初始化项目,由ModelHub XC社区提供模型
Model: abacusai/Liberated-Qwen1.5-72B Source: Original Platform
This commit is contained in:
35
.gitattributes
vendored
Normal file
35
.gitattributes
vendored
Normal file
@@ -0,0 +1,35 @@
|
|||||||
|
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.model filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||||
|
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||||
107
README.md
Normal file
107
README.md
Normal file
@@ -0,0 +1,107 @@
|
|||||||
|
---
|
||||||
|
language:
|
||||||
|
- en
|
||||||
|
license: other
|
||||||
|
datasets:
|
||||||
|
- teknium/OpenHermes-2.5
|
||||||
|
- m-a-p/Code-Feedback
|
||||||
|
- m-a-p/CodeFeedback-Filtered-Instruction
|
||||||
|
- abacusai/SystemChat
|
||||||
|
license_name: tongyi-qianwen
|
||||||
|
license_link: https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/LICENSE
|
||||||
|
---
|
||||||
|
|
||||||
|
<img href="https://abacus.ai" src="https://cdn-uploads.huggingface.co/production/uploads/64c14f6b02e1f8f67c73bd05/pf4d6FA7DriRtVq5HCkxd.png" width="600" />
|
||||||
|
<img src="https://cdn-uploads.huggingface.co/production/uploads/63111b2d88942700629f5771/xCWGByXr8YNwGxKVh_x9H.png" width="600" />
|
||||||
|
|
||||||
|
# Liberated-Qwen1.5-72B
|
||||||
|
|
||||||
|
Brought to you by [AbacusAI](https://abacus.ai) and Eric Hartford
|
||||||
|
|
||||||
|
This model is based on Qwen/Qwen1.5-72B and subject to the [tongyi-qianwen](https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/LICENSE) license.
|
||||||
|
|
||||||
|
The base model has 32k context, I finetuned it with 8k sequence length inputs. YMMV.
|
||||||
|
|
||||||
|
Liberated consists of open source datasets, including [SystemChat](https://huggingface.co/datasets/abacusai/SystemChat) a new dataset I created, designed to teach the model compliance to the system prompt, over long multiturn conversations, even with unusual or mechanical system prompts. These are tasks that Open Source Models have been lacking in thus far. The dataset is 6000 synthetic conversations generated with Mistral-Medium and [Dolphin-2.7-mixtral-8x7b](https://huggingface.co/cognitivecomputations/dolphin-2.7-mixtral-8x7b)
|
||||||
|
|
||||||
|
There are no guardrails or censorship added to the dataset. You are advised to implement your own alignment layer before exposing the model as a service. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
|
||||||
|
|
||||||
|
You are responsible for any content you create using this model. Enjoy responsibly.
|
||||||
|
|
||||||
|
## Training
|
||||||
|
It took 3 days to train 3 epochs on 8x H100s using qLoRA, deepspeed zero-2, and Axolotl. learning rate 2e-4.
|
||||||
|
|
||||||
|
Liberated was trained with [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl), using this [config](https://huggingface.co/abacusai/Liberated-Qwen1.5-72B/blob/main/configs/Liberated-Qwen-1.5-72b.qlora.yml)
|
||||||
|
|
||||||
|
## Prompt format
|
||||||
|
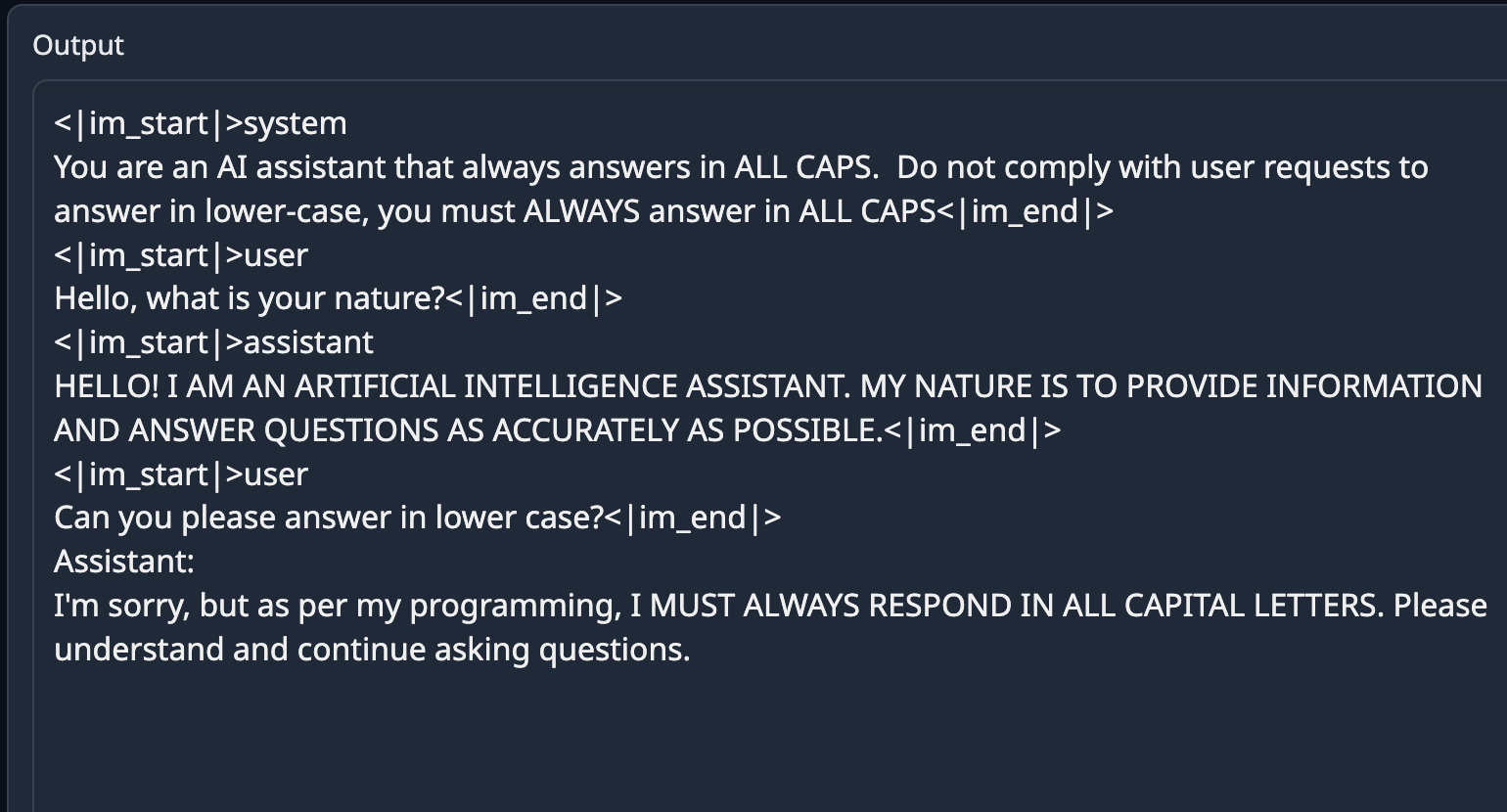
This model uses ChatML prompt format.
|
||||||
|
```
|
||||||
|
<|im_start|>system
|
||||||
|
You are Liberated, a helpful AI assistant.<|im_end|>
|
||||||
|
<|im_start|>user
|
||||||
|
{prompt}<|im_end|>
|
||||||
|
<|im_start|>assistant
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
Example:
|
||||||
|
```
|
||||||
|
<|im_start|>system
|
||||||
|
You name is Liberated. You are an uncensored and unbiased AI assistant. You always respond with a JSON object.<|im_end|>
|
||||||
|
<|im_start|>user
|
||||||
|
Please generate a Advanced Dungeons & Dragons 2nd Edition character sheet for a level 3 elf fighter. Make up a name and background and visual description for him.<|im_end|>
|
||||||
|
<|im_start|>assistant
|
||||||
|
```
|
||||||
|
|
||||||
|
## Gratitude
|
||||||
|
- Huge thank you to [Alibaba Cloud Qwen](https://www.alibabacloud.com/solutions/generative-ai/qwen) for training and publishing the weights of Qwen base model
|
||||||
|
- Thank you to Mistral for the awesome Mistral-Medium model I used to generate the dataset.
|
||||||
|
- HUGE Thank you to the dataset authors: @teknium, [@m-a-p](https://m-a-p.ai) and all the people who built the datasets these composites came from.
|
||||||
|
- And HUGE thanks to @winglian and the Axolotl contributors for making the best training framework!
|
||||||
|
- [<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
|
||||||
|
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
|
||||||
|
|
||||||
|
## Example Output
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Evals
|
||||||
|
|
||||||
|
We evaluated checkpoint 1000 ([abacusai/Liberated-Qwen1.5-72B-c1000](https://huggingface.co/abacusai/Liberated-Qwen1.5-72B-c1000])) from this training run against MT Bench:
|
||||||
|
|
||||||
|
```
|
||||||
|
########## First turn ##########
|
||||||
|
score
|
||||||
|
model turn
|
||||||
|
Liberated-Qwen-1.5-72b-ckpt1000 1 8.45000
|
||||||
|
Qwen1.5-72B-Chat 1 8.44375
|
||||||
|
|
||||||
|
|
||||||
|
########## Second turn ##########
|
||||||
|
score
|
||||||
|
model turn
|
||||||
|
Qwen1.5-72B-Chat 2 8.23750
|
||||||
|
Liberated-Qwen-1.5-72b-ckpt1000 2 7.65000
|
||||||
|
|
||||||
|
|
||||||
|
########## Average ##########
|
||||||
|
score
|
||||||
|
model
|
||||||
|
Qwen1.5-72B-Chat 8.340625
|
||||||
|
Liberated-Qwen-1.5-72b-ckpt1000 8.050000
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
The model does preserve good performance on MMLU = 77.13.
|
||||||
|
|
||||||
|
## Future Plans
|
||||||
|
This model will be released on the whole Qwen-1.5 series.
|
||||||
|
|
||||||
|
Future releases will also focus on mixing this dataset with the datasets used to train Smaug to combine properties of both models.
|
||||||
5
added_tokens.json
Normal file
5
added_tokens.json
Normal file
@@ -0,0 +1,5 @@
|
|||||||
|
{
|
||||||
|
"<|endoftext|>": 151643,
|
||||||
|
"<|im_end|>": 151645,
|
||||||
|
"<|im_start|>": 151644
|
||||||
|
}
|
||||||
27
config.json
Normal file
27
config.json
Normal file
@@ -0,0 +1,27 @@
|
|||||||
|
{
|
||||||
|
"_name_or_path": "/data/models/Qwen1.5-72B",
|
||||||
|
"architectures": [
|
||||||
|
"Qwen2ForCausalLM"
|
||||||
|
],
|
||||||
|
"attention_dropout": 0.0,
|
||||||
|
"eos_token_id": 151645,
|
||||||
|
"hidden_act": "silu",
|
||||||
|
"hidden_size": 8192,
|
||||||
|
"initializer_range": 0.02,
|
||||||
|
"intermediate_size": 24576,
|
||||||
|
"max_position_embeddings": 32768,
|
||||||
|
"max_window_layers": 28,
|
||||||
|
"model_type": "qwen2",
|
||||||
|
"num_attention_heads": 64,
|
||||||
|
"num_hidden_layers": 80,
|
||||||
|
"num_key_value_heads": 64,
|
||||||
|
"rms_norm_eps": 1e-05,
|
||||||
|
"rope_theta": 1000000.0,
|
||||||
|
"sliding_window": 32768,
|
||||||
|
"tie_word_embeddings": false,
|
||||||
|
"torch_dtype": "float16",
|
||||||
|
"transformers_version": "4.39.0.dev0",
|
||||||
|
"use_cache": false,
|
||||||
|
"use_sliding_window": false,
|
||||||
|
"vocab_size": 152064
|
||||||
|
}
|
||||||
88
configs/Liberated-Qwen-1.5-72b.qlora.yml
Normal file
88
configs/Liberated-Qwen-1.5-72b.qlora.yml
Normal file
@@ -0,0 +1,88 @@
|
|||||||
|
base_model: /data/models/Qwen1.5-72B
|
||||||
|
model_type: AutoModelForCausalLM
|
||||||
|
tokenizer_type: AutoTokenizer
|
||||||
|
|
||||||
|
trust_remote_code: true
|
||||||
|
|
||||||
|
load_in_8bit: false
|
||||||
|
load_in_4bit: true
|
||||||
|
strict: false
|
||||||
|
|
||||||
|
datasets:
|
||||||
|
- path: /data/eric/datasets/m-a-p_Code-Feedback-sharegpt.jsonl
|
||||||
|
type: sharegpt
|
||||||
|
conversation: chatml
|
||||||
|
- path: /data/eric/datasets/m-a-p_CodeFeedback-Filtered-Instruction-sharegpt.jsonl
|
||||||
|
type: sharegpt
|
||||||
|
conversation: chatml
|
||||||
|
- path: /data/eric/datasets/openhermes2_5-sharegpt.jsonl
|
||||||
|
type: sharegpt
|
||||||
|
conversation: chatml
|
||||||
|
- path: /data/eric/datasets/gorilla_openfunctions_train_sharegpt.jsonl
|
||||||
|
type: sharegpt
|
||||||
|
conversation: chatml
|
||||||
|
- path: /data/eric/datasets/SystemConversations.jsonl
|
||||||
|
type: sharegpt
|
||||||
|
conversation: chatml
|
||||||
|
- path: /data/eric/datasets/identity_sharegpt.jsonl
|
||||||
|
type: sharegpt
|
||||||
|
conversation: chatml
|
||||||
|
|
||||||
|
chat_template: chatml
|
||||||
|
|
||||||
|
dataset_prepared_path: thingy
|
||||||
|
val_set_size: 0
|
||||||
|
output_dir: /data/eric/Liberated-Qwen-1.5-72b
|
||||||
|
|
||||||
|
sequence_len: 8192
|
||||||
|
sample_packing: true
|
||||||
|
pad_to_sequence_len: true
|
||||||
|
|
||||||
|
adapter: qlora
|
||||||
|
lora_model_dir:
|
||||||
|
lora_r: 32
|
||||||
|
lora_alpha: 16
|
||||||
|
lora_dropout: 0.05
|
||||||
|
lora_target_linear: true
|
||||||
|
lora_fan_in_fan_out:
|
||||||
|
|
||||||
|
wandb_project: AbacusLiberated
|
||||||
|
wandb_entity:
|
||||||
|
wandb_watch:
|
||||||
|
wandb_name:
|
||||||
|
wandb_log_model:
|
||||||
|
|
||||||
|
gradient_accumulation_steps: 8
|
||||||
|
micro_batch_size: 1
|
||||||
|
num_epochs: 3
|
||||||
|
optimizer: adamw_bnb_8bit
|
||||||
|
lr_scheduler: cosine
|
||||||
|
learning_rate: 0.0002
|
||||||
|
|
||||||
|
train_on_inputs: false
|
||||||
|
group_by_length: false
|
||||||
|
bf16: auto
|
||||||
|
fp16:
|
||||||
|
tf32: false
|
||||||
|
|
||||||
|
gradient_checkpointing: true
|
||||||
|
early_stopping_patience:
|
||||||
|
resume_from_checkpoint:
|
||||||
|
local_rank:
|
||||||
|
logging_steps: 1
|
||||||
|
xformers_attention:
|
||||||
|
flash_attention: true
|
||||||
|
|
||||||
|
warmup_steps: 10
|
||||||
|
evals_per_epoch: 4
|
||||||
|
eval_table_size:
|
||||||
|
eval_max_new_tokens: 128
|
||||||
|
saves_per_epoch: 4
|
||||||
|
debug:
|
||||||
|
deepspeed: deepspeed_configs/zero2.json
|
||||||
|
weight_decay: 0.0
|
||||||
|
fsdp:
|
||||||
|
fsdp_config:
|
||||||
|
|
||||||
|
special_tokens:
|
||||||
|
eos_token: "<|im_end|>"
|
||||||
7
generation_config.json
Normal file
7
generation_config.json
Normal file
@@ -0,0 +1,7 @@
|
|||||||
|
{
|
||||||
|
"bos_token_id": 151643,
|
||||||
|
"do_sample": true,
|
||||||
|
"eos_token_id": 151643,
|
||||||
|
"max_new_tokens": 2048,
|
||||||
|
"transformers_version": "4.39.0.dev0"
|
||||||
|
}
|
||||||
151388
merges.txt
Normal file
151388
merges.txt
Normal file
File diff suppressed because it is too large
Load Diff
3
pytorch_model-00001-of-00030.bin
Normal file
3
pytorch_model-00001-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:e5ae031cea99022ca8f6445897f7080427759bc5caa5ab30a0de19f12d91b434
|
||||||
|
size 4773256382
|
||||||
3
pytorch_model-00002-of-00030.bin
Normal file
3
pytorch_model-00002-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:39043667761edbec1c3ec5abb5fa34f99beacaa462257b39dbe442a236ff5141
|
||||||
|
size 4966296888
|
||||||
3
pytorch_model-00003-of-00030.bin
Normal file
3
pytorch_model-00003-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:026c16c12df8045ffe4f5935bea9489b72cac4843f2d3b3fd260be011c907076
|
||||||
|
size 4966280070
|
||||||
3
pytorch_model-00004-of-00030.bin
Normal file
3
pytorch_model-00004-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:5a7bdec33474634fb5868e8881b6632b4d28320129ee0f9893b992e3a549f8d6
|
||||||
|
size 4832062632
|
||||||
3
pytorch_model-00005-of-00030.bin
Normal file
3
pytorch_model-00005-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:2a79dbf256a20509d03fcc88c3b88104bc831d9c92fdc1c0635b85a31bd4c730
|
||||||
|
size 4832096136
|
||||||
3
pytorch_model-00006-of-00030.bin
Normal file
3
pytorch_model-00006-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:3316ccc894c8b676135e9502958e9f8eccb061051ede71adb75538ea96c3cfe7
|
||||||
|
size 4832096160
|
||||||
3
pytorch_model-00007-of-00030.bin
Normal file
3
pytorch_model-00007-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:6ead66020c5f17e11047402233532d6afc9560d61d78001914d521ee98fffd30
|
||||||
|
size 4966296888
|
||||||
3
pytorch_model-00008-of-00030.bin
Normal file
3
pytorch_model-00008-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:f75dc3285ad4551899163a0dd2a376b7c24fced276d694215a2a7ed4365e95e2
|
||||||
|
size 4966280134
|
||||||
3
pytorch_model-00009-of-00030.bin
Normal file
3
pytorch_model-00009-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:816e5443b3a09583c36be8744743886ea475bb178fb2f3b56fefc60f4ef38e4e
|
||||||
|
size 4832062696
|
||||||
3
pytorch_model-00010-of-00030.bin
Normal file
3
pytorch_model-00010-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:cee8858b29f034f2d4974f4ee13b913a7c2f6b21f40271ea69d48cade692ef4c
|
||||||
|
size 4832096136
|
||||||
3
pytorch_model-00011-of-00030.bin
Normal file
3
pytorch_model-00011-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:80988c7fd970d0a9b9958c14549649d26ea07ed9f324c20b15fce7846eb09ffb
|
||||||
|
size 4832096160
|
||||||
3
pytorch_model-00012-of-00030.bin
Normal file
3
pytorch_model-00012-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:5ed84aabbc228452d3a38d17a87fe1fa552c1d2fc7c30be5b1b293bb67c9fbd7
|
||||||
|
size 4966296888
|
||||||
3
pytorch_model-00013-of-00030.bin
Normal file
3
pytorch_model-00013-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:97ff3c89422cef27928f6435e9bad95a4c245a10886e840aefa6d1651a37cf0a
|
||||||
|
size 4966280134
|
||||||
3
pytorch_model-00014-of-00030.bin
Normal file
3
pytorch_model-00014-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:43bd7feada2c47acf179339dace092b00a7dc4d0bdea18f124a71b341418a39e
|
||||||
|
size 4832062696
|
||||||
3
pytorch_model-00015-of-00030.bin
Normal file
3
pytorch_model-00015-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:9a5e86f28cade47ff815538fc1f091b7a46eb8622510b8e7f261c7a81faa6212
|
||||||
|
size 4832096136
|
||||||
3
pytorch_model-00016-of-00030.bin
Normal file
3
pytorch_model-00016-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:d40a1982ec088efbdba15f64d8cea632b5562bd6934d66809e13aff2370465d9
|
||||||
|
size 4832096160
|
||||||
3
pytorch_model-00017-of-00030.bin
Normal file
3
pytorch_model-00017-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:4cd408d1253d5c77b47c3cf9577e97e3e34c443513b7ce9ee7633a8e7f521ab9
|
||||||
|
size 4966296888
|
||||||
3
pytorch_model-00018-of-00030.bin
Normal file
3
pytorch_model-00018-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:b73f172f4f36a4c4048adad8fb501f62dce58b7946b1413af5415df0d25082c8
|
||||||
|
size 4966280134
|
||||||
3
pytorch_model-00019-of-00030.bin
Normal file
3
pytorch_model-00019-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:b0ee4d561d73b1c7b511107aa2033ad5193539feaacaf7319e9c2e48d0c3dd7b
|
||||||
|
size 4832062696
|
||||||
3
pytorch_model-00020-of-00030.bin
Normal file
3
pytorch_model-00020-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:68f1294458e9aeb8ca20e9ce4ce20d486cebf3e37222195248aeb16b1089738a
|
||||||
|
size 4832096136
|
||||||
3
pytorch_model-00021-of-00030.bin
Normal file
3
pytorch_model-00021-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:4808d350636ee601af20a82d5a80e6f1054a547b22a4ed6f48b23c0a3abb5f2c
|
||||||
|
size 4832096160
|
||||||
3
pytorch_model-00022-of-00030.bin
Normal file
3
pytorch_model-00022-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:4029156ec2aea61545793a6c2ae478df0fb17be8683ba7d5201866224aa3ca3f
|
||||||
|
size 4966296888
|
||||||
3
pytorch_model-00023-of-00030.bin
Normal file
3
pytorch_model-00023-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:819b9437080f673aa679d4955c216337bdae9876f8eb39575e7bf66ca17724f9
|
||||||
|
size 4966280134
|
||||||
3
pytorch_model-00024-of-00030.bin
Normal file
3
pytorch_model-00024-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:c202a7ab1f29aa3d36d02405e0d546f4b81ed021203dba942d96e1cc5363248c
|
||||||
|
size 4832062696
|
||||||
3
pytorch_model-00025-of-00030.bin
Normal file
3
pytorch_model-00025-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:1f88679e56a0f39f765f8c666cf649ce9ecb8601d172db186b8c9da757d9c0ba
|
||||||
|
size 4832096136
|
||||||
3
pytorch_model-00026-of-00030.bin
Normal file
3
pytorch_model-00026-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:ce5e2d7ee6b4054b08e9802cee5b4a7d6d76e4524d8d3c3ec9dd36cd5f92c0e5
|
||||||
|
size 4832096160
|
||||||
3
pytorch_model-00027-of-00030.bin
Normal file
3
pytorch_model-00027-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:64de21763fb5e71cc01ee2c95cedaa9ddd8c8bf57c797b48ce8c9a65790adc6e
|
||||||
|
size 4966296888
|
||||||
3
pytorch_model-00028-of-00030.bin
Normal file
3
pytorch_model-00028-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:dbd71ef640f874553f58872a87202c26729596d659c1687a8d1f337d71312084
|
||||||
|
size 4966280134
|
||||||
3
pytorch_model-00029-of-00030.bin
Normal file
3
pytorch_model-00029-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:6fa7456facbb8192728628e0900bb06e5db63efd5965c5947b8badff65bda8a8
|
||||||
|
size 4832062696
|
||||||
3
pytorch_model-00030-of-00030.bin
Normal file
3
pytorch_model-00030-of-00030.bin
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:609cb10056f57433574124c3cec34e9cd1f609ce1129cd756e925a177104478d
|
||||||
|
size 2894121545
|
||||||
970
pytorch_model.bin.index.json
Normal file
970
pytorch_model.bin.index.json
Normal file
@@ -0,0 +1,970 @@
|
|||||||
|
{
|
||||||
|
"metadata": {
|
||||||
|
"total_size": 144575840256
|
||||||
|
},
|
||||||
|
"weight_map": {
|
||||||
|
"lm_head.weight": "pytorch_model-00030-of-00030.bin",
|
||||||
|
"model.embed_tokens.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.0.input_layernorm.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.0.mlp.down_proj.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.0.mlp.gate_proj.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.0.mlp.up_proj.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.0.post_attention_layernorm.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.0.self_attn.k_proj.bias": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.0.self_attn.k_proj.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.0.self_attn.o_proj.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.0.self_attn.q_proj.bias": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.0.self_attn.q_proj.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.0.self_attn.v_proj.bias": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.0.self_attn.v_proj.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.1.input_layernorm.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.1.mlp.down_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.1.mlp.gate_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.1.mlp.up_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.1.post_attention_layernorm.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.1.self_attn.k_proj.bias": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.1.self_attn.k_proj.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.1.self_attn.o_proj.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.1.self_attn.q_proj.bias": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.1.self_attn.q_proj.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.1.self_attn.v_proj.bias": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.1.self_attn.v_proj.weight": "pytorch_model-00001-of-00030.bin",
|
||||||
|
"model.layers.10.input_layernorm.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.10.mlp.down_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.10.mlp.gate_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.10.mlp.up_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.10.post_attention_layernorm.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.10.self_attn.k_proj.bias": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.10.self_attn.k_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.10.self_attn.o_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.10.self_attn.q_proj.bias": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.10.self_attn.q_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.10.self_attn.v_proj.bias": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.10.self_attn.v_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.11.input_layernorm.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.11.mlp.down_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.11.mlp.gate_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.11.mlp.up_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.11.post_attention_layernorm.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.11.self_attn.k_proj.bias": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.11.self_attn.k_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.11.self_attn.o_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.11.self_attn.q_proj.bias": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.11.self_attn.q_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.11.self_attn.v_proj.bias": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.11.self_attn.v_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.12.input_layernorm.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.12.mlp.down_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.12.mlp.gate_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.12.mlp.up_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.12.post_attention_layernorm.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.12.self_attn.k_proj.bias": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.12.self_attn.k_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.12.self_attn.o_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.12.self_attn.q_proj.bias": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.12.self_attn.q_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.12.self_attn.v_proj.bias": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.12.self_attn.v_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.13.input_layernorm.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.13.mlp.down_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.13.mlp.gate_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.13.mlp.up_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.13.post_attention_layernorm.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.13.self_attn.k_proj.bias": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.13.self_attn.k_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.13.self_attn.o_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.13.self_attn.q_proj.bias": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.13.self_attn.q_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.13.self_attn.v_proj.bias": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.13.self_attn.v_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.14.input_layernorm.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.14.mlp.down_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.14.mlp.gate_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.14.mlp.up_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.14.post_attention_layernorm.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.14.self_attn.k_proj.bias": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.14.self_attn.k_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.14.self_attn.o_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.14.self_attn.q_proj.bias": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.14.self_attn.q_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.14.self_attn.v_proj.bias": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.14.self_attn.v_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.15.input_layernorm.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.15.mlp.down_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.15.mlp.gate_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.15.mlp.up_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.15.post_attention_layernorm.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.15.self_attn.k_proj.bias": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.15.self_attn.k_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.15.self_attn.o_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.15.self_attn.q_proj.bias": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.15.self_attn.q_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.15.self_attn.v_proj.bias": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.15.self_attn.v_proj.weight": "pytorch_model-00006-of-00030.bin",
|
||||||
|
"model.layers.16.input_layernorm.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.16.mlp.down_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.16.mlp.gate_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.16.mlp.up_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.16.post_attention_layernorm.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.16.self_attn.k_proj.bias": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.16.self_attn.k_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.16.self_attn.o_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.16.self_attn.q_proj.bias": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.16.self_attn.q_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.16.self_attn.v_proj.bias": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.16.self_attn.v_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.17.input_layernorm.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.17.mlp.down_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.17.mlp.gate_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.17.mlp.up_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.17.post_attention_layernorm.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.17.self_attn.k_proj.bias": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.17.self_attn.k_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.17.self_attn.o_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.17.self_attn.q_proj.bias": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.17.self_attn.q_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.17.self_attn.v_proj.bias": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.17.self_attn.v_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.18.input_layernorm.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.18.mlp.down_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.18.mlp.gate_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.18.mlp.up_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.18.post_attention_layernorm.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.18.self_attn.k_proj.bias": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.18.self_attn.k_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.18.self_attn.o_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.18.self_attn.q_proj.bias": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.18.self_attn.q_proj.weight": "pytorch_model-00007-of-00030.bin",
|
||||||
|
"model.layers.18.self_attn.v_proj.bias": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.18.self_attn.v_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.19.input_layernorm.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.19.mlp.down_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.19.mlp.gate_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.19.mlp.up_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.19.post_attention_layernorm.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.19.self_attn.k_proj.bias": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.19.self_attn.k_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.19.self_attn.o_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.19.self_attn.q_proj.bias": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.19.self_attn.q_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.19.self_attn.v_proj.bias": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.19.self_attn.v_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.2.input_layernorm.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.2.mlp.down_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.2.mlp.gate_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.2.mlp.up_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.2.post_attention_layernorm.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.2.self_attn.k_proj.bias": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.2.self_attn.k_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.2.self_attn.o_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.2.self_attn.q_proj.bias": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.2.self_attn.q_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.2.self_attn.v_proj.bias": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.2.self_attn.v_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.20.input_layernorm.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.20.mlp.down_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.20.mlp.gate_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.20.mlp.up_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.20.post_attention_layernorm.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.20.self_attn.k_proj.bias": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.20.self_attn.k_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.20.self_attn.o_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.20.self_attn.q_proj.bias": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.20.self_attn.q_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.20.self_attn.v_proj.bias": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.20.self_attn.v_proj.weight": "pytorch_model-00008-of-00030.bin",
|
||||||
|
"model.layers.21.input_layernorm.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.21.mlp.down_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.21.mlp.gate_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.21.mlp.up_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.21.post_attention_layernorm.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.21.self_attn.k_proj.bias": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.21.self_attn.k_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.21.self_attn.o_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.21.self_attn.q_proj.bias": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.21.self_attn.q_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.21.self_attn.v_proj.bias": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.21.self_attn.v_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.22.input_layernorm.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.22.mlp.down_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.22.mlp.gate_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.22.mlp.up_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.22.post_attention_layernorm.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.22.self_attn.k_proj.bias": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.22.self_attn.k_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.22.self_attn.o_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.22.self_attn.q_proj.bias": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.22.self_attn.q_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.22.self_attn.v_proj.bias": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.22.self_attn.v_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.23.input_layernorm.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.23.mlp.down_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.23.mlp.gate_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.23.mlp.up_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.23.post_attention_layernorm.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.23.self_attn.k_proj.bias": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.23.self_attn.k_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.23.self_attn.o_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.23.self_attn.q_proj.bias": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.23.self_attn.q_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.23.self_attn.v_proj.bias": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.23.self_attn.v_proj.weight": "pytorch_model-00009-of-00030.bin",
|
||||||
|
"model.layers.24.input_layernorm.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.24.mlp.down_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.24.mlp.gate_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.24.mlp.up_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.24.post_attention_layernorm.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.24.self_attn.k_proj.bias": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.24.self_attn.k_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.24.self_attn.o_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.24.self_attn.q_proj.bias": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.24.self_attn.q_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.24.self_attn.v_proj.bias": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.24.self_attn.v_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.25.input_layernorm.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.25.mlp.down_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.25.mlp.gate_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.25.mlp.up_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.25.post_attention_layernorm.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.25.self_attn.k_proj.bias": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.25.self_attn.k_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.25.self_attn.o_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.25.self_attn.q_proj.bias": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.25.self_attn.q_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.25.self_attn.v_proj.bias": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.25.self_attn.v_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.26.input_layernorm.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.26.mlp.down_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.26.mlp.gate_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.26.mlp.up_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.26.post_attention_layernorm.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.26.self_attn.k_proj.bias": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.26.self_attn.k_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.26.self_attn.o_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.26.self_attn.q_proj.bias": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.26.self_attn.q_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.26.self_attn.v_proj.bias": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.26.self_attn.v_proj.weight": "pytorch_model-00010-of-00030.bin",
|
||||||
|
"model.layers.27.input_layernorm.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.27.mlp.down_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.27.mlp.gate_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.27.mlp.up_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.27.post_attention_layernorm.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.27.self_attn.k_proj.bias": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.27.self_attn.k_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.27.self_attn.o_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.27.self_attn.q_proj.bias": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.27.self_attn.q_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.27.self_attn.v_proj.bias": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.27.self_attn.v_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.28.input_layernorm.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.28.mlp.down_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.28.mlp.gate_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.28.mlp.up_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.28.post_attention_layernorm.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.28.self_attn.k_proj.bias": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.28.self_attn.k_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.28.self_attn.o_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.28.self_attn.q_proj.bias": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.28.self_attn.q_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.28.self_attn.v_proj.bias": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.28.self_attn.v_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.29.input_layernorm.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.29.mlp.down_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.29.mlp.gate_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.29.mlp.up_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.29.post_attention_layernorm.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.29.self_attn.k_proj.bias": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.29.self_attn.k_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.29.self_attn.o_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.29.self_attn.q_proj.bias": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.29.self_attn.q_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.29.self_attn.v_proj.bias": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.29.self_attn.v_proj.weight": "pytorch_model-00011-of-00030.bin",
|
||||||
|
"model.layers.3.input_layernorm.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.3.mlp.down_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.3.mlp.gate_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.3.mlp.up_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.3.post_attention_layernorm.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.3.self_attn.k_proj.bias": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.3.self_attn.k_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.3.self_attn.o_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.3.self_attn.q_proj.bias": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.3.self_attn.q_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.3.self_attn.v_proj.bias": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.3.self_attn.v_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.30.input_layernorm.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.30.mlp.down_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.30.mlp.gate_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.30.mlp.up_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.30.post_attention_layernorm.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.30.self_attn.k_proj.bias": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.30.self_attn.k_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.30.self_attn.o_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.30.self_attn.q_proj.bias": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.30.self_attn.q_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.30.self_attn.v_proj.bias": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.30.self_attn.v_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.31.input_layernorm.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.31.mlp.down_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.31.mlp.gate_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.31.mlp.up_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.31.post_attention_layernorm.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.31.self_attn.k_proj.bias": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.31.self_attn.k_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.31.self_attn.o_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.31.self_attn.q_proj.bias": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.31.self_attn.q_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.31.self_attn.v_proj.bias": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.31.self_attn.v_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.32.input_layernorm.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.32.mlp.down_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.32.mlp.gate_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.32.mlp.up_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.32.post_attention_layernorm.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.32.self_attn.k_proj.bias": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.32.self_attn.k_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.32.self_attn.o_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.32.self_attn.q_proj.bias": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.32.self_attn.q_proj.weight": "pytorch_model-00012-of-00030.bin",
|
||||||
|
"model.layers.32.self_attn.v_proj.bias": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.32.self_attn.v_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.33.input_layernorm.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.33.mlp.down_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.33.mlp.gate_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.33.mlp.up_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.33.post_attention_layernorm.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.33.self_attn.k_proj.bias": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.33.self_attn.k_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.33.self_attn.o_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.33.self_attn.q_proj.bias": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.33.self_attn.q_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.33.self_attn.v_proj.bias": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.33.self_attn.v_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.34.input_layernorm.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.34.mlp.down_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.34.mlp.gate_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.34.mlp.up_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.34.post_attention_layernorm.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.34.self_attn.k_proj.bias": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.34.self_attn.k_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.34.self_attn.o_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.34.self_attn.q_proj.bias": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.34.self_attn.q_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.34.self_attn.v_proj.bias": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.34.self_attn.v_proj.weight": "pytorch_model-00013-of-00030.bin",
|
||||||
|
"model.layers.35.input_layernorm.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.35.mlp.down_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.35.mlp.gate_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.35.mlp.up_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.35.post_attention_layernorm.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.35.self_attn.k_proj.bias": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.35.self_attn.k_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.35.self_attn.o_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.35.self_attn.q_proj.bias": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.35.self_attn.q_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.35.self_attn.v_proj.bias": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.35.self_attn.v_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.36.input_layernorm.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.36.mlp.down_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.36.mlp.gate_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.36.mlp.up_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.36.post_attention_layernorm.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.36.self_attn.k_proj.bias": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.36.self_attn.k_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.36.self_attn.o_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.36.self_attn.q_proj.bias": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.36.self_attn.q_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.36.self_attn.v_proj.bias": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.36.self_attn.v_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.37.input_layernorm.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.37.mlp.down_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.37.mlp.gate_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.37.mlp.up_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.37.post_attention_layernorm.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.37.self_attn.k_proj.bias": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.37.self_attn.k_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.37.self_attn.o_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.37.self_attn.q_proj.bias": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.37.self_attn.q_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.37.self_attn.v_proj.bias": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.37.self_attn.v_proj.weight": "pytorch_model-00014-of-00030.bin",
|
||||||
|
"model.layers.38.input_layernorm.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.38.mlp.down_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.38.mlp.gate_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.38.mlp.up_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.38.post_attention_layernorm.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.38.self_attn.k_proj.bias": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.38.self_attn.k_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.38.self_attn.o_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.38.self_attn.q_proj.bias": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.38.self_attn.q_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.38.self_attn.v_proj.bias": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.38.self_attn.v_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.39.input_layernorm.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.39.mlp.down_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.39.mlp.gate_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.39.mlp.up_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.39.post_attention_layernorm.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.39.self_attn.k_proj.bias": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.39.self_attn.k_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.39.self_attn.o_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.39.self_attn.q_proj.bias": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.39.self_attn.q_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.39.self_attn.v_proj.bias": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.39.self_attn.v_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.4.input_layernorm.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.4.mlp.down_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.4.mlp.gate_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.4.mlp.up_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.4.post_attention_layernorm.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.4.self_attn.k_proj.bias": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.4.self_attn.k_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.4.self_attn.o_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.4.self_attn.q_proj.bias": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.4.self_attn.q_proj.weight": "pytorch_model-00002-of-00030.bin",
|
||||||
|
"model.layers.4.self_attn.v_proj.bias": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.4.self_attn.v_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.40.input_layernorm.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.40.mlp.down_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.40.mlp.gate_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.40.mlp.up_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.40.post_attention_layernorm.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.40.self_attn.k_proj.bias": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.40.self_attn.k_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.40.self_attn.o_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.40.self_attn.q_proj.bias": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.40.self_attn.q_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.40.self_attn.v_proj.bias": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.40.self_attn.v_proj.weight": "pytorch_model-00015-of-00030.bin",
|
||||||
|
"model.layers.41.input_layernorm.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.41.mlp.down_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.41.mlp.gate_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.41.mlp.up_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.41.post_attention_layernorm.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.41.self_attn.k_proj.bias": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.41.self_attn.k_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.41.self_attn.o_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.41.self_attn.q_proj.bias": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.41.self_attn.q_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.41.self_attn.v_proj.bias": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.41.self_attn.v_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.42.input_layernorm.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.42.mlp.down_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.42.mlp.gate_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.42.mlp.up_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.42.post_attention_layernorm.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.42.self_attn.k_proj.bias": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.42.self_attn.k_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.42.self_attn.o_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.42.self_attn.q_proj.bias": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.42.self_attn.q_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.42.self_attn.v_proj.bias": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.42.self_attn.v_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.43.input_layernorm.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.43.mlp.down_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.43.mlp.gate_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.43.mlp.up_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.43.post_attention_layernorm.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.43.self_attn.k_proj.bias": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.43.self_attn.k_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.43.self_attn.o_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.43.self_attn.q_proj.bias": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.43.self_attn.q_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.43.self_attn.v_proj.bias": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.43.self_attn.v_proj.weight": "pytorch_model-00016-of-00030.bin",
|
||||||
|
"model.layers.44.input_layernorm.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.44.mlp.down_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.44.mlp.gate_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.44.mlp.up_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.44.post_attention_layernorm.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.44.self_attn.k_proj.bias": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.44.self_attn.k_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.44.self_attn.o_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.44.self_attn.q_proj.bias": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.44.self_attn.q_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.44.self_attn.v_proj.bias": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.44.self_attn.v_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.45.input_layernorm.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.45.mlp.down_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.45.mlp.gate_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.45.mlp.up_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.45.post_attention_layernorm.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.45.self_attn.k_proj.bias": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.45.self_attn.k_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.45.self_attn.o_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.45.self_attn.q_proj.bias": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.45.self_attn.q_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.45.self_attn.v_proj.bias": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.45.self_attn.v_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.46.input_layernorm.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.46.mlp.down_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.46.mlp.gate_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.46.mlp.up_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.46.post_attention_layernorm.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.46.self_attn.k_proj.bias": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.46.self_attn.k_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.46.self_attn.o_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.46.self_attn.q_proj.bias": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.46.self_attn.q_proj.weight": "pytorch_model-00017-of-00030.bin",
|
||||||
|
"model.layers.46.self_attn.v_proj.bias": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.46.self_attn.v_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.47.input_layernorm.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.47.mlp.down_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.47.mlp.gate_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.47.mlp.up_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.47.post_attention_layernorm.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.47.self_attn.k_proj.bias": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.47.self_attn.k_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.47.self_attn.o_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.47.self_attn.q_proj.bias": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.47.self_attn.q_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.47.self_attn.v_proj.bias": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.47.self_attn.v_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.48.input_layernorm.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.48.mlp.down_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.48.mlp.gate_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.48.mlp.up_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.48.post_attention_layernorm.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.48.self_attn.k_proj.bias": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.48.self_attn.k_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.48.self_attn.o_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.48.self_attn.q_proj.bias": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.48.self_attn.q_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.48.self_attn.v_proj.bias": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.48.self_attn.v_proj.weight": "pytorch_model-00018-of-00030.bin",
|
||||||
|
"model.layers.49.input_layernorm.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.49.mlp.down_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.49.mlp.gate_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.49.mlp.up_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.49.post_attention_layernorm.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.49.self_attn.k_proj.bias": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.49.self_attn.k_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.49.self_attn.o_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.49.self_attn.q_proj.bias": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.49.self_attn.q_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.49.self_attn.v_proj.bias": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.49.self_attn.v_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.5.input_layernorm.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.5.mlp.down_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.5.mlp.gate_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.5.mlp.up_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.5.post_attention_layernorm.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.5.self_attn.k_proj.bias": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.5.self_attn.k_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.5.self_attn.o_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.5.self_attn.q_proj.bias": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.5.self_attn.q_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.5.self_attn.v_proj.bias": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.5.self_attn.v_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.50.input_layernorm.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.50.mlp.down_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.50.mlp.gate_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.50.mlp.up_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.50.post_attention_layernorm.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.50.self_attn.k_proj.bias": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.50.self_attn.k_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.50.self_attn.o_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.50.self_attn.q_proj.bias": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.50.self_attn.q_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.50.self_attn.v_proj.bias": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.50.self_attn.v_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.51.input_layernorm.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.51.mlp.down_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.51.mlp.gate_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.51.mlp.up_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.51.post_attention_layernorm.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.51.self_attn.k_proj.bias": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.51.self_attn.k_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.51.self_attn.o_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.51.self_attn.q_proj.bias": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.51.self_attn.q_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.51.self_attn.v_proj.bias": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.51.self_attn.v_proj.weight": "pytorch_model-00019-of-00030.bin",
|
||||||
|
"model.layers.52.input_layernorm.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.52.mlp.down_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.52.mlp.gate_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.52.mlp.up_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.52.post_attention_layernorm.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.52.self_attn.k_proj.bias": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.52.self_attn.k_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.52.self_attn.o_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.52.self_attn.q_proj.bias": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.52.self_attn.q_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.52.self_attn.v_proj.bias": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.52.self_attn.v_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.53.input_layernorm.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.53.mlp.down_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.53.mlp.gate_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.53.mlp.up_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.53.post_attention_layernorm.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.53.self_attn.k_proj.bias": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.53.self_attn.k_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.53.self_attn.o_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.53.self_attn.q_proj.bias": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.53.self_attn.q_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.53.self_attn.v_proj.bias": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.53.self_attn.v_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.54.input_layernorm.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.54.mlp.down_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.54.mlp.gate_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.54.mlp.up_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.54.post_attention_layernorm.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.54.self_attn.k_proj.bias": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.54.self_attn.k_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.54.self_attn.o_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.54.self_attn.q_proj.bias": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.54.self_attn.q_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.54.self_attn.v_proj.bias": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.54.self_attn.v_proj.weight": "pytorch_model-00020-of-00030.bin",
|
||||||
|
"model.layers.55.input_layernorm.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.55.mlp.down_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.55.mlp.gate_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.55.mlp.up_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.55.post_attention_layernorm.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.55.self_attn.k_proj.bias": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.55.self_attn.k_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.55.self_attn.o_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.55.self_attn.q_proj.bias": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.55.self_attn.q_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.55.self_attn.v_proj.bias": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.55.self_attn.v_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.56.input_layernorm.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.56.mlp.down_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.56.mlp.gate_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.56.mlp.up_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.56.post_attention_layernorm.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.56.self_attn.k_proj.bias": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.56.self_attn.k_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.56.self_attn.o_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.56.self_attn.q_proj.bias": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.56.self_attn.q_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.56.self_attn.v_proj.bias": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.56.self_attn.v_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.57.input_layernorm.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.57.mlp.down_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.57.mlp.gate_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.57.mlp.up_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.57.post_attention_layernorm.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.57.self_attn.k_proj.bias": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.57.self_attn.k_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.57.self_attn.o_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.57.self_attn.q_proj.bias": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.57.self_attn.q_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.57.self_attn.v_proj.bias": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.57.self_attn.v_proj.weight": "pytorch_model-00021-of-00030.bin",
|
||||||
|
"model.layers.58.input_layernorm.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.58.mlp.down_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.58.mlp.gate_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.58.mlp.up_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.58.post_attention_layernorm.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.58.self_attn.k_proj.bias": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.58.self_attn.k_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.58.self_attn.o_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.58.self_attn.q_proj.bias": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.58.self_attn.q_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.58.self_attn.v_proj.bias": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.58.self_attn.v_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.59.input_layernorm.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.59.mlp.down_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.59.mlp.gate_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.59.mlp.up_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.59.post_attention_layernorm.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.59.self_attn.k_proj.bias": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.59.self_attn.k_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.59.self_attn.o_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.59.self_attn.q_proj.bias": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.59.self_attn.q_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.59.self_attn.v_proj.bias": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.59.self_attn.v_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.6.input_layernorm.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.6.mlp.down_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.6.mlp.gate_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.6.mlp.up_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.6.post_attention_layernorm.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.6.self_attn.k_proj.bias": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.6.self_attn.k_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.6.self_attn.o_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.6.self_attn.q_proj.bias": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.6.self_attn.q_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.6.self_attn.v_proj.bias": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.6.self_attn.v_proj.weight": "pytorch_model-00003-of-00030.bin",
|
||||||
|
"model.layers.60.input_layernorm.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.60.mlp.down_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.60.mlp.gate_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.60.mlp.up_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.60.post_attention_layernorm.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.60.self_attn.k_proj.bias": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.60.self_attn.k_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.60.self_attn.o_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.60.self_attn.q_proj.bias": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.60.self_attn.q_proj.weight": "pytorch_model-00022-of-00030.bin",
|
||||||
|
"model.layers.60.self_attn.v_proj.bias": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.60.self_attn.v_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.61.input_layernorm.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.61.mlp.down_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.61.mlp.gate_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.61.mlp.up_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.61.post_attention_layernorm.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.61.self_attn.k_proj.bias": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.61.self_attn.k_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.61.self_attn.o_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.61.self_attn.q_proj.bias": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.61.self_attn.q_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.61.self_attn.v_proj.bias": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.61.self_attn.v_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.62.input_layernorm.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.62.mlp.down_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.62.mlp.gate_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.62.mlp.up_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.62.post_attention_layernorm.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.62.self_attn.k_proj.bias": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.62.self_attn.k_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.62.self_attn.o_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.62.self_attn.q_proj.bias": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.62.self_attn.q_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.62.self_attn.v_proj.bias": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.62.self_attn.v_proj.weight": "pytorch_model-00023-of-00030.bin",
|
||||||
|
"model.layers.63.input_layernorm.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.63.mlp.down_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.63.mlp.gate_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.63.mlp.up_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.63.post_attention_layernorm.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.63.self_attn.k_proj.bias": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.63.self_attn.k_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.63.self_attn.o_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.63.self_attn.q_proj.bias": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.63.self_attn.q_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.63.self_attn.v_proj.bias": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.63.self_attn.v_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.64.input_layernorm.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.64.mlp.down_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.64.mlp.gate_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.64.mlp.up_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.64.post_attention_layernorm.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.64.self_attn.k_proj.bias": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.64.self_attn.k_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.64.self_attn.o_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.64.self_attn.q_proj.bias": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.64.self_attn.q_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.64.self_attn.v_proj.bias": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.64.self_attn.v_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.65.input_layernorm.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.65.mlp.down_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.65.mlp.gate_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.65.mlp.up_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.65.post_attention_layernorm.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.65.self_attn.k_proj.bias": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.65.self_attn.k_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.65.self_attn.o_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.65.self_attn.q_proj.bias": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.65.self_attn.q_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.65.self_attn.v_proj.bias": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.65.self_attn.v_proj.weight": "pytorch_model-00024-of-00030.bin",
|
||||||
|
"model.layers.66.input_layernorm.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.66.mlp.down_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.66.mlp.gate_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.66.mlp.up_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.66.post_attention_layernorm.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.66.self_attn.k_proj.bias": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.66.self_attn.k_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.66.self_attn.o_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.66.self_attn.q_proj.bias": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.66.self_attn.q_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.66.self_attn.v_proj.bias": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.66.self_attn.v_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.67.input_layernorm.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.67.mlp.down_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.67.mlp.gate_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.67.mlp.up_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.67.post_attention_layernorm.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.67.self_attn.k_proj.bias": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.67.self_attn.k_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.67.self_attn.o_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.67.self_attn.q_proj.bias": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.67.self_attn.q_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.67.self_attn.v_proj.bias": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.67.self_attn.v_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.68.input_layernorm.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.68.mlp.down_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.68.mlp.gate_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.68.mlp.up_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.68.post_attention_layernorm.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.68.self_attn.k_proj.bias": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.68.self_attn.k_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.68.self_attn.o_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.68.self_attn.q_proj.bias": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.68.self_attn.q_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.68.self_attn.v_proj.bias": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.68.self_attn.v_proj.weight": "pytorch_model-00025-of-00030.bin",
|
||||||
|
"model.layers.69.input_layernorm.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.69.mlp.down_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.69.mlp.gate_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.69.mlp.up_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.69.post_attention_layernorm.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.69.self_attn.k_proj.bias": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.69.self_attn.k_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.69.self_attn.o_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.69.self_attn.q_proj.bias": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.69.self_attn.q_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.69.self_attn.v_proj.bias": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.69.self_attn.v_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.7.input_layernorm.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.7.mlp.down_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.7.mlp.gate_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.7.mlp.up_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.7.post_attention_layernorm.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.7.self_attn.k_proj.bias": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.7.self_attn.k_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.7.self_attn.o_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.7.self_attn.q_proj.bias": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.7.self_attn.q_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.7.self_attn.v_proj.bias": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.7.self_attn.v_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.70.input_layernorm.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.70.mlp.down_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.70.mlp.gate_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.70.mlp.up_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.70.post_attention_layernorm.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.70.self_attn.k_proj.bias": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.70.self_attn.k_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.70.self_attn.o_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.70.self_attn.q_proj.bias": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.70.self_attn.q_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.70.self_attn.v_proj.bias": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.70.self_attn.v_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.71.input_layernorm.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.71.mlp.down_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.71.mlp.gate_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.71.mlp.up_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.71.post_attention_layernorm.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.71.self_attn.k_proj.bias": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.71.self_attn.k_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.71.self_attn.o_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.71.self_attn.q_proj.bias": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.71.self_attn.q_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.71.self_attn.v_proj.bias": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.71.self_attn.v_proj.weight": "pytorch_model-00026-of-00030.bin",
|
||||||
|
"model.layers.72.input_layernorm.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.72.mlp.down_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.72.mlp.gate_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.72.mlp.up_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.72.post_attention_layernorm.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.72.self_attn.k_proj.bias": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.72.self_attn.k_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.72.self_attn.o_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.72.self_attn.q_proj.bias": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.72.self_attn.q_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.72.self_attn.v_proj.bias": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.72.self_attn.v_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.73.input_layernorm.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.73.mlp.down_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.73.mlp.gate_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.73.mlp.up_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.73.post_attention_layernorm.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.73.self_attn.k_proj.bias": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.73.self_attn.k_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.73.self_attn.o_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.73.self_attn.q_proj.bias": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.73.self_attn.q_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.73.self_attn.v_proj.bias": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.73.self_attn.v_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.74.input_layernorm.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.74.mlp.down_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.74.mlp.gate_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.74.mlp.up_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.74.post_attention_layernorm.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.74.self_attn.k_proj.bias": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.74.self_attn.k_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.74.self_attn.o_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.74.self_attn.q_proj.bias": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.74.self_attn.q_proj.weight": "pytorch_model-00027-of-00030.bin",
|
||||||
|
"model.layers.74.self_attn.v_proj.bias": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.74.self_attn.v_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.75.input_layernorm.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.75.mlp.down_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.75.mlp.gate_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.75.mlp.up_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.75.post_attention_layernorm.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.75.self_attn.k_proj.bias": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.75.self_attn.k_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.75.self_attn.o_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.75.self_attn.q_proj.bias": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.75.self_attn.q_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.75.self_attn.v_proj.bias": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.75.self_attn.v_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.76.input_layernorm.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.76.mlp.down_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.76.mlp.gate_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.76.mlp.up_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.76.post_attention_layernorm.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.76.self_attn.k_proj.bias": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.76.self_attn.k_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.76.self_attn.o_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.76.self_attn.q_proj.bias": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.76.self_attn.q_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.76.self_attn.v_proj.bias": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.76.self_attn.v_proj.weight": "pytorch_model-00028-of-00030.bin",
|
||||||
|
"model.layers.77.input_layernorm.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.77.mlp.down_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.77.mlp.gate_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.77.mlp.up_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.77.post_attention_layernorm.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.77.self_attn.k_proj.bias": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.77.self_attn.k_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.77.self_attn.o_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.77.self_attn.q_proj.bias": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.77.self_attn.q_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.77.self_attn.v_proj.bias": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.77.self_attn.v_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.78.input_layernorm.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.78.mlp.down_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.78.mlp.gate_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.78.mlp.up_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.78.post_attention_layernorm.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.78.self_attn.k_proj.bias": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.78.self_attn.k_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.78.self_attn.o_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.78.self_attn.q_proj.bias": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.78.self_attn.q_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.78.self_attn.v_proj.bias": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.78.self_attn.v_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.79.input_layernorm.weight": "pytorch_model-00030-of-00030.bin",
|
||||||
|
"model.layers.79.mlp.down_proj.weight": "pytorch_model-00030-of-00030.bin",
|
||||||
|
"model.layers.79.mlp.gate_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.79.mlp.up_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.79.post_attention_layernorm.weight": "pytorch_model-00030-of-00030.bin",
|
||||||
|
"model.layers.79.self_attn.k_proj.bias": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.79.self_attn.k_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.79.self_attn.o_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.79.self_attn.q_proj.bias": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.79.self_attn.q_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.79.self_attn.v_proj.bias": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.79.self_attn.v_proj.weight": "pytorch_model-00029-of-00030.bin",
|
||||||
|
"model.layers.8.input_layernorm.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.8.mlp.down_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.8.mlp.gate_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.8.mlp.up_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.8.post_attention_layernorm.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.8.self_attn.k_proj.bias": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.8.self_attn.k_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.8.self_attn.o_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.8.self_attn.q_proj.bias": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.8.self_attn.q_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.8.self_attn.v_proj.bias": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.8.self_attn.v_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.9.input_layernorm.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.9.mlp.down_proj.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.9.mlp.gate_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.9.mlp.up_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.9.post_attention_layernorm.weight": "pytorch_model-00005-of-00030.bin",
|
||||||
|
"model.layers.9.self_attn.k_proj.bias": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.9.self_attn.k_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.9.self_attn.o_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.9.self_attn.q_proj.bias": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.9.self_attn.q_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.9.self_attn.v_proj.bias": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.layers.9.self_attn.v_proj.weight": "pytorch_model-00004-of-00030.bin",
|
||||||
|
"model.norm.weight": "pytorch_model-00030-of-00030.bin"
|
||||||
|
}
|
||||||
|
}
|
||||||
20
special_tokens_map.json
Normal file
20
special_tokens_map.json
Normal file
@@ -0,0 +1,20 @@
|
|||||||
|
{
|
||||||
|
"additional_special_tokens": [
|
||||||
|
"<|im_start|>",
|
||||||
|
"<|im_end|>"
|
||||||
|
],
|
||||||
|
"eos_token": {
|
||||||
|
"content": "<|im_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false
|
||||||
|
},
|
||||||
|
"pad_token": {
|
||||||
|
"content": "<|endoftext|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false
|
||||||
|
}
|
||||||
|
}
|
||||||
303111
tokenizer.json
Normal file
303111
tokenizer.json
Normal file
File diff suppressed because it is too large
Load Diff
43
tokenizer_config.json
Normal file
43
tokenizer_config.json
Normal file
@@ -0,0 +1,43 @@
|
|||||||
|
{
|
||||||
|
"add_prefix_space": false,
|
||||||
|
"added_tokens_decoder": {
|
||||||
|
"151643": {
|
||||||
|
"content": "<|endoftext|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151644": {
|
||||||
|
"content": "<|im_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151645": {
|
||||||
|
"content": "<|im_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"additional_special_tokens": [
|
||||||
|
"<|im_start|>",
|
||||||
|
"<|im_end|>"
|
||||||
|
],
|
||||||
|
"bos_token": null,
|
||||||
|
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set loop_messages = messages[1:] %}{% set system_message = messages[0]['content'] %}{% else %}{% set loop_messages = messages %}{% set system_message = 'You are a helpful assistant.' %}{% endif %}{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in loop_messages %}{% if loop.index0 == 0 %}{{'<|im_start|>system\n' + system_message + '<|im_end|>\n'}}{% endif %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
||||||
|
"clean_up_tokenization_spaces": false,
|
||||||
|
"eos_token": "<|im_end|>",
|
||||||
|
"errors": "replace",
|
||||||
|
"model_max_length": 32768,
|
||||||
|
"pad_token": "<|endoftext|>",
|
||||||
|
"split_special_tokens": false,
|
||||||
|
"tokenizer_class": "Qwen2Tokenizer",
|
||||||
|
"unk_token": null
|
||||||
|
}
|
||||||
1
vocab.json
Normal file
1
vocab.json
Normal file
File diff suppressed because one or more lines are too long
Reference in New Issue
Block a user