
📖 Documentation |
🚀 Quick Start |
📦 Installation |
💬 Slack





---
## Latest News 🔥
- [2026/02] 🧠 **GLM model family support** — Added GLM5, GLM-4.7 MTP (Multi-Token Prediction), and GLM-47 tool parser with thinking/non-thinking mode toggle
- [2026/02] ⚡ **Performance optimizations** — Fused MoE with small batches, optimized attention metadata building, Multi-LoRA inference achieves 80%+ of non-LoRA performance
- [2026/02] 🔧 **DeepSeek-V3.2 MTP support** — Added MTP (Multi-Token Prediction) for DeepSeek-V3.2, with RoPE and decoding stage kernel optimizations
- [2026/01] 🔢 **New quantization methods** — Support for compressed-tensors W4A16, AWQ MoE W4A16, and DeepSeek-V3.2 W8A8 quantization
- [2026/01] 🛠️ **CI/CD overhaul** — Added E2E tests, unit test CI, ruff format checks, and modular CI workflow refactoring
- [2025/12] 🎉 **v0.11.0rc1 released** — Added Qwen3-Omni, Qwen3-Next, Seed-OSS support ([Release Notes](https://github.com/baidu/vLLM-Kunlun/releases/tag/v0.11.0rc1))
- [2025/12] 📦 **v0.10.1.1 released** — 5+ multimodal models, AWQ/GPTQ quantization for dense models, Piecewise CUDA Graph, vLLM V1 engine, Flash-Infer Top-K/Top-P sampling with 10-100× speedup ([Release Notes](https://github.com/baidu/vLLM-Kunlun/releases/tag/v0.10.1.1))
- [2025/12] 🌟 Initial release of vLLM Kunlun — Open sourced on Dec 8, 2025
---
## Overview
**vLLM Kunlun** (`vllm-kunlun`) is a community-maintained hardware plugin designed to seamlessly run [vLLM](https://github.com/vllm-project/vllm) on the **Kunlun XPU**. It is the recommended approach for integrating the Kunlun backend within the vLLM community, adhering to the principles outlined in the [RFC Hardware Pluggable](https://github.com/vllm-project/vllm/issues/11162).
This plugin provides a hardware-pluggable interface that decouples the integration of the Kunlun XPU with vLLM. By utilizing vLLM Kunlun, popular open-source models — including Transformer-like, Mixture-of-Expert (MoE), Embedding, and Multi-modal LLMs — can run effortlessly on the Kunlun XPU.
### ✨ Key Features
- **Seamless Plugin Integration** — Works as a standard vLLM platform plugin via Python entry points, no need to modify vLLM source code
- **Broad Model Support** — Supports 15+ mainstream LLMs including Qwen, Llama, DeepSeek, Kimi-K2, and multimodal models
- **Quantization Support** — INT8 and other quantization methods for MoE and dense models
- **LoRA Fine-Tuning** — LoRA adapter support for Qwen series models
- **Piecewise Kunlun Graph** — Hardware-accelerated graph optimization for high-performance inference
- **FlashMLA Attention** — Optimized multi-head latent attention for DeepSeek MLA architectures
- **Tensor Parallelism** — Multi-device parallel inference with distributed execution support
- **OpenAI-Compatible API** — Serve models with the standard OpenAI API interface
---
## Prerequisites
- **Hardware**: Kunlun3 P800
- **OS**: Ubuntu 22.04
- **Software**:
- Python >= 3.10
- PyTorch >= 2.5.1
- vLLM (same version as vllm-kunlun)
- transformers >= 4.57.0
---
## Supported Models
### Generative Models
| Model | Support | Quantization | LoRA | Kunlun Graph |
|:------|:-------:|:------------:|:----:|:----------------------:|
| Qwen2 | ✅ | ✅| ✅ | ✅ |
| Qwen2.5 | ✅ |✅ | ✅ | ✅ |
| Qwen3 | ✅ |✅ | ✅ | ✅ |
| Qwen3-Moe | ✅ | ✅ | | ✅ |
| Qwen3-Next | ✅ | ✅ | | ✅ |
| MiMo-V2-Flash | ✅ | ✅| | ✅ |
| Llama2 | ✅ | ✅| ✅| ✅ |
| Llama3 | ✅ |✅ | ✅ | ✅ |
| Llama3.1 | ✅ |✅ | | ✅ |
| gpt-oss | ✅ | ✅| | |
| GLM4.5 | ✅ | ✅| | ✅ |
| GLM4.5Air | ✅ |✅ | | ✅ |
| GLM4.7 | ✅ | ✅| | ✅ |
| GLM5 | ✅ | ✅| | ✅ |
| Kimi-K2 | ✅ | ✅ | | ✅ |
| DeepSeek-R1 | ✅ | ✅ | | ✅ |
| DeepSeek-V3 | ✅ | ✅ | | ✅ |
| DeepSeek-V3.2 | ✅ | ✅ | | ✅ |
### Multimodal Language Models
| Model | Support | Quantization | LoRA | Kunlun Graph |
|:------|:-------:|:------------:|:----:|:----------------------:|
| Qwen2-VL | ✅ | ✅| | ✅ |
| Qwen2.5-VL | ✅ | ✅| | ✅ |
| Qwen3-VL | ✅ | ✅| | ✅ |
| Qwen3-VL-MoE | ✅ | ✅ | | ✅ |
| Qwen3-Omni-MoE | ✅ | | | ✅ |
| InternVL-2.5 | ✅ | | | ✅ |
| InternVL-3.5 | ✅ | | | ✅ |
| InternS1 | ✅ | | | ✅ |
---
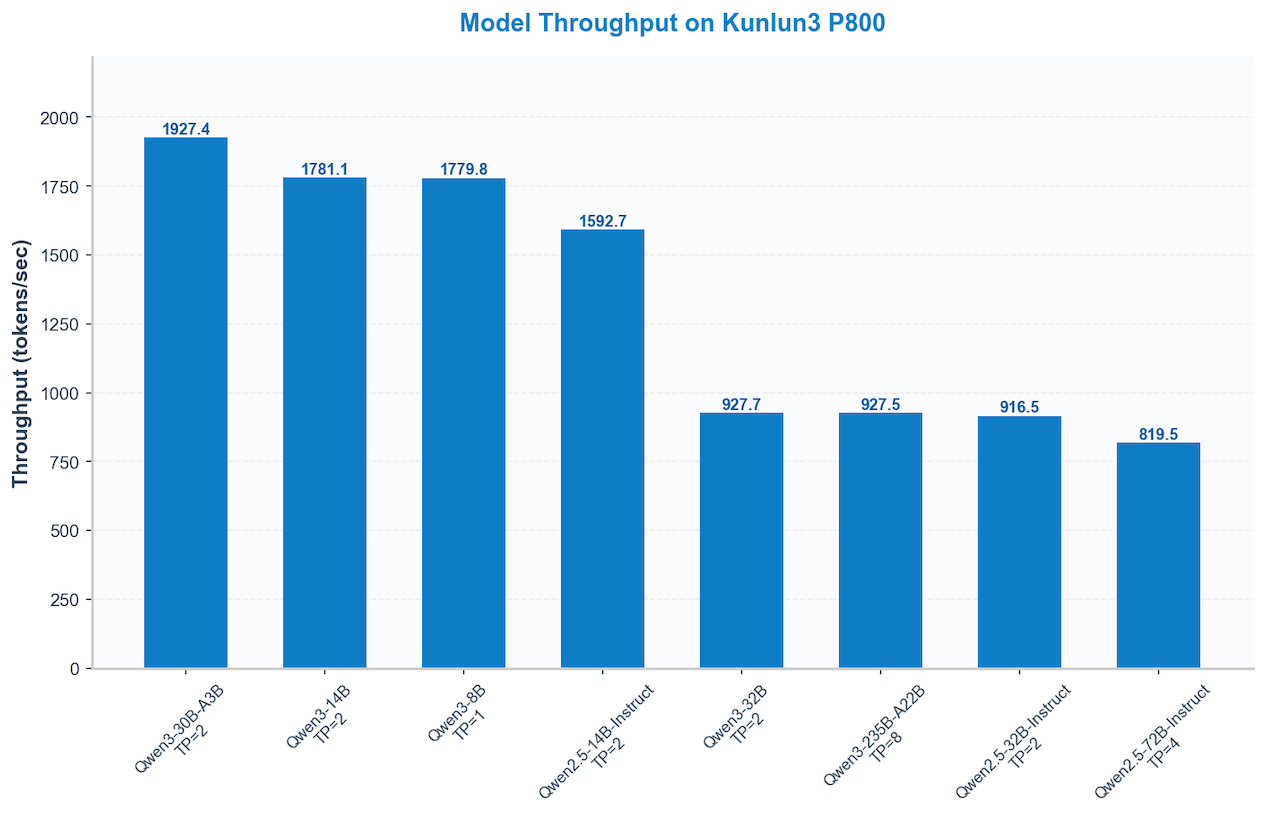
## Performance Visualization 🚀
### High-performance computing at work: How different models perform on the Kunlun3 P800.
Current environment: 16-way concurrency, input/output size 2048.
---
### Quick Start
#### Start an OpenAI-Compatible API Server
```bash
python -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 \
--port 8356 \
--model \
--gpu-memory-utilization 0.9 \
--trust-remote-code \
--max-model-len 32768 \
--tensor-parallel-size 1 \
--dtype float16 \
--max_num_seqs 128 \
--max_num_batched_tokens 32768 \
--block-size 128 \
--distributed-executor-backend mp \
--served-model-name
```
#### Send a Request
```bash
curl http://localhost:8356/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "",
"messages": [{"role": "user", "content": "Hello!"}],
"max_tokens": 512
}'
```
### Version Matrix
| Version | Release Type | Documentation |
|---------|:------------:|:-------------:|
| v0.11.0 | Latest stable version | [Quick Start](https://vllm-kunlun.readthedocs.io/en/latest/quick_start.html) · [Installation](https://vllm-kunlun.readthedocs.io/en/latest/installation.html) |
---
## Architecture
```
vllm-kunlun/
├── vllm_kunlun/ # Core plugin package
│ ├── platforms/ # Kunlun XPU platform implementation
│ ├── models/ # Model implementations (DeepSeek, Qwen, Llama, etc.)
│ ├── ops/ # Custom operators (attention, linear, sampling, etc.)
│ │ ├── attention/ # FlashMLA, paged attention, merge attention states
│ │ ├── fla/ # Flash linear attention operations
│ │ └── sample/ # Sampling operators
│ ├── v1/ # vLLM V1 engine adaptations
│ ├── compilation/ # Torch compile wrapper for Kunlun Graph
│ ├── csrc/ # C++ extensions (custom CUDA-compatible kernels)
│ └── config/ # Model configuration overrides
├── tests/ # Test suite
├── docs/ # Documentation (Sphinx-based, ReadTheDocs hosted)
├── ci/ # CI pipeline configurations
├── setup.py # Legacy build script (with C++ extensions)
└── pyproject.toml # Modern Python build configuration (hatchling)
```
---
## Contributing
We welcome contributions from the community! Please read our [Contributing Guide](CONTRIBUTING.md) before submitting a PR.
### PR Classification
Use the following prefixes for PR titles:
- `[Attention]` — Attention mechanism features/optimizations
- `[Core]` — Core vllm-kunlun logic (platform, attention, communicators, model runner)
- `[Kernel]` — Compute kernels and ops
- `[Bugfix]` — Bug fixes
- `[Doc]` — Documentation improvements
- `[Test]` — Tests
- `[CI]` — CI/CD improvements
- `[Misc]` — Other changes
---
## Star History 🔥
We opened the project at Dec 8, 2025. We love open source and collaboration ❤️
[](https://www.star-history.com/#baidu/vLLM-Kunlun&type=date&legend=bottom-right)
---
## Sponsors 👋
We sincerely appreciate the [**KunLunXin**](https://www.kunlunxin.com/) team for their support in providing XPU resources, which enabled efficient model adaptation debugging, comprehensive end-to-end testing, and broader model compatibility.
---
## License
Apache License 2.0, as found in the [LICENSE](./LICENSE) file.