---
base_model: qwen/Qwen2.5-VL-3B-Instruct
library_name: peft
---
# 基于 Qwen2.5-VL-3B-Instruct 的 LoRA 头盔检测模型
本模型是基于 Qwen2.5-VL-3B-Instruct 微调得到的 LoRA 轻量化模型,专门针对骑行人员头盔佩戴检测任务优化。
## 模型详情
本模型为 Qwen2.5-VL-3B-Instruct 的轻量级 LoRA 适配器,经微调后可判断图片中的骑行者是否佩戴安全头盔。
模型支持图像+文本指令输入,仅输出以下两种结果:
- 佩戴头盔
- 未佩戴头盔
- 研发团队:TLabFineTuning
- 模型类型:多模态大模型 LoRA 适配器
- 语言:中文
- 开源协议:Apache 2.0
- 基础模型:Qwen2.5-VL-3B-Instruct
## 使用场景
- 交通安全监测
- 骑行人员行为分析
- 智能安防监控
## 模型局限性
- 模型在清晰、无遮挡的骑行者图像上效果最佳
- 光线不足、遮挡严重的图像会降低识别准确率
- 模型基于少量样本训练,泛化能力有限
## 快速使用代码
```python
import torch
from peft import PeftModel
from transformers import AutoProcessor, AutoTokenizer, Qwen2_5_VLForConditionalGeneration
from qwen_vl_utils import process_vision_info
from PIL import Image
base_model_path = "qwen/Qwen2.5-VL-3B-Instruct"
lora_model_path = "./"
prompt = "识别图片中骑行者是否佩戴头盔,仅输出:佩戴头盔/未佩戴头盔"
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained(base_model_path, use_fast=False, trust_remote_code=True)
processor = AutoProcessor.from_pretrained(base_model_path, use_fast=False, trust_remote_code=True)
base_model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
base_model_path, torch_dtype=torch.bfloat16, trust_remote_code=True
).to(device)
model = PeftModel.from_pretrained(base_model, lora_model_path).to(device)
model.eval()
def infer_helmet(image_path):
img = Image.open(image_path).convert("RGB")
messages = [
{"role": "user", "content": [{"type": "image", "image": img}, {"type": "text", "text": prompt}]}
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, _ = process_vision_info(messages)
inputs = processor(text=[text], images=image_inputs, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=10, do_sample=False)
result = tokenizer.decode(outputs[0], skip_special_tokens=True).split("assistant")[-1].strip()
return result
```
## 训练信息
- 学习率:1e-5
- LoRA 秩:2
- 模型大小:1.8MB
- 训练设备:8GB 显存显卡
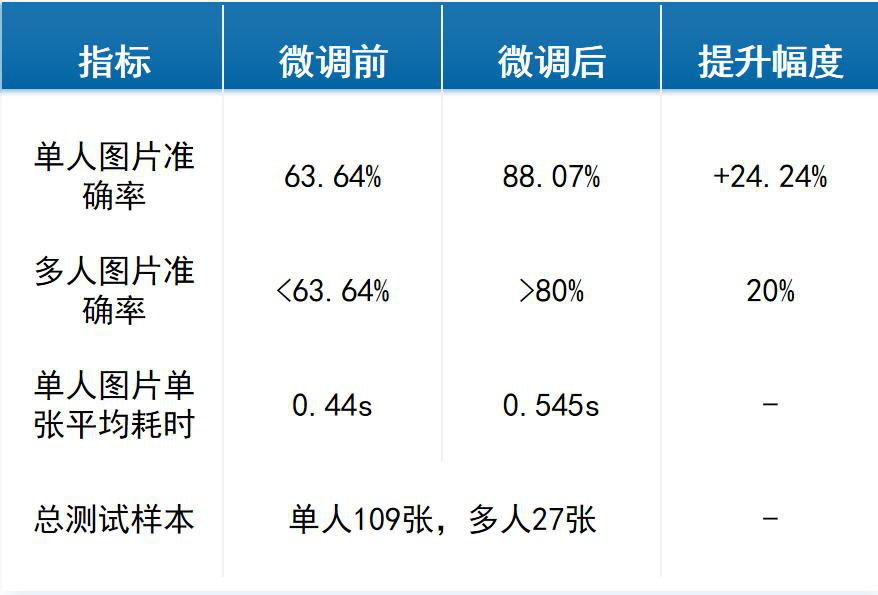
## 模型检测效果
### 图1:Qwen 微调结果
 ### 图2:Qwen 识别单人图片结果
### 图2:Qwen 识别单人图片结果
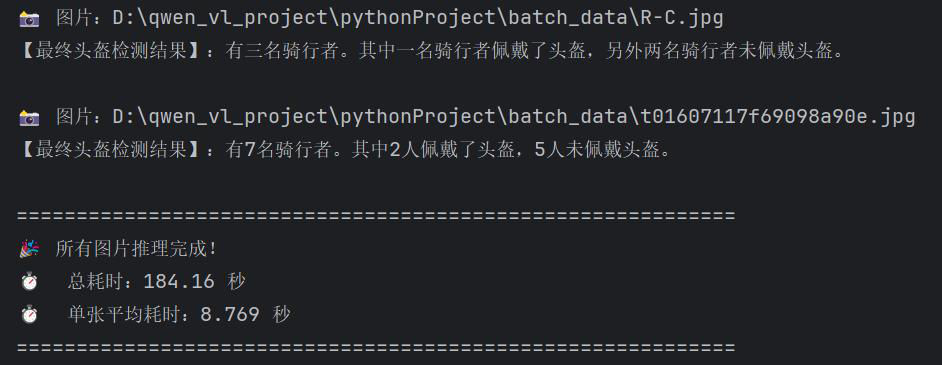
 ### 图3:Qwen 识别多人图片结果
### 图3:Qwen 识别多人图片结果
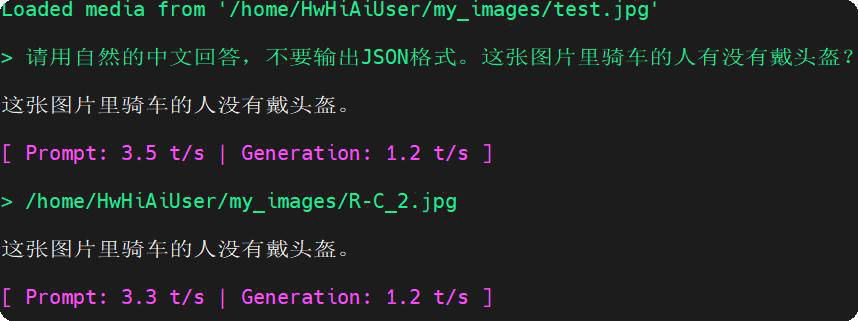
 ### 图4:微调模型部署后香橙派摄像头拍照识别结果
### 图4:微调模型部署后香橙派摄像头拍照识别结果
 ### 图5:实地部署图片
### 图5:实地部署图片
 ## 项目团队与贡献
### 模型研发与维护
TRIP 项目小组
### 核心贡献者
谭妍、刘天赐、王思远、薛栋、张乐鑫、张媛
### 支持单位
东南大学交通学院
东南大学网络与信息中心
### 致谢
感谢东南大学网络与信息中心提供的晟腾算力与香橙派硬件支持
### 免责声明
本模型仅用于科研与技术验证目的。使用者需遵守相关法律法规,并对模型输出结果的使用自行承担责任。
## 项目团队与贡献
### 模型研发与维护
TRIP 项目小组
### 核心贡献者
谭妍、刘天赐、王思远、薛栋、张乐鑫、张媛
### 支持单位
东南大学交通学院
东南大学网络与信息中心
### 致谢
感谢东南大学网络与信息中心提供的晟腾算力与香橙派硬件支持
### 免责声明
本模型仅用于科研与技术验证目的。使用者需遵守相关法律法规,并对模型输出结果的使用自行承担责任。