See https://user-images.githubusercontent.com/5284924/282995968-f6d39118-8008-4ce7-9d7c-d1d6387ac183.png
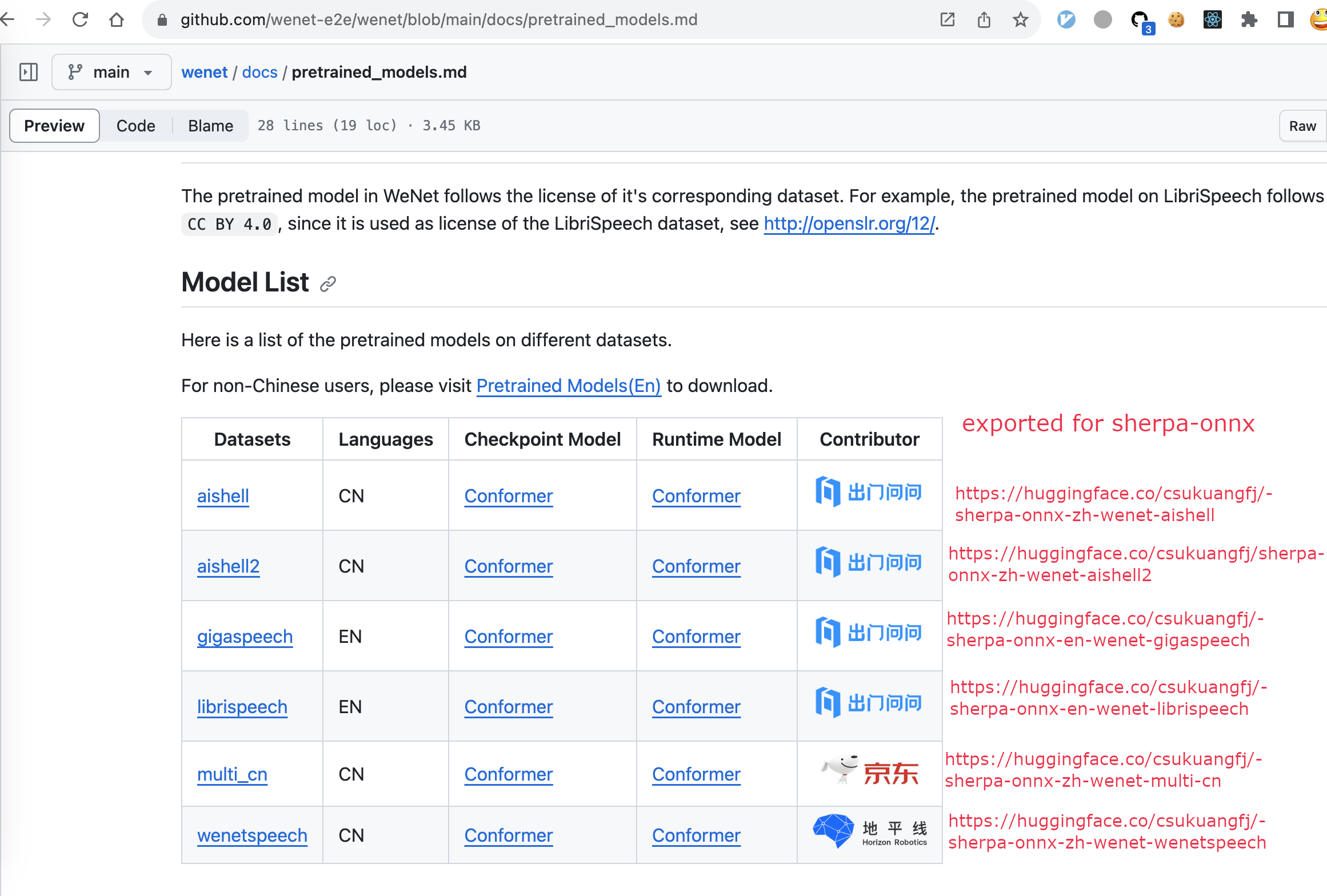{kind=link}
175 lines
5.3 KiB
Python
Executable File
175 lines
5.3 KiB
Python
Executable File
#!/usr/bin/env python3
|
|
# Copyright 2023 Xiaomi Corp. (authors: Fangjun Kuang)
|
|
|
|
import kaldi_native_fbank as knf
|
|
import onnxruntime as ort
|
|
import torch
|
|
import torchaudio
|
|
from torch.nn.utils.rnn import pad_sequence
|
|
|
|
|
|
class OnnxModel:
|
|
def __init__(
|
|
self,
|
|
filename: str,
|
|
):
|
|
session_opts = ort.SessionOptions()
|
|
session_opts.inter_op_num_threads = 1
|
|
session_opts.intra_op_num_threads = 4
|
|
|
|
self.session_opts = session_opts
|
|
|
|
self.model = ort.InferenceSession(
|
|
filename,
|
|
sess_options=self.session_opts,
|
|
providers=["CPUExecutionProvider"],
|
|
)
|
|
|
|
meta = self.model.get_modelmeta().custom_metadata_map
|
|
self.left_chunks = int(meta["left_chunks"])
|
|
self.num_blocks = int(meta["num_blocks"])
|
|
self.chunk_size = int(meta["chunk_size"])
|
|
self.head = int(meta["head"])
|
|
self.output_size = int(meta["output_size"])
|
|
self.cnn_module_kernel = int(meta["cnn_module_kernel"])
|
|
self.right_context = int(meta["right_context"])
|
|
self.subsampling_factor = int(meta["subsampling_factor"])
|
|
|
|
self._init_cache()
|
|
|
|
def _init_cache(self):
|
|
required_cache_size = self.chunk_size * self.left_chunks
|
|
|
|
self.attn_cache = torch.zeros(
|
|
self.num_blocks,
|
|
self.head,
|
|
required_cache_size,
|
|
self.output_size // self.head * 2,
|
|
dtype=torch.float32,
|
|
).numpy()
|
|
|
|
self.conv_cache = torch.zeros(
|
|
self.num_blocks,
|
|
1,
|
|
self.output_size,
|
|
self.cnn_module_kernel - 1,
|
|
dtype=torch.float32,
|
|
).numpy()
|
|
|
|
self.offset = torch.tensor([required_cache_size], dtype=torch.int64).numpy()
|
|
|
|
self.required_cache_size = torch.tensor(
|
|
[self.chunk_size * self.left_chunks], dtype=torch.int64
|
|
).numpy()
|
|
|
|
def __call__(self, x: torch.Tensor) -> torch.Tensor:
|
|
"""
|
|
Args:
|
|
x:
|
|
A 2-D tensor of shape (T, C)
|
|
Returns:
|
|
Return a 2-D tensor of shape (T, C) containing log_probs.
|
|
"""
|
|
attn_mask = torch.ones(
|
|
1, 1, int(self.required_cache_size + self.chunk_size), dtype=torch.bool
|
|
)
|
|
chunk_idx = self.offset // self.chunk_size - self.left_chunks
|
|
if chunk_idx < self.left_chunks:
|
|
attn_mask[
|
|
:, :, : int(self.required_cache_size - chunk_idx * self.chunk_size)
|
|
] = False
|
|
|
|
log_probs, new_attn_cache, new_conv_cache = self.model.run(
|
|
[
|
|
self.model.get_outputs()[0].name,
|
|
self.model.get_outputs()[1].name,
|
|
self.model.get_outputs()[2].name,
|
|
],
|
|
{
|
|
self.model.get_inputs()[0].name: x.unsqueeze(0).numpy(),
|
|
self.model.get_inputs()[1].name: self.offset,
|
|
self.model.get_inputs()[2].name: self.required_cache_size,
|
|
self.model.get_inputs()[3].name: self.attn_cache,
|
|
self.model.get_inputs()[4].name: self.conv_cache,
|
|
self.model.get_inputs()[5].name: attn_mask.numpy(),
|
|
},
|
|
)
|
|
|
|
self.attn_cache = new_attn_cache
|
|
self.conv_cache = new_conv_cache
|
|
|
|
log_probs = torch.from_numpy(log_probs)
|
|
|
|
self.offset += log_probs.shape[1]
|
|
|
|
return log_probs.squeeze(0)
|
|
|
|
|
|
def get_features(test_wav_filename):
|
|
wave, sample_rate = torchaudio.load(test_wav_filename)
|
|
audio = wave[0].contiguous() # only use the first channel
|
|
if sample_rate != 16000:
|
|
audio = torchaudio.functional.resample(
|
|
audio, orig_freq=sample_rate, new_freq=16000
|
|
)
|
|
audio *= 372768
|
|
|
|
opts = knf.FbankOptions()
|
|
opts.frame_opts.dither = 0
|
|
opts.mel_opts.num_bins = 80
|
|
opts.frame_opts.snip_edges = False
|
|
opts.mel_opts.debug_mel = False
|
|
|
|
fbank = knf.OnlineFbank(opts)
|
|
fbank.accept_waveform(16000, audio.numpy())
|
|
frames = []
|
|
for i in range(fbank.num_frames_ready):
|
|
frames.append(torch.from_numpy(fbank.get_frame(i)))
|
|
frames = torch.stack(frames)
|
|
return frames
|
|
|
|
|
|
def main():
|
|
model_filename = "./model-streaming.onnx"
|
|
model = OnnxModel(model_filename)
|
|
|
|
filename = "./0.wav"
|
|
x = get_features(filename)
|
|
|
|
padding = torch.zeros(int(16000 * 0.5), 80)
|
|
x = torch.cat([x, padding], dim=0)
|
|
|
|
chunk_length = (
|
|
(model.chunk_size - 1) * model.subsampling_factor + model.right_context + 1
|
|
)
|
|
chunk_length = int(chunk_length)
|
|
chunk_shift = int(model.required_cache_size)
|
|
print(chunk_length, chunk_shift)
|
|
|
|
num_frames = x.shape[0]
|
|
n = (num_frames - chunk_length) // chunk_shift + 1
|
|
tokens = []
|
|
for i in range(n):
|
|
start = i * chunk_shift
|
|
end = start + chunk_length
|
|
frames = x[start:end, :]
|
|
log_probs = model(frames)
|
|
|
|
indexes = log_probs.argmax(dim=1)
|
|
indexes = torch.unique_consecutive(indexes)
|
|
indexes = indexes[indexes != 0].tolist()
|
|
if indexes:
|
|
tokens.extend(indexes)
|
|
|
|
id2word = dict()
|
|
with open("./units.txt", encoding="utf-8") as f:
|
|
for line in f:
|
|
word, idx = line.strip().split()
|
|
id2word[int(idx)] = word
|
|
text = "".join([id2word[i] for i in tokens])
|
|
print(text)
|
|
|
|
|
|
if __name__ == "__main__":
|
|
main()
|