
Documentation |
Users Forum |
slack |
---
## Latest News🔥
- [2025/12] Initial release of vLLM Kunlun
---
# Overview
vLLM Kunlun (vllm-kunlun) is a community-maintained hardware plugin designed to seamlessly run vLLM on the Kunlun XPU. It is the recommended approach for integrating the Kunlun backend within the vLLM community, adhering to the principles outlined in the [RFC]: Hardware pluggable. This plugin provides a hardware-pluggable interface that decouples the integration of the Kunlun XPU with vLLM.
By utilizing the vLLM Kunlun plugin, popular open-source models, including Transformer-like, Mixture-of-Expert, Embedding, and Multi-modal LLMs, can run effortlessly on the Kunlun XPU.
---
## Prerequisites
- **Hardware**: Kunlun3 P800
- **OS**: Ubuntu 22.04
- **Software**:
- Python >=3.10
- PyTorch ≥ 2.5.1
- vLLM (same version as vllm-kunlun)
---
## Supported Models
Generaltive Models
| Model |
Support |
Quantization |
LoRA |
Piecewise Kunlun Graph |
Note |
| Qwen3 |
✅ |
|
✅ |
✅ |
|
| Qwen3-Moe |
✅ |
✅ |
✅ |
✅ |
|
| Qwen3-Next |
✅ |
✅ |
✅ |
✅ |
|
Multimodal Language Models
| Model |
Support |
Quantization |
LoRA |
Piecewise Kunlun Graph |
Note |
| Qwen3-VL |
✅ |
|
|
✅ |
|
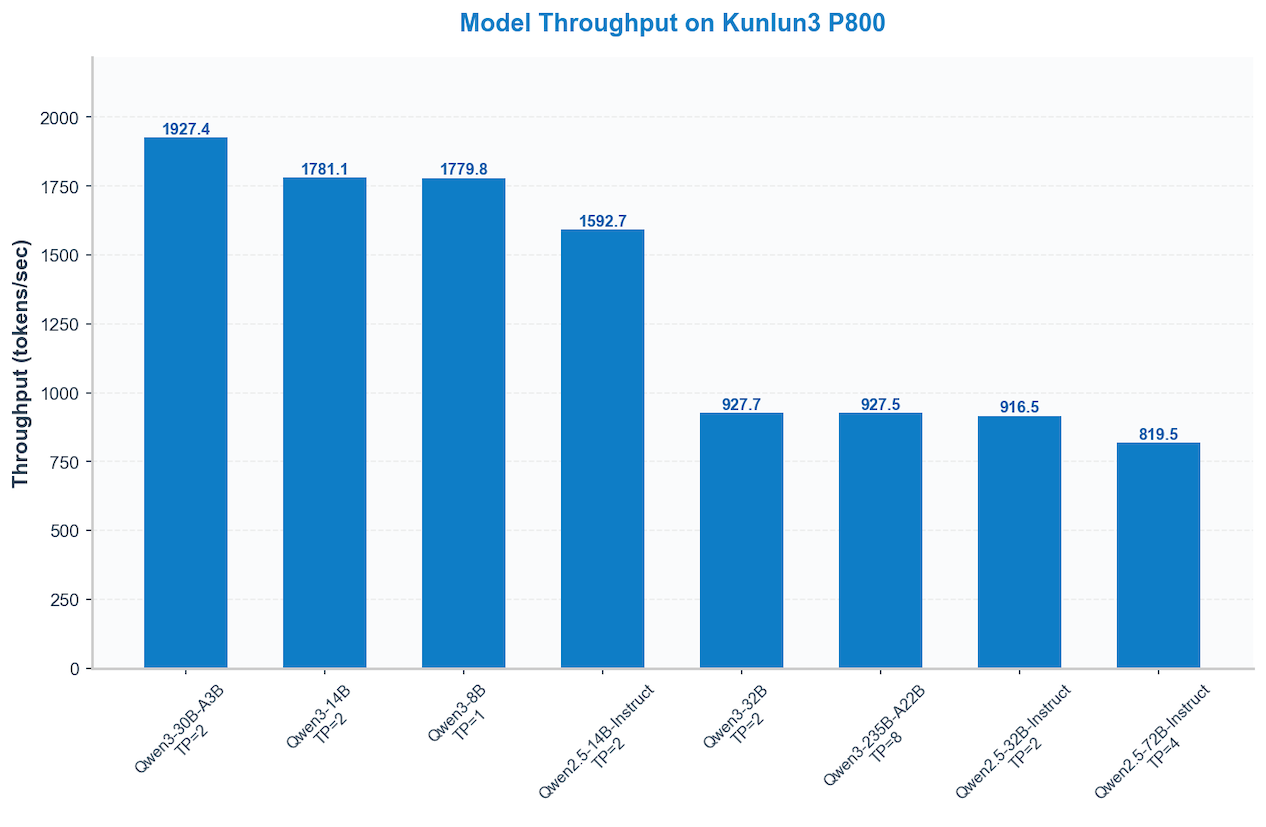
## Performance Visualization 🚀
### High-performance computing at work: How different models perform on the Kunlun3 P800.
Current environment: 16-way concurrency, input/output size 2048.
## Getting Started
Please use the following recommended versions to get started quickly:
| Version | Release type | Doc |
|----------|---------------|-----|
| v0.11.0 | Latest stable version | [QuickStart](./docs/_build/html/quick_start.html) and [Installation](./docs/_build/html/installation.html) for more details |
---
## Contributing
See [CONTRIBUTING]() for more details, which is a step-by-step guide to help you set up the development environment, build, and test.
We welcome and value any contributions and collaborations:
- Open an [Issue]() if you find a bug or have a feature request
## License
Apache License 2.0, as found in the [LICENSE](./LICENSE) file.