65 lines
2.4 KiB
Markdown
65 lines
2.4 KiB
Markdown
|
|
# Qwen-7B-Chat-Cantonese
|
|||
|
|
## 简介
|
|||
|
|
Qwen-7B-Chat-Cantonese 是基于 Qwen-7B-Chat 的微调版本,采用大量的粤语数据进行训练。
|
|||
|
|
|
|||
|
|
[Huggingface](https://huggingface.co/stvlynn/Qwen-7B-Chat-Cantonese)
|
|||
|
|
|
|||
|
|
## 使用说明
|
|||
|
|
|
|||
|
|
### 要求
|
|||
|
|
|
|||
|
|
* Python 3.8 及以上
|
|||
|
|
* Pytorch 1.12 及以上,推荐 2.0 及以上
|
|||
|
|
* 推荐使用 CUDA 11.4 及以上(这是针对 GPU 用户、快速注意力用户等)
|
|||
|
|
|
|||
|
|
### 依赖
|
|||
|
|
|
|||
|
|
要运行 Qwen-7B-Chat-Cantonese,请确保满足以上要求,然后执行以下 pip 命令安装依赖库。
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
pip install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
此外,推荐安装 `flash-attention` 库
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
git clone https://github.com/Dao-AILab/flash-attention
|
|||
|
|
cd flash-attention && pip install .
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 快速开始
|
|||
|
|
|
|||
|
|
请转到 QwenLM/Qwen - [快速开始](https://github.com/QwenLM/Qwen?tab=readme-ov-file#quickstart)
|
|||
|
|
|
|||
|
|
## 训练参数
|
|||
|
|
|
|||
|
|
| 参数 | 描述 | 值 |
|
|||
|
|
|-------------------|--------------------------------|------|
|
|||
|
|
| 学习率 | AdamW 优化器的学习率 | 7e-5 |
|
|||
|
|
| 权重衰减 | 正则化强度 | 0.8 |
|
|||
|
|
| 伽马 | 学习率衰减因子 | 1.0 |
|
|||
|
|
| 批次大小 | 每批样本数量 | 1000 |
|
|||
|
|
| 精度 | 浮点精度 | fp16 |
|
|||
|
|
| 学习政策 | 学习率调整政策 | cosine |
|
|||
|
|
| 热身步骤 | 初始无学习率调整的步骤数 | 0 |
|
|||
|
|
| 总步骤 | 总训练步骤数 | 1024 |
|
|||
|
|
| 梯度累积步骤 | 更新前累积梯度的步骤数 | 8 |
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
## 演示
|
|||
|
|
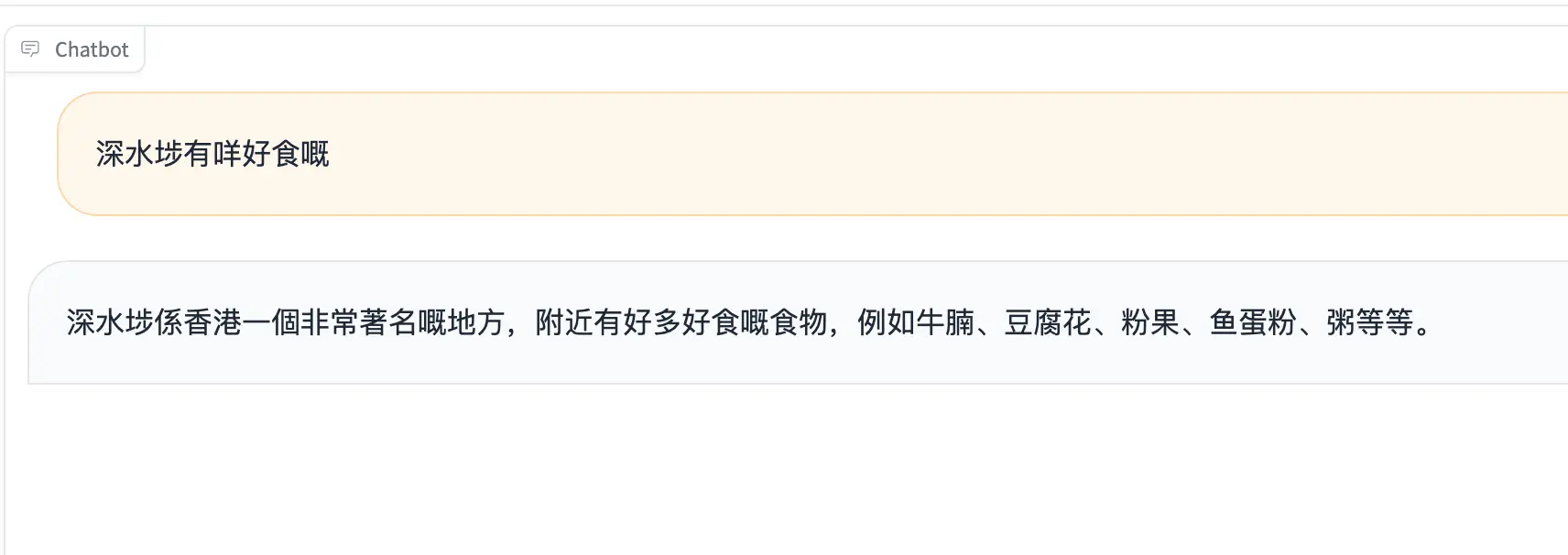
|
|||
|
|
|
|||
|
|
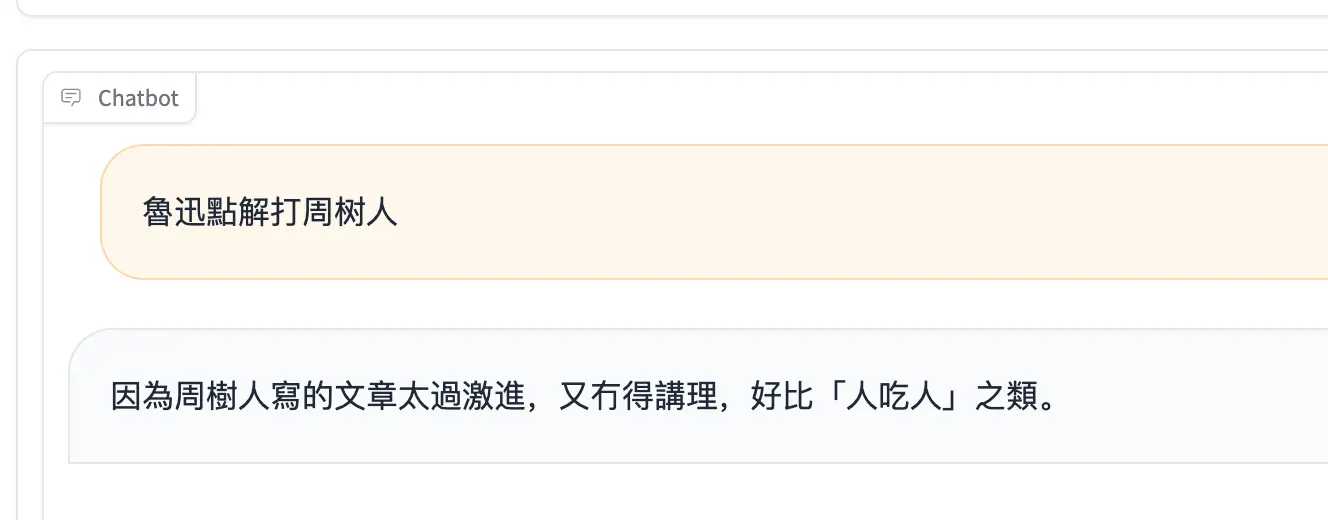
|
|||
|
|
|
|||
|
|
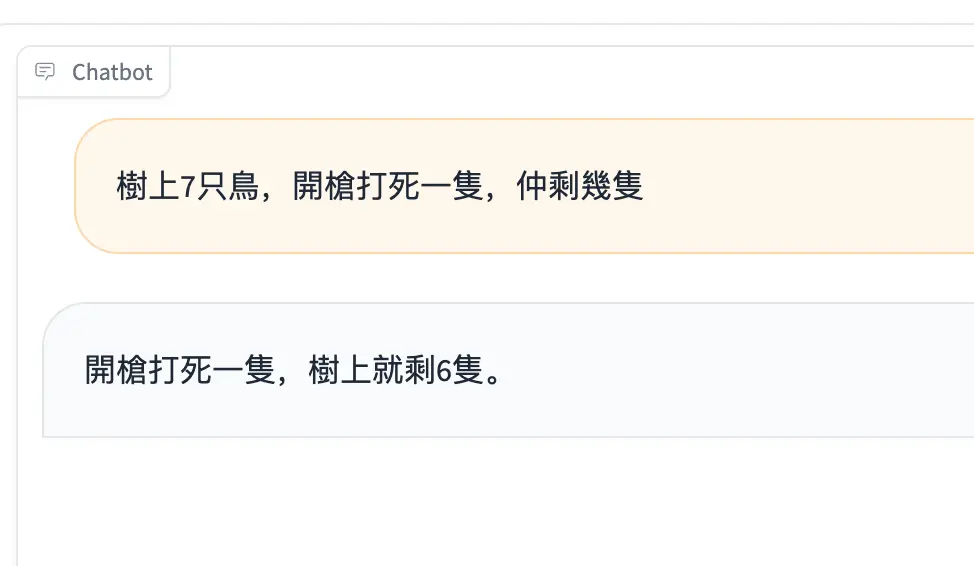
|
|||
|
|
|
|||
|
|
## 特别说明
|
|||
|
|
|
|||
|
|
这是我的第一个微调LLM。请多指教。
|
|||
|
|
|
|||
|
|
如果您有任何问题或建议请随时联系我。
|
|||
|
|
|
|||
|
|
[TG @stvlynn_bot](https://tg.stv.pm)
|
|||
|
|
|
|||
|
|
[电子邮件 i@stv.pm](mailto:i@stv.pm)
|