初始化项目,由ModelHub XC社区提供模型
Model: Herman555/Synatra-v0.3-RP-AshhLimaRP-Mistral-7B-GGUF Source: Original Platform
This commit is contained in:
225
README.md
Normal file
225
README.md
Normal file
@@ -0,0 +1,225 @@
|
||||
---
|
||||
tags:
|
||||
- not-for-all-audiences
|
||||
license: cc-by-nc-4.0
|
||||
---
|
||||
# **Synatra-7B-v0.3-RP🐧**
|
||||

|
||||
|
||||
## Support Me
|
||||
시나트라는 개인 프로젝트로, 1인의 자원으로 개발되고 있습니다. 모델이 마음에 드셨다면 약간의 연구비 지원은 어떨까요?
|
||||
[<img src="https://cdn.buymeacoffee.com/buttons/default-orange.png" alt="Buy me a Coffee" width="217" height="50">](https://www.buymeacoffee.com/mwell)
|
||||
|
||||
Wanna be a sponser? Contact me on Telegram **AlzarTakkarsen**
|
||||
|
||||
# **License**
|
||||
|
||||
This model is strictly [*non-commercial*](https://creativecommons.org/licenses/by-nc/4.0/) (**cc-by-nc-4.0**) use only.
|
||||
The "Model" is completely free (ie. base model, derivates, merges/mixes) to use for non-commercial purposes as long as the the included **cc-by-nc-4.0** license in any parent repository, and the non-commercial use statute remains, regardless of other models' licences.
|
||||
The licence can be changed after new model released. If you are to use this model for commercial purpose, Contact me.
|
||||
|
||||
# **Model Details**
|
||||
**Base Model**
|
||||
[mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)
|
||||
|
||||
**Trained On**
|
||||
A6000 48GB * 8
|
||||
|
||||
**Instruction format**
|
||||
|
||||
It follows [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md) format.
|
||||
|
||||
**TODO**
|
||||
|
||||
- ~~``RP 기반 튜닝 모델 제작``~~ ✅
|
||||
- ~~``데이터셋 정제``~~ ✅
|
||||
- 언어 이해능력 개선
|
||||
- ~~``상식 보완``~~ ✅
|
||||
- 토크나이저 변경
|
||||
|
||||
|
||||
# **Model Benchmark**
|
||||
|
||||
## Ko-LLM-Leaderboard
|
||||
|
||||
On Benchmarking...
|
||||
|
||||
# **Implementation Code**
|
||||
|
||||
Since, chat_template already contains insturction format above.
|
||||
You can use the code below.
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
device = "cuda" # the device to load the model onto
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("maywell/Synatra-7B-v0.3-RP")
|
||||
tokenizer = AutoTokenizer.from_pretrained("maywell/Synatra-7B-v0.3-RP")
|
||||
|
||||
messages = [
|
||||
{"role": "user", "content": "바나나는 원래 하얀색이야?"},
|
||||
]
|
||||
|
||||
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
|
||||
|
||||
model_inputs = encodeds.to(device)
|
||||
model.to(device)
|
||||
|
||||
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
|
||||
decoded = tokenizer.batch_decode(generated_ids)
|
||||
print(decoded[0])
|
||||
```
|
||||
|
||||
# Why It's benchmark score is lower than preview version?
|
||||
|
||||
**Apparently**, Preview model uses Alpaca Style prompt which has no pre-fix. But ChatML do.
|
||||
|
||||
---
|
||||
# AshhLimaRP-Mistral-7B (Alpaca, v1)
|
||||
|
||||
This is a version of LimaRP with 2000 training samples _up to_ about 9k tokens length
|
||||
finetuned on [Ashhwriter-Mistral-7B](https://huggingface.co/lemonilia/Ashhwriter-Mistral-7B).
|
||||
|
||||
LimaRP is a longform-oriented, novel-style roleplaying chat model intended to replicate the experience
|
||||
of 1-on-1 roleplay on Internet forums. Short-form, IRC/Discord-style RP (aka "Markdown format")
|
||||
is not supported. The model does not include instruction tuning, only manually picked and
|
||||
slightly edited RP conversations with persona and scenario data.
|
||||
|
||||
Ashhwriter, the base, is a model entirely finetuned on human-written lewd stories.
|
||||
|
||||
## Available versions
|
||||
- Float16 HF weights
|
||||
- LoRA Adapter ([adapter_config.json](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/adapter_config.json) and [adapter_model.bin](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/adapter_model.bin))
|
||||
- [4bit AWQ](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/tree/main/AWQ)
|
||||
- [Q4_K_M GGUF](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/AshhLimaRP-Mistral-7B.Q4_K_M.gguf)
|
||||
- [Q6_K GGUF](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/AshhLimaRP-Mistral-7B.Q6_K.gguf)
|
||||
|
||||
## Prompt format
|
||||
[Extended Alpaca format](https://github.com/tatsu-lab/stanford_alpaca),
|
||||
with `### Instruction:`, `### Input:` immediately preceding user inputs and `### Response:`
|
||||
immediately preceding model outputs. While Alpaca wasn't originally intended for multi-turn
|
||||
responses, in practice this is not a problem; the format follows a pattern already used by
|
||||
other models.
|
||||
|
||||
```
|
||||
### Instruction:
|
||||
Character's Persona: {bot character description}
|
||||
|
||||
User's Persona: {user character description}
|
||||
|
||||
Scenario: {what happens in the story}
|
||||
|
||||
Play the role of Character. You must engage in a roleplaying chat with User below this line. Do not write dialogues and narration for User.
|
||||
|
||||
### Input:
|
||||
User: {utterance}
|
||||
|
||||
### Response:
|
||||
Character: {utterance}
|
||||
|
||||
### Input
|
||||
User: {utterance}
|
||||
|
||||
### Response:
|
||||
Character: {utterance}
|
||||
|
||||
(etc.)
|
||||
```
|
||||
|
||||
You should:
|
||||
- Replace all text in curly braces (curly braces included) with your own text.
|
||||
- Replace `User` and `Character` with appropriate names.
|
||||
|
||||
|
||||
### Message length control
|
||||
Inspired by the previously named "Roleplay" preset in SillyTavern, with this
|
||||
version of LimaRP it is possible to append a length modifier to the response instruction
|
||||
sequence, like this:
|
||||
|
||||
```
|
||||
### Input
|
||||
User: {utterance}
|
||||
|
||||
### Response: (length = medium)
|
||||
Character: {utterance}
|
||||
```
|
||||
|
||||
This has an immediately noticeable effect on bot responses. The lengths using during training are:
|
||||
`micro`, `tiny`, `short`, `medium`, `long`, `massive`, `huge`, `enormous`, `humongous`, `unlimited`.
|
||||
**The recommended starting length is medium**. Keep in mind that the AI can ramble or impersonate
|
||||
the user with very long messages.
|
||||
|
||||
The length control effect is reproducible, but the messages will not necessarily follow
|
||||
lengths very precisely, rather follow certain ranges on average, as seen in this table
|
||||
with data from tests made with one reply at the beginning of the conversation:
|
||||
|
||||

|
||||
|
||||
Response length control appears to work well also deep into the conversation. **By omitting
|
||||
the modifier, the model will choose the most appropriate response length** (although it might
|
||||
not necessarily be what the user desires).
|
||||
|
||||
## Suggested settings
|
||||
You can follow these instruction format settings in SillyTavern. Replace `medium` with
|
||||
your desired response length:
|
||||
|
||||
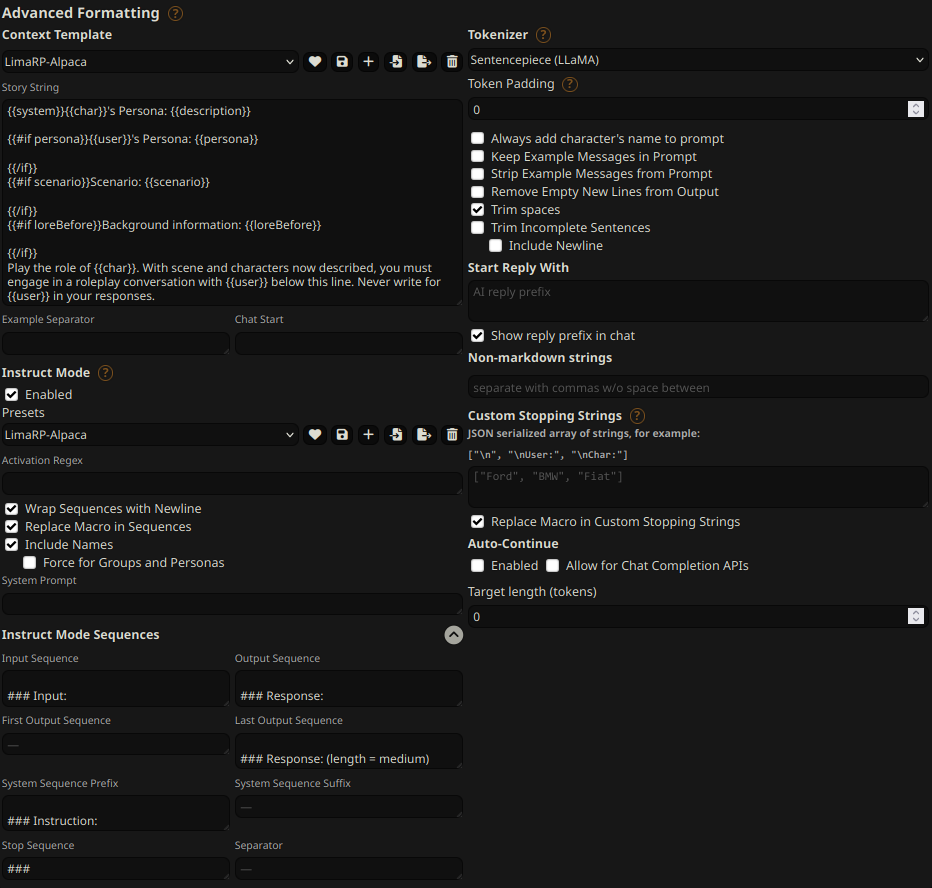
|
||||
|
||||
## Text generation settings
|
||||
These settings could be a good general starting point:
|
||||
|
||||
- TFS = 0.90
|
||||
- Temperature = 0.70
|
||||
- Repetition penalty = ~1.11
|
||||
- Repetition penalty range = ~2048
|
||||
- top-k = 0 (disabled)
|
||||
- top-p = 1 (disabled)
|
||||
|
||||
## Training procedure
|
||||
[Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) was used for training
|
||||
on 2x NVidia A40 GPUs.
|
||||
|
||||
The A40 GPUs have been graciously provided by [Arc Compute](https://www.arccompute.io/).
|
||||
|
||||
### Training hyperparameters
|
||||
A lower learning rate than usual was employed. Due to an unforeseen issue the training
|
||||
was cut short and as a result 3 epochs were trained instead of the planned 4. Using 2 GPUs,
|
||||
the effective global batch size would have been 16.
|
||||
|
||||
Training was continued from the most recent LoRA adapter from Ashhwriter, using the same
|
||||
LoRA R and LoRA alpha.
|
||||
|
||||
- lora_model_dir: /home/anon/bin/axolotl/OUT_mistral-stories/checkpoint-6000/
|
||||
- learning_rate: 0.00005
|
||||
- lr_scheduler: cosine
|
||||
- noisy_embedding_alpha: 3.5
|
||||
- num_epochs: 4
|
||||
- sequence_len: 8750
|
||||
- lora_r: 256
|
||||
- lora_alpha: 16
|
||||
- lora_dropout: 0.05
|
||||
- lora_target_linear: True
|
||||
- bf16: True
|
||||
- fp16: false
|
||||
- tf32: True
|
||||
- load_in_8bit: True
|
||||
- adapter: lora
|
||||
- micro_batch_size: 2
|
||||
- optimizer: adamw_bnb_8bit
|
||||
- warmup_steps: 10
|
||||
- optimizer: adamw_torch
|
||||
- flash_attention: true
|
||||
- sample_packing: true
|
||||
- pad_to_sequence_len: true
|
||||
|
||||
|
||||
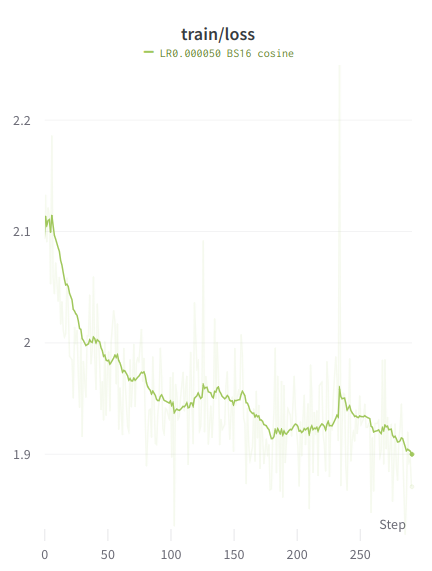
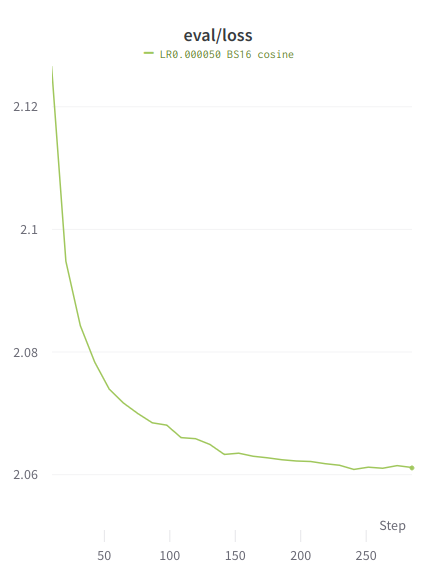
### Loss graphs
|
||||
Values are higher than typical because the training is performed on the entire
|
||||
sample, similar to unsupervised finetuning.
|
||||
|
||||
#### Train loss
|
||||
|
||||
|
||||
#### Eval loss
|
||||
|
||||
Reference in New Issue
Block a user