# TVP [[tvp]]
## 개요 [[overview]]
Text-Visual Prompting(TVP) 프레임워크는 Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding이 발표한 논문 [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://huggingface.co/papers/2303.04995)에서 제안되었습니다.
논문의 초록은 다음과 같습니다:
*본 논문에서는 길고, 편집되지 않은 비디오에서 문장으로 설명된 순간의 시작/종료 시점을 예측하는 것을 목표로 하는 Temporal Video Grounding(TVG) 문제를 다룹니다. 세밀한 3D 시각적 특징 덕분에 TVG 기술은 최근 몇 년 동안 놀라운 발전을 이뤘습니다. 하지만 3D 합성곱 신경망(CNN)의 높은 복잡성으로 인해 밀도 높은 3D 시각적 특징을 추출하는 데 시간이 오래 걸리고 그만큼 많은 메모리와 연산 자원을 필요로 합니다. 효율적인 TVG를 위해, 본 논문에서는 TVG 모델의 시각적 입력과 텍스트 특징 모두에 최적화된 교란 패턴('프롬프트'라고 부름)을 통합하는 새로운 Text-Visual Prompting(TVP) 프레임워크를 제안합니다. 3D CNN과 뚜렷이 대비되게 TVP가 2D TVG 모델에서 비전 인코더와 언어 인코더를 효과적으로 공동 학습할 수 있게 하고, 낮은 복잡도의 희소한 2D 시각적 특징만을 사용하여 크로스 모달 특징 융합의 성능을 향상시킵니다. 더 나아가, TVG의 효율적인 학습을 위해 Temporal-Distance IoU(TDIoU) 손실 함수를 제안합니다. 두 개의 벤치마크 데이터 세트인 Charades-STA와 ActivityNet Captions 데이터셋에 대한 실험을 통해, 제안된 TVP가 2D TVG의 성능을 크게 향상시키고(예: Charades-STA에서 9.79% 향상, ActivityNet Captions에서 30.77% 향상) 3D 시각적 특징을 사용하는 TVG에 비해 5배의 추론 가속을 달성함을 실험적으로 입증합니다.*
이 연구는 Temporal Video Grounding(TVG)을 다룹니다. TVG는 문장으로 설명된 특정 이벤트의 시작 및 종료 시점을 긴 비디오에서 정확히 찾아내는 과정입니다. TVG 성능을 향상시키기 위해 Text-Visual Prompting(TVP)이 제안되었습니다. TVP는 '프롬프트'라고 알려진 특별히 설계된 패턴을 TVG 모델의 시각적(이미지 기반) 및 텍스트(단어 기반) 입력 구성 요소 모두에 통합하는 것을 방식입니다. 이 프롬프트는 추가적인 시공간적 컨텍스트를 제공함으로써 모델이 비디오 내 이벤트 시점의 예측 정확도를 높입니다. 이 접근 방식은 3D 시각적 입력 대신 2D 입력을 사용합니다. 3D 입력은 보다 풍부한 시공간적 세부 정보를 제공하지만 처리하는 데 시간이 더 많이 걸립니다. 따라서 프롬프팅 메소드와 함께 2D 입력을 사용하여 이와 유사한 수준의 컨텍스트와 정확도를 더 효율적으로 제공하는 것을 목표로 합니다.
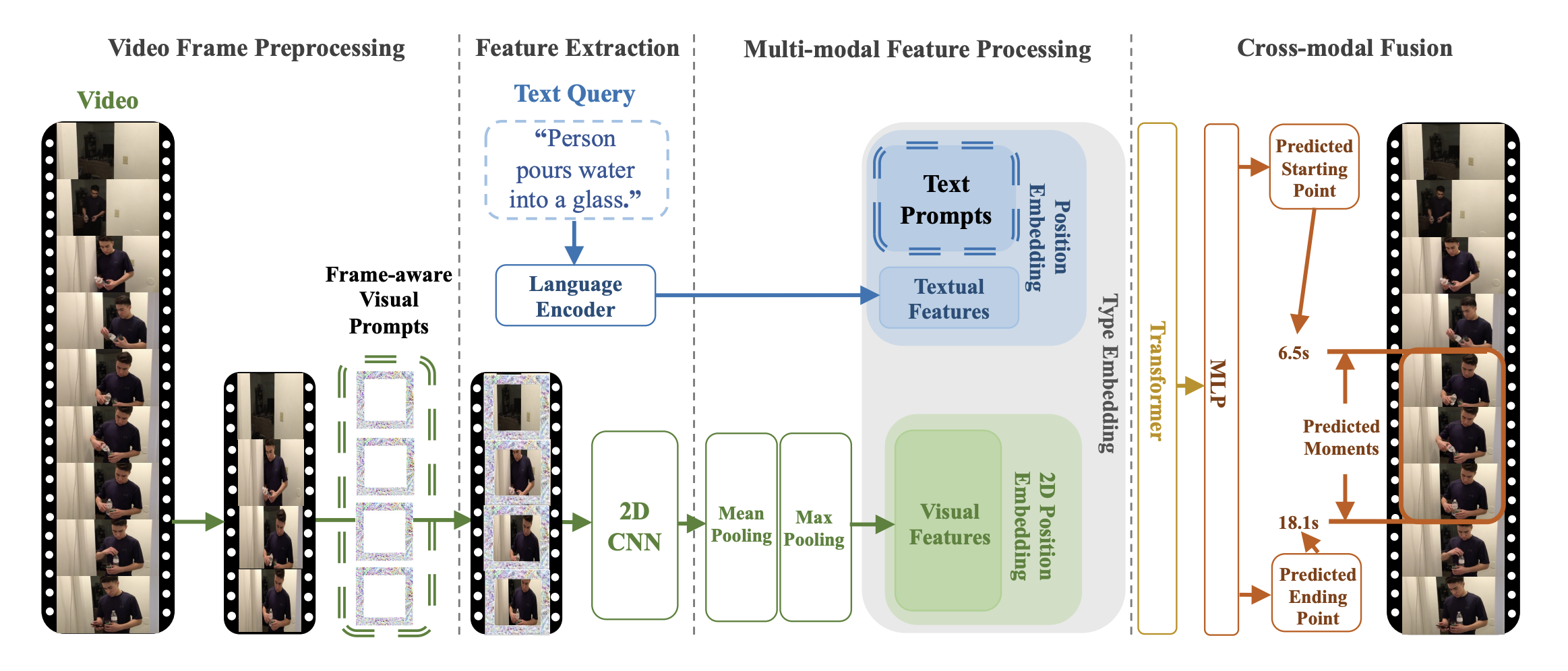 TVP 아키텍처. 원본 논문에서 발췌.
이 모델은 [Jiqing Feng](https://huggingface.co/Jiqing)님이 기여했습니다. 원본 코드는 [이 곳](https://github.com/intel/TVP)에서 찾을 수 있습니다.
## 사용 팁 및 예시 [[usage-tips-and-examples]]
프롬프트는 최적화된 교란 패턴으로 입력 비디오 프레임이나 텍스트 특징에 추가되는 패턴입니다. 범용 세트란 모든 입력에 대해 동일한 프롬프트 세트를 사용하는 것을 말합니다. 즉, 입력 내용과 관계없이 모든 비디오 프레임과 텍스트 특징에 이 프롬프트들을 일관적으로 추가합니다.
TVP는 시각 인코더와 크로스 모달 인코더로 구성됩니다. 범용 시각 프롬프트와 텍스트 프롬프트 세트가 각각 샘플링된 비디오 프레임과 텍스트 특징에 통합됩니다. 특히, 서로 다른 시각 프롬프트 세트가 편집되지 않은 한 비디오에서 균일하게 샘플링된 프레임에 순서대로 적용됩니다.
이 모델의 목표는 학습 가능한 프롬프트를 시각적 입력과 텍스트 특징 모두에 통합하여 Temporal Video Grounding(TVG) 문제를 해결하는 것입니다.
원칙적으로, 제안된 아키텍처에는 어떤 시각 인코더나 크로스 모달 인코더라도 적용할 수 있습니다.
[TvpProcessor]는 [BertTokenizer]와 [TvpImageProcessor]를 단일 인스턴스로 래핑하여 텍스트를 인코딩하고 이미지를 각각 준비합니다.
다음 예시는 [TvpProcessor]와 [TvpForVideoGrounding]을 사용하여 TVG를 실행하는 방법을 보여줍니다.
```python
import av
import cv2
import numpy as np
import torch
from huggingface_hub import hf_hub_download
from transformers import AutoProcessor, TvpForVideoGrounding
def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
'''
원본 fps의 비디오를 지정한 fps(target_fps)로 변환하고 PyAV 디코더로 비디오를 디코딩합니다.
Args:
container (container): pyav 컨테이너 객체입니다.
sampling_rate (int): 프레임 샘플링 속도입니다.(샘플링된 두개의 프레임 사이의 간격을 말합니다)
num_frames (int): 샘플링할 프레임 수입니다.
clip_idx (int): clip_idx가 -1이면 시간 축에서 무작위 샘플링을 수행합니다.
clip_idx가 -1보다 크면 비디오를 num_clips 개로 균등 분할한 후
clip_idx번째 비디오 클립을 선택합니다.
num_clips (int): 주어진 비디오에서 균일하게 샘플링할 전체 클립 수입니다.
target_fps (int): 입력 비디오의 fps가 다를 수 있으므로, 샘플링 전에
지정한 fps로 변환합니다
Returns:
frames (tensor): 비디오에서 디코딩된 프레임입니다. 비디오 스트림을 찾을 수 없는 경우
None을 반환합니다.
fps (float): 비디오의 초당 프레임 수입니다.
'''
video = container.streams.video[0]
fps = float(video.average_rate)
clip_size = sampling_rate * num_frames / target_fps * fps
delta = max(num_frames - clip_size, 0)
start_idx = delta * clip_idx / num_clips
end_idx = start_idx + clip_size - 1
timebase = video.duration / num_frames
video_start_pts = int(start_idx * timebase)
video_end_pts = int(end_idx * timebase)
seek_offset = max(video_start_pts - 1024, 0)
container.seek(seek_offset, any_frame=False, backward=True, stream=video)
frames = {}
for frame in container.decode(video=0):
if frame.pts < video_start_pts:
continue
frames[frame.pts] = frame
if frame.pts > video_end_pts:
break
frames = [frames[pts] for pts in sorted(frames)]
return frames, fps
def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
'''
비디오를 디코딩하고 시간 축 샘플링을 수행합니다.
Args:
container (container): pyav 컨테이너 객체입니다.
sampling_rate (int): 프레임 샘플링 속도입니다.(샘플링된 두개의 프레임 사이의 간격을 말합니다)
num_frames (int): 샘플링할 프레임 수입니다.
clip_idx (int): clip_idx가 -1이면 시간 축에서 무작위 샘플링을 수행합니다.
clip_idx가 -1보다 크면 비디오를 num_clips 개로 균등 분할한 후
clip_idx번째 비디오 클립을 선택합니다.
num_clips (int): 주어진 비디오에서 균일하게 샘플링할 전체 클립 수입니다.
target_fps (int): 입력 비디오의 fps가 다를 수 있으므로, 샘플링 전에
지정한 fps로 변환합니다
Returns:
frames (tensor): 비디오에서 디코딩된 프레임입니다.
'''
assert clip_idx >= -2, "Not a valid clip_idx {}".format(clip_idx)
frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
clip_size = sampling_rate * num_frames / target_fps * fps
index = np.linspace(0, clip_size - 1, num_frames)
index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
frames = frames.transpose(0, 3, 1, 2)
return frames
file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
decoder_kwargs = dict(
container=av.open(file, metadata_errors="ignore"),
sampling_rate=1,
num_frames=model.config.num_frames,
clip_idx=0,
num_clips=1,
target_fps=3,
)
raw_sampled_frms = decode(**decoder_kwargs)
text = "a person is sitting on a bed."
processor = AutoProcessor.from_pretrained("Intel/tvp-base")
model_inputs = processor(
text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
)
model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
output = model(**model_inputs)
def get_video_duration(filename):
cap = cv2.VideoCapture(filename)
if cap.isOpened():
rate = cap.get(5)
frame_num = cap.get(7)
duration = frame_num/rate
return duration
return -1
duration = get_video_duration(file)
start, end = processor.post_process_video_grounding(output.logits, duration)
print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
```
팁:
- 이 TVP 구현은 텍스트 임베딩을 생성하기 위해 [BertTokenizer]를 사용하고, 시각적 임베딩을 계산하기 위해 Resnet-50 모델을 사용합니다.
- 사전 학습된 [tvp-base](https://huggingface.co/Intel/tvp-base)의 체크포인트가 공개되어 있습니다.
- 시간적 비디오 그라운딩 작업에 대한 TVP의 성능은 [표 2](https://huggingface.co/papers/2303.04995)를 참고하세요.
## TvpConfig [[transformers.TvpConfig]]
[[autodoc]] TvpConfig
## TvpImageProcessor [[transformers.TvpImageProcessor]]
[[autodoc]] TvpImageProcessor
- preprocess
## TvpProcessor [[transformers.TvpProcessor]]
[[autodoc]] TvpProcessor
- __call__
## TvpModel [[transformers.TvpModel]]
[[autodoc]] TvpModel
- forward
## TvpForVideoGrounding [[transformers.TvpForVideoGrounding]]
[[autodoc]] TvpForVideoGrounding
- forward
TVP 아키텍처. 원본 논문에서 발췌.
이 모델은 [Jiqing Feng](https://huggingface.co/Jiqing)님이 기여했습니다. 원본 코드는 [이 곳](https://github.com/intel/TVP)에서 찾을 수 있습니다.
## 사용 팁 및 예시 [[usage-tips-and-examples]]
프롬프트는 최적화된 교란 패턴으로 입력 비디오 프레임이나 텍스트 특징에 추가되는 패턴입니다. 범용 세트란 모든 입력에 대해 동일한 프롬프트 세트를 사용하는 것을 말합니다. 즉, 입력 내용과 관계없이 모든 비디오 프레임과 텍스트 특징에 이 프롬프트들을 일관적으로 추가합니다.
TVP는 시각 인코더와 크로스 모달 인코더로 구성됩니다. 범용 시각 프롬프트와 텍스트 프롬프트 세트가 각각 샘플링된 비디오 프레임과 텍스트 특징에 통합됩니다. 특히, 서로 다른 시각 프롬프트 세트가 편집되지 않은 한 비디오에서 균일하게 샘플링된 프레임에 순서대로 적용됩니다.
이 모델의 목표는 학습 가능한 프롬프트를 시각적 입력과 텍스트 특징 모두에 통합하여 Temporal Video Grounding(TVG) 문제를 해결하는 것입니다.
원칙적으로, 제안된 아키텍처에는 어떤 시각 인코더나 크로스 모달 인코더라도 적용할 수 있습니다.
[TvpProcessor]는 [BertTokenizer]와 [TvpImageProcessor]를 단일 인스턴스로 래핑하여 텍스트를 인코딩하고 이미지를 각각 준비합니다.
다음 예시는 [TvpProcessor]와 [TvpForVideoGrounding]을 사용하여 TVG를 실행하는 방법을 보여줍니다.
```python
import av
import cv2
import numpy as np
import torch
from huggingface_hub import hf_hub_download
from transformers import AutoProcessor, TvpForVideoGrounding
def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
'''
원본 fps의 비디오를 지정한 fps(target_fps)로 변환하고 PyAV 디코더로 비디오를 디코딩합니다.
Args:
container (container): pyav 컨테이너 객체입니다.
sampling_rate (int): 프레임 샘플링 속도입니다.(샘플링된 두개의 프레임 사이의 간격을 말합니다)
num_frames (int): 샘플링할 프레임 수입니다.
clip_idx (int): clip_idx가 -1이면 시간 축에서 무작위 샘플링을 수행합니다.
clip_idx가 -1보다 크면 비디오를 num_clips 개로 균등 분할한 후
clip_idx번째 비디오 클립을 선택합니다.
num_clips (int): 주어진 비디오에서 균일하게 샘플링할 전체 클립 수입니다.
target_fps (int): 입력 비디오의 fps가 다를 수 있으므로, 샘플링 전에
지정한 fps로 변환합니다
Returns:
frames (tensor): 비디오에서 디코딩된 프레임입니다. 비디오 스트림을 찾을 수 없는 경우
None을 반환합니다.
fps (float): 비디오의 초당 프레임 수입니다.
'''
video = container.streams.video[0]
fps = float(video.average_rate)
clip_size = sampling_rate * num_frames / target_fps * fps
delta = max(num_frames - clip_size, 0)
start_idx = delta * clip_idx / num_clips
end_idx = start_idx + clip_size - 1
timebase = video.duration / num_frames
video_start_pts = int(start_idx * timebase)
video_end_pts = int(end_idx * timebase)
seek_offset = max(video_start_pts - 1024, 0)
container.seek(seek_offset, any_frame=False, backward=True, stream=video)
frames = {}
for frame in container.decode(video=0):
if frame.pts < video_start_pts:
continue
frames[frame.pts] = frame
if frame.pts > video_end_pts:
break
frames = [frames[pts] for pts in sorted(frames)]
return frames, fps
def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
'''
비디오를 디코딩하고 시간 축 샘플링을 수행합니다.
Args:
container (container): pyav 컨테이너 객체입니다.
sampling_rate (int): 프레임 샘플링 속도입니다.(샘플링된 두개의 프레임 사이의 간격을 말합니다)
num_frames (int): 샘플링할 프레임 수입니다.
clip_idx (int): clip_idx가 -1이면 시간 축에서 무작위 샘플링을 수행합니다.
clip_idx가 -1보다 크면 비디오를 num_clips 개로 균등 분할한 후
clip_idx번째 비디오 클립을 선택합니다.
num_clips (int): 주어진 비디오에서 균일하게 샘플링할 전체 클립 수입니다.
target_fps (int): 입력 비디오의 fps가 다를 수 있으므로, 샘플링 전에
지정한 fps로 변환합니다
Returns:
frames (tensor): 비디오에서 디코딩된 프레임입니다.
'''
assert clip_idx >= -2, "Not a valid clip_idx {}".format(clip_idx)
frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
clip_size = sampling_rate * num_frames / target_fps * fps
index = np.linspace(0, clip_size - 1, num_frames)
index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
frames = frames.transpose(0, 3, 1, 2)
return frames
file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
decoder_kwargs = dict(
container=av.open(file, metadata_errors="ignore"),
sampling_rate=1,
num_frames=model.config.num_frames,
clip_idx=0,
num_clips=1,
target_fps=3,
)
raw_sampled_frms = decode(**decoder_kwargs)
text = "a person is sitting on a bed."
processor = AutoProcessor.from_pretrained("Intel/tvp-base")
model_inputs = processor(
text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
)
model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
output = model(**model_inputs)
def get_video_duration(filename):
cap = cv2.VideoCapture(filename)
if cap.isOpened():
rate = cap.get(5)
frame_num = cap.get(7)
duration = frame_num/rate
return duration
return -1
duration = get_video_duration(file)
start, end = processor.post_process_video_grounding(output.logits, duration)
print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
```
팁:
- 이 TVP 구현은 텍스트 임베딩을 생성하기 위해 [BertTokenizer]를 사용하고, 시각적 임베딩을 계산하기 위해 Resnet-50 모델을 사용합니다.
- 사전 학습된 [tvp-base](https://huggingface.co/Intel/tvp-base)의 체크포인트가 공개되어 있습니다.
- 시간적 비디오 그라운딩 작업에 대한 TVP의 성능은 [표 2](https://huggingface.co/papers/2303.04995)를 참고하세요.
## TvpConfig [[transformers.TvpConfig]]
[[autodoc]] TvpConfig
## TvpImageProcessor [[transformers.TvpImageProcessor]]
[[autodoc]] TvpImageProcessor
- preprocess
## TvpProcessor [[transformers.TvpProcessor]]
[[autodoc]] TvpProcessor
- __call__
## TvpModel [[transformers.TvpModel]]
[[autodoc]] TvpModel
- forward
## TvpForVideoGrounding [[transformers.TvpForVideoGrounding]]
[[autodoc]] TvpForVideoGrounding
- forward