Compare commits
4 Commits
v0.5.4
...
v0.5.3_dev
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
a0fb70e9c1 | ||
|
|
848c5b8290 | ||
|
|
68277eac30 | ||
|
|
8f7453e3af |
1
.github/CODEOWNERS
vendored
1
.github/CODEOWNERS
vendored
@@ -12,7 +12,6 @@
|
||||
/python/sglang/srt/eplb @fzyzcjy
|
||||
/python/sglang/srt/function_call @CatherineSue @JustinTong0323
|
||||
/python/sglang/srt/layers @merrymercy @Ying1123 @zhyncs @ispobock @HaiShaw @ch-wan @BBuf @kushanam @Edwardf0t1
|
||||
/python/sglang/srt/layers/quantization @ch-wan @BBuf @Edwardf0t1 @FlamingoPg
|
||||
/python/sglang/srt/layers/attention/ascend_backend.py @ping1jing2
|
||||
/python/sglang/srt/lora @Ying1123 @Fridge003 @lifuhuang
|
||||
/python/sglang/srt/managers @merrymercy @Ying1123 @hnyls2002 @xiezhq-hermann
|
||||
|
||||
1
.github/REVIEWERS.md
vendored
1
.github/REVIEWERS.md
vendored
@@ -15,7 +15,6 @@ Here are some reviewers for common areas. You can ping them to review your code
|
||||
- flash attention backend @hebiao064
|
||||
- flashinfer attention backend @Fridge003
|
||||
- moe kernel @BBuf @fzyzcjy @ch-wan @Alcanderian
|
||||
- quantization @FlamingoPg @HandH1998
|
||||
|
||||
## Scheduler and memory pool
|
||||
- general @merrymercy @Ying1123 @hnyls2002 @xiezhq-hermann
|
||||
|
||||
46
.github/workflows/bot-bump-kernel-version.yml
vendored
46
.github/workflows/bot-bump-kernel-version.yml
vendored
@@ -1,46 +0,0 @@
|
||||
name: Bot Bump Kernel Version
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
new_version:
|
||||
description: 'New sgl-kernel version (e.g., 0.3.12)'
|
||||
required: true
|
||||
type: string
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
pull-requests: write
|
||||
|
||||
jobs:
|
||||
bump-kernel-version:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.10'
|
||||
|
||||
- name: Configure Git and branch
|
||||
run: |
|
||||
git config user.name "sglang-bot"
|
||||
git config user.email "sglang-bot@users.noreply.github.com"
|
||||
RANDOM_SUFFIX=$(echo $RANDOM | md5sum | head -c 4)
|
||||
BRANCH_NAME="bot/bump-kernel-version-${{ github.event.inputs.new_version }}-${RANDOM_SUFFIX}"
|
||||
git checkout -b "$BRANCH_NAME"
|
||||
echo "BRANCH_NAME=$BRANCH_NAME" >> $GITHUB_ENV
|
||||
|
||||
- name: Run kernel version bump script
|
||||
run: |
|
||||
python scripts/release/bump_kernel_version.py "${{ github.event.inputs.new_version }}"
|
||||
|
||||
- name: Commit and create PR
|
||||
env:
|
||||
GH_TOKEN: ${{ secrets.GH_PAT_FOR_TAGGING }}
|
||||
run: |
|
||||
bash scripts/release/commit_and_pr.sh "sgl-kernel" "${{ github.event.inputs.new_version }}" "$BRANCH_NAME"
|
||||
46
.github/workflows/bot-bump-sglang-version.yml
vendored
46
.github/workflows/bot-bump-sglang-version.yml
vendored
@@ -1,46 +0,0 @@
|
||||
name: Bot Bump SGLang Version
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
new_version:
|
||||
description: 'New SGLang version (e.g., 0.5.3 or 0.5.3rc0)'
|
||||
required: true
|
||||
type: string
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
pull-requests: write
|
||||
|
||||
jobs:
|
||||
bump-sglang-version:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.10'
|
||||
|
||||
- name: Configure Git and branch
|
||||
run: |
|
||||
git config user.name "sglang-bot"
|
||||
git config user.email "sglang-bot@users.noreply.github.com"
|
||||
RANDOM_SUFFIX=$(echo $RANDOM | md5sum | head -c 4)
|
||||
BRANCH_NAME="bot/bump-sglang-version-${{ github.event.inputs.new_version }}-${RANDOM_SUFFIX}"
|
||||
git checkout -b "$BRANCH_NAME"
|
||||
echo "BRANCH_NAME=$BRANCH_NAME" >> $GITHUB_ENV
|
||||
|
||||
- name: Run SGLang version bump script
|
||||
run: |
|
||||
python scripts/release/bump_sglang_version.py "${{ github.event.inputs.new_version }}"
|
||||
|
||||
- name: Commit and create PR
|
||||
env:
|
||||
GH_TOKEN: ${{ secrets.GH_PAT_FOR_TAGGING }}
|
||||
run: |
|
||||
bash scripts/release/commit_and_pr.sh "SGLang" "${{ github.event.inputs.new_version }}" "$BRANCH_NAME"
|
||||
4
.github/workflows/ci-monitor.yml
vendored
4
.github/workflows/ci-monitor.yml
vendored
@@ -44,7 +44,7 @@ jobs:
|
||||
PYTHONIOENCODING: utf-8
|
||||
run: |
|
||||
cd scripts/ci_monitor
|
||||
python ci_analyzer.py --token $GITHUB_TOKEN --limit ${{ inputs.limit || '1000' }} --output ci_analysis_$(date +%Y%m%d_%H%M%S).json
|
||||
python ci_analyzer.py --token $GITHUB_TOKEN --limit ${{ github.event.inputs.limit || '1000' }} --output ci_analysis_$(date +%Y%m%d_%H%M%S).json
|
||||
|
||||
- name: Run Performance Analysis
|
||||
env:
|
||||
@@ -53,7 +53,7 @@ jobs:
|
||||
PYTHONIOENCODING: utf-8
|
||||
run: |
|
||||
cd scripts/ci_monitor
|
||||
python ci_analyzer_perf.py --token $GITHUB_TOKEN --limit ${{ inputs.limit || '1000' }} --output-dir performance_tables_$(date +%Y%m%d_%H%M%S) --upload-to-github
|
||||
python ci_analyzer_perf.py --token $GITHUB_TOKEN --limit ${{ github.event.inputs.limit || '1000' }} --output-dir performance_tables_$(date +%Y%m%d_%H%M%S) --upload-to-github
|
||||
|
||||
- name: Upload Analysis Results
|
||||
uses: actions/upload-artifact@v4
|
||||
|
||||
8
.github/workflows/lint.yml
vendored
8
.github/workflows/lint.yml
vendored
@@ -1,10 +1,6 @@
|
||||
name: Lint
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [main]
|
||||
pull_request:
|
||||
branches: [main]
|
||||
on: [pull_request]
|
||||
|
||||
jobs:
|
||||
lint:
|
||||
@@ -23,7 +19,7 @@ jobs:
|
||||
pre-commit install
|
||||
|
||||
- name: Run pre-commit checks
|
||||
run: SKIP=no-commit-to-branch pre-commit run --all-files --show-diff-on-failure
|
||||
run: pre-commit run --all-files --show-diff-on-failure
|
||||
|
||||
- name: Run sgl-kernel clang-format checks
|
||||
uses: DoozyX/clang-format-lint-action@v0.18.1
|
||||
|
||||
146
.github/workflows/nightly-release-router.yml
vendored
146
.github/workflows/nightly-release-router.yml
vendored
@@ -1,146 +0,0 @@
|
||||
# Nightly release workflow for SGLang Router
|
||||
|
||||
name: Nightly Release SGLang Router to PyPI
|
||||
|
||||
on:
|
||||
schedule:
|
||||
# Run at 2 AM UTC every day
|
||||
- cron: '0 2 * * *'
|
||||
workflow_dispatch: # Allow manual trigger
|
||||
|
||||
jobs:
|
||||
build:
|
||||
name: Build on ${{ matrix.os }} (${{ matrix.target }})
|
||||
runs-on: ${{ matrix.os }}-latest
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
include:
|
||||
- os: ubuntu
|
||||
target: x86_64
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
path: sglang-repo
|
||||
|
||||
- name: Move sgl-router folder to root and delete sglang-repo
|
||||
run: |
|
||||
mv sglang-repo/sgl-router/* .
|
||||
rm -rf sglang-repo
|
||||
ls -alt
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: "3.11"
|
||||
|
||||
- name: Modify version for nightly release
|
||||
run: |
|
||||
# Get current version from pyproject.toml
|
||||
CURRENT_VERSION=$(python -c "import tomllib; print(tomllib.load(open('pyproject.toml', 'rb'))['project']['version'])" 2>/dev/null || python -c "import tomli; print(tomli.load(open('pyproject.toml', 'rb'))['project']['version'])")
|
||||
# Create nightly version with date: e.g., 0.1.9.dev20250112
|
||||
NIGHTLY_VERSION="${CURRENT_VERSION}.dev$(date +%Y%m%d)"
|
||||
echo "Nightly version: $NIGHTLY_VERSION"
|
||||
|
||||
# Update pyproject.toml with nightly version (temporary, not committed)
|
||||
sed -i "s/version = \"${CURRENT_VERSION}\"/version = \"${NIGHTLY_VERSION}\"/" pyproject.toml
|
||||
|
||||
# Verify the change
|
||||
cat pyproject.toml | grep "^version"
|
||||
|
||||
- name: Install build dependencies
|
||||
run: |
|
||||
python -m pip install -U pip
|
||||
python -m pip install build twine auditwheel tomli
|
||||
|
||||
- name: Build package
|
||||
uses: pypa/cibuildwheel@v2.21.3
|
||||
env:
|
||||
CIBW_BUILD: "cp38-manylinux_x86_64 cp39-manylinux_x86_64 cp310-manylinux_x86_64 cp311-manylinux_x86_64 cp312-manylinux_x86_64"
|
||||
CIBW_BEFORE_ALL: |
|
||||
yum update -y && yum install -y openssl-devel wget unzip && \
|
||||
# Install latest protoc (v32.0) that supports proto3
|
||||
cd /tmp && \
|
||||
wget https://github.com/protocolbuffers/protobuf/releases/download/v32.0/protoc-32.0-linux-x86_64.zip && \
|
||||
unzip protoc-32.0-linux-x86_64.zip -d /usr/local && \
|
||||
rm protoc-32.0-linux-x86_64.zip && \
|
||||
# Install Rust
|
||||
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y
|
||||
CIBW_ENVIRONMENT: "PATH=$HOME/.cargo/bin:$PATH"
|
||||
|
||||
- name: List built packages
|
||||
run: ls -lh wheelhouse/
|
||||
|
||||
- name: Check packages
|
||||
run: twine check --strict wheelhouse/*
|
||||
|
||||
- uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: packages-${{ matrix.os }}-${{ matrix.target }}
|
||||
path: wheelhouse/
|
||||
|
||||
build-sdist:
|
||||
name: Build SDist
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
path: sglang-repo
|
||||
|
||||
- name: Move sgl-router folder to root, copy the license file, and delete sglang-repo
|
||||
run: |
|
||||
mv sglang-repo/sgl-router/* .
|
||||
mv sglang-repo/LICENSE .
|
||||
rm -rf sglang-repo
|
||||
ls -alt
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: "3.11"
|
||||
|
||||
- name: Modify version for nightly release
|
||||
run: |
|
||||
# Get current version from pyproject.toml
|
||||
CURRENT_VERSION=$(python -c "import tomllib; print(tomllib.load(open('pyproject.toml', 'rb'))['project']['version'])" 2>/dev/null || python -c "import tomli; print(tomli.load(open('pyproject.toml', 'rb'))['project']['version'])")
|
||||
# Create nightly version with date: e.g., 0.1.9.dev20250112
|
||||
NIGHTLY_VERSION="${CURRENT_VERSION}.dev$(date +%Y%m%d)"
|
||||
echo "Nightly version: $NIGHTLY_VERSION"
|
||||
|
||||
# Update pyproject.toml with nightly version (temporary, not committed)
|
||||
sed -i "s/version = \"${CURRENT_VERSION}\"/version = \"${CURRENT_VERSION}\"/g" pyproject.toml
|
||||
sed -i "0,/version = \"${CURRENT_VERSION}\"/s//version = \"${NIGHTLY_VERSION}\"/" pyproject.toml
|
||||
|
||||
# Verify the change
|
||||
cat pyproject.toml | grep "^version"
|
||||
|
||||
- name: Build SDist
|
||||
run: |
|
||||
pip install build
|
||||
python -m pip install -U packaging tomli
|
||||
python -m build --sdist
|
||||
|
||||
- uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: sdist
|
||||
path: dist/*.tar.gz
|
||||
|
||||
upload:
|
||||
name: Upload to TestPyPI
|
||||
if: github.repository == 'sgl-project/sglang' # Ensure this job only runs for the sgl-project/sglang repository
|
||||
needs: [build, build-sdist]
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/download-artifact@v4
|
||||
with:
|
||||
path: dist
|
||||
merge-multiple: true
|
||||
|
||||
- name: Upload to TestPyPI
|
||||
env:
|
||||
TWINE_USERNAME: __token__
|
||||
TWINE_PASSWORD: ${{ secrets.TEST_PYPI_TOKEN_ROUTER }}
|
||||
run: |
|
||||
pip install twine
|
||||
twine upload --repository testpypi dist/* --verbose
|
||||
22
.github/workflows/nightly-test.yml
vendored
22
.github/workflows/nightly-test.yml
vendored
@@ -62,7 +62,7 @@ jobs:
|
||||
|
||||
nightly-test-eval-vlms:
|
||||
if: github.repository == 'sgl-project/sglang'
|
||||
runs-on: 2-gpu-runner
|
||||
runs-on: 1-gpu-runner
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
@@ -77,9 +77,10 @@ jobs:
|
||||
cd test/srt
|
||||
python3 test_nightly_vlms_mmmu_eval.py
|
||||
|
||||
|
||||
nightly-test-perf-vlms:
|
||||
if: github.repository == 'sgl-project/sglang'
|
||||
runs-on: 2-gpu-runner
|
||||
runs-on: 1-gpu-runner
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
@@ -104,20 +105,3 @@ jobs:
|
||||
GITHUB_RUN_NUMBER: ${{ github.run_number }}
|
||||
run: |
|
||||
python3 scripts/ci/publish_traces.py --vlm
|
||||
|
||||
nightly-test-1-gpu:
|
||||
if: github.repository == 'sgl-project/sglang'
|
||||
runs-on: 1-gpu-runner
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
bash scripts/ci/ci_install_dependency.sh
|
||||
|
||||
- name: Run test
|
||||
timeout-minutes: 10
|
||||
run: |
|
||||
cd test/srt
|
||||
python3 run_suite.py --suite nightly-1-gpu
|
||||
|
||||
2
.github/workflows/pr-benchmark-rust.yml
vendored
2
.github/workflows/pr-benchmark-rust.yml
vendored
@@ -1,4 +1,4 @@
|
||||
name: PR Benchmark (SMG Components)
|
||||
name: PR Benchmark (Rust Router)
|
||||
|
||||
on:
|
||||
push:
|
||||
|
||||
81
.github/workflows/pr-test-amd.yml
vendored
81
.github/workflows/pr-test-amd.yml
vendored
@@ -30,15 +30,12 @@ jobs:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
runner: [linux-mi300-gpu-1]
|
||||
runner: [linux-mi300-gpu-1, linux-mi325-gpu-1]
|
||||
runs-on: ${{matrix.runner}}
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Ensure VRAM is clear
|
||||
run: bash scripts/ensure_vram_clear.sh rocm
|
||||
|
||||
- name: Start CI container
|
||||
run: bash scripts/ci/amd_ci_start_container.sh
|
||||
env:
|
||||
@@ -59,15 +56,12 @@ jobs:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
runner: [linux-mi300-gpu-2]
|
||||
runner: [linux-mi300-gpu-2, linux-mi325-gpu-2, linux-mi35x-gpu-2]
|
||||
runs-on: ${{matrix.runner}}
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Ensure VRAM is clear
|
||||
run: bash scripts/ensure_vram_clear.sh rocm
|
||||
|
||||
- name: Start CI container
|
||||
run: bash scripts/ci/amd_ci_start_container.sh
|
||||
env:
|
||||
@@ -86,15 +80,12 @@ jobs:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
runner: [linux-mi300-gpu-1]
|
||||
runner: [linux-mi300-gpu-1, linux-mi325-gpu-1]
|
||||
runs-on: ${{matrix.runner}}
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Ensure VRAM is clear
|
||||
run: bash scripts/ensure_vram_clear.sh rocm
|
||||
|
||||
- name: Start CI container
|
||||
run: bash scripts/ci/amd_ci_start_container.sh
|
||||
env:
|
||||
@@ -113,15 +104,12 @@ jobs:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
runner: [linux-mi300-gpu-1]
|
||||
runner: [linux-mi300-gpu-1, linux-mi325-gpu-1]
|
||||
runs-on: ${{matrix.runner}}
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Ensure VRAM is clear
|
||||
run: bash scripts/ensure_vram_clear.sh rocm
|
||||
|
||||
- name: Start CI container
|
||||
run: bash scripts/ci/amd_ci_start_container.sh
|
||||
env:
|
||||
@@ -156,15 +144,12 @@ jobs:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
runner: [linux-mi300-gpu-1]
|
||||
runner: [linux-mi300-gpu-1, linux-mi325-gpu-1]
|
||||
runs-on: ${{matrix.runner}}
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Ensure VRAM is clear
|
||||
run: bash scripts/ensure_vram_clear.sh rocm
|
||||
|
||||
- name: Start CI container
|
||||
run: bash scripts/ci/amd_ci_start_container.sh
|
||||
env:
|
||||
@@ -193,15 +178,12 @@ jobs:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
runner: [linux-mi300-gpu-2]
|
||||
runner: [linux-mi300-gpu-2, linux-mi325-gpu-2]
|
||||
runs-on: ${{matrix.runner}}
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Ensure VRAM is clear
|
||||
run: bash scripts/ensure_vram_clear.sh rocm
|
||||
|
||||
- name: Start CI container
|
||||
run: bash scripts/ci/amd_ci_start_container.sh
|
||||
env:
|
||||
@@ -240,16 +222,13 @@ jobs:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
runner: [linux-mi300-gpu-1]
|
||||
part: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
|
||||
runner: [linux-mi300-gpu-1, linux-mi325-gpu-1]
|
||||
part: [0, 1, 2, 3, 4, 5, 6, 7]
|
||||
runs-on: ${{matrix.runner}}
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Ensure VRAM is clear
|
||||
run: bash scripts/ensure_vram_clear.sh rocm
|
||||
|
||||
- name: Start CI container
|
||||
run: bash scripts/ci/amd_ci_start_container.sh
|
||||
env:
|
||||
@@ -259,24 +238,45 @@ jobs:
|
||||
run: bash scripts/ci/amd_ci_install_dependency.sh
|
||||
|
||||
- name: Run test
|
||||
timeout-minutes: 30
|
||||
timeout-minutes: 50
|
||||
run: |
|
||||
bash scripts/ci/amd_ci_exec.sh python3 run_suite.py --suite per-commit-amd --auto-partition-id ${{ matrix.part }} --auto-partition-size 12
|
||||
bash scripts/ci/amd_ci_exec.sh python3 run_suite.py --suite per-commit-amd --auto-partition-id ${{ matrix.part }} --auto-partition-size 8
|
||||
|
||||
unit-test-backend-1-gpu-amd-mi35x:
|
||||
if: github.event_name != 'pull_request' || contains(github.event.pull_request.labels.*.name, 'run-ci')
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
runner: [linux-mi35x-gpu-1]
|
||||
runs-on: ${{matrix.runner}}
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Start CI container
|
||||
run: bash scripts/ci/amd_ci_start_container.sh
|
||||
env:
|
||||
GITHUB_WORKSPACE: ${{ github.workspace }}
|
||||
|
||||
- name: Install dependencies
|
||||
run: bash scripts/ci/amd_ci_install_dependency.sh
|
||||
|
||||
- name: Run test
|
||||
timeout-minutes: 50
|
||||
run: |
|
||||
bash scripts/ci/amd_ci_exec.sh python3 run_suite.py --suite per-commit-amd-mi35x
|
||||
|
||||
unit-test-backend-2-gpu-amd:
|
||||
if: github.event_name != 'pull_request' || contains(github.event.pull_request.labels.*.name, 'run-ci')
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
runner: [linux-mi300-gpu-2]
|
||||
runner: [linux-mi300-gpu-2, linux-mi325-gpu-2]
|
||||
runs-on: ${{matrix.runner}}
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Ensure VRAM is clear
|
||||
run: bash scripts/ensure_vram_clear.sh rocm
|
||||
|
||||
- name: Start CI container
|
||||
run: bash scripts/ci/amd_ci_start_container.sh
|
||||
env:
|
||||
@@ -296,15 +296,11 @@ jobs:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
runner: [linux-mi300-gpu-8]
|
||||
part: [0, 1]
|
||||
runs-on: ${{matrix.runner}}
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Ensure VRAM is clear
|
||||
run: bash scripts/ensure_vram_clear.sh rocm
|
||||
|
||||
- name: Start CI container
|
||||
run: bash scripts/ci/amd_ci_start_container.sh
|
||||
env:
|
||||
@@ -316,22 +312,19 @@ jobs:
|
||||
- name: Run test
|
||||
timeout-minutes: 60
|
||||
run: |
|
||||
bash scripts/ci/amd_ci_exec.sh python3 run_suite.py --suite per-commit-8-gpu-amd --auto-partition-id ${{ matrix.part }} --auto-partition-size 2 --timeout-per-file 3600
|
||||
bash scripts/ci/amd_ci_exec.sh python3 run_suite.py --suite per-commit-8-gpu-amd --timeout-per-file 3600
|
||||
|
||||
unit-test-sgl-kernel-amd:
|
||||
if: github.event_name != 'pull_request' || contains(github.event.pull_request.labels.*.name, 'run-ci')
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
runner: [linux-mi300-gpu-1]
|
||||
runner: [linux-mi300-gpu-1, linux-mi325-gpu-1]
|
||||
runs-on: ${{matrix.runner}}
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Ensure VRAM is clear
|
||||
run: bash scripts/ensure_vram_clear.sh rocm
|
||||
|
||||
- name: Start CI container
|
||||
run: bash scripts/ci/amd_ci_start_container.sh
|
||||
env:
|
||||
|
||||
106
.github/workflows/pr-test-h20.yml
vendored
Normal file
106
.github/workflows/pr-test-h20.yml
vendored
Normal file
@@ -0,0 +1,106 @@
|
||||
name: PR Test (H20)
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ main ]
|
||||
pull_request:
|
||||
branches: [ main ]
|
||||
types: [synchronize, labeled]
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
version:
|
||||
required: true
|
||||
type: choice
|
||||
default: 'release'
|
||||
options:
|
||||
- 'release'
|
||||
- 'nightly'
|
||||
|
||||
concurrency:
|
||||
group: pr-test-h20-${{ github.ref }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
check-changes:
|
||||
runs-on: ubuntu-latest
|
||||
outputs:
|
||||
h20_files: ${{ steps.filter.outputs.h20_files }}
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Fail if the PR does not have the 'run-ci' label
|
||||
if: github.event_name == 'pull_request' && !contains(github.event.pull_request.labels.*.name, 'run-ci')
|
||||
run: |
|
||||
echo "This pull request does not have the 'run-ci' label. Failing the workflow."
|
||||
exit 1
|
||||
|
||||
- name: Fail if the PR is a draft
|
||||
if: github.event_name == 'pull_request' && github.event.pull_request.draft == true
|
||||
run: |
|
||||
echo "This pull request is a draft. Failing the workflow."
|
||||
exit 1
|
||||
|
||||
- name: Detect file changes
|
||||
id: filter
|
||||
uses: dorny/paths-filter@v3
|
||||
with:
|
||||
filters: |
|
||||
h20_files:
|
||||
- "python/sglang/srt/models/deepseek*"
|
||||
- "python/sglang/srt/layers/moe/**"
|
||||
- ".github/workflows/pr-test-h20.yml"
|
||||
- "python/pyproject.toml"
|
||||
|
||||
per-commit-8-gpu-h20:
|
||||
needs: [check-changes]
|
||||
if: needs.check-changes.outputs.h20_files == 'true'
|
||||
runs-on: 8-gpu-h20
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
bash scripts/ci/ci_install_dependency.sh
|
||||
|
||||
- name: Run test
|
||||
timeout-minutes: 20
|
||||
|
||||
run: |
|
||||
cd test/srt
|
||||
python3 run_suite.py --suite per-commit-8-gpu-h20
|
||||
|
||||
pr-test-h20-finish:
|
||||
needs: [
|
||||
check-changes,
|
||||
per-commit-8-gpu-h20,
|
||||
]
|
||||
if: always()
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Check all dependent job statuses
|
||||
run: |
|
||||
# Convert the 'needs' context to a JSON string
|
||||
json_needs='${{ toJson(needs) }}'
|
||||
|
||||
# Get a list of all job names from the JSON keys
|
||||
job_names=$(echo "$json_needs" | jq -r 'keys_unsorted[]')
|
||||
|
||||
for job in $job_names; do
|
||||
# For each job, extract its result
|
||||
result=$(echo "$json_needs" | jq -r --arg j "$job" '.[$j].result')
|
||||
|
||||
# Print the job name and its result
|
||||
echo "$job: $result"
|
||||
|
||||
# Check for failure or cancellation and exit if found
|
||||
if [[ "$result" == "failure" || "$result" == "cancelled" ]]; then
|
||||
echo "The above jobs failed."
|
||||
exit 1
|
||||
fi
|
||||
done
|
||||
|
||||
# If the loop completes, all jobs were successful
|
||||
echo "All jobs completed successfully"
|
||||
exit 0
|
||||
46
.github/workflows/pr-test-npu.yml
vendored
46
.github/workflows/pr-test-npu.yml
vendored
@@ -38,10 +38,9 @@ jobs:
|
||||
CACHING_URL="cache-service.nginx-pypi-cache.svc.cluster.local"
|
||||
sed -Ei "s@(ports|archive).ubuntu.com@${CACHING_URL}:8081@g" /etc/apt/sources.list
|
||||
pip config set global.index-url http://${CACHING_URL}/pypi/simple
|
||||
pip config set global.extra-index-url "https://pypi.tuna.tsinghua.edu.cn/simple https://mirrors.aliyun.com/pypi/simple/"
|
||||
pip config set global.trusted-host "${CACHING_URL} pypi.tuna.tsinghua.edu.cn mirrors.aliyun.com"
|
||||
pip config set global.trusted-host ${CACHING_URL}
|
||||
|
||||
bash scripts/ci/npu_ci_install_dependency.sh 910b
|
||||
bash scripts/ci/npu_ci_install_dependency.sh
|
||||
# copy required file from our daily cache
|
||||
cp ~/.cache/modelscope/hub/datasets/otavia/ShareGPT_Vicuna_unfiltered/ShareGPT_V3_unfiltered_cleaned_split.json /tmp
|
||||
# copy download through proxy
|
||||
@@ -54,20 +53,13 @@ jobs:
|
||||
SGLANG_IS_IN_CI: true
|
||||
HF_ENDPOINT: https://hf-mirror.com
|
||||
TORCH_EXTENSIONS_DIR: /tmp/torch_extensions
|
||||
PYTORCH_NPU_ALLOC_CONF: "expandable_segments:True"
|
||||
STREAMS_PER_DEVICE: 32
|
||||
run: |
|
||||
export PATH="/usr/local/Ascend/8.3.RC1/compiler/bishengir/bin:${PATH}"
|
||||
cd test/srt
|
||||
python3 run_suite.py --suite per-commit-1-ascend-npu
|
||||
|
||||
per-commit-2-ascend-npu:
|
||||
if: github.event_name != 'pull_request' || contains(github.event.pull_request.labels.*.name, 'run-ci')
|
||||
runs-on: linux-arm64-npu-2
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
part: [0, 1, 2]
|
||||
container:
|
||||
image: swr.cn-southwest-2.myhuaweicloud.com/base_image/ascend-ci/cann:8.2.rc1-910b-ubuntu22.04-py3.11
|
||||
steps:
|
||||
@@ -80,28 +72,24 @@ jobs:
|
||||
CACHING_URL="cache-service.nginx-pypi-cache.svc.cluster.local"
|
||||
sed -Ei "s@(ports|archive).ubuntu.com@${CACHING_URL}:8081@g" /etc/apt/sources.list
|
||||
pip config set global.index-url http://${CACHING_URL}/pypi/simple
|
||||
pip config set global.extra-index-url "https://pypi.tuna.tsinghua.edu.cn/simple https://mirrors.aliyun.com/pypi/simple/"
|
||||
pip config set global.trusted-host "${CACHING_URL} pypi.tuna.tsinghua.edu.cn mirrors.aliyun.com"
|
||||
pip config set global.trusted-host ${CACHING_URL}
|
||||
|
||||
bash scripts/ci/npu_ci_install_dependency.sh 910b
|
||||
bash scripts/ci/npu_ci_install_dependency.sh
|
||||
# copy required file from our daily cache
|
||||
cp ~/.cache/modelscope/hub/datasets/otavia/ShareGPT_Vicuna_unfiltered/ShareGPT_V3_unfiltered_cleaned_split.json /tmp
|
||||
# copy download through proxy
|
||||
curl -o /tmp/test.jsonl -L https://gh-proxy.test.osinfra.cn/https://raw.githubusercontent.com/openai/grade-school-math/master/grade_school_math/data/test.jsonl
|
||||
|
||||
- name: Run test
|
||||
timeout-minutes: 60
|
||||
timeout-minutes: 90
|
||||
env:
|
||||
SGLANG_USE_MODELSCOPE: true
|
||||
SGLANG_IS_IN_CI: true
|
||||
HF_ENDPOINT: https://hf-mirror.com
|
||||
TORCH_EXTENSIONS_DIR: /tmp/torch_extensions
|
||||
PYTORCH_NPU_ALLOC_CONF: "expandable_segments:True"
|
||||
STREAMS_PER_DEVICE: 32
|
||||
run: |
|
||||
export PATH="/usr/local/Ascend/8.3.RC1/compiler/bishengir/bin:${PATH}"
|
||||
cd test/srt
|
||||
python3 run_suite.py --suite per-commit-2-ascend-npu --auto-partition-id ${{ matrix.part }} --auto-partition-size 3
|
||||
python3 run_suite.py --suite per-commit-2-ascend-npu
|
||||
|
||||
per-commit-4-ascend-npu:
|
||||
if: github.event_name != 'pull_request' || contains(github.event.pull_request.labels.*.name, 'run-ci')
|
||||
@@ -118,26 +106,22 @@ jobs:
|
||||
CACHING_URL="cache-service.nginx-pypi-cache.svc.cluster.local"
|
||||
sed -Ei "s@(ports|archive).ubuntu.com@${CACHING_URL}:8081@g" /etc/apt/sources.list
|
||||
pip config set global.index-url http://${CACHING_URL}/pypi/simple
|
||||
pip config set global.extra-index-url "https://pypi.tuna.tsinghua.edu.cn/simple https://mirrors.aliyun.com/pypi/simple/"
|
||||
pip config set global.trusted-host "${CACHING_URL} pypi.tuna.tsinghua.edu.cn mirrors.aliyun.com"
|
||||
pip config set global.trusted-host ${CACHING_URL}
|
||||
|
||||
bash scripts/ci/npu_ci_install_dependency.sh 910b
|
||||
bash scripts/ci/npu_ci_install_dependency.sh
|
||||
# copy required file from our daily cache
|
||||
cp ~/.cache/modelscope/hub/datasets/otavia/ShareGPT_Vicuna_unfiltered/ShareGPT_V3_unfiltered_cleaned_split.json /tmp
|
||||
# copy download through proxy
|
||||
curl -o /tmp/test.jsonl -L https://gh-proxy.test.osinfra.cn/https://raw.githubusercontent.com/openai/grade-school-math/master/grade_school_math/data/test.jsonl
|
||||
|
||||
- name: Run test
|
||||
timeout-minutes: 60
|
||||
timeout-minutes: 120
|
||||
env:
|
||||
SGLANG_USE_MODELSCOPE: true
|
||||
SGLANG_IS_IN_CI: true
|
||||
HF_ENDPOINT: https://hf-mirror.com
|
||||
TORCH_EXTENSIONS_DIR: /tmp/torch_extensions
|
||||
PYTORCH_NPU_ALLOC_CONF: "expandable_segments:True"
|
||||
STREAMS_PER_DEVICE: 32
|
||||
run: |
|
||||
export PATH="/usr/local/Ascend/8.3.RC1/compiler/bishengir/bin:${PATH}"
|
||||
cd test/srt
|
||||
python3 run_suite.py --suite per-commit-4-ascend-npu --timeout-per-file 3600
|
||||
|
||||
@@ -156,25 +140,21 @@ jobs:
|
||||
CACHING_URL="cache-service.nginx-pypi-cache.svc.cluster.local"
|
||||
sed -Ei "s@(ports|archive).ubuntu.com@${CACHING_URL}:8081@g" /etc/apt/sources.list
|
||||
pip config set global.index-url http://${CACHING_URL}/pypi/simple
|
||||
pip config set global.extra-index-url "https://pypi.tuna.tsinghua.edu.cn/simple https://mirrors.aliyun.com/pypi/simple/"
|
||||
pip config set global.trusted-host "${CACHING_URL} pypi.tuna.tsinghua.edu.cn mirrors.aliyun.com"
|
||||
pip config set global.trusted-host ${CACHING_URL}
|
||||
|
||||
bash scripts/ci/npu_ci_install_dependency.sh a3
|
||||
bash scripts/ci/npu_ci_install_dependency.sh
|
||||
# copy required file from our daily cache
|
||||
cp ~/.cache/modelscope/hub/datasets/otavia/ShareGPT_Vicuna_unfiltered/ShareGPT_V3_unfiltered_cleaned_split.json /tmp
|
||||
# copy download through proxy
|
||||
curl -o /tmp/test.jsonl -L https://gh-proxy.test.osinfra.cn/https://raw.githubusercontent.com/openai/grade-school-math/master/grade_school_math/data/test.jsonl
|
||||
|
||||
- name: Run test
|
||||
timeout-minutes: 60
|
||||
timeout-minutes: 90
|
||||
env:
|
||||
SGLANG_USE_MODELSCOPE: true
|
||||
SGLANG_IS_IN_CI: true
|
||||
HF_ENDPOINT: https://hf-mirror.com
|
||||
TORCH_EXTENSIONS_DIR: /tmp/torch_extensions
|
||||
PYTORCH_NPU_ALLOC_CONF: "expandable_segments:True"
|
||||
STREAMS_PER_DEVICE: 32
|
||||
run: |
|
||||
export PATH="/usr/local/Ascend/8.3.RC1/compiler/bishengir/bin:${PATH}"
|
||||
cd test/srt
|
||||
python3 run_suite.py --suite per-commit-16-ascend-a3 --timeout-per-file 3600
|
||||
python3 run_suite.py --suite per-commit-16-ascend-a3 --timeout-per-file 5400
|
||||
|
||||
10
.github/workflows/pr-test-pd-router.yml
vendored
10
.github/workflows/pr-test-pd-router.yml
vendored
@@ -1,4 +1,4 @@
|
||||
name: PR Benchmark (SMG PD Router)
|
||||
name: PR Test (PD Router)
|
||||
|
||||
on:
|
||||
push:
|
||||
@@ -28,7 +28,7 @@ permissions:
|
||||
jobs:
|
||||
test-disaggregation:
|
||||
if: github.event_name != 'pull_request' || (contains(github.event.pull_request.labels.*.name, 'run-ci') && contains(github.event.pull_request.labels.*.name, 'router-benchmark'))
|
||||
runs-on: [8-gpu-h200-oracle]
|
||||
runs-on: [h200]
|
||||
timeout-minutes: 45
|
||||
|
||||
steps:
|
||||
@@ -138,7 +138,7 @@ jobs:
|
||||
run: |
|
||||
echo "Installing SGLang with all extras..."
|
||||
python3 -m pip --no-cache-dir install --upgrade pip
|
||||
python3 -m pip --no-cache-dir install torch==2.8.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/test/cu128
|
||||
python3 -m pip --no-cache-dir install torch==2.8.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/test/cu126
|
||||
python3 -m pip --no-cache-dir install -e "python[all]" --break-system-packages
|
||||
python3 -m pip --no-cache-dir install mooncake-transfer-engine==0.3.6.post1
|
||||
python3 -m pip --no-cache-dir install --user --force-reinstall genai-bench==0.0.2
|
||||
@@ -257,7 +257,7 @@ jobs:
|
||||
{"role": "user", "content": "Write a Python function to calculate fibonacci numbers recursively"}
|
||||
],
|
||||
"stream": false,
|
||||
"max_completion_tokens": 100
|
||||
"max_tokens": 100
|
||||
}')
|
||||
|
||||
if echo "$response" | jq -e '.choices[0].message.content' > /dev/null 2>&1; then
|
||||
@@ -279,7 +279,7 @@ jobs:
|
||||
{"role": "user", "content": "Count from 1 to 5"}
|
||||
],
|
||||
"stream": true,
|
||||
"max_completion_tokens": 50
|
||||
"max_tokens": 50
|
||||
}')
|
||||
|
||||
if echo "$stream_response" | grep -q "data:"; then
|
||||
|
||||
64
.github/workflows/pr-test-rust.yml
vendored
64
.github/workflows/pr-test-rust.yml
vendored
@@ -1,4 +1,4 @@
|
||||
name: PR Test (SMG)
|
||||
name: PR Test (Rust)
|
||||
|
||||
on:
|
||||
push:
|
||||
@@ -54,9 +54,7 @@ jobs:
|
||||
run: |
|
||||
source "$HOME/.cargo/env"
|
||||
cd sgl-router/
|
||||
rustup component add --toolchain nightly-x86_64-unknown-linux-gnu rustfmt
|
||||
rustup toolchain install nightly --profile minimal
|
||||
cargo +nightly fmt -- --check
|
||||
cargo fmt -- --check
|
||||
|
||||
- name: Run Rust tests
|
||||
timeout-minutes: 20
|
||||
@@ -85,8 +83,8 @@ jobs:
|
||||
|
||||
pytest-rust:
|
||||
if: github.event_name != 'pull_request' || contains(github.event.pull_request.labels.*.name, 'run-ci')
|
||||
runs-on: 4-gpu-a10
|
||||
timeout-minutes: 32
|
||||
runs-on: BM.A10.4
|
||||
timeout-minutes: 25
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
@@ -109,7 +107,7 @@ jobs:
|
||||
|
||||
- name: Install SGLang dependencies
|
||||
run: |
|
||||
sudo --preserve-env=PATH bash scripts/ci/ci_install_dependency.sh
|
||||
sudo bash scripts/ci/ci_install_dependency.sh
|
||||
|
||||
- name: Build python binding
|
||||
run: |
|
||||
@@ -151,58 +149,8 @@ jobs:
|
||||
name: genai-bench-results-all-policies
|
||||
path: sgl-router/benchmark_**/
|
||||
|
||||
pytest-rust-2:
|
||||
if: github.event_name != 'pull_request' || contains(github.event.pull_request.labels.*.name, 'run-ci')
|
||||
runs-on: 4-gpu-a10
|
||||
timeout-minutes: 16
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Install rust dependencies
|
||||
run: |
|
||||
bash scripts/ci/ci_install_rust.sh
|
||||
|
||||
- name: Configure sccache
|
||||
uses: mozilla-actions/sccache-action@v0.0.9
|
||||
with:
|
||||
version: "v0.10.0"
|
||||
|
||||
- name: Rust cache
|
||||
uses: Swatinem/rust-cache@v2
|
||||
with:
|
||||
workspaces: sgl-router
|
||||
cache-all-crates: true
|
||||
cache-on-failure: true
|
||||
|
||||
- name: Install SGLang dependencies
|
||||
run: |
|
||||
sudo --preserve-env=PATH bash scripts/ci/ci_install_dependency.sh
|
||||
|
||||
- name: Build python binding
|
||||
run: |
|
||||
source "$HOME/.cargo/env"
|
||||
export RUSTC_WRAPPER=sccache
|
||||
cd sgl-router
|
||||
pip install setuptools-rust wheel build
|
||||
python3 -m build
|
||||
pip install --force-reinstall dist/*.whl
|
||||
|
||||
- name: Run Python E2E response API tests
|
||||
run: |
|
||||
bash scripts/killall_sglang.sh "nuk_gpus"
|
||||
cd sgl-router
|
||||
SHOW_ROUTER_LOGS=1 pytest py_test/e2e_response_api -s -vv -o log_cli=true --log-cli-level=INFO
|
||||
|
||||
- name: Run Python E2E gRPC tests
|
||||
run: |
|
||||
bash scripts/killall_sglang.sh "nuk_gpus"
|
||||
cd sgl-router
|
||||
SHOW_ROUTER_LOGS=1 ROUTER_LOCAL_MODEL_PATH="/home/ubuntu/models" pytest py_test/e2e_grpc -s -vv -o log_cli=true --log-cli-level=INFO
|
||||
|
||||
|
||||
finish:
|
||||
needs: [unit-test-rust, pytest-rust, pytest-rust-2]
|
||||
needs: [unit-test-rust, pytest-rust]
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Finish
|
||||
|
||||
20
.github/workflows/pr-test-xeon.yml
vendored
20
.github/workflows/pr-test-xeon.yml
vendored
@@ -41,13 +41,8 @@ jobs:
|
||||
run: |
|
||||
version=$(cat python/sglang/version.py | cut -d'"' -f2)
|
||||
tag=v${version}-xeon
|
||||
PR_REPO=${{ github.event.pull_request.head.repo.clone_url }}
|
||||
PR_HEAD_REF=${{ github.head_ref }}
|
||||
|
||||
docker build \
|
||||
${PR_REPO:+--build-arg SGLANG_REPO=$PR_REPO} \
|
||||
${PR_HEAD_REF:+--build-arg VER_SGLANG=$PR_HEAD_REF} \
|
||||
. -f docker/Dockerfile.xeon -t sglang_xeon --no-cache
|
||||
docker build . -f docker/Dockerfile.xeon -t sglang_xeon --no-cache
|
||||
|
||||
- name: Run container
|
||||
run: |
|
||||
@@ -57,18 +52,29 @@ jobs:
|
||||
--name ci_sglang_xeon \
|
||||
sglang_xeon
|
||||
|
||||
- name: Install dependencies
|
||||
timeout-minutes: 20
|
||||
run: |
|
||||
docker exec ci_sglang_xeon bash -c "python3 -m pip install --upgrade pip"
|
||||
docker exec ci_sglang_xeon pip uninstall sgl-kernel -y || true
|
||||
docker exec -w /sglang-checkout/sgl-kernel ci_sglang_xeon bash -c "cp pyproject_cpu.toml pyproject.toml && pip install -v ."
|
||||
docker exec -w /sglang-checkout/ ci_sglang_xeon bash -c "rm -rf python/pyproject.toml && mv python/pyproject_other.toml python/pyproject.toml"
|
||||
docker exec -w /sglang-checkout/ ci_sglang_xeon bash -c "pip install -e "python[dev_cpu]""
|
||||
|
||||
- name: Check AMX support
|
||||
id: check_amx
|
||||
timeout-minutes: 5
|
||||
run: |
|
||||
docker exec -w /sglang-checkout/ ci_sglang_xeon \
|
||||
bash -c "python3 -c 'import torch; import sgl_kernel; assert torch._C._cpu._is_amx_tile_supported(); assert hasattr(torch.ops.sgl_kernel, \"convert_weight_packed\"); '"
|
||||
continue-on-error: true
|
||||
|
||||
- name: Run unit tests
|
||||
if: steps.check_amx.outcome == 'success'
|
||||
timeout-minutes: 36
|
||||
run: |
|
||||
docker exec -w /sglang-checkout/ ci_sglang_xeon \
|
||||
bash -c "cd ./test/srt && python3 run_suite.py --suite per-commit-cpu --timeout-per-file 1500"
|
||||
bash -c "cd ./test/srt && python3 run_suite.py --suite per-commit-cpu"
|
||||
|
||||
- name: Change permission
|
||||
timeout-minutes: 2
|
||||
|
||||
99
.github/workflows/pr-test-xpu.yml
vendored
99
.github/workflows/pr-test-xpu.yml
vendored
@@ -1,99 +0,0 @@
|
||||
name: PR Test (XPU)
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ main ]
|
||||
paths:
|
||||
- "python/**"
|
||||
- "scripts/ci/**"
|
||||
- "test/**"
|
||||
- "sgl-kernel/**"
|
||||
- ".github/workflows/pr-test-xpu.yml"
|
||||
pull_request:
|
||||
branches: [ main ]
|
||||
paths:
|
||||
- "python/**"
|
||||
- "scripts/ci/**"
|
||||
- "test/**"
|
||||
- "sgl-kernel/**"
|
||||
- ".github/workflows/pr-test-xpu.yml"
|
||||
types: [synchronize, labeled]
|
||||
workflow_dispatch:
|
||||
|
||||
concurrency:
|
||||
group: pr-test-xpu-${{ github.ref }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
build-and-test:
|
||||
if: github.event_name != 'pull_request' || contains(github.event.pull_request.labels.*.name, 'run-ci')
|
||||
runs-on: intel-bmg
|
||||
env:
|
||||
HF_HOME: /home/sdp/.cache/huggingface
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0
|
||||
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v3
|
||||
|
||||
- name: Build Docker image
|
||||
run: |
|
||||
PR_REPO=${{ github.event.pull_request.head.repo.clone_url }}
|
||||
PR_HEAD_REF=${{ github.head_ref }}
|
||||
docker build \
|
||||
${PR_REPO:+--build-arg SG_LANG_REPO=$PR_REPO} \
|
||||
${PR_HEAD_REF:+--build-arg SG_LANG_BRANCH=$PR_HEAD_REF} \
|
||||
--no-cache --progress=plain -f docker/Dockerfile.xpu -t xpu_sglang_main:bmg .
|
||||
|
||||
- name: Run container
|
||||
id: start_container
|
||||
run: |
|
||||
container_id=$(docker run -dt \
|
||||
--group-add 992 \
|
||||
--group-add $(getent group video | cut -d: -f3) \
|
||||
-v ${HF_HOME}:/root/.cache/huggingface \
|
||||
--device /dev/dri \
|
||||
-e HF_TOKEN="$(cat ~/huggingface_token.txt)" \
|
||||
xpu_sglang_main:bmg)
|
||||
echo "Started container: $container_id"
|
||||
echo "container_id=$container_id" >> "$GITHUB_OUTPUT"
|
||||
|
||||
- name: Install Dependency
|
||||
timeout-minutes: 20
|
||||
run: |
|
||||
cid="${{ steps.start_container.outputs.container_id }}"
|
||||
docker exec "$cid" /home/sdp/miniforge3/envs/py3.10/bin/python3 -m pip install --upgrade pip
|
||||
docker exec "$cid" /home/sdp/miniforge3/envs/py3.10/bin/python3 -m pip install pytest expecttest ray huggingface_hub
|
||||
docker exec "$cid" /home/sdp/miniforge3/envs/py3.10/bin/python3 -m pip uninstall -y flashinfer-python
|
||||
docker exec "$cid" /bin/bash -c '/home/sdp/miniforge3/envs/py3.10/bin/huggingface-cli login --token ${HF_TOKEN} '
|
||||
docker exec -u root "$cid" /bin/bash -c "ln -sf /home/sdp/miniforge3/envs/py3.10/bin/python3 /usr/bin/python3"
|
||||
|
||||
- name: Run E2E Bfloat16 tests
|
||||
timeout-minutes: 20
|
||||
run: |
|
||||
cid="${{ steps.start_container.outputs.container_id }}"
|
||||
docker exec -w /home/sdp/sglang/ "$cid" \
|
||||
bash -c "LD_LIBRARY_PATH=/home/sdp/miniforge3/envs/py3.10/lib:$LD_LIBRARY_PATH && cd ./test/srt && python3 run_suite.py --suite per-commit-xpu"
|
||||
|
||||
- name: Cleanup container
|
||||
if: always()
|
||||
run: |
|
||||
cid="${{ steps.start_container.outputs.container_id }}"
|
||||
docker rm -f "$cid" || true
|
||||
|
||||
finish:
|
||||
if: always()
|
||||
needs: [build-and-test]
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Check job status
|
||||
run: |
|
||||
if [ "${{ needs.build-and-test.result }}" != "success" ]; then
|
||||
echo "Job failed with result: ${{ needs.build-and-test.result }}"
|
||||
exit 1
|
||||
fi
|
||||
echo "All jobs completed successfully"
|
||||
exit 0
|
||||
218
.github/workflows/pr-test.yml
vendored
218
.github/workflows/pr-test.yml
vendored
@@ -12,10 +12,10 @@ on:
|
||||
description: "FlashInfer version"
|
||||
required: true
|
||||
type: choice
|
||||
default: "release"
|
||||
default: 'release'
|
||||
options:
|
||||
- "release"
|
||||
- "nightly"
|
||||
- 'release'
|
||||
- 'nightly'
|
||||
|
||||
concurrency:
|
||||
group: pr-test-${{ github.ref }}
|
||||
@@ -62,15 +62,13 @@ jobs:
|
||||
sgl-kernel-build-wheels:
|
||||
needs: [check-changes]
|
||||
if: needs.check-changes.outputs.sgl_kernel == 'true'
|
||||
runs-on: x64-kernel-build-node
|
||||
runs-on: sgl-kernel-build-node
|
||||
strategy:
|
||||
matrix:
|
||||
include:
|
||||
- python-version: "3.10"
|
||||
cuda-version: "12.9"
|
||||
- python-version: "3.10"
|
||||
cuda-version: "13.0"
|
||||
name: Build Wheel
|
||||
name: Build Wheel (CUDA ${{ matrix.cuda-version }})
|
||||
steps:
|
||||
- name: Cleanup
|
||||
run: |
|
||||
@@ -86,6 +84,7 @@ jobs:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Build wheel for Python ${{ matrix.python-version }} and CUDA ${{ matrix.cuda-version }}
|
||||
if: github.event_name != 'push' || (matrix.cuda-version != '11.8')
|
||||
run: |
|
||||
cd sgl-kernel
|
||||
./build.sh "${{ matrix.python-version }}" "${{ matrix.cuda-version }}"
|
||||
@@ -156,7 +155,7 @@ jobs:
|
||||
|
||||
sgl-kernel-benchmark-test:
|
||||
needs: [check-changes, sgl-kernel-build-wheels]
|
||||
if: needs.check-changes.outputs.sgl_kernel == 'true'
|
||||
if: always() && !failure() && !cancelled()
|
||||
runs-on: 1-gpu-runner
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
||||
@@ -198,43 +197,12 @@ jobs:
|
||||
|
||||
echo "All benchmark tests completed!"
|
||||
|
||||
# Adding a single CUDA13 smoke test to verify that the kernel builds and runs
|
||||
# TODO: Add back this test when it can pass on CI
|
||||
# cuda13-kernel-smoke-test:
|
||||
# needs: [check-changes, sgl-kernel-build-wheels]
|
||||
# if: needs.check-changes.outputs.sgl_kernel == 'true'
|
||||
# runs-on: x64-cu13-kernel-tests
|
||||
# steps:
|
||||
# - uses: actions/checkout@v4
|
||||
|
||||
# - name: Cleanup
|
||||
# run: |
|
||||
# ls -alh sgl-kernel/dist || true
|
||||
# rm -rf sgl-kernel/dist/* || true
|
||||
|
||||
# - name: Download CUDA 13.0 artifacts
|
||||
# uses: actions/download-artifact@v4
|
||||
# with:
|
||||
# path: sgl-kernel/dist/
|
||||
# merge-multiple: true
|
||||
# pattern: wheel-python3.10-cuda13.0
|
||||
|
||||
# - name: Install dependencies
|
||||
# run: |
|
||||
# CUSTOM_BUILD_SGL_KERNEL=${{needs.check-changes.outputs.sgl_kernel}} bash scripts/ci/ci_install_dependency.sh
|
||||
|
||||
# - name: Run kernel unit tests
|
||||
# timeout-minutes: 30
|
||||
# run: |
|
||||
# cd sgl-kernel
|
||||
# pytest tests/
|
||||
|
||||
# =============================================== primary ====================================================
|
||||
|
||||
unit-test-frontend:
|
||||
needs: [check-changes, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 1-gpu-runner
|
||||
steps:
|
||||
- name: Checkout code
|
||||
@@ -261,7 +229,7 @@ jobs:
|
||||
unit-test-backend-1-gpu:
|
||||
needs: [check-changes, unit-test-frontend, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 1-gpu-runner
|
||||
strategy:
|
||||
fail-fast: false
|
||||
@@ -287,12 +255,12 @@ jobs:
|
||||
timeout-minutes: 30
|
||||
run: |
|
||||
cd test/srt
|
||||
python3 run_suite.py --suite per-commit-1-gpu --auto-partition-id ${{ matrix.part }} --auto-partition-size 11
|
||||
python3 run_suite.py --suite per-commit --auto-partition-id ${{ matrix.part }} --auto-partition-size 11
|
||||
|
||||
unit-test-backend-2-gpu:
|
||||
needs: [check-changes, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 2-gpu-runner
|
||||
strategy:
|
||||
fail-fast: false
|
||||
@@ -323,8 +291,8 @@ jobs:
|
||||
unit-test-backend-4-gpu:
|
||||
needs: [check-changes, unit-test-backend-2-gpu, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 4-gpu-h100
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 4-gpu-runner
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
@@ -351,15 +319,15 @@ jobs:
|
||||
cd test/srt
|
||||
python3 run_suite.py --suite per-commit-4-gpu --auto-partition-id ${{ matrix.part }} --auto-partition-size 2
|
||||
|
||||
unit-test-backend-8-gpu-h200:
|
||||
unit-test-backend-8-gpu:
|
||||
needs: [check-changes, unit-test-backend-2-gpu, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 8-gpu-h200
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 8-gpu-runner
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
part: [0, 1]
|
||||
part: [0, 1, 2]
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
@@ -380,45 +348,12 @@ jobs:
|
||||
timeout-minutes: 20
|
||||
run: |
|
||||
cd test/srt
|
||||
python3 run_suite.py --suite per-commit-8-gpu-h200 --auto-partition-id ${{ matrix.part }} --auto-partition-size 2
|
||||
|
||||
unit-test-backend-8-gpu-h20:
|
||||
needs: [check-changes, unit-test-backend-2-gpu, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 8-gpu-h20
|
||||
env:
|
||||
SGLANG_CI_RDMA_ALL_DEVICES: "mlx5_1,mlx5_2,mlx5_3,mlx5_4"
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
part: [0, 1]
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Download artifacts
|
||||
if: needs.check-changes.outputs.sgl_kernel == 'true'
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
path: sgl-kernel/dist/
|
||||
merge-multiple: true
|
||||
pattern: wheel-python3.10-cuda12.9
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
CUSTOM_BUILD_SGL_KERNEL=${{needs.check-changes.outputs.sgl_kernel}} bash scripts/ci/ci_install_dependency.sh
|
||||
|
||||
- name: Run test
|
||||
timeout-minutes: 20
|
||||
run: |
|
||||
cd test/srt
|
||||
python3 run_suite.py --suite per-commit-8-gpu-h20 --auto-partition-id ${{ matrix.part }} --auto-partition-size 2
|
||||
python3 run_suite.py --suite per-commit-8-gpu --auto-partition-id ${{ matrix.part }} --auto-partition-size 3
|
||||
|
||||
performance-test-1-gpu-part-1:
|
||||
needs: [check-changes, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 1-gpu-runner
|
||||
steps:
|
||||
- name: Checkout code
|
||||
@@ -477,7 +412,7 @@ jobs:
|
||||
performance-test-1-gpu-part-2:
|
||||
needs: [check-changes, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 1-gpu-runner
|
||||
steps:
|
||||
- name: Checkout code
|
||||
@@ -525,43 +460,10 @@ jobs:
|
||||
cd test/srt
|
||||
python3 -m unittest test_bench_serving.TestBenchServing.test_vlm_online_latency
|
||||
|
||||
performance-test-1-gpu-part-3:
|
||||
needs: [check-changes, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 1-gpu-runner
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Download artifacts
|
||||
if: needs.check-changes.outputs.sgl_kernel == 'true'
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
path: sgl-kernel/dist/
|
||||
merge-multiple: true
|
||||
pattern: wheel-python3.10-cuda12.9
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
CUSTOM_BUILD_SGL_KERNEL=${{needs.check-changes.outputs.sgl_kernel}} bash scripts/ci/ci_install_dependency.sh
|
||||
|
||||
- name: Benchmark Scores online latency and throughput
|
||||
timeout-minutes: 10
|
||||
run: |
|
||||
cd test/srt
|
||||
python3 -m unittest test_bench_serving.TestBenchServing.test_score_api_latency_throughput
|
||||
|
||||
- name: Benchmark Scores online latency and throughput (batch size scaling)
|
||||
timeout-minutes: 10
|
||||
run: |
|
||||
cd test/srt
|
||||
python3 -m unittest test_bench_serving.TestBenchServing.test_score_api_batch_scaling
|
||||
|
||||
performance-test-2-gpu:
|
||||
needs: [check-changes, unit-test-backend-2-gpu, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 2-gpu-runner
|
||||
steps:
|
||||
- name: Checkout code
|
||||
@@ -618,7 +520,7 @@ jobs:
|
||||
accuracy-test-1-gpu:
|
||||
needs: [check-changes, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 1-gpu-runner
|
||||
steps:
|
||||
- name: Checkout code
|
||||
@@ -648,7 +550,7 @@ jobs:
|
||||
accuracy-test-2-gpu:
|
||||
needs: [check-changes, accuracy-test-1-gpu, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 2-gpu-runner
|
||||
steps:
|
||||
- name: Checkout code
|
||||
@@ -678,8 +580,8 @@ jobs:
|
||||
unit-test-deepep-4-gpu:
|
||||
needs: [check-changes, unit-test-backend-2-gpu, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 4-gpu-h100
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 4-gpu-runner
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
@@ -705,8 +607,8 @@ jobs:
|
||||
unit-test-deepep-8-gpu:
|
||||
needs: [check-changes, unit-test-backend-2-gpu, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 8-gpu-h200
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 8-gpu-runner
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
@@ -727,40 +629,13 @@ jobs:
|
||||
timeout-minutes: 20
|
||||
run: |
|
||||
cd test/srt
|
||||
python3 run_suite.py --suite per-commit-8-gpu-h200-deepep
|
||||
|
||||
unit-test-backend-8-gpu-deepseek-v32:
|
||||
needs: [check-changes, unit-test-backend-2-gpu, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 8-gpu-h200
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Download artifacts
|
||||
if: needs.check-changes.outputs.sgl_kernel == 'true'
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
path: sgl-kernel/dist/
|
||||
merge-multiple: true
|
||||
pattern: wheel-python3.10-cuda12.9
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
CUSTOM_BUILD_SGL_KERNEL=${{needs.check-changes.outputs.sgl_kernel}} RUN_DEEPSEEK_V32=1 bash scripts/ci/ci_install_dependency.sh
|
||||
|
||||
- name: Run test
|
||||
timeout-minutes: 20
|
||||
run: |
|
||||
cd test/srt
|
||||
python3 run_suite.py --suite per-commit-8-gpu-h200-deepseek-v32
|
||||
python3 run_suite.py --suite per-commit-8-gpu-deepep
|
||||
|
||||
unit-test-backend-4-gpu-b200:
|
||||
needs: [check-changes, unit-test-backend-2-gpu, sgl-kernel-build-wheels]
|
||||
if: always() && !failure() && !cancelled() &&
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 4-gpu-b200
|
||||
((needs.check-changes.outputs.main_package == 'true') || (needs.check-changes.outputs.sgl_kernel == 'true'))
|
||||
runs-on: 4-b200-runner
|
||||
strategy:
|
||||
fail-fast: false
|
||||
steps:
|
||||
@@ -786,30 +661,19 @@ jobs:
|
||||
python3 run_suite.py --suite per-commit-4-gpu-b200 --auto-partition-id 0 --auto-partition-size 1 --timeout-per-file 3600
|
||||
|
||||
pr-test-finish:
|
||||
needs:
|
||||
[
|
||||
check-changes,
|
||||
needs: [
|
||||
check-changes,
|
||||
|
||||
sgl-kernel-build-wheels,
|
||||
sgl-kernel-unit-test,
|
||||
sgl-kernel-mla-test,
|
||||
sgl-kernel-benchmark-test,
|
||||
sgl-kernel-build-wheels,
|
||||
sgl-kernel-unit-test, sgl-kernel-mla-test, sgl-kernel-benchmark-test,
|
||||
|
||||
unit-test-frontend,
|
||||
unit-test-backend-1-gpu,
|
||||
unit-test-backend-2-gpu,
|
||||
unit-test-backend-4-gpu,
|
||||
unit-test-backend-8-gpu-h200,
|
||||
performance-test-1-gpu-part-1,
|
||||
performance-test-1-gpu-part-2,
|
||||
performance-test-1-gpu-part-3,
|
||||
performance-test-2-gpu,
|
||||
accuracy-test-1-gpu,
|
||||
accuracy-test-2-gpu,
|
||||
unit-test-deepep-4-gpu,
|
||||
unit-test-deepep-8-gpu,
|
||||
unit-test-backend-4-gpu-b200,
|
||||
]
|
||||
unit-test-frontend, unit-test-backend-1-gpu,
|
||||
unit-test-backend-2-gpu, unit-test-backend-4-gpu, unit-test-backend-8-gpu,
|
||||
performance-test-1-gpu-part-1, performance-test-1-gpu-part-2, performance-test-2-gpu,
|
||||
accuracy-test-1-gpu, accuracy-test-2-gpu,
|
||||
unit-test-deepep-4-gpu, unit-test-deepep-8-gpu,
|
||||
unit-test-backend-4-gpu-b200,
|
||||
]
|
||||
if: always()
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
|
||||
72
.github/workflows/release-docker-amd-nightly.yml
vendored
72
.github/workflows/release-docker-amd-nightly.yml
vendored
@@ -63,75 +63,3 @@ jobs:
|
||||
|
||||
docker build . -f docker/Dockerfile.rocm --build-arg BUILD_TYPE=${{ matrix.build_type }} --build-arg GPU_ARCH=${{ matrix.gpu_arch }} -t rocm/sgl-dev:${tag}-${{ env.DATE }}${tag_suffix} --no-cache
|
||||
docker push rocm/sgl-dev:${tag}-${{ env.DATE }}${tag_suffix}
|
||||
|
||||
cache:
|
||||
if: github.repository == 'sgl-project/sglang'
|
||||
runs-on: linux-mi300-gpu-1
|
||||
environment: 'prod'
|
||||
needs: publish
|
||||
strategy:
|
||||
matrix:
|
||||
gpu_arch: ['gfx942', 'gfx942-rocm700']
|
||||
build_type: ['all']
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: "Set Date"
|
||||
run: |
|
||||
echo "DATE=$(date +%Y%m%d)" >> $GITHUB_ENV
|
||||
|
||||
- name: Login to Docker Hub
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
username: ${{ secrets.DOCKERHUB_AMD_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_AMD_TOKEN }}
|
||||
|
||||
- name: Pull and Save Docker Image to Cache
|
||||
run: |
|
||||
set -euxo pipefail
|
||||
|
||||
version=$(cat python/sglang/version.py | cut -d'"' -f2)
|
||||
|
||||
if [ "${{ matrix.gpu_arch }}" = "gfx942" ]; then
|
||||
rocm_tag="rocm630-mi30x"
|
||||
elif [ "${{ matrix.gpu_arch }}" = "gfx942-rocm700" ]; then
|
||||
rocm_tag="rocm700-mi30x"
|
||||
else
|
||||
echo "Unsupported gfx arch"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
tag=v${version}-${rocm_tag}
|
||||
|
||||
if [ "${{ matrix.build_type }}" = "all" ]; then
|
||||
tag_suffix=""
|
||||
else
|
||||
echo "Unsupported build type"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
image="rocm/sgl-dev:${tag}-${{ env.DATE }}${tag_suffix}"
|
||||
|
||||
# Determine target cache file name based on ROCm variant
|
||||
if [[ "${rocm_tag}" == rocm630* ]]; then
|
||||
final_path="/home/runner/sgl-data/docker/image.tar"
|
||||
elif [[ "${rocm_tag}" == rocm700* ]]; then
|
||||
final_path="/home/runner/sgl-data/docker/image-700.tar"
|
||||
else
|
||||
echo "Unexpected ROCm tag: ${rocm_tag}"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
tmp_path="${final_path}.tmp"
|
||||
|
||||
echo "Pulling image: ${image}"
|
||||
docker pull "${image}"
|
||||
|
||||
echo "Saving to temp file: ${tmp_path}"
|
||||
docker save "${image}" -o "${tmp_path}"
|
||||
|
||||
echo "Moving to final path: ${final_path}"
|
||||
mv -f "${tmp_path}" "${final_path}"
|
||||
|
||||
echo "Cache populated successfully at ${final_path}"
|
||||
|
||||
108
.github/workflows/release-docker-dev.yml
vendored
108
.github/workflows/release-docker-dev.yml
vendored
@@ -3,27 +3,18 @@ name: Build and Push Development Docker Images
|
||||
on:
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: "0 0 * * *"
|
||||
- cron: '0 0 * * *'
|
||||
|
||||
jobs:
|
||||
build-dev:
|
||||
build-dev-x86:
|
||||
if: ${{ github.repository == 'sgl-project/sglang' }}
|
||||
runs-on: ${{ matrix.runner }}
|
||||
runs-on: nvidia
|
||||
strategy:
|
||||
matrix:
|
||||
include:
|
||||
- runner: x64-docker-build-node
|
||||
platform: linux/amd64
|
||||
build_type: all
|
||||
grace_blackwell: 0
|
||||
tag: dev-x86
|
||||
version: 12.9.1
|
||||
- runner: arm-docker-build-node
|
||||
platform: linux/arm64
|
||||
build_type: all
|
||||
grace_blackwell: 1
|
||||
tag: dev-arm64
|
||||
version: 12.9.1
|
||||
variant:
|
||||
- version: 12.9.1
|
||||
type: all
|
||||
tag: dev
|
||||
steps:
|
||||
- name: Delete huge unnecessary tools folder
|
||||
run: rm -rf /opt/hostedtoolcache
|
||||
@@ -51,60 +42,69 @@ jobs:
|
||||
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_TOKEN }}
|
||||
|
||||
- name: Build and Push Dev Image
|
||||
- name: Build and Push Dev Image (x86)
|
||||
run: |
|
||||
docker buildx build --platform ${{ matrix.platform }} --push -f docker/Dockerfile --build-arg CUDA_VERSION=${{ matrix.version }} --build-arg BUILD_TYPE=${{ matrix.build_type }} --build-arg GRACE_BLACKWELL=${{ matrix.grace_blackwell }} --build-arg CMAKE_BUILD_PARALLEL_LEVEL=$(nproc) -t lmsysorg/sglang:${{ matrix.tag }} --no-cache .
|
||||
docker buildx build --platform linux/amd64 --push -f docker/Dockerfile --build-arg CUDA_VERSION=${{ matrix.variant.version }} --build-arg BUILD_TYPE=${{ matrix.variant.type }} --build-arg CMAKE_BUILD_PARALLEL_LEVEL=$(nproc) -t lmsysorg/sglang:${{ matrix.variant.tag }} --no-cache .
|
||||
|
||||
build-blackwell-arm:
|
||||
if: ${{ github.repository == 'sgl-project/sglang' }}
|
||||
runs-on: labubu
|
||||
strategy:
|
||||
matrix:
|
||||
variant:
|
||||
- version: 12.9.1
|
||||
type: blackwell_aarch
|
||||
tag: blackwell-cu129
|
||||
steps:
|
||||
- name: Delete huge unnecessary tools folder
|
||||
run: rm -rf /opt/hostedtoolcache
|
||||
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Free disk space
|
||||
uses: jlumbroso/free-disk-space@main
|
||||
with:
|
||||
tool-cache: true
|
||||
docker-images: true
|
||||
android: true
|
||||
dotnet: true
|
||||
haskell: true
|
||||
large-packages: true
|
||||
swap-storage: true
|
||||
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v3
|
||||
|
||||
- name: Login to Docker Hub
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_TOKEN }}
|
||||
|
||||
- name: Build and Push Blackwell Image (ARM)
|
||||
run: |
|
||||
docker buildx build --platform linux/arm64 --push -f docker/Dockerfile --build-arg CUDA_VERSION=${{ matrix.variant.version }} --build-arg BUILD_TYPE=${{ matrix.variant.type }} --build-arg CMAKE_BUILD_PARALLEL_LEVEL=$(nproc) -t lmsysorg/sglang:${{ matrix.variant.tag }}-arm64 --no-cache .
|
||||
|
||||
|
||||
create-manifests:
|
||||
runs-on: ubuntu-22.04
|
||||
needs: [build-dev]
|
||||
needs: [build-dev-x86, build-blackwell-arm]
|
||||
if: ${{ github.repository == 'sgl-project/sglang' }}
|
||||
strategy:
|
||||
matrix:
|
||||
variant:
|
||||
- tag: dev
|
||||
x86_tag: dev-x86
|
||||
arm64_tag: dev-arm64
|
||||
- tag: dev-manifest
|
||||
x86_tag: dev
|
||||
arm64_tag: blackwell-cu129-arm64
|
||||
steps:
|
||||
- uses: docker/setup-buildx-action@v3
|
||||
|
||||
- uses: docker/login-action@v2
|
||||
with:
|
||||
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_TOKEN }}
|
||||
- run: |
|
||||
SHORT_SHA="${{ github.sha }}"
|
||||
docker buildx imagetools create \
|
||||
-t lmsysorg/sglang:${{ matrix.variant.tag }} \
|
||||
-t lmsysorg/sglang:nightly-${{ matrix.variant.tag }}-$(date +%Y%m%d)-${SHORT_SHA:0:8} \
|
||||
lmsysorg/sglang:${{ matrix.variant.x86_tag }} \
|
||||
lmsysorg/sglang:${{ matrix.variant.arm64_tag }}
|
||||
|
||||
- name: Cleanup Old Nightly Builds
|
||||
run: |
|
||||
# Get JWT token for Docker Hub API
|
||||
TOKEN=$(curl -s -H "Content-Type: application/json" -X POST -d '{"username": "${{ secrets.DOCKERHUB_USERNAME }}", "password": "${{ secrets.DOCKERHUB_TOKEN }}"}' https://hub.docker.com/v2/users/login/ | jq -r .token)
|
||||
|
||||
# Get all tags for the repository
|
||||
TAGS_RESPONSE=$(curl -s -H "Authorization: JWT $TOKEN" "https://hub.docker.com/v2/repositories/lmsysorg/sglang/tags/?page_size=100")
|
||||
|
||||
# Extract tags that match our pattern and sort by last_updated timestamp (most recent first)
|
||||
TAGS=$(echo "$TAGS_RESPONSE" | jq -r '.results[] | select(.name | startswith("nightly-${{ matrix.variant.tag }}-")) | "\(.last_updated)|\(.name)"' | sort -r | cut -d'|' -f2)
|
||||
|
||||
# Count total tags and keep only the 14 most recent
|
||||
TAG_COUNT=$(echo "$TAGS" | wc -l)
|
||||
if [ "$TAG_COUNT" -gt 14 ]; then
|
||||
echo "Found $TAG_COUNT nightly builds, keeping only the 14 most recent"
|
||||
TAGS_TO_DELETE=$(echo "$TAGS" | tail -n +15)
|
||||
echo "Tags to delete: $TAGS_TO_DELETE"
|
||||
|
||||
# Delete old tags
|
||||
for tag in $TAGS_TO_DELETE; do
|
||||
echo "Deleting tag: $tag"
|
||||
curl -X DELETE \
|
||||
-H "Authorization: JWT $TOKEN" \
|
||||
"https://hub.docker.com/v2/repositories/lmsysorg/sglang/tags/$tag/"
|
||||
done
|
||||
else
|
||||
echo "Only $TAG_COUNT nightly builds found, no cleanup needed"
|
||||
fi
|
||||
|
||||
@@ -73,6 +73,6 @@ jobs:
|
||||
push: ${{ github.repository == 'sgl-project/sglang' && github.event_name != 'pull_request' }}
|
||||
provenance: false
|
||||
build-args: |
|
||||
SGLANG_KERNEL_NPU_TAG=20250926
|
||||
SGLANG_KERNEL_NPU_TAG=20250913
|
||||
CANN_VERSION=${{ matrix.cann_version }}
|
||||
DEVICE_TYPE=${{ matrix.device_type }}
|
||||
|
||||
2
.github/workflows/release-docker-npu.yml
vendored
2
.github/workflows/release-docker-npu.yml
vendored
@@ -69,6 +69,6 @@ jobs:
|
||||
push: ${{ github.repository == 'sgl-project/sglang' && github.event_name != 'pull_request' }}
|
||||
provenance: false
|
||||
build-args: |
|
||||
SGLANG_KERNEL_NPU_TAG=20250926
|
||||
SGLANG_KERNEL_NPU_TAG=20250913
|
||||
CANN_VERSION=${{ matrix.cann_version }}
|
||||
DEVICE_TYPE=${{ matrix.device_type }}
|
||||
|
||||
112
.github/workflows/release-docker.yml
vendored
112
.github/workflows/release-docker.yml
vendored
@@ -10,14 +10,17 @@ on:
|
||||
jobs:
|
||||
publish-x86:
|
||||
if: github.repository == 'sgl-project/sglang'
|
||||
environment: "prod"
|
||||
environment: 'prod'
|
||||
strategy:
|
||||
matrix:
|
||||
variant:
|
||||
- cuda_version: "12.9.1"
|
||||
build_type: "all"
|
||||
grace_blackwell: 0
|
||||
runs-on: x64-docker-build-node
|
||||
- cuda_version: '12.6.1'
|
||||
build_type: 'all'
|
||||
- cuda_version: '12.8.1'
|
||||
build_type: 'blackwell'
|
||||
- cuda_version: '12.9.1'
|
||||
build_type: 'blackwell'
|
||||
runs-on: nvidia
|
||||
steps:
|
||||
- name: Delete huge unnecessary tools folder
|
||||
run: rm -rf /opt/hostedtoolcache
|
||||
@@ -48,29 +51,44 @@ jobs:
|
||||
- name: Build and Push AMD64
|
||||
run: |
|
||||
version=$(cat python/sglang/version.py | cut -d'"' -f2)
|
||||
tag=v${version}-cu129-amd64
|
||||
|
||||
docker buildx build \
|
||||
--platform linux/amd64 \
|
||||
--push \
|
||||
-f docker/Dockerfile \
|
||||
--build-arg CUDA_VERSION=${{ matrix.variant.cuda_version }} \
|
||||
--build-arg BUILD_TYPE=${{ matrix.variant.build_type }} \
|
||||
--build-arg GRACE_BLACKWELL=${{ matrix.variant.grace_blackwell }} \
|
||||
-t lmsysorg/sglang:${tag} \
|
||||
--no-cache \
|
||||
.
|
||||
if [ "${{ matrix.variant.cuda_version }}" = "12.6.1" ]; then
|
||||
cuda_tag="cu126"
|
||||
elif [ "${{ matrix.variant.cuda_version }}" = "12.8.1" ]; then
|
||||
cuda_tag="cu128"
|
||||
elif [ "${{ matrix.variant.cuda_version }}" = "12.9.1" ]; then
|
||||
cuda_tag="cu129"
|
||||
else
|
||||
echo "Unsupported CUDA version"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
tag=v${version}-${cuda_tag}
|
||||
|
||||
if [ "${{ matrix.variant.build_type }}" = "all" ]; then
|
||||
tag_suffix=""
|
||||
elif [ "${{ matrix.variant.build_type }}" = "blackwell" ]; then
|
||||
tag_suffix="-b200"
|
||||
else
|
||||
echo "Unsupported build type"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ "${{ matrix.variant.cuda_version }}" = "12.9.1" ]; then
|
||||
docker buildx build --platform linux/amd64 --push -f docker/Dockerfile --build-arg CUDA_VERSION=${{ matrix.variant.cuda_version }} --build-arg BUILD_TYPE=${{ matrix.variant.build_type }} -t lmsysorg/sglang:${tag}${tag_suffix} -t lmsysorg/sglang:latest --no-cache .
|
||||
else
|
||||
docker buildx build --platform linux/amd64 --push -f docker/Dockerfile --build-arg CUDA_VERSION=${{ matrix.variant.cuda_version }} --build-arg BUILD_TYPE=${{ matrix.variant.build_type }} -t lmsysorg/sglang:${tag}${tag_suffix} --no-cache .
|
||||
fi
|
||||
|
||||
publish-arm64:
|
||||
if: github.repository == 'sgl-project/sglang'
|
||||
environment: "prod"
|
||||
environment: 'prod'
|
||||
strategy:
|
||||
matrix:
|
||||
variant:
|
||||
- cuda_version: "12.9.1"
|
||||
build_type: "all"
|
||||
grace_blackwell: 1
|
||||
runs-on: arm-docker-build-node
|
||||
- cuda_version: '12.9.1'
|
||||
build_type: 'blackwell_aarch'
|
||||
runs-on: labubu
|
||||
steps:
|
||||
- name: Delete huge unnecessary tools folder
|
||||
run: rm -rf /opt/hostedtoolcache
|
||||
@@ -90,49 +108,15 @@ jobs:
|
||||
- name: Build and Push ARM64
|
||||
run: |
|
||||
version=$(cat python/sglang/version.py | cut -d'"' -f2)
|
||||
tag=v${version}-cu129-arm64
|
||||
|
||||
docker buildx build \
|
||||
--platform linux/arm64 \
|
||||
--push \
|
||||
-f docker/Dockerfile \
|
||||
--build-arg CUDA_VERSION=${{ matrix.variant.cuda_version }} \
|
||||
--build-arg BUILD_TYPE=${{ matrix.variant.build_type }} \
|
||||
--build-arg GRACE_BLACKWELL=${{ matrix.variant.grace_blackwell }} \
|
||||
-t lmsysorg/sglang:${tag} \
|
||||
--no-cache \
|
||||
.
|
||||
if [ "${{ matrix.variant.cuda_version }}" = "12.9.1" ]; then
|
||||
cuda_tag="cu129"
|
||||
else
|
||||
echo "Unsupported CUDA version"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
create-manifests:
|
||||
runs-on: ubuntu-22.04
|
||||
needs: [publish-x86, publish-arm64]
|
||||
if: github.repository == 'sgl-project/sglang'
|
||||
environment: "prod"
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
tag=v${version}-${cuda_tag}
|
||||
tag_suffix="-gb200"
|
||||
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v3
|
||||
|
||||
- name: Login to Docker Hub
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_TOKEN }}
|
||||
|
||||
- name: Create multi-arch manifests
|
||||
run: |
|
||||
version=$(cat python/sglang/version.py | cut -d'"' -f2)
|
||||
|
||||
# Create versioned manifest
|
||||
docker buildx imagetools create \
|
||||
-t lmsysorg/sglang:v${version} \
|
||||
lmsysorg/sglang:v${version}-cu129-amd64 \
|
||||
lmsysorg/sglang:v${version}-cu129-arm64
|
||||
|
||||
# Create latest manifest
|
||||
docker buildx imagetools create \
|
||||
-t lmsysorg/sglang:latest \
|
||||
lmsysorg/sglang:v${version}-cu129-amd64 \
|
||||
lmsysorg/sglang:v${version}-cu129-arm64
|
||||
docker buildx build --platform linux/arm64 --push -f docker/Dockerfile --build-arg CUDA_VERSION=${{ matrix.variant.cuda_version }} --build-arg BUILD_TYPE=${{ matrix.variant.build_type }} -t lmsysorg/sglang:${tag}${tag_suffix} --no-cache .
|
||||
|
||||
92
.github/workflows/release-whl-kernel-cu118.yml
vendored
Normal file
92
.github/workflows/release-whl-kernel-cu118.yml
vendored
Normal file
@@ -0,0 +1,92 @@
|
||||
name: Release SGLang Kernel Wheel (cu118)
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
tag_name:
|
||||
type: string
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
paths:
|
||||
- sgl-kernel/python/sgl_kernel/version.py
|
||||
|
||||
jobs:
|
||||
build-wheels:
|
||||
if: github.repository == 'sgl-project/sglang'
|
||||
runs-on: sgl-kernel-release-node
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.9"]
|
||||
cuda-version: ["11.8"]
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
submodules: "recursive"
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Build wheels for Python ${{ matrix.python-version }} and CUDA ${{ matrix.cuda-version }}
|
||||
run: |
|
||||
cd sgl-kernel
|
||||
chmod +x ./build.sh
|
||||
./build.sh "${{ matrix.python-version }}" "${{ matrix.cuda-version }}"
|
||||
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: wheel-python${{ matrix.python-version }}-cuda${{ matrix.cuda-version }}
|
||||
path: sgl-kernel/dist/*
|
||||
|
||||
release:
|
||||
needs: build-wheels
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Download artifacts
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
path: sgl-kernel/dist/
|
||||
merge-multiple: true
|
||||
pattern: wheel-*
|
||||
|
||||
- name: Set tag name
|
||||
id: set_tag_name
|
||||
run: |
|
||||
if [ -z "${{ inputs.tag_name }}" ]; then
|
||||
TAG_NAME="v$(cat sgl-kernel/python/sgl_kernel/version.py | cut -d'"' -f2)"
|
||||
echo "tag_name=$TAG_NAME" >> $GITHUB_OUTPUT
|
||||
else
|
||||
echo "tag_name=${{ inputs.tag_name }}" >> $GITHUB_OUTPUT
|
||||
fi
|
||||
|
||||
- name: Release
|
||||
uses: softprops/action-gh-release@v2
|
||||
with:
|
||||
tag_name: ${{ steps.set_tag_name.outputs.tag_name }}
|
||||
repository: sgl-project/whl
|
||||
token: ${{ secrets.WHL_TOKEN }}
|
||||
files: |
|
||||
sgl-kernel/dist/*
|
||||
|
||||
- name: Clone wheel index
|
||||
run: git clone https://oauth2:${WHL_TOKEN}@github.com/sgl-project/whl.git sgl-whl
|
||||
env:
|
||||
WHL_TOKEN: ${{ secrets.WHL_TOKEN }}
|
||||
|
||||
- name: Update wheel index
|
||||
run: python3 scripts/update_kernel_whl_index.py
|
||||
|
||||
- name: Push wheel index
|
||||
run: |
|
||||
cd sgl-whl
|
||||
git config --local user.name "github-actions[bot]"
|
||||
git config --local user.email "41898282+github-actions[bot]@users.noreply.github.com"
|
||||
git add -A
|
||||
git commit -m "update whl index"
|
||||
git push
|
||||
292
.github/workflows/release-whl-kernel.yml
vendored
292
.github/workflows/release-whl-kernel.yml
vendored
@@ -17,18 +17,13 @@ concurrency:
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
build-cu129-matrix:
|
||||
build-cu129:
|
||||
if: github.repository == 'sgl-project/sglang'
|
||||
runs-on: sgl-kernel-release-node
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
cuda-version: ["12.9"]
|
||||
include:
|
||||
- arch: x86_64
|
||||
runner: x64-kernel-build-node
|
||||
- arch: aarch64
|
||||
runner: arm-kernel-build-node
|
||||
runs-on: ${{ matrix.runner }}
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
@@ -43,7 +38,194 @@ jobs:
|
||||
run: |
|
||||
cd sgl-kernel
|
||||
chmod +x ./build.sh
|
||||
./build.sh "${{ matrix.python-version }}" "${{ matrix.cuda-version }}" ${{ matrix.arch == 'aarch64' && 'aarch64' || '' }}
|
||||
./build.sh "${{ matrix.python-version }}" "${{ matrix.cuda-version }}"
|
||||
|
||||
- name: Upload to PyPI
|
||||
working-directory: sgl-kernel
|
||||
run: |
|
||||
pip install twine
|
||||
python3 -m twine upload --skip-existing dist/* -u __token__ -p ${{ secrets.PYPI_TOKEN }}
|
||||
|
||||
build-cu124:
|
||||
if: github.repository == 'sgl-project/sglang'
|
||||
needs: build-cu129
|
||||
runs-on: sgl-kernel-release-node
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
cuda-version: ["12.4"]
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
submodules: "recursive"
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Build wheels
|
||||
run: |
|
||||
cd sgl-kernel
|
||||
chmod +x ./build.sh
|
||||
./build.sh "${{ matrix.python-version }}" "${{ matrix.cuda-version }}"
|
||||
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: wheel-python${{ matrix.python-version }}-cuda${{ matrix.cuda-version }}
|
||||
path: sgl-kernel/dist/*
|
||||
|
||||
release-cu124:
|
||||
needs: build-cu124
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Download artifacts
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
path: sgl-kernel/dist/
|
||||
merge-multiple: true
|
||||
pattern: wheel-*
|
||||
|
||||
- name: Set tag name
|
||||
id: set_tag_name
|
||||
run: |
|
||||
if [ -z "${{ inputs.tag_name }}" ]; then
|
||||
TAG_NAME="v$(cat sgl-kernel/python/sgl_kernel/version.py | cut -d'"' -f2)"
|
||||
echo "tag_name=$TAG_NAME" >> $GITHUB_OUTPUT
|
||||
else
|
||||
echo "tag_name=${{ inputs.tag_name }}" >> $GITHUB_OUTPUT
|
||||
fi
|
||||
|
||||
- name: Release
|
||||
uses: softprops/action-gh-release@v2
|
||||
with:
|
||||
tag_name: ${{ steps.set_tag_name.outputs.tag_name }}
|
||||
repository: sgl-project/whl
|
||||
token: ${{ secrets.WHL_TOKEN }}
|
||||
files: |
|
||||
sgl-kernel/dist/*
|
||||
|
||||
- name: Clone wheel index
|
||||
run: git clone https://oauth2:${WHL_TOKEN}@github.com/sgl-project/whl.git sgl-whl
|
||||
env:
|
||||
WHL_TOKEN: ${{ secrets.WHL_TOKEN }}
|
||||
|
||||
- name: Update wheel index
|
||||
run: python3 scripts/update_kernel_whl_index.py --cuda 124
|
||||
|
||||
- name: Push wheel index
|
||||
run: |
|
||||
cd sgl-whl
|
||||
git config --local user.name "github-actions[bot]"
|
||||
git config --local user.email "41898282+github-actions[bot]@users.noreply.github.com"
|
||||
git add -A
|
||||
git commit -m "update whl index"
|
||||
git push
|
||||
|
||||
build-cu128:
|
||||
if: github.repository == 'sgl-project/sglang'
|
||||
needs: build-cu129
|
||||
runs-on: sgl-kernel-release-node
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
cuda-version: ["12.8"]
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
submodules: "recursive"
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Build wheels
|
||||
run: |
|
||||
cd sgl-kernel
|
||||
chmod +x ./build.sh
|
||||
./build.sh "${{ matrix.python-version }}" "${{ matrix.cuda-version }}"
|
||||
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: wheel-python${{ matrix.python-version }}-cuda${{ matrix.cuda-version }}
|
||||
path: sgl-kernel/dist/*
|
||||
|
||||
release-cu128:
|
||||
needs: build-cu128
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Download artifacts
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
path: sgl-kernel/dist/
|
||||
merge-multiple: true
|
||||
pattern: wheel-*
|
||||
|
||||
- name: Set tag name
|
||||
id: set_tag_name
|
||||
run: |
|
||||
if [ -z "${{ inputs.tag_name }}" ]; then
|
||||
TAG_NAME="v$(cat sgl-kernel/python/sgl_kernel/version.py | cut -d'"' -f2)"
|
||||
echo "tag_name=$TAG_NAME" >> $GITHUB_OUTPUT
|
||||
else
|
||||
echo "tag_name=${{ inputs.tag_name }}" >> $GITHUB_OUTPUT
|
||||
fi
|
||||
|
||||
- name: Release
|
||||
uses: softprops/action-gh-release@v2
|
||||
with:
|
||||
tag_name: ${{ steps.set_tag_name.outputs.tag_name }}
|
||||
repository: sgl-project/whl
|
||||
token: ${{ secrets.WHL_TOKEN }}
|
||||
files: |
|
||||
sgl-kernel/dist/*
|
||||
|
||||
- name: Clone wheel index
|
||||
run: git clone https://oauth2:${WHL_TOKEN}@github.com/sgl-project/whl.git sgl-whl
|
||||
env:
|
||||
WHL_TOKEN: ${{ secrets.WHL_TOKEN }}
|
||||
|
||||
- name: Update wheel index
|
||||
run: python3 scripts/update_kernel_whl_index.py --cuda 128
|
||||
|
||||
- name: Push wheel index
|
||||
run: |
|
||||
cd sgl-whl
|
||||
git config --local user.name "github-actions[bot]"
|
||||
git config --local user.email "41898282+github-actions[bot]@users.noreply.github.com"
|
||||
git add -A
|
||||
git commit -m "update whl index"
|
||||
git push
|
||||
|
||||
build-cu129-aarch64:
|
||||
if: github.repository == 'sgl-project/sglang'
|
||||
runs-on: labubu
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
cuda-version: ["12.9"]
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
submodules: "recursive"
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Build wheels
|
||||
run: |
|
||||
cd sgl-kernel
|
||||
chmod +x ./build.sh
|
||||
./build.sh "${{ matrix.python-version }}" "${{ matrix.cuda-version }}" aarch64
|
||||
|
||||
- name: Upload to PyPI
|
||||
working-directory: sgl-kernel
|
||||
@@ -54,11 +236,11 @@ jobs:
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: wheel-python${{ matrix.python-version }}-cuda${{ matrix.cuda-version }}${{ matrix.arch == 'aarch64' && '-aarch64' || '' }}
|
||||
name: wheel-python${{ matrix.python-version }}-cuda${{ matrix.cuda-version }}-aarch64
|
||||
path: sgl-kernel/dist/*
|
||||
|
||||
release-cu129:
|
||||
needs: build-cu129-matrix
|
||||
release-cu129-aarch64:
|
||||
needs: build-cu129-aarch64
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
@@ -100,92 +282,8 @@ jobs:
|
||||
- name: Push wheel index
|
||||
run: |
|
||||
cd sgl-whl
|
||||
git config --local user.name "sglang-bot"
|
||||
git config --local user.email "sglangbot@gmail.com"
|
||||
git add -A
|
||||
git commit -m "update whl index"
|
||||
git push
|
||||
|
||||
# for now we do not release CUDA 13.0 wheels to pypi
|
||||
build-cu130-matrix:
|
||||
if: github.repository == 'sgl-project/sglang'
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
cuda-version: ["13.0"]
|
||||
include:
|
||||
- arch: x86_64
|
||||
runner: x64-kernel-build-node
|
||||
- arch: aarch64
|
||||
runner: arm-kernel-build-node
|
||||
runs-on: ${{ matrix.runner }}
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
submodules: "recursive"
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Build wheels
|
||||
run: |
|
||||
cd sgl-kernel
|
||||
chmod +x ./build.sh
|
||||
./build.sh "${{ matrix.python-version }}" "${{ matrix.cuda-version }}" ${{ matrix.arch == 'aarch64' && 'aarch64' || '' }}
|
||||
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: wheel-python${{ matrix.python-version }}-cuda${{ matrix.cuda-version }}${{ matrix.arch == 'aarch64' && '-aarch64' || '' }}
|
||||
path: sgl-kernel/dist/*
|
||||
|
||||
release-cu130:
|
||||
needs: build-cu130-matrix
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Download artifacts
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
path: sgl-kernel/dist/
|
||||
merge-multiple: true
|
||||
pattern: wheel-*
|
||||
|
||||
- name: Set tag name
|
||||
id: set_tag_name
|
||||
run: |
|
||||
if [ -z "${{ inputs.tag_name }}" ]; then
|
||||
TAG_NAME="v$(cat sgl-kernel/python/sgl_kernel/version.py | cut -d'"' -f2)"
|
||||
echo "tag_name=$TAG_NAME" >> $GITHUB_OUTPUT
|
||||
else
|
||||
echo "tag_name=${{ inputs.tag_name }}" >> $GITHUB_OUTPUT
|
||||
fi
|
||||
|
||||
- name: Release
|
||||
uses: softprops/action-gh-release@v2
|
||||
with:
|
||||
tag_name: ${{ steps.set_tag_name.outputs.tag_name }}
|
||||
repository: sgl-project/whl
|
||||
token: ${{ secrets.WHL_TOKEN }}
|
||||
files: |
|
||||
sgl-kernel/dist/*
|
||||
|
||||
- name: Clone wheel index
|
||||
run: git clone https://oauth2:${WHL_TOKEN}@github.com/sgl-project/whl.git sgl-whl
|
||||
env:
|
||||
WHL_TOKEN: ${{ secrets.WHL_TOKEN }}
|
||||
|
||||
- name: Update wheel index
|
||||
run: python3 scripts/update_kernel_whl_index.py --cuda 130
|
||||
|
||||
- name: Push wheel index
|
||||
run: |
|
||||
cd sgl-whl
|
||||
git config --local user.name "sglang-bot"
|
||||
git config --local user.email "sglangbot@gmail.com"
|
||||
git config --local user.name "github-actions[bot]"
|
||||
git config --local user.email "41898282+github-actions[bot]@users.noreply.github.com"
|
||||
git add -A
|
||||
git commit -m "update whl index"
|
||||
git push
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
default_stages: [pre-commit, pre-push, manual]
|
||||
exclude: ^python/sglang/srt/grpc/
|
||||
|
||||
repos:
|
||||
- repo: https://github.com/pre-commit/pre-commit-hooks
|
||||
@@ -27,11 +28,9 @@ repos:
|
||||
rev: v0.11.7
|
||||
hooks:
|
||||
- id: ruff
|
||||
args:
|
||||
- --select=F401,F821
|
||||
- --fix
|
||||
files: ^(benchmark/|docs/|examples/|python/sglang/|sgl-router/py_*)
|
||||
exclude: __init__\.py$|\.ipynb$|^python/sglang/srt/grpc/.*_pb2\.py$|^python/sglang/srt/grpc/.*_pb2_grpc\.py$|^python/sglang/srt/grpc/.*_pb2\.pyi$|^python/sglang/srt/grpc/.*_pb2_grpc\.pyi$
|
||||
args: [--select=F401, --fixable=F401]
|
||||
files: ^(benchmark/|docs/|examples/)
|
||||
exclude: \.ipynb$|^python/sglang/srt/grpc/.*_pb2\.py$|^python/sglang/srt/grpc/.*_pb2_grpc\.py$|^python/sglang/srt/grpc/.*_pb2\.pyi$|^python/sglang/srt/grpc/.*_pb2_grpc\.pyi$
|
||||
- repo: https://github.com/psf/black
|
||||
rev: 24.10.0
|
||||
hooks:
|
||||
|
||||
@@ -1,128 +0,0 @@
|
||||
# Contributor Covenant Code of Conduct
|
||||
|
||||
## Our Pledge
|
||||
|
||||
We as members, contributors, and leaders pledge to make participation in our
|
||||
community a harassment-free experience for everyone, regardless of age, body
|
||||
size, visible or invisible disability, ethnicity, sex characteristics, gender
|
||||
identity and expression, level of experience, education, socio-economic status,
|
||||
nationality, personal appearance, race, religion, or sexual identity
|
||||
and orientation.
|
||||
|
||||
We pledge to act and interact in ways that contribute to an open, welcoming,
|
||||
diverse, inclusive, and healthy community.
|
||||
|
||||
## Our Standards
|
||||
|
||||
Examples of behavior that contributes to a positive environment for our
|
||||
community include:
|
||||
|
||||
* Demonstrating empathy and kindness toward other people
|
||||
* Being respectful of differing opinions, viewpoints, and experiences
|
||||
* Giving and gracefully accepting constructive feedback
|
||||
* Accepting responsibility and apologizing to those affected by our mistakes,
|
||||
and learning from the experience
|
||||
* Focusing on what is best not just for us as individuals, but for the
|
||||
overall community
|
||||
|
||||
Examples of unacceptable behavior include:
|
||||
|
||||
* The use of sexualized language or imagery, and sexual attention or
|
||||
advances of any kind
|
||||
* Trolling, insulting or derogatory comments, and personal or political attacks
|
||||
* Public or private harassment
|
||||
* Publishing others' private information, such as a physical or email
|
||||
address, without their explicit permission
|
||||
* Other conduct which could reasonably be considered inappropriate in a
|
||||
professional setting
|
||||
|
||||
## Enforcement Responsibilities
|
||||
|
||||
Community leaders are responsible for clarifying and enforcing our standards of
|
||||
acceptable behavior and will take appropriate and fair corrective action in
|
||||
response to any behavior that they deem inappropriate, threatening, offensive,
|
||||
or harmful.
|
||||
|
||||
Community leaders have the right and responsibility to remove, edit, or reject
|
||||
comments, commits, code, wiki edits, issues, and other contributions that are
|
||||
not aligned to this Code of Conduct, and will communicate reasons for moderation
|
||||
decisions when appropriate.
|
||||
|
||||
## Scope
|
||||
|
||||
This Code of Conduct applies within all community spaces, and also applies when
|
||||
an individual is officially representing the community in public spaces.
|
||||
Examples of representing our community include using an official e-mail address,
|
||||
posting via an official social media account, or acting as an appointed
|
||||
representative at an online or offline event.
|
||||
|
||||
## Enforcement
|
||||
|
||||
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
||||
reported to the community leaders responsible for enforcement at
|
||||
.
|
||||
All complaints will be reviewed and investigated promptly and fairly.
|
||||
|
||||
All community leaders are obligated to respect the privacy and security of the
|
||||
reporter of any incident.
|
||||
|
||||
## Enforcement Guidelines
|
||||
|
||||
Community leaders will follow these Community Impact Guidelines in determining
|
||||
the consequences for any action they deem in violation of this Code of Conduct:
|
||||
|
||||
### 1. Correction
|
||||
|
||||
**Community Impact**: Use of inappropriate language or other behavior deemed
|
||||
unprofessional or unwelcome in the community.
|
||||
|
||||
**Consequence**: A private, written warning from community leaders, providing
|
||||
clarity around the nature of the violation and an explanation of why the
|
||||
behavior was inappropriate. A public apology may be requested.
|
||||
|
||||
### 2. Warning
|
||||
|
||||
**Community Impact**: A violation through a single incident or series
|
||||
of actions.
|
||||
|
||||
**Consequence**: A warning with consequences for continued behavior. No
|
||||
interaction with the people involved, including unsolicited interaction with
|
||||
those enforcing the Code of Conduct, for a specified period of time. This
|
||||
includes avoiding interactions in community spaces as well as external channels
|
||||
like social media. Violating these terms may lead to a temporary or
|
||||
permanent ban.
|
||||
|
||||
### 3. Temporary Ban
|
||||
|
||||
**Community Impact**: A serious violation of community standards, including
|
||||
sustained inappropriate behavior.
|
||||
|
||||
**Consequence**: A temporary ban from any sort of interaction or public
|
||||
communication with the community for a specified period of time. No public or
|
||||
private interaction with the people involved, including unsolicited interaction
|
||||
with those enforcing the Code of Conduct, is allowed during this period.
|
||||
Violating these terms may lead to a permanent ban.
|
||||
|
||||
### 4. Permanent Ban
|
||||
|
||||
**Community Impact**: Demonstrating a pattern of violation of community
|
||||
standards, including sustained inappropriate behavior, harassment of an
|
||||
individual, or aggression toward or disparagement of classes of individuals.
|
||||
|
||||
**Consequence**: A permanent ban from any sort of public interaction within
|
||||
the community.
|
||||
|
||||
## Attribution
|
||||
|
||||
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
|
||||
version 2.0, available at
|
||||
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
|
||||
|
||||
Community Impact Guidelines were inspired by [Mozilla's code of conduct
|
||||
enforcement ladder](https://github.com/mozilla/diversity).
|
||||
|
||||
[homepage]: https://www.contributor-covenant.org
|
||||
|
||||
For answers to common questions about this code of conduct, see the FAQ at
|
||||
https://www.contributor-covenant.org/faq. Translations are available at
|
||||
https://www.contributor-covenant.org/translations.
|
||||
2
Makefile
2
Makefile
@@ -24,8 +24,6 @@ FILES_TO_UPDATE = docker/Dockerfile.rocm \
|
||||
docs/get_started/install.md \
|
||||
docs/platforms/amd_gpu.md \
|
||||
docs/platforms/ascend_npu.md \
|
||||
docs/platforms/cpu_server.md \
|
||||
docs/platforms/xpu.md \
|
||||
benchmark/deepseek_v3/README.md
|
||||
|
||||
update: ## Update version numbers across project files. Usage: make update <new_version>
|
||||
|
||||
30
README.md
30
README.md
@@ -20,20 +20,18 @@
|
||||
| [**Slides**](https://github.com/sgl-project/sgl-learning-materials?tab=readme-ov-file#slides) |
|
||||
|
||||
## News
|
||||
- [2025/09] 🔥 Deploying DeepSeek on GB200 NVL72 with PD and Large Scale EP (Part II): 3.8x Prefill, 4.8x Decode Throughput ([blog](https://lmsys.org/blog/2025-09-25-gb200-part-2/)).
|
||||
- [2025/09] 🔥 SGLang Day 0 Support for DeepSeek-V3.2 with Sparse Attention ([blog](https://lmsys.org/blog/2025-09-29-deepseek-V32/)).
|
||||
- [2025/08] 🔔 SGLang x AMD SF Meetup on 8/22: Hands-on GPU workshop, tech talks by AMD/xAI/SGLang, and networking ([Roadmap](https://github.com/sgl-project/sgl-learning-materials/blob/main/slides/amd_meetup_sglang_roadmap.pdf), [Large-scale EP](https://github.com/sgl-project/sgl-learning-materials/blob/main/slides/amd_meetup_sglang_ep.pdf), [Highlights](https://github.com/sgl-project/sgl-learning-materials/blob/main/slides/amd_meetup_highlights.pdf), [AITER/MoRI](https://github.com/sgl-project/sgl-learning-materials/blob/main/slides/amd_meetup_aiter_mori.pdf), [Wave](https://github.com/sgl-project/sgl-learning-materials/blob/main/slides/amd_meetup_wave.pdf)).
|
||||
- [2025/08] SGLang provides day-0 support for OpenAI gpt-oss model ([instructions](https://github.com/sgl-project/sglang/issues/8833))
|
||||
- [2025/05] Deploying DeepSeek with PD Disaggregation and Large-scale Expert Parallelism on 96 H100 GPUs ([blog](https://lmsys.org/blog/2025-05-05-large-scale-ep/)).
|
||||
- [2025/08] 🔥 SGLang provides day-0 support for OpenAI gpt-oss model ([instructions](https://github.com/sgl-project/sglang/issues/8833))
|
||||
- [2025/06] 🔥 SGLang, the high-performance serving infrastructure powering trillions of tokens daily, has been awarded the third batch of the Open Source AI Grant by a16z ([a16z blog](https://a16z.com/advancing-open-source-ai-through-benchmarks-and-bold-experimentation/)).
|
||||
- [2025/06] 🔥 Deploying DeepSeek on GB200 NVL72 with PD and Large Scale EP (Part I): 2.7x Higher Decoding Throughput ([blog](https://lmsys.org/blog/2025-06-16-gb200-part-1/)).
|
||||
- [2025/05] 🔥 Deploying DeepSeek with PD Disaggregation and Large-scale Expert Parallelism on 96 H100 GPUs ([blog](https://lmsys.org/blog/2025-05-05-large-scale-ep/)).
|
||||
- [2025/03] Supercharge DeepSeek-R1 Inference on AMD Instinct MI300X ([AMD blog](https://rocm.blogs.amd.com/artificial-intelligence/DeepSeekR1-Part2/README.html))
|
||||
- [2025/03] SGLang Joins PyTorch Ecosystem: Efficient LLM Serving Engine ([PyTorch blog](https://pytorch.org/blog/sglang-joins-pytorch/))
|
||||
- [2024/12] v0.4 Release: Zero-Overhead Batch Scheduler, Cache-Aware Load Balancer, Faster Structured Outputs ([blog](https://lmsys.org/blog/2024-12-04-sglang-v0-4/)).
|
||||
|
||||
<details>
|
||||
<summary>More</summary>
|
||||
|
||||
- [2025/06] SGLang, the high-performance serving infrastructure powering trillions of tokens daily, has been awarded the third batch of the Open Source AI Grant by a16z ([a16z blog](https://a16z.com/advancing-open-source-ai-through-benchmarks-and-bold-experimentation/)).
|
||||
- [2025/06] Deploying DeepSeek on GB200 NVL72 with PD and Large Scale EP (Part I): 2.7x Higher Decoding Throughput ([blog](https://lmsys.org/blog/2025-06-16-gb200-part-1/)).
|
||||
- [2025/03] Supercharge DeepSeek-R1 Inference on AMD Instinct MI300X ([AMD blog](https://rocm.blogs.amd.com/artificial-intelligence/DeepSeekR1-Part2/README.html))
|
||||
- [2025/02] Unlock DeepSeek-R1 Inference Performance on AMD Instinct™ MI300X GPU ([AMD blog](https://rocm.blogs.amd.com/artificial-intelligence/DeepSeekR1_Perf/README.html))
|
||||
- [2025/01] SGLang provides day one support for DeepSeek V3/R1 models on NVIDIA and AMD GPUs with DeepSeek-specific optimizations. ([instructions](https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3), [AMD blog](https://www.amd.com/en/developer/resources/technical-articles/amd-instinct-gpus-power-deepseek-v3-revolutionizing-ai-development-with-sglang.html), [10+ other companies](https://x.com/lmsysorg/status/1887262321636221412))
|
||||
- [2024/10] The First SGLang Online Meetup ([slides](https://github.com/sgl-project/sgl-learning-materials?tab=readme-ov-file#the-first-sglang-online-meetup)).
|
||||
@@ -46,15 +44,14 @@
|
||||
</details>
|
||||
|
||||
## About
|
||||
SGLang is a high-performance serving framework for large language models and vision-language models.
|
||||
It is designed to deliver low-latency and high-throughput inference across a wide range of setups, from a single GPU to large distributed clusters.
|
||||
Its core features include:
|
||||
SGLang is a fast serving framework for large language models and vision language models.
|
||||
It makes your interaction with models faster and more controllable by co-designing the backend runtime and frontend language.
|
||||
The core features include:
|
||||
|
||||
- **Fast Backend Runtime**: Provides efficient serving with RadixAttention for prefix caching, a zero-overhead CPU scheduler, prefill-decode disaggregation, speculative decoding, continuous batching, paged attention, tensor/pipeline/expert/data parallelism, structured outputs, chunked prefill, quantization (FP4/FP8/INT4/AWQ/GPTQ), and multi-LoRA batching.
|
||||
- **Extensive Model Support**: Supports a wide range of generative models (Llama, Qwen, DeepSeek, Kimi, GLM, GPT, Gemma, Mistral, etc.), embedding models (e5-mistral, gte, mcdse), and reward models (Skywork), with easy extensibility for integrating new models. Compatible with most Hugging Face models and OpenAI APIs.
|
||||
- **Extensive Hardware Support**: Runs on NVIDIA GPUs (GB200/B300/H100/A100/Spark), AMD GPUs (MI355/MI300), Intel Xeon CPUs, Google TPUs, Ascend NPUs, and more.
|
||||
- **Flexible Frontend Language**: Offers an intuitive interface for programming LLM applications, supporting chained generation calls, advanced prompting, control flow, multi-modal inputs, parallelism, and external interactions.
|
||||
- **Active Community**: SGLang is open-source and supported by a vibrant community with widespread industry adoption, powering over 300,000 GPUs worldwide.
|
||||
- **Fast Backend Runtime**: Provides efficient serving with RadixAttention for prefix caching, zero-overhead CPU scheduler, prefill-decode disaggregation, speculative decoding, continuous batching, paged attention, tensor/pipeline/expert/data parallelism, structured outputs, chunked prefill, quantization (FP4/FP8/INT4/AWQ/GPTQ), and multi-lora batching.
|
||||
- **Flexible Frontend Language**: Offers an intuitive interface for programming LLM applications, including chained generation calls, advanced prompting, control flow, multi-modal inputs, parallelism, and external interactions.
|
||||
- **Extensive Model Support**: Supports a wide range of generative models (Llama, Qwen, DeepSeek, Kimi, GPT, Gemma, Mistral, etc.), embedding models (e5-mistral, gte, mcdse) and reward models (Skywork), with easy extensibility for integrating new models.
|
||||
- **Active Community**: SGLang is open-source and backed by an active community with wide industry adoption.
|
||||
|
||||
## Getting Started
|
||||
- [Install SGLang](https://docs.sglang.ai/get_started/install.html)
|
||||
@@ -70,8 +67,7 @@ Learn more in the release blogs: [v0.2 blog](https://lmsys.org/blog/2024-07-25-s
|
||||
[Development Roadmap (2025 H2)](https://github.com/sgl-project/sglang/issues/7736)
|
||||
|
||||
## Adoption and Sponsorship
|
||||
SGLang has been deployed at large scale, generating trillions of tokens in production each day. It is trusted and adopted by a wide range of leading enterprises and institutions, including xAI, AMD, NVIDIA, Intel, LinkedIn, Cursor, Oracle Cloud, Google Cloud, Microsoft Azure, AWS, Atlas Cloud, Voltage Park, Nebius, DataCrunch, Novita, InnoMatrix, MIT, UCLA, the University of Washington, Stanford, UC Berkeley, Tsinghua University, Jam & Tea Studios, Baseten, and other major technology organizations across North America and Asia. As an open-source LLM inference engine, SGLang has become the de facto industry standard, with deployments running on over 300,000 GPUs worldwide.
|
||||
SGLang is currently hosted under the non-profit open-source organization [LMSYS](https://lmsys.org/about/).
|
||||
SGLang has been deployed at large scale, generating trillions of tokens in production each day. It is trusted and adopted by a wide range of leading enterprises and institutions, including xAI, AMD, NVIDIA, Intel, LinkedIn, Cursor, Oracle Cloud, Google Cloud, Microsoft Azure, AWS, Atlas Cloud, Voltage Park, Nebius, DataCrunch, Novita, InnoMatrix, MIT, UCLA, the University of Washington, Stanford, UC Berkeley, Tsinghua University, Jam & Tea Studios, Baseten, and other major technology organizations across North America and Asia. As an open-source LLM inference engine, SGLang has become the de facto industry standard, with deployments running on over 1,000,000 GPUs worldwide.
|
||||
|
||||
<img src="https://raw.githubusercontent.com/sgl-project/sgl-learning-materials/refs/heads/main/slides/adoption.png" alt="logo" width="800" margin="10px"></img>
|
||||
|
||||
|
||||
@@ -33,7 +33,7 @@ Add [performance optimization options](#performance-optimization-options) as nee
|
||||
|
||||
```bash
|
||||
# Installation
|
||||
pip install "sglang[all]>=0.5.4"
|
||||
pip install "sglang[all]>=0.5.3rc0"
|
||||
|
||||
# Launch
|
||||
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code
|
||||
|
||||
@@ -8,7 +8,7 @@ from datasets import load_dataset
|
||||
|
||||
import sglang as sgl
|
||||
from sglang.global_config import global_config
|
||||
from sglang.srt.utils.hf_transformers_utils import get_tokenizer
|
||||
from sglang.srt.hf_transformers_utils import get_tokenizer
|
||||
from sglang.test.test_utils import (
|
||||
add_common_sglang_args_and_parse,
|
||||
select_sglang_backend,
|
||||
|
||||
@@ -1,234 +0,0 @@
|
||||
"""For Now, SYMM_MEM is only supported on TP8 case
|
||||
|
||||
export WORLD_SIZE=1
|
||||
export RANK=0
|
||||
export MASTER_ADDR=127.0.0.1
|
||||
export MASTER_PORT=12345
|
||||
|
||||
torchrun --nproc_per_node gpu \
|
||||
--nnodes $WORLD_SIZE \
|
||||
--node_rank $RANK \
|
||||
--master_addr $MASTER_ADDR \
|
||||
--master_port $MASTER_PORT ./benchmark/kernels/all_reduce/benchmark_symm_mem.py
|
||||
"""
|
||||
|
||||
import os
|
||||
from contextlib import nullcontext
|
||||
from typing import List
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from torch.distributed import ProcessGroup
|
||||
|
||||
from sglang.srt.distributed import init_distributed_environment
|
||||
from sglang.srt.distributed.device_communicators.pynccl import PyNcclCommunicator
|
||||
from sglang.srt.distributed.device_communicators.symm_mem import SymmMemCommunicator
|
||||
from sglang.srt.distributed.parallel_state import (
|
||||
get_tensor_model_parallel_group,
|
||||
graph_capture,
|
||||
initialize_model_parallel,
|
||||
set_symm_mem_all_reduce,
|
||||
)
|
||||
|
||||
# CI environment detection
|
||||
IS_CI = (
|
||||
os.getenv("CI", "false").lower() == "true"
|
||||
or os.getenv("GITHUB_ACTIONS", "false").lower() == "true"
|
||||
)
|
||||
|
||||
|
||||
def torch_allreduce(torch_input: torch.Tensor, group: ProcessGroup) -> torch.Tensor:
|
||||
dist.all_reduce(torch_input, group=group)
|
||||
return torch_input
|
||||
|
||||
|
||||
def symm_mem_allreduce(
|
||||
symm_mem_input: torch.Tensor, symm_mem_comm: SymmMemCommunicator
|
||||
) -> torch.Tensor:
|
||||
return symm_mem_comm.all_reduce(symm_mem_input)
|
||||
|
||||
|
||||
def pynccl_allreduce(
|
||||
pynccl_input: torch.Tensor, pynccl_comm: PyNcclCommunicator
|
||||
) -> torch.Tensor:
|
||||
pynccl_comm.all_reduce(pynccl_input)
|
||||
return pynccl_input
|
||||
|
||||
|
||||
def _bench_graph_time(func, inp_randn, warmup_loop=2, graph_loop=10, test_loop=10):
|
||||
graph_input = inp_randn.clone()
|
||||
with graph_capture() as graph_capture_context:
|
||||
graph = torch.cuda.CUDAGraph()
|
||||
with torch.cuda.graph(graph, stream=graph_capture_context.stream):
|
||||
for _ in range(graph_loop):
|
||||
graph_out = func(graph_input)
|
||||
|
||||
graph.replay()
|
||||
func_output = graph_out.clone()
|
||||
|
||||
for _ in range(warmup_loop):
|
||||
graph.replay()
|
||||
torch.cuda.synchronize()
|
||||
|
||||
start_event = torch.cuda.Event(enable_timing=True)
|
||||
end_event = torch.cuda.Event(enable_timing=True)
|
||||
|
||||
latencies: List[float] = []
|
||||
for _ in range(test_loop):
|
||||
torch.cuda.synchronize()
|
||||
dist.barrier()
|
||||
start_event.record()
|
||||
graph.replay()
|
||||
end_event.record()
|
||||
end_event.synchronize()
|
||||
latencies.append(start_event.elapsed_time(end_event))
|
||||
func_cost_us = sum(latencies) / len(latencies) / graph_loop * 1000
|
||||
graph.reset()
|
||||
return func_output, func_cost_us
|
||||
|
||||
|
||||
def _bench_eager_time(func, inp_randn, warmup_loop=2, test_loop=10):
|
||||
eager_input = inp_randn.clone()
|
||||
eager_output = func(eager_input)
|
||||
func_output = eager_output.clone()
|
||||
|
||||
for _ in range(warmup_loop):
|
||||
func(eager_input)
|
||||
torch.cuda.synchronize()
|
||||
|
||||
start_event = torch.cuda.Event(enable_timing=True)
|
||||
end_event = torch.cuda.Event(enable_timing=True)
|
||||
torch.cuda.synchronize()
|
||||
start_event.record()
|
||||
for _ in range(test_loop):
|
||||
func(eager_input)
|
||||
end_event.record()
|
||||
torch.cuda.synchronize()
|
||||
func_cost_us = start_event.elapsed_time(end_event) / test_loop * 1000
|
||||
|
||||
return func_output, func_cost_us
|
||||
|
||||
|
||||
def get_torch_prof_ctx(do_prof: bool):
|
||||
ctx = (
|
||||
torch.profiler.profile(
|
||||
activities=[
|
||||
torch.profiler.ProfilerActivity.CPU,
|
||||
torch.profiler.ProfilerActivity.CUDA,
|
||||
],
|
||||
record_shapes=True,
|
||||
with_stack=True,
|
||||
)
|
||||
if do_prof
|
||||
else nullcontext()
|
||||
)
|
||||
return ctx
|
||||
|
||||
|
||||
def human_readable_size(size, decimal_places=1):
|
||||
for unit in ["B", "KiB", "MiB", "GiB", "TiB", "PiB"]:
|
||||
if size < 1024.0 or unit == "PiB":
|
||||
break
|
||||
size /= 1024.0
|
||||
return f"{size:.{decimal_places}f} {unit}"
|
||||
|
||||
|
||||
try:
|
||||
from tabulate import tabulate
|
||||
except ImportError:
|
||||
print("tabulate not installed, skipping table printing")
|
||||
tabulate = None
|
||||
|
||||
|
||||
def print_markdown_table(data):
|
||||
if tabulate is not None:
|
||||
print(tabulate(data, headers="keys", tablefmt="github"))
|
||||
return
|
||||
headers = data[0].keys()
|
||||
header_row = "| " + " | ".join(headers) + " |"
|
||||
separator = "| " + " | ".join(["---"] * len(headers)) + " |"
|
||||
rows = []
|
||||
for item in data:
|
||||
row = "| " + " | ".join(str(item[key]) for key in headers) + " |"
|
||||
rows.append(row)
|
||||
markdown_table = "\n".join([header_row, separator] + rows)
|
||||
print(markdown_table)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import logging
|
||||
|
||||
logging.basicConfig(
|
||||
level=logging.INFO,
|
||||
format="%(asctime)s - %(levelname)s - %(message)s",
|
||||
datefmt="%Y-%m-%d %H:%M:%S",
|
||||
force=True,
|
||||
)
|
||||
if not dist.is_initialized():
|
||||
dist.init_process_group(backend="nccl")
|
||||
world, world_size = dist.group.WORLD, dist.get_world_size()
|
||||
rank = dist.get_rank()
|
||||
torch.cuda.set_device(rank % 8)
|
||||
device = torch.cuda.current_device()
|
||||
set_symm_mem_all_reduce(True)
|
||||
init_distributed_environment(
|
||||
world_size=world_size,
|
||||
rank=rank,
|
||||
local_rank=rank % 8,
|
||||
)
|
||||
initialize_model_parallel(tensor_model_parallel_size=world_size)
|
||||
group = get_tensor_model_parallel_group().device_group
|
||||
cpu_group = get_tensor_model_parallel_group().cpu_group
|
||||
pynccl_comm = get_tensor_model_parallel_group().pynccl_comm
|
||||
symm_mem_comm = get_tensor_model_parallel_group().symm_mem_comm
|
||||
dist.barrier()
|
||||
profile = False
|
||||
dtype = torch.bfloat16
|
||||
ctx = get_torch_prof_ctx(profile)
|
||||
result = []
|
||||
|
||||
with ctx:
|
||||
if IS_CI:
|
||||
i_range = range(10, 11)
|
||||
else:
|
||||
i_range = range(10, 20)
|
||||
for i in i_range:
|
||||
sz = 2**i
|
||||
if sz * dtype.itemsize > 2**24:
|
||||
break
|
||||
inp_randn = torch.randint(1, 16, (sz,), dtype=dtype, device=device)
|
||||
|
||||
memory = torch.empty_like(inp_randn)
|
||||
memory_out = torch.empty_like(memory)
|
||||
torch_eager_output, torch_eager_time = _bench_eager_time(
|
||||
lambda inp: torch_allreduce(inp, group), inp_randn
|
||||
)
|
||||
symm_mem_eager_output, symm_mem_eager_time = _bench_eager_time(
|
||||
lambda inp: symm_mem_allreduce(inp, symm_mem_comm), inp_randn
|
||||
)
|
||||
symm_mem_graph_output, symm_mem_graph_time = _bench_graph_time(
|
||||
lambda inp: symm_mem_allreduce(inp, symm_mem_comm), inp_randn
|
||||
)
|
||||
# since pynccl is inplace op, this return result is not correct if graph loop > 1
|
||||
_, pynccl_graph_time = _bench_graph_time(
|
||||
lambda inp: pynccl_allreduce(inp, pynccl_comm), inp_randn
|
||||
)
|
||||
torch.testing.assert_close(torch_eager_output, symm_mem_graph_output)
|
||||
torch.testing.assert_close(torch_eager_output, symm_mem_eager_output)
|
||||
result.append(
|
||||
{
|
||||
"msg_size": human_readable_size(inp_randn.nbytes),
|
||||
"torch eager time": torch_eager_time,
|
||||
"symm mem eager time": symm_mem_eager_time,
|
||||
"symm mem graph time": symm_mem_graph_time,
|
||||
"pynccl graph time": pynccl_graph_time,
|
||||
}
|
||||
)
|
||||
if rank == 0:
|
||||
print(f"sz={sz}, dtype={dtype}: correctness check PASS!")
|
||||
if rank == 0:
|
||||
print_markdown_table(result)
|
||||
if profile:
|
||||
prof_dir = f"prof/symm_mem"
|
||||
os.makedirs(prof_dir, exist_ok=True)
|
||||
ctx.export_chrome_trace(f"{prof_dir}/trace_rank{dist.get_rank()}.json.gz")
|
||||
@@ -381,8 +381,8 @@ def test_main(
|
||||
|
||||
# Tune combine performance
|
||||
best_time, best_results = 1e10, None
|
||||
for nvl_chunk_size in range(1, 8, 1):
|
||||
for rdma_chunk_size in range(12 if num_nodes == 2 else 8, 33, 4):
|
||||
for nvl_chunk_size in range(1, 5, 1):
|
||||
for rdma_chunk_size in range(8, 33, 4):
|
||||
config_kwargs = {
|
||||
"num_sms": num_sms,
|
||||
"num_max_nvl_chunked_send_tokens": nvl_chunk_size,
|
||||
|
||||
29
benchmark/kernels/fbgemm/README.md
Normal file
29
benchmark/kernels/fbgemm/README.md
Normal file
@@ -0,0 +1,29 @@
|
||||
## Benchmark FBGEMM Grouped GEMM
|
||||
|
||||
Benchmark FBGEMM Grouped GEMM in both Triton and CUDA version and SGLang Triton Grouped GEMM, it will be used to compare the bandwidth of different implementations.
|
||||
|
||||
### Requirements
|
||||
|
||||
```shell
|
||||
pip install fbgemm-gpu-genai
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
```bash
|
||||
python3 benchmark/fbgemm/benchmark_fbgemm_grouped_gemm.py --model Qwen/Qwen2-57B-A14B-Instruct --tp-size 4 --use-fp8-w8a8
|
||||
```
|
||||
|
||||
For example, in H200, the Qwen2-57B-A14B-Instruct TP4 fp8w8a8 grouped gemm bandwidth result is as follows:
|
||||
|
||||
```shell
|
||||
grouped-gemm-performance:
|
||||
batch_size FBGEMM Triton Grouped GEMM FP8 FBGEMM CUTLASS F8F8BF16 Rowwise SGLang Grouped GEMM FP8
|
||||
0 256.0 3704.841339 3042.626402 2254.725030
|
||||
1 512.0 3691.426346 3029.065684 2269.504543
|
||||
2 1024.0 3653.938629 2258.471467 2358.319020
|
||||
3 2048.0 3596.644313 2271.611904 2476.895397
|
||||
4 4096.0 3468.496435 2231.283986 2179.473910
|
||||
```
|
||||
|
||||
The theoretical peak bandwidth of H200 is 4.8 TB/s. Taking batch_size 256 as an example, the bandwidth of FBGEMM Triton Grouped GEMM FP8 is 3704.841339 GB/s, the bandwidth of FBGEMM CUTLASS F8F8BF16 Rowwise is 3042.626402 GB/s, and the bandwidth of SGLang Grouped GEMM FP8 is 2254.725030 GB/s. Therefore, FBGEMM Triton Grouped GEMM FP8 achieves 77.9% of H200's theoretical peak bandwidth, FBGEMM CUTLASS F8F8BF16 Rowwise achieves 63.4% of H200's theoretical peak bandwidth, and SGLang Grouped GEMM FP8 achieves 46.9% of H200's theoretical peak bandwidth.
|
||||
516
benchmark/kernels/fbgemm/benchmark_fbgemm_grouped_gemm.py
Normal file
516
benchmark/kernels/fbgemm/benchmark_fbgemm_grouped_gemm.py
Normal file
@@ -0,0 +1,516 @@
|
||||
# python3 benchmark/fbgemm/benchmark_fbgemm_grouped_gemm.py --model Qwen/Qwen2-57B-A14B-Instruct --tp-size 4 --use-fp8-w8a8
|
||||
import argparse
|
||||
|
||||
import torch
|
||||
import triton
|
||||
from fbgemm_gpu.experimental.gemm.triton_gemm.fp8_gemm import (
|
||||
quantize_fp8_row,
|
||||
triton_quantize_fp8_row,
|
||||
)
|
||||
from fbgemm_gpu.experimental.gemm.triton_gemm.grouped_gemm import (
|
||||
grouped_gemm as fbgemm_grouped_gemm,
|
||||
)
|
||||
from fbgemm_gpu.experimental.gemm.triton_gemm.grouped_gemm import (
|
||||
grouped_gemm_fp8_rowwise as fbgemm_grouped_gemm_fp8_rowwise,
|
||||
)
|
||||
from transformers import AutoConfig
|
||||
|
||||
from sglang.srt.layers.moe.ep_moe.kernels import (
|
||||
grouped_gemm_triton as sglang_grouped_gemm,
|
||||
)
|
||||
|
||||
|
||||
def get_model_config(model_name: str, tp_size: int):
|
||||
config = AutoConfig.from_pretrained(model_name, trust_remote_code=True)
|
||||
|
||||
if config.architectures[0] == "DbrxForCausalLM":
|
||||
num_groups = config.ffn_config.moe_num_experts
|
||||
intermediate_size = config.ffn_config.ffn_hidden_size
|
||||
elif config.architectures[0] == "JambaForCausalLM":
|
||||
num_groups = config.num_experts
|
||||
intermediate_size = config.intermediate_size
|
||||
elif config.architectures[0] == "Qwen2MoeForCausalLM":
|
||||
num_groups = config.num_experts
|
||||
intermediate_size = config.moe_intermediate_size
|
||||
elif config.architectures[0] == "Qwen3MoeForCausalLM":
|
||||
num_groups = config.num_experts
|
||||
intermediate_size = config.moe_intermediate_size
|
||||
elif config.architectures[0] in [
|
||||
"DeepseekV2ForCausalLM",
|
||||
"DeepseekV3ForCausalLM",
|
||||
]:
|
||||
num_groups = config.n_routed_experts
|
||||
intermediate_size = config.moe_intermediate_size
|
||||
elif config.architectures[0] == "Llama4ForConditionalGeneration":
|
||||
num_groups = config.text_config.num_local_experts
|
||||
intermediate_size = config.text_config.intermediate_size
|
||||
elif config.architectures[0] in [
|
||||
"Grok1ForCausalLM",
|
||||
"Grok1ImgGen",
|
||||
"Grok1AForCausalLM",
|
||||
]:
|
||||
num_groups = config.num_local_experts
|
||||
intermediate_size = config.moe_intermediate_size
|
||||
else:
|
||||
num_groups = config.num_local_experts
|
||||
intermediate_size = config.intermediate_size
|
||||
|
||||
shape_configs = {
|
||||
"num_groups": num_groups,
|
||||
"hidden_size": config.hidden_size,
|
||||
"intermediate_size": intermediate_size,
|
||||
"dtype": config.torch_dtype,
|
||||
}
|
||||
print(f"{shape_configs=}")
|
||||
return shape_configs
|
||||
|
||||
|
||||
def create_test_data(batch_size, num_groups, hidden_size, intermediate_size):
|
||||
torch.manual_seed(42)
|
||||
|
||||
tokens_per_group = batch_size // num_groups
|
||||
m_sizes = torch.full(
|
||||
(num_groups,), tokens_per_group, dtype=torch.int32, device="cuda"
|
||||
)
|
||||
|
||||
x = torch.randn(batch_size, hidden_size, dtype=torch.bfloat16, device="cuda")
|
||||
|
||||
base_weights = torch.randn(
|
||||
num_groups, intermediate_size, hidden_size, dtype=torch.bfloat16, device="cuda"
|
||||
)
|
||||
|
||||
w_fbgemm = base_weights.reshape(num_groups * intermediate_size, hidden_size)
|
||||
w_sglang = base_weights
|
||||
|
||||
c_fbgemm = torch.empty(
|
||||
batch_size, intermediate_size, dtype=torch.bfloat16, device="cuda"
|
||||
)
|
||||
c_sglang = torch.empty(
|
||||
batch_size, intermediate_size, dtype=torch.bfloat16, device="cuda"
|
||||
)
|
||||
|
||||
seg_indptr = torch.zeros(num_groups + 1, dtype=torch.int32, device="cuda")
|
||||
for i in range(1, num_groups + 1):
|
||||
seg_indptr[i] = seg_indptr[i - 1] + tokens_per_group
|
||||
|
||||
weight_indices = torch.arange(num_groups, dtype=torch.int32, device="cuda")
|
||||
|
||||
return (
|
||||
x,
|
||||
w_fbgemm,
|
||||
w_sglang,
|
||||
c_fbgemm,
|
||||
c_sglang,
|
||||
m_sizes,
|
||||
seg_indptr,
|
||||
weight_indices,
|
||||
)
|
||||
|
||||
|
||||
def create_fp8_test_data(
|
||||
batch_size, num_groups, hidden_size, intermediate_size, backend="triton"
|
||||
):
|
||||
"""
|
||||
Create test data for FP8 grouped GEMM operations.
|
||||
|
||||
Args:
|
||||
batch_size: Total batch size
|
||||
num_groups: Number of groups
|
||||
hidden_size: Hidden dimension size
|
||||
intermediate_size: Intermediate dimension size
|
||||
backend: "triton" for Triton GEMM, "cutlass" for CUTLASS GEMM
|
||||
|
||||
Returns:
|
||||
For triton: (x_fp8, w_fp8, m_sizes, x_scale, w_scale)
|
||||
For cutlass: (x, wq, w_scale, m_sizes)
|
||||
"""
|
||||
torch.manual_seed(42)
|
||||
|
||||
tokens_per_group = batch_size // num_groups
|
||||
|
||||
# Create weight matrices for each group
|
||||
w_list = []
|
||||
for _ in range(num_groups):
|
||||
w = torch.randn(
|
||||
intermediate_size, hidden_size, dtype=torch.float16, device="cuda"
|
||||
)
|
||||
w_list.append(w)
|
||||
|
||||
# Quantize weights using quantize_fp8_row for each group
|
||||
wq_list, w_scale_list = zip(*[quantize_fp8_row(w) for w in w_list])
|
||||
|
||||
if backend == "triton":
|
||||
# Triton format: concatenated weights
|
||||
w_fp8 = torch.concat(wq_list, dim=0).contiguous()
|
||||
w_scale = torch.concat(w_scale_list, dim=0).contiguous()
|
||||
|
||||
# Create m_sizes as int32 for triton
|
||||
m_sizes = torch.full(
|
||||
(num_groups,), tokens_per_group, dtype=torch.int32, device="cuda"
|
||||
)
|
||||
|
||||
# Create and quantize input
|
||||
x_fp16 = torch.randn(
|
||||
batch_size, hidden_size, dtype=torch.float16, device="cuda"
|
||||
)
|
||||
x_fp8, x_scale = triton_quantize_fp8_row(x_fp16)
|
||||
x_scale = x_scale.view(batch_size, -1)
|
||||
|
||||
return x_fp8, w_fp8, m_sizes, x_scale, w_scale
|
||||
|
||||
elif backend == "cutlass":
|
||||
# CUTLASS format: stacked weights
|
||||
wq = torch.stack(wq_list, dim=0).contiguous()
|
||||
w_scale = torch.stack(w_scale_list, dim=0).contiguous()
|
||||
|
||||
# Create m_sizes as int64 for cutlass
|
||||
m_values = [tokens_per_group] * num_groups
|
||||
m_sizes = torch.tensor(m_values).to(dtype=torch.int64, device="cuda")
|
||||
|
||||
# Create input data - separate for each group then concat
|
||||
x_list = []
|
||||
for _ in range(num_groups):
|
||||
x = torch.randn(
|
||||
tokens_per_group, hidden_size, dtype=torch.float16, device="cuda"
|
||||
)
|
||||
x_list.append(x)
|
||||
|
||||
# Concatenate inputs into single tensor
|
||||
x = torch.concat(x_list, dim=0).contiguous()
|
||||
|
||||
return x, wq, w_scale, m_sizes
|
||||
|
||||
else:
|
||||
raise ValueError(f"Unsupported backend: {backend}")
|
||||
|
||||
|
||||
def calculate_memory_bandwidth(m_sizes, hidden_size, intermediate_size, dtype):
|
||||
"""
|
||||
Calculate memory bandwidth based on accessed expert weights.
|
||||
|
||||
Args:
|
||||
m_sizes: Tensor containing batch sizes for each group
|
||||
hidden_size: Hidden dimension size
|
||||
intermediate_size: Intermediate dimension size
|
||||
dtype: Data type of weights
|
||||
|
||||
Returns:
|
||||
Memory size in bytes for accessed expert weights
|
||||
"""
|
||||
# Count non-zero groups (active experts)
|
||||
if hasattr(m_sizes, "cpu"):
|
||||
active_experts = torch.count_nonzero(m_sizes).item()
|
||||
else:
|
||||
active_experts = sum(1 for m in m_sizes if m > 0)
|
||||
|
||||
# Calculate bytes per element based on dtype
|
||||
if dtype in [torch.float16, torch.bfloat16]:
|
||||
bytes_per_element = 2
|
||||
elif dtype in [torch.float8_e4m3fn, torch.float8_e5m2]:
|
||||
bytes_per_element = 1
|
||||
elif dtype == torch.float32:
|
||||
bytes_per_element = 4
|
||||
else:
|
||||
# Default to 2 bytes for unknown dtypes
|
||||
bytes_per_element = 2
|
||||
|
||||
# Memory per expert weight matrix
|
||||
memory_per_expert = hidden_size * intermediate_size * bytes_per_element
|
||||
|
||||
# Total memory for active experts
|
||||
total_memory_bytes = active_experts * memory_per_expert
|
||||
|
||||
return total_memory_bytes
|
||||
|
||||
|
||||
def get_benchmark_config(use_fp8_w8a8=False):
|
||||
if use_fp8_w8a8:
|
||||
return {
|
||||
"line_vals": [
|
||||
"fbgemm_triton_grouped_gemm_fp8",
|
||||
"fbgemm_cutlass_f8f8bf16_rowwise",
|
||||
"sglang_grouped_gemm",
|
||||
],
|
||||
"line_names": [
|
||||
"FBGEMM Triton Grouped GEMM FP8",
|
||||
"FBGEMM CUTLASS F8F8BF16 Rowwise",
|
||||
"SGLang Grouped GEMM FP8",
|
||||
],
|
||||
"styles": [("blue", "-"), ("orange", "-"), ("red", "-")],
|
||||
}
|
||||
else:
|
||||
return {
|
||||
"line_vals": ["fbgemm_triton_grouped_gemm", "sglang_grouped_gemm"],
|
||||
"line_names": [
|
||||
"FBGEMM Triton Grouped GEMM BF16",
|
||||
"SGLang Grouped GEMM BF16",
|
||||
],
|
||||
"styles": [("blue", "-"), ("green", "-")],
|
||||
}
|
||||
|
||||
|
||||
def run_benchmark(
|
||||
model_config, use_fp8_w8a8=False, save_path="./benchmark_grouped_gemm/"
|
||||
):
|
||||
config = get_benchmark_config(use_fp8_w8a8)
|
||||
|
||||
benchmark_config = triton.testing.Benchmark(
|
||||
x_names=["batch_size"],
|
||||
x_vals=[256, 512, 1024, 2048, 4096],
|
||||
line_arg="provider",
|
||||
line_vals=config["line_vals"],
|
||||
line_names=config["line_names"],
|
||||
styles=config["styles"],
|
||||
ylabel="Bandwidth (GB/s)",
|
||||
plot_name="grouped-gemm-performance",
|
||||
args={},
|
||||
)
|
||||
|
||||
@triton.testing.perf_report(benchmark_config)
|
||||
def dynamic_benchmark(batch_size, provider, model_config, use_fp8_w8a8=False):
|
||||
print(f"Benchmarking {provider} with batch_size={batch_size}")
|
||||
torch.cuda.manual_seed_all(0)
|
||||
|
||||
num_groups = model_config["num_groups"]
|
||||
hidden_size = model_config["hidden_size"]
|
||||
intermediate_size = model_config["intermediate_size"]
|
||||
|
||||
if provider == "fbgemm_triton_grouped_gemm_fp8":
|
||||
try:
|
||||
test_data = create_fp8_test_data(
|
||||
batch_size,
|
||||
num_groups,
|
||||
hidden_size,
|
||||
intermediate_size,
|
||||
backend="triton",
|
||||
)
|
||||
x_fp8, w_fp8, m_sizes, x_scale, w_scale = test_data
|
||||
|
||||
# Calculate memory bandwidth
|
||||
memory_bytes = calculate_memory_bandwidth(
|
||||
m_sizes, hidden_size, intermediate_size, torch.float8_e4m3fn
|
||||
)
|
||||
|
||||
def run_func():
|
||||
return fbgemm_grouped_gemm_fp8_rowwise(
|
||||
x_fp8, w_fp8, m_sizes, x_scale, w_scale, use_fast_accum=True
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
print(f"FP8 not supported, skipping: {e}")
|
||||
return float("inf"), float("inf"), float("inf")
|
||||
|
||||
elif provider == "fbgemm_cutlass_f8f8bf16_rowwise":
|
||||
try:
|
||||
test_data = create_fp8_test_data(
|
||||
batch_size,
|
||||
num_groups,
|
||||
hidden_size,
|
||||
intermediate_size,
|
||||
backend="cutlass",
|
||||
)
|
||||
x, wq, w_scale, m_sizes = test_data
|
||||
|
||||
# Calculate memory bandwidth
|
||||
memory_bytes = calculate_memory_bandwidth(
|
||||
m_sizes, hidden_size, intermediate_size, torch.float8_e4m3fn
|
||||
)
|
||||
|
||||
# Quantize input using triton_quantize_fp8_row
|
||||
xq, x_scale = triton_quantize_fp8_row(x)
|
||||
x_scale = x_scale.view(batch_size, -1)
|
||||
|
||||
def run_func():
|
||||
return torch.ops.fbgemm.f8f8bf16_rowwise_grouped_stacked(
|
||||
xq, wq, x_scale, w_scale, m_sizes
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
print(
|
||||
f"CUTLASS f8f8bf16_rowwise_grouped_stacked not supported, "
|
||||
f"skipping: {e}"
|
||||
)
|
||||
return float("inf"), float("inf"), float("inf")
|
||||
else:
|
||||
test_data = create_test_data(
|
||||
batch_size, num_groups, hidden_size, intermediate_size
|
||||
)
|
||||
(
|
||||
x,
|
||||
w_fbgemm,
|
||||
w_sglang,
|
||||
c_fbgemm,
|
||||
c_sglang,
|
||||
m_sizes,
|
||||
seg_indptr,
|
||||
weight_indices,
|
||||
) = test_data
|
||||
|
||||
# Calculate memory bandwidth for BF16 operations
|
||||
memory_bytes = calculate_memory_bandwidth(
|
||||
m_sizes, hidden_size, intermediate_size, torch.bfloat16
|
||||
)
|
||||
|
||||
if provider == "fbgemm_triton_grouped_gemm":
|
||||
|
||||
def run_func():
|
||||
return fbgemm_grouped_gemm(
|
||||
x, w_fbgemm, m_sizes, use_fast_accum=True
|
||||
)
|
||||
|
||||
else:
|
||||
|
||||
def run_func():
|
||||
return sglang_grouped_gemm(
|
||||
x,
|
||||
w_sglang,
|
||||
c_sglang,
|
||||
num_groups,
|
||||
weight_column_major=True,
|
||||
seg_indptr=seg_indptr,
|
||||
weight_indices=weight_indices,
|
||||
c_dtype=c_sglang.dtype,
|
||||
)
|
||||
|
||||
for _ in range(10):
|
||||
try:
|
||||
run_func()
|
||||
except Exception as e:
|
||||
print(f"Error during warmup for {provider}: {e}")
|
||||
return float("inf"), float("inf"), float("inf")
|
||||
|
||||
torch.cuda.synchronize()
|
||||
|
||||
try:
|
||||
quantiles = [0.5, 0.2, 0.8]
|
||||
ms, min_ms, max_ms = triton.testing.do_bench(run_func, quantiles=quantiles)
|
||||
|
||||
# Convert time (ms) to bandwidth (GB/s)
|
||||
# Bandwidth = Memory (bytes) / Time (seconds)
|
||||
# Convert ms to seconds and bytes to GB (1e9)
|
||||
gb_per_s = (memory_bytes / 1e9) / (ms / 1000)
|
||||
# min bandwidth = max time, max bandwidth = min time
|
||||
min_gb_per_s = (memory_bytes / 1e9) / (max_ms / 1000)
|
||||
max_gb_per_s = (memory_bytes / 1e9) / (min_ms / 1000)
|
||||
|
||||
return gb_per_s, min_gb_per_s, max_gb_per_s
|
||||
except Exception as e:
|
||||
print(f"Error during benchmarking for {provider}: {e}")
|
||||
return 0.0, 0.0, 0.0
|
||||
|
||||
dynamic_benchmark.run(
|
||||
show_plots=True,
|
||||
print_data=True,
|
||||
save_path=save_path,
|
||||
model_config=model_config,
|
||||
use_fp8_w8a8=use_fp8_w8a8,
|
||||
)
|
||||
|
||||
|
||||
def verify_correctness(model_config):
|
||||
print("Verifying correctness...")
|
||||
batch_size = 128
|
||||
num_groups = model_config["num_groups"]
|
||||
hidden_size = model_config["hidden_size"]
|
||||
intermediate_size = model_config["intermediate_size"]
|
||||
|
||||
test_data = create_test_data(batch_size, num_groups, hidden_size, intermediate_size)
|
||||
(
|
||||
x,
|
||||
w_fbgemm,
|
||||
w_sglang,
|
||||
c_fbgemm,
|
||||
c_sglang,
|
||||
m_sizes,
|
||||
seg_indptr,
|
||||
weight_indices,
|
||||
) = test_data
|
||||
|
||||
result_fbgemm = fbgemm_grouped_gemm(x, w_fbgemm, m_sizes, use_fast_accum=True)
|
||||
|
||||
result_sglang = sglang_grouped_gemm(
|
||||
x,
|
||||
w_sglang,
|
||||
c_sglang,
|
||||
num_groups,
|
||||
weight_column_major=True,
|
||||
seg_indptr=seg_indptr,
|
||||
weight_indices=weight_indices,
|
||||
c_dtype=c_sglang.dtype,
|
||||
)
|
||||
|
||||
if torch.allclose(result_fbgemm, result_sglang, rtol=1e-3, atol=1e-3):
|
||||
print("✓ BF16 Correctness verification passed!")
|
||||
else:
|
||||
max_diff = torch.max(torch.abs(result_fbgemm - result_sglang))
|
||||
print(f"✗ BF16 Correctness verification failed! Max diff: {max_diff}")
|
||||
return False
|
||||
|
||||
return True
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser(
|
||||
description="Benchmark FBGEMM vs SGLang Grouped GEMM"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--model",
|
||||
type=str,
|
||||
default="mistralai/Mixtral-8x7B-Instruct-v0.1",
|
||||
help="Model name to get configuration from",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tp-size", type=int, default=1, help="Tensor parallelism size"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use-fp8-w8a8", action="store_true", help="Enable FP8 W8A8 benchmark"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--save-path",
|
||||
type=str,
|
||||
default="./benchmark_grouped_gemm/",
|
||||
help="Path to save benchmark results",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--verify-correctness",
|
||||
action="store_true",
|
||||
help="Verify correctness before benchmarking",
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
try:
|
||||
model_config = get_model_config(args.model, args.tp_size)
|
||||
except Exception as e:
|
||||
print(f"Failed to get model config: {e}")
|
||||
print("Using default configuration...")
|
||||
model_config = {
|
||||
"num_groups": 8,
|
||||
"hidden_size": 4096,
|
||||
"intermediate_size": 14336,
|
||||
"dtype": torch.bfloat16,
|
||||
}
|
||||
|
||||
print("Running benchmark with:")
|
||||
print(f" num_groups: {model_config['num_groups']}")
|
||||
print(f" hidden_size: {model_config['hidden_size']}")
|
||||
print(f" intermediate_size: {model_config['intermediate_size']}")
|
||||
print(f" use_fp8_w8a8: {args.use_fp8_w8a8}")
|
||||
|
||||
if args.verify_correctness:
|
||||
if not verify_correctness(model_config):
|
||||
print("Correctness verification failed. Exiting...")
|
||||
return
|
||||
|
||||
try:
|
||||
run_benchmark(
|
||||
model_config=model_config,
|
||||
use_fp8_w8a8=args.use_fp8_w8a8,
|
||||
save_path=args.save_path,
|
||||
)
|
||||
except Exception as e:
|
||||
print(f"Benchmark failed: {e}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -1,17 +1,9 @@
|
||||
import os
|
||||
|
||||
import torch
|
||||
import triton
|
||||
import triton.language as tl
|
||||
from sgl_kernel import moe_sum_reduce as moe_sum_reduce_cuda
|
||||
from triton.testing import do_bench
|
||||
|
||||
# CI environment detection
|
||||
IS_CI = (
|
||||
os.getenv("CI", "false").lower() == "true"
|
||||
or os.getenv("GITHUB_ACTIONS", "false").lower() == "true"
|
||||
)
|
||||
|
||||
|
||||
@triton.jit
|
||||
def _moe_sum_reduce_kernel(
|
||||
@@ -46,6 +38,7 @@ def _moe_sum_reduce_kernel(
|
||||
base_ptrs = input_ptr + offs_token[:, None] * input_stride_0 + offs_dim[None, :]
|
||||
|
||||
accumulator = tl.zeros((BLOCK_M, BLOCK_DIM), dtype=tl.float32)
|
||||
|
||||
for i in tl.range(0, topk_num, num_stages=NUM_STAGE):
|
||||
tile = tl.load(
|
||||
base_ptrs + i * input_stride_1,
|
||||
@@ -117,7 +110,7 @@ def compute_sum_scaled_compiled(
|
||||
return out
|
||||
|
||||
|
||||
def get_benchmark(dtype=torch.bfloat16):
|
||||
def get_benchmark():
|
||||
num_tokens_range = [2**i for i in range(0, 13)]
|
||||
|
||||
@triton.testing.perf_report(
|
||||
@@ -129,7 +122,7 @@ def get_benchmark(dtype=torch.bfloat16):
|
||||
line_names=["Original", "TorchCompile", "TritonKernel", "CudaKernel"],
|
||||
styles=[("blue", "-"), ("green", "-"), ("red", "-"), ("yellow", "-")],
|
||||
ylabel="us",
|
||||
plot_name=f"sum_scaled_performance_{str(dtype).split('.')[-1]}",
|
||||
plot_name="sum_scaled_performance",
|
||||
args={},
|
||||
)
|
||||
)
|
||||
@@ -181,8 +174,8 @@ def get_benchmark(dtype=torch.bfloat16):
|
||||
return benchmark
|
||||
|
||||
|
||||
def verify_correctness(num_tokens=1024, dtype=torch.bfloat16):
|
||||
x = torch.randn(num_tokens, 9, 4096, device="cuda", dtype=dtype)
|
||||
def verify_correctness(num_tokens=1024):
|
||||
x = torch.randn(num_tokens, 9, 4096, device="cuda", dtype=torch.bfloat16)
|
||||
scaling_factor = 0.3
|
||||
|
||||
out_baseline = torch.empty_like(x[:, 0])
|
||||
@@ -191,60 +184,33 @@ def verify_correctness(num_tokens=1024, dtype=torch.bfloat16):
|
||||
out_compiled = torch.empty_like(out_baseline)
|
||||
compute_sum_scaled_compiled(x, out_compiled, scaling_factor)
|
||||
|
||||
out_triton = torch.empty_like(out_baseline)
|
||||
moe_sum_reduce_triton(x, out_triton, scaling_factor)
|
||||
|
||||
out_cuda = torch.empty_like(out_baseline)
|
||||
moe_sum_reduce_cuda(x, out_cuda, scaling_factor)
|
||||
|
||||
triton_skipped = dtype == torch.float64
|
||||
if not triton_skipped:
|
||||
out_triton = torch.empty_like(out_baseline)
|
||||
moe_sum_reduce_triton(x, out_triton, scaling_factor)
|
||||
|
||||
if dtype == torch.float64:
|
||||
atol, rtol = 1e-12, 1e-12
|
||||
elif dtype == torch.float32:
|
||||
atol, rtol = 1e-6, 1e-6
|
||||
else: # bfloat16 / float16
|
||||
atol, rtol = 1e-2, 1e-2
|
||||
|
||||
ok_compiled = torch.allclose(out_baseline, out_compiled, atol=atol, rtol=rtol)
|
||||
ok_cuda = torch.allclose(out_baseline, out_cuda, atol=atol, rtol=rtol)
|
||||
ok_triton = (
|
||||
True
|
||||
if triton_skipped
|
||||
else torch.allclose(out_baseline, out_triton, atol=atol, rtol=rtol)
|
||||
)
|
||||
|
||||
if ok_compiled and ok_triton and ok_cuda:
|
||||
msg = "✅ All implementations match"
|
||||
if triton_skipped:
|
||||
msg += " (Triton skipped for float64)"
|
||||
print(msg)
|
||||
if (
|
||||
torch.allclose(out_baseline, out_compiled, atol=1e-2, rtol=1e-2)
|
||||
and torch.allclose(out_baseline, out_triton, atol=1e-2, rtol=1e-2)
|
||||
and torch.allclose(out_baseline, out_cuda, atol=1e-2, rtol=1e-2)
|
||||
):
|
||||
print("✅ All implementations match")
|
||||
else:
|
||||
print("❌ Implementations differ")
|
||||
print(
|
||||
f"Baseline vs Compiled: {(out_baseline - out_compiled).abs().max().item()}"
|
||||
)
|
||||
if not triton_skipped:
|
||||
print(
|
||||
f"Baseline vs Triton: {(out_baseline - out_triton).abs().max().item()}"
|
||||
)
|
||||
print(f"Baseline vs Triton: {(out_baseline - out_triton).abs().max().item()}")
|
||||
print(f"Baseline vs Cuda: {(out_baseline - out_cuda).abs().max().item()}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
print("Running correctness verification for bfloat16...")
|
||||
verify_correctness(dtype=torch.bfloat16)
|
||||
print("Running correctness verification...")
|
||||
verify_correctness()
|
||||
|
||||
# CI environment uses simplified parameters
|
||||
if not IS_CI:
|
||||
print("Running correctness verification for float64...")
|
||||
verify_correctness(dtype=torch.float64)
|
||||
|
||||
print("Running correctness verification for float64...")
|
||||
verify_correctness(dtype=torch.float64)
|
||||
|
||||
print("\nRunning performance benchmark for bfloat16...")
|
||||
benchmark = get_benchmark(dtype=torch.bfloat16)
|
||||
print("\nRunning performance benchmark...")
|
||||
benchmark = get_benchmark()
|
||||
benchmark.run(
|
||||
print_data=True,
|
||||
# save_path="./configs/benchmark_ops/sum_scaled/"
|
||||
@@ -167,7 +167,6 @@ class MiniMaxText01LightningAttention(nn.Module):
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
use_cache: bool = False,
|
||||
slope_rate: Optional[torch.Tensor] = None,
|
||||
do_eval: bool = False,
|
||||
**kwargs,
|
||||
):
|
||||
if (not self.training) and (not do_eval):
|
||||
|
||||
@@ -1,5 +1,4 @@
|
||||
import itertools
|
||||
import logging
|
||||
import math
|
||||
import os
|
||||
from typing import Optional, Tuple
|
||||
@@ -11,8 +10,6 @@ import triton
|
||||
import triton.language as tl
|
||||
from einops import rearrange
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
# Adapted from https://github.com/OpenNLPLab/lightning-attention/blob/main/lightning_attn/ops/triton/lightning_attn2.py
|
||||
@triton.jit
|
||||
@@ -305,7 +302,6 @@ class MiniMaxText01LightningAttention(nn.Module):
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
use_cache: bool = False,
|
||||
slope_rate: Optional[torch.Tensor] = None,
|
||||
do_eval: bool = False,
|
||||
**kwargs,
|
||||
):
|
||||
if (not self.training) and (not do_eval):
|
||||
|
||||
@@ -6,8 +6,8 @@ import triton
|
||||
from sgl_kernel import scaled_fp4_grouped_quant, silu_and_mul_scaled_fp4_grouped_quant
|
||||
from sgl_kernel.elementwise import silu_and_mul
|
||||
|
||||
from sglang.srt.layers import deep_gemm_wrapper
|
||||
from sglang.srt.layers.moe.ep_moe.kernels import silu_and_mul_masked_post_quant_fwd
|
||||
from sglang.srt.layers.quantization import deep_gemm_wrapper
|
||||
|
||||
|
||||
def _test_accuracy_once(E, M, K, input_dtype, device):
|
||||
|
||||
@@ -28,8 +28,6 @@ def launch_server(args):
|
||||
cmd += "--disable-custom-all-reduce"
|
||||
if args.enable_mscclpp:
|
||||
cmd += "--enable-mscclpp"
|
||||
if args.enable_torch_symm_mem:
|
||||
cmd += "--enable-torch-symm-mem"
|
||||
print(cmd)
|
||||
os.system(cmd)
|
||||
|
||||
@@ -72,11 +70,6 @@ if __name__ == "__main__":
|
||||
action="store_true",
|
||||
help="Enable using mscclpp for small messages for all-reduce kernel and fall back to NCCL.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--enable-torch-symm-mem",
|
||||
action="store_true",
|
||||
help="Enable using torch symm mem for all-reduce kernel and fall back to NCCL.",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
launch_server(args)
|
||||
|
||||
@@ -75,6 +75,12 @@ CAT_SHORT2LONG = {
|
||||
}
|
||||
|
||||
|
||||
# DATA SAVING
|
||||
def save_json(filename, ds):
|
||||
with open(filename, "w") as f:
|
||||
json.dump(ds, f, indent=4)
|
||||
|
||||
|
||||
def get_multi_choice_info(options):
|
||||
"""
|
||||
Given the list of options for multiple choice question
|
||||
|
||||
@@ -36,7 +36,6 @@ class EvalArgs:
|
||||
profile: bool = False
|
||||
profile_number: int = 5
|
||||
concurrency: int = 1
|
||||
max_new_tokens: int = 30
|
||||
response_answer_regex: str = "(.*)"
|
||||
lora_path: Optional[str] = None
|
||||
|
||||
@@ -95,12 +94,6 @@ class EvalArgs:
|
||||
default=EvalArgs.concurrency,
|
||||
help="Number of concurrent requests to make during evaluation. Default is 1, which means no concurrency.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--max-new-tokens",
|
||||
type=int,
|
||||
default=EvalArgs.max_new_tokens,
|
||||
help="Maximum number of new tokens to generate per sample.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--response-answer-regex",
|
||||
type=str,
|
||||
@@ -241,7 +234,7 @@ def prepare_samples(eval_args: EvalArgs):
|
||||
|
||||
|
||||
def get_sampling_params(eval_args):
|
||||
max_new_tokens = eval_args.max_new_tokens
|
||||
max_new_tokens = 30
|
||||
temperature = 0.001
|
||||
|
||||
extra_request_body = {}
|
||||
|
||||
@@ -7,7 +7,7 @@ from pathlib import Path
|
||||
from tqdm import tqdm
|
||||
|
||||
import sglang as sgl
|
||||
from sglang.srt.utils.hf_transformers_utils import get_tokenizer
|
||||
from sglang.srt.hf_transformers_utils import get_tokenizer
|
||||
from sglang.test.test_utils import (
|
||||
add_common_sglang_args_and_parse,
|
||||
select_sglang_backend,
|
||||
|
||||
@@ -1,15 +1,11 @@
|
||||
ARG CUDA_VERSION=12.9.1
|
||||
FROM nvidia/cuda:${CUDA_VERSION}-cudnn-devel-ubuntu22.04 AS base
|
||||
ARG TARGETARCH
|
||||
|
||||
ARG GRACE_BLACKWELL=0
|
||||
ARG BUILD_TYPE=all
|
||||
ARG BRANCH_TYPE=remote
|
||||
ARG DEEPEP_COMMIT=9af0e0d0e74f3577af1979c9b9e1ac2cad0104ee
|
||||
ARG FLASHMLA_COMMIT=1408756a88e52a25196b759eaf8db89d2b51b5a1
|
||||
ARG FAST_HADAMARD_TRANSFORM_COMMIT=7fd811c2b47f63b0b08d2582619f939e14dad77c
|
||||
ARG CMAKE_BUILD_PARALLEL_LEVEL=2
|
||||
ARG SGL_KERNEL_VERSION=0.3.16.post3
|
||||
ARG SGL_KERNEL_VERSION=0.3.12
|
||||
ENV DEBIAN_FRONTEND=noninteractive \
|
||||
CUDA_HOME=/usr/local/cuda \
|
||||
GDRCOPY_HOME=/usr/src/gdrdrv-2.4.4/ \
|
||||
@@ -97,12 +93,11 @@ RUN python3 -m pip install --no-cache-dir --upgrade pip setuptools wheel html5li
|
||||
&& FLASHINFER_LOGGING_LEVEL=warning python3 -m flashinfer --download-cubin
|
||||
|
||||
|
||||
# Download NVSHMEM source files
|
||||
# We use Tom's DeepEP fork for GB200 for now; the 1fd57b0276311d035d16176bb0076426166e52f3 commit is https://github.com/fzyzcjy/DeepEP/tree/gb200_blog_part_2
|
||||
# Download source files
|
||||
RUN wget https://developer.download.nvidia.com/compute/redist/nvshmem/3.3.9/source/nvshmem_src_cuda12-all-all-3.3.9.tar.gz && \
|
||||
if [ "$GRACE_BLACKWELL" = "1" ]; then \
|
||||
if [ "$BUILD_TYPE" = "blackwell_aarch" ] && [ "$(uname -m)" = "aarch64" ]; then \
|
||||
git clone https://github.com/fzyzcjy/DeepEP.git \
|
||||
&& cd DeepEP && git checkout 1fd57b0276311d035d16176bb0076426166e52f3 && sed -i 's/#define NUM_CPU_TIMEOUT_SECS 100/#define NUM_CPU_TIMEOUT_SECS 1000/' csrc/kernels/configs.cuh && cd .. ; \
|
||||
&& cd DeepEP && git checkout 1b14ad661c7640137fcfe93cccb2694ede1220b0 && sed -i 's/#define NUM_CPU_TIMEOUT_SECS 100/#define NUM_CPU_TIMEOUT_SECS 1000/' csrc/kernels/configs.cuh && cd .. ; \
|
||||
else \
|
||||
git clone https://github.com/deepseek-ai/DeepEP.git \
|
||||
&& cd DeepEP && git checkout ${DEEPEP_COMMIT} && sed -i 's/#define NUM_CPU_TIMEOUT_SECS 100/#define NUM_CPU_TIMEOUT_SECS 1000/' csrc/kernels/configs.cuh && cd .. ; \
|
||||
@@ -113,7 +108,7 @@ RUN wget https://developer.download.nvidia.com/compute/redist/nvshmem/3.3.9/sour
|
||||
|
||||
# Build and install NVSHMEM
|
||||
RUN cd /sgl-workspace/nvshmem && \
|
||||
if [ "$GRACE_BLACKWELL" = "1" ]; then CUDA_ARCH="90;100;120"; else CUDA_ARCH="90"; fi && \
|
||||
if [ "$BUILD_TYPE" = "blackwell" ] || [ "$BUILD_TYPE" = "blackwell_aarch" ]; then CUDA_ARCH="90;100;120"; else CUDA_ARCH="90"; fi && \
|
||||
NVSHMEM_SHMEM_SUPPORT=0 \
|
||||
NVSHMEM_UCX_SUPPORT=0 \
|
||||
NVSHMEM_USE_NCCL=0 \
|
||||
@@ -140,15 +135,6 @@ RUN cd /sgl-workspace/DeepEP && \
|
||||
esac && \
|
||||
NVSHMEM_DIR=${NVSHMEM_DIR} TORCH_CUDA_ARCH_LIST="${CHOSEN_TORCH_CUDA_ARCH_LIST}" pip install .
|
||||
|
||||
# Install flashmla
|
||||
RUN git clone https://github.com/deepseek-ai/FlashMLA.git flash-mla && \
|
||||
cd flash-mla && \
|
||||
git checkout ${FLASHMLA_COMMIT} && \
|
||||
git submodule update --init --recursive && \
|
||||
if [ "$CUDA_VERSION" = "12.6.1" ]; then \
|
||||
export FLASH_MLA_DISABLE_SM100=1; \
|
||||
fi && \
|
||||
pip install -v . ;
|
||||
|
||||
# Python tools
|
||||
RUN python3 -m pip install --no-cache-dir \
|
||||
|
||||
@@ -6,13 +6,12 @@ ARG PYTHON_VERSION=py3.11
|
||||
FROM quay.io/ascend/cann:$CANN_VERSION-$DEVICE_TYPE-$OS-$PYTHON_VERSION
|
||||
|
||||
# Update pip & apt sources
|
||||
ARG DEVICE_TYPE
|
||||
ARG PIP_INDEX_URL="https://pypi.org/simple/"
|
||||
ARG APTMIRROR=""
|
||||
ARG MEMFABRIC_URL=https://sglang-ascend.obs.cn-east-3.myhuaweicloud.com/sglang/mf_adapter-1.0.0-cp311-cp311-linux_aarch64.whl
|
||||
ARG PYTORCH_VERSION=2.6.0
|
||||
ARG TORCHVISION_VERSION=0.21.0
|
||||
ARG PTA_URL="https://sglang-ascend.obs.cn-east-3.myhuaweicloud.com/ops/torch_npu-2.6.0.post2%2Bgit95d6260-cp311-cp311-linux_aarch64.whl"
|
||||
ARG PTA_URL="https://gitee.com/ascend/pytorch/releases/download/v7.1.0.1-pytorch2.6.0/torch_npu-2.6.0.post1-cp311-cp311-manylinux_2_28_aarch64.whl"
|
||||
ARG VLLM_TAG=v0.8.5
|
||||
ARG TRITON_ASCEND_URL="https://sglang-ascend.obs.cn-east-3.myhuaweicloud.com/sglang/triton_ascend-3.2.0%2Bgitb0ea0850-cp311-cp311-linux_aarch64.whl"
|
||||
ARG BISHENG_URL="https://sglang-ascend.obs.cn-east-3.myhuaweicloud.com/sglang/Ascend-BiSheng-toolkit_aarch64.run"
|
||||
@@ -72,7 +71,7 @@ RUN git clone --depth 1 https://github.com/vllm-project/vllm.git --branch $VLLM_
|
||||
|
||||
# TODO: install from pypi released triton-ascend
|
||||
RUN pip install torch==$PYTORCH_VERSION torchvision==$TORCHVISION_VERSION --index-url https://download.pytorch.org/whl/cpu --no-cache-dir \
|
||||
&& wget ${PTA_URL} && pip install "./torch_npu-2.6.0.post2+git95d6260-cp311-cp311-linux_aarch64.whl" --no-cache-dir \
|
||||
&& wget ${PTA_URL} && pip install "./torch_npu-2.6.0.post1-cp311-cp311-manylinux_2_28_aarch64.whl" --no-cache-dir \
|
||||
&& python3 -m pip install --no-cache-dir attrs==24.2.0 numpy==1.26.4 scipy==1.13.1 decorator==5.1.1 psutil==6.0.0 pytest==8.3.2 pytest-xdist==3.6.1 pyyaml pybind11 \
|
||||
&& pip install ${TRITON_ASCEND_URL} --no-cache-dir
|
||||
|
||||
@@ -93,13 +92,6 @@ RUN pip install wheel==0.45.1 && git clone --branch $SGLANG_KERNEL_NPU_TAG http
|
||||
&& cd .. && rm -rf sgl-kernel-npu \
|
||||
&& cd "$(pip show deep-ep | awk '/^Location:/ {print $2}')" && ln -s deep_ep/deep_ep_cpp*.so
|
||||
|
||||
# Install CustomOps
|
||||
RUN wget https://sglang-ascend.obs.cn-east-3.myhuaweicloud.com/ops/CANN-custom_ops-8.2.0.0-$DEVICE_TYPE-linux.aarch64.run && \
|
||||
chmod a+x ./CANN-custom_ops-8.2.0.0-$DEVICE_TYPE-linux.aarch64.run && \
|
||||
./CANN-custom_ops-8.2.0.0-$DEVICE_TYPE-linux.aarch64.run --quiet --install-path=/usr/local/Ascend/ascend-toolkit/latest/opp && \
|
||||
wget https://sglang-ascend.obs.cn-east-3.myhuaweicloud.com/ops/custom_ops-1.0.$DEVICE_TYPE-cp311-cp311-linux_aarch64.whl && \
|
||||
pip install ./custom_ops-1.0.$DEVICE_TYPE-cp311-cp311-linux_aarch64.whl
|
||||
|
||||
# Install Bisheng
|
||||
RUN wget ${BISHENG_URL} && chmod a+x Ascend-BiSheng-toolkit_aarch64.run && ./Ascend-BiSheng-toolkit_aarch64.run --install && rm Ascend-BiSheng-toolkit_aarch64.run
|
||||
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
# Usage (to build SGLang ROCm docker image):
|
||||
# docker build --build-arg SGL_BRANCH=v0.5.4 --build-arg GPU_ARCH=gfx942 -t v0.5.4-rocm630-mi30x -f Dockerfile.rocm .
|
||||
# docker build --build-arg SGL_BRANCH=v0.5.4 --build-arg GPU_ARCH=gfx942-rocm700 -t v0.5.4-rocm700-mi30x -f Dockerfile.rocm .
|
||||
# docker build --build-arg SGL_BRANCH=v0.5.4 --build-arg GPU_ARCH=gfx950 -t v0.5.4-rocm700-mi35x -f Dockerfile.rocm .
|
||||
# docker build --build-arg SGL_BRANCH=v0.5.3rc0 --build-arg GPU_ARCH=gfx942 -t v0.5.3rc0-rocm630-mi30x -f Dockerfile.rocm .
|
||||
# docker build --build-arg SGL_BRANCH=v0.5.3rc0 --build-arg GPU_ARCH=gfx942-rocm700 -t v0.5.3rc0-rocm700-mi30x -f Dockerfile.rocm .
|
||||
# docker build --build-arg SGL_BRANCH=v0.5.3rc0 --build-arg GPU_ARCH=gfx950 -t v0.5.3rc0-rocm700-mi35x -f Dockerfile.rocm .
|
||||
|
||||
|
||||
# Default base images
|
||||
@@ -31,7 +31,7 @@ ENV BUILD_TRITON="0"
|
||||
ENV BUILD_LLVM="0"
|
||||
ENV BUILD_AITER_ALL="1"
|
||||
ENV BUILD_MOONCAKE="1"
|
||||
ENV AITER_COMMIT="v0.1.6.post1"
|
||||
ENV AITER_COMMIT="v0.1.5.post3"
|
||||
ENV NO_DEPS_FLAG=""
|
||||
|
||||
# ===============================
|
||||
@@ -42,7 +42,7 @@ ENV BUILD_TRITON="0"
|
||||
ENV BUILD_LLVM="0"
|
||||
ENV BUILD_AITER_ALL="1"
|
||||
ENV BUILD_MOONCAKE="1"
|
||||
ENV AITER_COMMIT="v0.1.6.post1"
|
||||
ENV AITER_COMMIT="v0.1.5.post3"
|
||||
ENV NO_DEPS_FLAG="--no-deps"
|
||||
|
||||
# ===============================
|
||||
@@ -69,13 +69,6 @@ ARG LLVM_COMMIT="6520ace8227ffe2728148d5f3b9872a870b0a560"
|
||||
ARG MOONCAKE_REPO="https://github.com/kvcache-ai/Mooncake.git"
|
||||
ARG MOONCAKE_COMMIT="dcdf1c784b40aa6975a8ed89fe26321b028e40e8"
|
||||
|
||||
ARG TILELANG_REPO="https://github.com/HaiShaw/tilelang.git"
|
||||
ARG TILELANG_BRANCH="dsv32-mi35x"
|
||||
ARG TILELANG_COMMIT="ae938cf885743f165a19656d1122ad42bb0e30b8"
|
||||
|
||||
ARG FHT_REPO="https://github.com/jeffdaily/fast-hadamard-transform.git"
|
||||
ARG FHT_BRANCH="rocm"
|
||||
ARG FHT_COMMIT="46efb7d776d38638fc39f3c803eaee3dd7016bd1"
|
||||
USER root
|
||||
|
||||
# Install some basic utilities
|
||||
@@ -97,6 +90,8 @@ RUN if [ "$BUILD_LLVM" = "1" ]; then \
|
||||
&& make -j$(nproc); \
|
||||
fi
|
||||
|
||||
# -----------------------
|
||||
|
||||
# -----------------------
|
||||
# AITER
|
||||
RUN pip uninstall -y aiter
|
||||
@@ -160,6 +155,7 @@ RUN if [ "$BUILD_MOONCAKE" = "1" ]; then \
|
||||
make -j "$(nproc)" && make install; \
|
||||
fi
|
||||
|
||||
|
||||
# -----------------------
|
||||
# Build SGLang
|
||||
ARG BUILD_TYPE=all
|
||||
@@ -211,89 +207,6 @@ RUN python3 -m pip install --no-cache-dir setuptools-rust \
|
||||
&& python3 -m pip install --no-cache-dir . \
|
||||
&& rm -rf /root/.cache
|
||||
|
||||
# -----------------------
|
||||
# TileLang
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
ENV LIBGL_ALWAYS_INDIRECT=1
|
||||
RUN echo "LC_ALL=en_US.UTF-8" >> /etc/environment
|
||||
|
||||
RUN /bin/bash -lc 'set -euo pipefail; \
|
||||
# Build TileLang only for gfx950
|
||||
if [ "${GPU_ARCH:-}" != "gfx950" ]; then \
|
||||
echo "[TileLang] Skipping (GPU_ARCH=${GPU_ARCH:-unset})"; \
|
||||
exit 0; \
|
||||
fi; \
|
||||
echo "[TileLang] Building TileLang for ${GPU_ARCH}"; \
|
||||
\
|
||||
# System dependencies (NO llvm-dev to avoid llvm-config-16 shadowing)
|
||||
apt-get update && apt-get install -y --no-install-recommends \
|
||||
build-essential git wget curl ca-certificates gnupg \
|
||||
libgtest-dev libgmock-dev \
|
||||
libprotobuf-dev protobuf-compiler libgflags-dev libsqlite3-dev \
|
||||
python3 python3-dev python3-setuptools python3-pip \
|
||||
gcc libtinfo-dev zlib1g-dev libedit-dev libxml2-dev \
|
||||
cmake ninja-build pkg-config libstdc++6 \
|
||||
&& rm -rf /var/lib/apt/lists/*; \
|
||||
\
|
||||
# Build GoogleTest static libs (Ubuntu package ships sources only)
|
||||
cmake -S /usr/src/googletest -B /tmp/build-gtest -DBUILD_GTEST=ON -DBUILD_GMOCK=ON -DCMAKE_BUILD_TYPE=Release && \
|
||||
cmake --build /tmp/build-gtest -j"$(nproc)" && \
|
||||
cp -v /tmp/build-gtest/lib/*.a /usr/lib/x86_64-linux-gnu/ && \
|
||||
rm -rf /tmp/build-gtest; \
|
||||
\
|
||||
# Keep setuptools < 80 (compat with base image)
|
||||
python3 -m pip install --upgrade "setuptools>=77.0.3,<80" wheel cmake ninja && \
|
||||
python3 -m pip cache purge || true; \
|
||||
\
|
||||
# Locate ROCm llvm-config; fallback to installing LLVM 18 if missing
|
||||
LLVM_CONFIG_PATH=""; \
|
||||
for p in /opt/rocm/llvm/bin/llvm-config /opt/rocm/llvm-*/bin/llvm-config /opt/rocm-*/llvm*/bin/llvm-config; do \
|
||||
if [ -x "$p" ]; then LLVM_CONFIG_PATH="$p"; break; fi; \
|
||||
done; \
|
||||
if [ -z "$LLVM_CONFIG_PATH" ]; then \
|
||||
echo "[TileLang] ROCm llvm-config not found; installing LLVM 18..."; \
|
||||
curl -fsSL https://apt.llvm.org/llvm.sh -o /tmp/llvm.sh; \
|
||||
chmod +x /tmp/llvm.sh; \
|
||||
/tmp/llvm.sh 18; \
|
||||
LLVM_CONFIG_PATH="$(command -v llvm-config-18)"; \
|
||||
if [ -z "$LLVM_CONFIG_PATH" ]; then echo "ERROR: llvm-config-18 not found after install"; exit 1; fi; \
|
||||
fi; \
|
||||
echo "[TileLang] Using LLVM_CONFIG at: $LLVM_CONFIG_PATH"; \
|
||||
export PATH="$(dirname "$LLVM_CONFIG_PATH"):/usr/local/bin:${PATH}"; \
|
||||
export LLVM_CONFIG="$LLVM_CONFIG_PATH"; \
|
||||
\
|
||||
# Optional shim for tools that expect llvm-config-16
|
||||
mkdir -p /usr/local/bin && \
|
||||
printf "#!/usr/bin/env bash\nexec \"%s\" \"\$@\"\n" "$LLVM_CONFIG_PATH" > /usr/local/bin/llvm-config-16 && \
|
||||
chmod +x /usr/local/bin/llvm-config-16; \
|
||||
\
|
||||
# TVM Python bits need Cython
|
||||
python3 -m pip install --no-cache-dir "cython>=0.29.36,<3.0"; \
|
||||
\
|
||||
# Clone + pin TileLang (bundled TVM), then build
|
||||
git clone --recursive --branch "${TILELANG_BRANCH}" "${TILELANG_REPO}" /opt/tilelang && \
|
||||
cd /opt/tilelang && \
|
||||
git fetch --depth=1 origin "${TILELANG_COMMIT}" || true && \
|
||||
git checkout -f "${TILELANG_COMMIT}" && \
|
||||
git submodule update --init --recursive && \
|
||||
export CMAKE_ARGS="-DLLVM_CONFIG=${LLVM_CONFIG} ${CMAKE_ARGS:-}" && \
|
||||
bash ./install_rocm.sh'
|
||||
|
||||
# -----------------------
|
||||
# Hadamard-transform (HIP build)
|
||||
RUN /bin/bash -lc 'set -euo pipefail; \
|
||||
git clone --branch "${FHT_BRANCH}" "${FHT_REPO}" fast-hadamard-transform; \
|
||||
cd fast-hadamard-transform; \
|
||||
git checkout -f "${FHT_COMMIT}"; \
|
||||
python setup.py install'
|
||||
|
||||
# -----------------------
|
||||
# Python tools
|
||||
RUN python3 -m pip install --no-cache-dir \
|
||||
py-spy \
|
||||
pre-commit
|
||||
|
||||
# -----------------------
|
||||
# Performance environment variable.
|
||||
ENV HIP_FORCE_DEV_KERNARG=1
|
||||
ENV HSA_NO_SCRATCH_RECLAIM=1
|
||||
|
||||
@@ -29,14 +29,10 @@ RUN curl -LsSf https://astral.sh/uv/install.sh | sh
|
||||
# install python
|
||||
RUN uv venv --python ${PYTHON_VERSION} --seed ${VIRTUAL_ENV}
|
||||
|
||||
FROM scratch AS local_src
|
||||
COPY . /src
|
||||
|
||||
######################### BUILD IMAGE #########################
|
||||
FROM base AS build-image
|
||||
|
||||
ARG SGLANG_REPO_REF=main
|
||||
ARG BRANCH_TYPE=remote
|
||||
|
||||
# set the environment variables
|
||||
ENV PATH="/root/.cargo/bin:${PATH}"
|
||||
@@ -51,25 +47,17 @@ RUN apt update -y \
|
||||
RUN curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y \
|
||||
&& rustc --version && cargo --version && protoc --version
|
||||
|
||||
# pull the github repository or use local source
|
||||
COPY --from=local_src /src /tmp/local_src
|
||||
RUN if [ "$BRANCH_TYPE" = "local" ]; then \
|
||||
cp -r /tmp/local_src /opt/sglang; \
|
||||
else \
|
||||
cd /opt \
|
||||
&& git clone --depth=1 https://github.com/sgl-project/sglang.git \
|
||||
&& cd /opt/sglang \
|
||||
&& git checkout ${SGLANG_REPO_REF}; \
|
||||
fi \
|
||||
&& rm -rf /tmp/local_src
|
||||
# pull the github repository
|
||||
RUN cd /opt \
|
||||
&& git clone --depth=1 https://github.com/sgl-project/sglang.git \
|
||||
&& cd /opt/sglang \
|
||||
&& git checkout ${SGLANG_REPO_REF}
|
||||
|
||||
# working directory
|
||||
WORKDIR /opt/sglang/sgl-router
|
||||
|
||||
# build the rust dependencies
|
||||
RUN cargo clean \
|
||||
&& rm -rf dist/ \
|
||||
&& cargo build --release \
|
||||
RUN cargo build --release \
|
||||
&& uv build \
|
||||
&& rm -rf /root/.cache
|
||||
|
||||
|
||||
@@ -1,9 +1,7 @@
|
||||
FROM ubuntu:24.04
|
||||
SHELL ["/bin/bash", "-c"]
|
||||
|
||||
ARG SGLANG_REPO=https://github.com/sgl-project/sglang.git
|
||||
ARG VER_SGLANG=main
|
||||
|
||||
ARG VER_TORCH=2.7.1
|
||||
ARG VER_TORCHVISION=0.22.1
|
||||
ARG VER_TRITON=3.3.1
|
||||
@@ -22,7 +20,7 @@ RUN apt-get update && \
|
||||
|
||||
WORKDIR /sgl-workspace
|
||||
|
||||
RUN curl -fsSL -o miniforge.sh -O https://github.com/conda-forge/miniforge/releases/download/25.3.1-0/Miniforge3-25.3.1-0-Linux-x86_64.sh && \
|
||||
RUN curl -fsSL -v -o miniforge.sh -O https://github.com/conda-forge/miniforge/releases/download/24.11.3-2/Miniforge3-24.11.3-2-Linux-x86_64.sh && \
|
||||
bash miniforge.sh -b -p ./miniforge3 && \
|
||||
rm -f miniforge.sh && \
|
||||
. miniforge3/bin/activate && \
|
||||
@@ -35,14 +33,13 @@ ENV CONDA_PREFIX=/sgl-workspace/miniforge3
|
||||
RUN pip config set global.index-url https://download.pytorch.org/whl/cpu && \
|
||||
pip config set global.extra-index-url https://pypi.org/simple
|
||||
|
||||
RUN git clone ${SGLANG_REPO} sglang && \
|
||||
RUN git clone https://github.com/sgl-project/sglang.git && \
|
||||
cd sglang && \
|
||||
rm -rf python/pyproject.toml && mv python/pyproject_other.toml python/pyproject.toml && \
|
||||
git checkout ${VER_SGLANG} && \
|
||||
cd python && \
|
||||
cp pyproject_cpu.toml pyproject.toml && \
|
||||
pip install . && \
|
||||
pip install -e "python[all_cpu]" && \
|
||||
pip install torch==${VER_TORCH} torchvision==${VER_TORCHVISION} triton==${VER_TRITON} --force-reinstall && \
|
||||
cd ../sgl-kernel && \
|
||||
cd sgl-kernel && \
|
||||
cp pyproject_cpu.toml pyproject.toml && \
|
||||
pip install .
|
||||
|
||||
|
||||
@@ -1,73 +0,0 @@
|
||||
# If the device is Battlemage, we need to set UBUNTU_VERSION to 24.10
|
||||
|
||||
# Usage: docker build --build-arg UBUNTU_VERSION=24.04 --build-arg PYTHON_VERSION=3.10 -t sglang:xpu_kernel -f Dockerfile.xpu --no-cache .
|
||||
|
||||
# Use Intel deep learning essentials base image with Ubuntu 24.04
|
||||
FROM intel/deep-learning-essentials:2025.1.3-0-devel-ubuntu24.04
|
||||
|
||||
# Avoid interactive prompts during package install
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
# Define build arguments
|
||||
ARG PYTHON_VERSION=3.10
|
||||
|
||||
ARG SG_LANG_REPO=https://github.com/sgl-project/sglang.git
|
||||
ARG SG_LANG_BRANCH=main
|
||||
|
||||
ARG SG_LANG_KERNEL_REPO=https://github.com/sgl-project/sgl-kernel-xpu.git
|
||||
ARG SG_LANG_KERNEL_BRANCH=main
|
||||
|
||||
RUN useradd -m -d /home/sdp -s /bin/bash sdp && \
|
||||
chown -R sdp:sdp /home/sdp
|
||||
|
||||
# Switch to non-root user 'sdp'
|
||||
USER sdp
|
||||
|
||||
# Set HOME and WORKDIR to user's home directory
|
||||
ENV HOME=/home/sdp
|
||||
WORKDIR /home/sdp
|
||||
|
||||
RUN curl -fsSL -v -o miniforge.sh -O https://github.com/conda-forge/miniforge/releases/download/25.1.1-0/Miniforge3-Linux-x86_64.sh && \
|
||||
bash miniforge.sh -b -p ./miniforge3 && \
|
||||
rm miniforge.sh && \
|
||||
# Initialize conda environment and install pip
|
||||
. ./miniforge3/bin/activate && \
|
||||
conda create -y -n py${PYTHON_VERSION} python=${PYTHON_VERSION} && \
|
||||
conda activate py${PYTHON_VERSION} && \
|
||||
conda install pip && \
|
||||
# Append environment activation to .bashrc for interactive shells
|
||||
echo ". /home/sdp/miniforge3/bin/activate; conda activate py${PYTHON_VERSION}; . /opt/intel/oneapi/setvars.sh; cd /home/sdp" >> /home/sdp/.bashrc
|
||||
|
||||
USER root
|
||||
RUN apt-get update && apt install -y intel-ocloc
|
||||
|
||||
# Switch back to user sdp
|
||||
USER sdp
|
||||
|
||||
RUN --mount=type=secret,id=github_token \
|
||||
cd /home/sdp && \
|
||||
. /home/sdp/miniforge3/bin/activate && \
|
||||
conda activate py${PYTHON_VERSION} && \
|
||||
pip3 install torch==2.8.0+xpu torchao torchvision torchaudio pytorch-triton-xpu==3.4.0 --index-url https://download.pytorch.org/whl/xpu
|
||||
|
||||
RUN --mount=type=secret,id=github_token \
|
||||
cd /home/sdp && \
|
||||
. /home/sdp/miniforge3/bin/activate && \
|
||||
conda activate py${PYTHON_VERSION} && \
|
||||
echo "Cloning ${SG_LANG_BRANCH} from ${SG_LANG_REPO}" && \
|
||||
git clone --branch ${SG_LANG_BRANCH} --single-branch ${SG_LANG_REPO} && \
|
||||
cd sglang && cd python && \
|
||||
cp pyproject_xpu.toml pyproject.toml && \
|
||||
pip install . && \
|
||||
pip install xgrammar --no-deps && \
|
||||
pip install msgspec blake3 py-cpuinfo compressed_tensors gguf partial_json_parser einops --root-user-action=ignore && \
|
||||
conda install libsqlite=3.48.0 -y && \
|
||||
# Add environment setup commands to .bashrc again (in case it was overwritten)
|
||||
echo ". /home/sdp/miniforge3/bin/activate; conda activate py${PYTHON_VERSION}; cd /home/sdp" >> /home/sdp/.bashrc
|
||||
|
||||
# Use bash as default shell with initialization from .bashrc
|
||||
SHELL ["bash", "-c"]
|
||||
|
||||
# Start an interactive bash shell with all environment set up
|
||||
USER sdp
|
||||
CMD ["bash", "-c", "source /home/sdp/.bashrc && exec bash"]
|
||||
@@ -1,107 +1,27 @@
|
||||
# Attention Backend
|
||||
|
||||
SGLang supports a large variety of attention backends. Each of them has different pros and cons.
|
||||
SGLang supports multiple attention backends. Each of them has different pros and cons.
|
||||
You can test them according to your needs.
|
||||
|
||||
```{important}
|
||||
Selecting an optimal attention backend is crucial for maximizing your performance. Different backends excel in various scenarios, so choose based on your model, hardware, and use case. Not all backends are supported on all platforms and model architectures.
|
||||
```
|
||||
## Supporting matrix for different attention backends
|
||||
|
||||
## Support Matrix
|
||||
| **Backend** | **Page Size > 1** | **Spec Decoding** | **MLA** | **Sliding Window** | **MultiModal** |
|
||||
|--------------------------|-------------------|-------------------|---------|--------------------|----------------|
|
||||
| **FlashInfer** | ❌ | ✅ | ✅ | ✅ | ✅ |
|
||||
| **FA3** | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| **Triton** | ❌ | ✅ | ✅ | ✅ | ❌ |
|
||||
| **Torch Native** | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| **FlashMLA** | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| **TRTLLM MLA** | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| **Ascend** | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| **Wave** | ✅ | ❌ | ❌ | ❌ | ❌ |
|
||||
|
||||
The support matrix is split into two parts: MHA (standard attention) and MLA (multi-head latent attention). For an explanation of the key differences between MHA and MLA, please see the [SGLang documentation on DeepSeek MLA](https://github.com/sgl-project/sglang/blob/main/docs/basic_usage/deepseek.md#multi-head-latent-attention-mla) and the original [DeepSeek MLA paper](https://arxiv.org/pdf/2405.04434).
|
||||
**Notes:**
|
||||
- TRTLLM MLA only implements decode operations. For prefill operations (including multimodal inputs), it falls back to FlashInfer MLA backend.
|
||||
|
||||
### MHA Backends
|
||||
|
||||
| **Backend** | **Page Size > 1 (native)** | **FP8 KV Cache** | **Spec topk=1** | **Spec topk>1** | **Sliding Window** | **MultiModal** |
|
||||
|---------------------------------|-----------------------------|------------------|-----------------|-----------------|--------------------|----------------|
|
||||
| **FlashInfer** | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| **FA3 (FlashAttention 3)** | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| **FA4 (FlashAttention 4)** | 128 | ❌ | ❌ | ❌ | ❌ | ❌ |
|
||||
| **Triton** | ❌ | ❌ | ✅ | ✅ | ✅ | ✅ |
|
||||
| **Torch Native (SDPA)** | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
|
||||
| **FlexAttention (PyTorch)** | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
|
||||
| **TRTLLM MHA** | 16, 32 or 64 | ❌ | ✅ | ❌ | ❌ | ❌ |
|
||||
| **Dual Chunk FlashAttention** | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
|
||||
| **AITER (ROCm)** | ✅ | ❌ | ✅ | ✅ | ❌ | ❌ |
|
||||
| **Wave (ROCm)** | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
|
||||
| **Ascend (NPU)** | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
|
||||
| **Intel XPU** | ✅ | ❌ | ❌ | ❌ | ✅ | ❌ |
|
||||
|
||||
### MLA Backends
|
||||
|
||||
| **Backend** | **Native Page Sizes** | **FP8 KV Cache** | **Chunked Prefix Cache** | **Spec topk=1** | **Spec topk>1** |
|
||||
|----------------------------|---------------------------|------------------|--------------------------|-----------------|-----------------|
|
||||
| **FlashInfer MLA** | 1 | ❌ | ✅ | ✅ | ❌ |
|
||||
| **FlashMLA** | 64 | ❌ | ✅ | ✅ | ❌ |
|
||||
| **Cutlass MLA** | 128 | ✅ | ✅ | ✅ | ❌ |
|
||||
| **TRTLLM MLA (Blackwell)** | 32 or 64 | ✅ | ✅ | ✅ | ❌ |
|
||||
| **FA3 (FlashAttention 3)** | n/a | ❌ | ✅ | ✅ | ⚠️ (page_size=1 only) |
|
||||
| **Triton** | n/a | ❌ | ❌ | ✅ | ⚠️ (page_size=1 only) |
|
||||
| **FA4** | 128 | ❌ | ❌ | ❌ | ❌ |
|
||||
| **Ascend MLA (NPU)** | 128 | ❌ | ❌ | ❌ | ❌ |
|
||||
|
||||
```{warning}
|
||||
FlashMLA FP8 KV cache is currently not working. See upstream issue [#8856](https://github.com/sgl-project/sglang/pull/8856). Use non-FP8 KV or another backend when FP8 KV cache is required.
|
||||
```
|
||||
|
||||
```{note}
|
||||
- FlashAttention 4 is prefill-only for now.
|
||||
- NSA is specifically designed for [DeepSeek V3.2 DSA](https://lmsys.org/blog/2025-09-29-deepseek-V32/).
|
||||
```
|
||||
|
||||
```{tip}
|
||||
Speculative decoding topk: `topk` is the number of draft tokens sampled per step from the draft model. `topk = 1` follows classic EAGLE; `topk > 1` explores multiple branches and requires backend support in both draft and verification paths.
|
||||
```
|
||||
|
||||
Note: Many backends that do not natively operate on pages can emulate `page_size > 1` at the wrapper layer by expanding page tables to per-token indices. The "Page Size > 1 (native)" column indicates true in-kernel paging. Some backends require fixed native page sizes and cannot be reduced/emulated differently: TRTLLM MHA (16/32/64), TRTLLM MLA (32/64), FlashMLA (64), Cutlass MLA (128), FA4 (128), Ascend (128).
|
||||
|
||||
MLA page-size constraints:
|
||||
- FlashInfer MLA: page_size = 1.
|
||||
- FlashMLA: page_size = 64.
|
||||
- Cutlass MLA: page_size = 128.
|
||||
- TRTLLM MLA: page_size ∈ {32, 64}.
|
||||
- FA4: page_size = 128.
|
||||
|
||||
### Hybrid attention (different backends for prefill vs decode) (Experimental)
|
||||
|
||||
```{warning}
|
||||
Hybrid attention is an experimental feature.
|
||||
```
|
||||
|
||||
You can mix-and-match attention backends for prefill and decode. This is useful when one backend excels at prefill and another excels at decode. For the implementation details, please see `python/sglang/srt/layers/attention/hybrid_attn_backend.py`.
|
||||
|
||||
```bash
|
||||
# Example: Prefill with FA4, Decode with TRTLLM MLA (Blackwell)
|
||||
python3 -m sglang.launch_server \
|
||||
--model-path nvidia/DeepSeek-R1-FP4 \
|
||||
--tp 8 \
|
||||
--attention-backend trtllm_mla \
|
||||
--moe-runner-backend flashinfer_trtllm \
|
||||
--quantization modelopt_fp4 \
|
||||
--prefill-attention-backend fa4
|
||||
```
|
||||
|
||||
#### Speculative decoding with hybrid attention
|
||||
|
||||
Hybrid attention also works with speculative decoding. The backend used for draft decoding and target verification depends on `--speculative-attention-mode`:
|
||||
|
||||
- `--speculative-attention-mode decode` (recommended): draft/verify use the decode backend.
|
||||
- `--speculative-attention-mode prefill` (default): draft/verify use the prefill backend.
|
||||
|
||||
Constraints when combining hybrid attention with speculative decoding:
|
||||
|
||||
- If any attention backend is `trtllm_mha`, speculative decoding supports only `--speculative-eagle-topk 1`.
|
||||
- For paged MHA backends with `--page-size > 1` and `--speculative-eagle-topk > 1`, only `flashinfer` is supported.
|
||||
- `flex_attention` is not supported with speculative decoding.
|
||||
- For MLA backends, `trtllm_mla` supports `topk > 1`; `flashmla` and `flashinfer_mla` support only `topk = 1`.
|
||||
- CUDA Graph: the decode backend is always captured; the prefill backend is captured only when `--speculative-attention-mode prefill`.
|
||||
|
||||
|
||||
```{tip}
|
||||
If you set only one of `--prefill-attention-backend` or `--decode-attention-backend`, the unspecified phase inherits `--attention-backend`.
|
||||
If both are specified and differ, SGLang automatically enables a hybrid wrapper to dispatch to the chosen backend per phase.
|
||||
```
|
||||
Note: Every kernel backend is compatible with a page size > 1 by specifying an argument such as `--page-size 16`.
|
||||
This is because a page size of 16 can be converted to a page size of 1 in the kernel backend.
|
||||
The "❌" and "✅" symbols in the table above under "Page Size > 1" indicate whether the kernel actually operates with a page size greater than 1, rather than treating a page size of 16 as a page size of 1.
|
||||
|
||||
## User guide
|
||||
|
||||
@@ -191,13 +111,6 @@ python3 -m sglang.launch_server \
|
||||
--attention-backend ascend
|
||||
```
|
||||
|
||||
- Intel XPU
|
||||
```bash
|
||||
python3 -m sglang.launch_server \
|
||||
--model meta-llama/Meta-Llama-3.1-8B-Instruct \
|
||||
--attention-backend intel_xpu
|
||||
```
|
||||
|
||||
- Wave
|
||||
```bash
|
||||
python3 -m sglang.launch_server \
|
||||
@@ -205,38 +118,6 @@ python3 -m sglang.launch_server \
|
||||
--attention-backend wave
|
||||
```
|
||||
|
||||
- FlexAttention
|
||||
```bash
|
||||
python3 -m sglang.launch_server \
|
||||
--model meta-llama/Meta-Llama-3.1-8B-Instruct \
|
||||
--attention-backend flex_attention
|
||||
```
|
||||
|
||||
- Dual Chunk FlashAttention (MHA-only)
|
||||
```bash
|
||||
python3 -m sglang.launch_server \
|
||||
--model Qwen/Qwen2.5-14B-Instruct-1M \
|
||||
--attention-backend dual_chunk_flash_attn
|
||||
```
|
||||
|
||||
- Cutlass MLA
|
||||
```bash
|
||||
python3 -m sglang.launch_server \
|
||||
--tp 8 \
|
||||
--model deepseek-ai/DeepSeek-R1 \
|
||||
--attention-backend cutlass_mla \
|
||||
--trust-remote-code
|
||||
```
|
||||
|
||||
- FlashAttention 4 (MHA & MLA)
|
||||
```bash
|
||||
python3 -m sglang.launch_server \
|
||||
--tp 8 \
|
||||
--model deepseek-ai/DeepSeek-R1 \
|
||||
--prefill-attention-backend fa4 \
|
||||
--trust-remote-code
|
||||
```
|
||||
|
||||
## Steps to add a new attention backend
|
||||
To add a new attention backend, you can learn from the existing backends
|
||||
(`python/sglang/srt/layers/attention/triton_backend.py`, `python/sglang/srt/layers/attention/flashattention_backend.py`)
|
||||
|
||||
@@ -1,154 +0,0 @@
|
||||
# Deterministic Inference
|
||||
|
||||
## Why Deterministic Inference Matters
|
||||
|
||||
Deterministic inference ensures consistent LLM outputs across runs, which is critical for:
|
||||
- **Reinforcement Learning**: Ensures consistent logprobs across runs, reducing stochastic noise and making RL training more stable, reproducible, and debuggable.
|
||||
- **Testing & Debugging**: Enables reproducible validation
|
||||
- **Production**: Improves reliability and user experience
|
||||
|
||||
Even with `temperature=0`, standard LLM inference can produce different outputs due to dynamic batching and varying reduction orders in GPU kernels.
|
||||
|
||||
## The Root Cause of Non-Determinism
|
||||
|
||||
The main source is **varying batch sizes**. Different batch sizes cause GPU kernels to split reduction operations differently, leading to different addition orders. Due to floating-point non-associativity (`(a + b) + c ≠ a + (b + c)`), this produces different results even for identical inputs.
|
||||
|
||||
|
||||
## SGLang's Solution
|
||||
|
||||
Building on [Thinking Machines Lab's batch-invariant operators](https://github.com/thinking-machines-lab/batch_invariant_ops), SGLang achieves fully deterministic inference while maintaining compatibility with chunked prefill, CUDA graphs, radix cache, and non-greedy sampling. The development roadmap for deterministic inference features can be found in this [issue](https://github.com/sgl-project/sglang/issues/10278).
|
||||
|
||||
### Supported Backends
|
||||
|
||||
Deterministic inference is only supported with the following three attention backends: **FlashInfer**, **FlashAttention 3 (FA3)**, and **Triton**.
|
||||
|
||||
The following table shows feature compatibility for deterministic inference across different attention backends:
|
||||
|
||||
| Attention Backend | CUDA Graph | Chunked Prefill | Radix Cache | Non-greedy Sampling (Temp > 0) |
|
||||
|-------------------|------------|-----------------|-------------|---------------------|
|
||||
| **FlashInfer** | ✅ Yes | ✅ Yes | ❌ No | ✅ Yes |
|
||||
| **FlashAttention 3 (FA3)** | ✅ Yes | ✅ Yes | ✅ Yes | ✅ Yes |
|
||||
| **Triton** | ✅ Yes | ✅ Yes | ✅ Yes | ✅ Yes |
|
||||
|
||||
## Usage
|
||||
|
||||
### Basic Usage
|
||||
|
||||
Enable deterministic inference by adding the `--enable-deterministic-inference` flag:
|
||||
|
||||
```bash
|
||||
python3 -m sglang.launch_server \
|
||||
--model-path Qwen/Qwen3-8B \
|
||||
--attention-backend fa3 \
|
||||
--enable-deterministic-inference
|
||||
```
|
||||
|
||||
### Server Arguments
|
||||
|
||||
| Argument | Type/Default | Description |
|
||||
|----------|--------------|-------------|
|
||||
| `--enable-deterministic-inference` | flag; default: disabled | Enable deterministic inference with batch-invariant operations |
|
||||
| `--attention-backend` | string; default: fa3 | Choose attention backend (flashinfer, fa3, or triton) |
|
||||
|
||||
### Example Configurations
|
||||
|
||||
#### Qwen3-8B
|
||||
```bash
|
||||
python3 -m sglang.launch_server \
|
||||
--model-path Qwen/Qwen3-8B \
|
||||
--attention-backend flashinfer \
|
||||
--enable-deterministic-inference
|
||||
```
|
||||
|
||||
#### Llama Models
|
||||
```bash
|
||||
python3 -m sglang.launch_server \
|
||||
--model-path meta-llama/Llama-3.1-8B-Instruct \
|
||||
--attention-backend fa3 \
|
||||
--enable-deterministic-inference
|
||||
```
|
||||
|
||||
#### Qwen3-30B-A3B (MoE Model)
|
||||
```bash
|
||||
python3 -m sglang.launch_server \
|
||||
--model-path Qwen/Qwen3-30B-A3B \
|
||||
--attention-backend fa3 \
|
||||
--enable-deterministic-inference
|
||||
```
|
||||
|
||||
### Deterministic Inference with Non-Greedy Sampling (Temperature > 0)
|
||||
|
||||
SGLang supports deterministic inference even with non-greedy sampling by using sampling seeds. This is particularly useful for reinforcement learning scenarios like GRPO (Group Relative Policy Optimization) where you need multiple diverse but reproducible responses.
|
||||
|
||||
#### Default Behavior
|
||||
|
||||
By default, SGLang uses a sampling seed of `42` for reproducible sampling:
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
response = requests.post(
|
||||
"http://localhost:30000/generate",
|
||||
json={
|
||||
"text": "Tell me a joke",
|
||||
"sampling_params": {
|
||||
"temperature": 0.8, # Non-greedy sampling
|
||||
"max_new_tokens": 128,
|
||||
},
|
||||
},
|
||||
)
|
||||
print(response.json())
|
||||
# This will always produce the same response across runs
|
||||
```
|
||||
|
||||
#### Generating Multiple Reproducible Responses
|
||||
|
||||
To sample different responses from the same prompt while maintaining reproducibility (e.g., for GRPO training), provide different sampling seeds in your requests:
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
# Prepare a list of sampling seeds for different responses
|
||||
sampling_seeds = [42, 43, 44, 45, 46]
|
||||
|
||||
responses = []
|
||||
for seed in sampling_seeds:
|
||||
response = requests.post(
|
||||
"http://localhost:30000/generate",
|
||||
json={
|
||||
"text": "Tell me a joke",
|
||||
"sampling_params": {
|
||||
"temperature": 0.8,
|
||||
"max_new_tokens": 128,
|
||||
"sampling_seed": seed, # Specify sampling seed
|
||||
},
|
||||
},
|
||||
)
|
||||
responses.append(response.json())
|
||||
|
||||
# Each seed will produce a different but reproducible response
|
||||
# Using the same seed will always produce the same response
|
||||
```
|
||||
|
||||
This approach ensures that:
|
||||
- Different seeds produce diverse responses
|
||||
- The same seed always produces the same response across different runs
|
||||
- Results are reproducible for debugging and evaluation
|
||||
|
||||
|
||||
## Verification
|
||||
|
||||
Run deterministic tests to verify consistent outputs:
|
||||
|
||||
```bash
|
||||
# Single test: same prompt, varying batch sizes
|
||||
python3 -m sglang.test.test_deterministic --test-mode single --n-trials 50
|
||||
|
||||
# Prefix test: prompts with different prefix lengths
|
||||
python3 -m sglang.test.test_deterministic --test-mode prefix --n-trials 50
|
||||
|
||||
# Radix Cache Consistency mode: test radix cache determinism (cached vs uncached prefill)
|
||||
python3 -m sglang.test.test_deterministic --test-mode radix_cache
|
||||
```
|
||||
|
||||
Expected result: All tests should show `Unique samples: 1` (perfectly deterministic).
|
||||
@@ -1,8 +0,0 @@
|
||||
Hierarchical KV Caching (HiCache)
|
||||
======================
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
|
||||
hicache_best_practices.md
|
||||
hicache_design.md
|
||||
@@ -1,195 +0,0 @@
|
||||
# SGLang HiCache Best Practices
|
||||
|
||||
## Why HiCache Matters
|
||||
|
||||
SGLang HiCache extends the traditional RadixAttention with a three-tier hierarchical KV caching system that dramatically improves performance for long-context and multi-turn conversation scenarios. By intelligently managing KV caches across GPU memory, host memory, and external storage backends, HiCache addresses the fundamental capacity bottleneck that limits cache hit rates in conventional systems.
|
||||
|
||||
## Configuration Guidelines
|
||||
|
||||
## Core HiCache Parameters
|
||||
|
||||
```bash
|
||||
# Essential HiCache flags
|
||||
--page-size 64 # Page size for cache management
|
||||
--enable-hierarchical-cache # Enable HiCache
|
||||
--hicache-ratio 2 # Host memory ratio (2x GPU memory)
|
||||
--hicache-size 100 # Host memory size in GBs, will override the above ratio
|
||||
--hicache-io-backend kernel # The I/O backend of moving data between CPU and GPU
|
||||
--hicache-write-policy write_through # Cache write policy from GPU to CPU
|
||||
--hicache-storage-backend # Optional storage backend (e.g., hf3fs, mooncake, etc.)
|
||||
```
|
||||
|
||||
## Key Configurations with Storage Backends Enabled
|
||||
|
||||
### Memory Layout Optimization
|
||||
|
||||
```bash
|
||||
# Page-first: Optimized for I/O efficiency with zero-copy (recommended with kernel backend)
|
||||
--hicache-mem-layout page_first
|
||||
# Page-first-direct: Optimized for direct I/O operations (Compatible with fa3 and same zero-copy performance as page_first)
|
||||
--hicache-mem-layout page_first_direct
|
||||
# Layer-first
|
||||
--hicache-mem-layout layer_first
|
||||
```
|
||||
**Layout Compatibility:**
|
||||
- `page_first`: Only compatible with `kernel` I/O backend, automatically switches to `layer_first` with `direct` backend
|
||||
- `page_first_direct`: Specifically designed for `direct` I/O backend with optimized memory organization
|
||||
|
||||
### Prefetch Policies
|
||||
|
||||
```bash
|
||||
# Best-effort: Terminate prefetch when needed
|
||||
--hicache-storage-prefetch-policy best_effort
|
||||
# Wait-complete: Ensure complete prefetch, higher cache reuse
|
||||
--hicache-storage-prefetch-policy wait_complete
|
||||
# Timeout: Balance between completion and best-effort
|
||||
--hicache-storage-prefetch-policy timeout
|
||||
```
|
||||
|
||||
### Integration with PD Disaggregation
|
||||
|
||||
HiCache works seamlessly with PD Disaggregation. You can choose between two configurations:
|
||||
|
||||
1. **Prefill-only HiCache**: Enable HiCache only on Prefill nodes, allowing KV cache sharing among Prefill instances
|
||||
2. **Full HiCache with async offloading**: Enable HiCache on Prefill nodes and async KV cache offloading on Decode nodes, allowing Prefill nodes to reuse KV caches from Decode nodes in multi-turn dialogue scenarios
|
||||
|
||||
```bash
|
||||
# Prefill node with HiCache enabled for cross-prefill sharing (ideal for SystemPrompt scenarios)
|
||||
python3 -m sglang.launch_server \
|
||||
--model-path /xxx/DeepSeek-R1/ \
|
||||
--tp 8 \
|
||||
--host 0.0.0.0 \
|
||||
--port 10000 \
|
||||
--enable-metrics \
|
||||
--enable-cache-report \
|
||||
--mem-fraction-static 0.85 \
|
||||
--page-size 64 \
|
||||
--enable-hierarchical-cache \
|
||||
--hicache-ratio 2 \
|
||||
--hicache-size 0 \
|
||||
--hicache-mem-layout page_first_direct \
|
||||
--hicache-io-backend direct \
|
||||
--hicache-write-policy write_through \
|
||||
--hicache-storage-backend hf3fs \
|
||||
--hicache-storage-prefetch-policy wait_complete \
|
||||
--disaggregation-ib-device mlx5_0 \
|
||||
--disaggregation-mode prefill \
|
||||
--disaggregation-transfer-backend mooncake
|
||||
|
||||
# Decode node with async offloading enabled for KV cache reuse by Prefill (ideal for multi-turn conversations)
|
||||
python3 -m sglang.launch_server \
|
||||
--model-path /xxx/DeepSeek-R1/ \
|
||||
--tp 8 \
|
||||
--host 0.0.0.0 \
|
||||
--port 10000 \
|
||||
--enable-metrics \
|
||||
--enable-cache-report \
|
||||
--page-size 64 \
|
||||
--hicache-ratio 2 \
|
||||
--hicache-size 0 \
|
||||
--hicache-mem-layout page_first_direct \
|
||||
--hicache-io-backend direct \
|
||||
--hicache-write-policy write_through \
|
||||
--hicache-storage-backend hf3fs \
|
||||
--hicache-storage-prefetch-policy wait_complete \
|
||||
--disaggregation-decode-enable-offload-kvcache \ # Enable async KV cache offloading in decode node
|
||||
--disaggregation-ib-device mlx5_0 \
|
||||
--disaggregation-mode decode \
|
||||
--disaggregation-transfer-backend mooncake
|
||||
```
|
||||
|
||||
|
||||
### Deployment with HF3FS
|
||||
|
||||
Here is an example of deploying DeepSeek-R1 with HiCache-HF3FS. For more details, see the [HF3FS Documentation](../../python/sglang/srt/mem_cache/storage/hf3fs/docs/README.md).
|
||||
|
||||
```bash
|
||||
python3 -m sglang.launch_server \
|
||||
--model-path /xxx/DeepSeek-R1/ \
|
||||
--log-level info \
|
||||
--tp 8 \
|
||||
--host 0.0.0.0 \
|
||||
--port 10000 \
|
||||
--enable-metrics \
|
||||
--enable-cache-report \
|
||||
--page-size 64 \
|
||||
--mem-fraction-static 0.85 \
|
||||
--enable-hierarchical-cache \
|
||||
--hicache-ratio 2 \
|
||||
--hicache-size 0 \
|
||||
--hicache-mem-layout page_first_direct \
|
||||
--hicache-io-backend direct \
|
||||
--hicache-write-policy write_through \
|
||||
--hicache-storage-backend hf3fs \
|
||||
--hicache-storage-prefetch-policy wait_complete \
|
||||
```
|
||||
|
||||
### Deployment with Mooncake
|
||||
|
||||
Here is an example of deploying Qwen3-235B-A22B-Instruct-2507 with Mooncake. For more details, see the [Mooncake Documentation](../../python/sglang/srt/mem_cache/storage/mooncake_store/README.md).
|
||||
|
||||
```bash
|
||||
# Set Mooncake environment variables
|
||||
export MOONCAKE_TE_META_DATA_SERVER="http://127.0.0.1:8080/metadata"
|
||||
export MOONCAKE_GLOBAL_SEGMENT_SIZE=816043786240
|
||||
export MOONCAKE_PROTOCOL="rdma"
|
||||
export MOONCAKE_DEVICE="$DEVICE_LIST"
|
||||
export MOONCAKE_MASTER=127.0.0.1:50051
|
||||
|
||||
# Launch SGLang server with Mooncake backend
|
||||
python3 -m sglang.launch_server \
|
||||
--model-path $MODEL_PATH \
|
||||
--tp 8 \
|
||||
--page-size 64 \
|
||||
--enable-hierarchical-cache \
|
||||
--hicache-ratio 2 \
|
||||
--hicache-mem-layout page_first_direct \
|
||||
--hicache-io-backend direct \
|
||||
--hicache-storage-backend mooncake \
|
||||
--hicache-write-policy write_through \
|
||||
--hicache-storage-prefetch-policy timeout
|
||||
```
|
||||
|
||||
|
||||
## Custom Storage Backend Integration
|
||||
|
||||
To integrate a new storage backend:
|
||||
|
||||
1. **Implement three core methods:**
|
||||
- `get(key)`: Retrieve value by key
|
||||
- `exists(key)`: Check key existence
|
||||
- `set(key, value)`: Store key-value pair
|
||||
|
||||
2. **Register your backend:** Add your storage backend to the HiCache [BackendFactory](../../python/sglang/srt/mem_cache/storage/backend_factory.py#L188)
|
||||
|
||||
The HiCache controller handles all scheduling and synchronization automatically.
|
||||
|
||||
### Dynamic Backend Loading
|
||||
|
||||
Alternatively, you can use dynamic loading to avoid hard-coding your backend in the repository:
|
||||
|
||||
```bash
|
||||
python3 -m sglang.launch_server \
|
||||
--model-path your-model \
|
||||
--enable-hierarchical-cache \
|
||||
--hicache-storage-backend dynamic \
|
||||
--hicache-storage-backend-extra-config '{"backend_name":"custom_backend_name", "module_path": "your_module_path", "class_name": "YourHiCacheClassName"}'
|
||||
```
|
||||
|
||||
**Configuration Parameters:**
|
||||
- `--hicache-storage-backend`: Set to `dynamic`
|
||||
- `--hicache-storage-backend-extra-config`: JSON configuration with:
|
||||
- `backend_name`: Custom backend identifier
|
||||
- `module_path`: Python module path to your implementation
|
||||
- `class_name`: Your HiCache implementation class name
|
||||
|
||||
|
||||
## Community and Support
|
||||
|
||||
- **GitHub Issues**: Report bugs and feature requests
|
||||
- **Slack Channel**: Join community discussions in #sgl-kv-cache-store
|
||||
- **Documentation**: Refer to storage backend-specific guides
|
||||
|
||||
---
|
||||
|
||||
*This document will be continuously updated based on community feedback and new features. Contributions and suggestions are welcome!*
|
||||
@@ -1,155 +0,0 @@
|
||||
# HiCache System Design and Optimization
|
||||
|
||||
This document provides a comprehensive overview of SGLang HiCache, covering its system architecture, workflow and key components. It also details configuration parameters, optimization techniques, and integration with various L3 storage backends, serving as a complete reference for users and developers to understand and tune HiCache for efficient LLM inference.
|
||||
|
||||
## Why and What is HiCache?
|
||||
|
||||
In large language model inference, the prefill phase is often time-consuming: input sequences need to be first converted into Key-Value cache (KV cache) for subsequent decoding. When multiple requests share the same prefix, the KV cache for that prefix is identical. By caching and reusing these shared KV caches, redundant computation can be avoided. To address this, SGLang introduced RadixAttention, which leverages idle GPU memory to cache and reuse prefix KV caches, and **HiCache**, which extends this idea to host memory and distributed storage.
|
||||
|
||||
Inspired by the classic three-level cache design of modern CPUs, HiCache organizes GPU memory as L1, host memory as L2, and distributed storage as L3. This hierarchy enables HiCache to fully exploit the "idle" storage space of GPUs and CPUs, while integrating distributed cache systems such as Mooncake, 3FS, NIXL, and AIBrix KVCache for global KV cache storage and scheduling. As a result, HiCache significantly expands KV cache capacity while maintaining strong read performance—especially in workloads such as multi-QA and long-context inference, where KV cache reuse is frequent. For detailed benchmark results, see [this blog](https://lmsys.org/blog/2025-09-10-sglang-hicache/).
|
||||
|
||||
|
||||
## System Design
|
||||
|
||||
### Overall Architecture
|
||||
|
||||
In many modern CPU architectures, the small but fast L1 and L2 caches are private to each core, enabling rapid access to the hottest data, while the larger L3 cache is shared across all cores to significantly reduce redundancy within the cache. Similarly, in HiCache, the L1 and L2 KV caches are private to each inference instance, whereas the L3 KV cache is shared among all inference instances within the cluster.
|
||||
|
||||
### HiRadixTree: Metadata Organization in HiCache
|
||||
|
||||
For KV cache data organization, HiCache builds upon the RadixTree structure introduced in RadixAttention and proposes HiRadixTree. In RadixAttention, each node of the RadixTree corresponds to the KV cache of a consecutive span of tokens in GPU memory. A path from the root to a leaf node represents the prefix of a request, and shared prefixes across multiple requests can reuse the same nodes, thereby avoiding redundant storage.
|
||||
|
||||
HiRadixTree extends this idea: each node corresponds to the KV cache of a span of consecutive tokens and records where that KV cache is stored—whether in local GPU memory, CPU memory, L3 storage, or multiple of these tiers. If stored locally, HiRadixTree maintains precise metadata, including the exact storage address. However, to reduce overhead, HiRadixTree does not store or continuously synchronize metadata for L3 KV cache. Instead, when accessing L3 data, it queries the backend in real time to retrieve the necessary metadata, such as whether the data exists and on which server and location it resides.
|
||||
|
||||
### Overall Workflow
|
||||
|
||||
The workflow of HiCache mainly involves three key operations: **local match**, **prefetch** and **write-back**. When the system receives a new request, it first searches the local L1 and L2 caches for matching KV caches. For parts not found locally, it attempts to prefetch from L3. After prefetching, all required KV caches are loaded into the GPU for computation. Once the prefill computation is complete, the system considers storing the newly generated data into L2 or L3.
|
||||
|
||||
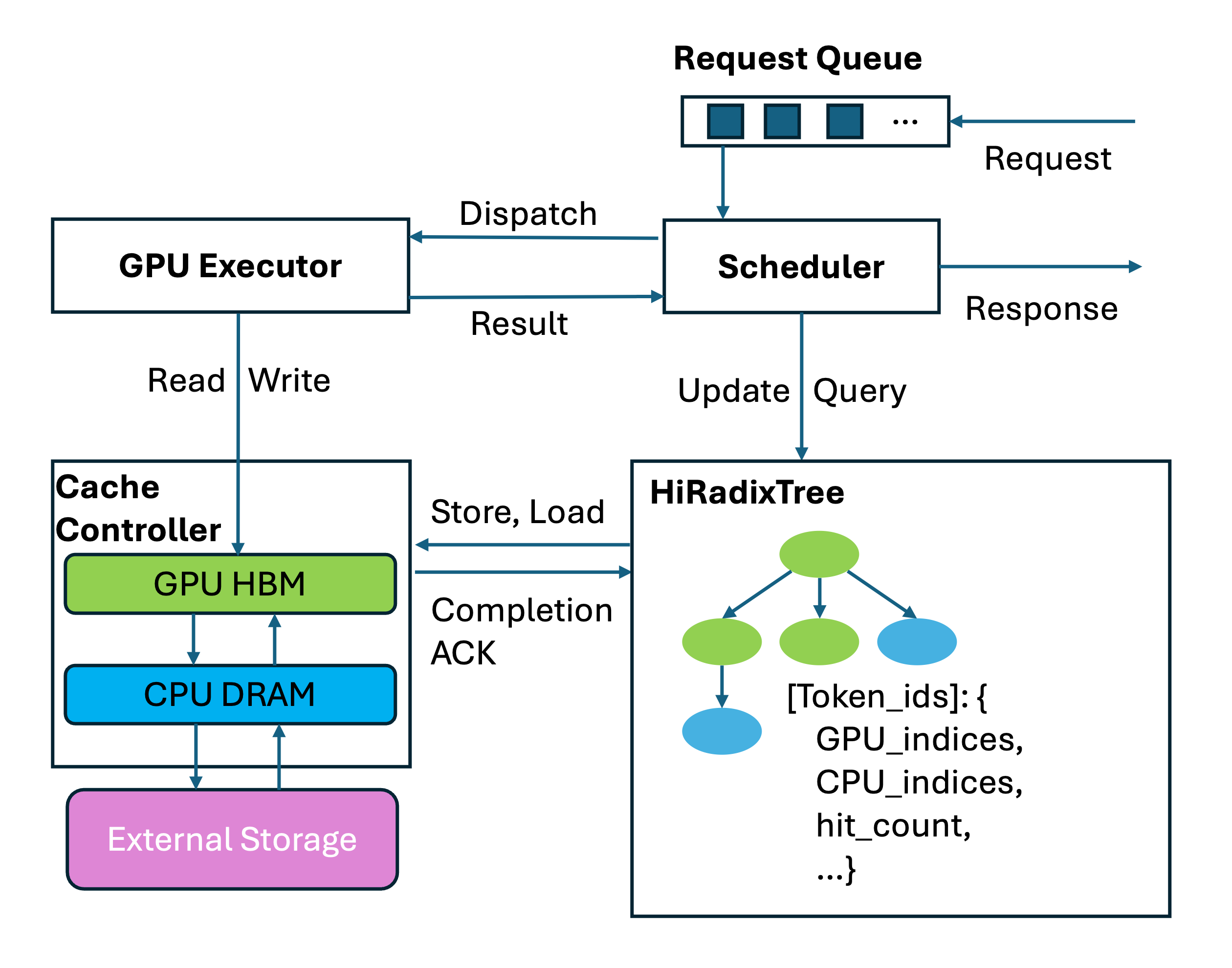
|
||||
|
||||
### Local Match
|
||||
|
||||
Local matching is the first step in HiCache's workflow, where incoming request tokens are matched against the HiRadixTree to locate cached KV data in local memory tiers (L1 GPU memory and L2 host memory).
|
||||
|
||||
The matching algorithm traverses the HiRadixTree from the root node, following child nodes that match the token sequence prefix. At each node, the incoming token sequence is compared with the node’s stored token sequence. When `page_size > 1`, matching is performed at the page granularity to optimize memory access patterns. If a match terminates within a node’s stored sequence, the node is automatically split to create an exact boundary, improving the efficiency of future matches.
|
||||
|
||||
The algorithm returns a continuous prefix of the request, with the first part residing in L1 and the latter part in L2.
|
||||
|
||||
Since the process only requires traversing the local HiRadixTree and does not involve any actual data copying, local matching is extremely fast.
|
||||
|
||||
### Prefetch from L3
|
||||
|
||||
Data prefetching is one of HiCache’s core optimization techniques, designed to proactively load KV caches from L3 storage into local L2 memory, thereby reducing access latency during subsequent operations.
|
||||
|
||||
**Prefetch Trigger Conditions**:
|
||||
After local matching, for the parts not found in L1 or L2, the system queries L3 to retrieve metadata for the next continuous matching KV caches. If the length of hit cache in L3 exceeds a threshold (default: 256 tokens, configurable), a prefetch operation is triggered.
|
||||
|
||||
**Prefetch Strategies**: HiCache provides three different prefetch termination strategies to address different scenario needs:
|
||||
- **best_effort**: Terminates immediately when GPU can execute prefill computation, with no waiting time, suitable for scenarios extremely sensitive to latency.
|
||||
- **wait_complete**: Must wait for all prefetch operations to complete, suitable for scenarios requiring high cache hit rates.
|
||||
- **timeout**: Terminates after specified time or when complete, balancing latency and cache hit rate needs.
|
||||
|
||||
After prefetching stops, the data already fetched is used together with the local data for the prefill computation.
|
||||
|
||||
For **timeout** strategy, HiCache introduces two configuration parameters to support fine-grained control over prefetch timeout conditions:
|
||||
|
||||
* `prefetch_timeout_base`: the base timeout, representing overhead unrelated to the number of tokens (e.g., scheduling and synchronization).
|
||||
* `prefetch_timeout_per_ki_token`: the incremental timeout per thousand tokens.
|
||||
|
||||
The timeout is computed as:
|
||||
|
||||
```
|
||||
timeout = prefetch_timeout_base + prefetch_timeout_per_ki_token * num_token_to_fetch / 1024
|
||||
```
|
||||
|
||||
### Data Write-back
|
||||
|
||||
The write-back mechanism is responsible for moving frequently accessed KV caches from L1 to L2 and L3, enabling larger and longer-term storage as well as cache sharing across instances.
|
||||
|
||||
**Configurable Write-back Policies**: HiCache supports three write-back strategies:
|
||||
|
||||
* **write_through**: Every access is immediately written back to the next level. When bandwidth is sufficient, this strategy provides the strongest caching benefit.
|
||||
* **write_through_selective**: Data is written back only after the access frequency exceeds a threshold. This strategy backs up only hot data, reducing I/O overhead.
|
||||
* **write_back**: Data is written back to the next level only when it is evicted from the upper level. This strategy alleviates storage pressure and is suitable for scenarios where storage capacity is limited but memory utilization must be maximized.
|
||||
|
||||
**Cross-instance Sharing**: When data is written back from L2 to L3, only data not already present in L3 is transferred. KV caches stored in L3 can then be shared across all SGLang instances in the cluster (depending on the L3 backend implementation), significantly improving cache hit rates within the same memory budget.
|
||||
|
||||
### Multi-Rank Synchronization
|
||||
|
||||
During multi-GPU parallel computation, such as tensor parallelism (TP), HiCache must ensure consistent states across different ranks. Therefore, critical computation steps require the use of `all_reduce` for state synchronization.
|
||||
|
||||
For example, during prefetching, `all_reduce(op=min)` is used to ensure that all ranks obtain the same number of L3 hits, preventing inconsistent judgments about whether the prefetch threshold has been reached. Similarly, after prefetching completes or terminates, `all_reduce(op=min)` is again required to guarantee consensus among ranks on the prefix length of the successfully retrieved KV cache.
|
||||
|
||||
### Data Transfer Optimization
|
||||
|
||||
**Zero-Copy Data Transfers**: Both prefetching and write-back involve substantial data movement. Minimizing the number of data copies can significantly improve system performance. HiCache supports passing memory addresses and sizes directly when transferring data from L2 memory to an L3 backend.
|
||||
|
||||
**“Batch-Oriented” Data Organization**: The granularity of data reads and writes has a major impact on performance. To address this, HiCache L3 stores and transfers KV cache data at the granularity of **pages** and supports different data layouts beyond the existing `layer first` scheme, including `page first` and `page first direct`. Under the `page first` and `page first direct` layouts, all KV cache data belonging to the same page is placed in contiguous memory, allowing it to be passed as a single object to L3 using zero-copy transfers.
|
||||
|
||||
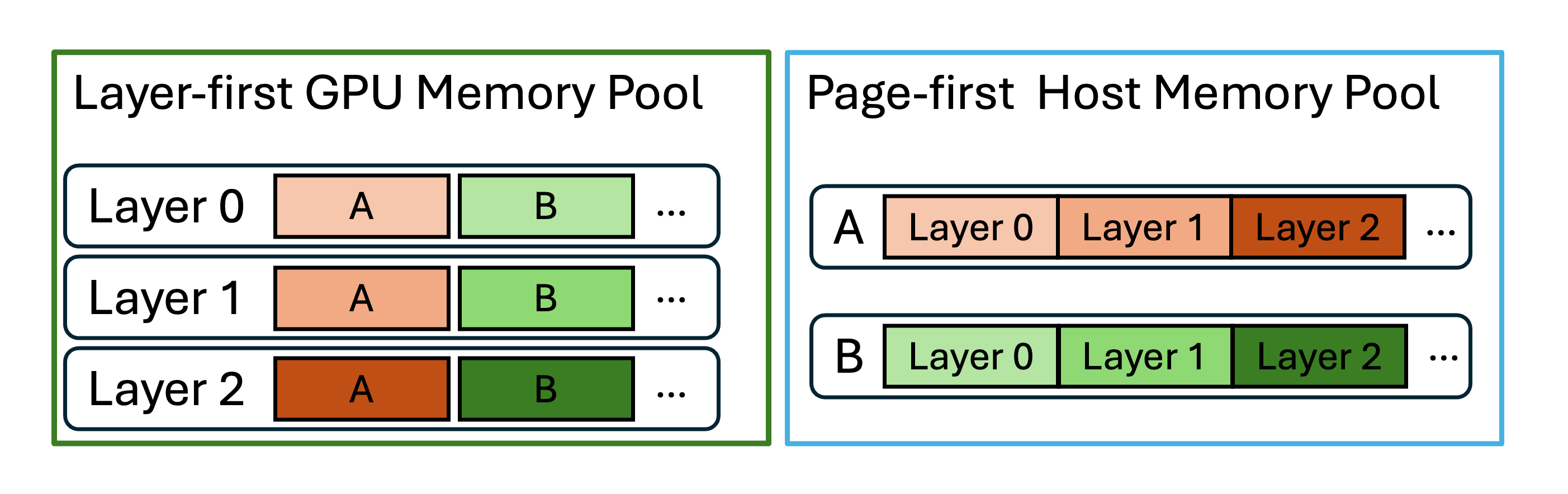
|
||||
|
||||
However, because GPU KV computation is naturally performed layer by layer, the GPU inherently operates in a `layer first` layout. When transferring `page first` data from L2 to the GPU, data must be transferred at the granularity of one token per layer. The `page first direct` layout mitigates this issue by grouping together all tokens of a given layer within a page, allowing transfers from L2 to GPU to be aggregated at the page-layer level.
|
||||
|
||||
**CPU-to-GPU Transfer Optimizations**: In HiCache, moving data from CPU memory to GPU is as performance-critical as prefetching data from L3 to L2. HiCache employs several optimizations for this process:
|
||||
|
||||
* **Compute-Transfer Overlap**: During the prefill phase, when transferring data from CPU to GPU, HiCache overlaps layers by concurrently loading the KV cache of layer N+1 while computing layer N. This effectively hides data transfer latency.
|
||||
* **GPU-assisted I/O Kernels**: On top of `cudaMemcpyAsync`, HiCache implements a set of GPU-assisted I/O kernels specifically optimized for KV cache transfers between CPU and GPU. Compared to the baseline approach, these kernels achieve up to 3x higher transfer speed.
|
||||
|
||||
**Write-back Optimization for MLA**: For MHA (Multi-Head Attention) models under multi-TP, each rank holds `1/tp_size` of a token’s KV data. In contrast, for MLA (Multi-Layer Attention) models, all ranks hold the complete and identical KV data for each token. HiCache includes a dedicated optimization for MLA: only one rank initiates the write-back operation, ensuring that data is not redundantly stored across ranks.
|
||||
|
||||
### Integration with PD-Disaggregation Deployment Mode
|
||||
|
||||
SGLang supports a PD (Prefill-Decode) disaggregation deployment mode through the Mooncake TransferEngine (for details, see [this doc](https://docs.sglang.ai/advanced_features/pd_disaggregation.html)). In the PD-disaggregation deployment mode, HiCache can be enabled on both the prefill nodes and decode nodes to optimize prefill performance. If enabled on decode nodes, the decode output will also be written back to L3.
|
||||
|
||||
### Unified Interfaces and Rich L3 Storage Backends
|
||||
|
||||
HiCache encapsulates all read, write, and query operations on L3 backends within the `class HiCacheStorage(ABC)`, exposing a set of simple and consistent interfaces. This design supports a wide range of L3 storage backends and allows users to select the one that best fits their specific use cases.
|
||||
|
||||
- **Mooncake**: Mooncake is a high-performance caching system for LLM inference that leverages RDMA and multi-NIC resources to enable zero-copy, ultra-fast data transfers. Try Mooncake [here](https://github.com/sgl-project/sglang/tree/main/python/sglang/srt/mem_cache/storage/mooncake_store).
|
||||
|
||||
- **DeepSeek 3FS (HF3FS)**: HF3FS is a Kubernetes-native distributed storage solution with operator-based deployment. Try HF3FS [here](https://github.com/sgl-project/sglang/tree/main/python/sglang/srt/mem_cache/storage/hf3fs).
|
||||
|
||||
- **NIXL**: NIXL provides a unified API for accessing various storage plugins, including but not limited to DeepSeek's 3FS, GPU Direct Storage (GDS) and Amazon S3-compatible object storage. Try NIXL [here](https://github.com/sgl-project/sglang/tree/main/python/sglang/srt/mem_cache/storage/nixl).
|
||||
|
||||
- **AIBrix KVCache**: AIBrix KVCache is a production-ready KVCache Offloading Framework, which enables efficient memory tiering and low-overhead cross-engine reuse. Try AIBrix KVCache [here](https://github.com/sgl-project/sglang/tree/main/python/sglang/srt/mem_cache/storage/aibrix_kvcache).
|
||||
|
||||
- **HiCacheFile**: A simple file-based storage backend for demonstration purposes.
|
||||
|
||||
Specifically, **LMCache**, an efficient KV cache layer for enterprise-scale LLM inference, provides an alternative solution to HiCache. Try LMCache [here](https://github.com/sgl-project/sglang/tree/main/python/sglang/srt/mem_cache/storage/lmcache).
|
||||
|
||||
## Related Parameters
|
||||
|
||||
- **`--enable-hierarchical-cache`**: Enable hierarchical cache functionality. This is required to use HiCache.
|
||||
|
||||
- **`--hicache-ratio HICACHE_RATIO`**: The ratio of the size of host KV cache memory pool to the size of device pool. For example, a value of 2 means the host memory pool is twice as large as the device memory pool. The minimum allowed value is 2.
|
||||
|
||||
- **`--hicache-size HICACHE_SIZE`**: The size of host KV cache memory pool in gigabytes. This parameter overrides `hicache-ratio` if set. For example, `--hicache-size 30` allocates 30GB for the host memory pool **for each rank**. If there are 8 ranks, then the total memory size is 240GB.
|
||||
|
||||
**Note**: `--hicache-ratio` and `--hicache-size` are two critical parameters. In general, a larger HiCache size leads to a higher cache hit rate, which improves prefill performance. However, the relationship between cache size and hit rate is not linear. Once most reusable KV data—especially hot tokens—are already cached, further increasing the size may yield only marginal performance gains. Users can set these parameters based on their workload characteristics and performance requirements.
|
||||
|
||||
- **`--page-size PAGE_SIZE`**: The number of tokens per page. This parameter determines the granularity of KV cache storage and retrieval. Larger page sizes reduce metadata overhead and improve I/O efficiency for storage backends, but may lower the cache hit rate when only part of a page matches the stored KV cache. For workloads with long common prefixes, larger pages can improve performance, while workloads with more diverse prefixes may benefit from smaller pages. See [Data Transfer Optimization](#data-transfer-optimization) for how page granularity affects I/O performance.
|
||||
|
||||
- **`--hicache-storage-prefetch-policy {best_effort,wait_complete,timeout}`**: Controls when prefetching from storage should stop. See [Prefetch from L3](#prefetch-from-l3) for details.
|
||||
- `best_effort`: Prefetch as much as possible without blocking
|
||||
- `wait_complete`: Wait for prefetch to complete before proceeding
|
||||
- `timeout`: Terminates after specified time or when complete (Recommended for production environments, as setting an appropriate timeout helps the system meet required SLOs)
|
||||
|
||||
- **`--hicache-write-policy {write_back,write_through,write_through_selective}`**: Controls how data is written from faster to slower memory tiers. See [Data Write-back](#data-write-back) for details.
|
||||
- `write_through`: Immediately writes data to all tiers (strongest caching benefits)
|
||||
- `write_through_selective`: Uses hit-count tracking to back up only frequently accessed data
|
||||
- `write_back`: Writes data back to slower tiers only when eviction is needed (reduces I/O load)
|
||||
|
||||
- **`--hicache-io-backend {direct,kernel}`**: Choose the I/O backend for KV cache transfer between CPU and GPU. See [Data Transfer Optimization](#data-transfer-optimization) for details.
|
||||
- `direct`: Standard CUDA memory copy operations
|
||||
- `kernel`: GPU-assisted I/O kernels (recommended for better performance)
|
||||
|
||||
- **`--hicache-mem-layout {layer_first,page_first,page_first_direct}`**: Memory layout for the host memory pool. See [Data Transfer Optimization](#data-transfer-optimization) for details.
|
||||
- `layer_first`: Compatible with GPU computation kernels (default for GPU memory)
|
||||
- `page_first`: Optimized for I/O efficiency
|
||||
- `page_first_direct`: Groups all tokens of a given layer within a page, allowing transfers from L2 to GPU to be aggregated at the page-layer level
|
||||
|
||||
- **`--hicache-storage-backend {file,mooncake,hf3fs,nixl,aibrix,dynamic}`**: Choose the storage backend for the L3 tier. Built-in backends: file, mooncake, hf3fs, nixl, aibrix. For dynamic backend, use --hicache-storage-backend-extra-config to specify: `backend_name` (custom name), `module_path` (Python module path), `class_name` (backend class name). See [Unified Interfaces and Rich L3 Storage Backends](#unified-interfaces-and-rich-l3-storage-backends) for available backends.
|
||||
|
||||
- **`--enable-lmcache`**: Using LMCache as an alternative hierarchical cache solution.
|
||||
|
||||
- **`--hicache-storage-backend-extra-config HICACHE_STORAGE_BACKEND_EXTRA_CONFIG`**: JSON string containing extra configuration for the storage backend, e.g., `--hicache-storage-backend-extra-config '{"prefetch_threshold":512, "prefetch_timeout_base": 0.5, "prefetch_timeout_per_ki_token": 0.25}' `
|
||||
@@ -35,8 +35,6 @@
|
||||
"\n",
|
||||
"* `max_loaded_loras`: If specified, it limits the maximum number of LoRA adapters loaded in CPU memory at a time. The value must be greater than or equal to `max-loras-per-batch`.\n",
|
||||
"\n",
|
||||
"* `lora_eviction_policy`: LoRA adapter eviction policy when GPU memory pool is full. `lru`: Least Recently Used (default, better cache efficiency). `fifo`: First-In-First-Out.\n",
|
||||
"\n",
|
||||
"* `lora_backend`: The backend of running GEMM kernels for Lora modules. Currently we support Triton LoRA backend (`triton`) and Chunked SGMV backend (`csgmv`). In the future, faster backend built upon Cutlass or Cuda kernels will be added.\n",
|
||||
"\n",
|
||||
"* `max_lora_rank`: The maximum LoRA rank that should be supported. If not specified, it will be automatically inferred from the adapters provided in `--lora-paths`. This argument is needed when you expect to dynamically load adapters of larger LoRA rank after server startup.\n",
|
||||
@@ -59,17 +57,6 @@
|
||||
"### Serving Single Adaptor"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"**Note:** SGLang supports LoRA adapters through two APIs:\n",
|
||||
"\n",
|
||||
"1. **OpenAI-Compatible API** (`/v1/chat/completions`, `/v1/completions`): Use the `model:adapter-name` syntax. See [OpenAI API with LoRA](../basic_usage/openai_api_completions.ipynb#Using-LoRA-Adapters) for examples.\n",
|
||||
"\n",
|
||||
"2. **Native API** (`/generate`): Pass `lora_path` in the request body (shown below)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
@@ -390,15 +377,6 @@
|
||||
"print(f\"Output from lora1 (updated): \\n{response.json()[1]['text']}\\n\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### OpenAI-compatible API usage\n",
|
||||
"\n",
|
||||
"You can use LoRA adapters via the OpenAI-compatible APIs by specifying the adapter in the `model` field using the `base-model:adapter-name` syntax (for example, `qwen/qwen2.5-0.5b-instruct:adapter_a`). For more details and examples, see the “Using LoRA Adapters” section in the OpenAI API documentation: [openai_api_completions.ipynb](../basic_usage/openai_api_completions.ipynb).\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
|
||||
@@ -17,10 +17,6 @@ For the design details, please refer to [link](https://docs.google.com/document/
|
||||
|
||||
Currently, we support Mooncake and NIXL as the transfer engine.
|
||||
|
||||
## Profiling in PD Disaggregation Mode
|
||||
|
||||
When you need to profile prefill or decode workers in PD disaggregation mode, please refer to the [Profile In PD Disaggregation Mode](https://docs.sglang.ai/developer_guide/benchmark_and_profiling.html#profile-in-pd-disaggregation-mode) section in the Benchmark and Profiling guide. Due to torch profiler limitations, prefill and decode workers must be profiled separately using dedicated command-line options.
|
||||
|
||||
## Router Integration
|
||||
|
||||
For deploying PD disaggregation at scale with load balancing and fault tolerance, SGLang provides a router. The router can distribute requests between prefill and decode instances using various routing policies. For detailed information on setting up routing with PD disaggregation, including configuration options and deployment patterns, see the [SGLang Router documentation](router.md#mode-3-prefill-decode-disaggregation).
|
||||
@@ -41,7 +37,6 @@ uv pip install mooncake-transfer-engine
|
||||
python -m sglang.launch_server \
|
||||
--model-path meta-llama/Llama-3.1-8B-Instruct \
|
||||
--disaggregation-mode prefill \
|
||||
--port 30000 \
|
||||
--disaggregation-ib-device mlx5_roce0
|
||||
python -m sglang.launch_server \
|
||||
--model-path meta-llama/Llama-3.1-8B-Instruct \
|
||||
@@ -126,14 +121,6 @@ python -m sglang.launch_server \
|
||||
|
||||
PD Disaggregation with Mooncake supports the following environment variables for fine-grained control over system behavior.
|
||||
|
||||
#### NVLink Transport Configuration
|
||||
To enable NVLink transport for KV cache transfers with the mooncake backend (recommended for NVL72 deployments), set the following environment variables. Note that auxiliary data transfer will still use TCP as a temporary workaround.
|
||||
|
||||
```bash
|
||||
export SGLANG_MOONCAKE_CUSTOM_MEM_POOL=True
|
||||
export MC_FORCE_MNNVL=True
|
||||
```
|
||||
|
||||
#### Prefill Server Configuration
|
||||
| Variable | Description | Default |
|
||||
|:--------:|:-----------:|:--------:
|
||||
@@ -180,7 +167,6 @@ pip install . --config-settings=setup-args="-Ducx_path=/path/to/ucx"
|
||||
python -m sglang.launch_server \
|
||||
--model-path meta-llama/Llama-3.1-8B-Instruct \
|
||||
--disaggregation-mode prefill \
|
||||
--port 30000 \
|
||||
--disaggregation-transfer-backend nixl
|
||||
python -m sglang.launch_server \
|
||||
--model-path meta-llama/Llama-3.1-8B-Instruct \
|
||||
@@ -284,7 +270,6 @@ export ENABLE_ASCEND_TRANSFER_WITH_MOONCAKE=true
|
||||
python -m sglang.launch_server \
|
||||
--model-path meta-llama/Llama-3.1-8B-Instruct \
|
||||
--disaggregation-mode prefill \
|
||||
--port 30000 \
|
||||
--disaggregation-transfer-backend ascend
|
||||
python -m sglang.launch_server \
|
||||
--model-path meta-llama/Llama-3.1-8B-Instruct \
|
||||
|
||||
@@ -1,56 +0,0 @@
|
||||
|
||||
# PD Multiplexing
|
||||
|
||||
|
||||
## Server Arguments
|
||||
|
||||
| Argument | Type/Default | Description |
|
||||
|-----------------------------|-------------------------|----------------------------------------------------------|
|
||||
| `--enable-pdmux` | flag; default: disabled | Enable PD-Multiplexing (PD running on greenctx stream). |
|
||||
| `--pdmux-config-path <path>`| string path; none | Path to the PD-Multiplexing YAML config file. |
|
||||
|
||||
### YAML Configuration
|
||||
|
||||
Example configuration for an H200 (132 SMs)
|
||||
|
||||
```yaml
|
||||
# Number of SM groups to divide the GPU into.
|
||||
# Includes two default groups:
|
||||
# - Group 0: all SMs for prefill
|
||||
# - Last group: all SMs for decode
|
||||
# The number of manual divisions must be (sm_group_num - 2).
|
||||
sm_group_num: 8
|
||||
|
||||
# Optional manual divisions of SMs.
|
||||
# Each entry contains:
|
||||
# - prefill_sm: number of SMs allocated for prefill
|
||||
# - decode_sm: number of SMs allocated for decode
|
||||
# - decode_bs_threshold: minimum decode batch size to select this group
|
||||
#
|
||||
# The sum of `prefill_sm` and `decode_sm` must equal the total number of SMs.
|
||||
# If provided, the number of entries must equal (sm_group_num - 2).
|
||||
manual_divisions:
|
||||
- [112, 20, 1]
|
||||
- [104, 28, 5]
|
||||
- [96, 36, 10]
|
||||
- [80, 52, 15]
|
||||
- [64, 68, 20]
|
||||
- [56, 76, 25]
|
||||
|
||||
# Divisor for default stream index calculation.
|
||||
# Used when manual_divisions are not provided.
|
||||
# Formula:
|
||||
# stream_idx = max(
|
||||
# 1,
|
||||
# min(sm_group_num - 2,
|
||||
# decode_bs * (sm_group_num - 2) // decode_bs_divisor
|
||||
# )
|
||||
# )
|
||||
decode_bs_divisor: 36
|
||||
|
||||
# Maximum token budget for split_forward in the prefill stage.
|
||||
# Determines how many layers are executed per split_forward.
|
||||
# Formula:
|
||||
# forward_count = max(1, split_forward_token_budget // extend_num_tokens)
|
||||
split_forward_token_budget: 65536
|
||||
```
|
||||
@@ -110,157 +110,6 @@ python3 -m sglang.launch_server \
|
||||
--port 30000 --host 0.0.0.0
|
||||
```
|
||||
|
||||
#### Using [NVIDIA ModelOpt](https://github.com/NVIDIA/TensorRT-Model-Optimizer)
|
||||
|
||||
NVIDIA Model Optimizer (ModelOpt) provides advanced quantization techniques optimized for NVIDIA hardware. SGLang includes a streamlined workflow for quantizing models with ModelOpt and automatically exporting them for deployment.
|
||||
|
||||
##### Installation
|
||||
|
||||
First, install ModelOpt. You can either install it directly or as an optional SGLang dependency:
|
||||
|
||||
```bash
|
||||
# Option 1: Install ModelOpt directly
|
||||
pip install nvidia-modelopt
|
||||
|
||||
# Option 2: Install SGLang with ModelOpt support (recommended)
|
||||
pip install sglang[modelopt]
|
||||
```
|
||||
|
||||
##### Quantization and Export Workflow
|
||||
|
||||
SGLang provides an example script that demonstrates the complete ModelOpt quantization and export workflow:
|
||||
|
||||
```bash
|
||||
# Quantize and export a model using ModelOpt FP8 quantization
|
||||
python examples/usage/modelopt_quantize_and_export.py quantize \
|
||||
--model-path TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
|
||||
--export-dir ./quantized_tinyllama_fp8 \
|
||||
--quantization-method modelopt_fp8
|
||||
|
||||
# For FP4 quantization
|
||||
python examples/usage/modelopt_quantize_and_export.py quantize \
|
||||
--model-path TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
|
||||
--export-dir ./quantized_tinyllama_fp4 \
|
||||
--quantization-method modelopt_fp4
|
||||
```
|
||||
|
||||
##### Available Quantization Methods
|
||||
|
||||
- `modelopt_fp8`: FP8 quantization with optimal performance on NVIDIA Hopper and Blackwell GPUs
|
||||
- `modelopt_fp4`: FP4 quantization with optimal performance on Nvidia Blackwell GPUs
|
||||
|
||||
##### Python API Usage
|
||||
|
||||
You can also use ModelOpt quantization programmatically:
|
||||
|
||||
```python
|
||||
import sglang as sgl
|
||||
from sglang.srt.configs.device_config import DeviceConfig
|
||||
from sglang.srt.configs.load_config import LoadConfig
|
||||
from sglang.srt.configs.model_config import ModelConfig
|
||||
from sglang.srt.model_loader.loader import get_model_loader
|
||||
|
||||
# Configure model with ModelOpt quantization and export
|
||||
model_config = ModelConfig(
|
||||
model_path="TinyLlama/TinyLlama-1.1B-Chat-v1.0",
|
||||
quantization="modelopt_fp8", # or "modelopt_fp4"
|
||||
trust_remote_code=True,
|
||||
)
|
||||
|
||||
load_config = LoadConfig(
|
||||
modelopt_export_path="./exported_model",
|
||||
modelopt_checkpoint_save_path="./checkpoint.pth", # optional, fake quantized checkpoint
|
||||
)
|
||||
device_config = DeviceConfig(device="cuda")
|
||||
|
||||
# Load and quantize the model (export happens automatically)
|
||||
model_loader = get_model_loader(load_config, model_config)
|
||||
quantized_model = model_loader.load_model(
|
||||
model_config=model_config,
|
||||
device_config=device_config,
|
||||
)
|
||||
```
|
||||
|
||||
##### Deploying Quantized Models
|
||||
|
||||
After quantization and export, you can deploy the model with SGLang:
|
||||
|
||||
```bash
|
||||
# Deploy the exported quantized model
|
||||
python -m sglang.launch_server \
|
||||
--model-path ./quantized_tinyllama_fp8 \
|
||||
--quantization modelopt \
|
||||
--port 30000 --host 0.0.0.0
|
||||
```
|
||||
|
||||
Or using the Python API:
|
||||
|
||||
```python
|
||||
import sglang as sgl
|
||||
|
||||
# Deploy exported ModelOpt quantized model
|
||||
llm = sgl.Engine(
|
||||
model_path="./quantized_tinyllama_fp8",
|
||||
quantization="modelopt"
|
||||
)
|
||||
|
||||
# Run inference
|
||||
prompts = ["Hello, how are you?", "What is the capital of France?"]
|
||||
sampling_params = {"temperature": 0.8, "top_p": 0.95, "max_new_tokens": 100}
|
||||
outputs = llm.generate(prompts, sampling_params)
|
||||
|
||||
for i, output in enumerate(outputs):
|
||||
print(f"Prompt: {prompts[i]}")
|
||||
print(f"Output: {output.outputs[0].text}")
|
||||
```
|
||||
|
||||
##### Advanced Features
|
||||
|
||||
**Checkpoint Management**: Save and restore fake quantized checkpoints for reuse:
|
||||
|
||||
```bash
|
||||
# Save the fake quantized checkpoint during quantization
|
||||
python examples/usage/modelopt_quantize_and_export.py quantize \
|
||||
--model-path meta-llama/Llama-3.2-1B-Instruct \
|
||||
--export-dir ./quantized_model \
|
||||
--quantization-method modelopt_fp8 \
|
||||
--checkpoint-save-path ./my_checkpoint.pth
|
||||
|
||||
# The checkpoint can be reused for future quantization runs and skip calibration
|
||||
```
|
||||
|
||||
**Export-only Workflow**: If you have a pre-existing fake quantized ModelOpt checkpoint, you can export it directly:
|
||||
|
||||
```python
|
||||
from sglang.srt.configs.device_config import DeviceConfig
|
||||
from sglang.srt.configs.load_config import LoadConfig
|
||||
from sglang.srt.configs.model_config import ModelConfig
|
||||
from sglang.srt.model_loader.loader import get_model_loader
|
||||
|
||||
model_config = ModelConfig(
|
||||
model_path="meta-llama/Llama-3.2-1B-Instruct",
|
||||
quantization="modelopt_fp8",
|
||||
trust_remote_code=True,
|
||||
)
|
||||
|
||||
load_config = LoadConfig(
|
||||
modelopt_checkpoint_restore_path="./my_checkpoint.pth",
|
||||
modelopt_export_path="./exported_model",
|
||||
)
|
||||
|
||||
# Load and export the model
|
||||
model_loader = get_model_loader(load_config, model_config)
|
||||
model_loader.load_model(model_config=model_config, device_config=DeviceConfig())
|
||||
```
|
||||
|
||||
##### Benefits of ModelOpt
|
||||
|
||||
- **Hardware Optimization**: Specifically optimized for NVIDIA GPU architectures
|
||||
- **Advanced Quantization**: Supports cutting-edge FP8 and FP4 quantization techniques
|
||||
- **Seamless Integration**: Automatic export to HuggingFace format for easy deployment
|
||||
- **Calibration-based**: Uses calibration datasets for optimal quantization quality
|
||||
- **Production Ready**: Enterprise-grade quantization with NVIDIA support
|
||||
|
||||
## Online Quantization
|
||||
|
||||
To enable online quantization, you can simply specify `--quantization` in the command line. For example, you can launch the server with the following command to enable `FP8` quantization for model `meta-llama/Meta-Llama-3.1-8B-Instruct`:
|
||||
@@ -299,6 +148,5 @@ python3 -m sglang.launch_server \
|
||||
|
||||
- [GPTQModel](https://github.com/ModelCloud/GPTQModel)
|
||||
- [LLM Compressor](https://github.com/vllm-project/llm-compressor/)
|
||||
- [NVIDIA Model Optimizer (ModelOpt)](https://github.com/NVIDIA/TensorRT-Model-Optimizer)
|
||||
- [Torchao: PyTorch Architecture Optimization](https://github.com/pytorch/ao)
|
||||
- [vLLM Quantization](https://docs.vllm.ai/en/latest/quantization/)
|
||||
|
||||
@@ -1,469 +1,445 @@
|
||||
# SGLang Model Gateway (formerly SGLang Router)
|
||||
# SGLang Router
|
||||
|
||||
SGLang Model Gateway is a high-performance model-routing gateway for large-scale LLM deployments. It centralizes worker lifecycle management, balances traffic across heterogeneous protocols (HTTP, gRPC, OpenAI-compatible), and provides enterprise-ready control over history storage, MCP tooling, and privacy-sensitive workflows. The router is deeply optimized for the SGLang serving runtime, but can route to any OpenAI-compatible backend.
|
||||
The SGLang Router is a high-performance request distribution system that routes inference requests across multiple SGLang runtime instances. It features cache-aware load balancing, fault tolerance, and support for advanced deployment patterns including data parallelism and prefill-decode disaggregation.
|
||||
|
||||
---
|
||||
## Key Features
|
||||
|
||||
## Table of Contents
|
||||
1. [Overview](#overview)
|
||||
2. [Architecture](#architecture)
|
||||
- [Control Plane](#control-plane)
|
||||
- [Data Plane](#data-plane)
|
||||
- [Storage & Privacy](#storage--privacy)
|
||||
3. [Deployment Modes](#deployment-modes)
|
||||
- [Co-launch Router + Workers](#co-launch-router--workers)
|
||||
- [Separate Launch (HTTP)](#separate-launch-http)
|
||||
- [gRPC Launch](#grpc-launch)
|
||||
- [Prefill/Decode Disaggregation](#prefilldecode-disaggregation)
|
||||
- [OpenAI Backend Proxy](#openai-backend-proxy)
|
||||
4. [Worker Lifecycle & Dynamic Scaling](#worker-lifecycle--dynamic-scaling)
|
||||
5. [Reliability & Flow Control](#reliability--flow-control)
|
||||
6. [Load Balancing Policies](#load-balancing-policies)
|
||||
7. [Service Discovery (Kubernetes)](#service-discovery-kubernetes)
|
||||
8. [Security & Authentication](#security--authentication)
|
||||
9. [History & Data Connectors](#history--data-connectors)
|
||||
10. [MCP & Advanced Tooling](#mcp--advanced-tooling)
|
||||
11. [API Surface](#api-surface)
|
||||
12. [Configuration Reference](#configuration-reference)
|
||||
13. [Observability](#observability)
|
||||
14. [Troubleshooting](#troubleshooting)
|
||||
- **Cache-Aware Load Balancing**: Optimizes cache utilization while maintaining balanced load distribution
|
||||
- **Multiple Routing Policies**: Choose from random, round-robin, cache-aware, or power-of-two policies
|
||||
- **Fault Tolerance**: Automatic retry and circuit breaker mechanisms for resilient operation
|
||||
- **Dynamic Scaling**: Add or remove workers at runtime without service interruption
|
||||
- **Kubernetes Integration**: Native service discovery and pod management
|
||||
- **Prefill-Decode Disaggregation**: Support for disaggregated serving load balancing
|
||||
- **Prometheus Metrics**: Built-in observability and monitoring
|
||||
|
||||
---
|
||||
## Installation
|
||||
|
||||
## Overview
|
||||
- **Unified control plane** for registering, monitoring, and orchestrating regular, prefill, and decode workers across heterogeneous model fleets.
|
||||
- **Multi-protocol data plane** that routes traffic across HTTP, PD (prefill/decode), gRPC, and OpenAI-compatible backends with shared reliability primitives.
|
||||
- **Industry-first gRPC pipeline** with native Rust tokenization, reasoning parsers, and tool-call execution for high-throughput, OpenAI-compatible serving; supports both single-stage and PD topologies.
|
||||
- **Inference Gateway Mode (`--enable-igw`)** dynamically instantiates multiple router stacks (HTTP regular/PD, gRPC) and applies per-model policies for multi-tenant deployments.
|
||||
- **Conversation & responses connectors** centralize chat history inside the router so the same context can be reused across models and MCP loops without leaking data to upstream vendors (memory, none, Oracle ATP).
|
||||
- **Enterprise privacy**: agentic multi-turn `/v1/responses`, native MCP client (STDIO/HTTP/SSE/Streamable), and history storage all operate within the router boundary.
|
||||
- **Reliability core**: retries with jitter, worker-scoped circuit breakers, token-bucket rate limiting with queuing, background health checks, and cache-aware load monitoring.
|
||||
- **Observability**: Prometheus metrics, structured tracing, request ID propagation, and detailed job queue stats.
|
||||
```bash
|
||||
pip install sglang-router
|
||||
```
|
||||
|
||||
---
|
||||
## Quick Start
|
||||
|
||||
## Architecture
|
||||
To see all available options:
|
||||
|
||||
### Control Plane
|
||||
- **Worker Manager** discovers capabilities (`/get_server_info`, `/get_model_info`), tracks load, and registers/removes workers in the shared registry.
|
||||
- **Job Queue** serializes add/remove requests and exposes status (`/workers/{url}`) so clients can track onboarding progress.
|
||||
- **Load Monitor** feeds cache-aware and power-of-two policies with live worker load statistics.
|
||||
- **Health Checker** continuously probes workers and updates readiness, circuit breaker state, and router metrics.
|
||||
|
||||
### Data Plane
|
||||
- **HTTP routers** (regular & PD) implement `/generate`, `/v1/chat/completions`, `/v1/completions`, `/v1/responses`, `/v1/embeddings`, `/v1/rerank`, and associated admin endpoints.
|
||||
- **gRPC router** streams tokenized requests directly to SRT gRPC workers, running fully in Rust—tokenizer, reasoning parser, and tool parser all reside in-process. Supports both single-stage and PD routing.
|
||||
- **OpenAI router** proxies OpenAI-compatible endpoints to external vendors (OpenAI, xAI, etc.) while keeping chat history and multi-turn orchestration local.
|
||||
|
||||
### Storage & Privacy
|
||||
- Conversation and response history is stored at the router tier (memory, none, or Oracle ATP). The same history can power multiple models or MCP loops without sending data to upstream vendors.
|
||||
- `/v1/responses` agentic flows, MCP sessions, and conversation APIs share the same storage layer, enabling compliance for regulated workloads.
|
||||
|
||||
---
|
||||
```bash
|
||||
python -m sglang_router.launch_server --help # Co-launch router and workers
|
||||
python -m sglang_router.launch_router --help # Launch router only
|
||||
```
|
||||
|
||||
## Deployment Modes
|
||||
|
||||
### Co-launch Router + Workers
|
||||
Launch the router and a fleet of SGLang workers in one process (ideal for single-node or quick starts). The CLI accepts two namespaces of arguments:
|
||||
- **Worker arguments** (no prefix) configure the SGLang runtime (`--model`, `--tp-size`, `--dp-size`, `--grpc-mode`, etc.).
|
||||
- **Router arguments** are prefixed with `--router-` and map directly to `launch_router` flags (`--router-policy`, `--router-model-path`, `--router-log-level`, ...).
|
||||
The router supports three primary deployment patterns:
|
||||
|
||||
1. **Co-launch Mode**: Router and workers launch together (simplest for single-node deployments)
|
||||
2. **Separate Launch Mode**: Router and workers launch independently (best for multi-node setups)
|
||||
3. **Prefill-Decode Disaggregation**: Specialized mode for disaggregated serving
|
||||
|
||||
### Mode 1: Co-launch Router and Workers
|
||||
|
||||
This mode launches both the router and multiple worker instances in a single command. It's the simplest deployment option and replaces the `--dp-size` argument of SGLang Runtime.
|
||||
|
||||
```bash
|
||||
# Launch router with 4 workers
|
||||
python -m sglang_router.launch_server \
|
||||
--model meta-llama/Meta-Llama-3.1-8B-Instruct \
|
||||
--dp-size 4 \
|
||||
--host 0.0.0.0 \
|
||||
--port 30000
|
||||
--model-path meta-llama/Meta-Llama-3.1-8B-Instruct \
|
||||
--dp-size 4 \
|
||||
--host 0.0.0.0 \
|
||||
--port 30000
|
||||
```
|
||||
|
||||
Comprehensive example:
|
||||
```bash
|
||||
python3 -m sglang_router.launch_server \
|
||||
--host 0.0.0.0 \
|
||||
--port 8080 \
|
||||
--model meta-llama/Llama-3.1-8B-Instruct \
|
||||
--tp-size 1 \
|
||||
--dp-size 8 \
|
||||
--grpc-mode \
|
||||
--log-level debug \
|
||||
--router-prometheus-port 10001 \
|
||||
--router-tool-call-parser llama \
|
||||
--router-health-success-threshold 2 \
|
||||
--router-health-check-timeout-secs 6000 \
|
||||
--router-health-check-interval-secs 60 \
|
||||
--router-model-path meta-llama/Llama-3.1-8B-Instruct \
|
||||
--router-policy round_robin \
|
||||
--router-log-level debug
|
||||
#### Sending Requests
|
||||
|
||||
Once the server is ready, send requests to the router endpoint:
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
# Using the /generate endpoint
|
||||
url = "http://localhost:30000/generate"
|
||||
data = {
|
||||
"text": "What is the capital of France?",
|
||||
"sampling_params": {
|
||||
"temperature": 0.7,
|
||||
"max_new_tokens": 100
|
||||
}
|
||||
}
|
||||
|
||||
response = requests.post(url, json=data)
|
||||
print(response.json())
|
||||
|
||||
# OpenAI-compatible endpoint
|
||||
url = "http://localhost:30000/v1/chat/completions"
|
||||
data = {
|
||||
"model": "meta-llama/Meta-Llama-3.1-8B-Instruct",
|
||||
"messages": [{"role": "user", "content": "What is the capital of France?"}]
|
||||
}
|
||||
|
||||
response = requests.post(url, json=data)
|
||||
print(response.json())
|
||||
```
|
||||
|
||||
### Separate Launch (HTTP)
|
||||
Run workers independently and point the router at their HTTP endpoints.
|
||||
### Mode 2: Separate Launch Mode
|
||||
|
||||
This mode is ideal for multi-node deployments where workers run on different machines.
|
||||
|
||||
#### Step 1: Launch Workers
|
||||
|
||||
On each worker node:
|
||||
|
||||
```bash
|
||||
# Worker nodes
|
||||
python -m sglang.launch_server --model meta-llama/Meta-Llama-3.1-8B-Instruct --port 8000
|
||||
python -m sglang.launch_server --model meta-llama/Meta-Llama-3.1-8B-Instruct --port 8001
|
||||
|
||||
# Router node
|
||||
python -m sglang_router.launch_router \
|
||||
--worker-urls http://worker1:8000 http://worker2:8001 \
|
||||
--policy cache_aware \
|
||||
--host 0.0.0.0 --port 30000
|
||||
```
|
||||
|
||||
### gRPC Launch
|
||||
Use SRT gRPC workers to unlock the highest throughput and access native reasoning/tool pipelines.
|
||||
|
||||
```bash
|
||||
# Workers expose gRPC endpoints
|
||||
# Worker node 1
|
||||
python -m sglang.launch_server \
|
||||
--model meta-llama/Llama-3.1-8B-Instruct \
|
||||
--grpc-mode \
|
||||
--port 20000
|
||||
--model-path meta-llama/Meta-Llama-3.1-8B-Instruct \
|
||||
--host 0.0.0.0 \
|
||||
--port 8000
|
||||
|
||||
# Router
|
||||
python -m sglang_router.launch_router \
|
||||
--worker-urls grpc://127.0.0.1:20000 \
|
||||
--model-path meta-llama/Llama-3.1-8B-Instruct \
|
||||
--reasoning-parser deepseek-r1 \
|
||||
--tool-call-parser json \
|
||||
--host 0.0.0.0 --port 8080
|
||||
# Worker node 2
|
||||
python -m sglang.launch_server \
|
||||
--model-path meta-llama/Meta-Llama-3.1-8B-Instruct \
|
||||
--host 0.0.0.0 \
|
||||
--port 8001
|
||||
```
|
||||
|
||||
> gRPC router supports both single-stage and PD serving. Provide `--tokenizer-path` or `--model-path` (HF repo or local directory) plus optional `--chat-template`.
|
||||
#### Step 2: Launch Router
|
||||
|
||||
### Prefill/Decode Disaggregation
|
||||
Split prefill and decode workers for PD-aware caching and balancing.
|
||||
On the router node:
|
||||
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--pd-disaggregation \
|
||||
--prefill http://prefill1:30001 9001 \
|
||||
--decode http://decode1:30011 \
|
||||
--policy cache_aware \
|
||||
--prefill-policy cache_aware \
|
||||
--decode-policy power_of_two
|
||||
--worker-urls http://worker1:8000 http://worker2:8001 \
|
||||
--host 0.0.0.0 \
|
||||
--port 30000 \
|
||||
--policy cache_aware # or random, round_robin, power_of_two
|
||||
```
|
||||
|
||||
### OpenAI Backend Proxy
|
||||
Proxy OpenAI-compatible endpoints (OpenAI, xAI, etc.) while keeping history and MCP sessions local.
|
||||
### Mode 3: Prefill-Decode Disaggregation
|
||||
|
||||
This advanced mode separates prefill and decode operations for optimized performance:
|
||||
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--backend openai \
|
||||
--worker-urls https://api.openai.com \
|
||||
--history-backend memory
|
||||
--pd-disaggregation \
|
||||
--prefill http://prefill1:8000 9000 \
|
||||
--prefill http://prefill2:8001 9001 \
|
||||
--decode http://decode1:8002 \
|
||||
--decode http://decode2:8003 \
|
||||
--prefill-policy cache_aware \
|
||||
--decode-policy round_robin
|
||||
```
|
||||
|
||||
> OpenAI backend mode expects exactly one `--worker-urls` entry per router instance.
|
||||
#### Understanding --prefill Arguments
|
||||
|
||||
---
|
||||
The `--prefill` flag accepts URLs with optional bootstrap ports:
|
||||
- `--prefill http://server:8000` - No bootstrap port
|
||||
- `--prefill http://server:8000 9000` - Bootstrap port 9000
|
||||
- `--prefill http://server:8000 none` - Explicitly no bootstrap port
|
||||
|
||||
## Worker Lifecycle & Dynamic Scaling
|
||||
#### Policy Inheritance in PD Mode
|
||||
|
||||
Add or remove workers at runtime using the REST APIs. Jobs are queued and tracked for eventual consistency.
|
||||
The router intelligently handles policy configuration for prefill and decode nodes:
|
||||
|
||||
```bash
|
||||
# Add a worker (HTTP or gRPC)
|
||||
curl -X POST http://localhost:30000/workers \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{"url":"grpc://0.0.0.0:31000","worker_type":"regular"}'
|
||||
1. **Only `--policy` specified**: Both prefill and decode nodes use this policy
|
||||
2. **`--policy` and `--prefill-policy` specified**: Prefill nodes use `--prefill-policy`, decode nodes use `--policy`
|
||||
3. **`--policy` and `--decode-policy` specified**: Prefill nodes use `--policy`, decode nodes use `--decode-policy`
|
||||
4. **All three specified**: Prefill nodes use `--prefill-policy`, decode nodes use `--decode-policy` (main `--policy` is ignored)
|
||||
|
||||
# Inspect registry
|
||||
curl http://localhost:30000/workers
|
||||
|
||||
# Remove a worker
|
||||
curl -X DELETE http://localhost:30000/workers/grpc://0.0.0.0:31000
|
||||
```
|
||||
|
||||
Legacy endpoints (`/add_worker`, `/remove_worker`, `/list_workers`) remain available but will be deprecated. `/workers/{url}` returns both registry data and queued job status.
|
||||
|
||||
---
|
||||
|
||||
## Reliability & Flow Control
|
||||
|
||||
### Retries
|
||||
Example with mixed policies:
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--worker-urls http://worker1:8000 http://worker2:8001 \
|
||||
--retry-max-retries 5 \
|
||||
--retry-initial-backoff-ms 50 \
|
||||
--retry-max-backoff-ms 30000 \
|
||||
--retry-backoff-multiplier 1.5 \
|
||||
--retry-jitter-factor 0.2
|
||||
--pd-disaggregation \
|
||||
--prefill http://prefill1:8000
|
||||
--prefill http://prefill2:8000 \
|
||||
--decode http://decode1:8001
|
||||
--decode http://decode2:8001 \
|
||||
--policy round_robin \
|
||||
--prefill-policy cache_aware # Prefill uses cache_aware and decode uses round_robin from --policy
|
||||
```
|
||||
|
||||
#### PD Mode with Service Discovery
|
||||
|
||||
For Kubernetes deployments with separate prefill and decode server pools:
|
||||
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--pd-disaggregation \
|
||||
--service-discovery \
|
||||
--prefill-selector app=prefill-server tier=gpu \
|
||||
--decode-selector app=decode-server tier=cpu \
|
||||
--service-discovery-namespace production \
|
||||
--prefill-policy cache_aware \
|
||||
--decode-policy round_robin
|
||||
```
|
||||
|
||||
## Dynamic Scaling
|
||||
|
||||
The router supports runtime scaling through REST APIs:
|
||||
|
||||
### Adding Workers
|
||||
|
||||
```bash
|
||||
# Launch a new worker
|
||||
python -m sglang.launch_server \
|
||||
--model-path meta-llama/Meta-Llama-3.1-8B-Instruct \
|
||||
--port 30001
|
||||
|
||||
# Add it to the router
|
||||
curl -X POST "http://localhost:30000/add_worker?url=http://127.0.0.1:30001"
|
||||
```
|
||||
|
||||
### Removing Workers
|
||||
|
||||
```bash
|
||||
curl -X POST "http://localhost:30000/remove_worker?url=http://127.0.0.1:30001"
|
||||
```
|
||||
|
||||
**Note**: When using cache-aware routing, removed workers are cleanly evicted from the routing tree and request queues.
|
||||
|
||||
## Fault Tolerance
|
||||
|
||||
The router includes comprehensive fault tolerance mechanisms:
|
||||
|
||||
### Retry Configuration
|
||||
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--worker-urls http://worker1:8000 http://worker2:8001 \
|
||||
--retry-max-retries 3 \
|
||||
--retry-initial-backoff-ms 100 \
|
||||
--retry-max-backoff-ms 10000 \
|
||||
--retry-backoff-multiplier 2.0 \
|
||||
--retry-jitter-factor 0.1
|
||||
```
|
||||
|
||||
### Circuit Breaker
|
||||
|
||||
Protects against cascading failures:
|
||||
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--worker-urls http://worker1:8000 http://worker2:8001 \
|
||||
--cb-failure-threshold 5 \
|
||||
--cb-success-threshold 2 \
|
||||
--cb-timeout-duration-secs 30 \
|
||||
--cb-window-duration-secs 60
|
||||
--worker-urls http://worker1:8000 http://worker2:8001 \
|
||||
--cb-failure-threshold 5 \
|
||||
--cb-success-threshold 2 \
|
||||
--cb-timeout-duration-secs 30 \
|
||||
--cb-window-duration-secs 60
|
||||
```
|
||||
|
||||
### Rate Limiting & Queuing
|
||||
**Behavior**:
|
||||
- Worker is marked unhealthy after `cb-failure-threshold` consecutive failures
|
||||
- Returns to service after `cb-success-threshold` successful health checks
|
||||
- Circuit breaker can be disabled with `--disable-circuit-breaker`
|
||||
|
||||
## Routing Policies
|
||||
|
||||
The router supports multiple routing strategies:
|
||||
|
||||
### 1. Random Routing
|
||||
Distributes requests randomly across workers.
|
||||
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--worker-urls http://worker1:8000 http://worker2:8001 \
|
||||
--max-concurrent-requests 256 \
|
||||
--rate-limit-tokens-per-second 512 \
|
||||
--queue-size 128 \
|
||||
--queue-timeout-secs 30
|
||||
--policy random
|
||||
```
|
||||
|
||||
Requests beyond the concurrency limit wait in a FIFO queue (up to `queue-size`). A `429` is returned when the queue is full; `408` is returned when `queue-timeout-secs` expires.
|
||||
### 2. Round-Robin Routing
|
||||
Cycles through workers in order.
|
||||
|
||||
---
|
||||
|
||||
## Load Balancing Policies
|
||||
|
||||
| Policy | Description | Usage |
|
||||
|--------------------|--------------------------------------------------------------------------------------------------|-------------------------------|
|
||||
| `random` | Uniform random selection. | `--policy random` |
|
||||
| `round_robin` | Cycles through workers in order. | `--policy round_robin` |
|
||||
| `power_of_two` | Samples two workers and picks the lighter one (requires Load Monitor). | `--policy power_of_two` |
|
||||
| `cache_aware` | Default policy; combines cache locality with load balancing, falling back to shortest queue. | `--policy cache_aware` + tuning flags |
|
||||
|
||||
Key tuning flags:
|
||||
```bash
|
||||
--policy round_robin
|
||||
```
|
||||
|
||||
### 3. Power of Two Choices
|
||||
Samples two workers and routes to the less loaded one.
|
||||
|
||||
```bash
|
||||
--policy power_of_two
|
||||
```
|
||||
|
||||
### 4. Cache-Aware Load Balancing (Default)
|
||||
|
||||
The most sophisticated policy that combines cache optimization with load balancing:
|
||||
|
||||
```bash
|
||||
--policy cache_aware \
|
||||
--cache-threshold 0.5 \
|
||||
--balance-abs-threshold 32 \
|
||||
--balance-rel-threshold 1.5 \
|
||||
--eviction-interval-secs 120 \
|
||||
--max-tree-size 67108864
|
||||
--balance-rel-threshold 1.0001
|
||||
```
|
||||
|
||||
---
|
||||
#### How It Works
|
||||
|
||||
## Service Discovery (Kubernetes)
|
||||
1. **Load Assessment**: Checks if the system is balanced
|
||||
- Imbalanced if: `(max_load - min_load) > balance_abs_threshold` AND `max_load > balance_rel_threshold * min_load`
|
||||
|
||||
Enable automatic worker discovery via Kubernetes pod selectors.
|
||||
2. **Routing Decision**:
|
||||
- **Balanced System**: Uses cache-aware routing
|
||||
- Routes to worker with highest prefix match if match > `cache_threshold`
|
||||
- Otherwise routes to worker with most available cache capacity
|
||||
- **Imbalanced System**: Uses shortest queue routing to the least busy worker
|
||||
|
||||
3. **Cache Management**:
|
||||
- Maintains approximate radix trees per worker
|
||||
- Periodically evicts LRU entries based on `--eviction-interval-secs` and `--max-tree-size`
|
||||
|
||||
### Data Parallelism Aware Routing
|
||||
|
||||
Enables fine-grained control over data parallel replicas:
|
||||
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--service-discovery \
|
||||
--selector app=sglang-worker role=inference \
|
||||
--service-discovery-namespace production \
|
||||
--service-discovery-port 8000
|
||||
--dp-aware \
|
||||
--api-key your_api_key # Required for worker authentication
|
||||
```
|
||||
|
||||
PD deployments can specify `--prefill-selector` and `--decode-selector` plus the `sglang.ai/bootstrap-port` annotation for prefill bootstrap ports. Ensure RBAC grants `get/list/watch` on pods.
|
||||
|
||||
---
|
||||
|
||||
## Security & Authentication
|
||||
|
||||
- **Router API key (`--api-key`)**: clients must supply `Authorization: Bearer <key>`.
|
||||
- **Worker API keys**: when adding workers dynamically, include `api_key` in the payload; workers listed via CLI inherit the router key.
|
||||
- **Full-stack auth**: start router with `--api-key`, then add workers with their own keys:
|
||||
```bash
|
||||
curl -H "Authorization: Bearer router-key" \
|
||||
-X POST http://localhost:30000/workers \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{"url":"http://worker:8000","api_key":"worker-key"}'
|
||||
```
|
||||
- **Privacy**: All conversation history, `/v1/responses` state, and MCP sessions stay inside the router. Nothing is persisted at remote model vendors unless explicitly proxied.
|
||||
|
||||
---
|
||||
|
||||
## History & Data Connectors
|
||||
|
||||
| Backend | Description | Usage |
|
||||
|---------|-------------|-------|
|
||||
| `memory` (default) | In-memory storage for quick prototyping. | `--history-backend memory` |
|
||||
| `none` | No persistence; APIs operate but store nothing. | `--history-backend none` |
|
||||
| `oracle` | Oracle Autonomous Database-backed storage (pooled connections). | `--history-backend oracle` |
|
||||
|
||||
Oracle configuration (choose DSN *or* TNS alias):
|
||||
Install the Oracle Instant Client and set `LD_LIBRARY_PATH` accordingly.
|
||||
Choose **one** connection method:
|
||||
```bash
|
||||
# Option 1: Full connection descriptor
|
||||
export ATP_DSN="(description=(address=(protocol=tcps)(port=1522)(host=adb.region.oraclecloud.com))(connect_data=(service_name=service_name)))"
|
||||
|
||||
# Option 2: TNS alias (requires wallet)
|
||||
export ATP_TNS_ALIAS="sglroutertestatp_high"
|
||||
export ATP_WALLET_PATH="/path/to/wallet"
|
||||
```
|
||||
Provide database credentials and optional pool sizing:
|
||||
```bash
|
||||
export ATP_USER="admin"
|
||||
export ATP_PASSWORD="secret"
|
||||
export ATP_POOL_MIN=4
|
||||
export ATP_POOL_MAX=32
|
||||
|
||||
python -m sglang_router.launch_router \
|
||||
--backend openai \
|
||||
--worker-urls https://api.openai.com \
|
||||
--history-backend oracle
|
||||
```
|
||||
|
||||
> History backends currently apply to OpenAI router mode. gRPC parity for `/v1/responses` is on the roadmap.
|
||||
|
||||
---
|
||||
|
||||
## MCP & Advanced Tooling
|
||||
|
||||
- Native MCP client supports **STDIO**, **HTTP**, **SSE**, and **Streamable** transports—no external config files required.
|
||||
- Tool-call parsers cover JSON, Pythonic, XML, and custom schemas with streaming/non-streaming execution loops.
|
||||
- Reasoning parsers ship for DeepSeek-R1, Qwen3, Step-3, GLM4, Llama families, Kimi K2, GPT-OSS, Mistral, and more (`src/reasoning_parser`).
|
||||
- Tokenizer factory accepts HuggingFace IDs, local directories, and explicit `tokenizer.json` files with chat template overrides (`src/tokenizer`).
|
||||
|
||||
Use CLI flags to select parsers:
|
||||
```bash
|
||||
--reasoning-parser deepseek-r1 \
|
||||
--tool-call-parser json \
|
||||
--chat-template /path/to/template.json
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## API Surface
|
||||
|
||||
| Method | Path | Description |
|
||||
|-----------------------|------------------------------------------|------------------------------------------------|
|
||||
| `POST` | `/generate` | SGLang generate API. |
|
||||
| `POST` | `/v1/chat/completions` | OpenAI-compatible chat (streaming/tool calls). |
|
||||
| `POST` | `/v1/completions` | OpenAI-compatible text completions. |
|
||||
| `POST` | `/v1/responses` | Create background responses (agentic loops). |
|
||||
| `GET` | `/v1/responses/{id}` | Retrieve stored responses. |
|
||||
| `POST` | `/v1/embeddings` | Forward embedding requests. |
|
||||
| `POST` | `/v1/rerank` | Ranking endpoint (`/rerank` synonym). |
|
||||
| `POST` | `/v1/conversations` | Create conversation metadata. |
|
||||
| `GET`/`POST`/`DELETE` | `/v1/conversations/{id}` | Get/update/delete conversation. |
|
||||
| `GET`/`POST` | `/v1/conversations/{id}/items` | List or append conversation items. |
|
||||
| `GET`/`DELETE` | `/v1/conversations/{id}/items/{item_id}` | Inspect/delete conversation item. |
|
||||
| `GET` | `/workers` | List registered workers with health/load. |
|
||||
| `POST` | `/workers` | Queue worker registration. |
|
||||
| `DELETE` | `/workers/{url}` | Queue worker removal. |
|
||||
| `POST` | `/flush_cache` | Flush worker caches (HTTP workers). |
|
||||
| `GET` | `/get_loads` | Retrieve worker load snapshot. |
|
||||
| `GET` | `/liveness` / `/readiness` / `/health` | Health probes. |
|
||||
|
||||
---
|
||||
This mode coordinates with SGLang's DP controller for optimized request distribution across data parallel ranks.
|
||||
|
||||
## Configuration Reference
|
||||
|
||||
### Core Settings
|
||||
|
||||
| Parameter | Type | Default | Description |
|
||||
|-----------------------------|------|-------------|--------------------------------------------------------------------------|
|
||||
| `--host` | str | 127.0.0.1 | Router host. |
|
||||
| `--port` | int | 30000 | Router port. |
|
||||
| `--worker-urls` | list | [] | Worker URLs (HTTP or gRPC). |
|
||||
| `--policy` | str | cache_aware | Routing policy (`random`, `round_robin`, `cache_aware`, `power_of_two`). |
|
||||
| `--max-concurrent-requests` | int | -1 | Concurrency limit (-1 disables rate limiting). |
|
||||
| `--request-timeout-secs` | int | 600 | Request timeout. |
|
||||
| `--max-payload-size` | int | 256MB | Maximum request payload. |
|
||||
| Parameter | Type | Default | Description |
|
||||
| --------------------------- | ---- | ----------- | --------------------------------------------------------------- |
|
||||
| `--host` | str | 127.0.0.1 | Router server host address |
|
||||
| `--port` | int | 30000 | Router server port |
|
||||
| `--worker-urls` | list | [] | Worker URLs for separate launch mode |
|
||||
| `--policy` | str | cache_aware | Routing policy (random, round_robin, cache_aware, power_of_two) |
|
||||
| `--max-concurrent-requests` | int | 64 | Maximum concurrent requests (rate limiting) |
|
||||
| `--request-timeout-secs` | int | 600 | Request timeout in seconds |
|
||||
| `--max-payload-size` | int | 256MB | Maximum request payload size |
|
||||
|
||||
### Cache-Aware Tuning
|
||||
### Cache-Aware Routing Parameters
|
||||
|
||||
| Parameter | Type | Default | Description |
|
||||
|----------------------------|-------|----------|-----------------------------|
|
||||
| `--cache-threshold` | float | 0.3 | Minimum prefix match ratio. |
|
||||
| `--balance-abs-threshold` | int | 64 | Absolute load threshold. |
|
||||
| `--balance-rel-threshold` | float | 1.5 | Relative load ratio. |
|
||||
| `--eviction-interval-secs` | int | 120 | Cache eviction cadence. |
|
||||
| `--max-tree-size` | int | 67108864 | Max nodes in cache tree. |
|
||||
| Parameter | Type | Default | Description |
|
||||
| -------------------------- | ----- | -------- | ------------------------------------------------------ |
|
||||
| `--cache-threshold` | float | 0.5 | Minimum prefix match ratio for cache routing (0.0-1.0) |
|
||||
| `--balance-abs-threshold` | int | 32 | Absolute load difference threshold |
|
||||
| `--balance-rel-threshold` | float | 1.0001 | Relative load ratio threshold |
|
||||
| `--eviction-interval-secs` | int | 60 | Seconds between cache eviction cycles |
|
||||
| `--max-tree-size` | int | 16777216 | Maximum nodes in routing tree |
|
||||
|
||||
### Fault Tolerance
|
||||
### Fault Tolerance Parameters
|
||||
|
||||
| Parameter | Type | Default | Description |
|
||||
|------------------------------|-------|---------|----------------------------------|
|
||||
| `--retry-max-retries` | int | 5 | Max retries. |
|
||||
| `--retry-initial-backoff-ms` | int | 50 | Initial backoff (ms). |
|
||||
| `--retry-max-backoff-ms` | int | 30000 | Max backoff (ms). |
|
||||
| `--retry-backoff-multiplier` | float | 1.5 | Backoff multiplier. |
|
||||
| `--retry-jitter-factor` | float | 0.2 | Retry jitter (0.0-1.0). |
|
||||
| `--disable-retries` | flag | False | Disable retries. |
|
||||
| `--cb-failure-threshold` | int | 5 | Failures before opening circuit. |
|
||||
| `--cb-success-threshold` | int | 2 | Successes to close circuit. |
|
||||
| `--cb-timeout-duration-secs` | int | 30 | Cooldown period. |
|
||||
| `--cb-window-duration-secs` | int | 60 | Window size. |
|
||||
| `--disable-circuit-breaker` | flag | False | Disable circuit breaker. |
|
||||
| Parameter | Type | Default | Description |
|
||||
| ---------------------------- | ----- | ------- | ------------------------------------- |
|
||||
| `--retry-max-retries` | int | 3 | Maximum retry attempts per request |
|
||||
| `--retry-initial-backoff-ms` | int | 100 | Initial retry backoff in milliseconds |
|
||||
| `--retry-max-backoff-ms` | int | 10000 | Maximum retry backoff in milliseconds |
|
||||
| `--retry-backoff-multiplier` | float | 2.0 | Backoff multiplier between retries |
|
||||
| `--retry-jitter-factor` | float | 0.1 | Random jitter factor for retries |
|
||||
| `--disable-retries` | flag | False | Disable retry mechanism |
|
||||
| `--cb-failure-threshold` | int | 5 | Failures before circuit opens |
|
||||
| `--cb-success-threshold` | int | 2 | Successes to close circuit |
|
||||
| `--cb-timeout-duration-secs` | int | 30 | Circuit breaker timeout duration |
|
||||
| `--cb-window-duration-secs` | int | 60 | Circuit breaker window duration |
|
||||
| `--disable-circuit-breaker` | flag | False | Disable circuit breaker |
|
||||
|
||||
### Prefill/Decode
|
||||
### Prefill-Decode Disaggregation Parameters
|
||||
|
||||
| Parameter | Type | Default | Description |
|
||||
|-----------------------------------|------|---------|------------------------------------------|
|
||||
| `--pd-disaggregation` | flag | False | Enable PD mode. |
|
||||
| `--prefill` | list | [] | Prefill URLs + optional bootstrap ports. |
|
||||
| `--decode` | list | [] | Decode URLs. |
|
||||
| `--prefill-policy` | str | None | Override policy for prefill nodes. |
|
||||
| `--decode-policy` | str | None | Override policy for decode nodes. |
|
||||
| `--worker-startup-timeout-secs` | int | 600 | Worker init timeout. |
|
||||
| `--worker-startup-check-interval` | int | 30 | Polling interval. |
|
||||
| Parameter | Type | Default | Description |
|
||||
| --------------------------------- | ---- | ------- | ----------------------------------------------------- |
|
||||
| `--pd-disaggregation` | flag | False | Enable PD disaggregated mode |
|
||||
| `--prefill` | list | [] | Prefill server URLs with optional bootstrap ports |
|
||||
| `--decode` | list | [] | Decode server URLs |
|
||||
| `--prefill-policy` | str | None | Routing policy for prefill nodes (overrides --policy) |
|
||||
| `--decode-policy` | str | None | Routing policy for decode nodes (overrides --policy) |
|
||||
| `--worker-startup-timeout-secs` | int | 300 | Timeout for worker startup |
|
||||
| `--worker-startup-check-interval` | int | 10 | Interval between startup checks |
|
||||
|
||||
### Kubernetes Discovery
|
||||
### Kubernetes Integration
|
||||
|
||||
| Parameter | Type | Description |
|
||||
|--------------------------------------------|------|--------------------------------------------------------------------|
|
||||
| `--service-discovery` | flag | Enable discovery. |
|
||||
| `--selector key=value ...` | list | Label selectors (regular mode). |
|
||||
| `--prefill-selector` / `--decode-selector` | list | Label selectors for PD mode. |
|
||||
| `--service-discovery-namespace` | str | Namespace to watch. |
|
||||
| `--service-discovery-port` | int | Worker port (default 80). |
|
||||
| `--bootstrap-port-annotation` | str | Prefill bootstrap annotation (default `sglang.ai/bootstrap-port`). |
|
||||
| Parameter | Type | Default | Description |
|
||||
| ------------------------------- | ---- | ------------------------ | ---------------------------------------------------- |
|
||||
| `--service-discovery` | flag | False | Enable Kubernetes service discovery |
|
||||
| `--selector` | list | [] | Label selector for workers (key1=value1 key2=value2) |
|
||||
| `--prefill-selector` | list | [] | Label selector for prefill servers in PD mode |
|
||||
| `--decode-selector` | list | [] | Label selector for decode servers in PD mode |
|
||||
| `--service-discovery-port` | int | 80 | Port for discovered pods |
|
||||
| `--service-discovery-namespace` | str | None | Kubernetes namespace to watch |
|
||||
| `--bootstrap-port-annotation` | str | sglang.ai/bootstrap-port | Annotation for bootstrap ports |
|
||||
|
||||
---
|
||||
### Observability
|
||||
|
||||
## Observability
|
||||
| Parameter | Type | Default | Description |
|
||||
| ---------------------- | ---- | --------- | ----------------------------------------------------- |
|
||||
| `--prometheus-port` | int | 29000 | Prometheus metrics port |
|
||||
| `--prometheus-host` | str | 127.0.0.1 | Prometheus metrics host |
|
||||
| `--log-dir` | str | None | Directory for log files |
|
||||
| `--log-level` | str | info | Logging level (debug, info, warning, error, critical) |
|
||||
| `--request-id-headers` | list | None | Custom headers for request tracing |
|
||||
|
||||
Enable Prometheus metrics:
|
||||
### CORS Configuration
|
||||
|
||||
| Parameter | Type | Default | Description |
|
||||
| ------------------------ | ---- | ------- | -------------------- |
|
||||
| `--cors-allowed-origins` | list | [] | Allowed CORS origins |
|
||||
|
||||
## Advanced Features
|
||||
|
||||
### Kubernetes Service Discovery
|
||||
|
||||
Automatically discover and manage workers in Kubernetes:
|
||||
|
||||
#### Standard Mode
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--worker-urls http://worker1:8000 http://worker2:8001 \
|
||||
--prometheus-host 0.0.0.0 \
|
||||
--prometheus-port 29000
|
||||
--service-discovery \
|
||||
--selector app=sglang-worker env=prod \
|
||||
--service-discovery-namespace production \
|
||||
--service-discovery-port 8000
|
||||
```
|
||||
|
||||
Key metrics:
|
||||
|
||||
| Metric | Type | Description |
|
||||
|--------|------|-------------|
|
||||
| `sgl_router_requests_total` | Counter | Total requests by endpoint/method. |
|
||||
| `sgl_router_processed_requests_total` | Counter | Requests processed per worker. |
|
||||
| `sgl_router_active_workers` | Gauge | Healthy worker count. |
|
||||
| `sgl_router_running_requests` | Gauge | In-flight requests per worker. |
|
||||
| `sgl_router_cache_hits_total` / `misses_total` | Counter | Cache-aware routing hits/misses. |
|
||||
| `sgl_router_generate_duration_seconds` | Histogram | Request latency distribution. |
|
||||
|
||||
Enable request ID propagation:
|
||||
#### Prefill-Decode Disaggregation Mode
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--worker-urls http://worker1:8000 \
|
||||
--request-id-headers x-request-id x-trace-id
|
||||
--pd-disaggregation \
|
||||
--service-discovery \
|
||||
--prefill-selector app=prefill-server env=prod \
|
||||
--decode-selector app=decode-server env=prod \
|
||||
--service-discovery-namespace production
|
||||
```
|
||||
|
||||
---
|
||||
**Note**: The `--bootstrap-port-annotation` (default: `sglang.ai/bootstrap-port`) is used to discover bootstrap ports for prefill servers in PD mode. Prefill pods should have this annotation set to their bootstrap port value.
|
||||
|
||||
### Prometheus Metrics
|
||||
|
||||
Expose metrics for monitoring:
|
||||
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--worker-urls http://worker1:8000 http://worker2:8001 \
|
||||
--prometheus-port 29000 \
|
||||
--prometheus-host 0.0.0.0
|
||||
```
|
||||
|
||||
Metrics available at `http://localhost:29000/metrics`
|
||||
|
||||
### Request Tracing
|
||||
|
||||
Enable request ID tracking:
|
||||
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--worker-urls http://worker1:8000 http://worker2:8001 \
|
||||
--request-id-headers x-request-id x-trace-id
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
1. **Workers never ready**
|
||||
Increase `--worker-startup-timeout-secs` or ensure health probes respond before router startup.
|
||||
### Common Issues
|
||||
|
||||
2. **Load imbalance / hot workers**
|
||||
Inspect `sgl_router_processed_requests_total` and tune cache-aware thresholds (`--balance-*`, `--cache-threshold`).
|
||||
1. **Workers not connecting**: Ensure workers are fully initialized before starting the router. Use `--worker-startup-timeout-secs` to increase wait time.
|
||||
|
||||
3. **Circuit breaker flapping**
|
||||
Increase `--cb-failure-threshold` or extend the timeout/window durations. Consider temporarily disabling retries.
|
||||
2. **High latency**: Check if cache-aware routing is causing imbalance. Try adjusting `--balance-abs-threshold` and `--balance-rel-threshold`.
|
||||
|
||||
4. **Queue overflow (429)**
|
||||
Increase `--queue-size` or reduce client concurrency. Ensure `--max-concurrent-requests` matches downstream capacity.
|
||||
3. **Memory growth**: Reduce `--max-tree-size` or decrease `--eviction-interval-secs` for more aggressive cache cleanup.
|
||||
|
||||
5. **Memory growth**
|
||||
Reduce `--max-tree-size` or lower `--eviction-interval-secs` for more aggressive cache pruning.
|
||||
4. **Circuit breaker triggering frequently**: Increase `--cb-failure-threshold` or extend `--cb-window-duration-secs`.
|
||||
|
||||
6. **Debugging**
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--worker-urls http://worker1:8000 \
|
||||
--log-level debug \
|
||||
--log-dir ./router_logs
|
||||
```
|
||||
### Debug Mode
|
||||
|
||||
---
|
||||
Enable detailed logging:
|
||||
|
||||
SGLang Model Gateway continues to evolve alongside the SGLang runtime. Keep CLI flags, integrations, and documentation aligned when adopting new features or contributing improvements.
|
||||
```bash
|
||||
python -m sglang_router.launch_router \
|
||||
--worker-urls http://worker1:8000 http://worker2:8001 \
|
||||
--log-level debug \
|
||||
--log-dir ./router_logs
|
||||
```
|
||||
|
||||
@@ -55,7 +55,6 @@ You can find all arguments by `python3 -m sglang.launch_server --help`
|
||||
- To enable torchao quantization, add `--torchao-config int4wo-128`. It supports other [quantization strategies (INT8/FP8)](https://github.com/sgl-project/sglang/blob/v0.3.6/python/sglang/srt/server_args.py#L671) as well.
|
||||
- To enable fp8 weight quantization, add `--quantization fp8` on a fp16 checkpoint or directly load a fp8 checkpoint without specifying any arguments.
|
||||
- To enable fp8 kv cache quantization, add `--kv-cache-dtype fp8_e5m2`.
|
||||
- To enable deterministic inference and batch invariant operations, add `--enable-deterministic-inference`. More details can be found in [deterministic inference document](../advanced_features/deterministic_inference.md).
|
||||
- If the model does not have a chat template in the Hugging Face tokenizer, you can specify a [custom chat template](../references/custom_chat_template.md).
|
||||
- To run tensor parallelism on multiple nodes, add `--nnodes 2`. If you have two nodes with two GPUs on each node and want to run TP=4, let `sgl-dev-0` be the hostname of the first node and `50000` be an available port, you can use the following commands. If you meet deadlock, please try to add `--disable-cuda-graph`
|
||||
|
||||
@@ -113,7 +112,7 @@ Please consult the documentation below and [server_args.py](https://github.com/s
|
||||
| `--dtype` | Data type for model weights and activations. 'auto' will use FP16 precision for FP32 and FP16 models, and BF16 precision for BF16 models. 'half' for FP16. Recommended for AWQ quantization. 'float16' is the same as 'half'. 'bfloat16' for a balance between precision and range. 'float' is shorthand for FP32 precision. 'float32' for FP32 precision. | auto |
|
||||
| `--quantization` | The quantization method. | None |
|
||||
| `--quantization-param-path` | Path to the JSON file containing the KV cache scaling factors. This should generally be supplied, when KV cache dtype is FP8. Otherwise, KV cache scaling factors default to 1.0, which may cause accuracy issues. | None |
|
||||
| `--kv-cache-dtype` | Data type for kv cache storage. 'auto' will use model data type. 'bf16' or 'bfloat16' for BF16 KV cache. 'fp8_e5m2' and 'fp8_e4m3' are supported for CUDA 11.8+. | auto |
|
||||
| `--kv-cache-dtype` | Data type for kv cache storage. 'auto' will use model data type. 'fp8_e5m2' and 'fp8_e4m3' is supported for CUDA 11.8+. | auto |
|
||||
| `--enable-fp32-lm-head` | If set, the LM head outputs (logits) are in FP32. | False |
|
||||
|
||||
## Memory and scheduling
|
||||
@@ -135,11 +134,9 @@ Please consult the documentation below and [server_args.py](https://github.com/s
|
||||
| Arguments | Description | Defaults |
|
||||
|-----------|-------------|----------|
|
||||
| `--device` | The device to use ('cuda', 'xpu', 'hpu', 'npu', 'cpu'). Defaults to auto-detection if not specified. | None |
|
||||
| `--elastic-ep-backend` | Select the collective communication backend for elastic EP. Currently supports 'mooncake'. | None |
|
||||
| `--mooncake-ib-device` | The InfiniBand devices for Mooncake Backend, accepts multiple comma-separated devices. Default is None, which triggers automatic device detection when Mooncake Backend is enabled. | None |
|
||||
| `--tp-size` | The tensor parallelism size. | 1 |
|
||||
| `--pp-size` | The pipeline parallelism size. | 1 |
|
||||
| `--pp-max-micro-batch-size` | The maximum micro batch size in pipeline parallelism. | None |
|
||||
| `--max-micro-batch-size` | The maximum micro batch size in pipeline parallelism. | None |
|
||||
| `--stream-interval` | The interval (or buffer size) for streaming in terms of the token length. A smaller value makes streaming smoother, while a larger value makes the throughput higher. | 1 |
|
||||
| `--stream-output` | Whether to output as a sequence of disjoint segments. | False |
|
||||
| `--random-seed` | The random seed. | None |
|
||||
@@ -216,7 +213,6 @@ Please consult the documentation below and [server_args.py](https://github.com/s
|
||||
| `--lora-paths` | The list of LoRA adapters to load. Each adapter must be specified in one of the following formats: <PATH> | <NAME>=<PATH> | JSON with schema {"lora_name":str,"lora_path":str,"pinned":bool} | None |
|
||||
| `--max-loras-per-batch` | Maximum number of adapters for a running batch, include base-only request. | 8 |
|
||||
| `--max-loaded-loras` | If specified, it limits the maximum number of LoRA adapters loaded in CPU memory at a time. The value must be greater than or equal to `--max-loras-per-batch`. | None |
|
||||
| `--lora-eviction-policy` | LoRA adapter eviction policy when GPU memory pool is full. `lru`: Least Recently Used (better cache efficiency). `fifo`: First-In-First-Out. | lru |
|
||||
| `--lora-backend` | Choose the kernel backend for multi-LoRA serving. | triton |
|
||||
|
||||
## Kernel backend
|
||||
@@ -229,8 +225,6 @@ Please consult the documentation below and [server_args.py](https://github.com/s
|
||||
| `--sampling-backend` | Choose the kernels for sampling layers. | None |
|
||||
| `--grammar-backend` | Choose the backend for grammar-guided decoding. | None |
|
||||
| `--mm-attention-backend` | Set multimodal attention backend. | None |
|
||||
| `--nsa-prefill-backend` | Prefill attention implementation for nsa backend. | `flashmla_sparse` |
|
||||
| `--nsa-decode-backend` | Decode attention implementation for nsa backend. | `flashmla_kv` |
|
||||
|
||||
## Speculative decoding
|
||||
|
||||
@@ -251,8 +245,8 @@ Please consult the documentation below and [server_args.py](https://github.com/s
|
||||
| Arguments | Description | Defaults |
|
||||
|-----------|-------------|----------|
|
||||
| `--ep-size` | The expert parallelism size. | 1 |
|
||||
| `--moe-a2a-backend` | Select the backend for all-to-all communication for expert parallelism, could be `deepep` or `mooncake`. | none |
|
||||
| `--moe-runner-backend` | Select the runner backend for MoE. | auto |
|
||||
| `--moe-a2a-backend` | Select the backend for all-to-all communication for expert parallelism. | none |
|
||||
| `--moe-runner-backend` | Select the runner backend for MoE. | 'triton' |
|
||||
| `--deepep-mode` | Select the mode when enable DeepEP MoE, could be `normal`, `low_latency` or `auto`. Default is `auto`, which means `low_latency` for decode batch and `normal` for prefill batch. | auto |
|
||||
| `--ep-num-redundant-experts` | Allocate this number of redundant experts in expert parallel. | 0 |
|
||||
| `--ep-dispatch-algorithm` | The algorithm to choose ranks for redundant experts in EPLB. | None |
|
||||
@@ -300,7 +294,6 @@ Please consult the documentation below and [server_args.py](https://github.com/s
|
||||
| `--enable-dp-lm-head` | Enable vocabulary parallel across the attention TP group to avoid all-gather across DP groups, optimizing performance under DP attention. | False |
|
||||
| `--enable-two-batch-overlap` | Enabling two micro batches to overlap. | False |
|
||||
| `--tbo-token-distribution-threshold` | The threshold of token distribution between two batches in micro-batch-overlap, determines whether to two-batch-overlap or two-chunk-overlap. Set to 0 denote disable two-chunk-overlap. | 0.48 |
|
||||
| `--enable-single-batch-overlap` | Enabling single batch overlap. | False |
|
||||
| `--enable-torch-compile` | Optimize the model with torch.compile. Experimental feature. | False |
|
||||
| `--torch-compile-max-bs` | Set the maximum batch size when using torch compile. | 32 |
|
||||
| `--torchao-config` | Optimize the model with torchao. Experimental feature. Current choices are: int8dq, int8wo, int4wo-<group_size>, fp8wo, fp8dq-per_tensor, fp8dq-per_row. | |
|
||||
@@ -311,7 +304,6 @@ Please consult the documentation below and [server_args.py](https://github.com/s
|
||||
| `--num-continuous-decode-steps` | Run multiple continuous decoding steps to reduce scheduling overhead. This can potentially increase throughput but may also increase time-to-first-token latency. The default value is 1, meaning only run one decoding step at a time. | 1 |
|
||||
| `--delete-ckpt-after-loading` | Delete the model checkpoint after loading the model. | False |
|
||||
| `--enable-memory-saver` | Allow saving memory using release_memory_occupation and resume_memory_occupation. | False |
|
||||
| `--enable-weights-cpu-backup` | Save model weights to CPU memory during release_weights_occupation and resume_weights_occupation | False |
|
||||
| `--allow-auto-truncate` | Allow automatically truncating requests that exceed the maximum input length instead of returning an error. | False |
|
||||
| `--enable-custom-logit-processor` | Enable users to pass custom logit processors to the server (disabled by default for security). | False |
|
||||
| `--flashinfer-mla-disable-ragged` | Disable ragged processing in Flashinfer MLA. | False |
|
||||
@@ -327,6 +319,7 @@ Please consult the documentation below and [server_args.py](https://github.com/s
|
||||
| `--debug-tensor-dump-output-folder` | The output folder for debug tensor dumps. | None |
|
||||
| `--debug-tensor-dump-input-file` | The input file for debug tensor dumps. | None |
|
||||
| `--debug-tensor-dump-inject` | Enable injection of debug tensor dumps. | False |
|
||||
| `--debug-tensor-dump-prefill-only` | Enable prefill-only mode for debug tensor dumps. | False |
|
||||
|
||||
## PD disaggregation
|
||||
|
||||
|
||||
@@ -349,50 +349,6 @@
|
||||
"print_highlight(response.choices[0].message.content)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Support for XGrammar latest structural tag format\n",
|
||||
"# https://xgrammar.mlc.ai/docs/tutorials/structural_tag.html\n",
|
||||
"\n",
|
||||
"response = client.chat.completions.create(\n",
|
||||
" model=\"meta-llama/Meta-Llama-3.1-8B-Instruct\",\n",
|
||||
" messages=messages,\n",
|
||||
" response_format={\n",
|
||||
" \"type\": \"structural_tag\",\n",
|
||||
" \"format\": {\n",
|
||||
" \"type\": \"triggered_tags\",\n",
|
||||
" \"triggers\": [\"<function=\"],\n",
|
||||
" \"tags\": [\n",
|
||||
" {\n",
|
||||
" \"begin\": \"<function=get_current_weather>\",\n",
|
||||
" \"content\": {\n",
|
||||
" \"type\": \"json_schema\",\n",
|
||||
" \"json_schema\": schema_get_current_weather,\n",
|
||||
" },\n",
|
||||
" \"end\": \"</function>\",\n",
|
||||
" },\n",
|
||||
" {\n",
|
||||
" \"begin\": \"<function=get_current_date>\",\n",
|
||||
" \"content\": {\n",
|
||||
" \"type\": \"json_schema\",\n",
|
||||
" \"json_schema\": schema_get_current_date,\n",
|
||||
" },\n",
|
||||
" \"end\": \"</function>\",\n",
|
||||
" },\n",
|
||||
" ],\n",
|
||||
" \"at_least_one\": False,\n",
|
||||
" \"stop_after_first\": False,\n",
|
||||
" },\n",
|
||||
" },\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"print_highlight(response.choices[0].message.content)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
@@ -638,56 +594,6 @@
|
||||
"print_highlight(response.json())"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Support for XGrammar latest structural tag format\n",
|
||||
"# https://xgrammar.mlc.ai/docs/tutorials/structural_tag.html\n",
|
||||
"\n",
|
||||
"payload = {\n",
|
||||
" \"text\": text,\n",
|
||||
" \"sampling_params\": {\n",
|
||||
" \"structural_tag\": json.dumps(\n",
|
||||
" {\n",
|
||||
" \"type\": \"structural_tag\",\n",
|
||||
" \"format\": {\n",
|
||||
" \"type\": \"triggered_tags\",\n",
|
||||
" \"triggers\": [\"<function=\"],\n",
|
||||
" \"tags\": [\n",
|
||||
" {\n",
|
||||
" \"begin\": \"<function=get_current_weather>\",\n",
|
||||
" \"content\": {\n",
|
||||
" \"type\": \"json_schema\",\n",
|
||||
" \"json_schema\": schema_get_current_weather,\n",
|
||||
" },\n",
|
||||
" \"end\": \"</function>\",\n",
|
||||
" },\n",
|
||||
" {\n",
|
||||
" \"begin\": \"<function=get_current_date>\",\n",
|
||||
" \"content\": {\n",
|
||||
" \"type\": \"json_schema\",\n",
|
||||
" \"json_schema\": schema_get_current_date,\n",
|
||||
" },\n",
|
||||
" \"end\": \"</function>\",\n",
|
||||
" },\n",
|
||||
" ],\n",
|
||||
" \"at_least_one\": False,\n",
|
||||
" \"stop_after_first\": False,\n",
|
||||
" },\n",
|
||||
" }\n",
|
||||
" )\n",
|
||||
" },\n",
|
||||
"}\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Send POST request to the API endpoint\n",
|
||||
"response = requests.post(f\"http://localhost:{port}/generate\", json=payload)\n",
|
||||
"print_highlight(response.json())"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
@@ -919,57 +825,6 @@
|
||||
" print_highlight(f\"Prompt: {prompt}\\nGenerated text: {output['text']}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Support for XGrammar latest structural tag format\n",
|
||||
"# https://xgrammar.mlc.ai/docs/tutorials/structural_tag.html\n",
|
||||
"\n",
|
||||
"sampling_params = {\n",
|
||||
" \"temperature\": 0.8,\n",
|
||||
" \"top_p\": 0.95,\n",
|
||||
" \"structural_tag\": json.dumps(\n",
|
||||
" {\n",
|
||||
" \"type\": \"structural_tag\",\n",
|
||||
" \"format\": {\n",
|
||||
" \"type\": \"triggered_tags\",\n",
|
||||
" \"triggers\": [\"<function=\"],\n",
|
||||
" \"tags\": [\n",
|
||||
" {\n",
|
||||
" \"begin\": \"<function=get_current_weather>\",\n",
|
||||
" \"content\": {\n",
|
||||
" \"type\": \"json_schema\",\n",
|
||||
" \"json_schema\": schema_get_current_weather,\n",
|
||||
" },\n",
|
||||
" \"end\": \"</function>\",\n",
|
||||
" },\n",
|
||||
" {\n",
|
||||
" \"begin\": \"<function=get_current_date>\",\n",
|
||||
" \"content\": {\n",
|
||||
" \"type\": \"json_schema\",\n",
|
||||
" \"json_schema\": schema_get_current_date,\n",
|
||||
" },\n",
|
||||
" \"end\": \"</function>\",\n",
|
||||
" },\n",
|
||||
" ],\n",
|
||||
" \"at_least_one\": False,\n",
|
||||
" \"stop_after_first\": False,\n",
|
||||
" },\n",
|
||||
" }\n",
|
||||
" ),\n",
|
||||
"}\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Send POST request to the API endpoint\n",
|
||||
"outputs = llm.generate(prompts, sampling_params)\n",
|
||||
"for prompt, output in zip(prompts, outputs):\n",
|
||||
" print_highlight(\"===============================\")\n",
|
||||
" print_highlight(f\"Prompt: {prompt}\\nGenerated text: {output['text']}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
|
||||
@@ -17,18 +17,14 @@
|
||||
"\n",
|
||||
"| Parser | Supported Models | Notes |\n",
|
||||
"|---|---|---|\n",
|
||||
"| `deepseekv3` | DeepSeek-v3 (e.g., `deepseek-ai/DeepSeek-V3-0324`) | Recommend adding `--chat-template ./examples/chat_template/tool_chat_template_deepseekv3.jinja` to launch command. |\n",
|
||||
"| `deepseekv31` | DeepSeek-V3.1 and DeepSeek-V3.2 (e.g. `deepseek-ai/DeepSeek-V3.1`, `deepseek-ai/DeepSeek-V3.2-Exp`) | Recommend adding `--chat-template ./examples/chat_template/tool_chat_template_deepseekv31.jinja` (Or ..deepseekv32.jinja for DeepSeek-V3.2) to launch command. |\n",
|
||||
"| `glm` | GLM series (e.g. `zai-org/GLM-4.6`) | |\n",
|
||||
"| `gpt-oss` | GPT-OSS (e.g., `openai/gpt-oss-120b`, `openai/gpt-oss-20b`, `lmsys/gpt-oss-120b-bf16`, `lmsys/gpt-oss-20b-bf16`) | The gpt-oss tool parser filters out analysis channel events and only preserves normal text. This can cause the content to be empty when explanations are in the analysis channel. To work around this, complete the tool round by returning tool results as `role=\"tool\"` messages, which enables the model to generate the final content. |\n",
|
||||
"| `kimi_k2` | `moonshotai/Kimi-K2-Instruct` | |\n",
|
||||
"| `llama3` | Llama 3.1 / 3.2 / 3.3 (e.g. `meta-llama/Llama-3.1-8B-Instruct`, `meta-llama/Llama-3.2-1B-Instruct`, `meta-llama/Llama-3.3-70B-Instruct`) | |\n",
|
||||
"| `llama4` | Llama 4 (e.g. `meta-llama/Llama-4-Scout-17B-16E-Instruct`) | |\n",
|
||||
"| `mistral` | Mistral (e.g. `mistralai/Mistral-7B-Instruct-v0.3`, `mistralai/Mistral-Nemo-Instruct-2407`, `mistralai/Mistral-7B-v0.3`) | |\n",
|
||||
"| `pythonic` | Llama-3.2 / Llama-3.3 / Llama-4 | Model outputs function calls as Python code. Requires `--tool-call-parser pythonic` and is recommended to use with a specific chat template. |\n",
|
||||
"| `qwen` | Qwen series (e.g. `Qwen/Qwen3-Next-80B-A3B-Instruct`, `Qwen/Qwen3-VL-30B-A3B-Thinking`) except Qwen3-Coder| |\n",
|
||||
"| `qwen3_coder` | Qwen3-Coder (e.g. `Qwen/Qwen3-Coder-30B-A3B-Instruct`) | |\n",
|
||||
"| `step3` | Step-3 | |\n"
|
||||
"| `qwen25` | Qwen 2.5 (e.g. `Qwen/Qwen2.5-1.5B-Instruct`, `Qwen/Qwen2.5-7B-Instruct`) and QwQ (i.e. `Qwen/QwQ-32B`) | For QwQ, reasoning parser can be enabled together with tool call parser. See [reasoning parser](https://docs.sglang.ai/backend/separate_reasoning.html). |\n",
|
||||
"| `deepseekv3` | DeepSeek-v3 (e.g., `deepseek-ai/DeepSeek-V3-0324`) | |\n",
|
||||
"| `gpt-oss` | GPT-OSS (e.g., `openai/gpt-oss-120b`, `openai/gpt-oss-20b`, `lmsys/gpt-oss-120b-bf16`, `lmsys/gpt-oss-20b-bf16`) | The gpt-oss tool parser filters out analysis channel events and only preserves normal text. This can cause the content to be empty when explanations are in the analysis channel. To work around this, complete the tool round by returning tool results as `role=\"tool\"` messages, which enables the model to generate the final content. |\n",
|
||||
"| `kimi_k2` | `moonshotai/Kimi-K2-Instruct` | |\n",
|
||||
"| `pythonic` | Llama-3.2 / Llama-3.3 / Llama-4 | Model outputs function calls as Python code. Requires `--tool-call-parser pythonic` and is recommended to use with a specific chat template. |\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -144,7 +144,7 @@ With data parallelism attention enabled, we have achieved up to **1.9x** decodin
|
||||
|
||||
- **DeepGEMM**: The [DeepGEMM](https://github.com/deepseek-ai/DeepGEMM) kernel library optimized for FP8 matrix multiplications.
|
||||
|
||||
**Usage**: The activation and weight optimization above are turned on by default for DeepSeek V3 models. DeepGEMM is enabled by default on NVIDIA Hopper GPUs and disabled by default on other devices. DeepGEMM can also be manually turned off by setting the environment variable `SGLANG_ENABLE_JIT_DEEPGEMM=0`.
|
||||
**Usage**: The activation and weight optimization above are turned on by default for DeepSeek V3 models. DeepGEMM is enabled by default on NVIDIA Hopper GPUs and disabled by default on other devices. DeepGEMM can also be manually turned off by setting the environment variable `SGL_ENABLE_JIT_DEEPGEMM=0`.
|
||||
|
||||
Before serving the DeepSeek model, precompile the DeepGEMM kernels using:
|
||||
```bash
|
||||
@@ -235,44 +235,6 @@ Important Notes:
|
||||
2. To receive more consistent tool call results, it is recommended to use `--chat-template examples/chat_template/tool_chat_template_deepseekv3.jinja`. It provides an improved unified prompt.
|
||||
|
||||
|
||||
### Thinking Budget for DeepSeek R1
|
||||
|
||||
In SGLang, we can implement thinking budget with `CustomLogitProcessor`.
|
||||
|
||||
Launch a server with `--enable-custom-logit-processor` flag on.
|
||||
|
||||
```
|
||||
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1 --tp 8 --port 30000 --host 0.0.0.0 --mem-fraction-static 0.9 --disable-cuda-graph --reasoning-parser deepseek-r1 --enable-custom-logit-processor
|
||||
```
|
||||
|
||||
Sample Request:
|
||||
|
||||
```python
|
||||
import openai
|
||||
from rich.pretty import pprint
|
||||
from sglang.srt.sampling.custom_logit_processor import DeepSeekR1ThinkingBudgetLogitProcessor
|
||||
|
||||
|
||||
client = openai.Client(base_url="http://127.0.0.1:30000/v1", api_key="*")
|
||||
response = client.chat.completions.create(
|
||||
model="deepseek-ai/DeepSeek-R1",
|
||||
messages=[
|
||||
{
|
||||
"role": "user",
|
||||
"content": "Question: Is Paris the Capital of France?",
|
||||
}
|
||||
],
|
||||
max_tokens=1024,
|
||||
extra_body={
|
||||
"custom_logit_processor": DeepSeekR1ThinkingBudgetLogitProcessor().to_str(),
|
||||
"custom_params": {
|
||||
"thinking_budget": 512,
|
||||
},
|
||||
},
|
||||
)
|
||||
pprint(response)
|
||||
```
|
||||
|
||||
## FAQ
|
||||
|
||||
**Q: Model loading is taking too long, and I'm encountering an NCCL timeout. What should I do?**
|
||||
|
||||
@@ -21,8 +21,6 @@
|
||||
"- `/start_expert_distribution_record`\n",
|
||||
"- `/stop_expert_distribution_record`\n",
|
||||
"- `/dump_expert_distribution_record`\n",
|
||||
"- `/tokenize`\n",
|
||||
"- `/detokenize`\n",
|
||||
"- A full list of these APIs can be found at [http_server.py](https://github.com/sgl-project/sglang/blob/main/python/sglang/srt/entrypoints/http_server.py)\n",
|
||||
"\n",
|
||||
"We mainly use `requests` to test these APIs in the following examples. You can also use `curl`.\n"
|
||||
@@ -479,104 +477,6 @@
|
||||
"source": [
|
||||
"terminate_process(expert_record_server_process)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Tokenize/Detokenize Example (Round Trip)\n",
|
||||
"\n",
|
||||
"This example demonstrates how to use the /tokenize and /detokenize endpoints together. We first tokenize a string, then detokenize the resulting IDs to reconstruct the original text. This workflow is useful when you need to handle tokenization externally but still leverage the server for detokenization."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"tokenizer_free_server_process, port = launch_server_cmd(\n",
|
||||
" \"\"\"\n",
|
||||
"python3 -m sglang.launch_server --model-path qwen/qwen2.5-0.5b-instruct\n",
|
||||
"\"\"\"\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"wait_for_server(f\"http://localhost:{port}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import requests\n",
|
||||
"from sglang.utils import print_highlight\n",
|
||||
"\n",
|
||||
"base_url = f\"http://localhost:{port}\"\n",
|
||||
"tokenize_url = f\"{base_url}/tokenize\"\n",
|
||||
"detokenize_url = f\"{base_url}/detokenize\"\n",
|
||||
"\n",
|
||||
"model_name = \"qwen/qwen2.5-0.5b-instruct\"\n",
|
||||
"input_text = \"SGLang provides efficient tokenization endpoints.\"\n",
|
||||
"print_highlight(f\"Original Input Text:\\n'{input_text}'\")\n",
|
||||
"\n",
|
||||
"# --- tokenize the input text ---\n",
|
||||
"tokenize_payload = {\n",
|
||||
" \"model\": model_name,\n",
|
||||
" \"prompt\": input_text,\n",
|
||||
" \"add_special_tokens\": False,\n",
|
||||
"}\n",
|
||||
"try:\n",
|
||||
" tokenize_response = requests.post(tokenize_url, json=tokenize_payload)\n",
|
||||
" tokenize_response.raise_for_status()\n",
|
||||
" tokenization_result = tokenize_response.json()\n",
|
||||
" token_ids = tokenization_result.get(\"tokens\")\n",
|
||||
"\n",
|
||||
" if not token_ids:\n",
|
||||
" raise ValueError(\"Tokenization returned empty tokens.\")\n",
|
||||
"\n",
|
||||
" print_highlight(f\"\\nTokenized Output (IDs):\\n{token_ids}\")\n",
|
||||
" print_highlight(f\"Token Count: {tokenization_result.get('count')}\")\n",
|
||||
" print_highlight(f\"Max Model Length: {tokenization_result.get('max_model_len')}\")\n",
|
||||
"\n",
|
||||
" # --- detokenize the obtained token IDs ---\n",
|
||||
" detokenize_payload = {\n",
|
||||
" \"model\": model_name,\n",
|
||||
" \"tokens\": token_ids,\n",
|
||||
" \"skip_special_tokens\": True,\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" detokenize_response = requests.post(detokenize_url, json=detokenize_payload)\n",
|
||||
" detokenize_response.raise_for_status()\n",
|
||||
" detokenization_result = detokenize_response.json()\n",
|
||||
" reconstructed_text = detokenization_result.get(\"text\")\n",
|
||||
"\n",
|
||||
" print_highlight(f\"\\nDetokenized Output (Text):\\n'{reconstructed_text}'\")\n",
|
||||
"\n",
|
||||
" if input_text == reconstructed_text:\n",
|
||||
" print_highlight(\n",
|
||||
" \"\\nRound Trip Successful: Original and reconstructed text match.\"\n",
|
||||
" )\n",
|
||||
" else:\n",
|
||||
" print_highlight(\n",
|
||||
" \"\\nRound Trip Mismatch: Original and reconstructed text differ.\"\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
"except requests.exceptions.RequestException as e:\n",
|
||||
" print_highlight(f\"\\nHTTP Request Error: {e}\")\n",
|
||||
"except Exception as e:\n",
|
||||
" print_highlight(f\"\\nAn error occurred: {e}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"terminate_process(tokenizer_free_server_process)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
@@ -593,5 +493,5 @@
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
|
||||
@@ -361,50 +361,6 @@
|
||||
"For OpenAI compatible structured outputs API, refer to [Structured Outputs](../advanced_features/structured_outputs.ipynb) for more details.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Using LoRA Adapters\n",
|
||||
"\n",
|
||||
"SGLang supports LoRA (Low-Rank Adaptation) adapters with OpenAI-compatible APIs. You can specify which adapter to use directly in the `model` parameter using the `base-model:adapter-name` syntax.\n",
|
||||
"\n",
|
||||
"**Server Setup:**\n",
|
||||
"```bash\n",
|
||||
"python -m sglang.launch_server \\\n",
|
||||
" --model-path qwen/qwen2.5-0.5b-instruct \\\n",
|
||||
" --enable-lora \\\n",
|
||||
" --lora-paths adapter_a=/path/to/adapter_a adapter_b=/path/to/adapter_b\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"For more details on LoRA serving configuration, see the [LoRA documentation](../advanced_features/lora.ipynb).\n",
|
||||
"\n",
|
||||
"**API Call:**\n",
|
||||
"\n",
|
||||
"(Recommended) Use the `model:adapter` syntax to specify which adapter to use:\n",
|
||||
"```python\n",
|
||||
"response = client.chat.completions.create(\n",
|
||||
" model=\"qwen/qwen2.5-0.5b-instruct:adapter_a\", # ← base-model:adapter-name\n",
|
||||
" messages=[{\"role\": \"user\", \"content\": \"Convert to SQL: show all users\"}],\n",
|
||||
" max_tokens=50,\n",
|
||||
")\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"**Backward Compatible: Using `extra_body`**\n",
|
||||
"\n",
|
||||
"The old `extra_body` method is still supported for backward compatibility:\n",
|
||||
"```python\n",
|
||||
"# Backward compatible method\n",
|
||||
"response = client.chat.completions.create(\n",
|
||||
" model=\"qwen/qwen2.5-0.5b-instruct\",\n",
|
||||
" messages=[{\"role\": \"user\", \"content\": \"Convert to SQL: show all users\"}],\n",
|
||||
" extra_body={\"lora_path\": \"adapter_a\"}, # ← old method\n",
|
||||
" max_tokens=50,\n",
|
||||
")\n",
|
||||
"```\n",
|
||||
"**Note:** When both `model:adapter` and `extra_body[\"lora_path\"]` are specified, the `model:adapter` syntax takes precedence."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
|
||||
@@ -30,18 +30,6 @@ The `/generate` endpoint accepts the following parameters in JSON format. For de
|
||||
|
||||
The object is defined at `sampling_params.py::SamplingParams`. You can also read the source code to find more arguments and docs.
|
||||
|
||||
### Note on defaults
|
||||
|
||||
By default, SGLang initializes several sampling parameters from the model's `generation_config.json` (when the server is launched with `--sampling-defaults model`, which is the default). To use SGLang/OpenAI constant defaults instead, start the server with `--sampling-defaults openai`. You can always override any parameter per request via `sampling_params`.
|
||||
|
||||
```bash
|
||||
# Use model-provided defaults from generation_config.json (default behavior)
|
||||
python -m sglang.launch_server --model-path <MODEL> --sampling-defaults model
|
||||
|
||||
# Use SGLang/OpenAI constant defaults instead
|
||||
python -m sglang.launch_server --model-path <MODEL> --sampling-defaults openai
|
||||
```
|
||||
|
||||
### Core parameters
|
||||
|
||||
| Argument | Type/Default | Description |
|
||||
@@ -49,11 +37,10 @@ python -m sglang.launch_server --model-path <MODEL> --sampling-defaults openai
|
||||
| max_new_tokens | `int = 128` | The maximum output length measured in tokens. |
|
||||
| stop | `Optional[Union[str, List[str]]] = None` | One or multiple [stop words](https://platform.openai.com/docs/api-reference/chat/create#chat-create-stop). Generation will stop if one of these words is sampled. |
|
||||
| stop_token_ids | `Optional[List[int]] = None` | Provide stop words in the form of token IDs. Generation will stop if one of these token IDs is sampled. |
|
||||
| stop_regex | `Optional[Union[str, List[str]]] = None` | Stop when hitting any of the regex patterns in this list |
|
||||
| temperature | `float (model default; fallback 1.0)` | [Temperature](https://platform.openai.com/docs/api-reference/chat/create#chat-create-temperature) when sampling the next token. `temperature = 0` corresponds to greedy sampling, a higher temperature leads to more diversity. |
|
||||
| top_p | `float (model default; fallback 1.0)` | [Top-p](https://platform.openai.com/docs/api-reference/chat/create#chat-create-top_p) selects tokens from the smallest sorted set whose cumulative probability exceeds `top_p`. When `top_p = 1`, this reduces to unrestricted sampling from all tokens. |
|
||||
| top_k | `int (model default; fallback -1)` | [Top-k](https://developer.nvidia.com/blog/how-to-get-better-outputs-from-your-large-language-model/#predictability_vs_creativity) randomly selects from the `k` highest-probability tokens. |
|
||||
| min_p | `float (model default; fallback 0.0)` | [Min-p](https://github.com/huggingface/transformers/issues/27670) samples from tokens with probability larger than `min_p * highest_token_probability`. |
|
||||
| temperature | `float = 1.0` | [Temperature](https://platform.openai.com/docs/api-reference/chat/create#chat-create-temperature) when sampling the next token. `temperature = 0` corresponds to greedy sampling, a higher temperature leads to more diversity. |
|
||||
| top_p | `float = 1.0` | [Top-p](https://platform.openai.com/docs/api-reference/chat/create#chat-create-top_p) selects tokens from the smallest sorted set whose cumulative probability exceeds `top_p`. When `top_p = 1`, this reduces to unrestricted sampling from all tokens. |
|
||||
| top_k | `int = -1` | [Top-k](https://developer.nvidia.com/blog/how-to-get-better-outputs-from-your-large-language-model/#predictability_vs_creativity) randomly selects from the `k` highest-probability tokens. |
|
||||
| min_p | `float = 0.0` | [Min-p](https://github.com/huggingface/transformers/issues/27670) samples from tokens with probability larger than `min_p * highest_token_probability`. |
|
||||
|
||||
### Penalizers
|
||||
|
||||
@@ -319,27 +306,3 @@ response = requests.post(
|
||||
)
|
||||
print(response.json())
|
||||
```
|
||||
|
||||
Send an OpenAI chat completion request:
|
||||
|
||||
```python
|
||||
import openai
|
||||
from sglang.utils import print_highlight
|
||||
|
||||
client = openai.Client(base_url="http://127.0.0.1:30000/v1", api_key="None")
|
||||
|
||||
response = client.chat.completions.create(
|
||||
model="meta-llama/Meta-Llama-3-8B-Instruct",
|
||||
messages=[
|
||||
{"role": "user", "content": "List 3 countries and their capitals."},
|
||||
],
|
||||
temperature=0.0,
|
||||
max_tokens=32,
|
||||
extra_body={
|
||||
"custom_logit_processor": DeterministicLogitProcessor().to_str(),
|
||||
"custom_params": {"token_id": 5},
|
||||
},
|
||||
)
|
||||
|
||||
print_highlight(f"Response: {response}")
|
||||
```
|
||||
|
||||
@@ -59,16 +59,15 @@ Select with `--dataset-name`:
|
||||
- `sharegpt` (default): loads ShareGPT-style pairs; optionally restrict with `--sharegpt-context-len` and override outputs with `--sharegpt-output-len`
|
||||
- `random`: random text lengths; sampled from ShareGPT token space
|
||||
- `random-ids`: random token ids (can lead to gibberish)
|
||||
- `image`: generates images and wraps them in chat messages; supports custom resolutions, multiple formats, and different content types
|
||||
- `random-image`: generates random images and wraps them in chat messages; supports custom resolutions via 'heightxwidth' format
|
||||
- `generated-shared-prefix`: synthetic dataset with shared long system prompts and short questions
|
||||
- `mmmu`: samples from MMMU (Math split) and includes images
|
||||
|
||||
Common dataset flags:
|
||||
|
||||
- `--num-prompts N`: number of requests
|
||||
- `--random-input-len`, `--random-output-len`, `--random-range-ratio`: for random/random-ids/image
|
||||
- `--image-count`: Number of images per request (for `image` dataset).
|
||||
|
||||
- `--random-input-len`, `--random-output-len`, `--random-range-ratio`: for random/random-ids/random-image
|
||||
- `--random-image-num-images`, `--random-image-resolution`: for random-image dataset (supports presets 1080p/720p/360p or custom 'heightxwidth' format)
|
||||
- `--apply-chat-template`: apply tokenizer chat template when constructing prompts
|
||||
- `--dataset-path PATH`: file path for ShareGPT json; if blank and missing, it will be downloaded and cached
|
||||
|
||||
@@ -80,16 +79,14 @@ Generated Shared Prefix flags (for `generated-shared-prefix`):
|
||||
- `--gsp-question-len`
|
||||
- `--gsp-output-len`
|
||||
|
||||
Image dataset flags (for `image`):
|
||||
Random Image dataset flags (for `random-image`):
|
||||
|
||||
- `--image-count`: Number of images per request
|
||||
- `--image-resolution`: Image resolution; supports presets (4k, 1080p, 720p, 360p) or custom 'heightxwidth' format (e.g., 1080x1920, 512x768)
|
||||
- `--image-format`: Image format (jpeg or png)
|
||||
- `--image-content`: Image content type (random or blank)
|
||||
- `--random-image-num-images`: Number of images per request
|
||||
- `--random-image-resolution`: Image resolution; supports presets (1080p, 720p, 360p) or custom 'heightxwidth' format (e.g., 1080x1920, 512x768)
|
||||
|
||||
### Examples
|
||||
|
||||
1. To benchmark image dataset with 3 images per request, 500 prompts, 512 input length, and 512 output length, you can run:
|
||||
1. To benchmark random-image dataset with 3 images per request, 500 prompts, 512 input length, and 512 output length, you can run:
|
||||
|
||||
```bash
|
||||
python -m sglang.launch_server --model-path Qwen/Qwen2.5-VL-3B-Instruct --disable-radix-cache
|
||||
@@ -98,10 +95,10 @@ python -m sglang.launch_server --model-path Qwen/Qwen2.5-VL-3B-Instruct --disabl
|
||||
```bash
|
||||
python -m sglang.bench_serving \
|
||||
--backend sglang-oai-chat \
|
||||
--dataset-name image \
|
||||
--dataset-name random-image \
|
||||
--num-prompts 500 \
|
||||
--image-count 3 \
|
||||
--image-resolution 720p \
|
||||
--random-image-num-images 3 \
|
||||
--random-image-resolution 720p \
|
||||
--random-input-len 512 \
|
||||
--random-output-len 512
|
||||
```
|
||||
@@ -162,10 +159,9 @@ The script will add `Authorization: Bearer $OPENAI_API_KEY` automatically for Op
|
||||
Printed after each run:
|
||||
|
||||
- Request throughput (req/s)
|
||||
- Input token throughput (tok/s) - includes both text and vision tokens
|
||||
- Input token throughput (tok/s)
|
||||
- Output token throughput (tok/s)
|
||||
- Total token throughput (tok/s) - includes both text and vision tokens
|
||||
- Total input text tokens and Total input vision tokens - per-modality breakdown
|
||||
- Total token throughput (tok/s)
|
||||
- Concurrency: aggregate time of all requests divided by wall time
|
||||
- End-to-End Latency (ms): mean/median/std/p99 per-request total latency
|
||||
- Time to First Token (TTFT, ms): mean/median/std/p99 for streaming mode
|
||||
@@ -231,48 +227,31 @@ python3 -m sglang.bench_serving \
|
||||
--apply-chat-template
|
||||
```
|
||||
|
||||
4) Images (VLM) with chat template:
|
||||
4) Random images (VLM) with chat template:
|
||||
|
||||
```bash
|
||||
python3 -m sglang.bench_serving \
|
||||
--backend sglang \
|
||||
--host 127.0.0.1 --port 30000 \
|
||||
--model your-vlm-model \
|
||||
--dataset-name image \
|
||||
--image-count 2 \
|
||||
--image-resolution 720p \
|
||||
--dataset-name random-image \
|
||||
--random-image-num-images 2 \
|
||||
--random-image-resolution 720p \
|
||||
--random-input-len 128 --random-output-len 256 \
|
||||
--num-prompts 200 \
|
||||
--apply-chat-template
|
||||
```
|
||||
|
||||
4a) Images with custom resolution:
|
||||
4a) Random images with custom resolution:
|
||||
|
||||
```bash
|
||||
python3 -m sglang.bench_serving \
|
||||
--backend sglang \
|
||||
--host 127.0.0.1 --port 30000 \
|
||||
--model your-vlm-model \
|
||||
--dataset-name image \
|
||||
--image-count 1 \
|
||||
--image-resolution 512x768 \
|
||||
--random-input-len 64 --random-output-len 128 \
|
||||
--num-prompts 100 \
|
||||
--apply-chat-template
|
||||
```
|
||||
|
||||
4b) 1080p images with PNG format and blank content:
|
||||
|
||||
```bash
|
||||
python3 -m sglang.bench_serving \
|
||||
--backend sglang \
|
||||
--host 127.0.0.1 --port 30000 \
|
||||
--model your-vlm-model \
|
||||
--dataset-name image \
|
||||
--image-count 1 \
|
||||
--image-resolution 1080p \
|
||||
--image-format png \
|
||||
--image-content blank \
|
||||
--dataset-name random-image \
|
||||
--random-image-num-images 1 \
|
||||
--random-image-resolution 512x768 \
|
||||
--random-input-len 64 --random-output-len 128 \
|
||||
--num-prompts 100 \
|
||||
--apply-chat-template
|
||||
@@ -346,7 +325,7 @@ python3 -m sglang.bench_serving \
|
||||
- All requests failed: verify `--backend`, server URL/port, `--model`, and authentication. Check warmup errors printed by the script.
|
||||
- Throughput seems too low: adjust `--request-rate` and `--max-concurrency`; verify server batch size/scheduling; ensure streaming is enabled if appropriate.
|
||||
- Token counts look odd: prefer chat/instruct models with proper chat templates; otherwise tokenization of gibberish may be inconsistent.
|
||||
- Image/MMMU datasets: ensure you installed extra deps (`pillow`, `datasets`, `pybase64`).
|
||||
- Random-image/MMMU datasets: ensure you installed extra deps (`pillow`, `datasets`, `pybase64`).
|
||||
- Authentication errors (401/403): set `OPENAI_API_KEY` or disable auth on your server.
|
||||
|
||||
### Notes
|
||||
|
||||
@@ -47,48 +47,6 @@ Please make sure that the `SGLANG_TORCH_PROFILER_DIR` should be set at both serv
|
||||
|
||||
For more details, please refer to [Bench Serving Guide](./bench_serving.md).
|
||||
|
||||
### Profile In PD Disaggregation Mode
|
||||
|
||||
When profiling in PD disaggregation mode, prefill and decode workers **must be profiled separately** due to torch profiler limitations. The `bench_serving` command provides dedicated options for this:
|
||||
|
||||
#### Profile Prefill Workers
|
||||
|
||||
```bash
|
||||
# set trace path
|
||||
export SGLANG_TORCH_PROFILER_DIR=/root/sglang/profile_log
|
||||
|
||||
# start prefill and decode servers (see PD disaggregation docs for setup)
|
||||
python -m sglang.launch_server --model-path meta-llama/Llama-3.1-8B-Instruct --disaggregation-mode prefill
|
||||
python -m sglang.launch_server --model-path meta-llama/Llama-3.1-8B-Instruct --disaggregation-mode decode --port 30001 --base-gpu-id 1
|
||||
|
||||
# start router
|
||||
python -m sglang_router.launch_router --pd-disaggregation --prefill http://127.0.0.1:30000 --decode http://127.0.0.1:30001 --host 0.0.0.0 --port 8000
|
||||
|
||||
# send profiling request targeting prefill workers
|
||||
python -m sglang.bench_serving --backend sglang --model meta-llama/Llama-3.1-8B-Instruct --num-prompts 10 --sharegpt-output-len 100 --profile --pd-separated --profile-prefill-url http://127.0.0.1:30000
|
||||
```
|
||||
|
||||
#### Profile Decode Workers
|
||||
|
||||
```bash
|
||||
# send profiling request targeting decode workers
|
||||
python -m sglang.bench_serving --backend sglang --model meta-llama/Llama-3.1-8B-Instruct --num-prompts 10 --sharegpt-output-len 100 --profile --pd-separated --profile-decode-url http://127.0.0.1:30001
|
||||
```
|
||||
|
||||
#### Important Notes
|
||||
|
||||
- `--profile-prefill-url` and `--profile-decode-url` are **mutually exclusive** - you cannot profile both at the same time
|
||||
- Both options support multiple worker URLs for multi-instance setups:
|
||||
```bash
|
||||
# Profile multiple prefill workers
|
||||
python -m sglang.bench_serving --backend sglang --model meta-llama/Llama-3.1-8B-Instruct --num-prompts 10 --profile --pd-separated --profile-prefill-url http://127.0.0.1:30000 http://127.0.0.1:30002
|
||||
|
||||
# Profile multiple decode workers
|
||||
python -m sglang.bench_serving --backend sglang --model meta-llama/Llama-3.1-8B-Instruct --num-prompts 10 --profile --pd-separated --profile-decode-url http://127.0.0.1:30001 http://127.0.0.1:30003
|
||||
```
|
||||
- Make sure `SGLANG_TORCH_PROFILER_DIR` is set on all worker nodes before starting the servers
|
||||
- For more details on setting up PD disaggregation, see [PD Disaggregation Guide](../advanced_features/pd_disaggregation.md)
|
||||
|
||||
### Profile a server with `sglang.bench_offline_throughput`
|
||||
```bash
|
||||
export SGLANG_TORCH_PROFILER_DIR=/root/sglang/profile_log
|
||||
@@ -116,54 +74,6 @@ python3 -m sglang.test.send_one
|
||||
python3 -m sglang.profiler
|
||||
```
|
||||
|
||||
You can also combine the above operations into a single command
|
||||
|
||||
```
|
||||
python3 -m sglang.test.send_one --profile
|
||||
```
|
||||
|
||||
### Profiler Trace Merger for Distributed Traces
|
||||
|
||||
SGLang now supports automatic merging of profiling traces from distributed setups with multiple parallelism types (TP, DP, PP, EP). This feature is particularly useful for analyzing performance across distributed runs.
|
||||
|
||||
#### Multi-Node Profiling and Shared Storage Considerations
|
||||
|
||||
Single-node profiler output merging is completely supported. When profiling in distributed environments spanning multiple nodes, shared storage (e.g., NFS, Lustre) should be accessible by all nodes for the output directory to enable merging of trace files.
|
||||
|
||||
If there is no shared storage accessible across nodes, automatic merging of trace files during profiling is not supported directly as of now.
|
||||
|
||||
#### HTTP API Usage
|
||||
|
||||
```bash
|
||||
# Start profiling with automatic trace merging enabled
|
||||
curl -X POST <BASE_URL>/start_profile \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"output_dir": "/tmp/profiles", # where to store profile traces
|
||||
"num_steps": 10,
|
||||
"activities": ["CPU", "GPU"],
|
||||
"merge_profiles": true # optional argument to merge profile traces (default=False)
|
||||
}'
|
||||
```
|
||||
|
||||
#### Command Line Usage
|
||||
|
||||
```bash
|
||||
# Start profiling with merge enabled
|
||||
python -m sglang.profiler \
|
||||
--num-steps 10 \
|
||||
--cpu \
|
||||
--gpu \
|
||||
--output-dir /tmp/profiles \
|
||||
--merge-profiles # optional argument to merge profile traces (default=False)
|
||||
```
|
||||
|
||||
#### Output Files
|
||||
|
||||
The profile merger generates:
|
||||
- Individual rank trace files: `{profile_id}-TP-{tp}-DP-{dp}-PP-{pp}-EP-{ep}.trace.json.gz`
|
||||
- Merged trace file: `merged-{profile_id}.trace.json.gz`
|
||||
|
||||
### Possible PyTorch bugs
|
||||
If in any cases you encounter the following error (for example, using qwen 2.5 VL):
|
||||
```bash
|
||||
|
||||
@@ -3,7 +3,7 @@
|
||||
You can install SGLang using one of the methods below.
|
||||
|
||||
This page primarily applies to common NVIDIA GPU platforms.
|
||||
For other or newer platforms, please refer to the dedicated pages for [AMD GPUs](../platforms/amd_gpu.md), [Intel Xeon CPUs](../platforms/cpu_server.md), [NVIDIA Jetson](../platforms/nvidia_jetson.md), [Ascend NPUs](../platforms/ascend_npu.md).
|
||||
For other or newer platforms, please refer to the dedicated pages for [NVIDIA Blackwell GPUs](../platforms/blackwell_gpu.md), [AMD GPUs](../platforms/amd_gpu.md), [Intel Xeon CPUs](../platforms/cpu_server.md), [NVIDIA Jetson](../platforms/nvidia_jetson.md), [Ascend NPUs](../platforms/ascend_npu.md).
|
||||
|
||||
## Method 1: With pip or uv
|
||||
|
||||
@@ -12,7 +12,7 @@ It is recommended to use uv for faster installation:
|
||||
```bash
|
||||
pip install --upgrade pip
|
||||
pip install uv
|
||||
uv pip install sglang --prerelease=allow
|
||||
uv pip install "sglang[all]>=0.5.3rc0"
|
||||
```
|
||||
|
||||
**Quick fixes to common problems**
|
||||
@@ -24,12 +24,12 @@ uv pip install sglang --prerelease=allow
|
||||
|
||||
```bash
|
||||
# Use the last release branch
|
||||
git clone -b v0.5.4 https://github.com/sgl-project/sglang.git
|
||||
git clone -b v0.5.3rc0 https://github.com/sgl-project/sglang.git
|
||||
cd sglang
|
||||
|
||||
# Install the python packages
|
||||
pip install --upgrade pip
|
||||
pip install -e "python"
|
||||
pip install -e "python[all]"
|
||||
```
|
||||
|
||||
**Quick fixes to common problems**
|
||||
@@ -51,8 +51,6 @@ docker run --gpus all \
|
||||
python3 -m sglang.launch_server --model-path meta-llama/Llama-3.1-8B-Instruct --host 0.0.0.0 --port 30000
|
||||
```
|
||||
|
||||
You can also find the nightly docker images [here](https://hub.docker.com/r/lmsysorg/sglang/tags?name=nightly).
|
||||
|
||||
## Method 4: Using Kubernetes
|
||||
|
||||
Please check out [OME](https://github.com/sgl-project/ome), a Kubernetes operator for enterprise-grade management and serving of large language models (LLMs).
|
||||
@@ -129,3 +127,5 @@ sky status --endpoint 30000 sglang
|
||||
|
||||
- [FlashInfer](https://github.com/flashinfer-ai/flashinfer) is the default attention kernel backend. It only supports sm75 and above. If you encounter any FlashInfer-related issues on sm75+ devices (e.g., T4, A10, A100, L4, L40S, H100), please switch to other kernels by adding `--attention-backend triton --sampling-backend pytorch` and open an issue on GitHub.
|
||||
- To reinstall flashinfer locally, use the following command: `pip3 install --upgrade flashinfer-python --force-reinstall --no-deps` and then delete the cache with `rm -rf ~/.cache/flashinfer`.
|
||||
- If you only need to use OpenAI API models with the frontend language, you can avoid installing other dependencies by using `pip install "sglang[openai]"`.
|
||||
- The language frontend operates independently of the backend runtime. You can install the frontend locally without needing a GPU, while the backend can be set up on a GPU-enabled machine. To install the frontend, run `pip install sglang`, and for the backend, use `pip install sglang[srt]`. `srt` is the abbreviation of SGLang runtime.
|
||||
|
||||
@@ -1,15 +1,14 @@
|
||||
SGLang Documentation
|
||||
====================
|
||||
|
||||
SGLang is a high-performance serving framework for large language models and vision-language models.
|
||||
It is designed to deliver low-latency and high-throughput inference across a wide range of setups, from a single GPU to large distributed clusters.
|
||||
Its core features include:
|
||||
SGLang is a fast serving framework for large language models and vision language models.
|
||||
It makes your interaction with models faster and more controllable by co-designing the backend runtime and frontend language.
|
||||
The core features include:
|
||||
|
||||
- **Fast Backend Runtime**: Provides efficient serving with RadixAttention for prefix caching, a zero-overhead CPU scheduler, prefill-decode disaggregation, speculative decoding, continuous batching, paged attention, tensor/pipeline/expert/data parallelism, structured outputs, chunked prefill, quantization (FP4/FP8/INT4/AWQ/GPTQ), and multi-LoRA batching.
|
||||
- **Extensive Model Support**: Supports a wide range of generative models (Llama, Qwen, DeepSeek, Kimi, GLM, GPT, Gemma, Mistral, etc.), embedding models (e5-mistral, gte, mcdse), and reward models (Skywork), with easy extensibility for integrating new models. Compatible with most Hugging Face models and OpenAI APIs.
|
||||
- **Extensive Hardware Support**: Runs on NVIDIA GPUs (GB200/B300/H100/A100/Spark), AMD GPUs (MI355/MI300), Intel Xeon CPUs, Google TPUs, Ascend NPUs, and more.
|
||||
- **Flexible Frontend Language**: Offers an intuitive interface for programming LLM applications, supporting chained generation calls, advanced prompting, control flow, multi-modal inputs, parallelism, and external interactions.
|
||||
- **Active Community**: SGLang is open-source and supported by a vibrant community with widespread industry adoption, powering over 300,000 GPUs worldwide.
|
||||
- **Fast Backend Runtime**: Provides efficient serving with RadixAttention for prefix caching, zero-overhead CPU scheduler, prefill-decode disaggregation, speculative decoding, continuous batching, paged attention, tensor/pipeline/expert/data parallelism, structured outputs, chunked prefill, quantization (FP4/FP8/INT4/AWQ/GPTQ), and multi-lora batching.
|
||||
- **Flexible Frontend Language**: Offers an intuitive interface for programming LLM applications, including chained generation calls, advanced prompting, control flow, multi-modal inputs, parallelism, and external interactions.
|
||||
- **Extensive Model Support**: Supports a wide range of generative models (Llama, Qwen, DeepSeek, Kimi, GPT, Gemma, Mistral, etc.), embedding models (e5-mistral, gte, mcdse) and reward models (Skywork), with easy extensibility for integrating new models.
|
||||
- **Active Community**: SGLang is open-source and backed by an active community with wide industry adoption.
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
@@ -37,7 +36,6 @@ Its core features include:
|
||||
|
||||
advanced_features/server_arguments.md
|
||||
advanced_features/hyperparameter_tuning.md
|
||||
advanced_features/attention_backend.md
|
||||
advanced_features/speculative_decoding.ipynb
|
||||
advanced_features/structured_outputs.ipynb
|
||||
advanced_features/structured_outputs_for_reasoning_models.ipynb
|
||||
@@ -46,12 +44,10 @@ Its core features include:
|
||||
advanced_features/quantization.md
|
||||
advanced_features/lora.ipynb
|
||||
advanced_features/pd_disaggregation.md
|
||||
advanced_features/hicache.rst
|
||||
advanced_features/pd_multiplexing.md
|
||||
advanced_features/vlm_query.ipynb
|
||||
advanced_features/router.md
|
||||
advanced_features/deterministic_inference.md
|
||||
advanced_features/observability.md
|
||||
advanced_features/attention_backend.md
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
@@ -76,7 +72,6 @@ Its core features include:
|
||||
platforms/tpu.md
|
||||
platforms/nvidia_jetson.md
|
||||
platforms/ascend_npu.md
|
||||
platforms/xpu.md
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
|
||||
@@ -44,7 +44,7 @@ You can install SGLang using one of the methods below.
|
||||
|
||||
```bash
|
||||
# Use the last release branch
|
||||
git clone -b v0.5.4 https://github.com/sgl-project/sglang.git
|
||||
git clone -b v0.5.3rc0 https://github.com/sgl-project/sglang.git
|
||||
cd sglang
|
||||
|
||||
# Compile sgl-kernel
|
||||
@@ -54,7 +54,6 @@ python setup_rocm.py install
|
||||
|
||||
# Install sglang python package
|
||||
cd ..
|
||||
rm -rf python/pyproject.toml && mv python/pyproject_other.toml python/pyproject.toml
|
||||
pip install -e "python[all_hip]"
|
||||
```
|
||||
|
||||
|
||||
@@ -99,7 +99,7 @@ We are also providing a DeepEP-compatible Library as a drop-in replacement of de
|
||||
|
||||
```shell
|
||||
# Use the last release branch
|
||||
git clone -b v0.5.4 https://github.com/sgl-project/sglang.git
|
||||
git clone -b v0.5.3rc0 https://github.com/sgl-project/sglang.git
|
||||
cd sglang
|
||||
|
||||
pip install --upgrade pip
|
||||
|
||||
9
docs/platforms/blackwell_gpu.md
Normal file
9
docs/platforms/blackwell_gpu.md
Normal file
@@ -0,0 +1,9 @@
|
||||
# Blackwell GPUs
|
||||
|
||||
We will release the pre-built wheels soon. Before that, please try to compile from source or check the blackwell docker images from [lmsysorg/sglang](https://hub.docker.com/r/lmsysorg/sglang/tags).
|
||||
|
||||
## B200 with x86 CPUs
|
||||
TODO
|
||||
|
||||
## GB200/GB300 with ARM CPUs
|
||||
TODO
|
||||
@@ -1,19 +1,18 @@
|
||||
# CPU Servers
|
||||
|
||||
The document addresses how to set up the [SGLang](https://github.com/sgl-project/sglang) environment and run LLM inference on CPU servers.
|
||||
SGLang is enabled and optimized on the CPUs equipped with Intel® AMX® Instructions,
|
||||
Specifically, SGLang is well optimized on the CPUs equipped with Intel® AMX® Instructions,
|
||||
which are 4th generation or newer Intel® Xeon® Scalable Processors.
|
||||
|
||||
## Optimized Model List
|
||||
|
||||
A list of popular LLMs are optimized and run efficiently on CPU,
|
||||
including the most notable open-source models like Llama series, Qwen series,
|
||||
and DeepSeek series like DeepSeek-R1 and DeepSeek-V3.1-Terminus.
|
||||
and the phenomenal high-quality reasoning model DeepSeek-R1.
|
||||
|
||||
| Model Name | BF16 | W8A8_INT8 | FP8 |
|
||||
| Model Name | BF16 | w8a8_int8 | FP8 |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| DeepSeek-R1 | | [meituan/DeepSeek-R1-Channel-INT8](https://huggingface.co/meituan/DeepSeek-R1-Channel-INT8) | [deepseek-ai/DeepSeek-R1](https://huggingface.co/deepseek-ai/DeepSeek-R1) |
|
||||
| DeepSeek-V3.1-Terminus | | [IntervitensInc/DeepSeek-V3.1-Terminus-Channel-int8](https://huggingface.co/IntervitensInc/DeepSeek-V3.1-Terminus-Channel-int8) | [deepseek-ai/DeepSeek-V3.1-Terminus](https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Terminus) |
|
||||
| Llama-3.2-3B | [meta-llama/Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct) | [RedHatAI/Llama-3.2-3B-quantized.w8a8](https://huggingface.co/RedHatAI/Llama-3.2-3B-Instruct-quantized.w8a8) | |
|
||||
| Llama-3.1-8B | [meta-llama/Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct) | [RedHatAI/Meta-Llama-3.1-8B-quantized.w8a8](https://huggingface.co/RedHatAI/Meta-Llama-3.1-8B-quantized.w8a8) | |
|
||||
| QwQ-32B | | [RedHatAI/QwQ-32B-quantized.w8a8](https://huggingface.co/RedHatAI/QwQ-32B-quantized.w8a8) | |
|
||||
@@ -37,7 +36,7 @@ git clone https://github.com/sgl-project/sglang.git
|
||||
cd sglang/docker
|
||||
|
||||
# Build the docker image
|
||||
docker build -t sglang-cpu:latest -f Dockerfile.xeon .
|
||||
docker build -t sglang-cpu:main -f Dockerfile.xeon .
|
||||
|
||||
# Initiate a docker container
|
||||
docker run \
|
||||
@@ -49,7 +48,7 @@ docker run \
|
||||
-v ~/.cache/huggingface:/root/.cache/huggingface \
|
||||
-p 30000:30000 \
|
||||
-e "HF_TOKEN=<secret>" \
|
||||
sglang-cpu:latest /bin/bash
|
||||
sglang-cpu:main /bin/bash
|
||||
```
|
||||
|
||||
### Install From Source
|
||||
@@ -83,16 +82,15 @@ cd sglang
|
||||
git checkout <YOUR-DESIRED-VERSION>
|
||||
|
||||
# Use dedicated toml file
|
||||
cd python
|
||||
cp pyproject_cpu.toml pyproject.toml
|
||||
cp python/pyproject_other.toml python/pyproject.toml
|
||||
# Install SGLang dependent libs, and build SGLang main package
|
||||
pip install --upgrade pip setuptools
|
||||
conda install -y libsqlite==3.48.0 gperftools tbb libnuma numactl
|
||||
pip install .
|
||||
pip install -e "python[all_cpu]"
|
||||
pip install torch==2.7.1 torchvision==0.22.1 triton==3.3.1 --force-reinstall
|
||||
|
||||
# Build the CPU backend kernels
|
||||
cd ../sgl-kernel
|
||||
cd sgl-kernel
|
||||
cp pyproject_cpu.toml pyproject.toml
|
||||
pip install .
|
||||
|
||||
@@ -122,9 +120,9 @@ Notes:
|
||||
|
||||
2. The flag `--tp 6` specifies that tensor parallelism will be applied using 6 ranks (TP6).
|
||||
The number of TP specified is how many TP ranks will be used during the execution.
|
||||
On a CPU platform, a TP rank means a sub-NUMA cluster (SNC).
|
||||
Usually we can get the SNC information (How many available) from the Operating System.
|
||||
Users can specify TP to be no more than the total available SNCs in current system.
|
||||
In a CPU platform, a TP rank means a sub-NUMA cluster (SNC).
|
||||
Usually we can get the SNC information (How many available) from Operation System.
|
||||
User can specify TP to be no more than the total available SNCs in current system.
|
||||
|
||||
If the specified TP rank number differs from the total SNC count,
|
||||
the system will automatically utilize the first `n` SNCs.
|
||||
@@ -176,29 +174,29 @@ Additionally, the requests can be formed with
|
||||
[OpenAI Completions API](https://docs.sglang.ai/basic_usage/openai_api_completions.html)
|
||||
and sent via the command line (e.g. using `curl`) or via your own script.
|
||||
|
||||
## Example: Running DeepSeek-V3.1-Terminus
|
||||
## Example: Running DeepSeek-R1
|
||||
|
||||
An example command to launch service for W8A8_INT8 DeepSeek-V3.1-Terminus on a Xeon® 6980P server:
|
||||
|
||||
```bash
|
||||
python -m sglang.launch_server \
|
||||
--model IntervitensInc/DeepSeek-V3.1-Terminus-Channel-int8 \
|
||||
--trust-remote-code \
|
||||
--disable-overlap-schedule \
|
||||
--device cpu \
|
||||
--quantization w8a8_int8 \
|
||||
--host 0.0.0.0 \
|
||||
--mem-fraction-static 0.8 \
|
||||
--enable-torch-compile \
|
||||
--torch-compile-max-bs 4 \
|
||||
--tp 6
|
||||
```
|
||||
|
||||
Similarly, an example command to launch service for FP8 DeepSeek-V3.1-Terminus would be:
|
||||
An example command to launch service for W8A8 DeepSeek-R1 on a Xeon® 6980P server
|
||||
|
||||
```bash
|
||||
python -m sglang.launch_server \
|
||||
--model deepseek-ai/DeepSeek-V3.1-Terminus \
|
||||
--model meituan/DeepSeek-R1-Channel-INT8 \
|
||||
--trust-remote-code \
|
||||
--disable-overlap-schedule \
|
||||
--device cpu \
|
||||
--quantization w8a8_int8 \
|
||||
--host 0.0.0.0 \
|
||||
--mem-fraction-static 0.8 \
|
||||
--enable-torch-compile \
|
||||
--torch-compile-max-bs 4 \
|
||||
--tp 6
|
||||
```
|
||||
|
||||
Similarly, an example command to launch service for FP8 DeepSeek-R1 would be
|
||||
|
||||
```bash
|
||||
python -m sglang.launch_server \
|
||||
--model deepseek-ai/DeepSeek-R1 \
|
||||
--trust-remote-code \
|
||||
--disable-overlap-schedule \
|
||||
--device cpu \
|
||||
|
||||
@@ -1,3 +1,3 @@
|
||||
# TPU
|
||||
|
||||
See https://github.com/sgl-project/sglang-jax
|
||||
The support for TPU is under active development. Please stay tuned.
|
||||
|
||||
@@ -1,92 +0,0 @@
|
||||
# XPU
|
||||
|
||||
The document addresses how to set up the [SGLang](https://github.com/sgl-project/sglang) environment and run LLM inference on Intel GPU, [see more context about Intel GPU support within PyTorch ecosystem](https://docs.pytorch.org/docs/stable/notes/get_start_xpu.html).
|
||||
|
||||
Specifically, SGLang is optimized for [Intel® Arc™ Pro B-Series Graphics](https://www.intel.com/content/www/us/en/ark/products/series/242616/intel-arc-pro-b-series-graphics.html) and [
|
||||
Intel® Arc™ B-Series Graphics](https://www.intel.com/content/www/us/en/ark/products/series/240391/intel-arc-b-series-graphics.html).
|
||||
|
||||
## Optimized Model List
|
||||
|
||||
A list of LLMs have been optimized on Intel GPU, and more are on the way:
|
||||
|
||||
| Model Name | BF16 |
|
||||
|:---:|:---:|
|
||||
| Llama-3.2-3B | [meta-llama/Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct) |
|
||||
| Llama-3.1-8B | [meta-llama/Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct) |
|
||||
| Qwen2.5-1.5B | [Qwen/Qwen2.5-1.5B](https://huggingface.co/Qwen/Qwen2.5-1.5B) |
|
||||
|
||||
**Note:** The model identifiers listed in the table above
|
||||
have been verified on [Intel® Arc™ B580 Graphics](https://www.intel.com/content/www/us/en/products/sku/241598/intel-arc-b580-graphics/specifications.html).
|
||||
|
||||
## Installation
|
||||
|
||||
### Install From Source
|
||||
|
||||
Currently SGLang XPU only supports installation from source. Please refer to ["Getting Started on Intel GPU"](https://docs.pytorch.org/docs/stable/notes/get_start_xpu.html) to install XPU dependency.
|
||||
|
||||
```bash
|
||||
# Create and activate a conda environment
|
||||
conda create -n sgl-xpu python=3.12 -y
|
||||
conda activate sgl-xpu
|
||||
|
||||
# Set PyTorch XPU as primary pip install channel to avoid installing the larger CUDA-enabled version and prevent potential runtime issues.
|
||||
pip3 install torch==2.8.0+xpu torchao torchvision torchaudio pytorch-triton-xpu==3.4.0 --index-url https://download.pytorch.org/whl/xpu
|
||||
pip3 install xgrammar --no-deps # xgrammar will introduce CUDA-enabled triton which might conflict with XPU
|
||||
|
||||
# Clone the SGLang code
|
||||
git clone https://github.com/sgl-project/sglang.git
|
||||
cd sglang
|
||||
git checkout <YOUR-DESIRED-VERSION>
|
||||
|
||||
# Use dedicated toml file
|
||||
cd python
|
||||
cp pyproject_xpu.toml pyproject.toml
|
||||
# Install SGLang dependent libs, and build SGLang main package
|
||||
pip install --upgrade pip setuptools
|
||||
pip install -v .
|
||||
```
|
||||
|
||||
### Install Using Docker
|
||||
|
||||
The docker for XPU is under active development. Please stay tuned.
|
||||
|
||||
## Launch of the Serving Engine
|
||||
|
||||
Example command to launch SGLang serving:
|
||||
|
||||
```bash
|
||||
python -m sglang.launch_server \
|
||||
--model <MODEL_ID_OR_PATH> \
|
||||
--trust-remote-code \
|
||||
--disable-overlap-schedule \
|
||||
--device xpu \
|
||||
--host 0.0.0.0 \
|
||||
--tp 2 \ # using multi GPUs
|
||||
--attention-backend intel_xpu \ # using intel optimized XPU attention backend
|
||||
--page-size \ # intel_xpu attention backend supports [32, 64, 128]
|
||||
```
|
||||
|
||||
## Benchmarking with Requests
|
||||
|
||||
You can benchmark the performance via the `bench_serving` script.
|
||||
Run the command in another terminal.
|
||||
|
||||
```bash
|
||||
python -m sglang.bench_serving \
|
||||
--dataset-name random \
|
||||
--random-input-len 1024 \
|
||||
--random-output-len 1024 \
|
||||
--num-prompts 1 \
|
||||
--request-rate inf \
|
||||
--random-range-ratio 1.0
|
||||
```
|
||||
|
||||
The detail explanations of the parameters can be looked up by the command:
|
||||
|
||||
```bash
|
||||
python -m sglang.bench_serving -h
|
||||
```
|
||||
|
||||
Additionally, the requests can be formed with
|
||||
[OpenAI Completions API](https://docs.sglang.ai/basic_usage/openai_api_completions.html)
|
||||
and sent via the command line (e.g. using `curl`) or via your own script.
|
||||
@@ -32,9 +32,9 @@ SGLang supports various environment variables that can be used to configure its
|
||||
|
||||
| Environment Variable | Description | Default Value |
|
||||
| --- | --- | --- |
|
||||
| `SGLANG_ENABLE_JIT_DEEPGEMM` | Enable Just-In-Time compilation of DeepGEMM kernels | `"true"` |
|
||||
| `SGLANG_JIT_DEEPGEMM_PRECOMPILE` | Enable precompilation of DeepGEMM kernels | `"true"` |
|
||||
| `SGLANG_JIT_DEEPGEMM_COMPILE_WORKERS` | Number of workers for parallel DeepGEMM kernel compilation | `4` |
|
||||
| `SGL_ENABLE_JIT_DEEPGEMM` | Enable Just-In-Time compilation of DeepGEMM kernels | `"true"` |
|
||||
| `SGL_JIT_DEEPGEMM_PRECOMPILE` | Enable precompilation of DeepGEMM kernels | `"true"` |
|
||||
| `SGL_JIT_DEEPGEMM_COMPILE_WORKERS` | Number of workers for parallel DeepGEMM kernel compilation | `4` |
|
||||
| `SGL_IN_DEEPGEMM_PRECOMPILE_STAGE` | Indicator flag used during the DeepGEMM precompile script | `"false"` |
|
||||
| `SGL_DG_CACHE_DIR` | Directory for caching compiled DeepGEMM kernels | `~/.cache/deep_gemm` |
|
||||
| `SGL_DG_USE_NVRTC` | Use NVRTC (instead of Triton) for JIT compilation (Experimental) | `"0"` |
|
||||
@@ -74,7 +74,6 @@ SGLang supports various environment variables that can be used to configure its
|
||||
| `SGLANG_BLOCK_NONZERO_RANK_CHILDREN` | Control blocking of non-zero rank children processes | `1` |
|
||||
| `SGL_IS_FIRST_RANK_ON_NODE` | Indicates if the current process is the first rank on its node | `"true"` |
|
||||
| `SGLANG_PP_LAYER_PARTITION` | Pipeline parallel layer partition specification | Not set |
|
||||
| `SGLANG_ONE_VISIBLE_DEVICE_PER_PROCESS` | Set one visible device per process for distributed computing | `false` |
|
||||
|
||||
## Testing & Debugging (Internal/CI)
|
||||
|
||||
@@ -83,7 +82,7 @@ SGLang supports various environment variables that can be used to configure its
|
||||
| Environment Variable | Description | Default Value |
|
||||
| --- | --- | --- |
|
||||
| `SGLANG_IS_IN_CI` | Indicates if running in CI environment | `false` |
|
||||
| `SGLANG_IS_IN_CI_AMD` | Indicates running in AMD CI environment | `0` |
|
||||
| `SGLANG_AMD_CI` | Indicates running in AMD CI environment | `0` |
|
||||
| `SGLANG_TEST_RETRACT` | Enable retract decode testing | `false` |
|
||||
| `SGLANG_RECORD_STEP_TIME` | Record step time for profiling | `false` |
|
||||
| `SGLANG_TEST_REQUEST_TIME_STATS` | Test request time statistics | `false` |
|
||||
@@ -100,5 +99,4 @@ SGLang supports various environment variables that can be used to configure its
|
||||
|
||||
| Environment Variable | Description | Default Value |
|
||||
| --- | --- | --- |
|
||||
| `SGLANG_WAIT_WEIGHTS_READY_TIMEOUT` | Timeout period for waiting on weights | `120` |
|
||||
| `SGLANG_DISABLE_OUTLINES_DISK_CACHE` | Disable Outlines disk cache | `true` |
|
||||
|
||||
@@ -80,7 +80,7 @@ spec:
|
||||
value: "true"
|
||||
- name: SGLANG_MOONCAKE_TRANS_THREAD
|
||||
value: "16"
|
||||
- name: SGLANG_ENABLE_JIT_DEEPGEMM
|
||||
- name: SGL_ENABLE_JIT_DEEPGEMM
|
||||
value: "1"
|
||||
- name: NCCL_IB_HCA
|
||||
value: ^=mlx5_0,mlx5_5,mlx5_6
|
||||
@@ -217,7 +217,7 @@ spec:
|
||||
value: "5"
|
||||
- name: SGLANG_MOONCAKE_TRANS_THREAD
|
||||
value: "16"
|
||||
- name: SGLANG_ENABLE_JIT_DEEPGEMM
|
||||
- name: SGL_ENABLE_JIT_DEEPGEMM
|
||||
value: "1"
|
||||
- name: NCCL_IB_HCA
|
||||
value: ^=mlx5_0,mlx5_5,mlx5_6
|
||||
|
||||
@@ -71,7 +71,7 @@ spec:
|
||||
value: "1"
|
||||
- name: SGLANG_SET_CPU_AFFINITY
|
||||
value: "true"
|
||||
- name: SGLANG_ENABLE_JIT_DEEPGEMM
|
||||
- name: SGL_ENABLE_JIT_DEEPGEMM
|
||||
value: "1"
|
||||
- name: NCCL_IB_QPS_PER_CONNECTION
|
||||
value: "8"
|
||||
@@ -224,7 +224,7 @@ spec:
|
||||
value: "0"
|
||||
- name: SGLANG_MOONCAKE_TRANS_THREAD
|
||||
value: "8"
|
||||
- name: SGLANG_ENABLE_JIT_DEEPGEMM
|
||||
- name: SGL_ENABLE_JIT_DEEPGEMM
|
||||
value: "1"
|
||||
- name: SGL_CHUNKED_PREFIX_CACHE_THRESHOLD
|
||||
value: "0"
|
||||
|
||||
@@ -98,7 +98,7 @@ spec:
|
||||
value: "1"
|
||||
- name: SGLANG_SET_CPU_AFFINITY
|
||||
value: "true"
|
||||
- name: SGLANG_ENABLE_JIT_DEEPGEMM
|
||||
- name: SGL_ENABLE_JIT_DEEPGEMM
|
||||
value: "1"
|
||||
- name: NCCL_IB_QPS_PER_CONNECTION
|
||||
value: "8"
|
||||
@@ -257,7 +257,7 @@ spec:
|
||||
value: "0"
|
||||
- name: SGLANG_MOONCAKE_TRANS_THREAD
|
||||
value: "8"
|
||||
- name: SGLANG_ENABLE_JIT_DEEPGEMM
|
||||
- name: SGL_ENABLE_JIT_DEEPGEMM
|
||||
value: "1"
|
||||
- name: SGL_CHUNKED_PREFIX_CACHE_THRESHOLD
|
||||
value: "0"
|
||||
@@ -421,7 +421,7 @@ spec:
|
||||
value: "true"
|
||||
- name: SGLANG_MOONCAKE_TRANS_THREAD
|
||||
value: "16"
|
||||
- name: SGLANG_ENABLE_JIT_DEEPGEMM
|
||||
- name: SGL_ENABLE_JIT_DEEPGEMM
|
||||
value: "1"
|
||||
- name: NCCL_IB_HCA
|
||||
value: ^=mlx5_0,mlx5_5,mlx5_6
|
||||
@@ -560,7 +560,7 @@ spec:
|
||||
value: "5"
|
||||
- name: SGLANG_MOONCAKE_TRANS_THREAD
|
||||
value: "16"
|
||||
- name: SGLANG_ENABLE_JIT_DEEPGEMM
|
||||
- name: SGL_ENABLE_JIT_DEEPGEMM
|
||||
value: "1"
|
||||
- name: NCCL_IB_HCA
|
||||
value: ^=mlx5_0,mlx5_5,mlx5_6
|
||||
|
||||
@@ -16,5 +16,5 @@ sphinx-tabs
|
||||
nbstripout
|
||||
sphinxcontrib-mermaid
|
||||
urllib3<2.0.0
|
||||
gguf>=0.17.1
|
||||
gguf>=0.10.0
|
||||
sphinx-autobuild
|
||||
|
||||
@@ -1,162 +0,0 @@
|
||||
# Classification API
|
||||
|
||||
This document describes the `/v1/classify` API endpoint implementation in SGLang, which is compatible with vLLM's classification API format.
|
||||
|
||||
## Overview
|
||||
|
||||
The classification API allows you to classify text inputs using classification models. This implementation follows the same format as vLLM's 0.7.0 classification API.
|
||||
|
||||
## API Endpoint
|
||||
|
||||
```
|
||||
POST /v1/classify
|
||||
```
|
||||
|
||||
## Request Format
|
||||
|
||||
```json
|
||||
{
|
||||
"model": "model_name",
|
||||
"input": "text to classify"
|
||||
}
|
||||
```
|
||||
|
||||
### Parameters
|
||||
|
||||
- `model` (string, required): The name of the classification model to use
|
||||
- `input` (string, required): The text to classify
|
||||
- `user` (string, optional): User identifier for tracking
|
||||
- `rid` (string, optional): Request ID for tracking
|
||||
- `priority` (integer, optional): Request priority
|
||||
|
||||
## Response Format
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "classify-9bf17f2847b046c7b2d5495f4b4f9682",
|
||||
"object": "list",
|
||||
"created": 1745383213,
|
||||
"model": "jason9693/Qwen2.5-1.5B-apeach",
|
||||
"data": [
|
||||
{
|
||||
"index": 0,
|
||||
"label": "Default",
|
||||
"probs": [0.565970778465271, 0.4340292513370514],
|
||||
"num_classes": 2
|
||||
}
|
||||
],
|
||||
"usage": {
|
||||
"prompt_tokens": 10,
|
||||
"total_tokens": 10,
|
||||
"completion_tokens": 0,
|
||||
"prompt_tokens_details": null
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Response Fields
|
||||
|
||||
- `id`: Unique identifier for the classification request
|
||||
- `object`: Always "list"
|
||||
- `created`: Unix timestamp when the request was created
|
||||
- `model`: The model used for classification
|
||||
- `data`: Array of classification results
|
||||
- `index`: Index of the result
|
||||
- `label`: Predicted class label
|
||||
- `probs`: Array of probabilities for each class
|
||||
- `num_classes`: Total number of classes
|
||||
- `usage`: Token usage information
|
||||
- `prompt_tokens`: Number of input tokens
|
||||
- `total_tokens`: Total number of tokens
|
||||
- `completion_tokens`: Number of completion tokens (always 0 for classification)
|
||||
- `prompt_tokens_details`: Additional token details (optional)
|
||||
|
||||
## Example Usage
|
||||
|
||||
### Using curl
|
||||
|
||||
```bash
|
||||
curl -v "http://127.0.0.1:8000/v1/classify" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "jason9693/Qwen2.5-1.5B-apeach",
|
||||
"input": "Loved the new café—coffee was great."
|
||||
}'
|
||||
```
|
||||
|
||||
### Using Python
|
||||
|
||||
```python
|
||||
import requests
|
||||
import json
|
||||
|
||||
# Make classification request
|
||||
response = requests.post(
|
||||
"http://127.0.0.1:8000/v1/classify",
|
||||
headers={"Content-Type": "application/json"},
|
||||
json={
|
||||
"model": "jason9693/Qwen2.5-1.5B-apeach",
|
||||
"input": "Loved the new café—coffee was great."
|
||||
}
|
||||
)
|
||||
|
||||
# Parse response
|
||||
result = response.json()
|
||||
print(json.dumps(result, indent=2))
|
||||
```
|
||||
|
||||
## Supported Models
|
||||
|
||||
The classification API works with any classification model supported by SGLang, including:
|
||||
|
||||
### Classification Models (Multi-class)
|
||||
- `LlamaForSequenceClassification` - Multi-class classification
|
||||
- `Qwen2ForSequenceClassification` - Multi-class classification
|
||||
- `Qwen3ForSequenceClassification` - Multi-class classification
|
||||
- `BertForSequenceClassification` - Multi-class classification
|
||||
- `Gemma2ForSequenceClassification` - Multi-class classification
|
||||
|
||||
**Label Mapping**: The API automatically uses the `id2label` mapping from the model's `config.json` file to provide meaningful label names instead of generic class names. If `id2label` is not available, it falls back to `LABEL_0`, `LABEL_1`, etc., or `Class_0`, `Class_1` as a last resort.
|
||||
|
||||
### Reward Models (Single score)
|
||||
- `InternLM2ForRewardModel` - Single reward score
|
||||
- `Qwen2ForRewardModel` - Single reward score
|
||||
- `LlamaForSequenceClassificationWithNormal_Weights` - Special reward model
|
||||
|
||||
**Note**: The `/classify` endpoint in SGLang was originally designed for reward models but now supports all non-generative models. Our `/v1/classify` endpoint provides a standardized vLLM-compatible interface for classification tasks.
|
||||
|
||||
## Error Handling
|
||||
|
||||
The API returns appropriate HTTP status codes and error messages:
|
||||
|
||||
- `400 Bad Request`: Invalid request format or missing required fields
|
||||
- `500 Internal Server Error`: Server-side processing error
|
||||
|
||||
Error response format:
|
||||
```json
|
||||
{
|
||||
"error": "Error message",
|
||||
"type": "error_type",
|
||||
"code": 400
|
||||
}
|
||||
```
|
||||
|
||||
## Implementation Details
|
||||
|
||||
The classification API is implemented using:
|
||||
|
||||
1. **Rust Router**: Handles routing and request/response models in `sgl-router/src/protocols/spec.rs`
|
||||
2. **Python HTTP Server**: Implements the actual endpoint in `python/sglang/srt/entrypoints/http_server.py`
|
||||
3. **Classification Service**: Handles the classification logic in `python/sglang/srt/entrypoints/openai/serving_classify.py`
|
||||
|
||||
## Testing
|
||||
|
||||
Use the provided test script to verify the implementation:
|
||||
|
||||
```bash
|
||||
python test_classify_api.py
|
||||
```
|
||||
|
||||
## Compatibility
|
||||
|
||||
This implementation is compatible with vLLM's classification API format, allowing seamless migration from vLLM to SGLang for classification tasks.
|
||||
@@ -33,7 +33,6 @@ in the GitHub search bar.
|
||||
| **Gemma** (v1, v2, v3) | `google/gemma-3-1b-it` | Google’s family of efficient multilingual models (1B–27B); Gemma 3 offers a 128K context window, and its larger (4B+) variants support vision input. |
|
||||
| **Phi** (Phi-1.5, Phi-2, Phi-3, Phi-4, Phi-MoE series) | `microsoft/Phi-4-multimodal-instruct`, `microsoft/Phi-3.5-MoE-instruct` | Microsoft’s Phi family of small models (1.3B–5.6B); Phi-4-multimodal (5.6B) processes text, images, and speech, Phi-4-mini is a high-accuracy text model and Phi-3.5-MoE is a mixture-of-experts model. |
|
||||
| **MiniCPM** (v3, 4B) | `openbmb/MiniCPM3-4B` | OpenBMB’s series of compact LLMs for edge devices; MiniCPM 3 (4B) achieves GPT-3.5-level results in text tasks. |
|
||||
| **OLMo** (2, 3) | `allenai/OLMo-2-1124-7B-Instruct` | Allen AI’s series of Open Language Models designed to enable the science of language models. |
|
||||
| **OLMoE** (Open MoE) | `allenai/OLMoE-1B-7B-0924` | Allen AI’s open Mixture-of-Experts model (7B total, 1B active parameters) delivering state-of-the-art results with sparse expert activation. |
|
||||
| **StableLM** (3B, 7B) | `stabilityai/stablelm-tuned-alpha-7b` | StabilityAI’s early open-source LLM (3B & 7B) for general text generation; a demonstration model with basic instruction-following ability. |
|
||||
| **Command-R** (Cohere) | `CohereForAI/c4ai-command-r-v01` | Cohere’s open conversational LLM (Command series) optimized for long context, retrieval-augmented generation, and tool use. |
|
||||
@@ -54,7 +53,5 @@ in the GitHub search bar.
|
||||
| **Ling** (16.8B–290B) | `inclusionAI/Ling-lite`, `inclusionAI/Ling-plus` | InclusionAI’s open MoE models. Ling-Lite has 16.8B total / 2.75B active parameters, and Ling-Plus has 290B total / 28.8B active parameters. They are designed for high performance on NLP and complex reasoning tasks. |
|
||||
| **Granite 3.0, 3.1** (IBM) | `ibm-granite/granite-3.1-8b-instruct` | IBM's open dense foundation models optimized for reasoning, code, and business AI use cases. Integrated with Red Hat and watsonx systems. |
|
||||
| **Granite 3.0 MoE** (IBM) | `ibm-granite/granite-3.0-3b-a800m-instruct` | IBM’s Mixture-of-Experts models offering strong performance with cost-efficiency. MoE expert routing designed for enterprise deployment at scale. |
|
||||
| **Llama Nemotron Super** (v1, v1.5, NVIDIA) | `nvidia/Llama-3_3-Nemotron-Super-49B-v1`, `nvidia/Llama-3_3-Nemotron-Super-49B-v1_5` | The [NVIDIA Nemotron](https://www.nvidia.com/en-us/ai-data-science/foundation-models/nemotron/) family of multimodal models provides state-of-the-art reasoning models specifically designed for enterprise-ready AI agents. |
|
||||
| **Llama Nemotron Ultra** (v1, NVIDIA) | `nvidia/Llama-3_1-Nemotron-Ultra-253B-v1` | The [NVIDIA Nemotron](https://www.nvidia.com/en-us/ai-data-science/foundation-models/nemotron/) family of multimodal models provides state-of-the-art reasoning models specifically designed for enterprise-ready AI agents. |
|
||||
| **NVIDIA Nemotron Nano 2.0** | `nvidia/NVIDIA-Nemotron-Nano-9B-v2` | The [NVIDIA Nemotron](https://www.nvidia.com/en-us/ai-data-science/foundation-models/nemotron/) family of multimodal models provides state-of-the-art reasoning models specifically designed for enterprise-ready AI agents. `Nemotron-Nano-9B-v2` is a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. |
|
||||
| **StarCoder2** (3B-15B) | `bigcode/starcoder2-7b` | StarCoder2 is a family of open large language models (LLMs) specialized for code generation and understanding. It is the successor to StarCoder, jointly developed by the BigCode project (a collaboration between Hugging Face, ServiceNow Research, and other contributors). |
|
||||
| **Llama Nemotron Super** (v1, v1.5, NVIDIA) | `nvidia/Llama-3_3-Nemotron-Super-49B-v1`, `nvidia/Llama-3_3-Nemotron-Super-49B-v1_5` | The [NVIDIA Nemotron](https://www.nvidia.com/en-us/ai-data-science/foundation-models/nemotron/) family builds on the strongest open models in the ecosystem by enhancing them with greater accuracy, efficiency, and transparency using NVIDIA open synthetic datasets, advanced techniques, and tools. This enables the creation of practical, right-sized, and high-performing AI agents. |
|
||||
| **Llama Nemotron Ultra** (v1, NVIDIA) | `nvidia/Llama-3_1-Nemotron-Ultra-253B-v1` | The [NVIDIA Nemotron](https://www.nvidia.com/en-us/ai-data-science/foundation-models/nemotron/) family builds on the strongest open models in the ecosystem by enhancing them with greater accuracy, efficiency, and transparency using NVIDIA open synthetic datasets, advanced techniques, and tools. This enables the creation of practical, right-sized, and high-performing AI agents. |
|
||||
|
||||
@@ -11,8 +11,6 @@ python3 -m sglang.launch_server \
|
||||
--port 30000 \
|
||||
```
|
||||
|
||||
> See the [OpenAI APIs section](https://docs.sglang.ai/basic_usage/openai_api_vision.html) for how to send multimodal requests.
|
||||
|
||||
## Supported models
|
||||
|
||||
Below the supported models are summarized in a table.
|
||||
@@ -26,32 +24,19 @@ repo:sgl-project/sglang path:/^python\/sglang\/srt\/models\// Qwen2_5_VLForCondi
|
||||
in the GitHub search bar.
|
||||
|
||||
|
||||
| Model Family (Variants) | Example HuggingFace Identifier | Description | Notes |
|
||||
|----------------------------|--------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------|
|
||||
| **Qwen-VL** | `Qwen/Qwen3-VL-235B-A22B-Instruct` | Alibaba's vision-language extension of Qwen; for example, Qwen2.5-VL (7B and larger variants) can analyze and converse about image content. | |
|
||||
| **DeepSeek-VL2** | `deepseek-ai/deepseek-vl2` | Vision-language variant of DeepSeek (with a dedicated image processor), enabling advanced multimodal reasoning on image and text inputs. | |
|
||||
| **Janus-Pro** (1B, 7B) | `deepseek-ai/Janus-Pro-7B` | DeepSeek's open-source multimodal model capable of both image understanding and generation. Janus-Pro employs a decoupled architecture for separate visual encoding paths, enhancing performance in both tasks. | |
|
||||
| **MiniCPM-V / MiniCPM-o** | `openbmb/MiniCPM-V-2_6` | MiniCPM-V (2.6, ~8B) supports image inputs, and MiniCPM-o adds audio/video; these multimodal LLMs are optimized for end-side deployment on mobile/edge devices. | |
|
||||
| **Llama 3.2 Vision** (11B) | `meta-llama/Llama-3.2-11B-Vision-Instruct` | Vision-enabled variant of Llama 3 (11B) that accepts image inputs for visual question answering and other multimodal tasks. | |
|
||||
| **LLaVA** (v1.5 & v1.6) | *e.g.* `liuhaotian/llava-v1.5-13b` | Open vision-chat models that add an image encoder to LLaMA/Vicuna (e.g. LLaMA2 13B) for following multimodal instruction prompts. | |
|
||||
| **LLaVA-NeXT** (8B, 72B) | `lmms-lab/llava-next-72b` | Improved LLaVA models (with an 8B Llama3 version and a 72B version) offering enhanced visual instruction-following and accuracy on multimodal benchmarks. | |
|
||||
| **LLaVA-OneVision** | `lmms-lab/llava-onevision-qwen2-7b-ov` | Enhanced LLaVA variant integrating Qwen as the backbone; supports multiple images (and even video frames) as inputs via an OpenAI Vision API-compatible format. | |
|
||||
| **Gemma 3 (Multimodal)** | `google/gemma-3-4b-it` | Gemma 3's larger models (4B, 12B, 27B) accept images (each image encoded as 256 tokens) alongside text in a combined 128K-token context. | |
|
||||
| **Kimi-VL** (A3B) | `moonshotai/Kimi-VL-A3B-Instruct` | Kimi-VL is a multimodal model that can understand and generate text from images. | |
|
||||
| **Mistral-Small-3.1-24B** | `mistralai/Mistral-Small-3.1-24B-Instruct-2503` | Mistral 3.1 is a multimodal model that can generate text from text or images input. It also supports tool calling and structured output. | |
|
||||
| **Phi-4-multimodal-instruct** | `microsoft/Phi-4-multimodal-instruct` | Phi-4-multimodal-instruct is the multimodal variant of the Phi-4-mini model, enhanced with LoRA for improved multimodal capabilities. It supports text, vision and audio modalities in SGLang. | |
|
||||
| **MiMo-VL** (7B) | `XiaomiMiMo/MiMo-VL-7B-RL` | Xiaomi's compact yet powerful vision-language model featuring a native resolution ViT encoder for fine-grained visual details, an MLP projector for cross-modal alignment, and the MiMo-7B language model optimized for complex reasoning tasks. | |
|
||||
| **GLM-4.5V** (106B) / **GLM-4.1V**(9B) | `zai-org/GLM-4.5V` | GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning | Use `--chat-template glm-4v` |
|
||||
| **DotsVLM** (General/OCR) | `rednote-hilab/dots.vlm1.inst` | RedNote's vision-language model built on a 1.2B vision encoder and DeepSeek V3 LLM, featuring NaViT vision encoder trained from scratch with dynamic resolution support and enhanced OCR capabilities through structured image data training. | |
|
||||
| **DotsVLM-OCR** | `rednote-hilab/dots.ocr` | Specialized OCR variant of DotsVLM optimized for optical character recognition tasks with enhanced text extraction and document understanding capabilities. | Don't use `--trust-remote-code` |
|
||||
|
||||
## Usage Notes
|
||||
|
||||
### Performance Optimization
|
||||
|
||||
For multimodal models, you can use the `--keep-mm-feature-on-device` flag to optimize for latency at the cost of increased GPU memory usage:
|
||||
|
||||
- **Default behavior**: Multimodal feature tensors are moved to CPU after processing to save GPU memory
|
||||
- **With `--keep-mm-feature-on-device`**: Feature tensors remain on GPU, reducing device-to-host copy overhead and improving latency, but consuming more GPU memory
|
||||
|
||||
Use this flag when you have sufficient GPU memory and want to minimize latency for multimodal inference.
|
||||
| Model Family (Variants) | Example HuggingFace Identifier | Chat Template | Description |
|
||||
|----------------------------|--------------------------------------------|------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| **Qwen-VL** (Qwen2 series) | `Qwen/Qwen2.5-VL-7B-Instruct` | `qwen2-vl` | Alibaba’s vision-language extension of Qwen; for example, Qwen2.5-VL (7B and larger variants) can analyze and converse about image content. |
|
||||
| **DeepSeek-VL2** | `deepseek-ai/deepseek-vl2` | `deepseek-vl2` | Vision-language variant of DeepSeek (with a dedicated image processor), enabling advanced multimodal reasoning on image and text inputs. |
|
||||
| **Janus-Pro** (1B, 7B) | `deepseek-ai/Janus-Pro-7B` | `janus-pro` | DeepSeek’s open-source multimodal model capable of both image understanding and generation. Janus-Pro employs a decoupled architecture for separate visual encoding paths, enhancing performance in both tasks. |
|
||||
| **MiniCPM-V / MiniCPM-o** | `openbmb/MiniCPM-V-2_6` | `minicpmv` | MiniCPM-V (2.6, ~8B) supports image inputs, and MiniCPM-o adds audio/video; these multimodal LLMs are optimized for end-side deployment on mobile/edge devices. |
|
||||
| **Llama 3.2 Vision** (11B) | `meta-llama/Llama-3.2-11B-Vision-Instruct` | `llama_3_vision` | Vision-enabled variant of Llama 3 (11B) that accepts image inputs for visual question answering and other multimodal tasks. |
|
||||
| **LLaVA** (v1.5 & v1.6) | *e.g.* `liuhaotian/llava-v1.5-13b` | `vicuna_v1.1` | Open vision-chat models that add an image encoder to LLaMA/Vicuna (e.g. LLaMA2 13B) for following multimodal instruction prompts. |
|
||||
| **LLaVA-NeXT** (8B, 72B) | `lmms-lab/llava-next-72b` | `chatml-llava` | Improved LLaVA models (with an 8B Llama3 version and a 72B version) offering enhanced visual instruction-following and accuracy on multimodal benchmarks. |
|
||||
| **LLaVA-OneVision** | `lmms-lab/llava-onevision-qwen2-7b-ov` | `chatml-llava` | Enhanced LLaVA variant integrating Qwen as the backbone; supports multiple images (and even video frames) as inputs via an OpenAI Vision API-compatible format. |
|
||||
| **Gemma 3 (Multimodal)** | `google/gemma-3-4b-it` | `gemma-it` | Gemma 3's larger models (4B, 12B, 27B) accept images (each image encoded as 256 tokens) alongside text in a combined 128K-token context. |
|
||||
| **Kimi-VL** (A3B) | `moonshotai/Kimi-VL-A3B-Instruct` | `kimi-vl` | Kimi-VL is a multimodal model that can understand and generate text from images. |
|
||||
| **Mistral-Small-3.1-24B** | `mistralai/Mistral-Small-3.1-24B-Instruct-2503` | `mistral` | Mistral 3.1 is a multimodal model that can generate text from text or images input. It also supports tool calling and structured output. |
|
||||
| **Phi-4-multimodal-instruct** | `microsoft/Phi-4-multimodal-instruct` | `phi-4-mm` | Phi-4-multimodal-instruct is the multimodal variant of the Phi-4-mini model, enhanced with LoRA for improved multimodal capabilities. It supports text, vision and audio modalities in SGLang. |
|
||||
| **MiMo-VL** (7B) | `XiaomiMiMo/MiMo-VL-7B-RL` | `mimo-vl` | Xiaomi's compact yet powerful vision-language model featuring a native resolution ViT encoder for fine-grained visual details, an MLP projector for cross-modal alignment, and the MiMo-7B language model optimized for complex reasoning tasks. |
|
||||
| **GLM-4.5V** (106B) / **GLM-4.1V**(9B) | `zai-org/GLM-4.5V` | `glm-4v` | GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning |
|
||||
|
||||
@@ -1,100 +0,0 @@
|
||||
{% if not add_generation_prompt is defined %}
|
||||
{% set add_generation_prompt = false %}
|
||||
{% endif %}
|
||||
{% if not thinking is defined %}
|
||||
{% set thinking = false %}
|
||||
{% endif %}
|
||||
{% set ns = namespace(is_first=false, is_tool=false, system_prompt='', is_first_sp=true, is_last_user=false, is_only_sys=false, is_prefix=false) %}
|
||||
{%- for message in messages %}
|
||||
{%- if message['role'] == 'system' %}
|
||||
{%- if ns.is_first_sp %}
|
||||
{% set ns.system_prompt = ns.system_prompt + message['content'] %}
|
||||
{% set ns.is_first_sp = false %}
|
||||
{%- else %}
|
||||
{% set ns.system_prompt = ns.system_prompt + '\n\n' + message['content'] %}
|
||||
{%- endif %}
|
||||
{% set ns.is_only_sys = true %}
|
||||
{%- endif %}
|
||||
{%- endfor %}
|
||||
|
||||
{% if tools is defined and tools is not none %}
|
||||
{% set tool_ns = namespace(text='## Tools\nYou have access to the following tools:\n') %}
|
||||
{% for tool in tools %}
|
||||
{% set tool_ns.text = tool_ns.text + '\n### ' + tool.function.name + '\nDescription: ' + tool.function.description + '\n\nParameters: ' + (tool.function.parameters | tojson) + '\n' %}
|
||||
{% endfor %}
|
||||
{% set tool_ns.text = tool_ns.text + "\nIMPORTANT: ALWAYS adhere to this exact format for tool use:\n<|tool▁calls▁begin|><|tool▁call▁begin|>tool_call_name<|tool▁sep|>tool_call_arguments<|tool▁call▁end|>{{additional_tool_calls}}<|tool▁calls▁end|>\n\nWhere:\n\n- `tool_call_name` must be an exact match to one of the available tools\n- `tool_call_arguments` must be valid JSON that strictly follows the tool's Parameters Schema\n- For multiple tool calls, chain them directly without separators or spaces\n" %}
|
||||
{% set ns.system_prompt = ns.system_prompt + '\n\n' + tool_ns.text %}
|
||||
{% endif %}
|
||||
|
||||
{{ bos_token }}{{ ns.system_prompt }}
|
||||
{%- for message in messages %}
|
||||
{%- if message['role'] == 'user' %}
|
||||
{%- set ns.is_tool = false -%}
|
||||
{%- set ns.is_first = false -%}
|
||||
{%- set ns.is_last_user = true -%}
|
||||
{{'<|User|>' + message['content']}}
|
||||
{%- endif %}
|
||||
{%- if message['role'] == 'assistant' and message['tool_calls'] is defined and message['tool_calls'] is not none %}
|
||||
{%- if ns.is_last_user or ns.is_only_sys %}
|
||||
{{'<|Assistant|></think>'}}
|
||||
{%- endif %}
|
||||
{%- set ns.is_last_user = false -%}
|
||||
{%- set ns.is_first = false %}
|
||||
{%- set ns.is_tool = false -%}
|
||||
{%- for tool in message['tool_calls'] %}
|
||||
{%- if not ns.is_first %}
|
||||
{%- if message['content'] is none %}
|
||||
{{'<|tool▁calls▁begin|><|tool▁call▁begin|>'+ tool['function']['name'] + '<|tool▁sep|>' + tool['function']['arguments']|tojson + '<|tool▁call▁end|>'}}
|
||||
{%- else %}
|
||||
{{message['content'] + '<|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['function']['name'] + '<|tool▁sep|>' + tool['function']['arguments']|tojson + '<|tool▁call▁end|>'}}
|
||||
{%- endif %}
|
||||
{%- set ns.is_first = true -%}
|
||||
{%- else %}
|
||||
{{'<|tool▁call▁begin|>'+ tool['function']['name'] + '<|tool▁sep|>' + tool['function']['arguments']|tojson + '<|tool▁call▁end|>'}}
|
||||
{%- endif %}
|
||||
{%- endfor %}
|
||||
{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}
|
||||
{%- endif %}
|
||||
{%- if message['role'] == 'assistant' and (message['tool_calls'] is not defined or message['tool_calls'] is none) %}
|
||||
{%- if ns.is_last_user %}
|
||||
{{'<|Assistant|>'}}
|
||||
{%- if message['prefix'] is defined and message['prefix'] and thinking %}
|
||||
{{'<think>'}}
|
||||
{%- else %}
|
||||
{{'</think>'}}
|
||||
{%- endif %}
|
||||
{%- endif %}
|
||||
{%- if message['prefix'] is defined and message['prefix'] %}
|
||||
{%- set ns.is_prefix = true -%}
|
||||
{%- endif %}
|
||||
{%- set ns.is_last_user = false -%}
|
||||
{%- if ns.is_tool %}
|
||||
{{message['content'] + '<|end▁of▁sentence|>'}}
|
||||
{%- set ns.is_tool = false -%}
|
||||
{%- else %}
|
||||
{%- set content = message['content'] -%}
|
||||
{%- if '</think>' in content %}
|
||||
{%- set content = content.split('</think>', 1)[1] -%}
|
||||
{%- endif %}
|
||||
{{content + '<|end▁of▁sentence|>'}}
|
||||
{%- endif %}
|
||||
{%- endif %}
|
||||
{%- if message['role'] == 'tool' %}
|
||||
{%- set ns.is_last_user = false -%}
|
||||
{%- set ns.is_tool = true -%}
|
||||
{{'<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}
|
||||
{%- endif %}
|
||||
{%- if message['role'] != 'system' %}
|
||||
{% set ns.is_only_sys = false %}
|
||||
{%- endif %}
|
||||
{%- endfor -%}
|
||||
{% if add_generation_prompt and not ns.is_tool%}
|
||||
{% if ns.is_last_user or ns.is_only_sys or not ns.is_prefix %}
|
||||
{{'<|Assistant|>'}}
|
||||
{%- if not thinking %}
|
||||
{{'</think>'}}
|
||||
{%- else %}
|
||||
{{'<think>'}}
|
||||
{%- endif %}
|
||||
{% endif %}
|
||||
{% endif %}
|
||||
@@ -1,241 +0,0 @@
|
||||
"""
|
||||
Usage:
|
||||
1) Launch the server with wait-for-initial-weights option in one terminal:
|
||||
python -m sglang.launch_server --model-path /workspace/Qwen/Qwen3-4B/ --tensor-parallel-size 2 --port 19730 --load-format dummy --checkpoint-engine-wait-weights-before-ready --mem-fraction-static 0.7
|
||||
|
||||
2) Torchrun this script in another terminal:
|
||||
torchrun --nproc-per-node 2 update.py --update-method broadcast --checkpoint-path /workspace/Qwen/Qwen3-4B/ --inference-parallel-size 2
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import pickle
|
||||
import time
|
||||
from collections import defaultdict
|
||||
from collections.abc import Callable
|
||||
from contextlib import contextmanager
|
||||
from typing import Literal
|
||||
|
||||
import httpx
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from checkpoint_engine.ps import ParameterServer
|
||||
from loguru import logger
|
||||
from safetensors import safe_open
|
||||
|
||||
|
||||
@contextmanager
|
||||
def timer(msg: str):
|
||||
start = time.perf_counter()
|
||||
yield
|
||||
end = time.perf_counter()
|
||||
logger.info(f"{msg} duration: {end - start:.2f} seconds")
|
||||
|
||||
|
||||
def check_sglang_ready(
|
||||
endpoint: str, inference_parallel_size: int, uds: str | None = None
|
||||
):
|
||||
if rank != rank // inference_parallel_size * inference_parallel_size:
|
||||
return
|
||||
retry_num = 0
|
||||
transport = None
|
||||
if uds is not None:
|
||||
transport = httpx.HTTPTransport(uds=uds)
|
||||
with httpx.Client(transport=transport) as client:
|
||||
while True:
|
||||
try:
|
||||
response = client.get(f"{endpoint}/ping", timeout=10)
|
||||
response.raise_for_status()
|
||||
break
|
||||
except (httpx.ConnectError, httpx.HTTPStatusError) as e:
|
||||
if retry_num % 10 == 0:
|
||||
logger.warning(
|
||||
f"fail to check sglang ready, retry {retry_num} times, error: {e}"
|
||||
)
|
||||
retry_num += 1
|
||||
time.sleep(0.1)
|
||||
|
||||
|
||||
def split_checkpoint_files(
|
||||
checkpoint_path: str, rank: int, world_size: int
|
||||
) -> list[str]:
|
||||
checkpoint_files = [
|
||||
os.path.join(checkpoint_path, f)
|
||||
for f in filter(
|
||||
lambda x: x.endswith(".safetensors"), os.listdir(checkpoint_path)
|
||||
)
|
||||
]
|
||||
files_per_rank = (len(checkpoint_files) + world_size - 1) // world_size
|
||||
return checkpoint_files[rank * files_per_rank : (rank + 1) * files_per_rank]
|
||||
|
||||
|
||||
def split_tensors(
|
||||
checkpoint_path: str, rank: int, world_size: int
|
||||
) -> dict[str, torch.Tensor]:
|
||||
index_fn = os.path.join(checkpoint_path, "model.safetensors.index.json")
|
||||
with open(index_fn) as f:
|
||||
weight_map: dict[str, str] = json.load(f)["weight_map"]
|
||||
weights_per_rank = (len(weight_map) + world_size - 1) // world_size
|
||||
fn_tensors: dict[str, list[str]] = defaultdict(list)
|
||||
weight_keys = list(weight_map.items())
|
||||
for name, file in weight_keys[
|
||||
rank * weights_per_rank : (rank + 1) * weights_per_rank
|
||||
]:
|
||||
fn_tensors[file].append(name)
|
||||
named_tensors = {}
|
||||
for file, names in fn_tensors.items():
|
||||
with safe_open(os.path.join(checkpoint_path, file), framework="pt") as f:
|
||||
for name in names:
|
||||
named_tensors[name] = f.get_tensor(name)
|
||||
return named_tensors
|
||||
|
||||
|
||||
def req_inference(
|
||||
endpoint: str,
|
||||
inference_parallel_size: int,
|
||||
timeout: float = 300.0,
|
||||
uds: str | None = None,
|
||||
weight_version: str | None = None,
|
||||
) -> Callable[[list[tuple[str, str]]], None]:
|
||||
rank = int(os.getenv("RANK", 0))
|
||||
src = rank // inference_parallel_size * inference_parallel_size
|
||||
|
||||
def req_func(socket_paths: list[tuple[str, str]]):
|
||||
if rank == src:
|
||||
with httpx.Client(transport=httpx.HTTPTransport(uds=uds)) as client:
|
||||
resp = client.post(
|
||||
f"{endpoint}/update_weights_from_ipc",
|
||||
json={
|
||||
"zmq_handles": dict(
|
||||
socket_paths[src : src + inference_parallel_size]
|
||||
),
|
||||
"flush_cache": True,
|
||||
"weight_version": weight_version,
|
||||
},
|
||||
timeout=timeout,
|
||||
)
|
||||
resp.raise_for_status()
|
||||
|
||||
return req_func
|
||||
|
||||
|
||||
def update_weights(
|
||||
ps: ParameterServer,
|
||||
checkpoint_name: str,
|
||||
checkpoint_files: list[str],
|
||||
named_tensors: dict[str, torch.Tensor],
|
||||
req_func: Callable[[list[tuple[str, str]]], None],
|
||||
inference_parallel_size: int,
|
||||
endpoint: str,
|
||||
save_metas_file: str | None = None,
|
||||
update_method: Literal["broadcast", "p2p", "all"] = "broadcast",
|
||||
uds: str | None = None,
|
||||
):
|
||||
ps.register_checkpoint(
|
||||
checkpoint_name, files=checkpoint_files, named_tensors=named_tensors
|
||||
)
|
||||
ps.init_process_group()
|
||||
check_sglang_ready(endpoint, inference_parallel_size, uds)
|
||||
dist.barrier()
|
||||
with timer("Gather metas"):
|
||||
ps.gather_metas(checkpoint_name)
|
||||
if save_metas_file and int(os.getenv("RANK")) == 0:
|
||||
with open(save_metas_file, "wb") as f:
|
||||
pickle.dump(ps.get_metas(), f)
|
||||
|
||||
if update_method == "broadcast" or update_method == "all":
|
||||
with timer("Update weights without setting ranks"):
|
||||
ps.update(checkpoint_name, req_func)
|
||||
|
||||
if update_method == "p2p" or update_method == "all":
|
||||
if update_method:
|
||||
# sleep 2s to wait destroy process group
|
||||
time.sleep(2)
|
||||
with timer("Update weights with setting ranks"):
|
||||
ps.update(
|
||||
checkpoint_name, req_func, ranks=list(range(inference_parallel_size))
|
||||
)
|
||||
|
||||
|
||||
def join(
|
||||
ps: ParameterServer,
|
||||
checkpoint_name: str,
|
||||
load_metas_file: str,
|
||||
req_func: Callable[[list[tuple[str, str]]], None],
|
||||
inference_parallel_size: int,
|
||||
endpoint: str,
|
||||
uds: str | None = None,
|
||||
):
|
||||
assert load_metas_file, "load_metas_file is required"
|
||||
with open(load_metas_file, "rb") as f:
|
||||
metas = pickle.load(f)
|
||||
ps.init_process_group()
|
||||
check_sglang_ready(endpoint, inference_parallel_size, uds)
|
||||
dist.barrier()
|
||||
with timer("Gather metas before join"):
|
||||
ps.gather_metas(checkpoint_name)
|
||||
ps.load_metas(metas)
|
||||
with timer(
|
||||
f"Update weights with setting ranks as range(0, {inference_parallel_size}) by using p2p"
|
||||
):
|
||||
ps.update(checkpoint_name, req_func, ranks=list(range(inference_parallel_size)))
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Update weights example")
|
||||
parser.add_argument("--checkpoint-path", type=str, default=None)
|
||||
parser.add_argument("--save-metas-file", type=str, default=None)
|
||||
parser.add_argument("--load-metas-file", type=str, default=None)
|
||||
parser.add_argument("--sleep-time", type=int, default=0)
|
||||
parser.add_argument("--endpoint", type=str, default="http://localhost:19730")
|
||||
parser.add_argument("--inference-parallel-size", type=int, default=8)
|
||||
parser.add_argument("--checkpoint-name", type=str, default="my-checkpoint-iter-0")
|
||||
parser.add_argument("--update-method", type=str, default="broadcast")
|
||||
parser.add_argument("--uds", type=str, default=None)
|
||||
parser.add_argument("--weight-version", type=str, default=None)
|
||||
args = parser.parse_args()
|
||||
rank = int(os.getenv("RANK"))
|
||||
world_size = int(os.getenv("WORLD_SIZE"))
|
||||
req_func = req_inference(
|
||||
args.endpoint,
|
||||
args.inference_parallel_size,
|
||||
uds=args.uds,
|
||||
weight_version=args.weight_version,
|
||||
)
|
||||
ps = ParameterServer(auto_pg=True)
|
||||
ps._p2p_store = None
|
||||
if args.load_metas_file:
|
||||
join(
|
||||
ps,
|
||||
args.checkpoint_name,
|
||||
args.load_metas_file,
|
||||
req_func,
|
||||
args.inference_parallel_size,
|
||||
args.endpoint,
|
||||
args.uds,
|
||||
)
|
||||
else:
|
||||
if os.path.exists(
|
||||
os.path.join(args.checkpoint_path, "model.safetensors.index.json")
|
||||
):
|
||||
named_tensors = split_tensors(args.checkpoint_path, rank, world_size)
|
||||
checkpoint_files = []
|
||||
else:
|
||||
checkpoint_files = split_checkpoint_files(
|
||||
args.checkpoint_path, rank, world_size
|
||||
)
|
||||
named_tensors = {}
|
||||
update_weights(
|
||||
ps,
|
||||
args.checkpoint_name,
|
||||
checkpoint_files,
|
||||
named_tensors,
|
||||
req_func,
|
||||
args.inference_parallel_size,
|
||||
args.endpoint,
|
||||
args.save_metas_file,
|
||||
args.update_method,
|
||||
args.uds,
|
||||
)
|
||||
time.sleep(args.sleep_time)
|
||||
@@ -4,7 +4,7 @@ FastAPI server example for text generation using SGLang Engine and demonstrating
|
||||
Starts the server, sends requests to it, and prints responses.
|
||||
|
||||
Usage:
|
||||
python fastapi_engine_inference.py --model-path Qwen/Qwen2.5-0.5B-Instruct --tp_size 1 --host 127.0.0.1 --port 8000 [--startup-timeout 60]
|
||||
python fastapi_engine_inference.py --model-path Qwen/Qwen2.5-0.5B-Instruct --tp_size 1 --host 127.0.0.1 --port 8000
|
||||
"""
|
||||
|
||||
import os
|
||||
@@ -160,12 +160,6 @@ if __name__ == "__main__":
|
||||
parser.add_argument("--port", type=int, default=8000)
|
||||
parser.add_argument("--model-path", type=str, default="Qwen/Qwen2.5-0.5B-Instruct")
|
||||
parser.add_argument("--tp_size", type=int, default=1)
|
||||
parser.add_argument(
|
||||
"--startup-timeout",
|
||||
type=int,
|
||||
default=60,
|
||||
help="Time in seconds to wait for the server to be ready (default: %(default)s)",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
# Pass the model to the child uvicorn process via an env var
|
||||
@@ -173,7 +167,7 @@ if __name__ == "__main__":
|
||||
os.environ["TP_SIZE"] = str(args.tp_size)
|
||||
|
||||
# Start the server
|
||||
process = start_server(args, timeout=args.startup_timeout)
|
||||
process = start_server(args)
|
||||
|
||||
# Define the prompts and sampling parameters
|
||||
prompts = [
|
||||
|
||||
@@ -1,67 +1,37 @@
|
||||
"""
|
||||
OpenAI-compatible LoRA adapter usage with SGLang.
|
||||
# launch server
|
||||
# python -m sglang.launch_server --model mistralai/Mistral-7B-Instruct-v0.3 --lora-paths /home/ying/test_lora lora1=/home/ying/test_lora_1 lora2=/home/ying/test_lora_2 --disable-radix --disable-cuda-graph --max-loras-per-batch 4
|
||||
|
||||
Server Setup:
|
||||
python -m sglang.launch_server \\
|
||||
--model meta-llama/Llama-3.1-8B-Instruct \\
|
||||
--enable-lora \\
|
||||
--lora-paths sql=/path/to/sql python=/path/to/python
|
||||
"""
|
||||
# send requests
|
||||
# lora_path[i] specifies the LoRA used for text[i], so make sure they have the same length
|
||||
# use None to specify base-only prompt, e.x. "lora_path": [None, "/home/ying/test_lora"]
|
||||
import json
|
||||
|
||||
import openai
|
||||
import requests
|
||||
|
||||
client = openai.Client(base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")
|
||||
|
||||
|
||||
def main():
|
||||
print("SGLang OpenAI-Compatible LoRA Examples\n")
|
||||
|
||||
# Example 1: NEW - Adapter in model parameter (OpenAI-compatible)
|
||||
print("1. Chat with LoRA adapter in model parameter:")
|
||||
response = client.chat.completions.create(
|
||||
model="meta-llama/Llama-3.1-8B-Instruct:sql", # ← adapter:name syntax
|
||||
messages=[{"role": "user", "content": "Convert to SQL: show all users"}],
|
||||
max_tokens=50,
|
||||
)
|
||||
print(f" Response: {response.choices[0].message.content}\n")
|
||||
|
||||
# Example 2: Completions API with adapter
|
||||
print("2. Completion with LoRA adapter:")
|
||||
response = client.completions.create(
|
||||
model="meta-llama/Llama-3.1-8B-Instruct:python",
|
||||
prompt="def fibonacci(n):",
|
||||
max_tokens=50,
|
||||
)
|
||||
print(f" Response: {response.choices[0].text}\n")
|
||||
|
||||
# Example 3: OLD - Backward compatible with explicit lora_path
|
||||
print("3. Backward compatible (explicit lora_path):")
|
||||
response = client.chat.completions.create(
|
||||
model="meta-llama/Llama-3.1-8B-Instruct",
|
||||
messages=[{"role": "user", "content": "Convert to SQL: show all users"}],
|
||||
extra_body={"lora_path": "sql"},
|
||||
max_tokens=50,
|
||||
)
|
||||
print(f" Response: {response.choices[0].message.content}\n")
|
||||
|
||||
# Example 4: Base model (no adapter)
|
||||
print("4. Base model without adapter:")
|
||||
response = client.chat.completions.create(
|
||||
model="meta-llama/Llama-3.1-8B-Instruct",
|
||||
messages=[{"role": "user", "content": "Hello!"}],
|
||||
max_tokens=30,
|
||||
)
|
||||
print(f" Response: {response.choices[0].message.content}\n")
|
||||
|
||||
print("All examples completed!")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
try:
|
||||
main()
|
||||
except Exception as e:
|
||||
print(f"Error: {e}")
|
||||
print(
|
||||
"\nEnsure server is running:\n"
|
||||
" python -m sglang.launch_server --model ... --enable-lora --lora-paths ..."
|
||||
)
|
||||
url = "http://127.0.0.1:30000"
|
||||
json_data = {
|
||||
"text": [
|
||||
"prompt 1",
|
||||
"prompt 2",
|
||||
"prompt 3",
|
||||
"prompt 4",
|
||||
"prompt 5",
|
||||
"prompt 6",
|
||||
"prompt 7",
|
||||
],
|
||||
"sampling_params": {"max_new_tokens": 32},
|
||||
"lora_path": [
|
||||
"/home/ying/test_lora",
|
||||
"lora1",
|
||||
"lora2",
|
||||
"lora1",
|
||||
"lora2",
|
||||
None,
|
||||
None,
|
||||
],
|
||||
}
|
||||
response = requests.post(
|
||||
url + "/generate",
|
||||
json=json_data,
|
||||
)
|
||||
print(json.dumps(response.json()))
|
||||
|
||||
@@ -6,6 +6,7 @@ python3 -m sglang.launch_server --model-path lmms-lab/llava-onevision-qwen2-72b-
|
||||
python3 llava_onevision_server.py
|
||||
"""
|
||||
|
||||
import base64
|
||||
import io
|
||||
import os
|
||||
import sys
|
||||
@@ -13,7 +14,6 @@ import time
|
||||
|
||||
import numpy as np
|
||||
import openai
|
||||
import pybase64
|
||||
import requests
|
||||
from decord import VideoReader, cpu
|
||||
from PIL import Image
|
||||
@@ -213,7 +213,7 @@ def prepare_video_messages(video_path):
|
||||
pil_img = Image.fromarray(frame)
|
||||
buff = io.BytesIO()
|
||||
pil_img.save(buff, format="JPEG")
|
||||
base64_str = pybase64.b64encode(buff.getvalue()).decode("utf-8")
|
||||
base64_str = base64.b64encode(buff.getvalue()).decode("utf-8")
|
||||
base64_frames.append(base64_str)
|
||||
|
||||
messages = [{"role": "user", "content": []}]
|
||||
|
||||
@@ -3,7 +3,7 @@ This example demonstrates how to provide tokenized ids to LLM as input instead o
|
||||
"""
|
||||
|
||||
import sglang as sgl
|
||||
from sglang.srt.utils.hf_transformers_utils import get_tokenizer
|
||||
from sglang.srt.hf_transformers_utils import get_tokenizer
|
||||
|
||||
MODEL_PATH = "meta-llama/Llama-3.1-8B-Instruct"
|
||||
|
||||
|
||||
@@ -7,7 +7,7 @@ python token_in_token_out_llm_server.py
|
||||
|
||||
import requests
|
||||
|
||||
from sglang.srt.utils.hf_transformers_utils import get_tokenizer
|
||||
from sglang.srt.hf_transformers_utils import get_tokenizer
|
||||
from sglang.test.test_utils import is_in_ci
|
||||
from sglang.utils import terminate_process, wait_for_server
|
||||
|
||||
|
||||
@@ -1,303 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
"""
|
||||
Example: ModelOpt Quantization and Export with SGLang
|
||||
|
||||
This example demonstrates the streamlined workflow for quantizing a model with
|
||||
ModelOpt and automatically exporting it for deployment with SGLang.
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import os
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
|
||||
import sglang as sgl
|
||||
from sglang.srt.configs.device_config import DeviceConfig
|
||||
from sglang.srt.configs.load_config import LoadConfig
|
||||
from sglang.srt.configs.model_config import ModelConfig
|
||||
from sglang.srt.distributed.parallel_state import (
|
||||
init_distributed_environment,
|
||||
initialize_model_parallel,
|
||||
)
|
||||
from sglang.srt.model_loader.loader import get_model_loader
|
||||
|
||||
|
||||
def _validate_export(export_dir: str) -> bool:
|
||||
"""Validate that an exported model directory contains the expected files."""
|
||||
import glob
|
||||
|
||||
required_files = ["config.json", "tokenizer_config.json"]
|
||||
|
||||
if not os.path.exists(export_dir):
|
||||
return False
|
||||
|
||||
# Check required files
|
||||
for file in required_files:
|
||||
if not os.path.exists(os.path.join(export_dir, file)):
|
||||
return False
|
||||
|
||||
# Check for model files using pattern matching to handle sharded models
|
||||
model_patterns = [
|
||||
"model*.safetensors",
|
||||
"pytorch_model*.bin",
|
||||
]
|
||||
|
||||
has_model_file = False
|
||||
for pattern in model_patterns:
|
||||
matching_files = glob.glob(os.path.join(export_dir, pattern))
|
||||
if matching_files:
|
||||
has_model_file = True
|
||||
break
|
||||
|
||||
return has_model_file
|
||||
|
||||
|
||||
def _get_export_info(export_dir: str) -> Optional[dict]:
|
||||
"""Get information about an exported model."""
|
||||
import json
|
||||
|
||||
if not _validate_export(export_dir):
|
||||
return None
|
||||
|
||||
try:
|
||||
config_path = os.path.join(export_dir, "config.json")
|
||||
with open(config_path, "r") as f:
|
||||
config = json.load(f)
|
||||
|
||||
return {
|
||||
"model_type": config.get("model_type", "unknown"),
|
||||
"architectures": config.get("architectures", []),
|
||||
"quantization_config": config.get("quantization_config", {}),
|
||||
"export_dir": export_dir,
|
||||
}
|
||||
except Exception:
|
||||
return None
|
||||
|
||||
|
||||
def quantize_and_export_model(
|
||||
model_path: str,
|
||||
export_dir: str,
|
||||
quantization_method: str = "modelopt_fp8",
|
||||
checkpoint_save_path: Optional[str] = None,
|
||||
device: str = "cuda",
|
||||
) -> None:
|
||||
"""
|
||||
Quantize a model with ModelOpt and export it for SGLang deployment.
|
||||
|
||||
Args:
|
||||
model_path: Path to the original model
|
||||
export_dir: Directory to export the quantized model
|
||||
quantization_method: Quantization method ("modelopt_fp8" or "modelopt_fp4")
|
||||
checkpoint_save_path: Optional path to save ModelOpt checkpoint
|
||||
device: Device to use for quantization
|
||||
"""
|
||||
print("🚀 Starting ModelOpt quantization and export workflow")
|
||||
print(f"📥 Input model: {model_path}")
|
||||
print(f"📤 Export directory: {export_dir}")
|
||||
print(f"⚙️ Quantization method: {quantization_method}")
|
||||
|
||||
# Initialize minimal distributed environment for single GPU quantization
|
||||
if not torch.distributed.is_initialized():
|
||||
print("🔧 Initializing distributed environment...")
|
||||
# Set up environment variables for single-process distributed
|
||||
os.environ["RANK"] = "0"
|
||||
os.environ["WORLD_SIZE"] = "1"
|
||||
os.environ["MASTER_ADDR"] = "localhost"
|
||||
os.environ["MASTER_PORT"] = "12355" # Use a different port than tests
|
||||
os.environ["LOCAL_RANK"] = "0"
|
||||
|
||||
init_distributed_environment(
|
||||
world_size=1,
|
||||
rank=0,
|
||||
local_rank=0,
|
||||
backend="nccl" if device == "cuda" else "gloo",
|
||||
)
|
||||
initialize_model_parallel(
|
||||
tensor_model_parallel_size=1,
|
||||
pipeline_model_parallel_size=1,
|
||||
)
|
||||
|
||||
# Configure model loading with ModelOpt quantization and export
|
||||
model_config = ModelConfig(
|
||||
model_path=model_path,
|
||||
quantization=quantization_method, # Use unified quantization flag
|
||||
trust_remote_code=True,
|
||||
)
|
||||
|
||||
load_config = LoadConfig(
|
||||
modelopt_checkpoint_save_path=checkpoint_save_path,
|
||||
modelopt_export_path=export_dir,
|
||||
)
|
||||
device_config = DeviceConfig(device=device)
|
||||
|
||||
# Load and quantize the model (export happens automatically)
|
||||
print("🔄 Loading and quantizing model...")
|
||||
model_loader = get_model_loader(load_config, model_config)
|
||||
|
||||
try:
|
||||
model_loader.load_model(
|
||||
model_config=model_config,
|
||||
device_config=device_config,
|
||||
)
|
||||
print("✅ Model quantized successfully!")
|
||||
|
||||
# Validate the export
|
||||
if _validate_export(export_dir):
|
||||
print("✅ Export validation passed!")
|
||||
|
||||
info = _get_export_info(export_dir)
|
||||
if info:
|
||||
print("📋 Model info:")
|
||||
print(f" - Type: {info['model_type']}")
|
||||
print(f" - Architecture: {info['architectures']}")
|
||||
print(f" - Quantization: {info['quantization_config']}")
|
||||
else:
|
||||
print("❌ Export validation failed!")
|
||||
return
|
||||
|
||||
except Exception as e:
|
||||
print(f"❌ Quantization failed: {e}")
|
||||
return
|
||||
|
||||
print("\n🎉 Workflow completed successfully!")
|
||||
print(f"📁 Quantized model exported to: {export_dir}")
|
||||
print("\n🚀 To use the exported model:")
|
||||
print(
|
||||
f" python -m sglang.launch_server --model-path {export_dir} --quantization modelopt"
|
||||
)
|
||||
print("\n # Or in Python:")
|
||||
print(" import sglang as sgl")
|
||||
print(f" llm = sgl.Engine(model_path='{export_dir}', quantization='modelopt')")
|
||||
print(" # Note: 'modelopt' auto-detects FP4/FP8 from model config")
|
||||
|
||||
|
||||
def deploy_exported_model(
|
||||
export_dir: str,
|
||||
host: str = "127.0.0.1",
|
||||
port: int = 30000,
|
||||
) -> None:
|
||||
"""
|
||||
Deploy an exported ModelOpt quantized model with SGLang.
|
||||
|
||||
Args:
|
||||
export_dir: Directory containing the exported model
|
||||
host: Host to bind the server to
|
||||
port: Port to bind the server to
|
||||
"""
|
||||
print(f"🚀 Deploying exported model from: {export_dir}")
|
||||
|
||||
# Validate export first
|
||||
if not _validate_export(export_dir):
|
||||
print("❌ Invalid export directory!")
|
||||
return
|
||||
|
||||
try:
|
||||
# Launch SGLang engine with the exported model
|
||||
# Using generic "modelopt" for auto-detection of FP4/FP8
|
||||
llm = sgl.Engine(
|
||||
model_path=export_dir,
|
||||
quantization="modelopt",
|
||||
host=host,
|
||||
port=port,
|
||||
)
|
||||
|
||||
print("✅ Model deployed successfully!")
|
||||
print(f"🌐 Server running at http://{host}:{port}")
|
||||
|
||||
# Example inference
|
||||
prompts = ["Hello, how are you?", "What is the capital of France?"]
|
||||
sampling_params = {"temperature": 0.8, "top_p": 0.95, "max_new_tokens": 100}
|
||||
|
||||
print("\n🧪 Running example inference...")
|
||||
outputs = llm.generate(prompts, sampling_params)
|
||||
|
||||
for i, output in enumerate(outputs):
|
||||
print(f"Prompt {i+1}: {prompts[i]}")
|
||||
print(f"Output: {output['text']}")
|
||||
print()
|
||||
|
||||
except Exception as e:
|
||||
print(f"❌ Deployment failed: {e}")
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser(
|
||||
description="ModelOpt Quantization and Export with SGLang",
|
||||
formatter_class=argparse.RawDescriptionHelpFormatter,
|
||||
epilog="""
|
||||
Examples:
|
||||
# Quantize and export a model (recommended workflow)
|
||||
python modelopt_quantize_and_export.py quantize \\
|
||||
--model-path TinyLlama/TinyLlama-1.1B-Chat-v1.0 \\
|
||||
--export-dir ./quantized_model \\
|
||||
--quantization-method modelopt_fp8
|
||||
|
||||
# Deploy a pre-exported model
|
||||
python modelopt_quantize_and_export.py deploy \\
|
||||
--export-dir ./quantized_model
|
||||
""",
|
||||
)
|
||||
|
||||
subparsers = parser.add_subparsers(dest="command", help="Available commands")
|
||||
|
||||
# Quantize command
|
||||
quantize_parser = subparsers.add_parser(
|
||||
"quantize", help="Quantize and export a model"
|
||||
)
|
||||
quantize_parser.add_argument(
|
||||
"--model-path", required=True, help="Path to the model to quantize"
|
||||
)
|
||||
quantize_parser.add_argument(
|
||||
"--export-dir", required=True, help="Directory to export the quantized model"
|
||||
)
|
||||
quantize_parser.add_argument(
|
||||
"--quantization-method",
|
||||
choices=["modelopt_fp8", "modelopt_fp4"],
|
||||
default="modelopt_fp8",
|
||||
help="Quantization method to use",
|
||||
)
|
||||
quantize_parser.add_argument(
|
||||
"--checkpoint-save-path", help="Optional path to save ModelOpt checkpoint"
|
||||
)
|
||||
quantize_parser.add_argument(
|
||||
"--device", default="cuda", help="Device to use for quantization"
|
||||
)
|
||||
|
||||
# TODO: Quantize-and-serve command removed due to compatibility issues
|
||||
# Use the separate quantize-then-deploy workflow instead
|
||||
|
||||
# Deploy command
|
||||
deploy_parser = subparsers.add_parser("deploy", help="Deploy an exported model")
|
||||
deploy_parser.add_argument(
|
||||
"--export-dir", required=True, help="Directory containing the exported model"
|
||||
)
|
||||
deploy_parser.add_argument(
|
||||
"--host", default="127.0.0.1", help="Host to bind the server to"
|
||||
)
|
||||
deploy_parser.add_argument(
|
||||
"--port", type=int, default=30000, help="Port to bind the server to"
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
if args.command == "quantize":
|
||||
quantize_and_export_model(
|
||||
model_path=args.model_path,
|
||||
export_dir=args.export_dir,
|
||||
quantization_method=args.quantization_method,
|
||||
checkpoint_save_path=args.checkpoint_save_path,
|
||||
device=args.device,
|
||||
)
|
||||
elif args.command == "deploy":
|
||||
deploy_exported_model(
|
||||
export_dir=args.export_dir,
|
||||
host=args.host,
|
||||
port=args.port,
|
||||
)
|
||||
else:
|
||||
parser.print_help()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta"
|
||||
|
||||
[project]
|
||||
name = "sglang"
|
||||
version = "0.5.4"
|
||||
version = "0.5.3rc0"
|
||||
description = "SGLang is a fast serving framework for large language models and vision language models."
|
||||
readme = "README.md"
|
||||
requires-python = ">=3.10"
|
||||
@@ -13,20 +13,19 @@ classifiers = [
|
||||
"Programming Language :: Python :: 3",
|
||||
"License :: OSI Approved :: Apache Software License",
|
||||
]
|
||||
|
||||
dependencies = [
|
||||
"IPython",
|
||||
"aiohttp",
|
||||
"anthropic>=0.20.0",
|
||||
"requests",
|
||||
"tqdm",
|
||||
"numpy",
|
||||
"IPython",
|
||||
"setproctitle",
|
||||
"blobfile==3.0.0",
|
||||
"build",
|
||||
"compressed-tensors",
|
||||
"cuda-python",
|
||||
"decord2",
|
||||
"datasets",
|
||||
"einops",
|
||||
"fastapi",
|
||||
"flashinfer_python==0.4.1",
|
||||
"hf_transfer",
|
||||
"huggingface_hub",
|
||||
"interegular",
|
||||
@@ -34,10 +33,8 @@ dependencies = [
|
||||
"modelscope",
|
||||
"msgspec",
|
||||
"ninja",
|
||||
"numpy",
|
||||
"nvidia-cutlass-dsl==4.2.1",
|
||||
"openai-harmony==0.0.4",
|
||||
"openai==1.99.1",
|
||||
"openai-harmony==0.0.4",
|
||||
"orjson",
|
||||
"outlines==0.1.11",
|
||||
"packaging",
|
||||
@@ -45,75 +42,57 @@ dependencies = [
|
||||
"pillow",
|
||||
"prometheus-client>=0.20.0",
|
||||
"psutil",
|
||||
"py-spy",
|
||||
"pybase64",
|
||||
"pydantic",
|
||||
"nvidia-ml-py",
|
||||
"pynvml",
|
||||
"python-multipart",
|
||||
"pyzmq>=25.1.2",
|
||||
"requests",
|
||||
"scipy",
|
||||
"sentencepiece",
|
||||
"setproctitle",
|
||||
"sgl-kernel==0.3.16.post3",
|
||||
"soundfile==0.13.1",
|
||||
"tiktoken",
|
||||
"timm==1.0.16",
|
||||
"torch==2.8.0",
|
||||
"torch_memory_saver==0.0.9",
|
||||
"tiktoken",
|
||||
"torchao==0.9.0",
|
||||
"torchaudio==2.8.0",
|
||||
"torchvision",
|
||||
"tqdm",
|
||||
"transformers==4.57.1",
|
||||
"transformers==4.56.1",
|
||||
"uvicorn",
|
||||
"uvloop",
|
||||
"xgrammar==0.1.25",
|
||||
"grpcio==1.75.1", # keep it align with compile_proto.py
|
||||
"grpcio-tools==1.75.1", # keep it align with compile_proto.py
|
||||
"grpcio-reflection==1.75.1", # required by srt/entrypoints/grpc_server.py
|
||||
"grpcio-health-checking==1.75.1", # required for Kubernetes gRPC health probes
|
||||
"xgrammar==0.1.24",
|
||||
"sgl-kernel==0.3.13",
|
||||
"torch==2.8.0",
|
||||
"torchaudio==2.8.0",
|
||||
"torchvision",
|
||||
"cuda-python",
|
||||
"flashinfer_python==0.4.0rc1",
|
||||
"openai==1.99.1",
|
||||
"tiktoken",
|
||||
"anthropic>=0.20.0",
|
||||
"torch_memory_saver==0.0.8",
|
||||
"nvidia-cutlass-dsl==4.2.1",
|
||||
]
|
||||
|
||||
[project.optional-dependencies]
|
||||
modelopt = ["nvidia-modelopt"]
|
||||
decord = ["decord"]
|
||||
test = [
|
||||
"accelerate",
|
||||
"expecttest",
|
||||
"gguf",
|
||||
"jsonlines",
|
||||
"matplotlib",
|
||||
"pandas",
|
||||
"peft",
|
||||
"pytest",
|
||||
"sentence_transformers",
|
||||
"pytest",
|
||||
"tabulate",
|
||||
]
|
||||
checkpoint-engine = ["checkpoint-engine==0.1.2"]
|
||||
all = []
|
||||
dev = ["sglang[test]"]
|
||||
|
||||
# Temporary tags
|
||||
cu130 = [
|
||||
"torch==2.9.0",
|
||||
"torchaudio==2.9.0",
|
||||
"torchvision==0.24.0",
|
||||
]
|
||||
cu130_all = [
|
||||
"sglang[test]",
|
||||
"sglang[decord]",
|
||||
"sglang[cu130]"
|
||||
]
|
||||
tracing = [
|
||||
"opentelemetry-api",
|
||||
"opentelemetry-exporter-otlp",
|
||||
"opentelemetry-exporter-otlp-proto-grpc",
|
||||
"opentelemetry-sdk",
|
||||
"opentelemetry-sdk",
|
||||
"opentelemetry-api",
|
||||
"opentelemetry-exporter-otlp",
|
||||
"opentelemetry-exporter-otlp-proto-grpc",
|
||||
]
|
||||
|
||||
# To be deprecated in 2 weeks
|
||||
blackwell = ["sglang[dev]"]
|
||||
blackwell_aarch64 = ["sglang[dev]"]
|
||||
all = ["sglang[test]", "sglang[decord]"]
|
||||
blackwell = ["sglang[test]", "sglang[decord]"]
|
||||
blackwell_aarch64 = ["sglang[test]"]
|
||||
dev = ["sglang[test]", "sglang[decord]"]
|
||||
|
||||
[project.urls]
|
||||
"Homepage" = "https://github.com/sgl-project/sglang"
|
||||
|
||||
@@ -1,128 +0,0 @@
|
||||
# https://docs.sglang.ai/platforms/cpu_server.html
|
||||
[build-system]
|
||||
requires = ["setuptools>=61.0", "wheel"]
|
||||
build-backend = "setuptools.build_meta"
|
||||
|
||||
[project]
|
||||
name = "sglang"
|
||||
version = "0.5.4"
|
||||
description = "SGLang is a fast serving framework for large language models and vision language models."
|
||||
readme = "README.md"
|
||||
requires-python = ">=3.10"
|
||||
license = { file = "LICENSE" }
|
||||
classifiers = [
|
||||
"Programming Language :: Python :: 3",
|
||||
"License :: OSI Approved :: Apache Software License",
|
||||
]
|
||||
|
||||
dependencies = [
|
||||
"IPython",
|
||||
"aiohttp",
|
||||
"anthropic>=0.20.0",
|
||||
"blobfile==3.0.0",
|
||||
"build",
|
||||
"compressed-tensors",
|
||||
"datasets",
|
||||
"decord",
|
||||
"einops",
|
||||
"fastapi",
|
||||
"hf_transfer",
|
||||
"huggingface_hub",
|
||||
"intel-openmp",
|
||||
"interegular",
|
||||
"llguidance>=0.7.11,<0.8.0",
|
||||
"modelscope",
|
||||
"msgspec",
|
||||
"ninja",
|
||||
"numpy",
|
||||
"openai-harmony==0.0.4",
|
||||
"openai==1.99.1",
|
||||
"orjson",
|
||||
"outlines==0.1.11",
|
||||
"packaging",
|
||||
"partial_json_parser",
|
||||
"pillow",
|
||||
"prometheus-client>=0.20.0",
|
||||
"psutil",
|
||||
"py-spy",
|
||||
"pybase64",
|
||||
"pydantic",
|
||||
"python-multipart",
|
||||
"pyzmq>=25.1.2",
|
||||
"requests",
|
||||
"scipy",
|
||||
"sentencepiece",
|
||||
"setproctitle",
|
||||
"soundfile==0.13.1",
|
||||
"tiktoken",
|
||||
"timm==1.0.16",
|
||||
"torchao==0.9.0",
|
||||
"tqdm",
|
||||
"transformers==4.57.1",
|
||||
"uvicorn",
|
||||
"uvloop",
|
||||
"xgrammar==0.1.25",
|
||||
"grpcio==1.75.1", # keep it align with compile_proto.py
|
||||
"grpcio-tools==1.75.1", # keep it align with compile_proto.py
|
||||
"grpcio-reflection==1.75.1", # required by srt/entrypoints/grpc_server.py
|
||||
]
|
||||
|
||||
[project.optional-dependencies]
|
||||
tracing = [
|
||||
"opentelemetry-sdk",
|
||||
"opentelemetry-api",
|
||||
"opentelemetry-exporter-otlp",
|
||||
"opentelemetry-exporter-otlp-proto-grpc",
|
||||
]
|
||||
test = [
|
||||
"accelerate",
|
||||
"expecttest",
|
||||
"jsonlines",
|
||||
"matplotlib",
|
||||
"pandas",
|
||||
"peft",
|
||||
"pytest",
|
||||
"sentence_transformers",
|
||||
"tabulate",
|
||||
]
|
||||
all = []
|
||||
dev = ["sglang[test]"]
|
||||
|
||||
[project.urls]
|
||||
"Homepage" = "https://github.com/sgl-project/sglang"
|
||||
"Bug Tracker" = "https://github.com/sgl-project/sglang/issues"
|
||||
|
||||
[tool.setuptools.package-data]
|
||||
"sglang" = [
|
||||
"srt/layers/moe/fused_moe_triton/configs/*/*.json",
|
||||
"srt/layers/quantization/configs/*.json",
|
||||
"srt/mem_cache/storage/hf3fs/hf3fs_utils.cpp",
|
||||
"srt/speculative/cpp_ngram/*.cpp",
|
||||
"srt/speculative/cpp_ngram/*.h",
|
||||
]
|
||||
|
||||
[tool.setuptools.packages.find]
|
||||
exclude = [
|
||||
"assets*",
|
||||
"benchmark*",
|
||||
"docs*",
|
||||
"dist*",
|
||||
"playground*",
|
||||
"scripts*",
|
||||
"tests*",
|
||||
]
|
||||
|
||||
[tool.wheel]
|
||||
exclude = [
|
||||
"assets*",
|
||||
"benchmark*",
|
||||
"docs*",
|
||||
"dist*",
|
||||
"playground*",
|
||||
"scripts*",
|
||||
"tests*",
|
||||
]
|
||||
|
||||
[tool.codespell]
|
||||
ignore-words-list = "ans, als, hel, boostrap, childs, te, vas, hsa, ment"
|
||||
skip = "*.json,*.jsonl,*.patch,*.txt"
|
||||
@@ -4,111 +4,137 @@ build-backend = "setuptools.build_meta"
|
||||
|
||||
[project]
|
||||
name = "sglang"
|
||||
version = "0.5.4"
|
||||
version = "0.5.3rc0"
|
||||
description = "SGLang is a fast serving framework for large language models and vision language models."
|
||||
readme = "README.md"
|
||||
requires-python = ">=3.10"
|
||||
license = { file = "LICENSE" }
|
||||
classifiers = [
|
||||
"Programming Language :: Python :: 3",
|
||||
"License :: OSI Approved :: Apache Software License",
|
||||
"Programming Language :: Python :: 3",
|
||||
"License :: OSI Approved :: Apache Software License",
|
||||
]
|
||||
dependencies = ["aiohttp", "requests", "tqdm", "numpy", "IPython", "setproctitle"]
|
||||
|
||||
[project.optional-dependencies]
|
||||
runtime_common = [
|
||||
"IPython",
|
||||
"aiohttp",
|
||||
"anthropic>=0.20.0",
|
||||
"blobfile==3.0.0",
|
||||
"build",
|
||||
"compressed-tensors",
|
||||
"decord2",
|
||||
"datasets",
|
||||
"einops",
|
||||
"fastapi",
|
||||
"hf_transfer",
|
||||
"huggingface_hub",
|
||||
"interegular",
|
||||
"llguidance>=0.7.11,<0.8.0",
|
||||
"modelscope",
|
||||
"msgspec",
|
||||
"ninja",
|
||||
"numpy",
|
||||
"openai-harmony==0.0.4",
|
||||
"openai==1.99.1",
|
||||
"orjson",
|
||||
"outlines==0.1.11",
|
||||
"packaging",
|
||||
"partial_json_parser",
|
||||
"pillow",
|
||||
"prometheus-client>=0.20.0",
|
||||
"psutil",
|
||||
"py-spy",
|
||||
"pybase64",
|
||||
"pydantic",
|
||||
"python-multipart",
|
||||
"pyzmq>=25.1.2",
|
||||
"requests",
|
||||
"scipy",
|
||||
"sentencepiece",
|
||||
"setproctitle",
|
||||
"soundfile==0.13.1",
|
||||
"tiktoken",
|
||||
"timm==1.0.16",
|
||||
"torchao==0.9.0",
|
||||
"tqdm",
|
||||
"transformers==4.57.1",
|
||||
"uvicorn",
|
||||
"uvloop",
|
||||
"xgrammar==0.1.25",
|
||||
"grpcio==1.75.1", # keep it align with compile_proto.py
|
||||
"grpcio-tools==1.75.1", # keep it align with compile_proto.py
|
||||
"grpcio-reflection==1.75.1", # required by srt/entrypoints/grpc_server.py
|
||||
"blobfile==3.0.0",
|
||||
"build",
|
||||
"compressed-tensors",
|
||||
"datasets",
|
||||
"einops",
|
||||
"fastapi",
|
||||
"hf_transfer",
|
||||
"huggingface_hub",
|
||||
"interegular",
|
||||
"llguidance>=0.7.11,<0.8.0",
|
||||
"modelscope",
|
||||
"msgspec",
|
||||
"ninja",
|
||||
"openai==1.99.1",
|
||||
"openai-harmony==0.0.4",
|
||||
"orjson",
|
||||
"outlines==0.1.11",
|
||||
"packaging",
|
||||
"partial_json_parser",
|
||||
"pillow",
|
||||
"prometheus-client>=0.20.0",
|
||||
"psutil",
|
||||
"pybase64",
|
||||
"pydantic",
|
||||
"pynvml",
|
||||
"python-multipart",
|
||||
"pyzmq>=25.1.2",
|
||||
"scipy",
|
||||
"sentencepiece",
|
||||
"soundfile==0.13.1",
|
||||
"timm==1.0.16",
|
||||
"tiktoken",
|
||||
"torchao==0.9.0",
|
||||
"transformers==4.56.1",
|
||||
"uvicorn",
|
||||
"uvloop",
|
||||
"xgrammar==0.1.24",
|
||||
]
|
||||
|
||||
tracing = [
|
||||
"opentelemetry-sdk",
|
||||
"opentelemetry-api",
|
||||
"opentelemetry-exporter-otlp",
|
||||
"opentelemetry-exporter-otlp-proto-grpc",
|
||||
"opentelemetry-sdk",
|
||||
"opentelemetry-api",
|
||||
"opentelemetry-exporter-otlp",
|
||||
"opentelemetry-exporter-otlp-proto-grpc",
|
||||
]
|
||||
|
||||
srt = [
|
||||
"sglang[runtime_common]",
|
||||
"sgl-kernel==0.3.13",
|
||||
"torch==2.8.0",
|
||||
"torchaudio==2.8.0",
|
||||
"torchvision",
|
||||
"cuda-python",
|
||||
"flashinfer_python==0.4.0rc1",
|
||||
]
|
||||
|
||||
blackwell = [
|
||||
"sglang[runtime_common]",
|
||||
"sgl-kernel==0.3.13",
|
||||
"torch==2.8.0",
|
||||
"torchaudio==2.8.0",
|
||||
"torchvision",
|
||||
"cuda-python",
|
||||
"flashinfer_python==0.4.0rc1",
|
||||
"nvidia-cutlass-dsl==4.2.1",
|
||||
]
|
||||
|
||||
# HIP (Heterogeneous-computing Interface for Portability) for AMD
|
||||
# => base docker rocm/vllm-dev:20250114, not from public vllm whl
|
||||
srt_hip = [
|
||||
"sglang[runtime_common]",
|
||||
"torch",
|
||||
"petit_kernel==0.0.2",
|
||||
"wave-lang==3.8.0",
|
||||
"sglang[runtime_common]",
|
||||
"torch",
|
||||
"petit_kernel==0.0.2",
|
||||
"wave-lang==3.7.0",
|
||||
]
|
||||
|
||||
# https://docs.sglang.ai/platforms/cpu_server.html
|
||||
srt_cpu = ["sglang[runtime_common]", "intel-openmp"]
|
||||
|
||||
# https://docs.sglang.ai/platforms/ascend_npu.html
|
||||
srt_npu = ["sglang[runtime_common]"]
|
||||
|
||||
# xpu is not enabled in public vllm and torch whl,
|
||||
# need to follow https://docs.vllm.ai/en/latest/getting_started/xpu-installation.htmlinstall vllm
|
||||
srt_xpu = ["sglang[runtime_common]"]
|
||||
|
||||
# For Intel Gaudi(device : hpu) follow the installation guide
|
||||
# https://docs.vllm.ai/en/latest/getting_started/gaudi-installation.html
|
||||
srt_hpu = ["sglang[runtime_common]"]
|
||||
|
||||
openai = ["openai==1.99.1", "tiktoken"]
|
||||
anthropic = ["anthropic>=0.20.0"]
|
||||
litellm = ["litellm>=1.0.0"]
|
||||
torch_memory_saver = ["torch_memory_saver==0.0.8"]
|
||||
decord = ["decord"]
|
||||
test = [
|
||||
"accelerate",
|
||||
"expecttest",
|
||||
"gguf",
|
||||
"jsonlines",
|
||||
"matplotlib",
|
||||
"pandas",
|
||||
"peft",
|
||||
"pytest",
|
||||
"sentence_transformers",
|
||||
"tabulate",
|
||||
"accelerate",
|
||||
"expecttest",
|
||||
"jsonlines",
|
||||
"matplotlib",
|
||||
"pandas",
|
||||
"peft",
|
||||
"sentence_transformers",
|
||||
"pytest",
|
||||
"tabulate",
|
||||
]
|
||||
all_hip = ["sglang[srt_hip]"]
|
||||
all_npu = ["sglang[srt_npu]"]
|
||||
all_hpu = ["sglang[srt_hpu]"]
|
||||
all = ["sglang[srt]", "sglang[openai]", "sglang[anthropic]", "sglang[torch_memory_saver]", "sglang[decord]"]
|
||||
all_hip = ["sglang[srt_hip]", "sglang[openai]", "sglang[anthropic]", "sglang[decord]"]
|
||||
all_xpu = ["sglang[srt_xpu]", "sglang[openai]", "sglang[anthropic]", "sglang[decord]"]
|
||||
all_hpu = ["sglang[srt_hpu]", "sglang[openai]", "sglang[anthropic]", "sglang[decord]"]
|
||||
all_cpu = ["sglang[srt_cpu]", "sglang[openai]", "sglang[anthropic]", "sglang[decord]"]
|
||||
all_npu = ["sglang[srt_npu]", "sglang[openai]", "sglang[anthropic]", "sglang[decord]"]
|
||||
|
||||
dev = ["sglang[all]", "sglang[test]"]
|
||||
dev_hip = ["sglang[all_hip]", "sglang[test]"]
|
||||
dev_npu = ["sglang[all_npu]", "sglang[test]"]
|
||||
dev_xpu = ["sglang[all_xpu]", "sglang[test]"]
|
||||
dev_hpu = ["sglang[all_hpu]", "sglang[test]"]
|
||||
dev_cpu = ["sglang[all_cpu]", "sglang[test]"]
|
||||
|
||||
[project.urls]
|
||||
"Homepage" = "https://github.com/sgl-project/sglang"
|
||||
@@ -116,33 +142,31 @@ dev_hpu = ["sglang[all_hpu]", "sglang[test]"]
|
||||
|
||||
[tool.setuptools.package-data]
|
||||
"sglang" = [
|
||||
"srt/layers/moe/fused_moe_triton/configs/*/*.json",
|
||||
"srt/layers/quantization/configs/*.json",
|
||||
"srt/mem_cache/storage/hf3fs/hf3fs_utils.cpp",
|
||||
"srt/speculative/cpp_ngram/*.cpp",
|
||||
"srt/speculative/cpp_ngram/*.h",
|
||||
"srt/layers/moe/fused_moe_triton/configs/*/*.json",
|
||||
"srt/layers/quantization/configs/*.json",
|
||||
"srt/mem_cache/storage/hf3fs/hf3fs_utils.cpp",
|
||||
]
|
||||
|
||||
[tool.setuptools.packages.find]
|
||||
exclude = [
|
||||
"assets*",
|
||||
"benchmark*",
|
||||
"docs*",
|
||||
"dist*",
|
||||
"playground*",
|
||||
"scripts*",
|
||||
"tests*",
|
||||
"assets*",
|
||||
"benchmark*",
|
||||
"docs*",
|
||||
"dist*",
|
||||
"playground*",
|
||||
"scripts*",
|
||||
"tests*",
|
||||
]
|
||||
|
||||
[tool.wheel]
|
||||
exclude = [
|
||||
"assets*",
|
||||
"benchmark*",
|
||||
"docs*",
|
||||
"dist*",
|
||||
"playground*",
|
||||
"scripts*",
|
||||
"tests*",
|
||||
"assets*",
|
||||
"benchmark*",
|
||||
"docs*",
|
||||
"dist*",
|
||||
"playground*",
|
||||
"scripts*",
|
||||
"tests*",
|
||||
]
|
||||
|
||||
[tool.codespell]
|
||||
|
||||
@@ -1,130 +0,0 @@
|
||||
[build-system]
|
||||
requires = ["setuptools>=61.0", "wheel"]
|
||||
build-backend = "setuptools.build_meta"
|
||||
|
||||
[project]
|
||||
name = "sglang"
|
||||
version = "0.5.4"
|
||||
description = "SGLang is a fast serving framework for large language models and vision language models."
|
||||
readme = "README.md"
|
||||
requires-python = ">=3.10"
|
||||
license = { file = "LICENSE" }
|
||||
classifiers = [
|
||||
"Programming Language :: Python :: 3",
|
||||
"License :: OSI Approved :: Apache Software License",
|
||||
]
|
||||
|
||||
dependencies = [
|
||||
"torch==2.8.0",
|
||||
"torchaudio==2.8.0",
|
||||
"torchvision",
|
||||
"sgl-kernel @ git+https://github.com/sgl-project/sgl-kernel-xpu.git",
|
||||
"IPython",
|
||||
"aiohttp",
|
||||
"anthropic>=0.20.0",
|
||||
"blobfile==3.0.0",
|
||||
"build",
|
||||
"compressed-tensors",
|
||||
"datasets",
|
||||
"decord",
|
||||
"einops",
|
||||
"fastapi",
|
||||
"hf_transfer",
|
||||
"huggingface_hub",
|
||||
"interegular",
|
||||
"llguidance>=0.7.11,<0.8.0",
|
||||
"modelscope",
|
||||
"msgspec",
|
||||
"ninja",
|
||||
"numpy",
|
||||
"openai-harmony==0.0.4",
|
||||
"openai==1.99.1",
|
||||
"orjson",
|
||||
"outlines==0.1.11",
|
||||
"packaging",
|
||||
"partial_json_parser",
|
||||
"pillow",
|
||||
"prometheus-client>=0.20.0",
|
||||
"psutil",
|
||||
"py-spy",
|
||||
"pybase64",
|
||||
"pydantic",
|
||||
"python-multipart",
|
||||
"pyzmq>=25.1.2",
|
||||
"requests",
|
||||
"scipy",
|
||||
"sentencepiece",
|
||||
"setproctitle",
|
||||
"soundfile==0.13.1",
|
||||
"tiktoken",
|
||||
"timm==1.0.16",
|
||||
"torchao==0.9.0",
|
||||
"tqdm",
|
||||
"transformers==4.57.1",
|
||||
"uvicorn",
|
||||
"uvloop",
|
||||
# "xgrammar==0.1.24", , xgrammar depends on CUDA PyTorch and Triton only
|
||||
"grpcio==1.75.1", # keep it align with compile_proto.py
|
||||
"grpcio-tools==1.75.1", # keep it align with compile_proto.py
|
||||
"grpcio-reflection==1.75.1", # required by srt/entrypoints/grpc_server.py
|
||||
]
|
||||
|
||||
[project.optional-dependencies]
|
||||
tracing = [
|
||||
"opentelemetry-sdk",
|
||||
"opentelemetry-api",
|
||||
"opentelemetry-exporter-otlp",
|
||||
"opentelemetry-exporter-otlp-proto-grpc",
|
||||
]
|
||||
test = [
|
||||
"accelerate",
|
||||
"expecttest",
|
||||
"jsonlines",
|
||||
"matplotlib",
|
||||
"pandas",
|
||||
"peft",
|
||||
"pytest",
|
||||
"sentence_transformers",
|
||||
"tabulate",
|
||||
]
|
||||
all = []
|
||||
dev = ["sglang[test]"]
|
||||
|
||||
[project.urls]
|
||||
"Homepage" = "https://github.com/sgl-project/sglang"
|
||||
"Bug Tracker" = "https://github.com/sgl-project/sglang/issues"
|
||||
|
||||
[tool.setuptools.package-data]
|
||||
"sglang" = [
|
||||
"srt/layers/moe/fused_moe_triton/configs/*/*.json",
|
||||
"srt/layers/quantization/configs/*.json",
|
||||
"srt/mem_cache/storage/hf3fs/hf3fs_utils.cpp",
|
||||
"srt/speculative/cpp_ngram/*.cpp",
|
||||
"srt/speculative/cpp_ngram/*.h",
|
||||
]
|
||||
|
||||
[tool.setuptools.packages.find]
|
||||
exclude = [
|
||||
"assets*",
|
||||
"benchmark*",
|
||||
"docs*",
|
||||
"dist*",
|
||||
"playground*",
|
||||
"scripts*",
|
||||
"tests*",
|
||||
]
|
||||
|
||||
[tool.wheel]
|
||||
exclude = [
|
||||
"assets*",
|
||||
"benchmark*",
|
||||
"docs*",
|
||||
"dist*",
|
||||
"playground*",
|
||||
"scripts*",
|
||||
"tests*",
|
||||
]
|
||||
|
||||
[tool.codespell]
|
||||
ignore-words-list = "ans, als, hel, boostrap, childs, te, vas, hsa, ment"
|
||||
skip = "*.json,*.jsonl,*.patch,*.txt"
|
||||
@@ -51,7 +51,6 @@ import logging
|
||||
import multiprocessing
|
||||
import os
|
||||
import time
|
||||
from types import SimpleNamespace
|
||||
from typing import Tuple
|
||||
|
||||
import numpy as np
|
||||
@@ -61,6 +60,7 @@ import torch.distributed as dist
|
||||
from sglang.srt.configs.model_config import ModelConfig
|
||||
from sglang.srt.distributed.parallel_state import destroy_distributed_environment
|
||||
from sglang.srt.entrypoints.engine import _set_envs_and_config
|
||||
from sglang.srt.hf_transformers_utils import get_tokenizer
|
||||
from sglang.srt.layers.moe import initialize_moe_config
|
||||
from sglang.srt.managers.schedule_batch import Req, ScheduleBatch
|
||||
from sglang.srt.managers.scheduler import Scheduler
|
||||
@@ -72,25 +72,12 @@ from sglang.srt.speculative.spec_info import SpeculativeAlgorithm
|
||||
from sglang.srt.utils import (
|
||||
configure_logger,
|
||||
get_bool_env_var,
|
||||
is_cuda_alike,
|
||||
is_xpu,
|
||||
kill_process_tree,
|
||||
maybe_reindex_device_id,
|
||||
require_mlp_sync,
|
||||
require_mlp_tp_gather,
|
||||
set_gpu_proc_affinity,
|
||||
suppress_other_loggers,
|
||||
)
|
||||
from sglang.srt.utils.hf_transformers_utils import get_tokenizer
|
||||
|
||||
profile_activities = [torch.profiler.ProfilerActivity.CPU] + [
|
||||
profiler_activity
|
||||
for available, profiler_activity in [
|
||||
(is_cuda_alike(), torch.profiler.ProfilerActivity.CUDA),
|
||||
(is_xpu(), torch.profiler.ProfilerActivity.XPU),
|
||||
]
|
||||
if available
|
||||
]
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
@@ -160,7 +147,7 @@ class BenchArgs:
|
||||
)
|
||||
|
||||
|
||||
def load_model(server_args, port_args, gpu_id, tp_rank):
|
||||
def load_model(server_args, port_args, tp_rank):
|
||||
suppress_other_loggers()
|
||||
rank_print = print if tp_rank == 0 else lambda *args, **kwargs: None
|
||||
moe_ep_rank = tp_rank // (server_args.tp_size // server_args.ep_size)
|
||||
@@ -169,7 +156,7 @@ def load_model(server_args, port_args, gpu_id, tp_rank):
|
||||
model_runner = ModelRunner(
|
||||
model_config=model_config,
|
||||
mem_fraction_static=server_args.mem_fraction_static,
|
||||
gpu_id=gpu_id,
|
||||
gpu_id=tp_rank,
|
||||
tp_rank=tp_rank,
|
||||
tp_size=server_args.tp_size,
|
||||
moe_ep_rank=moe_ep_rank,
|
||||
@@ -217,6 +204,7 @@ def prepare_inputs_for_correctness_test(bench_args, tokenizer, custom_prompts):
|
||||
origin_input_ids=tmp_input_ids,
|
||||
sampling_params=sampling_params,
|
||||
)
|
||||
req.prefix_indices = []
|
||||
req.fill_ids = req.origin_input_ids
|
||||
req.extend_input_len = len(req.fill_ids) - len(req.prefix_indices)
|
||||
req.logprob_start_len = len(req.origin_input_ids) - 1
|
||||
@@ -260,6 +248,7 @@ def prepare_synthetic_inputs_for_latency_test(
|
||||
origin_input_ids=list(input_ids[i]),
|
||||
sampling_params=sampling_params,
|
||||
)
|
||||
req.prefix_indices = []
|
||||
req.fill_ids = req.origin_input_ids
|
||||
req.extend_input_len = len(req.fill_ids) - len(req.prefix_indices)
|
||||
req.logprob_start_len = len(req.origin_input_ids) - 1
|
||||
@@ -270,18 +259,11 @@ def prepare_synthetic_inputs_for_latency_test(
|
||||
|
||||
@torch.no_grad
|
||||
def extend(reqs, model_runner):
|
||||
# Create dummy tree_cache for benchmarks (no prefix caching, just allocation)
|
||||
dummy_tree_cache = SimpleNamespace(
|
||||
page_size=model_runner.server_args.page_size,
|
||||
device=model_runner.device,
|
||||
token_to_kv_pool_allocator=model_runner.token_to_kv_pool_allocator,
|
||||
)
|
||||
|
||||
batch = ScheduleBatch.init_new(
|
||||
reqs=reqs,
|
||||
req_to_token_pool=model_runner.req_to_token_pool,
|
||||
token_to_kv_pool_allocator=model_runner.token_to_kv_pool_allocator,
|
||||
tree_cache=dummy_tree_cache,
|
||||
tree_cache=None,
|
||||
model_config=model_runner.model_config,
|
||||
enable_overlap=False,
|
||||
spec_algorithm=SpeculativeAlgorithm.NONE,
|
||||
@@ -320,7 +302,6 @@ def _maybe_prepare_mlp_sync_batch(batch: ScheduleBatch, model_runner):
|
||||
speculative_num_draft_tokens=None,
|
||||
require_mlp_tp_gather=require_mlp_tp_gather(model_runner.server_args),
|
||||
disable_overlap_schedule=model_runner.server_args.disable_overlap_schedule,
|
||||
offload_tags=set(),
|
||||
)
|
||||
|
||||
|
||||
@@ -352,7 +333,6 @@ def correctness_test(
|
||||
server_args,
|
||||
port_args,
|
||||
bench_args,
|
||||
gpu_id,
|
||||
tp_rank,
|
||||
):
|
||||
# Configure the logger
|
||||
@@ -360,7 +340,7 @@ def correctness_test(
|
||||
rank_print = print if tp_rank == 0 else lambda *args, **kwargs: None
|
||||
|
||||
# Load the model
|
||||
model_runner, tokenizer = load_model(server_args, port_args, gpu_id, tp_rank)
|
||||
model_runner, tokenizer = load_model(server_args, port_args, tp_rank)
|
||||
|
||||
# Prepare inputs
|
||||
custom_prompts = _read_prompts_from_file(bench_args.prompt_filename, rank_print)
|
||||
@@ -438,7 +418,10 @@ def latency_test_run_once(
|
||||
profiler = None
|
||||
if profile:
|
||||
profiler = torch.profiler.profile(
|
||||
activities=profile_activities,
|
||||
activities=[
|
||||
torch.profiler.ProfilerActivity.CPU,
|
||||
torch.profiler.ProfilerActivity.CUDA,
|
||||
],
|
||||
with_stack=True,
|
||||
record_shapes=profile_record_shapes,
|
||||
)
|
||||
@@ -471,7 +454,10 @@ def latency_test_run_once(
|
||||
if profile and i == output_len / 2:
|
||||
profiler = None
|
||||
profiler = torch.profiler.profile(
|
||||
activities=profile_activities,
|
||||
activities=[
|
||||
torch.profiler.ProfilerActivity.CPU,
|
||||
torch.profiler.ProfilerActivity.CUDA,
|
||||
],
|
||||
with_stack=True,
|
||||
record_shapes=profile_record_shapes,
|
||||
)
|
||||
@@ -520,23 +506,20 @@ def latency_test(
|
||||
server_args,
|
||||
port_args,
|
||||
bench_args,
|
||||
gpu_id,
|
||||
tp_rank,
|
||||
):
|
||||
initialize_moe_config(server_args)
|
||||
|
||||
# Set CPU affinity
|
||||
if get_bool_env_var("SGLANG_SET_CPU_AFFINITY"):
|
||||
set_gpu_proc_affinity(
|
||||
server_args.pp_size, server_args.tp_size, server_args.nnodes, tp_rank
|
||||
)
|
||||
set_gpu_proc_affinity(server_args.tp_size, server_args.nnodes, tp_rank)
|
||||
|
||||
# Configure the logger
|
||||
configure_logger(server_args, prefix=f" TP{tp_rank}")
|
||||
rank_print = print if tp_rank == 0 else lambda *args, **kwargs: None
|
||||
|
||||
# Load the model
|
||||
model_runner, tokenizer = load_model(server_args, port_args, gpu_id, tp_rank)
|
||||
model_runner, tokenizer = load_model(server_args, port_args, tp_rank)
|
||||
|
||||
# Prepare inputs for warm up
|
||||
reqs = prepare_synthetic_inputs_for_latency_test(
|
||||
@@ -638,23 +621,21 @@ def main(server_args, bench_args):
|
||||
port_args = PortArgs.init_new(server_args)
|
||||
|
||||
if server_args.tp_size == 1:
|
||||
work_func(server_args, port_args, bench_args, 0, 0)
|
||||
work_func(server_args, port_args, bench_args, 0)
|
||||
else:
|
||||
workers = []
|
||||
for tp_rank in range(server_args.tp_size):
|
||||
with maybe_reindex_device_id(tp_rank) as gpu_id:
|
||||
proc = multiprocessing.Process(
|
||||
target=work_func,
|
||||
args=(
|
||||
server_args,
|
||||
port_args,
|
||||
bench_args,
|
||||
gpu_id,
|
||||
tp_rank,
|
||||
),
|
||||
)
|
||||
proc.start()
|
||||
workers.append(proc)
|
||||
proc = multiprocessing.Process(
|
||||
target=work_func,
|
||||
args=(
|
||||
server_args,
|
||||
port_args,
|
||||
bench_args,
|
||||
tp_rank,
|
||||
),
|
||||
)
|
||||
proc.start()
|
||||
workers.append(proc)
|
||||
|
||||
for proc in workers:
|
||||
proc.join()
|
||||
|
||||
@@ -16,7 +16,6 @@ import argparse
|
||||
import dataclasses
|
||||
import itertools
|
||||
import json
|
||||
import logging
|
||||
import multiprocessing
|
||||
import os
|
||||
import random
|
||||
@@ -26,10 +25,8 @@ from typing import List, Optional, Tuple
|
||||
import numpy as np
|
||||
import requests
|
||||
from pydantic import BaseModel
|
||||
from transformers import AutoProcessor, PreTrainedTokenizer
|
||||
|
||||
from sglang.bench_serving import (
|
||||
get_processor,
|
||||
get_tokenizer,
|
||||
sample_mmmu_requests,
|
||||
sample_random_requests,
|
||||
@@ -40,8 +37,6 @@ from sglang.srt.server_args import ServerArgs
|
||||
from sglang.srt.utils import is_blackwell, kill_process_tree
|
||||
from sglang.test.test_utils import is_in_ci, write_github_step_summary
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class ProfileLinks(BaseModel):
|
||||
"""Pydantic model for profile trace links."""
|
||||
@@ -109,14 +104,8 @@ Note: To view the traces through perfetto-ui, please:
|
||||
if self.profile_links.extend or self.profile_links.decode:
|
||||
# Create a combined link or use the first available one
|
||||
trace_files = [self.profile_links.extend, self.profile_links.decode]
|
||||
if any(trace_file is None for trace_file in trace_files):
|
||||
logger.error("Some trace files are None", f"{trace_files=}")
|
||||
trace_files_relay_links = [
|
||||
(
|
||||
f"[trace]({get_perfetto_relay_link_from_trace_file(trace_file)})"
|
||||
if trace_file
|
||||
else "N/A"
|
||||
)
|
||||
f"[trace]({get_perfetto_relay_link_from_trace_file(trace_file)})"
|
||||
for trace_file in trace_files
|
||||
]
|
||||
|
||||
@@ -125,29 +114,30 @@ Note: To view the traces through perfetto-ui, please:
|
||||
# Build the row
|
||||
return f"| {self.batch_size} | {self.input_len} | {self.latency:.2f} | {self.input_throughput:.2f} | {self.output_throughput:.2f} | {accept_length} | {itl:.2f} | {input_cost:.2f} | {output_cost:.2f} | {profile_link} |\n"
|
||||
|
||||
@classmethod
|
||||
def generate_markdown_report(
|
||||
cls, trace_dir, results: List["BenchmarkResult"]
|
||||
) -> str:
|
||||
"""Generate a markdown report from a list of BenchmarkResult object from a single run."""
|
||||
import os
|
||||
|
||||
def generate_markdown_report(trace_dir, results: List["BenchmarkResult"]) -> str:
|
||||
"""Generate a markdown report from a list of BenchmarkResult object from a single run."""
|
||||
import os
|
||||
summary = f"### {results[0].model_path}\n"
|
||||
|
||||
summary = f"### {results[0].model_path}\n"
|
||||
# summary += (
|
||||
# f"Input lens: {result.input_len}. Output lens: {result.output_len}.\n"
|
||||
# )
|
||||
summary += "| batch size | input len | latency (s) | input throughput (tok/s) | output throughput (tok/s) | acc length | ITL (ms) | input cost ($/1M) | output cost ($/1M) | profile (extend) | profile (decode)|\n"
|
||||
summary += "| ---------- | --------- | ----------- | ------------------------- | ------------------------- | ---------- | -------- | ----------------- | ------------------ | --------------- | -------------- |\n"
|
||||
|
||||
# summary += (
|
||||
# f"Input lens: {result.input_len}. Output lens: {result.output_len}.\n"
|
||||
# )
|
||||
summary += "| batch size | input len | latency (s) | input throughput (tok/s) | output throughput (tok/s) | acc length | ITL (ms) | input cost ($/1M) | output cost ($/1M) | profile (extend) | profile (decode)|\n"
|
||||
summary += "| ---------- | --------- | ----------- | ------------------------- | ------------------------- | ---------- | -------- | ----------------- | ------------------ | --------------- | -------------- |\n"
|
||||
# all results should share the same isl & osl
|
||||
for result in results:
|
||||
base_url = os.getenv("TRACE_BASE_URL", "").rstrip("/")
|
||||
relay_base = os.getenv("PERFETTO_RELAY_URL", "").rstrip("/")
|
||||
relay_base = "https://docs.sglang.ai/ci-data/pages/perfetto_relay.html"
|
||||
# base_url = "https://github.com/sgl-project/ci-data/traces"
|
||||
summary += result.to_markdown_row(trace_dir, base_url, relay_base)
|
||||
|
||||
# all results should share the same isl & osl
|
||||
for result in results:
|
||||
base_url = os.getenv("TRACE_BASE_URL", "").rstrip("/")
|
||||
relay_base = os.getenv(
|
||||
"PERFETTO_RELAY_URL",
|
||||
"",
|
||||
).rstrip("/")
|
||||
summary += result.to_markdown_row(trace_dir, base_url, relay_base)
|
||||
|
||||
return summary
|
||||
return summary
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
@@ -298,7 +288,7 @@ def run_one_case(
|
||||
input_len_step_percentage: float,
|
||||
run_name: str,
|
||||
result_filename: str,
|
||||
tokenizer: PreTrainedTokenizer | AutoProcessor,
|
||||
tokenizer,
|
||||
dataset_name="",
|
||||
profile: bool = False,
|
||||
profile_steps: int = 3,
|
||||
@@ -312,8 +302,9 @@ def run_one_case(
|
||||
if dataset_name == "mmmu":
|
||||
input_requests = sample_mmmu_requests(
|
||||
num_requests=batch_size,
|
||||
processor=tokenizer,
|
||||
tokenizer=tokenizer,
|
||||
fixed_output_len=output_len,
|
||||
apply_chat_template=True,
|
||||
random_sample=False,
|
||||
)
|
||||
elif dataset_name == "random":
|
||||
@@ -373,8 +364,6 @@ def run_one_case(
|
||||
if dataset_name == "mmmu":
|
||||
# vlm
|
||||
input_ids = []
|
||||
# for vlms, tokenizer is an instance of AutoProcessor
|
||||
tokenizer = tokenizer.tokenizer
|
||||
for input_req in input_requests:
|
||||
input_ids += [tokenizer.encode(input_req.prompt)]
|
||||
payload["image_data"] = [req.image_data for req in input_requests]
|
||||
@@ -620,12 +609,7 @@ def run_benchmark(server_args: ServerArgs, bench_args: BenchArgs):
|
||||
tokenizer_path = server_info["tokenizer_path"]
|
||||
elif "prefill" in server_info:
|
||||
tokenizer_path = server_info["prefill"][0]["tokenizer_path"]
|
||||
|
||||
if bench_args.dataset_name == "mmmu":
|
||||
# mmmu implies this is a MLLM
|
||||
tokenizer = get_processor(tokenizer_path)
|
||||
else:
|
||||
tokenizer = get_tokenizer(tokenizer_path)
|
||||
tokenizer = get_tokenizer(tokenizer_path)
|
||||
|
||||
# warmup
|
||||
if not bench_args.skip_warmup:
|
||||
|
||||
@@ -12,6 +12,7 @@ python3 -m sglang.bench_serving --backend sglang --dataset-name random --num-pro
|
||||
|
||||
import argparse
|
||||
import asyncio
|
||||
import base64
|
||||
import io
|
||||
import json
|
||||
import os
|
||||
@@ -31,13 +32,9 @@ from typing import Any, AsyncGenerator, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import aiohttp
|
||||
import numpy as np
|
||||
import pybase64
|
||||
import requests
|
||||
from datasets import load_dataset
|
||||
from PIL import Image
|
||||
from tqdm.asyncio import tqdm
|
||||
from transformers import (
|
||||
AutoProcessor,
|
||||
AutoTokenizer,
|
||||
PreTrainedTokenizer,
|
||||
PreTrainedTokenizerBase,
|
||||
@@ -212,11 +209,6 @@ async def async_request_openai_completions(
|
||||
**request_func_input.extra_request_body,
|
||||
}
|
||||
|
||||
# hack to accommodate different LoRA conventions between SGLang and vLLM.
|
||||
if request_func_input.lora_name:
|
||||
payload["model"] = request_func_input.lora_name
|
||||
payload["lora_path"] = request_func_input.lora_name
|
||||
|
||||
if request_func_input.image_data:
|
||||
payload.update({"image_data": request_func_input.image_data})
|
||||
|
||||
@@ -330,17 +322,10 @@ async def async_request_openai_chat_completions(
|
||||
"model": request_func_input.model,
|
||||
"messages": messages,
|
||||
"temperature": 0.0,
|
||||
"max_completion_tokens": request_func_input.output_len,
|
||||
"max_tokens": request_func_input.output_len,
|
||||
"stream": not args.disable_stream,
|
||||
"ignore_eos": not args.disable_ignore_eos,
|
||||
**request_func_input.extra_request_body,
|
||||
}
|
||||
|
||||
# hack to accommodate different LoRA conventions between SGLang and vLLM.
|
||||
if request_func_input.lora_name:
|
||||
payload["model"] = request_func_input.lora_name
|
||||
payload["lora_path"] = request_func_input.lora_name
|
||||
|
||||
headers = get_auth_headers()
|
||||
|
||||
output = RequestFuncOutput.init_new(request_func_input)
|
||||
@@ -625,48 +610,6 @@ async def async_request_profile(api_url: str) -> RequestFuncOutput:
|
||||
return output
|
||||
|
||||
|
||||
def _build_profile_urls(
|
||||
profile_prefill_url: Optional[List[str]],
|
||||
profile_decode_url: Optional[List[str]],
|
||||
) -> List[Tuple[str, str]]:
|
||||
"""Build profile URLs list from prefill/decode URL arguments.
|
||||
|
||||
Returns:
|
||||
List of (worker_type, url) tuples. e.g., [("Prefill-0", "http://..."), ("Decode-0", "http://...")]
|
||||
"""
|
||||
profile_urls = []
|
||||
if profile_prefill_url:
|
||||
for idx, url in enumerate(profile_prefill_url):
|
||||
profile_urls.append((f"Prefill-{idx}", url))
|
||||
if profile_decode_url:
|
||||
for idx, url in enumerate(profile_decode_url):
|
||||
profile_urls.append((f"Decode-{idx}", url))
|
||||
return profile_urls
|
||||
|
||||
|
||||
async def _call_profile_pd(profile_urls: List[Tuple[str, str]], mode: str) -> None:
|
||||
"""Call profile endpoint (start/stop) on PD separated workers.
|
||||
|
||||
Args:
|
||||
profile_urls: List of (worker_type, url) tuples
|
||||
mode: "start" or "stop"
|
||||
"""
|
||||
endpoint = "/start_profile" if mode == "start" else "/stop_profile"
|
||||
action = "Starting" if mode == "start" else "Stopping"
|
||||
action_past = "started" if mode == "start" else "stopped"
|
||||
|
||||
print(f"{action} profiler...")
|
||||
|
||||
for worker_type, url in profile_urls:
|
||||
profile_output = await async_request_profile(api_url=url + endpoint)
|
||||
if profile_output.success:
|
||||
print(f"Profiler {action_past} for {worker_type} worker at {url}")
|
||||
else:
|
||||
print(
|
||||
f"Failed to {mode} profiler for {worker_type} worker at {url}: {profile_output.error}"
|
||||
)
|
||||
|
||||
|
||||
def get_model(pretrained_model_name_or_path: str) -> str:
|
||||
if os.getenv("SGLANG_USE_MODELSCOPE", "false").lower() == "true":
|
||||
import huggingface_hub.constants
|
||||
@@ -692,7 +635,7 @@ def get_tokenizer(
|
||||
if pretrained_model_name_or_path.endswith(
|
||||
".json"
|
||||
) or pretrained_model_name_or_path.endswith(".model"):
|
||||
from sglang.srt.utils.hf_transformers_utils import get_tokenizer
|
||||
from sglang.srt.hf_transformers_utils import get_tokenizer
|
||||
|
||||
return get_tokenizer(pretrained_model_name_or_path)
|
||||
|
||||
@@ -705,30 +648,7 @@ def get_tokenizer(
|
||||
)
|
||||
|
||||
|
||||
def get_processor(
|
||||
pretrained_model_name_or_path: str,
|
||||
) -> Union[PreTrainedTokenizer, PreTrainedTokenizerFast]:
|
||||
assert (
|
||||
pretrained_model_name_or_path is not None
|
||||
and pretrained_model_name_or_path != ""
|
||||
)
|
||||
if pretrained_model_name_or_path.endswith(
|
||||
".json"
|
||||
) or pretrained_model_name_or_path.endswith(".model"):
|
||||
from sglang.srt.utils.hf_transformers_utils import get_processor
|
||||
|
||||
return get_processor(pretrained_model_name_or_path)
|
||||
|
||||
if pretrained_model_name_or_path is not None and not os.path.exists(
|
||||
pretrained_model_name_or_path
|
||||
):
|
||||
pretrained_model_name_or_path = get_model(pretrained_model_name_or_path)
|
||||
return AutoProcessor.from_pretrained(
|
||||
pretrained_model_name_or_path, trust_remote_code=True
|
||||
)
|
||||
|
||||
|
||||
def get_dataset(args, tokenizer, model_id=None):
|
||||
def get_dataset(args, tokenizer):
|
||||
tokenize_prompt = getattr(args, "tokenize_prompt", False)
|
||||
if args.dataset_name == "sharegpt":
|
||||
assert not tokenize_prompt
|
||||
@@ -741,7 +661,7 @@ def get_dataset(args, tokenizer, model_id=None):
|
||||
prompt_suffix=args.prompt_suffix,
|
||||
apply_chat_template=args.apply_chat_template,
|
||||
)
|
||||
elif args.dataset_name.startswith("random"):
|
||||
elif args.dataset_name.startswith("random") and args.dataset_name != "random-image":
|
||||
input_requests = sample_random_requests(
|
||||
input_len=args.random_input_len,
|
||||
output_len=args.random_output_len,
|
||||
@@ -752,18 +672,17 @@ def get_dataset(args, tokenizer, model_id=None):
|
||||
random_sample=args.dataset_name == "random",
|
||||
return_text=not tokenize_prompt,
|
||||
)
|
||||
elif args.dataset_name == "image":
|
||||
processor = get_processor(model_id)
|
||||
input_requests = sample_image_requests(
|
||||
elif args.dataset_name == "random-image":
|
||||
assert not tokenize_prompt, "random-image does not support --tokenize-prompt"
|
||||
input_requests = sample_random_image_requests(
|
||||
num_requests=args.num_prompts,
|
||||
image_count=args.image_count,
|
||||
num_images=args.random_image_num_images,
|
||||
input_len=args.random_input_len,
|
||||
output_len=args.random_output_len,
|
||||
range_ratio=args.random_range_ratio,
|
||||
processor=processor,
|
||||
image_content=args.image_content,
|
||||
image_format=args.image_format,
|
||||
image_resolution=args.image_resolution,
|
||||
tokenizer=tokenizer,
|
||||
apply_chat_template=args.apply_chat_template,
|
||||
image_resolution=args.random_image_resolution,
|
||||
)
|
||||
elif args.dataset_name == "generated-shared-prefix":
|
||||
assert not tokenize_prompt
|
||||
@@ -777,11 +696,12 @@ def get_dataset(args, tokenizer, model_id=None):
|
||||
args=args,
|
||||
)
|
||||
elif args.dataset_name == "mmmu":
|
||||
processor = get_processor(model_id)
|
||||
assert not tokenize_prompt
|
||||
input_requests = sample_mmmu_requests(
|
||||
num_requests=args.num_prompts,
|
||||
processor=processor,
|
||||
tokenizer=tokenizer,
|
||||
fixed_output_len=args.random_output_len,
|
||||
apply_chat_template=args.apply_chat_template,
|
||||
random_sample=True,
|
||||
)
|
||||
elif args.dataset_name == "mooncake":
|
||||
@@ -826,8 +746,6 @@ ASYNC_REQUEST_FUNCS = {
|
||||
class BenchmarkMetrics:
|
||||
completed: int
|
||||
total_input: int
|
||||
total_input_text: int
|
||||
total_input_vision: int
|
||||
total_output: int
|
||||
total_output_retokenized: int
|
||||
request_throughput: float
|
||||
@@ -921,17 +839,9 @@ class DatasetRow:
|
||||
prompt: str
|
||||
prompt_len: int
|
||||
output_len: int
|
||||
text_prompt_len: Optional[int] = None
|
||||
vision_prompt_len: Optional[int] = None
|
||||
image_data: Optional[List[str]] = None
|
||||
timestamp: Optional[float] = None
|
||||
|
||||
def __post_init__(self):
|
||||
if self.text_prompt_len is None:
|
||||
self.text_prompt_len = self.prompt_len
|
||||
if self.vision_prompt_len is None:
|
||||
self.vision_prompt_len = 0
|
||||
|
||||
|
||||
async def get_mooncake_request_over_time(
|
||||
input_requests: List[Dict],
|
||||
@@ -979,7 +889,7 @@ async def get_mooncake_request_over_time(
|
||||
for i in range(num_rounds):
|
||||
# Add user query for the current round
|
||||
chat_history.append(
|
||||
{"role": "user", "content": f"Round {i + 1}: {user_query_base}"}
|
||||
{"role": "user", "content": f"Round {i+1}: {user_query_base}"}
|
||||
)
|
||||
|
||||
# Form the full prompt from history
|
||||
@@ -1008,8 +918,9 @@ async def get_mooncake_request_over_time(
|
||||
|
||||
def sample_mmmu_requests(
|
||||
num_requests: int,
|
||||
processor: AutoProcessor | AutoTokenizer,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
fixed_output_len: Optional[int] = None,
|
||||
apply_chat_template: bool = True,
|
||||
random_sample: bool = True,
|
||||
) -> List[DatasetRow]:
|
||||
"""
|
||||
@@ -1017,12 +928,22 @@ def sample_mmmu_requests(
|
||||
|
||||
Args:
|
||||
num_requests: Number of requests to sample.
|
||||
tokenizer: Tokenizer to use for token counting.
|
||||
fixed_output_len: If provided, use this fixed output length for all requests.
|
||||
apply_chat_template: Whether to apply the chat template to the prompt.
|
||||
random_sample: Whether to randomly sample or take the first N.
|
||||
|
||||
Returns:
|
||||
List of tuples (prompt, prompt_token_len, output_token_len).
|
||||
"""
|
||||
try:
|
||||
import io
|
||||
|
||||
import pybase64
|
||||
from datasets import load_dataset
|
||||
except ImportError:
|
||||
raise ImportError("Please install datasets: pip install datasets")
|
||||
|
||||
print("Loading MMMU dataset from HuggingFace...")
|
||||
|
||||
try:
|
||||
@@ -1078,12 +999,54 @@ def sample_mmmu_requests(
|
||||
question = example.get("question")
|
||||
|
||||
# Construct the prompt
|
||||
text_prompt = f"Question: {question}\n\nAnswer: "
|
||||
prompt = f"Question: {question}\n\nAnswer: "
|
||||
if apply_chat_template:
|
||||
try:
|
||||
is_phi4_multimodal = (
|
||||
"phi-4-multimodal" in tokenizer.name_or_path.lower()
|
||||
)
|
||||
if is_phi4_multimodal:
|
||||
# <|endoftext10|> is the image token used in the phi-4-multimodal model.
|
||||
content = prompt.replace("image 1", "<|endoftext10|>")
|
||||
else:
|
||||
content = [
|
||||
{
|
||||
"type": "image_url",
|
||||
"image_url": {"url": image_data},
|
||||
},
|
||||
{"type": "text", "text": prompt},
|
||||
]
|
||||
prompt = tokenizer.apply_chat_template(
|
||||
[
|
||||
{
|
||||
"role": "user",
|
||||
"content": content,
|
||||
}
|
||||
],
|
||||
add_generation_prompt=True,
|
||||
tokenize=False,
|
||||
)
|
||||
except Exception as e:
|
||||
# Note (Xinyuan): This is a workaround for an issue where some tokenizers do not support content as a list. (e.g. InternVL)
|
||||
print(
|
||||
f"Error applying chat template: {e}, fallback to <image> tag"
|
||||
)
|
||||
prompt = f"<image>{prompt}"
|
||||
|
||||
# Calculate token lengths for text only (without image data)
|
||||
prompt_token_ids = tokenizer.encode(prompt)
|
||||
prompt_len = len(prompt_token_ids)
|
||||
|
||||
output_len = fixed_output_len if fixed_output_len is not None else 256
|
||||
data_row = create_mm_data_row(
|
||||
text_prompt, [image], [image_data], output_len, processor
|
||||
|
||||
filtered_dataset.append(
|
||||
DatasetRow(
|
||||
prompt=prompt,
|
||||
prompt_len=prompt_len,
|
||||
output_len=output_len,
|
||||
image_data=[image_data],
|
||||
)
|
||||
)
|
||||
filtered_dataset.append(data_row)
|
||||
|
||||
except Exception as e:
|
||||
print(f"Error processing example {i}: {e}")
|
||||
@@ -1171,11 +1134,7 @@ def sample_sharegpt_requests(
|
||||
continue
|
||||
|
||||
filtered_dataset.append(
|
||||
DatasetRow(
|
||||
prompt=prompt,
|
||||
prompt_len=prompt_len,
|
||||
output_len=output_len,
|
||||
)
|
||||
DatasetRow(prompt=prompt, prompt_len=prompt_len, output_len=output_len)
|
||||
)
|
||||
|
||||
print(f"#Input tokens: {np.sum([x.prompt_len for x in filtered_dataset])}")
|
||||
@@ -1286,7 +1245,7 @@ def sample_random_requests(
|
||||
return input_requests
|
||||
|
||||
|
||||
def parse_image_resolution(image_resolution: str) -> Tuple[int, int]:
|
||||
def parse_random_image_resolution(image_resolution: str) -> Tuple[int, int]:
|
||||
"""Parse image resolution into (width, height).
|
||||
|
||||
Supports presets '1080p', '720p', '360p' and custom 'heightxwidth' format
|
||||
@@ -1311,94 +1270,44 @@ def parse_image_resolution(image_resolution: str) -> Tuple[int, int]:
|
||||
return (width, height)
|
||||
|
||||
raise ValueError(
|
||||
f"Unsupported image resolution: {image_resolution}. "
|
||||
f"Unsupported random-image resolution: {image_resolution}. "
|
||||
"Choose from 4k, 1080p, 720p, 360p, or provide custom 'heightxwidth' (e.g., 1080x1920)."
|
||||
)
|
||||
|
||||
|
||||
def create_mm_data_row(text_prompt, images: list, images_base64, output_len, processor):
|
||||
try:
|
||||
content_items = [
|
||||
{"type": "image", "image": {"url": image_base64}}
|
||||
for image_base64 in images_base64
|
||||
]
|
||||
content_items.append({"type": "text", "text": text_prompt})
|
||||
prompt_str = processor.apply_chat_template(
|
||||
[{"role": "user", "content": content_items}],
|
||||
add_generation_prompt=True,
|
||||
tokenize=False,
|
||||
)
|
||||
except Exception as e:
|
||||
# Note (Xinyuan): This is a workaround for an issue where some tokenizers do not support content as a list. (e.g. InternVL)
|
||||
print(f"Error applying chat template: {e}, fallback to <image> tag")
|
||||
# Some tokenizers do not support list content; fall back to a placeholder in the text
|
||||
prompt_str = f"<image>{text_prompt}"
|
||||
|
||||
# Calculate total tokens (text + vision)
|
||||
prompt_len = processor(
|
||||
text=[prompt_str],
|
||||
images=images,
|
||||
padding=False,
|
||||
return_tensors="pt",
|
||||
)["input_ids"].numel()
|
||||
|
||||
# Calculate text-only tokens
|
||||
try:
|
||||
# Create text-only version of the prompt
|
||||
text_only_prompt = processor.apply_chat_template(
|
||||
[{"role": "user", "content": text_prompt}],
|
||||
add_generation_prompt=True,
|
||||
tokenize=False,
|
||||
)
|
||||
text_prompt_len = processor(
|
||||
text=[text_only_prompt],
|
||||
padding=False,
|
||||
return_tensors="pt",
|
||||
)["input_ids"].numel()
|
||||
except Exception:
|
||||
# Fallback: just tokenize the text prompt directly
|
||||
text_prompt_len = len(processor.tokenizer.encode(text_prompt))
|
||||
|
||||
# Vision tokens = total tokens - text tokens
|
||||
vision_prompt_len = prompt_len - text_prompt_len
|
||||
|
||||
return DatasetRow(
|
||||
prompt=text_prompt,
|
||||
prompt_len=prompt_len,
|
||||
output_len=output_len,
|
||||
text_prompt_len=text_prompt_len,
|
||||
vision_prompt_len=vision_prompt_len,
|
||||
image_data=images_base64,
|
||||
)
|
||||
|
||||
|
||||
def sample_image_requests(
|
||||
def sample_random_image_requests(
|
||||
num_requests: int,
|
||||
image_count: int,
|
||||
num_images: int,
|
||||
input_len: int,
|
||||
output_len: int,
|
||||
range_ratio: float,
|
||||
processor: AutoProcessor,
|
||||
image_content: str,
|
||||
image_format: str,
|
||||
image_resolution: str,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
apply_chat_template: bool = True,
|
||||
image_resolution: str = "1080p",
|
||||
) -> List[DatasetRow]:
|
||||
"""Generate requests with images.
|
||||
"""Generate requests with random images.
|
||||
|
||||
- Each request includes ``image_count`` images.
|
||||
- Each request includes ``num_images`` random images.
|
||||
- Supported resolutions: 4k (3840x2160), 1080p (1920x1080), 720p (1280x720), 360p (640x360),
|
||||
or custom 'heightxwidth' (e.g., 1080x1920).
|
||||
- Text lengths follow the 'random' dataset sampling rule. ``prompt_len``
|
||||
only counts text tokens and excludes image data.
|
||||
"""
|
||||
try:
|
||||
import pybase64
|
||||
from PIL import Image
|
||||
except ImportError as e:
|
||||
raise ImportError(
|
||||
"Please install Pillow to generate random images: pip install pillow"
|
||||
) from e
|
||||
|
||||
# Parse resolution (supports presets and 'heightxwidth')
|
||||
width, height = parse_image_resolution(image_resolution)
|
||||
width, height = parse_random_image_resolution(image_resolution)
|
||||
|
||||
# Check for potentially problematic combinations and warn user
|
||||
if width * height >= 1920 * 1080 and image_count * num_requests >= 100:
|
||||
if width * height >= 1920 * 1080 and num_images * num_requests >= 100:
|
||||
warnings.warn(
|
||||
f"High resolution ({width}x{height}) with {image_count * num_requests} total images "
|
||||
f"High resolution ({width}x{height}) with {num_images * num_requests} total images "
|
||||
f"may take a long time. Consider reducing resolution or image count.",
|
||||
UserWarning,
|
||||
stacklevel=2,
|
||||
@@ -1412,50 +1321,53 @@ def sample_image_requests(
|
||||
int(output_len * range_ratio), output_len + 1, size=num_requests
|
||||
)
|
||||
|
||||
def _gen_random_image_data_uri(
|
||||
width: int = width, height: int = height
|
||||
) -> (Image, str, int):
|
||||
if image_content == "blank":
|
||||
# Generate blank white image
|
||||
arr = np.full((height, width, 3), 255, dtype=np.uint8)
|
||||
else:
|
||||
# Generate random colored image
|
||||
arr = (np.random.rand(height, width, 3) * 255).astype(np.uint8)
|
||||
img = Image.fromarray(arr)
|
||||
def _gen_random_image_data_uri(width: int = width, height: int = height) -> str:
|
||||
arr = (np.random.rand(height, width, 3) * 255).astype(np.uint8)
|
||||
img = Image.fromarray(arr, mode="RGB")
|
||||
buf = io.BytesIO()
|
||||
img.save(buf, format=image_format, quality=85)
|
||||
img.save(buf, format="JPEG", quality=85)
|
||||
encoded = pybase64.b64encode(buf.getvalue()).decode("utf-8")
|
||||
image_data = f"data:image/{image_format};base64,{encoded}"
|
||||
image_bytes = len(image_data.encode("utf-8"))
|
||||
return img, image_data, image_bytes
|
||||
return f"data:image/jpeg;base64,{encoded}"
|
||||
|
||||
dataset: List[DatasetRow] = []
|
||||
total_image_bytes = 0
|
||||
for i in range(num_requests):
|
||||
# Generate text prompt
|
||||
text_prompt = gen_prompt(processor.tokenizer, int(input_lens[i]))
|
||||
text_prompt = gen_prompt(tokenizer, int(input_lens[i]))
|
||||
|
||||
# Generate image list
|
||||
images, images_base64, images_bytes = zip(
|
||||
*[_gen_random_image_data_uri() for _ in range(image_count)]
|
||||
)
|
||||
total_image_bytes += sum(list(images_bytes))
|
||||
images = [_gen_random_image_data_uri() for _ in range(num_images)]
|
||||
|
||||
data_row = create_mm_data_row(
|
||||
text_prompt,
|
||||
list(images),
|
||||
list(images_base64),
|
||||
int(output_lens[i]),
|
||||
processor,
|
||||
)
|
||||
prompt_str = text_prompt
|
||||
if apply_chat_template:
|
||||
try:
|
||||
content_items = [
|
||||
{"type": "image_url", "image_url": {"url": img_url}}
|
||||
for img_url in images
|
||||
]
|
||||
content_items.append({"type": "text", "text": text_prompt})
|
||||
prompt_str = tokenizer.apply_chat_template(
|
||||
[{"role": "user", "content": content_items}],
|
||||
add_generation_prompt=True,
|
||||
tokenize=False,
|
||||
)
|
||||
except Exception:
|
||||
# Some tokenizers do not support list content; fall back to a placeholder in the text
|
||||
prompt_str = f"<image>{text_prompt}"
|
||||
|
||||
dataset.append(data_row)
|
||||
prompt_token_ids = tokenizer.encode(prompt_str)
|
||||
prompt_token_len = len(prompt_token_ids)
|
||||
|
||||
dataset.append(
|
||||
DatasetRow(
|
||||
prompt=prompt_str,
|
||||
prompt_len=prompt_token_len,
|
||||
output_len=int(output_lens[i]),
|
||||
image_data=images,
|
||||
)
|
||||
)
|
||||
|
||||
print(f"#Input tokens: {np.sum([x.prompt_len for x in dataset])}")
|
||||
print(f"#Output tokens: {np.sum([x.output_len for x in dataset])}")
|
||||
print(
|
||||
f"\nCreated {len(dataset)} {image_content} {image_format} images with average {total_image_bytes // num_requests} bytes per request"
|
||||
)
|
||||
return dataset
|
||||
|
||||
|
||||
@@ -1527,9 +1439,7 @@ def sample_generated_shared_prefix_requests(
|
||||
|
||||
input_requests.append(
|
||||
DatasetRow(
|
||||
prompt=full_prompt,
|
||||
prompt_len=prompt_len,
|
||||
output_len=output_len,
|
||||
prompt=full_prompt, prompt_len=prompt_len, output_len=output_len
|
||||
)
|
||||
)
|
||||
total_input_tokens += prompt_len
|
||||
@@ -1611,8 +1521,6 @@ def calculate_metrics(
|
||||
output_lens: List[int] = []
|
||||
retokenized_output_lens: List[int] = []
|
||||
total_input = 0
|
||||
total_input_text = 0
|
||||
total_input_vision = 0
|
||||
completed = 0
|
||||
itls: List[float] = []
|
||||
tpots: List[float] = []
|
||||
@@ -1626,9 +1534,7 @@ def calculate_metrics(
|
||||
tokenizer.encode(outputs[i].generated_text, add_special_tokens=False)
|
||||
)
|
||||
retokenized_output_lens.append(retokenized_output_len)
|
||||
total_input += input_requests[i].prompt_len
|
||||
total_input_text += input_requests[i].text_prompt_len
|
||||
total_input_vision += input_requests[i].vision_prompt_len
|
||||
total_input += outputs[i].prompt_len
|
||||
if output_len > 1:
|
||||
tpots.append((outputs[i].latency - outputs[i].ttft) / (output_len - 1))
|
||||
itls += outputs[i].itl
|
||||
@@ -1650,8 +1556,6 @@ def calculate_metrics(
|
||||
metrics = BenchmarkMetrics(
|
||||
completed=completed,
|
||||
total_input=total_input,
|
||||
total_input_text=total_input_text,
|
||||
total_input_vision=total_input_vision,
|
||||
total_output=sum(output_lens),
|
||||
total_output_retokenized=sum(retokenized_output_lens),
|
||||
request_throughput=completed / dur_s,
|
||||
@@ -1705,8 +1609,6 @@ async def benchmark(
|
||||
use_trace_timestamps: bool = False,
|
||||
mooncake_slowdown_factor=1.0,
|
||||
mooncake_num_rounds=1,
|
||||
profile_prefill_url: Optional[List[str]] = None,
|
||||
profile_decode_url: Optional[List[str]] = None,
|
||||
):
|
||||
if backend in ASYNC_REQUEST_FUNCS:
|
||||
request_func = ASYNC_REQUEST_FUNCS[backend]
|
||||
@@ -1796,28 +1698,14 @@ async def benchmark(
|
||||
|
||||
time.sleep(1.0)
|
||||
|
||||
# Build profile URLs for PD separated mode (do this once at the beginning)
|
||||
pd_profile_urls = []
|
||||
if profile and pd_separated:
|
||||
pd_profile_urls = _build_profile_urls(profile_prefill_url, profile_decode_url)
|
||||
if not pd_profile_urls:
|
||||
print(
|
||||
"Warning: PD separated mode requires --profile-prefill-url or --profile-decode-url"
|
||||
)
|
||||
print("Skipping profiler start. Please specify worker URLs for profiling.")
|
||||
|
||||
# Start profiler
|
||||
if profile:
|
||||
if pd_separated:
|
||||
if pd_profile_urls:
|
||||
await _call_profile_pd(pd_profile_urls, "start")
|
||||
else:
|
||||
print("Starting profiler...")
|
||||
profile_output = await async_request_profile(
|
||||
api_url=base_url + "/start_profile"
|
||||
)
|
||||
if profile_output.success:
|
||||
print("Profiler started")
|
||||
print("Starting profiler...")
|
||||
profile_output = await async_request_profile(
|
||||
api_url=base_url + "/start_profile"
|
||||
)
|
||||
if profile_output.success:
|
||||
print("Profiler started")
|
||||
|
||||
# Run all requests
|
||||
benchmark_start_time = time.perf_counter()
|
||||
@@ -1866,16 +1754,10 @@ async def benchmark(
|
||||
|
||||
# Stop profiler
|
||||
if profile:
|
||||
if pd_separated:
|
||||
if pd_profile_urls:
|
||||
await _call_profile_pd(pd_profile_urls, "stop")
|
||||
else:
|
||||
print("Stopping profiler...")
|
||||
profile_output = await async_request_profile(
|
||||
api_url=base_url + "/stop_profile"
|
||||
)
|
||||
if profile_output.success:
|
||||
print("Profiler stopped")
|
||||
print("Stopping profiler...")
|
||||
profile_output = await async_request_profile(api_url=base_url + "/stop_profile")
|
||||
if profile_output.success:
|
||||
print("Profiler stopped")
|
||||
|
||||
if pbar is not None:
|
||||
pbar.close()
|
||||
@@ -1888,15 +1770,9 @@ async def benchmark(
|
||||
server_info_json = server_info.json()
|
||||
if "decode" in server_info_json:
|
||||
server_info_json = server_info_json["decode"][0]
|
||||
if (
|
||||
"internal_states" in server_info_json
|
||||
and server_info_json["internal_states"]
|
||||
):
|
||||
accept_length = server_info_json["internal_states"][0].get(
|
||||
"avg_spec_accept_length", None
|
||||
)
|
||||
else:
|
||||
accept_length = None
|
||||
accept_length = server_info_json["internal_states"][0].get(
|
||||
"avg_spec_accept_length", None
|
||||
)
|
||||
else:
|
||||
accept_length = None
|
||||
else:
|
||||
@@ -1928,10 +1804,6 @@ async def benchmark(
|
||||
print("{:<40} {:<10}".format("Successful requests:", metrics.completed))
|
||||
print("{:<40} {:<10.2f}".format("Benchmark duration (s):", benchmark_duration))
|
||||
print("{:<40} {:<10}".format("Total input tokens:", metrics.total_input))
|
||||
print("{:<40} {:<10}".format("Total input text tokens:", metrics.total_input_text))
|
||||
print(
|
||||
"{:<40} {:<10}".format("Total input vision tokens:", metrics.total_input_vision)
|
||||
)
|
||||
print("{:<40} {:<10}".format("Total generated tokens:", metrics.total_output))
|
||||
print(
|
||||
"{:<40} {:<10}".format(
|
||||
@@ -2001,8 +1873,6 @@ async def benchmark(
|
||||
"duration": benchmark_duration,
|
||||
"completed": metrics.completed,
|
||||
"total_input_tokens": metrics.total_input,
|
||||
"total_input_text_tokens": metrics.total_input_text,
|
||||
"total_input_vision_tokens": metrics.total_input_vision,
|
||||
"total_output_tokens": metrics.total_output,
|
||||
"total_output_tokens_retokenized": metrics.total_output_retokenized,
|
||||
"request_throughput": metrics.request_throughput,
|
||||
@@ -2037,11 +1907,11 @@ async def benchmark(
|
||||
output_file_name = args.output_file
|
||||
else:
|
||||
now = datetime.now().strftime("%m%d")
|
||||
if args.dataset_name == "image":
|
||||
if args.dataset_name == "random-image":
|
||||
output_file_name = (
|
||||
f"{args.backend}_{now}_{args.num_prompts}_{args.random_input_len}_"
|
||||
f"{args.random_output_len}_{args.image_count}imgs_"
|
||||
f"{args.image_resolution}.jsonl"
|
||||
f"{args.random_output_len}_{args.random_image_num_images}imgs_"
|
||||
f"{args.random_image_resolution}.jsonl"
|
||||
)
|
||||
elif args.dataset_name.startswith("random"):
|
||||
output_file_name = f"{args.backend}_{now}_{args.num_prompts}_{args.random_input_len}_{args.random_output_len}.jsonl"
|
||||
@@ -2217,12 +2087,6 @@ def run_benchmark(args_: argparse.Namespace):
|
||||
"Because when the tokenizer counts the output tokens, if there is gibberish, it might count incorrectly.\n"
|
||||
)
|
||||
|
||||
if args.dataset_name in ["image", "mmmu"]:
|
||||
args.apply_chat_template = True
|
||||
assert (
|
||||
not args.tokenize_prompt
|
||||
), "`--tokenize-prompt` not compatible with image dataset"
|
||||
|
||||
print(f"{args}\n")
|
||||
|
||||
# Read dataset
|
||||
@@ -2230,7 +2094,7 @@ def run_benchmark(args_: argparse.Namespace):
|
||||
model_id = args.model
|
||||
tokenizer_id = args.tokenizer if args.tokenizer is not None else args.model
|
||||
tokenizer = get_tokenizer(tokenizer_id)
|
||||
input_requests = get_dataset(args, tokenizer, model_id)
|
||||
input_requests = get_dataset(args, tokenizer)
|
||||
|
||||
# compatible with SimpleNamespace
|
||||
if not hasattr(args, "flush_cache"):
|
||||
@@ -2256,8 +2120,6 @@ def run_benchmark(args_: argparse.Namespace):
|
||||
use_trace_timestamps=args.use_trace_timestamps,
|
||||
mooncake_slowdown_factor=args.mooncake_slowdown_factor,
|
||||
mooncake_num_rounds=args.mooncake_num_rounds,
|
||||
profile_prefill_url=getattr(args, "profile_prefill_url", None),
|
||||
profile_decode_url=getattr(args, "profile_decode_url", None),
|
||||
)
|
||||
)
|
||||
|
||||
@@ -2313,7 +2175,7 @@ if __name__ == "__main__":
|
||||
"random-ids",
|
||||
"generated-shared-prefix",
|
||||
"mmmu",
|
||||
"image",
|
||||
"random-image",
|
||||
"mooncake",
|
||||
],
|
||||
help="Name of the dataset to benchmark on.",
|
||||
@@ -2353,49 +2215,37 @@ if __name__ == "__main__":
|
||||
"--random-input-len",
|
||||
type=int,
|
||||
default=1024,
|
||||
help="Number of input tokens per request, used only for random and image dataset.",
|
||||
help="Number of input tokens per request, used only for random dataset.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--random-output-len",
|
||||
default=1024,
|
||||
type=int,
|
||||
help="Number of output tokens per request, used only for random and image dataset.",
|
||||
help="Number of output tokens per request, used only for random dataset.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--random-range-ratio",
|
||||
type=float,
|
||||
default=0.0,
|
||||
help="Range of sampled ratio of input/output length, "
|
||||
"used only for random and image dataset.",
|
||||
"used only for random dataset.",
|
||||
)
|
||||
# image dataset args
|
||||
# random-image dataset args
|
||||
parser.add_argument(
|
||||
"--image-count",
|
||||
"--random-image-num-images",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Number of images per request (only available with the image dataset)",
|
||||
help="Number of images per request (only available with the random-image dataset)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--image-resolution",
|
||||
"--random-image-resolution",
|
||||
type=str,
|
||||
default="1080p",
|
||||
help=(
|
||||
"Resolution of images for image dataset. "
|
||||
"Resolution of random images for random-image dataset. "
|
||||
"Supports presets 4k/1080p/720p/360p or custom 'heightxwidth' (e.g., 1080x1920)."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--image-format",
|
||||
type=str,
|
||||
default="jpeg",
|
||||
help=("Format of images for image dataset. " "Supports jpeg and png."),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--image-content",
|
||||
type=str,
|
||||
default="random",
|
||||
help=("Content for images for image dataset. " "Supports random and blank."),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--request-rate",
|
||||
type=float,
|
||||
@@ -2483,30 +2333,6 @@ if __name__ == "__main__":
|
||||
action="store_true",
|
||||
help="Benchmark PD disaggregation server",
|
||||
)
|
||||
|
||||
# Create a mutually exclusive group for profiling URLs
|
||||
# In PD separated mode, prefill and decode workers must be profiled separately
|
||||
profile_url_group = parser.add_mutually_exclusive_group()
|
||||
profile_url_group.add_argument(
|
||||
"--profile-prefill-url",
|
||||
type=str,
|
||||
nargs="*",
|
||||
default=None,
|
||||
help="URL(s) of the prefill worker(s) for profiling in PD separated mode. "
|
||||
"Can specify multiple URLs: --profile-prefill-url http://localhost:30000 http://localhost:30001. "
|
||||
"NOTE: Cannot be used together with --profile-decode-url. "
|
||||
"In PD separated mode, prefill and decode workers must be profiled separately.",
|
||||
)
|
||||
profile_url_group.add_argument(
|
||||
"--profile-decode-url",
|
||||
type=str,
|
||||
nargs="*",
|
||||
default=None,
|
||||
help="URL(s) of the decode worker(s) for profiling in PD separated mode. "
|
||||
"Can specify multiple URLs: --profile-decode-url http://localhost:30010 http://localhost:30011. "
|
||||
"NOTE: Cannot be used together with --profile-prefill-url. "
|
||||
"In PD separated mode, prefill and decode workers must be profiled separately.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--flush-cache",
|
||||
action="store_true",
|
||||
|
||||
@@ -47,7 +47,7 @@ PACKAGE_LIST = [
|
||||
"tiktoken",
|
||||
"anthropic",
|
||||
"litellm",
|
||||
"decord2",
|
||||
"decord",
|
||||
]
|
||||
|
||||
|
||||
|
||||
@@ -19,7 +19,6 @@ import requests
|
||||
|
||||
from sglang.srt.disaggregation.utils import FAKE_BOOTSTRAP_HOST
|
||||
from sglang.srt.entrypoints.http_server import launch_server
|
||||
from sglang.srt.environ import envs
|
||||
from sglang.srt.managers.io_struct import GenerateReqInput
|
||||
from sglang.srt.managers.tokenizer_manager import TokenizerManager
|
||||
from sglang.srt.server_args import ServerArgs
|
||||
@@ -29,9 +28,9 @@ from sglang.srt.warmup import warmup
|
||||
multiprocessing.set_start_method("spawn", force=True)
|
||||
|
||||
# Reduce warning
|
||||
envs.SGLANG_IN_DEEPGEMM_PRECOMPILE_STAGE.set(True)
|
||||
os.environ["SGL_IN_DEEPGEMM_PRECOMPILE_STAGE"] = "1"
|
||||
# Force enable deep gemm
|
||||
envs.SGLANG_ENABLE_JIT_DEEPGEMM.set(True)
|
||||
os.environ["SGL_ENABLE_JIT_DEEPGEMM"] = "1"
|
||||
# Force enable mha chunked kv for DeepSeek V3 to avoid missing kv_b_proj DeepGEMM case
|
||||
os.environ["SGL_CHUNKED_PREFIX_CACHE_THRESHOLD"] = "0"
|
||||
|
||||
@@ -142,9 +141,6 @@ def refine_server_args(server_args: ServerArgs, compile_args: CompileArgs):
|
||||
server_args.enable_torch_compile = False
|
||||
print(f"Disable CUDA Graph and Torch Compile to save time...")
|
||||
|
||||
server_args.load_format = "dummy"
|
||||
print(f"Set load format to dummy to save time...")
|
||||
|
||||
# Set watchdog timeout to compile_args.timeout because compilation will take a long time
|
||||
server_args.watchdog_timeout = compile_args.timeout
|
||||
server_args.warmups = "compile-deep-gemm"
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user