6.8 KiB
license, tags, language, pipeline_tag, library_name, extra_gated_fields
| license | tags | language | pipeline_tag | library_name | extra_gated_fields | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| apache-2.0 |
|
|
text-generation | transformers |
|

Tri-7B
Introduction
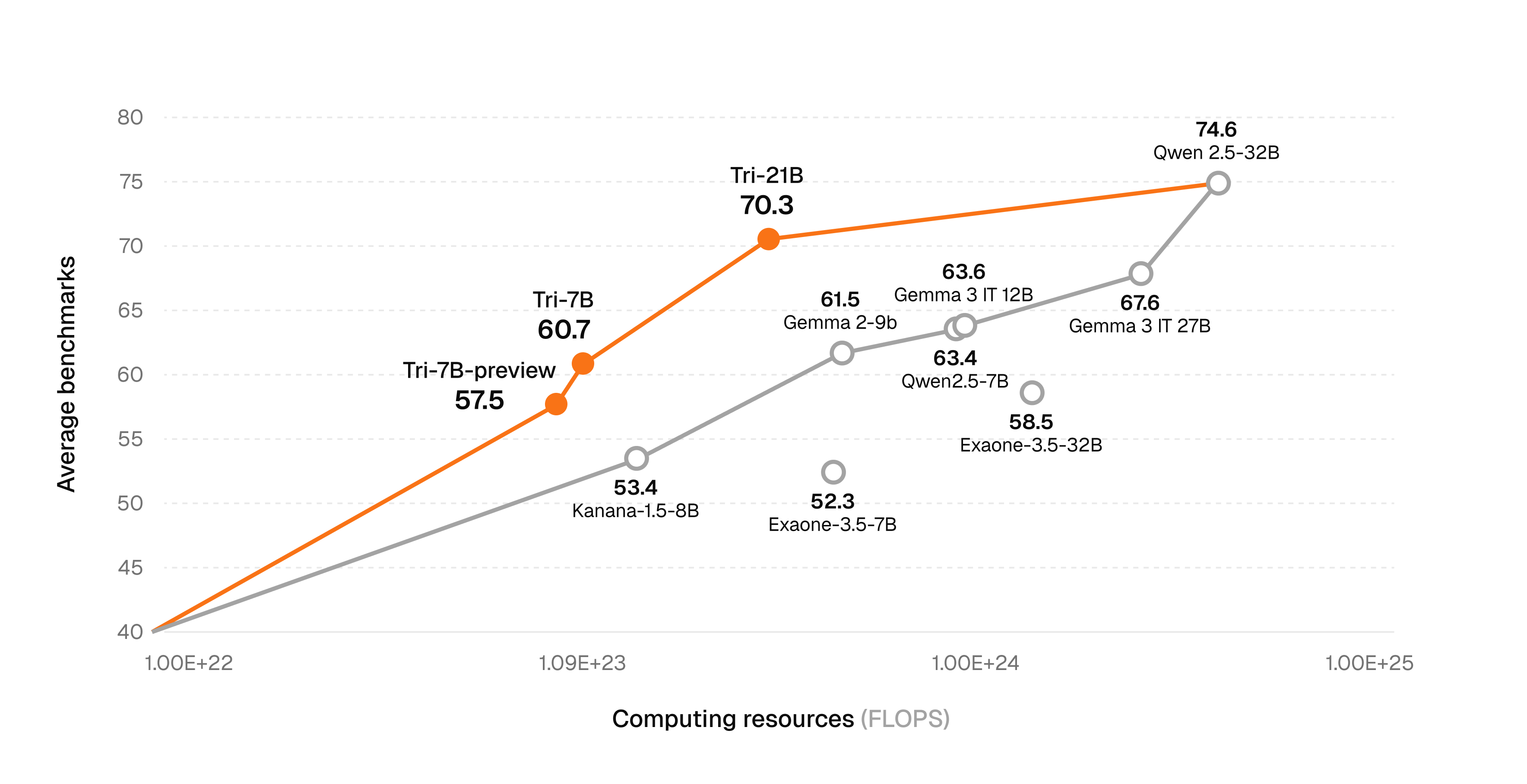
We introduce Tri-7B, the next generation model following Trillion-7B-preview, that continues to push the boundaries of efficient training while achieving exceptional performance at the 7B parameter scale.
Key Highlights
- Enhanced Reasoning: Modified training dataset mixture specifically optimized for reasoning capabilities
- Advanced Post-Training: Significantly improved RL training pipeline focusing on mathematical reasoning and everyday usage
- Extended Context: Supports up to 32K context length for long-form understanding
- Multi-lingual: Specially optimized for Korean, English, and Japanese.
Our Tri-7B model represents a significant advancement over Trillion-7B-preview, achieving substantial performance improvements across all evaluated domains while maintaining the same efficient parameter count.
Model Specifications
Tri-7B
- Type: Causal Language Model
- Training Stage: Pre-training & Post-training
- Architecture: Transformer Decoder with RoPE, SwiGLU, RMSNorm
- Number of Parameters: 7.76B
- Number of Layers: 32
- Number of Attention Heads: 32
- Context Length: 32,768
- Vocab Size: 128,256
Quickstart
Here is a code snippet with apply_chat_template that demonstrates how to load the tokenizer and model and generate text.
Tri-7B Usage
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "trillionlabs/Tri-7B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Explain the concept of quantum computing in simple terms."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
Tri-7B is also available with vLLM and SGLang!
# vLLM
vllm serve trillionlabs/Tri-7B --dtype bfloat16 --max-model-len 32768
# vLLM with custom options
vllm serve trillionlabs/Tri-7B \
--dtype bfloat16 \
--max-model-len 32768 \
--gpu-memory-utilization 0.95 \
--port 8000
# SGLang
python3 -m sglang.launch_server --model-path trillionlabs/Tri-7B --dtype bfloat16
# SGLang with custom options
python3 -m sglang.launch_server \
--model-path trillionlabs/Tri-7B \
--dtype bfloat16 \
--context-length 32768 \
--port 30000 \
--host 0.0.0.0
Evaluation
We evaluated Tri-7B across a comprehensive suite of benchmarks assessing general reasoning, knowledge recall, coding abilities, mathematical reasoning, and instruction-following capabilities. Compared to our previous generation model Trillion-7B-preview, Tri-7B achieves significant gains across all domains.
Full evaluation settings
| Benchmark | Language | Evaluation Setting | Metric |
|---|---|---|---|
| General Reasoning and Factuality | |||
| • HellaSwag | English | 0-shot | accuracy |
| • ARC:C | English | 0-shot | accuracy |
| • HAERAE | Korean | 3-shot | accuracy |
| • CLIcK | Korean | 0-shot | accuracy |
| • KoBEST | Korean | 5-shot | accuracy |
| Knowledge and Reasoning | |||
| • KMMLU | Korean | 5-shot (0-shot, CoT) | accuracy |
| • MMLU | English | 5-shot (0-shot, CoT) | accuracy |
| • Global-MMLU-Lite-ja | English | 5-shot | accuracy |
| Coding | |||
| • HumanEval | English | 0-shot | pass@1 |
| • MBPPPlus | English | 0-shot | pass@1 |
| Mathematical Reasoning | |||
| • GSM8k | English | 0-shot, CoT | exact-match |
| • MATH | English | 0-shot, CoT | exact-match |
| • GPQA | English | 4-shot | accuracy |
| • HRM8k | Korean | 0-shot, CoT | exact-match |
| Instruction Following and Chat | |||
| • IFEval | English | 0-shot | strict-average |
| • koIFEval | Korean | 0-shot | strict-average |
| • MT-Bench | English | LLM-as-a-judge (gpt-4o) | LLM score |
| • KO-MT-Bench | Korean | LLM-as-a-judge (gpt-4o) | LLM score |
| • systemIFEval | English | 0-shot | strict-average |
- *Note that koIFEval, systemIFEval, and KoRuler are our in-house evaluation benchmarks adapted for Korean to better assess model capabilities in Korean language tasks.
- **Note that MT-Bench, KO-MT-Bench, and LogicKor use a 10-point scale.
Benchmark Results
Models compared:
- Tri-7B (Next Generation)
- Trillion-7B-preview (Previous Generation)
General Reasoning and Factuality
| Benchmark | Tri-7B | Trillion-7B-preview | Improvement |
|---|---|---|---|
| HellaSwag | 59.52 | 58.94 | +0.58 |
| ARC:C | 58.28 | 54.44 | +3.84 |
| HAERAE | 82.49 | 80.02 | +2.47 |
| KoBEST | 82.72 | 79.61 | +3.11 |
| CLIcK | 64.43 | 60.41 | +4.02 |
| KMMLU | 51.74 (53.51) | 48.09 | +3.65 |
| MMLU | 68.16 (74.67) | 63.52 | +4.64 |
| Global-MMLU-Lite-ja | 59.25 | 60.75 | -1.50 |
Coding
| Benchmark | Tri-7B | Trillion-7B-preview | Improvement |
|---|---|---|---|
| HumanEval | 53.66 | 55.48 | -1.82 |
| MBPPPlus | 64.29 | 58.99 | +5.30 |
Mathematical Reasoning
| Benchmark | Tri-7B | Trillion-7B-preview | Improvement |
|---|---|---|---|
| GSM8k | 77.94 | 72.25 | +5.69 |
| MATH | 49.40 | 32.70 | +16.70 |
| GPQA | 34.15 | 32.81 | +1.34 |
| HRM8k | 39.08 | 30.10 | +8.98 |
Instruction Following and Chat
| Benchmark | Tri-7B | Trillion-7B-preview | Improvement |
|---|---|---|---|
| IFEval | 79.26 | 79.13 | +0.13 |
| koIFEval | 76.63 | 66.58 | +10.05 |
| MT-Bench | 7.82 | 6.53 | +1.29 |
| KO-MT-Bench | 7.64 | 6.27 | +1.37 |
| systemIFEval | 66.43 | 27.28 | +39.15 |
Limitations
- Language Support: The model is optimized for English, Korean, and Japanese. Usage with other languages may result in degraded performance.
- Knowledge Cutoff: The model's information is limited to data available up to Febuary, 2025.
License
This model is licensed under the Apache License 2.0.
Contact
For inquiries, please contact: info@trillionlabs.co