初始化项目,由ModelHub XC社区提供模型
Model: Vikhrmodels/it-5.4-fp16-orpo-v2 Source: Original Platform
This commit is contained in:
54
.gitattributes
vendored
Normal file
54
.gitattributes
vendored
Normal file
@@ -0,0 +1,54 @@
|
||||
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||
|
||||
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
||||
*.tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
*.db* filter=lfs diff=lfs merge=lfs -text
|
||||
*.ark* filter=lfs diff=lfs merge=lfs -text
|
||||
**/*ckpt*data* filter=lfs diff=lfs merge=lfs -text
|
||||
**/*ckpt*.meta filter=lfs diff=lfs merge=lfs -text
|
||||
**/*ckpt*.index filter=lfs diff=lfs merge=lfs -text
|
||||
|
||||
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||
*.gguf* filter=lfs diff=lfs merge=lfs -text
|
||||
*.ggml filter=lfs diff=lfs merge=lfs -text
|
||||
*.llamafile* filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
|
||||
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
||||
model-00004-of-00004.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
tokenizer.model filter=lfs diff=lfs merge=lfs -text
|
||||
model-00003-of-00004.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
model-00002-of-00004.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
model-00001-of-00004.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
87
README.md
Normal file
87
README.md
Normal file
@@ -0,0 +1,87 @@
|
||||
---
|
||||
language:
|
||||
- ru
|
||||
---
|
||||
## Инструктивный вихрь 5.4
|
||||
|
||||
Базовый Вихрь 5той версии (мистраль) обученный на переведенных инструкциях и ответах GPT-4 и улучшенный с помощью [ORPO](https://argilla.io/blog/mantisnlp-rlhf-part-8/) на нашем внутреннем датасете.
|
||||
|
||||
Модель имеет довольно высокое разннобразие ответов, поэтому рекомендуется использовать temperature в рендже [0.1, 0.4].
|
||||
|
||||
- [GGUF](https://huggingface.co/Vikhrmodels/it-5.4-fp16-orpo-v2-GGUF)
|
||||
|
||||
### Использование через transformers
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
import torch
|
||||
|
||||
model_name = 'Vikhrmodels/it-5.4-fp16-orpo-v2'
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model_name,
|
||||
device_map="sequential",
|
||||
attn_implementation="sdpa",
|
||||
torch_dtype=torch.bfloat16
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
||||
|
||||
test_input = tokenizer.apply_chat_template([
|
||||
{'role': 'user', 'content': 'Привет, объясни что такое черные дыры'}
|
||||
], add_generation_prompt=True, tokenize=True, return_tensors='pt')
|
||||
test_input = test_input.to(model.device)
|
||||
|
||||
answer = model.generate(
|
||||
test_input,
|
||||
do_sample=True,
|
||||
use_cache=True,
|
||||
max_new_tokens=256,
|
||||
temperature=0.3,
|
||||
)[:, test_input.shape[-1]:]
|
||||
answer = tokenizer.batch_decode(answer, skip_special_tokens=True)[0]
|
||||
print(answer)
|
||||
```
|
||||
|
||||
Ответ модели:
|
||||
|
||||
> Привет! Черные дыры - это удивительные объекты, которые существуют в космосе. Они образуются из остатков массивных звезд, которые взрываются в результате сверхновой. После взрыва остается ядро звезды, которое коллапсирует под действием собственной гравитации, образуя черную дыру.
|
||||
>
|
||||
> Черная дыра - это область пространства, где гравитационное притяжение настолько сильное, что ничто, даже свет, не может вырваться из нее. Это происходит потому, что гравитационное поле черной дыры настолько сильное, что оно искривляет пространство-время настолько, что даже свет не может покинуть ее.
|
||||
>
|
||||
> Черные дыры могут быть разных размеров, от маленьких, которые могут быть размером с планету, до огромных, которые могут быть размером с галактику. Они могут быть как неподвижными, так и движущимися, и могут взаимодействовать с другими объектами в космосе, такими как звезды и планеты.
|
||||
>
|
||||
> Черные дыры - это удивительные объекты, которые продолжают изучать ученые, и они могут многое рассказать нам о Вселенной и ее происхождении.
|
||||
|
||||
### Использование через vllm + openai client
|
||||
|
||||
Запуск сервера в терминале: \
|
||||
`python -m vllm.entrypoints.openai.api_server --model Vikhrmodels/it-5.4-fp16-orpo-v2 --dtype half --api-key token-abc123 -tp 1`
|
||||
|
||||
```python
|
||||
import openai
|
||||
|
||||
llm_model = "Vikhrmodels/it-5.4-fp16-orpo-v2"
|
||||
llm_client = openai.OpenAI(
|
||||
base_url="http://localhost:8000/v1",
|
||||
api_key="token-abc123",
|
||||
)
|
||||
|
||||
def make_completion(history, client, model):
|
||||
completion = client.chat.completions.create(
|
||||
model=model,
|
||||
messages=history,
|
||||
temperature=0.3,
|
||||
max_tokens=2048,
|
||||
stop=["</s>", "<eos>", "<|eot_id|>", "<|im_end|>"]
|
||||
)
|
||||
output = completion.choices[0].message.content
|
||||
return output
|
||||
|
||||
answer = make_completion([
|
||||
{'role': 'user', 'content': 'Привет, объясни что такое черные дыры'}
|
||||
], llm_client, llm_model)
|
||||
print(answer)
|
||||
```
|
||||
|
||||
### Метрики на ru_arena_general
|
||||
|
||||
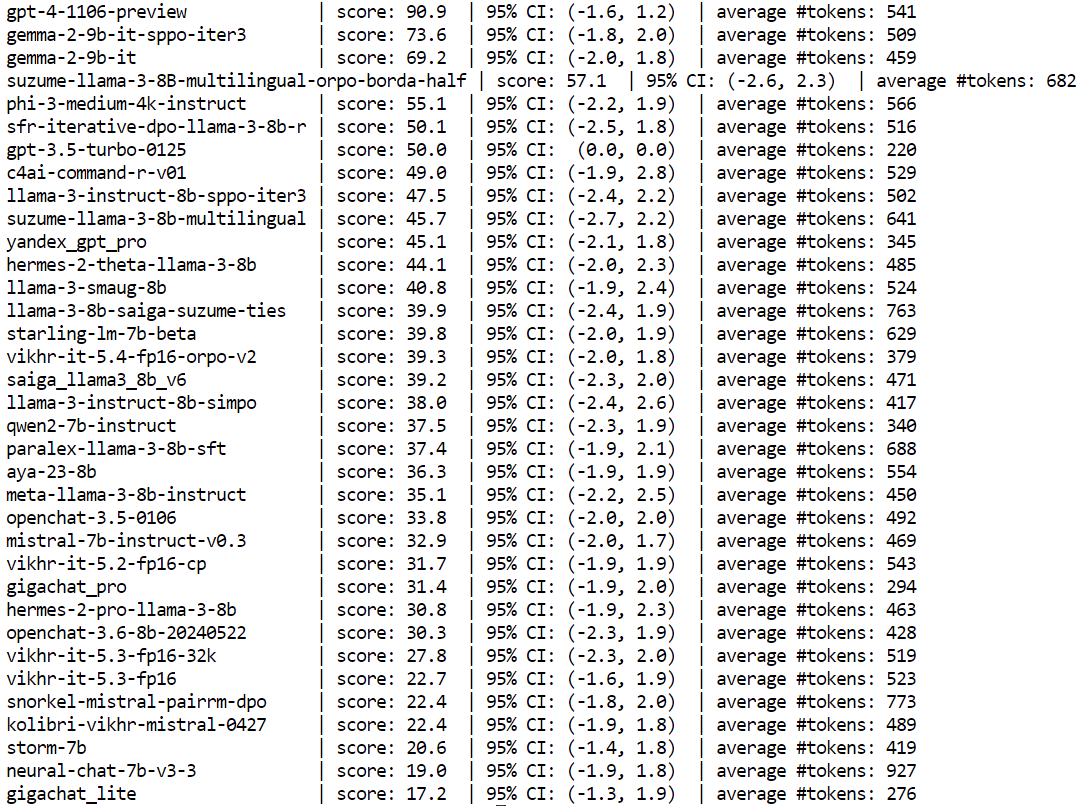
|
||||
17
added_tokens.json
Normal file
17
added_tokens.json
Normal file
@@ -0,0 +1,17 @@
|
||||
{
|
||||
"<|end_header_id|>": 79098,
|
||||
"<|eot_id|>": 79099,
|
||||
"<|future_token_0|>": 79085,
|
||||
"<|future_token_10|>": 79095,
|
||||
"<|future_token_11|>": 79096,
|
||||
"<|future_token_1|>": 79086,
|
||||
"<|future_token_2|>": 79087,
|
||||
"<|future_token_3|>": 79088,
|
||||
"<|future_token_4|>": 79089,
|
||||
"<|future_token_5|>": 79090,
|
||||
"<|future_token_6|>": 79091,
|
||||
"<|future_token_7|>": 79092,
|
||||
"<|future_token_8|>": 79093,
|
||||
"<|future_token_9|>": 79094,
|
||||
"<|start_header_id|>": 79097
|
||||
}
|
||||
29
config.json
Normal file
29
config.json
Normal file
@@ -0,0 +1,29 @@
|
||||
{
|
||||
"_name_or_path": "/home/work/hermes-sft-vikhr-lora-48-embqkvogdulm/checkpoint-6400/merged",
|
||||
"architectures": [
|
||||
"LlamaForCausalLM"
|
||||
],
|
||||
"attention_bias": false,
|
||||
"attention_dropout": 0.0,
|
||||
"bos_token_id": 1,
|
||||
"eos_token_id": 79099,
|
||||
"hidden_act": "silu",
|
||||
"hidden_size": 4096,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 14336,
|
||||
"max_position_embeddings": 32768,
|
||||
"model_type": "llama",
|
||||
"num_attention_heads": 32,
|
||||
"num_hidden_layers": 32,
|
||||
"num_key_value_heads": 8,
|
||||
"pretraining_tp": 1,
|
||||
"rms_norm_eps": 1e-05,
|
||||
"rope_scaling": null,
|
||||
"rope_theta": 10000.0,
|
||||
"sliding_window": 4096,
|
||||
"tie_word_embeddings": false,
|
||||
"torch_dtype": "float16",
|
||||
"transformers_version": "4.40.1",
|
||||
"use_cache": false,
|
||||
"vocab_size": 79100
|
||||
}
|
||||
1
configuration.json
Normal file
1
configuration.json
Normal file
@@ -0,0 +1 @@
|
||||
{"framework": "pytorch", "task": "text-generation", "allow_remote": true}
|
||||
8
generation_config.json
Normal file
8
generation_config.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"_from_model_config": true,
|
||||
"bos_token_id": 1,
|
||||
"eos_token_id": 79099,
|
||||
"pad_token_id": 2,
|
||||
"transformers_version": "4.40.1",
|
||||
"use_cache": false
|
||||
}
|
||||
3
model-00001-of-00004.safetensors
Normal file
3
model-00001-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:cba063a1ba4e10f2d122eabe62980c757afa16cc45f3ea0e0018234233e38862
|
||||
size 4892780424
|
||||
3
model-00002-of-00004.safetensors
Normal file
3
model-00002-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:9b97a7380e81bd9e06ae9c239ea1eb8a3cce11b3ad08c8257b8a5065c1837ce9
|
||||
size 4999819232
|
||||
3
model-00003-of-00004.safetensors
Normal file
3
model-00003-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:d0c823cbb808d3ae4e7af6f20adeb1109e075a59db232895b98e423fb1949ba4
|
||||
size 4714597192
|
||||
3
model-00004-of-00004.safetensors
Normal file
3
model-00004-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:344ad797f676c407e2b7d4a7e15a2258eac8f717e3e0c4f6f5f667f8a9a0771a
|
||||
size 647987328
|
||||
298
model.safetensors.index.json
Normal file
298
model.safetensors.index.json
Normal file
@@ -0,0 +1,298 @@
|
||||
{
|
||||
"metadata": {
|
||||
"total_size": 15255150592
|
||||
},
|
||||
"weight_map": {
|
||||
"lm_head.weight": "model-00004-of-00004.safetensors",
|
||||
"model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.10.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.20.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.20.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.20.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.20.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.20.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.21.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.21.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.21.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.21.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.21.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.21.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.21.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.21.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.21.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.22.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.22.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.30.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.31.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||
"model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.9.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.9.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||
"model.norm.weight": "model-00003-of-00004.safetensors"
|
||||
}
|
||||
}
|
||||
35
special_tokens_map.json
Normal file
35
special_tokens_map.json
Normal file
@@ -0,0 +1,35 @@
|
||||
{
|
||||
"additional_special_tokens": [
|
||||
"<|start_header_id|>",
|
||||
"<|end_header_id|>",
|
||||
"<|eot_id|>"
|
||||
],
|
||||
"bos_token": {
|
||||
"content": "<s>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"eos_token": {
|
||||
"content": "<|eot_id|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"pad_token": {
|
||||
"content": "</s>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
},
|
||||
"unk_token": {
|
||||
"content": "<unk>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false
|
||||
}
|
||||
}
|
||||
3
tokenizer.json
Normal file
3
tokenizer.json
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:99afe6828be0c75507590f1a41ef7c1aab1e1e778256f06108648353c63aacc3
|
||||
size 5754812
|
||||
3
tokenizer.model
Normal file
3
tokenizer.model
Normal file
@@ -0,0 +1,3 @@
|
||||
version https://git-lfs.github.com/spec/v1
|
||||
oid sha256:e3f0f84b42f79947ab92931c7c5ded699e845e6862e4e29f0b97f87e279da601
|
||||
size 1636166
|
||||
167
tokenizer_config.json
Normal file
167
tokenizer_config.json
Normal file
@@ -0,0 +1,167 @@
|
||||
{
|
||||
"add_bos_token": true,
|
||||
"add_eos_token": false,
|
||||
"added_tokens_decoder": {
|
||||
"0": {
|
||||
"content": "<unk>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"1": {
|
||||
"content": "<s>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"2": {
|
||||
"content": "</s>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"79085": {
|
||||
"content": "<|future_token_0|>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"79086": {
|
||||
"content": "<|future_token_1|>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"79087": {
|
||||
"content": "<|future_token_2|>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"79088": {
|
||||
"content": "<|future_token_3|>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"79089": {
|
||||
"content": "<|future_token_4|>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"79090": {
|
||||
"content": "<|future_token_5|>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"79091": {
|
||||
"content": "<|future_token_6|>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"79092": {
|
||||
"content": "<|future_token_7|>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"79093": {
|
||||
"content": "<|future_token_8|>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"79094": {
|
||||
"content": "<|future_token_9|>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"79095": {
|
||||
"content": "<|future_token_10|>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"79096": {
|
||||
"content": "<|future_token_11|>",
|
||||
"lstrip": false,
|
||||
"normalized": true,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"79097": {
|
||||
"content": "<|start_header_id|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"79098": {
|
||||
"content": "<|end_header_id|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"79099": {
|
||||
"content": "<|eot_id|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
}
|
||||
},
|
||||
"additional_special_tokens": [
|
||||
"<|start_header_id|>",
|
||||
"<|end_header_id|>",
|
||||
"<|eot_id|>"
|
||||
],
|
||||
"bos_token": "<s>",
|
||||
"chat_template": "{{ bos_token }}{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\\n\\n'+ message['content'] | trim + '<|eot_id|>' %}{{ content }}{% endfor %}{% if add_generation_prompt %}{{ '<|start_header_id|>assistant<|end_header_id|>\\n\\n' }}{% endif %}",
|
||||
"clean_up_tokenization_spaces": false,
|
||||
"eos_token": "<|eot_id|>",
|
||||
"legacy": true,
|
||||
"model_max_length": 8192,
|
||||
"pad_token": "</s>",
|
||||
"sp_model_kwargs": {},
|
||||
"spaces_between_special_tokens": false,
|
||||
"tokenizer_class": "LlamaTokenizer",
|
||||
"unk_token": "<unk>",
|
||||
"use_default_system_prompt": true
|
||||
}
|
||||
Reference in New Issue
Block a user