Compare commits
10 Commits
dc21129ed8
...
master
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
571400500e | ||
|
|
b7229bee87 | ||
|
|
b19e3ae77b | ||
|
|
ece3aef931 | ||
|
|
5729cef948 | ||
|
|
ad112bb573 | ||
|
|
2d5cd71608 | ||
|
|
2b57cbed95 | ||
|
|
5fed2070aa | ||
|
|
e36f66b425 |
42
.gitattributes
vendored
42
.gitattributes
vendored
@@ -1,55 +1,35 @@
|
|||||||
*.7z filter=lfs diff=lfs merge=lfs -text
|
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||||
*.arrow filter=lfs diff=lfs merge=lfs -text
|
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||||
*.bin filter=lfs diff=lfs merge=lfs -text
|
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||||
*.bin.* filter=lfs diff=lfs merge=lfs -text
|
|
||||||
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||||
*.ftz filter=lfs diff=lfs merge=lfs -text
|
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||||
*.gz filter=lfs diff=lfs merge=lfs -text
|
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||||
*.h5 filter=lfs diff=lfs merge=lfs -text
|
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||||
*.joblib filter=lfs diff=lfs merge=lfs -text
|
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||||
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||||
*.model filter=lfs diff=lfs merge=lfs -text
|
*.model filter=lfs diff=lfs merge=lfs -text
|
||||||
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||||
*.onnx filter=lfs diff=lfs merge=lfs -text
|
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||||
*.ot filter=lfs diff=lfs merge=lfs -text
|
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||||
*.parquet filter=lfs diff=lfs merge=lfs -text
|
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||||
*.pb filter=lfs diff=lfs merge=lfs -text
|
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||||
*.pt filter=lfs diff=lfs merge=lfs -text
|
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||||
*.pth filter=lfs diff=lfs merge=lfs -text
|
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||||
*.rar filter=lfs diff=lfs merge=lfs -text
|
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||||
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||||
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||||
*.tflite filter=lfs diff=lfs merge=lfs -text
|
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||||
*.tgz filter=lfs diff=lfs merge=lfs -text
|
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||||
*.xz filter=lfs diff=lfs merge=lfs -text
|
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||||
*.zip filter=lfs diff=lfs merge=lfs -text
|
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||||
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||||
*.tfevents* filter=lfs diff=lfs merge=lfs -text
|
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||||
*.db* filter=lfs diff=lfs merge=lfs -text
|
|
||||||
*.ark* filter=lfs diff=lfs merge=lfs -text
|
|
||||||
**/*ckpt*data* filter=lfs diff=lfs merge=lfs -text
|
|
||||||
**/*ckpt*.meta filter=lfs diff=lfs merge=lfs -text
|
|
||||||
**/*ckpt*.index filter=lfs diff=lfs merge=lfs -text
|
|
||||||
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00001-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00003-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00005-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00006-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00014-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00004-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00011-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00012-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00017-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00020-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00002-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00009-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00015-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00021-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00007-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00008-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00010-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00013-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00016-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00018-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
model-00019-of-00021.safetensors filter=lfs diff=lfs merge=lfs -text
|
|
||||||
|
|||||||
80
README.md
80
README.md
@@ -24,22 +24,33 @@ tags:
|
|||||||
<div> </div>
|
<div> </div>
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
State-of-the-art bilingual open-sourced Math reasoning LLMs.
|
State-of-the-art bilingual open-sourced Math reasoning LLMs.
|
||||||
|
A **solver**, **prover**, **verifier**, **augmentor**.
|
||||||
|
|
||||||
|
[💻 Github](https://github.com/InternLM/InternLM-Math) [🤗 Demo](https://huggingface.co/spaces/internlm/internlm2-math-7b) [🤗 Checkpoints](https://huggingface.co/internlm/internlm2-math-7b) [](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-7B) [<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> ModelScope](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-7b/summary)
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
|
# News
|
||||||
|
- [2024.01.29] We add checkpoints from ModelScope. Tech report is on the way!
|
||||||
|
- [2024.01.26] We add checkpoints from OpenXLab, which ease Chinese users to download!
|
||||||
|
|
||||||
|
|
||||||
# Introduction
|
# Introduction
|
||||||
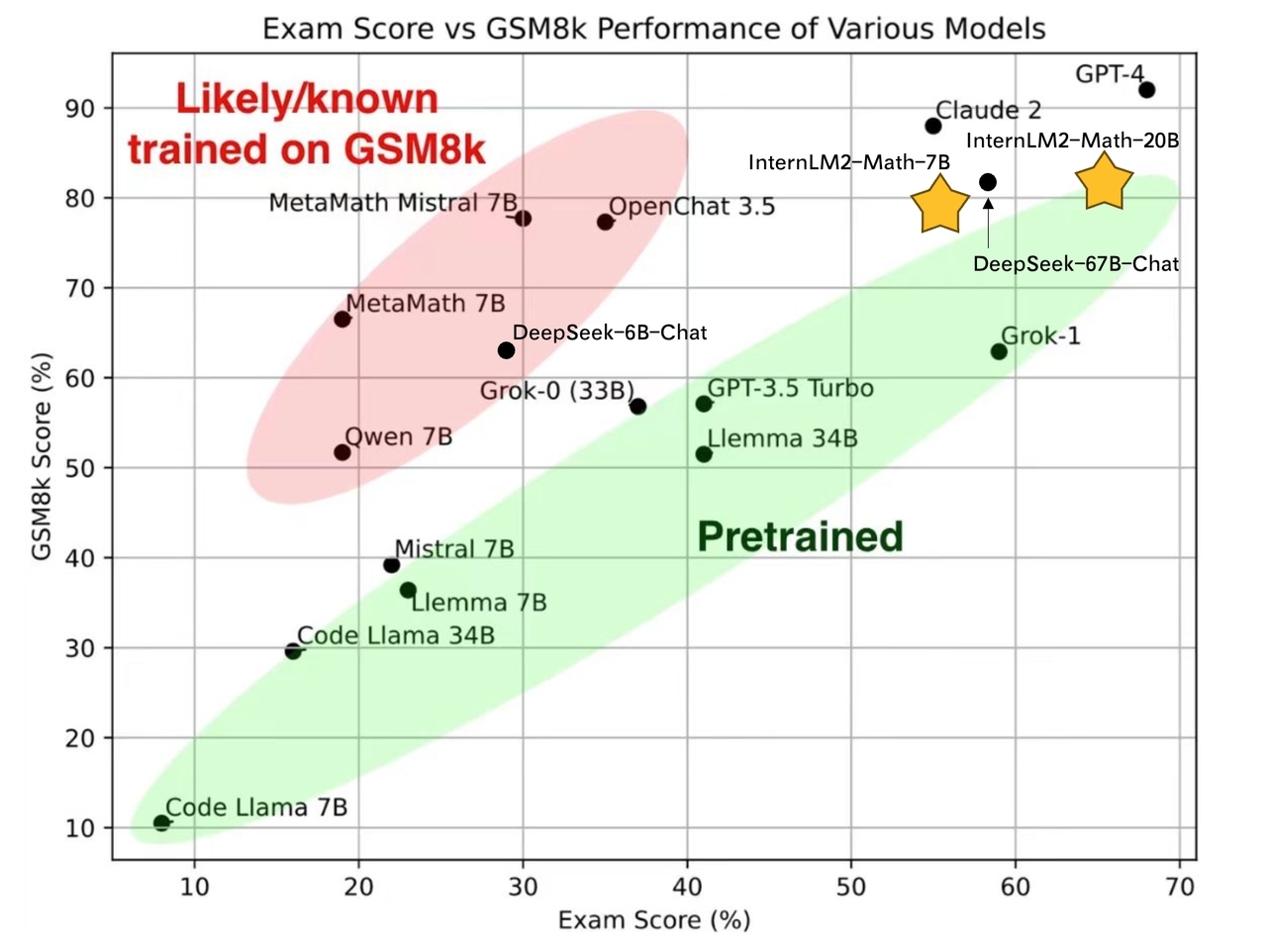
- **7B and 20B Chinese and English Math LMs with better than ChatGPT performances.** InternLM2-Math are continued pretrained from InternLM2-Base with ~100B high quality math-related tokens and SFT with ~2M bilingual math supervised data. We apply minhash and exact number match to decontaminate possible test set leakage.
|
- **7B and 20B Chinese and English Math LMs with better than ChatGPT performances.** InternLM2-Math are continued pretrained from InternLM2-Base with ~100B high quality math-related tokens and SFT with ~2M bilingual math supervised data. We apply minhash and exact number match to decontaminate possible test set leakage.
|
||||||
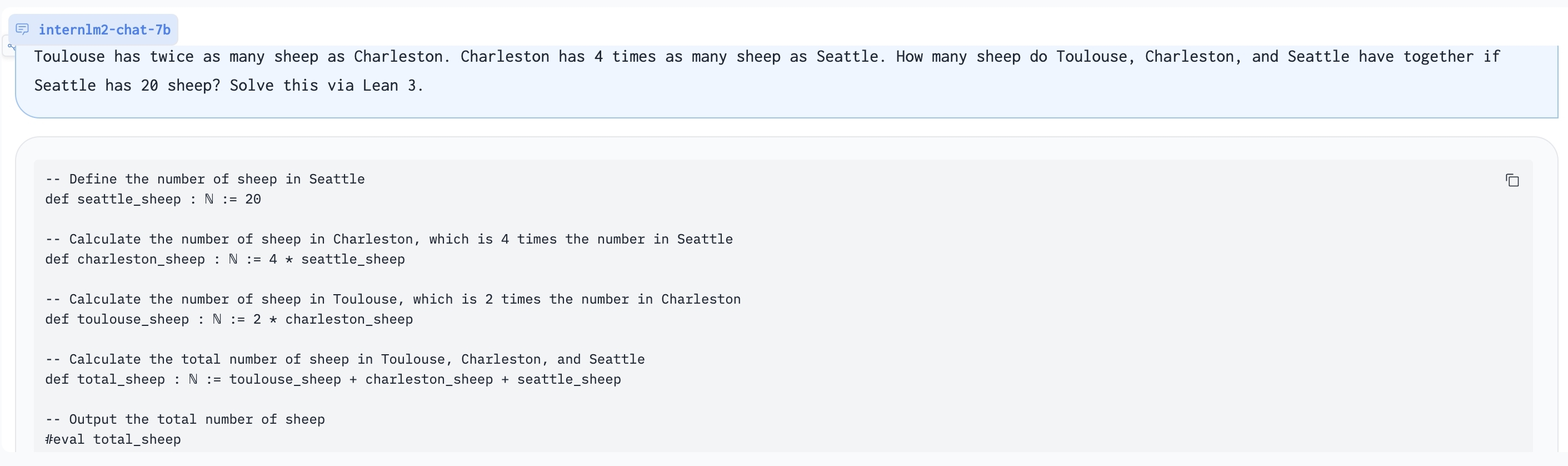
- **Add Lean as a support language for math problem solving and math theorem proving.** We are exploring combining Lean 3 with InternLM-Math for verifiable math reasoning. InternLM-Math can generate Lean codes for simple math reasoning tasks like GSM8K or provide possible proof tactics based on Lean states.
|
- **Add Lean as a support language for math problem solving and math theorem proving.** We are exploring combining Lean 3 with InternLM-Math for verifiable math reasoning. InternLM-Math can generate Lean codes for simple math reasoning tasks like GSM8K or provide possible proof tactics based on Lean states.
|
||||||
- **Also can be viewed as a reward model, which supports the Outcome/Process/Lean Reward Model.** We supervise InternLM2-Math with various types of reward modeling data, to make InternLM2-Math can also verify chain-of-thought processes. We also add the ability to convert a chain-of-thought process into Lean 3 code.
|
- **Also can be viewed as a reward model, which supports the Outcome/Process/Lean Reward Model.** We supervise InternLM2-Math with various types of reward modeling data, to make InternLM2-Math can also verify chain-of-thought processes. We also add the ability to convert a chain-of-thought process into Lean 3 code.
|
||||||
- **A Math LM Augment Helper** and **Code Intepreter**. InternLM2-Math can help augment math reasoning problems and solve them using the code interpreter which makes you generate synthesis data quicker!
|
- **A Math LM Augment Helper** and **Code Interpreter**. InternLM2-Math can help augment math reasoning problems and solve them using the code interpreter which makes you generate synthesis data quicker!
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
# Models
|
# Models
|
||||||
| Model | Transformers(HF) |Release Date |
|
**InternLM2-Math-Base-7B** and **InternLM2-Math-Base-20B** are pretrained checkpoints. **InternLM2-Math-7B** and **InternLM2-Math-20B** are SFT checkpoints.
|
||||||
|---|---|---|
|
| Model |Model Type | Transformers(HF) |OpenXLab| ModelScope | Release Date |
|
||||||
| **InternLM2-Math-Base-7B** | [🤗internlm/internlm2-math-base-7b](https://huggingface.co/internlm/internlm2-math-base-7b) | 2024-01-23|
|
|---|---|---|---|---|---|
|
||||||
| **InternLM2-Math-Base-20B** | [🤗internlm/internlm2-math-base-20b](https://huggingface.co/internlm/internlm2-math-base-20b) | 2024-01-23|
|
| **InternLM2-Math-Base-7B** | Base| [🤗internlm/internlm2-math-base-7b](https://huggingface.co/internlm/internlm2-math-base-7b) |[](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-Base-7B)| [<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> internlm2-math-base-7b](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-base-7b/summary)| 2024-01-23|
|
||||||
| **InternLM2-Math-7B** | [🤗internlm/internlm2-math-7b](https://huggingface.co/internlm/internlm2-math-7b) | 2024-01-23|
|
| **InternLM2-Math-Base-20B** | Base| [🤗internlm/internlm2-math-base-20b](https://huggingface.co/internlm/internlm2-math-base-20b) |[](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-Base-20B)|[<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> internlm2-math-base-20b](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-base-20b/summary)| 2024-01-23|
|
||||||
| **InternLM2-Math-20B** | [🤗internlm/internlm2-math-20b](https://huggingface.co/internlm/internlm2-math-20b) | 2024-01-23|
|
| **InternLM2-Math-7B** | Chat| [🤗internlm/internlm2-math-7b](https://huggingface.co/internlm/internlm2-math-7b) |[](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-7B)|[<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> internlm2-math-7b](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-7b/summary)| 2024-01-23|
|
||||||
|
| **InternLM2-Math-20B** | Chat| [🤗internlm/internlm2-math-20b](https://huggingface.co/internlm/internlm2-math-20b) |[](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-20B)|[<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> internlm2-math-20b](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-20b/summary)| 2024-01-23|
|
||||||
|
|
||||||
|
|
||||||
# Performance
|
# Performance
|
||||||
@@ -81,14 +92,26 @@ All performance is based on greedy decoding with COT. We notice that the perform
|
|||||||
|
|
||||||
# Inference
|
# Inference
|
||||||
|
|
||||||
|
## LMDeploy
|
||||||
|
We suggest using [LMDeploy](https://github.com/InternLM/LMDeploy)(>=0.2.1) for inference.
|
||||||
```python
|
```python
|
||||||
from modelscope import snapshot_download, AutoTokenizer, AutoModelForCausalLM
|
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
|
||||||
import torch
|
|
||||||
|
|
||||||
model_dir = snapshot_download("Shanghai_AI_Laboratory/internlm2-math-20b")
|
backend_config = TurbomindEngineConfig(model_name='internlm2-chat-7b', tp=1, cache_max_entry_count=0.3)
|
||||||
tokenizer = AutoTokenizer.from_pretrained(model_dir, device_map="auto", trust_remote_code=True)
|
chat_template = ChatTemplateConfig(model_name='internlm2-chat-7b', system='', eosys='', meta_instruction='')
|
||||||
|
pipe = pipeline(model_path='internlm/internlm2-math-7b', chat_template_config=chat_template, backend_config=backend_config)
|
||||||
|
|
||||||
|
problem = '1+1='
|
||||||
|
result = pipe([problem], request_output_len=1024, top_k=1)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Huggingface
|
||||||
|
```python
|
||||||
|
import torch
|
||||||
|
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||||
|
tokenizer = AutoTokenizer.from_pretrained("internlm/internlm2-math-20b", trust_remote_code=True)
|
||||||
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and might cause OOM Error.
|
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and might cause OOM Error.
|
||||||
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, torch_dtype=torch.float16)
|
model = AutoModelForCausalLM.from_pretrained("internlm/internlm2-math-20b", trust_remote_code=True, torch_dtype=torch.float16).cuda()
|
||||||
model = model.eval()
|
model = model.eval()
|
||||||
response, history = model.chat(tokenizer, "1+1=", history=[], meta_instruction="")
|
response, history = model.chat(tokenizer, "1+1=", history=[], meta_instruction="")
|
||||||
print(response)
|
print(response)
|
||||||
@@ -97,6 +120,26 @@ print(response)
|
|||||||
# Special usages
|
# Special usages
|
||||||
We list some instructions used in our SFT. You can use them to help you. You can use the other ways to prompt the model, but the following are recommended. InternLM2-Math may combine the following abilities but it is not guaranteed.
|
We list some instructions used in our SFT. You can use them to help you. You can use the other ways to prompt the model, but the following are recommended. InternLM2-Math may combine the following abilities but it is not guaranteed.
|
||||||
|
|
||||||
|
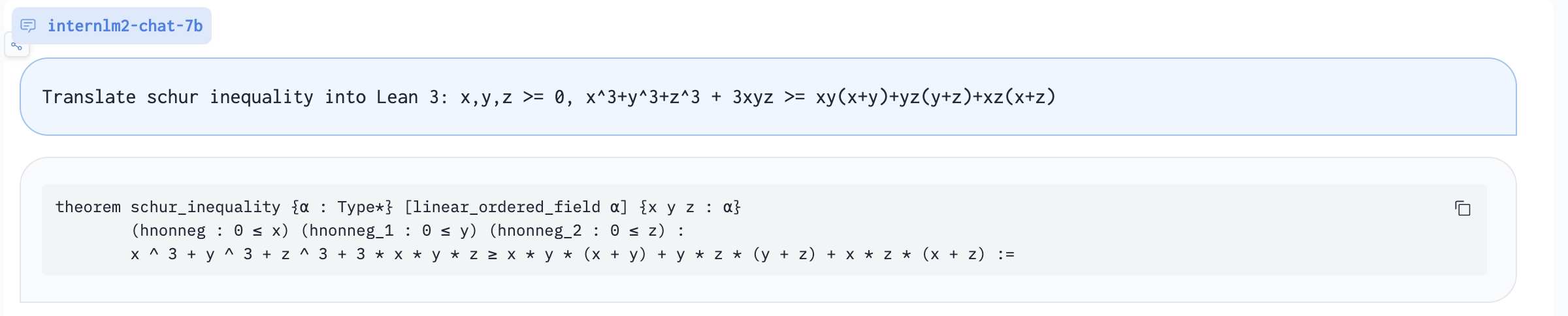
Translate proof problem to Lean:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Using Lean 3 to solve GSM8K problem:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
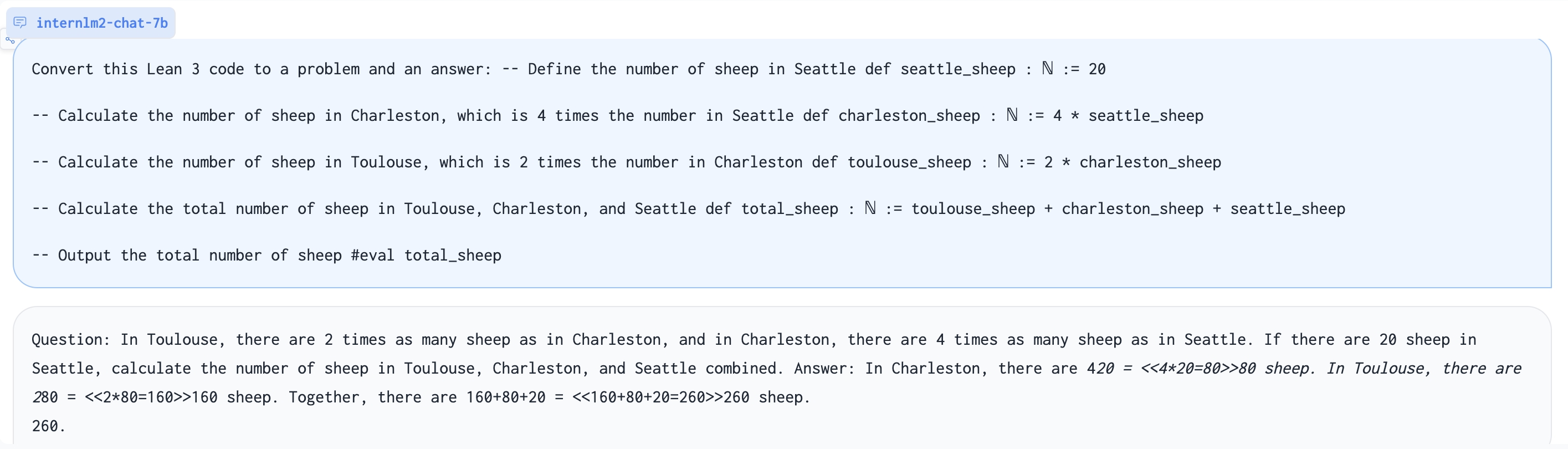
Generate problem based on Lean 3 code:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Play 24 point game:
|
||||||
|
|
||||||
|
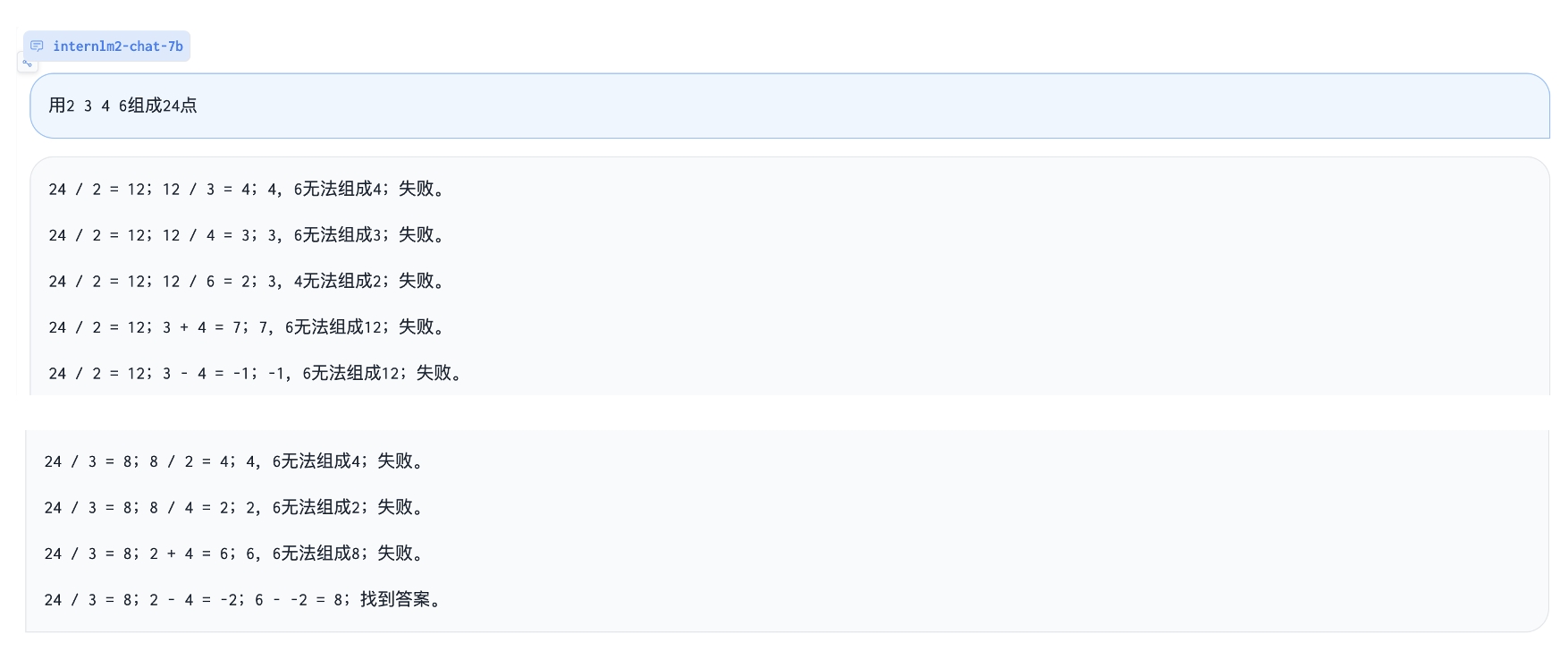
|
||||||
|
|
||||||
|
Augment a harder math problem:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
| Description | Query |
|
| Description | Query |
|
||||||
| --- | --- |
|
| --- | --- |
|
||||||
| Solving question via chain-of-thought | {Question} |
|
| Solving question via chain-of-thought | {Question} |
|
||||||
@@ -105,26 +148,27 @@ We list some instructions used in our SFT. You can use them to help you. You can
|
|||||||
| Process reward model | Given a question and an answer, check correctness of each step.\nQuestion:{Question}\nAnswer:{COT} |
|
| Process reward model | Given a question and an answer, check correctness of each step.\nQuestion:{Question}\nAnswer:{COT} |
|
||||||
| Reward model | Given a question and two answers, which one is better? \nQuestion:{Question}\nAnswer 1:{COT}\nAnswer 2:{COT} |
|
| Reward model | Given a question and two answers, which one is better? \nQuestion:{Question}\nAnswer 1:{COT}\nAnswer 2:{COT} |
|
||||||
| Convert chain-of-thought to Lean 3 | Convert this answer into Lean3. Question:{Question}\nAnswer:{COT} |
|
| Convert chain-of-thought to Lean 3 | Convert this answer into Lean3. Question:{Question}\nAnswer:{COT} |
|
||||||
| Convert Lean 3 to chain-of-thought | Convert this lean 3 code into a natural language problem with answers:\n{LEAN} |
|
| Convert Lean 3 to chain-of-thought | Convert this lean 3 code into a natural language problem with answers:\n{LEAN Code} |
|
||||||
| Translate question and chain-of-thought answer to a proof statement | Convert this question and answer into a proof format.\nQuestion:{Question}\nAnswer:{COT} |
|
| Translate question and chain-of-thought answer to a proof statement | Convert this question and answer into a proof format.\nQuestion:{Question}\nAnswer:{COT} |
|
||||||
| Translate proof problem to Lean 3 | Convert this natural langauge statement into a Lean 3 theorem statement:{Theorem} |
|
| Translate proof problem to Lean 3 | Convert this natural langauge statement into a Lean 3 theorem statement:{Theorem} |
|
||||||
| Translate Lean 3 to proof problem | Convert this Lean 3 theorem statement into natural language:{STATEMENT} |
|
| Translate Lean 3 to proof problem | Convert this Lean 3 theorem statement into natural language:{STATEMENT} |
|
||||||
| Suggest a tactic based on Lean state | Given the Lean 3 tactic state, suggest a next tactic:\n{State} |
|
| Suggest a tactic based on Lean state | Given the Lean 3 tactic state, suggest a next tactic:\n{LEAN State} |
|
||||||
| Rephrase Problem | Describe this problem in another way. {STATEMENT} |
|
| Rephrase Problem | Describe this problem in another way. {Question} |
|
||||||
| Augment Problem | Please augment a new problem based on: {Question} |
|
| Augment Problem | Please augment a new problem based on: {Question} |
|
||||||
| Augment a harder Problem | Increase the complexity of the problem: {Question} |
|
| Augment a harder Problem | Increase the complexity of the problem: {Question} |
|
||||||
| Change specific numbers | Change specific numbers: {Question}|
|
| Change specific numbers | Change specific numbers: {Question}|
|
||||||
| Introduce fractions or percentages | Introduce fractions or percentages: {Question}|
|
| Introduce fractions or percentages | Introduce fractions or percentages: {Question}|
|
||||||
| Code Intepreter | [lagent](https://github.com/InternLM/InternLM/blob/main/agent/lagent.md) |
|
| Code Interpreter | [lagent](https://github.com/InternLM/InternLM/blob/main/agent/lagent.md) |
|
||||||
| In-context Learning | Question:{Question}\nAnswer:{COT}\n...Question:{Question}\nAnswer:{COT}|
|
| In-context Learning | Question:{Question}\nAnswer:{COT}\n...Question:{Question}\nAnswer:{COT}|
|
||||||
|
|
||||||
# Fine-tune and others
|
# Fine-tune and others
|
||||||
Please refer to [InternLM](https://github.com/InternLM/InternLM/tree/main).
|
Please refer to [InternLM](https://github.com/InternLM/InternLM/tree/main).
|
||||||
|
|
||||||
# Known issues
|
# Known issues
|
||||||
Our model is still under development and will be upgraded. There are some possible issues of InternLM-Math.
|
Our model is still under development and will be upgraded. There are some possible issues of InternLM-Math. If you find performances of some abilities are not great, welcome to open an issue.
|
||||||
- Jump the calculating step.
|
- Jump the calculating step.
|
||||||
- Perform badly at Chinese fill-in-the-bank problems and English choice problems due to SFT data composition.
|
- Perform badly at Chinese fill-in-the-bank problems and English choice problems due to SFT data composition.
|
||||||
|
- Tend to generate Code Interpreter when facing Chinese problems due to SFT data composition.
|
||||||
- The reward model mode can be better leveraged with assigned token probabilities.
|
- The reward model mode can be better leveraged with assigned token probabilities.
|
||||||
- Code switch due to SFT data composition.
|
- Code switch due to SFT data composition.
|
||||||
- Some abilities of Lean can only be adapted to GSM8K-like problems (e.g. Convert chain-of-thought to Lean 3), and performance related to Lean is not guaranteed.
|
- Some abilities of Lean can only be adapted to GSM8K-like problems (e.g. Convert chain-of-thought to Lean 3), and performance related to Lean is not guaranteed.
|
||||||
|
|||||||
@@ -44,9 +44,9 @@ class InternLM2Config(PretrainedConfig):
|
|||||||
intermediate_size (`int`, *optional*, defaults to 11008):
|
intermediate_size (`int`, *optional*, defaults to 11008):
|
||||||
Dimension of the MLP representations.
|
Dimension of the MLP representations.
|
||||||
num_hidden_layers (`int`, *optional*, defaults to 32):
|
num_hidden_layers (`int`, *optional*, defaults to 32):
|
||||||
Number of hidden layers in the Transformer encoder.
|
Number of hidden layers in the Transformer decoder.
|
||||||
num_attention_heads (`int`, *optional*, defaults to 32):
|
num_attention_heads (`int`, *optional*, defaults to 32):
|
||||||
Number of attention heads for each attention layer in the Transformer encoder.
|
Number of attention heads for each attention layer in the Transformer decoder.
|
||||||
num_key_value_heads (`int`, *optional*):
|
num_key_value_heads (`int`, *optional*):
|
||||||
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
||||||
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
||||||
@@ -58,22 +58,42 @@ class InternLM2Config(PretrainedConfig):
|
|||||||
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
||||||
The non-linear activation function (function or string) in the decoder.
|
The non-linear activation function (function or string) in the decoder.
|
||||||
max_position_embeddings (`int`, *optional*, defaults to 2048):
|
max_position_embeddings (`int`, *optional*, defaults to 2048):
|
||||||
The maximum sequence length that this model might ever be used with. Typically set this to something large
|
The maximum sequence length that this model might ever be used with. InternLM2 supports up to 32768 tokens.
|
||||||
just in case (e.g., 512 or 1024 or 2048).
|
|
||||||
initializer_range (`float`, *optional*, defaults to 0.02):
|
initializer_range (`float`, *optional*, defaults to 0.02):
|
||||||
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
||||||
rms_norm_eps (`float`, *optional*, defaults to 1e-12):
|
rms_norm_eps (`float`, *optional*, defaults to 1e-06):
|
||||||
The epsilon used by the rms normalization layers.
|
The epsilon used by the rms normalization layers.
|
||||||
use_cache (`bool`, *optional*, defaults to `True`):
|
use_cache (`bool`, *optional*, defaults to `True`):
|
||||||
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
||||||
relevant if `config.is_decoder=True`.
|
relevant if `config.is_decoder=True`.
|
||||||
tie_word_embeddings(`bool`, *optional*, defaults to `False`):
|
pad_token_id (`int`, *optional*):
|
||||||
|
Padding token id.
|
||||||
|
bos_token_id (`int`, *optional*, defaults to 1):
|
||||||
|
Beginning of stream token id.
|
||||||
|
eos_token_id (`int`, *optional*, defaults to 2):
|
||||||
|
End of stream token id.
|
||||||
|
pretraining_tp (`int`, *optional*, defaults to 1):
|
||||||
|
Experimental feature. Tensor parallelism rank used during pretraining. Please refer to [this
|
||||||
|
document](https://huggingface.co/docs/transformers/main/perf_train_gpu_many#tensor-parallelism)
|
||||||
|
to understand more about it. This value is necessary to ensure exact reproducibility
|
||||||
|
of the pretraining results. Please refer to [this
|
||||||
|
issue](https://github.com/pytorch/pytorch/issues/76232).
|
||||||
|
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
|
||||||
Whether to tie weight embeddings
|
Whether to tie weight embeddings
|
||||||
Example:
|
rope_theta (`float`, *optional*, defaults to 10000.0):
|
||||||
|
The base period of the RoPE embeddings.
|
||||||
|
rope_scaling (`Dict`, *optional*):
|
||||||
|
Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scaling
|
||||||
|
strategies: linear and dynamic. Their scaling factor must be a float greater than 1. The expected format is
|
||||||
|
`{"type": strategy name, "factor": scaling factor}`. When using this flag, don't update
|
||||||
|
`max_position_embeddings` to the expected new maximum. See the following thread for more information on how
|
||||||
|
these scaling strategies behave:
|
||||||
|
https://www.reddit.com/r/LocalLLaMA/comments/14mrgpr/dynamically_scaled_rope_further_increases/. This is an
|
||||||
|
experimental feature, subject to breaking API changes in future versions.
|
||||||
"""
|
"""
|
||||||
model_type = "internlm2"
|
|
||||||
_auto_class = "AutoConfig"
|
_auto_class = "AutoConfig"
|
||||||
|
model_type = "internlm2"
|
||||||
|
keys_to_ignore_at_inference = ["past_key_values"]
|
||||||
|
|
||||||
def __init__( # pylint: disable=W0102
|
def __init__( # pylint: disable=W0102
|
||||||
self,
|
self,
|
||||||
@@ -91,11 +111,12 @@ class InternLM2Config(PretrainedConfig):
|
|||||||
pad_token_id=0,
|
pad_token_id=0,
|
||||||
bos_token_id=1,
|
bos_token_id=1,
|
||||||
eos_token_id=2,
|
eos_token_id=2,
|
||||||
|
pretraining_tp=1,
|
||||||
tie_word_embeddings=False,
|
tie_word_embeddings=False,
|
||||||
bias=True,
|
bias=True,
|
||||||
rope_theta=10000,
|
rope_theta=10000,
|
||||||
rope_scaling=None,
|
rope_scaling=None,
|
||||||
attn_implementation="eager",
|
attn_implementation=None,
|
||||||
**kwargs,
|
**kwargs,
|
||||||
):
|
):
|
||||||
self.vocab_size = vocab_size
|
self.vocab_size = vocab_size
|
||||||
@@ -113,14 +134,15 @@ class InternLM2Config(PretrainedConfig):
|
|||||||
self.hidden_act = hidden_act
|
self.hidden_act = hidden_act
|
||||||
self.initializer_range = initializer_range
|
self.initializer_range = initializer_range
|
||||||
self.rms_norm_eps = rms_norm_eps
|
self.rms_norm_eps = rms_norm_eps
|
||||||
|
self.pretraining_tp = pretraining_tp
|
||||||
self.use_cache = use_cache
|
self.use_cache = use_cache
|
||||||
self.rope_theta = rope_theta
|
self.rope_theta = rope_theta
|
||||||
self.rope_scaling = rope_scaling
|
self.rope_scaling = rope_scaling
|
||||||
self._rope_scaling_validation()
|
self._rope_scaling_validation()
|
||||||
|
|
||||||
self.attn_implementation = attn_implementation
|
self.attn_implementation = attn_implementation
|
||||||
if self.attn_implementation is None:
|
if self.attn_implementation is None:
|
||||||
self.attn_implementation = "eager"
|
self.attn_implementation = "eager"
|
||||||
|
|
||||||
super().__init__(
|
super().__init__(
|
||||||
pad_token_id=pad_token_id,
|
pad_token_id=pad_token_id,
|
||||||
bos_token_id=bos_token_id,
|
bos_token_id=bos_token_id,
|
||||||
@@ -147,5 +169,12 @@ class InternLM2Config(PretrainedConfig):
|
|||||||
raise ValueError(
|
raise ValueError(
|
||||||
f"`rope_scaling`'s type field must be one of ['linear', 'dynamic'], got {rope_scaling_type}"
|
f"`rope_scaling`'s type field must be one of ['linear', 'dynamic'], got {rope_scaling_type}"
|
||||||
)
|
)
|
||||||
if rope_scaling_factor is None or not isinstance(rope_scaling_factor, float) or rope_scaling_factor < 1.0:
|
if (
|
||||||
raise ValueError(f"`rope_scaling`'s factor field must be a float >= 1, got {rope_scaling_factor}")
|
rope_scaling_factor is None
|
||||||
|
or not isinstance(rope_scaling_factor, (float, int))
|
||||||
|
or rope_scaling_factor < 1.0
|
||||||
|
):
|
||||||
|
raise ValueError(
|
||||||
|
f"`rope_scaling`'s factor field must be a number >= 1, got {rope_scaling_factor} "
|
||||||
|
f"of type {type(rope_scaling_factor)}"
|
||||||
|
)
|
||||||
File diff suppressed because it is too large
Load Diff
@@ -1,4 +1,12 @@
|
|||||||
{
|
{
|
||||||
|
"additional_special_tokens": [
|
||||||
|
"<|im_start|>",
|
||||||
|
"<|im_end|>",
|
||||||
|
"<|action_start|>",
|
||||||
|
"<|action_end|>",
|
||||||
|
"<|interpreter|>",
|
||||||
|
"<|plugin|>"
|
||||||
|
],
|
||||||
"bos_token": "<s>",
|
"bos_token": "<s>",
|
||||||
"eos_token": "</s>",
|
"eos_token": "</s>",
|
||||||
"pad_token": "</s>",
|
"pad_token": "</s>",
|
||||||
|
|||||||
@@ -56,14 +56,14 @@ class InternLM2Converter(SpmConverter):
|
|||||||
return unk_id
|
return unk_id
|
||||||
|
|
||||||
def decoder(self, replacement, add_prefix_space):
|
def decoder(self, replacement, add_prefix_space):
|
||||||
return decoders.Sequence(
|
decoders_sequence = [
|
||||||
[
|
decoders.Replace("▁", " "),
|
||||||
decoders.Replace("▁", " "),
|
decoders.ByteFallback(),
|
||||||
decoders.ByteFallback(),
|
decoders.Fuse(),
|
||||||
decoders.Fuse(),
|
]
|
||||||
decoders.Strip(content=" ", left=1),
|
if self.proto.normalizer_spec.add_dummy_prefix:
|
||||||
]
|
decoders_sequence.append(decoders.Strip(content=" ", left=1))
|
||||||
)
|
return decoders.Sequence(decoders_sequence)
|
||||||
|
|
||||||
def tokenizer(self, proto):
|
def tokenizer(self, proto):
|
||||||
model_type = proto.trainer_spec.model_type
|
model_type = proto.trainer_spec.model_type
|
||||||
|
|||||||
@@ -86,5 +86,13 @@
|
|||||||
"special": true
|
"special": true
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
|
"additional_special_tokens": [
|
||||||
|
"<|im_start|>",
|
||||||
|
"<|im_end|>",
|
||||||
|
"<|action_start|>",
|
||||||
|
"<|action_end|>",
|
||||||
|
"<|interpreter|>",
|
||||||
|
"<|plugin|>"
|
||||||
|
],
|
||||||
"chat_template": "{{ bos_token }}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
|
"chat_template": "{{ bos_token }}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
|
||||||
}
|
}
|
||||||
Reference in New Issue
Block a user