Add scripts to export ASR models from wenet to ONNX (#425)
See https://user-images.githubusercontent.com/5284924/282995968-f6d39118-8008-4ce7-9d7c-d1d6387ac183.png
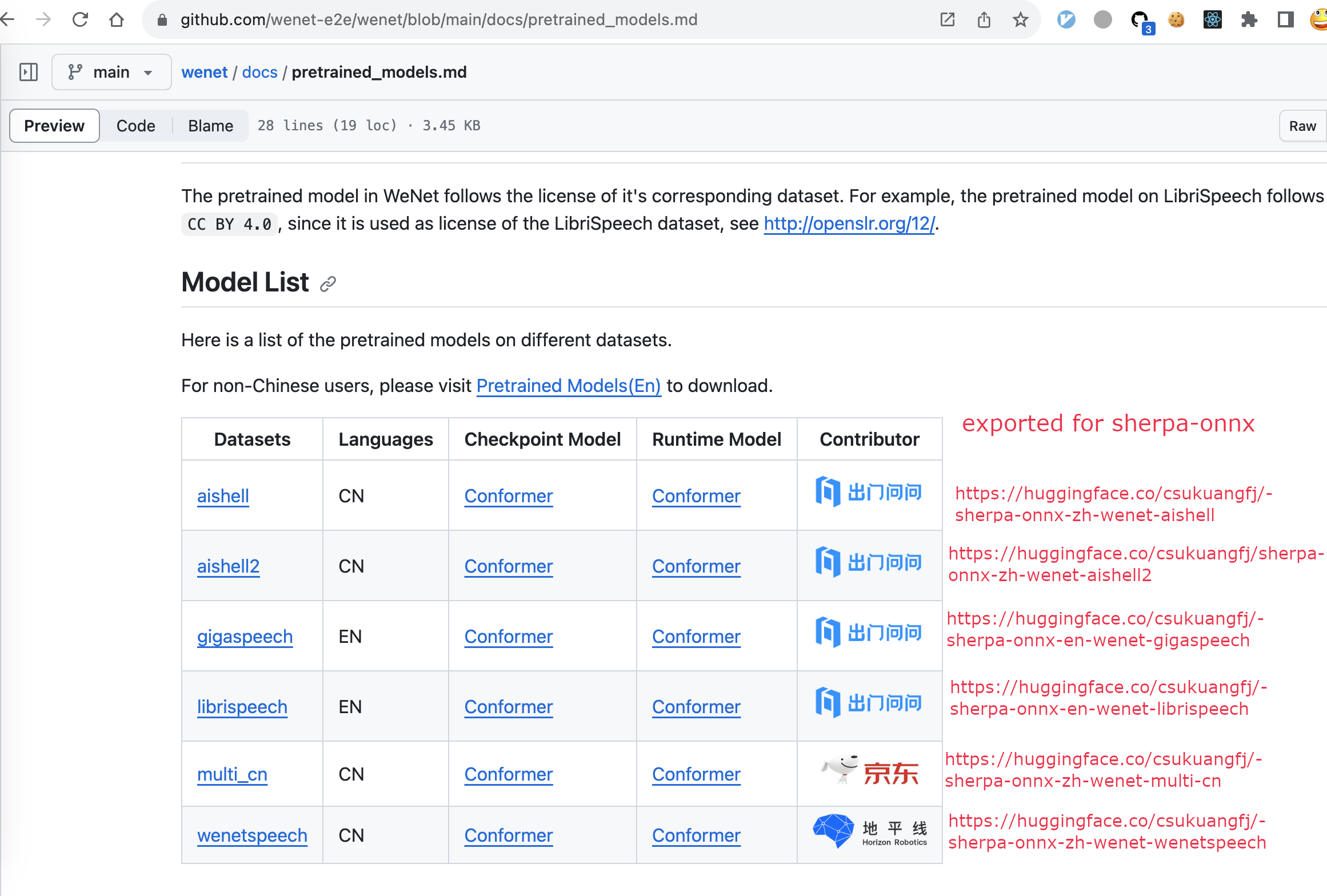{kind=link}
This commit is contained in:
293
.github/workflows/export-wenet-to-onnx.yaml
vendored
Normal file
293
.github/workflows/export-wenet-to-onnx.yaml
vendored
Normal file
@@ -0,0 +1,293 @@
|
||||
name: export-wenet-to-onnx
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- master
|
||||
paths:
|
||||
- 'scripts/wenet/**'
|
||||
- '.github/workflows/export-wenet-to-onnx.yaml'
|
||||
pull_request:
|
||||
paths:
|
||||
- 'scripts/wenet/**'
|
||||
- '.github/workflows/export-wenet-to-onnx.yaml'
|
||||
|
||||
workflow_dispatch:
|
||||
|
||||
concurrency:
|
||||
group: export-wenet-to-onnx-${{ github.ref }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
export-wenet-to-onnx:
|
||||
if: github.repository_owner == 'k2-fsa' || github.repository_owner == 'csukuangfj'
|
||||
name: export wenet
|
||||
runs-on: ${{ matrix.os }}
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
os: [ubuntu-latest]
|
||||
python-version: ["3.8"]
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Setup Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Run
|
||||
shell: bash
|
||||
run: |
|
||||
sudo apt-get install tree sox
|
||||
cd scripts/wenet
|
||||
./run.sh
|
||||
|
||||
- name: Publish to huggingface (aishell)
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
||||
uses: nick-fields/retry@v2
|
||||
with:
|
||||
max_attempts: 20
|
||||
timeout_seconds: 200
|
||||
shell: bash
|
||||
command: |
|
||||
git config --global user.email "csukuangfj@gmail.com"
|
||||
git config --global user.name "Fangjun Kuang"
|
||||
|
||||
rm -rf huggingface
|
||||
export GIT_LFS_SKIP_SMUDGE=1
|
||||
|
||||
git clone https://huggingface.co/csukuangfj/sherpa-onnx-zh-wenet-aishell huggingface
|
||||
cd huggingface
|
||||
git fetch
|
||||
git pull
|
||||
|
||||
cp -v ../scripts/wenet/aishell_u2pp_conformer_exp/*.onnx .
|
||||
cp -v ../scripts/wenet/aishell_u2pp_conformer_exp/units.txt tokens.txt
|
||||
cp -v ../scripts/wenet/aishell_u2pp_conformer_exp/README.md .
|
||||
|
||||
if [ ! -d test_wavs ]; then
|
||||
mkdir test_wavs
|
||||
cd test_wavs
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-zh-14M-2023-02-23/resolve/main/test_wavs/0.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-zh-14M-2023-02-23/resolve/main/test_wavs/1.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-zh-14M-2023-02-23/resolve/main/test_wavs/8k.wav
|
||||
cd ..
|
||||
fi
|
||||
git lfs track "*.onnx"
|
||||
git add .
|
||||
|
||||
git commit -m "add aishell models"
|
||||
git push https://csukuangfj:$HF_TOKEN@huggingface.co/csukuangfj/sherpa-onnx-zh-wenet-aishell main || true
|
||||
|
||||
cd ..
|
||||
rm -rf huggingface
|
||||
|
||||
- name: Publish to huggingface (aishell2)
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
||||
uses: nick-fields/retry@v2
|
||||
with:
|
||||
max_attempts: 20
|
||||
timeout_seconds: 200
|
||||
shell: bash
|
||||
command: |
|
||||
git config --global user.email "csukuangfj@gmail.com"
|
||||
git config --global user.name "Fangjun Kuang"
|
||||
|
||||
rm -rf huggingface
|
||||
export GIT_LFS_SKIP_SMUDGE=1
|
||||
|
||||
git clone https://huggingface.co/csukuangfj/sherpa-onnx-zh-wenet-aishell2 huggingface
|
||||
cd huggingface
|
||||
git fetch
|
||||
git pull
|
||||
|
||||
cp -v ../scripts/wenet/aishell2_u2pp_conformer_exp/*.onnx .
|
||||
cp -v ../scripts/wenet/aishell2_u2pp_conformer_exp/units.txt tokens.txt
|
||||
cp -v ../scripts/wenet/aishell2_u2pp_conformer_exp/README.md .
|
||||
|
||||
if [ ! -d test_wavs ]; then
|
||||
mkdir test_wavs
|
||||
cd test_wavs
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-zh-14M-2023-02-23/resolve/main/test_wavs/0.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-zh-14M-2023-02-23/resolve/main/test_wavs/1.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-zh-14M-2023-02-23/resolve/main/test_wavs/8k.wav
|
||||
cd ..
|
||||
fi
|
||||
git lfs track "*.onnx"
|
||||
git add .
|
||||
|
||||
git commit -m "add aishell2 models"
|
||||
git push https://csukuangfj:$HF_TOKEN@huggingface.co/csukuangfj/sherpa-onnx-zh-wenet-aishell2 main || true
|
||||
|
||||
cd ..
|
||||
rm -rf huggingface
|
||||
|
||||
- name: Publish to huggingface (multi_cn)
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
||||
uses: nick-fields/retry@v2
|
||||
with:
|
||||
max_attempts: 20
|
||||
timeout_seconds: 200
|
||||
shell: bash
|
||||
command: |
|
||||
git config --global user.email "csukuangfj@gmail.com"
|
||||
git config --global user.name "Fangjun Kuang"
|
||||
|
||||
rm -rf huggingface
|
||||
export GIT_LFS_SKIP_SMUDGE=1
|
||||
|
||||
git clone https://huggingface.co/csukuangfj/sherpa-onnx-zh-wenet-multi-cn huggingface
|
||||
cd huggingface
|
||||
git fetch
|
||||
git pull
|
||||
|
||||
cp -v ../scripts/wenet/multi_cn_unified_conformer_exp/*.onnx .
|
||||
cp -v ../scripts/wenet/multi_cn_unified_conformer_exp/units.txt tokens.txt
|
||||
cp -v ../scripts/wenet/multi_cn_unified_conformer_exp/README.md .
|
||||
|
||||
if [ ! -d test_wavs ]; then
|
||||
mkdir test_wavs
|
||||
cd test_wavs
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-zh-14M-2023-02-23/resolve/main/test_wavs/0.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-zh-14M-2023-02-23/resolve/main/test_wavs/1.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-zh-14M-2023-02-23/resolve/main/test_wavs/8k.wav
|
||||
cd ..
|
||||
fi
|
||||
git lfs track "*.onnx"
|
||||
git add .
|
||||
|
||||
git commit -m "add multi_cn models"
|
||||
git push https://csukuangfj:$HF_TOKEN@huggingface.co/csukuangfj/sherpa-onnx-zh-wenet-multi-cn main || true
|
||||
|
||||
cd ..
|
||||
rm -rf huggingface
|
||||
|
||||
- name: Publish to huggingface (wenetspeech)
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
||||
uses: nick-fields/retry@v2
|
||||
with:
|
||||
max_attempts: 20
|
||||
timeout_seconds: 200
|
||||
shell: bash
|
||||
command: |
|
||||
git config --global user.email "csukuangfj@gmail.com"
|
||||
git config --global user.name "Fangjun Kuang"
|
||||
|
||||
rm -rf huggingface
|
||||
export GIT_LFS_SKIP_SMUDGE=1
|
||||
|
||||
git clone https://huggingface.co/csukuangfj/sherpa-onnx-zh-wenet-wenetspeech huggingface
|
||||
cd huggingface
|
||||
git fetch
|
||||
git pull
|
||||
|
||||
cp -v ../scripts/wenet/20220506_u2pp_conformer_exp/*.onnx .
|
||||
cp -v ../scripts/wenet/20220506_u2pp_conformer_exp/units.txt tokens.txt
|
||||
cp -v ../scripts/wenet/20220506_u2pp_conformer_exp/README.md .
|
||||
|
||||
if [ ! -d test_wavs ]; then
|
||||
mkdir test_wavs
|
||||
cd test_wavs
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-zh-14M-2023-02-23/resolve/main/test_wavs/0.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-zh-14M-2023-02-23/resolve/main/test_wavs/1.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-zh-14M-2023-02-23/resolve/main/test_wavs/8k.wav
|
||||
cd ..
|
||||
fi
|
||||
git lfs track "*.onnx"
|
||||
git add .
|
||||
|
||||
git commit -m "add wenetspeech models"
|
||||
git push https://csukuangfj:$HF_TOKEN@huggingface.co/csukuangfj/sherpa-onnx-zh-wenet-wenetspeech main || true
|
||||
|
||||
cd ..
|
||||
rm -rf huggingface
|
||||
|
||||
- name: Publish to huggingface (librispeech)
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
||||
uses: nick-fields/retry@v2
|
||||
with:
|
||||
max_attempts: 20
|
||||
timeout_seconds: 200
|
||||
shell: bash
|
||||
command: |
|
||||
git config --global user.email "csukuangfj@gmail.com"
|
||||
git config --global user.name "Fangjun Kuang"
|
||||
|
||||
rm -rf huggingface
|
||||
export GIT_LFS_SKIP_SMUDGE=1
|
||||
|
||||
git clone https://huggingface.co/csukuangfj/sherpa-onnx-en-wenet-librispeech huggingface
|
||||
cd huggingface
|
||||
git fetch
|
||||
git pull
|
||||
|
||||
cp -v ../scripts/wenet/librispeech_u2pp_conformer_exp/*.onnx .
|
||||
cp -v ../scripts/wenet/librispeech_u2pp_conformer_exp/units.txt tokens.txt
|
||||
cp -v ../scripts/wenet/librispeech_u2pp_conformer_exp/README.md .
|
||||
|
||||
if [ ! -d test_wavs ]; then
|
||||
mkdir test_wavs
|
||||
cd test_wavs
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-en-2023-02-21/resolve/main/test_wavs/0.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-en-2023-02-21/resolve/main/test_wavs/1.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-en-2023-02-21/resolve/main/test_wavs/8k.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-en-2023-02-21/resolve/main/test_wavs/trans.txt
|
||||
cd ..
|
||||
fi
|
||||
git lfs track "*.onnx"
|
||||
git add .
|
||||
|
||||
git commit -m "add librispeech models"
|
||||
git push https://csukuangfj:$HF_TOKEN@huggingface.co/csukuangfj/sherpa-onnx-en-wenet-librispeech main || true
|
||||
|
||||
cd ..
|
||||
rm -rf huggingface
|
||||
|
||||
- name: Publish to huggingface (gigaspeech)
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
||||
uses: nick-fields/retry@v2
|
||||
with:
|
||||
max_attempts: 20
|
||||
timeout_seconds: 200
|
||||
shell: bash
|
||||
command: |
|
||||
git config --global user.email "csukuangfj@gmail.com"
|
||||
git config --global user.name "Fangjun Kuang"
|
||||
|
||||
rm -rf huggingface
|
||||
export GIT_LFS_SKIP_SMUDGE=1
|
||||
|
||||
git clone https://huggingface.co/csukuangfj/sherpa-onnx-en-wenet-gigaspeech huggingface
|
||||
cd huggingface
|
||||
git fetch
|
||||
git pull
|
||||
|
||||
cp -v ../scripts/wenet/20210728_u2pp_conformer_exp/*.onnx .
|
||||
cp -v ../scripts/wenet/20210728_u2pp_conformer_exp/units.txt tokens.txt
|
||||
cp -v ../scripts/wenet/20210728_u2pp_conformer_exp/README.md .
|
||||
|
||||
if [ ! -d test_wavs ]; then
|
||||
mkdir test_wavs
|
||||
cd test_wavs
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-en-2023-02-21/resolve/main/test_wavs/0.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-en-2023-02-21/resolve/main/test_wavs/1.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-en-2023-02-21/resolve/main/test_wavs/8k.wav
|
||||
wget -q https://huggingface.co/csukuangfj/sherpa-onnx-streaming-zipformer-en-2023-02-21/resolve/main/test_wavs/trans.txt
|
||||
cd ..
|
||||
fi
|
||||
git lfs track "*.onnx"
|
||||
git add .
|
||||
|
||||
git commit -m "add gigaspeech models"
|
||||
git push https://csukuangfj:$HF_TOKEN@huggingface.co/csukuangfj/sherpa-onnx-en-wenet-gigaspeech main || true
|
||||
|
||||
cd ..
|
||||
rm -rf huggingface
|
||||
10
scripts/wenet/README.md
Normal file
10
scripts/wenet/README.md
Normal file
@@ -0,0 +1,10 @@
|
||||
# Introduction
|
||||
|
||||
This folder contains script for exporting models
|
||||
from [wenet](https://github.com/wenet-e2e/wenet)
|
||||
to onnx. You can use the exported models in sherpa-onnx.
|
||||
|
||||
Note that both **streaming** and **non-streaming** models are supported.
|
||||
|
||||
We only use the CTC branch. Rescore with the attention decoder
|
||||
is not supported, though decoding with H, HL, and HLG is supported.
|
||||
203
scripts/wenet/export-onnx-streaming.py
Executable file
203
scripts/wenet/export-onnx-streaming.py
Executable file
@@ -0,0 +1,203 @@
|
||||
#!/usr/bin/env python3
|
||||
# Copyright 2023 Xiaomi Corp. (authors: Fangjun Kuang)
|
||||
|
||||
# pip install git+https://github.com/wenet-e2e/wenet.git
|
||||
# pip install onnxruntime onnx pyyaml
|
||||
# cp -a ~/open-source/wenet/wenet/transducer/search .
|
||||
# cp -a ~/open-source//wenet/wenet/e_branchformer .
|
||||
# cp -a ~/open-source/wenet/wenet/ctl_model .
|
||||
|
||||
import os
|
||||
from typing import Dict
|
||||
|
||||
import onnx
|
||||
import torch
|
||||
import yaml
|
||||
from onnxruntime.quantization import QuantType, quantize_dynamic
|
||||
|
||||
from wenet.utils.init_model import init_model
|
||||
|
||||
|
||||
def add_meta_data(filename: str, meta_data: Dict[str, str]):
|
||||
"""Add meta data to an ONNX model. It is changed in-place.
|
||||
|
||||
Args:
|
||||
filename:
|
||||
Filename of the ONNX model to be changed.
|
||||
meta_data:
|
||||
Key-value pairs.
|
||||
"""
|
||||
model = onnx.load(filename)
|
||||
for key, value in meta_data.items():
|
||||
meta = model.metadata_props.add()
|
||||
meta.key = key
|
||||
meta.value = str(value)
|
||||
|
||||
onnx.save(model, filename)
|
||||
|
||||
|
||||
class OnnxModel(torch.nn.Module):
|
||||
def __init__(self, encoder: torch.nn.Module, ctc: torch.nn.Module):
|
||||
super().__init__()
|
||||
self.encoder = encoder
|
||||
self.ctc = ctc
|
||||
|
||||
def forward(
|
||||
self,
|
||||
x: torch.Tensor,
|
||||
offset: torch.Tensor,
|
||||
required_cache_size: torch.Tensor,
|
||||
attn_cache: torch.Tensor,
|
||||
conv_cache: torch.Tensor,
|
||||
attn_mask: torch.Tensor,
|
||||
):
|
||||
"""
|
||||
Args:
|
||||
x:
|
||||
A 3-D float32 tensor of shape (N, T, C). It supports only N == 1.
|
||||
offset:
|
||||
A scalar of dtype torch.int64.
|
||||
required_cache_size:
|
||||
A scalar of dtype torch.int64.
|
||||
attn_cache:
|
||||
A 4-D float32 tensor of shape (num_blocks, head, required_cache_size, encoder_output_size / head /2).
|
||||
conv_cache:
|
||||
A 4-D float32 tensor of shape (num_blocks, N, encoder_output_size, cnn_module_kernel - 1).
|
||||
attn_mask:
|
||||
A 3-D bool tensor of shape (N, 1, required_cache_size + chunk_size)
|
||||
Returns:
|
||||
Return a tuple of 3 tensors:
|
||||
- A 3-D float32 tensor of shape (N, T, C) containing log_probs
|
||||
- next_attn_cache
|
||||
- next_conv_cache
|
||||
"""
|
||||
encoder_out, next_att_cache, next_conv_cache = self.encoder.forward_chunk(
|
||||
xs=x,
|
||||
offset=offset,
|
||||
required_cache_size=required_cache_size,
|
||||
att_cache=attn_cache,
|
||||
cnn_cache=conv_cache,
|
||||
att_mask=attn_mask,
|
||||
)
|
||||
log_probs = self.ctc.log_softmax(encoder_out)
|
||||
|
||||
return log_probs, next_att_cache, next_conv_cache
|
||||
|
||||
|
||||
class Foo:
|
||||
pass
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def main():
|
||||
args = Foo()
|
||||
args.checkpoint = "./final.pt"
|
||||
config_file = "./train.yaml"
|
||||
|
||||
with open(config_file, "r") as fin:
|
||||
configs = yaml.load(fin, Loader=yaml.FullLoader)
|
||||
torch_model, configs = init_model(args, configs)
|
||||
torch_model.eval()
|
||||
|
||||
head = configs["encoder_conf"]["attention_heads"]
|
||||
num_blocks = configs["encoder_conf"]["num_blocks"]
|
||||
output_size = configs["encoder_conf"]["output_size"]
|
||||
cnn_module_kernel = configs["encoder_conf"].get("cnn_module_kernel", 1)
|
||||
|
||||
right_context = torch_model.right_context()
|
||||
subsampling_factor = torch_model.encoder.embed.subsampling_rate
|
||||
chunk_size = 16
|
||||
left_chunks = 4
|
||||
|
||||
decoding_window = (chunk_size - 1) * subsampling_factor + right_context + 1
|
||||
|
||||
required_cache_size = chunk_size * left_chunks
|
||||
|
||||
offset = required_cache_size
|
||||
|
||||
attn_cache = torch.zeros(
|
||||
num_blocks,
|
||||
head,
|
||||
required_cache_size,
|
||||
output_size // head * 2,
|
||||
dtype=torch.float32,
|
||||
)
|
||||
|
||||
attn_mask = torch.ones(1, 1, required_cache_size + chunk_size, dtype=torch.bool)
|
||||
attn_mask[:, :, :required_cache_size] = 0
|
||||
|
||||
conv_cache = torch.zeros(
|
||||
num_blocks, 1, output_size, cnn_module_kernel - 1, dtype=torch.float32
|
||||
)
|
||||
|
||||
sos = torch_model.sos_symbol()
|
||||
eos = torch_model.eos_symbol()
|
||||
|
||||
onnx_model = OnnxModel(
|
||||
encoder=torch_model.encoder,
|
||||
ctc=torch_model.ctc,
|
||||
)
|
||||
filename = "model-streaming.onnx"
|
||||
|
||||
N = 1
|
||||
T = decoding_window
|
||||
C = 80
|
||||
x = torch.rand(N, T, C, dtype=torch.float32)
|
||||
offset = torch.tensor([offset], dtype=torch.int64)
|
||||
required_cache_size = torch.tensor([required_cache_size], dtype=torch.int64)
|
||||
|
||||
opset_version = 13
|
||||
torch.onnx.export(
|
||||
onnx_model,
|
||||
(x, offset, required_cache_size, attn_cache, conv_cache, attn_mask),
|
||||
filename,
|
||||
opset_version=opset_version,
|
||||
input_names=[
|
||||
"x",
|
||||
"offset",
|
||||
"required_cache_size",
|
||||
"attn_cache",
|
||||
"conv_cache",
|
||||
"attn_mask",
|
||||
],
|
||||
output_names=["log_probs", "next_att_cache", "next_conv_cache"],
|
||||
dynamic_axes={
|
||||
"x": {0: "N", 1: "T"},
|
||||
"attn_cache": {2: "T"},
|
||||
"log_probs": {0: "N"},
|
||||
"new_attn_cache": {2: "T"},
|
||||
},
|
||||
)
|
||||
|
||||
# https://wenet.org.cn/downloads?models=wenet&version=aishell_u2pp_conformer_exp.tar.gz
|
||||
url = os.environ.get("WENET_URL", "")
|
||||
meta_data = {
|
||||
"model_type": "wenet-ctc",
|
||||
"version": "1",
|
||||
"model_author": "wenet",
|
||||
"comment": "streaming",
|
||||
"url": "https://wenet.org.cn/downloads?models=wenet&version=aishell_u2pp_conformer_exp.tar.gz",
|
||||
"chunk_size": chunk_size,
|
||||
"left_chunks": left_chunks,
|
||||
"head": head,
|
||||
"num_blocks": num_blocks,
|
||||
"output_size": output_size,
|
||||
"cnn_module_kernel": cnn_module_kernel,
|
||||
"right_context": right_context,
|
||||
"subsampling_factor": subsampling_factor,
|
||||
}
|
||||
add_meta_data(filename=filename, meta_data=meta_data)
|
||||
|
||||
print("Generate int8 quantization models")
|
||||
|
||||
filename_int8 = f"model-streaming.int8.onnx"
|
||||
quantize_dynamic(
|
||||
model_input=filename,
|
||||
model_output=filename_int8,
|
||||
op_types_to_quantize=["MatMul"],
|
||||
weight_type=QuantType.QInt8,
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
130
scripts/wenet/export-onnx.py
Executable file
130
scripts/wenet/export-onnx.py
Executable file
@@ -0,0 +1,130 @@
|
||||
#!/usr/bin/env python3
|
||||
# Copyright 2023 Xiaomi Corp. (authors: Fangjun Kuang)
|
||||
|
||||
# pip install git+https://github.com/wenet-e2e/wenet.git
|
||||
# pip install onnxruntime onnx pyyaml
|
||||
# cp -a ~/open-source/wenet/wenet/transducer/search .
|
||||
# cp -a ~/open-source//wenet/wenet/e_branchformer .
|
||||
# cp -a ~/open-source/wenet/wenet/ctl_model .
|
||||
|
||||
import os
|
||||
from typing import Dict
|
||||
|
||||
import onnx
|
||||
import torch
|
||||
import yaml
|
||||
from onnxruntime.quantization import QuantType, quantize_dynamic
|
||||
|
||||
from wenet.utils.init_model import init_model
|
||||
|
||||
|
||||
class Foo:
|
||||
pass
|
||||
|
||||
|
||||
def add_meta_data(filename: str, meta_data: Dict[str, str]):
|
||||
"""Add meta data to an ONNX model. It is changed in-place.
|
||||
|
||||
Args:
|
||||
filename:
|
||||
Filename of the ONNX model to be changed.
|
||||
meta_data:
|
||||
Key-value pairs.
|
||||
"""
|
||||
model = onnx.load(filename)
|
||||
for key, value in meta_data.items():
|
||||
meta = model.metadata_props.add()
|
||||
meta.key = key
|
||||
meta.value = str(value)
|
||||
|
||||
onnx.save(model, filename)
|
||||
|
||||
|
||||
class OnnxModel(torch.nn.Module):
|
||||
def __init__(self, encoder: torch.nn.Module, ctc: torch.nn.Module):
|
||||
super().__init__()
|
||||
self.encoder = encoder
|
||||
self.ctc = ctc
|
||||
|
||||
def forward(self, x, x_lens):
|
||||
"""
|
||||
Args:
|
||||
x:
|
||||
A 3-D tensor of shape (N, T, C)
|
||||
x_lens:
|
||||
A 1-D tensor of shape (N,) containing valid lengths in x before
|
||||
padding. Its type is torch.int64
|
||||
"""
|
||||
encoder_out, encoder_out_mask = self.encoder(
|
||||
x,
|
||||
x_lens,
|
||||
decoding_chunk_size=-1,
|
||||
num_decoding_left_chunks=-1,
|
||||
)
|
||||
log_probs = self.ctc.log_softmax(encoder_out)
|
||||
log_probs_lens = encoder_out_mask.int().squeeze(1).sum(1)
|
||||
|
||||
return log_probs, log_probs_lens
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def main():
|
||||
args = Foo()
|
||||
args.checkpoint = "./final.pt"
|
||||
config_file = "./train.yaml"
|
||||
|
||||
with open(config_file, "r") as fin:
|
||||
configs = yaml.load(fin, Loader=yaml.FullLoader)
|
||||
torch_model, configs = init_model(args, configs)
|
||||
torch_model.eval()
|
||||
|
||||
onnx_model = OnnxModel(encoder=torch_model.encoder, ctc=torch_model.ctc)
|
||||
filename = "model.onnx"
|
||||
|
||||
N = 1
|
||||
T = 1000
|
||||
C = 80
|
||||
x = torch.rand(N, T, C, dtype=torch.float)
|
||||
x_lens = torch.full((N,), fill_value=T, dtype=torch.int64)
|
||||
|
||||
opset_version = 13
|
||||
onnx_model = torch.jit.script(onnx_model)
|
||||
torch.onnx.export(
|
||||
onnx_model,
|
||||
(x, x_lens),
|
||||
filename,
|
||||
opset_version=opset_version,
|
||||
input_names=["x", "x_lens"],
|
||||
output_names=["log_probs", "log_probs_lens"],
|
||||
dynamic_axes={
|
||||
"x": {0: "N", 1: "T"},
|
||||
"x_lens": {0: "N"},
|
||||
"log_probs": {0: "N", 1: "T"},
|
||||
"log_probs_lens": {0: "N"},
|
||||
},
|
||||
)
|
||||
|
||||
# https://wenet.org.cn/downloads?models=wenet&version=aishell_u2pp_conformer_exp.tar.gz
|
||||
url = os.environ.get("WENET_URL", "")
|
||||
meta_data = {
|
||||
"model_type": "wenet-ctc",
|
||||
"version": "1",
|
||||
"model_author": "wenet",
|
||||
"comment": "non-streaming",
|
||||
"url": url,
|
||||
}
|
||||
add_meta_data(filename=filename, meta_data=meta_data)
|
||||
|
||||
print("Generate int8 quantization models")
|
||||
|
||||
filename_int8 = f"model.int8.onnx"
|
||||
quantize_dynamic(
|
||||
model_input=filename,
|
||||
model_output=filename_int8,
|
||||
op_types_to_quantize=["MatMul"],
|
||||
weight_type=QuantType.QInt8,
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
249
scripts/wenet/run.sh
Executable file
249
scripts/wenet/run.sh
Executable file
@@ -0,0 +1,249 @@
|
||||
#!/usr/bin/env bash
|
||||
#
|
||||
# Copyright 2023 Xiaomi Corp. (authors: Fangjun Kuang)
|
||||
#
|
||||
# Please refer to
|
||||
# https://github.com/wenet-e2e/wenet/blob/main/docs/pretrained_models.en.md
|
||||
# for a table of pre-trained models.
|
||||
# Please select the column "Checkpoint Model" for downloading.
|
||||
|
||||
set -ex
|
||||
|
||||
function install_dependencies() {
|
||||
pip install soundfile
|
||||
pip install torch==2.1.0+cpu torchaudio==2.1.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
|
||||
pip install k2==1.24.4.dev20231022+cpu.torch2.1.0 -f https://k2-fsa.github.io/k2/cpu.html
|
||||
|
||||
pip install onnxruntime onnx kaldi-native-fbank pyyaml
|
||||
|
||||
pip install git+https://github.com/wenet-e2e/wenet.git
|
||||
wenet_dir=$(dirname $(python3 -c "import wenet; print(wenet.__file__)"))
|
||||
git clone https://github.com/wenet-e2e/wenet
|
||||
if [ ! -d $wenet_dir/transducer/search ]; then
|
||||
cp -av ./wenet/wenet/transducer/search $wenet_dir/transducer
|
||||
fi
|
||||
|
||||
if [ ! -d $wenet_dir/e_branchformer ]; then
|
||||
cp -a .//wenet/wenet/e_branchformer $wenet_dir
|
||||
fi
|
||||
|
||||
if [ ! -d $wenet_dir/ctl_model ]; then
|
||||
cp -a ./wenet/wenet/ctl_model $wenet_dir
|
||||
fi
|
||||
|
||||
rm -rf wenet
|
||||
}
|
||||
|
||||
function aishell() {
|
||||
echo "aishell"
|
||||
wget -q https://huggingface.co/openspeech/wenet-models/resolve/main/aishell_u2pp_conformer_exp.tar.gz
|
||||
tar xvf aishell_u2pp_conformer_exp.tar.gz
|
||||
rm -v aishell_u2pp_conformer_exp.tar.gz
|
||||
|
||||
pushd aishell_u2pp_conformer_exp
|
||||
mkdir -p exp/20210601_u2++_conformer_exp
|
||||
cp global_cmvn ./exp/20210601_u2++_conformer_exp
|
||||
cp ../*.py .
|
||||
|
||||
export WENET_URL=https://wenet.org.cn/downloads?models=wenet&version=aishell_u2pp_conformer_exp.tar.gz
|
||||
wget -O 0.wav https://huggingface.co/openspeech/wenet-models/resolve/main/zh.wav
|
||||
soxi 0.wav
|
||||
|
||||
echo "Test streaming"
|
||||
./export-onnx-streaming.py
|
||||
ls -lh
|
||||
./test-onnx-streaming.py
|
||||
|
||||
echo "Test non-streaming"
|
||||
./export-onnx.py
|
||||
ls -lh
|
||||
./test-onnx.py
|
||||
|
||||
cat > README.md <<EOF
|
||||
# Introduction
|
||||
This model is converted from https://wenet.org.cn/downloads?models=wenet&version=aishell_u2pp_conformer_exp.tar.gz
|
||||
EOF
|
||||
|
||||
popd
|
||||
}
|
||||
|
||||
function aishell2() {
|
||||
echo "aishell2"
|
||||
wget -q https://huggingface.co/openspeech/wenet-models/resolve/main/aishell2_u2pp_conformer_exp.tar.gz
|
||||
tar xvf aishell2_u2pp_conformer_exp.tar.gz
|
||||
rm -v aishell2_u2pp_conformer_exp.tar.gz
|
||||
|
||||
pushd aishell2_u2pp_conformer_exp
|
||||
mkdir -p exp/u2++_conformer
|
||||
cp global_cmvn ./exp/u2++_conformer
|
||||
cp ../*.py .
|
||||
|
||||
export WENET_URL=https://wenet.org.cn/downloads?models=wenet&version=aishell2_u2pp_conformer_exp.tar.gz
|
||||
wget -O 0.wav https://huggingface.co/openspeech/wenet-models/resolve/main/zh.wav
|
||||
soxi 0.wav
|
||||
|
||||
echo "Test streaming"
|
||||
./export-onnx-streaming.py
|
||||
ls -lh
|
||||
./test-onnx-streaming.py
|
||||
|
||||
echo "Test non-streaming"
|
||||
./export-onnx.py
|
||||
ls -lh
|
||||
./test-onnx.py
|
||||
|
||||
cat > README.md <<EOF
|
||||
# Introduction
|
||||
This model is converted from https://wenet.org.cn/downloads?models=wenet&version=aishell2_u2pp_conformer_exp.tar.gz
|
||||
EOF
|
||||
|
||||
popd
|
||||
}
|
||||
|
||||
function multi_cn() {
|
||||
echo "multi_cn"
|
||||
wget -q https://huggingface.co/openspeech/wenet-models/resolve/main/multi_cn_unified_conformer_exp.tar.gz
|
||||
tar xvf multi_cn_unified_conformer_exp.tar.gz
|
||||
rm -v multi_cn_unified_conformer_exp.tar.gz
|
||||
|
||||
pushd multi_cn_unified_conformer_exp
|
||||
mkdir -p exp/20210815_unified_conformer_exp
|
||||
cp global_cmvn ./exp/20210815_unified_conformer_exp
|
||||
cp ../*.py .
|
||||
|
||||
export WENET_URL=https://wenet.org.cn/downloads?models=wenet&version=multi_cn_unified_conformer_exp.tar.gz
|
||||
wget -O 0.wav https://huggingface.co/openspeech/wenet-models/resolve/main/zh.wav
|
||||
soxi 0.wav
|
||||
|
||||
echo "Test streaming"
|
||||
./export-onnx-streaming.py
|
||||
ls -lh
|
||||
./test-onnx-streaming.py
|
||||
|
||||
echo "Test non-streaming"
|
||||
./export-onnx.py
|
||||
ls -lh
|
||||
./test-onnx.py
|
||||
|
||||
cat > README.md <<EOF
|
||||
# Introduction
|
||||
This model is converted from https://wenet.org.cn/downloads?models=wenet&version=multi_cn_unified_conformer_exp.tar.gz
|
||||
EOF
|
||||
|
||||
popd
|
||||
}
|
||||
|
||||
function wenetspeech() {
|
||||
echo "wenetspeech"
|
||||
wget -q https://huggingface.co/openspeech/wenet-models/resolve/main/wenetspeech_u2pp_conformer_exp.tar.gz
|
||||
tar xvf wenetspeech_u2pp_conformer_exp.tar.gz
|
||||
rm -v wenetspeech_u2pp_conformer_exp.tar.gz
|
||||
|
||||
pushd 20220506_u2pp_conformer_exp
|
||||
mkdir -p exp/20220506_u2pp_conformer_exp
|
||||
cp global_cmvn ./exp/20220506_u2pp_conformer_exp
|
||||
cp ../*.py .
|
||||
|
||||
export WENET_URL=https://wenet.org.cn/downloads?models=wenet&version=wenetspeech_u2pp_conformer_exp.tar.gz
|
||||
wget -O 0.wav https://huggingface.co/openspeech/wenet-models/resolve/main/zh.wav
|
||||
soxi 0.wav
|
||||
|
||||
echo "Test streaming"
|
||||
./export-onnx-streaming.py
|
||||
ls -lh
|
||||
./test-onnx-streaming.py
|
||||
|
||||
echo "Test non-streaming"
|
||||
./export-onnx.py
|
||||
ls -lh
|
||||
./test-onnx.py
|
||||
|
||||
cat > README.md <<EOF
|
||||
# Introduction
|
||||
This model is converted from https://wenet.org.cn/downloads?models=wenet&version=wenetspeech_u2pp_conformer_exp.tar.gz
|
||||
EOF
|
||||
|
||||
popd
|
||||
}
|
||||
|
||||
function librispeech() {
|
||||
echo "librispeech"
|
||||
wget -q https://huggingface.co/openspeech/wenet-models/resolve/main/librispeech_u2pp_conformer_exp.tar.gz
|
||||
tar xvf librispeech_u2pp_conformer_exp.tar.gz
|
||||
rm -v librispeech_u2pp_conformer_exp.tar.gz
|
||||
|
||||
pushd librispeech_u2pp_conformer_exp
|
||||
mkdir -p data/train_960
|
||||
cp global_cmvn ./data/train_960
|
||||
cp ../*.py .
|
||||
|
||||
export WENET_URL=https://wenet.org.cn/downloads?models=wenet&version=librispeech_u2pp_conformer_exp.tar.gz
|
||||
wget -O 0.wav https://huggingface.co/openspeech/wenet-models/resolve/main/en.wav
|
||||
soxi 0.wav
|
||||
|
||||
echo "Test streaming"
|
||||
./export-onnx-streaming.py
|
||||
ls -lh
|
||||
./test-onnx-streaming.py
|
||||
|
||||
echo "Test non-streaming"
|
||||
./export-onnx.py
|
||||
ls -lh
|
||||
./test-onnx.py
|
||||
|
||||
cat > README.md <<EOF
|
||||
# Introduction
|
||||
This model is converted from https://wenet.org.cn/downloads?models=wenet&version=librispeech_u2pp_conformer_exp.tar.gz
|
||||
EOF
|
||||
|
||||
popd
|
||||
}
|
||||
|
||||
function gigaspeech() {
|
||||
echo "gigaspeech"
|
||||
wget -q https://huggingface.co/openspeech/wenet-models/resolve/main/gigaspeech_u2pp_conformer_exp.tar.gz
|
||||
tar xvf gigaspeech_u2pp_conformer_exp.tar.gz
|
||||
rm -v gigaspeech_u2pp_conformer_exp.tar.gz
|
||||
|
||||
pushd 20210728_u2pp_conformer_exp
|
||||
mkdir -p data/gigaspeech_train_xl
|
||||
cp global_cmvn ./data/gigaspeech_train_xl
|
||||
cp ../*.py .
|
||||
|
||||
export WENET_URL=https://wenet.org.cn/downloads?models=wenet&version=gigaspeech_u2pp_conformer_exp.tar.gz
|
||||
wget -O 0.wav https://huggingface.co/openspeech/wenet-models/resolve/main/en.wav
|
||||
soxi 0.wav
|
||||
|
||||
echo "Test streaming"
|
||||
./export-onnx-streaming.py
|
||||
ls -lh
|
||||
./test-onnx-streaming.py
|
||||
|
||||
echo "Test non-streaming"
|
||||
./export-onnx.py
|
||||
ls -lh
|
||||
./test-onnx.py
|
||||
|
||||
cat > README.md <<EOF
|
||||
# Introduction
|
||||
This model is converted from https://wenet.org.cn/downloads?models=wenet&version=gigaspeech_u2pp_conformer_exp.tar.gz
|
||||
EOF
|
||||
|
||||
popd
|
||||
}
|
||||
|
||||
install_dependencies
|
||||
|
||||
aishell
|
||||
|
||||
aishell2
|
||||
|
||||
multi_cn
|
||||
|
||||
wenetspeech
|
||||
|
||||
librispeech
|
||||
|
||||
gigaspeech
|
||||
|
||||
tree .
|
||||
174
scripts/wenet/test-onnx-streaming.py
Executable file
174
scripts/wenet/test-onnx-streaming.py
Executable file
@@ -0,0 +1,174 @@
|
||||
#!/usr/bin/env python3
|
||||
# Copyright 2023 Xiaomi Corp. (authors: Fangjun Kuang)
|
||||
|
||||
import kaldi_native_fbank as knf
|
||||
import onnxruntime as ort
|
||||
import torch
|
||||
import torchaudio
|
||||
from torch.nn.utils.rnn import pad_sequence
|
||||
|
||||
|
||||
class OnnxModel:
|
||||
def __init__(
|
||||
self,
|
||||
filename: str,
|
||||
):
|
||||
session_opts = ort.SessionOptions()
|
||||
session_opts.inter_op_num_threads = 1
|
||||
session_opts.intra_op_num_threads = 4
|
||||
|
||||
self.session_opts = session_opts
|
||||
|
||||
self.model = ort.InferenceSession(
|
||||
filename,
|
||||
sess_options=self.session_opts,
|
||||
providers=["CPUExecutionProvider"],
|
||||
)
|
||||
|
||||
meta = self.model.get_modelmeta().custom_metadata_map
|
||||
self.left_chunks = int(meta["left_chunks"])
|
||||
self.num_blocks = int(meta["num_blocks"])
|
||||
self.chunk_size = int(meta["chunk_size"])
|
||||
self.head = int(meta["head"])
|
||||
self.output_size = int(meta["output_size"])
|
||||
self.cnn_module_kernel = int(meta["cnn_module_kernel"])
|
||||
self.right_context = int(meta["right_context"])
|
||||
self.subsampling_factor = int(meta["subsampling_factor"])
|
||||
|
||||
self._init_cache()
|
||||
|
||||
def _init_cache(self):
|
||||
required_cache_size = self.chunk_size * self.left_chunks
|
||||
|
||||
self.attn_cache = torch.zeros(
|
||||
self.num_blocks,
|
||||
self.head,
|
||||
required_cache_size,
|
||||
self.output_size // self.head * 2,
|
||||
dtype=torch.float32,
|
||||
).numpy()
|
||||
|
||||
self.conv_cache = torch.zeros(
|
||||
self.num_blocks,
|
||||
1,
|
||||
self.output_size,
|
||||
self.cnn_module_kernel - 1,
|
||||
dtype=torch.float32,
|
||||
).numpy()
|
||||
|
||||
self.offset = torch.tensor([required_cache_size], dtype=torch.int64).numpy()
|
||||
|
||||
self.required_cache_size = torch.tensor(
|
||||
[self.chunk_size * self.left_chunks], dtype=torch.int64
|
||||
).numpy()
|
||||
|
||||
def __call__(self, x: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Args:
|
||||
x:
|
||||
A 2-D tensor of shape (T, C)
|
||||
Returns:
|
||||
Return a 2-D tensor of shape (T, C) containing log_probs.
|
||||
"""
|
||||
attn_mask = torch.ones(
|
||||
1, 1, int(self.required_cache_size + self.chunk_size), dtype=torch.bool
|
||||
)
|
||||
chunk_idx = self.offset // self.chunk_size - self.left_chunks
|
||||
if chunk_idx < self.left_chunks:
|
||||
attn_mask[
|
||||
:, :, : int(self.required_cache_size - chunk_idx * self.chunk_size)
|
||||
] = False
|
||||
|
||||
log_probs, new_attn_cache, new_conv_cache = self.model.run(
|
||||
[
|
||||
self.model.get_outputs()[0].name,
|
||||
self.model.get_outputs()[1].name,
|
||||
self.model.get_outputs()[2].name,
|
||||
],
|
||||
{
|
||||
self.model.get_inputs()[0].name: x.unsqueeze(0).numpy(),
|
||||
self.model.get_inputs()[1].name: self.offset,
|
||||
self.model.get_inputs()[2].name: self.required_cache_size,
|
||||
self.model.get_inputs()[3].name: self.attn_cache,
|
||||
self.model.get_inputs()[4].name: self.conv_cache,
|
||||
self.model.get_inputs()[5].name: attn_mask.numpy(),
|
||||
},
|
||||
)
|
||||
|
||||
self.attn_cache = new_attn_cache
|
||||
self.conv_cache = new_conv_cache
|
||||
|
||||
log_probs = torch.from_numpy(log_probs)
|
||||
|
||||
self.offset += log_probs.shape[1]
|
||||
|
||||
return log_probs.squeeze(0)
|
||||
|
||||
|
||||
def get_features(test_wav_filename):
|
||||
wave, sample_rate = torchaudio.load(test_wav_filename)
|
||||
audio = wave[0].contiguous() # only use the first channel
|
||||
if sample_rate != 16000:
|
||||
audio = torchaudio.functional.resample(
|
||||
audio, orig_freq=sample_rate, new_freq=16000
|
||||
)
|
||||
audio *= 372768
|
||||
|
||||
opts = knf.FbankOptions()
|
||||
opts.frame_opts.dither = 0
|
||||
opts.mel_opts.num_bins = 80
|
||||
opts.frame_opts.snip_edges = False
|
||||
opts.mel_opts.debug_mel = False
|
||||
|
||||
fbank = knf.OnlineFbank(opts)
|
||||
fbank.accept_waveform(16000, audio.numpy())
|
||||
frames = []
|
||||
for i in range(fbank.num_frames_ready):
|
||||
frames.append(torch.from_numpy(fbank.get_frame(i)))
|
||||
frames = torch.stack(frames)
|
||||
return frames
|
||||
|
||||
|
||||
def main():
|
||||
model_filename = "./model-streaming.onnx"
|
||||
model = OnnxModel(model_filename)
|
||||
|
||||
filename = "./0.wav"
|
||||
x = get_features(filename)
|
||||
|
||||
padding = torch.zeros(int(16000 * 0.5), 80)
|
||||
x = torch.cat([x, padding], dim=0)
|
||||
|
||||
chunk_length = (
|
||||
(model.chunk_size - 1) * model.subsampling_factor + model.right_context + 1
|
||||
)
|
||||
chunk_length = int(chunk_length)
|
||||
chunk_shift = int(model.required_cache_size)
|
||||
print(chunk_length, chunk_shift)
|
||||
|
||||
num_frames = x.shape[0]
|
||||
n = (num_frames - chunk_length) // chunk_shift + 1
|
||||
tokens = []
|
||||
for i in range(n):
|
||||
start = i * chunk_shift
|
||||
end = start + chunk_length
|
||||
frames = x[start:end, :]
|
||||
log_probs = model(frames)
|
||||
|
||||
indexes = log_probs.argmax(dim=1)
|
||||
indexes = torch.unique_consecutive(indexes)
|
||||
indexes = indexes[indexes != 0].tolist()
|
||||
if indexes:
|
||||
tokens.extend(indexes)
|
||||
|
||||
id2word = dict()
|
||||
with open("./units.txt", encoding="utf-8") as f:
|
||||
for line in f:
|
||||
word, idx = line.strip().split()
|
||||
id2word[int(idx)] = word
|
||||
text = "".join([id2word[i] for i in tokens])
|
||||
print(text)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
104
scripts/wenet/test-onnx.py
Executable file
104
scripts/wenet/test-onnx.py
Executable file
@@ -0,0 +1,104 @@
|
||||
#!/usr/bin/env python3
|
||||
# Copyright 2023 Xiaomi Corp. (authors: Fangjun Kuang)
|
||||
|
||||
import kaldi_native_fbank as knf
|
||||
import onnxruntime as ort
|
||||
import torch
|
||||
import torchaudio
|
||||
from torch.nn.utils.rnn import pad_sequence
|
||||
|
||||
|
||||
class OnnxModel:
|
||||
def __init__(
|
||||
self,
|
||||
filename: str,
|
||||
):
|
||||
session_opts = ort.SessionOptions()
|
||||
session_opts.inter_op_num_threads = 1
|
||||
session_opts.intra_op_num_threads = 4
|
||||
|
||||
self.session_opts = session_opts
|
||||
|
||||
self.model = ort.InferenceSession(
|
||||
filename,
|
||||
sess_options=self.session_opts,
|
||||
providers=["CPUExecutionProvider"],
|
||||
)
|
||||
|
||||
def __call__(self, x: torch.Tensor, x_lens: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Args:
|
||||
x:
|
||||
A 3-D tensor of shape (N, T, C)
|
||||
x_lens:
|
||||
A 1-D tensor of shape (N,). Its dtype is torch.int64
|
||||
Returns:
|
||||
Return a 3-D tensor of shape (N, T, C) containing log_probs.
|
||||
"""
|
||||
log_probs, log_probs_lens = self.model.run(
|
||||
[self.model.get_outputs()[0].name, self.model.get_outputs()[1].name],
|
||||
{
|
||||
self.model.get_inputs()[0].name: x.numpy(),
|
||||
self.model.get_inputs()[1].name: x_lens.numpy(),
|
||||
},
|
||||
)
|
||||
return torch.from_numpy(log_probs), torch.from_numpy(log_probs_lens)
|
||||
|
||||
|
||||
def get_features(test_wav_filename):
|
||||
wave, sample_rate = torchaudio.load(test_wav_filename)
|
||||
audio = wave[0].contiguous() # only use the first channel
|
||||
if sample_rate != 16000:
|
||||
audio = torchaudio.functional.resample(
|
||||
audio, orig_freq=sample_rate, new_freq=16000
|
||||
)
|
||||
audio *= 372768
|
||||
|
||||
opts = knf.FbankOptions()
|
||||
opts.frame_opts.dither = 0
|
||||
opts.mel_opts.num_bins = 80
|
||||
opts.frame_opts.snip_edges = False
|
||||
opts.mel_opts.debug_mel = False
|
||||
|
||||
fbank = knf.OnlineFbank(opts)
|
||||
fbank.accept_waveform(16000, audio.numpy())
|
||||
frames = []
|
||||
for i in range(fbank.num_frames_ready):
|
||||
frames.append(torch.from_numpy(fbank.get_frame(i)))
|
||||
frames = torch.stack(frames)
|
||||
return frames
|
||||
|
||||
|
||||
def main():
|
||||
model_filename = "./model.onnx"
|
||||
model = OnnxModel(model_filename)
|
||||
|
||||
filename = "./0.wav"
|
||||
x = get_features(filename)
|
||||
x = x.unsqueeze(0)
|
||||
|
||||
# Note: It supports only batch size == 1
|
||||
x_lens = torch.tensor([x.shape[1]], dtype=torch.int64)
|
||||
|
||||
print(x.shape, x_lens)
|
||||
|
||||
log_probs, log_probs_lens = model(x, x_lens)
|
||||
log_probs = log_probs[0]
|
||||
print(log_probs.shape)
|
||||
|
||||
indexes = log_probs.argmax(dim=1)
|
||||
print(indexes)
|
||||
indexes = torch.unique_consecutive(indexes)
|
||||
indexes = indexes[indexes != 0].tolist()
|
||||
|
||||
id2word = dict()
|
||||
with open("./units.txt", encoding="utf-8") as f:
|
||||
for line in f:
|
||||
word, idx = line.strip().split()
|
||||
id2word[int(idx)] = word
|
||||
text = "".join([id2word[i] for i in indexes])
|
||||
print(text)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
Reference in New Issue
Block a user