初始化项目,由ModelHub XC社区提供模型
Model: bigcode/starcoder2-15b-instruct-v0.1 Source: Original Platform
This commit is contained in:
35
.gitattributes
vendored
Normal file
35
.gitattributes
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||
*.model filter=lfs diff=lfs merge=lfs -text
|
||||
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
235
README.md
Normal file
235
README.md
Normal file
@@ -0,0 +1,235 @@
|
||||
---
|
||||
pipeline_tag: text-generation
|
||||
base_model: bigcode/starcoder2-15b
|
||||
datasets:
|
||||
- bigcode/self-oss-instruct-sc2-exec-filter-50k
|
||||
license: bigcode-openrail-m
|
||||
library_name: transformers
|
||||
tags:
|
||||
- code
|
||||
model-index:
|
||||
- name: starcoder2-15b-instruct-v0.1
|
||||
results:
|
||||
- task:
|
||||
type: text-generation
|
||||
dataset:
|
||||
name: LiveCodeBench (code generation)
|
||||
type: livecodebench-codegeneration
|
||||
metrics:
|
||||
- type: pass@1
|
||||
value: 20.4
|
||||
- task:
|
||||
type: text-generation
|
||||
dataset:
|
||||
name: LiveCodeBench (self repair)
|
||||
type: livecodebench-selfrepair
|
||||
metrics:
|
||||
- type: pass@1
|
||||
value: 20.9
|
||||
- task:
|
||||
type: text-generation
|
||||
dataset:
|
||||
name: LiveCodeBench (test output prediction)
|
||||
type: livecodebench-testoutputprediction
|
||||
metrics:
|
||||
- type: pass@1
|
||||
value: 29.8
|
||||
- task:
|
||||
type: text-generation
|
||||
dataset:
|
||||
name: LiveCodeBench (code execution)
|
||||
type: livecodebench-codeexecution
|
||||
metrics:
|
||||
- type: pass@1
|
||||
value: 28.1
|
||||
- task:
|
||||
type: text-generation
|
||||
dataset:
|
||||
name: HumanEval
|
||||
type: humaneval
|
||||
metrics:
|
||||
- type: pass@1
|
||||
value: 72.6
|
||||
- task:
|
||||
type: text-generation
|
||||
dataset:
|
||||
name: HumanEval+
|
||||
type: humanevalplus
|
||||
metrics:
|
||||
- type: pass@1
|
||||
value: 63.4
|
||||
- task:
|
||||
type: text-generation
|
||||
dataset:
|
||||
name: MBPP
|
||||
type: mbpp
|
||||
metrics:
|
||||
- type: pass@1
|
||||
value: 75.2
|
||||
- task:
|
||||
type: text-generation
|
||||
dataset:
|
||||
name: MBPP+
|
||||
type: mbppplus
|
||||
metrics:
|
||||
- type: pass@1
|
||||
value: 61.2
|
||||
- task:
|
||||
type: text-generation
|
||||
dataset:
|
||||
name: DS-1000
|
||||
type: ds-1000
|
||||
metrics:
|
||||
- type: pass@1
|
||||
value: 40.6
|
||||
---
|
||||
|
||||
# StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation
|
||||
|
||||

|
||||
|
||||
## Model Summary
|
||||
|
||||
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
|
||||
|
||||
- **Model:** [bigcode/starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
|
||||
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
|
||||
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
|
||||
- **Authors:**
|
||||
[Yuxiang Wei](https://yuxiang.cs.illinois.edu),
|
||||
[Federico Cassano](https://federico.codes/),
|
||||
[Jiawei Liu](https://jw-liu.xyz),
|
||||
[Yifeng Ding](https://yifeng-ding.com),
|
||||
[Naman Jain](https://naman-ntc.github.io),
|
||||
[Harm de Vries](https://www.harmdevries.com),
|
||||
[Leandro von Werra](https://twitter.com/lvwerra),
|
||||
[Arjun Guha](https://www.khoury.northeastern.edu/home/arjunguha/main/home/),
|
||||
[Lingming Zhang](https://lingming.cs.illinois.edu).
|
||||
|
||||

|
||||
|
||||
## Citation
|
||||
|
||||
```bibtex
|
||||
@article{wei2024selfcodealign,
|
||||
title={SelfCodeAlign: Self-Alignment for Code Generation},
|
||||
author={Yuxiang Wei and Federico Cassano and Jiawei Liu and Yifeng Ding and Naman Jain and Zachary Mueller and Harm de Vries and Leandro von Werra and Arjun Guha and Lingming Zhang},
|
||||
year={2024},
|
||||
journal={arXiv preprint arXiv:2410.24198}
|
||||
}
|
||||
```
|
||||
|
||||
## Use
|
||||
|
||||
### Intended use
|
||||
|
||||
The model is designed to respond to **coding-related instructions in a single turn**. Instructions in other styles may result in less accurate responses.
|
||||
|
||||
Here is an example to get started with the model using the [transformers](https://huggingface.co/docs/transformers/index) library:
|
||||
|
||||
```python
|
||||
import transformers
|
||||
import torch
|
||||
|
||||
pipeline = transformers.pipeline(
|
||||
model="bigcode/starcoder2-15b-instruct-v0.1",
|
||||
task="text-generation",
|
||||
torch_dtype=torch.bfloat16,
|
||||
device_map="auto",
|
||||
)
|
||||
|
||||
def respond(instruction: str, response_prefix: str) -> str:
|
||||
messages = [{"role": "user", "content": instruction}]
|
||||
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False)
|
||||
prompt += response_prefix
|
||||
|
||||
teminators = [
|
||||
pipeline.tokenizer.eos_token_id,
|
||||
pipeline.tokenizer.convert_tokens_to_ids("###"),
|
||||
]
|
||||
|
||||
result = pipeline(
|
||||
prompt,
|
||||
max_length=256,
|
||||
num_return_sequences=1,
|
||||
do_sample=False,
|
||||
eos_token_id=teminators,
|
||||
pad_token_id=pipeline.tokenizer.eos_token_id,
|
||||
truncation=True,
|
||||
)
|
||||
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
|
||||
return response
|
||||
|
||||
|
||||
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria."
|
||||
response_prefix = ""
|
||||
|
||||
print(respond(instruction, response_prefix))
|
||||
```
|
||||
|
||||
Here is the expected output:
|
||||
|
||||
``````
|
||||
Here's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:
|
||||
|
||||
```python
|
||||
from typing import TypeVar, Callable
|
||||
|
||||
T = TypeVar('T')
|
||||
|
||||
def quicksort(items: list[T], less_than: Callable[[T, T], bool] = lambda x, y: x < y) -> list[T]:
|
||||
if len(items) <= 1:
|
||||
return items
|
||||
|
||||
pivot = items[0]
|
||||
less = [x for x in items[1:] if less_than(x, pivot)]
|
||||
greater = [x for x in items[1:] if not less_than(x, pivot)]
|
||||
return quicksort(less, less_than) + [pivot] + quicksort(greater, less_than)
|
||||
```
|
||||
``````
|
||||
|
||||
### Bias, Risks, and Limitations
|
||||
|
||||
StarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a **response prefix** or a **one-shot example** to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.
|
||||
|
||||
The model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the [StarCoder2-15B model card](https://huggingface.co/bigcode/starcoder2-15b).
|
||||
|
||||
## Evaluation on EvalPlus, LiveCodeBench, and DS-1000
|
||||
|
||||
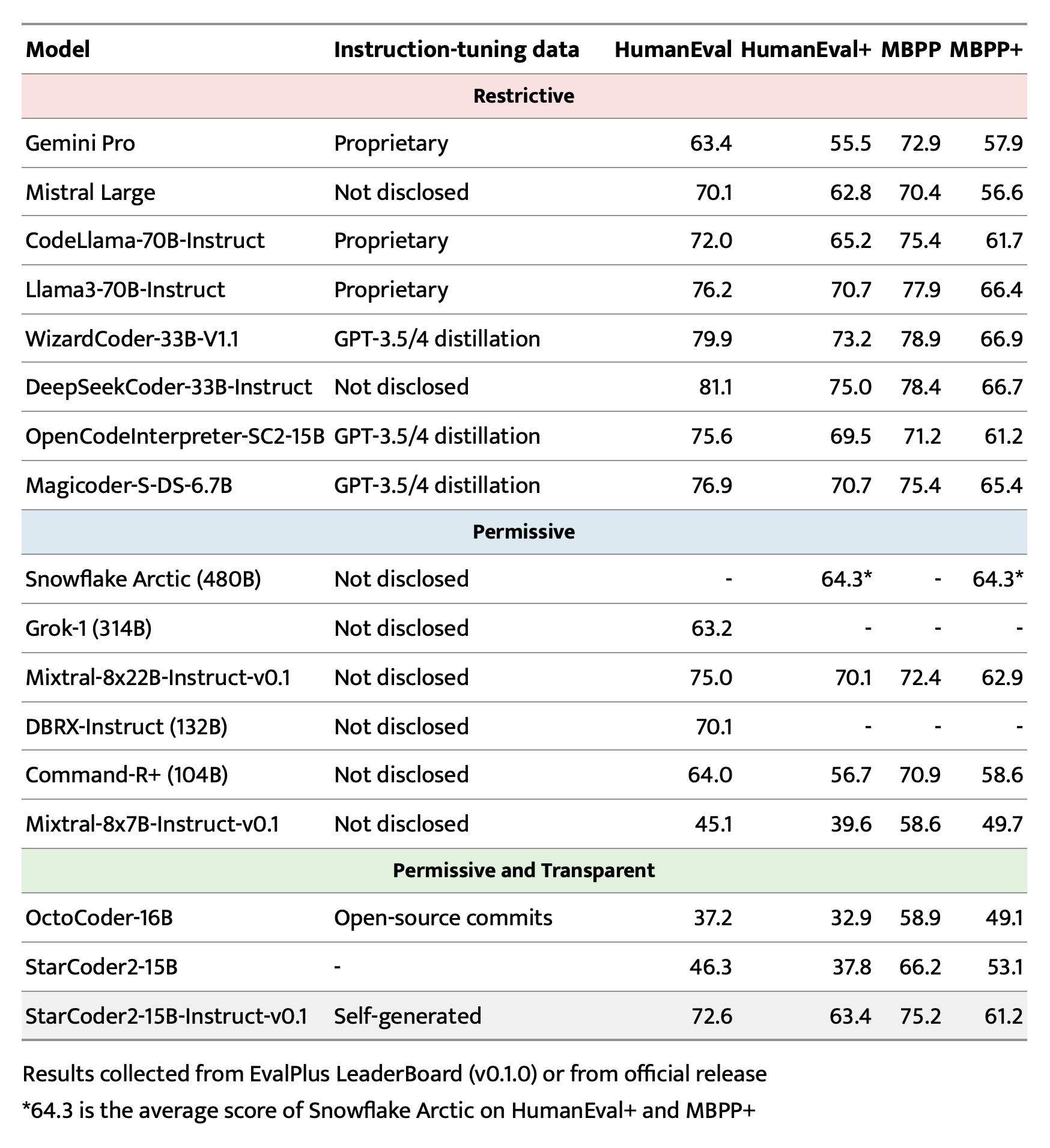
|
||||
|
||||
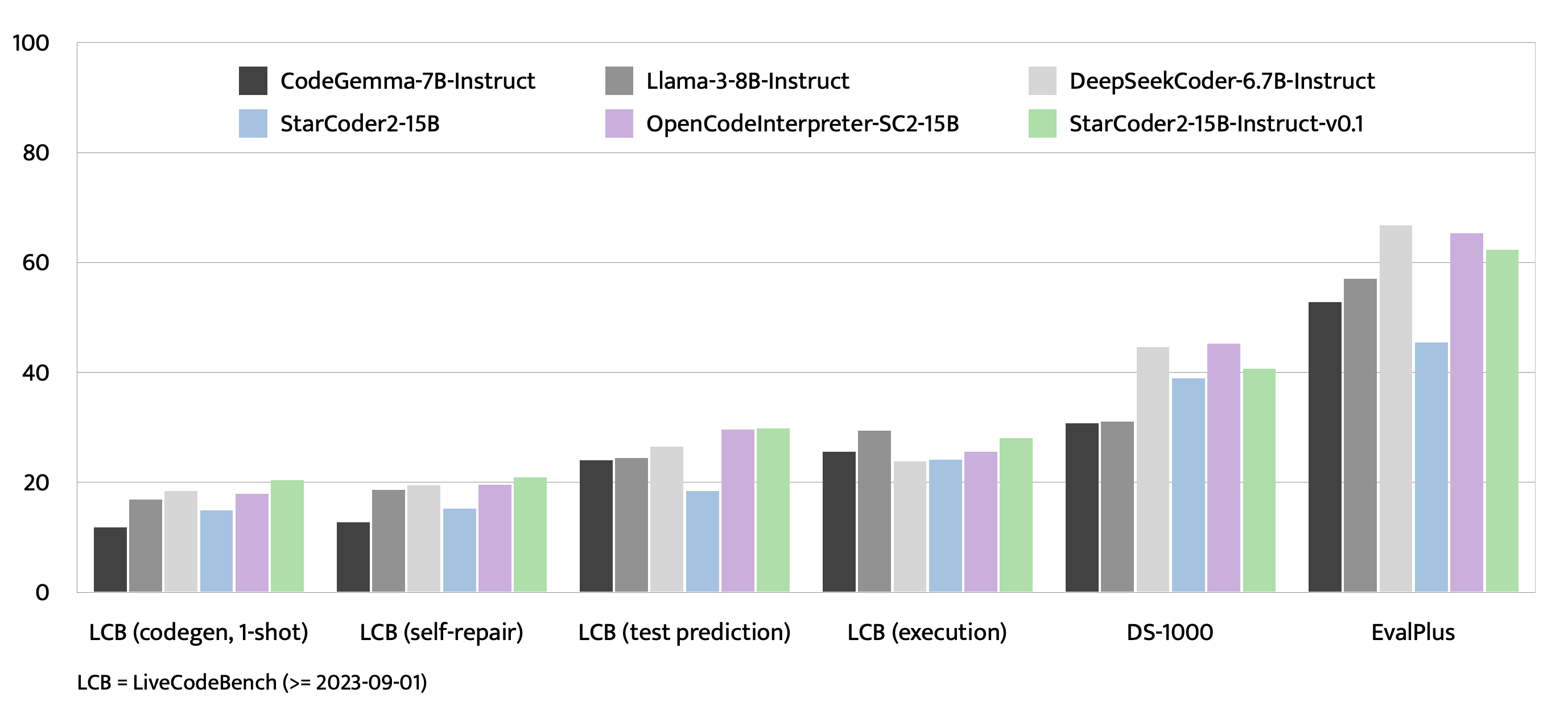
|
||||
|
||||
## Training Details
|
||||
|
||||
### Hyperparameters
|
||||
|
||||
- **Optimizer:** Adafactor
|
||||
- **Learning rate:** 1e-5
|
||||
- **Epoch:** 4
|
||||
- **Batch size:** 64
|
||||
- **Warmup ratio:** 0.05
|
||||
- **Scheduler:** Linear
|
||||
- **Sequence length:** 1280
|
||||
- **Dropout**: Not applied
|
||||
|
||||
### Hardware
|
||||
|
||||
1 x NVIDIA A100 80GB
|
||||
|
||||
## Resources
|
||||
|
||||
- **Model:** [bigcode/starCoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
|
||||
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
|
||||
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
|
||||
|
||||
### Full Data Pipeline
|
||||
|
||||
Our dataset generation pipeline has several steps. We provide intermediate datasets for every step of the pipeline:
|
||||
1. Original seed dataset filtered from The Stack v1: https://huggingface.co/datasets/bigcode/python-stack-v1-functions-filtered
|
||||
2. Seed dataset filtered using StarCoder2-15B as a judge for removing items with bad docstrings: https://huggingface.co/datasets/bigcode/python-stack-v1-functions-filtered-sc2
|
||||
3. seed -> concepts: https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-concepts
|
||||
4. concepts -> instructions: https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-instructions
|
||||
5. instructions -> response: https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-responses-unfiltered
|
||||
6. Responses filtered by executing them: https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-500k-raw
|
||||
7. Executed responses filtered by deduplicating them (final dataset): https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k
|
||||
31
config.json
Normal file
31
config.json
Normal file
@@ -0,0 +1,31 @@
|
||||
{
|
||||
"_name_or_path": "starcoder2-instruct-15b-v0.1",
|
||||
"architectures": [
|
||||
"Starcoder2ForCausalLM"
|
||||
],
|
||||
"attention_dropout": 0.0,
|
||||
"bos_token_id": 0,
|
||||
"embedding_dropout": 0.0,
|
||||
"eos_token_id": 0,
|
||||
"hidden_act": "gelu_pytorch_tanh",
|
||||
"hidden_size": 6144,
|
||||
"initializer_range": 0.01275,
|
||||
"intermediate_size": 24576,
|
||||
"max_position_embeddings": 16384,
|
||||
"mlp_type": "default",
|
||||
"model_type": "starcoder2",
|
||||
"norm_epsilon": 1e-05,
|
||||
"norm_type": "layer_norm",
|
||||
"num_attention_heads": 48,
|
||||
"num_hidden_layers": 40,
|
||||
"num_key_value_heads": 4,
|
||||
"residual_dropout": 0.0,
|
||||
"rope_theta": 100000,
|
||||
"sliding_window": 4096,
|
||||
"tie_word_embeddings": false,
|
||||
"torch_dtype": "bfloat16",
|
||||
"transformers_version": "4.39.0.dev0",
|
||||
"use_bias": true,
|
||||
"use_cache": true,
|
||||
"vocab_size": 49152
|
||||
}
|
||||
6
generation_config.json
Normal file
6
generation_config.json
Normal file
@@ -0,0 +1,6 @@
|
||||
{
|
||||
"_from_model_config": true,
|
||||
"bos_token_id": 0,
|
||||
"eos_token_id": 0,
|
||||
"transformers_version": "4.39.0.dev0"
|
||||
}
|
||||
48873
merges.txt
Normal file
48873
merges.txt
Normal file
File diff suppressed because it is too large
Load Diff
3
model-00001-of-00007.safetensors
Normal file
3
model-00001-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:43d33bf7c1b53275516d62a59ddff346d3a1f76233ab8cb59d33cc1cebac9703
|
||||
size 4908107736
|
||||
3
model-00002-of-00007.safetensors
Normal file
3
model-00002-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:9229d1be2521206ef9515a670580e950c4bfca717089c7530d40bd7c99caae5c
|
||||
size 4996327240
|
||||
3
model-00003-of-00007.safetensors
Normal file
3
model-00003-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:3a3929123a6be822be50155f54d80a5dc5e4ec572c89e25cffc6402c70794358
|
||||
size 4983729152
|
||||
3
model-00004-of-00007.safetensors
Normal file
3
model-00004-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:d9789987dcbd988018703ef5be9f160897c443d85aad4e0f566e181128fdb18a
|
||||
size 4996327312
|
||||
3
model-00005-of-00007.safetensors
Normal file
3
model-00005-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:1a2bb6f565b51266478b4ad4203d3ad7287bea9b3350fc2097907057d000094a
|
||||
size 4983729152
|
||||
3
model-00006-of-00007.safetensors
Normal file
3
model-00006-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:a5dbba6976ac770ab2dc87848f2a12450da8129a078b5b7084bde316d13e642c
|
||||
size 4996327312
|
||||
3
model-00007-of-00007.safetensors
Normal file
3
model-00007-of-00007.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:8f94fe718571ca9a7eab7de3a5c9b87d378a75c06e1c48d23c376fd9fef086c6
|
||||
size 2051302552
|
||||
651
model.safetensors.index.json
Normal file
651
model.safetensors.index.json
Normal file
@@ -0,0 +1,651 @@
|
||||
{
|
||||
"metadata": {
|
||||
"total_size": 31915778048
|
||||
},
|
||||
"weight_map": {
|
||||
"lm_head.weight": "model-00007-of-00007.safetensors",
|
||||
"model.embed_tokens.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.input_layernorm.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.mlp.c_fc.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.mlp.c_fc.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.mlp.c_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.mlp.c_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.post_attention_layernorm.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.o_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.input_layernorm.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.mlp.c_fc.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.mlp.c_fc.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.mlp.c_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.mlp.c_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.post_attention_layernorm.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.o_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.10.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.mlp.c_fc.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.mlp.c_fc.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.o_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.10.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.mlp.c_fc.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.mlp.c_fc.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.o_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.12.input_layernorm.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.mlp.c_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.mlp.c_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.post_attention_layernorm.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.13.input_layernorm.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.mlp.c_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.mlp.c_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.post_attention_layernorm.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.13.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.input_layernorm.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.mlp.c_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.mlp.c_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.post_attention_layernorm.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.14.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.input_layernorm.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.mlp.c_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.mlp.c_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.post_attention_layernorm.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.15.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.input_layernorm.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.mlp.c_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.mlp.c_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.post_attention_layernorm.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.16.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.input_layernorm.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.input_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.mlp.c_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.mlp.c_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.post_attention_layernorm.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.post_attention_layernorm.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.17.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.18.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.mlp.c_fc.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.18.mlp.c_fc.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.18.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.k_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.k_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.o_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.o_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.q_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.q_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.v_proj.bias": "model-00003-of-00007.safetensors",
|
||||
"model.layers.18.self_attn.v_proj.weight": "model-00003-of-00007.safetensors",
|
||||
"model.layers.19.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.mlp.c_fc.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.mlp.c_fc.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.o_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.19.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.2.input_layernorm.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.mlp.c_fc.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.mlp.c_fc.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.mlp.c_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.mlp.c_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.post_attention_layernorm.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.o_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.20.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.mlp.c_fc.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.mlp.c_fc.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.o_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.20.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.mlp.c_fc.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.mlp.c_fc.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.o_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.21.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.mlp.c_fc.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.mlp.c_fc.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.o_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.22.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.mlp.c_fc.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.mlp.c_fc.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.o_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.23.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.input_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.input_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.mlp.c_fc.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.mlp.c_fc.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.mlp.c_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.mlp.c_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.post_attention_layernorm.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.post_attention_layernorm.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.o_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.o_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.24.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.25.input_layernorm.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.25.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.25.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.25.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.25.mlp.c_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.25.mlp.c_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.25.post_attention_layernorm.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.25.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.k_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.k_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.q_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.q_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.v_proj.bias": "model-00004-of-00007.safetensors",
|
||||
"model.layers.25.self_attn.v_proj.weight": "model-00004-of-00007.safetensors",
|
||||
"model.layers.26.input_layernorm.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.mlp.c_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.mlp.c_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.post_attention_layernorm.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.26.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.input_layernorm.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.mlp.c_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.mlp.c_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.post_attention_layernorm.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.27.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.input_layernorm.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.mlp.c_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.mlp.c_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.post_attention_layernorm.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.28.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.input_layernorm.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.mlp.c_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.mlp.c_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.post_attention_layernorm.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.29.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.3.input_layernorm.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.mlp.c_fc.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.mlp.c_fc.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.mlp.c_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.mlp.c_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.post_attention_layernorm.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.o_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.30.input_layernorm.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.input_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.mlp.c_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.mlp.c_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.post_attention_layernorm.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.post_attention_layernorm.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.30.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.31.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.31.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.31.mlp.c_fc.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.31.mlp.c_fc.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.31.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.31.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.31.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.31.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.31.self_attn.k_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.31.self_attn.k_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.31.self_attn.o_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.31.self_attn.o_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.31.self_attn.q_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.31.self_attn.q_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.31.self_attn.v_proj.bias": "model-00005-of-00007.safetensors",
|
||||
"model.layers.31.self_attn.v_proj.weight": "model-00005-of-00007.safetensors",
|
||||
"model.layers.32.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.mlp.c_fc.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.mlp.c_fc.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.self_attn.o_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.32.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.mlp.c_fc.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.mlp.c_fc.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.self_attn.o_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.33.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.mlp.c_fc.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.mlp.c_fc.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.self_attn.o_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.34.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.mlp.c_fc.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.mlp.c_fc.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.self_attn.o_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.35.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.mlp.c_fc.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.mlp.c_fc.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.self_attn.o_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.36.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.input_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.input_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.mlp.c_fc.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.mlp.c_fc.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.mlp.c_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.mlp.c_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.post_attention_layernorm.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.post_attention_layernorm.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.self_attn.o_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.self_attn.o_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.37.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.38.input_layernorm.bias": "model-00007-of-00007.safetensors",
|
||||
"model.layers.38.input_layernorm.weight": "model-00007-of-00007.safetensors",
|
||||
"model.layers.38.mlp.c_fc.bias": "model-00007-of-00007.safetensors",
|
||||
"model.layers.38.mlp.c_fc.weight": "model-00007-of-00007.safetensors",
|
||||
"model.layers.38.mlp.c_proj.bias": "model-00007-of-00007.safetensors",
|
||||
"model.layers.38.mlp.c_proj.weight": "model-00007-of-00007.safetensors",
|
||||
"model.layers.38.post_attention_layernorm.bias": "model-00007-of-00007.safetensors",
|
||||
"model.layers.38.post_attention_layernorm.weight": "model-00007-of-00007.safetensors",
|
||||
"model.layers.38.self_attn.k_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.38.self_attn.k_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.38.self_attn.o_proj.bias": "model-00007-of-00007.safetensors",
|
||||
"model.layers.38.self_attn.o_proj.weight": "model-00007-of-00007.safetensors",
|
||||
"model.layers.38.self_attn.q_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.38.self_attn.q_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.38.self_attn.v_proj.bias": "model-00006-of-00007.safetensors",
|
||||
"model.layers.38.self_attn.v_proj.weight": "model-00006-of-00007.safetensors",
|
||||
"model.layers.39.input_layernorm.bias": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.input_layernorm.weight": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.mlp.c_fc.bias": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.mlp.c_fc.weight": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.mlp.c_proj.bias": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.mlp.c_proj.weight": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.post_attention_layernorm.bias": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.post_attention_layernorm.weight": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.self_attn.k_proj.bias": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.self_attn.k_proj.weight": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.self_attn.o_proj.bias": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.self_attn.o_proj.weight": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.self_attn.q_proj.bias": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.self_attn.q_proj.weight": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.self_attn.v_proj.bias": "model-00007-of-00007.safetensors",
|
||||
"model.layers.39.self_attn.v_proj.weight": "model-00007-of-00007.safetensors",
|
||||
"model.layers.4.input_layernorm.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.input_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.mlp.c_fc.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.mlp.c_fc.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.mlp.c_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.mlp.c_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.post_attention_layernorm.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.o_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.5.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.mlp.c_fc.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.5.mlp.c_fc.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.5.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.k_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.o_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.q_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.v_proj.bias": "model-00001-of-00007.safetensors",
|
||||
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00007.safetensors",
|
||||
"model.layers.6.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.mlp.c_fc.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.mlp.c_fc.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.o_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.6.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.mlp.c_fc.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.mlp.c_fc.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.o_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.7.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.mlp.c_fc.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.mlp.c_fc.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.o_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.8.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.input_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.input_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.mlp.c_fc.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.mlp.c_fc.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.mlp.c_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.mlp.c_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.post_attention_layernorm.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.k_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.k_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.o_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.o_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.q_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.q_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.v_proj.bias": "model-00002-of-00007.safetensors",
|
||||
"model.layers.9.self_attn.v_proj.weight": "model-00002-of-00007.safetensors",
|
||||
"model.norm.bias": "model-00007-of-00007.safetensors",
|
||||
"model.norm.weight": "model-00007-of-00007.safetensors"
|
||||
}
|
||||
}
|
||||
63
special_tokens_map.json
Normal file
63
special_tokens_map.json
Normal file
@@ -0,0 +1,63 @@
|
||||
{
|
||||
"additional_special_tokens": [
|
||||
"<|endoftext|>",
|
||||
"<fim_prefix>",
|
||||
"<fim_middle>",
|
||||
"<fim_suffix>",
|
||||
"<fim_pad>",
|
||||
"<repo_name>",
|
||||
"<file_sep>",
|
||||
"<issue_start>",
|
||||
"<issue_comment>",
|
||||
"<issue_closed>",
|
||||
"<jupyter_start>",
|
||||
"<jupyter_text>",
|
||||
"<jupyter_code>",
|
||||
"<jupyter_output>",
|
||||
"<jupyter_script>",
|
||||
"<empty_output>",
|
||||
"<code_to_intermediate>",
|
||||
"<intermediate_to_code>",
|
||||
"<pr>",
|
||||
"<pr_status>",
|
||||
"<pr_is_merged>",
|
||||
"<pr_base>",
|
||||
"<pr_file>",
|
||||
"<pr_base_code>",
|
||||
"<pr_diff>",
|
||||
"<pr_diff_hunk>",
|
||||
"<pr_comment>",
|
||||
"<pr_event_id>",
|
||||
"<pr_review>",
|
||||
"<pr_review_state>",
|
||||
"<pr_review_comment>",
|
||||
"<pr_in_reply_to_review_id>",
|
||||
"<pr_in_reply_to_comment_id>",
|
||||
"<pr_diff_hunk_comment_line>",
|
||||
"<NAME>",
|
||||
"<EMAIL>",
|
||||
"<KEY>",
|
||||
"<PASSWORD>"
|
||||
],
|
||||
"bos_token": {
|
||||
"content": "<|endoftext|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"eos_token": {
|
||||
"content": "<|endoftext|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"unk_token": {
|
||||
"content": "<|endoftext|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
}
|
||||
}
|
||||
98409
tokenizer.json
Normal file
98409
tokenizer.json
Normal file
File diff suppressed because it is too large
Load Diff
357
tokenizer_config.json
Normal file
357
tokenizer_config.json
Normal file
@@ -0,0 +1,357 @@
|
||||
{
|
||||
"add_prefix_space": false,
|
||||
"added_tokens_decoder": {
|
||||
"0": {
|
||||
"content": "<|endoftext|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"1": {
|
||||
"content": "<fim_prefix>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"2": {
|
||||
"content": "<fim_middle>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"3": {
|
||||
"content": "<fim_suffix>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"4": {
|
||||
"content": "<fim_pad>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"5": {
|
||||
"content": "<repo_name>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"6": {
|
||||
"content": "<file_sep>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"7": {
|
||||
"content": "<issue_start>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"8": {
|
||||
"content": "<issue_comment>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"9": {
|
||||
"content": "<issue_closed>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"10": {
|
||||
"content": "<jupyter_start>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"11": {
|
||||
"content": "<jupyter_text>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"12": {
|
||||
"content": "<jupyter_code>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"13": {
|
||||
"content": "<jupyter_output>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"14": {
|
||||
"content": "<jupyter_script>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"15": {
|
||||
"content": "<empty_output>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"16": {
|
||||
"content": "<code_to_intermediate>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"17": {
|
||||
"content": "<intermediate_to_code>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"18": {
|
||||
"content": "<pr>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"19": {
|
||||
"content": "<pr_status>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"20": {
|
||||
"content": "<pr_is_merged>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"21": {
|
||||
"content": "<pr_base>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"22": {
|
||||
"content": "<pr_file>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"23": {
|
||||
"content": "<pr_base_code>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"24": {
|
||||
"content": "<pr_diff>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"25": {
|
||||
"content": "<pr_diff_hunk>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"26": {
|
||||
"content": "<pr_comment>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"27": {
|
||||
"content": "<pr_event_id>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"28": {
|
||||
"content": "<pr_review>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"29": {
|
||||
"content": "<pr_review_state>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"30": {
|
||||
"content": "<pr_review_comment>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"31": {
|
||||
"content": "<pr_in_reply_to_review_id>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"32": {
|
||||
"content": "<pr_in_reply_to_comment_id>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"33": {
|
||||
"content": "<pr_diff_hunk_comment_line>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"34": {
|
||||
"content": "<NAME>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"35": {
|
||||
"content": "<EMAIL>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"36": {
|
||||
"content": "<KEY>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"37": {
|
||||
"content": "<PASSWORD>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
}
|
||||
},
|
||||
"additional_special_tokens": [
|
||||
"<|endoftext|>",
|
||||
"<fim_prefix>",
|
||||
"<fim_middle>",
|
||||
"<fim_suffix>",
|
||||
"<fim_pad>",
|
||||
"<repo_name>",
|
||||
"<file_sep>",
|
||||
"<issue_start>",
|
||||
"<issue_comment>",
|
||||
"<issue_closed>",
|
||||
"<jupyter_start>",
|
||||
"<jupyter_text>",
|
||||
"<jupyter_code>",
|
||||
"<jupyter_output>",
|
||||
"<jupyter_script>",
|
||||
"<empty_output>",
|
||||
"<code_to_intermediate>",
|
||||
"<intermediate_to_code>",
|
||||
"<pr>",
|
||||
"<pr_status>",
|
||||
"<pr_is_merged>",
|
||||
"<pr_base>",
|
||||
"<pr_file>",
|
||||
"<pr_base_code>",
|
||||
"<pr_diff>",
|
||||
"<pr_diff_hunk>",
|
||||
"<pr_comment>",
|
||||
"<pr_event_id>",
|
||||
"<pr_review>",
|
||||
"<pr_review_state>",
|
||||
"<pr_review_comment>",
|
||||
"<pr_in_reply_to_review_id>",
|
||||
"<pr_in_reply_to_comment_id>",
|
||||
"<pr_diff_hunk_comment_line>",
|
||||
"<NAME>",
|
||||
"<EMAIL>",
|
||||
"<KEY>",
|
||||
"<PASSWORD>"
|
||||
],
|
||||
"bos_token": "<|endoftext|>",
|
||||
"chat_template": "{{bos_token}}{{'You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.\n\n'}}\n{%- for message in messages %}\n {%- if message['role'] == 'system' %}\n {{ raise_exception('System messages are not allowed in this template.') }}\n {%- else %}\n {%- if message['role'] == 'user' %}\n{{'### Instruction\n' + message['content'] + '\n\n'}}\n {%- else %}\n{{'### Response\n' + message['content'] + eos_token + '\n\n'}}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{{'### Response\n'}}",
|
||||
"clean_up_tokenization_spaces": true,
|
||||
"eos_token": "<|endoftext|>",
|
||||
"model_max_length": 1000000000000000019884624838656,
|
||||
"tokenizer_class": "GPT2Tokenizer",
|
||||
"unk_token": "<|endoftext|>",
|
||||
"vocab_size": 49152
|
||||
}
|
||||
1
vocab.json
Normal file
1
vocab.json
Normal file
File diff suppressed because one or more lines are too long
Reference in New Issue
Block a user