---
library_name: transformers
pipeline_tag: text-generation
tags:
- base_model:adapter:unsloth/Qwen3-1.7B
- lora
- sft
- transformers
- trl
- unsloth
license: apache-2.0
datasets:
- az-llm/az_academic_qa-v1.0
- az-llm/az_creative-v1.0
- tahmaz/azerbaijani_text_math_qa1
- omar07ibrahim/Alpaca_Stanford_Azerbaijan
language:
- az
metrics:
- accuracy
base_model:
- unsloth/Qwen3-1.7B
---

Nizami-1.7B
A Lightweight Language Model
Model Description 📝
Nizami-1.7B is a fine-tuned version of Qwen3-1.7B in Azerbaijani.
It was trained on a curated dataset of 35,916 examples from historical, legal, math, philosophical, and social science texts.
Key Features ✨
* **Architecture**: Transformer-based language model 🏗️
* **Developed by**: Rustam Shiriyev
* **Language(s)**: Azerbaijani
* **License**: MIT
* **Fine-Tuning Method**: Supervised fine-tuning
* **Domain**: Academic texts (History, Math, Law, Philosophy, Social Sciences) 📚
* **Finetuned from model**: unsloth/Qwen3-1.7B
Intended Use
* Academic research assistance in Azerbaijani 🏆
* Question answering on humanities/social science topics 🎯
* Knowledge exploration in Azerbaijani⚡
Limitations ⚠️
* Generating factual statements without verification
* Limited dataset size (35,916 examples) → may not generalize perfectly outside training domains.
* Possible hallucinations if asked for factual details.
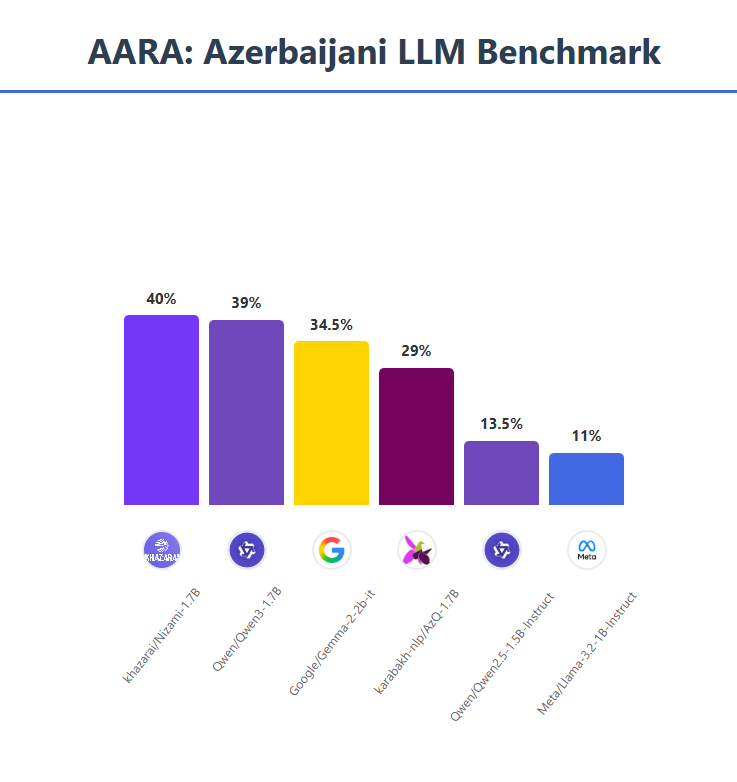
Evaluation 📊
AARA: [khazarai/AARA_Azerbaijani_LLM_Benchmark](https://huggingface.co/datasets/khazarai/AARA_Azerbaijani_LLM_Benchmark)
How to Get Started with the Model 💻
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("khazarai/Nizami-1.7B")
model = AutoModelForCausalLM.from_pretrained(
"khazarai/Nizami-1.7B",
device_map={"": 0}
)
model = PeftModel.from_pretrained(base_model,"khazarai/Nizami-1.7B")
question = """
Əldə olunan arxeoloji qazıntı materiallarına əsasən, Eneolit dövründə Azərbaycanda metalın ilk istifadəsi ilə bağlı hansı konkret obyektlər tapılmışdır və bu obyektlər həmin dövrdə cəmiyyətin sosial strukturunun inkişafına necə təsir etmişdir? Əlavə olaraq, həmin dövrdə metallurgiya və metalişləmə sənətkarlığının inkişafının iqtisadi və mədəni aspektləri haqqında nə deyə bilərsiniz?
"""
messages = [
{"role" : "user", "content" : question}
]
text = tokenizer.apply_chat_template(
messages,
tokenize = False,
add_generation_prompt = True,
enable_thinking = False,
)
from transformers import TextStreamer
_ = model.generate(
**tokenizer(text, return_tensors = "pt").to("cuda"),
max_new_tokens = 1800,
temperature = 0.7,
top_p = 0.8,
top_k = 20,
streamer = TextStreamer(tokenizer, skip_prompt = True),
)
```
Training Data
Dataset I: [az-llm/az_academic_qa-v1.0](https://huggingface.co/datasets/az-llm/az_academic_qa-v1.0)
Description:
A 7,000-example dataset for academic-style comprehension and reasoning in Azerbaijani.
Dataset II: [az-llm/az_creative-v1.0](https://huggingface.co/datasets/az-llm/az_creative-v1.0)
Description:
A 4,000-example creative dataset with imaginative Azerbaijani prompts and expressive responses.
Includes role-based instructions (e.g., Galileo, interstellar assistant, detective), fictional narratives, poetic reasoning, and emotional simulations.
Dataset III: [tahmaz/azerbaijani_text_math_qa1](https://huggingface.co/datasets/tahmaz/azerbaijani_text_math_qa1)
Description: A dataset of 6,500 high school math examples in Azerbaijani.
Dataset IV: [omar07ibrahim/Alpaca_Stanford_Azerbaijan](https://huggingface.co/datasets/omar07ibrahim/Alpaca_Stanford_Azerbaijan)
Description: Azerbaijani version of the Alpaca dataset for instruction-following tasks.