---
library_name: transformers
license_link: https://huggingface.co/Qwen/Qwen3-1.7B/blob/main/LICENSE
pipeline_tag: text-generation
license: cc-by-nc-4.0
extra_gated_prompt: >
### FAUST-1 NON-COMMERCIAL LICENSE AGREEMENT
Version 1.0 — January 2025
"Faust-1" refers to the language model weights, code, and documentation made
available by Tabularis AI GmbH ("Tabularis") under this agreement.
1. License Grant
You are granted a non-exclusive, non-transferable, royalty-free license to
use, copy, and modify Faust-1 for non-commercial research and personal
purposes only.
2. Non-Commercial Use
"Non-commercial" means academic research, personal projects, and educational
use. Any use intended to generate revenue, provide commercial services, or
benefit a for-profit entity requires a separate commercial license.
3. Commercial Licensing
For commercial use, please contact: info@tabularis.ai
4. Attribution
You must include "Built with Faust-1 by Tabularis AI" in any derivative work
or publication.
5. No Warranty
Faust-1 is provided "as is" without warranties of any kind.
6. Termination
This license terminates automatically if you violate any terms.
---
### Additional Access Requirement
Access to this repository is approval-based.
You must join our Discord server: https://discord.gg/7WqEKw652R
extra_gated_fields:
Name: text
Email: text
Affiliation: text
I have joined the Tabularis AI Discord server: checkbox
I accept the Faust-1 Non-Commercial License Agreement: checkbox
extra_gated_description: |
Faust-1 is for non-commercial use only.
For commercial licensing contact info@tabularis.ai
Approval requires Discord membership.
Join: https://discord.gg/7WqEKw652R
extra_gated_button_content: Submit
language:
- de
- en
tags:
- llama.cpp
- synthetic data
---

# Faust-1 — German-First Large Language Model (1.6B)
Faust-1 is a German-first large language model with 1.6B parameters, trained entirely from scratch. Model development comprises large-scale data collection and synthetic data generation, followed by data cleaning, normalization, and deduplication to reduce contamination and redundancy. Pre-training is performed on a predominantly German corpus using a decoder-only language modeling objective, resulting in a foundation model for the German language that captures lexical, syntactic, and semantic regularities at scale.
Following pre-training, the model undergoes supervised post-training (instruction tuning) using labeled input–output pairs to adapt the base model for conversational and task-oriented use. In later stages, preference-based optimization, including Direct Preference Optimization (DPO), is applied to improve response quality, stability, and alignment with human expectations, while preserving the efficiency constraints required for small-scale and local deployment.
> [!TIP]
> **Designed for local and cost-efficient deployment.**
> Faust-1 is deliberately sized and optimized to run on **consumer-grade hardware** and **does not require expensive data-center GPUs**.
---
## Model summary
- Repository: tabularisai/Faust-1
- Model type: decoder-only causal language model
- Parameters: 1.6B
- Interface: conversational / instruction (chat template provided)
- Primary language: German (~90%)
- Custom State-of-the-Art tokenizer for German language
---
## Quickstart
### Conversational usage (recommended)
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "tabularisai/Faust-1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
)
messages = [
{"role": "user", "content": "Gib mir eine kurze Einführung in große Sprachmodelle (LLM)."}
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(
inputs,
max_new_tokens=256,
temperature=0.6,
do_sample=True,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
---
## Conditional Generation
```python
!pip install git+https://github.com/tabularis-ai/guidegen.git
import sys
import os
import json
import time
import guidegen as gg
from pydantic import BaseModel, Field
from typing import Literal, List
# Hugging Face access token - set via environment variable or .env file
# You can set it with: export HUGGINGFACE_HUB_TOKEN=your_token_here
# Or create a .env file with: HUGGINGFACE_HUB_TOKEN=your_token_here
MODEL_NAME = "tabularisai/Faust-1"
# --- Schema ---
class EmailSummary(BaseModel):
"""Structured summary of an email."""
Absender: str = Field(description="Der Name des Absenders.")
Betreff: str = Field(description="Worum geht es in der E-Mail? (max 5 Wörter)")
Zusammenfassung: str = Field(description="Kurze Zusammenfassung (max 2 Sätze).")
Prioritaet: Literal["hoch", "mittel", "niedrig"] = Field(description="Wie wichtig die E-Mail ist.")
# AntwortNoetig: bool = Field(description="Muss man auf die E-Mail antworten?")
# --- Input ---
email_text = """Hallo Jens,
wir hatten uns bei CampusFounders im Rahmen unserer Pre-Seed-Runde kennengelernt.
Seitdem haben wir große Fortschritte gemacht und bereiten aktuell unsere Seed-Runde vor.
Wir entwickeln eine Infrastruktur für hocheffiziente, lokal trainierbare KI-Modelle – vollständig ohne Cloud.
Sehr gern würden wir uns mit dir austauschen und prüfen, ob ein Intro zu US-VCs oder ein Gespräch mit Crestlight möglich wäre.
Anbei ein kurzer OnePager zur Weiterleitung.
Beste Grüße
Ricard"""
# --- Prompt ---
prompt = f"""
Du bist ein intelligenter Assistent, der E-Mails analysiert und als JSON zusammenfasst.
Halte die Zusammenfassung kurz (1-2 Sätze). Betreff maximal 5 Wörter.
--- Beispiel ---
E-Mail-Text:
Sehr geehrte Damen und Herren, ich wollte nur nachfragen, ob meine Bestellung #12345 schon versandt wurde. Vielen Dank, Max Mustermann
JSON-Antwort:
{{
"Absender": "Max Mustermann",
"Betreff": "Bestellstatus Anfrage",
"Zusammenfassung": "Anfrage zum Versandstatus der Bestellung #12345.",
"Prioritaet": "mittel",
}}
--- Ende Beispiel ---
Jetzt analysiere die folgende E-Mail und erstelle das JSON-Objekt.
E-Mail-Text:
{email_text}
"""
def main():
print("=" * 60)
print("EMAIL SUMMARIZATION WITH GUIDEGEN")
print("=" * 60)
print(f"\nLoading model: {MODEL_NAME}")
load_start = time.time()
gen = gg.GuideGen(
MODEL_NAME,
verbose=True,
use_chat_template=True,
enable_thinking=False,
)
load_time = time.time() - load_start
print(f"Model loaded in {load_time:.2f}s")
# --- Generate ---
print("\nGenerating structured summary...")
gen_start = time.time()
options = gg.GuideGenOptions(
temperature=0.6,
max_tokens=400,
do_sample=False,
)
summary = gen.generate(prompt, EmailSummary, options=options)
gen_time = time.time() - gen_start
print(f"Generation complete in {gen_time:.2f}s")
# --- Output ---
print("\n--- Email Summary (JSON) ---")
print(json.dumps(summary.model_dump(), indent=2, ensure_ascii=False))
print(f"\n Model load: {load_time:.2f}s | Generation: {gen_time:.2f}s | Total: {load_time + gen_time:.2f}s")
```
---
## Training focus
### German-first data distribution
Faust-1 is trained from scratch with a German-dominant corpus. German syntax, compounding, morphology, and typical reasoning patterns are treated as the default operating regime rather than an edge case.
### Verified synthetic data
A substantial portion of the training signal comes from synthetic data. To keep this signal usable, generation is paired with explicit verification and filtering:
- LLM-as-judge style evaluations
- rule-based and programmatic checks
- consistency and self-agreement filtering
This allows broad coverage of instruction-following and reasoning patterns while maintaining quality control.
---
## Tokenizer optimized for German
Faust-1 uses a custom tokenizer optimized for German morphology and compounding. Token efficiency is treated as a deployment constraint, not just a preprocessing detail.
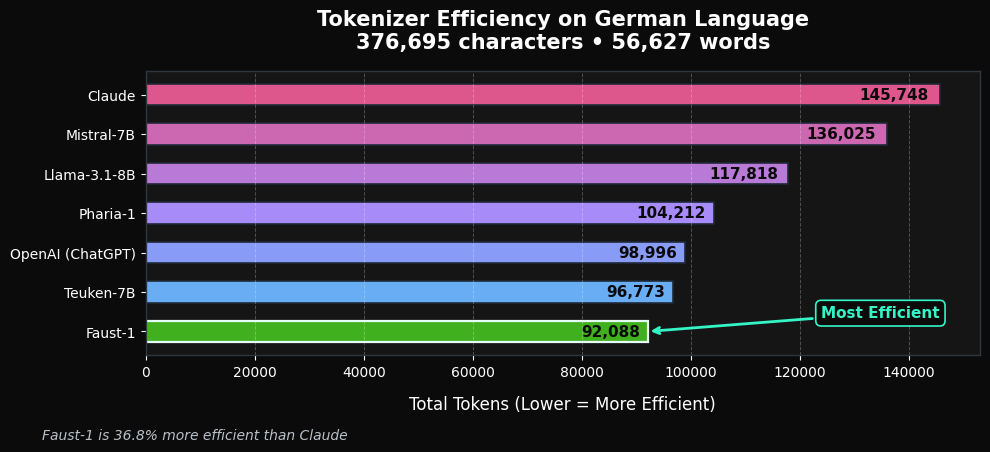
Lower token counts on German text translate directly into more usable context, lower inference cost, and less fragmentation on compound-heavy inputs.
 ---
## German benchmark performance
Faust-1 is evaluated on a set of standard German-language benchmarks:
- ARC_de
- GSM8K_de
- HellaSwag_de
- MMLU_de
- TruthfulQA_de

The target is best-in-class performance within the 1–2B parameter range for German-focused models, using benchmarks that are easy to reproduce in Hugging Face-based evaluation pipelines.
---
## Deployment examples
Faust-1 can be deployed with common inference stacks that support decoder-only language models.
vLLM (OpenAI-compatible API)
```sh
vllm serve tabularisai/Faust-1 --dtype float16
```
SGLang
```sh
python -m sglang.launch_server \
--model-path tabularisai/Faust-1 \
--dtype float16
```
llama.cpp (GGUF, local / on-device)
```sh
./llama-cli \
-m faust_1_q8_0.gguf \
-p "Erkläre kurz, was ein großes Sprachmodell ist."
```
The repository includes a prebuilt Q8_0 GGUF file for efficient local inference.
---
## Intended use
- German conversational assistants
- research and benchmarking on German NLP tasks
- local and privacy-sensitive deployments
- on-device or edge experimentation
---
## Roadmap
- Reasoning-focused variant (comming soon)
- Agent-oriented variant (comming soon)
---
## Citation
A technical paper describing training methodology, tokenizer design, and evaluation is in preparation.
Developed by [tabularis.ai](https://tabularis.ai) in Tübingen.
---
## German benchmark performance
Faust-1 is evaluated on a set of standard German-language benchmarks:
- ARC_de
- GSM8K_de
- HellaSwag_de
- MMLU_de
- TruthfulQA_de

The target is best-in-class performance within the 1–2B parameter range for German-focused models, using benchmarks that are easy to reproduce in Hugging Face-based evaluation pipelines.
---
## Deployment examples
Faust-1 can be deployed with common inference stacks that support decoder-only language models.
vLLM (OpenAI-compatible API)
```sh
vllm serve tabularisai/Faust-1 --dtype float16
```
SGLang
```sh
python -m sglang.launch_server \
--model-path tabularisai/Faust-1 \
--dtype float16
```
llama.cpp (GGUF, local / on-device)
```sh
./llama-cli \
-m faust_1_q8_0.gguf \
-p "Erkläre kurz, was ein großes Sprachmodell ist."
```
The repository includes a prebuilt Q8_0 GGUF file for efficient local inference.
---
## Intended use
- German conversational assistants
- research and benchmarking on German NLP tasks
- local and privacy-sensitive deployments
- on-device or edge experimentation
---
## Roadmap
- Reasoning-focused variant (comming soon)
- Agent-oriented variant (comming soon)
---
## Citation
A technical paper describing training methodology, tokenizer design, and evaluation is in preparation.
Developed by [tabularis.ai](https://tabularis.ai) in Tübingen.