初始化项目,由ModelHub XC社区提供模型
Model: sometimesanotion/Qwen2.5-14B-Vimarckoso-v3 Source: Original Platform
This commit is contained in:
36
.gitattributes
vendored
Normal file
36
.gitattributes
vendored
Normal file
@@ -0,0 +1,36 @@
|
|||||||
|
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.model filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||||
|
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
||||||
169
README.md
Normal file
169
README.md
Normal file
@@ -0,0 +1,169 @@
|
|||||||
|
---
|
||||||
|
base_model:
|
||||||
|
- arcee-ai/Virtuoso-Small
|
||||||
|
- rombodawg/Rombos-LLM-V2.6-Qwen-14b
|
||||||
|
- sometimesanotion/Qwentinuum-14B-v013
|
||||||
|
- sometimesanotion/Lamarck-14B-v0.3
|
||||||
|
- EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2
|
||||||
|
- allura-org/TQ2.5-14B-Sugarquill-v1
|
||||||
|
- oxyapi/oxy-1-small
|
||||||
|
- v000000/Qwen2.5-Lumen-14B
|
||||||
|
- sthenno-com/miscii-14b-1225
|
||||||
|
- underwoods/medius-erebus-magnum-14b
|
||||||
|
- huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2
|
||||||
|
library_name: transformers
|
||||||
|
tags:
|
||||||
|
- mergekit
|
||||||
|
- merge
|
||||||
|
license: apache-2.0
|
||||||
|
language:
|
||||||
|
- en
|
||||||
|
metrics:
|
||||||
|
- accuracy
|
||||||
|
- code_eval
|
||||||
|
pipeline_tag: text-generation
|
||||||
|
---
|
||||||
|
|
||||||
|
Vimarckoso is a reasoning-focused part of the [Lamarck](https://huggingface.co/sometimesanotion/Lamarck-14B-v0.4-Qwenvergence) project. It began with a [recipe](https://huggingface.co/sometimesanotion/Qwen2.5-14B-Vimarckoso) based on [Wernicke](https://huggingface.co/CultriX/Qwen2.5-14B-Wernicke), and then I set out to boost instruction following without any great loss to reasoning. The results surpassed my expectations.
|
||||||
|
|
||||||
|
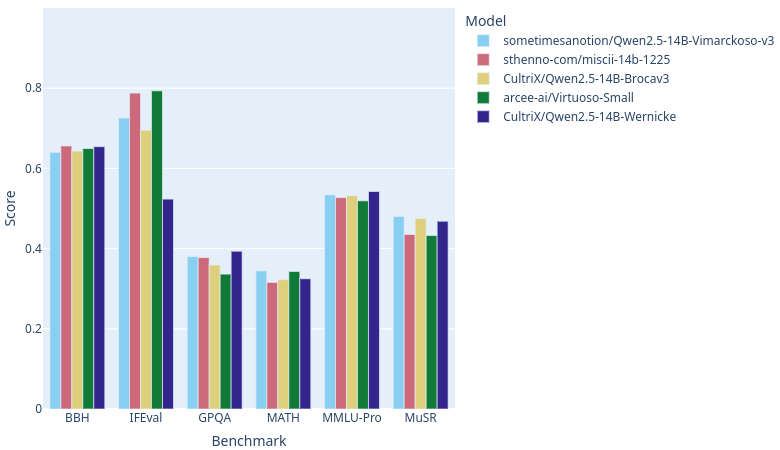
As of this writing, with [open-llm-leaderboard](https://huggingface.co/open-llm-leaderboard) catching up on rankings, Vimarckoso v3 should join Arcee AI's [Virtuoso-Small](https://huggingface.co/arcee-ai/Virtuoso-Small), Sthenno's [miscii-14b-1225](https://huggingface.co/sthenno-com/miscii-14b-1225) and Cultrix's [Qwen2.5-14B-Brocav3](https://huggingface.co/CultriX/Qwen2.5-14B-Brocav3) at the top of the 14B parameter text generation LLM category on this site. As the recipe below will show, their models are strong contributors to Vimarckoso. Congratulations to everyone whose work went into this!
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Wernicke and Vimarckoso both inherit very strong reasoning, and hence high GPQA and MUSR scores, from [EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2](https://huggingface.co/EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2). Prose quality gets a boost from models blended in [Qwenvergence-14B-v6-Prose](https://huggingface.co/Qwenvergence-14B-v6-Prose), and instruction following gets healed after the merges thanks to LoRAs based on [huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2](https://huggingface.co/huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2).
|
||||||
|
|
||||||
|
Thank you, @mradermacher, @Sangto, and @MaziyarPanahi for the [GGUFs](https://huggingface.co/models?other=base_model:quantized:sometimesanotion/Qwen2.5-14B-Vimarckoso-v3). Anyone who needs to use them with Ollama can use the same modelfile as any Qwen2.5 14B Instruct model. I recommend a temperature of 0.8.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Configuration
|
||||||
|
|
||||||
|
The following YAML configuration was used to produce this model:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
name: Qwenvergence-14B-v6-Prose-model_stock
|
||||||
|
merge_method: model_stock
|
||||||
|
base_model: Qwen/Qwen2.5-14B
|
||||||
|
tokenizer_source: huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2
|
||||||
|
parameters:
|
||||||
|
int8_mask: true
|
||||||
|
normalize: true
|
||||||
|
rescale: false
|
||||||
|
models:
|
||||||
|
- model: arcee-ai/Virtuoso-Small
|
||||||
|
- model: sometimesanotion/Lamarck-14B-v0.3
|
||||||
|
- model: EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2
|
||||||
|
- model: allura-org/TQ2.5-14B-Sugarquill-v1
|
||||||
|
- model: oxyapi/oxy-1-small
|
||||||
|
- model: v000000/Qwen2.5-Lumen-14B
|
||||||
|
- model: sthenno-com/miscii-14b-1225
|
||||||
|
- model: sthenno-com/miscii-14b-1225
|
||||||
|
- model: underwoods/medius-erebus-magnum-14b
|
||||||
|
- model: huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2
|
||||||
|
dtype: float32
|
||||||
|
out_dtype: bfloat16
|
||||||
|
---
|
||||||
|
# Nifty TIES to allow a series of LoRA exchange among the above models
|
||||||
|
---
|
||||||
|
name: Qwenvergence-14B-v6-Prose
|
||||||
|
merge_method: ties
|
||||||
|
base_model: Qwen/Qwen2.5-14B
|
||||||
|
tokenizer_source: base
|
||||||
|
parameters:
|
||||||
|
density: 1.00
|
||||||
|
weight: 1.00
|
||||||
|
int8_mask: true
|
||||||
|
normalize: true
|
||||||
|
rescale: false
|
||||||
|
dtype: float32
|
||||||
|
out_dtype: bfloat16
|
||||||
|
models:
|
||||||
|
- model: sometimesanotion/Qwenvergence-14B-v6-Prose-slerp
|
||||||
|
parameters:
|
||||||
|
density: 1.00
|
||||||
|
weight: 1.00
|
||||||
|
---
|
||||||
|
# The last stable version of the Qwentinuum project which used successive breadcrumbs and SLERP merges to boost IFEval, merged back into Qwenvergence
|
||||||
|
name: Qwentinuum-14B-v6-Prose-slerp
|
||||||
|
merge_method: slerp
|
||||||
|
base_model: sometimesanotion/Qwenvergence-14B-v6-Prose
|
||||||
|
tokenizer_source: sometimesanotion/Qwenvergence-14B-v6-Prose
|
||||||
|
dtype: bfloat16
|
||||||
|
out_dtype: bfloat16
|
||||||
|
parameters:
|
||||||
|
int8_mask: true
|
||||||
|
normalize: true
|
||||||
|
rescale: false
|
||||||
|
parameters:
|
||||||
|
t:
|
||||||
|
- value: 0.40
|
||||||
|
slices:
|
||||||
|
- sources:
|
||||||
|
- model: sometimesanotion/Qwenvergence-14B-v6-Prose
|
||||||
|
layer_range: [ 0, 8 ]
|
||||||
|
- model: sometimesanotion/Qwentinuum-14B-v6
|
||||||
|
layer_range: [ 0, 8 ]
|
||||||
|
- sources:
|
||||||
|
- model: sometimesanotion/Qwenvergence-14B-v6-Prose
|
||||||
|
layer_range: [ 8, 16 ]
|
||||||
|
- model: sometimesanotion/Qwentinuum-14B-v6
|
||||||
|
layer_range: [ 8, 16 ]
|
||||||
|
- sources:
|
||||||
|
- model: sometimesanotion/Qwenvergence-14B-v6-Prose
|
||||||
|
layer_range: [ 16, 24 ]
|
||||||
|
- model: sometimesanotion/Qwentinuum-14B-v6
|
||||||
|
layer_range: [ 16, 24 ]
|
||||||
|
- sources:
|
||||||
|
- model: sometimesanotion/Qwenvergence-14B-v6-Prose
|
||||||
|
layer_range: [ 24, 32 ]
|
||||||
|
- model: sometimesanotion/Qwentinuum-14B-v6
|
||||||
|
layer_range: [ 24, 32 ]
|
||||||
|
- sources:
|
||||||
|
- model: sometimesanotion/Qwenvergence-14B-v6-Prose
|
||||||
|
layer_range: [ 32, 40 ]
|
||||||
|
- model: sometimesanotion/Qwentinuum-14B-v6
|
||||||
|
layer_range: [ 32, 40 ]
|
||||||
|
- sources:
|
||||||
|
- model: sometimesanotion/Qwenvergence-14B-v6-Prose
|
||||||
|
layer_range: [ 40, 48 ]
|
||||||
|
- model: sometimesanotion/Qwentinuum-14B-v6
|
||||||
|
layer_range: [ 40, 48 ]
|
||||||
|
|
||||||
|
---
|
||||||
|
name: Qwen2.5-14B-Vimarckoso-v3-model_stock
|
||||||
|
merge_method: model_stock
|
||||||
|
base_model: sometimesanotion/Base-Qwenvergence
|
||||||
|
tokenizer_source: sometimesanotion/Abliterate-Qwenvergence
|
||||||
|
dtype: bfloat16
|
||||||
|
out_dtype: bfloat16
|
||||||
|
parameters:
|
||||||
|
int8_mask: true
|
||||||
|
normalize: true
|
||||||
|
rescale: false
|
||||||
|
# With this many models, it's good to pre-merge some LoRAs from Abliterate-Qwenvergence, with their ranks indicated in the suffixes.
|
||||||
|
models:
|
||||||
|
- model: EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2-qv512
|
||||||
|
- model: arcee-ai/Virtuoso-Small-qv128
|
||||||
|
- model: v000000/Qwen2.5-Lumen-14B-qv256
|
||||||
|
- model: VAGOsolutions/SauerkrautLM-v2-14b-DPO-qv256
|
||||||
|
- model: rombodawg/Rombos-LLM-V2.6-Qwen-14b
|
||||||
|
- model: sometimesanotion/Qwentinuum-14B-v013
|
||||||
|
- model: sometimesanotion/Abliterate-Qwenvergence
|
||||||
|
---
|
||||||
|
name: Qwen2.5-14B-Vimarckoso-v3-slerp
|
||||||
|
merge_method: slerp
|
||||||
|
base_model: sometimesanotion/Qwen2.5-14B-Vimarckoso-v3-model_stock
|
||||||
|
tokenizer_source: base
|
||||||
|
dtype: float32
|
||||||
|
out_dtype: bfloat16
|
||||||
|
parameters:
|
||||||
|
t:
|
||||||
|
- value: 0.20
|
||||||
|
slices:
|
||||||
|
- sources:
|
||||||
|
- model: sometimesanotion/Qwen2.5-14B-Vimarckoso-v3-model_stock
|
||||||
|
layer_range: [ 0, 48 ]
|
||||||
|
- model: sometimesanotion/Qwentinuum-14B-v6-Prose+sometimesanotion/Qwenvergence-Abliterate-256
|
||||||
|
layer_range: [ 0, 48 ]
|
||||||
|
|
||||||
|
```
|
||||||
BIN
Vimarckoso-v3.png
Normal file
BIN
Vimarckoso-v3.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 40 KiB |
24
added_tokens.json
Normal file
24
added_tokens.json
Normal file
@@ -0,0 +1,24 @@
|
|||||||
|
{
|
||||||
|
"</tool_call>": 151658,
|
||||||
|
"<tool_call>": 151657,
|
||||||
|
"<|box_end|>": 151649,
|
||||||
|
"<|box_start|>": 151648,
|
||||||
|
"<|endoftext|>": 151643,
|
||||||
|
"<|file_sep|>": 151664,
|
||||||
|
"<|fim_middle|>": 151660,
|
||||||
|
"<|fim_pad|>": 151662,
|
||||||
|
"<|fim_prefix|>": 151659,
|
||||||
|
"<|fim_suffix|>": 151661,
|
||||||
|
"<|im_end|>": 151645,
|
||||||
|
"<|im_start|>": 151644,
|
||||||
|
"<|image_pad|>": 151655,
|
||||||
|
"<|object_ref_end|>": 151647,
|
||||||
|
"<|object_ref_start|>": 151646,
|
||||||
|
"<|quad_end|>": 151651,
|
||||||
|
"<|quad_start|>": 151650,
|
||||||
|
"<|repo_name|>": 151663,
|
||||||
|
"<|video_pad|>": 151656,
|
||||||
|
"<|vision_end|>": 151653,
|
||||||
|
"<|vision_pad|>": 151654,
|
||||||
|
"<|vision_start|>": 151652
|
||||||
|
}
|
||||||
28
config.json
Normal file
28
config.json
Normal file
@@ -0,0 +1,28 @@
|
|||||||
|
{
|
||||||
|
"_name_or_path": "sometimesanotion/Qwen2.5-14B-Vimarckoso-v3-slerp",
|
||||||
|
"architectures": [
|
||||||
|
"Qwen2ForCausalLM"
|
||||||
|
],
|
||||||
|
"attention_dropout": 0.0,
|
||||||
|
"eos_token_id": 151645,
|
||||||
|
"hidden_act": "silu",
|
||||||
|
"hidden_size": 5120,
|
||||||
|
"initializer_range": 0.02,
|
||||||
|
"intermediate_size": 13824,
|
||||||
|
"max_position_embeddings": 131072,
|
||||||
|
"max_window_layers": 70,
|
||||||
|
"model_type": "qwen2",
|
||||||
|
"num_attention_heads": 40,
|
||||||
|
"num_hidden_layers": 48,
|
||||||
|
"num_key_value_heads": 8,
|
||||||
|
"rms_norm_eps": 1e-06,
|
||||||
|
"rope_scaling": null,
|
||||||
|
"rope_theta": 1000000.0,
|
||||||
|
"sliding_window": null,
|
||||||
|
"tie_word_embeddings": false,
|
||||||
|
"torch_dtype": "bfloat16",
|
||||||
|
"transformers_version": "4.46.2",
|
||||||
|
"use_cache": false,
|
||||||
|
"use_sliding_window": false,
|
||||||
|
"vocab_size": 151665
|
||||||
|
}
|
||||||
15
mergekit_config.yml
Normal file
15
mergekit_config.yml
Normal file
@@ -0,0 +1,15 @@
|
|||||||
|
name: Qwen2.5-14B-Vimarckoso-v3
|
||||||
|
merge_method: slerp
|
||||||
|
base_model: sometimesanotion/Qwen2.5-14B-Vimarckoso-v3-slerp
|
||||||
|
tokenizer_source: sometimesanotion/Qwen2.5-14B-Vimarckoso-v3-slerp
|
||||||
|
dtype: float32
|
||||||
|
out_dtype: bfloat16
|
||||||
|
parameters:
|
||||||
|
t:
|
||||||
|
- value: 0.20
|
||||||
|
slices:
|
||||||
|
- sources:
|
||||||
|
- model: sometimesanotion/Qwen2.5-14B-Vimarckoso-v3-slerp
|
||||||
|
layer_range: [ 0, 48 ]
|
||||||
|
- model: arcee-ai/Virtuoso-Small
|
||||||
|
layer_range: [ 0, 48 ]
|
||||||
151388
merges.txt
Normal file
151388
merges.txt
Normal file
File diff suppressed because it is too large
Load Diff
3
model-00001-of-00006.safetensors
Normal file
3
model-00001-of-00006.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:f62d818ef33b721b9411aefad601511ccfa2512f15a413be9f7be735ccfbd055
|
||||||
|
size 4899283440
|
||||||
3
model-00002-of-00006.safetensors
Normal file
3
model-00002-of-00006.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:06331dbe5f036450e1aaac2713d55af3b25490d6525290bafc0a1b69d99f67bd
|
||||||
|
size 4954847384
|
||||||
3
model-00003-of-00006.safetensors
Normal file
3
model-00003-of-00006.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:8deab5c2c5157a99f59a44190da06db06642826fa8f7d197b565c583883ab99d
|
||||||
|
size 4954847376
|
||||||
3
model-00004-of-00006.safetensors
Normal file
3
model-00004-of-00006.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:8fb94442796505943596e019dad9d643a36b9771c1cb3167f21fb9849c6e9dca
|
||||||
|
size 4954847376
|
||||||
3
model-00005-of-00006.safetensors
Normal file
3
model-00005-of-00006.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:becca85bb2cb607bc1ba1c737b71123799a7f45e0634165879315b55267794b9
|
||||||
|
size 4954847376
|
||||||
3
model-00006-of-00006.safetensors
Normal file
3
model-00006-of-00006.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:b5a7dc192c9cd7125ed2cf60b2f72d3ca58f39b47d3d4d5574559a6ab8d0843e
|
||||||
|
size 4813289432
|
||||||
1
model.safetensors.index.json
Normal file
1
model.safetensors.index.json
Normal file
File diff suppressed because one or more lines are too long
31
special_tokens_map.json
Normal file
31
special_tokens_map.json
Normal file
@@ -0,0 +1,31 @@
|
|||||||
|
{
|
||||||
|
"additional_special_tokens": [
|
||||||
|
"<|im_start|>",
|
||||||
|
"<|im_end|>",
|
||||||
|
"<|object_ref_start|>",
|
||||||
|
"<|object_ref_end|>",
|
||||||
|
"<|box_start|>",
|
||||||
|
"<|box_end|>",
|
||||||
|
"<|quad_start|>",
|
||||||
|
"<|quad_end|>",
|
||||||
|
"<|vision_start|>",
|
||||||
|
"<|vision_end|>",
|
||||||
|
"<|vision_pad|>",
|
||||||
|
"<|image_pad|>",
|
||||||
|
"<|video_pad|>"
|
||||||
|
],
|
||||||
|
"eos_token": {
|
||||||
|
"content": "<|im_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false
|
||||||
|
},
|
||||||
|
"pad_token": {
|
||||||
|
"content": "<|endoftext|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false
|
||||||
|
}
|
||||||
|
}
|
||||||
BIN
tokenizer.json
(Stored with Git LFS)
Normal file
BIN
tokenizer.json
(Stored with Git LFS)
Normal file
Binary file not shown.
207
tokenizer_config.json
Normal file
207
tokenizer_config.json
Normal file
@@ -0,0 +1,207 @@
|
|||||||
|
{
|
||||||
|
"add_bos_token": false,
|
||||||
|
"add_prefix_space": false,
|
||||||
|
"added_tokens_decoder": {
|
||||||
|
"151643": {
|
||||||
|
"content": "<|endoftext|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151644": {
|
||||||
|
"content": "<|im_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151645": {
|
||||||
|
"content": "<|im_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151646": {
|
||||||
|
"content": "<|object_ref_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151647": {
|
||||||
|
"content": "<|object_ref_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151648": {
|
||||||
|
"content": "<|box_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151649": {
|
||||||
|
"content": "<|box_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151650": {
|
||||||
|
"content": "<|quad_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151651": {
|
||||||
|
"content": "<|quad_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151652": {
|
||||||
|
"content": "<|vision_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151653": {
|
||||||
|
"content": "<|vision_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151654": {
|
||||||
|
"content": "<|vision_pad|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151655": {
|
||||||
|
"content": "<|image_pad|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151656": {
|
||||||
|
"content": "<|video_pad|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151657": {
|
||||||
|
"content": "<tool_call>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151658": {
|
||||||
|
"content": "</tool_call>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151659": {
|
||||||
|
"content": "<|fim_prefix|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151660": {
|
||||||
|
"content": "<|fim_middle|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151661": {
|
||||||
|
"content": "<|fim_suffix|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151662": {
|
||||||
|
"content": "<|fim_pad|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151663": {
|
||||||
|
"content": "<|repo_name|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151664": {
|
||||||
|
"content": "<|file_sep|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"additional_special_tokens": [
|
||||||
|
"<|im_start|>",
|
||||||
|
"<|im_end|>",
|
||||||
|
"<|object_ref_start|>",
|
||||||
|
"<|object_ref_end|>",
|
||||||
|
"<|box_start|>",
|
||||||
|
"<|box_end|>",
|
||||||
|
"<|quad_start|>",
|
||||||
|
"<|quad_end|>",
|
||||||
|
"<|vision_start|>",
|
||||||
|
"<|vision_end|>",
|
||||||
|
"<|vision_pad|>",
|
||||||
|
"<|image_pad|>",
|
||||||
|
"<|video_pad|>"
|
||||||
|
],
|
||||||
|
"bos_token": null,
|
||||||
|
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are Virtuoso Small, created by Arcee AI. You are a helpful assistant.' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
|
||||||
|
"clean_up_tokenization_spaces": false,
|
||||||
|
"eos_token": "<|im_end|>",
|
||||||
|
"errors": "replace",
|
||||||
|
"model_max_length": 131072,
|
||||||
|
"pad_token": "<|endoftext|>",
|
||||||
|
"split_special_tokens": false,
|
||||||
|
"tokenizer_class": "Qwen2Tokenizer",
|
||||||
|
"unk_token": null
|
||||||
|
}
|
||||||
1
vocab.json
Normal file
1
vocab.json
Normal file
File diff suppressed because one or more lines are too long
Reference in New Issue
Block a user