine(engine, os.path.join(args.output_dir, engine_name))
|
||||
|
||||
# if rank == 0:
|
||||
# ok = builder.save_timing_cache(
|
||||
# builder_config, os.path.join(args.output_dir, "model.cache"))
|
||||
# assert ok, "Failed to save timing cache."
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = parse_arguments()
|
||||
tik = time.time()
|
||||
if args.parallel_build and args.world_size > 1 and \
|
||||
torch.cuda.device_count() >= args.world_size:
|
||||
logger.warning(
|
||||
f'Parallelly build TensorRT engines. Please make sure that all of the {args.world_size} GPUs are totally free.'
|
||||
)
|
||||
mp.spawn(build, nprocs=args.world_size, args=(args, ))
|
||||
else:
|
||||
args.parallel_build = False
|
||||
logger.info('Serially build TensorRT engines.')
|
||||
build(0, args)
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Total time of building all {args.world_size} engines: {t}')
|
||||
16
examples/gptneox/get_weights.sh
Normal file
16
examples/gptneox/get_weights.sh
Normal file
@@ -0,0 +1,16 @@
|
||||
mkdir -p downloads
|
||||
pushd downloads
|
||||
rm -rf gptneox_model
|
||||
git clone https://huggingface.co/EleutherAI/gpt-neox-20b gptneox_model
|
||||
|
||||
rm -f gptneox_model/model-*.safetensors
|
||||
rm -f gptneox_model/model.safetensors.index.json
|
||||
wget -q https://huggingface.co/EleutherAI/gpt-neox-20b/resolve/main/model.safetensors.index.json --directory-prefix gptneox_model
|
||||
|
||||
for i in $(seq -f %05g 46)
|
||||
do
|
||||
echo -n "Downloading $i of 00046..."
|
||||
wget -q https://huggingface.co/EleutherAI/gpt-neox-20b/resolve/main/model-$i-of-00046.safetensors --directory-prefix gptneox_model
|
||||
echo "Done"
|
||||
done
|
||||
popd
|
||||
9
examples/gptneox/gptq_convert.sh
Normal file
9
examples/gptneox/gptq_convert.sh
Normal file
@@ -0,0 +1,9 @@
|
||||
git clone https://github.com/qwopqwop200/GPTQ-for-LLaMa.git GPTQ-for-LLaMa
|
||||
|
||||
pip install -r ./GPTQ-for-LLaMa/requirements.txt
|
||||
|
||||
CUDA_VISIBLE_DEVICES=0 python3 GPTQ-for-LLaMa/neox.py ./gptneox_model \
|
||||
wikitext2 \
|
||||
--wbits 4 \
|
||||
--groupsize 128 \
|
||||
--save_safetensors ./gptneox_model/gptneox-20b-4bit-gs128.safetensors
|
||||
2
examples/gptneox/requirements.txt
Normal file
2
examples/gptneox/requirements.txt
Normal file
@@ -0,0 +1,2 @@
|
||||
datasets~=2.3.2
|
||||
rouge_score~=0.1.2
|
||||
141
examples/gptneox/run.py
Normal file
141
examples/gptneox/run.py
Normal file
@@ -0,0 +1,141 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import numpy as np
|
||||
|
||||
import torch
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm.runtime import ModelConfig, SamplingConfig
|
||||
|
||||
from build import get_engine_name # isort:skip
|
||||
|
||||
|
||||
def parse_arguments():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--max_output_len', type=int, required=True)
|
||||
parser.add_argument('--log_level', type=str, default='error')
|
||||
parser.add_argument('--engine_dir', type=str, default='gptneox_outputs')
|
||||
parser.add_argument('--tokenizer_dir',
|
||||
type=str,
|
||||
default="gptneox_model",
|
||||
help="Directory containing the tokenizer.model.")
|
||||
parser.add_argument('--input_text',
|
||||
type=str,
|
||||
default='Born in north-east France, Soyer trained as a')
|
||||
parser.add_argument('--performance_test_scale',
|
||||
type=str,
|
||||
help=
|
||||
"Scale for performance test. e.g., 8x1024x64 (batch_size, input_text_length, max_output_length)",
|
||||
default="")
|
||||
return parser.parse_args()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = parse_arguments()
|
||||
xtrt_llm.logger.set_level(args.log_level)
|
||||
|
||||
config_path = os.path.join(args.engine_dir, 'config.json')
|
||||
with open(config_path, 'r') as f:
|
||||
config = json.load(f)
|
||||
use_gpt_attention_plugin = config['plugin_config']['gpt_attention_plugin']
|
||||
remove_input_padding = config['plugin_config']['remove_input_padding']
|
||||
dtype = config['builder_config']['precision']
|
||||
world_size = config['builder_config']['tensor_parallel']
|
||||
assert world_size == xtrt_llm.mpi_world_size(), \
|
||||
f'Engine world size ({world_size}) != Runtime world size ({xtrt_llm.mpi_world_size()})'
|
||||
num_heads = config['builder_config']['num_heads'] // world_size
|
||||
hidden_size = config['builder_config']['hidden_size'] // world_size
|
||||
vocab_size = config['builder_config']['vocab_size']
|
||||
num_layers = config['builder_config']['num_layers']
|
||||
|
||||
runtime_rank = xtrt_llm.mpi_rank()
|
||||
if world_size > 1:
|
||||
os.environ["XCCL_GROUP_ID"] = str(runtime_rank // world_size)
|
||||
os.environ["XCCL_NRANKS"] = str(world_size)
|
||||
os.environ["XCCL_CUR_RANK"] = str(runtime_rank % world_size)
|
||||
os.environ["XCCL_DEVICE_ID"] = str(runtime_rank)
|
||||
os.environ["MP_RUN"] = str(1)
|
||||
runtime_mapping = xtrt_llm.Mapping(world_size,
|
||||
runtime_rank,
|
||||
tp_size=world_size)
|
||||
torch.cuda.set_device(runtime_rank % runtime_mapping.gpus_per_node)
|
||||
|
||||
engine_name = get_engine_name('gptneox', dtype, world_size, runtime_rank)
|
||||
#serialize_path = os.path.join(args.engine_dir, engine_name)
|
||||
serialize_path = str(args.engine_dir) + "/" + engine_name
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_dir)
|
||||
input_ids = torch.tensor(tokenizer.encode(args.input_text),
|
||||
dtype=torch.int32).cuda().unsqueeze(0)
|
||||
|
||||
model_config = ModelConfig(num_heads=num_heads,
|
||||
num_kv_heads=num_heads,
|
||||
hidden_size=hidden_size,
|
||||
vocab_size=vocab_size,
|
||||
num_layers=num_layers,
|
||||
gpt_attention_plugin=use_gpt_attention_plugin,
|
||||
remove_input_padding=remove_input_padding,
|
||||
dtype=dtype)
|
||||
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
end_id = tokenizer.encode(tokenizer.eos_token, add_special_tokens=False)[0]
|
||||
pad_id = tokenizer.encode(tokenizer.pad_token, add_special_tokens=False)[0]
|
||||
|
||||
sampling_config = SamplingConfig(end_id=end_id, pad_id=pad_id)
|
||||
input_lengths = torch.tensor(
|
||||
[input_ids.size(1) for _ in range(input_ids.size(0))]).int().cuda()
|
||||
|
||||
#with open(serialize_path, 'rb') as f:
|
||||
# engine_buffer = f.read()
|
||||
decoder = xtrt_llm.runtime.GenerationSession(model_config,
|
||||
serialize_path,
|
||||
runtime_mapping,
|
||||
debug_mode=False)
|
||||
|
||||
if args.performance_test_scale != "":
|
||||
performance_test_scale_list = args.performance_test_scale.split("E")
|
||||
for scale in performance_test_scale_list:
|
||||
xtrt_llm.logger.info(f"Running performance test with scale {scale}")
|
||||
bs, seqlen, max_output_len = [int(x) for x in scale.split("x")]
|
||||
_input_ids = torch.from_numpy(
|
||||
np.zeros((bs, seqlen)).astype("int32")).cuda()
|
||||
_input_lengths = torch.from_numpy(
|
||||
np.full((bs, ), seqlen).astype("int32")).cuda()
|
||||
|
||||
import time
|
||||
_t_begin = time.time()
|
||||
decoder.setup(_input_ids.size(0), _input_ids.size(1), max_output_len)
|
||||
_output_ids = decoder.decode(_input_ids,
|
||||
_input_lengths,
|
||||
sampling_config)
|
||||
_t_end = time.time()
|
||||
xtrt_llm.logger.info(
|
||||
f"Total latency: {(_t_end - _t_begin) * 1000:.3f} ms")
|
||||
|
||||
if remove_input_padding:
|
||||
decoder.setup(1, torch.max(input_lengths).item(), args.max_output_len)
|
||||
else:
|
||||
decoder.setup(input_ids.size(0), input_ids.size(1), args.max_output_len)
|
||||
output_ids = decoder.decode(input_ids, input_lengths, sampling_config)
|
||||
torch.cuda.synchronize()
|
||||
|
||||
output_ids = output_ids.tolist()[0][0][input_ids.size(1):]
|
||||
output_text = tokenizer.decode(output_ids)
|
||||
print(f'Input: \"{args.input_text}\"')
|
||||
print(f'Output: \"{output_text}\"')
|
||||
8
examples/gptneox/run.sh
Executable file
8
examples/gptneox/run.sh
Executable file
@@ -0,0 +1,8 @@
|
||||
BKCL_PCIE_RING=1 PYTORCH_NO_XPU_MEMORY_CACHING=1 XMLIR_D_XPU_L3_SIZE=0 \
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python3 run.py \
|
||||
--max_output_len=50 \
|
||||
--engine_dir=./downloads/gptneox_model/trt_engines/fp16/2-XPU/ \
|
||||
--tokenizer_dir=./downloads/gptneox_model \
|
||||
--performance_test_scale=1x512x256E2x512x256E4x512x256E8x512x256 \
|
||||
--log_level=info
|
||||
373
examples/gptneox/summarize.py
Normal file
373
examples/gptneox/summarize.py
Normal file
@@ -0,0 +1,373 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import copy
|
||||
import json
|
||||
import os
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from datasets import load_dataset, load_metric
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
import tensorrt_llm
|
||||
import tensorrt_llm.profiler as profiler
|
||||
from tensorrt_llm.logger import logger
|
||||
|
||||
from build import get_engine_name # isort:skip
|
||||
|
||||
|
||||
def TRTGPTNeoX(args, config):
|
||||
dtype = config['builder_config']['precision']
|
||||
world_size = config['builder_config']['tensor_parallel']
|
||||
assert world_size == tensorrt_llm.mpi_world_size(), \
|
||||
f'Engine world size ({world_size}) != Runtime world size ({tensorrt_llm.mpi_world_size()})'
|
||||
|
||||
world_size = config['builder_config']['tensor_parallel']
|
||||
num_heads = config['builder_config']['num_heads'] // world_size
|
||||
hidden_size = config['builder_config']['hidden_size'] // world_size
|
||||
vocab_size = config['builder_config']['vocab_size']
|
||||
num_layers = config['builder_config']['num_layers']
|
||||
use_gpt_attention_plugin = bool(
|
||||
config['plugin_config']['gpt_attention_plugin'])
|
||||
remove_input_padding = config['plugin_config']['remove_input_padding']
|
||||
|
||||
model_config = tensorrt_llm.runtime.ModelConfig(
|
||||
vocab_size=vocab_size,
|
||||
num_layers=num_layers,
|
||||
num_heads=num_heads,
|
||||
num_kv_heads=num_heads,
|
||||
hidden_size=hidden_size,
|
||||
gpt_attention_plugin=use_gpt_attention_plugin,
|
||||
remove_input_padding=remove_input_padding,
|
||||
dtype=dtype)
|
||||
|
||||
runtime_rank = tensorrt_llm.mpi_rank()
|
||||
runtime_mapping = tensorrt_llm.Mapping(world_size,
|
||||
runtime_rank,
|
||||
tp_size=world_size)
|
||||
torch.cuda.set_device(runtime_rank % runtime_mapping.gpus_per_node)
|
||||
|
||||
engine_name = get_engine_name('gptneox', dtype, world_size, runtime_rank)
|
||||
serialize_path = os.path.join(args.engine_dir, engine_name)
|
||||
|
||||
tensorrt_llm.logger.set_level(args.log_level)
|
||||
|
||||
with open(serialize_path, 'rb') as f:
|
||||
engine_buffer = f.read()
|
||||
decoder = tensorrt_llm.runtime.GenerationSession(model_config,
|
||||
engine_buffer,
|
||||
runtime_mapping)
|
||||
|
||||
return decoder
|
||||
|
||||
|
||||
def main(args):
|
||||
runtime_rank = tensorrt_llm.mpi_rank()
|
||||
logger.set_level(args.log_level)
|
||||
|
||||
test_hf = args.test_hf and runtime_rank == 0 # only run hf on rank 0
|
||||
test_trt_llm = args.test_trt_llm
|
||||
model_dir = args.model_dir
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_dir,
|
||||
padding_side='left',
|
||||
model_max_length=2048,
|
||||
truncation=True)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
dataset_cnn = load_dataset("ccdv/cnn_dailymail",
|
||||
'3.0.0',
|
||||
cache_dir=args.dataset_path)
|
||||
|
||||
config_path = os.path.join(args.engine_dir, 'config.json')
|
||||
with open(config_path, 'r') as f:
|
||||
config = json.load(f)
|
||||
|
||||
max_batch_size = args.batch_size
|
||||
|
||||
# runtime parameters
|
||||
# repetition_penalty = 1
|
||||
top_k = args.top_k
|
||||
output_len = args.output_len
|
||||
test_token_num = 923
|
||||
# top_p = 0.0
|
||||
# random_seed = 5
|
||||
temperature = 1
|
||||
num_beams = args.num_beams
|
||||
|
||||
pad_id = tokenizer.encode(tokenizer.pad_token, add_special_tokens=False)[0]
|
||||
end_id = tokenizer.encode(tokenizer.eos_token, add_special_tokens=False)[0]
|
||||
|
||||
if test_trt_llm:
|
||||
tensorrt_llm_gpt = TRTGPTNeoX(args, config)
|
||||
|
||||
if test_hf:
|
||||
model = AutoModelForCausalLM.from_pretrained(model_dir)
|
||||
model.cuda()
|
||||
if args.data_type == 'fp16':
|
||||
model.half()
|
||||
|
||||
def summarize_tensorrt_llm(datapoint):
|
||||
batch_size = len(datapoint['article'])
|
||||
|
||||
line = copy.copy(datapoint['article'])
|
||||
line_encoded = []
|
||||
input_lengths = []
|
||||
for i in range(batch_size):
|
||||
line[i] = line[i] + ' TL;DR: '
|
||||
|
||||
line[i] = line[i].strip()
|
||||
line[i] = line[i].replace(" n't", "n't")
|
||||
|
||||
input_id = tokenizer.encode(line[i],
|
||||
return_tensors='pt').type(torch.int32)
|
||||
input_id = input_id[:, -test_token_num:]
|
||||
|
||||
line_encoded.append(input_id)
|
||||
input_lengths.append(input_id.shape[-1])
|
||||
|
||||
# do padding, should move outside the profiling to prevent the overhead
|
||||
max_length = max(input_lengths)
|
||||
if tensorrt_llm_gpt.remove_input_padding:
|
||||
line_encoded = [
|
||||
torch.tensor(t, dtype=torch.int32).cuda() for t in line_encoded
|
||||
]
|
||||
else:
|
||||
# do padding, should move outside the profiling to prevent the overhead
|
||||
for i in range(batch_size):
|
||||
pad_size = max_length - input_lengths[i]
|
||||
|
||||
pad = torch.ones([1, pad_size]).type(torch.int32) * pad_id
|
||||
line_encoded[i] = torch.cat(
|
||||
[torch.tensor(line_encoded[i], dtype=torch.int32), pad],
|
||||
axis=-1)
|
||||
|
||||
line_encoded = torch.cat(line_encoded, axis=0).cuda()
|
||||
input_lengths = torch.tensor(input_lengths,
|
||||
dtype=torch.int32).cuda()
|
||||
|
||||
sampling_config = tensorrt_llm.runtime.SamplingConfig(
|
||||
end_id=end_id, pad_id=pad_id, top_k=top_k, num_beams=num_beams)
|
||||
|
||||
with torch.no_grad():
|
||||
tensorrt_llm_gpt.setup(batch_size,
|
||||
max_context_length=max_length,
|
||||
max_new_tokens=output_len,
|
||||
beam_width=num_beams)
|
||||
|
||||
if tensorrt_llm_gpt.remove_input_padding:
|
||||
output_ids = tensorrt_llm_gpt.decode_batch(
|
||||
line_encoded, sampling_config)
|
||||
else:
|
||||
output_ids = tensorrt_llm_gpt.decode(
|
||||
line_encoded,
|
||||
input_lengths,
|
||||
sampling_config,
|
||||
)
|
||||
|
||||
torch.cuda.synchronize()
|
||||
|
||||
# Extract a list of tensors of shape beam_width x output_ids.
|
||||
if tensorrt_llm_gpt.mapping.is_first_pp_rank():
|
||||
output_beams_list = [
|
||||
tokenizer.batch_decode(output_ids[batch_idx, :,
|
||||
input_lengths[batch_idx]:],
|
||||
skip_special_tokens=True)
|
||||
for batch_idx in range(batch_size)
|
||||
]
|
||||
return output_beams_list, output_ids[:, :, max_length:].tolist()
|
||||
return [], []
|
||||
|
||||
def summarize_hf(datapoint):
|
||||
batch_size = len(datapoint['article'])
|
||||
if batch_size > 1:
|
||||
logger.warning(
|
||||
f"HF does not support batch_size > 1 to verify correctness due to padding. Current batch size is {batch_size}"
|
||||
)
|
||||
|
||||
line = copy.copy(datapoint['article'])
|
||||
for i in range(batch_size):
|
||||
line[i] = line[i] + ' TL;DR: '
|
||||
|
||||
line[i] = line[i].strip()
|
||||
line[i] = line[i].replace(" n't", "n't")
|
||||
|
||||
line_encoded = tokenizer(line,
|
||||
return_tensors='pt',
|
||||
padding=True,
|
||||
truncation=True)["input_ids"].type(torch.int64)
|
||||
|
||||
line_encoded = line_encoded[:, -test_token_num:]
|
||||
line_encoded = line_encoded.cuda()
|
||||
|
||||
with torch.no_grad():
|
||||
output = model.generate(line_encoded,
|
||||
max_length=len(line_encoded[0]) +
|
||||
output_len,
|
||||
top_k=top_k,
|
||||
temperature=temperature,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
num_beams=num_beams,
|
||||
num_return_sequences=num_beams,
|
||||
early_stopping=True)
|
||||
|
||||
tokens_list = output[:, len(line_encoded[0]):].tolist()
|
||||
output = output.reshape([batch_size, num_beams, -1])
|
||||
output_lines_list = [
|
||||
tokenizer.batch_decode(output[:, i, len(line_encoded[0]):],
|
||||
skip_special_tokens=True)
|
||||
for i in range(num_beams)
|
||||
]
|
||||
|
||||
return output_lines_list, tokens_list
|
||||
|
||||
if test_trt_llm:
|
||||
datapoint = dataset_cnn['test'][0:1]
|
||||
summary, _ = summarize_tensorrt_llm(datapoint)
|
||||
if runtime_rank == 0:
|
||||
logger.info(
|
||||
"---------------------------------------------------------")
|
||||
logger.info("XTRT-LLM Generated : ")
|
||||
logger.info(f" Article : {datapoint['article']}")
|
||||
logger.info(f"\n Highlights : {datapoint['highlights']}")
|
||||
logger.info(f"\n Summary : {summary}")
|
||||
logger.info(
|
||||
"---------------------------------------------------------")
|
||||
|
||||
if test_hf:
|
||||
datapoint = dataset_cnn['test'][0:1]
|
||||
summary, _ = summarize_hf(datapoint)
|
||||
logger.info("---------------------------------------------------------")
|
||||
logger.info("HF Generated : ")
|
||||
logger.info(f" Article : {datapoint['article']}")
|
||||
logger.info(f"\n Highlights : {datapoint['highlights']}")
|
||||
logger.info(f"\n Summary : {summary}")
|
||||
logger.info("---------------------------------------------------------")
|
||||
|
||||
metric_tensorrt_llm = [load_metric("rouge") for _ in range(num_beams)]
|
||||
metric_hf = [load_metric("rouge") for _ in range(num_beams)]
|
||||
for i in range(num_beams):
|
||||
metric_tensorrt_llm[i].seed = 0
|
||||
metric_hf[i].seed = 0
|
||||
|
||||
ite_count = 0
|
||||
data_point_idx = 0
|
||||
while (data_point_idx < len(dataset_cnn['test'])) and (ite_count <
|
||||
args.max_ite):
|
||||
if runtime_rank == 0:
|
||||
logger.debug(
|
||||
f"run data_point {data_point_idx} ~ {data_point_idx + max_batch_size}"
|
||||
)
|
||||
datapoint = dataset_cnn['test'][data_point_idx:(data_point_idx +
|
||||
max_batch_size)]
|
||||
|
||||
if test_trt_llm:
|
||||
profiler.start('tensorrt_llm')
|
||||
summary_tensorrt_llm, tokens_tensorrt_llm = summarize_tensorrt_llm(
|
||||
datapoint)
|
||||
profiler.stop('tensorrt_llm')
|
||||
|
||||
if test_hf:
|
||||
profiler.start('hf')
|
||||
summary_hf, tokens_hf = summarize_hf(datapoint)
|
||||
profiler.stop('hf')
|
||||
|
||||
if runtime_rank == 0:
|
||||
if test_trt_llm:
|
||||
for batch_idx in range(len(summary_tensorrt_llm)):
|
||||
for beam_idx in range(num_beams):
|
||||
metric_tensorrt_llm[beam_idx].add_batch(
|
||||
predictions=[
|
||||
summary_tensorrt_llm[batch_idx][beam_idx]
|
||||
],
|
||||
references=[datapoint['highlights'][batch_idx]])
|
||||
if test_hf:
|
||||
for beam_idx in range(num_beams):
|
||||
for i in range(len(summary_hf[beam_idx])):
|
||||
metric_hf[beam_idx].add_batch(
|
||||
predictions=[summary_hf[beam_idx][i]],
|
||||
references=[datapoint['highlights'][i]])
|
||||
|
||||
logger.debug('-' * 100)
|
||||
logger.debug(f"Article : {datapoint['article']}")
|
||||
if test_trt_llm:
|
||||
logger.debug(f'XTRT-LLM Summary: {summary_tensorrt_llm}')
|
||||
if test_hf:
|
||||
logger.debug(f'HF Summary: {summary_hf}')
|
||||
logger.debug(f"highlights : {datapoint['highlights']}")
|
||||
|
||||
data_point_idx += max_batch_size
|
||||
ite_count += 1
|
||||
|
||||
if runtime_rank == 0:
|
||||
if test_trt_llm:
|
||||
np.random.seed(0) # rouge score use sampling to compute the score
|
||||
logger.info(
|
||||
f'XTRT-LLM (total latency: {profiler.elapsed_time_in_sec("tensorrt_llm")} sec)'
|
||||
)
|
||||
for beam_idx in range(num_beams):
|
||||
logger.info(f"XTRT-LLM beam {beam_idx} result")
|
||||
computed_metrics_tensorrt_llm = metric_tensorrt_llm[
|
||||
beam_idx].compute()
|
||||
for key in computed_metrics_tensorrt_llm.keys():
|
||||
logger.info(
|
||||
f' {key} : {computed_metrics_tensorrt_llm[key].mid[2]*100}'
|
||||
)
|
||||
|
||||
if args.check_accuracy and beam_idx == 0:
|
||||
assert computed_metrics_tensorrt_llm['rouge1'].mid[
|
||||
2] * 100 > args.tensorrt_llm_rouge1_threshold
|
||||
if test_hf:
|
||||
np.random.seed(0) # rouge score use sampling to compute the score
|
||||
logger.info(
|
||||
f'Hugging Face (total latency: {profiler.elapsed_time_in_sec("hf")} sec)'
|
||||
)
|
||||
for beam_idx in range(num_beams):
|
||||
logger.info(f"HF beam {beam_idx} result")
|
||||
computed_metrics_hf = metric_hf[beam_idx].compute()
|
||||
for key in computed_metrics_hf.keys():
|
||||
logger.info(
|
||||
f' {key} : {computed_metrics_hf[key].mid[2]*100}')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--model_dir',
|
||||
type=str,
|
||||
default='EleutherAI/gpt-neox-20b')
|
||||
parser.add_argument('--test_hf', action='store_true')
|
||||
parser.add_argument('--test_trt_llm', action='store_true')
|
||||
parser.add_argument('--data_type',
|
||||
type=str,
|
||||
choices=['fp32', 'fp16'],
|
||||
default='fp32')
|
||||
parser.add_argument('--dataset_path', type=str, default='')
|
||||
parser.add_argument('--log_level', type=str, default='info')
|
||||
parser.add_argument('--engine_dir', type=str, default='gptneox_engine')
|
||||
parser.add_argument('--batch_size', type=int, default=1)
|
||||
parser.add_argument('--max_ite', type=int, default=20)
|
||||
parser.add_argument('--output_len', type=int, default=100)
|
||||
parser.add_argument('--check_accuracy', action='store_true')
|
||||
parser.add_argument('--tensorrt_llm_rouge1_threshold',
|
||||
type=float,
|
||||
default=15.0)
|
||||
parser.add_argument('--num_beams', type=int, default=1)
|
||||
parser.add_argument('--top_k', type=int, default=1)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
main(args)
|
||||
464
examples/gptneox/weight.py
Normal file
464
examples/gptneox/weight.py
Normal file
@@ -0,0 +1,464 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import time
|
||||
from operator import attrgetter
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm._utils import pad_vocab_size
|
||||
from xtrt_llm.models import GPTNeoXForCausalLM
|
||||
from xtrt_llm._utils import str_dtype_to_torch
|
||||
|
||||
UINT4_TO_INT4_FLAG = 1
|
||||
GPTQ_FLAG = 1
|
||||
GROUP_SIZE = 128
|
||||
|
||||
|
||||
def numpy_split(v, tp_size, idx, dim=0):
|
||||
if tp_size == 1:
|
||||
return v
|
||||
else:
|
||||
return np.ascontiguousarray(np.split(v, tp_size, axis=dim)[idx])
|
||||
|
||||
|
||||
def torch_split(v, tp_size, idx, dim=0):
|
||||
if tp_size == 1:
|
||||
return v
|
||||
else:
|
||||
return (torch.split(v, v.shape[dim] // tp_size,
|
||||
dim=dim)[idx]).contiguous()
|
||||
|
||||
|
||||
def unpack_int32_into_int8(w_packed):
|
||||
# Unpack inputs packed in int32/float32 into uint4 and store them in int8 format
|
||||
w_packed_int4x2 = w_packed.contiguous().view(torch.uint8)
|
||||
w_unpacked = torch.zeros(w_packed_int4x2.shape[0],
|
||||
w_packed_int4x2.shape[1] * 2,
|
||||
dtype=torch.int8)
|
||||
w_unpacked[:, ::2] = w_packed_int4x2 % 16
|
||||
w_unpacked[:, 1::2] = w_packed_int4x2 // 16
|
||||
return w_unpacked.contiguous()
|
||||
|
||||
|
||||
def preprocess_groupwise_weight_params(qweight_unpacked_int8, scales_fp16,
|
||||
qzeros_unpacked_int8):
|
||||
packer = torch.ops.fastertransformer.pack_int8_tensor_to_packed_int4
|
||||
preprocessor = torch.ops.fastertransformer.preprocess_weights_for_mixed_gemm
|
||||
|
||||
qweight_interleaved = preprocessor(packer(qweight_unpacked_int8),
|
||||
torch.quint4x2).view(torch.float32)
|
||||
|
||||
# zeros = zeros * scales
|
||||
zeros_x_scales_fp16 = (-qzeros_unpacked_int8 + 8 * UINT4_TO_INT4_FLAG -
|
||||
GPTQ_FLAG) * scales_fp16
|
||||
zeros_x_scales_fp16 = zeros_x_scales_fp16.half()
|
||||
|
||||
# return processed interleaved weight, original scales and zeros * scales
|
||||
return qweight_interleaved.contiguous().numpy(), scales_fp16.contiguous(
|
||||
).numpy(), zeros_x_scales_fp16.contiguous().numpy()
|
||||
|
||||
|
||||
def load_from_hf_gpt_neox(xtrt_llm_gpt_neox: GPTNeoXForCausalLM,
|
||||
hf_gpt_neox,
|
||||
dtype="float32",
|
||||
rank=0,
|
||||
tp_size=1,
|
||||
use_weight_only_groupwise_quant_matmul_plugin=False):
|
||||
|
||||
hf_model_gptneox_block_names = [
|
||||
"input_layernorm.weight",
|
||||
"input_layernorm.bias",
|
||||
"post_attention_layernorm.weight",
|
||||
"post_attention_layernorm.bias",
|
||||
]
|
||||
|
||||
xtrt_llm_model_gptneox_block_names = [
|
||||
"input_layernorm.weight",
|
||||
"input_layernorm.bias",
|
||||
"post_attention_layernorm.weight",
|
||||
"post_attention_layernorm.bias",
|
||||
]
|
||||
|
||||
if not use_weight_only_groupwise_quant_matmul_plugin:
|
||||
hf_model_gptneox_block_names += [
|
||||
"attention.dense.weight",
|
||||
"attention.dense.bias",
|
||||
"mlp.dense_h_to_4h.weight",
|
||||
"mlp.dense_h_to_4h.bias",
|
||||
"mlp.dense_4h_to_h.weight",
|
||||
"mlp.dense_4h_to_h.bias",
|
||||
]
|
||||
xtrt_llm_model_gptneox_block_names += [
|
||||
"attention.dense.weight",
|
||||
"attention.dense.bias",
|
||||
"mlp.fc.weight",
|
||||
"mlp.fc.bias",
|
||||
"mlp.proj.weight",
|
||||
"mlp.proj.bias",
|
||||
]
|
||||
|
||||
if not use_weight_only_groupwise_quant_matmul_plugin:
|
||||
xtrt_llm.logger.info('Loading weights from HF GPT-NeoX...')
|
||||
else:
|
||||
xtrt_llm.logger.info(
|
||||
'Loading weights from GPTQ quantized HF GPT-NeoX...')
|
||||
|
||||
tik = time.time()
|
||||
|
||||
torch_dtype = str_dtype_to_torch(dtype)
|
||||
hf_gpt_neox_state_dict = hf_gpt_neox.state_dict()
|
||||
|
||||
# [vocab_size, hidden_size]
|
||||
v = hf_gpt_neox_state_dict.get('gpt_neox.embed_in.weight').to(
|
||||
torch_dtype).cpu().numpy()
|
||||
if xtrt_llm_gpt_neox._use_parallel_embedding:
|
||||
v = numpy_split(v, tp_size, rank,
|
||||
xtrt_llm_gpt_neox._embedding_sharding_dim)
|
||||
xtrt_llm_gpt_neox.embedding.weight.value = v
|
||||
|
||||
n_layer = hf_gpt_neox.config.num_hidden_layers
|
||||
|
||||
for layer_idx in range(n_layer):
|
||||
prefix = "gpt_neox.layers." + str(layer_idx) + "."
|
||||
for idx, hf_attr in enumerate(hf_model_gptneox_block_names):
|
||||
v = hf_gpt_neox_state_dict.get(prefix + hf_attr).to(
|
||||
torch_dtype).cpu().numpy()
|
||||
|
||||
layer = attrgetter(xtrt_llm_model_gptneox_block_names[idx])(
|
||||
xtrt_llm_gpt_neox.layers[layer_idx])
|
||||
|
||||
if tp_size > 1:
|
||||
if 'dense.weight' in hf_attr:
|
||||
# [n=hidden_size, k=hidden_size] ->
|
||||
# [n=hidden_size, k=hidden_size // tp_size]
|
||||
split_v = numpy_split(v, tp_size, rank, dim=1)
|
||||
elif 'dense_h_to_4h.weight' in hf_attr:
|
||||
# [hidden_size * 4, hidden_size] ->
|
||||
# [hidden_size * 4 // tp_size, hidden_size]
|
||||
split_v = numpy_split(v, tp_size, rank, dim=0)
|
||||
elif 'dense_h_to_4h.bias' in hf_attr:
|
||||
# [hidden_size * 4] -> [hidden_size * 4 // tp_size]
|
||||
split_v = numpy_split(v, tp_size, rank, dim=0)
|
||||
elif 'dense_4h_to_h.weight' in hf_attr:
|
||||
# [hidden_size, hidden_size * 4] ->
|
||||
# [hidden_size, hidden_size * 4 // tp_size]
|
||||
split_v = numpy_split(v, tp_size, rank, dim=1)
|
||||
else:
|
||||
split_v = v
|
||||
setattr(layer, 'value', split_v)
|
||||
else:
|
||||
setattr(layer, 'value', v)
|
||||
|
||||
num_heads = hf_gpt_neox.config.num_attention_heads
|
||||
hidden_size = hf_gpt_neox.config.hidden_size
|
||||
head_size = hidden_size // num_heads
|
||||
|
||||
if not use_weight_only_groupwise_quant_matmul_plugin:
|
||||
# Attention QKV Linear
|
||||
# qkv_weights [num_heads x (q|k|v), hidden_size] ->
|
||||
# [(num_heads x q)|(num_heads x k)|(num_heads x v), hidden_size]
|
||||
qkv_weights = hf_gpt_neox_state_dict.get(
|
||||
prefix + "attention.query_key_value.weight")
|
||||
qkv_bias = hf_gpt_neox_state_dict.get(
|
||||
prefix + "attention.query_key_value.bias")
|
||||
|
||||
new_qkv_weight_shape = torch.Size(
|
||||
[num_heads, 3, head_size * qkv_weights.size()[-1]])
|
||||
new_qkv_bias_shape = torch.Size([num_heads, 3, head_size])
|
||||
|
||||
qkv_weights = qkv_weights.view(new_qkv_weight_shape).permute(
|
||||
1, 0, 2).reshape([hidden_size * 3, hidden_size])
|
||||
qkv_bias = qkv_bias.view(new_qkv_bias_shape).permute(
|
||||
1, 0, 2).reshape([hidden_size * 3])
|
||||
|
||||
if tp_size > 1:
|
||||
qkv_weights = qkv_weights.reshape(
|
||||
3, hidden_size, hidden_size).to(torch_dtype).cpu().numpy()
|
||||
split_qkv_weights = numpy_split(
|
||||
qkv_weights, tp_size, rank,
|
||||
dim=1).reshape(3 * (hidden_size // tp_size), hidden_size)
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].attention.qkv.weight.value = \
|
||||
np.ascontiguousarray(split_qkv_weights)
|
||||
|
||||
qkv_bias = qkv_bias.reshape(
|
||||
3, hidden_size).to(torch_dtype).cpu().numpy()
|
||||
split_qkv_bias = numpy_split(qkv_bias, tp_size, rank,
|
||||
dim=1).reshape(
|
||||
3 * (hidden_size // tp_size))
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].attention.qkv.bias.value = \
|
||||
np.ascontiguousarray(split_qkv_bias)
|
||||
else:
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].attention.qkv.weight.value = \
|
||||
qkv_weights.to(torch_dtype).cpu().numpy()
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].attention.qkv.bias.value = \
|
||||
qkv_bias.to(torch_dtype).cpu().numpy()
|
||||
else:
|
||||
# use_weight_only_groupwise_quant_matmul_plugin
|
||||
|
||||
qweight_int32 = hf_gpt_neox_state_dict.get(
|
||||
prefix + "attention.query_key_value.qweight")
|
||||
scales_fp16 = hf_gpt_neox_state_dict.get(
|
||||
prefix + "attention.query_key_value.scales")
|
||||
qzeros_int32 = hf_gpt_neox_state_dict.get(
|
||||
prefix + "attention.query_key_value.qzeros")
|
||||
biases_fp16 = hf_gpt_neox_state_dict.get(
|
||||
prefix + "attention.query_key_value.bias")
|
||||
|
||||
# [hidden_size // 8, hidden_size * 3] -> [hidden_size * 3, hidden_size]
|
||||
qweight_unpacked_int8 = unpack_int32_into_int8(
|
||||
qweight_int32.T).contiguous() - 8
|
||||
# [hidden_size // GROUP_SIZE, hidden_size * 3 // 8] ->
|
||||
# [hidden_size // GROUP_SIZE, hidden_size * 3]
|
||||
qzeros_unpacked_int8 = unpack_int32_into_int8(qzeros_int32)
|
||||
|
||||
# qkv_weights [num_heads x (q|k|v), hidden_size] ->
|
||||
# [(num_heads x q)|(num_heads x k)|(num_heads x v), hidden_size]
|
||||
new_qkv_weight_shape = torch.Size(
|
||||
[num_heads, 3, head_size * qweight_unpacked_int8.size()[-1]])
|
||||
# [hidden_size * 3, hidden_size]
|
||||
qweight_unpacked_int8 = qweight_unpacked_int8.view(
|
||||
new_qkv_weight_shape).permute(1, 0, 2).reshape(
|
||||
[hidden_size * 3, hidden_size]).contiguous()
|
||||
|
||||
new_qkv_scale_shape = torch.Size(
|
||||
[num_heads, 3, head_size * (hidden_size // GROUP_SIZE)])
|
||||
# [hidden_size * 3, hidden_size // GROUP_SIZE]
|
||||
scales_fp16 = scales_fp16.T.contiguous().view(
|
||||
new_qkv_scale_shape).permute(1, 0, 2).reshape(
|
||||
[hidden_size * 3, hidden_size // GROUP_SIZE]).contiguous()
|
||||
|
||||
new_qkv_zero_shape = torch.Size(
|
||||
[num_heads, 3, head_size * (hidden_size // GROUP_SIZE)])
|
||||
# [hidden_size * 3, hidden_size // GROUP_SIZE]
|
||||
qzeros_unpacked_int8 = qzeros_unpacked_int8.T.contiguous().view(
|
||||
new_qkv_zero_shape).permute(1, 0, 2).reshape(
|
||||
[hidden_size * 3, hidden_size // GROUP_SIZE]).contiguous()
|
||||
|
||||
new_qkv_bias_shape = torch.Size([num_heads, 3, head_size])
|
||||
biases_fp16 = biases_fp16.view(new_qkv_bias_shape).permute(
|
||||
1, 0, 2).reshape([hidden_size * 3]).numpy()
|
||||
|
||||
if tp_size > 1:
|
||||
qweight_unpacked_int8 = qweight_unpacked_int8.reshape(
|
||||
[3, hidden_size, hidden_size])
|
||||
qweight_unpacked_int8 = torch_split(qweight_unpacked_int8,
|
||||
tp_size,
|
||||
rank,
|
||||
dim=1)
|
||||
qweight_unpacked_int8 = qweight_unpacked_int8.reshape(
|
||||
[3 * hidden_size // tp_size, hidden_size])
|
||||
|
||||
scales_fp16 = scales_fp16.reshape(
|
||||
[3, hidden_size, hidden_size // GROUP_SIZE])
|
||||
scales_fp16 = torch_split(scales_fp16, tp_size, rank, dim=1)
|
||||
scales_fp16 = scales_fp16.reshape(
|
||||
[3 * hidden_size // tp_size, hidden_size // GROUP_SIZE])
|
||||
|
||||
qzeros_unpacked_int8 = qzeros_unpacked_int8.reshape(
|
||||
[3, hidden_size, hidden_size // GROUP_SIZE])
|
||||
qzeros_unpacked_int8 = torch_split(qzeros_unpacked_int8,
|
||||
tp_size,
|
||||
rank,
|
||||
dim=1)
|
||||
qzeros_unpacked_int8 = qzeros_unpacked_int8.reshape(
|
||||
[3 * hidden_size // tp_size, hidden_size // GROUP_SIZE])
|
||||
|
||||
biases_fp16 = biases_fp16.reshape([3, hidden_size])
|
||||
biases_fp16 = numpy_split(biases_fp16, tp_size, rank, dim=1)
|
||||
biases_fp16 = biases_fp16.reshape([3 * hidden_size // tp_size])
|
||||
|
||||
qweight_fp32, scales_fp16, zeros_fp16 = preprocess_groupwise_weight_params(
|
||||
qweight_unpacked_int8.T.contiguous(),
|
||||
scales_fp16.T.contiguous(), qzeros_unpacked_int8.T.contiguous())
|
||||
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].attention.qkv.qweight.value = \
|
||||
qweight_fp32
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].attention.qkv.scale.value = \
|
||||
scales_fp16
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].attention.qkv.zero.value = \
|
||||
zeros_fp16
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].attention.qkv.bias.value = \
|
||||
biases_fp16
|
||||
|
||||
qweight_int32 = hf_gpt_neox_state_dict.get(
|
||||
prefix + "attention.dense.qweight")
|
||||
scales_fp16 = hf_gpt_neox_state_dict.get(prefix +
|
||||
"attention.dense.scales")
|
||||
qzeros_int32 = hf_gpt_neox_state_dict.get(prefix +
|
||||
"attention.dense.qzeros")
|
||||
biases_fp16 = hf_gpt_neox_state_dict.get(
|
||||
prefix + "attention.dense.bias").numpy()
|
||||
|
||||
# [k=hidden_size // 8, n=hidden_size] -> [n=hidden_size, k=hidden_size]
|
||||
qweight_unpacked_int8 = unpack_int32_into_int8(
|
||||
qweight_int32.T).contiguous() - 8
|
||||
# [n=hidden_size, k=hidden_size] -> [k=hidden_size, n=hidden_size]
|
||||
qweight_unpacked_int8 = qweight_unpacked_int8.T.contiguous()
|
||||
# [k=hidden_size // GROUP_SIZE, n=hidden_size // 8] ->
|
||||
# [k=hidden_size // GROUP_SIZE, n=hidden_size]
|
||||
qzeros_unpacked_int8 = unpack_int32_into_int8(qzeros_int32)
|
||||
|
||||
if tp_size > 1:
|
||||
qweight_unpacked_int8 = torch_split(qweight_unpacked_int8,
|
||||
tp_size,
|
||||
rank,
|
||||
dim=0)
|
||||
scales_fp16 = torch_split(scales_fp16, tp_size, rank, dim=0)
|
||||
qzeros_unpacked_int8 = torch_split(qzeros_unpacked_int8,
|
||||
tp_size,
|
||||
rank,
|
||||
dim=0)
|
||||
if rank > 0:
|
||||
biases_fp16 = np.zeros_like(biases_fp16)
|
||||
|
||||
qweight_fp32, scales_fp16, zeros_fp16 = preprocess_groupwise_weight_params(
|
||||
qweight_unpacked_int8, scales_fp16, qzeros_unpacked_int8)
|
||||
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].attention.dense.qweight.value = \
|
||||
qweight_fp32
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].attention.dense.scale.value = \
|
||||
scales_fp16
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].attention.dense.zero.value = \
|
||||
zeros_fp16
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].attention.dense.bias.value = \
|
||||
biases_fp16
|
||||
|
||||
qweight_int32 = hf_gpt_neox_state_dict.get(
|
||||
prefix + "mlp.dense_h_to_4h.qweight")
|
||||
scales_fp16 = hf_gpt_neox_state_dict.get(prefix +
|
||||
"mlp.dense_h_to_4h.scales")
|
||||
qzeros_int32 = hf_gpt_neox_state_dict.get(
|
||||
prefix + "mlp.dense_h_to_4h.qzeros")
|
||||
biases_fp16 = hf_gpt_neox_state_dict.get(
|
||||
prefix + "mlp.dense_h_to_4h.bias").numpy()
|
||||
|
||||
# [hidden_size // 8, hidden_size * 4] -> [hidden_size, hidden_size * 4]
|
||||
qweight_unpacked_int8 = unpack_int32_into_int8(
|
||||
qweight_int32.T).contiguous() - 8
|
||||
qweight_unpacked_int8 = qweight_unpacked_int8.T.contiguous()
|
||||
|
||||
# [hidden_size // GROUP_SIZE, hidden_size * 4 // 8] ->
|
||||
# [hidden_size // GROUP_SIZE, hidden_size * 4]
|
||||
qzeros_unpacked_int8 = unpack_int32_into_int8(qzeros_int32)
|
||||
|
||||
if tp_size > 1:
|
||||
# [hidden_size, hidden_size * 4] ->
|
||||
# [hidden_size, hidden_size * 4 // tp_size]
|
||||
qweight_unpacked_int8 = torch_split(qweight_unpacked_int8,
|
||||
tp_size,
|
||||
rank,
|
||||
dim=1)
|
||||
# [hidden_size // GROUP_SIZE, hidden_size * 4] ->
|
||||
# [hidden_size // GROUP_SIZE, hidden_size * 4 // tp_size]
|
||||
scales_fp16 = torch_split(scales_fp16, tp_size, rank, dim=1)
|
||||
# [hidden_size // GROUP_SIZE, hidden_size * 4] ->
|
||||
# [hidden_size // GROUP_SIZE, hidden_size * 4 // tp_size]
|
||||
qzeros_unpacked_int8 = torch_split(qzeros_unpacked_int8,
|
||||
tp_size,
|
||||
rank,
|
||||
dim=1)
|
||||
# [hidden_size * 4] -> [hidden_size * 4 // tp_size]
|
||||
biases_fp16 = numpy_split(biases_fp16, tp_size, rank, dim=0)
|
||||
|
||||
qweight_fp32, scales_fp16, zeros_fp16 = preprocess_groupwise_weight_params(
|
||||
qweight_unpacked_int8, scales_fp16, qzeros_unpacked_int8)
|
||||
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].mlp.fc.qweight.value = \
|
||||
qweight_fp32
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].mlp.fc.scale.value = \
|
||||
scales_fp16
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].mlp.fc.zero.value = \
|
||||
zeros_fp16
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].mlp.fc.bias.value = \
|
||||
biases_fp16
|
||||
|
||||
qweight_int32 = hf_gpt_neox_state_dict.get(
|
||||
prefix + "mlp.dense_4h_to_h.qweight")
|
||||
scales_fp16 = hf_gpt_neox_state_dict.get(prefix +
|
||||
"mlp.dense_4h_to_h.scales")
|
||||
qzeros_int32 = hf_gpt_neox_state_dict.get(
|
||||
prefix + "mlp.dense_4h_to_h.qzeros")
|
||||
biases_fp16 = hf_gpt_neox_state_dict.get(
|
||||
prefix + "mlp.dense_4h_to_h.bias").numpy()
|
||||
|
||||
# [hidden_size * 4 // 8, hidden_size] -> [hidden_size * 4, hidden_size]
|
||||
qweight_unpacked_int8 = unpack_int32_into_int8(
|
||||
qweight_int32.T).contiguous() - 8
|
||||
qweight_unpacked_int8 = qweight_unpacked_int8.T.contiguous()
|
||||
|
||||
# [hidden_size * 4 // GROUP_SIZE, hidden_size // 8] ->
|
||||
# [hidden_size * 4 // GROUP_SIZE, hidden_size]
|
||||
qzeros_unpacked_int8 = unpack_int32_into_int8(qzeros_int32)
|
||||
|
||||
if tp_size > 1:
|
||||
# [hidden_size * 4, hidden_size] ->
|
||||
# [hidden_size * 4 // tp_size, hidden_size]
|
||||
qweight_unpacked_int8 = torch_split(qweight_unpacked_int8,
|
||||
tp_size,
|
||||
rank,
|
||||
dim=0)
|
||||
# [hidden_size * 4 // GROUP_SIZE, hidden_size] ->
|
||||
# [hidden_size * 4 // GROUP_SIZE // tp_size, hidden_size] ->
|
||||
scales_fp16 = torch_split(scales_fp16, tp_size, rank, dim=0)
|
||||
# [hidden_size * 4 // GROUP_SIZE, hidden_size] ->
|
||||
# [hidden_size * 4 // GROUP_SIZE // tp_size, hidden_size]
|
||||
qzeros_unpacked_int8 = torch_split(qzeros_unpacked_int8,
|
||||
tp_size,
|
||||
rank,
|
||||
dim=0)
|
||||
if rank > 0:
|
||||
biases_fp16 = np.zeros_like(biases_fp16)
|
||||
|
||||
qweight_fp32, scales_fp16, zeros_fp16 = preprocess_groupwise_weight_params(
|
||||
qweight_unpacked_int8, scales_fp16, qzeros_unpacked_int8)
|
||||
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].mlp.proj.qweight.value = \
|
||||
qweight_fp32
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].mlp.proj.scale.value = \
|
||||
scales_fp16
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].mlp.proj.zero.value = \
|
||||
zeros_fp16
|
||||
xtrt_llm_gpt_neox.layers[layer_idx].mlp.proj.bias.value = \
|
||||
biases_fp16
|
||||
|
||||
v = hf_gpt_neox_state_dict.get('gpt_neox.final_layer_norm.weight')
|
||||
xtrt_llm_gpt_neox.ln_f.weight.value = v.to(torch_dtype).cpu().numpy()
|
||||
|
||||
v = hf_gpt_neox_state_dict.get('gpt_neox.final_layer_norm.bias')
|
||||
xtrt_llm_gpt_neox.ln_f.bias.value = v.to(torch_dtype).cpu().numpy()
|
||||
|
||||
v = hf_gpt_neox_state_dict.get('embed_out.weight').to(
|
||||
torch_dtype).cpu().numpy()
|
||||
if tp_size > 1:
|
||||
# [vocab_size, hidden_size] ->
|
||||
# [vocab_size // tp_size, hidden_size]
|
||||
if v.shape[0] % tp_size != 0:
|
||||
# padding
|
||||
vocab_size_padded = pad_vocab_size(v.shape[0], tp_size)
|
||||
pad_width = vocab_size_padded - v.shape[0]
|
||||
v = np.pad(v, ((0, pad_width), (0, 0)),
|
||||
'constant',
|
||||
constant_values=0)
|
||||
|
||||
split_v = numpy_split(v, tp_size, rank, dim=0)
|
||||
xtrt_llm_gpt_neox.lm_head.weight.value = split_v
|
||||
else:
|
||||
xtrt_llm_gpt_neox.lm_head.weight.value = v
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
xtrt_llm.logger.info(f'Weights loaded. Total time: {t}')
|
||||
2
examples/llama/.gitignore
vendored
Normal file
2
examples/llama/.gitignore
vendored
Normal file
@@ -0,0 +1,2 @@
|
||||
llama*
|
||||
tokenizer.model
|
||||
183
examples/llama/README.md
Normal file
183
examples/llama/README.md
Normal file
@@ -0,0 +1,183 @@
|
||||
# LLaMA
|
||||
|
||||
This document shows how to build and run a LLaMA model in XTRT-LLM on both single XPU and single node multi-XPU.
|
||||
|
||||
## Overview
|
||||
|
||||
The XTRT-LLM LLaMA example code is located in [`examples/llama`](./). There are several main files in that folder:
|
||||
|
||||
* [`build.py`](./build.py) to build the engine(s) needed to run the LLaMA model,
|
||||
* [`run.py`](./run.py) to run the inference on an input text,
|
||||
|
||||
## Support Matrix
|
||||
* FP16
|
||||
* INT8 & INT4 Weight-Only
|
||||
* Tensor Parallel
|
||||
|
||||
## Usage
|
||||
|
||||
The XTRT-LLM LLaMA example code locates at [examples/llama](./). It takes HF weights as input, and builds the corresponding XTRT engines. The number of XTRT engines depends on the number of XPUs used to run inference.
|
||||
|
||||
### Build XTRT engine(s)
|
||||
|
||||
Need to prepare the HF LLaMA checkpoint first by following the guides here https://huggingface.co/docs/transformers/main/en/model_doc/llama.
|
||||
|
||||
XTRT-LLM LLaMA builds XTRT engine(s) from HF checkpoint. If no checkpoint directory is specified, XTRT-LLM will build engine(s) with dummy weights.
|
||||
|
||||
Normally `build.py` only requires single XPU, but if you've already got all the XPUs needed while inferencing, you could enable parallelly building to make the engine building process faster by adding `--parallel_build` argument. Please note that currently `parallel_build` feature only supports single node.
|
||||
|
||||
Here're some examples:
|
||||
|
||||
```bash
|
||||
# Build a single-XPU float16 engine from HF weights.
|
||||
# use_gpt_attention_plugin is necessary in LLaMA.
|
||||
# It is recommend to use --use_gpt_attention_plugin for better performance
|
||||
|
||||
# Build the LLaMA 7B model using a single XPU and FP16.
|
||||
python build.py --model_dir ./downloads/llama-7b-hf/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/llama-7b-hf/trt_engines/fp16/1-XPU/
|
||||
|
||||
|
||||
# Build the LLaMA 7B model using a single XPU and apply INT8 weight-only quantization.
|
||||
python build.py --model_dir ./downloads/llama-7b-hf/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_weight_only \
|
||||
--output_dir ./downloads/llama-7b-hf/trt_engines/weight_only/1-XPU/
|
||||
|
||||
# Build LLaMA 7B using 2-way tensor parallelism.
|
||||
python build.py --model_dir ./downloads/llama-7b-hf/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/llama-7b-hf/trt_engines/fp16/2-XPU/ \
|
||||
--world_size 2 \
|
||||
--tp_size 2 \
|
||||
--parallel_build
|
||||
|
||||
|
||||
# Build LLaMA 13B using 2-way tensor parallelism.
|
||||
python build.py --model_dir ./downloads/llama13b/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/llama13b/trt_engines/fp16/2-XPU/ \
|
||||
--world_size 2 \
|
||||
--tp_size 2 \
|
||||
--parallel_build
|
||||
```
|
||||
|
||||
#### LLaMA v2 Updates
|
||||
The LLaMA v2 models with 7B and 13B are compatible with the LLaMA v1 implementation. The above
|
||||
commands still work.
|
||||
|
||||
|
||||
For LLaMA v2 70B, there is a restriction on tensor parallelism that the number of KV heads
|
||||
must be **divisible by the number of XPUs**. For example, since the 70B model has 8 KV heads, you can run it with
|
||||
2, 4 or 8 XPUs
|
||||
|
||||
|
||||
```bash
|
||||
# Build LLaMA 70B using 8-way tensor parallelism.
|
||||
python build.py --model_dir ./downloads/llama2-70b/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/llama2-70b/trt_engines/fp16/8-XPU/ \
|
||||
--world_size 8 \
|
||||
--tp_size 8 \
|
||||
--parallel_build
|
||||
```
|
||||
|
||||
Same instructions can be applied to fine-tuned versions of the LLaMA v2 models (e.g. 7Bf or llama-2-7b-chat).
|
||||
|
||||
|
||||
Test with `summarize.py`: `pip install nltk rouge_score`
|
||||
|
||||
```bash
|
||||
python summarize.py --test_trt_llm \
|
||||
--hf_model_location ./downloads/llama-7b-hf \
|
||||
--data_type fp16 \
|
||||
--engine_dir ./downloads/llama-7b-hf/trt_engines/fp16/1-XPU
|
||||
```
|
||||
|
||||
#### SmoothQuant
|
||||
|
||||
The smoothquant supports both LLaMA v1 and LLaMA v2. Unlike the FP16 build where the HF weights are processed and loaded into the XTRT-LLM directly, the SmoothQuant needs to load INT8 weights which should be pre-processed before building an engine.
|
||||
|
||||
Example:
|
||||
```bash
|
||||
python3 hf_llama_convert.py -i ./downloads/llama-7b-hf -o ./downloads/smooth_llama_7B/sq0.8/ -sq 0.8 --tensor-parallelism 1 --storage-type fp16
|
||||
```
|
||||
|
||||
Note `hf_llama_convert.py` run with pytorch, and
|
||||
1. `torch-cpu` has better accuracy than XPyTorch generally.
|
||||
2. XPyTorch often use more than 32GB GM, thus more XPU are necessary to finish it.
|
||||
3. add `-p=1` if run with XPyTorch.
|
||||
|
||||
We offer converted data [here](https://fsh.bcebos.com/v1/klx-llm/pretrained_models/quantization/smooth_llama_7B.tar.gz) for LLaMa-7b with sq of 0.6.
|
||||
|
||||
[`build.py`](./build.py) add new options for the support of INT8 inference of SmoothQuant models.
|
||||
|
||||
`--use_smooth_quant` is the starting point of INT8 inference. By default, it
|
||||
will run the model in the _per-tensor_ mode.
|
||||
|
||||
`--per-token` and `--per-channel` are not supported yet.
|
||||
|
||||
Examples of build invocations:
|
||||
|
||||
```bash
|
||||
# Build model for SmoothQuant in the _per_tensor_ mode.
|
||||
python3 build.py --ft_model_dir=./downloads/smooth_llama_7B/sq0.8/1-XPU/ \
|
||||
--use_smooth_quant \
|
||||
--output_dir ./downloads/smooth_llama_7B/sq0.8/trt_engines/fp16/1-XPU/
|
||||
```
|
||||
|
||||
Note we use `--ft_model_dir` instead of `--model_dir` and `--meta_ckpt_dir` since SmoothQuant model needs INT8 weights and various scales from the binary files.
|
||||
|
||||
### Run
|
||||
|
||||
Before running the examples, make sure set the environment variables:
|
||||
```
|
||||
export PYTORCH_NO_XPU_MEMORY_CACHING=0 # disable XPytorch cache XPU memory.
|
||||
export XMLIR_D_XPU_L3_SIZE=0 # disable XPytorch use L3.
|
||||
```
|
||||
If you are runing with multiple XPUs and no L3 space, you can set `BKCL_CCIX_BUFFER_GM=1` to disable L3.
|
||||
|
||||
|
||||
To run a XTRT-LLM LLaMA model using the engines generated by `build.py`
|
||||
|
||||
```bash
|
||||
# With fp16 inference
|
||||
python3 run.py --max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/llama-7b-hf/ \
|
||||
--engine_dir=./downloads/llama-7b-hf/trt_engines/fp16/1-XPU/
|
||||
|
||||
# With fp16 inference, SmoothQuant
|
||||
python3 run.py --max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/llama-7b-hf/ \
|
||||
--engine_dir=./downloads/smooth_llama_7B/sq0.8/trt_engines/fp16/1-XPU/
|
||||
|
||||
```
|
||||
|
||||
### Summarization using the LLaMA model
|
||||
|
||||
```bash
|
||||
# Run summarization using the LLaMA 7B model in FP16.
|
||||
python summarize.py --test_trt_llm \
|
||||
--hf_model_location ./downloads/llama-7b-hf/ \
|
||||
--data_type fp16 \
|
||||
--engine_dir ./downloads/llama-7b-hf/trt_engines/fp16/1-XPU/
|
||||
|
||||
# Run summarization using the LLaMA 7B model quantized to INT8.
|
||||
python summarize.py --test_trt_llm \
|
||||
--hf_model_location ./downloads/llama-7b-hf/ \
|
||||
--data_type fp16 \
|
||||
--engine_dir ./downloads/llama-7b-hf/trt_engines/weight_only/1-XPU/
|
||||
|
||||
# Run summarization using the LLaMA 7B model in FP16 using two XPUs.
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python summarize.py --test_trt_llm \
|
||||
--hf_model_location ./downloads/llama-7b-hf/ \
|
||||
--data_type fp16 \
|
||||
--engine_dir ./downloads/llama-7b-hf/trt_engines/fp16/2-XPU/
|
||||
```
|
||||
179
examples/llama/README_CN.md
Normal file
179
examples/llama/README_CN.md
Normal file
@@ -0,0 +1,179 @@
|
||||
# LLaMA
|
||||
|
||||
本文档介绍了如何使用昆仑芯XTRT-LLM在单XPU和单节点多XPU上构建和运行LLaMA模型。
|
||||
|
||||
## 概述
|
||||
|
||||
XTRT-LLM LLMa示例代码位于 [`examples/llama`](./). 此文件夹中有以下几个主要文件:
|
||||
|
||||
* [`build.py`](./build.py) 构建运行LLaMa模型所需的XTRT引擎
|
||||
* [`run.py`](./run.py) 基于输入的文字进行推理
|
||||
|
||||
## 支持的矩阵
|
||||
|
||||
* FP16
|
||||
* INT8 Weight-Only
|
||||
* Tensor Parallel
|
||||
|
||||
## 使用说明
|
||||
|
||||
XTRT-LLM LLaMa示例代码位于[examples/llama](./)。它使用HF权重作为输入,并且构建对应的XTRT引擎。XTRT引擎的数量取决于为了运行推理而是用的XPU个数。
|
||||
|
||||
### 构建XTRT引擎
|
||||
|
||||
需要先按照下面的指南准备HF LLaMA checkpoint:https://huggingface.co/docs/transformers/main/en/model_doc/llama。
|
||||
|
||||
XTRT-LLM LLaMA从HF checkpoint构建XTRT引擎。如果未指定checkpoint目录,XTRT-LLM将使用伪权重构建引擎。
|
||||
|
||||
通常 `build.py`只需要单个XPU,但如果您已经获得了推理所需的所有XPU,则可以通过添加 `--parallel_build` 参数来启用并行构建,从而加快引擎构建过程。请注意,目前`parallel_build`仅支持单个节点XPU。
|
||||
|
||||
以下是一些示例:
|
||||
|
||||
```bash
|
||||
# Build a single-XPU float16 engine from HF weights.
|
||||
# use_gpt_attention_plugin is necessary in LLaMA.
|
||||
# It is recommend to use --use_gpt_attention_plugin for better performance
|
||||
|
||||
# Build the LLaMA 7B model using a single XPU and FP16.
|
||||
python build.py --model_dir ./downloads/llama-7b-hf/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/llama-7b-hf/trt_engines/fp16/1-XPU/
|
||||
|
||||
|
||||
# Build the LLaMA 7B model using a single XPU and apply INT8 weight-only quantization.
|
||||
python build.py --model_dir ./downloads/llama-7b-hf/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_weight_only \
|
||||
--output_dir ./downloads/llama-7b-hf/trt_engines/weight_only/1-XPU/
|
||||
|
||||
# Build LLaMA 7B using 2-way tensor parallelism.
|
||||
python build.py --model_dir ./downloads/llama-7b-hf/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/llama-7b-hf/trt_engines/fp16/2-XPU/ \
|
||||
--world_size 2 \
|
||||
--tp_size 2 \
|
||||
--parallel_build
|
||||
|
||||
|
||||
# Build LLaMA 13B using 2-way tensor parallelism.
|
||||
python build.py --model_dir ./downloads/llama13b/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/llama13b/trt_engines/fp16/2-XPU/ \
|
||||
--world_size 2 \
|
||||
--tp_size 2 \
|
||||
--parallel_build
|
||||
```
|
||||
|
||||
#### LLaMA v2 更新
|
||||
|
||||
LLaMA v2-7B和13B模型与 LLaMA v1的实现是兼容的,以上命令仍然有效。
|
||||
|
||||
对于LLaMA v2 70B,张量并行性有一个限制,即KV heads的数量必须可以被XPU的数量整除。例如,由于70B模型有8个KV heads,您可以使用2、4或8个XPU运行它。
|
||||
|
||||
|
||||
```bash
|
||||
# Build LLaMA 70B using 8-way tensor parallelism.
|
||||
python build.py --model_dir ./downloads/llama2-70b/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/llama2-70b/trt_engines/fp16/8-XPU/ \
|
||||
--world_size 8 \
|
||||
--tp_size 8 \
|
||||
--parallel_build
|
||||
```
|
||||
|
||||
相同的指令可以应用于LLaMA v2模型的微调版本(例如7Bf或LLaMA-2-7b-chat)。
|
||||
|
||||
使用`summarize.py`进行测试:`pip install nltk rouge_score`
|
||||
|
||||
```bash
|
||||
python summarize.py --test_trt_llm \
|
||||
--hf_model_location ./downloads/llama-7b-hf \
|
||||
--data_type fp16 \
|
||||
--engine_dir ./downloads/llama-7b-hf/trt_engines/fp16/1-XPU
|
||||
```
|
||||
|
||||
#### SmoothQuant
|
||||
|
||||
SmoothQuant同时支持LLaMA v1和v2。与FP16的HF权重可以直接被处理并加载到XTRT-LLM不同,SmoothQuant需要加载INT8权重,而INT8权重在构建引擎之前需要进行预处理。
|
||||
|
||||
示例:
|
||||
```bash
|
||||
python3 hf_llama_convert.py -i ./downloads/llama-7b-hf -o ./downloads/smooth_llama_7B/sq0.8/ -sq 0.8 --tensor-parallelism 1 --storage-type fp16
|
||||
```
|
||||
|
||||
注意:使用PyTorch运行`hf_llama_convert.py`,并且
|
||||
1. 'torch-cpu' 通常比XPyTorch精度更高
|
||||
2. XPyTorch 通常使用超过32GB的GM,因此需要更多的XPU来完成它。
|
||||
3. 使用XPyTorch运行时,请添加`-p=1`。
|
||||
|
||||
为SmoothQuant 0.6的LLaMa 7B模型,我们提供这些[转换数据](https://fsh.bcebos.com/v1/klx-llm/pretrained_models/quantization/smooth_llama_7B.tar.gz):
|
||||
|
||||
`build.py`增加了新的选项来支持SmoothQuant模型的INT8推理。
|
||||
|
||||
`--use_smooth_quant` 是INT8推理的起点。默认情况下,它将以`--per-token`模式运行模型。
|
||||
`--per-token`和`--per-channel`目前还不支持。
|
||||
|
||||
构建调用实例:
|
||||
|
||||
```bash
|
||||
# Build model for SmoothQuant in the _per_tensor_ mode.
|
||||
python3 build.py --ft_model_dir=./downloads/smooth_llama_7B/sq0.8/1-XPU/ \
|
||||
--use_smooth_quant \
|
||||
--output_dir ./downloads/smooth_llama_7B/sq0.8/trt_engines/fp16/1-XPU/
|
||||
```
|
||||
|
||||
注意:我们使用`--ft_model_dir`而不是`--model_dir`和`--meta_ckpt_dir`,因为SmoothQuant模型需要INT8权重和二进制文件中的各种scales。
|
||||
|
||||
### 运行
|
||||
|
||||
在运行示例之前,请确保设置环境变量:
|
||||
|
||||
```
|
||||
export PYTORCH_NO_XPU_MEMORY_CACHING=0 # disable XPytorch cache XPU memory.
|
||||
export XMLIR_D_XPU_L3_SIZE=0 # disable XPytorch use L3.
|
||||
```
|
||||
|
||||
如果使用多个XPU且没有L3空间运行,则可以通过设置`BKCL_CCIX_BUFFER_GM=1`以禁用L3。
|
||||
|
||||
使用`build.py`生成的引擎运行XTRT-LLM LLaMA模型:
|
||||
|
||||
```bash
|
||||
# With fp16 inference
|
||||
python3 run.py --max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/llama-7b-hf/ \
|
||||
--engine_dir=./downloads/llama-7b-hf/trt_engines/fp16/1-XPU/
|
||||
|
||||
# With fp16 inference, SmoothQuant
|
||||
python3 run.py --max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/llama-7b-hf/ \
|
||||
--engine_dir=./downloads/smooth_llama_7B/sq0.8/trt_engines/fp16/1-XPU/
|
||||
|
||||
```
|
||||
|
||||
### 使用LLaMA模型进行总结
|
||||
|
||||
```bash
|
||||
# Run summarization using the LLaMA 7B model in FP16.
|
||||
python summarize.py --test_trt_llm \
|
||||
--hf_model_location ./downloads/llama-7b-hf/ \
|
||||
--data_type fp16 \
|
||||
--engine_dir ./downloads/llama-7b-hf/trt_engines/fp16/1-XPU/
|
||||
|
||||
# Run summarization using the LLaMA 7B model quantized to INT8.
|
||||
python summarize.py --test_trt_llm \
|
||||
--hf_model_location ./downloads/llama-7b-hf/ \
|
||||
--data_type fp16 \
|
||||
--engine_dir ./downloads/llama-7b-hf/trt_engines/weight_only/1-XPU/
|
||||
|
||||
# Run summarization using the LLaMA 7B model in FP16 using two XPUs.
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python summarize.py --test_trt_llm \
|
||||
--hf_model_location ./downloads/llama-7b-hf/ \
|
||||
--data_type fp16 \
|
||||
--engine_dir ./downloads/llama-7b-hf/trt_engines/fp16/2-XPU/
|
||||
```
|
||||
BIN
examples/llama/__pycache__/build.cpython-38.pyc
Normal file
BIN
examples/llama/__pycache__/build.cpython-38.pyc
Normal file
Binary file not shown.
BIN
examples/llama/__pycache__/weight.cpython-38.pyc
Normal file
BIN
examples/llama/__pycache__/weight.cpython-38.pyc
Normal file
Binary file not shown.
662
examples/llama/build.py
Normal file
662
examples/llama/build.py
Normal file
@@ -0,0 +1,662 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import time
|
||||
from pathlib import Path
|
||||
|
||||
import torch.multiprocessing as mp
|
||||
from transformers import LlamaConfig, LlamaForCausalLM
|
||||
from weight import (load_from_awq_llama, load_from_binary, load_from_gptq_llama,
|
||||
load_from_hf_llama, load_from_meta_llama)
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm._utils import str_dtype_to_xtrt
|
||||
from xtrt_llm.builder import Builder
|
||||
from xtrt_llm.layers.attention import PositionEmbeddingType
|
||||
from xtrt_llm.logger import logger
|
||||
from xtrt_llm.mapping import Mapping
|
||||
from xtrt_llm.models import (smooth_quantize, weight_only_groupwise_quantize,
|
||||
weight_only_quantize)
|
||||
from xtrt_llm.network import net_guard
|
||||
from xtrt_llm.plugin.plugin import ContextFMHAType
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
from weight import parse_ft_config # isort:skip
|
||||
|
||||
MODEL_NAME = "llama"
|
||||
|
||||
# 2 routines: get_engine_name, serialize_engine
|
||||
# are direct copy from gpt example, TODO: put in utils?
|
||||
|
||||
|
||||
def get_engine_name(model, dtype, tp_size, pp_size, rank):
|
||||
if pp_size == 1:
|
||||
return '{}_{}_tp{}_rank{}.engine'.format(model, dtype, tp_size, rank)
|
||||
return '{}_{}_tp{}_pp{}_rank{}.engine'.format(model, dtype, tp_size,
|
||||
pp_size, rank)
|
||||
|
||||
|
||||
def serialize_engine(engine, path):
|
||||
logger.info(f'Serializing engine to {path}...')
|
||||
tik = time.time()
|
||||
engine.serialize(path)
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Engine serialized. Total time: {t}')
|
||||
|
||||
|
||||
def parse_arguments():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--world_size', type=int, default=1)
|
||||
parser.add_argument('--tp_size', type=int, default=1)
|
||||
parser.add_argument('--pp_size', type=int, default=1)
|
||||
parser.add_argument('--model_dir', type=str, default=None)
|
||||
parser.add_argument('--ft_model_dir', type=str, default=None)
|
||||
parser.add_argument('--meta_ckpt_dir', type=str, default=None)
|
||||
parser.add_argument('--quant_ckpt_path', type=str, default=None)
|
||||
parser.add_argument(
|
||||
'--dtype',
|
||||
type=str,
|
||||
default='float16',
|
||||
# choices=['float32', 'bfloat16', 'float16'])
|
||||
choices=['float32', 'float16'])
|
||||
parser.add_argument(
|
||||
'--timing_cache',
|
||||
type=str,
|
||||
default='model.cache',
|
||||
help=
|
||||
'The path of to read timing cache from, will be ignored if the file does not exist'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--opt_memory_use',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help='Whether to use Host memory optimization for building engine')
|
||||
parser.add_argument('--log_level', type=str, default='info')
|
||||
parser.add_argument('--vocab_size', type=int, default=32000)
|
||||
parser.add_argument('--n_layer', type=int, default=32)
|
||||
parser.add_argument('--n_positions', type=int, default=2048)
|
||||
parser.add_argument('--n_embd', type=int, default=4096)
|
||||
parser.add_argument('--n_head', type=int, default=32)
|
||||
parser.add_argument('--n_kv_head', type=int, default=None)
|
||||
parser.add_argument('--multiple_of', type=int, default=256)
|
||||
parser.add_argument('--ffn_dim_multiplier', type=float, default=1.0)
|
||||
parser.add_argument('--inter_size', type=int, default=None)
|
||||
parser.add_argument('--hidden_act', type=str, default='silu')
|
||||
parser.add_argument('--rms_norm_eps', type=float, default=1e-06)
|
||||
parser.add_argument('--max_batch_size', type=int, default=8)
|
||||
parser.add_argument('--max_input_len', type=int, default=2048)
|
||||
parser.add_argument('--max_output_len', type=int, default=512)
|
||||
parser.add_argument('--max_beam_width', type=int, default=1)
|
||||
parser.add_argument('--rotary_base', type=float, default=10000.0)
|
||||
parser.add_argument('--rotary_scaling', nargs=2, type=str, default=None)
|
||||
parser.add_argument(
|
||||
'--use_gpt_attention_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
# choices=['float16', 'bfloat16', 'float32'])
|
||||
choices=['float32', 'float16'])
|
||||
parser.add_argument(
|
||||
'--use_gemm_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
# choices=['float16', 'bfloat16', 'float32'])
|
||||
choices=['float32', 'float16'])
|
||||
|
||||
parser.add_argument(
|
||||
'--use_rmsnorm_plugin',
|
||||
nargs='?',
|
||||
const='float16',
|
||||
type=str,
|
||||
default=False,
|
||||
# choices=['float16', 'float32', 'bfloat16'])
|
||||
choices=['float32', 'float16'])
|
||||
parser.add_argument('--parallel_build', default=False, action='store_true')
|
||||
parser.add_argument('--enable_context_fmha',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--enable_context_fmha_fp32_acc',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--enable_debug_output',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--gpus_per_node', type=int, default=8)
|
||||
parser.add_argument('--builder_opt', type=int, default=None)
|
||||
parser.add_argument(
|
||||
'--output_dir',
|
||||
type=str,
|
||||
default='llama_outputs',
|
||||
help=
|
||||
'The path to save the serialized engine files, timing cache file and model configs'
|
||||
)
|
||||
parser.add_argument('--remove_input_padding',
|
||||
default=False,
|
||||
action='store_true')
|
||||
|
||||
# Arguments related to the quantization of the model.
|
||||
parser.add_argument(
|
||||
'--use_smooth_quant',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'Use the SmoothQuant method to quantize activations and weights for the various GEMMs.'
|
||||
'See --per_channel and --per_token for finer-grained quantization options.'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--per_channel',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use a single static scaling factor for the GEMM\'s result. '
|
||||
'per_channel instead uses a different static scaling factor for each channel. '
|
||||
'The latter is usually more accurate, but a little slower.')
|
||||
parser.add_argument(
|
||||
'--per_token',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use a single static scaling factor to scale activations in the int8 range. '
|
||||
'per_token chooses at run time, and for each token, a custom scaling factor. '
|
||||
'The latter is usually more accurate, but a little slower.')
|
||||
parser.add_argument(
|
||||
'--per_group',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use a single static scaling factor to scale weights in the int4 range. '
|
||||
'per_group chooses at run time, and for each group, a custom scaling factor. '
|
||||
'The flag is built for GPTQ/AWQ quantization.')
|
||||
parser.add_argument('--group_size',
|
||||
type=int,
|
||||
default=128,
|
||||
help='Group size used in GPTQ/AWQ quantization.')
|
||||
parser.add_argument(
|
||||
'--int8_kv_cache',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use dtype for KV cache. int8_kv_cache chooses int8 quantization for KV'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_parallel_embedding',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help=
|
||||
'By default embedding parallelism is disabled. By setting this flag, embedding parallelism is enabled'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--embedding_sharding_dim',
|
||||
type=int,
|
||||
default=1, # Meta does TP on hidden dim
|
||||
choices=[0, 1],
|
||||
help=
|
||||
'By default the embedding lookup table is sharded along vocab dimension (embedding_sharding_dim=0). '
|
||||
'To shard it along hidden dimension, set embedding_sharding_dim=1'
|
||||
'Note: embedding sharing is only enabled when embedding_sharding_dim = 0'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_weight_only',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help='Quantize weights for the various GEMMs to INT4/INT8.'
|
||||
'See --weight_only_precision to set the precision')
|
||||
parser.add_argument(
|
||||
'--weight_only_precision',
|
||||
const='int8',
|
||||
type=str,
|
||||
nargs='?',
|
||||
default='int8',
|
||||
choices=['int16', 'int8', 'int4', 'int4_awq', 'int4_gptq'],
|
||||
help=
|
||||
'Define the precision for the weights when using weight-only quantization.'
|
||||
'You must also use --use_weight_only for that argument to have an impact.'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_inflight_batching',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Activates inflight batching mode of gptAttentionPlugin.")
|
||||
parser.add_argument(
|
||||
'--paged_kv_cache',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help=
|
||||
'By default we use contiguous KV cache. By setting this flag you enable paged KV cache'
|
||||
)
|
||||
parser.add_argument('--tokens_per_block',
|
||||
type=int,
|
||||
default=64,
|
||||
help='Number of tokens per block in paged KV cache')
|
||||
parser.add_argument(
|
||||
'--max_num_tokens',
|
||||
type=int,
|
||||
default=None,
|
||||
help='Define the max number of tokens supported by the engine')
|
||||
parser.add_argument(
|
||||
'--strongly_typed',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'This option is introduced with trt 9.1.0.1+ and will reduce the building time significantly for fp8.'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_custom_all_reduce',
|
||||
action='store_true',
|
||||
help=
|
||||
'Activates latency-optimized algorithm for all-reduce instead of NCCL.')
|
||||
parser.add_argument('--gather_all_token_logits',
|
||||
action='store_true',
|
||||
default=False)
|
||||
|
||||
args = parser.parse_args()
|
||||
xtrt_llm.logger.set_level(args.log_level)
|
||||
|
||||
assert not (
|
||||
args.use_smooth_quant and args.use_weight_only
|
||||
), "You cannot enable both SmoothQuant and INT8 weight-only together."
|
||||
|
||||
if not args.remove_input_padding:
|
||||
if args.use_gpt_attention_plugin:
|
||||
logger.warning(
|
||||
f"It is recommended to specify --remove_input_padding when using GPT attention plugin"
|
||||
)
|
||||
|
||||
if args.use_inflight_batching:
|
||||
if not args.use_gpt_attention_plugin:
|
||||
args.use_gpt_attention_plugin = 'float16'
|
||||
logger.info(
|
||||
f"Using GPT attention plugin for inflight batching mode. Setting to default '{args.use_gpt_attention_plugin}'"
|
||||
)
|
||||
if not args.remove_input_padding:
|
||||
args.remove_input_padding = True
|
||||
logger.info(
|
||||
"Using remove input padding for inflight batching mode.")
|
||||
if not args.paged_kv_cache:
|
||||
args.paged_kv_cache = True
|
||||
logger.info("Using paged KV cache for inflight batching mode.")
|
||||
|
||||
if args.use_smooth_quant:
|
||||
args.quant_mode = QuantMode.use_smooth_quant(args.per_token,
|
||||
args.per_channel)
|
||||
elif args.use_weight_only:
|
||||
if args.per_group:
|
||||
args.quant_mode = QuantMode.from_description(
|
||||
quantize_weights=True,
|
||||
quantize_activations=False,
|
||||
per_token=False,
|
||||
per_channel=False,
|
||||
per_group=True,
|
||||
use_int4_weights=True)
|
||||
else:
|
||||
args.quant_mode = QuantMode.use_weight_only(
|
||||
args.weight_only_precision == 'int4')
|
||||
else:
|
||||
args.quant_mode = QuantMode(0)
|
||||
|
||||
if args.int8_kv_cache:
|
||||
args.quant_mode = args.quant_mode.set_int8_kv_cache()
|
||||
|
||||
if args.rotary_scaling is not None:
|
||||
rotary_scaling = {
|
||||
"type": args.rotary_scaling[0],
|
||||
"factor": float(args.rotary_scaling[1])
|
||||
}
|
||||
assert rotary_scaling["type"] in ["linear", "dynamic"]
|
||||
assert rotary_scaling["factor"] > 1.0
|
||||
args.rotary_scaling = rotary_scaling
|
||||
if rotary_scaling["type"] == "dynamic":
|
||||
assert not args.remove_input_padding, "TODO: Not supported yet"
|
||||
|
||||
# Since gpt_attenttion_plugin is the only way to apply RoPE now,
|
||||
# force use the plugin for now with the correct data type.
|
||||
args.use_gpt_attention_plugin = args.dtype
|
||||
if args.model_dir is not None:
|
||||
hf_config = LlamaConfig.from_pretrained(args.model_dir)
|
||||
args.inter_size = hf_config.intermediate_size # override the inter_size for LLaMA
|
||||
args.n_embd = hf_config.hidden_size
|
||||
args.n_head = hf_config.num_attention_heads
|
||||
if hasattr(hf_config, "num_key_value_heads"):
|
||||
args.n_kv_head = hf_config.num_key_value_heads
|
||||
args.n_layer = hf_config.num_hidden_layers
|
||||
args.n_positions = hf_config.max_position_embeddings
|
||||
args.vocab_size = hf_config.vocab_size
|
||||
args.hidden_act = hf_config.hidden_act
|
||||
args.rms_norm_eps = hf_config.rms_norm_eps
|
||||
elif args.meta_ckpt_dir is not None:
|
||||
with open(Path(args.meta_ckpt_dir, "params.json")) as fp:
|
||||
meta_config: dict = json.load(fp)
|
||||
args.n_embd = meta_config["dim"]
|
||||
args.n_head = meta_config["n_heads"]
|
||||
args.n_layer = meta_config["n_layers"]
|
||||
args.n_kv_head = meta_config.get("n_kv_heads", args.n_head)
|
||||
args.multiple_of = meta_config["multiple_of"]
|
||||
args.ffn_dim_multiplier = meta_config.get("ffn_dim_multiplier", 1)
|
||||
n_embd = int(4 * args.n_embd * 2 / 3)
|
||||
args.inter_size = args.multiple_of * (
|
||||
(int(n_embd * args.ffn_dim_multiplier) + args.multiple_of - 1) //
|
||||
args.multiple_of)
|
||||
args.rms_norm_eps = meta_config["norm_eps"]
|
||||
elif args.ft_model_dir is not None:
|
||||
n_embd, n_head, n_layer, n_positions, vocab_size, hidden_act, inter_size, n_kv_head = parse_ft_config(
|
||||
Path(args.ft_model_dir) / "config.ini")
|
||||
args.inter_size = inter_size # override the inter_size for LLaMA
|
||||
args.n_kv_head = n_kv_head
|
||||
args.n_embd = n_embd
|
||||
args.n_head = n_head
|
||||
args.n_layer = n_layer
|
||||
args.n_positions = n_positions
|
||||
args.vocab_size = vocab_size
|
||||
args.hidden_act = hidden_act
|
||||
args.rms_norm_eps = 1e-06
|
||||
logger.warning("Set rms_norm_eps to 1e-06 directly.")
|
||||
assert args.use_gpt_attention_plugin, "LLaMa must use gpt attention plugin"
|
||||
if args.n_kv_head is None:
|
||||
args.n_kv_head = args.n_head
|
||||
elif args.n_kv_head != args.n_head:
|
||||
assert (args.n_head % args.n_kv_head) == 0, \
|
||||
"MQA/GQA requires the number of heads to be divisible by the number of K/V heads."
|
||||
assert (args.n_kv_head % args.tp_size) == 0 or (args.tp_size % args.n_kv_head) == 0, \
|
||||
"MQA/GQA requires either the number of K/V heads to be divisible by the tensor parallelism size OR " \
|
||||
"the tensor parallelism size to be divisible by the number of K/V heads."
|
||||
|
||||
# if args.dtype == 'bfloat16':
|
||||
# assert args.use_gemm_plugin, "Please use gemm plugin when dtype is bfloat16"
|
||||
|
||||
assert args.pp_size * args.tp_size == args.world_size
|
||||
|
||||
if args.max_num_tokens is not None:
|
||||
assert args.enable_context_fmha
|
||||
|
||||
if args.inter_size is None:
|
||||
# this should not be need when loading a real model
|
||||
# but it is helpful when creating a dummy model without loading any real weights
|
||||
n_embd = int(4 * args.n_embd * 2 / 3)
|
||||
args.inter_size = args.multiple_of * (
|
||||
(int(n_embd * args.ffn_dim_multiplier) + args.multiple_of - 1) //
|
||||
args.multiple_of)
|
||||
logger.info(f"Setting inter_size to {args.inter_size}.")
|
||||
|
||||
return args
|
||||
|
||||
|
||||
def build_rank_engine(builder: Builder,
|
||||
builder_config: xtrt_llm.builder.BuilderConfig,
|
||||
engine_name, rank, args):
|
||||
'''
|
||||
@brief: Build the engine on the given rank.
|
||||
@param rank: The rank to build the engine.
|
||||
@param args: The cmd line arguments.
|
||||
@return: The built engine.
|
||||
'''
|
||||
dtype = str_dtype_to_xtrt(args.dtype)
|
||||
mapping = Mapping(world_size=args.world_size,
|
||||
rank=rank,
|
||||
tp_size=args.tp_size,
|
||||
pp_size=args.pp_size)
|
||||
|
||||
assert args.n_layer % args.pp_size == 0, \
|
||||
f"num_layers {args.n_layer} must be a multiple of pipeline parallelism size {args.pp_size}"
|
||||
|
||||
# Initialize Module
|
||||
xtrt_llm_llama = xtrt_llm.models.LLaMAForCausalLM(
|
||||
num_layers=args.n_layer,
|
||||
num_heads=args.n_head,
|
||||
num_kv_heads=args.n_kv_head,
|
||||
hidden_size=args.n_embd,
|
||||
vocab_size=args.vocab_size,
|
||||
hidden_act=args.hidden_act,
|
||||
max_position_embeddings=args.n_positions,
|
||||
dtype=dtype,
|
||||
mlp_hidden_size=args.inter_size,
|
||||
position_embedding_type=PositionEmbeddingType.rope_gpt_neox,
|
||||
mapping=mapping,
|
||||
rotary_base=args.rotary_base,
|
||||
rotary_scaling=args.rotary_scaling,
|
||||
use_parallel_embedding=args.use_parallel_embedding,
|
||||
embedding_sharding_dim=args.embedding_sharding_dim,
|
||||
quant_mode=args.quant_mode,
|
||||
rms_norm_eps=args.rms_norm_eps,
|
||||
gather_all_token_logits=args.gather_all_token_logits)
|
||||
if args.use_smooth_quant:
|
||||
xtrt_llm_llama = smooth_quantize(xtrt_llm_llama, args.quant_mode)
|
||||
elif args.use_weight_only:
|
||||
if args.weight_only_precision == 'int8' or args.weight_only_precision == 'int16':
|
||||
'''
|
||||
xtrt_llm_llama = weight_only_quantize(xtrt_llm_llama,
|
||||
args.quant_mode)
|
||||
'''
|
||||
elif args.weight_only_precision == 'int4':
|
||||
'''
|
||||
xtrt_llm_llama = weight_only_quantize(xtrt_llm_llama,
|
||||
args.quant_mode)
|
||||
'''
|
||||
elif args.weight_only_precision == 'int4_awq':
|
||||
xtrt_llm_llama = weight_only_groupwise_quantize(
|
||||
model=xtrt_llm_llama,
|
||||
quant_mode=args.quant_mode,
|
||||
group_size=args.group_size,
|
||||
zero=False,
|
||||
pre_quant_scale=True,
|
||||
exclude_modules=[])
|
||||
elif args.weight_only_precision == 'int4_gptq':
|
||||
xtrt_llm_llama = weight_only_groupwise_quantize(
|
||||
model=xtrt_llm_llama,
|
||||
quant_mode=args.quant_mode,
|
||||
group_size=args.group_size,
|
||||
zero=True,
|
||||
pre_quant_scale=False)
|
||||
|
||||
if args.per_group:
|
||||
load_func = load_from_awq_llama if args.weight_only_precision == 'int4_awq' else load_from_gptq_llama
|
||||
load_func(xtrt_llm_llama=xtrt_llm_llama,
|
||||
quant_ckpt_path=args.quant_ckpt_path,
|
||||
mapping=mapping,
|
||||
dtype=args.dtype)
|
||||
elif args.meta_ckpt_dir is not None:
|
||||
load_from_meta_llama(xtrt_llm_llama, args.meta_ckpt_dir, mapping,
|
||||
args.dtype)
|
||||
elif args.model_dir is not None:
|
||||
logger.info(f'Loading HF LLaMA ... from {args.model_dir}')
|
||||
tik = time.time()
|
||||
hf_llama = LlamaForCausalLM.from_pretrained(
|
||||
args.model_dir,
|
||||
device_map={
|
||||
"model": "cpu",
|
||||
"lm_head": "cpu"
|
||||
}, # Load to CPU memory
|
||||
torch_dtype="auto")
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'HF LLaMA loaded. Total time: {t}')
|
||||
load_from_hf_llama(xtrt_llm_llama,
|
||||
hf_llama,
|
||||
mapping=mapping,
|
||||
dtype=args.dtype)
|
||||
del hf_llama
|
||||
elif args.ft_model_dir is not None:
|
||||
load_from_binary(xtrt_llm_llama,
|
||||
args.ft_model_dir,
|
||||
mapping,
|
||||
fp16=(args.dtype == 'float16'),
|
||||
multi_query_mode=(args.n_kv_head != args.n_head))
|
||||
|
||||
# Module -> Network
|
||||
network = builder.create_network()
|
||||
network.trt_network.name = engine_name
|
||||
if args.use_gpt_attention_plugin:
|
||||
network.plugin_config.set_gpt_attention_plugin(
|
||||
dtype=args.use_gpt_attention_plugin)
|
||||
if args.use_gemm_plugin:
|
||||
network.plugin_config.set_gemm_plugin(dtype=args.use_gemm_plugin)
|
||||
if args.use_rmsnorm_plugin:
|
||||
network.plugin_config.set_rmsnorm_plugin(dtype=args.use_rmsnorm_plugin)
|
||||
|
||||
# Quantization plugins.
|
||||
if args.use_smooth_quant:
|
||||
network.plugin_config.set_smooth_quant_gemm_plugin(dtype=args.dtype)
|
||||
network.plugin_config.set_rmsnorm_quantization_plugin(dtype=args.dtype)
|
||||
network.plugin_config.set_quantize_tensor_plugin()
|
||||
network.plugin_config.set_quantize_per_token_plugin()
|
||||
assert not (args.enable_context_fmha and args.enable_context_fmha_fp32_acc)
|
||||
if args.enable_context_fmha:
|
||||
network.plugin_config.set_context_fmha(ContextFMHAType.enabled)
|
||||
if args.enable_context_fmha_fp32_acc:
|
||||
network.plugin_config.set_context_fmha(
|
||||
ContextFMHAType.enabled_with_fp32_acc)
|
||||
if args.use_weight_only:
|
||||
if args.per_group:
|
||||
network.plugin_config.set_weight_only_groupwise_quant_matmul_plugin(
|
||||
dtype='float16')
|
||||
else:
|
||||
network.plugin_config.set_weight_only_quant_matmul_plugin(
|
||||
dtype='float16')
|
||||
if args.world_size > 1:
|
||||
network.plugin_config.set_nccl_plugin(args.dtype,
|
||||
args.use_custom_all_reduce)
|
||||
if args.remove_input_padding:
|
||||
network.plugin_config.enable_remove_input_padding()
|
||||
if args.paged_kv_cache:
|
||||
network.plugin_config.enable_paged_kv_cache(args.tokens_per_block)
|
||||
if args.quant_mode.is_weight_only():
|
||||
builder_config.trt_builder_config.use_weight_only = args.weight_only_precision
|
||||
|
||||
with net_guard(network):
|
||||
# Prepare
|
||||
network.set_named_parameters(xtrt_llm_llama.named_parameters())
|
||||
|
||||
# Forward
|
||||
inputs = xtrt_llm_llama.prepare_inputs(args.max_batch_size,
|
||||
args.max_input_len,
|
||||
args.max_output_len, True,
|
||||
args.max_beam_width,
|
||||
args.max_num_tokens)
|
||||
xtrt_llm_llama(*inputs)
|
||||
if args.enable_debug_output:
|
||||
# mark intermediate nodes' outputs
|
||||
for k, v in xtrt_llm_llama.named_network_outputs():
|
||||
v = v.trt_tensor
|
||||
v.name = k
|
||||
network.trt_network.mark_output(v)
|
||||
v.dtype = dtype
|
||||
|
||||
# xtrt_llm.graph_rewriting.optimize(network)
|
||||
|
||||
engine = None
|
||||
|
||||
# Network -> Engine
|
||||
engine = builder.build_engine(network, builder_config, compiler="gr")
|
||||
if rank == 0:
|
||||
config_path = os.path.join(args.output_dir, 'config.json')
|
||||
builder.save_config(builder_config, config_path)
|
||||
|
||||
if args.opt_memory_use:
|
||||
return engine, network
|
||||
return engine
|
||||
|
||||
|
||||
def build(rank, args):
|
||||
# torch.cuda.set_device(rank % args.gpus_per_node)
|
||||
logger.set_level(args.log_level)
|
||||
if not os.path.exists(args.output_dir):
|
||||
os.makedirs(args.output_dir)
|
||||
|
||||
# when doing serializing build, all ranks share one engine
|
||||
builder = Builder()
|
||||
|
||||
cache = None
|
||||
for cur_rank in range(args.world_size):
|
||||
# skip other ranks if parallel_build is enabled
|
||||
if args.parallel_build and cur_rank != rank:
|
||||
continue
|
||||
# NOTE: when only int8 kv cache is used together with paged kv cache no int8 tensors are exposed to TRT
|
||||
int8_trt_flag = args.quant_mode.has_act_and_weight_quant() or (
|
||||
not args.paged_kv_cache and args.quant_mode.has_int8_kv_cache())
|
||||
builder_config = builder.create_builder_config(
|
||||
name=MODEL_NAME,
|
||||
precision=args.dtype,
|
||||
timing_cache=args.timing_cache if cache is None else cache,
|
||||
tensor_parallel=args.tp_size,
|
||||
pipeline_parallel=args.pp_size,
|
||||
parallel_build=args.parallel_build,
|
||||
num_layers=args.n_layer,
|
||||
num_heads=args.n_head,
|
||||
num_kv_heads=args.n_kv_head,
|
||||
hidden_size=args.n_embd,
|
||||
vocab_size=args.vocab_size,
|
||||
hidden_act=args.hidden_act,
|
||||
inter_size = args.inter_size,
|
||||
max_position_embeddings=args.n_positions,
|
||||
max_batch_size=args.max_batch_size,
|
||||
max_input_len=args.max_input_len,
|
||||
max_output_len=args.max_output_len,
|
||||
max_num_tokens=args.max_num_tokens,
|
||||
int8=int8_trt_flag,
|
||||
fp8=False,
|
||||
quant_mode=args.quant_mode,
|
||||
strongly_typed=args.strongly_typed,
|
||||
opt_level=args.builder_opt,
|
||||
fusion_pattern_list=["remove_dup_mask"],
|
||||
gather_all_token_logits=args.gather_all_token_logits)
|
||||
guard = xtrt_llm.fusion_patterns.FuseonPatternGuard()
|
||||
print(guard)
|
||||
engine_name = get_engine_name(MODEL_NAME, args.dtype, args.tp_size,
|
||||
args.pp_size, cur_rank)
|
||||
if args.opt_memory_use:
|
||||
engine, network = build_rank_engine(builder, builder_config,
|
||||
engine_name, cur_rank, args)
|
||||
else:
|
||||
engine = build_rank_engine(builder, builder_config, engine_name,
|
||||
cur_rank, args)
|
||||
assert engine is not None, f'Failed to build engine for rank {cur_rank}'
|
||||
|
||||
# if cur_rank == 0:
|
||||
# # Use in-memory timing cache for multiple builder passes.
|
||||
# if not args.parallel_build:
|
||||
# cache = builder_config.trt_builder_config.get_timing_cache()
|
||||
|
||||
serialize_engine(engine, os.path.join(args.output_dir, engine_name))
|
||||
del engine
|
||||
if args.opt_memory_use:
|
||||
network.__del__()
|
||||
|
||||
# if rank == 0:
|
||||
# ok = builder.save_timing_cache(
|
||||
# builder_config, os.path.join(args.output_dir, "model.cache"))
|
||||
# assert ok, "Failed to save timing cache."
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = parse_arguments()
|
||||
tik = time.time()
|
||||
if args.parallel_build and args.world_size:
|
||||
logger.warning(
|
||||
f'Parallelly build TensorRT engines. Please make sure that all of the {args.world_size} GPUs are totally free.'
|
||||
)
|
||||
mp.spawn(build, nprocs=args.world_size, args=(args, ))
|
||||
else:
|
||||
args.parallel_build = False
|
||||
logger.info('Serially build TensorRT engines.')
|
||||
build(0, args)
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Total time of building all {args.world_size} engines: {t}')
|
||||
313
examples/llama/convert.py
Normal file
313
examples/llama/convert.py
Normal file
@@ -0,0 +1,313 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""
|
||||
Utilities for exporting a model to our custom format.
|
||||
"""
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
|
||||
def save_val(val, dir, key, tp_num=None):
|
||||
suffix = "bin" if tp_num is None else f"{tp_num}.bin"
|
||||
val.tofile(dir / f"model.{key}.{suffix}")
|
||||
|
||||
|
||||
def save_split(split_vals, dir, key, i, factor):
|
||||
for j, val in enumerate(split_vals):
|
||||
save_val(val, dir, key, i * factor + j)
|
||||
|
||||
|
||||
def generate_int8(weights, act_range, is_qkv=False, multi_query_mode=False):
|
||||
"""
|
||||
This function has two purposes:
|
||||
- compute quantized weights, scaled either per-tensor or per-column
|
||||
- compute scaling factors
|
||||
|
||||
Depending on the GEMM API (CUTLASS/CUBLAS) the required scaling factors differ.
|
||||
CUTLASS uses two sets of scaling factors. One for the activation X, one for the weight W.
|
||||
CUBLAS only has one (we can't do per-row scaling). So we must provide pre-multiplied scaling factor.
|
||||
|
||||
Here is the list of what we need (T means per-tensor, C per-column):
|
||||
- scale_x_orig_quant puts fp activation into the quantized range (i.e. [-128, 127], for int8). Used before the GEMM. (T)
|
||||
- scale_y_quant_orig puts quantized activation into the fp range. Used if the GEMM outputs int8. (T)
|
||||
- scale_w_quant_orig puts weights from quant range to fp range (used with CUTLASS) (T, C)
|
||||
- scale_y_accum_quant puts the GEMM result (XW) from accumulation range (int32)
|
||||
to quant range (int8) (used for CUBLAS) (T, C)
|
||||
|
||||
Note that we don't do anything special about row-parallel GEMM. Theoretically, we could have per-GPU scaling factors too,
|
||||
but then the model would change depending on the number of GPUs used.
|
||||
|
||||
For QKV projection, the behavior is special. Even if we have a single matrix to perform QKV projection, we consider it
|
||||
as three different matrices: Q, K, and V. So per-tensor actually means one scaling factor for each Q, K and V.
|
||||
For our GEMM implementation to respect this behavior, we use per-column mode and replicate values along columns.
|
||||
"""
|
||||
|
||||
# compute weight scaling factors for fp->int8 and int8->fp
|
||||
if is_qkv and not multi_query_mode:
|
||||
scale_w_orig_quant_t = 127. / act_range["w"].reshape(3, -1).max(
|
||||
dim=-1, keepdims=True)[0].cpu().numpy()
|
||||
scale_w_orig_quant_c = 127. / act_range["w"].reshape(3,
|
||||
-1).cpu().numpy()
|
||||
elif is_qkv and multi_query_mode:
|
||||
hidden_dim = weights.shape[0]
|
||||
local_dim = act_range["w"].shape[0]
|
||||
kv_dim = (local_dim - hidden_dim) // 2
|
||||
scale_w_q = act_range["w"][0:hidden_dim]
|
||||
scale_w_k = act_range["w"][hidden_dim:hidden_dim + kv_dim]
|
||||
scale_w_v = act_range["w"][-kv_dim:]
|
||||
|
||||
scale_w_qkv_t = torch.concat([
|
||||
scale_w_q.max(dim=0, keepdim=True)[0],
|
||||
scale_w_k.max(dim=0, keepdim=True)[0],
|
||||
scale_w_v.max(dim=0, keepdim=True)[0]
|
||||
])
|
||||
|
||||
scale_w_orig_quant_t = 127. / scale_w_qkv_t.cpu().numpy()
|
||||
scale_w_orig_quant_c = 127. / act_range["w"].cpu().numpy()
|
||||
else:
|
||||
scale_w_orig_quant_t = 127. / act_range["w"].max().cpu().numpy()
|
||||
scale_w_orig_quant_c = 127. / act_range["w"].cpu().numpy()
|
||||
scale_w_quant_orig_t = 1.0 / scale_w_orig_quant_t
|
||||
scale_w_quant_orig_c = 1.0 / scale_w_orig_quant_c
|
||||
|
||||
# compute the rest of needed scaling factors
|
||||
scale_x_orig_quant_t = np.array(127. / act_range["x"].max().item())
|
||||
scale_y_orig_quant_t = np.array(127. / act_range["y"].max().item())
|
||||
scale_y_quant_orig_t = np.array(act_range["y"].max().item() / 127.)
|
||||
scale_y_accum_quant_t = scale_y_orig_quant_t / (scale_x_orig_quant_t *
|
||||
scale_w_orig_quant_t)
|
||||
scale_y_accum_quant_c = scale_y_orig_quant_t / (scale_x_orig_quant_t *
|
||||
scale_w_orig_quant_c)
|
||||
if is_qkv and not multi_query_mode:
|
||||
scale_y_accum_quant_t = np.broadcast_to(scale_y_accum_quant_t,
|
||||
scale_w_orig_quant_c.shape)
|
||||
scale_w_quant_orig_t = np.broadcast_to(scale_w_quant_orig_t,
|
||||
scale_w_orig_quant_c.shape)
|
||||
if is_qkv and multi_query_mode:
|
||||
scale_q_y_accum_t = np.broadcast_to(scale_y_accum_quant_t[0],
|
||||
scale_w_q.shape)
|
||||
scale_k_y_accum_t = np.broadcast_to(scale_y_accum_quant_t[1],
|
||||
scale_w_k.shape)
|
||||
scale_v_y_accum_t = np.broadcast_to(scale_y_accum_quant_t[2],
|
||||
scale_w_v.shape)
|
||||
scale_y_accum_quant_t = np.concatenate(
|
||||
[scale_q_y_accum_t, scale_k_y_accum_t, scale_v_y_accum_t])
|
||||
scale_w_quant_orig_t = np.concatenate([
|
||||
np.broadcast_to(scale_w_quant_orig_t[0], scale_w_q.shape),
|
||||
np.broadcast_to(scale_w_quant_orig_t[1], scale_w_k.shape),
|
||||
np.broadcast_to(scale_w_quant_orig_t[2], scale_w_v.shape)
|
||||
])
|
||||
|
||||
to_i8 = lambda x: x.round().clip(-127, 127).astype(np.int8)
|
||||
|
||||
if is_qkv and multi_query_mode:
|
||||
scale_w_quant_orig_t_expand = np.ones([weights.shape[-1]])
|
||||
scale_w_quant_orig_t_expand[:hidden_dim] = scale_w_quant_orig_t[0]
|
||||
scale_w_quant_orig_t_expand[hidden_dim:hidden_dim +
|
||||
kv_dim] = scale_w_quant_orig_t[1]
|
||||
scale_w_quant_orig_t_expand[-kv_dim:] = scale_w_quant_orig_t[2]
|
||||
weight_int8 = to_i8(weights * scale_w_quant_orig_t_expand)
|
||||
else:
|
||||
weight_int8 = to_i8(weights * scale_w_orig_quant_t)
|
||||
return {
|
||||
"weight.int8": weight_int8,
|
||||
"weight.int8.col": to_i8(weights * scale_w_orig_quant_c),
|
||||
"scale_x_orig_quant": scale_x_orig_quant_t.astype(np.float32),
|
||||
"scale_w_quant_orig": scale_w_quant_orig_t.astype(np.float32),
|
||||
"scale_w_quant_orig.col": scale_w_quant_orig_c.astype(np.float32),
|
||||
"scale_y_accum_quant": scale_y_accum_quant_t.astype(np.float32),
|
||||
"scale_y_accum_quant.col": scale_y_accum_quant_c.astype(np.float32),
|
||||
"scale_y_quant_orig": scale_y_quant_orig_t.astype(np.float32),
|
||||
}
|
||||
|
||||
|
||||
def save_multi_query_mode_qkv_int8(val, dir, base_key, saved_key, factor, rank,
|
||||
local_dim, head_size):
|
||||
q, k, v = np.split(val, [local_dim, local_dim + head_size], axis=-1)
|
||||
q_split = np.split(q, factor, axis=-1)
|
||||
k_split = np.split(k, factor, axis=-1)
|
||||
v_split = np.split(v, factor, axis=-1)
|
||||
split_vals = [
|
||||
np.concatenate((q_split[ii], k_split[ii], v_split[ii]), axis=-1)
|
||||
for ii in range(factor)
|
||||
]
|
||||
save_split(split_vals, dir, f"{base_key}.{saved_key}", rank, factor)
|
||||
|
||||
|
||||
def write_int8(vals,
|
||||
dir,
|
||||
base_key,
|
||||
split_dim,
|
||||
i,
|
||||
factor,
|
||||
is_qkv=False,
|
||||
multi_query_mode=False):
|
||||
saved_keys_once = [
|
||||
"scale_x_orig_quant", "scale_w_quant_orig", "scale_y_accum_quant",
|
||||
"scale_y_quant_orig"
|
||||
]
|
||||
|
||||
if is_qkv and multi_query_mode:
|
||||
assert split_dim == -1
|
||||
local_dim = vals["weight.int8"].shape[0]
|
||||
head_size = (vals["weight.int8"].shape[1] - local_dim) // 2
|
||||
|
||||
save_multi_query_mode_qkv_int8(vals["weight.int8"], dir, base_key,
|
||||
"weight.int8", factor, i, local_dim,
|
||||
head_size)
|
||||
save_multi_query_mode_qkv_int8(vals["weight.int8.col"], dir, base_key,
|
||||
"weight.int8.col", factor, i, local_dim,
|
||||
head_size)
|
||||
save_multi_query_mode_qkv_int8(vals["scale_w_quant_orig.col"], dir,
|
||||
base_key, "scale_w_quant_orig.col",
|
||||
factor, i, local_dim, head_size)
|
||||
save_multi_query_mode_qkv_int8(vals["scale_y_accum_quant.col"], dir,
|
||||
base_key, "scale_y_accum_quant.col",
|
||||
factor, i, local_dim, head_size)
|
||||
save_multi_query_mode_qkv_int8(vals["scale_w_quant_orig"], dir,
|
||||
base_key, "scale_w_quant_orig", factor,
|
||||
i, local_dim, head_size)
|
||||
save_multi_query_mode_qkv_int8(vals["scale_y_accum_quant"], dir,
|
||||
base_key, "scale_y_accum_quant", factor,
|
||||
i, local_dim, head_size)
|
||||
saved_keys_once = ["scale_x_orig_quant", "scale_y_quant_orig"]
|
||||
else:
|
||||
save_split(np.split(vals["weight.int8"], factor, axis=split_dim), dir,
|
||||
f"{base_key}.weight.int8", i, factor)
|
||||
save_split(np.split(vals["weight.int8.col"], factor, axis=split_dim),
|
||||
dir, f"{base_key}.weight.int8.col", i, factor)
|
||||
|
||||
if split_dim == -1:
|
||||
save_split(
|
||||
np.split(vals["scale_w_quant_orig.col"], factor,
|
||||
axis=split_dim), dir,
|
||||
f"{base_key}.scale_w_quant_orig.col", i, factor)
|
||||
save_split(
|
||||
np.split(vals["scale_y_accum_quant.col"],
|
||||
factor,
|
||||
axis=split_dim), dir,
|
||||
f"{base_key}.scale_y_accum_quant.col", i, factor)
|
||||
if is_qkv:
|
||||
save_split(
|
||||
np.split(vals["scale_y_accum_quant"],
|
||||
factor,
|
||||
axis=split_dim), dir,
|
||||
f"{base_key}.scale_y_accum_quant", i, factor)
|
||||
save_split(
|
||||
np.split(vals["scale_w_quant_orig"], factor,
|
||||
axis=split_dim), dir,
|
||||
f"{base_key}.scale_w_quant_orig", i, factor)
|
||||
saved_keys_once = ["scale_x_orig_quant", "scale_y_quant_orig"]
|
||||
else:
|
||||
saved_keys_once += [
|
||||
"scale_w_quant_orig.col", "scale_y_accum_quant.col"
|
||||
]
|
||||
|
||||
if i == 0:
|
||||
for save_key in saved_keys_once:
|
||||
save_val(vals[save_key], dir, f"{base_key}.{save_key}")
|
||||
|
||||
|
||||
def str_to_np_dtype(type_str):
|
||||
convert_dict = {
|
||||
"fp32": np.float32,
|
||||
"fp16": np.float16,
|
||||
}
|
||||
dtype = convert_dict.get(type_str)
|
||||
if dtype is None:
|
||||
raise ValueError(f"{type_str} is an invalid storage type")
|
||||
return dtype
|
||||
|
||||
|
||||
def split_and_save_weight(i, saved_dir, factor, key, val, act_range, config):
|
||||
# The split_factor indicates the number of ranks to implement
|
||||
# distributed GEMMs. For Tensor Parallelism, each rank/GPU works
|
||||
# on split_hidden_dim // split_factor channels.
|
||||
|
||||
int8_outputs = config.get("int8_outputs", None)
|
||||
multi_query_mode = config.get("multi_query_mode", False)
|
||||
local_dim = config.get("local_dim", None)
|
||||
|
||||
save_int8 = int8_outputs == "all" or int8_outputs == "kv_cache_only"
|
||||
|
||||
if "input_layernorm.weight" in key or "input_layernorm.bias" in key or \
|
||||
"attention.dense.bias" in key or "post_layernorm.weight" in key or \
|
||||
"post_attention_layernorm.bias" in key or "mlp.dense_4h_to_h.bias" in key or \
|
||||
"final_layernorm.weight" in key or "final_layernorm.bias" in key:
|
||||
|
||||
# shared weights, only need to convert the weights of rank 0
|
||||
if i == 0:
|
||||
save_val(val, saved_dir, key)
|
||||
|
||||
elif "attention.dense.weight" in key or "mlp.proj.weight" in key:
|
||||
split_dim = 0
|
||||
split_vals = np.split(val, factor, axis=split_dim)
|
||||
save_split(split_vals, saved_dir, key, i, factor)
|
||||
if act_range is not None and int8_outputs == "all":
|
||||
base_key = key.replace(".weight", "")
|
||||
vals_i8 = generate_int8(val, act_range)
|
||||
write_int8(vals_i8, saved_dir, base_key, split_dim, i, factor)
|
||||
|
||||
elif "mlp.fc.weight" in key or "mlp.gate.weight" in key:
|
||||
split_dim = -1
|
||||
split_vals = np.split(val, factor, axis=split_dim)
|
||||
save_split(split_vals, saved_dir, key, i, factor)
|
||||
if act_range is not None and int8_outputs == "all":
|
||||
base_key = key.replace(".weight", "")
|
||||
vals_i8 = generate_int8(val, act_range)
|
||||
write_int8(vals_i8, saved_dir, base_key, split_dim, i, factor)
|
||||
|
||||
elif "attention.query_key_value.weight" in key:
|
||||
hidden_dim = val.shape[0]
|
||||
if local_dim is None:
|
||||
local_dim = val.shape[-1] // 3
|
||||
if multi_query_mode:
|
||||
head_size = (val.shape[-1] - local_dim) // 2
|
||||
val = val.reshape(hidden_dim, local_dim + 2 * head_size)
|
||||
w_q, w_k, w_v = np.split(val, [local_dim, local_dim + head_size],
|
||||
axis=-1)
|
||||
w_q_split = np.split(w_q, factor, axis=-1)
|
||||
w_k_split = np.split(w_k, factor, axis=-1)
|
||||
w_v_split = np.split(w_v, factor, axis=-1)
|
||||
split_vals = [
|
||||
np.concatenate((w_q_split[ii], w_k_split[ii], w_v_split[ii]),
|
||||
axis=-1) for ii in range(factor)
|
||||
]
|
||||
split_dim = -1
|
||||
else:
|
||||
val = val.reshape(hidden_dim, 3, local_dim)
|
||||
split_dim = -1
|
||||
split_vals = np.split(val, factor, axis=split_dim)
|
||||
save_split(split_vals, saved_dir, key, i, factor)
|
||||
if save_int8:
|
||||
base_key = key.replace(".weight", "")
|
||||
vals_i8 = generate_int8(val,
|
||||
act_range,
|
||||
is_qkv=True,
|
||||
multi_query_mode=multi_query_mode)
|
||||
write_int8(vals_i8,
|
||||
saved_dir,
|
||||
base_key,
|
||||
split_dim,
|
||||
i,
|
||||
factor,
|
||||
is_qkv=True,
|
||||
multi_query_mode=multi_query_mode)
|
||||
elif "attention.dense.smoother" in key or "mlp.proj.smoother" in key:
|
||||
split_vals = np.split(val, factor, axis=0)
|
||||
save_split(split_vals, saved_dir, key, i, factor)
|
||||
|
||||
else:
|
||||
print(f"[WARNING] {key} not handled by converter")
|
||||
335
examples/llama/hf_llama_convert.py
Normal file
335
examples/llama/hf_llama_convert.py
Normal file
@@ -0,0 +1,335 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
'''
|
||||
Convert huggingface GPT model. Use https://huggingface.co/gpt2 as demo.
|
||||
'''
|
||||
import argparse
|
||||
import configparser
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
import torch.multiprocessing as multiprocessing
|
||||
from convert import split_and_save_weight, str_to_np_dtype
|
||||
from smoothquant import (capture_activation_range, smooth_gemm,
|
||||
smooth_gemm_fc1_gate)
|
||||
from tqdm import tqdm
|
||||
from transformers import LlamaForCausalLM, LlamaTokenizer
|
||||
from transformers.models.llama.modeling_llama import LlamaDecoderLayer
|
||||
|
||||
|
||||
def merge_qkv_scales(q_name, hf_model, scales, llama_qkv_para):
|
||||
layer_name_q = q_name.replace(".weight", "")
|
||||
layer_name_k = layer_name_q.replace("q_proj", "k_proj")
|
||||
layer_name_v = layer_name_q.replace("q_proj", "v_proj")
|
||||
layer_name_qkv = layer_name_q.replace("q_proj", "qkv_proj")
|
||||
|
||||
q = hf_model.state_dict()[layer_name_q + ".weight"]
|
||||
k = hf_model.state_dict()[layer_name_k + ".weight"]
|
||||
v = hf_model.state_dict()[layer_name_v + ".weight"]
|
||||
|
||||
weight = torch.cat([q, k, v], dim=0)
|
||||
|
||||
scales[layer_name_qkv]["x"] = scales[layer_name_q]["x"]
|
||||
scales[layer_name_qkv]["w"] = weight.abs().max(dim=1)[0]
|
||||
print(scales[layer_name_q])
|
||||
scales[layer_name_qkv]["y"] = torch.cat([
|
||||
scales[layer_name_q]["y"], scales[layer_name_k]["y"],
|
||||
scales[layer_name_v]["y"]
|
||||
],
|
||||
dim=0)
|
||||
|
||||
llama_qkv_para[layer_name_qkv] = weight.transpose(0, 1)
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def smooth_llama_model(model, scales, alpha, llama_qkv_para, llama_smoother):
|
||||
# Smooth the activation and weights with smoother = $\diag{s}$
|
||||
for name, module in model.named_modules():
|
||||
if not isinstance(module, LlamaDecoderLayer):
|
||||
continue
|
||||
# qkv_proj
|
||||
layer_name_q = name + ".self_attn.q_proj"
|
||||
layer_name_k = name + ".self_attn.k_proj"
|
||||
layer_name_v = name + ".self_attn.v_proj"
|
||||
layer_name_qkv = name + ".self_attn.qkv_proj"
|
||||
|
||||
weight = torch.cat([
|
||||
module.self_attn.q_proj.weight, module.self_attn.k_proj.weight,
|
||||
module.self_attn.v_proj.weight
|
||||
],
|
||||
dim=0)
|
||||
|
||||
smoother = smooth_gemm(weight, scales[layer_name_q]["x"],
|
||||
module.input_layernorm.weight, None, alpha)
|
||||
|
||||
scales[layer_name_qkv]["x"] = scales[layer_name_q]["x"] / smoother
|
||||
scales[layer_name_qkv]["w"] = weight.abs().max(dim=1)[0]
|
||||
scales[layer_name_qkv]["y"] = torch.cat([
|
||||
scales[layer_name_q]["y"], scales[layer_name_k]["y"],
|
||||
scales[layer_name_v]["y"]
|
||||
],
|
||||
dim=0)
|
||||
|
||||
# see transpose_weights function
|
||||
llama_qkv_para[layer_name_qkv] = weight.transpose(0, 1)
|
||||
|
||||
# =================================================================
|
||||
layer_name = name + ".self_attn.o_proj"
|
||||
smoother = smooth_gemm(module.self_attn.o_proj.weight,
|
||||
scales[layer_name]["x"], None, None, alpha)
|
||||
llama_smoother[layer_name] = smoother.float()
|
||||
|
||||
scales[layer_name]["x"] = scales[layer_name]["x"] / smoother
|
||||
scales[layer_name]["w"] = module.self_attn.o_proj.weight.abs().max(
|
||||
dim=1)[0]
|
||||
|
||||
# ==================================================================
|
||||
fc1_layer_name = name + ".mlp.gate_proj"
|
||||
gate_layer_name = name + ".mlp.up_proj"
|
||||
|
||||
smoother = smooth_gemm_fc1_gate(module.mlp.gate_proj.weight,
|
||||
module.mlp.up_proj.weight,
|
||||
scales[fc1_layer_name]["x"],
|
||||
module.post_attention_layernorm.weight,
|
||||
None, alpha)
|
||||
|
||||
scales[fc1_layer_name]["x"] = scales[fc1_layer_name]["x"] / smoother
|
||||
scales[fc1_layer_name]["w"] = module.mlp.gate_proj.weight.abs().max(
|
||||
dim=1)[0]
|
||||
|
||||
scales[gate_layer_name]["x"] = scales[gate_layer_name]["x"] / smoother
|
||||
scales[gate_layer_name]["w"] = module.mlp.up_proj.weight.abs().max(
|
||||
dim=1)[0]
|
||||
|
||||
# ==================================================================
|
||||
layer_name = name + ".mlp.down_proj"
|
||||
smoother = smooth_gemm(module.mlp.down_proj.weight,
|
||||
scales[layer_name]["x"], None, None, alpha)
|
||||
llama_smoother[layer_name] = smoother.float()
|
||||
scales[layer_name]["x"] = scales[layer_name]["x"] / smoother
|
||||
scales[layer_name]["w"] = module.mlp.down_proj.weight.abs().max(
|
||||
dim=1)[0]
|
||||
|
||||
|
||||
def gpt_to_ft_name(orig_name):
|
||||
global_ft_weights = {
|
||||
"model.embed_tokens.weight": 'vocab_embedding.weight',
|
||||
"model.norm.weight": 'ln_f.weight',
|
||||
"lm_head.weight": 'lm_head.weight',
|
||||
}
|
||||
|
||||
if orig_name in global_ft_weights:
|
||||
return global_ft_weights[orig_name]
|
||||
|
||||
_, _, layer_id, *weight_name = orig_name.split(".")
|
||||
|
||||
layer_id = int(layer_id)
|
||||
weight_name = ".".join(weight_name)
|
||||
|
||||
if weight_name == 'self_attn.q_proj.weight':
|
||||
return f"layers.{layer_id}.attention.query_key_value.weight"
|
||||
elif weight_name == 'self_attn.k_proj.weight' or weight_name == 'self_attn.v_proj.weight':
|
||||
return f"layers.{layer_id}.attention.kv.weight"
|
||||
|
||||
per_layer_weights = {
|
||||
"input_layernorm.weight": "input_layernorm.weight",
|
||||
"self_attn.o_proj.weight": "attention.dense.weight",
|
||||
"mlp.gate_proj.weight": "mlp.fc.weight",
|
||||
"mlp.down_proj.weight": "mlp.proj.weight",
|
||||
"mlp.up_proj.weight": "mlp.gate.weight",
|
||||
"post_attention_layernorm.weight": "post_layernorm.weight",
|
||||
}
|
||||
|
||||
return f"layers.{layer_id}.{per_layer_weights[weight_name]}"
|
||||
|
||||
|
||||
# LLaMA uses nn.Linear for these following ops whose weight matrix is transposed compared to gpt2.
|
||||
# In order to use the preprocess codes of gpt2, we transpose them firstly.
|
||||
def transpose_weights(hf_name, param):
|
||||
weight_to_transpose = ["o_proj", "gate_proj", "down_proj", "up_proj"]
|
||||
if any([k in hf_name for k in weight_to_transpose]):
|
||||
if len(param.shape) == 2:
|
||||
param = param.transpose(0, 1)
|
||||
return param
|
||||
|
||||
|
||||
def hf_gpt_converter(args):
|
||||
infer_tp = args.tensor_parallelism
|
||||
saved_dir = Path(args.out_dir) / f"{infer_tp}-XPU"
|
||||
saved_dir.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
model = LlamaForCausalLM.from_pretrained(args.in_file, device_map="auto")
|
||||
|
||||
act_range = {}
|
||||
llama_qkv_para = {}
|
||||
# smoother for inputs of self_attn.o_proj and mlp.down_proj
|
||||
llama_smoother = {}
|
||||
|
||||
if args.smoothquant is not None or args.calibrate_kv_cache:
|
||||
os.environ["TOKENIZERS_PARALLELISM"] = os.environ.get(
|
||||
"TOKENIZERS_PARALLELISM", "false")
|
||||
act_range = capture_activation_range(
|
||||
model,
|
||||
LlamaTokenizer.from_pretrained(args.in_file, padding_side='left'))
|
||||
if args.smoothquant is not None:
|
||||
smooth_llama_model(model, act_range, args.smoothquant,
|
||||
llama_qkv_para, llama_smoother)
|
||||
|
||||
config = configparser.ConfigParser()
|
||||
config["llama"] = {}
|
||||
for key in vars(args):
|
||||
config["llama"][key] = f"{vars(args)[key]}"
|
||||
for k, v in vars(model.config).items():
|
||||
config["llama"][k] = f"{v}"
|
||||
config["llama"]["weight_data_type"] = args.storage_type
|
||||
config["llama"]["multi_query_mode"] = str(args.multi_query_mode)
|
||||
with open(saved_dir / "config.ini", 'w') as configfile:
|
||||
config.write(configfile)
|
||||
|
||||
storage_type = str_to_np_dtype(args.storage_type)
|
||||
|
||||
global_ft_weights = [
|
||||
'vocab_embedding.weight', 'ln_f.weight', 'lm_head.weight'
|
||||
]
|
||||
|
||||
int8_outputs = None
|
||||
if args.calibrate_kv_cache:
|
||||
int8_outputs = "kv_cache_only"
|
||||
if args.smoothquant is not None:
|
||||
int8_outputs = "all"
|
||||
|
||||
starmap_args = []
|
||||
for name, param in model.named_parameters():
|
||||
if "weight" not in name and "bias" not in name:
|
||||
continue
|
||||
ft_name = gpt_to_ft_name(name)
|
||||
|
||||
if name.replace(".weight", "") in llama_smoother.keys():
|
||||
smoother = llama_smoother[name.replace(".weight", "")]
|
||||
smoother = smoother.detach().cpu().numpy()
|
||||
starmap_args.append(
|
||||
(0, saved_dir, infer_tp,
|
||||
f"{ft_name}.smoother".replace(".weight", ""), smoother, None, {
|
||||
"int8_outputs": int8_outputs,
|
||||
"multi_query_mode": args.multi_query_mode,
|
||||
"local_dim": None,
|
||||
}))
|
||||
|
||||
param = transpose_weights(name, param)
|
||||
|
||||
param = param.detach().cpu().numpy().astype(storage_type)
|
||||
|
||||
if ft_name in global_ft_weights:
|
||||
param.tofile(saved_dir / f"{ft_name}.bin")
|
||||
elif ft_name.split('.')[-2] == 'query_key_value':
|
||||
# Is there other ways to get local_dim? local_dim = hidden_size in llama2
|
||||
local_dim = model.config.hidden_size if args.multi_query_mode else None
|
||||
if args.smoothquant is None:
|
||||
merge_qkv_scales(name, model, act_range, llama_qkv_para)
|
||||
qkv = (0, saved_dir, infer_tp, ft_name,
|
||||
llama_qkv_para.get(
|
||||
name.replace(".weight", "").replace(
|
||||
".q_proj",
|
||||
".qkv_proj")).cpu().numpy().astype(storage_type),
|
||||
act_range.get(
|
||||
name.replace(".weight",
|
||||
"").replace(".q_proj", ".qkv_proj")), {
|
||||
"int8_outputs": int8_outputs,
|
||||
"multi_query_mode":
|
||||
args.multi_query_mode,
|
||||
"local_dim": local_dim,
|
||||
})
|
||||
starmap_args.append(qkv)
|
||||
elif ft_name.split('.')[-2] == 'kv':
|
||||
continue
|
||||
else:
|
||||
starmap_args.append((0, saved_dir, infer_tp, ft_name, param,
|
||||
act_range.get(name.replace(".weight", "")), {
|
||||
"int8_outputs": int8_outputs,
|
||||
"multi_query_mode": args.multi_query_mode,
|
||||
"local_dim": None,
|
||||
}))
|
||||
|
||||
starmap_args = tqdm(starmap_args, desc="saving weights")
|
||||
if args.processes > 1:
|
||||
with multiprocessing.Pool(args.processes) as pool:
|
||||
pool.starmap(split_and_save_weight, starmap_args)
|
||||
else:
|
||||
# simpler for debug situations
|
||||
for starmap_arg in starmap_args:
|
||||
split_and_save_weight(*starmap_arg)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
torch.multiprocessing.set_start_method("spawn")
|
||||
|
||||
parser = argparse.ArgumentParser(
|
||||
formatter_class=argparse.RawTextHelpFormatter)
|
||||
parser.add_argument('--out-dir',
|
||||
'-o',
|
||||
type=str,
|
||||
help='file name of output directory',
|
||||
required=True)
|
||||
parser.add_argument('--in-file',
|
||||
'-i',
|
||||
type=str,
|
||||
help='file name of input checkpoint file',
|
||||
required=True)
|
||||
parser.add_argument('--tensor-parallelism',
|
||||
'-tp',
|
||||
type=int,
|
||||
help='Requested tensor parallelism for inference',
|
||||
default=1)
|
||||
parser.add_argument(
|
||||
"--processes",
|
||||
"-p",
|
||||
type=int,
|
||||
help="How many processes to spawn for conversion (default: 4)",
|
||||
default=4)
|
||||
parser.add_argument(
|
||||
"--calibrate-kv-cache",
|
||||
"-kv",
|
||||
action="store_true",
|
||||
help=
|
||||
"Generate scaling factors for KV cache. Used for storing KV cache in int8."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--smoothquant",
|
||||
"-sq",
|
||||
type=float,
|
||||
default=None,
|
||||
help="Set the α parameter (see https://arxiv.org/pdf/2211.10438.pdf)"
|
||||
" to Smoothquant the model, and output int8 weights."
|
||||
" A good first try is 0.5. Must be in [0, 1]")
|
||||
parser.add_argument("--storage-type",
|
||||
"-t",
|
||||
type=str,
|
||||
default="fp32",
|
||||
choices=["fp32", "fp16"])
|
||||
parser.add_argument("--multi-query-mode",
|
||||
action="store_true",
|
||||
help="Use multi-query-attention.")
|
||||
|
||||
args = parser.parse_args()
|
||||
print("\n=============== Argument ===============")
|
||||
for key in vars(args):
|
||||
print("{}: {}".format(key, vars(args)[key]))
|
||||
print("========================================")
|
||||
|
||||
assert (args.calibrate_kv_cache or args.smoothquant), \
|
||||
"Either INT8 kv cache or SmoothQuant must be enabled for this script. Otherwise you can directly build engines from HuggingFace checkpoints, no need to do this FT-format conversion. "
|
||||
|
||||
hf_gpt_converter(args)
|
||||
135
examples/llama/quantize.py
Normal file
135
examples/llama/quantize.py
Normal file
@@ -0,0 +1,135 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""
|
||||
Adapted from examples/quantization/hf_ptq.py
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import random
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from torch.utils.data import DataLoader
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
from tensorrt_llm._utils import str_dtype_to_torch
|
||||
from tensorrt_llm.logger import logger
|
||||
from tensorrt_llm.models.quantized.ammo import quantize_and_export
|
||||
|
||||
|
||||
def get_calib_dataloader(data="cnn_dailymail",
|
||||
tokenizer=None,
|
||||
batch_size=1,
|
||||
calib_size=512,
|
||||
block_size=512):
|
||||
print("Loading calibration dataset")
|
||||
if data == "pileval":
|
||||
dataset = load_dataset(
|
||||
"json",
|
||||
data_files="https://the-eye.eu/public/AI/pile/val.jsonl.zst",
|
||||
split="train")
|
||||
dataset = dataset["text"][:calib_size]
|
||||
elif data == "cnn_dailymail":
|
||||
dataset = load_dataset("cnn_dailymail", name="3.0.0", split="train")
|
||||
dataset = dataset["article"][:calib_size]
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
batch_encoded = tokenizer.batch_encode_plus(dataset,
|
||||
return_tensors="pt",
|
||||
padding=True,
|
||||
max_length=block_size)
|
||||
batch_encoded = batch_encoded["input_ids"]
|
||||
batch_encoded = batch_encoded.cuda()
|
||||
|
||||
calib_dataloader = DataLoader(batch_encoded,
|
||||
batch_size=batch_size,
|
||||
shuffle=False)
|
||||
|
||||
return calib_dataloader
|
||||
|
||||
|
||||
def get_tokenizer(ckpt_path, **kwargs):
|
||||
logger.info(f"Loading tokenizer from {ckpt_path}")
|
||||
tokenizer = AutoTokenizer.from_pretrained(ckpt_path,
|
||||
padding_side="left",
|
||||
**kwargs)
|
||||
if tokenizer.pad_token is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
return tokenizer
|
||||
|
||||
|
||||
def get_model(ckpt_path, dtype="float16"):
|
||||
logger.info(f"Loading model from {ckpt_path}")
|
||||
torch_dtype = str_dtype_to_torch(dtype)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
ckpt_path,
|
||||
device_map="auto",
|
||||
trust_remote_code=True,
|
||||
torch_dtype=torch_dtype,
|
||||
)
|
||||
model.eval()
|
||||
model = model.to(memory_format=torch.channels_last)
|
||||
return model
|
||||
|
||||
|
||||
def get_args():
|
||||
parser = argparse.ArgumentParser(description=__doc__)
|
||||
parser.add_argument("--model_dir",
|
||||
type=str,
|
||||
required=True,
|
||||
help="Directory of a HF model checkpoint")
|
||||
parser.add_argument("--dtype", help="Model data type.", default="float16")
|
||||
parser.add_argument(
|
||||
"--qformat",
|
||||
type=str,
|
||||
choices=['fp8', 'int4_awq'],
|
||||
default='fp8',
|
||||
help='Quantization format. Currently only fp8 is supported. '
|
||||
'For int8 smoothquant, use smoothquant.py instead. ')
|
||||
parser.add_argument("--calib_size",
|
||||
type=int,
|
||||
default=512,
|
||||
help="Number of samples for calibration.")
|
||||
parser.add_argument("--export_path", default="exported_model")
|
||||
parser.add_argument('--seed', type=int, default=None, help='Random seed')
|
||||
args = parser.parse_args()
|
||||
return args
|
||||
|
||||
|
||||
def main():
|
||||
if not torch.cuda.is_available():
|
||||
raise EnvironmentError("GPU is required for inference.")
|
||||
|
||||
args = get_args()
|
||||
|
||||
if args.seed is not None:
|
||||
random.seed(args.seed)
|
||||
np.random.seed(args.seed)
|
||||
|
||||
tokenizer = get_tokenizer(args.model_dir)
|
||||
model = get_model(args.model_dir, args.dtype)
|
||||
|
||||
calib_dataloader = get_calib_dataloader(tokenizer=tokenizer,
|
||||
calib_size=args.calib_size)
|
||||
model = quantize_and_export(model,
|
||||
qformat=args.qformat,
|
||||
calib_dataloader=calib_dataloader,
|
||||
export_path=args.export_path)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
3
examples/llama/requirements.txt
Normal file
3
examples/llama/requirements.txt
Normal file
@@ -0,0 +1,3 @@
|
||||
datasets==2.14.5
|
||||
rouge_score~=0.1.2
|
||||
sentencepiece~=0.1.99
|
||||
328
examples/llama/run.py
Normal file
328
examples/llama/run.py
Normal file
@@ -0,0 +1,328 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import csv
|
||||
import json
|
||||
from pathlib import Path
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from transformers import LlamaTokenizer
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
from xtrt_llm.runtime import ModelConfig, SamplingConfig
|
||||
|
||||
from build import get_engine_name # isort:skip
|
||||
|
||||
EOS_TOKEN = 2
|
||||
PAD_TOKEN = 2
|
||||
|
||||
import os
|
||||
|
||||
|
||||
def throttle_generator(generator, stream_interval):
|
||||
for i, out in enumerate(generator):
|
||||
if not i % stream_interval:
|
||||
yield out
|
||||
|
||||
if i % stream_interval:
|
||||
yield out
|
||||
|
||||
|
||||
def read_config(config_path: Path):
|
||||
with open(config_path, 'r') as f:
|
||||
config = json.load(f)
|
||||
use_gpt_attention_plugin = config['plugin_config']['gpt_attention_plugin']
|
||||
remove_input_padding = config['plugin_config']['remove_input_padding']
|
||||
dtype = config['builder_config']['precision']
|
||||
tp_size = config['builder_config']['tensor_parallel']
|
||||
pp_size = config['builder_config']['pipeline_parallel']
|
||||
world_size = tp_size * pp_size
|
||||
assert world_size == xtrt_llm.mpi_world_size(), \
|
||||
f'Engine world size ({world_size}) != Runtime world size ({xtrt_llm.mpi_world_size()})'
|
||||
num_heads = config['builder_config']['num_heads'] // tp_size
|
||||
hidden_size = config['builder_config']['hidden_size'] // tp_size
|
||||
vocab_size = config['builder_config']['vocab_size']
|
||||
num_layers = config['builder_config']['num_layers']
|
||||
num_kv_heads = config['builder_config'].get('num_kv_heads', num_heads)
|
||||
paged_kv_cache = config['plugin_config']['paged_kv_cache']
|
||||
tokens_per_block = config['plugin_config']['tokens_per_block']
|
||||
quant_mode = QuantMode(config['builder_config']['quant_mode'])
|
||||
gather_all_token_logits = config['builder_config'][
|
||||
'gather_all_token_logits']
|
||||
if config['builder_config'].get('multi_query_mode', False):
|
||||
xtrt_llm.logger.warning(
|
||||
"`multi_query_mode` config is deprecated. Please rebuild the engine."
|
||||
)
|
||||
num_kv_heads = 1
|
||||
num_kv_heads = (num_kv_heads + tp_size - 1) // tp_size
|
||||
use_custom_all_reduce = config['plugin_config'].get('use_custom_all_reduce',
|
||||
False)
|
||||
|
||||
model_config = ModelConfig(num_heads=num_heads,
|
||||
num_kv_heads=num_kv_heads,
|
||||
hidden_size=hidden_size,
|
||||
vocab_size=vocab_size,
|
||||
num_layers=num_layers,
|
||||
gpt_attention_plugin=use_gpt_attention_plugin,
|
||||
paged_kv_cache=paged_kv_cache,
|
||||
tokens_per_block=tokens_per_block,
|
||||
remove_input_padding=remove_input_padding,
|
||||
dtype=dtype,
|
||||
quant_mode=quant_mode,
|
||||
use_custom_all_reduce=use_custom_all_reduce,
|
||||
gather_all_token_logits=gather_all_token_logits)
|
||||
|
||||
return model_config, tp_size, pp_size, dtype
|
||||
|
||||
|
||||
def parse_input(input_text: str, input_file: str, tokenizer, end_id: int,
|
||||
remove_input_padding: bool):
|
||||
input_tokens = []
|
||||
if input_file is None:
|
||||
input_tokens.append(
|
||||
tokenizer.encode(input_text, add_special_tokens=False))
|
||||
else:
|
||||
if input_file.endswith('.csv'):
|
||||
with open(input_file, 'r') as csv_file:
|
||||
csv_reader = csv.reader(csv_file, delimiter=',')
|
||||
for line in csv_reader:
|
||||
input_tokens.append(np.array(line, dtype='int32'))
|
||||
elif input_file.endswith('.npy'):
|
||||
inputs = np.load(input_file)
|
||||
for row in inputs:
|
||||
row = row[row != end_id]
|
||||
input_tokens.append(row)
|
||||
elif input_file.endswith('.txt'):
|
||||
with open(input_file, 'r', encoding='utf-8') as file:
|
||||
for line in file.readlines():
|
||||
line = line.strip("\n")
|
||||
input_tokens.append(
|
||||
tokenizer.encode(line, add_special_tokens=False))
|
||||
else:
|
||||
print('Input file format not supported.')
|
||||
raise SystemExit
|
||||
|
||||
input_ids = None
|
||||
input_lengths = torch.tensor([len(x) for x in input_tokens],
|
||||
dtype=torch.int32).cuda()
|
||||
if remove_input_padding:
|
||||
input_ids = np.concatenate(input_tokens)
|
||||
input_ids = torch.tensor(input_ids, dtype=torch.int32,
|
||||
device='cuda').unsqueeze(0)
|
||||
else:
|
||||
input_ids = torch.nested.to_padded_tensor(
|
||||
torch.nested.nested_tensor(input_tokens, dtype=torch.int32),
|
||||
end_id).cuda()
|
||||
print(input_ids)
|
||||
|
||||
return input_ids, input_lengths
|
||||
|
||||
|
||||
def print_output(output_ids, input_lengths, max_output_len, tokenizer,
|
||||
output_csv, output_npy, remove_input_padding):
|
||||
num_beams = output_ids.size(1)
|
||||
if output_csv is None and output_npy is None:
|
||||
for b in range(input_lengths.size(0)):
|
||||
inputs = output_ids[b][0][:input_lengths[b]].tolist()
|
||||
input_text = tokenizer.decode(inputs)
|
||||
print(f'Input: \"{input_text}\"')
|
||||
for beam in range(num_beams):
|
||||
output_begin = max(input_lengths)
|
||||
output_end = output_begin + max_output_len
|
||||
outputs = output_ids[b][beam][output_begin:output_end].tolist()
|
||||
output_text = tokenizer.decode(outputs)
|
||||
print(f'Output: \"{output_text}\"')
|
||||
|
||||
output_ids = output_ids.reshape((-1, output_ids.size(2)))
|
||||
|
||||
if output_csv is not None:
|
||||
output_file = Path(output_csv)
|
||||
output_file.parent.mkdir(exist_ok=True, parents=True)
|
||||
outputs = output_ids.tolist()
|
||||
with open(output_file, 'w') as csv_file:
|
||||
writer = csv.writer(csv_file, delimiter=',')
|
||||
writer.writerows(outputs)
|
||||
|
||||
if output_npy is not None:
|
||||
output_file = Path(output_npy)
|
||||
output_file.parent.mkdir(exist_ok=True, parents=True)
|
||||
outputs = np.array(output_ids.cpu().contiguous(), dtype='int32')
|
||||
np.save(output_file, outputs)
|
||||
|
||||
|
||||
def parse_arguments():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--max_output_len', type=int, required=True)
|
||||
parser.add_argument('--log_level', type=str, default='error')
|
||||
parser.add_argument('--engine_dir', type=str, default='llama_outputs')
|
||||
parser.add_argument('--tokenizer_dir',
|
||||
type=str,
|
||||
default=".",
|
||||
help="Directory containing the tokenizer.model.")
|
||||
parser.add_argument('--input_text',
|
||||
type=str,
|
||||
default='Born in north-east France, Soyer trained as a')
|
||||
parser.add_argument(
|
||||
'--input_tokens',
|
||||
dest='input_file',
|
||||
type=str,
|
||||
help=
|
||||
'CSV or Numpy file containing tokenized input. Alternative to text input.',
|
||||
default=None)
|
||||
parser.add_argument('--output_csv',
|
||||
type=str,
|
||||
help='CSV file where the tokenized output is stored.',
|
||||
default=None)
|
||||
parser.add_argument('--output_npy',
|
||||
type=str,
|
||||
help='Numpy file where the tokenized output is stored.',
|
||||
default=None)
|
||||
parser.add_argument('--num_beams',
|
||||
type=int,
|
||||
help="Use beam search if num_beams >1",
|
||||
default=1)
|
||||
parser.add_argument('--streaming', default=False, action='store_true')
|
||||
parser.add_argument('--streaming_interval',
|
||||
type=int,
|
||||
help="How often to return tokens when streaming.",
|
||||
default=5)
|
||||
parser.add_argument(
|
||||
'--performance_test_scale',
|
||||
type=str,
|
||||
help=
|
||||
"Scale for performance test. e.g., 8x1024x64 (batch_size, input_text_length, max_output_length)",
|
||||
default="")
|
||||
parser.add_argument('--not_warmup', default=False, action='store_true')
|
||||
return parser.parse_args()
|
||||
|
||||
|
||||
def generate(
|
||||
max_output_len: int,
|
||||
log_level: str = 'error',
|
||||
engine_dir: str = 'llama_outputs',
|
||||
input_text: str = 'Born in north-east France, Soyer trained as a',
|
||||
input_file: str = None,
|
||||
output_csv: str = None,
|
||||
output_npy: str = None,
|
||||
tokenizer_dir: str = None,
|
||||
num_beams: int = 1,
|
||||
streaming: bool = False,
|
||||
streaming_interval: int = 5,
|
||||
performance_test_scale: str = "",
|
||||
not_warmup: bool = False,
|
||||
):
|
||||
xtrt_llm.logger.set_level(log_level)
|
||||
|
||||
engine_dir = Path(engine_dir)
|
||||
config_path = engine_dir / 'config.json'
|
||||
model_config, tp_size, pp_size, dtype = read_config(config_path)
|
||||
world_size = tp_size * pp_size
|
||||
|
||||
runtime_rank = xtrt_llm.mpi_rank()
|
||||
if world_size > 1:
|
||||
os.environ["XCCL_GROUP_ID"] = str(runtime_rank // world_size)
|
||||
os.environ["XCCL_NRANKS"] = str(world_size)
|
||||
os.environ["XCCL_CUR_RANK"] = str(runtime_rank % world_size)
|
||||
os.environ["XCCL_DEVICE_ID"] = str(runtime_rank)
|
||||
os.environ["MP_RUN"] = str(1)
|
||||
# if runtime_rank == 0:
|
||||
# os.environ["XTCL_PRINT_L3_PLAN"] = "3"
|
||||
runtime_mapping = xtrt_llm.Mapping(world_size,
|
||||
runtime_rank,
|
||||
tp_size=tp_size,
|
||||
pp_size=pp_size)
|
||||
torch.cuda.set_device(runtime_rank % runtime_mapping.gpus_per_node)
|
||||
|
||||
tokenizer = LlamaTokenizer.from_pretrained(tokenizer_dir, legacy=False)
|
||||
|
||||
sampling_config = SamplingConfig(end_id=EOS_TOKEN,
|
||||
pad_id=PAD_TOKEN,
|
||||
num_beams=num_beams)
|
||||
|
||||
engine_name = get_engine_name('llama', dtype, tp_size, pp_size,
|
||||
runtime_rank)
|
||||
serialize_path = str(engine_dir) + "/" + engine_name
|
||||
# with open(serialize_path, 'rb') as f:
|
||||
# engine_buffer = f.read()
|
||||
decoder = xtrt_llm.runtime.GenerationSession(model_config,
|
||||
serialize_path,
|
||||
runtime_mapping,
|
||||
debug_mode=False,
|
||||
debug_tensors_to_save=None)
|
||||
if runtime_rank == 0:
|
||||
print(f"Running the {dtype} engine ...")
|
||||
|
||||
input_ids, input_lengths = parse_input(input_text, input_file, tokenizer,
|
||||
EOS_TOKEN,
|
||||
model_config.remove_input_padding)
|
||||
|
||||
if performance_test_scale != "":
|
||||
performance_test_scale_list = performance_test_scale.split("E")
|
||||
for scale in performance_test_scale_list:
|
||||
xtrt_llm.logger.info(f"Running performance test with scale {scale}")
|
||||
bs, seqlen, _max_output_len = [int(x) for x in scale.split("x")]
|
||||
_input_ids = torch.from_numpy(
|
||||
np.zeros((bs, seqlen)).astype("int32")).cuda()
|
||||
_input_lengths = torch.from_numpy(
|
||||
np.full((bs, ), seqlen).astype("int32")).cuda()
|
||||
_max_input_length = torch.max(_input_lengths).item()
|
||||
if model_config.remove_input_padding:
|
||||
_input_ids = _input_ids.view((1, -1)).contiguous()
|
||||
import time
|
||||
_t_begin = time.time()
|
||||
decoder.setup(_input_lengths.size(0), _max_input_length,
|
||||
_max_output_len, num_beams)
|
||||
_output_gen_ids = decoder.decode(_input_ids,
|
||||
_input_lengths,
|
||||
sampling_config,
|
||||
streaming=streaming)
|
||||
_t_end = time.time()
|
||||
xtrt_llm.logger.info(
|
||||
f"Total latency: {(_t_end - _t_begin) * 1000:.3f} ms")
|
||||
xtrt_llm.logger.info(
|
||||
f"Throughput: {bs * _max_output_len / (_t_end - _t_begin):.3f} tokens/sec"
|
||||
)
|
||||
exit(0)
|
||||
|
||||
max_input_length = torch.max(input_lengths).item()
|
||||
|
||||
decoder.setup(input_lengths.size(0), max_input_length, max_output_len,
|
||||
num_beams)
|
||||
output_gen_ids = decoder.decode(input_ids,
|
||||
input_lengths,
|
||||
sampling_config,
|
||||
streaming=streaming,
|
||||
stop_words_list=[EOS_TOKEN])
|
||||
torch.cuda.synchronize()
|
||||
if streaming:
|
||||
for output_ids in throttle_generator(output_gen_ids,
|
||||
streaming_interval):
|
||||
if runtime_rank == 0:
|
||||
print_output(output_ids, input_lengths, max_output_len,
|
||||
tokenizer, output_csv, output_npy,
|
||||
model_config.remove_input_padding)
|
||||
else:
|
||||
output_ids = output_gen_ids
|
||||
if runtime_rank == 0:
|
||||
print_output(output_ids, input_lengths, max_output_len, tokenizer,
|
||||
output_csv, output_npy,
|
||||
model_config.remove_input_padding)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = parse_arguments()
|
||||
generate(**vars(args))
|
||||
20
examples/llama/run.sh
Normal file
20
examples/llama/run.sh
Normal file
@@ -0,0 +1,20 @@
|
||||
SCALE=""
|
||||
for _b in {1..8}; do
|
||||
for _len in {64..1024..32}; do
|
||||
SCALE+="${_b}x${_len}x${_len}E"
|
||||
done
|
||||
done
|
||||
for i in {8..1}; do
|
||||
SCALE+="${i}x2000x64E"
|
||||
done
|
||||
SCALE+="1x2000x64"
|
||||
|
||||
PYTORCH_NO_XPU_MEMORY_CACHING=1 XMLIR_D_XPU_L3_SIZE=0 \
|
||||
python3 run.py \
|
||||
--engine_dir=/root/.cache/llama_outputs/ \
|
||||
--max_output_len 256 \
|
||||
--performance_test_scale 1x2000x64E2x2000x64E4x2000x64E8x2000x64E11x2000x64E1x2000x64E2x2000x64E4x2000x64E8x2000x64E11x2000x64 \
|
||||
--tokenizer_dir=/root/.cache/huggingface/hub/models--huggyllama--llama-7b/snapshots/8416d3fefb0cb3ff5775a7b13c1692d10ff1aa16/ \
|
||||
--log_level=info
|
||||
|
||||
#_remove_padding
|
||||
205
examples/llama/smoothquant.py
Normal file
205
examples/llama/smoothquant.py
Normal file
@@ -0,0 +1,205 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
'''
|
||||
Utilities for SmoothQuant models
|
||||
'''
|
||||
|
||||
import copy
|
||||
import functools
|
||||
from collections import defaultdict
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from tqdm import tqdm
|
||||
from transformers.pytorch_utils import Conv1D
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def apply_smoothing(scales,
|
||||
gemm_weights,
|
||||
layernorm_weights=None,
|
||||
layernorm_bias=None,
|
||||
dtype=torch.float32,
|
||||
layernorm_1p=False):
|
||||
if not isinstance(gemm_weights, list):
|
||||
gemm_weights = [gemm_weights]
|
||||
|
||||
if layernorm_weights is not None:
|
||||
assert layernorm_weights.numel() == scales.numel()
|
||||
layernorm_weights.div_(scales).to(dtype)
|
||||
if layernorm_bias is not None:
|
||||
assert layernorm_bias.numel() == scales.numel()
|
||||
layernorm_bias.div_(scales).to(dtype)
|
||||
if layernorm_1p:
|
||||
layernorm_weights += (1 / scales) - 1
|
||||
|
||||
for gemm in gemm_weights:
|
||||
gemm.mul_(scales.view(1, -1)).to(dtype)
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def smooth_gemm(gemm_weights,
|
||||
act_scales,
|
||||
layernorm_weights=None,
|
||||
layernorm_bias=None,
|
||||
alpha=0.5,
|
||||
weight_scales=None):
|
||||
if not isinstance(gemm_weights, list):
|
||||
gemm_weights = [gemm_weights]
|
||||
orig_dtype = gemm_weights[0].dtype
|
||||
|
||||
for gemm in gemm_weights:
|
||||
# gemm_weights are expected to be transposed
|
||||
assert gemm.shape[1] == act_scales.numel()
|
||||
|
||||
if weight_scales is None:
|
||||
weight_scales = torch.cat(
|
||||
[gemm.abs().max(dim=0, keepdim=True)[0] for gemm in gemm_weights],
|
||||
dim=0)
|
||||
weight_scales = weight_scales.max(dim=0)[0]
|
||||
weight_scales.to(float).clamp(min=1e-5)
|
||||
scales = (act_scales.to(gemm_weights[0].device).to(float).pow(alpha) /
|
||||
weight_scales.pow(1 - alpha)).clamp(min=1e-5)
|
||||
|
||||
apply_smoothing(scales, gemm_weights, layernorm_weights, layernorm_bias,
|
||||
orig_dtype)
|
||||
|
||||
return scales
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def smooth_gemm_fc1_gate(fc1_weights,
|
||||
gate_weights,
|
||||
act_scales,
|
||||
layernorm_weights=None,
|
||||
layernorm_bias=None,
|
||||
alpha=0.5,
|
||||
weight_scales=None):
|
||||
gemm_weights = []
|
||||
if not isinstance(fc1_weights, list):
|
||||
fc1_weights = [fc1_weights]
|
||||
if not isinstance(gate_weights, list):
|
||||
gate_weights = [gate_weights]
|
||||
|
||||
for i in range(len(fc1_weights)):
|
||||
gemm_weight = torch.cat([fc1_weights[i], gate_weights[i]], dim=0)
|
||||
gemm_weights.append(gemm_weight)
|
||||
|
||||
orig_dtype = gemm_weights[0].dtype
|
||||
|
||||
for gemm in gemm_weights:
|
||||
# gemm_weights are expected to be transposed
|
||||
assert gemm.shape[1] == act_scales.numel()
|
||||
|
||||
if weight_scales is None:
|
||||
weight_scales = torch.cat(
|
||||
[gemm.abs().max(dim=0, keepdim=True)[0] for gemm in gemm_weights],
|
||||
dim=0)
|
||||
weight_scales = weight_scales.max(dim=0)[0]
|
||||
weight_scales.to(float).clamp(min=1e-5)
|
||||
scales = (act_scales.to(gemm_weights[0].device).to(float).pow(alpha) /
|
||||
weight_scales.pow(1 - alpha)).clamp(min=1e-5)
|
||||
|
||||
apply_smoothing(scales, fc1_weights + gate_weights, layernorm_weights,
|
||||
layernorm_bias, orig_dtype)
|
||||
|
||||
return scales
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def smooth_ln_fcs(ln, fcs, act_scales, alpha=0.5):
|
||||
if not isinstance(fcs, list):
|
||||
fcs = [fcs]
|
||||
for fc in fcs:
|
||||
assert isinstance(fc, nn.Linear)
|
||||
assert ln.weight.numel() == fc.in_features == act_scales.numel()
|
||||
|
||||
device, dtype = fcs[0].weight.device, fcs[0].weight.dtype
|
||||
act_scales = act_scales.to(device=device, dtype=dtype)
|
||||
weight_scales = torch.cat(
|
||||
[fc.weight.abs().max(dim=0, keepdim=True)[0] for fc in fcs], dim=0)
|
||||
weight_scales = weight_scales.max(dim=0)[0].clamp(min=1e-5)
|
||||
|
||||
scales = (act_scales.pow(alpha) /
|
||||
weight_scales.pow(1 - alpha)).clamp(min=1e-5).to(device).to(dtype)
|
||||
|
||||
if ln is not None:
|
||||
ln.weight.div_(scales)
|
||||
ln.bias.div_(scales)
|
||||
|
||||
for fc in fcs:
|
||||
fc.weight.mul_(scales.view(1, -1))
|
||||
return scales
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def capture_activation_range(model, tokenizer, num_samples=512, seq_len=512):
|
||||
model.eval()
|
||||
next(model.parameters()).device
|
||||
act_scales = defaultdict(lambda: {"x": None, "y": None, "w": None})
|
||||
|
||||
test_token_num = 923
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
def stat_tensor(name, tensor, act_scales, key):
|
||||
hidden_dim = tensor.shape[-1]
|
||||
tensor = tensor.view(-1, hidden_dim).abs().detach()
|
||||
comming_max = torch.max(tensor, dim=0)[0].float()
|
||||
|
||||
if act_scales[name][key] is None:
|
||||
act_scales[name][key] = comming_max
|
||||
else:
|
||||
act_scales[name][key] = torch.max(act_scales[name][key],
|
||||
comming_max)
|
||||
|
||||
def stat_input_hook(m, x, y, name):
|
||||
if isinstance(x, tuple):
|
||||
x = x[0]
|
||||
stat_tensor(name, x, act_scales, "x")
|
||||
stat_tensor(name, y, act_scales, "y")
|
||||
|
||||
if act_scales[name]["w"] is None:
|
||||
act_scales[name]["w"] = m.weight.abs().clip(1e-8,
|
||||
None).max(dim=1)[0]
|
||||
|
||||
hooks = []
|
||||
for name, m in model.named_modules():
|
||||
if isinstance(m, nn.Linear) or isinstance(m, Conv1D):
|
||||
hooks.append(
|
||||
m.register_forward_hook(
|
||||
functools.partial(stat_input_hook, name=name)))
|
||||
|
||||
from datasets import load_dataset
|
||||
dataset_cnn = load_dataset("ccdv/cnn_dailymail", '3.0.0')
|
||||
|
||||
for i in tqdm(range(num_samples), desc="calibrating model"):
|
||||
datapoint = dataset_cnn['train'][i:i + 1]
|
||||
line = copy.copy(datapoint['article'])
|
||||
line[0] = line[0] + ' TL;DR: '
|
||||
line[0] = line[0].strip()
|
||||
line[0] = line[0].replace(" n't", "n't")
|
||||
line_encoded = tokenizer(line,
|
||||
return_tensors="pt",
|
||||
padding=True,
|
||||
truncation=True)["input_ids"].type(torch.int64)
|
||||
line_encoded = line_encoded[:, -test_token_num:]
|
||||
if torch.cuda.is_available():
|
||||
line_encoded = line_encoded.cuda()
|
||||
model(line_encoded)
|
||||
|
||||
for h in hooks:
|
||||
h.remove()
|
||||
|
||||
return act_scales
|
||||
411
examples/llama/summarize.py
Normal file
411
examples/llama/summarize.py
Normal file
@@ -0,0 +1,411 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import copy
|
||||
import json
|
||||
import os
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from datasets import load_dataset, load_metric
|
||||
from transformers import AutoModelForCausalLM, LlamaTokenizer
|
||||
|
||||
import xtrt_llm
|
||||
import xtrt_llm.profiler as profiler
|
||||
from xtrt_llm.logger import logger
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
from build import get_engine_name # isort:skip
|
||||
|
||||
|
||||
def TRTLLaMA(args, config):
|
||||
dtype = config['builder_config']['precision']
|
||||
tp_size = config['builder_config']['tensor_parallel']
|
||||
pp_size = config['builder_config']['pipeline_parallel']
|
||||
world_size = tp_size * pp_size
|
||||
|
||||
assert world_size == xtrt_llm.mpi_world_size(), \
|
||||
f'Engine world size ({world_size}) != Runtime world size ({xtrt_llm.mpi_world_size()})'
|
||||
|
||||
num_heads = config['builder_config']['num_heads'] // tp_size
|
||||
hidden_size = config['builder_config']['hidden_size'] // tp_size
|
||||
vocab_size = config['builder_config']['vocab_size']
|
||||
num_layers = config['builder_config']['num_layers']
|
||||
use_gpt_attention_plugin = bool(
|
||||
config['plugin_config']['gpt_attention_plugin'])
|
||||
remove_input_padding = config['plugin_config']['remove_input_padding']
|
||||
num_kv_heads = config['builder_config'].get('num_kv_heads', num_heads)
|
||||
builder_config = config['builder_config']
|
||||
gather_all_token_logits = builder_config.get('gather_all_token_logits',
|
||||
False)
|
||||
paged_kv_cache = config['plugin_config']['paged_kv_cache']
|
||||
tokens_per_block = config['plugin_config']['tokens_per_block']
|
||||
use_custom_all_reduce = config['plugin_config'].get('use_custom_all_reduce',
|
||||
False)
|
||||
|
||||
quant_mode = QuantMode(config['builder_config']['quant_mode'])
|
||||
if config['builder_config'].get('multi_query_mode', False):
|
||||
xtrt_llm.logger.warning(
|
||||
"`multi_query_mode` config is deprecated. Please rebuild the engine."
|
||||
)
|
||||
num_kv_heads = 1
|
||||
num_kv_heads = (num_kv_heads + tp_size - 1) // tp_size
|
||||
|
||||
model_config = xtrt_llm.runtime.ModelConfig(
|
||||
vocab_size=vocab_size,
|
||||
num_layers=num_layers,
|
||||
num_heads=num_heads,
|
||||
num_kv_heads=num_kv_heads,
|
||||
hidden_size=hidden_size,
|
||||
paged_kv_cache=paged_kv_cache,
|
||||
tokens_per_block=tokens_per_block,
|
||||
gpt_attention_plugin=use_gpt_attention_plugin,
|
||||
remove_input_padding=remove_input_padding,
|
||||
use_custom_all_reduce=use_custom_all_reduce,
|
||||
dtype=dtype,
|
||||
quant_mode=quant_mode,
|
||||
gather_all_token_logits=gather_all_token_logits)
|
||||
|
||||
runtime_rank = xtrt_llm.mpi_rank()
|
||||
runtime_mapping = xtrt_llm.Mapping(world_size,
|
||||
runtime_rank,
|
||||
tp_size=tp_size,
|
||||
pp_size=pp_size)
|
||||
if world_size > 1:
|
||||
os.environ["XCCL_GROUP_ID"] = str(runtime_rank // world_size)
|
||||
os.environ["XCCL_NRANKS"] = str(world_size)
|
||||
os.environ["XCCL_CUR_RANK"] = str(runtime_rank % world_size)
|
||||
os.environ["XCCL_DEVICE_ID"] = str(runtime_rank)
|
||||
os.environ["MP_RUN"] = str(1)
|
||||
torch.cuda.set_device(runtime_rank % runtime_mapping.gpus_per_node)
|
||||
|
||||
engine_name = get_engine_name('llama', dtype, tp_size, pp_size,
|
||||
runtime_rank)
|
||||
serialize_path = str(os.path.join(args.engine_dir, engine_name))
|
||||
|
||||
xtrt_llm.logger.set_level(args.log_level)
|
||||
|
||||
profiler.start('load xtrt_llm engine')
|
||||
# with open(serialize_path, 'rb') as f:
|
||||
# engine_buffer = f.read()
|
||||
decoder = xtrt_llm.runtime.GenerationSession(model_config, serialize_path,
|
||||
runtime_mapping)
|
||||
profiler.stop('load xtrt_llm engine')
|
||||
xtrt_llm.logger.info(
|
||||
f'Load engine takes: {profiler.elapsed_time_in_sec("load xtrt_llm engine")} sec'
|
||||
)
|
||||
return decoder
|
||||
|
||||
|
||||
def main(args):
|
||||
runtime_rank = xtrt_llm.mpi_rank()
|
||||
logger.set_level(args.log_level)
|
||||
|
||||
test_hf = args.test_hf and runtime_rank == 0 # only run hf on rank 0
|
||||
test_trt_llm = args.test_trt_llm
|
||||
hf_model_location = args.hf_model_location
|
||||
profiler.start('load tokenizer')
|
||||
tokenizer = LlamaTokenizer.from_pretrained(hf_model_location,
|
||||
legacy=False,
|
||||
padding_side='left')
|
||||
profiler.stop('load tokenizer')
|
||||
xtrt_llm.logger.info(
|
||||
f'Load tokenizer takes: {profiler.elapsed_time_in_sec("load tokenizer")} sec'
|
||||
)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
dataset_cnn = load_dataset("ccdv/cnn_dailymail",
|
||||
'3.0.0',
|
||||
cache_dir=args.dataset_path)
|
||||
|
||||
max_batch_size = args.batch_size
|
||||
|
||||
# runtime parameters
|
||||
# repetition_penalty = 1
|
||||
top_k = args.top_k
|
||||
output_len = 100
|
||||
test_token_num = 923
|
||||
# top_p = 0.0
|
||||
# random_seed = 5
|
||||
temperature = 1
|
||||
num_beams = args.num_beams
|
||||
|
||||
pad_id = tokenizer.encode(tokenizer.pad_token, add_special_tokens=False)[0]
|
||||
end_id = tokenizer.encode(tokenizer.eos_token, add_special_tokens=False)[0]
|
||||
|
||||
if test_trt_llm:
|
||||
config_path = os.path.join(args.engine_dir, 'config.json')
|
||||
with open(config_path, 'r') as f:
|
||||
config = json.load(f)
|
||||
|
||||
xtrt_llm_llama = TRTLLaMA(args, config)
|
||||
|
||||
if test_hf:
|
||||
profiler.start('load HF model')
|
||||
model = AutoModelForCausalLM.from_pretrained(hf_model_location)
|
||||
profiler.stop('load HF model')
|
||||
xtrt_llm.logger.info(
|
||||
f'Load HF model takes: {profiler.elapsed_time_in_sec("load HF model")} sec'
|
||||
)
|
||||
if args.data_type == 'fp16':
|
||||
model.half()
|
||||
model.cuda()
|
||||
|
||||
def summarize_xtrt_llm(datapoint):
|
||||
batch_size = len(datapoint['article'])
|
||||
|
||||
line = copy.copy(datapoint['article'])
|
||||
line_encoded = []
|
||||
input_lengths = []
|
||||
for i in range(batch_size):
|
||||
line[i] = line[i] + ' TL;DR: '
|
||||
|
||||
line[i] = line[i].strip()
|
||||
line[i] = line[i].replace(" n't", "n't")
|
||||
|
||||
input_id = tokenizer.encode(line[i],
|
||||
return_tensors='pt').type(torch.int32)
|
||||
input_id = input_id[:, -test_token_num:]
|
||||
|
||||
line_encoded.append(input_id)
|
||||
input_lengths.append(input_id.shape[-1])
|
||||
|
||||
# do padding, should move outside the profiling to prevent the overhead
|
||||
max_length = max(input_lengths)
|
||||
if xtrt_llm_llama.remove_input_padding:
|
||||
line_encoded = [
|
||||
torch.tensor(t, dtype=torch.int32).cuda() for t in line_encoded
|
||||
]
|
||||
else:
|
||||
# do padding, should move outside the profiling to prevent the overhead
|
||||
for i in range(batch_size):
|
||||
pad_size = max_length - input_lengths[i]
|
||||
|
||||
pad = torch.ones([1, pad_size]).type(torch.int32) * pad_id
|
||||
line_encoded[i] = torch.cat(
|
||||
[torch.tensor(line_encoded[i], dtype=torch.int32), pad],
|
||||
axis=-1)
|
||||
|
||||
line_encoded = torch.cat(line_encoded, axis=0).cuda()
|
||||
input_lengths = torch.tensor(input_lengths,
|
||||
dtype=torch.int32).cuda()
|
||||
|
||||
sampling_config = xtrt_llm.runtime.SamplingConfig(end_id=end_id,
|
||||
pad_id=pad_id,
|
||||
top_k=top_k,
|
||||
num_beams=num_beams)
|
||||
|
||||
with torch.no_grad():
|
||||
xtrt_llm_llama.setup(batch_size,
|
||||
max_context_length=max_length,
|
||||
max_new_tokens=output_len,
|
||||
beam_width=num_beams)
|
||||
|
||||
if xtrt_llm_llama.remove_input_padding:
|
||||
output_ids = xtrt_llm_llama.decode_batch(
|
||||
line_encoded, sampling_config)
|
||||
else:
|
||||
output_ids = xtrt_llm_llama.decode(
|
||||
line_encoded,
|
||||
input_lengths,
|
||||
sampling_config,
|
||||
)
|
||||
|
||||
torch.cuda.synchronize()
|
||||
|
||||
# Extract a list of tensors of shape beam_width x output_ids.
|
||||
if xtrt_llm_llama.mapping.is_first_pp_rank():
|
||||
output_beams_list = [
|
||||
tokenizer.batch_decode(output_ids[batch_idx, :,
|
||||
input_lengths[batch_idx]:],
|
||||
skip_special_tokens=True)
|
||||
for batch_idx in range(batch_size)
|
||||
]
|
||||
return output_beams_list, output_ids[:, :, max_length:].tolist()
|
||||
return [], []
|
||||
|
||||
def summarize_hf(datapoint):
|
||||
batch_size = len(datapoint['article'])
|
||||
if batch_size > 1:
|
||||
logger.warning(
|
||||
f"HF does not support batch_size > 1 to verify correctness due to padding. Current batch size is {batch_size}"
|
||||
)
|
||||
|
||||
line = copy.copy(datapoint['article'])
|
||||
for i in range(batch_size):
|
||||
line[i] = line[i] + ' TL;DR: '
|
||||
|
||||
line[i] = line[i].strip()
|
||||
line[i] = line[i].replace(" n't", "n't")
|
||||
|
||||
line_encoded = tokenizer(line,
|
||||
return_tensors='pt',
|
||||
padding=True,
|
||||
truncation=True)["input_ids"].type(torch.int64)
|
||||
|
||||
line_encoded = line_encoded[:, -test_token_num:]
|
||||
line_encoded = line_encoded.cuda()
|
||||
|
||||
with torch.no_grad():
|
||||
output = model.generate(line_encoded,
|
||||
max_length=len(line_encoded[0]) +
|
||||
output_len,
|
||||
top_k=top_k,
|
||||
temperature=temperature,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
num_beams=num_beams,
|
||||
num_return_sequences=num_beams,
|
||||
early_stopping=True)
|
||||
|
||||
tokens_list = output[:, len(line_encoded[0]):].tolist()
|
||||
output = output.reshape([batch_size, num_beams, -1])
|
||||
output_lines_list = [
|
||||
tokenizer.batch_decode(output[:, i, len(line_encoded[0]):],
|
||||
skip_special_tokens=True)
|
||||
for i in range(num_beams)
|
||||
]
|
||||
|
||||
return output_lines_list, tokens_list
|
||||
|
||||
if test_trt_llm:
|
||||
datapoint = dataset_cnn['test'][0:1]
|
||||
summary, _ = summarize_xtrt_llm(datapoint)
|
||||
if runtime_rank == 0:
|
||||
logger.info(
|
||||
"---------------------------------------------------------")
|
||||
logger.info("XTRT-LLM Generated : ")
|
||||
logger.info(f" Article : {datapoint['article']}")
|
||||
logger.info(f"\n Highlights : {datapoint['highlights']}")
|
||||
logger.info(f"\n Summary : {summary}")
|
||||
logger.info(
|
||||
"---------------------------------------------------------")
|
||||
|
||||
if test_hf:
|
||||
datapoint = dataset_cnn['test'][0:1]
|
||||
summary, _ = summarize_hf(datapoint)
|
||||
logger.info("---------------------------------------------------------")
|
||||
logger.info("HF Generated : ")
|
||||
logger.info(f" Article : {datapoint['article']}")
|
||||
logger.info(f"\n Highlights : {datapoint['highlights']}")
|
||||
logger.info(f"\n Summary : {summary}")
|
||||
logger.info("---------------------------------------------------------")
|
||||
|
||||
metric_xtrt_llm = [load_metric("rouge") for _ in range(num_beams)]
|
||||
metric_hf = [load_metric("rouge") for _ in range(num_beams)]
|
||||
for i in range(num_beams):
|
||||
metric_xtrt_llm[i].seed = 0
|
||||
metric_hf[i].seed = 0
|
||||
|
||||
ite_count = 0
|
||||
data_point_idx = 0
|
||||
while (data_point_idx < len(dataset_cnn['test'])) and (ite_count <
|
||||
args.max_ite):
|
||||
if runtime_rank == 0:
|
||||
logger.debug(
|
||||
f"run data_point {data_point_idx} ~ {data_point_idx + max_batch_size}"
|
||||
)
|
||||
datapoint = dataset_cnn['test'][data_point_idx:(data_point_idx +
|
||||
max_batch_size)]
|
||||
|
||||
if test_trt_llm:
|
||||
profiler.start('xtrt_llm')
|
||||
summary_xtrt_llm, tokens_xtrt_llm = summarize_xtrt_llm(datapoint)
|
||||
profiler.stop('xtrt_llm')
|
||||
|
||||
if test_hf:
|
||||
profiler.start('hf')
|
||||
summary_hf, tokens_hf = summarize_hf(datapoint)
|
||||
profiler.stop('hf')
|
||||
|
||||
if runtime_rank == 0:
|
||||
if test_trt_llm:
|
||||
for batch_idx in range(len(summary_xtrt_llm)):
|
||||
for beam_idx in range(num_beams):
|
||||
metric_xtrt_llm[beam_idx].add_batch(
|
||||
predictions=[summary_xtrt_llm[batch_idx][beam_idx]],
|
||||
references=[datapoint['highlights'][batch_idx]])
|
||||
if test_hf:
|
||||
for beam_idx in range(num_beams):
|
||||
for batch_idx in range(len(summary_hf[beam_idx])):
|
||||
metric_hf[beam_idx].add_batch(
|
||||
predictions=[summary_hf[beam_idx][batch_idx]],
|
||||
references=[datapoint['highlights'][batch_idx]])
|
||||
|
||||
logger.debug('-' * 100)
|
||||
logger.debug(f"Article : {datapoint['article']}")
|
||||
if test_trt_llm:
|
||||
logger.debug(f'XTRT-LLM Summary: {summary_xtrt_llm}')
|
||||
if test_hf:
|
||||
logger.debug(f'HF Summary: {summary_hf}')
|
||||
logger.debug(f"highlights : {datapoint['highlights']}")
|
||||
|
||||
data_point_idx += max_batch_size
|
||||
ite_count += 1
|
||||
|
||||
if runtime_rank == 0:
|
||||
if test_trt_llm:
|
||||
np.random.seed(0) # rouge score use sampling to compute the score
|
||||
logger.info(
|
||||
f'XTRT-LLM (total latency: {profiler.elapsed_time_in_sec("xtrt_llm")} sec)'
|
||||
)
|
||||
for beam_idx in range(num_beams):
|
||||
logger.info(f"XTRT-LLM beam {beam_idx} result")
|
||||
computed_metrics_xtrt_llm = metric_xtrt_llm[beam_idx].compute()
|
||||
for key in computed_metrics_xtrt_llm.keys():
|
||||
logger.info(
|
||||
f' {key} : {computed_metrics_xtrt_llm[key].mid[2]*100}'
|
||||
)
|
||||
|
||||
if args.check_accuracy and beam_idx == 0:
|
||||
assert computed_metrics_xtrt_llm['rouge1'].mid[
|
||||
2] * 100 > args.xtrt_llm_rouge1_threshold
|
||||
if test_hf:
|
||||
np.random.seed(0) # rouge score use sampling to compute the score
|
||||
logger.info(
|
||||
f'Hugging Face (total latency: {profiler.elapsed_time_in_sec("hf")} sec)'
|
||||
)
|
||||
for beam_idx in range(num_beams):
|
||||
logger.info(f"HF beam {beam_idx} result")
|
||||
computed_metrics_hf = metric_hf[beam_idx].compute()
|
||||
for key in computed_metrics_hf.keys():
|
||||
logger.info(
|
||||
f' {key} : {computed_metrics_hf[key].mid[2]*100}')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--hf_model_location',
|
||||
type=str,
|
||||
default='/workspace/models/llama-models/llama-7b-hf')
|
||||
parser.add_argument('--test_hf', action='store_true')
|
||||
parser.add_argument('--test_trt_llm', action='store_true')
|
||||
parser.add_argument('--data_type',
|
||||
type=str,
|
||||
choices=['fp32', 'fp16'],
|
||||
default='fp16')
|
||||
parser.add_argument('--dataset_path', type=str, default='')
|
||||
parser.add_argument('--log_level', type=str, default='info')
|
||||
parser.add_argument('--engine_dir', type=str, default='llama_outputs')
|
||||
parser.add_argument('--batch_size', type=int, default=1)
|
||||
parser.add_argument('--max_ite', type=int, default=20)
|
||||
parser.add_argument('--check_accuracy', action='store_true')
|
||||
parser.add_argument('--xtrt_llm_rouge1_threshold', type=float, default=14.5)
|
||||
parser.add_argument('--num_beams', type=int, default=1)
|
||||
parser.add_argument('--top_k', type=int, default=1)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
main(args)
|
||||
1360
examples/llama/weight.py
Normal file
1360
examples/llama/weight.py
Normal file
File diff suppressed because it is too large
Load Diff
92
examples/quantization/README.md
Normal file
92
examples/quantization/README.md
Normal file
@@ -0,0 +1,92 @@
|
||||
# XTRT-LLM Quantization Toolkit Installation Guide
|
||||
|
||||
## Introduction
|
||||
|
||||
This document introduces:
|
||||
|
||||
- The steps to install the XTRT-LLM quantization toolkit.
|
||||
- The Python APIs to quantize the models.
|
||||
|
||||
The detailed LLM quantization recipe is distributed to the README.md of the corresponding model examples.
|
||||
|
||||
## Installation
|
||||
|
||||
1. If the dev environment is a docker container, please launch the docker with the following flags
|
||||
|
||||
```bash
|
||||
docker run --gpus all --ipc=host --ulimit memlock=-1 --shm-size=20g -it <the docker image with XTRT-LLM installed> bash
|
||||
```
|
||||
|
||||
2. Install the quantization toolkit `ammo` and the related dependencies on top of the XTRT-LLM installation or docker file.
|
||||
|
||||
```bash
|
||||
# Obtain the cuda version from the system. Assuming nvcc is available in path.
|
||||
cuda_version=$(nvcc --version | grep 'release' | awk '{print $6}' | awk -F'[V.]' '{print $2$3}')
|
||||
# Obtain the python version from the system.
|
||||
python_version=$(python3 --version 2>&1 | awk '{print $2}' | awk -F. '{print $1$2}')
|
||||
# Download and install the AMMO package from the DevZone.
|
||||
wget https://developer.nvidia.com/downloads/assets/cuda/files/nvidia-ammo/nvidia_ammo-0.3.0.tar.gz
|
||||
tar -xzf nvidia_ammo-0.3.0.tar.gz
|
||||
pip install nvidia_ammo-0.3.0/nvidia_ammo-0.3.0+cu$cuda_version-cp$python_version-cp$python_version-linux_x86_64.whl
|
||||
# Install the additional requirements
|
||||
cd <this example folder>
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
## APIs
|
||||
|
||||
[`ammo.py`](../../xtrt_llm/models/quantized/ammo.py) uses the quantization toolkit to calibrate the PyTorch models, and generate a model config, saved as a json (for the model structure) and npz files (for the model weights) that XTRT-LLM could parse. The model config includes everything needed by XTRT-LLM to build the TensorRT inference engine, as explained below.
|
||||
|
||||
> *This quantization step may take a long time to finish and requires large GPU memory. Please use a server grade GPU if a GPU out-of-memory error occurs*
|
||||
|
||||
> *If the model is trained with multi-GPU with tensor parallelism, the PTQ calibration process requires the same amount of GPUs as the training time too.*
|
||||
|
||||
|
||||
### PTQ (Post Training Quantization)
|
||||
|
||||
PTQ can be achieved with simple calibration on a small set of training or evaluation data (typically 128-512 samples) after converting a regular PyTorch model to a quantized model.
|
||||
|
||||
```python
|
||||
import ammo.torch.quantization as atq
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("...")
|
||||
|
||||
# Select the quantization config, for example, FP8
|
||||
config = atq.FP8_DEFAULT_CFG
|
||||
|
||||
|
||||
# Prepare the calibration set and define a forward loop
|
||||
def forward_loop():
|
||||
for data in calib_set:
|
||||
model(data)
|
||||
|
||||
|
||||
# PTQ with in-place replacement to quantized modules
|
||||
with torch.no_grad():
|
||||
atq.quantize(model, config, forward_loop)
|
||||
```
|
||||
|
||||
### Export Quantized Model
|
||||
|
||||
After the model is quantized, the model config can be stored. The model config files include all the information needed by XTRT-LLM to generate the deployable engine, including the quantized scaling factors.
|
||||
|
||||
The exported model config are stored as
|
||||
|
||||
- A single JSON file recording the model structure and metadata and
|
||||
- A group of npz files each recording the model on a single tensor parallel rank (model weights, scaling factors per GPU).
|
||||
|
||||
The export API is
|
||||
|
||||
```python
|
||||
from ammo.torch.export import export_model_config
|
||||
|
||||
with torch.inference_mode():
|
||||
export_model_config(
|
||||
model, # The quantized model.
|
||||
decoder_type, # The type of the model as str, e.g gptj, llama or gptnext.
|
||||
dtype, # The exported weights data type as torch.dtype.
|
||||
quantization, # The quantization algorithm applied, e.g. fp8 or int8_sq.
|
||||
export_dir, # The directory where the exported files will be stored.
|
||||
inference_gpus, # The number of GPUs used in the inference time for tensor parallelism.
|
||||
)
|
||||
```
|
||||
3
examples/quantization/requirements.txt
Normal file
3
examples/quantization/requirements.txt
Normal file
@@ -0,0 +1,3 @@
|
||||
datasets>=2.14.4
|
||||
nemo-toolkit[all]<=1.20.0,>=1.18.0
|
||||
rouge_score~=0.1.2
|
||||
0
examples/qwen/-d
Normal file
0
examples/qwen/-d
Normal file
202
examples/qwen/README.md
Normal file
202
examples/qwen/README.md
Normal file
@@ -0,0 +1,202 @@
|
||||
# Qwen
|
||||
|
||||
This document shows how to build and run a Qwen model in XTRT-LLM on both single XPU and single node multi-XPU.
|
||||
|
||||
Support Qwen1.5 model as well
|
||||
|
||||
## Overview
|
||||
|
||||
The XTRT-LLM Qwen example code is located in [`qwen`](./). There is one main file:
|
||||
|
||||
* [`build.py`](./build.py) to build the XTRT-LLM engine(s) needed to run the Qwen model.
|
||||
|
||||
In addition, there are two shared files in the parent folder [`examples`](../) for inference and evaluation:
|
||||
|
||||
* [`../run.py`](../run.py) to run the inference on an input text;
|
||||
* [`../summarize.py`](../summarize.py) to summarize the articles in the [cnn_dailymail](https://huggingface.co/datasets/cnn_dailymail) dataset.
|
||||
|
||||
## Support Matrix
|
||||
* FP16
|
||||
* INT8 Weight-Only
|
||||
* Tensor Parallel
|
||||
|
||||
## Usage
|
||||
|
||||
The XTRT-LLM Qwen example code locates at [qwen](./). It takes HF weights as input, and builds the corresponding XTRT engines. The number of XTRT engines depends on the number of XPUs used to run inference.
|
||||
|
||||
### Build XTRT engine(s)
|
||||
|
||||
Need to prepare the HF Qwen checkpoint first by following the guides here [Qwen-7B-Chat](https://huggingface.co/Qwen/Qwen-7B-Chat) or [Qwen-14B-Chat](https://huggingface.co/Qwen/Qwen-14B-Chat)
|
||||
|
||||
Create a `downloads` directory to store the weights downloaded from huaggingface.
|
||||
```bash
|
||||
mkdir -p ./downloads
|
||||
```
|
||||
|
||||
Store Qwen-7B-Chat or Qwen-14B-Chat separately.
|
||||
- for Qwen-7B-Chat
|
||||
```bash
|
||||
mv Qwen-7B-Chat ./downloads/qwen-7b/
|
||||
```
|
||||
- for Qwen-14B-Chat
|
||||
```bash
|
||||
mv Qwen-14B-Chat ./downloads/qwen-14b/
|
||||
```
|
||||
- for Qwen1.5-7B-Chat
|
||||
```bash
|
||||
mv Qwen1.5-7B-Chat ./downloads/Qwen1.5-7B-Chat/
|
||||
```
|
||||
|
||||
XTRT-LLM Qwen builds XTRT engine(s) from HF checkpoint.
|
||||
|
||||
Normally `build.py` only requires single XPU, but if you've already got all the XPUs needed while inferencing, you could enable parallelly building to make the engine building process faster by adding `--parallel_build` argument. Please note that currently `parallel_build` feature only supports single node.
|
||||
|
||||
** Notice: Qwen1.5 require arg "--version=1.5 **
|
||||
** Notice: `pip install transformers-stream-generator` in build phase**
|
||||
|
||||
Here're some examples:
|
||||
|
||||
```bash
|
||||
# Build a single-XPU float16 engine from HF weights.
|
||||
# use_gpt_attention_plugin is necessary in Qwen.
|
||||
# Try use_gemm_plugin to prevent accuracy issue.
|
||||
# It is recommend to use --use_gpt_attention_plugin for better performance
|
||||
|
||||
# Build the Qwen 7B model using a single XPU and FP16.
|
||||
python build.py --hf_model_dir ./downloads/qwen-7b \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/qwen-7b/trt_engines/fp16/1-XPU/
|
||||
|
||||
# Build the Qwen1.5 7B model using a single XPU and FP16.
|
||||
python build.py --hf_model_dir ./downloads/Qwen1.5-7B-Chat \
|
||||
--version 1.5 \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/Qwen1.5-7B-Chat/trt_engines/fp16/1-XPU/
|
||||
|
||||
# Build the Qwen 7B model using a single XPU and apply INT8 weight-only quantization.
|
||||
python build.py --hf_model_dir ./downloads/qwen-7b/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_weight_only \
|
||||
--weight_only_precision int8 \
|
||||
--output_dir ./downloads/qwen-7b/trt_engines/int8_weight_only/1-XPU/
|
||||
|
||||
# Build Qwen 7B using 2-way tensor parallelism.
|
||||
python build.py --hf_model_dir ./downloads/qwen-7b/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/qwen-7b/trt_engines/fp16/2-XPU/ \
|
||||
--world_size 2 \
|
||||
--tp_size 2
|
||||
|
||||
|
||||
# Build Qwen 14B using 2-way tensor parallelism.
|
||||
python build.py --hf_model_dir ./downloads/qwen-14b/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/qwen-14b/trt_engines/fp16/2-XPU/ \
|
||||
--world_size 2 \
|
||||
--tp_size 2
|
||||
```
|
||||
|
||||
#### SmoothQuant
|
||||
|
||||
The smoothquant supports both Qwen v1 and Qwen v2. Unlike the FP16 build where the HF weights are processed and loaded into the XTRT-LLM directly, the SmoothQuant needs to load INT8 weights which should be pre-processed before building an engine.
|
||||
|
||||
Example:
|
||||
```bash
|
||||
python3 hf_qwen_convert.py -i ./downloads/qwen-7b/ -o ./downloads/qwen-7b/sq0.5/ -sq 0.5 --tensor-parallelism 1 --storage-type float16
|
||||
```
|
||||
|
||||
Note `hf_qwen_convert.py` run with PyTorch, and
|
||||
1. `torch-cpu` has better accuracy than xpytorch generally.
|
||||
2. XPyTorch often use more than 32GB GM, thus more XPU are necessary to finish it.
|
||||
3. add `-p=1` if run with XPyTorch.
|
||||
|
||||
[`build.py`](./build.py) add new options for the support of INT8 inference of SmoothQuant models.
|
||||
|
||||
`--use_smooth_quant` is the starting point of INT8 inference. By default, it
|
||||
will run the model in the _per-tensor_ mode.
|
||||
|
||||
`--per-token` and `--per-channel` are not supported yet.
|
||||
|
||||
Examples of build invocations:
|
||||
|
||||
```bash
|
||||
# Build model for SmoothQuant in the _per_tensor_ mode.
|
||||
python3 build.py --ft_dir_path=./downloads/qwen-7b/sq0.5/1-XPU/ \
|
||||
--use_smooth_quant \
|
||||
--hf_model_dir ./downloads/qwen-7b/ \
|
||||
--output_dir ./downloads/qwen-7b/trt_engines/sq0.5/1-XPU/
|
||||
```
|
||||
|
||||
- run
|
||||
```bash
|
||||
python3 ../run.py --input_text "你好,请问你叫什么?" \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/qwen-7b/ \
|
||||
--engine_dir=./downloads/qwen-7b/trt_engines/sq0.5/1-XPU/
|
||||
```
|
||||
|
||||
- summarize
|
||||
```bash
|
||||
python ../summarize.py --test_trt_llm \
|
||||
--tokenizer_dir ./downloads/qwen-7b/ \
|
||||
--data_type fp16 \
|
||||
--engine_dir=./downloads/qwen-7b/trt_engines/sq0.5/1-XPU/ \
|
||||
--max_input_length 2048 \
|
||||
--output_len 2048
|
||||
```
|
||||
|
||||
|
||||
### Run
|
||||
|
||||
**Notice: `pip install tiktoken` in run phase**
|
||||
|
||||
To run a XTRT-LLM Qwen model using the engines generated by `build.py`
|
||||
|
||||
```bash
|
||||
# With fp16 inference
|
||||
python3 ../run.py --input_text "你好,请问你叫什么?答:" \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/qwen-7b/ \
|
||||
--engine_dir=./downloads/qwen-7b/trt_engines/fp16/1-XPU/
|
||||
|
||||
# Qwen1.5 With fp16 inference
|
||||
python3 ../run.py --input_text "你好,请问你叫什么?答:" \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/Qwen1.5-7B-Chat/ \
|
||||
--engine_dir=./downloads/Qwen1.5-7B-Chat/trt_engines/fp16/1-XPU/
|
||||
|
||||
# With int8 weight only inference
|
||||
python3 ../run.py --input_text "你好,请问你叫什么?答:" \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/qwen-7b/ \
|
||||
--engine_dir=./downloads/qwen-7b/trt_engines/int8_weight_only/1-XPU/
|
||||
|
||||
# Run Qwen 7B model in FP16 using two XPUs.
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python ../run.py --input_text "你好,请问你叫什么?答:" \
|
||||
--tokenizer_dir ./downloads/qwen-7b/ \
|
||||
--max_output_len=50 \
|
||||
--engine_dir ./downloads/qwen-7b/trt_engines/fp16/2-XPU/
|
||||
```
|
||||
**Demo output of run.py:**
|
||||
```bash
|
||||
python3 ../run.py --input_text "你好,请问你叫什么?答:" \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/qwen-7b/ \
|
||||
--engine_dir ./downloads/qwen-7b/trt_engines/fp16/1-XPU/
|
||||
```
|
||||
```
|
||||
Loading engine from ./downloads/qwen-7b/trt_engines/fp16/1-XPU/qwen_float16_tp1_rank0.engine
|
||||
Input: "<|im_start|>system
|
||||
You are a helpful assistant.<|im_end|>
|
||||
<|im_start|>user
|
||||
你好,请问你叫什么?<|im_end|>
|
||||
<|im_start|>assistant
|
||||
"
|
||||
Output: "我是来自阿里云的大规模语言模型,我叫通义千问。"
|
||||
```
|
||||
189
examples/qwen/README_CN.md
Normal file
189
examples/qwen/README_CN.md
Normal file
@@ -0,0 +1,189 @@
|
||||
# Qwen
|
||||
|
||||
本文档描述了如何使用昆仑芯XTRT-LLM中在单XPU和单节点多XPU上构建和运行Qwen模型。
|
||||
|
||||
## 概述
|
||||
|
||||
XTRT-LLM Qwen 示例代码的位置在文件夹`examples/qwen`下,此文件夹下有一个主要文件:
|
||||
|
||||
* [`build.py`](./build.py) 构建运行Qwen模型所需的XTRT-LLM引擎
|
||||
|
||||
除此之外,还有两个可以用来推理和评估的共享文件在父节点 [`examples`](../) 下:
|
||||
|
||||
* [`../run.py`](../run.py) 基于输入的文字进行推理
|
||||
* [`../summarize.py`](../summarize.py) 使用此模型对[cnn_dailymail](https://huggingface.co/datasets/cnn_dailymail) 数据集中的文章进行总结
|
||||
|
||||
## 支持的矩阵
|
||||
|
||||
* FP16
|
||||
* INT8 Weight-Only
|
||||
* Tensor Parallel
|
||||
|
||||
## 使用说明
|
||||
|
||||
XTRT-LLM Qwen 示例代码位于 [qwen](./)。它使用HF权重作为输入,并且构建对应的XTRT引擎。XTRT引擎的数量取决于为了运行推理而使用的XPU个数。
|
||||
|
||||
### 构建XTRT引擎
|
||||
|
||||
需要先按照下面的指南准备HF Qwen checkpoint: [Qwen-7B-Chat](https://huggingface.co/Qwen/Qwen-7B-Chat) 或 [Qwen-14B-Chat](https://huggingface.co/Qwen/Qwen-14B-Chat)
|
||||
|
||||
创建一个 `downloads` 目录,用来存储自Huggingface社区下载的权重。
|
||||
|
||||
```bash
|
||||
mkdir -p ./downloads
|
||||
```
|
||||
|
||||
将Qwen-7B-Chat和Qwen-14B-Chat分开存储。
|
||||
|
||||
- 存储 Qwen-7B-Chat
|
||||
|
||||
```bash
|
||||
mv Qwen-7B-Chat ./downloads/qwen-7b/
|
||||
```
|
||||
|
||||
- 存储 Qwen-14B-Chat
|
||||
|
||||
```bash
|
||||
mv Qwen-14B-Chat ./downloads/qwen-14b/
|
||||
```
|
||||
|
||||
XTRT-LLM从HFcheckpoint构建XTRT引擎。
|
||||
|
||||
通常`build.py`只需要一个XPU,但如果您在推理时已经获得了所需的所有XPU,则可以通过添加`--parallel_build`参数来启用并行构建,从而加快引擎构建过程。请注意,当前并行构建功能仅支持单个节点。
|
||||
|
||||
**请注意:在构建阶段执行安装命令`pip install transformers-stream-generator`**
|
||||
|
||||
以下是一些示例:
|
||||
|
||||
```bash
|
||||
# Build a single-XPU float16 engine from HF weights.
|
||||
# use_gpt_attention_plugin is necessary in Qwen.
|
||||
# Try use_gemm_plugin to prevent accuracy issue.
|
||||
# It is recommend to use --use_gpt_attention_plugin for better performance
|
||||
|
||||
# Build the Qwen 7B model using a single XPU and FP16.
|
||||
python build.py --hf_model_dir ./downloads/qwen-7b \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/qwen-7b/trt_engines/fp16/1-XPU/
|
||||
|
||||
|
||||
# Build the Qwen 7B model using a single XPU and apply INT8 weight-only quantization.
|
||||
python build.py --hf_model_dir ./downloads/qwen-7b/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--use_weight_only \
|
||||
--weight_only_precision int8 \
|
||||
--output_dir ./downloads/qwen-7b/trt_engines/int8_weight_only/1-XPU/
|
||||
|
||||
# Build Qwen 7B using 2-way tensor parallelism.
|
||||
python build.py --hf_model_dir ./downloads/qwen-7b/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/qwen-7b/trt_engines/fp16/2-XPU/ \
|
||||
--world_size 2 \
|
||||
--tp_size 2
|
||||
|
||||
|
||||
# Build Qwen 14B using 2-way tensor parallelism.
|
||||
python build.py --hf_model_dir ./downloads/qwen-14b/ \
|
||||
--dtype float16 \
|
||||
--use_gpt_attention_plugin float16 \
|
||||
--output_dir ./downloads/qwen-14b/trt_engines/fp16/2-XPU/ \
|
||||
--world_size 2 \
|
||||
--tp_size 2
|
||||
```
|
||||
|
||||
#### SmoothQuant
|
||||
|
||||
SmootQuant同时支持Qwen v1和Qwen v2。与FP16的HF权重可以直接被处理并加载到XTRT-LLM不同,SmoothQuant需要加载INT8权重,而INT8权重在构建引擎之前需要进行预处理。
|
||||
|
||||
示例:
|
||||
```bash
|
||||
python3 hf_qwen_convert.py -i ./downloads/qwen-7b/ -o ./downloads/qwen-7b/sq0.5/ -sq 0.5 --tensor-parallelism 1 --storage-type float16
|
||||
```
|
||||
|
||||
注意:`hf_qwen_convert.py`使用pytorch运行,并且
|
||||
1. 'torch-cpu' 通常比XPyTorch精度更高
|
||||
2. XPyTorch 通常使用超过32GB的GM,因此需要更多的XPU来完成它。
|
||||
3. 使用XPyTorch运行时,请添加`-p=1`。
|
||||
|
||||
`build.py`增加了新的选项来支持SmoothQuant模型的INT8推理。
|
||||
|
||||
`--use_smooth_quant` 是INT8推理的起点。默认情况下,它将以`--per-token`模式运行模型。
|
||||
`--per-token`和`--per-channel`目前还不支持。
|
||||
|
||||
构建调用示例:
|
||||
```bash
|
||||
# Build model for SmoothQuant in the _per_tensor_ mode.
|
||||
python3 build.py --ft_dir_path=./downloads/qwen-7b/sq0.5/1-XPU/ \
|
||||
--use_smooth_quant \
|
||||
--hf_model_dir ./downloads/qwen-7b/ \
|
||||
--output_dir ./downloads/qwen-7b/trt_engines/sq0.5/1-XPU/
|
||||
```
|
||||
|
||||
- 运行
|
||||
```bash
|
||||
python3 ../run.py --input_text "你好,请问你叫什么?" \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/qwen-7b/ \
|
||||
--engine_dir=./downloads/qwen-7b/trt_engines/sq0.5/1-XPU/
|
||||
```
|
||||
|
||||
- 总结
|
||||
```bash
|
||||
python ../summarize.py --test_trt_llm \
|
||||
--tokenizer_dir ./downloads/qwen-7b/ \
|
||||
--data_type fp16 \
|
||||
--engine_dir=./downloads/qwen-7b/trt_engines/sq0.5/1-XPU/ \
|
||||
--max_input_length 2048 \
|
||||
--output_len 2048
|
||||
```
|
||||
|
||||
|
||||
### 运行
|
||||
|
||||
**注意:在运行阶段执行安装命令`pip install tiktoken`**
|
||||
|
||||
要使用`build.py`生成的引擎运行XTRT-LLM Qwen模型,请执行以下操作:
|
||||
|
||||
```bash
|
||||
# With fp16 inference
|
||||
python3 ../run.py --input_text "你好,请问你叫什么?" \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/qwen-7b/ \
|
||||
--engine_dir=./downloads/qwen-7b/trt_engines/fp16/1-XPU/
|
||||
|
||||
|
||||
# With int8 weight only inference
|
||||
python3 ../run.py --input_text "你好,请问你叫什么?" \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/qwen-7b/ \
|
||||
--engine_dir=./downloads/qwen-7b/trt_engines/int8_weight_only/1-XPU/
|
||||
|
||||
# Run Qwen 7B model in FP16 using two XPUs.
|
||||
mpirun -n 2 --allow-run-as-root \
|
||||
python ../run.py --input_text "你好,请问你叫什么?" \
|
||||
--tokenizer_dir ./downloads/qwen-7b/ \
|
||||
--max_output_len=50 \
|
||||
--engine_dir ./downloads/qwen-7b/trt_engines/fp16/2-XPU/
|
||||
```
|
||||
|
||||
`run.py`的演示输出:
|
||||
|
||||
```bash
|
||||
python3 ../run.py --input_text "你好,请问你叫什么?" \
|
||||
--max_output_len=50 \
|
||||
--tokenizer_dir ./downloads/qwen-7b/ \
|
||||
--engine_dir ./downloads/qwen-7b/trt_engines/fp16/1-XPU/
|
||||
```
|
||||
```
|
||||
Loading engine from ./downloads/qwen-7b/trt_engines/fp16/1-XPU/qwen_float16_tp1_rank0.engine
|
||||
Input: "<|im_start|>system
|
||||
You are a helpful assistant.<|im_end|>
|
||||
<|im_start|>user
|
||||
你好,请问你叫什么?<|im_end|>
|
||||
<|im_start|>assistant
|
||||
"
|
||||
Output: "我是来自阿里云的大规模语言模型,我叫通义千问。"
|
||||
```
|
||||
BIN
examples/qwen/__pycache__/qwen_weight.cpython-38.pyc
Normal file
BIN
examples/qwen/__pycache__/qwen_weight.cpython-38.pyc
Normal file
Binary file not shown.
402
examples/qwen/benchmark.py
Normal file
402
examples/qwen/benchmark.py
Normal file
@@ -0,0 +1,402 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""Benchmark offline inference throughput."""
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import random
|
||||
import time
|
||||
from typing import List, Tuple
|
||||
|
||||
import torch
|
||||
from tqdm import tqdm, trange
|
||||
from transformers import (AutoModelForCausalLM, AutoTokenizer,
|
||||
PreTrainedTokenizerBase)
|
||||
from utils.utils import get_stop_words_ids, make_context
|
||||
|
||||
import tensorrt_llm
|
||||
from tensorrt_llm.runtime import ModelRunner, SamplingConfig
|
||||
|
||||
now_dir = os.path.dirname(os.path.abspath(__file__))
|
||||
|
||||
MAX_INPUT_LEN = 2048
|
||||
MAX_SEQ_LEN = 4096
|
||||
|
||||
TRT_MAX_BATCH_SIZE = 2
|
||||
TEMPERATURE = 1.0
|
||||
TOP_P = 0.5
|
||||
TOP_K = 1
|
||||
|
||||
|
||||
def sample_requests(
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
dataset_path: str,
|
||||
num_requests: int,
|
||||
chat_format: str = "chatml",
|
||||
) -> List[Tuple[str, int, int]]:
|
||||
# Load the dataset.
|
||||
with open(dataset_path) as f:
|
||||
dataset = json.load(f)
|
||||
# Filter out the conversations with less than 2 turns.
|
||||
dataset = [data for data in dataset if len(data["conversations"]) >= 2]
|
||||
# Only keep the first two turns of each conversation.
|
||||
dataset = [(data["conversations"][0]["value"],
|
||||
data["conversations"][1]["value"]) for data in dataset]
|
||||
|
||||
# Tokenize the prompts and completions.
|
||||
tokenized_dataset = []
|
||||
for i in trange(len(dataset), desc="Tokenizing for sample"):
|
||||
prompt = dataset[i][0]
|
||||
output_text = dataset[i][1]
|
||||
raw_text, prompt_tokens = make_context(tokenizer=tokenizer,
|
||||
query=prompt,
|
||||
max_input_length=MAX_INPUT_LEN,
|
||||
chat_format=chat_format)
|
||||
new_token_len = len(tokenizer(output_text).input_ids)
|
||||
tokenized_dataset.append((raw_text, prompt_tokens, new_token_len))
|
||||
|
||||
# Filter out too long sequences.
|
||||
filtered_dataset: List[Tuple[str, int, int]] = []
|
||||
for prompt, prompt_token_ids, new_token_len in tokenized_dataset:
|
||||
prompt_len = len(prompt_token_ids)
|
||||
if prompt_len < 4 or new_token_len < 4:
|
||||
# Prune too short sequences.
|
||||
continue
|
||||
if prompt_len > MAX_INPUT_LEN or (prompt_len +
|
||||
new_token_len) > MAX_SEQ_LEN:
|
||||
# Prune too long sequences.
|
||||
continue
|
||||
# limit by MAX_SEQ_LEN
|
||||
filtered_dataset.append((prompt, prompt_len, new_token_len))
|
||||
|
||||
# Sample the requests.
|
||||
sampled_requests = random.sample(filtered_dataset, num_requests)
|
||||
return sampled_requests
|
||||
|
||||
|
||||
def run_trt_llm(
|
||||
requests: List[Tuple[str, int, int]],
|
||||
engine_dir: str,
|
||||
tokenizer_dir: str,
|
||||
n: int,
|
||||
max_batch_size: int,
|
||||
) -> float:
|
||||
global_max_input_len = MAX_INPUT_LEN
|
||||
global_max_output_len = MAX_SEQ_LEN
|
||||
if max_batch_size > TRT_MAX_BATCH_SIZE:
|
||||
raise Exception(
|
||||
"max batch size {} must be lower than trt_max_batch_size {}".format(
|
||||
max_batch_size, TRT_MAX_BATCH_SIZE))
|
||||
|
||||
# Ad hoc update to ModelRunner
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
tokenizer_dir,
|
||||
legacy=False,
|
||||
trust_remote_code=True,
|
||||
)
|
||||
gen_config_path = os.path.join(tokenizer_dir, 'generation_config.json')
|
||||
with open(gen_config_path, 'r') as f:
|
||||
gen_config = json.load(f)
|
||||
top_k = gen_config['top_k']
|
||||
top_p = gen_config['top_p']
|
||||
chat_format = gen_config['chat_format']
|
||||
if chat_format == "raw":
|
||||
eos_token_id = gen_config['eos_token_id']
|
||||
pad_token_id = gen_config['pad_token_id']
|
||||
elif chat_format == "chatml":
|
||||
pad_token_id = eos_token_id = tokenizer.im_end_id
|
||||
else:
|
||||
raise Exception("unknown chat format ", chat_format)
|
||||
|
||||
sampling_config = SamplingConfig(
|
||||
end_id=eos_token_id,
|
||||
pad_id=pad_token_id,
|
||||
num_beams=1,
|
||||
top_k=top_k,
|
||||
top_p=top_p,
|
||||
)
|
||||
|
||||
runtime_rank = tensorrt_llm.mpi_rank()
|
||||
runner = ModelRunner.from_dir(engine_dir, rank=runtime_rank)
|
||||
decoder = runner.session
|
||||
|
||||
# Add the requests to the engine.
|
||||
sampling_config.num_beams = n
|
||||
sampling_config.temperature = 0.0 if n > 1 else TEMPERATURE
|
||||
sampling_config.top_p = TOP_P
|
||||
sampling_config.top_k = TOP_K
|
||||
start = time.time()
|
||||
pad_id = tokenizer.im_end_id
|
||||
|
||||
batch: List[str] = []
|
||||
max_new_tokens = 0
|
||||
total_num_tokens = []
|
||||
for i, (prompt, prompt_len, new_token_len) in tqdm(enumerate(requests),
|
||||
total=len(requests)):
|
||||
# Add the prompt to the batch.
|
||||
batch.append(prompt)
|
||||
max_new_tokens = max(max_new_tokens, new_token_len)
|
||||
if len(batch) < max_batch_size and i < len(requests) - 1:
|
||||
continue
|
||||
input_ids = []
|
||||
input_lengths = []
|
||||
for input_text in batch:
|
||||
input_id = tokenizer(
|
||||
input_text,
|
||||
return_tensors="pt",
|
||||
truncation=True,
|
||||
max_length=global_max_input_len,
|
||||
).input_ids.type(torch.int32)
|
||||
input_ids.append(input_id)
|
||||
input_lengths.append(input_id.shape[-1])
|
||||
# padding
|
||||
max_length = max(input_lengths)
|
||||
# do padding, should move outside the profiling to prevent the overhead
|
||||
for i in range(len(input_ids)):
|
||||
pad_size = max_length - input_lengths[i]
|
||||
|
||||
pad = torch.ones([1, pad_size]).type(torch.int32) * pad_id
|
||||
input_ids[i] = torch.cat([torch.IntTensor(input_ids[i]), pad],
|
||||
axis=-1)
|
||||
# do inference
|
||||
input_ids = torch.cat(input_ids, axis=0).cuda()
|
||||
input_lengths = torch.IntTensor(input_lengths).type(torch.int32).cuda()
|
||||
output_ids = decoder.generate(
|
||||
input_ids=input_ids,
|
||||
input_lengths=input_lengths,
|
||||
sampling_config=sampling_config,
|
||||
max_new_tokens=min(max_new_tokens,
|
||||
global_max_output_len - input_ids.shape[1]),
|
||||
)
|
||||
pure_output_ids = []
|
||||
for i in range(len(batch)):
|
||||
temp_ids = output_ids[i, input_lengths[i]:]
|
||||
pure_ids = []
|
||||
for i in range(len(temp_ids)):
|
||||
if temp_ids[i] in [tokenizer.im_start_id, tokenizer.im_end_id]:
|
||||
pure_ids = temp_ids[:i + 1]
|
||||
break
|
||||
if len(pure_ids) == 0:
|
||||
pure_ids = temp_ids
|
||||
pure_output_ids.append(pure_ids)
|
||||
# get the output text
|
||||
output_texts = [
|
||||
tokenizer.decode(out_ids, skip_special_tokens=True)
|
||||
for out_ids in pure_output_ids
|
||||
]
|
||||
# get the total num of tokens
|
||||
output_lengths = [len(out_ids) for out_ids in pure_output_ids]
|
||||
assert len(output_lengths) == len(batch)
|
||||
for input_len, new_token_len in zip(input_lengths, output_lengths):
|
||||
total_num_tokens.append(input_len + new_token_len)
|
||||
batch = []
|
||||
max_new_tokens = 0
|
||||
|
||||
end = time.time()
|
||||
during = end - start
|
||||
sum_total_num_tokens = sum(total_num_tokens)
|
||||
return during, sum_total_num_tokens
|
||||
|
||||
|
||||
def run_hf(
|
||||
requests: List[Tuple[str, int, int]],
|
||||
model: str,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
n: int,
|
||||
max_batch_size: int,
|
||||
chat_format: str = "chatml",
|
||||
) -> float:
|
||||
global_max_input_len = MAX_INPUT_LEN
|
||||
global_max_output_len = MAX_SEQ_LEN
|
||||
llm = AutoModelForCausalLM.from_pretrained(model,
|
||||
torch_dtype=torch.bfloat16,
|
||||
trust_remote_code=True)
|
||||
if llm.config.model_type == "llama":
|
||||
# To enable padding in the HF backend.
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
elif llm.config.model_type == "qwen":
|
||||
tokenizer.pad_token = tokenizer.decode(tokenizer.im_end_id)
|
||||
llm = llm.cuda()
|
||||
stop_words_ids = []
|
||||
stop_words_ids.extend(get_stop_words_ids(chat_format, tokenizer))
|
||||
stop_words_ids2 = [idx for ids in stop_words_ids for idx in ids]
|
||||
pbar = tqdm(total=len(requests))
|
||||
start = time.time()
|
||||
total_num_tokens = []
|
||||
batch: List[str] = []
|
||||
input_lengths: List[int] = []
|
||||
max_prompt_len = 0
|
||||
max_new_tokens = 0
|
||||
for i in range(len(requests)):
|
||||
prompt, prompt_len, new_token_len = requests[i]
|
||||
# Add the prompt to the batch.
|
||||
batch.append(prompt)
|
||||
input_lengths.append(prompt_len)
|
||||
max_prompt_len = max(max_prompt_len, prompt_len)
|
||||
max_new_tokens = max(max_new_tokens, new_token_len)
|
||||
if len(batch) < max_batch_size and i != len(requests) - 1:
|
||||
# Check if we can add more requests to the batch.
|
||||
_, next_prompt_len, next_output_len = requests[i + 1]
|
||||
temp_input_max = max(max_prompt_len, next_prompt_len)
|
||||
temp_new_token_max = max(max_new_tokens, next_output_len)
|
||||
if temp_input_max <= global_max_input_len and \
|
||||
(temp_input_max + temp_new_token_max) <= global_max_output_len:
|
||||
continue
|
||||
# Generate the sequences.
|
||||
input_ids = tokenizer(
|
||||
batch,
|
||||
return_tensors="pt",
|
||||
padding=True,
|
||||
truncation=True,
|
||||
max_length=global_max_input_len,
|
||||
).input_ids
|
||||
|
||||
# limit the max_new_tokens
|
||||
max_new_tokens = min(max_new_tokens,
|
||||
global_max_output_len - input_ids.shape[1])
|
||||
llm_outputs = llm.generate(
|
||||
input_ids=input_ids.cuda(),
|
||||
do_sample=True,
|
||||
stop_words_ids=stop_words_ids,
|
||||
num_return_sequences=n,
|
||||
top_k=TOP_K,
|
||||
top_p=TOP_P,
|
||||
temperature=TEMPERATURE,
|
||||
use_cache=True,
|
||||
max_new_tokens=max_new_tokens,
|
||||
)
|
||||
pure_output_ids = llm_outputs[:, input_ids.shape[-1]:]
|
||||
# get the output text
|
||||
output_texts = tokenizer.batch_decode(pure_output_ids,
|
||||
skip_special_tokens=True)
|
||||
output_lengths = []
|
||||
for out_ids in pure_output_ids:
|
||||
early_stop = False
|
||||
for i in range(len(out_ids)):
|
||||
if out_ids[i] in stop_words_ids2:
|
||||
output_lengths.append(i + 1)
|
||||
early_stop = True
|
||||
break
|
||||
if not early_stop:
|
||||
output_lengths.append(len(out_ids))
|
||||
assert len(output_lengths) == len(batch)
|
||||
for input_len, new_token_len in zip(input_lengths, output_lengths):
|
||||
total_num_tokens.append(input_len + new_token_len)
|
||||
pbar.update(len(batch))
|
||||
|
||||
# Clear the batch.
|
||||
batch = []
|
||||
input_lengths = []
|
||||
max_prompt_len = 0
|
||||
max_new_tokens = 0
|
||||
end = time.time()
|
||||
during = end - start
|
||||
sum_total_num_tokens = sum(total_num_tokens)
|
||||
return during, sum_total_num_tokens
|
||||
|
||||
|
||||
def main(args: argparse.Namespace):
|
||||
print(args)
|
||||
random.seed(args.seed)
|
||||
|
||||
# Sample the requests.
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
args.tokenizer_dir,
|
||||
padding_side='left',
|
||||
trust_remote_code=True,
|
||||
)
|
||||
requests = sample_requests(tokenizer=tokenizer,
|
||||
dataset_path=args.dataset,
|
||||
num_requests=args.num_prompts,
|
||||
chat_format=args.chat_format)
|
||||
|
||||
if args.backend == "trt_llm":
|
||||
elapsed_time, total_num_tokens = run_trt_llm(
|
||||
requests=requests,
|
||||
engine_dir=args.engine_dir,
|
||||
tokenizer_dir=args.tokenizer_dir,
|
||||
n=args.n,
|
||||
max_batch_size=args.trt_max_batch_size,
|
||||
)
|
||||
elif args.backend == "hf":
|
||||
elapsed_time, total_num_tokens = run_hf(
|
||||
requests=requests,
|
||||
model=args.hf_model_dir,
|
||||
tokenizer=tokenizer,
|
||||
n=args.n,
|
||||
max_batch_size=args.hf_max_batch_size,
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unknown backend: {args.backend}")
|
||||
print(f"Throughput: {len(requests) / elapsed_time:.2f} requests/s, "
|
||||
f"{total_num_tokens / elapsed_time:.2f} tokens/s")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Benchmark the throughput.")
|
||||
parser.add_argument(
|
||||
"--backend",
|
||||
type=str,
|
||||
choices=["trt_llm", "hf"],
|
||||
default="trt_llm",
|
||||
)
|
||||
parser.add_argument("--dataset",
|
||||
type=str,
|
||||
default=os.path.join(
|
||||
now_dir,
|
||||
"ShareGPT_V3_unfiltered_cleaned_split.json"),
|
||||
help="Path to the dataset.")
|
||||
parser.add_argument("--hf_model_dir", type=str, default=None)
|
||||
parser.add_argument("--tokenizer_dir",
|
||||
type=str,
|
||||
default=".",
|
||||
help="Directory containing the tokenizer.model.")
|
||||
parser.add_argument('--engine_dir', type=str, default='qwen_outputs')
|
||||
parser.add_argument("--n",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Number of generated sequences per prompt.")
|
||||
parser.add_argument("--num-prompts",
|
||||
type=int,
|
||||
default=100,
|
||||
help="Number of prompts to process.")
|
||||
parser.add_argument("--seed", type=int, default=0)
|
||||
parser.add_argument("--hf_max_batch_size",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Maximum batch size for HF backend.")
|
||||
|
||||
parser.add_argument("--trt_max_batch_size",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Maximum batch size for TRT-LLM backend.")
|
||||
parser.add_argument("--chat-format",
|
||||
type=str,
|
||||
default="chatml",
|
||||
choices=["chatml", "raw"],
|
||||
help="choice the model format, base or chat")
|
||||
args = parser.parse_args()
|
||||
|
||||
if args.backend == "trt-llm":
|
||||
if args.trt_max_batch_size is None:
|
||||
raise ValueError(
|
||||
"trt max batch size is required for TRT-LLM backend.")
|
||||
elif args.backend == "hf":
|
||||
if args.hf_max_batch_size is None:
|
||||
raise ValueError("hf max batch size is required for HF backend.")
|
||||
if args.tokenizer_dir is None:
|
||||
args.tokenizer_dir = args.hf_model
|
||||
|
||||
main(args)
|
||||
727
examples/qwen/build.py
Normal file
727
examples/qwen/build.py
Normal file
@@ -0,0 +1,727 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import argparse
|
||||
import math
|
||||
import os
|
||||
import time
|
||||
|
||||
# isort: off
|
||||
import torch
|
||||
import torch.multiprocessing as mp
|
||||
import tvm.tensorrt as trt
|
||||
# isort: on
|
||||
from transformers import AutoConfig, AutoModelForCausalLM
|
||||
|
||||
try:
|
||||
from transformers import Qwen2ForCausalLM
|
||||
except ImportError:
|
||||
print(
|
||||
"Qwen1.5 requires transformers>=4.37.1, type pip install transformers==4.37.1"
|
||||
)
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm._utils import str_dtype_to_xtrt
|
||||
from xtrt_llm.builder import Builder
|
||||
from xtrt_llm.logger import logger
|
||||
from xtrt_llm.mapping import Mapping
|
||||
from xtrt_llm.models import quantize_model
|
||||
from xtrt_llm.network import net_guard
|
||||
from xtrt_llm.plugin.plugin import ContextFMHAType
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
MODEL_NAME = "qwen"
|
||||
|
||||
import onnx
|
||||
import tvm.tensorrt as trt
|
||||
from onnx import TensorProto, helper
|
||||
|
||||
now_dir = os.path.dirname(os.path.abspath(__file__))
|
||||
|
||||
|
||||
def trt_dtype_to_onnx(dtype):
|
||||
if dtype == trt.float16:
|
||||
return TensorProto.DataType.FLOAT16
|
||||
elif dtype == trt.float32:
|
||||
return TensorProto.DataType.FLOAT
|
||||
elif dtype == trt.int32:
|
||||
return TensorProto.DataType.INT32
|
||||
else:
|
||||
raise TypeError("%s is not supported" % dtype)
|
||||
|
||||
|
||||
def to_onnx(network, path):
|
||||
inputs = []
|
||||
for i in range(network.num_inputs):
|
||||
network_input = network.get_input(i)
|
||||
inputs.append(
|
||||
helper.make_tensor_value_info(
|
||||
network_input.name, trt_dtype_to_onnx(network_input.dtype),
|
||||
list(network_input.shape)))
|
||||
|
||||
outputs = []
|
||||
for i in range(network.num_outputs):
|
||||
network_output = network.get_output(i)
|
||||
outputs.append(
|
||||
helper.make_tensor_value_info(
|
||||
network_output.name, trt_dtype_to_onnx(network_output.dtype),
|
||||
list(network_output.shape)))
|
||||
|
||||
nodes = []
|
||||
for i in range(network.num_layers):
|
||||
layer = network.get_layer(i)
|
||||
layer_inputs = []
|
||||
for j in range(layer.num_inputs):
|
||||
ipt = layer.get_input(j)
|
||||
if ipt is not None:
|
||||
layer_inputs.append(layer.get_input(j).name)
|
||||
layer_outputs = [
|
||||
layer.get_output(j).name for j in range(layer.num_outputs)
|
||||
]
|
||||
nodes.append(
|
||||
helper.make_node(str(layer.type),
|
||||
name=layer.name,
|
||||
inputs=layer_inputs,
|
||||
outputs=layer_outputs,
|
||||
domain="com.nvidia"))
|
||||
|
||||
onnx_model = helper.make_model(helper.make_graph(nodes,
|
||||
'attention',
|
||||
inputs,
|
||||
outputs,
|
||||
initializer=None),
|
||||
producer_name='NVIDIA')
|
||||
onnx.save(onnx_model, path)
|
||||
|
||||
|
||||
def get_engine_name(model, dtype, tp_size, pp_size, rank):
|
||||
if pp_size == 1:
|
||||
return '{}_{}_tp{}_rank{}.engine'.format(model, dtype, tp_size, rank)
|
||||
return '{}_{}_tp{}_pp{}_rank{}.engine'.format(model, dtype, tp_size,
|
||||
pp_size, rank)
|
||||
|
||||
|
||||
def serialize_engine(engine, path):
|
||||
logger.info(f'Serializing engine to {path}...')
|
||||
tik = time.time()
|
||||
engine.serialize(path)
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Engine serialized. Total time: {t}')
|
||||
|
||||
|
||||
def parse_arguments():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--world_size",
|
||||
type=int,
|
||||
default=1,
|
||||
help="world size, only support tensor parallelism now",
|
||||
)
|
||||
parser.add_argument("--tp_size", type=int, default=1)
|
||||
parser.add_argument("--pp_size", type=int, default=1)
|
||||
parser.add_argument("--hf_model_dir", type=str, default=None)
|
||||
parser.add_argument("--version",
|
||||
"-v",
|
||||
type=str,
|
||||
default="1",
|
||||
help="qwen version, support 1, 1.5")
|
||||
parser.add_argument("--ft_dir_path", type=str, default=None)
|
||||
parser.add_argument(
|
||||
"--dtype",
|
||||
type=str,
|
||||
default="float16",
|
||||
choices=["float32", "bfloat16", "float16"],
|
||||
)
|
||||
parser.add_argument(
|
||||
'--timing_cache',
|
||||
type=str,
|
||||
default='model.cache',
|
||||
help=
|
||||
'The path of to read timing cache from, will be ignored if the file does not exist'
|
||||
)
|
||||
parser.add_argument('--log_level',
|
||||
type=str,
|
||||
default='info',
|
||||
choices=[
|
||||
'internal_error',
|
||||
'error',
|
||||
'warning',
|
||||
'info',
|
||||
'verbose',
|
||||
])
|
||||
parser.add_argument('--vocab_size', type=int, default=32000)
|
||||
parser.add_argument('--n_layer', type=int, default=32)
|
||||
parser.add_argument('--n_positions', type=int, default=2048)
|
||||
parser.add_argument('--n_embd', type=int, default=4096)
|
||||
parser.add_argument('--n_head', type=int, default=32)
|
||||
parser.add_argument('--n_kv_head', type=int, default=None)
|
||||
parser.add_argument('--inter_size', type=int, default=11008)
|
||||
parser.add_argument('--hidden_act', type=str, default='silu')
|
||||
parser.add_argument('--max_batch_size', type=int, default=2)
|
||||
parser.add_argument('--max_input_len', type=int, default=2048)
|
||||
parser.add_argument('--max_output_len', type=int, default=2048)
|
||||
parser.add_argument('--max_beam_width', type=int, default=1)
|
||||
parser.add_argument('--rotary_base', type=float, default=10000.0)
|
||||
parser.add_argument('--rotary_scaling', nargs=2, type=str, default=None)
|
||||
parser.add_argument('--use_gpt_attention_plugin',
|
||||
nargs='?',
|
||||
type=str,
|
||||
default="float16",
|
||||
choices=['float16', 'bfloat16', 'float32', None])
|
||||
parser.add_argument('--use_gemm_plugin',
|
||||
nargs='?',
|
||||
type=str,
|
||||
default="float16",
|
||||
choices=['float16', 'bfloat16', 'float32', None])
|
||||
parser.add_argument('--parallel_build', default=False, action='store_true')
|
||||
parser.add_argument('--enable_context_fmha',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--enable_context_fmha_fp32_acc',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--visualize', default=False, action='store_true')
|
||||
parser.add_argument('--enable_debug_output',
|
||||
default=False,
|
||||
action='store_true')
|
||||
parser.add_argument('--gpus_per_node', type=int, default=8)
|
||||
parser.add_argument('--builder_opt', type=int, default=None)
|
||||
parser.add_argument(
|
||||
'--output_dir',
|
||||
type=str,
|
||||
default='engine_outputs',
|
||||
help=
|
||||
'The path to save the serialized engine files, timing cache file and model configs'
|
||||
)
|
||||
parser.add_argument('--remove_input_padding',
|
||||
default=False,
|
||||
action='store_true')
|
||||
# Arguments related to the quantization of the model.
|
||||
parser.add_argument(
|
||||
'--use_smooth_quant',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'Use the SmoothQuant method to quantize activations and weights for the various GEMMs.'
|
||||
'See --per_channel and --per_token for finer-grained quantization options.'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--per_channel',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use a single static scaling factor for the GEMM\'s result. '
|
||||
'per_channel instead uses a different static scaling factor for each channel. '
|
||||
'The latter is usually more accurate, but a little slower.')
|
||||
parser.add_argument(
|
||||
'--per_token',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use a single static scaling factor to scale activations in the int8 range. '
|
||||
'per_token chooses at run time, and for each token, a custom scaling factor. '
|
||||
'The latter is usually more accurate, but a little slower.')
|
||||
|
||||
parser.add_argument(
|
||||
'--per_group',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use a single static scaling factor to scale weights in the int4 range. '
|
||||
'per_group chooses at run time, and for each group, a custom scaling factor. '
|
||||
'The flag is built for GPTQ/AWQ quantization.')
|
||||
|
||||
parser.add_argument(
|
||||
'--use_weight_only',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help='Quantize weights for the various GEMMs to INT4/INT8.'
|
||||
'See --weight_only_precision to set the precision')
|
||||
|
||||
parser.add_argument(
|
||||
'--weight_only_precision',
|
||||
const='int8',
|
||||
type=str,
|
||||
nargs='?',
|
||||
default='int8',
|
||||
choices=['int8', 'int4'],
|
||||
help=
|
||||
'Define the precision for the weights when using weight-only quantization.'
|
||||
'You must also use --use_weight_only for that argument to have an impact.'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_inflight_batching',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Activates inflight batching mode of gptAttentionPlugin.")
|
||||
parser.add_argument(
|
||||
'--paged_kv_cache',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help=
|
||||
'By default we use contiguous KV cache. By setting this flag you enable paged KV cache'
|
||||
)
|
||||
parser.add_argument('--tokens_per_block',
|
||||
type=int,
|
||||
default=128,
|
||||
help='Number of tokens per block in paged KV cache')
|
||||
|
||||
parser.add_argument(
|
||||
'--max_num_tokens',
|
||||
type=int,
|
||||
default=None,
|
||||
help='Define the max number of tokens supported by the engine')
|
||||
|
||||
parser.add_argument(
|
||||
'--int8_kv_cache',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'By default, we use dtype for KV cache. int8_kv_cache chooses int8 quantization for KV'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--use_parallel_embedding',
|
||||
action="store_true",
|
||||
default=False,
|
||||
help=
|
||||
'By default embedding parallelism is disabled. By setting this flag, embedding parallelism is enabled'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--embedding_sharding_dim',
|
||||
type=int,
|
||||
default=1, # Meta does TP on hidden dim
|
||||
choices=[0, 1],
|
||||
help=
|
||||
'By default the embedding lookup table is sharded along vocab dimension (embedding_sharding_dim=0). '
|
||||
'To shard it along hidden dimension, set embedding_sharding_dim=1'
|
||||
'Note: embedding sharing is only enabled when embedding_sharding_dim = 0'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--strongly_typed',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help=
|
||||
'This option is introduced with trt 9.1.0.1+ and will reduce the building time significantly for fp8.'
|
||||
)
|
||||
parser.add_argument(
|
||||
'--opt_memory_use',
|
||||
default=False,
|
||||
action="store_true",
|
||||
help='Whether to use Host memory optimization for building engine')
|
||||
parser.add_argument(
|
||||
'--use_custom_all_reduce',
|
||||
action='store_true',
|
||||
help=
|
||||
'Activates latency-optimized algorithm for all-reduce instead of NCCL.')
|
||||
parser.add_argument('--gather_all_token_logits',
|
||||
action='store_true',
|
||||
default=False)
|
||||
|
||||
args = parser.parse_args()
|
||||
assert not (
|
||||
args.use_smooth_quant and args.use_weight_only
|
||||
), "You cannot enable both SmoothQuant and INT8 weight-only together."
|
||||
|
||||
if not args.remove_input_padding:
|
||||
if args.use_gpt_attention_plugin:
|
||||
logger.warning(
|
||||
f"It is recommended to specify --remove_input_padding when using GPT attention plugin"
|
||||
)
|
||||
|
||||
if args.use_inflight_batching:
|
||||
if not args.use_gpt_attention_plugin:
|
||||
args.use_gpt_attention_plugin = 'float16'
|
||||
logger.info(
|
||||
f"Using GPT attention plugin for inflight batching mode. Setting to default '{args.use_gpt_attention_plugin}'"
|
||||
)
|
||||
if not args.remove_input_padding:
|
||||
args.remove_input_padding = True
|
||||
logger.info(
|
||||
"Using remove input padding for inflight batching mode.")
|
||||
if not args.paged_kv_cache:
|
||||
args.paged_kv_cache = True
|
||||
logger.info("Using paged KV cache for inflight batching mode.")
|
||||
|
||||
if args.use_smooth_quant:
|
||||
args.quant_mode = QuantMode.use_smooth_quant(args.per_token,
|
||||
args.per_channel)
|
||||
elif args.use_weight_only:
|
||||
if args.per_group:
|
||||
args.quant_mode = QuantMode.from_description(
|
||||
quantize_weights=True,
|
||||
quantize_activations=False,
|
||||
per_token=False,
|
||||
per_channel=False,
|
||||
per_group=True,
|
||||
use_int4_weights=True)
|
||||
else:
|
||||
args.quant_mode = QuantMode.use_weight_only(
|
||||
args.weight_only_precision == 'int4')
|
||||
else:
|
||||
args.quant_mode = QuantMode(0)
|
||||
|
||||
if args.int8_kv_cache:
|
||||
args.quant_mode = args.quant_mode.set_int8_kv_cache()
|
||||
|
||||
if args.hf_model_dir is not None:
|
||||
hf_config = AutoConfig.from_pretrained(
|
||||
args.hf_model_dir,
|
||||
trust_remote_code=True,
|
||||
)
|
||||
args.inter_size = hf_config.intermediate_size # override the inter_size for QWen
|
||||
args.n_embd = hf_config.hidden_size
|
||||
args.n_head = hf_config.num_attention_heads
|
||||
if hasattr(hf_config, "num_key_value_heads"):
|
||||
args.n_kv_head = hf_config.num_key_value_heads
|
||||
args.n_layer = hf_config.num_hidden_layers
|
||||
args.n_positions = hf_config.max_position_embeddings
|
||||
args.vocab_size = hf_config.vocab_size
|
||||
args.hidden_act = "silu"
|
||||
if hasattr(hf_config, "kv_channels"):
|
||||
args.kv_channels = hf_config.kv_channels
|
||||
elif hasattr(hf_config, "num_key_value_heads"):
|
||||
args.kv_channels = hf_config.num_key_value_heads
|
||||
else:
|
||||
raise
|
||||
if hasattr(hf_config, "rotary_emb_base"):
|
||||
args.rotary_emb_base = hf_config.rotary_emb_base
|
||||
else:
|
||||
args.rotary_emb_base = 10000.0
|
||||
assert args.use_gpt_attention_plugin is not None, "QWen must use gpt attention plugin"
|
||||
# if args.n_kv_head is not None and args.n_kv_head != args.n_head:
|
||||
# assert (args.n_head % args.n_kv_head) == 0, \
|
||||
# "MQA/GQA requires the number of heads to be divisible by the number of K/V heads."
|
||||
# assert args.n_kv_head == args.tp_size, \
|
||||
# "The current implementation of GQA requires the number of K/V heads to match the number of GPUs." \
|
||||
# "This limitation will be removed in a future version."
|
||||
|
||||
assert args.pp_size * args.tp_size == args.world_size
|
||||
|
||||
if args.max_num_tokens is not None:
|
||||
assert args.enable_context_fmha
|
||||
|
||||
assert (math.log2(args.tokens_per_block).is_integer()
|
||||
), "tokens_per_block must be power of 2"
|
||||
if args.enable_context_fmha or args.enable_context_fmha_fp32_acc:
|
||||
assert (args.tokens_per_block >=
|
||||
128), "Context fMHA requires >= 128 tokens per block"
|
||||
|
||||
return args
|
||||
|
||||
|
||||
def build_rank_engine(builder: Builder,
|
||||
builder_config: xtrt_llm.builder.BuilderConfig,
|
||||
engine_name, rank, multi_query_mode, args):
|
||||
'''
|
||||
@brief: Build the engine on the given rank.
|
||||
@param rank: The rank to build the engine.
|
||||
@param args: The cmd line arguments.
|
||||
@return: The built engine.
|
||||
'''
|
||||
kv_dtype = str_dtype_to_xtrt(args.dtype)
|
||||
mapping = Mapping(world_size=args.world_size,
|
||||
rank=rank,
|
||||
tp_size=args.tp_size,
|
||||
pp_size=args.pp_size)
|
||||
|
||||
# Initialize Module
|
||||
assert args.version in ["1", "1.5"], "Only support version 1 and 1.5"
|
||||
if args.version == "1.5":
|
||||
from qwen2_weight import load_from_ft, load_from_hf_qwen
|
||||
|
||||
xtrt_llm_qwen = xtrt_llm.models.Qwen2ForCausalLM(
|
||||
num_layers=args.n_layer,
|
||||
num_heads=args.n_head,
|
||||
num_kv_heads=args.n_kv_head,
|
||||
hidden_size=args.n_embd,
|
||||
seq_length=args.max_input_len,
|
||||
vocab_size=args.vocab_size,
|
||||
hidden_act=args.hidden_act,
|
||||
max_position_embeddings=args.n_positions,
|
||||
dtype=kv_dtype,
|
||||
mlp_hidden_size=args.inter_size,
|
||||
mapping=mapping,
|
||||
rotary_base=args.rotary_base,
|
||||
rotary_scaling=args.rotary_scaling,
|
||||
use_parallel_embedding=args.use_parallel_embedding,
|
||||
embedding_sharding_dim=args.embedding_sharding_dim,
|
||||
quant_mode=args.quant_mode,
|
||||
gather_all_token_logits=args.gather_all_token_logits,
|
||||
)
|
||||
else:
|
||||
from qwen_weight import load_from_ft, load_from_hf_qwen
|
||||
|
||||
xtrt_llm_qwen = xtrt_llm.models.QWenForCausalLM(
|
||||
num_layers=args.n_layer,
|
||||
num_heads=args.n_head,
|
||||
num_kv_heads=args.n_kv_head,
|
||||
hidden_size=args.n_embd,
|
||||
seq_length=args.max_input_len,
|
||||
vocab_size=args.vocab_size,
|
||||
hidden_act=args.hidden_act,
|
||||
max_position_embeddings=args.n_positions,
|
||||
dtype=kv_dtype,
|
||||
mlp_hidden_size=args.inter_size,
|
||||
neox_rotary_style=True,
|
||||
mapping=mapping,
|
||||
rotary_base=args.rotary_base,
|
||||
rotary_scaling=args.rotary_scaling,
|
||||
use_parallel_embedding=args.use_parallel_embedding,
|
||||
embedding_sharding_dim=args.embedding_sharding_dim,
|
||||
quant_mode=args.quant_mode,
|
||||
gather_all_token_logits=args.gather_all_token_logits,
|
||||
)
|
||||
|
||||
quantize_kwargs = {}
|
||||
if args.use_smooth_quant or args.use_weight_only:
|
||||
if args.weight_only_precision == 'int4_awq':
|
||||
quantize_kwargs = {
|
||||
"group_size": args.group_size,
|
||||
"zero": False,
|
||||
"pre_quant_scale": True,
|
||||
"exclude_modules": [],
|
||||
}
|
||||
elif args.weight_only_precision == 'int4_gptq':
|
||||
quantize_kwargs = {
|
||||
"group_size": args.group_size,
|
||||
"zero": True,
|
||||
"pre_quant_scale": False,
|
||||
}
|
||||
xtrt_llm_qwen = quantize_model(xtrt_llm_qwen, args.quant_mode,
|
||||
**quantize_kwargs)
|
||||
ft_dir_path = args.ft_dir_path
|
||||
if args.hf_model_dir is not None and \
|
||||
(ft_dir_path is None or not os.path.exists(ft_dir_path)):
|
||||
logger.info(f'Loading HF QWen ... from {args.hf_model_dir}')
|
||||
tik = time.time()
|
||||
|
||||
if args.version == "1":
|
||||
hf_qwen = AutoModelForCausalLM.from_pretrained(
|
||||
args.hf_model_dir,
|
||||
device_map={
|
||||
"transformer": "cpu",
|
||||
"lm_head": "cpu",
|
||||
}, # Load to CPU memory
|
||||
torch_dtype="auto",
|
||||
trust_remote_code=True,
|
||||
)
|
||||
else:
|
||||
hf_qwen = Qwen2ForCausalLM.from_pretrained(
|
||||
args.hf_model_dir,
|
||||
# device_map="cpu",
|
||||
device_map={
|
||||
"model": "cpu",
|
||||
"lm_head": "cpu"
|
||||
}, # Load to CPU memory
|
||||
torch_dtype="auto",
|
||||
trust_remote_code=True,
|
||||
)
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'HF QWen loaded. Total time: {t}')
|
||||
load_from_hf_qwen(xtrt_llm_qwen,
|
||||
hf_qwen,
|
||||
mapping,
|
||||
max_position_embeddings=args.n_positions,
|
||||
kv_channels=args.kv_channels,
|
||||
rotary_emb_base=args.rotary_emb_base,
|
||||
dtype=args.dtype,
|
||||
multi_query_mode=multi_query_mode)
|
||||
del hf_qwen
|
||||
elif ft_dir_path is not None:
|
||||
dir_path = ft_dir_path
|
||||
logger.info(f'Loading FT QWen ... from {ft_dir_path}')
|
||||
load_from_ft(xtrt_llm_qwen,
|
||||
dir_path,
|
||||
mapping,
|
||||
dtype=args.dtype,
|
||||
multi_query_mode=multi_query_mode)
|
||||
else:
|
||||
raise ValueError(
|
||||
"You must specify either --hf_model_dir or --ft_dir_path")
|
||||
|
||||
# Module -> Network
|
||||
network = builder.create_network()
|
||||
network.trt_network.name = engine_name
|
||||
if args.use_gpt_attention_plugin:
|
||||
network.plugin_config.set_gpt_attention_plugin(
|
||||
dtype=args.use_gpt_attention_plugin)
|
||||
if args.use_gemm_plugin:
|
||||
network.plugin_config.set_gemm_plugin(dtype=args.use_gemm_plugin)
|
||||
# Quantization plugins.
|
||||
if args.use_smooth_quant:
|
||||
network.plugin_config.set_smooth_quant_gemm_plugin(dtype=args.dtype)
|
||||
network.plugin_config.set_rmsnorm_quantization_plugin(dtype=args.dtype)
|
||||
network.plugin_config.set_quantize_tensor_plugin()
|
||||
network.plugin_config.set_quantize_per_token_plugin()
|
||||
assert not (args.enable_context_fmha and args.enable_context_fmha_fp32_acc)
|
||||
if args.enable_context_fmha:
|
||||
network.plugin_config.set_context_fmha(ContextFMHAType.enabled)
|
||||
if args.enable_context_fmha_fp32_acc:
|
||||
network.plugin_config.set_context_fmha(
|
||||
ContextFMHAType.enabled_with_fp32_acc)
|
||||
if args.use_weight_only:
|
||||
if args.per_group:
|
||||
network.plugin_config.set_weight_only_groupwise_quant_matmul_plugin(
|
||||
dtype='float16')
|
||||
else:
|
||||
network.plugin_config.set_weight_only_quant_matmul_plugin(
|
||||
dtype='float16')
|
||||
if args.quant_mode.is_weight_only():
|
||||
builder_config.trt_builder_config.use_weight_only = args.weight_only_precision
|
||||
if args.world_size > 1:
|
||||
network.plugin_config.set_nccl_plugin(args.dtype,
|
||||
args.use_custom_all_reduce)
|
||||
if args.remove_input_padding:
|
||||
network.plugin_config.enable_remove_input_padding()
|
||||
|
||||
if args.paged_kv_cache:
|
||||
network.plugin_config.enable_paged_kv_cache(args.tokens_per_block)
|
||||
|
||||
with net_guard(network):
|
||||
# Prepare
|
||||
network.set_named_parameters(xtrt_llm_qwen.named_parameters())
|
||||
|
||||
# Forward
|
||||
inputs = xtrt_llm_qwen.prepare_inputs(
|
||||
max_batch_size=args.max_batch_size,
|
||||
max_input_len=args.max_input_len,
|
||||
max_new_tokens=args.max_output_len,
|
||||
use_cache=True,
|
||||
max_beam_width=args.max_beam_width,
|
||||
max_num_tokens=args.max_num_tokens,
|
||||
)
|
||||
xtrt_llm_qwen(*inputs)
|
||||
if args.enable_debug_output:
|
||||
# mark intermediate nodes' outputs
|
||||
for k, v in xtrt_llm_qwen.named_network_outputs():
|
||||
v = v.trt_tensor
|
||||
v.name = k
|
||||
network.trt_network.mark_output(v)
|
||||
v.dtype = kv_dtype
|
||||
if args.visualize:
|
||||
model_path = os.path.join(args.output_dir, 'test.onnx')
|
||||
to_onnx(network.trt_network, model_path)
|
||||
|
||||
engine = None
|
||||
|
||||
# Network -> Engine
|
||||
engine = builder.build_engine(network, builder_config)
|
||||
if rank == 0:
|
||||
config_path = os.path.join(args.output_dir, 'config.json')
|
||||
builder.save_config(builder_config, config_path)
|
||||
|
||||
if args.opt_memory_use:
|
||||
return engine, network
|
||||
return engine
|
||||
|
||||
|
||||
def build(rank, args):
|
||||
torch.cuda.set_device(rank % args.gpus_per_node)
|
||||
xtrt_llm.logger.set_level(args.log_level)
|
||||
if not os.path.exists(args.output_dir):
|
||||
os.makedirs(args.output_dir)
|
||||
multi_query_mode = (args.n_kv_head
|
||||
is not None) and (args.n_kv_head != args.n_head)
|
||||
|
||||
# when doing serializing build, all ranks share one engine
|
||||
builder = Builder()
|
||||
|
||||
cache = None
|
||||
for cur_rank in range(args.world_size):
|
||||
# skip other ranks if parallel_build is enabled
|
||||
if args.parallel_build and cur_rank != rank:
|
||||
continue
|
||||
int8_trt_flag = args.quant_mode.has_act_and_weight_quant() or (
|
||||
not args.paged_kv_cache and args.quant_mode.has_int8_kv_cache())
|
||||
builder_config = builder.create_builder_config(
|
||||
name=MODEL_NAME,
|
||||
precision=args.dtype,
|
||||
timing_cache=args.timing_cache if cache is None else cache,
|
||||
tensor_parallel=args.tp_size,
|
||||
pipeline_parallel=args.pp_size,
|
||||
parallel_build=args.parallel_build,
|
||||
num_layers=args.n_layer,
|
||||
num_heads=args.n_head,
|
||||
hidden_size=args.n_embd,
|
||||
inter_size=args.inter_size,
|
||||
vocab_size=args.vocab_size,
|
||||
hidden_act=args.hidden_act,
|
||||
max_position_embeddings=args.n_positions,
|
||||
max_batch_size=args.max_batch_size,
|
||||
max_beam_width=args.max_beam_width,
|
||||
max_input_len=args.max_input_len,
|
||||
max_output_len=args.max_output_len,
|
||||
max_num_tokens=args.max_num_tokens,
|
||||
fusion_pattern_list=["remove_dup_mask"],
|
||||
int8=int8_trt_flag,
|
||||
fp8=args.quant_mode.has_fp8_qdq(),
|
||||
quant_mode=args.quant_mode,
|
||||
strongly_typed=args.strongly_typed,
|
||||
opt_level=args.builder_opt,
|
||||
max_prompt_embedding_table_size=0,
|
||||
# max_prompt_embedding_table_size=args.max_prompt_embedding_table_size,
|
||||
gather_all_token_logits=args.gather_all_token_logits)
|
||||
guard = xtrt_llm.fusion_patterns.FuseonPatternGuard()
|
||||
print(guard)
|
||||
engine_name = get_engine_name(MODEL_NAME, args.dtype, args.tp_size,
|
||||
args.pp_size, cur_rank)
|
||||
if args.opt_memory_use:
|
||||
engine, network = build_rank_engine(builder, builder_config,
|
||||
engine_name, cur_rank,
|
||||
multi_query_mode, args)
|
||||
else:
|
||||
engine = build_rank_engine(builder, builder_config, engine_name,
|
||||
cur_rank, multi_query_mode, args)
|
||||
assert engine is not None, f'Failed to build engine for rank {cur_rank}'
|
||||
|
||||
if cur_rank == 0:
|
||||
# Use in-memory timing cache for multiple builder passes.
|
||||
if not args.parallel_build:
|
||||
cache = builder_config.trt_builder_config.get_timing_cache()
|
||||
|
||||
serialize_engine(engine, os.path.join(args.output_dir, engine_name))
|
||||
|
||||
del engine
|
||||
if args.opt_memory_use:
|
||||
network.__del__()
|
||||
|
||||
# if rank == 0:
|
||||
# ok = builder.save_timing_cache(
|
||||
# builder_config, os.path.join(args.output_dir, "model.cache"))
|
||||
# assert ok, "Failed to save timing cache."
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = parse_arguments()
|
||||
logger.set_level(args.log_level)
|
||||
tik = time.time()
|
||||
if args.version == "1.5":
|
||||
MODEL_NAME = 'qwen2'
|
||||
if args.parallel_build and args.world_size > 1 and \
|
||||
torch.cuda.device_count() >= args.world_size:
|
||||
logger.warning(
|
||||
f'Parallelly build TensorRT engines. Please make sure that all of the {args.world_size} GPUs are totally free.'
|
||||
)
|
||||
mp.spawn(build, nprocs=args.world_size, args=(args, ))
|
||||
else:
|
||||
args.parallel_build = False
|
||||
logger.info('Serially build TensorRT engines.')
|
||||
build(0, args)
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
logger.info(f'Total time of building all {args.world_size} engines: {t}')
|
||||
361
examples/qwen/hf_qwen_convert.py
Normal file
361
examples/qwen/hf_qwen_convert.py
Normal file
@@ -0,0 +1,361 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
'''
|
||||
Convert huggingface QWen-7B-Chat model to numpy file.
|
||||
Use https://huggingface.co/Qwen/Qwen-7B-Chat as demo.
|
||||
'''
|
||||
import argparse
|
||||
import configparser
|
||||
import dataclasses
|
||||
import json
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
import torch.multiprocessing as multiprocessing
|
||||
from smoothquant import capture_activation_range, smooth_gemm, smooth_gemm_mlp
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoModelForCausalLM # transformers-4.10.0-py3
|
||||
from transformers import AutoTokenizer, GenerationConfig
|
||||
# for debug
|
||||
from utils.convert import split_and_save_weight
|
||||
|
||||
from xtrt_llm._utils import str_dtype_to_torch, torch_to_numpy
|
||||
|
||||
now_dir = os.path.dirname(os.path.abspath(__file__))
|
||||
|
||||
|
||||
@dataclasses.dataclass(frozen=True)
|
||||
class ProgArgs:
|
||||
out_dir: str
|
||||
in_file: str
|
||||
max_input_len: int = 2048
|
||||
tensor_parallelism: int = 1
|
||||
processes: int = 1
|
||||
calibrate_kv_cache: bool = False
|
||||
smoothquant: float = None
|
||||
model: str = "qwen"
|
||||
storage_type: str = "fp32"
|
||||
dataset_cache_dir: str = None
|
||||
|
||||
@staticmethod
|
||||
def parse(args=None) -> 'ProgArgs':
|
||||
parser = argparse.ArgumentParser(
|
||||
formatter_class=argparse.RawTextHelpFormatter)
|
||||
parser.add_argument('--out-dir',
|
||||
'-o',
|
||||
type=str,
|
||||
help='file name of output directory',
|
||||
required=True)
|
||||
parser.add_argument('--in-file',
|
||||
'-i',
|
||||
type=str,
|
||||
help='file name of input checkpoint file',
|
||||
required=True)
|
||||
parser.add_argument(
|
||||
'--max_input_len',
|
||||
type=int,
|
||||
help=
|
||||
"This should be consistent with the max_input_len you used when building engine.",
|
||||
default=2048)
|
||||
parser.add_argument('--tensor-parallelism',
|
||||
'-tp',
|
||||
type=int,
|
||||
help='Requested tensor parallelism for inference',
|
||||
default=1)
|
||||
parser.add_argument(
|
||||
"--processes",
|
||||
"-p",
|
||||
type=int,
|
||||
help=
|
||||
"How many processes to spawn for conversion (default: 1). Set it to a lower value to reduce RAM usage.",
|
||||
default=1)
|
||||
parser.add_argument(
|
||||
"--calibrate-kv-cache",
|
||||
"-kv",
|
||||
action="store_true",
|
||||
help=
|
||||
"Generate scaling factors for KV cache. Used for storing KV cache in int8."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--smoothquant",
|
||||
"-sq",
|
||||
type=float,
|
||||
default=None,
|
||||
help="Set the α parameter (see https://arxiv.org/pdf/2211.10438.pdf)"
|
||||
" to Smoothquant the model, and output int8 weights."
|
||||
" A good first try is 0.5. Must be in [0, 1]")
|
||||
parser.add_argument(
|
||||
"--model",
|
||||
default="qwen",
|
||||
type=str,
|
||||
help="Specify GPT variants to convert checkpoints correctly",
|
||||
choices=["qwen", "gpt2", "santacoder", "starcoder"])
|
||||
parser.add_argument("--storage-type",
|
||||
"-t",
|
||||
type=str,
|
||||
default="float16",
|
||||
choices=["float32", "float16", "bfloat16"])
|
||||
parser.add_argument("--dataset-cache-dir",
|
||||
type=str,
|
||||
default=None,
|
||||
help="cache dir to load the hugging face dataset")
|
||||
return ProgArgs(**vars(parser.parse_args(args)))
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def smooth_qwen_model(model, scales, alpha, qwen_smoother):
|
||||
# Smooth the activation and weights with smoother = $\diag{s}$
|
||||
for name, module in model.named_modules():
|
||||
# if not isinstance(module, QWenBlock):
|
||||
if not str(type(module)).endswith("QWenBlock'>"):
|
||||
continue
|
||||
|
||||
# qkv_proj
|
||||
layer_name = name + ".attn.c_attn"
|
||||
smoother = smooth_gemm(module.attn.c_attn.weight,
|
||||
scales[layer_name]["x"],
|
||||
module.ln_1.weight,
|
||||
alpha=alpha)
|
||||
scales[layer_name]["x"] = scales[layer_name]["x"] / smoother
|
||||
scales[layer_name]["w"] = module.attn.c_attn.weight.abs().max(dim=1)[0]
|
||||
|
||||
# attention dense
|
||||
layer_name = name + ".attn.c_proj"
|
||||
smoother3 = smooth_gemm(
|
||||
module.attn.c_proj.weight,
|
||||
scales[layer_name]["x"],
|
||||
None,
|
||||
alpha=alpha,
|
||||
)
|
||||
qwen_smoother[layer_name] = smoother3.float()
|
||||
|
||||
scales[layer_name]["x"] = scales[layer_name]["x"] / smoother3
|
||||
scales[layer_name]["w"] = module.attn.c_proj.weight.abs().max(dim=1)[0]
|
||||
|
||||
# mlp w1 / w2, because then use some input hidden_states as input, so we need to smooth it with same scale
|
||||
mlp_w1_name = name + ".mlp.w1"
|
||||
mlp_w2_name = name + ".mlp.w2"
|
||||
smoother2 = smooth_gemm_mlp(module.mlp.w1.weight,
|
||||
module.mlp.w2.weight,
|
||||
scales[mlp_w1_name]["x"],
|
||||
module.ln_2.weight,
|
||||
alpha=alpha)
|
||||
scales[mlp_w1_name]["x"] = scales[mlp_w1_name]["x"] / smoother2
|
||||
scales[mlp_w2_name]["x"] = scales[mlp_w2_name]["x"] / smoother2
|
||||
scales[mlp_w1_name]["w"] = module.mlp.w1.weight.abs().max(dim=1)[0]
|
||||
scales[mlp_w2_name]["w"] = module.mlp.w2.weight.abs().max(dim=1)[0]
|
||||
|
||||
# mlp c_proj
|
||||
layer_name = name + ".mlp.c_proj"
|
||||
smoother4 = smooth_gemm(module.mlp.c_proj.weight,
|
||||
scales[layer_name]["x"],
|
||||
None,
|
||||
alpha=alpha)
|
||||
qwen_smoother[layer_name] = smoother4.float()
|
||||
scales[layer_name]["x"] = scales[layer_name]["x"] / smoother4
|
||||
scales[layer_name]["w"] = module.mlp.c_proj.weight.abs().max(dim=1)[0]
|
||||
|
||||
|
||||
# SantaCoder separates Q projection from KV projection
|
||||
def concat_qkv_weight_bias(q, hf_key, hf_model):
|
||||
kv = hf_model.state_dict()[hf_key.replace("q_attn", "kv_attn")]
|
||||
return torch.cat([q, kv], dim=-1)
|
||||
|
||||
|
||||
# StarCoder uses nn.Linear for these following ops whose weight matrix is transposed compared to transformer.Conv1D
|
||||
def transpose_weights(hf_name, param):
|
||||
weight_to_transpose = [
|
||||
"attn.c_attn", "attn.c_proj", "mlp.c_proj", "mlp.w1", "mlp.w2"
|
||||
]
|
||||
if any([k in hf_name for k in weight_to_transpose]):
|
||||
if len(param.shape) == 2:
|
||||
param = param.transpose(0, 1)
|
||||
return param
|
||||
|
||||
|
||||
def convert_qwen_name(orig_name):
|
||||
global_weights = {
|
||||
"transformer.wte.weight": "vocab_embedding.weight",
|
||||
"transformer.ln_f.weight": "ln_f.weight",
|
||||
"lm_head.weight": "lm_head.weight"
|
||||
}
|
||||
|
||||
if orig_name in global_weights:
|
||||
return global_weights[orig_name]
|
||||
|
||||
_, _, layer_id, *weight_name = orig_name.split(".")
|
||||
layer_id = int(layer_id)
|
||||
weight_name = "transformer." + ".".join(weight_name)
|
||||
|
||||
per_layer_weights = {
|
||||
"transformer.ln_1.weight": "ln_1.weight",
|
||||
"transformer.ln_2.weight": "ln_2.weight",
|
||||
"transformer.attn.c_attn.weight": "attention.qkv.weight",
|
||||
"transformer.attn.c_attn.bias": "attention.qkv.bias",
|
||||
"transformer.attn.c_proj.weight": "attention.dense.weight",
|
||||
"transformer.mlp.w1.weight": "mlp.w1.weight",
|
||||
"transformer.mlp.w2.weight": "mlp.w2.weight",
|
||||
"transformer.mlp.c_proj.weight": "mlp.c_proj.weight",
|
||||
}
|
||||
return f"layers.{layer_id}.{per_layer_weights[weight_name]}"
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def hf_qwen_converter(args: ProgArgs):
|
||||
infer_tp = args.tensor_parallelism
|
||||
multi_query_mode = True if args.model in ["santacoder", "starcoder"
|
||||
] else False
|
||||
saved_dir = Path(args.out_dir) / f"{infer_tp}-XPU"
|
||||
saved_dir.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
# load position_embedding from rank 0
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
args.in_file,
|
||||
device_map=
|
||||
"auto", # if you gpu memory is not enough, you can set device_map="cpu"
|
||||
trust_remote_code=True,
|
||||
torch_dtype=str_dtype_to_torch(args.storage_type),
|
||||
).float() # if you gpu memory is not enough, you can set .half() to .float()
|
||||
model.generation_config = GenerationConfig.from_pretrained(
|
||||
args.in_file, trust_remote_code=True)
|
||||
act_range = {}
|
||||
qwen_smoother = {}
|
||||
if args.smoothquant is not None or args.calibrate_kv_cache:
|
||||
os.environ["TOKENIZERS_PARALLELISM"] = os.environ.get(
|
||||
"TOKENIZERS_PARALLELISM", "false")
|
||||
from datasets import load_dataset
|
||||
|
||||
# copy from summarize.py
|
||||
dataset_cnn = load_dataset("ccdv/cnn_dailymail", '3.0.0')
|
||||
dataset = dataset_cnn["test"]
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
args.in_file,
|
||||
legacy=False,
|
||||
padding_side='left',
|
||||
trust_remote_code=True,
|
||||
)
|
||||
gen_config_path = os.path.join(args.in_file, 'generation_config.json')
|
||||
with open(gen_config_path, 'r') as f:
|
||||
gen_config = json.load(f)
|
||||
chat_format = gen_config['chat_format']
|
||||
tokenizer.pad_token_id = tokenizer.im_end_id
|
||||
# use this prompt to make chat model do summarize
|
||||
system_prompt = "You are a useful assistant, please directly output the corresponding summary according to the article entered by the user."
|
||||
act_range = capture_activation_range(
|
||||
model,
|
||||
tokenizer,
|
||||
dataset,
|
||||
system_prompt=system_prompt,
|
||||
chat_format=chat_format,
|
||||
max_input_len=args.max_input_len,
|
||||
)
|
||||
if args.smoothquant is not None:
|
||||
smooth_qwen_model(model, act_range, args.smoothquant, qwen_smoother)
|
||||
|
||||
config = configparser.ConfigParser()
|
||||
config["qwen"] = {}
|
||||
for key in vars(args):
|
||||
config["qwen"][key] = f"{vars(args)[key]}"
|
||||
for k, v in vars(model.config).items():
|
||||
config["qwen"][k] = f"{v}"
|
||||
config["qwen"]["storage_dtype"] = args.storage_type
|
||||
config["qwen"]["multi_query_mode"] = str(multi_query_mode)
|
||||
with open(saved_dir / "config.ini", 'w') as configfile:
|
||||
config.write(configfile)
|
||||
|
||||
storage_type = str_dtype_to_torch(args.storage_type)
|
||||
|
||||
global_weights = ["vocab_embedding.weight", "ln_f.weight", "lm_head.weight"]
|
||||
|
||||
int8_outputs = None
|
||||
if args.calibrate_kv_cache:
|
||||
int8_outputs = "kv_cache_only"
|
||||
if args.smoothquant is not None:
|
||||
int8_outputs = "all"
|
||||
|
||||
starmap_args = []
|
||||
for name, param in tqdm(
|
||||
model.named_parameters(),
|
||||
desc="convert and save",
|
||||
total=len(list(model.parameters())),
|
||||
ncols=80,
|
||||
):
|
||||
if "weight" not in name and "bias" not in name:
|
||||
continue
|
||||
converted_name = convert_qwen_name(name)
|
||||
if name.replace(".weight", "") in qwen_smoother.keys():
|
||||
smoother = qwen_smoother[name.replace(".weight", "")]
|
||||
starmap_arg = (
|
||||
0,
|
||||
saved_dir,
|
||||
infer_tp,
|
||||
f"{converted_name}.smoother".replace(".weight", ""),
|
||||
smoother,
|
||||
storage_type,
|
||||
None,
|
||||
{
|
||||
"int8_outputs": int8_outputs,
|
||||
"multi_query_mode": multi_query_mode,
|
||||
"local_dim": None,
|
||||
},
|
||||
)
|
||||
if args.processes > 1:
|
||||
starmap_args.append(starmap_arg)
|
||||
else:
|
||||
split_and_save_weight(*starmap_arg)
|
||||
|
||||
param = transpose_weights(name, param)
|
||||
if converted_name in global_weights:
|
||||
torch_to_numpy(param.to(storage_type).cpu()).tofile(
|
||||
saved_dir / f"{converted_name}.bin")
|
||||
else:
|
||||
if 'q_attn' in name:
|
||||
param = concat_qkv_weight_bias(param, name, model)
|
||||
converted_name = converted_name.replace("query",
|
||||
"query_key_value")
|
||||
# Needed by QKV projection weight split. With multi_query_mode one does not simply take
|
||||
# out_dim and divide it by 3 to get local_dim because out_dim = local_dim + 2 * head_size
|
||||
local_dim = model.transformer.h[
|
||||
0].attn.embed_dim if multi_query_mode else None
|
||||
starmap_arg = (0, saved_dir, infer_tp, converted_name,
|
||||
param.to(storage_type), storage_type,
|
||||
act_range.get(name.replace(".weight", "")), {
|
||||
"int8_outputs": int8_outputs,
|
||||
"multi_query_mode": multi_query_mode,
|
||||
"local_dim": local_dim
|
||||
})
|
||||
if args.processes > 1:
|
||||
starmap_args.append(starmap_arg)
|
||||
else:
|
||||
split_and_save_weight(*starmap_arg)
|
||||
|
||||
if args.processes > 1:
|
||||
starmap_args = tqdm(starmap_args, desc="saving weights")
|
||||
with multiprocessing.Pool(args.processes) as pool:
|
||||
pool.starmap(split_and_save_weight, starmap_args)
|
||||
|
||||
|
||||
def run_conversion(args: ProgArgs):
|
||||
print("\n=============== Arguments ===============")
|
||||
for key, value in vars(args).items():
|
||||
print(f"{key}: {value}")
|
||||
print("========================================")
|
||||
hf_qwen_converter(args)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
torch.multiprocessing.set_start_method("spawn")
|
||||
run_conversion(ProgArgs.parse())
|
||||
1220
examples/qwen/qwen2_weight.py
Normal file
1220
examples/qwen/qwen2_weight.py
Normal file
File diff suppressed because it is too large
Load Diff
564
examples/qwen/qwen_weight.py
Normal file
564
examples/qwen/qwen_weight.py
Normal file
@@ -0,0 +1,564 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import configparser
|
||||
import time
|
||||
from pathlib import Path
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from tqdm import tqdm
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm._utils import str_dtype_to_np, str_dtype_to_torch, torch_to_numpy
|
||||
from xtrt_llm.mapping import Mapping
|
||||
from xtrt_llm.models import QWenForCausalLM
|
||||
from xtrt_llm.quantization import QuantMode
|
||||
|
||||
|
||||
def gen_suffix(rank, use_smooth_quant, quant_per_channel):
|
||||
suffix = f"{rank}.bin"
|
||||
if use_smooth_quant:
|
||||
sq_prefix = "int8."
|
||||
if quant_per_channel:
|
||||
sq_prefix += "col."
|
||||
suffix = sq_prefix + suffix
|
||||
return suffix
|
||||
|
||||
|
||||
def extract_layer_idx(name):
|
||||
ss = name.split('.')
|
||||
for s in ss:
|
||||
if s.isdigit():
|
||||
return s
|
||||
return None
|
||||
|
||||
|
||||
def custom_slice(array, begin, end, axis):
|
||||
if axis < 0:
|
||||
axis += len(array.shape)
|
||||
assert axis >= 0 and axis < len(array.shape), \
|
||||
f"Invalid axis {axis} for array with shape {array.shape}"
|
||||
if axis == 0:
|
||||
return array[begin:end]
|
||||
elif axis == 1:
|
||||
return array[:, begin:end]
|
||||
elif axis == 2:
|
||||
return array[:, :, begin:end]
|
||||
elif axis == 3:
|
||||
return array[:, :, :, begin:end]
|
||||
elif axis == 4:
|
||||
return array[:, :, :, :, begin:end]
|
||||
elif axis == 5:
|
||||
return array[:, :, :, :, :, begin:end]
|
||||
elif axis == 6:
|
||||
return array[:, :, :, :, :, :, begin:end]
|
||||
else:
|
||||
raise ValueError(f"Unsupported axis {axis}")
|
||||
|
||||
|
||||
def split(v, tp_size, idx, dim=0):
|
||||
if tp_size == 1:
|
||||
return v
|
||||
if len(v.shape) == 1:
|
||||
if v.shape[0] % tp_size != 0:
|
||||
# padding 0 to align the split
|
||||
pad_tensor = np.zeros([tp_size - v.shape[0] % tp_size],
|
||||
dtype=v.dtype)
|
||||
v = np.concatenate([v, pad_tensor])
|
||||
return np.ascontiguousarray(np.split(v, tp_size)[idx])
|
||||
else:
|
||||
if dim < 0:
|
||||
dim += len(v.shape)
|
||||
slice_size = (v.shape[dim] + tp_size - 1) // tp_size
|
||||
bound = v.shape[dim]
|
||||
nd = custom_slice(v,
|
||||
idx * slice_size,
|
||||
min((idx + 1) * slice_size, bound),
|
||||
axis=dim)
|
||||
if (idx + 1) * slice_size > bound:
|
||||
pad_shape = list(v.shape)
|
||||
pad_shape[dim] = tp_size - v.shape[dim] % tp_size
|
||||
pad_tensor = np.zeros(pad_shape, dtype=v.dtype)
|
||||
nd = np.concatenate([nd, pad_tensor], axis=dim)
|
||||
return np.ascontiguousarray(nd)
|
||||
|
||||
|
||||
def parse_ft_config(ini_file):
|
||||
qwen_config = configparser.ConfigParser()
|
||||
qwen_config.read(ini_file)
|
||||
|
||||
vocab_size = qwen_config.getint('qwen', 'vocab_size')
|
||||
hidden_size = qwen_config.getint('qwen', 'hidden_size')
|
||||
inter_size = qwen_config.getint('qwen', 'intermediate_size', fallback=None)
|
||||
num_hidden_layers = qwen_config.getint(
|
||||
"qwen",
|
||||
"num_hidden_layers",
|
||||
fallback=32,
|
||||
)
|
||||
max_position_embeddings = qwen_config.getint("qwen",
|
||||
"max_position_embeddings",
|
||||
fallback=8192)
|
||||
kv_channels = qwen_config.getint('qwen', 'kv_channels', fallback=128)
|
||||
rotary_pct = qwen_config.getfloat('qwen', 'rotary_pct', fallback=0.0)
|
||||
rotary_emb_base = qwen_config.getint('qwen',
|
||||
'rotary_emb_base',
|
||||
fallback=10000)
|
||||
multi_query_mode = qwen_config.getboolean('qwen',
|
||||
'multi_query_mode',
|
||||
fallback=False)
|
||||
return (vocab_size, hidden_size, inter_size, num_hidden_layers, kv_channels,
|
||||
rotary_pct, rotary_emb_base, multi_query_mode,
|
||||
max_position_embeddings)
|
||||
|
||||
|
||||
def load_from_ft(xtrt_llm_qwen: QWenForCausalLM,
|
||||
dir_path,
|
||||
mapping=Mapping(),
|
||||
dtype='float16',
|
||||
share_embedding_table=False,
|
||||
parallel_embedding_table=False,
|
||||
multi_query_mode=False):
|
||||
xtrt_llm.logger.info('Loading weights from FT...')
|
||||
tik = time.time()
|
||||
quant_mode = getattr(xtrt_llm_qwen, 'quant_mode', QuantMode(0))
|
||||
if quant_mode.is_int8_weight_only():
|
||||
plugin_weight_only_quant_type = torch.int8
|
||||
elif quant_mode.is_int4_weight_only():
|
||||
plugin_weight_only_quant_type = torch.quint4x2
|
||||
(vocab_size, hidden_size, inter_size, num_hidden_layers, kv_channels,
|
||||
rotary_pct, rotary_emb_base, multi_query_mode,
|
||||
max_position_embeddings) = parse_ft_config(Path(dir_path) / 'config.ini')
|
||||
np_dtype = str_dtype_to_np(dtype)
|
||||
|
||||
def fromfile(dir_path, name, shape=None, dtype=np.float16):
|
||||
dtype = np_dtype if dtype is None else dtype
|
||||
p = dir_path + '/' + name
|
||||
if Path(p).exists():
|
||||
t = np.fromfile(p, dtype=dtype)
|
||||
if shape is not None:
|
||||
t = t.reshape(shape)
|
||||
return t
|
||||
else:
|
||||
print(f"Warning: {p} not found.")
|
||||
return None
|
||||
|
||||
def set_smoothquant_scale_factors(
|
||||
module,
|
||||
pre_scale_weight,
|
||||
dir_path,
|
||||
basename,
|
||||
shape,
|
||||
per_tok_dyn,
|
||||
per_channel,
|
||||
is_qkv=False,
|
||||
rank=None,
|
||||
):
|
||||
suffix = "bin"
|
||||
if per_channel:
|
||||
if rank is not None:
|
||||
suffix = f"{rank}." + suffix
|
||||
suffix = "col." + suffix
|
||||
|
||||
col_shape = shape if (per_channel or is_qkv) else [1, 1]
|
||||
if per_tok_dyn:
|
||||
if pre_scale_weight is not None:
|
||||
pre_scale_weight.value = np.array([1.0], dtype=np.float32)
|
||||
t = fromfile(dir_path, f"{basename}scale_w_quant_orig.{suffix}",
|
||||
col_shape, np.float32)
|
||||
module.per_channel_scale.value = t
|
||||
else:
|
||||
t = fromfile(dir_path, f"{basename}scale_x_orig_quant.bin", [1],
|
||||
np.float32)
|
||||
pre_scale_weight.value = t
|
||||
t = fromfile(dir_path, f"{basename}scale_y_accum_quant.{suffix}",
|
||||
col_shape, np.float32)
|
||||
module.per_channel_scale.value = t
|
||||
t = fromfile(dir_path, f"{basename}scale_y_quant_orig.bin", [1, 1],
|
||||
np.float32)
|
||||
module.act_scale.value = t
|
||||
|
||||
def set_smoother(module, dir_path, base_name, shape, rank):
|
||||
suffix = f"{rank}.bin"
|
||||
t = fromfile(dir_path, f"{base_name}.smoother.{suffix}", shape,
|
||||
np.float32)
|
||||
module.smoother.value = t
|
||||
|
||||
# Determine the quantization mode.
|
||||
quant_mode = getattr(xtrt_llm_qwen, "quant_mode", QuantMode(0))
|
||||
# Do we use SmoothQuant?
|
||||
use_smooth_quant = quant_mode.has_act_and_weight_quant()
|
||||
# Do we use quantization per token?
|
||||
quant_per_token_dyn = quant_mode.has_per_token_dynamic_scaling()
|
||||
# Do we use quantization per channel?
|
||||
quant_per_channel = quant_mode.has_per_channel_scaling()
|
||||
|
||||
# Do we use INT4/INT8 weight-only?
|
||||
use_weight_only = quant_mode.is_weight_only()
|
||||
|
||||
# Int8 KV cache
|
||||
use_int8_kv_cache = quant_mode.has_int8_kv_cache()
|
||||
|
||||
# Debug
|
||||
suffix = gen_suffix(mapping.tp_rank, use_smooth_quant, quant_per_channel)
|
||||
# The type of weights.
|
||||
w_type = np_dtype if not use_smooth_quant else np.int8
|
||||
|
||||
if mapping.is_first_pp_rank():
|
||||
xtrt_llm_qwen.vocab_embedding.weight.value = (fromfile(
|
||||
dir_path, 'vocab_embedding.weight.bin', [vocab_size, hidden_size]))
|
||||
|
||||
if mapping.is_last_pp_rank():
|
||||
xtrt_llm_qwen.ln_f.weight.value = (fromfile(dir_path,
|
||||
'ln_f.weight.bin'))
|
||||
|
||||
lm_head_weight = fromfile(dir_path, 'lm_head.weight.bin',
|
||||
[vocab_size, hidden_size])
|
||||
|
||||
if vocab_size % mapping.tp_size != 0:
|
||||
# padding
|
||||
vocab_size_padded = xtrt_llm_qwen.lm_head.out_features * mapping.tp_size
|
||||
pad_width = vocab_size_padded - vocab_size
|
||||
lm_head_weight = np.pad(lm_head_weight, ((0, pad_width), (0, 0)),
|
||||
'constant',
|
||||
constant_values=0)
|
||||
if mapping.is_last_pp_rank():
|
||||
xtrt_llm_qwen.lm_head.weight.value = np.ascontiguousarray(
|
||||
split(lm_head_weight, mapping.tp_size, mapping.tp_rank))
|
||||
|
||||
layers_range = list(
|
||||
range(mapping.pp_rank * xtrt_llm_qwen.num_layers,
|
||||
(mapping.pp_rank + 1) * xtrt_llm_qwen.num_layers, 1))
|
||||
|
||||
for i in layers_range:
|
||||
c_attn_out_dim = (3 * hidden_size //
|
||||
mapping.tp_size) if not multi_query_mode else (
|
||||
hidden_size // mapping.tp_size +
|
||||
(hidden_size // num_hidden_layers) * 2)
|
||||
|
||||
xtrt_llm_qwen.layers[i].ln_1.weight.value = fromfile(
|
||||
dir_path, 'model.layers.' + str(i) + '.ln_1.weight.bin')
|
||||
|
||||
dst = xtrt_llm_qwen.layers[i].ln_2.weight
|
||||
dst.value = fromfile(dir_path,
|
||||
'model.layers.' + str(i) + '.ln_2.weight.bin')
|
||||
|
||||
t = fromfile(
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.attention.qkv.weight.' + suffix,
|
||||
[hidden_size, c_attn_out_dim], w_type)
|
||||
if t is not None:
|
||||
dst = xtrt_llm_qwen.layers[i].attention.qkv.weight
|
||||
if use_smooth_quant:
|
||||
dst.value = np.ascontiguousarray(np.transpose(t, [1, 0]))
|
||||
set_smoothquant_scale_factors(
|
||||
xtrt_llm_qwen.layers[i].attention.qkv,
|
||||
xtrt_llm_qwen.layers[i].ln_1.scale_to_int,
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.attention.qkv.',
|
||||
[1, c_attn_out_dim],
|
||||
quant_per_token_dyn,
|
||||
quant_per_channel,
|
||||
rank=mapping.tp_rank,
|
||||
is_qkv=True)
|
||||
elif use_weight_only:
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(t), plugin_weight_only_quant_type)
|
||||
dst.value = processed_torch_weights.numpy()
|
||||
scales = xtrt_llm_qwen.layers[i].attention.qkv.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
dst.value = np.ascontiguousarray(np.transpose(t, [1, 0]))
|
||||
|
||||
dst = xtrt_llm_qwen.layers[i].attention.qkv.bias
|
||||
t = fromfile(
|
||||
dir_path, 'model.layers.' + str(i) + '.attention.qkv.bias.' +
|
||||
str(mapping.tp_rank) + '.bin', [c_attn_out_dim])
|
||||
dst.value = np.ascontiguousarray(t)
|
||||
|
||||
dst = xtrt_llm_qwen.layers[i].attention.dense.weight
|
||||
t = fromfile(
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.attention.dense.weight.' + suffix,
|
||||
[hidden_size // mapping.tp_size, hidden_size], w_type)
|
||||
if use_smooth_quant:
|
||||
dst.value = np.ascontiguousarray(np.transpose(t, [1, 0]))
|
||||
dense_scale = getattr(xtrt_llm_qwen.layers[i].attention,
|
||||
"quantization_scaling_factor", None)
|
||||
set_smoothquant_scale_factors(
|
||||
xtrt_llm_qwen.layers[i].attention.dense,
|
||||
dense_scale,
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.attention.dense.',
|
||||
[1, hidden_size],
|
||||
quant_per_token_dyn,
|
||||
quant_per_channel,
|
||||
)
|
||||
set_smoother(xtrt_llm_qwen.layers[i].attention.dense, dir_path,
|
||||
'model.layers.' + str(i) + '.attention.dense',
|
||||
[1, hidden_size // mapping.tp_size], mapping.tp_rank)
|
||||
|
||||
elif use_weight_only:
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(t), plugin_weight_only_quant_type)
|
||||
dst.value = processed_torch_weights.numpy()
|
||||
scales = xtrt_llm_qwen.layers[i].attention.dense.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
dst.value = np.ascontiguousarray(np.transpose(t, [1, 0]))
|
||||
|
||||
t = fromfile(dir_path,
|
||||
'model.layers.' + str(i) + '.mlp.w1.weight.' + suffix,
|
||||
[hidden_size, inter_size // mapping.tp_size // 2], w_type)
|
||||
if use_smooth_quant:
|
||||
xtrt_llm_qwen.layers[
|
||||
i].mlp.gate.weight.value = np.ascontiguousarray(
|
||||
np.transpose(t, [1, 0]))
|
||||
set_smoothquant_scale_factors(
|
||||
xtrt_llm_qwen.layers[i].mlp.gate,
|
||||
xtrt_llm_qwen.layers[i].ln_2.scale_to_int,
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.mlp.w1.',
|
||||
[1, inter_size // mapping.tp_size // 2],
|
||||
quant_per_token_dyn,
|
||||
quant_per_channel,
|
||||
rank=mapping.tp_rank)
|
||||
elif use_weight_only:
|
||||
dst = xtrt_llm_qwen.layers[i].mlp.gate.weight
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(t), plugin_weight_only_quant_type)
|
||||
dst.value = processed_torch_weights.numpy()
|
||||
scales = xtrt_llm_qwen.layers[i].mlp.gate.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
xtrt_llm_qwen.layers[
|
||||
i].mlp.gate.weight.value = np.ascontiguousarray(
|
||||
np.transpose(t, [1, 0]))
|
||||
|
||||
t = fromfile(dir_path,
|
||||
'model.layers.' + str(i) + '.mlp.w2.weight.' + suffix,
|
||||
[hidden_size, inter_size // mapping.tp_size // 2], w_type)
|
||||
if use_smooth_quant:
|
||||
xtrt_llm_qwen.layers[i].mlp.fc.weight.value = np.ascontiguousarray(
|
||||
np.transpose(t, [1, 0]))
|
||||
set_smoothquant_scale_factors(
|
||||
xtrt_llm_qwen.layers[i].mlp.fc,
|
||||
xtrt_llm_qwen.layers[i].ln_2.scale_to_int,
|
||||
dir_path,
|
||||
'model.layers.' + str(i) + '.mlp.w2.',
|
||||
[1, inter_size // mapping.tp_size // 2],
|
||||
quant_per_token_dyn,
|
||||
quant_per_channel,
|
||||
rank=mapping.tp_rank)
|
||||
elif use_weight_only:
|
||||
dst = xtrt_llm_qwen.layers[i].mlp.fc.weight
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(t), plugin_weight_only_quant_type)
|
||||
dst.value = processed_torch_weights.numpy()
|
||||
scales = xtrt_llm_qwen.layers[i].mlp.fc.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
xtrt_llm_qwen.layers[i].mlp.fc.weight.value = np.ascontiguousarray(
|
||||
np.transpose(t, [1, 0]))
|
||||
|
||||
t = fromfile(dir_path,
|
||||
'model.layers.' + str(i) + '.mlp.c_proj.weight.' + suffix,
|
||||
[inter_size // mapping.tp_size // 2, hidden_size], w_type)
|
||||
if use_smooth_quant:
|
||||
xtrt_llm_qwen.layers[
|
||||
i].mlp.proj.weight.value = np.ascontiguousarray(
|
||||
np.transpose(t, [1, 0]))
|
||||
proj_scale = getattr(xtrt_llm_qwen.layers[i].mlp,
|
||||
"quantization_scaling_factor", None)
|
||||
set_smoothquant_scale_factors(
|
||||
xtrt_llm_qwen.layers[i].mlp.proj, proj_scale, dir_path,
|
||||
'model.layers.' + str(i) + '.mlp.c_proj.', [1, hidden_size],
|
||||
quant_per_token_dyn, quant_per_channel)
|
||||
set_smoother(xtrt_llm_qwen.layers[i].mlp.proj, dir_path,
|
||||
'model.layers.' + str(i) + '.mlp.c_proj',
|
||||
[1, inter_size // mapping.tp_size // 2],
|
||||
mapping.tp_rank)
|
||||
elif use_weight_only:
|
||||
dst = xtrt_llm_qwen.layers[i].mlp.proj.weight
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(t), plugin_weight_only_quant_type)
|
||||
dst.value = processed_torch_weights.numpy()
|
||||
scales = xtrt_llm_qwen.layers[i].mlp.proj.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
xtrt_llm_qwen.layers[
|
||||
i].mlp.proj.weight.value = np.ascontiguousarray(
|
||||
np.transpose(t, [1, 0]))
|
||||
|
||||
if use_int8_kv_cache:
|
||||
t = fromfile(
|
||||
dir_path, 'model.layers.' + str(i) +
|
||||
'.attention.qkv.scale_y_quant_orig.bin', [1], np.float32)
|
||||
xtrt_llm_qwen.layers[
|
||||
i].attention.kv_orig_quant_scale.value = 1.0 / t
|
||||
xtrt_llm_qwen.layers[i].attention.kv_quant_orig_scale.value = t
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
xtrt_llm.logger.info(f'Weights loaded. Total time: {t}')
|
||||
|
||||
|
||||
def load_from_hf_qwen(xtrt_llm_qwen: xtrt_llm.models.QWenForCausalLM,
|
||||
hf_qwen,
|
||||
mapping=Mapping(),
|
||||
max_position_embeddings=8192,
|
||||
rotary_emb_base=10000,
|
||||
kv_channels=128,
|
||||
dtype="float32",
|
||||
multi_query_mode=False):
|
||||
xtrt_llm.logger.info('Loading weights from HF QWen...')
|
||||
tik = time.time()
|
||||
|
||||
quant_mode = getattr(xtrt_llm_qwen, 'quant_mode', QuantMode(0))
|
||||
if quant_mode.is_int8_weight_only():
|
||||
plugin_weight_only_quant_type = torch.int8
|
||||
elif quant_mode.is_int4_weight_only():
|
||||
plugin_weight_only_quant_type = torch.quint4x2
|
||||
# use_weight_only = quant_mode.is_weight_only()
|
||||
use_weight_only = 0
|
||||
|
||||
model_params = dict(hf_qwen.named_parameters())
|
||||
torch_dtype = str_dtype_to_torch(dtype)
|
||||
for k, v in tqdm(model_params.items(),
|
||||
total=len(model_params),
|
||||
ncols=80,
|
||||
desc="Converting..."):
|
||||
if isinstance(v, list):
|
||||
v = [torch_to_numpy(vv.to(torch_dtype).detach().cpu()) for vv in v]
|
||||
else:
|
||||
v = torch_to_numpy(v.to(torch_dtype).detach().cpu())
|
||||
if 'transformer.wte.weight' in k:
|
||||
if xtrt_llm_qwen.use_parallel_embedding:
|
||||
v = split(v, mapping.tp_size, mapping.tp_rank,
|
||||
xtrt_llm_qwen.embedding_sharding_dim)
|
||||
if mapping.is_first_pp_rank():
|
||||
xtrt_llm_qwen.vocab_embedding.weight.value = v
|
||||
elif 'transformer.ln_f.weight' in k:
|
||||
xtrt_llm_qwen.ln_f.weight.value = v
|
||||
elif 'lm_head.weight' in k:
|
||||
xtrt_llm_qwen.lm_head.weight.value = np.ascontiguousarray(
|
||||
split(v, mapping.tp_size, mapping.tp_rank))
|
||||
else:
|
||||
layer_idx = extract_layer_idx(k)
|
||||
if layer_idx is None:
|
||||
continue
|
||||
idx = int(layer_idx)
|
||||
if idx >= xtrt_llm_qwen.num_layers:
|
||||
continue
|
||||
if 'ln_1.weight' in k:
|
||||
xtrt_llm_qwen.layers[idx].ln_1.weight.value = v
|
||||
elif 'ln_2.weight' in k:
|
||||
xtrt_llm_qwen.layers[idx].ln_2.weight.value = v
|
||||
elif 'attn.c_attn.weight' in k:
|
||||
dst = xtrt_llm_qwen.layers[idx].attention.qkv.weight
|
||||
if multi_query_mode:
|
||||
assert isinstance(v, list) and len(v) == 3
|
||||
wq = split(v[0], mapping.tp_size, mapping.tp_rank)
|
||||
wk = split(v[1], mapping.tp_size, mapping.tp_rank)
|
||||
wv = split(v[2], mapping.tp_size, mapping.tp_rank)
|
||||
split_v = np.concatenate((wq, wk, wv))
|
||||
else:
|
||||
q_emb = v.shape[0] // 3
|
||||
model_emb = v.shape[1]
|
||||
v = v.reshape(3, q_emb, model_emb)
|
||||
split_v = split(v, mapping.tp_size, mapping.tp_rank, dim=1)
|
||||
split_v = split_v.reshape(3 * (q_emb // mapping.tp_size),
|
||||
model_emb)
|
||||
if use_weight_only:
|
||||
v = np.ascontiguousarray(split_v.transpose())
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(v), plugin_weight_only_quant_type)
|
||||
dst.value = processed_torch_weights.numpy()
|
||||
scales = xtrt_llm_qwen.layers[
|
||||
idx].attention.qkv.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
dst.value = np.ascontiguousarray(split_v)
|
||||
elif 'attn.c_attn.bias' in k:
|
||||
dst = xtrt_llm_qwen.layers[idx].attention.qkv.bias
|
||||
if multi_query_mode:
|
||||
assert isinstance(v, list) and len(v) == 3
|
||||
wq = split(v[0], mapping.tp_size, mapping.tp_rank)
|
||||
wk = split(v[1], mapping.tp_size, mapping.tp_rank)
|
||||
wv = split(v[2], mapping.tp_size, mapping.tp_rank)
|
||||
split_v = np.concatenate((wq, wk, wv))
|
||||
else:
|
||||
q_emb = v.shape[0] // 3
|
||||
v = v.reshape(3, q_emb)
|
||||
split_v = split(v, mapping.tp_size, mapping.tp_rank, dim=1)
|
||||
split_v = split_v.reshape(3 * (q_emb // mapping.tp_size))
|
||||
dst.value = np.ascontiguousarray(split_v)
|
||||
elif 'attn.c_proj.weight' in k:
|
||||
dst = xtrt_llm_qwen.layers[idx].attention.dense.weight
|
||||
split_v = split(v, mapping.tp_size, mapping.tp_rank, dim=1)
|
||||
if use_weight_only:
|
||||
v = np.ascontiguousarray(split_v.transpose())
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(v), plugin_weight_only_quant_type)
|
||||
dst.value = processed_torch_weights.numpy()
|
||||
scales = xtrt_llm_qwen.layers[
|
||||
idx].attention.dense.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
dst.value = np.ascontiguousarray(split_v)
|
||||
elif 'mlp.w1.weight' in k:
|
||||
dst = xtrt_llm_qwen.layers[idx].mlp.gate.weight
|
||||
split_v = split(v, mapping.tp_size, mapping.tp_rank, dim=0)
|
||||
if use_weight_only:
|
||||
v = np.ascontiguousarray(split_v.transpose())
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(v), plugin_weight_only_quant_type)
|
||||
dst.value = processed_torch_weights.numpy()
|
||||
scales = xtrt_llm_qwen.layers[
|
||||
idx].mlp.gate.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
dst.value = np.ascontiguousarray(split_v)
|
||||
elif 'mlp.w2.weight' in k:
|
||||
dst = xtrt_llm_qwen.layers[idx].mlp.fc.weight
|
||||
split_v = split(v, mapping.tp_size, mapping.tp_rank, dim=0)
|
||||
if use_weight_only:
|
||||
v = np.ascontiguousarray(split_v.transpose())
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(v), plugin_weight_only_quant_type)
|
||||
dst.value = processed_torch_weights.numpy()
|
||||
scales = xtrt_llm_qwen.layers[idx].mlp.fc.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
dst.value = np.ascontiguousarray(split_v)
|
||||
elif 'mlp.c_proj.weight' in k:
|
||||
dst = xtrt_llm_qwen.layers[idx].mlp.proj.weight
|
||||
split_v = split(v, mapping.tp_size, mapping.tp_rank, dim=1)
|
||||
if use_weight_only:
|
||||
v = np.ascontiguousarray(split_v.transpose())
|
||||
processed_torch_weights, torch_weight_scales = torch.ops.fastertransformer.symmetric_quantize_last_axis_of_batched_matrix(
|
||||
torch.tensor(v), plugin_weight_only_quant_type)
|
||||
dst.value = processed_torch_weights.numpy()
|
||||
scales = xtrt_llm_qwen.layers[
|
||||
idx].mlp.proj.per_channel_scale
|
||||
scales.value = torch_weight_scales.numpy()
|
||||
else:
|
||||
dst.value = np.ascontiguousarray(split_v)
|
||||
else:
|
||||
print("unknown key: ", k)
|
||||
|
||||
tok = time.time()
|
||||
t = time.strftime('%H:%M:%S', time.gmtime(tok - tik))
|
||||
xtrt_llm.logger.info(f'Weights loaded. Total time: {t}')
|
||||
return
|
||||
16
examples/qwen/requirements.txt
Normal file
16
examples/qwen/requirements.txt
Normal file
@@ -0,0 +1,16 @@
|
||||
datasets~=2.3.2
|
||||
evaluate~=0.4.1
|
||||
rouge_score~=0.1.2
|
||||
transformers==4.37.1
|
||||
accelerate==0.21.0
|
||||
transformers-stream-generator
|
||||
sentencepiece~=0.1.99
|
||||
tiktoken
|
||||
einops
|
||||
|
||||
# optional dependencies
|
||||
gradio==3.40.1
|
||||
mdtex2html
|
||||
sse_starlette
|
||||
aiohttp_sse_client
|
||||
openai
|
||||
209
examples/qwen/smoothquant.py
Normal file
209
examples/qwen/smoothquant.py
Normal file
@@ -0,0 +1,209 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
'''
|
||||
Utilities for SmoothQuant models
|
||||
'''
|
||||
|
||||
import functools
|
||||
import os
|
||||
import sys
|
||||
from collections import defaultdict
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from tqdm import tqdm
|
||||
from transformers.pytorch_utils import Conv1D
|
||||
|
||||
project_dir = os.path.dirname(
|
||||
os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
||||
sys.path.append(project_dir)
|
||||
from utils.utils import make_context
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def apply_smoothing(scales,
|
||||
gemm_weights,
|
||||
rmsnorm_weights=None,
|
||||
dtype=torch.float32,
|
||||
rmsnorm_1p=False):
|
||||
if not isinstance(gemm_weights, list):
|
||||
gemm_weights = [gemm_weights]
|
||||
|
||||
if rmsnorm_weights is not None:
|
||||
assert rmsnorm_weights.numel() == scales.numel()
|
||||
rmsnorm_weights.div_(scales).to(dtype)
|
||||
if rmsnorm_1p:
|
||||
rmsnorm_weights += (1 / scales) - 1
|
||||
|
||||
for gemm in gemm_weights:
|
||||
gemm.mul_(scales.view(1, -1)).to(dtype)
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def smooth_gemm(gemm_weights,
|
||||
act_scales,
|
||||
rmsnorm_weights=None,
|
||||
alpha=0.5,
|
||||
weight_scales=None):
|
||||
if not isinstance(gemm_weights, list):
|
||||
gemm_weights = [gemm_weights]
|
||||
orig_dtype = gemm_weights[0].dtype
|
||||
|
||||
for gemm in gemm_weights:
|
||||
# gemm_weights are expected to be transposed
|
||||
assert gemm.shape[1] == act_scales.numel()
|
||||
|
||||
if weight_scales is None:
|
||||
weight_scales = torch.cat(
|
||||
[gemm.abs().max(dim=0, keepdim=True)[0] for gemm in gemm_weights],
|
||||
dim=0)
|
||||
weight_scales = weight_scales.max(dim=0)[0]
|
||||
weight_scales.to(float).clamp(min=1e-5)
|
||||
scales = (act_scales.to(gemm_weights[0].device).to(float).pow(alpha) /
|
||||
weight_scales.pow(1 - alpha)).clamp(min=1e-5)
|
||||
|
||||
apply_smoothing(scales, gemm_weights, rmsnorm_weights, orig_dtype)
|
||||
|
||||
return scales
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def smooth_gemm_mlp(w1_weights,
|
||||
w2_weights,
|
||||
act_scales,
|
||||
rmsnorm_weights=None,
|
||||
alpha=0.5,
|
||||
weight_scales=None):
|
||||
gemm_weights = []
|
||||
if not isinstance(w1_weights, list):
|
||||
w1_weights = [w1_weights]
|
||||
if not isinstance(w2_weights, list):
|
||||
w2_weights = [w2_weights]
|
||||
|
||||
for i in range(len(w1_weights)):
|
||||
gemm_weight = torch.cat([w1_weights[i], w2_weights[i]], dim=0)
|
||||
gemm_weights.append(gemm_weight)
|
||||
|
||||
orig_dtype = gemm_weights[0].dtype
|
||||
|
||||
for gemm in gemm_weights:
|
||||
# gemm_weights are expected to be transposed
|
||||
assert gemm.shape[1] == act_scales.numel()
|
||||
|
||||
if weight_scales is None:
|
||||
weight_scales = torch.cat(
|
||||
[gemm.abs().max(dim=0, keepdim=True)[0] for gemm in gemm_weights],
|
||||
dim=0)
|
||||
weight_scales = weight_scales.max(dim=0)[0]
|
||||
weight_scales.to(float).clamp(min=1e-5)
|
||||
scales = (act_scales.to(gemm_weights[0].device).to(float).pow(alpha) /
|
||||
weight_scales.pow(1 - alpha)).clamp(min=1e-5)
|
||||
|
||||
apply_smoothing(scales, w1_weights + w2_weights, rmsnorm_weights,
|
||||
orig_dtype)
|
||||
|
||||
return scales
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def smooth_ln_fcs(ln, fcs, act_scales, alpha=0.5):
|
||||
if not isinstance(fcs, list):
|
||||
fcs = [fcs]
|
||||
for fc in fcs:
|
||||
assert isinstance(fc, nn.Linear)
|
||||
assert ln.weight.numel() == fc.in_features == act_scales.numel()
|
||||
|
||||
device, dtype = fcs[0].weight.device, fcs[0].weight.dtype
|
||||
act_scales = act_scales.to(device=device, dtype=dtype)
|
||||
weight_scales = torch.cat(
|
||||
[fc.weight.abs().max(dim=0, keepdim=True)[0] for fc in fcs], dim=0)
|
||||
weight_scales = weight_scales.max(dim=0)[0].clamp(min=1e-5)
|
||||
|
||||
scales = (act_scales.pow(alpha) /
|
||||
weight_scales.pow(1 - alpha)).clamp(min=1e-5).to(device).to(dtype)
|
||||
|
||||
if ln is not None:
|
||||
ln.weight.div_(scales)
|
||||
ln.bias.div_(scales)
|
||||
|
||||
for fc in fcs:
|
||||
fc.weight.mul_(scales.view(1, -1))
|
||||
return scales
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def capture_activation_range(
|
||||
model,
|
||||
tokenizer,
|
||||
dataset,
|
||||
system_prompt,
|
||||
chat_format,
|
||||
max_input_len,
|
||||
num_samples=512,
|
||||
):
|
||||
model.eval()
|
||||
device = next(model.parameters()).device
|
||||
act_scales = defaultdict(lambda: {"x": None, "y": None, "w": None})
|
||||
|
||||
def stat_tensor(name, tensor, act_scales, key):
|
||||
hidden_dim = tensor.shape[-1]
|
||||
tensor = tensor.view(-1, hidden_dim).abs().detach()
|
||||
comming_max = torch.max(tensor, dim=0)[0].float()
|
||||
|
||||
if act_scales[name][key] is None:
|
||||
act_scales[name][key] = comming_max
|
||||
else:
|
||||
act_scales[name][key] = torch.max(act_scales[name][key],
|
||||
comming_max)
|
||||
|
||||
def stat_input_hook(m, x, y, name):
|
||||
if isinstance(x, tuple):
|
||||
x = x[0]
|
||||
stat_tensor(name, x, act_scales, "x")
|
||||
stat_tensor(name, y, act_scales, "y")
|
||||
|
||||
if act_scales[name]["w"] is None:
|
||||
act_scales[name]["w"] = m.weight.abs().clip(1e-8,
|
||||
None).max(dim=1)[0]
|
||||
|
||||
hooks = []
|
||||
for name, m in model.named_modules():
|
||||
if isinstance(m, nn.Linear) or isinstance(m, Conv1D):
|
||||
hooks.append(
|
||||
m.register_forward_hook(
|
||||
functools.partial(stat_input_hook, name=name)))
|
||||
num_samples = min(num_samples, len(dataset))
|
||||
for i in tqdm(range(num_samples), desc="calibrating model"):
|
||||
line = dataset[i]["article"]
|
||||
line = line + ' TL;DR: '
|
||||
line = line.strip()
|
||||
line = line.replace(" n't", "n't")
|
||||
# use make_content to generate prompt
|
||||
_, input_id_list = make_context(tokenizer=tokenizer,
|
||||
query=line,
|
||||
history=[],
|
||||
system=system_prompt,
|
||||
chat_format=chat_format,
|
||||
max_input_length=max_input_len)
|
||||
line_encoded = torch.from_numpy(np.array(
|
||||
input_id_list, dtype=np.int32)).type(torch.int32).unsqueeze(0)
|
||||
line_encoded = line_encoded.to(device)
|
||||
model(line_encoded)
|
||||
|
||||
for h in hooks:
|
||||
h.remove()
|
||||
|
||||
return act_scales
|
||||
14
examples/qwen/utils/__init__.py
Normal file
14
examples/qwen/utils/__init__.py
Normal file
@@ -0,0 +1,14 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
304
examples/qwen/utils/convert.py
Normal file
304
examples/qwen/utils/convert.py
Normal file
@@ -0,0 +1,304 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""
|
||||
Utilities for exporting a model to our custom format.
|
||||
"""
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
from xtrt_llm._utils import torch_to_numpy
|
||||
|
||||
|
||||
def cpu_map_location(storage, loc):
|
||||
return storage.cpu()
|
||||
|
||||
|
||||
def gpu_map_location(storage, loc):
|
||||
if loc.startswith("cuda"):
|
||||
training_gpu_idx = int(loc.split(":")[1])
|
||||
inference_gpu_idx = training_gpu_idx % torch.cuda.device_count()
|
||||
return storage.cuda(inference_gpu_idx)
|
||||
elif loc.startswith("cpu"):
|
||||
return storage.cpu()
|
||||
else:
|
||||
raise ValueError(f"Not handled {loc}")
|
||||
|
||||
|
||||
def save_val(val, dir, key, tp_num=None):
|
||||
suffix = "bin" if tp_num is None else f"{tp_num}.bin"
|
||||
val.tofile(dir / f"model.{key}.{suffix}")
|
||||
|
||||
|
||||
def save_split(split_vals, dir, key, i, split_factor):
|
||||
for j, val in enumerate(split_vals):
|
||||
save_val(val, dir, key, i * split_factor + j)
|
||||
|
||||
|
||||
def generate_int8(weights, act_range, is_qkv=False, multi_query_mode=False):
|
||||
"""
|
||||
This function has two purposes:
|
||||
- compute quantized weights, scaled either per-tensor or per-column
|
||||
- compute scaling factors
|
||||
|
||||
Depending on the GEMM API (CUTLASS/CUBLAS) the required scaling factors differ.
|
||||
CUTLASS uses two sets of scaling factors. One for the activation X, one for the weight W.
|
||||
CUBLAS only has one (we can't do per-row scaling). So we must provide pre-multiplied scaling factor.
|
||||
|
||||
Here is the list of what we need (T means per-tensor, C per-column):
|
||||
- scale_x_orig_quant puts fp activation into the quantized range (i.e. [-128, 127], for int8). Used before the GEMM. (T)
|
||||
- scale_y_quant_orig puts quantized activation into the fp range. Used if the GEMM outputs int8. (T)
|
||||
- scale_w_quant_orig puts weights from quant range to fp range (used with CUTLASS) (T, C)
|
||||
- scale_y_accum_quant puts the GEMM result (XW) from accumulation range (int32)
|
||||
to quant range (int8) (used for CUBLAS) (T, C)
|
||||
|
||||
Note that we don't do anything special about row-parallel GEMM. Theoretically, we could have per-GPU scaling factors too,
|
||||
but then the model would change depending on the number of GPUs used.
|
||||
|
||||
For QKV projection, the behavior is special. Even if we have a single matrix to perform QKV projection, we consider it
|
||||
as three different matrices: Q, K, and V. So per-tensor actually means one scaling factor for each Q, K and V.
|
||||
"""
|
||||
|
||||
# compute weight scaling factors for fp->int8 and int8->fp
|
||||
if is_qkv and not multi_query_mode:
|
||||
scale_w_orig_quant_t = 127. / torch_to_numpy(act_range["w"].reshape(
|
||||
3, -1).max(dim=-1, keepdims=True)[0].cpu()).astype(np.float32)
|
||||
scale_w_orig_quant_c = 127. / torch_to_numpy(act_range["w"].reshape(
|
||||
3, -1).cpu()).astype(np.float32)
|
||||
elif is_qkv and multi_query_mode:
|
||||
raise ValueError(
|
||||
f"Multi-query w/ int8 quant has not been supported yet")
|
||||
else:
|
||||
scale_w_orig_quant_t = 127. / torch_to_numpy(
|
||||
act_range["w"].max().cpu()).astype(np.float32)
|
||||
scale_w_orig_quant_c = 127. / torch_to_numpy(
|
||||
act_range["w"].cpu()).astype(np.float32)
|
||||
scale_w_quant_orig_t = 1.0 / scale_w_orig_quant_t
|
||||
scale_w_quant_orig_c = 1.0 / scale_w_orig_quant_c
|
||||
|
||||
# compute the rest of needed scaling factors
|
||||
scale_x_orig_quant_t = np.array(127. / act_range["x"].max().item())
|
||||
scale_y_orig_quant_t = np.array(127. / act_range["y"].max().item())
|
||||
scale_y_quant_orig_t = np.array(act_range["y"].max().item() / 127.)
|
||||
scale_y_accum_quant_t = scale_y_orig_quant_t / (scale_x_orig_quant_t *
|
||||
scale_w_orig_quant_t)
|
||||
scale_y_accum_quant_c = scale_y_orig_quant_t / (scale_x_orig_quant_t *
|
||||
scale_w_orig_quant_c)
|
||||
if is_qkv:
|
||||
scale_y_accum_quant_t = np.broadcast_to(scale_y_accum_quant_t,
|
||||
scale_w_orig_quant_c.shape)
|
||||
scale_w_quant_orig_t = np.broadcast_to(scale_w_quant_orig_t,
|
||||
scale_w_orig_quant_c.shape)
|
||||
|
||||
to_i8 = lambda x: x.round().clip(-127, 127).astype(np.int8)
|
||||
return {
|
||||
"weight.int8": to_i8(weights * scale_w_orig_quant_t),
|
||||
"weight.int8.col": to_i8(weights * scale_w_orig_quant_c),
|
||||
"scale_x_orig_quant": scale_x_orig_quant_t.astype(np.float32),
|
||||
"scale_w_quant_orig": scale_w_quant_orig_t.astype(np.float32),
|
||||
"scale_w_quant_orig.col": scale_w_quant_orig_c.astype(np.float32),
|
||||
"scale_y_accum_quant": scale_y_accum_quant_t.astype(np.float32),
|
||||
"scale_y_accum_quant.col": scale_y_accum_quant_c.astype(np.float32),
|
||||
"scale_y_quant_orig": scale_y_quant_orig_t.astype(np.float32),
|
||||
}
|
||||
|
||||
|
||||
def write_int8(vals,
|
||||
dir,
|
||||
base_key,
|
||||
split_dim,
|
||||
tp_rank,
|
||||
split_factor,
|
||||
kv_cache_only=False):
|
||||
if not kv_cache_only:
|
||||
save_split(np.split(vals["weight.int8"], split_factor, axis=split_dim),
|
||||
dir, f"{base_key}.weight.int8", tp_rank, split_factor)
|
||||
save_split(
|
||||
np.split(vals["weight.int8.col"], split_factor, axis=split_dim),
|
||||
dir, f"{base_key}.weight.int8.col", tp_rank, split_factor)
|
||||
|
||||
saved_keys_once = ["scale_y_quant_orig"]
|
||||
if not kv_cache_only:
|
||||
saved_keys_once += [
|
||||
"scale_x_orig_quant", "scale_w_quant_orig", "scale_y_accum_quant"
|
||||
]
|
||||
# per-column scaling factors are loaded per-gpu for ColumnParallel GEMMs (QKV, FC1)
|
||||
if not kv_cache_only:
|
||||
if split_dim == -1:
|
||||
save_split(
|
||||
np.split(vals["scale_w_quant_orig.col"],
|
||||
split_factor,
|
||||
axis=split_dim), dir,
|
||||
f"{base_key}.scale_w_quant_orig.col", tp_rank, split_factor)
|
||||
save_split(
|
||||
np.split(vals["scale_y_accum_quant.col"],
|
||||
split_factor,
|
||||
axis=split_dim), dir,
|
||||
f"{base_key}.scale_y_accum_quant.col", tp_rank, split_factor)
|
||||
else:
|
||||
saved_keys_once += [
|
||||
"scale_w_quant_orig.col", "scale_y_accum_quant.col"
|
||||
]
|
||||
|
||||
if tp_rank == 0:
|
||||
for save_key in saved_keys_once:
|
||||
save_val(vals[save_key], dir, f"{base_key}.{save_key}")
|
||||
|
||||
|
||||
# Note: in multi_query_mode, only query heads are split between multiple GPUs, while key/value head
|
||||
# are not split as there is only one head per key/value.
|
||||
@torch.no_grad()
|
||||
def split_and_save_weight(tp_rank, saved_dir, split_factor, key, vals,
|
||||
storage_type, act_range, config):
|
||||
use_attention_nemo_shape = config.get("use_attention_nemo_shape", False)
|
||||
split_gated_activation = config.get("split_gated_activation", False)
|
||||
num_attention_heads = config.get("num_attention_heads", 0)
|
||||
tp_size = config.get("tp_size", 1)
|
||||
int8_outputs = config.get("int8_outputs", None)
|
||||
multi_query_mode = config.get("multi_query_mode", False)
|
||||
local_dim = config.get("local_dim", None)
|
||||
|
||||
save_int8 = int8_outputs == "all" or int8_outputs == "kv_cache_only"
|
||||
|
||||
if not key.endswith(".smoother"):
|
||||
if not isinstance(vals, list):
|
||||
vals = [vals]
|
||||
|
||||
if config.get("transpose_weights", False) and vals[0].ndim == 2:
|
||||
vals = [val.T for val in vals]
|
||||
if "layernorm.weight" in key and config.get("apply_layernorm_1p",
|
||||
False):
|
||||
vals = [val + 1.0 for val in vals]
|
||||
vals = [torch_to_numpy(val.cpu().to(storage_type)) for val in vals]
|
||||
else:
|
||||
vals = torch_to_numpy(vals.cpu())
|
||||
|
||||
if "ln_1.weight" in key or "ln_1.bias" in key or \
|
||||
"attention.dense.bias" in key or \
|
||||
"ln_2.weight" in key or "ln_2.bias" in key or \
|
||||
"mlp.c_proj.bias" in key or "ln_f.weight" in key:
|
||||
# "final_layernorm.weight" in key or "final_layernorm.bias" in key:
|
||||
|
||||
# shared weights, only need to convert the weights of rank 0
|
||||
if tp_rank == 0:
|
||||
save_val(vals[0], saved_dir, key)
|
||||
|
||||
elif "attention.dense.weight" in key or "mlp.c_proj.weight" in key:
|
||||
cat_dim = 0
|
||||
val = np.concatenate(vals, axis=cat_dim)
|
||||
split_vals = np.split(val, split_factor, axis=cat_dim)
|
||||
save_split(split_vals, saved_dir, key, tp_rank, split_factor)
|
||||
if act_range is not None and int8_outputs == "all":
|
||||
base_key = key.replace(".weight", "")
|
||||
vals_i8 = generate_int8(val,
|
||||
act_range,
|
||||
multi_query_mode=multi_query_mode)
|
||||
write_int8(vals_i8, saved_dir, base_key, cat_dim, tp_rank,
|
||||
split_factor)
|
||||
|
||||
elif "mlp.w1.weight" in key or "mlp.w2.weight" in key or "mlp.w1.bias" in key or "mlp.w2.bias" in key:
|
||||
if split_gated_activation:
|
||||
splits = [np.split(val, 2, axis=-1) for val in vals]
|
||||
vals, gates = list(zip(*splits))
|
||||
cat_dim = -1
|
||||
val = np.concatenate(vals, axis=cat_dim)
|
||||
split_vals = np.split(val, split_factor, axis=cat_dim)
|
||||
save_split(split_vals, saved_dir, key, tp_rank, split_factor)
|
||||
if act_range is not None and int8_outputs == "all":
|
||||
base_key = key.replace(".weight", "")
|
||||
vals_i8 = generate_int8(val,
|
||||
act_range,
|
||||
multi_query_mode=multi_query_mode)
|
||||
write_int8(vals_i8, saved_dir, base_key, cat_dim, tp_rank,
|
||||
split_factor)
|
||||
|
||||
if split_gated_activation:
|
||||
assert not save_int8
|
||||
prefix, dot, suffix = key.rpartition(".")
|
||||
key = prefix + ".gate" + dot + suffix
|
||||
|
||||
gate = np.concatenate(gates, axis=cat_dim)
|
||||
split_vals = np.split(gate, split_factor, axis=cat_dim)
|
||||
save_split(split_vals, saved_dir, key, tp_rank, split_factor)
|
||||
|
||||
elif "attention.qkv.bias" in key:
|
||||
if local_dim is None:
|
||||
local_dim = vals[0].shape[-1] // 3
|
||||
|
||||
if multi_query_mode:
|
||||
val = vals[0]
|
||||
# out_feature = local_dim + 2 * head_size; assumes local_dim equals to hidden_dim
|
||||
b_q, b_kv = np.split(val, [local_dim], axis=-1)
|
||||
b_q_split = np.split(b_q, split_factor, axis=-1)
|
||||
split_vals = [np.concatenate((i, b_kv), axis=-1) for i in b_q_split]
|
||||
else:
|
||||
if use_attention_nemo_shape:
|
||||
head_num = num_attention_heads // tp_size
|
||||
size_per_head = local_dim // num_attention_heads
|
||||
nemo_shape = (head_num, 3, size_per_head)
|
||||
vals = [val.reshape(nemo_shape) for val in vals]
|
||||
vals = [val.transpose(1, 0, 2) for val in vals]
|
||||
|
||||
vals = [val.reshape(3, local_dim) for val in vals]
|
||||
val = np.concatenate(vals, axis=-1)
|
||||
split_vals = np.split(val, split_factor, axis=-1)
|
||||
save_split(split_vals, saved_dir, key, tp_rank, split_factor)
|
||||
|
||||
elif "attention.qkv.weight" in key:
|
||||
hidden_dim = vals[0].shape[0]
|
||||
if local_dim is None:
|
||||
local_dim = vals[0].shape[-1] // 3
|
||||
if multi_query_mode:
|
||||
val = vals[0]
|
||||
# out_feature = local_dim + 2 * head_size; assumes local_dim equals to hidden_dim
|
||||
head_size = (val.shape[-1] - local_dim) // 2
|
||||
val = val.reshape(hidden_dim, local_dim + 2 * head_size)
|
||||
w_q, w_kv = np.split(val, [local_dim], axis=-1)
|
||||
w_q_split = np.split(w_q, split_factor, axis=-1)
|
||||
split_vals = [np.concatenate((i, w_kv), axis=-1) for i in w_q_split]
|
||||
else:
|
||||
if use_attention_nemo_shape:
|
||||
head_num = num_attention_heads // tp_size
|
||||
size_per_head = hidden_dim // num_attention_heads
|
||||
vals = [
|
||||
val.reshape(hidden_dim, head_num, 3, size_per_head)
|
||||
for val in vals
|
||||
]
|
||||
vals = [val.transpose(0, 2, 1, 3) for val in vals]
|
||||
|
||||
vals = [val.reshape(hidden_dim, 3, local_dim) for val in vals]
|
||||
cat_dim = -1
|
||||
val = np.concatenate(vals, axis=cat_dim)
|
||||
split_vals = np.split(val, split_factor, axis=cat_dim)
|
||||
save_split(split_vals, saved_dir, key, tp_rank, split_factor)
|
||||
if save_int8:
|
||||
base_key = key.replace(".weight", "")
|
||||
vals_i8 = generate_int8(val,
|
||||
act_range,
|
||||
is_qkv=True,
|
||||
multi_query_mode=multi_query_mode)
|
||||
write_int8(vals_i8,
|
||||
saved_dir,
|
||||
base_key,
|
||||
cat_dim,
|
||||
tp_rank,
|
||||
split_factor,
|
||||
kv_cache_only=int8_outputs == "kv_cache_only")
|
||||
|
||||
elif "attention.dense.smoother" in key or "mlp.c_proj.smoother" in key:
|
||||
split_vals = np.split(vals, split_factor, axis=0)
|
||||
save_split(split_vals, saved_dir, key, tp_rank, split_factor)
|
||||
else:
|
||||
print(f"[WARNING] {key} not handled by converter")
|
||||
134
examples/qwen/utils/utils.py
Normal file
134
examples/qwen/utils/utils.py
Normal file
@@ -0,0 +1,134 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from typing import List, Tuple
|
||||
|
||||
from transformers import PreTrainedTokenizer
|
||||
|
||||
|
||||
def make_context(
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
query: str,
|
||||
history: List[Tuple[str, str]] = None,
|
||||
system: str = "You are a helpful assistant.",
|
||||
max_input_length:
|
||||
int = 2048, # if you want to change this, you need to change the max_input_len in tensorrt_llm_july-release-v1/examples/qwen/build.py
|
||||
max_window_size: int = 6144,
|
||||
chat_format: str = "chatml",
|
||||
):
|
||||
if history is None:
|
||||
history = []
|
||||
|
||||
if chat_format == "chatml":
|
||||
im_start, im_end = "<|im_start|>", "<|im_end|>"
|
||||
im_start_tokens = [tokenizer.im_start_id]
|
||||
im_end_tokens = [tokenizer.im_end_id]
|
||||
nl_tokens = tokenizer.encode("\n")
|
||||
|
||||
def _tokenize_str(role, content):
|
||||
return (f"{role}\n{content}",
|
||||
tokenizer.encode(
|
||||
role,
|
||||
allowed_special=set(),
|
||||
) + nl_tokens + tokenizer.encode(
|
||||
content,
|
||||
allowed_special=set(),
|
||||
))
|
||||
|
||||
system_text, system_tokens_part = _tokenize_str("system", system)
|
||||
system_tokens = im_start_tokens + system_tokens_part + im_end_tokens
|
||||
raw_text = ""
|
||||
context_tokens = []
|
||||
|
||||
for turn_query, turn_response in reversed(history):
|
||||
query_text, query_tokens_part = _tokenize_str("user", turn_query)
|
||||
query_tokens = im_start_tokens + query_tokens_part + im_end_tokens
|
||||
|
||||
response_text, response_tokens_part = _tokenize_str(
|
||||
"assistant", turn_response)
|
||||
response_tokens = im_start_tokens + response_tokens_part + im_end_tokens
|
||||
next_context_tokens = nl_tokens + query_tokens + nl_tokens + response_tokens
|
||||
prev_chat = (
|
||||
f"\n{im_start}{query_text}{im_end}\n{im_start}{response_text}{im_end}"
|
||||
)
|
||||
|
||||
current_context_size = (len(system_tokens) +
|
||||
len(next_context_tokens) +
|
||||
len(context_tokens))
|
||||
if current_context_size < max_window_size:
|
||||
context_tokens = next_context_tokens + context_tokens
|
||||
raw_text = prev_chat + raw_text
|
||||
else:
|
||||
break
|
||||
|
||||
context_tokens = system_tokens + context_tokens
|
||||
raw_text = f"{im_start}{system_text}{im_end}" + raw_text
|
||||
context_tokens += (nl_tokens + im_start_tokens +
|
||||
_tokenize_str("user", query)[1] + im_end_tokens +
|
||||
nl_tokens + im_start_tokens +
|
||||
tokenizer.encode("assistant") + nl_tokens)
|
||||
raw_text += f"\n{im_start}user\n{query}{im_end}\n{im_start}assistant\n"
|
||||
|
||||
elif chat_format == "raw":
|
||||
raw_text = query
|
||||
context_tokens = tokenizer.encode(raw_text)
|
||||
else:
|
||||
raise NotImplementedError(f"Unknown chat format {chat_format!r}")
|
||||
# truncate to max_input_length, truncate from the front
|
||||
return raw_text, context_tokens[-max_input_length:]
|
||||
|
||||
|
||||
def _decode_chatml(tokens: List[int],
|
||||
stop_words: List[str],
|
||||
eod_token_ids: List[int],
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
raw_text_len: int,
|
||||
context_length: int,
|
||||
verbose: bool = False,
|
||||
return_end_reason: bool = False,
|
||||
errors: str = 'replace'):
|
||||
end_reason = f"Gen length {len(tokens)}"
|
||||
eod_token_idx = context_length
|
||||
for eod_token_idx in range(context_length, len(tokens)):
|
||||
if tokens[eod_token_idx] in eod_token_ids:
|
||||
end_reason = f"Gen {tokenizer.decode([tokens[eod_token_idx]])!r}"
|
||||
break
|
||||
|
||||
trim_decode_tokens = tokenizer.decode(tokens[:eod_token_idx],
|
||||
errors=errors)[raw_text_len:]
|
||||
if verbose:
|
||||
print("\nRaw Generate w/o EOD:",
|
||||
tokenizer.decode(tokens, errors=errors)[raw_text_len:])
|
||||
print("\nRaw Generate:", trim_decode_tokens)
|
||||
print("\nEnd Reason:", end_reason)
|
||||
for stop_word in stop_words:
|
||||
trim_decode_tokens = trim_decode_tokens.replace(stop_word, "").strip()
|
||||
trim_decode_tokens = trim_decode_tokens.strip()
|
||||
if verbose:
|
||||
print("\nGenerate:", trim_decode_tokens)
|
||||
|
||||
if return_end_reason:
|
||||
return trim_decode_tokens, end_reason
|
||||
else:
|
||||
return trim_decode_tokens
|
||||
|
||||
|
||||
def get_stop_words_ids(chat_format, tokenizer):
|
||||
if chat_format == "raw":
|
||||
stop_words_ids = [tokenizer.encode("Human:"), [tokenizer.eod_id]]
|
||||
elif chat_format == "chatml":
|
||||
stop_words_ids = [[tokenizer.im_end_id], [tokenizer.im_start_id]]
|
||||
else:
|
||||
raise NotImplementedError(f"Unknown chat format {chat_format!r}")
|
||||
return stop_words_ids
|
||||
166
examples/rouge.py
Normal file
166
examples/rouge.py
Normal file
@@ -0,0 +1,166 @@
|
||||
# Copyright 2020 The HuggingFace Evaluate Authors.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" ROUGE metric from Google Research github repo. """
|
||||
|
||||
# The dependencies in https://github.com/google-research/google-research/blob/master/rouge/requirements.txt
|
||||
import absl # Here to have a nice missing dependency error message early on
|
||||
import datasets
|
||||
import evaluate
|
||||
import nltk # Here to have a nice missing dependency error message early on
|
||||
import numpy # Here to have a nice missing dependency error message early on
|
||||
import six # Here to have a nice missing dependency error message early on
|
||||
from rouge_score import rouge_scorer, scoring
|
||||
|
||||
_CITATION = """\
|
||||
@inproceedings{lin-2004-rouge,
|
||||
title = "{ROUGE}: A Package for Automatic Evaluation of Summaries",
|
||||
author = "Lin, Chin-Yew",
|
||||
booktitle = "Text Summarization Branches Out",
|
||||
month = jul,
|
||||
year = "2004",
|
||||
address = "Barcelona, Spain",
|
||||
publisher = "Association for Computational Linguistics",
|
||||
url = "https://www.aclweb.org/anthology/W04-1013",
|
||||
pages = "74--81",
|
||||
}
|
||||
"""
|
||||
|
||||
_DESCRIPTION = """\
|
||||
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics and a software package used for
|
||||
evaluating automatic summarization and machine translation software in natural language processing.
|
||||
The metrics compare an automatically produced summary or translation against a reference or a set of references (human-produced) summary or translation.
|
||||
|
||||
Note that ROUGE is case insensitive, meaning that upper case letters are treated the same way as lower case letters.
|
||||
|
||||
This metrics is a wrapper around Google Research reimplementation of ROUGE:
|
||||
https://github.com/google-research/google-research/tree/master/rouge
|
||||
"""
|
||||
|
||||
_KWARGS_DESCRIPTION = """
|
||||
Calculates average rouge scores for a list of hypotheses and references
|
||||
Args:
|
||||
predictions: list of predictions to score. Each prediction
|
||||
should be a string with tokens separated by spaces.
|
||||
references: list of reference for each prediction. Each
|
||||
reference should be a string with tokens separated by spaces.
|
||||
rouge_types: A list of rouge types to calculate.
|
||||
Valid names:
|
||||
`"rouge{n}"` (e.g. `"rouge1"`, `"rouge2"`) where: {n} is the n-gram based scoring,
|
||||
`"rougeL"`: Longest common subsequence based scoring.
|
||||
`"rougeLsum"`: rougeLsum splits text using `"\n"`.
|
||||
See details in https://github.com/huggingface/datasets/issues/617
|
||||
use_stemmer: Bool indicating whether Porter stemmer should be used to strip word suffixes.
|
||||
use_aggregator: Return aggregates if this is set to True
|
||||
Returns:
|
||||
rouge1: rouge_1 (f1),
|
||||
rouge2: rouge_2 (f1),
|
||||
rougeL: rouge_l (f1),
|
||||
rougeLsum: rouge_lsum (f1)
|
||||
Examples:
|
||||
|
||||
>>> rouge = evaluate.load('rouge')
|
||||
>>> predictions = ["hello there", "general kenobi"]
|
||||
>>> references = ["hello there", "general kenobi"]
|
||||
>>> results = rouge.compute(predictions=predictions, references=references)
|
||||
>>> print(results)
|
||||
{'rouge1': 1.0, 'rouge2': 1.0, 'rougeL': 1.0, 'rougeLsum': 1.0}
|
||||
"""
|
||||
|
||||
|
||||
class Tokenizer:
|
||||
"""Helper class to wrap a callable into a class with a `tokenize` method as used by rouge-score."""
|
||||
|
||||
def __init__(self, tokenizer_func):
|
||||
self.tokenizer_func = tokenizer_func
|
||||
|
||||
def tokenize(self, text):
|
||||
return self.tokenizer_func(text)
|
||||
|
||||
|
||||
@evaluate.utils.file_utils.add_start_docstrings(_DESCRIPTION,
|
||||
_KWARGS_DESCRIPTION)
|
||||
class Rouge(evaluate.Metric):
|
||||
|
||||
def _info(self):
|
||||
return evaluate.MetricInfo(
|
||||
description=_DESCRIPTION,
|
||||
citation=_CITATION,
|
||||
inputs_description=_KWARGS_DESCRIPTION,
|
||||
features=[
|
||||
datasets.Features({
|
||||
"predictions":
|
||||
datasets.Value("string", id="sequence"),
|
||||
"references":
|
||||
datasets.Sequence(datasets.Value("string", id="sequence")),
|
||||
}),
|
||||
datasets.Features({
|
||||
"predictions":
|
||||
datasets.Value("string", id="sequence"),
|
||||
"references":
|
||||
datasets.Value("string", id="sequence"),
|
||||
}),
|
||||
],
|
||||
codebase_urls=[
|
||||
"https://github.com/google-research/google-research/tree/master/rouge"
|
||||
],
|
||||
reference_urls=[
|
||||
"https://en.wikipedia.org/wiki/ROUGE_(metric)",
|
||||
"https://github.com/google-research/google-research/tree/master/rouge",
|
||||
],
|
||||
)
|
||||
|
||||
def _compute(self,
|
||||
predictions,
|
||||
references,
|
||||
rouge_types=None,
|
||||
use_aggregator=True,
|
||||
use_stemmer=False,
|
||||
tokenizer=None):
|
||||
if rouge_types is None:
|
||||
rouge_types = ["rouge1", "rouge2", "rougeL", "rougeLsum"]
|
||||
|
||||
multi_ref = isinstance(references[0], list)
|
||||
|
||||
if tokenizer is not None:
|
||||
tokenizer = Tokenizer(tokenizer)
|
||||
|
||||
scorer = rouge_scorer.RougeScorer(rouge_types=rouge_types,
|
||||
use_stemmer=use_stemmer,
|
||||
tokenizer=tokenizer)
|
||||
if use_aggregator:
|
||||
aggregator = scoring.BootstrapAggregator()
|
||||
else:
|
||||
scores = []
|
||||
|
||||
for ref, pred in zip(references, predictions):
|
||||
if multi_ref:
|
||||
score = scorer.score_multi(ref, pred)
|
||||
else:
|
||||
score = scorer.score(ref, pred)
|
||||
if use_aggregator:
|
||||
aggregator.add_scores(score)
|
||||
else:
|
||||
scores.append(score)
|
||||
|
||||
if use_aggregator:
|
||||
result = aggregator.aggregate()
|
||||
for key in result:
|
||||
result[key] = result[key].mid.fmeasure
|
||||
|
||||
else:
|
||||
result = {}
|
||||
for key in scores[0]:
|
||||
result[key] = list(score[key].fmeasure for score in scores)
|
||||
|
||||
return result
|
||||
397
examples/run.py
Normal file
397
examples/run.py
Normal file
@@ -0,0 +1,397 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import csv
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from utils import (DEFAULT_HF_MODEL_DIRS, DEFAULT_PROMPT_TEMPLATES,
|
||||
load_tokenizer, read_model_name_from_config,
|
||||
throttle_generator)
|
||||
|
||||
import xtrt_llm
|
||||
from xtrt_llm.logger import logger
|
||||
from xtrt_llm.runtime import ModelRunner, read_config
|
||||
|
||||
|
||||
def parse_arguments(args=None):
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--max_output_len', type=int, required=True)
|
||||
parser.add_argument('--max_kv_cache_length',
|
||||
type=int,
|
||||
default=None,
|
||||
help='The max kv cache length. \
|
||||
If the final sequence length exceeds the kv cache length, we will enable cyclic kv cache. \
|
||||
If it is set to None, we will use the max sequence length.')
|
||||
parser.add_argument('--log_level', type=str, default='error')
|
||||
parser.add_argument('--engine_dir', type=str, default='engine_outputs')
|
||||
parser.add_argument(
|
||||
'--input_text',
|
||||
type=str,
|
||||
nargs='+',
|
||||
default=["Born in north-east France, Soyer trained as a"])
|
||||
parser.add_argument(
|
||||
'--no_prompt_template',
|
||||
dest='use_prompt_template',
|
||||
default=True,
|
||||
action='store_false',
|
||||
help=
|
||||
"Whether or not to use default prompt template to wrap the input text.")
|
||||
parser.add_argument(
|
||||
'--input_file',
|
||||
type=str,
|
||||
help=
|
||||
'CSV or Numpy file containing tokenized input. Alternative to text input.',
|
||||
default=None)
|
||||
parser.add_argument('--max_input_length', type=int, default=923)
|
||||
parser.add_argument('--output_csv',
|
||||
type=str,
|
||||
help='CSV file where the tokenized output is stored.',
|
||||
default=None)
|
||||
parser.add_argument('--output_npy',
|
||||
type=str,
|
||||
help='Numpy file where the tokenized output is stored.',
|
||||
default=None)
|
||||
parser.add_argument(
|
||||
'--output_logits_npy',
|
||||
type=str,
|
||||
help=
|
||||
'Numpy file where the generation logits are stored. Use only when num_beams==1',
|
||||
default=None)
|
||||
parser.add_argument('--tokenizer_dir',
|
||||
help="HF tokenizer config path",
|
||||
default='gpt2')
|
||||
parser.add_argument('--vocab_file',
|
||||
help="Used for sentencepiece tokenizers")
|
||||
parser.add_argument('--num_beams',
|
||||
type=int,
|
||||
help="Use beam search if num_beams >1",
|
||||
default=1)
|
||||
parser.add_argument('--temperature', type=float, default=1.0)
|
||||
parser.add_argument('--top_k', type=int, default=1)
|
||||
parser.add_argument('--top_p', type=float, default=0.0)
|
||||
parser.add_argument('--length_penalty', type=float, default=1.0)
|
||||
parser.add_argument('--repetition_penalty', type=float, default=1.0)
|
||||
parser.add_argument('--debug_mode',
|
||||
default=False,
|
||||
action='store_true',
|
||||
help="Whether or not to turn on the debug mode")
|
||||
parser.add_argument('--no_add_special_tokens',
|
||||
dest='add_special_tokens',
|
||||
default=True,
|
||||
action='store_false',
|
||||
help="Whether or not to add special tokens")
|
||||
parser.add_argument('--streaming', default=False, action='store_true')
|
||||
parser.add_argument('--streaming_interval',
|
||||
type=int,
|
||||
help="How often to return tokens when streaming.",
|
||||
default=5)
|
||||
parser.add_argument(
|
||||
'--prompt_table_path',
|
||||
type=str,
|
||||
help="Path to .npy file, exported by nemo_prompt_convert.py")
|
||||
parser.add_argument(
|
||||
'--prompt_tasks',
|
||||
help="Comma-separated list of tasks for prompt tuning, e.g., 0,3,1,0")
|
||||
parser.add_argument('--lora_dir',
|
||||
type=str,
|
||||
default=None,
|
||||
help="The directory of LoRA weights")
|
||||
parser.add_argument(
|
||||
'--lora_task_uids',
|
||||
type=str,
|
||||
default=None,
|
||||
nargs="+",
|
||||
help="The list of LoRA task uids; use -1 to disable the LoRA module")
|
||||
parser.add_argument(
|
||||
'--performance_test_scale',
|
||||
type=str,
|
||||
help=
|
||||
"Scale for performance test. e.g., 8x1024x64 (batch_size, input_text_length, max_output_length)"
|
||||
)
|
||||
|
||||
return parser.parse_args(args=args)
|
||||
|
||||
|
||||
def parse_input(tokenizer,
|
||||
input_text=None,
|
||||
prompt_template=None,
|
||||
input_file=None,
|
||||
add_special_tokens=True,
|
||||
max_input_length=923,
|
||||
pad_id=None):
|
||||
if pad_id is None:
|
||||
pad_id = tokenizer.pad_token_id
|
||||
|
||||
batch_input_ids = []
|
||||
if input_file is None:
|
||||
for curr_text in input_text:
|
||||
if prompt_template is not None:
|
||||
curr_text = prompt_template.format(input_text=curr_text)
|
||||
input_ids = tokenizer.encode(curr_text,
|
||||
add_special_tokens=add_special_tokens,
|
||||
truncation=True,
|
||||
max_length=max_input_length)
|
||||
batch_input_ids.append(input_ids)
|
||||
else:
|
||||
if input_file.endswith('.csv'):
|
||||
with open(input_file, 'r') as csv_file:
|
||||
csv_reader = csv.reader(csv_file, delimiter=',')
|
||||
for line in csv_reader:
|
||||
input_ids = np.array(line, dtype='int32')
|
||||
batch_input_ids.append(input_ids[-max_input_length:])
|
||||
elif input_file.endswith('.npy'):
|
||||
inputs = np.load(input_file)
|
||||
for row in inputs:
|
||||
input_ids = row[row != pad_id]
|
||||
batch_input_ids.append(input_ids[-max_input_length:])
|
||||
elif input_file.endswith('.txt'):
|
||||
with open(input_file, 'r', encoding='utf-8',
|
||||
errors='replace') as txt_file:
|
||||
input_text = txt_file.read()
|
||||
input_ids = tokenizer.encode(
|
||||
input_text,
|
||||
add_special_tokens=add_special_tokens,
|
||||
truncation=True,
|
||||
max_length=max_input_length)
|
||||
batch_input_ids.append(input_ids)
|
||||
else:
|
||||
print('Input file format not supported.')
|
||||
raise SystemExit
|
||||
|
||||
batch_input_ids = [
|
||||
torch.tensor(x, dtype=torch.int32).unsqueeze(0) for x in batch_input_ids
|
||||
]
|
||||
return batch_input_ids
|
||||
|
||||
|
||||
def print_output(tokenizer,
|
||||
output_ids,
|
||||
input_lengths,
|
||||
sequence_lengths,
|
||||
output_csv=None,
|
||||
output_npy=None,
|
||||
context_logits=None,
|
||||
generation_logits=None,
|
||||
output_logits_npy=None):
|
||||
batch_size, num_beams, _ = output_ids.size()
|
||||
if output_csv is None and output_npy is None:
|
||||
for batch_idx in range(batch_size):
|
||||
inputs = output_ids[batch_idx][0][:input_lengths[batch_idx]].tolist(
|
||||
)
|
||||
input_text = tokenizer.decode(inputs)
|
||||
print(f'Input idx: [Text {batch_idx}]')
|
||||
print(f'Input: \"{input_text}\"')
|
||||
for beam in range(num_beams):
|
||||
output_begin = input_lengths[batch_idx]
|
||||
output_end = sequence_lengths[batch_idx][beam]
|
||||
outputs = output_ids[batch_idx][beam][
|
||||
output_begin:output_end].tolist()
|
||||
output_text = tokenizer.decode(outputs)
|
||||
print(f'Output idx: [Text {batch_idx} Beam {beam}]')
|
||||
print(f'Output: \"{output_text}\"')
|
||||
|
||||
output_ids = output_ids.reshape((-1, output_ids.size(2)))
|
||||
|
||||
if output_csv is not None:
|
||||
output_file = Path(output_csv)
|
||||
output_file.parent.mkdir(exist_ok=True, parents=True)
|
||||
outputs = output_ids.tolist()
|
||||
with open(output_file, 'w') as csv_file:
|
||||
writer = csv.writer(csv_file, delimiter=',')
|
||||
writer.writerows(outputs)
|
||||
|
||||
if output_npy is not None:
|
||||
output_file = Path(output_npy)
|
||||
output_file.parent.mkdir(exist_ok=True, parents=True)
|
||||
outputs = np.array(output_ids.cpu().contiguous(), dtype='int32')
|
||||
np.save(output_file, outputs)
|
||||
|
||||
if generation_logits is not None and output_logits_npy is not None and num_beams == 1:
|
||||
input_lengths = torch.Tensor(input_lengths)
|
||||
context_logits = torch.cat(context_logits, axis=0)
|
||||
generation_logits = [logit.unsqueeze(1) for logit in generation_logits]
|
||||
generation_logits = torch.cat(generation_logits, axis=1)
|
||||
last_token_ids = torch.cumsum(input_lengths, dim=0).int().cuda()
|
||||
batch_size = input_lengths.size(0)
|
||||
vocab_size_padded = context_logits.shape[-1]
|
||||
context_logits = context_logits.reshape([1, -1, vocab_size_padded])
|
||||
context_logits = torch.index_select(context_logits, 1,
|
||||
last_token_ids - 1).view(
|
||||
batch_size, 1,
|
||||
vocab_size_padded)
|
||||
logits = torch.cat([context_logits, generation_logits], axis=1)
|
||||
logits = logits.reshape(-1, num_beams, logits.shape[1], logits.shape[2])
|
||||
output_file = Path(output_logits_npy)
|
||||
output_file.parent.mkdir(exist_ok=True, parents=True)
|
||||
outputs = np.array(logits.cpu().contiguous(), dtype='float32')
|
||||
np.save(output_file, outputs)
|
||||
|
||||
|
||||
def main(args):
|
||||
runtime_rank = xtrt_llm.mpi_rank()
|
||||
logger.set_level(args.log_level)
|
||||
|
||||
model_name = read_model_name_from_config(
|
||||
Path(args.engine_dir) / "config.json")
|
||||
if args.tokenizer_dir is None:
|
||||
args.tokenizer_dir = DEFAULT_HF_MODEL_DIRS[model_name]
|
||||
_, other_cfg = read_config(Path(args.engine_dir) / "config.json")
|
||||
tp_size, pp_size = other_cfg["tp_size"], other_cfg["pp_size"]
|
||||
world_size = tp_size * pp_size
|
||||
if world_size > 1:
|
||||
os.environ["XCCL_GROUP_ID"] = str(runtime_rank // world_size)
|
||||
os.environ["XCCL_NRANKS"] = str(world_size)
|
||||
os.environ["XCCL_CUR_RANK"] = str(runtime_rank % world_size)
|
||||
os.environ["XCCL_DEVICE_ID"] = str(runtime_rank)
|
||||
os.environ["MP_RUN"] = str(1)
|
||||
|
||||
tokenizer, pad_id, end_id = load_tokenizer(
|
||||
tokenizer_dir=args.tokenizer_dir,
|
||||
vocab_file=args.vocab_file,
|
||||
model_name=model_name,
|
||||
)
|
||||
|
||||
runner = ModelRunner.from_dir(engine_dir=args.engine_dir,
|
||||
lora_dir=args.lora_dir,
|
||||
rank=runtime_rank,
|
||||
debug_mode=args.debug_mode)
|
||||
|
||||
# # An example to stop generation when the model generate " London" on first sentence, " eventually became" on second sentence
|
||||
stop_words_list = [["<|endoftext|>"]]
|
||||
stop_words_list = xtrt_llm.runtime.to_word_list_format(
|
||||
stop_words_list, tokenizer)
|
||||
stop_words_list = torch.Tensor(stop_words_list).to(
|
||||
torch.int32).to("cuda").contiguous()
|
||||
# stop_words_list = None
|
||||
|
||||
# # An example to prevent generating " chef" on first sentence, " eventually" and " chef before" on second sentence
|
||||
# bad_words_list = [[" chef"], [" eventually, chef before"]]
|
||||
# bad_words_list = xtrt_llm.runtime.to_word_list_format(bad_words_list, tokenizer)
|
||||
# bad_words_list = torch.Tensor(bad_words_list).to(torch.int32).to("cuda").contiguous()
|
||||
bad_words_list = None
|
||||
|
||||
if args.use_prompt_template and model_name in DEFAULT_PROMPT_TEMPLATES:
|
||||
prompt_template = DEFAULT_PROMPT_TEMPLATES[model_name]
|
||||
else:
|
||||
prompt_template = None
|
||||
if args.performance_test_scale is not None:
|
||||
performance_test_scale_list = args.performance_test_scale.split("E")
|
||||
for scale in performance_test_scale_list:
|
||||
xtrt_llm.logger.info(f"Running performance test with scale {scale}")
|
||||
import time
|
||||
_t_s = time.time()
|
||||
bs, seqlen, _max_output_len = [int(x) for x in scale.split("x")]
|
||||
batch_input_ids = [
|
||||
torch.from_numpy(np.zeros((seqlen, )).astype("int32"))
|
||||
for _ in range(bs)
|
||||
]
|
||||
with torch.no_grad():
|
||||
outputs = runner.generate(
|
||||
batch_input_ids,
|
||||
max_new_tokens=_max_output_len,
|
||||
max_kv_cache_length=args.max_kv_cache_length,
|
||||
end_id=end_id,
|
||||
pad_id=pad_id,
|
||||
temperature=args.temperature,
|
||||
top_k=args.top_k,
|
||||
top_p=args.top_p,
|
||||
num_beams=args.num_beams,
|
||||
length_penalty=args.length_penalty,
|
||||
repetition_penalty=args.repetition_penalty,
|
||||
stop_words_list=stop_words_list,
|
||||
bad_words_list=bad_words_list,
|
||||
lora_uids=args.lora_task_uids,
|
||||
prompt_table_path=args.prompt_table_path,
|
||||
prompt_tasks=args.prompt_tasks,
|
||||
streaming=args.streaming,
|
||||
output_sequence_lengths=True,
|
||||
return_dict=True)
|
||||
torch.cuda.synchronize()
|
||||
_t_e = time.time()
|
||||
xtrt_llm.logger.info(
|
||||
f"Total latency: {(_t_e - _t_s)* 1000 :.3f} ms")
|
||||
exit(0)
|
||||
else:
|
||||
batch_input_ids = parse_input(
|
||||
tokenizer=tokenizer,
|
||||
input_text=args.input_text,
|
||||
prompt_template=prompt_template,
|
||||
input_file=args.input_file,
|
||||
add_special_tokens=args.add_special_tokens,
|
||||
max_input_length=args.max_input_length,
|
||||
pad_id=pad_id)
|
||||
input_lengths = [x.size(1) for x in batch_input_ids]
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = runner.generate(
|
||||
batch_input_ids,
|
||||
max_new_tokens=args.max_output_len,
|
||||
max_kv_cache_length=args.max_kv_cache_length,
|
||||
end_id=end_id,
|
||||
pad_id=pad_id,
|
||||
temperature=args.temperature,
|
||||
top_k=args.top_k,
|
||||
top_p=args.top_p,
|
||||
num_beams=args.num_beams,
|
||||
length_penalty=args.length_penalty,
|
||||
repetition_penalty=args.repetition_penalty,
|
||||
stop_words_list=stop_words_list,
|
||||
bad_words_list=bad_words_list,
|
||||
lora_uids=args.lora_task_uids,
|
||||
prompt_table_path=args.prompt_table_path,
|
||||
prompt_tasks=args.prompt_tasks,
|
||||
streaming=args.streaming,
|
||||
output_sequence_lengths=True,
|
||||
return_dict=True)
|
||||
torch.cuda.synchronize()
|
||||
|
||||
if runtime_rank == 0:
|
||||
if args.streaming:
|
||||
for curr_outputs in throttle_generator(outputs,
|
||||
args.streaming_interval):
|
||||
output_ids = curr_outputs['output_ids']
|
||||
sequence_lengths = curr_outputs['sequence_lengths']
|
||||
print_output(tokenizer,
|
||||
output_ids,
|
||||
input_lengths,
|
||||
sequence_lengths,
|
||||
output_csv=args.output_csv,
|
||||
output_npy=args.output_npy)
|
||||
else:
|
||||
output_ids = outputs['output_ids']
|
||||
sequence_lengths = outputs['sequence_lengths']
|
||||
context_logits = None
|
||||
generation_logits = None
|
||||
if runner.session.gather_all_token_logits:
|
||||
context_logits = outputs['context_logits']
|
||||
generation_logits = outputs['generation_logits']
|
||||
print_output(tokenizer,
|
||||
output_ids,
|
||||
input_lengths,
|
||||
sequence_lengths,
|
||||
output_csv=args.output_csv,
|
||||
output_npy=args.output_npy,
|
||||
context_logits=context_logits,
|
||||
generation_logits=generation_logits,
|
||||
output_logits_npy=args.output_logits_npy)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = parse_arguments()
|
||||
main(args)
|
||||
551
examples/summarize.py
Normal file
551
examples/summarize.py
Normal file
@@ -0,0 +1,551 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
import evaluate
|
||||
import numpy as np
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from qwen.utils.utils import make_context
|
||||
from transformers import (AutoModel, AutoModelForCausalLM,
|
||||
AutoModelForSeq2SeqLM, GenerationConfig)
|
||||
from utils import (DEFAULT_HF_MODEL_DIRS, load_tokenizer,
|
||||
read_model_name_from_config)
|
||||
|
||||
import xtrt_llm as tensorrt_llm
|
||||
import xtrt_llm.profiler as profiler
|
||||
from xtrt_llm._utils import str_dtype_to_torch
|
||||
from xtrt_llm.logger import logger
|
||||
from xtrt_llm.runtime import ModelRunner
|
||||
from xtrt_llm.tools.ppl import ppl
|
||||
|
||||
|
||||
def main(args):
|
||||
runtime_rank = tensorrt_llm.mpi_rank()
|
||||
logger.set_level(args.log_level)
|
||||
|
||||
model_name = read_model_name_from_config(
|
||||
Path(args.engine_dir) / "config.json")
|
||||
if args.hf_model_dir is None:
|
||||
args.hf_model_dir = DEFAULT_HF_MODEL_DIRS[model_name]
|
||||
if args.tokenizer_dir is None:
|
||||
args.tokenizer_dir = args.hf_model_dir
|
||||
|
||||
test_hf = args.test_hf and runtime_rank == 0 # only run hf on rank 0
|
||||
test_trt_llm = args.test_trt_llm
|
||||
profiler.start('load tokenizer')
|
||||
tokenizer, pad_id, end_id = load_tokenizer(
|
||||
tokenizer_dir=args.tokenizer_dir,
|
||||
vocab_file=args.vocab_file,
|
||||
model_name=model_name,
|
||||
)
|
||||
profiler.stop('load tokenizer')
|
||||
logger.info(
|
||||
f'Load tokenizer takes: {profiler.elapsed_time_in_sec("load tokenizer")} sec'
|
||||
)
|
||||
|
||||
if args.eval_task == 'code_completion':
|
||||
dataset_name = "openai_humaneval"
|
||||
dataset_revision = None
|
||||
dataset_input_key = 'prompt'
|
||||
dataset_output_key = 'canonical_solution'
|
||||
dataset_split = 'test'
|
||||
elif args.eval_task == 'summarize':
|
||||
dataset_name = "ccdv/cnn_dailymail"
|
||||
dataset_revision = "3.0.0"
|
||||
dataset_input_key = 'article'
|
||||
dataset_output_key = 'highlights'
|
||||
dataset_split = 'test'
|
||||
elif args.eval_task == 'summarize_long':
|
||||
dataset_name = "tau/zero_scrolls"
|
||||
dataset_revision = 'squality'
|
||||
dataset_input_key = 'input'
|
||||
dataset_output_key = 'output'
|
||||
dataset_split = 'validation' # only this split contains reference strings
|
||||
dataset = load_dataset(dataset_name,
|
||||
dataset_revision,
|
||||
cache_dir=args.dataset_path,
|
||||
split=dataset_split,
|
||||
num_proc=os.cpu_count())
|
||||
|
||||
max_batch_size = args.batch_size
|
||||
|
||||
# runtime parameters
|
||||
top_k = args.top_k
|
||||
top_p = args.top_p
|
||||
output_len = args.output_len
|
||||
test_token_num = args.max_input_length
|
||||
# random_seed = 5
|
||||
temperature = args.temperature
|
||||
num_beams = args.num_beams
|
||||
length_penalty = args.length_penalty
|
||||
repetition_penalty = args.repetition_penalty
|
||||
|
||||
if test_trt_llm:
|
||||
runner = ModelRunner.from_dir(args.engine_dir,
|
||||
rank=runtime_rank,
|
||||
debug_mode=args.debug_mode)
|
||||
assert not (args.eval_ppl and not runner.session.gather_all_token_logits), \
|
||||
"PPL evaluation requires engine built with gather_all_token_logits enabled"
|
||||
|
||||
if test_hf:
|
||||
profiler.start('load HF model')
|
||||
dtype_alias_mapping = {
|
||||
'fp32': 'float32',
|
||||
'fp16': 'float16',
|
||||
'bf16': 'bfloat16'
|
||||
}
|
||||
args.data_type = dtype_alias_mapping.get(args.data_type, args.data_type)
|
||||
if model_name.startswith('chatglm'):
|
||||
auto_model_cls = AutoModel
|
||||
elif model_name.startswith('glm'):
|
||||
auto_model_cls = AutoModelForSeq2SeqLM
|
||||
else:
|
||||
auto_model_cls = AutoModelForCausalLM
|
||||
model = auto_model_cls.from_pretrained(
|
||||
args.hf_model_dir,
|
||||
trust_remote_code=True,
|
||||
torch_dtype=str_dtype_to_torch(args.data_type),
|
||||
device_map='auto' if args.hf_device_map_auto else None)
|
||||
model.to_bettertransformer()
|
||||
if not args.hf_device_map_auto:
|
||||
model.cuda()
|
||||
if model_name == 'qwen':
|
||||
model.generation_config = GenerationConfig.from_pretrained(
|
||||
args.hf_model_dir, trust_remote_code=True)
|
||||
profiler.stop('load HF model')
|
||||
logger.info(
|
||||
f'Load HF model takes: {profiler.elapsed_time_in_sec("load HF model")} sec'
|
||||
)
|
||||
|
||||
output_dir = Path(args.output_dir) if args.output_dir else None
|
||||
if output_dir is not None:
|
||||
output_dir.mkdir(exist_ok=True, parents=True)
|
||||
if test_trt_llm:
|
||||
with (output_dir / 'trtllm.out').open('w') as f:
|
||||
f.write(f'Engine path: {args.engine_dir}\n')
|
||||
f.write(f'Tokenizer path: {args.tokenizer_dir}\n')
|
||||
if test_hf:
|
||||
with (output_dir / 'hf.out').open('w') as f:
|
||||
f.write(f'Model path: {args.hf_model_dir}\n')
|
||||
f.write(f'Tokenizer path: {args.tokenizer_dir}\n')
|
||||
|
||||
def _prepare_inputs(batch_input_texts,
|
||||
eval_task='summarize',
|
||||
add_special_tokens=True):
|
||||
batch_size = len(batch_input_texts)
|
||||
append_str = ' TL;DR: ' if eval_task == 'summarize' else ''
|
||||
batch_input_ids = []
|
||||
for i in range(batch_size):
|
||||
curr_text = batch_input_texts[i] + append_str
|
||||
curr_text = curr_text.strip().replace(" n't", "n't")
|
||||
|
||||
# TODO: The below lines are used to be compatible with the original code; may need fix
|
||||
if model_name.startswith(('chatglm2', 'chatglm3')):
|
||||
input_ids = tokenizer.encode(curr_text, return_tensors='pt')
|
||||
input_ids = input_ids[:, :test_token_num]
|
||||
elif model_name == 'qwen':
|
||||
# use make_content to generate prompt
|
||||
system_prompt = "You are a useful assistant, please directly output the corresponding summary according to the article entered by the user."
|
||||
_, input_id_list = make_context(
|
||||
tokenizer=tokenizer,
|
||||
query=curr_text,
|
||||
history=[],
|
||||
system=system_prompt,
|
||||
max_input_length=test_token_num,
|
||||
)
|
||||
input_ids = torch.tensor(input_id_list).unsqueeze(0)
|
||||
else:
|
||||
input_ids = tokenizer.encode(
|
||||
curr_text,
|
||||
return_tensors='pt',
|
||||
add_special_tokens=add_special_tokens,
|
||||
truncation=True,
|
||||
max_length=test_token_num)
|
||||
|
||||
batch_input_ids.append(input_ids)
|
||||
return batch_input_ids
|
||||
|
||||
def eval_trt_llm(datapoint,
|
||||
eval_task='summarize',
|
||||
eval_ppl=False,
|
||||
add_special_tokens=True):
|
||||
batch_size = len(datapoint[dataset_input_key])
|
||||
batch_input_ids = _prepare_inputs(datapoint[dataset_input_key],
|
||||
eval_task=eval_task,
|
||||
add_special_tokens=add_special_tokens)
|
||||
input_lengths = [x.size(1) for x in batch_input_ids]
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = runner.generate(
|
||||
batch_input_ids,
|
||||
max_new_tokens=output_len,
|
||||
max_kv_cache_length=args.max_kv_cache_length,
|
||||
end_id=end_id,
|
||||
pad_id=pad_id,
|
||||
temperature=temperature,
|
||||
top_k=top_k,
|
||||
top_p=top_p,
|
||||
num_beams=num_beams,
|
||||
length_penalty=length_penalty,
|
||||
repetition_penalty=repetition_penalty,
|
||||
output_sequence_lengths=True,
|
||||
return_dict=True,
|
||||
stop_words_list=[end_id])
|
||||
torch.cuda.synchronize()
|
||||
|
||||
# Extract a list of tensors of shape beam_width x output_ids.
|
||||
if runner.session.mapping.is_first_pp_rank():
|
||||
output_ids = outputs['output_ids']
|
||||
output_beams_list = [
|
||||
tokenizer.batch_decode(output_ids[batch_idx, :,
|
||||
input_lengths[batch_idx]:],
|
||||
skip_special_tokens=True)
|
||||
for batch_idx in range(batch_size)
|
||||
]
|
||||
output_ids_list = [
|
||||
output_ids[batch_idx, :, input_lengths[batch_idx]:]
|
||||
for batch_idx in range(batch_size)
|
||||
]
|
||||
|
||||
ppls = []
|
||||
if eval_ppl:
|
||||
seq_lengths = outputs['sequence_lengths']
|
||||
context_logits = outputs['context_logits']
|
||||
# Remove the first generation logits which are same to last context logits
|
||||
generation_logits = torch.stack(
|
||||
outputs['generation_logits'][1:], dim=1)
|
||||
for bidx in range(batch_size):
|
||||
# [batch, beam, step]
|
||||
curr_len = seq_lengths[bidx, 0]
|
||||
curr_ctx_len = input_lengths[bidx]
|
||||
curr_gen_len = curr_len - curr_ctx_len
|
||||
|
||||
curr_ids = output_ids[bidx, 0, 1:curr_len]
|
||||
curr_logits = torch.cat([
|
||||
context_logits[bidx],
|
||||
generation_logits[bidx, :curr_gen_len - 1]
|
||||
],
|
||||
dim=0)
|
||||
curr_ppl = ppl(curr_logits, curr_ids)
|
||||
ppls.append(curr_ppl)
|
||||
logger.debug(
|
||||
f"XTRT-LLM PPL: {curr_ppl:.3f} | Generation length: {curr_gen_len}"
|
||||
)
|
||||
|
||||
return output_beams_list, output_ids_list, ppls
|
||||
return [], [], []
|
||||
|
||||
def eval_hf(datapoint,
|
||||
eval_task='summarize',
|
||||
eval_ppl=False,
|
||||
add_special_tokens=True):
|
||||
batch_size = len(datapoint[dataset_input_key])
|
||||
if batch_size > 1:
|
||||
logger.warning(
|
||||
f"HF does not support batch_size > 1 to verify correctness due to padding. Current batch size is {batch_size}"
|
||||
)
|
||||
batch_input_ids = _prepare_inputs(datapoint[dataset_input_key],
|
||||
eval_task=eval_task,
|
||||
add_special_tokens=add_special_tokens)
|
||||
input_lengths = [x.size(1) for x in batch_input_ids]
|
||||
# Left padding for HF
|
||||
max_length = max(input_lengths)
|
||||
paddings = [
|
||||
torch.ones(max_length - l, dtype=torch.int32) * pad_id
|
||||
for l in input_lengths
|
||||
]
|
||||
batch_input_ids = [
|
||||
torch.cat([pad, x.squeeze(0)])
|
||||
for x, pad in zip(batch_input_ids, paddings)
|
||||
]
|
||||
batch_input_ids = torch.stack(batch_input_ids)
|
||||
batch_input_ids = batch_input_ids.cuda()
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = model.generate(batch_input_ids,
|
||||
max_new_tokens=output_len,
|
||||
top_k=top_k,
|
||||
temperature=temperature,
|
||||
eos_token_id=end_id,
|
||||
pad_token_id=pad_id,
|
||||
num_beams=num_beams,
|
||||
num_return_sequences=num_beams,
|
||||
early_stopping=True,
|
||||
length_penalty=length_penalty,
|
||||
output_scores=True,
|
||||
return_dict_in_generate=True)
|
||||
if eval_ppl and batch_size == 1:
|
||||
# model.generate cannot return context logits?
|
||||
# Will cause additional latency
|
||||
context_outputs = model(batch_input_ids)
|
||||
|
||||
output_ids = outputs['sequences']
|
||||
tokens_list = output_ids[:, len(batch_input_ids[0]):].tolist()
|
||||
output_ids = output_ids.reshape([batch_size, num_beams, -1])
|
||||
output_lines_list = [
|
||||
tokenizer.batch_decode(output_ids[:, i,
|
||||
len(batch_input_ids[0]):],
|
||||
skip_special_tokens=True)
|
||||
for i in range(num_beams)
|
||||
]
|
||||
|
||||
ppls = []
|
||||
if eval_ppl and batch_size == 1:
|
||||
# Only for batch size of 1
|
||||
seq_lens = [output_ids.size(-1) for _ in range(batch_size)]
|
||||
context_logits = context_outputs['logits']
|
||||
# Remove the first generation logits which are same to last context logits
|
||||
generation_logits = torch.stack(outputs['scores'][1:], dim=1)
|
||||
|
||||
ppls = []
|
||||
for bidx in range(batch_size):
|
||||
curr_len = seq_lens[bidx]
|
||||
curr_ctx_len = input_lengths[bidx]
|
||||
curr_gen_len = curr_len - curr_ctx_len
|
||||
|
||||
curr_ids = output_ids[bidx, 0, 1:curr_len]
|
||||
curr_logits = torch.cat([
|
||||
context_logits[bidx],
|
||||
generation_logits[bidx, :curr_gen_len - 1]
|
||||
],
|
||||
dim=0)
|
||||
curr_ppl = ppl(curr_logits, curr_ids)
|
||||
ppls.append(curr_ppl)
|
||||
logger.debug(
|
||||
f"HF PPL: {curr_ppl:.3f} | Generation length: {curr_gen_len}"
|
||||
)
|
||||
|
||||
return output_lines_list, tokens_list, ppls
|
||||
|
||||
if test_trt_llm:
|
||||
datapoint = dataset[0:1]
|
||||
output, *_ = eval_trt_llm(datapoint,
|
||||
eval_task=args.eval_task,
|
||||
eval_ppl=args.eval_ppl,
|
||||
add_special_tokens=args.add_special_tokens)
|
||||
if runtime_rank == 0:
|
||||
logger.info(
|
||||
"---------------------------------------------------------")
|
||||
logger.info("XTRT-LLM Generated : ")
|
||||
logger.info(f" Input : {datapoint[dataset_input_key]}")
|
||||
logger.info(f"\n Reference : {datapoint[dataset_output_key]}")
|
||||
logger.info(f"\n Output : {output}")
|
||||
logger.info(
|
||||
"---------------------------------------------------------")
|
||||
|
||||
if test_hf:
|
||||
datapoint = dataset[0:1]
|
||||
output, *_ = eval_hf(datapoint,
|
||||
eval_task=args.eval_task,
|
||||
eval_ppl=args.eval_ppl,
|
||||
add_special_tokens=args.add_special_tokens)
|
||||
logger.info("---------------------------------------------------------")
|
||||
logger.info("HF Generated : ")
|
||||
logger.info(f" Input : {datapoint[dataset_input_key]}")
|
||||
logger.info(f"\n Reference : {datapoint[dataset_output_key]}")
|
||||
logger.info(f"\n Output : {output}")
|
||||
logger.info("---------------------------------------------------------")
|
||||
|
||||
# TODO: Add random_seed flag in gptj
|
||||
metric_tensorrt_llm = [
|
||||
evaluate.load(args.rouge_path) for _ in range(num_beams)
|
||||
]
|
||||
metric_hf = [evaluate.load(args.rouge_path) for _ in range(num_beams)]
|
||||
for i in range(num_beams):
|
||||
metric_tensorrt_llm[i].seed = 0
|
||||
metric_hf[i].seed = 0
|
||||
ppls_trt_llm, ppls_hf = [], []
|
||||
|
||||
ite_count = 0
|
||||
data_point_idx = 0
|
||||
while (data_point_idx < len(dataset)) and (ite_count < args.max_ite):
|
||||
if runtime_rank == 0:
|
||||
logger.debug(
|
||||
f"run data_point {data_point_idx} ~ {data_point_idx + max_batch_size}"
|
||||
)
|
||||
datapoint = dataset[data_point_idx:(data_point_idx + max_batch_size)]
|
||||
|
||||
if test_trt_llm:
|
||||
profiler.start('tensorrt_llm')
|
||||
output_tensorrt_llm, _, curr_ppls_trt_llm = eval_trt_llm(
|
||||
datapoint,
|
||||
eval_task=args.eval_task,
|
||||
eval_ppl=args.eval_ppl,
|
||||
add_special_tokens=args.add_special_tokens)
|
||||
profiler.stop('tensorrt_llm')
|
||||
|
||||
if test_hf:
|
||||
profiler.start('hf')
|
||||
output_hf, _, curr_ppls_hf = eval_hf(
|
||||
datapoint,
|
||||
eval_task=args.eval_task,
|
||||
eval_ppl=args.eval_ppl,
|
||||
add_special_tokens=args.add_special_tokens)
|
||||
profiler.stop('hf')
|
||||
|
||||
if runtime_rank == 0:
|
||||
if test_trt_llm:
|
||||
for batch_idx in range(len(output_tensorrt_llm)):
|
||||
for beam_idx in range(num_beams):
|
||||
metric_tensorrt_llm[beam_idx].add_batch(
|
||||
predictions=[
|
||||
output_tensorrt_llm[batch_idx][beam_idx]
|
||||
],
|
||||
references=[
|
||||
datapoint[dataset_output_key][batch_idx]
|
||||
])
|
||||
if output_dir is not None:
|
||||
# yapf: disable
|
||||
for i in range(len(output_tensorrt_llm[0])):
|
||||
for beam_idx in range(num_beams):
|
||||
with (output_dir / 'trtllm.out').open('a') as f:
|
||||
f.write(f'[{data_point_idx + i}] [Beam {beam_idx}] {output_tensorrt_llm[beam_idx][i]}\n')
|
||||
# yapf: enable
|
||||
ppls_trt_llm.extend(curr_ppls_trt_llm)
|
||||
if test_hf:
|
||||
for beam_idx in range(num_beams):
|
||||
for batch_idx in range(len(output_hf[beam_idx])):
|
||||
metric_hf[beam_idx].add_batch(
|
||||
predictions=[output_hf[beam_idx][batch_idx]],
|
||||
references=[
|
||||
datapoint[dataset_output_key][batch_idx]
|
||||
])
|
||||
if output_dir is not None:
|
||||
# yapf: disable
|
||||
for i in range(len(output_hf[0])):
|
||||
for beam_idx in range(num_beams):
|
||||
with (output_dir / 'hf.out').open('a') as f:
|
||||
f.write(f'[{data_point_idx + i}] [Beam {beam_idx}] {output_hf[beam_idx][i]}\n')
|
||||
# yapf: enable
|
||||
ppls_hf.extend(curr_ppls_hf)
|
||||
|
||||
logger.debug('-' * 100)
|
||||
logger.debug(f"Input : {datapoint[dataset_input_key]}")
|
||||
if test_trt_llm:
|
||||
logger.debug(f'XTRT-LLM Output: {output_tensorrt_llm}')
|
||||
if test_hf:
|
||||
logger.debug(f'HF Output: {output_hf}')
|
||||
logger.debug(f"Reference : {datapoint[dataset_output_key]}")
|
||||
|
||||
data_point_idx += max_batch_size
|
||||
ite_count += 1
|
||||
|
||||
if runtime_rank == 0:
|
||||
if test_trt_llm:
|
||||
np.random.seed(0) # rouge score use sampling to compute the score
|
||||
logger.info(
|
||||
f'XTRT-LLM (total latency: {profiler.elapsed_time_in_sec("tensorrt_llm")} sec)'
|
||||
)
|
||||
for beam_idx in range(num_beams):
|
||||
logger.info(f"XTRT-LLM beam {beam_idx} result")
|
||||
computed_metrics_tensorrt_llm = metric_tensorrt_llm[
|
||||
beam_idx].compute()
|
||||
for key in computed_metrics_tensorrt_llm.keys():
|
||||
logger.info(
|
||||
f' {key} : {computed_metrics_tensorrt_llm[key]*100}')
|
||||
|
||||
if args.check_accuracy and beam_idx == 0:
|
||||
assert computed_metrics_tensorrt_llm[
|
||||
'rouge1'] * 100 > args.tensorrt_llm_rouge1_threshold
|
||||
if args.eval_ppl:
|
||||
logger.info(f" Per-token perplexity: {np.mean(ppls_trt_llm)}")
|
||||
if test_hf:
|
||||
np.random.seed(0) # rouge score use sampling to compute the score
|
||||
logger.info(
|
||||
f'Hugging Face (total latency: {profiler.elapsed_time_in_sec("hf")} sec)'
|
||||
)
|
||||
for beam_idx in range(num_beams):
|
||||
logger.info(f"HF beam {beam_idx} result")
|
||||
computed_metrics_hf = metric_hf[beam_idx].compute()
|
||||
for key in computed_metrics_hf.keys():
|
||||
logger.info(f' {key} : {computed_metrics_hf[key]*100}')
|
||||
if args.eval_ppl and args.batch_size == 1:
|
||||
logger.info(f" Per-token perplexity: {np.mean(ppls_hf)}")
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--hf_model_dir', '--model_dir', type=str, default=None)
|
||||
parser.add_argument(
|
||||
'--tokenizer_dir',
|
||||
default=None,
|
||||
help='tokenizer path; defaults to hf_model_dir if left unspecified')
|
||||
parser.add_argument('--vocab_file')
|
||||
parser.add_argument('--test_hf', action='store_true')
|
||||
parser.add_argument('--test_trt_llm', action='store_true')
|
||||
parser.add_argument(
|
||||
'--data_type',
|
||||
type=str,
|
||||
choices=['fp32', 'fp16', 'bf16', 'float32', 'float16', 'bfloat16'],
|
||||
default='fp16')
|
||||
parser.add_argument('--engine_dir', type=str, default='engine_outputs')
|
||||
parser.add_argument(
|
||||
'--eval_task',
|
||||
type=str,
|
||||
default='summarize',
|
||||
choices=['summarize', 'summarize_long', 'code_completion'])
|
||||
parser.add_argument('--eval_ppl', action='store_true')
|
||||
parser.add_argument('--check_accuracy', action='store_true')
|
||||
parser.add_argument('--tensorrt_llm_rouge1_threshold',
|
||||
type=float,
|
||||
default=15.0)
|
||||
parser.add_argument('--dataset_path', type=str, default='')
|
||||
parser.add_argument('--log_level', type=str, default='info')
|
||||
parser.add_argument('--batch_size', type=int, default=1)
|
||||
parser.add_argument('--max_ite', type=int, default=20)
|
||||
parser.add_argument('--output_len', type=int, default=100)
|
||||
parser.add_argument('--max_input_length', type=int, default=923)
|
||||
parser.add_argument('--max_kv_cache_length',
|
||||
type=int,
|
||||
default=None,
|
||||
help='The max kv cache length. \
|
||||
If the final sequence length exceeds the kv cache length, we will enable cyclic kv cache. \
|
||||
If it is set to None, we will use the max sequence length.')
|
||||
parser.add_argument('--num_beams', type=int, default=1)
|
||||
parser.add_argument('--temperature', type=float, default=1.0)
|
||||
parser.add_argument('--top_k', type=int, default=1)
|
||||
parser.add_argument('--top_p', type=float, default=0.0)
|
||||
parser.add_argument('--length_penalty', type=float, default=1.0)
|
||||
parser.add_argument('--repetition_penalty', type=float, default=1.0)
|
||||
parser.add_argument('--debug_mode',
|
||||
default=False,
|
||||
action='store_true',
|
||||
help="Whether or not to turn on the debug mode")
|
||||
parser.add_argument('--no_add_special_tokens',
|
||||
dest='add_special_tokens',
|
||||
default=True,
|
||||
action='store_false',
|
||||
help="Whether or not to add special tokens")
|
||||
parser.add_argument(
|
||||
'--hf_device_map_auto',
|
||||
action='store_true',
|
||||
help="Use device map 'auto' to load a pretrained HF model. This may "
|
||||
"help to test a large model that cannot fit into a singlue GPU.")
|
||||
parser.add_argument(
|
||||
'--output_dir',
|
||||
type=str,
|
||||
default=None,
|
||||
help="Directory where to save output sentences. 'trtllm.out' for "
|
||||
"XTRT-LLM outputs, and 'hf.out' for HF outputs. If None, do not "
|
||||
"save outputs.")
|
||||
parser.add_argument('--rouge_path', type=str, default="rouge")
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
main(args)
|
||||
116
examples/utils.py
Normal file
116
examples/utils.py
Normal file
@@ -0,0 +1,116 @@
|
||||
# SPDX-FileCopyrightText: Copyright (c) 2022-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import json
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from transformers import AutoTokenizer, T5Tokenizer
|
||||
|
||||
DEFAULT_HF_MODEL_DIRS = {
|
||||
'baichuan': 'baichuan-inc/Baichuan-13B-Chat',
|
||||
'bloom': 'bigscience/bloom-560m',
|
||||
'chatglm_6b': 'THUDM/chatglm-6b',
|
||||
'chatglm2_6b': 'THUDM/chatglm2-6b',
|
||||
'chatglm2_6b_32k': 'THUDM/chatglm2-6b-32k',
|
||||
'chatglm3_6b': 'THUDM/chatglm3-6b',
|
||||
'chatglm3-6b': 'THUDM/chatglm3-6b',
|
||||
'chatglm3_6b_base': 'THUDM/chatglm3-6b-base',
|
||||
'chatglm3_6b_32k': 'THUDM/chatglm3-6b-32k',
|
||||
'falcon': 'tiiuae/falcon-rw-1b',
|
||||
'glm_10b': 'THUDM/glm-10b',
|
||||
'gpt': 'gpt2-medium',
|
||||
'gptj': 'EleutherAI/gpt-j-6b',
|
||||
'gptneox': 'EleutherAI/gpt-neox-20b',
|
||||
'internlm': 'internlm/internlm-chat-7b',
|
||||
'llama': 'meta-llama/Llama-2-7b-hf',
|
||||
'mpt': 'mosaicml/mpt-7b',
|
||||
'opt': 'facebook/opt-350m',
|
||||
'qwen': 'Qwen/Qwen-7B',
|
||||
}
|
||||
|
||||
DEFAULT_PROMPT_TEMPLATES = {
|
||||
'internlm':
|
||||
"<|User|>:{input_text}<eoh>\n<|Bot|>:",
|
||||
'qwen':
|
||||
"<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n{input_text}<|im_end|>\n<|im_start|>assistant\n",
|
||||
}
|
||||
|
||||
|
||||
def read_model_name_from_config(config_path: Path):
|
||||
with open(config_path, 'r') as f:
|
||||
config = json.load(f)
|
||||
return config['builder_config']['name']
|
||||
|
||||
|
||||
def throttle_generator(generator, stream_interval):
|
||||
for i, out in enumerate(generator):
|
||||
if not i % stream_interval:
|
||||
yield out
|
||||
|
||||
if i % stream_interval:
|
||||
yield out
|
||||
|
||||
|
||||
def load_tokenizer(tokenizer_dir: Optional[str] = None,
|
||||
vocab_file: Optional[str] = None,
|
||||
model_name: str = 'gpt'):
|
||||
if vocab_file is None:
|
||||
# Should set both padding_side and truncation_side to be 'left'
|
||||
tokenizer = AutoTokenizer.from_pretrained(tokenizer_dir,
|
||||
legacy=False,
|
||||
padding_side='left',
|
||||
truncation_side='left',
|
||||
trust_remote_code=True)
|
||||
else:
|
||||
# For gpt-next, directly load from tokenizer.model
|
||||
assert model_name == 'gpt'
|
||||
tokenizer = T5Tokenizer(vocab_file=vocab_file,
|
||||
padding_side='left',
|
||||
truncation_side='left')
|
||||
|
||||
if model_name == 'qwen':
|
||||
with open(Path(tokenizer_dir) / "generation_config.json") as f:
|
||||
gen_config = json.load(f)
|
||||
chat_format = gen_config['chat_format']
|
||||
if chat_format == 'raw':
|
||||
pad_id = gen_config['pad_token_id']
|
||||
end_id = gen_config['eos_token_id']
|
||||
elif chat_format == 'chatml':
|
||||
pad_id = tokenizer.im_end_id
|
||||
end_id = tokenizer.im_end_id
|
||||
else:
|
||||
raise Exception(f"unknown chat format: {chat_format}")
|
||||
elif model_name == 'qwen2':
|
||||
with open(Path(tokenizer_dir) / "generation_config.json") as f:
|
||||
gen_config = json.load(f)
|
||||
|
||||
### if model type is chat pad_id = end_id = gen_config["eos_token_id"][0]
|
||||
if isinstance (gen_config["eos_token_id"], list):
|
||||
pad_id = end_id = gen_config["eos_token_id"][0]
|
||||
### if model type is base, run this branch
|
||||
else:
|
||||
pad_id = gen_config["bos_token_id"]
|
||||
end_id = gen_config["eos_token_id"]
|
||||
elif model_name == 'glm_10b':
|
||||
pad_id = tokenizer.pad_token_id
|
||||
end_id = tokenizer.eop_token_id
|
||||
else:
|
||||
if tokenizer.pad_token_id is None:
|
||||
tokenizer.pad_token_id = tokenizer.eos_token_id
|
||||
pad_id = tokenizer.pad_token_id
|
||||
end_id = tokenizer.eos_token_id
|
||||
|
||||
return tokenizer, pad_id, end_id
|
||||
363
examples/vllm_test/benchmark_throughput.py
Normal file
363
examples/vllm_test/benchmark_throughput.py
Normal file
@@ -0,0 +1,363 @@
|
||||
"""Benchmark offline inference throughput."""
|
||||
import argparse
|
||||
import json
|
||||
import random
|
||||
import time
|
||||
import random
|
||||
from typing import List, Tuple, Union
|
||||
|
||||
import torch
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoModelForCausalLM, PreTrainedTokenizerBase
|
||||
|
||||
from xtrt_llm.vllm import LLM, SamplingParams
|
||||
from xtrt_llm.vllm.transformers_utils.tokenizer import get_tokenizer
|
||||
|
||||
|
||||
def dummy_sample_requests(
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
prompt: Union[str, List[str]],
|
||||
tokenid: int,
|
||||
output_len: Union[int, List[int]],
|
||||
input_len: Union[int, List[int]],
|
||||
max_model_len: int,
|
||||
num_requests: Union[int, List[int]],
|
||||
) -> List[Tuple[List[int], int, int]]:
|
||||
|
||||
if prompt is not None:
|
||||
if isinstance(prompt, str):
|
||||
assert isinstance(input_len, int) \
|
||||
and isinstance(output_len, int) and isinstance(num_requests, int)
|
||||
prompt_token_ids_list = [tokenizer(prompt).input_ids]
|
||||
input_len = [input_len]
|
||||
output_len = [output_len]
|
||||
num_requests = [num_requests]
|
||||
else:
|
||||
assert isinstance(input_len, list) \
|
||||
and isinstance(output_len, list) and isinstance(num_requests, list)
|
||||
prompt_token_ids_list = [tokenizer(x).input_ids for x in prompt]
|
||||
if tokenid is not None:
|
||||
if isinstance(input_len, int):
|
||||
assert isinstance(output_len, int) and isinstance(num_requests, int)
|
||||
prompt_token_ids_list = [[tokenid] * input_len]
|
||||
input_len = [input_len]
|
||||
output_len = [output_len]
|
||||
num_requests = [num_requests]
|
||||
else:
|
||||
assert isinstance(output_len, list) and isinstance(num_requests, list)
|
||||
prompt_token_ids_list = [[tokenid] * x for x in input_len]
|
||||
|
||||
sampled_requests: List[Tuple[List[int], int, int]] = []
|
||||
for i, prompt_token_ids in enumerate(prompt_token_ids_list):
|
||||
for idx in range(num_requests[i]):
|
||||
if len(prompt_token_ids) < input_len[i]:
|
||||
prompt_token_ids.extend([prompt_token_ids[0]] *
|
||||
(input_len[i] - len(prompt_token_ids)))
|
||||
if len(prompt_token_ids) > input_len[i]:
|
||||
prompt_token_ids = prompt_token_ids[:input_len[i] -
|
||||
len(prompt_token_ids)]
|
||||
sampled_requests.append(
|
||||
(prompt_token_ids, input_len[i], min(output_len[i], max_model_len - input_len[i])))
|
||||
|
||||
random.shuffle(sampled_requests)
|
||||
return sampled_requests
|
||||
|
||||
|
||||
def sample_requests(
|
||||
dataset_path: str,
|
||||
num_requests: int,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
) -> List[Tuple[str, int, int]]:
|
||||
# Load the dataset.
|
||||
with open(dataset_path) as f:
|
||||
dataset = json.load(f)
|
||||
# Filter out the conversations with less than 2 turns.
|
||||
dataset = [data for data in dataset if len(data["conversations"]) >= 2]
|
||||
# Only keep the first two turns of each conversation.
|
||||
dataset = [(data["conversations"][0]["value"],
|
||||
data["conversations"][1]["value"]) for data in dataset]
|
||||
|
||||
# Tokenize the prompts and completions.
|
||||
prompts = [prompt for prompt, _ in dataset]
|
||||
prompt_token_ids = tokenizer(prompts).input_ids
|
||||
completions = [completion for _, completion in dataset]
|
||||
completion_token_ids = tokenizer(completions).input_ids
|
||||
tokenized_dataset = []
|
||||
for i in range(len(dataset)):
|
||||
output_len = len(completion_token_ids[i])
|
||||
tokenized_dataset.append((prompts[i], prompt_token_ids[i], output_len))
|
||||
|
||||
# Filter out too long sequences.
|
||||
filtered_dataset: List[Tuple[str, int, int]] = []
|
||||
for prompt, prompt_token_ids, output_len in tokenized_dataset:
|
||||
prompt_len = len(prompt_token_ids)
|
||||
if prompt_len < 4 or output_len < 4:
|
||||
# Prune too short sequences.
|
||||
continue
|
||||
if prompt_len > 1024 or prompt_len + output_len > 2048:
|
||||
# Prune too long sequences.
|
||||
continue
|
||||
filtered_dataset.append((prompt, prompt_len, output_len))
|
||||
|
||||
# Sample the requests.
|
||||
sampled_requests = random.sample(filtered_dataset, num_requests)
|
||||
return sampled_requests
|
||||
|
||||
|
||||
def dummy_run_vllm(
|
||||
requests: List[Tuple[List[int], int, int]],
|
||||
model: str,
|
||||
tokenizer: str,
|
||||
tensor_parallel_size: int,
|
||||
seed: int,
|
||||
n: int,
|
||||
use_beam_search: bool,
|
||||
trust_remote_code: bool,
|
||||
max_model_len: int,
|
||||
engine_dir: str,
|
||||
max_num_seqs: int,
|
||||
max_num_batched_tokens: int,
|
||||
) -> float:
|
||||
llm = LLM(
|
||||
model=model,
|
||||
tokenizer=tokenizer,
|
||||
tensor_parallel_size=tensor_parallel_size,
|
||||
seed=seed,
|
||||
trust_remote_code=trust_remote_code,
|
||||
disable_log_stats=False,
|
||||
max_model_len=max_model_len,
|
||||
engine_dir=engine_dir,
|
||||
max_num_seqs=max_num_seqs,
|
||||
max_num_batched_tokens=max_num_batched_tokens,
|
||||
)
|
||||
start = time.time()
|
||||
# Add the requests to the engine.
|
||||
for prompt_tokenids, _, output_len in requests:
|
||||
sampling_params = SamplingParams(
|
||||
n=n,
|
||||
temperature=0.0 if use_beam_search else 1.0,
|
||||
top_p=1.0,
|
||||
use_beam_search=use_beam_search,
|
||||
ignore_eos=True,
|
||||
max_tokens=output_len,
|
||||
)
|
||||
# FIXME(woosuk): Do not use internal method.
|
||||
llm._add_request(
|
||||
# model_type="llama2",
|
||||
prompt=None,
|
||||
prompt_token_ids=prompt_tokenids,
|
||||
sampling_params=sampling_params,
|
||||
)
|
||||
|
||||
# FIXME(woosuk): Do use internal method.
|
||||
llm._run_engine(use_tqdm=True)
|
||||
end = time.time()
|
||||
return end - start
|
||||
|
||||
|
||||
def run_vllm(
|
||||
requests: List[Tuple[str, int, int]],
|
||||
model: str,
|
||||
tokenizer: str,
|
||||
tensor_parallel_size: int,
|
||||
seed: int,
|
||||
n: int,
|
||||
use_beam_search: bool,
|
||||
trust_remote_code: bool,
|
||||
) -> float:
|
||||
llm = LLM(
|
||||
model=model,
|
||||
tokenizer=tokenizer,
|
||||
tensor_parallel_size=tensor_parallel_size,
|
||||
seed=seed,
|
||||
trust_remote_code=trust_remote_code,
|
||||
)
|
||||
|
||||
# Add the requests to the engine.
|
||||
for prompt, _, output_len in requests:
|
||||
sampling_params = SamplingParams(
|
||||
n=n,
|
||||
temperature=0.0 if use_beam_search else 1.0,
|
||||
top_p=1.0,
|
||||
use_beam_search=use_beam_search,
|
||||
ignore_eos=True,
|
||||
max_tokens=output_len,
|
||||
)
|
||||
# FIXME(woosuk): Do not use internal method.
|
||||
llm._add_request(
|
||||
model_type="llama2",
|
||||
prompt=prompt,
|
||||
prompt_token_ids=None,
|
||||
sampling_params=sampling_params,
|
||||
)
|
||||
|
||||
start = time.time()
|
||||
# FIXME(woosuk): Do use internal method.
|
||||
llm._run_engine(use_tqdm=True)
|
||||
end = time.time()
|
||||
return end - start
|
||||
|
||||
|
||||
def run_hf(
|
||||
requests: List[Tuple[str, int, int]],
|
||||
model: str,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
n: int,
|
||||
use_beam_search: bool,
|
||||
max_batch_size: int,
|
||||
trust_remote_code: bool,
|
||||
) -> float:
|
||||
assert not use_beam_search
|
||||
llm = AutoModelForCausalLM.from_pretrained(
|
||||
model, torch_dtype=torch.float16, trust_remote_code=trust_remote_code)
|
||||
if llm.config.model_type == "llama":
|
||||
# To enable padding in the HF backend.
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
llm = llm.cuda()
|
||||
|
||||
pbar = tqdm(total=len(requests))
|
||||
start = time.time()
|
||||
batch: List[str] = []
|
||||
max_prompt_len = 0
|
||||
max_output_len = 0
|
||||
for i in range(len(requests)):
|
||||
prompt, prompt_len, output_len = requests[i]
|
||||
# Add the prompt to the batch.
|
||||
batch.append(prompt)
|
||||
max_prompt_len = max(max_prompt_len, prompt_len)
|
||||
max_output_len = max(max_output_len, output_len)
|
||||
if len(batch) < max_batch_size and i != len(requests) - 1:
|
||||
# Check if we can add more requests to the batch.
|
||||
_, next_prompt_len, next_output_len = requests[i + 1]
|
||||
if (max(max_prompt_len, next_prompt_len) +
|
||||
max(max_output_len, next_output_len)) <= 2048:
|
||||
# We can add more requests to the batch.
|
||||
continue
|
||||
|
||||
# Generate the sequences.
|
||||
input_ids = tokenizer(batch, return_tensors="pt",
|
||||
padding=True).input_ids
|
||||
llm_outputs = llm.generate(
|
||||
input_ids=input_ids.cuda(),
|
||||
do_sample=not use_beam_search,
|
||||
num_return_sequences=n,
|
||||
temperature=1.0,
|
||||
top_p=1.0,
|
||||
use_cache=True,
|
||||
max_new_tokens=max_output_len,
|
||||
)
|
||||
# Include the decoding time.
|
||||
tokenizer.batch_decode(llm_outputs, skip_special_tokens=True)
|
||||
pbar.update(len(batch))
|
||||
|
||||
# Clear the batch.
|
||||
batch = []
|
||||
max_prompt_len = 0
|
||||
max_output_len = 0
|
||||
end = time.time()
|
||||
return end - start
|
||||
|
||||
|
||||
def main(args: argparse.Namespace):
|
||||
print(args)
|
||||
random.seed(args.seed)
|
||||
|
||||
# Sample the requests.
|
||||
tokenizer = get_tokenizer(args.tokenizer,
|
||||
trust_remote_code=args.trust_remote_code)
|
||||
if args.dummy_dataset:
|
||||
requests = dummy_sample_requests(tokenizer, args.dummy_prompt,
|
||||
args.dummy_tokenid,
|
||||
args.dummy_output_len,
|
||||
args.dummy_input_len,
|
||||
args.max_model_len, args.num_prompts)
|
||||
|
||||
if args.backend == "vllm":
|
||||
elapsed_time = dummy_run_vllm(
|
||||
requests, args.model, args.tokenizer, args.tensor_parallel_size,
|
||||
args.seed, args.n, args.use_beam_search, args.trust_remote_code,
|
||||
args.max_model_len, args.engine_dir, args.max_num_seqs,
|
||||
args.max_num_batched_tokens)
|
||||
else:
|
||||
raise ValueError(f"Unknown backend: {args.backend}")
|
||||
total_num_tokens = sum(output_len
|
||||
for _, _, output_len in requests)
|
||||
print(f"Throughput: {len(requests) / elapsed_time:.2f} requests/s, "
|
||||
f"{total_num_tokens / elapsed_time:.2f} tokens/s")
|
||||
else:
|
||||
requests = sample_requests(args.dataset, args.num_prompts, tokenizer)
|
||||
|
||||
if args.backend == "vllm":
|
||||
elapsed_time = run_vllm(requests, args.model, args.tokenizer,
|
||||
args.tensor_parallel_size, args.seed,
|
||||
args.n, args.use_beam_search,
|
||||
args.trust_remote_code)
|
||||
elif args.backend == "hf":
|
||||
assert args.tensor_parallel_size == 1
|
||||
elapsed_time = run_hf(requests, args.model, tokenizer, args.n,
|
||||
args.use_beam_search, args.hf_max_batch_size,
|
||||
args.trust_remote_code)
|
||||
else:
|
||||
raise ValueError(f"Unknown backend: {args.backend}")
|
||||
total_num_tokens = sum(prompt_len + output_len
|
||||
for _, prompt_len, output_len in requests)
|
||||
print(f"Throughput: {len(requests) / elapsed_time:.2f} requests/s, "
|
||||
f"{total_num_tokens / elapsed_time:.2f} tokens/s")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Benchmark the throughput.")
|
||||
parser.add_argument("--backend",
|
||||
type=str,
|
||||
choices=["vllm", "hf"],
|
||||
default="vllm")
|
||||
parser.add_argument("--dataset", type=str, help="Path to the dataset.")
|
||||
parser.add_argument("--model", type=str, default="facebook/opt-125m")
|
||||
parser.add_argument("--tokenizer", type=str, default=None)
|
||||
parser.add_argument("--tensor-parallel-size", "-tp", type=int, default=1)
|
||||
parser.add_argument("--n",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Number of generated sequences per prompt.")
|
||||
parser.add_argument("--use-beam-search", action="store_true")
|
||||
parser.add_argument("--num-prompts",
|
||||
nargs='+',
|
||||
type=int,
|
||||
default=1000,
|
||||
help="Number of prompts to process.")
|
||||
parser.add_argument("--seed", type=int, default=0)
|
||||
parser.add_argument("--hf-max-batch-size",
|
||||
type=int,
|
||||
default=None,
|
||||
help="Maximum batch size for HF backend.")
|
||||
parser.add_argument('--trust-remote-code',
|
||||
action='store_true',
|
||||
help='trust remote code from huggingface')
|
||||
parser.add_argument('--max-model-len', type=int, default=2048)
|
||||
parser.add_argument('--max-num-batched-tokens', type=int, default=2048)
|
||||
parser.add_argument('--max-num-seqs', type=int, default=128)
|
||||
parser.add_argument('--dummy-dataset',
|
||||
action='store_true',
|
||||
help='use dummy data to test')
|
||||
parser.add_argument('--dummy-prompt', nargs='+', type=str, default=None)
|
||||
parser.add_argument('--dummy-tokenid', type=int, default=None)
|
||||
parser.add_argument('--dummy-input-len', nargs='+', type=int, default=1024)
|
||||
parser.add_argument('--dummy-output-len', nargs='+', type=int, default=1024)
|
||||
parser.add_argument("--engine_dir", type=str, help="Path to the engine.")
|
||||
args = parser.parse_args()
|
||||
|
||||
if args.backend == "vllm":
|
||||
if args.hf_max_batch_size is not None:
|
||||
raise ValueError("HF max batch size is only for HF backend.")
|
||||
elif args.backend == "hf":
|
||||
if args.hf_max_batch_size is None:
|
||||
raise ValueError("HF max batch size is required for HF backend.")
|
||||
if args.dummy_dataset:
|
||||
if args.dummy_prompt is None and args.dummy_tokenid is None:
|
||||
raise ValueError(
|
||||
"dummy_dataset is True, thus dummy_prompt is not None or dummy_tokenid is not None."
|
||||
)
|
||||
if args.tokenizer is None:
|
||||
args.tokenizer = args.model
|
||||
|
||||
main(args)
|
||||
37
examples/vllm_test/openai_chatcompletion_client.py
Normal file
37
examples/vllm_test/openai_chatcompletion_client.py
Normal file
@@ -0,0 +1,37 @@
|
||||
from openai import OpenAI
|
||||
|
||||
# Modify OpenAI's API key and API base to use vLLM's API server.
|
||||
openai_api_key = "EMPTY"
|
||||
openai_api_base = "http://localhost:8000/v1"
|
||||
|
||||
client = OpenAI(
|
||||
# defaults to os.environ.get("OPENAI_API_KEY")
|
||||
api_key=openai_api_key,
|
||||
base_url=openai_api_base,
|
||||
)
|
||||
|
||||
models = client.models.list()
|
||||
model = models.data[0].id
|
||||
|
||||
chat_completion = client.chat.completions.create(
|
||||
messages=[{
|
||||
"role": "system",
|
||||
"content": "You are a helpful assistant."
|
||||
}, {
|
||||
"role": "user",
|
||||
"content": "Who won the world series in 2020?"
|
||||
}, {
|
||||
"role":
|
||||
"assistant",
|
||||
"content":
|
||||
"The Los Angeles Dodgers won the World Series in 2020."
|
||||
}, {
|
||||
"role": "user",
|
||||
"content": "Where was it played?"
|
||||
}],
|
||||
model=model,
|
||||
)
|
||||
|
||||
|
||||
print("Chat completion results:")
|
||||
print(chat_completion)
|
||||
21
examples/vllm_test/run_llama1-7b_throughput.sh
Normal file
21
examples/vllm_test/run_llama1-7b_throughput.sh
Normal file
@@ -0,0 +1,21 @@
|
||||
#!/bin/bash
|
||||
# bash vllm_test/run_llama1-7b_throughput.sh /path/to/llama7b_hf_model /path/to/llama7b_vls_engine
|
||||
model_path=$1
|
||||
engine_path=$2
|
||||
|
||||
#run test fixed input/output benchmark# llama7b-1xpu
|
||||
XMLIR_D_XPU_L3_SIZE=0 python benchmark_throughput.py \
|
||||
--trust-remote-code \
|
||||
--backend vllm \
|
||||
--model $model_path \
|
||||
--tokenizer $model_path \
|
||||
--engine_dir $engine_path \
|
||||
--tensor-parallel-size 1 \
|
||||
--dummy-dataset \
|
||||
--max-num-seqs 14 \
|
||||
--max-num-batched-tokens 2048 \
|
||||
--dummy-tokenid 1 \
|
||||
--dummy-input-len 1024 \
|
||||
--dummy-output-len 1024 \
|
||||
--max-model-len 2048 \
|
||||
--num-prompts 14
|
||||
3
examples/vllm_test/run_stats.sh
Normal file
3
examples/vllm_test/run_stats.sh
Normal file
@@ -0,0 +1,3 @@
|
||||
#!/bin/bash
|
||||
tmp=`grep 'Avg prompt throughput' server.log > server.log.valid`
|
||||
python run_stats_server.py
|
||||
90
examples/vllm_test/run_stats_server.py
Normal file
90
examples/vllm_test/run_stats_server.py
Normal file
@@ -0,0 +1,90 @@
|
||||
import re
|
||||
import sys
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
# 用于记录每个度量的值
|
||||
first_token_times_values = []
|
||||
prompt_throughput_values = []
|
||||
generation_throughput_values = []
|
||||
running_values = []
|
||||
|
||||
# 从文件中读取数据
|
||||
file_path = "server.log.valid" # 替换成你的文件路径
|
||||
with open(file_path, 'r') as file:
|
||||
# 遍历文件中的每一行进行统计
|
||||
for line in file:
|
||||
# 使用正则表达式提取Avg First Token times和Avg generation throughput以及Running的值
|
||||
match_first_token = re.search(r"Avg First Token times:([0-9.]+)", line)
|
||||
match_prompt_throughput = re.search(r"Avg prompt throughput: ([0-9.]+)", line)
|
||||
match_generation_throughput = re.search(r"Avg generation throughput: ([0-9.]+)", line)
|
||||
match_running = re.search(r"Running: (\d+)", line)
|
||||
|
||||
# 统计Avg First Token times
|
||||
if match_first_token:
|
||||
first_token_times = float(match_first_token.group(1))
|
||||
if abs(first_token_times) > 1e-5:
|
||||
first_token_times_values.append(first_token_times)
|
||||
|
||||
if match_prompt_throughput:
|
||||
prompt_throughput = float(match_prompt_throughput.group(1))
|
||||
if abs(prompt_throughput) > 1e-5:
|
||||
prompt_throughput_values.append(prompt_throughput)
|
||||
|
||||
# 统计Avg generation throughput和Running
|
||||
if match_generation_throughput and match_running:
|
||||
generation_throughput = float(match_generation_throughput.group(1))
|
||||
running = int(match_running.group(1))
|
||||
if abs(generation_throughput) > 1e-5:
|
||||
generation_throughput_values.append(generation_throughput)
|
||||
running_values.append(running)
|
||||
|
||||
# 计算平均值
|
||||
avg_first_token_times = np.mean(first_token_times_values) if len(first_token_times_values) > 0 else 0
|
||||
max_first_token_times = np.max(first_token_times_values) if len(first_token_times_values) > 0 else 0
|
||||
min_first_token_times = np.min(first_token_times_values) if len(first_token_times_values) > 0 else 0
|
||||
p10_first_token_times = np.percentile(first_token_times_values, 10) if len(first_token_times_values) > 0 else 0
|
||||
p90_first_token_times = np.percentile(first_token_times_values, 90) if len(first_token_times_values) > 0 else 0
|
||||
p99_first_token_times = np.percentile(first_token_times_values, 99) if len(first_token_times_values) > 0 else 0
|
||||
cnt_first_token_times = len(first_token_times_values) if len(first_token_times_values) > 0 else 0
|
||||
|
||||
avg_prompt_throughput = np.mean(prompt_throughput_values) if len(prompt_throughput_values) > 0 else 0
|
||||
max_prompt_throughput = np.max(prompt_throughput_values) if len(prompt_throughput_values) > 0 else 0
|
||||
min_prompt_throughput = np.min(prompt_throughput_values) if len(prompt_throughput_values) > 0 else 0
|
||||
p10_prompt_throughput = np.percentile(prompt_throughput_values, 10) if len(prompt_throughput_values) > 0 else 0
|
||||
p90_prompt_throughput = np.percentile(prompt_throughput_values, 90) if len(prompt_throughput_values) > 0 else 0
|
||||
p99_prompt_throughput = np.percentile(prompt_throughput_values, 99) if len(prompt_throughput_values) > 0 else 0
|
||||
cnt_prompt_throughput = len(prompt_throughput_values) if len(prompt_throughput_values) > 0 else 0
|
||||
|
||||
avg_generation_throughput = np.mean(generation_throughput_values) if len(generation_throughput_values) > 0 else 0
|
||||
max_generation_throughput = np.max(generation_throughput_values) if len(generation_throughput_values) > 0 else 0
|
||||
min_generation_throughput = np.min(generation_throughput_values) if len(generation_throughput_values) > 0 else 0
|
||||
p10_generation_throughput = np.percentile(generation_throughput_values, 10) if len(generation_throughput_values) > 0 else 0
|
||||
p90_generation_throughput = np.percentile(generation_throughput_values, 90) if len(generation_throughput_values) > 0 else 0
|
||||
p99_generation_throughput = np.percentile(generation_throughput_values, 99) if len(generation_throughput_values) > 0 else 0
|
||||
cnt_generation_throughput = len(generation_throughput_values) if len(generation_throughput_values) > 0 else 0
|
||||
|
||||
avg_running = np.mean(running_values) if len(running_values) > 0 else 0
|
||||
max_running = np.max(running_values) if len(running_values) > 0 else 0
|
||||
min_running = np.min(running_values) if len(running_values) > 0 else 0
|
||||
p10_running = np.percentile(running_values, 10) if len(running_values) > 0 else 0
|
||||
p90_running = np.percentile(running_values, 90) if len(running_values) > 0 else 0
|
||||
p99_running = np.percentile(running_values, 99) if len(running_values) > 0 else 0
|
||||
cnt_running = len(running_values) if len(running_values) > 0 else 0
|
||||
|
||||
# Create a DataFrame
|
||||
data = {
|
||||
'avg': [avg_first_token_times, avg_prompt_throughput, avg_generation_throughput, avg_running],
|
||||
'max': [max_first_token_times, max_prompt_throughput, max_generation_throughput, max_running],
|
||||
'min': [min_first_token_times, min_prompt_throughput, min_generation_throughput, min_running],
|
||||
'p10': [p10_first_token_times, p10_prompt_throughput, p10_generation_throughput, p10_running],
|
||||
'p90': [p90_first_token_times, p90_prompt_throughput, p90_generation_throughput, p90_running],
|
||||
'p99': [p99_first_token_times, p99_prompt_throughput, p99_generation_throughput, p99_running],
|
||||
'num': [cnt_first_token_times, cnt_prompt_throughput, cnt_generation_throughput, cnt_running]
|
||||
}
|
||||
|
||||
df = pd.DataFrame(data, index=['first_token_times', 'prompt_throughput', 'generation_throughput', 'running'])
|
||||
|
||||
# Display the DataFrame
|
||||
print(df)
|
||||
|
||||
7
examples/vllm_test/run_throughput.sh
Normal file
7
examples/vllm_test/run_throughput.sh
Normal file
@@ -0,0 +1,7 @@
|
||||
#!/bin/bash
|
||||
|
||||
model_path=$1
|
||||
engine_path=$2
|
||||
|
||||
#run test fixed input/output benchmark
|
||||
XMLIR_D_XPU_L3_SIZE=0 python benchmark_throughput.py --backend vllm --model $model_path --tokenizer $model_path --engine_dir $engine_path --tensor-parallel-size 8 --dummy-dataset --max-num-seqs 128 --max-num-batched-tokens 2048 --dummy-tokenid 1 --dummy-input-len 1024 --dummy-output-len 1024 --max-model-len 2048 --num-prompts 128 > server.log
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user