 Qwen2.5-7B-ODA-Mixture-100k is a supervised fine-tuned (SFT) model built on top of **Qwen2.5-7B-Base**, trained with **[ODA-Mixture-100k](https://huggingface.co/datasets/OpenDataArena/ODA-Mixture-100k)**. This training set is curated by mixing top-performing open corpora selected via the *[OpenDataArena](https://opendataarena.github.io)* leaderboard, and refined through deduplication and benchmark decontamination, aiming to improve the model’s general capabilities across **General**, **Math**, **Code**, and **Reasoning** domains under a compact ~100K data budget.
---
## 🧠 Model Summary
- **Base Model**: `Qwen/Qwen2.5-7B-Base`
- **Training Data**: `OpenDataArena/ODA-Mixture-100k`
- **Domain Coverage**: General, Math, Code, Reasoning
- **Scale (selected training set)**: ~**100K** samples
- **Goal**: Achieve significant general-purpose gains with a compact curated dataset, improving multi-domain reasoning and problem-solving ability.
---
## ⚙️ Training Data Curation Pipeline
ODA-Mixture-100k is built by following a single rule: **trust the OpenDataArena leaderboard**.
### 1️⃣ Data Collection
We chose **LIMO** as our foundation because it achieves a high ranking on the ODA overall leaderboard with very few samples. This efficiency allows us to establish a strong reasoning baseline. We then augment this core with **AM-Thinking-v1-Distilled-math** and **AM-Thinking-v1-Distilled-code**, the top-performing and efficient datasets on the ODA Math and Code leaderboards, to enhance specialized domain capabilities.
### 2️⃣ Deduplication & Decontamination
We first perform **exact deduplication** over all questions to remove identical items, and then run **benchmark decontamination** to reduce evaluation leakage by removing overlaps with standard and competition benchmarks.
### 3️⃣ Data Selection
To adhere to our ~100K data budget while maximizing the impact of each sample, we employ semantic clustering to map the overall data distribution. Within each cluster, we preferentially sample the most challenging instances, using sequence length as a practical proxy for reasoning complexity and problem difficulty.
---
## 📚 Training Data Source Composition
| Source | Count | Percentage |
|---|---:|---:|
| LIMO | 817 | 0.81% |
| AM-Thinking-Distilled-math | 50,244 | 49.59% |
| AM-Thinking-Distilled-code| 50,245 | 49.60% |
---
## 🧩 Data Format
The training data sample format is as follows (aligned with the dataset schema):
```json
{
"id": "unique_identifier",
"source": "data source",
"question": "textual question or instruction",
"response": "textual response"
}
```
---
## 📈 Performance
Qwen2.5-7B-ODA-Mixture-100k is evaluated as an SFT model built on **Qwen2.5-7B-Base** across the full ODA benchmark suite spanning four domains:
- **General (DROP, IFEVAL, AGIEVAL, MMLU-Pro)**
- **Math (GSM8K, MATH500, Omni-Math, OlympiadBench, AIME2024)**
- **Code (HumanEval, MBPP, LCB (V5), HumanEval+)**
- **Reasoning (ARC-C, BBH, CALM, KOR-BENCH)**.
We observe consistent improvements over the base checkpoint, with particularly strong gains on several benchmarks.
Qwen2.5-7B-ODA-Mixture-100k is a supervised fine-tuned (SFT) model built on top of **Qwen2.5-7B-Base**, trained with **[ODA-Mixture-100k](https://huggingface.co/datasets/OpenDataArena/ODA-Mixture-100k)**. This training set is curated by mixing top-performing open corpora selected via the *[OpenDataArena](https://opendataarena.github.io)* leaderboard, and refined through deduplication and benchmark decontamination, aiming to improve the model’s general capabilities across **General**, **Math**, **Code**, and **Reasoning** domains under a compact ~100K data budget.
---
## 🧠 Model Summary
- **Base Model**: `Qwen/Qwen2.5-7B-Base`
- **Training Data**: `OpenDataArena/ODA-Mixture-100k`
- **Domain Coverage**: General, Math, Code, Reasoning
- **Scale (selected training set)**: ~**100K** samples
- **Goal**: Achieve significant general-purpose gains with a compact curated dataset, improving multi-domain reasoning and problem-solving ability.
---
## ⚙️ Training Data Curation Pipeline
ODA-Mixture-100k is built by following a single rule: **trust the OpenDataArena leaderboard**.
### 1️⃣ Data Collection
We chose **LIMO** as our foundation because it achieves a high ranking on the ODA overall leaderboard with very few samples. This efficiency allows us to establish a strong reasoning baseline. We then augment this core with **AM-Thinking-v1-Distilled-math** and **AM-Thinking-v1-Distilled-code**, the top-performing and efficient datasets on the ODA Math and Code leaderboards, to enhance specialized domain capabilities.
### 2️⃣ Deduplication & Decontamination
We first perform **exact deduplication** over all questions to remove identical items, and then run **benchmark decontamination** to reduce evaluation leakage by removing overlaps with standard and competition benchmarks.
### 3️⃣ Data Selection
To adhere to our ~100K data budget while maximizing the impact of each sample, we employ semantic clustering to map the overall data distribution. Within each cluster, we preferentially sample the most challenging instances, using sequence length as a practical proxy for reasoning complexity and problem difficulty.
---
## 📚 Training Data Source Composition
| Source | Count | Percentage |
|---|---:|---:|
| LIMO | 817 | 0.81% |
| AM-Thinking-Distilled-math | 50,244 | 49.59% |
| AM-Thinking-Distilled-code| 50,245 | 49.60% |
---
## 🧩 Data Format
The training data sample format is as follows (aligned with the dataset schema):
```json
{
"id": "unique_identifier",
"source": "data source",
"question": "textual question or instruction",
"response": "textual response"
}
```
---
## 📈 Performance
Qwen2.5-7B-ODA-Mixture-100k is evaluated as an SFT model built on **Qwen2.5-7B-Base** across the full ODA benchmark suite spanning four domains:
- **General (DROP, IFEVAL, AGIEVAL, MMLU-Pro)**
- **Math (GSM8K, MATH500, Omni-Math, OlympiadBench, AIME2024)**
- **Code (HumanEval, MBPP, LCB (V5), HumanEval+)**
- **Reasoning (ARC-C, BBH, CALM, KOR-BENCH)**.
We observe consistent improvements over the base checkpoint, with particularly strong gains on several benchmarks.
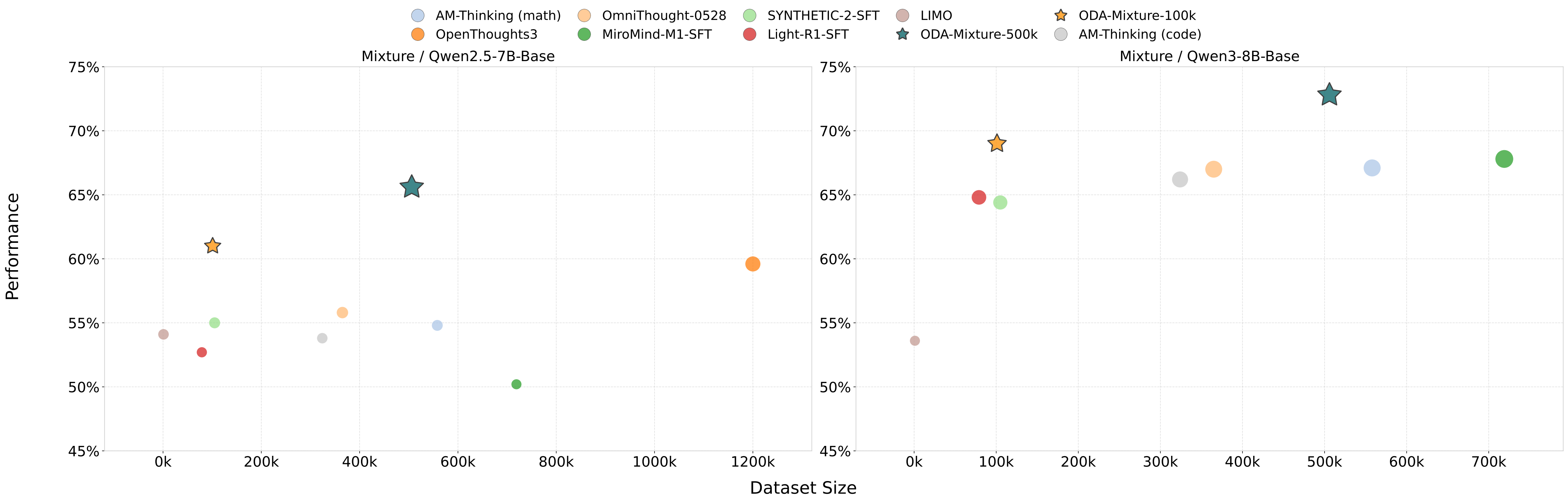
| Model / Training Data | Size | Eff. | General | Math | Code | Reasoning | AVG |
|---|---|---|---|---|---|---|---|
| Qwen2.5-7B-Base | |||||||
| Qwen2.5-7B-Base | - | - | 51.4 | 39.8 | 50.1 | 42.7 | 46.0 |
| OpenThoughts3-1.2M | 1.2M | +0.011 | 45.5 | 71.8 | 67.0 | 54.3 | 59.6 |
| OmniThought-0528 | 365k | +0.027 | 47.1 | 71.2 | 47.6 | 57.2 | 55.8 |
| SYNTHETIC-2-SFT-verified | 105k | +0.086 | 51.3 | 69.8 | 40.1 | 58.9 | 55.0 |
| AM-Thinking-v1-Distilled-math | 558k | +0.016 | 57.7 | 77.4 | 39.5 | 44.8 | 54.8 |
| LIMO | 817 | +9.920 | 60.7 | 44.0 | 57.9 | 53.8 | 54.1 |
| MiroMind-M1-SFT-719K | 719k | +0.006 | 52.0 | 71.0 | 26.3 | 51.5 | 50.2 |
| AM-Thinking-v1-Distilled-code | 324k | +0.024 | 49.9 | 52.3 | 68.7 | 44.4 | 53.8 |
| Light-R1-SFTData | 79k | +0.084 | 55.5 | 64.4 | 38.8 | 51.9 | 52.7 |
| ODA-Mixture-500k | 500k | +0.039 | 63.4 | 72.8 | 66.7 | 59.6 | 65.6 |
| ODA-Mixture-100k | 100k | +0.149 | 56.8 | 71.2 | 64.4 | 51.5 | 61.0 |