---
tasks:
- auto-speech-recognition
domain:
- audio
model-type:
- Non-autoregressive
frameworks:
- pytorch
backbone:
- transformer/conformer
metrics:
- CER
license: Apache License 2.0
language:
- cn
tags:
- FunASR
- Paraformer-Tiny
- Alibaba
- On Edge
datasets:
train:
- 300 hours Mandarin command word task
test:
- command word test set
indexing:
results:
- task:
name: Automatic Speech Recognition
dataset:
name: 300 hours Mandarin command word task
type: audio # optional
args: 16k sampling rate, 8404 characters # optional
metrics:
- type: CER
value: 0.24% # float
description: greedy search, withou lm, avg.
args: default
- type: RTF
value: 0.1385 # float
description: GPU inference on V100
args: batch_size=1
widgets:
- task: auto-speech-recognition
inputs:
- type: audio
name: input
title: 音频
examples:
- name: 1
title: 示例1
inputs:
- name: input
data: git://example/asr_example.wav
inferencespec:
cpu: 8 #CPU数量
memory: 4096
---
## Highlights
- 指令词识别:较小词表的常用智能家居交互指令词识别模型。
- 轻量:提供了验证有效的5M小参数量Paraformer模型配置,验证了share embedding的作用。
## [ModelScope-FunASR](https://github.com/alibaba-damo-academy/FunASR)
[FunASR](https://github.com/alibaba-damo-academy/FunASR)希望在语音识别方面建立学术研究和工业应用之间的桥梁。通过支持在ModelScope上发布的工业级语音识别模型的训练和微调,研究人员和开发人员可以更方便地进行语音识别模型的研究和生产,并促进语音识别生态系统的发展。
[**最新动态**](https://github.com/alibaba-damo-academy/FunASR#whats-new)
| [**环境安装**](https://github.com/alibaba-damo-academy/FunASR#installation)
| [**介绍文档**](https://alibaba-damo-academy.github.io/FunASR/en/index.html)
| [**中文教程**](https://github.com/alibaba-damo-academy/FunASR/wiki#funasr%E7%94%A8%E6%88%B7%E6%89%8B%E5%86%8C)
| [**服务部署**](https://github.com/alibaba-damo-academy/FunASR/tree/main/funasr/runtime)
| [**模型库**](https://github.com/alibaba-damo-academy/FunASR/blob/main/docs/model_zoo/modelscope_models.md)
| [**联系我们**](https://github.com/alibaba-damo-academy/FunASR#contact)
## 项目介绍
Paraformer是达摩院语音团队提出的一种高效的非自回归端到端语音识别框架。本项目为Paraformer中文通用语音识别模型,采用工业级数万小时的标注音频进行模型训练,保证了模型的通用识别效果。模型可以被应用于语音输入法、语音导航、智能会议纪要等场景。
Paraformer-Tiny-CommandWord是基于Paraformer框架的小参数量指令词自由说模型,旨在验证Paraformer模型在设备端参数量受限(5M)条件下的模型性能。本模型所建模的词表为智能家居语音交互中的常用指令词,共544个汉字与字母,指令词包括但不限于“打开/关闭/调大/调小 音乐/空调/照明”等。
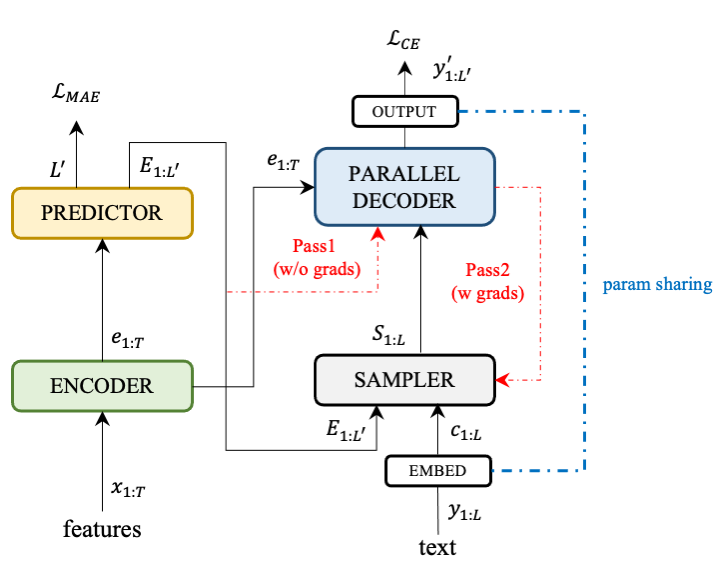 Paraformer-Tiny模型结构如上图所示,与Paraformer相同,由 Encoder、Predictor、Sampler、Decoder 与 Loss function 五部分组成。Encoder采用了Conformer结构,参数量在3.5M左右。Predictor 为一层一维卷积与线性层,预测目标文字个数以及抽取目标文字对应的声学向量。Sampler 为无可学习参数模块,依据输入的声学向量和目标向量,生产含有语义的特征向量。Decoder 结构与Paraformer中一致,参数量限制在1.6至1.8M。为了进一步缩小Decoder部分的参数量,Paraformer-Tiny模型启用了embedding sharing,将Decoder的输出层权重复用至char embedding。
其核心点主要有:
- Predictor 模块:基于 Continuous integrate-and-fire (CIF) 的 预测器 (Predictor) 来抽取目标文字对应的声学特征向量,可以更加准确的预测语音中目标文字个数。
- Sampler:通过采样,将声学特征向量与目标文字向量变换成含有语义信息的特征向量,配合双向的 Decoder 来增强模型对于上下文的建模能力。
- Embedding Sharing(es): Decoder输出层的权重本身也是对文本空间的一种建模,将其复用至char embedding层能够在节约参数量的同时提升建模能力。
更详细的细节见:
- 论文: [Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition](https://arxiv.org/abs/2206.08317)
- 论文解读:[Paraformer: 高识别率、高计算效率的单轮非自回归端到端语音识别模型](https://mp.weixin.qq.com/s/xQ87isj5_wxWiQs4qUXtVw)
## 如何使用与训练自己的模型
本项目提供的预训练模型是基于大数据训练的通用领域识别模型,开发者可以基于此模型进一步利用ModelScope的微调功能或者本项目对应的Github代码仓库[FunASR](https://github.com/alibaba-damo-academy/FunASR)进一步进行模型的领域定制化。
### 在Notebook中开发
对于有开发需求的使用者,特别推荐您使用Notebook进行离线处理。先登录ModelScope账号,点击模型页面右上角的“在Notebook中打开”按钮出现对话框,首次使用会提示您关联阿里云账号,按提示操作即可。关联账号后可进入选择启动实例界面,选择计算资源,建立实例,待实例创建完成后进入开发环境,进行调用。
#### 基于ModelScope进行推理
- 推理支持音频格式如下:
- wav文件路径,例如:data/test/audios/asr_example.wav
- wav文件url,例如:https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh_command.wav
- wav二进制数据,格式bytes,例如:用户直接从文件里读出bytes数据或者是麦克风录出bytes数据。
- 已解析的audio音频,例如:audio, rate = soundfile.read("asr_example_zh.wav"),类型为numpy.ndarray或者torch.Tensor。
- wav.scp文件,需符合如下要求:
```sh
cat wav.scp
asr_example1 data/test/audios/asr_example1.wav
asr_example2 data/test/audios/asr_example2.wav
...
```
- 若输入格式wav文件url,api调用方式可参考如下范例:
```python
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model='iic/speech_paraformer-tiny-commandword_asr_nat-zh-cn-16k-vocab544-pytorch',
model_revision="v2.0.4")
rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh_command.wav')
print(rec_result)
```
- 若输入格式为文件wav.scp(注:文件名需要以.scp结尾),可添加 output_dir 参数将识别结果写入文件中,并可设置解码batch_size,参考示例如下:
```python
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model='iic/speech_paraformer-tiny-commandword_asr_nat-zh-cn-16k-vocab544-pytorch',
model_revision="v2.0.4",
output_dir='./output_dir',
batch_size=32)
inference_pipeline("wav.scp")
```
识别结果输出路径结构如下:
```sh
tree output_dir/
output_dir/
└── 1best_recog
├── rtf
├── score
└── text
1 directory, 3 files
```
rtf:计算过程耗时统计
score:识别路径得分
text:语音识别结果文件
- 若输入音频为已解析的audio音频,api调用方式可参考如下范例:
```python
import soundfile
waveform, sample_rate = soundfile.read("asr_example_zh.wav")
rec_result = inference_pipeline(audio_in=waveform)
```
#### 模型效果
| | Infer Conf | #Param(Enc/Dec) | CER(Dev/Test) |
|-------------------------|-------------------------------|-----------------|---------------------|
| Conformer_Transformer | Beam=5_CTC=0.3 | 3.47M/1.59M | 0.21/0.21 |
| Conformer_Paraformer | Beam=5_CTC=0.3 | 3.47M/1.82M | 0.27/0.28 |
| Conformer_Paraformer_es | Beam=1_CTC=0.0 Beam=5_CTC=0.3 | 3.47M/1.69M | 0.27/0.24_0.25/0.24 |
#### 基于ModelScope进行微调
开发中,即将提供基于达摩院内部大数据训练的小参数量Paraformer模型作为基础模型,方便用户进行finetune。
### 在本地机器中开发
#### 基于ModelScope进行微调和推理
支持基于ModelScope上数据集及私有数据集进行定制微调和推理,使用方式同Notebook中开发。
#### 基于FunASR的模型训练和推理
FunASR框架支持魔搭社区开源的工业级的语音识别模型的training & finetuning,使得研究人员和开发者可以更加便捷的进行语音识别模型的研究和生产,目前已在github开源:https://github.com/alibaba-damo-academy/FunASR
#### FunASR框架安装
- 安装FunASR和ModelScope,[详见](https://github.com/alibaba-damo-academy/FunASR/wiki)
```sh
pip3 install -U modelscope
git clone https://github.com/alibaba/FunASR.git && cd FunASR
pip3 install -e ./
```
#### 推理
接下来会以AISHELL-1数据集为例,介绍如何在FunASR框架中使用Paraformer-large进行推理以及微调。
```sh
cd egs_modelscope/aishell/paraformer/
# 配置 paraformer_large_infer.sh 中参数
# ori_data: AISHELL-1原始数据路径
# data_dir: 数据处理路径
# exp_dir: 结果路径
# model_name: 配置模型名称
# use_lm: 是否使用LM
# beam_size: 设置beam_size
# lm_weight: 设置lm_weight
# 配置修改完成后,执行命令:
sh ./paraformer_large_infer.sh
```
## 使用方式以及适用范围
运行范围
- 支持Linux-x86_64、Mac和Windows运行。
使用方式
- 直接推理:可以直接对输入音频进行解码,输出目标文字。
- 微调:加载训练好的模型,采用私有或者开源数据进行模型训练。
使用范围与目标场景
- 适合进行指令词的识别,若需要具有通用asr能力的小参数量模型推荐使用对应数据对本模型进行finetune。
## 模型局限性以及可能的偏差
考虑到特征提取流程和工具以及训练工具差异,会对CER的数据带来一定的差异(<0.1%),推理GPU环境差异导致的RTF数值差异。
## 相关论文以及引用信息
```BibTeX
@inproceedings{gao2022paraformer,
title={Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition},
author={Gao, Zhifu and Zhang, Shiliang and McLoughlin, Ian and Yan, Zhijie},
booktitle={INTERSPEECH},
year={2022}
}
```
Paraformer-Tiny模型结构如上图所示,与Paraformer相同,由 Encoder、Predictor、Sampler、Decoder 与 Loss function 五部分组成。Encoder采用了Conformer结构,参数量在3.5M左右。Predictor 为一层一维卷积与线性层,预测目标文字个数以及抽取目标文字对应的声学向量。Sampler 为无可学习参数模块,依据输入的声学向量和目标向量,生产含有语义的特征向量。Decoder 结构与Paraformer中一致,参数量限制在1.6至1.8M。为了进一步缩小Decoder部分的参数量,Paraformer-Tiny模型启用了embedding sharing,将Decoder的输出层权重复用至char embedding。
其核心点主要有:
- Predictor 模块:基于 Continuous integrate-and-fire (CIF) 的 预测器 (Predictor) 来抽取目标文字对应的声学特征向量,可以更加准确的预测语音中目标文字个数。
- Sampler:通过采样,将声学特征向量与目标文字向量变换成含有语义信息的特征向量,配合双向的 Decoder 来增强模型对于上下文的建模能力。
- Embedding Sharing(es): Decoder输出层的权重本身也是对文本空间的一种建模,将其复用至char embedding层能够在节约参数量的同时提升建模能力。
更详细的细节见:
- 论文: [Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition](https://arxiv.org/abs/2206.08317)
- 论文解读:[Paraformer: 高识别率、高计算效率的单轮非自回归端到端语音识别模型](https://mp.weixin.qq.com/s/xQ87isj5_wxWiQs4qUXtVw)
## 如何使用与训练自己的模型
本项目提供的预训练模型是基于大数据训练的通用领域识别模型,开发者可以基于此模型进一步利用ModelScope的微调功能或者本项目对应的Github代码仓库[FunASR](https://github.com/alibaba-damo-academy/FunASR)进一步进行模型的领域定制化。
### 在Notebook中开发
对于有开发需求的使用者,特别推荐您使用Notebook进行离线处理。先登录ModelScope账号,点击模型页面右上角的“在Notebook中打开”按钮出现对话框,首次使用会提示您关联阿里云账号,按提示操作即可。关联账号后可进入选择启动实例界面,选择计算资源,建立实例,待实例创建完成后进入开发环境,进行调用。
#### 基于ModelScope进行推理
- 推理支持音频格式如下:
- wav文件路径,例如:data/test/audios/asr_example.wav
- wav文件url,例如:https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh_command.wav
- wav二进制数据,格式bytes,例如:用户直接从文件里读出bytes数据或者是麦克风录出bytes数据。
- 已解析的audio音频,例如:audio, rate = soundfile.read("asr_example_zh.wav"),类型为numpy.ndarray或者torch.Tensor。
- wav.scp文件,需符合如下要求:
```sh
cat wav.scp
asr_example1 data/test/audios/asr_example1.wav
asr_example2 data/test/audios/asr_example2.wav
...
```
- 若输入格式wav文件url,api调用方式可参考如下范例:
```python
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model='iic/speech_paraformer-tiny-commandword_asr_nat-zh-cn-16k-vocab544-pytorch',
model_revision="v2.0.4")
rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh_command.wav')
print(rec_result)
```
- 若输入格式为文件wav.scp(注:文件名需要以.scp结尾),可添加 output_dir 参数将识别结果写入文件中,并可设置解码batch_size,参考示例如下:
```python
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model='iic/speech_paraformer-tiny-commandword_asr_nat-zh-cn-16k-vocab544-pytorch',
model_revision="v2.0.4",
output_dir='./output_dir',
batch_size=32)
inference_pipeline("wav.scp")
```
识别结果输出路径结构如下:
```sh
tree output_dir/
output_dir/
└── 1best_recog
├── rtf
├── score
└── text
1 directory, 3 files
```
rtf:计算过程耗时统计
score:识别路径得分
text:语音识别结果文件
- 若输入音频为已解析的audio音频,api调用方式可参考如下范例:
```python
import soundfile
waveform, sample_rate = soundfile.read("asr_example_zh.wav")
rec_result = inference_pipeline(audio_in=waveform)
```
#### 模型效果
| | Infer Conf | #Param(Enc/Dec) | CER(Dev/Test) |
|-------------------------|-------------------------------|-----------------|---------------------|
| Conformer_Transformer | Beam=5_CTC=0.3 | 3.47M/1.59M | 0.21/0.21 |
| Conformer_Paraformer | Beam=5_CTC=0.3 | 3.47M/1.82M | 0.27/0.28 |
| Conformer_Paraformer_es | Beam=1_CTC=0.0 Beam=5_CTC=0.3 | 3.47M/1.69M | 0.27/0.24_0.25/0.24 |
#### 基于ModelScope进行微调
开发中,即将提供基于达摩院内部大数据训练的小参数量Paraformer模型作为基础模型,方便用户进行finetune。
### 在本地机器中开发
#### 基于ModelScope进行微调和推理
支持基于ModelScope上数据集及私有数据集进行定制微调和推理,使用方式同Notebook中开发。
#### 基于FunASR的模型训练和推理
FunASR框架支持魔搭社区开源的工业级的语音识别模型的training & finetuning,使得研究人员和开发者可以更加便捷的进行语音识别模型的研究和生产,目前已在github开源:https://github.com/alibaba-damo-academy/FunASR
#### FunASR框架安装
- 安装FunASR和ModelScope,[详见](https://github.com/alibaba-damo-academy/FunASR/wiki)
```sh
pip3 install -U modelscope
git clone https://github.com/alibaba/FunASR.git && cd FunASR
pip3 install -e ./
```
#### 推理
接下来会以AISHELL-1数据集为例,介绍如何在FunASR框架中使用Paraformer-large进行推理以及微调。
```sh
cd egs_modelscope/aishell/paraformer/
# 配置 paraformer_large_infer.sh 中参数
# ori_data: AISHELL-1原始数据路径
# data_dir: 数据处理路径
# exp_dir: 结果路径
# model_name: 配置模型名称
# use_lm: 是否使用LM
# beam_size: 设置beam_size
# lm_weight: 设置lm_weight
# 配置修改完成后,执行命令:
sh ./paraformer_large_infer.sh
```
## 使用方式以及适用范围
运行范围
- 支持Linux-x86_64、Mac和Windows运行。
使用方式
- 直接推理:可以直接对输入音频进行解码,输出目标文字。
- 微调:加载训练好的模型,采用私有或者开源数据进行模型训练。
使用范围与目标场景
- 适合进行指令词的识别,若需要具有通用asr能力的小参数量模型推荐使用对应数据对本模型进行finetune。
## 模型局限性以及可能的偏差
考虑到特征提取流程和工具以及训练工具差异,会对CER的数据带来一定的差异(<0.1%),推理GPU环境差异导致的RTF数值差异。
## 相关论文以及引用信息
```BibTeX
@inproceedings{gao2022paraformer,
title={Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition},
author={Gao, Zhifu and Zhang, Shiliang and McLoughlin, Ian and Yan, Zhijie},
booktitle={INTERSPEECH},
year={2022}
}
```