60 lines
2.3 KiB
Markdown
60 lines
2.3 KiB
Markdown
---
|
|
frameworks:
|
|
- Pytorch
|
|
license: Apache License 2.0
|
|
tasks:
|
|
- text-generation
|
|
datasets:
|
|
train:
|
|
- Data-Juicer/alpaca-cot-zh-refined-by-data-juicer
|
|
tags:
|
|
- data-juicer
|
|
- arxiv:2309.02033
|
|
---
|
|
## News
|
|
Our first data-centric LLM competition begins! Please visit the competition's official websites, **FT-Data Ranker** ([1B Track](https://tianchi.aliyun.com/competition/entrance/532157), [7B Track](https://tianchi.aliyun.com/competition/entrance/532158)), for more information.
|
|
## Introduction
|
|
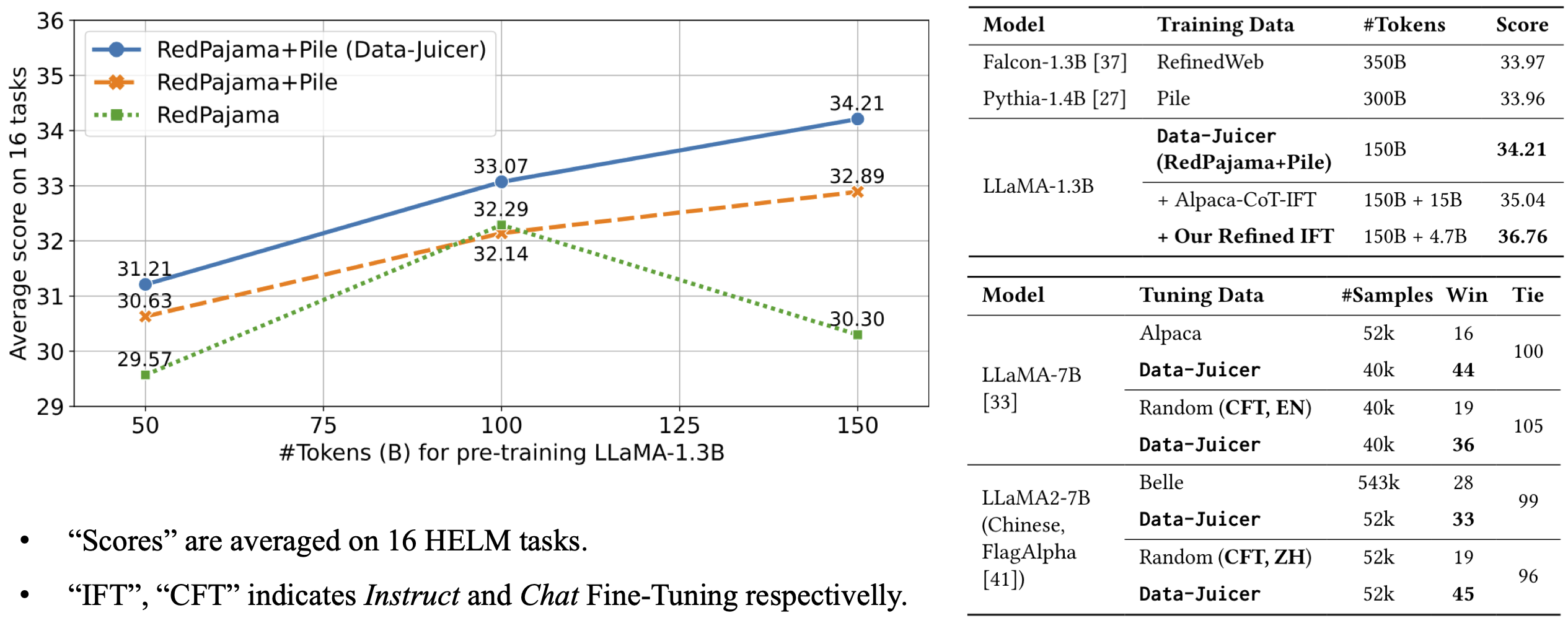
This is a reference LLM from [Data-Juicer](https://github.com/alibaba/data-juicer).
|
|
|
|
The model architecture is LLaMA2-7B and we built it upon the a pre-trained Chinese checkpoint from [FlagAlpha](https://huggingface.co/FlagAlpha/Atom-7B).
|
|
The model is fine-trained on 52k Chinese chat samples of Data-Juicer's refined [alpaca-CoT data](https://github.com/alibaba/data-juicer/blob/main/configs/data_juicer_recipes/alpaca_cot/README.md#refined-alpaca-cot-dataset-meta-info).
|
|
It beats LLaMA2-7B fine-tuned on 543k Belle samples in GPT-4 evaluation.
|
|
|
|
For more details, please refer to our [paper](https://arxiv.org/abs/2309.02033).
|
|
|
|
|
|
|
|
## 使用
|
|
```python
|
|
|
|
from modelscope import (
|
|
AutoModelForCausalLM, AutoTokenizer, GenerationConfig, snapshot_download
|
|
)
|
|
model_dir = 'LLaMA2-7B-ZH-Chat-52k'
|
|
|
|
tokenizer = AutoTokenizer.from_pretrained(model_dir)
|
|
model = AutoModelForCausalLM.from_pretrained(model_dir).eval()
|
|
|
|
inputs = tokenizer('How are you?', return_tensors='pt').to(model.device)
|
|
response = model.generate(inputs.input_ids, max_length=128)
|
|
print(tokenizer.decode(response.cpu()[0], skip_special_tokens=True))
|
|
```
|
|
|
|
## 参考
|
|
If you find our work useful for your research or development, please kindly cite the following [paper](https://arxiv.org/abs/2309.02033).
|
|
```
|
|
@misc{chen2023datajuicer,
|
|
title={Data-Juicer: A One-Stop Data Processing System for Large Language Models},
|
|
author={Daoyuan Chen and Yilun Huang and Zhijian Ma and Hesen Chen and Xuchen Pan and Ce Ge and Dawei Gao and Yuexiang Xie and Zhaoyang Liu and Jinyang Gao and Yaliang Li and Bolin Ding and Jingren Zhou},
|
|
year={2023},
|
|
eprint={2309.02033},
|
|
archivePrefix={arXiv},
|
|
primaryClass={cs.LG}
|
|
}
|
|
```
|
|
|
|
#### Clone with HTTP
|
|
```bash
|
|
git clone https://www.modelscope.cn/Data-Juicer/LLaMA2-7B-ZH-Chat-52k.git
|
|
```
|