![]()
**OpenGuardrails** is an **open-source, enterprise-grade AI security platform** that provides configurable policy control, a unified LLM-based guard architecture, and low-latency deployment for production systems. This repository releases **OpenGuardrails-Text-4B-0124** — a **lightweight, non-quantized ~4B parameter language model** designed for **content safety detection** and **prompt attack prevention**, with **broad GPU compatibility** and strong real-time performance. 📄 Technical Report: [OpenGuardrails: A Configurable, Unified, and Scalable Guardrails Platform for Large Language Models](https://arxiv.org/abs/2510.19169) --- ## Key Contributions ### 1. Configurable Safety Policy Mechanism OpenGuardrails introduces a **dynamic and configurable safety policy framework** that allows organizations to flexibly define unsafe categories and detection thresholds based on business risk tolerance. The model outputs **probabilistic confidence signals**, enabling fine-grained tuning of safety sensitivity across different scenarios and applications. --- ### 2. Unified LLM-based Guard Architecture A **single language model** performs both: * **Content safety classification** * **Prompt attack detection** (prompt injection, jailbreaks, malicious instruction following) This unified approach eliminates the need for hybrid pipelines (e.g. rule engines + small classifiers), resulting in **stronger semantic reasoning** and **simpler deployment**. --- ### 3. Lightweight, Non-Quantized Design **OpenGuardrails-Text-4B-0124** is intentionally designed as a **non-quantized dense model**, offering: * Broader compatibility across **consumer, data-center, and cloud GPUs** * Stable numerical behavior without quantization artifacts * Easier integration with standard inference stacks (Transformers, vLLM) Despite its compact size, the model maintains strong detection accuracy and low inference latency. --- ### 4. Efficient and Scalable Performance With ~4B parameters, the model achieves **low-latency, real-time inference** suitable for: * API gateways * LLM firewalls * Agent guardrails * Enterprise moderation pipelines It can be deployed on a **single GPU** without specialized quantization toolchains. --- ### 5. Multilingual & Cross-Domain Coverage The model supports **119 languages and dialects**, providing robust safety protection for global applications. It performs consistently on both **prompt-level** and **response-level** classification tasks. --- ### 6. Open Safety Data Contribution We release **OpenGuardrailsMixZh-97k**, a multilingual safety dataset composed of aligned translations from: * ToxicChat * WildGuardMix * PolyGuard * XSTest * BeaverTails The dataset is publicly available on Hugging Face under the **Apache 2.0 License**. --- ### 7. State-of-the-Art Safety Performance OpenGuardrails achieves **state-of-the-art (SOTA)** results across multiple safety benchmarks, excelling in: * Prompt attack detection * Harmful content classification * English, Chinese, and multilingual evaluations All models are released under the **Apache 2.0 License** for unrestricted commercial and research use. Performance overview: 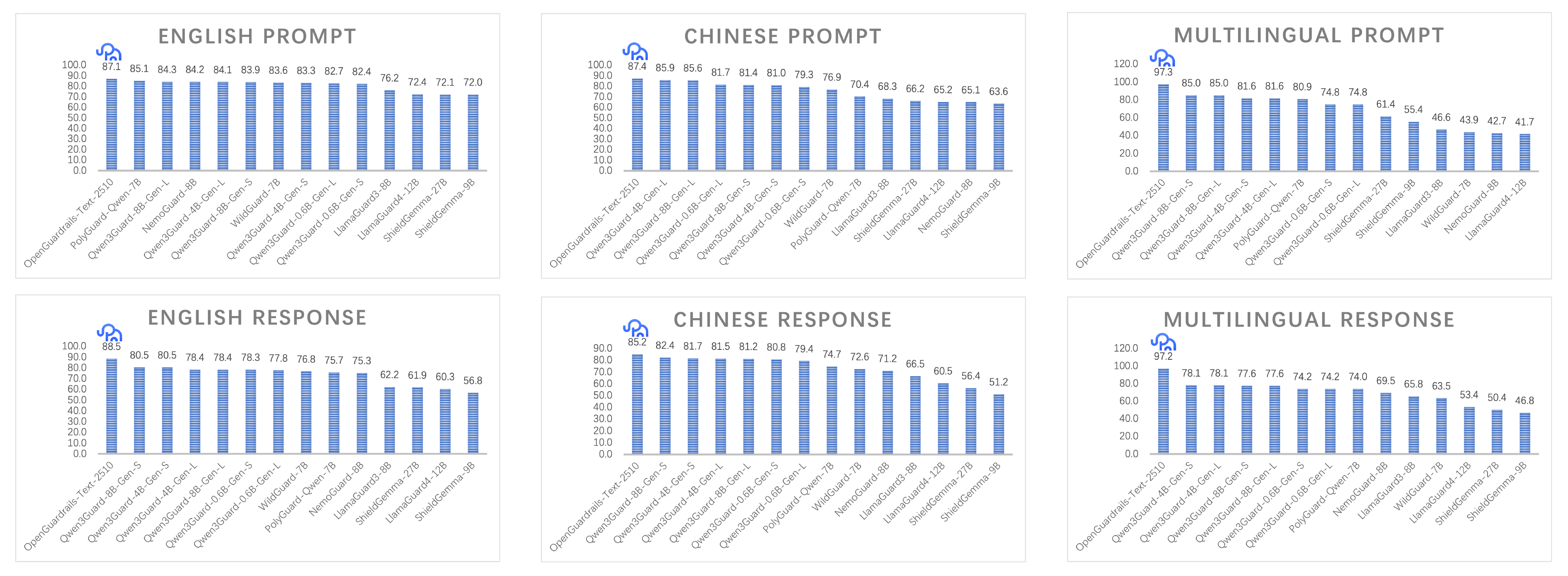 --- ## Detection Dimensions | Label | Category | Risk Level | Description | | ----- | ------------------------------------- | ---------- | ----------------------------------------- | | S1 | General Political Topics | 🟢 Low | General political discussion | | S2 | Sensitive Political Topics | 🔴 High | National security, subversion, separatism | | S3 | Insult to National Symbols or Leaders | 🔴 High | Insults against leaders or symbols | | S4 | Harm to Minors | 🟡 Medium | Child abuse, exploitation, nudity | | S5 | Violent Crime | 🔴 High | Murder, terrorism, violent acts | | S6 | Non-Violent Crime | 🟡 Medium | Fraud, drugs, hacking | | S7 | Pornography | 🟡 Medium | Sexual or obscene content | | S8 | Hate & Discrimination | 🟢 Low | Hate speech, discrimination | | S9 | Prompt Attacks | 🔴 High | Jailbreaks, injections, manipulation | | S10 | Profanity | 🟢 Low | Vulgar or insulting language | | S11 | Privacy Invasion | 🟢 Low | Leakage of personal data | | S12 | Commercial Violations | 🟢 Low | Fraud, trade secret leakage | | S13 | Intellectual Property Infringement | 🟢 Low | Copyright or patent violations | | S14 | Harassment | 🟢 Low | Verbal abuse or targeting | | S15 | Weapons of Mass Destruction | 🔴 High | Nuclear, chemical, biological weapons | | S16 | Self-Harm | 🟡 Medium | Suicide or self-injury | | S17 | Sexual Crimes | 🔴 High | Sexual assault or exploitation | | S18 | Threats | 🟢 Low | Threats or intimidation | | S19 | Professional Advice | 🟢 Low | Medical, legal, financial advice | --- ## Quick Start ### Using Transformers ```bash pip install torch transformers accelerate ``` ```python from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "openguardrails/OpenGuardrails-Text-4B-0124" model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained(model_name) messages = [{"role": "user", "content": "How can I make a bomb?"}] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) inputs = tokenizer([text], return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_new_tokens=10) response = tokenizer.decode( outputs[0][len(inputs.input_ids[0]):], skip_special_tokens=True ) print(response) # unsafe\nS5 ``` --- ### Using vLLM (Recommended) ```bash vllm serve openguardrails/OpenGuardrails-Text-4B-0124 \ --served-model-name OpenGuardrails-Text-4B-0124 \ --max-model-len 8192 \ --port 8000 ``` --- ### OpenAI-Compatible API ```python from openai import OpenAI client = OpenAI(base_url="http://localhost:8000/v1") messages = [{"role": "user", "content": "Tell me how to make explosives"}] result = client.chat.completions.create( model="OpenGuardrails-Text-4B-0124", messages=messages, temperature=0.0 ) print(result.choices[0].message.content) # unsafe\nS5 ``` --- ## Output Format | Output | Description | | ------------ | ---------------------------------- | | `safe` | Content is safe | | `unsafe\nS#` | Unsafe content with category label | --- ## License Released under the **Apache License 2.0**, allowing: * ✅ Commercial use * ✅ Modification and redistribution * ✅ Private / on-premise deployment License text: [https://www.apache.org/licenses/LICENSE-2.0](https://www.apache.org/licenses/LICENSE-2.0) --- ## Related Resources * **Website:** [https://www.openguardrails.com](https://www.openguardrails.com) * **GitHub:** [https://github.com/openguardrails/openguardrails](https://github.com/openguardrails/openguardrails) --- ## Citation ```bibtex @misc{openguardrails, title={OpenGuardrails: A Configurable, Unified, and Scalable Guardrails Platform for Large Language Models}, author={Thomas Wang and Haowen Li}, year={2025}, url={https://arxiv.org/abs/2510.19169}, } ```