初始化项目,由ModelHub XC社区提供模型
Model: Shanghai_AI_Laboratory/internlm2-math-7b Source: Original Platform
This commit is contained in:
35
.gitattributes
vendored
Normal file
35
.gitattributes
vendored
Normal file
@@ -0,0 +1,35 @@
|
|||||||
|
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.model filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||||
|
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||||
177
README.md
Normal file
177
README.md
Normal file
@@ -0,0 +1,177 @@
|
|||||||
|
---
|
||||||
|
pipeline_tag: text-generation
|
||||||
|
license: other
|
||||||
|
language:
|
||||||
|
- en
|
||||||
|
- zh
|
||||||
|
tags:
|
||||||
|
- math
|
||||||
|
---
|
||||||
|
|
||||||
|
# InternLM-Math
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
|
||||||
|
<img src="https://raw.githubusercontent.com/InternLM/InternLM/main/assets/logo.svg" width="200"/>
|
||||||
|
<div> </div>
|
||||||
|
<div align="center">
|
||||||
|
<b><font size="5">InternLM-Math</font></b>
|
||||||
|
<sup>
|
||||||
|
<a href="https://internlm.intern-ai.org.cn/">
|
||||||
|
<i><font size="4">HOT</font></i>
|
||||||
|
</a>
|
||||||
|
</sup>
|
||||||
|
<div> </div>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
State-of-the-art bilingual open-sourced Math reasoning LLMs.
|
||||||
|
A **solver**, **prover**, **verifier**, **augmentor**.
|
||||||
|
|
||||||
|
[💻 Github](https://github.com/InternLM/InternLM-Math) [🤗 Demo](https://huggingface.co/spaces/internlm/internlm2-math-7b) [🤗 Checkpoints](https://huggingface.co/internlm/internlm2-math-7b) [](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-7B) [<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> ModelScope](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-7b/summary)
|
||||||
|
</div>
|
||||||
|
|
||||||
|
# News
|
||||||
|
- [2024.01.29] We add checkpoints from ModelScope. Tech report is on the way!
|
||||||
|
- [2024.01.26] We add checkpoints from OpenXLab, which ease Chinese users to download!
|
||||||
|
|
||||||
|
|
||||||
|
# Introduction
|
||||||
|
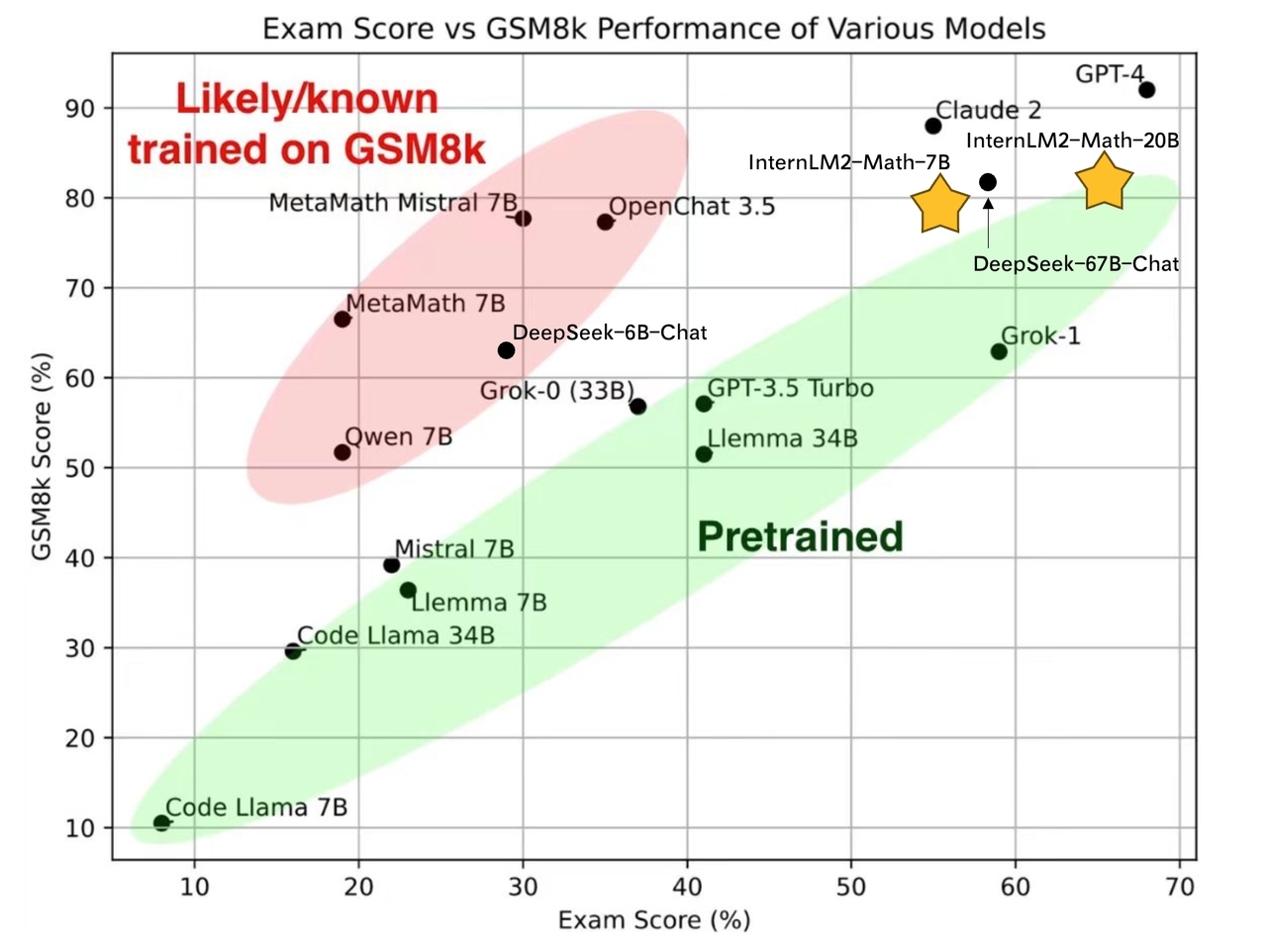
- **7B and 20B Chinese and English Math LMs with better than ChatGPT performances.** InternLM2-Math are continued pretrained from InternLM2-Base with ~100B high quality math-related tokens and SFT with ~2M bilingual math supervised data. We apply minhash and exact number match to decontaminate possible test set leakage.
|
||||||
|
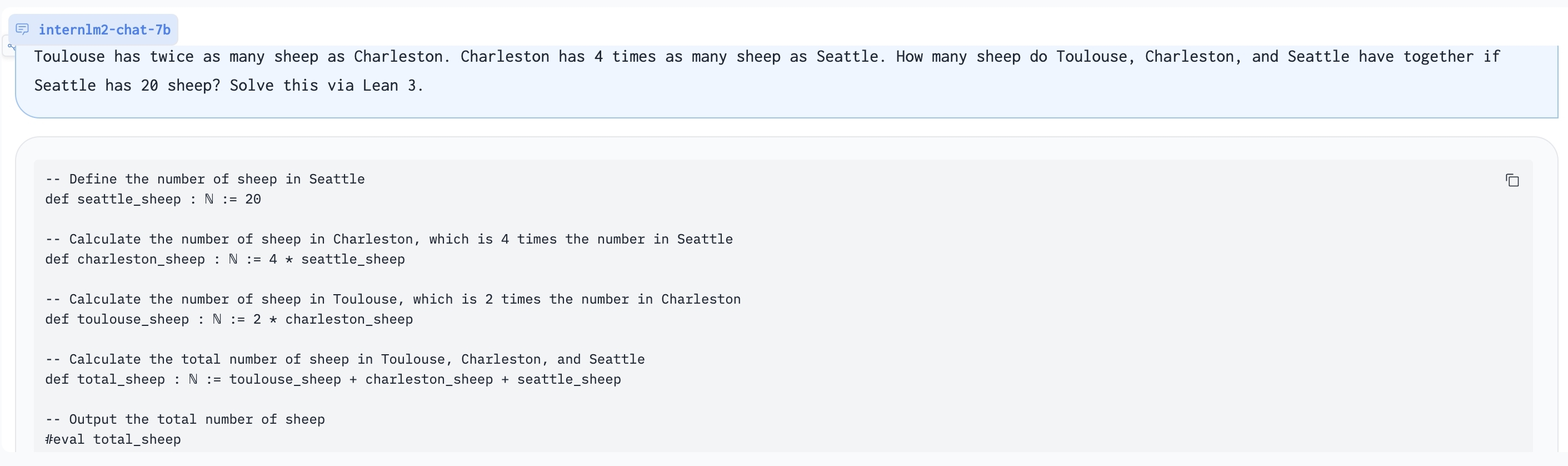
- **Add Lean as a support language for math problem solving and math theorem proving.** We are exploring combining Lean 3 with InternLM-Math for verifiable math reasoning. InternLM-Math can generate Lean codes for simple math reasoning tasks like GSM8K or provide possible proof tactics based on Lean states.
|
||||||
|
- **Also can be viewed as a reward model, which supports the Outcome/Process/Lean Reward Model.** We supervise InternLM2-Math with various types of reward modeling data, to make InternLM2-Math can also verify chain-of-thought processes. We also add the ability to convert a chain-of-thought process into Lean 3 code.
|
||||||
|
- **A Math LM Augment Helper** and **Code Interpreter**. InternLM2-Math can help augment math reasoning problems and solve them using the code interpreter which makes you generate synthesis data quicker!
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
# Models
|
||||||
|
**InternLM2-Math-Base-7B** and **InternLM2-Math-Base-20B** are pretrained checkpoints. **InternLM2-Math-7B** and **InternLM2-Math-20B** are SFT checkpoints.
|
||||||
|
| Model |Model Type | Transformers(HF) |OpenXLab| ModelScope | Release Date |
|
||||||
|
|---|---|---|---|---|---|
|
||||||
|
| **InternLM2-Math-Base-7B** | Base| [🤗internlm/internlm2-math-base-7b](https://huggingface.co/internlm/internlm2-math-base-7b) |[](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-Base-7B)| [<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> internlm2-math-base-7b](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-base-7b/summary)| 2024-01-23|
|
||||||
|
| **InternLM2-Math-Base-20B** | Base| [🤗internlm/internlm2-math-base-20b](https://huggingface.co/internlm/internlm2-math-base-20b) |[](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-Base-20B)|[<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> internlm2-math-base-20b](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-base-20b/summary)| 2024-01-23|
|
||||||
|
| **InternLM2-Math-7B** | Chat| [🤗internlm/internlm2-math-7b](https://huggingface.co/internlm/internlm2-math-7b) |[](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-7B)|[<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> internlm2-math-7b](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-7b/summary)| 2024-01-23|
|
||||||
|
| **InternLM2-Math-20B** | Chat| [🤗internlm/internlm2-math-20b](https://huggingface.co/internlm/internlm2-math-20b) |[](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-20B)|[<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> internlm2-math-20b](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-20b/summary)| 2024-01-23|
|
||||||
|
|
||||||
|
|
||||||
|
# Performance
|
||||||
|
|
||||||
|
## Pretrain Performance
|
||||||
|
We evaluate pretrain checkpoints based on greedy decoding with few-shot COT. Details of pretraining will be introduced in the tech report.
|
||||||
|
| Model | GSM8K | MATH |
|
||||||
|
|------------------------|---------|--------|
|
||||||
|
| Llama2-7B | 11.8 | 3.2 |
|
||||||
|
| Llemma-7B | 36.4 | 18.0 |
|
||||||
|
| InternLM2-Base-7B | 36.5 | 8.6 |
|
||||||
|
| **InternLM2-Math-Base-7B** | **49.2** | **21.5** |
|
||||||
|
| Minerva-8B | 16.2 | 14.1 |
|
||||||
|
| InternLM2-Base-20B | 54.6 | 13.7 |
|
||||||
|
| **InternLM2-Math-Base-20B** | **63.7** | **27.3** |
|
||||||
|
| Llemma-34B | 51.5 | 25.0 |
|
||||||
|
| Minerva-62B | 52.4 | 27.6 |
|
||||||
|
| Minerva-540B | 58.8 | 33.6 |
|
||||||
|
|
||||||
|
|
||||||
|
## SFT Peformance
|
||||||
|
All performance is based on greedy decoding with COT. We notice that the performance of Hungary has a big variance between our different checkpoints, while other performance is very stable. This may be due to the problem amount about Hungary.
|
||||||
|
| Model | Model Type | GSM8K | MATH | Hungary |
|
||||||
|
|------------------------|----------------------|--------|--------|---------|
|
||||||
|
| Qwen-7B-Chat | Genearl | 51.7 | 11.6 | - |
|
||||||
|
| DeepSeek-7B-Chat | General | 63.0 | 15.8 | 28.5 |
|
||||||
|
| InternLM2-Chat-7B | General | 70.7 | 23.0 | - |
|
||||||
|
| ChatGLM3-6B | General | 53.8 | 20.4 | 32 |
|
||||||
|
| MetaMath-Mistral-7B | Mathematics | 77.7 | 28.2 | 29 |
|
||||||
|
| MetaMath-Llemma-7B | Mathematics | 69.2 | 30.0 | - |
|
||||||
|
| **InternLM2-Math-7B** | Mathematics | **78.1** | **34.6** | **55** |
|
||||||
|
| InternLM2-Chat-20B | General | 79.6 | 31.9 | - |
|
||||||
|
| MetaMath-Llemma-34B | Mathematics | 75.8 | 34.8 | - |
|
||||||
|
| **InternLM2-Math-20B** | Mathematics | **82.6** | **37.7** | **66** |
|
||||||
|
| Qwen-72B | General | 78.9 | 35.2 | 52 |
|
||||||
|
| DeepSeek-67B | General | 84.1 | 32.6 | 58 |
|
||||||
|
| ChatGPT (GPT-3.5) | General | 80.8 | 34.1 | 41 |
|
||||||
|
| GPT4 (First version) | General | 92.0 | 42.5 | 68 |
|
||||||
|
|
||||||
|
# Inference
|
||||||
|
|
||||||
|
## LMDeploy
|
||||||
|
We suggest using [LMDeploy](https://github.com/InternLM/LMDeploy)(>=0.2.1) for inference.
|
||||||
|
```python
|
||||||
|
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
|
||||||
|
|
||||||
|
backend_config = TurbomindEngineConfig(model_name='internlm2-chat-7b', tp=1, cache_max_entry_count=0.3)
|
||||||
|
chat_template = ChatTemplateConfig(model_name='internlm2-chat-7b', system='', eosys='', meta_instruction='')
|
||||||
|
pipe = pipeline(model_path='internlm/internlm2-math-7b', chat_template_config=chat_template, backend_config=backend_config)
|
||||||
|
|
||||||
|
problem = '1+1='
|
||||||
|
result = pipe([problem], request_output_len=1024, top_k=1)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Huggingface
|
||||||
|
```python
|
||||||
|
import torch
|
||||||
|
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||||
|
tokenizer = AutoTokenizer.from_pretrained("internlm/internlm2-math-7b", trust_remote_code=True)
|
||||||
|
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and might cause OOM Error.
|
||||||
|
model = AutoModelForCausalLM.from_pretrained("internlm/internlm2-math-7b", trust_remote_code=True, torch_dtype=torch.float16).cuda()
|
||||||
|
model = model.eval()
|
||||||
|
response, history = model.chat(tokenizer, "1+1=", history=[], meta_instruction="")
|
||||||
|
print(response)
|
||||||
|
```
|
||||||
|
|
||||||
|
# Special usages
|
||||||
|
We list some instructions used in our SFT. You can use them to help you. You can use the other ways to prompt the model, but the following are recommended. InternLM2-Math may combine the following abilities but it is not guaranteed.
|
||||||
|
|
||||||
|
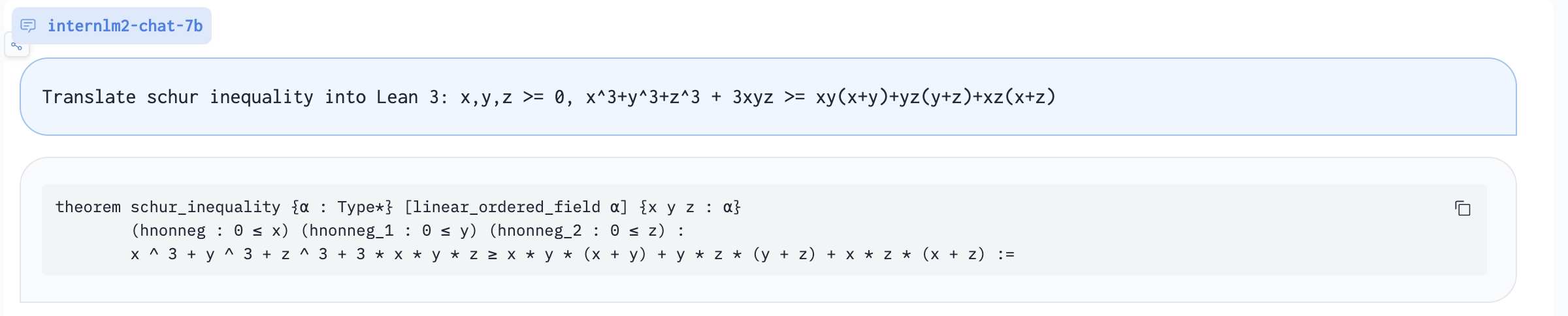
Translate proof problem to Lean:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Using Lean 3 to solve GSM8K problem:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
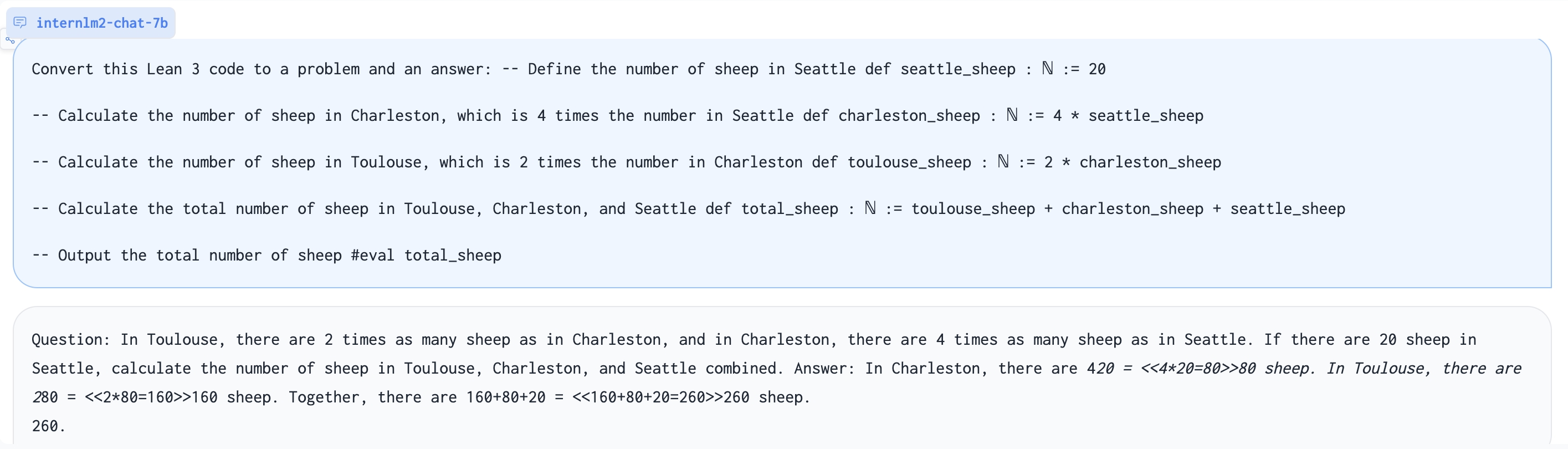
Generate problem based on Lean 3 code:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Play 24 point game:
|
||||||
|
|
||||||
|
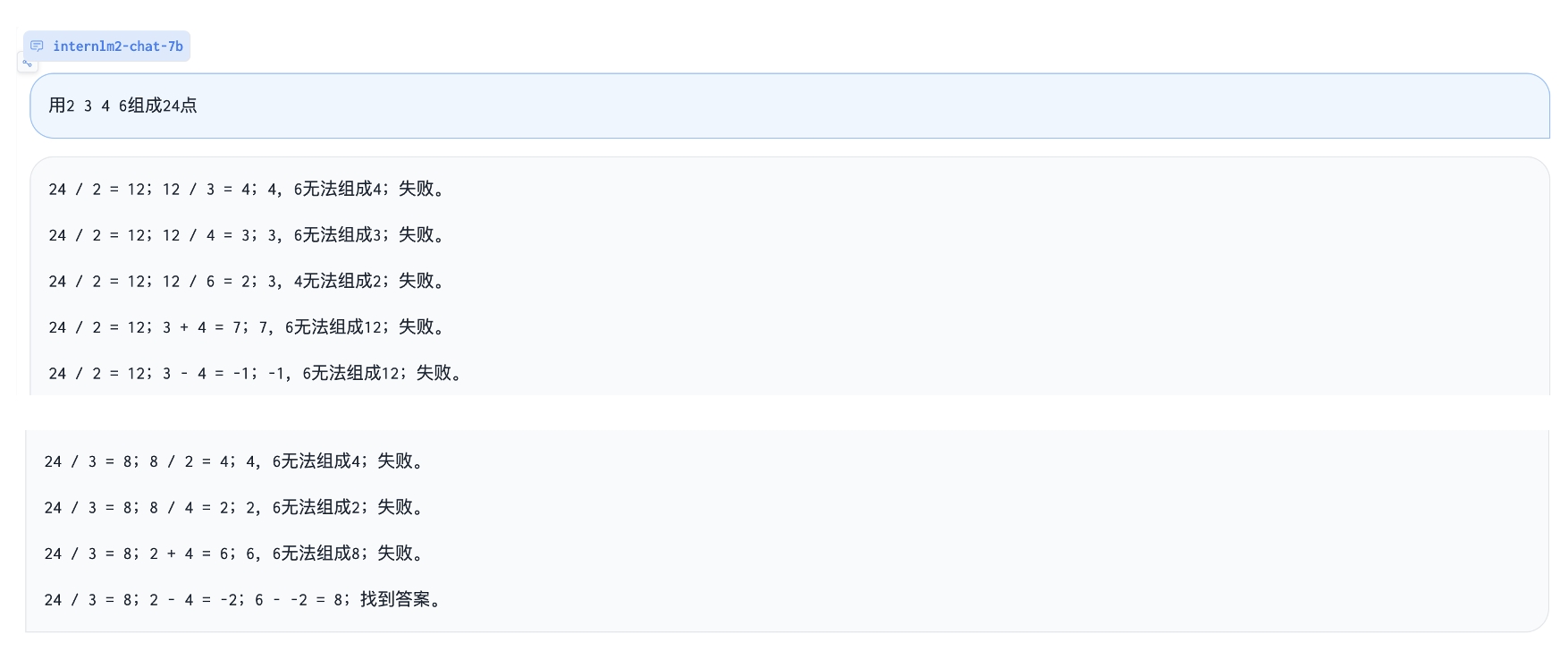
|
||||||
|
|
||||||
|
Augment a harder math problem:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
| Description | Query |
|
||||||
|
| --- | --- |
|
||||||
|
| Solving question via chain-of-thought | {Question} |
|
||||||
|
| Solving question via Lean 3 | {Question}\nSolve this via Lean 3 |
|
||||||
|
| Outcome reward model | Given a question and an answer, check is it correct?\nQuestion:{Question}\nAnswer:{COT} |
|
||||||
|
| Process reward model | Given a question and an answer, check correctness of each step.\nQuestion:{Question}\nAnswer:{COT} |
|
||||||
|
| Reward model | Given a question and two answers, which one is better? \nQuestion:{Question}\nAnswer 1:{COT}\nAnswer 2:{COT} |
|
||||||
|
| Convert chain-of-thought to Lean 3 | Convert this answer into Lean3. Question:{Question}\nAnswer:{COT} |
|
||||||
|
| Convert Lean 3 to chain-of-thought | Convert this lean 3 code into a natural language problem with answers:\n{LEAN Code} |
|
||||||
|
| Translate question and chain-of-thought answer to a proof statement | Convert this question and answer into a proof format.\nQuestion:{Question}\nAnswer:{COT} |
|
||||||
|
| Translate proof problem to Lean 3 | Convert this natural langauge statement into a Lean 3 theorem statement:{Theorem} |
|
||||||
|
| Translate Lean 3 to proof problem | Convert this Lean 3 theorem statement into natural language:{STATEMENT} |
|
||||||
|
| Suggest a tactic based on Lean state | Given the Lean 3 tactic state, suggest a next tactic:\n{LEAN State} |
|
||||||
|
| Rephrase Problem | Describe this problem in another way. {Question} |
|
||||||
|
| Augment Problem | Please augment a new problem based on: {Question} |
|
||||||
|
| Augment a harder Problem | Increase the complexity of the problem: {Question} |
|
||||||
|
| Change specific numbers | Change specific numbers: {Question}|
|
||||||
|
| Introduce fractions or percentages | Introduce fractions or percentages: {Question}|
|
||||||
|
| Code Interpreter | [lagent](https://github.com/InternLM/InternLM/blob/main/agent/lagent.md) |
|
||||||
|
| In-context Learning | Question:{Question}\nAnswer:{COT}\n...Question:{Question}\nAnswer:{COT}|
|
||||||
|
|
||||||
|
# Fine-tune and others
|
||||||
|
Please refer to [InternLM](https://github.com/InternLM/InternLM/tree/main).
|
||||||
|
|
||||||
|
# Known issues
|
||||||
|
Our model is still under development and will be upgraded. There are some possible issues of InternLM-Math. If you find performances of some abilities are not great, welcome to open an issue.
|
||||||
|
- Jump the calculating step.
|
||||||
|
- Perform badly at Chinese fill-in-the-bank problems and English choice problems due to SFT data composition.
|
||||||
|
- Tend to generate Code Interpreter when facing Chinese problems due to SFT data composition.
|
||||||
|
- The reward model mode can be better leveraged with assigned token probabilities.
|
||||||
|
- Code switch due to SFT data composition.
|
||||||
|
- Some abilities of Lean can only be adapted to GSM8K-like problems (e.g. Convert chain-of-thought to Lean 3), and performance related to Lean is not guaranteed.
|
||||||
|
|
||||||
|
# Citation and Tech Report
|
||||||
|
To be appended.
|
||||||
31
config.json
Normal file
31
config.json
Normal file
@@ -0,0 +1,31 @@
|
|||||||
|
{
|
||||||
|
"architectures": [
|
||||||
|
"InternLM2ForCausalLM"
|
||||||
|
],
|
||||||
|
"auto_map": {
|
||||||
|
"AutoConfig": "configuration_internlm2.InternLM2Config",
|
||||||
|
"AutoModelForCausalLM": "modeling_internlm2.InternLM2ForCausalLM",
|
||||||
|
"AutoModel": "modeling_internlm2.InternLM2ForCausalLM"
|
||||||
|
},
|
||||||
|
"bias": false,
|
||||||
|
"bos_token_id": 1,
|
||||||
|
"eos_token_id": 2,
|
||||||
|
"hidden_act": "silu",
|
||||||
|
"hidden_size": 4096,
|
||||||
|
"initializer_range": 0.02,
|
||||||
|
"intermediate_size": 14336,
|
||||||
|
"max_position_embeddings": 8192,
|
||||||
|
"model_type": "internlm2",
|
||||||
|
"num_attention_heads": 32,
|
||||||
|
"num_hidden_layers": 32,
|
||||||
|
"num_key_value_heads": 8,
|
||||||
|
"pad_token_id": 2,
|
||||||
|
"rms_norm_eps": 1e-05,
|
||||||
|
"rope_scaling": null,
|
||||||
|
"rope_theta": 1000000,
|
||||||
|
"tie_word_embeddings": false,
|
||||||
|
"torch_dtype": "bfloat16",
|
||||||
|
"transformers_version": "4.35.2",
|
||||||
|
"use_cache": true,
|
||||||
|
"vocab_size": 92544
|
||||||
|
}
|
||||||
1
configuration.json
Normal file
1
configuration.json
Normal file
@@ -0,0 +1 @@
|
|||||||
|
{"framework":"Pytorch","task":"text-generation"}
|
||||||
180
configuration_internlm2.py
Normal file
180
configuration_internlm2.py
Normal file
@@ -0,0 +1,180 @@
|
|||||||
|
# coding=utf-8
|
||||||
|
# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
|
||||||
|
#
|
||||||
|
# This code is based on transformers/src/transformers/models/llama/configuration_llama.py
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
""" InternLM2 model configuration"""
|
||||||
|
|
||||||
|
from transformers.configuration_utils import PretrainedConfig
|
||||||
|
from transformers.utils import logging
|
||||||
|
|
||||||
|
logger = logging.get_logger(__name__)
|
||||||
|
|
||||||
|
INTERNLM2_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
|
||||||
|
|
||||||
|
|
||||||
|
# Modified from transformers.model.llama.configuration_llama.LlamaConfig
|
||||||
|
class InternLM2Config(PretrainedConfig):
|
||||||
|
r"""
|
||||||
|
This is the configuration class to store the configuration of a [`InternLM2Model`]. It is used to instantiate
|
||||||
|
an InternLM2 model according to the specified arguments, defining the model architecture. Instantiating a
|
||||||
|
configuration with the defaults will yield a similar configuration to that of the InternLM2-7B.
|
||||||
|
|
||||||
|
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
||||||
|
documentation from [`PretrainedConfig`] for more information.
|
||||||
|
|
||||||
|
|
||||||
|
Args:
|
||||||
|
vocab_size (`int`, *optional*, defaults to 32000):
|
||||||
|
Vocabulary size of the InternLM2 model. Defines the number of different tokens that can be represented by the
|
||||||
|
`inputs_ids` passed when calling [`InternLM2Model`]
|
||||||
|
hidden_size (`int`, *optional*, defaults to 4096):
|
||||||
|
Dimension of the hidden representations.
|
||||||
|
intermediate_size (`int`, *optional*, defaults to 11008):
|
||||||
|
Dimension of the MLP representations.
|
||||||
|
num_hidden_layers (`int`, *optional*, defaults to 32):
|
||||||
|
Number of hidden layers in the Transformer decoder.
|
||||||
|
num_attention_heads (`int`, *optional*, defaults to 32):
|
||||||
|
Number of attention heads for each attention layer in the Transformer decoder.
|
||||||
|
num_key_value_heads (`int`, *optional*):
|
||||||
|
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
||||||
|
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
||||||
|
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
||||||
|
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
||||||
|
by meanpooling all the original heads within that group. For more details checkout [this
|
||||||
|
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
|
||||||
|
`num_attention_heads`.
|
||||||
|
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
||||||
|
The non-linear activation function (function or string) in the decoder.
|
||||||
|
max_position_embeddings (`int`, *optional*, defaults to 2048):
|
||||||
|
The maximum sequence length that this model might ever be used with. InternLM2 supports up to 32768 tokens.
|
||||||
|
initializer_range (`float`, *optional*, defaults to 0.02):
|
||||||
|
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
||||||
|
rms_norm_eps (`float`, *optional*, defaults to 1e-06):
|
||||||
|
The epsilon used by the rms normalization layers.
|
||||||
|
use_cache (`bool`, *optional*, defaults to `True`):
|
||||||
|
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
||||||
|
relevant if `config.is_decoder=True`.
|
||||||
|
pad_token_id (`int`, *optional*):
|
||||||
|
Padding token id.
|
||||||
|
bos_token_id (`int`, *optional*, defaults to 1):
|
||||||
|
Beginning of stream token id.
|
||||||
|
eos_token_id (`int`, *optional*, defaults to 2):
|
||||||
|
End of stream token id.
|
||||||
|
pretraining_tp (`int`, *optional*, defaults to 1):
|
||||||
|
Experimental feature. Tensor parallelism rank used during pretraining. Please refer to [this
|
||||||
|
document](https://huggingface.co/docs/transformers/main/perf_train_gpu_many#tensor-parallelism)
|
||||||
|
to understand more about it. This value is necessary to ensure exact reproducibility
|
||||||
|
of the pretraining results. Please refer to [this
|
||||||
|
issue](https://github.com/pytorch/pytorch/issues/76232).
|
||||||
|
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
|
||||||
|
Whether to tie weight embeddings
|
||||||
|
rope_theta (`float`, *optional*, defaults to 10000.0):
|
||||||
|
The base period of the RoPE embeddings.
|
||||||
|
rope_scaling (`Dict`, *optional*):
|
||||||
|
Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scaling
|
||||||
|
strategies: linear and dynamic. Their scaling factor must be a float greater than 1. The expected format is
|
||||||
|
`{"type": strategy name, "factor": scaling factor}`. When using this flag, don't update
|
||||||
|
`max_position_embeddings` to the expected new maximum. See the following thread for more information on how
|
||||||
|
these scaling strategies behave:
|
||||||
|
https://www.reddit.com/r/LocalLLaMA/comments/14mrgpr/dynamically_scaled_rope_further_increases/. This is an
|
||||||
|
experimental feature, subject to breaking API changes in future versions.
|
||||||
|
"""
|
||||||
|
_auto_class = "AutoConfig"
|
||||||
|
model_type = "internlm2"
|
||||||
|
keys_to_ignore_at_inference = ["past_key_values"]
|
||||||
|
|
||||||
|
def __init__( # pylint: disable=W0102
|
||||||
|
self,
|
||||||
|
vocab_size=103168,
|
||||||
|
hidden_size=4096,
|
||||||
|
intermediate_size=11008,
|
||||||
|
num_hidden_layers=32,
|
||||||
|
num_attention_heads=32,
|
||||||
|
num_key_value_heads=None,
|
||||||
|
hidden_act="silu",
|
||||||
|
max_position_embeddings=2048,
|
||||||
|
initializer_range=0.02,
|
||||||
|
rms_norm_eps=1e-6,
|
||||||
|
use_cache=True,
|
||||||
|
pad_token_id=0,
|
||||||
|
bos_token_id=1,
|
||||||
|
eos_token_id=2,
|
||||||
|
pretraining_tp=1,
|
||||||
|
tie_word_embeddings=False,
|
||||||
|
bias=True,
|
||||||
|
rope_theta=10000,
|
||||||
|
rope_scaling=None,
|
||||||
|
attn_implementation=None,
|
||||||
|
**kwargs,
|
||||||
|
):
|
||||||
|
self.vocab_size = vocab_size
|
||||||
|
self.max_position_embeddings = max_position_embeddings
|
||||||
|
self.hidden_size = hidden_size
|
||||||
|
self.intermediate_size = intermediate_size
|
||||||
|
self.num_hidden_layers = num_hidden_layers
|
||||||
|
self.num_attention_heads = num_attention_heads
|
||||||
|
self.bias = bias
|
||||||
|
|
||||||
|
if num_key_value_heads is None:
|
||||||
|
num_key_value_heads = num_attention_heads
|
||||||
|
self.num_key_value_heads = num_key_value_heads
|
||||||
|
|
||||||
|
self.hidden_act = hidden_act
|
||||||
|
self.initializer_range = initializer_range
|
||||||
|
self.rms_norm_eps = rms_norm_eps
|
||||||
|
self.pretraining_tp = pretraining_tp
|
||||||
|
self.use_cache = use_cache
|
||||||
|
self.rope_theta = rope_theta
|
||||||
|
self.rope_scaling = rope_scaling
|
||||||
|
self._rope_scaling_validation()
|
||||||
|
self.attn_implementation = attn_implementation
|
||||||
|
if self.attn_implementation is None:
|
||||||
|
self.attn_implementation = "eager"
|
||||||
|
|
||||||
|
super().__init__(
|
||||||
|
pad_token_id=pad_token_id,
|
||||||
|
bos_token_id=bos_token_id,
|
||||||
|
eos_token_id=eos_token_id,
|
||||||
|
tie_word_embeddings=tie_word_embeddings,
|
||||||
|
**kwargs,
|
||||||
|
)
|
||||||
|
|
||||||
|
def _rope_scaling_validation(self):
|
||||||
|
"""
|
||||||
|
Validate the `rope_scaling` configuration.
|
||||||
|
"""
|
||||||
|
if self.rope_scaling is None:
|
||||||
|
return
|
||||||
|
|
||||||
|
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
|
||||||
|
raise ValueError(
|
||||||
|
"`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
|
||||||
|
f"got {self.rope_scaling}"
|
||||||
|
)
|
||||||
|
rope_scaling_type = self.rope_scaling.get("type", None)
|
||||||
|
rope_scaling_factor = self.rope_scaling.get("factor", None)
|
||||||
|
if rope_scaling_type is None or rope_scaling_type not in ["linear", "dynamic"]:
|
||||||
|
raise ValueError(
|
||||||
|
f"`rope_scaling`'s type field must be one of ['linear', 'dynamic'], got {rope_scaling_type}"
|
||||||
|
)
|
||||||
|
if (
|
||||||
|
rope_scaling_factor is None
|
||||||
|
or not isinstance(rope_scaling_factor, (float, int))
|
||||||
|
or rope_scaling_factor < 1.0
|
||||||
|
):
|
||||||
|
raise ValueError(
|
||||||
|
f"`rope_scaling`'s factor field must be a number >= 1, got {rope_scaling_factor} "
|
||||||
|
f"of type {type(rope_scaling_factor)}"
|
||||||
|
)
|
||||||
7
generation_config.json
Normal file
7
generation_config.json
Normal file
@@ -0,0 +1,7 @@
|
|||||||
|
{
|
||||||
|
"_from_model_config": true,
|
||||||
|
"bos_token_id": 1,
|
||||||
|
"eos_token_id": 2,
|
||||||
|
"pad_token_id": 2,
|
||||||
|
"transformers_version": "4.35.2"
|
||||||
|
}
|
||||||
3
model-00001-of-00008.safetensors
Normal file
3
model-00001-of-00008.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:805c5cb26f13ef9372d1b5cd5eed7c874626bc855bd8681d708d403f5e690ac9
|
||||||
|
size 1949337704
|
||||||
3
model-00002-of-00008.safetensors
Normal file
3
model-00002-of-00008.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:000c206e25036da7f7fb575a784f523837b14bffaf4baeed6e73be16c61a33c1
|
||||||
|
size 1946242696
|
||||||
3
model-00003-of-00008.safetensors
Normal file
3
model-00003-of-00008.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:a1f07197d4a1e68282b703f8c082cfdb49a10bc64552c79993f112da2002bb00
|
||||||
|
size 1979780440
|
||||||
3
model-00004-of-00008.safetensors
Normal file
3
model-00004-of-00008.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:50c67c286659e0620bc1ad1a63715ac8e5792acb68f9a6bd3151f9e567db9013
|
||||||
|
size 1946242728
|
||||||
3
model-00005-of-00008.safetensors
Normal file
3
model-00005-of-00008.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:bd428388ca2dee0f5dfa37b7195c3bc19dc147076cf2329b258e2c3d7ac3fdee
|
||||||
|
size 1979780456
|
||||||
3
model-00006-of-00008.safetensors
Normal file
3
model-00006-of-00008.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:7f7080f96552a49b6dca1a1cd68dbbaf15d722d8ad5474b8fe14a0caef86ec92
|
||||||
|
size 1946242728
|
||||||
3
model-00007-of-00008.safetensors
Normal file
3
model-00007-of-00008.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:7aaff62b19c84b49fe6236425a2aaaa4856b586766cb8ddacf7aef2ac949c57a
|
||||||
|
size 1979780456
|
||||||
3
model-00008-of-00008.safetensors
Normal file
3
model-00008-of-00008.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:7b5aa160d13657d686c74c063030de0bde6999c3582c6993397dae8973d917b6
|
||||||
|
size 1748035640
|
||||||
234
model.safetensors.index.json
Normal file
234
model.safetensors.index.json
Normal file
@@ -0,0 +1,234 @@
|
|||||||
|
{
|
||||||
|
"metadata": {
|
||||||
|
"total_size": 15475417088
|
||||||
|
},
|
||||||
|
"weight_map": {
|
||||||
|
"model.layers.0.attention.wo.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.0.attention.wqkv.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.0.attention_norm.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.0.feed_forward.w1.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.0.feed_forward.w2.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.0.feed_forward.w3.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.0.ffn_norm.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.1.attention.wo.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.1.attention.wqkv.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.1.attention_norm.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.1.feed_forward.w1.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.1.feed_forward.w2.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.1.feed_forward.w3.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.1.ffn_norm.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.10.attention.wo.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.10.attention.wqkv.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.10.attention_norm.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.10.feed_forward.w1.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.10.feed_forward.w2.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.10.feed_forward.w3.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.10.ffn_norm.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.11.attention.wo.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.11.attention.wqkv.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.11.attention_norm.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.11.feed_forward.w1.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.11.feed_forward.w2.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.11.feed_forward.w3.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.11.ffn_norm.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.12.attention.wo.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.12.attention.wqkv.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.12.attention_norm.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.12.feed_forward.w1.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.12.feed_forward.w2.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.12.feed_forward.w3.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.12.ffn_norm.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.13.attention.wo.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.13.attention.wqkv.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.13.attention_norm.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.13.feed_forward.w1.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.13.feed_forward.w2.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.13.feed_forward.w3.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.13.ffn_norm.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.14.attention.wo.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.14.attention.wqkv.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.14.attention_norm.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.14.feed_forward.w1.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.14.feed_forward.w2.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.14.feed_forward.w3.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.14.ffn_norm.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.15.attention.wo.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.15.attention.wqkv.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.15.attention_norm.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.15.feed_forward.w1.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.15.feed_forward.w2.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.15.feed_forward.w3.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.15.ffn_norm.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.16.attention.wo.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.16.attention.wqkv.weight": "model-00004-of-00008.safetensors",
|
||||||
|
"model.layers.16.attention_norm.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.16.feed_forward.w1.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.16.feed_forward.w2.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.16.feed_forward.w3.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.16.ffn_norm.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.17.attention.wo.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.17.attention.wqkv.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.17.attention_norm.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.17.feed_forward.w1.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.17.feed_forward.w2.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.17.feed_forward.w3.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.17.ffn_norm.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.18.attention.wo.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.18.attention.wqkv.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.18.attention_norm.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.18.feed_forward.w1.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.18.feed_forward.w2.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.18.feed_forward.w3.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.18.ffn_norm.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.19.attention.wo.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.19.attention.wqkv.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.19.attention_norm.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.19.feed_forward.w1.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.19.feed_forward.w2.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.19.feed_forward.w3.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.19.ffn_norm.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.2.attention.wo.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.2.attention.wqkv.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.2.attention_norm.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.2.feed_forward.w1.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.2.feed_forward.w2.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.2.feed_forward.w3.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"model.layers.2.ffn_norm.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.20.attention.wo.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.20.attention.wqkv.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.20.attention_norm.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.20.feed_forward.w1.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.20.feed_forward.w2.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.20.feed_forward.w3.weight": "model-00005-of-00008.safetensors",
|
||||||
|
"model.layers.20.ffn_norm.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.21.attention.wo.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.21.attention.wqkv.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.21.attention_norm.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.21.feed_forward.w1.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.21.feed_forward.w2.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.21.feed_forward.w3.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.21.ffn_norm.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.22.attention.wo.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.22.attention.wqkv.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.22.attention_norm.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.22.feed_forward.w1.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.22.feed_forward.w2.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.22.feed_forward.w3.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.22.ffn_norm.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.23.attention.wo.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.23.attention.wqkv.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.23.attention_norm.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.23.feed_forward.w1.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.23.feed_forward.w2.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.23.feed_forward.w3.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.23.ffn_norm.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.24.attention.wo.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.24.attention.wqkv.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.24.attention_norm.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.24.feed_forward.w1.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.24.feed_forward.w2.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.24.feed_forward.w3.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.24.ffn_norm.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.25.attention.wo.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.25.attention.wqkv.weight": "model-00006-of-00008.safetensors",
|
||||||
|
"model.layers.25.attention_norm.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.25.feed_forward.w1.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.25.feed_forward.w2.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.25.feed_forward.w3.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.25.ffn_norm.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.26.attention.wo.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.26.attention.wqkv.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.26.attention_norm.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.26.feed_forward.w1.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.26.feed_forward.w2.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.26.feed_forward.w3.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.26.ffn_norm.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.27.attention.wo.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.27.attention.wqkv.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.27.attention_norm.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.27.feed_forward.w1.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.27.feed_forward.w2.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.27.feed_forward.w3.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.27.ffn_norm.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.28.attention.wo.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.28.attention.wqkv.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.28.attention_norm.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.28.feed_forward.w1.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.28.feed_forward.w2.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.28.feed_forward.w3.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.28.ffn_norm.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.29.attention.wo.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.29.attention.wqkv.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.29.attention_norm.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.29.feed_forward.w1.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.29.feed_forward.w2.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.29.feed_forward.w3.weight": "model-00007-of-00008.safetensors",
|
||||||
|
"model.layers.29.ffn_norm.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.3.attention.wo.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.3.attention.wqkv.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.3.attention_norm.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.3.feed_forward.w1.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.3.feed_forward.w2.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.3.feed_forward.w3.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.3.ffn_norm.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.30.attention.wo.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.30.attention.wqkv.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.30.attention_norm.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.30.feed_forward.w1.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.30.feed_forward.w2.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.30.feed_forward.w3.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.30.ffn_norm.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.31.attention.wo.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.31.attention.wqkv.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.31.attention_norm.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.31.feed_forward.w1.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.31.feed_forward.w2.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.31.feed_forward.w3.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.31.ffn_norm.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.layers.4.attention.wo.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.4.attention.wqkv.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.4.attention_norm.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.4.feed_forward.w1.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.4.feed_forward.w2.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.4.feed_forward.w3.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.4.ffn_norm.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.5.attention.wo.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.5.attention.wqkv.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.5.attention_norm.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.5.feed_forward.w1.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.5.feed_forward.w2.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.5.feed_forward.w3.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.5.ffn_norm.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.6.attention.wo.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.6.attention.wqkv.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.6.attention_norm.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.6.feed_forward.w1.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.6.feed_forward.w2.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.6.feed_forward.w3.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.6.ffn_norm.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.7.attention.wo.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.7.attention.wqkv.weight": "model-00002-of-00008.safetensors",
|
||||||
|
"model.layers.7.attention_norm.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.7.feed_forward.w1.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.7.feed_forward.w2.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.7.feed_forward.w3.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.7.ffn_norm.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.8.attention.wo.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.8.attention.wqkv.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.8.attention_norm.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.8.feed_forward.w1.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.8.feed_forward.w2.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.8.feed_forward.w3.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.8.ffn_norm.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.9.attention.wo.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.9.attention.wqkv.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.9.attention_norm.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.9.feed_forward.w1.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.9.feed_forward.w2.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.9.feed_forward.w3.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.layers.9.ffn_norm.weight": "model-00003-of-00008.safetensors",
|
||||||
|
"model.norm.weight": "model-00008-of-00008.safetensors",
|
||||||
|
"model.tok_embeddings.weight": "model-00001-of-00008.safetensors",
|
||||||
|
"output.weight": "model-00008-of-00008.safetensors"
|
||||||
|
}
|
||||||
|
}
|
||||||
1808
modeling_internlm2.py
Normal file
1808
modeling_internlm2.py
Normal file
File diff suppressed because it is too large
Load Diff
14
special_tokens_map.json
Normal file
14
special_tokens_map.json
Normal file
@@ -0,0 +1,14 @@
|
|||||||
|
{
|
||||||
|
"additional_special_tokens": [
|
||||||
|
"<|im_start|>",
|
||||||
|
"<|im_end|>",
|
||||||
|
"<|action_start|>",
|
||||||
|
"<|action_end|>",
|
||||||
|
"<|interpreter|>",
|
||||||
|
"<|plugin|>"
|
||||||
|
],
|
||||||
|
"bos_token": "<s>",
|
||||||
|
"eos_token": "</s>",
|
||||||
|
"pad_token": "</s>",
|
||||||
|
"unk_token": "<unk>"
|
||||||
|
}
|
||||||
236
tokenization_internlm2.py
Normal file
236
tokenization_internlm2.py
Normal file
@@ -0,0 +1,236 @@
|
|||||||
|
# coding=utf-8
|
||||||
|
# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
|
||||||
|
#
|
||||||
|
# This code is based on transformers/src/transformers/models/llama/tokenization_llama.py
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
|
||||||
|
"""Tokenization classes for InternLM."""
|
||||||
|
import os
|
||||||
|
from shutil import copyfile
|
||||||
|
from typing import Any, Dict, List, Optional, Tuple
|
||||||
|
|
||||||
|
import sentencepiece as spm
|
||||||
|
from transformers.tokenization_utils import PreTrainedTokenizer
|
||||||
|
from transformers.utils import logging
|
||||||
|
|
||||||
|
logger = logging.get_logger(__name__)
|
||||||
|
|
||||||
|
VOCAB_FILES_NAMES = {"vocab_file": "./tokenizer.model"}
|
||||||
|
|
||||||
|
PRETRAINED_VOCAB_FILES_MAP = {}
|
||||||
|
|
||||||
|
|
||||||
|
# Modified from transformers.model.llama.tokenization_llama.LlamaTokenizer
|
||||||
|
class InternLM2Tokenizer(PreTrainedTokenizer):
|
||||||
|
"""
|
||||||
|
Construct a InternLM2 tokenizer. Based on byte-level Byte-Pair-Encoding.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
vocab_file (`str`):
|
||||||
|
Path to the vocabulary file.
|
||||||
|
"""
|
||||||
|
|
||||||
|
vocab_files_names = VOCAB_FILES_NAMES
|
||||||
|
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
|
||||||
|
model_input_names = ["input_ids", "attention_mask"]
|
||||||
|
_auto_class = "AutoTokenizer"
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
vocab_file,
|
||||||
|
unk_token="<unk>",
|
||||||
|
bos_token="<s>",
|
||||||
|
eos_token="</s>",
|
||||||
|
pad_token="</s>",
|
||||||
|
sp_model_kwargs: Optional[Dict[str, Any]] = None,
|
||||||
|
add_bos_token=True,
|
||||||
|
add_eos_token=False,
|
||||||
|
decode_with_prefix_space=False,
|
||||||
|
clean_up_tokenization_spaces=False,
|
||||||
|
**kwargs,
|
||||||
|
):
|
||||||
|
self.sp_model_kwargs = {} if sp_model_kwargs is None else sp_model_kwargs
|
||||||
|
self.vocab_file = vocab_file
|
||||||
|
self.add_bos_token = add_bos_token
|
||||||
|
self.add_eos_token = add_eos_token
|
||||||
|
self.decode_with_prefix_space = decode_with_prefix_space
|
||||||
|
self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
|
||||||
|
self.sp_model.Load(vocab_file)
|
||||||
|
self._no_prefix_space_tokens = None
|
||||||
|
super().__init__(
|
||||||
|
bos_token=bos_token,
|
||||||
|
eos_token=eos_token,
|
||||||
|
unk_token=unk_token,
|
||||||
|
pad_token=pad_token,
|
||||||
|
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
|
||||||
|
**kwargs,
|
||||||
|
)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def no_prefix_space_tokens(self):
|
||||||
|
if self._no_prefix_space_tokens is None:
|
||||||
|
vocab = self.convert_ids_to_tokens(list(range(self.vocab_size)))
|
||||||
|
self._no_prefix_space_tokens = {i for i, tok in enumerate(vocab) if not tok.startswith("▁")}
|
||||||
|
return self._no_prefix_space_tokens
|
||||||
|
|
||||||
|
@property
|
||||||
|
def vocab_size(self):
|
||||||
|
"""Returns vocab size"""
|
||||||
|
return self.sp_model.get_piece_size()
|
||||||
|
|
||||||
|
@property
|
||||||
|
def bos_token_id(self) -> Optional[int]:
|
||||||
|
return self.sp_model.bos_id()
|
||||||
|
|
||||||
|
@property
|
||||||
|
def eos_token_id(self) -> Optional[int]:
|
||||||
|
return self.sp_model.eos_id()
|
||||||
|
|
||||||
|
def get_vocab(self):
|
||||||
|
"""Returns vocab as a dict"""
|
||||||
|
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
|
||||||
|
vocab.update(self.added_tokens_encoder)
|
||||||
|
return vocab
|
||||||
|
|
||||||
|
def _tokenize(self, text):
|
||||||
|
"""Returns a tokenized string."""
|
||||||
|
return self.sp_model.encode(text, out_type=str)
|
||||||
|
|
||||||
|
def _convert_token_to_id(self, token):
|
||||||
|
"""Converts a token (str) in an id using the vocab."""
|
||||||
|
return self.sp_model.piece_to_id(token)
|
||||||
|
|
||||||
|
def _convert_id_to_token(self, index):
|
||||||
|
"""Converts an index (integer) in a token (str) using the vocab."""
|
||||||
|
token = self.sp_model.IdToPiece(index)
|
||||||
|
return token
|
||||||
|
|
||||||
|
def _maybe_add_prefix_space(self, tokens, decoded):
|
||||||
|
if tokens and tokens[0] not in self.no_prefix_space_tokens:
|
||||||
|
return " " + decoded
|
||||||
|
else:
|
||||||
|
return decoded
|
||||||
|
|
||||||
|
def convert_tokens_to_string(self, tokens):
|
||||||
|
"""Converts a sequence of tokens (string) in a single string."""
|
||||||
|
current_sub_tokens = []
|
||||||
|
out_string = ""
|
||||||
|
prev_is_special = False
|
||||||
|
for token in tokens:
|
||||||
|
# make sure that special tokens are not decoded using sentencepiece model
|
||||||
|
if token in self.all_special_tokens:
|
||||||
|
if not prev_is_special:
|
||||||
|
out_string += " "
|
||||||
|
out_string += self.sp_model.decode(current_sub_tokens) + token
|
||||||
|
prev_is_special = True
|
||||||
|
current_sub_tokens = []
|
||||||
|
else:
|
||||||
|
current_sub_tokens.append(token)
|
||||||
|
prev_is_special = False
|
||||||
|
out_string += self.sp_model.decode(current_sub_tokens)
|
||||||
|
out_string = self.clean_up_tokenization(out_string)
|
||||||
|
out_string = self._maybe_add_prefix_space(tokens=tokens, decoded=out_string)
|
||||||
|
return out_string[1:]
|
||||||
|
|
||||||
|
def save_vocabulary(self, save_directory, filename_prefix: Optional[str] = None) -> Tuple[str]:
|
||||||
|
"""
|
||||||
|
Save the vocabulary and special tokens file to a directory.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
save_directory (`str`):
|
||||||
|
The directory in which to save the vocabulary.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
`Tuple(str)`: Paths to the files saved.
|
||||||
|
"""
|
||||||
|
if not os.path.isdir(save_directory):
|
||||||
|
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
|
||||||
|
return
|
||||||
|
out_vocab_file = os.path.join(
|
||||||
|
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
|
||||||
|
)
|
||||||
|
|
||||||
|
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file) and os.path.isfile(self.vocab_file):
|
||||||
|
copyfile(self.vocab_file, out_vocab_file)
|
||||||
|
elif not os.path.isfile(self.vocab_file):
|
||||||
|
with open(out_vocab_file, "wb") as fi:
|
||||||
|
content_spiece_model = self.sp_model.serialized_model_proto()
|
||||||
|
fi.write(content_spiece_model)
|
||||||
|
|
||||||
|
return (out_vocab_file,)
|
||||||
|
|
||||||
|
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
|
||||||
|
if self.add_bos_token:
|
||||||
|
bos_token_ids = [self.bos_token_id]
|
||||||
|
else:
|
||||||
|
bos_token_ids = []
|
||||||
|
|
||||||
|
output = bos_token_ids + token_ids_0
|
||||||
|
|
||||||
|
if token_ids_1 is not None:
|
||||||
|
output = output + token_ids_1
|
||||||
|
|
||||||
|
if self.add_eos_token:
|
||||||
|
output = output + [self.eos_token_id]
|
||||||
|
|
||||||
|
return output
|
||||||
|
|
||||||
|
def get_special_tokens_mask(
|
||||||
|
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
|
||||||
|
) -> List[int]:
|
||||||
|
"""
|
||||||
|
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
|
||||||
|
special tokens using the tokenizer `prepare_for_model` method.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
token_ids_0 (`List[int]`):
|
||||||
|
List of IDs.
|
||||||
|
token_ids_1 (`List[int]`, *optional*):
|
||||||
|
Optional second list of IDs for sequence pairs.
|
||||||
|
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
|
||||||
|
Whether or not the token list is already formatted with special tokens for the model.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
|
||||||
|
"""
|
||||||
|
if already_has_special_tokens:
|
||||||
|
return super().get_special_tokens_mask(
|
||||||
|
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
|
||||||
|
)
|
||||||
|
|
||||||
|
if token_ids_1 is None:
|
||||||
|
return [1] + ([0] * len(token_ids_0)) + [1]
|
||||||
|
return [1] + ([0] * len(token_ids_0)) + [1, 1] + ([0] * len(token_ids_1)) + [1]
|
||||||
|
|
||||||
|
def create_token_type_ids_from_sequences(
|
||||||
|
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
|
||||||
|
) -> List[int]:
|
||||||
|
"""
|
||||||
|
Create a mask from the two sequences passed to be used in a sequence-pair classification task. T5 does not make
|
||||||
|
use of token type ids, therefore a list of zeros is returned.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
token_ids_0 (`List[int]`):
|
||||||
|
List of IDs.
|
||||||
|
token_ids_1 (`List[int]`, *optional*):
|
||||||
|
Optional second list of IDs for sequence pairs.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
`List[int]`: List of zeros.
|
||||||
|
"""
|
||||||
|
eos = [self.eos_token_id]
|
||||||
|
|
||||||
|
if token_ids_1 is None:
|
||||||
|
return len(token_ids_0 + eos) * [0]
|
||||||
|
return len(token_ids_0 + eos + token_ids_1 + eos) * [0]
|
||||||
214
tokenization_internlm2_fast.py
Normal file
214
tokenization_internlm2_fast.py
Normal file
@@ -0,0 +1,214 @@
|
|||||||
|
# coding=utf-8
|
||||||
|
# Copyright (c) The InternLM team and The HuggingFace Inc. team. All rights reserved.
|
||||||
|
#
|
||||||
|
# This code is based on transformers/src/transformers/models/llama/tokenization_llama_fast.py
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
|
||||||
|
"""Tokenization Fast class for InternLM."""
|
||||||
|
import os
|
||||||
|
from shutil import copyfile
|
||||||
|
from typing import Any, Dict, Optional, Tuple
|
||||||
|
|
||||||
|
from tokenizers import processors, decoders, Tokenizer, normalizers
|
||||||
|
from tokenizers.models import BPE
|
||||||
|
|
||||||
|
from transformers.tokenization_utils_fast import PreTrainedTokenizerFast
|
||||||
|
from transformers.utils import logging
|
||||||
|
|
||||||
|
from transformers.convert_slow_tokenizer import (
|
||||||
|
SLOW_TO_FAST_CONVERTERS,
|
||||||
|
SpmConverter,
|
||||||
|
SentencePieceExtractor,
|
||||||
|
)
|
||||||
|
|
||||||
|
from .tokenization_internlm2 import InternLM2Tokenizer
|
||||||
|
|
||||||
|
logger = logging.get_logger(__name__)
|
||||||
|
|
||||||
|
VOCAB_FILES_NAMES = {"vocab_file": "./tokenizer.model"}
|
||||||
|
|
||||||
|
# Modified from transformers.convert_slow_tokenizer.LlamaConverter
|
||||||
|
class InternLM2Converter(SpmConverter):
|
||||||
|
handle_byte_fallback = True
|
||||||
|
|
||||||
|
def vocab(self, proto):
|
||||||
|
vocab = [
|
||||||
|
("<unk>", 0.0),
|
||||||
|
("<s>", 0.0),
|
||||||
|
("</s>", 0.0),
|
||||||
|
]
|
||||||
|
vocab += [(piece.piece, piece.score) for piece in proto.pieces[3:]]
|
||||||
|
return vocab
|
||||||
|
|
||||||
|
def unk_id(self, proto):
|
||||||
|
unk_id = 0
|
||||||
|
return unk_id
|
||||||
|
|
||||||
|
def decoder(self, replacement, add_prefix_space):
|
||||||
|
decoders_sequence = [
|
||||||
|
decoders.Replace("▁", " "),
|
||||||
|
decoders.ByteFallback(),
|
||||||
|
decoders.Fuse(),
|
||||||
|
]
|
||||||
|
if self.proto.normalizer_spec.add_dummy_prefix:
|
||||||
|
decoders_sequence.append(decoders.Strip(content=" ", left=1))
|
||||||
|
return decoders.Sequence(decoders_sequence)
|
||||||
|
|
||||||
|
def tokenizer(self, proto):
|
||||||
|
model_type = proto.trainer_spec.model_type
|
||||||
|
vocab_scores = self.vocab(proto)
|
||||||
|
# special tokens
|
||||||
|
added_tokens = self.original_tokenizer.added_tokens_decoder
|
||||||
|
for i in range(len(vocab_scores)):
|
||||||
|
piece, score = vocab_scores[i]
|
||||||
|
if i in added_tokens:
|
||||||
|
vocab_scores[i] = (added_tokens[i].content, score)
|
||||||
|
if model_type == 1:
|
||||||
|
raise RuntimeError("InternLM2 is supposed to be a BPE model!")
|
||||||
|
|
||||||
|
elif model_type == 2:
|
||||||
|
_, merges = SentencePieceExtractor(self.original_tokenizer.vocab_file).extract(vocab_scores)
|
||||||
|
bpe_vocab = {word: i for i, (word, _score) in enumerate(vocab_scores)}
|
||||||
|
tokenizer = Tokenizer(
|
||||||
|
BPE(bpe_vocab, merges, unk_token=proto.trainer_spec.unk_piece, fuse_unk=True, byte_fallback=True)
|
||||||
|
)
|
||||||
|
tokenizer.add_special_tokens(
|
||||||
|
[ added_token for index, added_token in added_tokens.items()]
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise Exception(
|
||||||
|
"You're trying to run a `Unigram` model but you're file was trained with a different algorithm"
|
||||||
|
)
|
||||||
|
|
||||||
|
return tokenizer
|
||||||
|
|
||||||
|
def normalizer(self, proto):
|
||||||
|
normalizers_list = []
|
||||||
|
if proto.normalizer_spec.add_dummy_prefix:
|
||||||
|
normalizers_list.append(normalizers.Prepend(prepend="▁"))
|
||||||
|
normalizers_list.append(normalizers.Replace(pattern=" ", content="▁"))
|
||||||
|
return normalizers.Sequence(normalizers_list)
|
||||||
|
|
||||||
|
def pre_tokenizer(self, replacement, add_prefix_space):
|
||||||
|
return None
|
||||||
|
|
||||||
|
SLOW_TO_FAST_CONVERTERS["InternLM2Tokenizer"] = InternLM2Converter
|
||||||
|
|
||||||
|
|
||||||
|
# Modified from transformers.model.llama.tokenization_llama_fast.LlamaTokenizerFast -> InternLM2TokenizerFast
|
||||||
|
class InternLM2TokenizerFast(PreTrainedTokenizerFast):
|
||||||
|
vocab_files_names = VOCAB_FILES_NAMES
|
||||||
|
slow_tokenizer_class = InternLM2Tokenizer
|
||||||
|
padding_side = "left"
|
||||||
|
model_input_names = ["input_ids", "attention_mask"]
|
||||||
|
_auto_class = "AutoTokenizer"
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
vocab_file,
|
||||||
|
unk_token="<unk>",
|
||||||
|
bos_token="<s>",
|
||||||
|
eos_token="</s>",
|
||||||
|
pad_token="</s>",
|
||||||
|
sp_model_kwargs: Optional[Dict[str, Any]] = None,
|
||||||
|
add_bos_token=True,
|
||||||
|
add_eos_token=False,
|
||||||
|
decode_with_prefix_space=False,
|
||||||
|
clean_up_tokenization_spaces=False,
|
||||||
|
**kwargs,
|
||||||
|
):
|
||||||
|
super().__init__(
|
||||||
|
vocab_file=vocab_file,
|
||||||
|
unk_token=unk_token,
|
||||||
|
bos_token=bos_token,
|
||||||
|
eos_token=eos_token,
|
||||||
|
pad_token=pad_token,
|
||||||
|
sp_model_kwargs=sp_model_kwargs,
|
||||||
|
add_bos_token=add_bos_token,
|
||||||
|
add_eos_token=add_eos_token,
|
||||||
|
decode_with_prefix_space=decode_with_prefix_space,
|
||||||
|
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
|
||||||
|
**kwargs,
|
||||||
|
)
|
||||||
|
self._add_bos_token = add_bos_token
|
||||||
|
self._add_eos_token = add_eos_token
|
||||||
|
self.update_post_processor()
|
||||||
|
self.vocab_file = vocab_file
|
||||||
|
|
||||||
|
@property
|
||||||
|
def can_save_slow_tokenizer(self) -> bool:
|
||||||
|
return os.path.isfile(self.vocab_file) if self.vocab_file else False
|
||||||
|
|
||||||
|
def update_post_processor(self):
|
||||||
|
"""
|
||||||
|
Updates the underlying post processor with the current `bos_token` and `eos_token`.
|
||||||
|
"""
|
||||||
|
bos = self.bos_token
|
||||||
|
bos_token_id = self.bos_token_id
|
||||||
|
if bos is None and self.add_bos_token:
|
||||||
|
raise ValueError("add_bos_token = True but bos_token = None")
|
||||||
|
|
||||||
|
eos = self.eos_token
|
||||||
|
eos_token_id = self.eos_token_id
|
||||||
|
if eos is None and self.add_eos_token:
|
||||||
|
raise ValueError("add_eos_token = True but eos_token = None")
|
||||||
|
|
||||||
|
single = f"{(bos+':0 ') if self.add_bos_token else ''}$A:0{(' '+eos+':0') if self.add_eos_token else ''}"
|
||||||
|
pair = f"{single}{(' '+bos+':1') if self.add_bos_token else ''} $B:1{(' '+eos+':1') if self.add_eos_token else ''}"
|
||||||
|
|
||||||
|
special_tokens = []
|
||||||
|
if self.add_bos_token:
|
||||||
|
special_tokens.append((bos, bos_token_id))
|
||||||
|
if self.add_eos_token:
|
||||||
|
special_tokens.append((eos, eos_token_id))
|
||||||
|
self._tokenizer.post_processor = processors.TemplateProcessing(
|
||||||
|
single=single, pair=pair, special_tokens=special_tokens
|
||||||
|
)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def add_eos_token(self):
|
||||||
|
return self._add_eos_token
|
||||||
|
|
||||||
|
@property
|
||||||
|
def add_bos_token(self):
|
||||||
|
return self._add_bos_token
|
||||||
|
|
||||||
|
@add_eos_token.setter
|
||||||
|
def add_eos_token(self, value):
|
||||||
|
self._add_eos_token = value
|
||||||
|
self.update_post_processor()
|
||||||
|
|
||||||
|
@add_bos_token.setter
|
||||||
|
def add_bos_token(self, value):
|
||||||
|
self._add_bos_token = value
|
||||||
|
self.update_post_processor()
|
||||||
|
|
||||||
|
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
|
||||||
|
if not self.can_save_slow_tokenizer:
|
||||||
|
raise ValueError(
|
||||||
|
"Your fast tokenizer does not have the necessary information to save the vocabulary for a slow "
|
||||||
|
"tokenizer."
|
||||||
|
)
|
||||||
|
|
||||||
|
if not os.path.isdir(save_directory):
|
||||||
|
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
|
||||||
|
return
|
||||||
|
out_vocab_file = os.path.join(
|
||||||
|
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
|
||||||
|
)
|
||||||
|
|
||||||
|
if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file):
|
||||||
|
copyfile(self.vocab_file, out_vocab_file)
|
||||||
|
|
||||||
|
return (out_vocab_file,)
|
||||||
3
tokenizer.model
Normal file
3
tokenizer.model
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:f868398fc4e05ee1e8aeba95ddf18ddcc45b8bce55d5093bead5bbf80429b48b
|
||||||
|
size 1477754
|
||||||
98
tokenizer_config.json
Normal file
98
tokenizer_config.json
Normal file
@@ -0,0 +1,98 @@
|
|||||||
|
{
|
||||||
|
"auto_map": {
|
||||||
|
"AutoTokenizer": [
|
||||||
|
"tokenization_internlm2.InternLM2Tokenizer",
|
||||||
|
"tokenization_internlm2_fast.InternLM2TokenizerFast"
|
||||||
|
]
|
||||||
|
},
|
||||||
|
"bos_token": "<s>",
|
||||||
|
"clean_up_tokenization_spaces": false,
|
||||||
|
"eos_token": "</s>",
|
||||||
|
"model_max_length": 1000000000000000019884624838656,
|
||||||
|
"pad_token": "</s>",
|
||||||
|
"tokenizer_class": "InternLM2Tokenizer",
|
||||||
|
"unk_token": "<unk>",
|
||||||
|
"added_tokens_decoder": {
|
||||||
|
"0": {
|
||||||
|
"content": "<unk>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"1": {
|
||||||
|
"content": "<s>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"2": {
|
||||||
|
"content": "</s>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"92543": {
|
||||||
|
"content": "<|im_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"92542": {
|
||||||
|
"content": "<|im_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"92541": {
|
||||||
|
"content": "<|action_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"92540": {
|
||||||
|
"content": "<|action_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"92539": {
|
||||||
|
"content": "<|interpreter|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"92538": {
|
||||||
|
"content": "<|plugin|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"additional_special_tokens": [
|
||||||
|
"<|im_start|>",
|
||||||
|
"<|im_end|>",
|
||||||
|
"<|action_start|>",
|
||||||
|
"<|action_end|>",
|
||||||
|
"<|interpreter|>",
|
||||||
|
"<|plugin|>"
|
||||||
|
],
|
||||||
|
"chat_template": "{{ bos_token }}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
|
||||||
|
}
|
||||||
Reference in New Issue
Block a user