初始化项目,由ModelHub XC社区提供模型
Model: norallm/normistral-11b-long Source: Original Platform
This commit is contained in:
35
.gitattributes
vendored
Normal file
35
.gitattributes
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||
*.model filter=lfs diff=lfs merge=lfs -text
|
||||
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
190
README.md
Normal file
190
README.md
Normal file
@@ -0,0 +1,190 @@
|
||||
---
|
||||
license: apache-2.0
|
||||
language:
|
||||
- nb
|
||||
- nn
|
||||
- 'no'
|
||||
- se
|
||||
- sv
|
||||
- da
|
||||
- en
|
||||
- is
|
||||
- fo
|
||||
base_model:
|
||||
- norallm/normistral-11b-warm
|
||||
library_name: transformers
|
||||
pipeline_tag: text-generation
|
||||
tags:
|
||||
- norwegian
|
||||
- sami
|
||||
- bokmaal
|
||||
- nynorsk
|
||||
---
|
||||
|
||||

|
||||
|
||||
|
||||
**NorMistral-11b-long** is a length-extended version of [NorMistral-11b-warm](https://huggingface.co/norallm/normistral-11b-warm). It has been extended to 32,768 context length by continual training on additional 50 billion subword tokens – using a mix of Scandinavian, Sámi, English and code data (four repetitions of open Norwegian texts). The model follows our earlier paper [Small Languages, Big Models: A Study of Continual Training on Languages of Norway](https://arxiv.org/abs/2412.06484) by Samuel et al. 2025, and forms part of the NORA.LLM family developed by [the Language Technology Group at the University of Oslo (LTG)](https://huggingface.co/ltg).
|
||||
|
||||
*Disclaimer: This model is pretrained on raw (mostly web-based) textual data. It is not finetuned to follow instructions, and it can generate harmful completions after inappropriate user prompts. It is primarily intended for research purposes.*
|
||||
|
||||
|
||||
## License
|
||||
|
||||
We release the model under Apache 2.0 license to indicate that we do not impose any additional constraints on the model weights.
|
||||
However, we do not own the data in the training collection.
|
||||
|
||||
|
||||
## Pretraining corpus
|
||||
|
||||
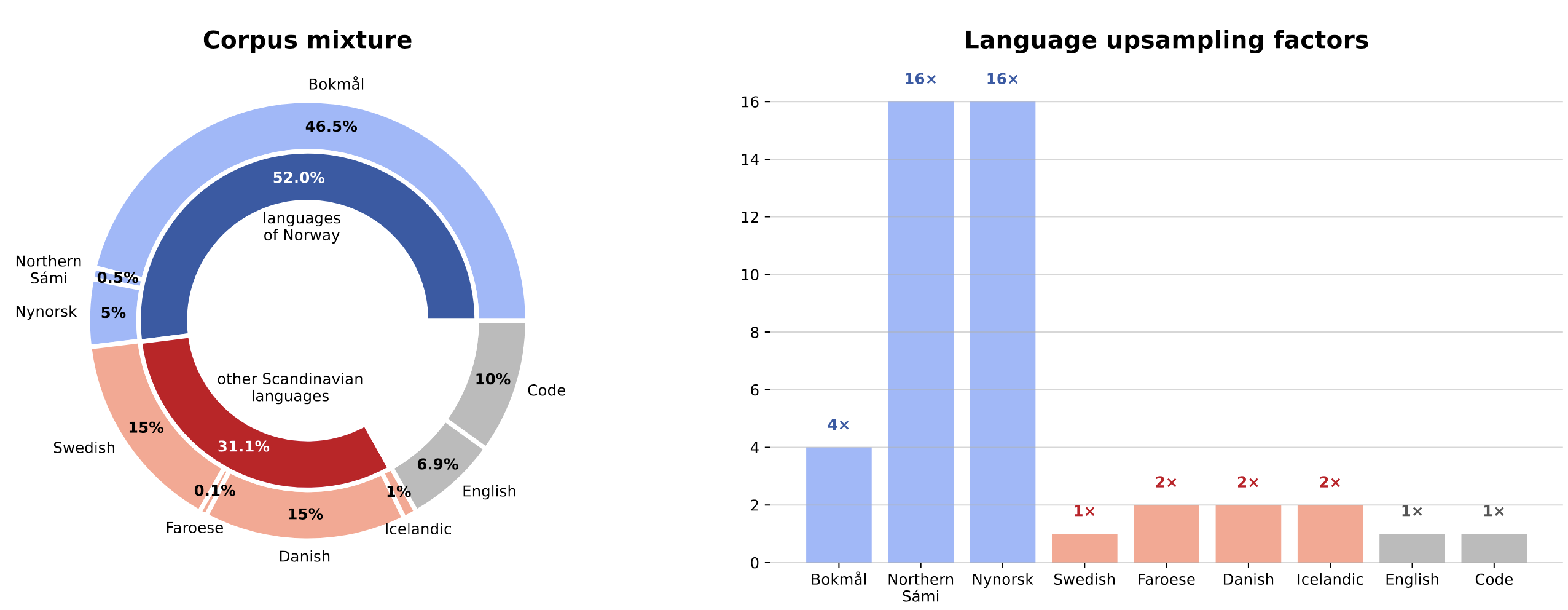
The model is pretrained on a combination of publicly available data and a custom web crawl for Sámi. The total training corpus consists of 250 billion tokens from the following sources:
|
||||
|
||||
1. Norwegian text (Bokmål and Nynorsk); this collection was created by the National Library of Norway and it's a prerelease of an update of NCC (codenamed "Mímir core"). It consists of: a) the public part of [Norwegian Colossal Corpus (NCC)](https://huggingface.co/datasets/NbAiLab/NCC) with permissible licenses (i.e. it doesn't include newspaper texts with the CC BY-NC 2.0 license); b) Bokmål and Nynorsk [CulturaX](https://huggingface.co/datasets/uonlp/CulturaX), and c) Bokmål and Nynorsk [HPLT corpus v1.2](https://hplt-project.org/datasets/v1.2).
|
||||
|
||||
2. Northern Sámi texts are sourced from a) [Glot500](https://huggingface.co/datasets/cis-lmu/Glot500); b) [the SIKOR North Saami free corpus](https://repo.clarino.uib.no/xmlui/handle/11509/100); and c) a custom web crawl (seeded from Sámi Wikipedia external links) published separately as [`ltg/saami-web`](https://huggingface.co/datasets/ltg/saami-web).
|
||||
|
||||
3. Additional languages for knowledge/language transfer: a) Danish, Swedish, Icelandic, and Faroese from CulturaX and Glot500; b) high-quality English from [FineWeb-edu](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu); and c) programming code from [The Stack v2 (the high-quality subset)](https://huggingface.co/datasets/bigcode/the-stack-v2-train-smol-ids).
|
||||
|
||||
The corpus is carefully balanced through strategic upsampling to handle the resource disparity between languages. Following data-constrained scaling laws, the corpus data for target languages is repeated multiple times (up to 16x for low-resource languages) to reach the optimal training budget while avoiding overfitting:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## Tokenizer
|
||||
|
||||
This model uses a new tokenizer, specially trained on the target languages. Therefore it offers substantially faster inference than the original Mistral-Nemo-Base-2407 model. Here are the subword-to-word split ratios across different languages:
|
||||
|
||||
| Tokenizer | # tokens | Bokmål | Nynorsk | Sámi | Danish | Swedish |
|
||||
|:------------|:--------:|:--------:|:---------:|:-------:|:--------:|:---------:|
|
||||
| Mistral-Nemo-Base-2407 | 131072 | 1.79 | 1.87 | 2.63 | 1.82 | 2.00 |
|
||||
| NorMistral-11b-long | 51200 | 1.22 | 1.28 | 1.82 | 1.33 | 1.39 |
|
||||
|
||||
|
||||
## Model details
|
||||
|
||||
**Model Developers:** Language Technology Group at the University of Oslo in collaboration with NORA.LLM.
|
||||
|
||||
**Architecture:** NorMistral-11B uses the Mistral architecture based on an improved Llama design, featuring:
|
||||
- Pre-normalization with RMSNorm
|
||||
- SwiGLU activation function
|
||||
- Rotary positional embeddings
|
||||
- Grouped-query attention
|
||||
- 40 transformer layers
|
||||
- Hidden dimension: 5,120
|
||||
- Intermediate dimension: 14,336
|
||||
- 32 query heads and 8 key & value heads (dimension 128)
|
||||
- Vocabulary size: 51,200 tokens
|
||||
- Total parameters: 11.4 billion
|
||||
|
||||
**Training Details:**
|
||||
- Training tokens: 250 + 50 billion
|
||||
- Batch size: 128 × 32,768 tokens (# sequences × sequence length)
|
||||
- Training steps: 12,000
|
||||
|
||||
|
||||
**Base Model:** Initialized from NorMistral-11b-warm
|
||||
|
||||
**License:** Apache-2.0
|
||||
|
||||
|
||||
|
||||
## Example usage
|
||||
|
||||
### Basic Causal Language Model Usage
|
||||
|
||||
Here's how to use NorMistral-11B as a standard causal language model for translation:
|
||||
|
||||
```python
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
import torch
|
||||
|
||||
# Import the tokenizer and model
|
||||
tokenizer = AutoTokenizer.from_pretrained("norallm/normistral-11b-long")
|
||||
model = AutoModelForCausalLM.from_pretrained("norallm/normistral-11b-long").cuda().eval()
|
||||
|
||||
# Define zero-shot translation prompt template
|
||||
prompt = """Engelsk: {0}
|
||||
Bokmål:"""
|
||||
|
||||
# Define tokens that should end the generation (any token with a newline)
|
||||
eos_token_ids = [
|
||||
token_id
|
||||
for token_id in range(tokenizer.vocab_size)
|
||||
if '\n' in tokenizer.decode([token_id])
|
||||
]
|
||||
|
||||
# Generation function
|
||||
@torch.no_grad()
|
||||
def generate(text):
|
||||
text = prompt.format(text)
|
||||
input_ids = tokenizer(text, return_tensors='pt').input_ids.cuda()
|
||||
prediction = model.generate(
|
||||
input_ids,
|
||||
max_new_tokens=64,
|
||||
do_sample=False,
|
||||
eos_token_id=eos_token_ids
|
||||
)
|
||||
return tokenizer.decode(prediction[0, input_ids.size(1):]).strip()
|
||||
|
||||
# Example usage
|
||||
generate("I'm excited to try this new Norwegian language model!")
|
||||
# > Expected output: 'Jeg er spent på å prøve denne nye norske språkmodellen!'
|
||||
```
|
||||
|
||||
### Memory-Efficient Loading
|
||||
|
||||
For systems with limited VRAM, you can load the model in 8-bit or 4-bit quantization:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("norallm/normistral-11b-long")
|
||||
|
||||
# Load in 8-bit mode (requires ~12GB VRAM)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
"norallm/normistral-11b-long",
|
||||
device_map='auto',
|
||||
load_in_8bit=True,
|
||||
torch_dtype=torch.bfloat16
|
||||
)
|
||||
|
||||
# Or load in 4-bit mode (requires ~8GB VRAM)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
"norallm/normistral-11b-long",
|
||||
device_map='auto',
|
||||
load_in_4bit=True,
|
||||
torch_dtype=torch.bfloat16
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
## Citation
|
||||
|
||||
```bibtex
|
||||
@inproceedings{samuel-etal-2025-small,
|
||||
title = "Small Languages, Big Models: {A} Study of Continual Training on Languages of {Norway}",
|
||||
author = "Samuel, David and
|
||||
Mikhailov, Vladislav and
|
||||
Velldal, Erik and
|
||||
{\O}vrelid, Lilja and
|
||||
Charpentier, Lucas Georges Gabriel and
|
||||
Kutuzov, Andrey and
|
||||
Oepen, Stephan",
|
||||
editor = "Johansson, Richard and
|
||||
Stymne, Sara",
|
||||
booktitle = "Proceedings of the Joint 25th Nordic Conference on Computational Linguistics and 11th Baltic Conference on Human Language Technologies (NoDaLiDa/Baltic-HLT 2025)",
|
||||
month = mar,
|
||||
year = "2025",
|
||||
address = "Tallinn, Estonia",
|
||||
publisher = "University of Tartu Library",
|
||||
url = "https://aclanthology.org/2025.nodalida-1.61/",
|
||||
pages = "573--608",
|
||||
ISBN = "978-9908-53-109-0",
|
||||
}
|
||||
```
|
||||
|
||||
## Contact
|
||||
|
||||
Please write [a community message](https://huggingface.co/norallm/normistral-11b-long/discussions) or contact David Samuel (davisamu@ifi.uio.no) if you have any questions about this model.
|
||||
28
config.json
Normal file
28
config.json
Normal file
@@ -0,0 +1,28 @@
|
||||
{
|
||||
"architectures": [
|
||||
"MistralForCausalLM"
|
||||
],
|
||||
"attention_dropout": 0.0,
|
||||
"bos_token_id": 1,
|
||||
"eos_token_id": 2,
|
||||
"head_dim": 128,
|
||||
"hidden_act": "silu",
|
||||
"hidden_size": 5120,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 14336,
|
||||
"mask_token_id": 4,
|
||||
"max_position_embeddings": 32768,
|
||||
"model_type": "mistral",
|
||||
"num_attention_heads": 32,
|
||||
"num_hidden_layers": 40,
|
||||
"num_key_value_heads": 8,
|
||||
"pad_token_id": 3,
|
||||
"rms_norm_eps": 1e-05,
|
||||
"rope_theta": 1000000.0,
|
||||
"sliding_window": null,
|
||||
"tie_word_embeddings": false,
|
||||
"torch_dtype": "bfloat16",
|
||||
"transformers_version": "4.55.3",
|
||||
"use_cache": true,
|
||||
"vocab_size": 51200
|
||||
}
|
||||
68
convert_to_safetensors.py
Normal file
68
convert_to_safetensors.py
Normal file
@@ -0,0 +1,68 @@
|
||||
import argparse
|
||||
import random
|
||||
from statistics import mean, stdev
|
||||
from typing import List
|
||||
import torch
|
||||
import torchmetrics
|
||||
from datasets import load_dataset
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--model_name_or_path",
|
||||
type=str,
|
||||
default=".",
|
||||
help="Path to the pre-trained model",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
return args
|
||||
|
||||
|
||||
def load_model(model_path: str):
|
||||
# Load the pre-trained model and tokenizer
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_path, torch_dtype=torch.bfloat16)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16).cuda().eval()
|
||||
|
||||
eos_token_ids = [
|
||||
token_id
|
||||
for token_id in range(tokenizer.vocab_size)
|
||||
if "\n" in tokenizer.decode([token_id])
|
||||
]
|
||||
|
||||
if hasattr(model.config, "n_positions"):
|
||||
max_length = model.config.n_positions
|
||||
elif hasattr(model.config, "max_position_embeddings"):
|
||||
max_length = model.config.max_position_embeddings
|
||||
elif hasattr(model.config, "max_length"):
|
||||
max_length = model.config.max_length
|
||||
elif hasattr(model.config, "n_ctx"):
|
||||
max_length = model.config.n_ctx
|
||||
else:
|
||||
max_length = 32768 # Default value
|
||||
|
||||
return {
|
||||
"name": model_path.split("/")[-1],
|
||||
"tokenizer": tokenizer,
|
||||
"model": model,
|
||||
"eos_token_ids": eos_token_ids,
|
||||
"max_length": max_length,
|
||||
}
|
||||
|
||||
|
||||
def main():
|
||||
args = parse_args()
|
||||
|
||||
model = load_model(args.model_name_or_path)
|
||||
|
||||
model["model"].save_pretrained(
|
||||
args.model_name_or_path,
|
||||
max_shard_size="5GB"
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
68
convert_weights.py
Normal file
68
convert_weights.py
Normal file
@@ -0,0 +1,68 @@
|
||||
import argparse
|
||||
import random
|
||||
from statistics import mean, stdev
|
||||
from typing import List
|
||||
import torch
|
||||
import torchmetrics
|
||||
from datasets import load_dataset
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--model_name_or_path",
|
||||
type=str,
|
||||
default=".",
|
||||
help="Path to the pre-trained model",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
return args
|
||||
|
||||
|
||||
def load_model(model_path: str):
|
||||
# Load the pre-trained model and tokenizer
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_path, torch_dtype=torch.bfloat16)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16).cuda().eval()
|
||||
|
||||
eos_token_ids = [
|
||||
token_id
|
||||
for token_id in range(tokenizer.vocab_size)
|
||||
if "\n" in tokenizer.decode([token_id])
|
||||
]
|
||||
|
||||
if hasattr(model.config, "n_positions"):
|
||||
max_length = model.config.n_positions
|
||||
elif hasattr(model.config, "max_position_embeddings"):
|
||||
max_length = model.config.max_position_embeddings
|
||||
elif hasattr(model.config, "max_length"):
|
||||
max_length = model.config.max_length
|
||||
elif hasattr(model.config, "n_ctx"):
|
||||
max_length = model.config.n_ctx
|
||||
else:
|
||||
max_length = 32768 # Default value
|
||||
|
||||
return {
|
||||
"name": model_path.split("/")[-1],
|
||||
"tokenizer": tokenizer,
|
||||
"model": model,
|
||||
"eos_token_ids": eos_token_ids,
|
||||
"max_length": max_length,
|
||||
}
|
||||
|
||||
|
||||
def main():
|
||||
args = parse_args()
|
||||
|
||||
model = load_model(args.model_name_or_path)
|
||||
|
||||
model["model"].save_pretrained(
|
||||
args.model_name_or_path,
|
||||
max_shard_size="4.7GB"
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
7
generation_config.json
Normal file
7
generation_config.json
Normal file
@@ -0,0 +1,7 @@
|
||||
{
|
||||
"_from_model_config": true,
|
||||
"bos_token_id": 1,
|
||||
"eos_token_id": 2,
|
||||
"pad_token_id": 3,
|
||||
"transformers_version": "4.55.3"
|
||||
}
|
||||
3
model-00001-of-00005.safetensors
Normal file
3
model-00001-of-00005.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:260b01db7b3635a8f0e9a3d0c7ca236142207d5624984e96bad1a0012b7af740
|
||||
size 4991394528
|
||||
3
model-00002-of-00005.safetensors
Normal file
3
model-00002-of-00005.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:44bb8a48a1e277579d063d94a6488f8e4c1cb5c6480eab70e3623e308dd06d51
|
||||
size 4907529440
|
||||
3
model-00003-of-00005.safetensors
Normal file
3
model-00003-of-00005.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:6113aa8ed533568dd5b49bf0272fb0f563d998de8f14578dd48dd8c794dae3b0
|
||||
size 4907529456
|
||||
3
model-00004-of-00005.safetensors
Normal file
3
model-00004-of-00005.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:52e09fbb297fcea266ac34627adb98bc48d35d678fc357f1fa9dd536d0643eb5
|
||||
size 4907529456
|
||||
3
model-00005-of-00005.safetensors
Normal file
3
model-00005-of-00005.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:0a3aa50b1637e7e4e543bef1255d2d0aec918c36e2585a40ce65667ac25952db
|
||||
size 3145845632
|
||||
371
model.safetensors.index.json
Normal file
371
model.safetensors.index.json
Normal file
@@ -0,0 +1,371 @@
|
||||
{
|
||||
"metadata": {
|
||||
"total_parameters": 11429893120,
|
||||
"total_size": 22859786240
|
||||
},
|
||||
"weight_map": {
|
||||
"lm_head.weight": "model-00005-of-00005.safetensors",
|
||||
"model.embed_tokens.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.0.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.1.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.10.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.10.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.10.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.10.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.10.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.10.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.11.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.12.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.13.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.14.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.15.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.16.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.17.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.17.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.17.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.17.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.17.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.18.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.18.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.18.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.18.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.18.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.18.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.18.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.18.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.18.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.19.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.19.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.19.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.19.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.19.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.19.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.19.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.19.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.19.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.2.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.20.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.20.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.20.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.20.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.20.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.20.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.20.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.20.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.20.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.21.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.21.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.21.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.21.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.21.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.21.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.21.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.21.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.21.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.22.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.22.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.22.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.22.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.22.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.23.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.24.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.25.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.26.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.26.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.26.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.26.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.26.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
||||
"model.layers.27.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.27.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.27.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.27.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.27.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.27.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.27.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.27.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.27.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.28.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.28.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.28.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.28.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.28.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.28.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.28.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.28.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.28.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.29.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.29.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.29.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.29.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.29.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.29.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.29.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.29.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.29.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.3.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.30.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.30.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.30.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.30.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.30.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.30.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.30.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.30.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.30.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.31.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.31.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.31.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.31.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.31.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.31.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.31.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.31.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.31.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.32.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.32.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.32.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.32.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.32.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.32.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.32.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.32.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.32.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.33.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.33.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.33.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.33.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.33.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.33.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.33.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.33.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.33.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.34.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.34.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.34.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.34.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.34.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.34.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.34.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.34.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.34.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.35.input_layernorm.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.35.mlp.down_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.35.mlp.gate_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.35.mlp.up_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.35.post_attention_layernorm.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.35.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.35.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.35.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.35.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
||||
"model.layers.36.input_layernorm.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.36.mlp.down_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.36.mlp.gate_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.36.mlp.up_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.36.post_attention_layernorm.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.36.self_attn.k_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.36.self_attn.o_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.36.self_attn.q_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.36.self_attn.v_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.37.input_layernorm.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.37.mlp.down_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.37.mlp.gate_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.37.mlp.up_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.37.post_attention_layernorm.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.37.self_attn.k_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.37.self_attn.o_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.37.self_attn.q_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.37.self_attn.v_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.38.input_layernorm.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.38.mlp.down_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.38.mlp.gate_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.38.mlp.up_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.38.post_attention_layernorm.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.38.self_attn.k_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.38.self_attn.o_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.38.self_attn.q_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.38.self_attn.v_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.39.input_layernorm.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.39.mlp.down_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.39.mlp.gate_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.39.mlp.up_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.39.post_attention_layernorm.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.39.self_attn.k_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.39.self_attn.o_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.39.self_attn.q_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.39.self_attn.v_proj.weight": "model-00005-of-00005.safetensors",
|
||||
"model.layers.4.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.5.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.6.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.7.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.8.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.8.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.8.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.8.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.8.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
||||
"model.layers.9.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.9.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.9.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.9.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.9.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.9.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.9.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.layers.9.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
||||
"model.norm.weight": "model-00005-of-00005.safetensors"
|
||||
}
|
||||
}
|
||||
3
pytorch_model.bin
Normal file
3
pytorch_model.bin
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:b525ca26e39206885397a28fac6438df4963d516d4ba796cb05403df3b014a49
|
||||
size 28575459562
|
||||
37
special_tokens_map.json
Normal file
37
special_tokens_map.json
Normal file
@@ -0,0 +1,37 @@
|
||||
{
|
||||
"bos_token": {
|
||||
"content": "<s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"eos_token": {
|
||||
"content": "</s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"unk_token": {
|
||||
"content": "<unk>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"pad_token": {
|
||||
"content": "<pad>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"mask_token": {
|
||||
"content": "<mask>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
}
|
||||
}
|
||||
102373
tokenizer.json
Normal file
102373
tokenizer.json
Normal file
File diff suppressed because it is too large
Load Diff
146
tokenizer_config.json
Normal file
146
tokenizer_config.json
Normal file
@@ -0,0 +1,146 @@
|
||||
{
|
||||
"unk_token_id": 0,
|
||||
"bos_token_id": 1,
|
||||
"eos_token_id": 2,
|
||||
"pad_token_id": 3,
|
||||
"add_bos_token": true,
|
||||
"add_eos_token": false,
|
||||
"add_prefix_space": false,
|
||||
"added_tokens_decoder": {
|
||||
"0": {
|
||||
"content": "<unk>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"1": {
|
||||
"content": "<s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"2": {
|
||||
"content": "</s>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"3": {
|
||||
"content": "<pad>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"4": {
|
||||
"content": "<mask>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"5": {
|
||||
"content": "<special_0>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"6": {
|
||||
"content": "<special_1>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"7": {
|
||||
"content": "<special_2>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"8": {
|
||||
"content": "<special_3>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"9": {
|
||||
"content": "<special_4>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"10": {
|
||||
"content": "<special_5>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"11": {
|
||||
"content": "<special_6>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"12": {
|
||||
"content": "<special_7>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"13": {
|
||||
"content": "<special_8>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"14": {
|
||||
"content": "<special_9>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"15": {
|
||||
"content": "<special_10>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
}
|
||||
},
|
||||
"bos_token": "<s>",
|
||||
"pad_token": "<pad>",
|
||||
"clean_up_tokenization_spaces": false,
|
||||
"eos_token": "</s>",
|
||||
"model_max_length": 32768,
|
||||
"tokenizer_class": "PreTrainedTokenizerFast",
|
||||
"unk_token": "<unk>"
|
||||
}
|
||||
Reference in New Issue
Block a user