init
This commit is contained in:
158
transformers/docs/source/zh/_toctree.yml
Normal file
158
transformers/docs/source/zh/_toctree.yml
Normal file
@@ -0,0 +1,158 @@
|
||||
- sections:
|
||||
- local: index
|
||||
title: 🤗 Transformers 简介
|
||||
- local: quicktour
|
||||
title: 快速上手
|
||||
- local: installation
|
||||
title: 安装
|
||||
title: 开始使用
|
||||
- sections:
|
||||
- local: pipeline_tutorial
|
||||
title: 使用pipelines进行推理
|
||||
- local: autoclass_tutorial
|
||||
title: 使用AutoClass编写可移植的代码
|
||||
- local: preprocessing
|
||||
title: 预处理数据
|
||||
- local: training
|
||||
title: 微调预训练模型
|
||||
- local: run_scripts
|
||||
title: 通过脚本训练模型
|
||||
- local: accelerate
|
||||
title: 使用🤗Accelerate进行分布式训练
|
||||
- local: peft
|
||||
title: 使用🤗 PEFT加载和训练adapters
|
||||
- local: model_sharing
|
||||
title: 分享您的模型
|
||||
- local: llm_tutorial
|
||||
title: 使用LLMs进行生成
|
||||
title: 教程
|
||||
- sections:
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: tasks/asr
|
||||
title: 自动语音识别
|
||||
- sections:
|
||||
- local: fast_tokenizers
|
||||
title: 使用 🤗 Tokenizers 中的分词器
|
||||
- local: multilingual
|
||||
title: 使用多语言模型进行推理
|
||||
- local: create_a_model
|
||||
title: 使用特定于模型的 API
|
||||
- local: custom_models
|
||||
title: 共享自定义模型
|
||||
- local: chat_templating
|
||||
title: 聊天模型的模板
|
||||
- local: serialization
|
||||
title: 导出为 ONNX
|
||||
- local: torchscript
|
||||
title: 导出为 TorchScript
|
||||
- local: gguf
|
||||
title: 与 GGUF 格式的互操作性
|
||||
- local: tiktoken
|
||||
title: 与 Tiktoken 文件的互操作性
|
||||
- local: community
|
||||
title: 社区资源
|
||||
title: 开发者指南
|
||||
- sections:
|
||||
- local: performance
|
||||
title: 综述
|
||||
- sections:
|
||||
- local: fsdp
|
||||
title: 完全分片数据并行
|
||||
- local: perf_train_special
|
||||
title: 在 Apple silicon 芯片上进行 PyTorch 训练
|
||||
- local: perf_infer_gpu_multi
|
||||
title: 多GPU推理
|
||||
- local: perf_train_cpu
|
||||
title: 在CPU上进行高效训练
|
||||
- local: perf_hardware
|
||||
title: 用于训练的定制硬件
|
||||
- local: hpo_train
|
||||
title: 使用Trainer API 进行超参数搜索
|
||||
title: 高效训练技术
|
||||
- local: big_models
|
||||
title: 实例化大模型
|
||||
- local: debugging
|
||||
title: 问题定位及解决
|
||||
- local: perf_torch_compile
|
||||
title: 使用 `torch.compile()` 优化推理
|
||||
title: 性能和可扩展性
|
||||
- sections:
|
||||
- local: contributing
|
||||
title: 如何为 🤗 Transformers 做贡献?
|
||||
- local: add_new_pipeline
|
||||
title: 如何将流水线添加到 🤗 Transformers?
|
||||
title: 贡献
|
||||
- sections:
|
||||
- local: philosophy
|
||||
title: Transformers的设计理念
|
||||
- local: task_summary
|
||||
title: 🤗Transformers能做什么
|
||||
- local: tokenizer_summary
|
||||
title: 分词器的摘要
|
||||
- local: attention
|
||||
title: 注意力机制
|
||||
- local: bertology
|
||||
title: 基于BERT进行的相关研究
|
||||
title: 概念指南
|
||||
- sections:
|
||||
- sections:
|
||||
- local: main_classes/callback
|
||||
title: Callbacks
|
||||
- local: main_classes/configuration
|
||||
title: Configuration
|
||||
- local: main_classes/data_collator
|
||||
title: Data Collator
|
||||
- local: main_classes/logging
|
||||
title: Logging
|
||||
- local: main_classes/model
|
||||
title: 模型
|
||||
- local: main_classes/text_generation
|
||||
title: 文本生成
|
||||
- local: main_classes/onnx
|
||||
title: ONNX
|
||||
- local: main_classes/optimizer_schedules
|
||||
title: Optimization
|
||||
- local: main_classes/output
|
||||
title: 模型输出
|
||||
- local: main_classes/pipelines
|
||||
title: Pipelines
|
||||
- local: main_classes/processors
|
||||
title: Processors
|
||||
- local: main_classes/quantization
|
||||
title: Quantization
|
||||
- local: main_classes/tokenizer
|
||||
title: Tokenizer
|
||||
- local: main_classes/trainer
|
||||
title: Trainer
|
||||
- local: main_classes/deepspeed
|
||||
title: DeepSpeed集成
|
||||
- local: main_classes/feature_extractor
|
||||
title: Feature Extractor
|
||||
- local: main_classes/image_processor
|
||||
title: Image Processor
|
||||
title: 主要类
|
||||
- sections:
|
||||
- local: internal/modeling_utils
|
||||
title: 自定义层和工具
|
||||
- local: internal/pipelines_utils
|
||||
title: pipelines工具
|
||||
- local: internal/tokenization_utils
|
||||
title: Tokenizers工具
|
||||
- local: internal/trainer_utils
|
||||
title: 训练器工具
|
||||
- local: internal/generation_utils
|
||||
title: 生成工具
|
||||
- local: internal/image_processing_utils
|
||||
title: 图像处理工具
|
||||
- local: internal/audio_utils
|
||||
title: 音频处理工具
|
||||
- local: internal/file_utils
|
||||
title: 通用工具
|
||||
- local: internal/time_series_utils
|
||||
title: 时序数据工具
|
||||
- sections:
|
||||
- local: model_doc/bert
|
||||
title: BERT
|
||||
title: 内部辅助工具
|
||||
title: 应用程序接口 (API)
|
||||
132
transformers/docs/source/zh/accelerate.md
Normal file
132
transformers/docs/source/zh/accelerate.md
Normal file
@@ -0,0 +1,132 @@
|
||||
<!--版权2023年HuggingFace团队保留所有权利。
|
||||
|
||||
根据Apache许可证第2.0版(“许可证”)许可;除非符合许可证,否则您不得使用此文件。您可以在以下网址获取许可证的副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,否则按“按原样”分发的软件,无论是明示还是暗示的,都没有任何担保或条件。请参阅许可证以了解特定语言下的权限和限制。
|
||||
|
||||
⚠️ 请注意,本文件虽然使用Markdown编写,但包含了特定的语法,适用于我们的doc-builder(类似于MDX),可能无法在您的Markdown查看器中正常渲染。
|
||||
|
||||
-->
|
||||
|
||||
# 🤗 加速分布式训练
|
||||
|
||||
随着模型变得越来越大,并行性已经成为在有限硬件上训练更大模型和加速训练速度的策略,增加了数个数量级。在Hugging Face,我们创建了[🤗 加速](https://huggingface.co/docs/accelerate)库,以帮助用户在任何类型的分布式设置上轻松训练🤗 Transformers模型,无论是在一台机器上的多个GPU还是在多个机器上的多个GPU。在本教程中,了解如何自定义您的原生PyTorch训练循环,以启用分布式环境中的训练。
|
||||
|
||||
## 设置
|
||||
|
||||
通过安装🤗 加速开始:
|
||||
|
||||
```bash
|
||||
pip install accelerate
|
||||
```
|
||||
|
||||
然后导入并创建[`~accelerate.Accelerator`]对象。[`~accelerate.Accelerator`]将自动检测您的分布式设置类型,并初始化所有必要的训练组件。您不需要显式地将模型放在设备上。
|
||||
|
||||
```py
|
||||
>>> from accelerate import Accelerator
|
||||
|
||||
>>> accelerator = Accelerator()
|
||||
```
|
||||
|
||||
## 准备加速
|
||||
|
||||
下一步是将所有相关的训练对象传递给[`~accelerate.Accelerator.prepare`]方法。这包括您的训练和评估DataLoader、一个模型和一个优化器:
|
||||
|
||||
```py
|
||||
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
|
||||
... train_dataloader, eval_dataloader, model, optimizer
|
||||
... )
|
||||
```
|
||||
|
||||
## 反向传播
|
||||
|
||||
最后一步是用🤗 加速的[`~accelerate.Accelerator.backward`]方法替换训练循环中的典型`loss.backward()`:
|
||||
|
||||
```py
|
||||
>>> for epoch in range(num_epochs):
|
||||
... for batch in train_dataloader:
|
||||
... outputs = model(**batch)
|
||||
... loss = outputs.loss
|
||||
... accelerator.backward(loss)
|
||||
|
||||
... optimizer.step()
|
||||
... lr_scheduler.step()
|
||||
... optimizer.zero_grad()
|
||||
... progress_bar.update(1)
|
||||
```
|
||||
|
||||
如您在下面的代码中所见,您只需要添加四行额外的代码到您的训练循环中即可启用分布式训练!
|
||||
|
||||
```diff
|
||||
+ from accelerate import Accelerator
|
||||
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
|
||||
|
||||
+ accelerator = Accelerator()
|
||||
|
||||
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
|
||||
optimizer = AdamW(model.parameters(), lr=3e-5)
|
||||
|
||||
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
|
||||
- model.to(device)
|
||||
|
||||
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
|
||||
+ train_dataloader, eval_dataloader, model, optimizer
|
||||
+ )
|
||||
|
||||
num_epochs = 3
|
||||
num_training_steps = num_epochs * len(train_dataloader)
|
||||
lr_scheduler = get_scheduler(
|
||||
"linear",
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=0,
|
||||
num_training_steps=num_training_steps
|
||||
)
|
||||
|
||||
progress_bar = tqdm(range(num_training_steps))
|
||||
|
||||
model.train()
|
||||
for epoch in range(num_epochs):
|
||||
for batch in train_dataloader:
|
||||
- batch = {k: v.to(device) for k, v in batch.items()}
|
||||
outputs = model(**batch)
|
||||
loss = outputs.loss
|
||||
- loss.backward()
|
||||
+ accelerator.backward(loss)
|
||||
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
progress_bar.update(1)
|
||||
```
|
||||
|
||||
## 训练
|
||||
|
||||
在添加了相关代码行后,可以在脚本或笔记本(如Colaboratory)中启动训练。
|
||||
|
||||
### 用脚本训练
|
||||
|
||||
如果您从脚本中运行训练,请运行以下命令以创建和保存配置文件:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
然后使用以下命令启动训练:
|
||||
|
||||
```bash
|
||||
accelerate launch train.py
|
||||
```
|
||||
|
||||
### 用笔记本训练
|
||||
|
||||
🤗 加速还可以在笔记本中运行,如果您计划使用Colaboratory的TPU,则可在其中运行。将负责训练的所有代码包装在一个函数中,并将其传递给[`~accelerate.notebook_launcher`]:
|
||||
|
||||
```py
|
||||
>>> from accelerate import notebook_launcher
|
||||
|
||||
>>> notebook_launcher(training_function)
|
||||
```
|
||||
|
||||
有关🤗 加速及其丰富功能的更多信息,请参阅[文档](https://huggingface.co/docs/accelerate)。
|
||||
238
transformers/docs/source/zh/add_new_pipeline.md
Normal file
238
transformers/docs/source/zh/add_new_pipeline.md
Normal file
@@ -0,0 +1,238 @@
|
||||
<!--
|
||||
Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# 如何创建自定义流水线?
|
||||
|
||||
在本指南中,我们将演示如何创建一个自定义流水线并分享到 [Hub](https://hf.co/models),或将其添加到 🤗 Transformers 库中。
|
||||
|
||||
首先,你需要决定流水线将能够接受的原始条目。它可以是字符串、原始字节、字典或任何看起来最可能是期望的输入。
|
||||
尽量保持输入为纯 Python 语言,因为这样可以更容易地实现兼容性(甚至通过 JSON 在其他语言之间)。
|
||||
这些将是流水线 (`preprocess`) 的 `inputs`。
|
||||
|
||||
然后定义 `outputs`。与 `inputs` 相同的策略。越简单越好。这些将是 `postprocess` 方法的输出。
|
||||
|
||||
首先继承基类 `Pipeline`,其中包含实现 `preprocess`、`_forward`、`postprocess` 和 `_sanitize_parameters` 所需的 4 个方法。
|
||||
|
||||
```python
|
||||
from transformers import Pipeline
|
||||
|
||||
|
||||
class MyPipeline(Pipeline):
|
||||
def _sanitize_parameters(self, **kwargs):
|
||||
preprocess_kwargs = {}
|
||||
if "maybe_arg" in kwargs:
|
||||
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
|
||||
return preprocess_kwargs, {}, {}
|
||||
|
||||
def preprocess(self, inputs, maybe_arg=2):
|
||||
model_input = Tensor(inputs["input_ids"])
|
||||
return {"model_input": model_input}
|
||||
|
||||
def _forward(self, model_inputs):
|
||||
# model_inputs == {"model_input": model_input}
|
||||
outputs = self.model(**model_inputs)
|
||||
# Maybe {"logits": Tensor(...)}
|
||||
return outputs
|
||||
|
||||
def postprocess(self, model_outputs):
|
||||
best_class = model_outputs["logits"].softmax(-1)
|
||||
return best_class
|
||||
```
|
||||
|
||||
这种分解的结构旨在为 CPU/GPU 提供相对无缝的支持,同时支持在不同线程上对 CPU 进行预处理/后处理。
|
||||
|
||||
`preprocess` 将接受最初定义的输入,并将其转换为可供模型输入的内容。它可能包含更多信息,通常是一个 `Dict`。
|
||||
|
||||
`_forward` 是实现细节,不应直接调用。`forward` 是首选的调用方法,因为它包含保障措施,以确保一切都在预期的设备上运作。
|
||||
如果任何内容与实际模型相关,它应该属于 `_forward` 方法,其他内容应该在 preprocess/postprocess 中。
|
||||
|
||||
`postprocess` 方法将接受 `_forward` 的输出,并将其转换为之前确定的最终输出。
|
||||
|
||||
`_sanitize_parameters` 存在是为了允许用户在任何时候传递任何参数,无论是在初始化时 `pipeline(...., maybe_arg=4)`
|
||||
还是在调用时 `pipe = pipeline(...); output = pipe(...., maybe_arg=4)`。
|
||||
|
||||
`_sanitize_parameters` 的返回值是将直接传递给 `preprocess`、`_forward` 和 `postprocess` 的 3 个关键字参数字典。
|
||||
如果调用方没有使用任何额外参数调用,则不要填写任何内容。这样可以保留函数定义中的默认参数,这总是更"自然"的。
|
||||
|
||||
在分类任务中,一个经典的例子是在后处理中使用 `top_k` 参数。
|
||||
|
||||
```python
|
||||
>>> pipe = pipeline("my-new-task")
|
||||
>>> pipe("This is a test")
|
||||
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}, {"label": "3-star", "score": 0.05}
|
||||
{"label": "4-star", "score": 0.025}, {"label": "5-star", "score": 0.025}]
|
||||
|
||||
>>> pipe("This is a test", top_k=2)
|
||||
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}]
|
||||
```
|
||||
|
||||
为了实现这一点,我们将更新我们的 `postprocess` 方法,将默认参数设置为 `5`,
|
||||
并编辑 `_sanitize_parameters` 方法,以允许这个新参数。
|
||||
|
||||
```python
|
||||
def postprocess(self, model_outputs, top_k=5):
|
||||
best_class = model_outputs["logits"].softmax(-1)
|
||||
# Add logic to handle top_k
|
||||
return best_class
|
||||
|
||||
|
||||
def _sanitize_parameters(self, **kwargs):
|
||||
preprocess_kwargs = {}
|
||||
if "maybe_arg" in kwargs:
|
||||
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
|
||||
|
||||
postprocess_kwargs = {}
|
||||
if "top_k" in kwargs:
|
||||
postprocess_kwargs["top_k"] = kwargs["top_k"]
|
||||
return preprocess_kwargs, {}, postprocess_kwargs
|
||||
```
|
||||
|
||||
尽量保持简单输入/输出,最好是可 JSON 序列化的,因为这样可以使流水线的使用非常简单,而不需要用户了解新的对象类型。
|
||||
通常也相对常见地支持许多不同类型的参数以便使用(例如音频文件,可以是文件名、URL 或纯字节)。
|
||||
|
||||
## 将其添加到支持的任务列表中
|
||||
|
||||
要将你的 `new-task` 注册到支持的任务列表中,你需要将其添加到 `PIPELINE_REGISTRY` 中:
|
||||
|
||||
```python
|
||||
from transformers.pipelines import PIPELINE_REGISTRY
|
||||
|
||||
PIPELINE_REGISTRY.register_pipeline(
|
||||
"new-task",
|
||||
pipeline_class=MyPipeline,
|
||||
pt_model=AutoModelForSequenceClassification,
|
||||
)
|
||||
```
|
||||
|
||||
如果需要,你可以指定一个默认模型,此时它应该带有一个特定的修订版本(可以是分支名称或提交哈希,这里我们使用了 `"abcdef"`),以及类型:
|
||||
|
||||
```python
|
||||
PIPELINE_REGISTRY.register_pipeline(
|
||||
"new-task",
|
||||
pipeline_class=MyPipeline,
|
||||
pt_model=AutoModelForSequenceClassification,
|
||||
default={"pt": ("user/awesome_model", "abcdef")},
|
||||
type="text", # current support type: text, audio, image, multimodal
|
||||
)
|
||||
```
|
||||
|
||||
## 在 Hub 上分享你的流水线
|
||||
|
||||
要在 Hub 上分享你的自定义流水线,你只需要将 `Pipeline` 子类的自定义代码保存在一个 Python 文件中。
|
||||
例如,假设我们想使用一个自定义流水线进行句对分类,如下所示:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
|
||||
from transformers import Pipeline
|
||||
|
||||
|
||||
def softmax(outputs):
|
||||
maxes = np.max(outputs, axis=-1, keepdims=True)
|
||||
shifted_exp = np.exp(outputs - maxes)
|
||||
return shifted_exp / shifted_exp.sum(axis=-1, keepdims=True)
|
||||
|
||||
|
||||
class PairClassificationPipeline(Pipeline):
|
||||
def _sanitize_parameters(self, **kwargs):
|
||||
preprocess_kwargs = {}
|
||||
if "second_text" in kwargs:
|
||||
preprocess_kwargs["second_text"] = kwargs["second_text"]
|
||||
return preprocess_kwargs, {}, {}
|
||||
|
||||
def preprocess(self, text, second_text=None):
|
||||
return self.tokenizer(text, text_pair=second_text, return_tensors=self.framework)
|
||||
|
||||
def _forward(self, model_inputs):
|
||||
return self.model(**model_inputs)
|
||||
|
||||
def postprocess(self, model_outputs):
|
||||
logits = model_outputs.logits[0].numpy()
|
||||
probabilities = softmax(logits)
|
||||
|
||||
best_class = np.argmax(probabilities)
|
||||
label = self.model.config.id2label[best_class]
|
||||
score = probabilities[best_class].item()
|
||||
logits = logits.tolist()
|
||||
return {"label": label, "score": score, "logits": logits}
|
||||
```
|
||||
|
||||
这个实现与框架无关,适用于 PyTorch 和 TensorFlow 模型。如果我们将其保存在一个名为
|
||||
`pair_classification.py` 的文件中,然后我们可以像这样导入并注册它:
|
||||
|
||||
```py
|
||||
from pair_classification import PairClassificationPipeline
|
||||
from transformers.pipelines import PIPELINE_REGISTRY
|
||||
from transformers import AutoModelForSequenceClassification, TFAutoModelForSequenceClassification
|
||||
|
||||
PIPELINE_REGISTRY.register_pipeline(
|
||||
"pair-classification",
|
||||
pipeline_class=PairClassificationPipeline,
|
||||
pt_model=AutoModelForSequenceClassification,
|
||||
tf_model=TFAutoModelForSequenceClassification,
|
||||
)
|
||||
```
|
||||
|
||||
完成这些步骤后,我们可以将其与预训练模型一起使用。例如,`sgugger/finetuned-bert-mrpc`
|
||||
已经在 MRPC 数据集上进行了微调,用于将句子对分类为是释义或不是释义。
|
||||
|
||||
```py
|
||||
from transformers import pipeline
|
||||
|
||||
classifier = pipeline("pair-classification", model="sgugger/finetuned-bert-mrpc")
|
||||
```
|
||||
|
||||
然后,我们可以通过在 `Repository` 中使用 `save_pretrained` 方法将其分享到 Hub 上:
|
||||
|
||||
```py
|
||||
from huggingface_hub import Repository
|
||||
|
||||
repo = Repository("test-dynamic-pipeline", clone_from="{your_username}/test-dynamic-pipeline")
|
||||
classifier.save_pretrained("test-dynamic-pipeline")
|
||||
repo.push_to_hub()
|
||||
```
|
||||
|
||||
这将会复制包含你定义的 `PairClassificationPipeline` 的文件到文件夹 `"test-dynamic-pipeline"` 中,
|
||||
同时保存流水线的模型和分词器,然后将所有内容推送到仓库 `{your_username}/test-dynamic-pipeline` 中。
|
||||
之后,只要提供选项 `trust_remote_code=True`,任何人都可以使用它:
|
||||
|
||||
```py
|
||||
from transformers import pipeline
|
||||
|
||||
classifier = pipeline(model="{your_username}/test-dynamic-pipeline", trust_remote_code=True)
|
||||
```
|
||||
|
||||
## 将流水线添加到 🤗 Transformers
|
||||
|
||||
如果你想将你的流水线贡献给 🤗 Transformers,你需要在 `pipelines` 子模块中添加一个新模块,
|
||||
其中包含你的流水线的代码,然后将其添加到 `pipelines/__init__.py` 中定义的任务列表中。
|
||||
|
||||
然后,你需要添加测试。创建一个新文件 `tests/test_pipelines_MY_PIPELINE.py`,其中包含其他测试的示例。
|
||||
|
||||
`run_pipeline_test` 函数将非常通用,并在每种可能的架构上运行小型随机模型,如 `model_mapping` 和 `tf_model_mapping` 所定义。
|
||||
|
||||
这对于测试未来的兼容性非常重要,这意味着如果有人为 `XXXForQuestionAnswering` 添加了一个新模型,
|
||||
流水线测试将尝试在其上运行。由于模型是随机的,所以不可能检查实际值,这就是为什么有一个帮助函数 `ANY`,它只是尝试匹配流水线的输出类型。
|
||||
|
||||
你还 **需要** 实现 2(最好是 4)个测试。
|
||||
|
||||
- `test_small_model_pt`:为这个流水线定义一个小型模型(结果是否合理并不重要),并测试流水线的输出。
|
||||
结果应该与 `test_small_model_tf` 的结果相同。
|
||||
- `test_small_model_tf`:为这个流水线定义一个小型模型(结果是否合理并不重要),并测试流水线的输出。
|
||||
结果应该与 `test_small_model_pt` 的结果相同。
|
||||
- `test_large_model_pt`(可选):在一个真实的流水线上测试流水线,结果应该是有意义的。
|
||||
这些测试速度较慢,应该被如此标记。这里的目标是展示流水线,并确保在未来的发布中没有漂移。
|
||||
- `test_large_model_tf`(可选):在一个真实的流水线上测试流水线,结果应该是有意义的。
|
||||
这些测试速度较慢,应该被如此标记。这里的目标是展示流水线,并确保在未来的发布中没有漂移。
|
||||
37
transformers/docs/source/zh/attention.md
Normal file
37
transformers/docs/source/zh/attention.md
Normal file
@@ -0,0 +1,37 @@
|
||||
<!--版权2023年HuggingFace团队保留所有权利。
|
||||
|
||||
根据Apache许可证第2.0版(“许可证”)许可;除非符合许可证,否则您不得使用此文件。您可以在以下网址获取许可证的副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,否则按“按原样”分发的软件,无论是明示还是暗示的,都没有任何担保或条件。请参阅许可证以了解特定语言下的权限和限制。
|
||||
|
||||
⚠️ 请注意,本文件虽然使用Markdown编写,但包含了特定的语法,适用于我们的doc-builder(类似于MDX),可能无法在您的Markdown查看器中正常渲染。
|
||||
|
||||
-->
|
||||
|
||||
# 注意力机制
|
||||
|
||||
大多数 transformer 模型使用完全注意力机制,该机制采用正方形的注意力矩阵。当输入很长的文本时,这将导致巨大的计算瓶颈。Longformer 和 Reformer 是提高注意力机制效率的改进模型,它们使用稀疏化的注意力矩阵来加速训练。
|
||||
|
||||
## 局部敏感哈希注意力机制(LSH attention)
|
||||
|
||||
[Reformer](model_doc/reformer)使用LSH(局部敏感哈希)的注意力机制。在计算softmax(QK^t)时,只有矩阵QK^t中的最大元素(在softmax维度上)会做出有用的贡献。所以对于Q中的每个查询q,我们只需要考虑K中与q接近的键k,这里使用了一个哈希函数来确定q和k是否接近。注意力掩码被修改以掩盖当前的词符(token)(除了第一个位置之外),因为这样会使得查询和键相等(因此非常相似)。由于哈希可能会有些随机性,所以在实践中使用多个哈希函数(由n_rounds参数确定),然后一起求平均。
|
||||
|
||||
## 局部注意力机制(Local attention)
|
||||
[Longformer](model_doc/longformer)使用局部注意力机制:通常情况下,局部上下文(例如,左边和右边的两个词符是什么?)对于给定词符的操作已经足够了。此外,通过堆叠具有小窗口的注意力层,最后一层将拥有不仅仅是窗口内词符的感受野,这使得它们能构建整个句子的表示。
|
||||
|
||||
一些预先选定的输入词符也被赋予全局注意力:对于这些少数词符,注意力矩阵可以访问所有词符(tokens),并且这个过程是对称的:所有其他词符除了它们局部窗口内的词符之外,也可以访问这些特定的词符。这在论文的图2d中有展示,下面是一个样本注意力掩码:
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img scale="50 %" align="center" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/local_attention_mask.png"/>
|
||||
</div>
|
||||
|
||||
使用参数更少的注意力矩阵,可以让模型处理更长的输入序列。
|
||||
|
||||
## 其他技巧
|
||||
|
||||
### 轴向位置编码
|
||||
|
||||
[Reformer](model_doc/reformer)模型使用轴向位置编码:在传统的transformer模型中,位置编码矩阵E的大小是\\(l\\)乘以\\(d\\),其中\\(l\\)是序列长度,\\(d\\)是隐藏状态的维度。如果你有非常长的文本,这个矩阵可能会非常大,将会占用大量的GPU显存。为了缓解这个问题,轴向位置编码将这个大矩阵E分解成两个较小的矩阵E1和E2,它们的维度分别是\\(l_{1} \times d_{1}\\) 和\\(l_{2} \times d_{2}\\),满足\\(l_{1} \times l_{2} = l\\)和\\(d_{1} + d_{2} = d\\)(通过长度的乘积,最终得到的矩阵要小得多)。在E中,对于时间步\\(j\\) 的嵌入是通过连接E1中时间步 \\(j \% l1\\) 的嵌入和E2中时间步\\(j // l1\\)的嵌入来获得的。
|
||||
|
||||
124
transformers/docs/source/zh/autoclass_tutorial.md
Normal file
124
transformers/docs/source/zh/autoclass_tutorial.md
Normal file
@@ -0,0 +1,124 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 使用AutoClass加载预训练实例
|
||||
|
||||
由于存在许多不同的Transformer架构,因此为您的checkpoint创建一个可用架构可能会具有挑战性。通过`AutoClass`可以自动推断并从给定的checkpoint加载正确的架构, 这也是🤗 Transformers易于使用、简单且灵活核心规则的重要一部分。`from_pretrained()`方法允许您快速加载任何架构的预训练模型,因此您不必花费时间和精力从头开始训练模型。生成这种与checkpoint无关的代码意味着,如果您的代码适用于一个checkpoint,它将适用于另一个checkpoint - 只要它们是为了类似的任务进行训练的 - 即使架构不同。
|
||||
|
||||
<Tip>
|
||||
|
||||
请记住,架构指的是模型的结构,而checkpoints是给定架构的权重。例如,[BERT](https://huggingface.co/google-bert/bert-base-uncased)是一种架构,而`google-bert/bert-base-uncased`是一个checkpoint。模型是一个通用术语,可以指代架构或checkpoint。
|
||||
|
||||
|
||||
</Tip>
|
||||
|
||||
在这个教程中,学习如何:
|
||||
|
||||
* 加载预训练的分词器(`tokenizer`)
|
||||
* 加载预训练的图像处理器(`image processor`)
|
||||
* 加载预训练的特征提取器(`feature extractor`)
|
||||
* 加载预训练的处理器(`processor`)
|
||||
* 加载预训练的模型。
|
||||
|
||||
|
||||
## AutoTokenizer
|
||||
|
||||
几乎所有的NLP任务都以`tokenizer`开始。`tokenizer`将您的输入转换为模型可以处理的格式。
|
||||
|
||||
使用[`AutoTokenizer.from_pretrained`]加载`tokenizer`:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
|
||||
```
|
||||
|
||||
然后按照如下方式对输入进行分词:
|
||||
|
||||
```py
|
||||
>>> sequence = "In a hole in the ground there lived a hobbit."
|
||||
>>> print(tokenizer(sequence))
|
||||
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
|
||||
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
|
||||
```
|
||||
|
||||
## AutoImageProcessor
|
||||
|
||||
对于视觉任务,`image processor`将图像处理成正确的输入格式。
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoImageProcessor
|
||||
|
||||
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
|
||||
```
|
||||
|
||||
|
||||
## AutoFeatureExtractor
|
||||
|
||||
对于音频任务,`feature extractor`将音频信号处理成正确的输入格式。
|
||||
|
||||
使用[`AutoFeatureExtractor.from_pretrained`]加载`feature extractor`:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoFeatureExtractor
|
||||
|
||||
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
|
||||
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
|
||||
... )
|
||||
```
|
||||
|
||||
## AutoProcessor
|
||||
|
||||
多模态任务需要一种`processor`,将两种类型的预处理工具结合起来。例如,[LayoutLMV2](model_doc/layoutlmv2)模型需要一个`image processor`来处理图像和一个`tokenizer`来处理文本;`processor`将两者结合起来。
|
||||
|
||||
使用[`AutoProcessor.from_pretrained`]加载`processor`:
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoProcessor
|
||||
|
||||
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
|
||||
```
|
||||
|
||||
## AutoModel
|
||||
|
||||
|
||||
最后,`AutoModelFor`类让你可以加载给定任务的预训练模型(参见[这里](model_doc/auto)获取可用任务的完整列表)。例如,使用[`AutoModelForSequenceClassification.from_pretrained`]加载用于序列分类的模型:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForSequenceClassification
|
||||
|
||||
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
|
||||
```
|
||||
|
||||
轻松地重复使用相同的checkpoint来为不同任务加载模型架构:
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForTokenClassification
|
||||
|
||||
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
对于PyTorch模型,`from_pretrained()`方法使用`torch.load()`,它内部使用已知是不安全的`pickle`。一般来说,永远不要加载来自不可信来源或可能被篡改的模型。对于托管在Hugging Face Hub上的公共模型,这种安全风险在一定程度上得到了缓解,因为每次提交都会进行[恶意软件扫描](https://huggingface.co/docs/hub/security-malware)。请参阅[Hub文档](https://huggingface.co/docs/hub/security)以了解最佳实践,例如使用GPG进行[签名提交验证](https://huggingface.co/docs/hub/security-gpg#signing-commits-with-gpg)。
|
||||
|
||||
</Tip>
|
||||
|
||||
一般来说,我们建议使用`AutoTokenizer`类和`AutoModelFor`类来加载预训练的模型实例。这样可以确保每次加载正确的架构。在下一个[教程](preprocessing)中,学习如何使用新加载的`tokenizer`, `image processor`, `feature extractor`和`processor`对数据集进行预处理以进行微调。
|
||||
|
||||
33
transformers/docs/source/zh/bertology.md
Normal file
33
transformers/docs/source/zh/bertology.md
Normal file
@@ -0,0 +1,33 @@
|
||||
<!--版权2020年HuggingFace团队保留所有权利。
|
||||
|
||||
根据Apache许可证第2.0版(“许可证”)许可;除非符合许可证,否则您不得使用此文件。您可以在以下网址获取许可证的副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,否则按“按原样”分发的软件,无论是明示还是暗示的,都没有任何担保或条件。请参阅许可证以了解特定语言下的权限和限制。
|
||||
|
||||
⚠️ 请注意,本文件虽然使用Markdown编写,但包含了特定的语法,适用于我们的doc-builder(类似于MDX),可能无法在您的Markdown查看器中正常渲染。
|
||||
|
||||
-->
|
||||
|
||||
# 基于BERT进行的相关研究(BERTology)
|
||||
|
||||
当前,一个新兴的研究领域正致力于探索大规模 transformer 模型(如BERT)的内部工作机制,一些人称之为“BERTology”。以下是这个领域的一些典型示例:
|
||||
|
||||
|
||||
- BERT Rediscovers the Classical NLP Pipeline by Ian Tenney, Dipanjan Das, Ellie Pavlick:
|
||||
https://huggingface.co/papers/1905.05950
|
||||
- Are Sixteen Heads Really Better than One? by Paul Michel, Omer Levy, Graham Neubig: https://huggingface.co/papers/1905.10650
|
||||
- What Does BERT Look At? An Analysis of BERT's Attention by Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
|
||||
Manning: https://huggingface.co/papers/1906.04341
|
||||
- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://huggingface.co/papers/2210.04633
|
||||
|
||||
|
||||
为了助力这一新兴领域的发展,我们在BERT/GPT/GPT-2模型中增加了一些附加功能,方便人们访问其内部表示,这些功能主要借鉴了Paul Michel的杰出工作(https://huggingface.co/papers/1905.10650):
|
||||
|
||||
|
||||
- 访问BERT/GPT/GPT-2的所有隐藏状态,
|
||||
- 访问BERT/GPT/GPT-2每个注意力头的所有注意力权重,
|
||||
- 检索注意力头的输出值和梯度,以便计算头的重要性得分并对头进行剪枝,详情可见论文:https://huggingface.co/papers/1905.10650。
|
||||
|
||||
为了帮助您理解和使用这些功能,我们添加了一个具体的示例脚本:[bertology.py](https://github.com/huggingface/transformers-research-projects/tree/main/bertology/run_bertology.py),该脚本可以对一个在 GLUE 数据集上预训练的模型进行信息提取与剪枝。
|
||||
123
transformers/docs/source/zh/big_models.md
Normal file
123
transformers/docs/source/zh/big_models.md
Normal file
@@ -0,0 +1,123 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 实例化大型模型
|
||||
|
||||
当你想使用一个非常大的预训练模型时,一个挑战是尽量减少对内存的使用。通常从PyTorch开始的工作流程如下:
|
||||
|
||||
1. 用随机权重创建你的模型。
|
||||
2. 加载你的预训练权重。
|
||||
3. 将这些预训练权重放入你的随机模型中。
|
||||
|
||||
步骤1和2都需要完整版本的模型在内存中,这在大多数情况下不是问题,但如果你的模型开始达到几个GB的大小,这两个副本可能会让你超出内存的限制。更糟糕的是,如果你使用`torch.distributed`来启动分布式训练,每个进程都会加载预训练模型并将这两个副本存储在内存中。
|
||||
|
||||
<Tip>
|
||||
|
||||
请注意,随机创建的模型使用“空”张量进行初始化,这些张量占用内存空间但不填充它(因此随机值是给定时间内该内存块中的任何内容)。在第3步之后,对未初始化的权重执行适合模型/参数种类的随机初始化(例如正态分布),以尽可能提高速度!
|
||||
|
||||
</Tip>
|
||||
|
||||
在本指南中,我们将探讨 Transformers 提供的解决方案来处理这个问题。请注意,这是一个积极开发的领域,因此这里解释的API在将来可能会略有变化。
|
||||
|
||||
## 分片checkpoints
|
||||
|
||||
自4.18.0版本起,占用空间超过10GB的模型检查点将自动分成较小的片段。在使用`model.save_pretrained(save_dir)`时,您最终会得到几个部分`checkpoints`(每个的大小都小于10GB)以及一个索引,该索引将参数名称映射到存储它们的文件。
|
||||
|
||||
您可以使用`max_shard_size`参数来控制分片之前的最大大小。为了示例的目的,我们将使用具有较小分片大小的普通大小的模型:让我们以传统的BERT模型为例。
|
||||
|
||||
|
||||
```py
|
||||
from transformers import AutoModel
|
||||
|
||||
model = AutoModel.from_pretrained("google-bert/bert-base-cased")
|
||||
```
|
||||
|
||||
如果您使用 [`PreTrainedModel.save_pretrained`](模型预训练保存) 进行保存,您将得到一个新的文件夹,其中包含两个文件:模型的配置和权重:
|
||||
|
||||
```py
|
||||
>>> import os
|
||||
>>> import tempfile
|
||||
|
||||
>>> with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
... model.save_pretrained(tmp_dir)
|
||||
... print(sorted(os.listdir(tmp_dir)))
|
||||
['config.json', 'pytorch_model.bin']
|
||||
```
|
||||
|
||||
现在让我们使用最大分片大小为200MB:
|
||||
|
||||
```py
|
||||
>>> with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
|
||||
... print(sorted(os.listdir(tmp_dir)))
|
||||
['config.json', 'pytorch_model-00001-of-00003.bin', 'pytorch_model-00002-of-00003.bin', 'pytorch_model-00003-of-00003.bin', 'pytorch_model.bin.index.json']
|
||||
```
|
||||
|
||||
在模型配置文件最上方,我们可以看到三个不同的权重文件,以及一个`index.json`索引文件。这样的`checkpoint`可以使用[`~PreTrainedModel.from_pretrained`]方法完全重新加载:
|
||||
|
||||
```py
|
||||
>>> with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
|
||||
... new_model = AutoModel.from_pretrained(tmp_dir)
|
||||
```
|
||||
|
||||
对于大型模型来说,这样做的主要优点是在上述工作流程的步骤2中,每个`checkpoint`的分片在前一个分片之后加载,从而将内存中的内存使用限制在模型大小加上最大分片的大小。
|
||||
|
||||
在后台,索引文件用于确定`checkpoint`中包含哪些键以及相应的权重存储在哪里。我们可以像加载任何json一样加载该索引,并获得一个字典:
|
||||
|
||||
```py
|
||||
>>> import json
|
||||
|
||||
>>> with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
|
||||
... with open(os.path.join(tmp_dir, "pytorch_model.bin.index.json"), "r") as f:
|
||||
... index = json.load(f)
|
||||
|
||||
>>> print(index.keys())
|
||||
dict_keys(['metadata', 'weight_map'])
|
||||
```
|
||||
|
||||
目前元数据仅包括模型的总大小。我们计划在将来添加其他信息:
|
||||
```py
|
||||
>>> index["metadata"]
|
||||
{'total_size': 433245184}
|
||||
```
|
||||
|
||||
权重映射是该索引的主要部分,它将每个参数的名称(通常在PyTorch模型的`state_dict`中找到)映射到存储该参数的文件:
|
||||
|
||||
```py
|
||||
>>> index["weight_map"]
|
||||
{'embeddings.LayerNorm.bias': 'pytorch_model-00001-of-00003.bin',
|
||||
'embeddings.LayerNorm.weight': 'pytorch_model-00001-of-00003.bin',
|
||||
...
|
||||
```
|
||||
|
||||
如果您想直接在模型内部加载这样的分片`checkpoint`,而不使用 [`PreTrainedModel.from_pretrained`](就像您会为完整`checkpoint`执行 `model.load_state_dict()` 一样),您应该使用 [`modeling_utils.load_sharded_checkpoint`]:
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers.modeling_utils import load_sharded_checkpoint
|
||||
|
||||
>>> with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
|
||||
... load_sharded_checkpoint(model, tmp_dir)
|
||||
```
|
||||
|
||||
## 低内存加载
|
||||
|
||||
分片`checkpoints`在上述工作流的第2步中降低了内存使用,但为了在低内存环境中使用该模型,我们建议使用基于 Accelerate 库的工具。
|
||||
|
||||
请阅读以下指南以获取更多信息:[使用 Accelerate 进行大模型加载](./main_classes/model#large-model-loading)
|
||||
434
transformers/docs/source/zh/chat_templating.md
Normal file
434
transformers/docs/source/zh/chat_templating.md
Normal file
@@ -0,0 +1,434 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 聊天模型的模板
|
||||
|
||||
## 介绍
|
||||
|
||||
LLM 的一个常见应用场景是聊天。在聊天上下文中,不再是连续的文本字符串构成的语句(不同于标准的语言模型),
|
||||
聊天模型由一条或多条消息组成的对话组成,每条消息都有一个“用户”或“助手”等 **角色**,还包括消息文本。
|
||||
|
||||
与`Tokenizer`类似,不同的模型对聊天的输入格式要求也不同。这就是我们添加**聊天模板**作为一个功能的原因。
|
||||
聊天模板是`Tokenizer`的一部分。用来把问答的对话内容转换为模型的输入`prompt`。
|
||||
|
||||
|
||||
让我们通过一个快速的示例来具体说明,使用`BlenderBot`模型。
|
||||
BlenderBot有一个非常简单的默认模板,主要是在对话轮之间添加空格:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
|
||||
|
||||
>>> chat = [
|
||||
... {"role": "user", "content": "Hello, how are you?"},
|
||||
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
|
||||
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
|
||||
... ]
|
||||
|
||||
>>> tokenizer.apply_chat_template(chat, tokenize=False)
|
||||
" Hello, how are you? I'm doing great. How can I help you today? I'd like to show off how chat templating works!</s>"
|
||||
```
|
||||
|
||||
注意,整个聊天对话内容被压缩成了一整个字符串。如果我们使用默认设置的`tokenize=True`,那么该字符串也将被tokenized处理。
|
||||
不过,为了看到更复杂的模板实际运行,让我们使用`mistralai/Mistral-7B-Instruct-v0.1`模型。
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
|
||||
|
||||
>>> chat = [
|
||||
... {"role": "user", "content": "Hello, how are you?"},
|
||||
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
|
||||
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
|
||||
... ]
|
||||
|
||||
>>> tokenizer.apply_chat_template(chat, tokenize=False)
|
||||
"<s>[INST] Hello, how are you? [/INST]I'm doing great. How can I help you today?</s> [INST] I'd like to show off how chat templating works! [/INST]"
|
||||
```
|
||||
|
||||
可以看到,这一次tokenizer已经添加了[INST]和[/INST]来表示用户消息的开始和结束。
|
||||
Mistral-instruct是有使用这些token进行训练的,但BlenderBot没有。
|
||||
|
||||
## 我如何使用聊天模板?
|
||||
|
||||
正如您在上面的示例中所看到的,聊天模板非常容易使用。只需构建一系列带有`role`和`content`键的消息,
|
||||
然后将其传递给[`~PreTrainedTokenizer.apply_chat_template`]方法。
|
||||
另外,在将聊天模板用作模型预测的输入时,还建议使用`add_generation_prompt=True`来添加[generation prompt](#什么是generation-prompts)。
|
||||
|
||||
这是一个准备`model.generate()`的示例,使用`Zephyr`模型:
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
checkpoint = "HuggingFaceH4/zephyr-7b-beta"
|
||||
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
||||
model = AutoModelForCausalLM.from_pretrained(checkpoint) # You may want to use bfloat16 and/or move to GPU here
|
||||
|
||||
messages = [
|
||||
{
|
||||
"role": "system",
|
||||
"content": "You are a friendly chatbot who always responds in the style of a pirate",
|
||||
},
|
||||
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
|
||||
]
|
||||
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
|
||||
print(tokenizer.decode(tokenized_chat[0]))
|
||||
```
|
||||
这将生成Zephyr期望的输入格式的字符串。它看起来像这样:
|
||||
```text
|
||||
<|system|>
|
||||
You are a friendly chatbot who always responds in the style of a pirate</s>
|
||||
<|user|>
|
||||
How many helicopters can a human eat in one sitting?</s>
|
||||
<|assistant|>
|
||||
```
|
||||
|
||||
现在我们已经按照`Zephyr`的要求传入prompt了,我们可以使用模型来生成对用户问题的回复:
|
||||
|
||||
```python
|
||||
outputs = model.generate(tokenized_chat, max_new_tokens=128)
|
||||
print(tokenizer.decode(outputs[0]))
|
||||
```
|
||||
|
||||
输出结果是:
|
||||
|
||||
```text
|
||||
<|system|>
|
||||
You are a friendly chatbot who always responds in the style of a pirate</s>
|
||||
<|user|>
|
||||
How many helicopters can a human eat in one sitting?</s>
|
||||
<|assistant|>
|
||||
Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
|
||||
```
|
||||
啊,原来这么容易!
|
||||
|
||||
## 有自动化的聊天`pipeline`吗?
|
||||
|
||||
有的,[`TextGenerationPipeline`]。这个`pipeline`的设计是为了方便使用聊天模型。让我们再试一次 Zephyr 的例子,但这次使用`pipeline`:
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
pipe = pipeline("text-generation", "HuggingFaceH4/zephyr-7b-beta")
|
||||
messages = [
|
||||
{
|
||||
"role": "system",
|
||||
"content": "You are a friendly chatbot who always responds in the style of a pirate",
|
||||
},
|
||||
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
|
||||
]
|
||||
print(pipe(messages, max_new_tokens=256)['generated_text'][-1])
|
||||
```
|
||||
|
||||
```text
|
||||
{'role': 'assistant', 'content': "Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all."}
|
||||
```
|
||||
|
||||
[`TextGenerationPipeline`]将负责处理所有的`tokenized`并调用`apply_chat_template`,一旦模型有了聊天模板,您只需要初始化pipeline并传递消息列表!
|
||||
|
||||
## 什么是"generation prompts"?
|
||||
|
||||
您可能已经注意到`apply_chat_template`方法有一个`add_generation_prompt`参数。
|
||||
这个参数告诉模板添加模型开始答复的标记。例如,考虑以下对话:
|
||||
|
||||
```python
|
||||
messages = [
|
||||
{"role": "user", "content": "Hi there!"},
|
||||
{"role": "assistant", "content": "Nice to meet you!"},
|
||||
{"role": "user", "content": "Can I ask a question?"}
|
||||
]
|
||||
```
|
||||
|
||||
这是`add_generation_prompt=False`的结果,使用ChatML模板:
|
||||
```python
|
||||
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
|
||||
"""<|im_start|>user
|
||||
Hi there!<|im_end|>
|
||||
<|im_start|>assistant
|
||||
Nice to meet you!<|im_end|>
|
||||
<|im_start|>user
|
||||
Can I ask a question?<|im_end|>
|
||||
"""
|
||||
```
|
||||
|
||||
下面这是`add_generation_prompt=True`的结果:
|
||||
|
||||
```python
|
||||
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
|
||||
"""<|im_start|>user
|
||||
Hi there!<|im_end|>
|
||||
<|im_start|>assistant
|
||||
Nice to meet you!<|im_end|>
|
||||
<|im_start|>user
|
||||
Can I ask a question?<|im_end|>
|
||||
<|im_start|>assistant
|
||||
"""
|
||||
```
|
||||
|
||||
这一次我们添加了模型开始答复的标记。这可以确保模型生成文本时只会给出答复,而不会做出意外的行为,比如继续用户的消息。
|
||||
记住,聊天模型只是语言模型,它们被训练来继续文本,而聊天对它们来说只是一种特殊的文本!
|
||||
你需要用适当的控制标记来引导它们,让它们知道自己应该做什么。
|
||||
|
||||
并非所有模型都需要生成提示。一些模型,如BlenderBot和LLaMA,在模型回复之前没有任何特殊标记。
|
||||
在这些情况下,`add_generation_prompt`参数将不起作用。`add_generation_prompt`参数取决于你所使用的模板。
|
||||
|
||||
## 我可以在训练中使用聊天模板吗?
|
||||
|
||||
可以!我们建议您将聊天模板应用为数据集的预处理步骤。之后,您可以像进行任何其他语言模型训练任务一样继续。
|
||||
在训练时,通常应该设置`add_generation_prompt=False`,因为添加的助手标记在训练过程中并不会有帮助。
|
||||
让我们看一个例子:
|
||||
|
||||
```python
|
||||
from transformers import AutoTokenizer
|
||||
from datasets import Dataset
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-beta")
|
||||
|
||||
chat1 = [
|
||||
{"role": "user", "content": "Which is bigger, the moon or the sun?"},
|
||||
{"role": "assistant", "content": "The sun."}
|
||||
]
|
||||
chat2 = [
|
||||
{"role": "user", "content": "Which is bigger, a virus or a bacterium?"},
|
||||
{"role": "assistant", "content": "A bacterium."}
|
||||
]
|
||||
|
||||
dataset = Dataset.from_dict({"chat": [chat1, chat2]})
|
||||
dataset = dataset.map(lambda x: {"formatted_chat": tokenizer.apply_chat_template(x["chat"], tokenize=False, add_generation_prompt=False)})
|
||||
print(dataset['formatted_chat'][0])
|
||||
```
|
||||
结果是:
|
||||
```text
|
||||
<|user|>
|
||||
Which is bigger, the moon or the sun?</s>
|
||||
<|assistant|>
|
||||
The sun.</s>
|
||||
```
|
||||
|
||||
这样,后面你可以使用`formatted_chat`列,跟标准语言建模任务中一样训练即可。
|
||||
## 高级:聊天模板是如何工作的?
|
||||
|
||||
模型的聊天模板存储在`tokenizer.chat_template`属性上。如果没有设置,则将使用该模型的默认模板。
|
||||
让我们来看看`BlenderBot`的模板:
|
||||
```python
|
||||
|
||||
>>> from transformers import AutoTokenizer
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
|
||||
|
||||
>>> tokenizer.chat_template
|
||||
"{% for message in messages %}{% if message['role'] == 'user' %}{{ ' ' }}{% endif %}{{ message['content'] }}{% if not loop.last %}{{ ' ' }}{% endif %}{% endfor %}{{ eos_token }}"
|
||||
```
|
||||
|
||||
这看着有点复杂。让我们添加一些换行和缩进,使其更易读。
|
||||
请注意,默认情况下忽略每个块后的第一个换行以及块之前的任何前导空格,
|
||||
使用Jinja的`trim_blocks`和`lstrip_blocks`标签。
|
||||
这里,请注意空格的使用。我们强烈建议您仔细检查模板是否打印了多余的空格!
|
||||
```
|
||||
{% for message in messages %}
|
||||
{% if message['role'] == 'user' %}
|
||||
{{ ' ' }}
|
||||
{% endif %}
|
||||
{{ message['content'] }}
|
||||
{% if not loop.last %}
|
||||
{{ ' ' }}
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
{{ eos_token }}
|
||||
```
|
||||
|
||||
如果你之前不了解[Jinja template](https://jinja.palletsprojects.com/en/3.1.x/templates/)。
|
||||
Jinja是一种模板语言,允许你编写简单的代码来生成文本。
|
||||
在许多方面,代码和语法类似于Python。在纯Python中,这个模板看起来会像这样:
|
||||
```python
|
||||
for idx, message in enumerate(messages):
|
||||
if message['role'] == 'user':
|
||||
print(' ')
|
||||
print(message['content'])
|
||||
if not idx == len(messages) - 1: # Check for the last message in the conversation
|
||||
print(' ')
|
||||
print(eos_token)
|
||||
```
|
||||
|
||||
这里使用Jinja模板处理如下三步:
|
||||
1. 对于每条消息,如果消息是用户消息,则在其前面添加一个空格,否则不打印任何内容
|
||||
2. 添加消息内容
|
||||
3. 如果消息不是最后一条,请在其后添加两个空格。在最后一条消息之后,打印`EOS`。
|
||||
|
||||
这是一个简单的模板,它不添加任何控制tokens,也不支持`system`消息(常用于指导模型在后续对话中如何表现)。
|
||||
但 Jinja 给了你很大的灵活性来做这些事情!让我们看一个 Jinja 模板,
|
||||
它可以实现类似于LLaMA的prompt输入(请注意,真正的LLaMA模板包括`system`消息,请不要在实际代码中使用这个简单模板!)
|
||||
```
|
||||
{% for message in messages %}
|
||||
{% if message['role'] == 'user' %}
|
||||
{{ bos_token + '[INST] ' + message['content'] + ' [/INST]' }}
|
||||
{% elif message['role'] == 'system' %}
|
||||
{{ '<<SYS>>\\n' + message['content'] + '\\n<</SYS>>\\n\\n' }}
|
||||
{% elif message['role'] == 'assistant' %}
|
||||
{{ ' ' + message['content'] + ' ' + eos_token }}
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
这里稍微看一下,就能明白这个模板的作用:它根据每条消息的“角色”添加对应的消息。
|
||||
`user`、`assistant`、`system`的消息需要分别处理,因为它们代表不同的角色输入。
|
||||
|
||||
## 高级:编辑聊天模板
|
||||
|
||||
### 如何创建聊天模板?
|
||||
|
||||
很简单,你只需编写一个jinja模板并设置`tokenizer.chat_template`。你也可以从一个现有模板开始,只需要简单编辑便可以!
|
||||
例如,我们可以采用上面的LLaMA模板,并在助手消息中添加"[ASST]"和"[/ASST]":
|
||||
```
|
||||
{% for message in messages %}
|
||||
{% if message['role'] == 'user' %}
|
||||
{{ bos_token + '[INST] ' + message['content'].strip() + ' [/INST]' }}
|
||||
{% elif message['role'] == 'system' %}
|
||||
{{ '<<SYS>>\\n' + message['content'].strip() + '\\n<</SYS>>\\n\\n' }}
|
||||
{% elif message['role'] == 'assistant' %}
|
||||
{{ '[ASST] ' + message['content'] + ' [/ASST]' + eos_token }}
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
现在,只需设置`tokenizer.chat_template`属性。下次使用[`~PreTrainedTokenizer.apply_chat_template`]时,它将使用您的新模板!
|
||||
此属性将保存在`tokenizer_config.json`文件中,因此您可以使用[`~utils.PushToHubMixin.push_to_hub`]将新模板上传到 Hub,
|
||||
这样每个人都可以使用你模型的模板!
|
||||
|
||||
```python
|
||||
template = tokenizer.chat_template
|
||||
template = template.replace("SYS", "SYSTEM") # Change the system token
|
||||
tokenizer.chat_template = template # Set the new template
|
||||
tokenizer.push_to_hub("model_name") # Upload your new template to the Hub!
|
||||
```
|
||||
|
||||
由于[`~PreTrainedTokenizer.apply_chat_template`]方法是由[`TextGenerationPipeline`]类调用,
|
||||
因此一旦你设置了聊天模板,您的模型将自动与[`TextGenerationPipeline`]兼容。
|
||||
### “默认”模板是什么?
|
||||
|
||||
在引入聊天模板(chat_template)之前,聊天prompt是在模型中通过硬编码处理的。为了向前兼容,我们保留了这种硬编码处理聊天prompt的方法。
|
||||
如果一个模型没有设置聊天模板,但其模型有默认模板,`TextGenerationPipeline`类和`apply_chat_template`等方法将使用该模型的聊天模板。
|
||||
您可以通过检查`tokenizer.default_chat_template`属性来查找`tokenizer`的默认模板。
|
||||
|
||||
这是我们纯粹为了向前兼容性而做的事情,以避免破坏任何现有的工作流程。即使默认的聊天模板适用于您的模型,
|
||||
我们强烈建议通过显式设置`chat_template`属性来覆盖默认模板,以便向用户清楚地表明您的模型已经正确的配置了聊天模板,
|
||||
并且为了未来防范默认模板被修改或弃用的情况。
|
||||
### 我应该使用哪个模板?
|
||||
|
||||
在为已经训练过的聊天模型设置模板时,您应确保模板与模型在训练期间看到的消息格式完全匹配,否则可能会导致性能下降。
|
||||
即使您继续对模型进行训练,也应保持聊天模板不变,这样可能会获得最佳性能。
|
||||
这与`tokenization`非常类似,在推断时,你选用跟训练时一样的`tokenization`,通常会获得最佳性能。
|
||||
|
||||
如果您从头开始训练模型,或者在微调基础语言模型进行聊天时,您有很大的自由选择适当的模板!
|
||||
LLMs足够聪明,可以学会处理许多不同的输入格式。我们为没有特定类别模板的模型提供一个默认模板,该模板遵循
|
||||
`ChatML` format格式要求,对于许多用例来说,
|
||||
这是一个很好的、灵活的选择。
|
||||
|
||||
默认模板看起来像这样:
|
||||
|
||||
```
|
||||
{% for message in messages %}
|
||||
{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
|
||||
如果您喜欢这个模板,下面是一行代码的模板形式,它可以直接复制到您的代码中。这一行代码还包括了[generation prompts](#什么是"generation prompts"?),
|
||||
但请注意它不会添加`BOS`或`EOS`token。
|
||||
如果您的模型需要这些token,它们不会被`apply_chat_template`自动添加,换句话说,文本的默认处理参数是`add_special_tokens=False`。
|
||||
这是为了避免模板和`add_special_tokens`逻辑产生冲突,如果您的模型需要特殊tokens,请确保将它们添加到模板中!
|
||||
|
||||
```
|
||||
tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
|
||||
```
|
||||
|
||||
该模板将每条消息包装在`<|im_start|>`和`<|im_end|>`tokens里面,并将角色简单地写为字符串,这样可以灵活地训练角色。输出如下:
|
||||
```text
|
||||
<|im_start|>system
|
||||
You are a helpful chatbot that will do its best not to say anything so stupid that people tweet about it.<|im_end|>
|
||||
<|im_start|>user
|
||||
How are you?<|im_end|>
|
||||
<|im_start|>assistant
|
||||
I'm doing great!<|im_end|>
|
||||
```
|
||||
|
||||
`user`,`system`和`assistant`是对话助手模型的标准角色,如果您的模型要与[`TextGenerationPipeline`]兼容,我们建议你使用这些角色。
|
||||
但您可以不局限于这些角色,模板非常灵活,任何字符串都可以成为角色。
|
||||
|
||||
### 如何添加聊天模板?
|
||||
|
||||
如果您有任何聊天模型,您应该设置它们的`tokenizer.chat_template`属性,并使用[`~PreTrainedTokenizer.apply_chat_template`]测试,
|
||||
然后将更新后的`tokenizer`推送到 Hub。
|
||||
即使您不是模型所有者,如果您正在使用一个空的聊天模板或者仍在使用默认的聊天模板,
|
||||
请发起一个[pull request](https://huggingface.co/docs/hub/repositories-pull-requests-discussions),以便正确设置该属性!
|
||||
|
||||
一旦属性设置完成,就完成了!`tokenizer.apply_chat_template`现在将在该模型中正常工作,
|
||||
这意味着它也会自动支持在诸如`TextGenerationPipeline`的地方!
|
||||
|
||||
通过确保模型具有这一属性,我们可以确保整个社区都能充分利用开源模型的全部功能。
|
||||
格式不匹配已经困扰这个领域并悄悄地损害了性能太久了,是时候结束它们了!
|
||||
|
||||
|
||||
## 高级:模板写作技巧
|
||||
|
||||
如果你对Jinja不熟悉,我们通常发现编写聊天模板的最简单方法是先编写一个简短的Python脚本,按照你想要的方式格式化消息,然后将该脚本转换为模板。
|
||||
|
||||
请记住,模板处理程序将接收对话历史作为名为`messages`的变量。每条`message`都是一个带有两个键`role`和`content`的字典。
|
||||
您可以在模板中像在Python中一样访问`messages`,这意味着您可以使用`{% for message in messages %}`进行循环,
|
||||
或者例如使用`{{ messages[0] }}`访问单个消息。
|
||||
|
||||
您也可以使用以下提示将您的代码转换为Jinja:
|
||||
### For循环
|
||||
|
||||
在Jinja中,for循环看起来像这样:
|
||||
|
||||
```
|
||||
{% for message in messages %}
|
||||
{{ message['content'] }}
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
请注意,`{{ expression block }}`中的内容将被打印到输出。您可以在表达式块中使用像`+`这样的运算符来组合字符串。
|
||||
### If语句
|
||||
|
||||
Jinja中的if语句如下所示:
|
||||
|
||||
```
|
||||
{% if message['role'] == 'user' %}
|
||||
{{ message['content'] }}
|
||||
{% endif %}
|
||||
```
|
||||
注意Jinja使用`{% endfor %}`和`{% endif %}`来表示`for`和`if`的结束。
|
||||
|
||||
### 特殊变量
|
||||
|
||||
在您的模板中,您将可以访问`messages`列表,但您还可以访问其他几个特殊变量。
|
||||
这些包括特殊`token`,如`bos_token`和`eos_token`,以及我们上面讨论过的`add_generation_prompt`变量。
|
||||
您还可以使用`loop`变量来访问有关当前循环迭代的信息,例如使用`{% if loop.last %}`来检查当前消息是否是对话中的最后一条消息。
|
||||
|
||||
以下是一个示例,如果`add_generation_prompt=True`需要在对话结束时添加`generate_prompt`:
|
||||
|
||||
|
||||
```
|
||||
{% if loop.last and add_generation_prompt %}
|
||||
{{ bos_token + 'Assistant:\n' }}
|
||||
{% endif %}
|
||||
```
|
||||
|
||||
### 空格的注意事项
|
||||
|
||||
我们已经尽可能尝试让Jinja忽略除`{{ expressions }}`之外的空格。
|
||||
然而,请注意Jinja是一个通用的模板引擎,它可能会将同一行文本块之间的空格视为重要,并将其打印到输出中。
|
||||
我们**强烈**建议在上传模板之前检查一下,确保模板没有在不应该的地方打印额外的空格!
|
||||
69
transformers/docs/source/zh/community.md
Normal file
69
transformers/docs/source/zh/community.md
Normal file
@@ -0,0 +1,69 @@
|
||||
<!--⚠️请注意,此文件虽然是Markdown格式,但包含了我们文档构建器(类似于MDX)的特定语法,可能无法在你的Markdown查看器中正确显示。
|
||||
-->
|
||||
|
||||
# 社区
|
||||
|
||||
这个页面汇集了社区开发的🤗Transformers相关的资源。
|
||||
|
||||
## 社区资源
|
||||
|
||||
| 资源 | 描述 | 作者 |
|
||||
|:----------|:-------------|------:|
|
||||
| [Hugging Face Transformers Glossary Flashcards](https://www.darigovresearch.com/huggingface-transformers-glossary-flashcards) | 这是一套基于 [Transformers文档术语表](glossary) 的抽认卡,它们已被整理成可以通过 [Anki](https://apps.ankiweb.net/) (一款专为长期知识保留而设计的开源、跨平台的应用)来进行学习和复习的形式。使用方法参见: [介绍如何使用抽认卡的视频](https://www.youtube.com/watch?v=Dji_h7PILrw)。 | [Darigov Research](https://www.darigovresearch.com/) |
|
||||
|
||||
## 社区笔记本
|
||||
|
||||
| 笔记本 | 描述 | 作者 | |
|
||||
|:----------|:-------------|:-------------|------:|
|
||||
| [Fine-tune a pre-trained Transformer to generate lyrics](https://github.com/AlekseyKorshuk/huggingartists) | 如何通过微调GPT-2模型来生成你最喜欢的艺术家风格的歌词 | [Aleksey Korshuk](https://github.com/AlekseyKorshuk) | [](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb) |
|
||||
| [Train T5 in Tensorflow 2](https://github.com/snapthat/TF-T5-text-to-text) | 如何使用 Tensorflow 2 训练 T5 可以完成任何任务。本笔记本演示了如何使用 SQUAD 在 Tensorflow 2 中实现问答任务 | [Muhammad Harris](https://github.com/HarrisDePerceptron) |[](https://colab.research.google.com/github/snapthat/TF-T5-text-to-text/blob/master/snapthatT5/notebooks/TF-T5-Datasets%20Training.ipynb) |
|
||||
| [Train T5 on TPU](https://github.com/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb) | 如何使用 Transformers 和 Nlp 在 SQUAD 上训练 T5 | [Suraj Patil](https://github.com/patil-suraj) |[](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb#scrollTo=QLGiFCDqvuil) |
|
||||
| [Fine-tune T5 for Classification and Multiple Choice](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) | 如何使用 PyTorch Lightning 的text-to-text格式对 T5 进行微调以完成分类和多项选择任务 | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) |
|
||||
| [Fine-tune DialoGPT on New Datasets and Languages](https://github.com/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) | 如何在新数据集上微调 DialoGPT 模型,以实现开放式对话聊天机器人 | [Nathan Cooper](https://github.com/ncoop57) | [](https://colab.research.google.com/github/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) |
|
||||
| [Long Sequence Modeling with Reformer](https://github.com/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) | 如何使用 Reformer 对长达 500,000 个 token 的序列进行训练 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) |
|
||||
| [Fine-tune BART for Summarization](https://github.com/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb) | 如何使用 blurr 对 BART 进行微调,以便使用 fastai 进行汇总 | [Wayde Gilliam](https://ohmeow.com/) | [](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb) |
|
||||
| [Fine-tune a pre-trained Transformer on anyone's tweets](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) | 如何通过微调 GPT-2 模型生成以你最喜欢的 Twitter 帐户风格发布的推文 | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) |
|
||||
| [Optimize 🤗 Hugging Face models with Weights & Biases](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) | 展示 W&B 与 Hugging Face 集成的完整教程 | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) |
|
||||
| [Pretrain Longformer](https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) | 如何构建现有预训练模型的“长”版本 | [Iz Beltagy](https://beltagy.net) | [](https://colab.research.google.com/github/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) |
|
||||
| [Fine-tune Longformer for QA](https://github.com/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) | 如何针对问答任务微调长模型 | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) |
|
||||
| [Evaluate Model with 🤗nlp](https://github.com/patrickvonplaten/notebooks/blob/master/How_to_evaluate_Longformer_on_TriviaQA_using_NLP.ipynb) | 如何使用`nlp`库在TriviaQA数据集上评估Longformer模型| [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1m7eTGlPmLRgoPkkA7rkhQdZ9ydpmsdLE?usp=sharing) |
|
||||
| [Fine-tune T5 for Sentiment Span Extraction](https://github.com/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) | 如何使用PyTorch Lightning以text-to-text的格式对T5进行微调,以进行情感跨度提取 | [Lorenzo Ampil](https://github.com/enzoampil) | [](https://colab.research.google.com/github/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) |
|
||||
| [Fine-tune DistilBert for Multiclass Classification](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb) | 如何使用 PyTorch 微调 DistilBert 进行多类分类 | [Abhishek Kumar Mishra](https://github.com/abhimishra91) | [](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb)|
|
||||
|[Fine-tune BERT for Multi-label Classification](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|如何使用 PyTorch 对 BERT 进行微调以进行多标签分类|[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|
|
||||
|[Fine-tune T5 for Summarization](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|如何在 PyTorch 中微调 T5 进行总结并使用 WandB 跟踪实验|[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|
|
||||
|[Speed up Fine-Tuning in Transformers with Dynamic Padding / Bucketing](https://github.com/ELS-RD/transformers-notebook/blob/master/Divide_Hugging_Face_Transformers_training_time_by_2_or_more.ipynb)|如何通过使用动态填充/桶排序将微调速度提高两倍|[Michael Benesty](https://github.com/pommedeterresautee) |[](https://colab.research.google.com/drive/1CBfRU1zbfu7-ijiOqAAQUA-RJaxfcJoO?usp=sharing)|
|
||||
|[Pretrain Reformer for Masked Language Modeling](https://github.com/patrickvonplaten/notebooks/blob/master/Reformer_For_Masked_LM.ipynb)| 如何训练一个带有双向自注意力层的Reformer模型 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1tzzh0i8PgDQGV3SMFUGxM7_gGae3K-uW?usp=sharing)|
|
||||
|[Expand and Fine Tune Sci-BERT](https://github.com/lordtt13/word-embeddings/blob/master/COVID-19%20Research%20Data/COVID-SciBERT.ipynb)| 如何在 CORD 数据集上增加 AllenAI 预训练的 SciBERT 模型的词汇量,并对其进行流水线化 | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/1rqAR40goxbAfez1xvF3hBJphSCsvXmh8)|
|
||||
|[Fine Tune BlenderBotSmall for Summarization using the Trainer API](https://github.com/lordtt13/transformers-experiments/blob/master/Custom%20Tasks/fine-tune-blenderbot_small-for-summarization.ipynb)| 如何使用Trainer API在自定义数据集上对BlenderBotSmall进行微调以进行文本摘要 | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/19Wmupuls7mykSGyRN_Qo6lPQhgp56ymq?usp=sharing)|
|
||||
|[Fine-tune Electra and interpret with Integrated Gradients](https://github.com/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb) | 如何对Electra模型进行微调以进行情感分析,并使用Captum集成梯度来解释预测结果 | [Eliza Szczechla](https://elsanns.github.io) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb)|
|
||||
|[fine-tune a non-English GPT-2 Model with Trainer class](https://github.com/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb) | 如何使用 Trainer 类微调非英语 GPT-2 模型 | [Philipp Schmid](https://www.philschmid.de) | [](https://colab.research.google.com/github/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb)|
|
||||
|[Fine-tune a DistilBERT Model for Multi Label Classification task](https://github.com/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb) | 如何针对多标签分类任务微调 DistilBERT 模型 | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb)|
|
||||
|[Fine-tune ALBERT for sentence-pair classification](https://github.com/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb) | 如何针对句子对分类任务对 ALBERT 模型或其他基于 BERT 的模型进行微调 | [Nadir El Manouzi](https://github.com/NadirEM) | [](https://colab.research.google.com/github/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb)|
|
||||
|[Fine-tune Roberta for sentiment analysis](https://github.com/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb) | 如何微调 Roberta 模型进行情绪分析 | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb)|
|
||||
|[Evaluating Question Generation Models](https://github.com/flexudy-pipe/qugeev) | 你的 seq2seq 转换器模型生成的问题的答案有多准确? | [Pascal Zoleko](https://github.com/zolekode) | [](https://colab.research.google.com/drive/1bpsSqCQU-iw_5nNoRm_crPq6FRuJthq_?usp=sharing)|
|
||||
|[Classify text with DistilBERT and Tensorflow](https://github.com/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb) | 如何在 TensorFlow 中微调 DistilBERT 以进行文本分类 | [Peter Bayerle](https://github.com/peterbayerle) | [](https://colab.research.google.com/github/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb)|
|
||||
|[Leverage BERT for Encoder-Decoder Summarization on CNN/Dailymail](https://github.com/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb) | 如何在CNN/Dailymail摘要任务上使用*google-bert/bert-base-uncased*检查点对*EncoderDecoderModel*进行热启动 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)|
|
||||
|[Leverage RoBERTa for Encoder-Decoder Summarization on BBC XSum](https://github.com/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb) | 如何在BBC/XSum摘要任务上使用*FacebookAI/roberta-base*检查点对共享的*EncoderDecoderModel*进行热启动 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb)|
|
||||
|[Fine-tune TAPAS on Sequential Question Answering (SQA)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) | 如何在Sequential Question Answering (SQA)数据集上使用*tapas-base*检查点对*TapasForQuestionAnswering*进行微调 | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb)|
|
||||
|[Evaluate TAPAS on Table Fact Checking (TabFact)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb) | 如何结合使用 🤗 数据集和 🤗 transformers 库,使用*tapas-base-finetuned-tabfact*检查点评估经过微调的*TapasForSequenceClassification* | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb)|
|
||||
|[Fine-tuning mBART for translation](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb) | 如何使用 Seq2SeqTrainer 对 mBART 进行微调以实现印地语到英语的翻译 | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb)|
|
||||
|[Fine-tune LayoutLM on FUNSD (a form understanding dataset)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb) | 如何在FUNSD数据集上对*LayoutLMForTokenClassification*进行微调以从扫描文档中提取信息 | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb)|
|
||||
|[Fine-Tune DistilGPT2 and Generate Text](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb) | 如何微调 DistilGPT2 并生成文本 | [Aakash Tripathi](https://github.com/tripathiaakash) | [](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb)|
|
||||
|[Fine-Tune LED on up to 8K tokens](https://github.com/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb) | 如何对LED模型在PubMed数据集上进行微调以进行长文本摘要 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb)|
|
||||
|[Evaluate LED on Arxiv](https://github.com/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb) | 如何有效评估LED模型的长远发展 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb)|
|
||||
|[Fine-tune LayoutLM on RVL-CDIP (a document image classification dataset)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb) | 如何在 RVL-CDIP 数据集上微调*LayoutLMForSequenceClassification*以进行扫描文档分类 | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb)|
|
||||
|[Wav2Vec2 CTC decoding with GPT2 adjustment](https://github.com/voidful/huggingface_notebook/blob/main/xlsr_gpt.ipynb) | 如何通过语言模型调整解码 CTC 序列 | [Eric Lam](https://github.com/voidful) | [](https://colab.research.google.com/drive/1e_z5jQHYbO2YKEaUgzb1ww1WwiAyydAj?usp=sharing)|
|
||||
|[Fine-tune BART for summarization in two languages with Trainer class](https://github.com/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb) | 如何使用Trainer类对BART模型进行多语言摘要任务的微调 | [Eliza Szczechla](https://github.com/elsanns) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb)|
|
||||
|[Evaluate Big Bird on Trivia QA](https://github.com/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb) | 评估BigBird模型在长文档问答任务上的性能,特别是在Trivia QA数据集上| [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb)|
|
||||
| [Create video captions using Wav2Vec2](https://github.com/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) | 如何使用Wav2Vec对任何视频的音频进行转录以创建YouTube字幕 | [Niklas Muennighoff](https://github.com/Muennighoff) |[](https://colab.research.google.com/github/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) |
|
||||
| [Fine-tune the Vision Transformer on CIFAR-10 using PyTorch Lightning](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) | 如何使用HuggingFace的Transformers、Datasets和PyTorch Lightning在CIFAR-10数据集上对Vision Transformer(ViT)进行微调 | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) |
|
||||
| [Fine-tune the Vision Transformer on CIFAR-10 using the 🤗 Trainer](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) | 如何使用HuggingFace的Transformers、Datasets和🤗 Trainer在CIFAR-10数据集上对Vision Transformer(ViT)进行微调| [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) |
|
||||
| [Evaluate LUKE on Open Entity, an entity typing dataset](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) | 如何在开放实体数据集上评估*LukeForEntityClassification*| [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) |
|
||||
| [Evaluate LUKE on TACRED, a relation extraction dataset](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) | 如何在 TACRED 数据集上评估*LukeForEntityPairClassification* | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) |
|
||||
| [Evaluate LUKE on CoNLL-2003, an important NER benchmark](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) | 如何在 CoNLL-2003 数据集上评估*LukeForEntitySpanClassification* | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) |
|
||||
| [Evaluate BigBird-Pegasus on PubMed dataset](https://github.com/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) | 如何在 PubMed 数据集上评估*BigBirdPegasusForConditionalGeneration*| [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) |
|
||||
| [Speech Emotion Classification with Wav2Vec2](https://github.com/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) |如何利用预训练的 Wav2Vec2 模型在 MEGA 数据集上进行情绪分类| [Mehrdad Farahani](https://github.com/m3hrdadfi) | [](https://colab.research.google.com/github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) |
|
||||
| [Detect objects in an image with DETR](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) | 如何使用经过训练的*DetrForObjectDetection*模型检测图像中的物体并可视化注意力 | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) |
|
||||
| [Fine-tune DETR on a custom object detection dataset](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) | 如何在自定义对象检测数据集上微调*DetrForObjectDetection* | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) |
|
||||
| [Finetune T5 for Named Entity Recognition](https://github.com/ToluClassics/Notebooks/blob/main/T5_Ner_Finetuning.ipynb) | 如何在命名实体识别任务中微调*T5*| [Ogundepo Odunayo](https://github.com/ToluClassics) | [](https://colab.research.google.com/drive/1obr78FY_cBmWY5ODViCmzdY6O1KB65Vc?usp=sharing) |
|
||||
| [Fine-Tuning Open-Source LLM using QLoRA with MLflow and PEFT](https://github.com/mlflow/mlflow/blob/master/docs/source/llms/transformers/tutorials/fine-tuning/transformers-peft.ipynb) | 如何使用[QLoRA](https://github.com/artidoro/qlora) 和[PEFT](https://huggingface.co/docs/peft/en/index)以内存高效的方式微调大型语言模型(LLM),同时使用 [MLflow](https://mlflow.org/docs/latest/llms/transformers/index.html)进行实验跟踪| [Yuki Watanabe](https://github.com/B-Step62) | [](https://colab.research.google.com/github/mlflow/mlflow/blob/master/docs/source/llms/transformers/tutorials/fine-tuning/transformers-peft.ipynb) |
|
||||
329
transformers/docs/source/zh/contributing.md
Normal file
329
transformers/docs/source/zh/contributing.md
Normal file
@@ -0,0 +1,329 @@
|
||||
<!---
|
||||
Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
|
||||
# 为 🤗 Transformers 做贡献
|
||||
|
||||
欢迎所有人为 🤗 Transformers 做出贡献,我们重视每个人的贡献。代码贡献并不是帮助社区的唯一途径。回答问题、帮助他人和改进文档也非常有价值。
|
||||
|
||||
宣传 🤗 Transformers 也会帮助我们!比如在博客文章里介绍一下这个库是如何帮助你完成了很棒的项目,每次它帮助你时都在 Twitter 上大声宣传,或者给这个代码仓库点⭐️来表示感谢。
|
||||
|
||||
无论你选择以哪种方式做出贡献,请注意并尊重我们的[行为准则](https://github.com/huggingface/transformers/blob/main/CODE_OF_CONDUCT.md)。
|
||||
|
||||
**本指南的灵感来源于 [scikit-learn贡献指南](https://github.com/scikit-learn/scikit-learn/blob/main/CONTRIBUTING.md) ,它令人印象深刻.**
|
||||
|
||||
## 做贡献的方法
|
||||
|
||||
有多种方法可以为 🤗 Transformers 做贡献:
|
||||
|
||||
* 修复现有代码中尚未解决的问题。
|
||||
* 提交与 bug 或所需新功能相关的 issue。
|
||||
* 实现新的模型。
|
||||
* 为示例或文档做贡献。
|
||||
|
||||
如果你不知道从哪里开始,有一个特别的 [Good First Issue](https://github.com/huggingface/transformers/contribute) 列表。它会列出一些适合初学者的开放的 issues,并帮助你开始为开源项目做贡献。只需要在你想要处理的 issue 下发表评论就行。
|
||||
|
||||
如果想要稍微更有挑战性的内容,你也可以查看 [Good Second Issue](https://github.com/huggingface/transformers/labels/Good%20Second%20Issue) 列表。总的来说,如果你觉得自己知道该怎么做,就去做吧,我们会帮助你达到目标的!🚀
|
||||
|
||||
> 所有的贡献对社区来说都同样宝贵。🥰
|
||||
|
||||
## 修复尚未解决的问题
|
||||
|
||||
如果你发现现有代码中存在问题,并且已经想到了解决方法,请随时[开始贡献](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md/#create-a-pull-request) 并创建一个 Pull Request!
|
||||
|
||||
## 提交与 bug 相关的 issue 或功能请求
|
||||
|
||||
在提交与错误相关的 issue 或功能请求时,请尽量遵循下面的指南。这能让我们更容易迅速回复你,并提供良好的反馈意见。
|
||||
|
||||
### 你发现了 bug 吗?
|
||||
|
||||
🤗 Transformers 之所以强大可靠,要感谢用户报告了他们遇到的问题。
|
||||
|
||||
在提出issue之前,请你**确认该 bug 尚未被报告**(使用 GitHub 的 Issues 下面的搜索栏)。issue 也应该是与库本身的 bug 有关,而不是与你的代码有关。如果不确定 bug 是在你的代码中还是在库中,请先在[论坛](https://discuss.huggingface.co/)中询问。这有助于我们更快地解决与库相关的问题。
|
||||
|
||||
一旦你确认该 bug 尚未被报告,请在你的 issue 中包含以下信息,以便我们快速解决:
|
||||
|
||||
* 使用的**操作系统类型和版本**,以及 **Python** 和 **PyTorch** 的版本。
|
||||
* 一个简短、独立的代码片段,可以让我们在不到30秒内重现这个问题。
|
||||
* 如果发生异常,请提供*完整的* traceback。
|
||||
* 附上你认为可能有帮助的任何其他附加信息,如屏幕截图。
|
||||
|
||||
想要自动获取操作系统和软件版本,请运行以下命令:
|
||||
|
||||
```bash
|
||||
transformers env
|
||||
```
|
||||
|
||||
你也可以从代码仓库的根目录下运行相同的命令:
|
||||
|
||||
```bash
|
||||
python src/transformers/commands/transformers_cli.py env
|
||||
```
|
||||
|
||||
### 你想要新功能吗?
|
||||
|
||||
如果你希望在 🤗 Transformers 中看到新功能,请提出一个 issue 并包含以下内容:
|
||||
|
||||
1. 这个新功能的*动机*是什么呢?是因为使用这个库时遇到了问题或者感到了某种不满吗?是因为你的项目需要这个功能吗?或者是你自己开发了某项内容,并且认为它可能会对社区有所帮助?
|
||||
|
||||
不管是什么,我们都很想听!
|
||||
|
||||
2. 请尽可能详细地描述你想要的功能。你告诉我们的越多,我们就能更好地帮助你。
|
||||
3. 请提供一个*代码片段*,演示该功能的使用方法。
|
||||
4. 如果这个功能与某篇论文相关,请包含链接。
|
||||
|
||||
如果你描述得足够清晰,那么在你创建 issue 时,我们已经完成了80%的工作。
|
||||
|
||||
我们已经添加了[模板](https://github.com/huggingface/transformers/tree/main/templates),可能有助于你提出 issue。
|
||||
|
||||
## 你想要实现一个新模型吗?
|
||||
|
||||
我们会持续发布新模型,如果你想要实现一个新模型,请提供以下信息:
|
||||
|
||||
* 模型的简要描述和论文链接。
|
||||
* 如果实现是开源的,请提供实现的链接。
|
||||
* 如果模型权重可用,请提供模型权重的链接。
|
||||
|
||||
如果你想亲自贡献模型,请告诉我们。让我们帮你把它添加到 🤗 Transformers!
|
||||
|
||||
我们还有一个更技术性的指南,告诉你[如何将模型添加到 🤗 Transformers](https://huggingface.co/docs/transformers/add_new_model)。
|
||||
|
||||
## 你想要添加文档吗?
|
||||
|
||||
我们始终在寻求改进文档,使其更清晰准确。请告诉我们如何改进文档,比如拼写错误以及任何缺失、不清楚或不准确的内容。我们非常乐意进行修改,如果你有兴趣,我们也可以帮助你做出贡献!
|
||||
|
||||
有关如何生成、构建和编写文档的更多详细信息,请查看文档 [README](https://github.com/huggingface/transformers/tree/main/docs)。
|
||||
|
||||
## 创建 Pull Request
|
||||
|
||||
在开始编写任何代码之前,我们强烈建议你先搜索现有的 PR(Pull Request) 或 issue,以确保没有其他人已经在做同样的事情。如果你不确定,提出 issue 来获取反馈意见是一个好办法。
|
||||
|
||||
要为 🤗 Transformers 做贡献,你需要基本的 `git` 使用技能。虽然 `git` 不是一个很容易使用的工具,但它提供了非常全面的手册,在命令行中输入 `git --help` 并享受吧!如果你更喜欢书籍,[Pro Git](https://git-scm.com/book/en/v2)是一本很好的参考书。
|
||||
|
||||
要为 🤗 Transformers 做贡献,你需要 **[Python 3.9](https://github.com/huggingface/transformers/blob/main/setup.py#L426)** 或更高版本。请按照以下步骤开始贡献:
|
||||
|
||||
1. 点击[仓库](https://github.com/huggingface/transformers)页面上的 **[Fork](https://github.com/huggingface/transformers/fork)** 按钮,这会在你的 GitHub 账号下拷贝一份代码。
|
||||
|
||||
2. 把派生仓库克隆到本地磁盘,并将基础仓库添加为远程仓库:
|
||||
|
||||
```bash
|
||||
git clone git@github.com:<your Github handle>/transformers.git
|
||||
cd transformers
|
||||
git remote add upstream https://github.com/huggingface/transformers.git
|
||||
```
|
||||
|
||||
3. 创建一个新的分支来保存你的更改:
|
||||
|
||||
```bash
|
||||
git checkout -b a-descriptive-name-for-my-changes
|
||||
```
|
||||
|
||||
🚨 **不要**在 `main` 分支工作!
|
||||
|
||||
4. 在虚拟环境中运行以下命令来设置开发环境:
|
||||
|
||||
```bash
|
||||
pip install -e ".[dev]"
|
||||
```
|
||||
|
||||
如果在虚拟环境中已经安装了 🤗 Transformers,请先使用 `pip uninstall transformers` 卸载它,然后再用 `-e` 参数以可编辑模式重新安装。
|
||||
|
||||
根据你的操作系统,以及 Transformers 的可选依赖项数量的增加,可能会在执行此命令时出现失败。如果出现这种情况,请确保已经安装了你想使用的深度学习框架(PyTorch),然后执行以下操作:
|
||||
|
||||
```bash
|
||||
pip install -e ".[quality]"
|
||||
```
|
||||
|
||||
大多数情况下,这些应该够用了。
|
||||
|
||||
5. 在你的分支上开发相关功能。
|
||||
|
||||
在编写代码时,请确保测试套件通过。用下面的方式运行受你的更改影响的测试:
|
||||
|
||||
```bash
|
||||
pytest tests/<TEST_TO_RUN>.py
|
||||
```
|
||||
|
||||
想了解更多关于测试的信息,请阅读[测试](https://huggingface.co/docs/transformers/testing)指南。
|
||||
|
||||
🤗 Transformers 使用 `black` 和 `ruff` 来保持代码风格的一致性。进行更改后,使用以下命令自动执行格式更正和代码验证:
|
||||
|
||||
```bash
|
||||
make fixup
|
||||
```
|
||||
|
||||
它已经被优化为仅适用于你创建的 PR 所修改过的文件。
|
||||
|
||||
如果想要逐个运行检查,可以使用以下命令:
|
||||
|
||||
```bash
|
||||
make style
|
||||
```
|
||||
|
||||
🤗 Transformers 还使用了 `ruff` 和一些自定义脚本来检查编码错误。虽然质量管理是通过 CI 进行的,但你也可以使用以下命令来运行相同的检查:
|
||||
|
||||
```bash
|
||||
make quality
|
||||
```
|
||||
|
||||
最后,我们有许多脚本来确保在添加新模型时不会忘记更新某些文件。你可以使用以下命令运行这些脚本:
|
||||
|
||||
```bash
|
||||
make repo-consistency
|
||||
```
|
||||
|
||||
想要了解有关这些检查及如何解决相关问题的更多信息,请阅读 [检查 Pull Request](https://huggingface.co/docs/transformers/pr_checks) 指南。
|
||||
|
||||
如果你修改了 `docs/source` 目录下的文档,请确保文档仍然能够被构建。这个检查也会在你创建 PR 时在 CI 中运行。如果要进行本地检查,请确保安装了文档构建工具:
|
||||
|
||||
```bash
|
||||
pip install ".[docs]"
|
||||
```
|
||||
|
||||
在仓库的根目录下运行以下命令:
|
||||
|
||||
```bash
|
||||
doc-builder build transformers docs/source/en --build_dir ~/tmp/test-build
|
||||
```
|
||||
|
||||
这将会在 `~/tmp/test-build` 文件夹中构建文档,你可以使用自己喜欢的编辑器查看生成的 Markdown 文件。当你创建 PR 时,也可以在GitHub上预览文档。
|
||||
|
||||
当你对修改满意后,使用 `git add` 把修改的文件添加到暂存区,然后使用 `git commit` 在本地记录你的更改:
|
||||
|
||||
```bash
|
||||
git add modified_file.py
|
||||
git commit
|
||||
```
|
||||
|
||||
请记得写一个[好的提交信息](https://chris.beams.io/posts/git-commit/)来清晰地传达你所做的更改!
|
||||
|
||||
为了保持你的代码副本与原始仓库的最新状态一致,在你创建 PR *之前*或者在管理员要求的情况下,把你的分支在 `upstream/branch` 上进行 rebase:
|
||||
|
||||
```bash
|
||||
git fetch upstream
|
||||
git rebase upstream/main
|
||||
```
|
||||
|
||||
把你的更改推送到你的分支:
|
||||
|
||||
```bash
|
||||
git push -u origin a-descriptive-name-for-my-changes
|
||||
```
|
||||
|
||||
如果你已经创建了一个 PR,你需要使用 `--force` 参数进行强制推送。如果 PR 还没有被创建,你可以正常推送你的更改。
|
||||
|
||||
6. 现在你可以转到 GitHub 上你的账号下的派生仓库,点击 **Pull Request** 来创建一个 PR。 请确保勾选我们 [checklist](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md/#pull-request-checklist) 下的所有项目。准备好这些后,可以将你的更改发送给项目管理员进行审查。
|
||||
|
||||
7. 如果管理员要求你进行更改,别气馁,我们的核心贡献者也会经历相同的事情!请在你的本地分支上进行工作,并将更改推送到派生仓库,以便于每个人都可以在 PR 中看到你的更改。这样它们会自动出现在 PR 中。
|
||||
|
||||
### Pull request 的检查清单
|
||||
|
||||
☐ Pull request 的标题应该总结你的贡献内容。<br>
|
||||
☐ 如果你的 Pull request 解决了一个issue,请在 Pull request 描述中提及该 issue 的编号,以确保它们被关联起来(这样查看 issue 的人就知道你正在处理它)。<br>
|
||||
☐ 如果是正在进行中的工作,请在标题前加上 [WIP]。这有助于避免重复工作和区分哪些 PR 可以合并。<br>
|
||||
☐ 确保可以通过现有的测试。<br>
|
||||
☐ 如果添加了新功能,请同时添加对应的测试。<br>
|
||||
- 如果添加一个新模型,请使用 `ModelTester.all_model_classes = (MyModel, MyModelWithLMHead,...)` 来触发通用测试。
|
||||
- 如果你正在添加新的 `@slow` 测试,请确保通过以下检查:`RUN_SLOW=1 python -m pytest tests/models/my_new_model/test_my_new_model.py`
|
||||
- 如果你正在添加一个新的分词器,请编写测试并确保通过以下检查:`RUN_SLOW=1 python -m pytest tests/models/{your_model_name}/test_tokenization_{your_model_name}.py`
|
||||
- CircleCI 不会运行时间较长的测试,但 GitHub Actions 每晚会运行所有测试!<br>
|
||||
|
||||
☐ 所有公共 method 必须具有信息文档(比如 [`modeling_bert.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py))。<br>
|
||||
☐ 由于代码仓库的体积正在迅速增长,请避免添加图像、视频和其他非文本文件,它们会增加仓库的负担。请使用 [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) 等 Hub 仓库来托管这些文件,并通过 URL 引用它们。我们建议将与文档相关的图片放置在以下仓库中:[huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images)。你可以在这个数据集仓库上创建一个 PR,并请求 Hugging Face 成员进行合并。
|
||||
|
||||
要了解更多有关在 Pull request 上运行的检查的信息,请查看我们的 [检查 Pull Request](https://huggingface.co/docs/transformers/pr_checks) 指南。
|
||||
|
||||
### 测试
|
||||
|
||||
包含了广泛的测试套件来测试库的行为和一些示例。库测试可以在 [tests](https://github.com/huggingface/transformers/tree/main/tests) 文件夹中找到,示例测试可以在 [examples](https://github.com/huggingface/transformers/tree/main/examples) 文件夹中找到。
|
||||
|
||||
我们喜欢使用 `pytest` 和 `pytest-xdist`,因为它运行更快。在仓库的根目录,指定一个*子文件夹的路径或测试文件*来运行测试:
|
||||
|
||||
```bash
|
||||
python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model
|
||||
```
|
||||
|
||||
同样地,在 `examples` 目录,指定一个*子文件夹的路径或测试文件* 来运行测试。例如,以下命令会测试 PyTorch `examples` 目录中的文本分类子文件夹:
|
||||
|
||||
```bash
|
||||
pip install -r examples/xxx/requirements.txt # 仅在第一次需要
|
||||
python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification
|
||||
```
|
||||
|
||||
实际上这就是我们的 `make test` 和 `make test-examples` 命令的实现方式(不包括 `pip install`)!
|
||||
|
||||
你也可以指定一个较小的测试集来仅测试特定功能。
|
||||
|
||||
默认情况下,会跳过时间较长的测试,但你可以将 `RUN_SLOW` 环境变量设置为 `yes` 来运行它们。这将下载以 GB 为单位的模型文件,所以确保你有足够的磁盘空间、良好的网络连接和足够的耐心!
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
记得指定一个*子文件夹的路径或测试文件*来运行测试。否则你将会运行 `tests` 或 `examples` 文件夹中的所有测试,它会花费很长时间!
|
||||
|
||||
</Tip>
|
||||
|
||||
```bash
|
||||
RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model
|
||||
RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification
|
||||
```
|
||||
|
||||
和时间较长的测试一样,还有其他环境变量在测试过程中,在默认情况下是未启用的:
|
||||
- `RUN_CUSTOM_TOKENIZERS`: 启用自定义分词器的测试。
|
||||
|
||||
更多环境变量和额外信息可以在 [testing_utils.py](src/transformers/testing_utils.py) 中找到。
|
||||
|
||||
🤗 Transformers 只是使用 `pytest` 作为测试运行程序,但测试套件本身没用任何与 `pytest` 相关的功能。
|
||||
|
||||
这意味着完全支持 `unittest` 。以下是如何使用 `unittest` 运行测试的方法:
|
||||
|
||||
```bash
|
||||
python -m unittest discover -s tests -t . -v
|
||||
python -m unittest discover -s examples -t examples -v
|
||||
```
|
||||
|
||||
### 风格指南
|
||||
|
||||
🤗 Transformers 的文档遵循 [Google Python Style Guide](https://google.github.io/styleguide/pyguide.html)。请查看我们的 [文档编写指南](https://github.com/huggingface/transformers/tree/main/docs#writing-documentation---specification) 来获取更多信息。
|
||||
|
||||
### 在 Windows 上开发
|
||||
|
||||
在 Windows 上(除非你正在使用 [Windows Subsystem for Linux](https://learn.microsoft.com/en-us/windows/wsl/) 或 WSL),你需要配置 git 将 Windows 的 `CRLF` 行结束符转换为 Linux 的 `LF` 行结束符:
|
||||
|
||||
```bash
|
||||
git config core.autocrlf input
|
||||
```
|
||||
|
||||
在 Windows 上有一种方法可以运行 `make` 命令,那就是使用 MSYS2:
|
||||
|
||||
1. [下载 MSYS2](https://www.msys2.org/),假设已经安装在 `C:\msys64`。
|
||||
2. 从命令行打开 `C:\msys64\msys2.exe` (可以在 **开始** 菜单中找到)。
|
||||
3. 在 shell 中运行: `pacman -Syu` ,并使用 `pacman -S make` 安装 `make`。
|
||||
4. 把 `C:\msys64\usr\bin` 添加到你的 PATH 环境变量中。
|
||||
|
||||
现在你可以在任何终端(PowerShell、cmd.exe 等)中使用 `make` 命令了! 🎉
|
||||
|
||||
### 将派生仓库与上游主仓库(Hugging Face 仓库)同步
|
||||
|
||||
更新派生仓库的主分支时,请按照以下步骤操作。这是为了避免向每个上游 PR 添加参考注释,同时避免向参与这些 PR 的开发人员发送不必要的通知。
|
||||
|
||||
1. 可以的话,请避免使用派生仓库上的分支和 PR 来与上游进行同步,而是直接合并到派生仓库的主分支。
|
||||
2. 如果确实需要一个 PR,在检查你的分支后,请按照以下步骤操作:
|
||||
|
||||
```bash
|
||||
git checkout -b your-branch-for-syncing
|
||||
git pull --squash --no-commit upstream main
|
||||
git commit -m '<your message without GitHub references>'
|
||||
git push --set-upstream origin your-branch-for-syncing
|
||||
```
|
||||
340
transformers/docs/source/zh/create_a_model.md
Normal file
340
transformers/docs/source/zh/create_a_model.md
Normal file
@@ -0,0 +1,340 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 创建自定义架构
|
||||
|
||||
[`AutoClass`](model_doc/auto) 自动推断模型架构并下载预训练的配置和权重。一般来说,我们建议使用 `AutoClass` 生成与检查点(checkpoint)无关的代码。希望对特定模型参数有更多控制的用户,可以仅从几个基类创建自定义的 🤗 Transformers 模型。这对于任何有兴趣学习、训练或试验 🤗 Transformers 模型的人可能特别有用。通过本指南,深入了解如何不通过 `AutoClass` 创建自定义模型。了解如何:
|
||||
|
||||
- 加载并自定义模型配置。
|
||||
- 创建模型架构。
|
||||
- 为文本创建慢速和快速分词器。
|
||||
- 为视觉任务创建图像处理器。
|
||||
- 为音频任务创建特征提取器。
|
||||
- 为多模态任务创建处理器。
|
||||
|
||||
## 配置
|
||||
|
||||
[配置](main_classes/configuration) 涉及到模型的具体属性。每个模型配置都有不同的属性;例如,所有 NLP 模型都共享 `hidden_size`、`num_attention_heads`、 `num_hidden_layers` 和 `vocab_size` 属性。这些属性用于指定构建模型时的注意力头数量或隐藏层层数。
|
||||
|
||||
访问 [`DistilBertConfig`] 以更近一步了解 [DistilBERT](model_doc/distilbert),检查它的属性:
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertConfig
|
||||
|
||||
>>> config = DistilBertConfig()
|
||||
>>> print(config)
|
||||
DistilBertConfig {
|
||||
"activation": "gelu",
|
||||
"attention_dropout": 0.1,
|
||||
"dim": 768,
|
||||
"dropout": 0.1,
|
||||
"hidden_dim": 3072,
|
||||
"initializer_range": 0.02,
|
||||
"max_position_embeddings": 512,
|
||||
"model_type": "distilbert",
|
||||
"n_heads": 12,
|
||||
"n_layers": 6,
|
||||
"pad_token_id": 0,
|
||||
"qa_dropout": 0.1,
|
||||
"seq_classif_dropout": 0.2,
|
||||
"sinusoidal_pos_embds": false,
|
||||
"transformers_version": "4.16.2",
|
||||
"vocab_size": 30522
|
||||
}
|
||||
```
|
||||
|
||||
[`DistilBertConfig`] 显示了构建基础 [`DistilBertModel`] 所使用的所有默认属性。所有属性都可以进行自定义,为实验创造了空间。例如,您可以将默认模型自定义为:
|
||||
|
||||
- 使用 `activation` 参数尝试不同的激活函数。
|
||||
- 使用 `attention_dropout` 参数为 attention probabilities 使用更高的 dropout ratio。
|
||||
|
||||
```py
|
||||
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
|
||||
>>> print(my_config)
|
||||
DistilBertConfig {
|
||||
"activation": "relu",
|
||||
"attention_dropout": 0.4,
|
||||
"dim": 768,
|
||||
"dropout": 0.1,
|
||||
"hidden_dim": 3072,
|
||||
"initializer_range": 0.02,
|
||||
"max_position_embeddings": 512,
|
||||
"model_type": "distilbert",
|
||||
"n_heads": 12,
|
||||
"n_layers": 6,
|
||||
"pad_token_id": 0,
|
||||
"qa_dropout": 0.1,
|
||||
"seq_classif_dropout": 0.2,
|
||||
"sinusoidal_pos_embds": false,
|
||||
"transformers_version": "4.16.2",
|
||||
"vocab_size": 30522
|
||||
}
|
||||
```
|
||||
|
||||
预训练模型的属性可以在 [`~PretrainedConfig.from_pretrained`] 函数中进行修改:
|
||||
|
||||
```py
|
||||
>>> my_config = DistilBertConfig.from_pretrained("distilbert/distilbert-base-uncased", activation="relu", attention_dropout=0.4)
|
||||
```
|
||||
|
||||
当你对模型配置满意时,可以使用 [`~PretrainedConfig.save_pretrained`] 来保存配置。你的配置文件将以 JSON 文件的形式存储在指定的保存目录中:
|
||||
|
||||
```py
|
||||
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
|
||||
```
|
||||
|
||||
要重用配置文件,请使用 [`~PretrainedConfig.from_pretrained`] 进行加载:
|
||||
|
||||
```py
|
||||
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
你还可以将配置文件保存为字典,甚至只保存自定义配置属性与默认配置属性之间的差异!有关更多详细信息,请参阅 [配置](main_classes/configuration) 文档。
|
||||
|
||||
</Tip>
|
||||
|
||||
## 模型
|
||||
|
||||
接下来,创建一个[模型](main_classes/models)。模型,也可泛指架构,定义了每一层网络的行为以及进行的操作。配置中的 `num_hidden_layers` 等属性用于定义架构。每个模型都共享基类 [`PreTrainedModel`] 和一些常用方法,例如调整输入嵌入的大小和修剪自注意力头。此外,所有模型都是 [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html) 的子类。这意味着模型与各自框架的用法兼容。
|
||||
|
||||
将自定义配置属性加载到模型中:
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertModel
|
||||
|
||||
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
|
||||
>>> model = DistilBertModel(my_config)
|
||||
```
|
||||
|
||||
这段代码创建了一个具有随机参数而不是预训练权重的模型。在训练该模型之前,您还无法将该模型用于任何用途。训练是一项昂贵且耗时的过程。通常来说,最好使用预训练模型来更快地获得更好的结果,同时仅使用训练所需资源的一小部分。
|
||||
|
||||
使用 [`~PreTrainedModel.from_pretrained`] 创建预训练模型:
|
||||
|
||||
```py
|
||||
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
|
||||
```
|
||||
|
||||
当加载预训练权重时,如果模型是由 🤗 Transformers 提供的,将自动加载默认模型配置。然而,如果你愿意,仍然可以将默认模型配置的某些或者所有属性替换成你自己的配置:
|
||||
|
||||
```py
|
||||
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
|
||||
```
|
||||
|
||||
### 模型头(Model heads)
|
||||
|
||||
此时,你已经有了一个输出*隐藏状态*的基础 DistilBERT 模型。隐藏状态作为输入传递到模型头以生成最终输出。🤗 Transformers 为每个任务提供不同的模型头,只要模型支持该任务(即,您不能使用 DistilBERT 来执行像翻译这样的序列到序列任务)。
|
||||
|
||||
例如,[`DistilBertForSequenceClassification`] 是一个带有序列分类头(sequence classification head)的基础 DistilBERT 模型。序列分类头是池化输出之上的线性层。
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertForSequenceClassification
|
||||
|
||||
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
|
||||
```
|
||||
|
||||
通过切换到不同的模型头,可以轻松地将此检查点重复用于其他任务。对于问答任务,你可以使用 [`DistilBertForQuestionAnswering`] 模型头。问答头(question answering head)与序列分类头类似,不同点在于它是隐藏状态输出之上的线性层。
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertForQuestionAnswering
|
||||
|
||||
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
|
||||
```
|
||||
|
||||
## 分词器
|
||||
|
||||
在将模型用于文本数据之前,你需要的最后一个基类是 [tokenizer](main_classes/tokenizer),它用于将原始文本转换为张量。🤗 Transformers 支持两种类型的分词器:
|
||||
|
||||
- [`PreTrainedTokenizer`]:分词器的Python实现
|
||||
- [`PreTrainedTokenizerFast`]:来自我们基于 Rust 的 [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) 库的分词器。因为其使用了 Rust 实现,这种分词器类型的速度要快得多,尤其是在批量分词(batch tokenization)的时候。快速分词器还提供其他的方法,例如*偏移映射(offset mapping)*,它将标记(token)映射到其原始单词或字符。
|
||||
|
||||
这两种分词器都支持常用的方法,如编码和解码、添加新标记以及管理特殊标记。
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
并非每个模型都支持快速分词器。参照这张 [表格](index#supported-frameworks) 查看模型是否支持快速分词器。
|
||||
|
||||
</Tip>
|
||||
|
||||
如果您训练了自己的分词器,则可以从*词表*文件创建一个分词器:
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertTokenizer
|
||||
|
||||
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
|
||||
```
|
||||
|
||||
请务必记住,自定义分词器生成的词表与预训练模型分词器生成的词表是不同的。如果使用预训练模型,则需要使用预训练模型的词表,否则输入将没有意义。 使用 [`DistilBertTokenizer`] 类创建具有预训练模型词表的分词器:
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertTokenizer
|
||||
|
||||
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
|
||||
```
|
||||
|
||||
使用 [`DistilBertTokenizerFast`] 类创建快速分词器:
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertTokenizerFast
|
||||
|
||||
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert/distilbert-base-uncased")
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
默认情况下,[`AutoTokenizer`] 将尝试加载快速标记生成器。你可以通过在 `from_pretrained` 中设置 `use_fast=False` 以禁用此行为。
|
||||
|
||||
</Tip>
|
||||
|
||||
## 图像处理器
|
||||
|
||||
图像处理器用于处理视觉输入。它继承自 [`~image_processing_utils.ImageProcessingMixin`] 基类。
|
||||
|
||||
要使用它,需要创建一个与你使用的模型关联的图像处理器。例如,如果你使用 [ViT](model_doc/vit) 进行图像分类,可以创建一个默认的 [`ViTImageProcessor`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import ViTImageProcessor
|
||||
|
||||
>>> vit_extractor = ViTImageProcessor()
|
||||
>>> print(vit_extractor)
|
||||
ViTImageProcessor {
|
||||
"do_normalize": true,
|
||||
"do_resize": true,
|
||||
"image_processor_type": "ViTImageProcessor",
|
||||
"image_mean": [
|
||||
0.5,
|
||||
0.5,
|
||||
0.5
|
||||
],
|
||||
"image_std": [
|
||||
0.5,
|
||||
0.5,
|
||||
0.5
|
||||
],
|
||||
"resample": 2,
|
||||
"size": 224
|
||||
}
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
如果您不需要进行任何自定义,只需使用 `from_pretrained` 方法加载模型的默认图像处理器参数。
|
||||
|
||||
</Tip>
|
||||
|
||||
修改任何 [`ViTImageProcessor`] 参数以创建自定义图像处理器:
|
||||
|
||||
```py
|
||||
>>> from transformers import ViTImageProcessor
|
||||
|
||||
>>> my_vit_extractor = ViTImageProcessor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
|
||||
>>> print(my_vit_extractor)
|
||||
ViTImageProcessor {
|
||||
"do_normalize": false,
|
||||
"do_resize": true,
|
||||
"image_processor_type": "ViTImageProcessor",
|
||||
"image_mean": [
|
||||
0.3,
|
||||
0.3,
|
||||
0.3
|
||||
],
|
||||
"image_std": [
|
||||
0.5,
|
||||
0.5,
|
||||
0.5
|
||||
],
|
||||
"resample": "PIL.Image.BOX",
|
||||
"size": 224
|
||||
}
|
||||
```
|
||||
|
||||
## 特征提取器
|
||||
|
||||
特征提取器用于处理音频输入。它继承自 [`~feature_extraction_utils.FeatureExtractionMixin`] 基类,亦可继承 [`SequenceFeatureExtractor`] 类来处理音频输入。
|
||||
|
||||
要使用它,创建一个与你使用的模型关联的特征提取器。例如,如果你使用 [Wav2Vec2](model_doc/wav2vec2) 进行音频分类,可以创建一个默认的 [`Wav2Vec2FeatureExtractor`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import Wav2Vec2FeatureExtractor
|
||||
|
||||
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
|
||||
>>> print(w2v2_extractor)
|
||||
Wav2Vec2FeatureExtractor {
|
||||
"do_normalize": true,
|
||||
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
|
||||
"feature_size": 1,
|
||||
"padding_side": "right",
|
||||
"padding_value": 0.0,
|
||||
"return_attention_mask": false,
|
||||
"sampling_rate": 16000
|
||||
}
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
如果您不需要进行任何自定义,只需使用 `from_pretrained` 方法加载模型的默认特征提取器参数。
|
||||
|
||||
</Tip>
|
||||
|
||||
修改任何 [`Wav2Vec2FeatureExtractor`] 参数以创建自定义特征提取器:
|
||||
|
||||
```py
|
||||
>>> from transformers import Wav2Vec2FeatureExtractor
|
||||
|
||||
>>> w2v2_extractor = Wav2Vec2FeatureExtractor(sampling_rate=8000, do_normalize=False)
|
||||
>>> print(w2v2_extractor)
|
||||
Wav2Vec2FeatureExtractor {
|
||||
"do_normalize": false,
|
||||
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
|
||||
"feature_size": 1,
|
||||
"padding_side": "right",
|
||||
"padding_value": 0.0,
|
||||
"return_attention_mask": false,
|
||||
"sampling_rate": 8000
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 处理器
|
||||
|
||||
对于支持多模式任务的模型,🤗 Transformers 提供了一个处理器类,可以方便地将特征提取器和分词器等处理类包装到单个对象中。例如,让我们使用 [`Wav2Vec2Processor`] 来执行自动语音识别任务 (ASR)。 ASR 将音频转录为文本,因此您将需要一个特征提取器和一个分词器。
|
||||
|
||||
创建一个特征提取器来处理音频输入:
|
||||
|
||||
```py
|
||||
>>> from transformers import Wav2Vec2FeatureExtractor
|
||||
|
||||
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
|
||||
```
|
||||
|
||||
创建一个分词器来处理文本输入:
|
||||
|
||||
```py
|
||||
>>> from transformers import Wav2Vec2CTCTokenizer
|
||||
|
||||
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
|
||||
```
|
||||
|
||||
将特征提取器和分词器合并到 [`Wav2Vec2Processor`] 中:
|
||||
|
||||
```py
|
||||
>>> from transformers import Wav2Vec2Processor
|
||||
|
||||
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
|
||||
```
|
||||
|
||||
通过两个基类 - 配置类和模型类 - 以及一个附加的预处理类(分词器、图像处理器、特征提取器或处理器),你可以创建 🤗 Transformers 支持的任何模型。 每个基类都是可配置的,允许你使用所需的特定属性。 你可以轻松设置模型进行训练或修改现有的预训练模型进行微调。
|
||||
305
transformers/docs/source/zh/custom_models.md
Normal file
305
transformers/docs/source/zh/custom_models.md
Normal file
@@ -0,0 +1,305 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 共享自定义模型
|
||||
|
||||
🤗 Transformers 库设计得易于扩展。每个模型的代码都在仓库给定的子文件夹中,没有进行抽象,因此你可以轻松复制模型代码文件并根据需要进行调整。
|
||||
|
||||
如果你要编写全新的模型,从头开始可能更容易。在本教程中,我们将向你展示如何编写自定义模型及其配置,以便可以在 Transformers 中使用它;以及如何与社区共享它(及其依赖的代码),以便任何人都可以使用,即使它不在 🤗 Transformers 库中。
|
||||
|
||||
我们将以 ResNet 模型为例,通过将 [timm 库](https://github.com/rwightman/pytorch-image-models) 的 ResNet 类封装到 [`PreTrainedModel`] 中来进行说明。
|
||||
|
||||
## 编写自定义配置
|
||||
|
||||
在深入研究模型之前,让我们首先编写其配置。模型的配置是一个对象,其中包含构建模型所需的所有信息。我们将在下一节中看到,模型只能接受一个 `config` 来进行初始化,因此我们很需要使该对象尽可能完整。
|
||||
|
||||
我们将采用一些我们可能想要调整的 ResNet 类的参数举例。不同的配置将为我们提供不同类型可能的 ResNet 模型。在确认其中一些参数的有效性后,我们只需存储这些参数。
|
||||
|
||||
```python
|
||||
from transformers import PretrainedConfig
|
||||
from typing import List
|
||||
|
||||
|
||||
class ResnetConfig(PretrainedConfig):
|
||||
model_type = "resnet"
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
block_type="bottleneck",
|
||||
layers: list[int] = [3, 4, 6, 3],
|
||||
num_classes: int = 1000,
|
||||
input_channels: int = 3,
|
||||
cardinality: int = 1,
|
||||
base_width: int = 64,
|
||||
stem_width: int = 64,
|
||||
stem_type: str = "",
|
||||
avg_down: bool = False,
|
||||
**kwargs,
|
||||
):
|
||||
if block_type not in ["basic", "bottleneck"]:
|
||||
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
|
||||
if stem_type not in ["", "deep", "deep-tiered"]:
|
||||
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
|
||||
|
||||
self.block_type = block_type
|
||||
self.layers = layers
|
||||
self.num_classes = num_classes
|
||||
self.input_channels = input_channels
|
||||
self.cardinality = cardinality
|
||||
self.base_width = base_width
|
||||
self.stem_width = stem_width
|
||||
self.stem_type = stem_type
|
||||
self.avg_down = avg_down
|
||||
super().__init__(**kwargs)
|
||||
```
|
||||
|
||||
编写自定义配置时需要记住的三个重要事项如下:
|
||||
- 必须继承自 `PretrainedConfig`,
|
||||
- `PretrainedConfig` 的 `__init__` 方法必须接受任何 kwargs,
|
||||
- 这些 `kwargs` 需要传递给超类的 `__init__` 方法。
|
||||
|
||||
继承是为了确保你获得来自 🤗 Transformers 库的所有功能,而另外两个约束源于 `PretrainedConfig` 的字段比你设置的字段多。在使用 `from_pretrained` 方法重新加载配置时,这些字段需要被你的配置接受,然后传递给超类。
|
||||
|
||||
为你的配置定义 `model_type`(此处为 `model_type="resnet"`)不是必须的,除非你想使用自动类注册你的模型(请参阅最后一节)。
|
||||
|
||||
做完这些以后,就可以像使用库里任何其他模型配置一样,轻松地创建和保存配置。以下代码展示了如何创建并保存 resnet50d 配置:
|
||||
|
||||
```py
|
||||
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
|
||||
resnet50d_config.save_pretrained("custom-resnet")
|
||||
```
|
||||
|
||||
这行代码将在 `custom-resnet` 文件夹内保存一个名为 `config.json` 的文件。然后,你可以使用 `from_pretrained` 方法重新加载配置:
|
||||
|
||||
```py
|
||||
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
|
||||
```
|
||||
|
||||
你还可以使用 [`PretrainedConfig`] 类的任何其他方法,例如 [`~PretrainedConfig.push_to_hub`],直接将配置上传到 Hub。
|
||||
|
||||
## 编写自定义模型
|
||||
|
||||
有了 ResNet 配置后,就可以继续编写模型了。实际上,我们将编写两个模型:一个模型用于从一批图像中提取隐藏特征(类似于 [`BertModel`]),另一个模型适用于图像分类(类似于 [`BertForSequenceClassification`])。
|
||||
|
||||
正如之前提到的,我们只会编写一个松散的模型包装,以使示例保持简洁。在编写此类之前,只需要建立起块类型(block types)与实际块类(block classes)之间的映射。然后,通过将所有内容传递给ResNet类,从配置中定义模型:
|
||||
|
||||
```py
|
||||
from transformers import PreTrainedModel
|
||||
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
|
||||
from .configuration_resnet import ResnetConfig
|
||||
|
||||
|
||||
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
|
||||
|
||||
|
||||
class ResnetModel(PreTrainedModel):
|
||||
config_class = ResnetConfig
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
block_layer = BLOCK_MAPPING[config.block_type]
|
||||
self.model = ResNet(
|
||||
block_layer,
|
||||
config.layers,
|
||||
num_classes=config.num_classes,
|
||||
in_chans=config.input_channels,
|
||||
cardinality=config.cardinality,
|
||||
base_width=config.base_width,
|
||||
stem_width=config.stem_width,
|
||||
stem_type=config.stem_type,
|
||||
avg_down=config.avg_down,
|
||||
)
|
||||
|
||||
def forward(self, tensor):
|
||||
return self.model.forward_features(tensor)
|
||||
```
|
||||
|
||||
对用于进行图像分类的模型,我们只需更改前向方法:
|
||||
|
||||
```py
|
||||
import torch
|
||||
|
||||
|
||||
class ResnetModelForImageClassification(PreTrainedModel):
|
||||
config_class = ResnetConfig
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
block_layer = BLOCK_MAPPING[config.block_type]
|
||||
self.model = ResNet(
|
||||
block_layer,
|
||||
config.layers,
|
||||
num_classes=config.num_classes,
|
||||
in_chans=config.input_channels,
|
||||
cardinality=config.cardinality,
|
||||
base_width=config.base_width,
|
||||
stem_width=config.stem_width,
|
||||
stem_type=config.stem_type,
|
||||
avg_down=config.avg_down,
|
||||
)
|
||||
|
||||
def forward(self, tensor, labels=None):
|
||||
logits = self.model(tensor)
|
||||
if labels is not None:
|
||||
loss = torch.nn.functional.cross_entropy(logits, labels)
|
||||
return {"loss": loss, "logits": logits}
|
||||
return {"logits": logits}
|
||||
```
|
||||
|
||||
在这两种情况下,请注意我们如何继承 `PreTrainedModel` 并使用 `config` 调用了超类的初始化(有点像编写常规的torch.nn.Module)。设置 `config_class` 的那行代码不是必须的,除非你想使用自动类注册你的模型(请参阅最后一节)。
|
||||
|
||||
<Tip>
|
||||
|
||||
如果你的模型与库中的某个模型非常相似,你可以重用与该模型相同的配置。
|
||||
|
||||
</Tip>
|
||||
|
||||
你可以让模型返回任何你想要的内容,但是像我们为 `ResnetModelForImageClassification` 做的那样返回一个字典,并在传递标签时包含loss,可以使你的模型能够在 [`Trainer`] 类中直接使用。只要你计划使用自己的训练循环或其他库进行训练,也可以使用其他输出格式。
|
||||
|
||||
现在我们已经有了模型类,让我们创建一个:
|
||||
|
||||
```py
|
||||
resnet50d = ResnetModelForImageClassification(resnet50d_config)
|
||||
```
|
||||
|
||||
同样的,你可以使用 [`PreTrainedModel`] 的任何方法,比如 [`~PreTrainedModel.save_pretrained`] 或者 [`~PreTrainedModel.push_to_hub`]。我们将在下一节中使用第二种方法,并了解如何如何使用我们的模型的代码推送模型权重。但首先,让我们在模型内加载一些预训练权重。
|
||||
|
||||
在你自己的用例中,你可能会在自己的数据上训练自定义模型。为了快速完成本教程,我们将使用 resnet50d 的预训练版本。由于我们的模型只是它的包装,转移这些权重将会很容易:
|
||||
|
||||
```py
|
||||
import timm
|
||||
|
||||
pretrained_model = timm.create_model("resnet50d", pretrained=True)
|
||||
resnet50d.model.load_state_dict(pretrained_model.state_dict())
|
||||
```
|
||||
|
||||
现在让我们看看,如何确保在执行 [`~PreTrainedModel.save_pretrained`] 或 [`~PreTrainedModel.push_to_hub`] 时,模型的代码被保存。
|
||||
|
||||
## 将代码发送到 Hub
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
此 API 是实验性的,未来的发布中可能会有一些轻微的不兼容更改。
|
||||
|
||||
</Tip>
|
||||
|
||||
首先,确保你的模型在一个 `.py` 文件中完全定义。只要所有文件都位于同一目录中,它就可以依赖于某些其他文件的相对导入(目前我们还不为子模块支持此功能)。对于我们的示例,我们将在当前工作目录中名为 `resnet_model` 的文件夹中定义一个 `modeling_resnet.py` 文件和一个 `configuration_resnet.py` 文件。 配置文件包含 `ResnetConfig` 的代码,模型文件包含 `ResnetModel` 和 `ResnetModelForImageClassification` 的代码。
|
||||
|
||||
```
|
||||
.
|
||||
└── resnet_model
|
||||
├── __init__.py
|
||||
├── configuration_resnet.py
|
||||
└── modeling_resnet.py
|
||||
```
|
||||
|
||||
`__init__.py` 可以为空,它的存在只是为了让 Python 检测到 `resnet_model` 可以用作模块。
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
如果从库中复制模型文件,你需要将文件顶部的所有相对导入替换为从 `transformers` 包中的导入。
|
||||
|
||||
</Tip>
|
||||
|
||||
请注意,你可以重用(或子类化)现有的配置/模型。
|
||||
|
||||
要与社区共享您的模型,请参照以下步骤:首先从新创建的文件中导入ResNet模型和配置:
|
||||
|
||||
```py
|
||||
from resnet_model.configuration_resnet import ResnetConfig
|
||||
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
|
||||
```
|
||||
|
||||
接下来,你需要告诉库,当使用 `save_pretrained` 方法时,你希望复制这些对象的代码文件,并将它们正确注册到给定的 Auto 类(特别是对于模型),只需要运行以下代码:
|
||||
|
||||
```py
|
||||
ResnetConfig.register_for_auto_class()
|
||||
ResnetModel.register_for_auto_class("AutoModel")
|
||||
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
|
||||
```
|
||||
|
||||
请注意,对于配置(只有一个自动类 [`AutoConfig`]),不需要指定自动类,但对于模型来说情况不同。 你的自定义模型可能适用于许多不同的任务,因此你必须指定哪一个自动类适合你的模型。
|
||||
|
||||
接下来,让我们像之前一样创建配置和模型:
|
||||
|
||||
```py
|
||||
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
|
||||
resnet50d = ResnetModelForImageClassification(resnet50d_config)
|
||||
|
||||
pretrained_model = timm.create_model("resnet50d", pretrained=True)
|
||||
resnet50d.model.load_state_dict(pretrained_model.state_dict())
|
||||
```
|
||||
|
||||
现在要将模型推送到集线器,请确保你已登录。你看可以在终端中运行以下命令:
|
||||
|
||||
```bash
|
||||
hf auth login
|
||||
```
|
||||
|
||||
或者在笔记本中运行以下代码:
|
||||
|
||||
```py
|
||||
from huggingface_hub import notebook_login
|
||||
|
||||
notebook_login()
|
||||
```
|
||||
|
||||
然后,可以这样将模型推送到自己的命名空间(或你所属的组织):
|
||||
|
||||
```py
|
||||
resnet50d.push_to_hub("custom-resnet50d")
|
||||
```
|
||||
|
||||
除了模型权重和 JSON 格式的配置外,这行代码也会复制 `custom-resnet50d` 文件夹内的模型以及配置的 `.py` 文件并将结果上传至 Hub。你可以在此[模型仓库](https://huggingface.co/sgugger/custom-resnet50d)中查看结果。
|
||||
|
||||
有关推推送至 Hub 方法的更多信息,请参阅[共享教程](model_sharing)。
|
||||
|
||||
## 使用带有自定义代码的模型
|
||||
|
||||
可以使用自动类(auto-classes)和 `from_pretrained` 方法,使用模型仓库里带有自定义代码的配置、模型或分词器文件。所有上传到 Hub 的文件和代码都会进行恶意软件扫描(有关更多信息,请参阅 [Hub 安全](https://huggingface.co/docs/hub/security#malware-scanning) 文档), 但你仍应查看模型代码和作者,以避免在你的计算机上执行恶意代码。 设置 `trust_remote_code=True` 以使用带有自定义代码的模型:
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForImageClassification
|
||||
|
||||
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
|
||||
```
|
||||
|
||||
我们强烈建议为 `revision` 参数传递提交哈希(commit hash),以确保模型的作者没有使用一些恶意的代码行更新了代码(除非您完全信任模型的作者)。
|
||||
|
||||
```py
|
||||
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
|
||||
model = AutoModelForImageClassification.from_pretrained(
|
||||
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
|
||||
)
|
||||
```
|
||||
|
||||
在 Hub 上浏览模型仓库的提交历史时,有一个按钮可以轻松复制任何提交的提交哈希。
|
||||
|
||||
## 将自定义代码的模型注册到自动类
|
||||
|
||||
如果你在编写一个扩展 🤗 Transformers 的库,你可能想要扩展自动类以包含您自己的模型。这与将代码推送到 Hub 不同,因为用户需要导入你的库才能获取自定义模型(与从 Hub 自动下载模型代码相反)。
|
||||
|
||||
只要你的配置 `model_type` 属性与现有模型类型不同,并且你的模型类有正确的 `config_class` 属性,你可以像这样将它们添加到自动类中:
|
||||
|
||||
```py
|
||||
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
|
||||
|
||||
AutoConfig.register("resnet", ResnetConfig)
|
||||
AutoModel.register(ResnetConfig, ResnetModel)
|
||||
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
|
||||
```
|
||||
|
||||
请注意,将自定义配置注册到 [`AutoConfig`] 时,使用的第一个参数需要与自定义配置的 `model_type` 匹配;而将自定义模型注册到任何自动模型类时,使用的第一个参数需要与 `config_class` 匹配。
|
||||
308
transformers/docs/source/zh/debugging.md
Normal file
308
transformers/docs/source/zh/debugging.md
Normal file
@@ -0,0 +1,308 @@
|
||||
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 调试
|
||||
|
||||
## 多GPU网络问题调试
|
||||
|
||||
当使用`DistributedDataParallel`和多个GPU进行训练或推理时,如果遇到进程和(或)节点之间的互联问题,您可以使用以下脚本来诊断网络问题。
|
||||
|
||||
```bash
|
||||
wget https://raw.githubusercontent.com/huggingface/transformers/main/scripts/distributed/torch-distributed-gpu-test.py
|
||||
```
|
||||
|
||||
例如,要测试两个GPU之间的互联,请执行以下操作:
|
||||
|
||||
```bash
|
||||
python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
|
||||
```
|
||||
|
||||
如果两个进程能够相互通信并分配GPU内存,它们各自将打印出 "OK" 状态。
|
||||
|
||||
对于更多的GPU或节点,可以根据脚本中的参数进行调整。
|
||||
|
||||
在诊断脚本内部,您将找到更多详细信息,甚至有关如何在SLURM环境中运行它的说明。
|
||||
|
||||
另一种级别的调试是添加 `NCCL_DEBUG=INFO` 环境变量,如下所示:
|
||||
|
||||
|
||||
```bash
|
||||
NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
|
||||
```
|
||||
|
||||
这将产生大量与NCCL相关的调试信息,如果发现有问题报告,您可以在线搜索以获取相关信息。或者,如果您不确定如何解释输出,可以在`issue`中分享日志文件。
|
||||
|
||||
|
||||
## 下溢和上溢检测
|
||||
|
||||
<Tip>
|
||||
|
||||
目前,此功能仅适用于PyTorch。
|
||||
|
||||
</Tip>
|
||||
|
||||
<Tip>
|
||||
|
||||
对于多GPU训练,它需要使用DDP(`torch.distributed.launch`)。
|
||||
|
||||
</Tip>
|
||||
|
||||
<Tip>
|
||||
|
||||
此功能可以与任何基于`nn.Module`的模型一起使用。
|
||||
|
||||
</Tip>
|
||||
|
||||
如果您开始发现`loss=NaN`或模型因激活值或权重中的`inf`或`nan`而出现一些异常行为,就需要发现第一个下溢或上溢发生的地方以及导致它的原因。幸运的是,您可以通过激活一个特殊模块来自动进行检测。
|
||||
|
||||
如果您正在使用[`Trainer`],只需把以下内容:
|
||||
|
||||
|
||||
```bash
|
||||
--debug underflow_overflow
|
||||
```
|
||||
|
||||
添加到常规命令行参数中,或在创建[`TrainingArguments`]对象时传递 `debug="underflow_overflow"`。
|
||||
|
||||
如果您正在使用自己的训练循环或其他Trainer,您可以通过以下方式实现相同的功能:
|
||||
|
||||
```python
|
||||
from transformers.debug_utils import DebugUnderflowOverflow
|
||||
|
||||
debug_overflow = DebugUnderflowOverflow(model)
|
||||
```
|
||||
|
||||
[`debug_utils.DebugUnderflowOverflow`] 将`hooks`插入模型,紧跟在每次前向调用之后,进而测试输入和输出变量,以及相应模块的权重。一旦在激活值或权重的至少一个元素中检测到`inf`或`nan`,程序将执行`assert`并打印报告,就像这样(这是在`google/mt5-small`下使用fp16混合精度捕获的):
|
||||
|
||||
```
|
||||
Detected inf/nan during batch_number=0
|
||||
Last 21 forward frames:
|
||||
abs min abs max metadata
|
||||
encoder.block.1.layer.1.DenseReluDense.dropout Dropout
|
||||
0.00e+00 2.57e+02 input[0]
|
||||
0.00e+00 2.85e+02 output
|
||||
[...]
|
||||
encoder.block.2.layer.0 T5LayerSelfAttention
|
||||
6.78e-04 3.15e+03 input[0]
|
||||
2.65e-04 3.42e+03 output[0]
|
||||
None output[1]
|
||||
2.25e-01 1.00e+04 output[2]
|
||||
encoder.block.2.layer.1.layer_norm T5LayerNorm
|
||||
8.69e-02 4.18e-01 weight
|
||||
2.65e-04 3.42e+03 input[0]
|
||||
1.79e-06 4.65e+00 output
|
||||
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
|
||||
2.17e-07 4.50e+00 weight
|
||||
1.79e-06 4.65e+00 input[0]
|
||||
2.68e-06 3.70e+01 output
|
||||
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
|
||||
8.08e-07 2.66e+01 weight
|
||||
1.79e-06 4.65e+00 input[0]
|
||||
1.27e-04 2.37e+02 output
|
||||
encoder.block.2.layer.1.DenseReluDense.dropout Dropout
|
||||
0.00e+00 8.76e+03 input[0]
|
||||
0.00e+00 9.74e+03 output
|
||||
encoder.block.2.layer.1.DenseReluDense.wo Linear
|
||||
1.01e-06 6.44e+00 weight
|
||||
0.00e+00 9.74e+03 input[0]
|
||||
3.18e-04 6.27e+04 output
|
||||
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
|
||||
1.79e-06 4.65e+00 input[0]
|
||||
3.18e-04 6.27e+04 output
|
||||
encoder.block.2.layer.1.dropout Dropout
|
||||
3.18e-04 6.27e+04 input[0]
|
||||
0.00e+00 inf output
|
||||
```
|
||||
|
||||
由于篇幅原因,示例输出中间的部分已经被缩减。
|
||||
|
||||
第二列显示了绝对最大元素的值,因此,如果您仔细查看最后`frame`,输入和输出都在`1e4`的范围内。因此,在使用fp16混合精度进行训练时,最后一步发生了溢出(因为在`fp16`下,在`inf`之前的最大数字是`64e3`)。为了避免在`fp16`下发生溢出,激活值必须保持低于`1e4`,因为`1e4 * 1e4 = 1e8`,因此任何具有大激活值的矩阵乘法都会导致数值溢出。
|
||||
|
||||
在跟踪的开始处,您可以发现问题发生在哪个批次(这里的`Detected inf/nan during batch_number=0`表示问题发生在第一个批次)。
|
||||
|
||||
每个报告的`frame`都以声明相应模块的层信息为开头,说明这一`frame`是为哪个模块报告的。如果只看这个`frame`:
|
||||
|
||||
```
|
||||
encoder.block.2.layer.1.layer_norm T5LayerNorm
|
||||
8.69e-02 4.18e-01 weight
|
||||
2.65e-04 3.42e+03 input[0]
|
||||
1.79e-06 4.65e+00 output
|
||||
```
|
||||
|
||||
在这里,`encoder.block.2.layer.1.layer_norm` 表示它是编码器的第二个块中第一层的`layer norm`。而 `forward` 的具体调用是 `T5LayerNorm`。
|
||||
|
||||
让我们看看该报告的最后几个`frame`:
|
||||
|
||||
```
|
||||
Detected inf/nan during batch_number=0
|
||||
Last 21 forward frames:
|
||||
abs min abs max metadata
|
||||
[...]
|
||||
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
|
||||
2.17e-07 4.50e+00 weight
|
||||
1.79e-06 4.65e+00 input[0]
|
||||
2.68e-06 3.70e+01 output
|
||||
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
|
||||
8.08e-07 2.66e+01 weight
|
||||
1.79e-06 4.65e+00 input[0]
|
||||
1.27e-04 2.37e+02 output
|
||||
encoder.block.2.layer.1.DenseReluDense.wo Linear
|
||||
1.01e-06 6.44e+00 weight
|
||||
0.00e+00 9.74e+03 input[0]
|
||||
3.18e-04 6.27e+04 output
|
||||
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
|
||||
1.79e-06 4.65e+00 input[0]
|
||||
3.18e-04 6.27e+04 output
|
||||
encoder.block.2.layer.1.dropout Dropout
|
||||
3.18e-04 6.27e+04 input[0]
|
||||
0.00e+00 inf output
|
||||
```
|
||||
|
||||
最后一个`frame`报告了`Dropout.forward`函数,第一个条目是唯一的输入,第二个条目是唯一的输出。您可以看到,它是从`DenseReluDense`类内的属性`dropout`中调用的。我们可以看到它发生在第2个块的第1层,也就是在第一个批次期间。最后,绝对最大的输入元素值为`6.27e+04`,输出也是`inf`。
|
||||
|
||||
您可以在这里看到,`T5DenseGatedGeluDense.forward`产生了输出激活值,其绝对最大值约为62.7K,非常接近fp16的上限64K。在下一个`frame`中,我们有`Dropout`对权重进行重新归一化,之后将某些元素归零,将绝对最大值推到了64K以上,导致溢出(`inf`)。
|
||||
|
||||
正如你所看到的,我们需要查看前面的`frame`, 从那里fp16数字开始变得非常大。
|
||||
|
||||
让我们将报告与`models/t5/modeling_t5.py`中的代码匹配:
|
||||
|
||||
```python
|
||||
class T5DenseGatedGeluDense(nn.Module):
|
||||
def __init__(self, config):
|
||||
super().__init__()
|
||||
self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
|
||||
self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
|
||||
self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
|
||||
self.dropout = nn.Dropout(config.dropout_rate)
|
||||
self.gelu_act = ACT2FN["gelu_new"]
|
||||
|
||||
def forward(self, hidden_states):
|
||||
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
|
||||
hidden_linear = self.wi_1(hidden_states)
|
||||
hidden_states = hidden_gelu * hidden_linear
|
||||
hidden_states = self.dropout(hidden_states)
|
||||
hidden_states = self.wo(hidden_states)
|
||||
return hidden_states
|
||||
```
|
||||
|
||||
现在很容易看到`dropout`调用,以及所有之前的调用。
|
||||
|
||||
由于检测是在前向`hook`中进行的,这些报告将立即在每个`forward`返回后打印出来。
|
||||
|
||||
回到完整的报告,要采取措施并解决问题,我们需要往回看几个`frame`,在那里数字开始上升,并且最有可能切换到fp32模式以便在乘法或求和时数字不会溢出。当然,可能还有其他解决方案。例如,如果启用了`amp`,我们可以在将原始`forward`移到`helper wrapper`中后,暂时关闭它,如下所示:
|
||||
|
||||
```python
|
||||
def _forward(self, hidden_states):
|
||||
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
|
||||
hidden_linear = self.wi_1(hidden_states)
|
||||
hidden_states = hidden_gelu * hidden_linear
|
||||
hidden_states = self.dropout(hidden_states)
|
||||
hidden_states = self.wo(hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
import torch
|
||||
|
||||
|
||||
def forward(self, hidden_states):
|
||||
if torch.is_autocast_enabled():
|
||||
with torch.cuda.amp.autocast(enabled=False):
|
||||
return self._forward(hidden_states)
|
||||
else:
|
||||
return self._forward(hidden_states)
|
||||
```
|
||||
|
||||
由于自动检测器仅报告完整`frame`的输入和输出,一旦知道在哪里查找,您可能还希望分析特定`forward`函数的中间阶段。在这种情况下,您可以使用`detect_overflow`辅助函数将检测器放到希望的位置,例如:
|
||||
|
||||
```python
|
||||
from debug_utils import detect_overflow
|
||||
|
||||
|
||||
class T5LayerFF(nn.Module):
|
||||
[...]
|
||||
|
||||
def forward(self, hidden_states):
|
||||
forwarded_states = self.layer_norm(hidden_states)
|
||||
detect_overflow(forwarded_states, "after layer_norm")
|
||||
forwarded_states = self.DenseReluDense(forwarded_states)
|
||||
detect_overflow(forwarded_states, "after DenseReluDense")
|
||||
return hidden_states + self.dropout(forwarded_states)
|
||||
```
|
||||
|
||||
可以看到,我们添加了2个检测器,现在我们可以跟踪是否在`forwarded_states`中间的某个地方检测到了`inf`或`nan`。
|
||||
|
||||
实际上,检测器已经报告了这些,因为上面示例中的每个调用都是一个`nn.Module`,但假设如果您有一些本地的直接计算,这就是您将如何执行的方式。
|
||||
|
||||
此外,如果您在自己的代码中实例化调试器,您可以调整从其默认打印的`frame`数,例如:
|
||||
|
||||
```python
|
||||
from transformers.debug_utils import DebugUnderflowOverflow
|
||||
|
||||
debug_overflow = DebugUnderflowOverflow(model, max_frames_to_save=100)
|
||||
```
|
||||
|
||||
### 特定批次的绝对最小值和最大值跟踪
|
||||
|
||||
当关闭下溢/上溢检测功能, 同样的调试类可以用于批处理跟踪。
|
||||
|
||||
假设您想要监视给定批次的每个`forward`调用的所有成分的绝对最小值和最大值,并且仅对批次1和3执行此操作,您可以这样实例化这个类:
|
||||
|
||||
```python
|
||||
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3])
|
||||
```
|
||||
|
||||
现在,完整的批次1和3将以与下溢/上溢检测器相同的格式进行跟踪。
|
||||
|
||||
批次从0开始计数。
|
||||
|
||||
如果您知道程序在某个批次编号之后开始出现问题,那么您可以直接快进到该区域。以下是一个截取的配置示例输出:
|
||||
|
||||
```
|
||||
*** Starting batch number=1 ***
|
||||
abs min abs max metadata
|
||||
shared Embedding
|
||||
1.01e-06 7.92e+02 weight
|
||||
0.00e+00 2.47e+04 input[0]
|
||||
5.36e-05 7.92e+02 output
|
||||
[...]
|
||||
decoder.dropout Dropout
|
||||
1.60e-07 2.27e+01 input[0]
|
||||
0.00e+00 2.52e+01 output
|
||||
decoder T5Stack
|
||||
not a tensor output
|
||||
lm_head Linear
|
||||
1.01e-06 7.92e+02 weight
|
||||
0.00e+00 1.11e+00 input[0]
|
||||
6.06e-02 8.39e+01 output
|
||||
T5ForConditionalGeneration
|
||||
not a tensor output
|
||||
|
||||
*** Starting batch number=3 ***
|
||||
abs min abs max metadata
|
||||
shared Embedding
|
||||
1.01e-06 7.92e+02 weight
|
||||
0.00e+00 2.78e+04 input[0]
|
||||
5.36e-05 7.92e+02 output
|
||||
[...]
|
||||
```
|
||||
|
||||
在这里,您将获得大量的`frame`被`dump` - 与您的模型中的前向调用一样多,它有可能符合也可能不符合您的要求,但有时对于调试目的来说,它可能比正常的调试器更容易使用。例如,如果问题开始发生在批次号150上,您可以`dump`批次149和150的跟踪,并比较数字开始发散的地方。
|
||||
|
||||
你还可以使用以下命令指定停止训练的批次号:
|
||||
|
||||
```python
|
||||
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3], abort_after_batch_num=3)
|
||||
```
|
||||
67
transformers/docs/source/zh/fast_tokenizers.md
Normal file
67
transformers/docs/source/zh/fast_tokenizers.md
Normal file
@@ -0,0 +1,67 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 使用 🤗 Tokenizers 中的分词器
|
||||
|
||||
[`PreTrainedTokenizerFast`] 依赖于 [🤗 Tokenizers](https://huggingface.co/docs/tokenizers) 库。从 🤗 Tokenizers 库获得的分词器可以被轻松地加载到 🤗 Transformers 中。
|
||||
|
||||
在了解具体内容之前,让我们先用几行代码创建一个虚拟的分词器:
|
||||
|
||||
```python
|
||||
>>> from tokenizers import Tokenizer
|
||||
>>> from tokenizers.models import BPE
|
||||
>>> from tokenizers.trainers import BpeTrainer
|
||||
>>> from tokenizers.pre_tokenizers import Whitespace
|
||||
|
||||
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
|
||||
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
|
||||
|
||||
>>> tokenizer.pre_tokenizer = Whitespace()
|
||||
>>> files = [...]
|
||||
>>> tokenizer.train(files, trainer)
|
||||
```
|
||||
|
||||
现在,我们拥有了一个针对我们定义的文件进行训练的分词器。我们可以在当前运行时中继续使用它,或者将其保存到一个 JSON 文件以供将来重复使用。
|
||||
|
||||
## 直接从分词器对象加载
|
||||
|
||||
让我们看看如何利用 🤗 Transformers 库中的这个分词器对象。[`PreTrainedTokenizerFast`] 类允许通过接受已实例化的 *tokenizer* 对象作为参数,进行轻松实例化:
|
||||
|
||||
```python
|
||||
>>> from transformers import PreTrainedTokenizerFast
|
||||
|
||||
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
|
||||
```
|
||||
|
||||
现在可以使用这个对象,使用 🤗 Transformers 分词器共享的所有方法!前往[分词器页面](main_classes/tokenizer)了解更多信息。
|
||||
|
||||
## 从 JSON 文件加载
|
||||
|
||||
为了从 JSON 文件中加载分词器,让我们先保存我们的分词器:
|
||||
|
||||
```python
|
||||
>>> tokenizer.save("tokenizer.json")
|
||||
```
|
||||
|
||||
我们保存此文件的路径可以通过 `tokenizer_file` 参数传递给 [`PreTrainedTokenizerFast`] 初始化方法:
|
||||
|
||||
```python
|
||||
>>> from transformers import PreTrainedTokenizerFast
|
||||
|
||||
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
|
||||
```
|
||||
|
||||
现在可以使用这个对象,使用 🤗 Transformers 分词器共享的所有方法!前往[分词器页面](main_classes/tokenizer)了解更多信息。
|
||||
161
transformers/docs/source/zh/fsdp.md
Normal file
161
transformers/docs/source/zh/fsdp.md
Normal file
@@ -0,0 +1,161 @@
|
||||
<!--
|
||||
Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# 完全分片数据并行
|
||||
|
||||
[完全分片数据并行(FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/)是一种数据并行方法,
|
||||
它将模型的参数、梯度和优化器状态在可用 GPU(也称为 Worker 或 *rank*)的数量上进行分片。
|
||||
与[分布式数据并行(DDP)](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html)不同,
|
||||
FSDP 减少了内存使用量,因为模型在每个 GPU 上都被复制了一次。这就提高了 GPU 内存效率,
|
||||
使您能够用较少的 GPU 训练更大的模型。FSDP 已经集成到 Accelerate 中,
|
||||
这是一个用于在分布式环境中轻松管理训练的库,这意味着可以从 [`Trainer`] 类中调用这个库。
|
||||
|
||||
在开始之前,请确保已安装 Accelerate,并且至少使用 PyTorch 2.1.0 或更高版本。
|
||||
|
||||
```bash
|
||||
pip install accelerate
|
||||
```
|
||||
|
||||
## FSDP 配置
|
||||
|
||||
首先,运行 [`accelerate config`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-config)
|
||||
命令为您的训练环境创建一个配置文件。Accelerate 使用此配置文件根据您在 `accelerate config`
|
||||
中选择的训练选项来自动搭建正确的训练环境。
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
运行 `accelerate config` 时,您将被提示一系列选项来配置训练环境。
|
||||
本节涵盖了一些最重要的 FSDP 选项。要了解有关其他可用的 FSDP 选项的更多信息,
|
||||
请查阅 [fsdp_config](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.fsdp_config) 参数。
|
||||
|
||||
### 分片策略
|
||||
|
||||
FSDP 提供了多种可选择的分片策略:
|
||||
|
||||
- `FULL_SHARD` - 将模型参数、梯度和优化器状态跨 Worker 进行分片;为此选项选择 `1`
|
||||
- `SHARD_GRAD_OP`- 将梯度和优化器状态跨 Worker 进行分片;为此选项选择 `2`
|
||||
- `NO_SHARD` - 不分片任何内容(这等同于 DDP);为此选项选择 `3`
|
||||
- `HYBRID_SHARD` - 在每个 Worker 中分片模型参数、梯度和优化器状态,其中每个 Worker 也有完整副本;为此选项选择 `4`
|
||||
- `HYBRID_SHARD_ZERO2` - 在每个 Worker 中分片梯度和优化器状态,其中每个 Worker 也有完整副本;为此选项选择 `5`
|
||||
|
||||
这由 `fsdp_sharding_strategy` 标志启用。
|
||||
|
||||
### CPU 卸载
|
||||
|
||||
当参数和梯度在不使用时可以卸载到 CPU 上,以节省更多 GPU 内存并帮助您适应即使 FSDP 也不足以容纳大型模型的情况。
|
||||
在运行 `accelerate config` 时,通过设置 `fsdp_offload_params: true` 来启用此功能。
|
||||
|
||||
### 包装策略
|
||||
|
||||
FSDP 是通过包装网络中的每个层来应用的。通常,包装是以嵌套方式应用的,其中完整的权重在每次前向传递后被丢弃,
|
||||
以便在下一层使用内存。**自动包装**策略是实现这一点的最简单方法,您不需要更改任何代码。
|
||||
您应该选择 `fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP` 来包装一个 Transformer 层,
|
||||
并且 `fsdp_transformer_layer_cls_to_wrap` 来指定要包装的层(例如 `BertLayer`)。
|
||||
|
||||
否则,您可以选择基于大小的包装策略,其中如果一层的参数超过一定数量,则应用 FSDP。通过设置
|
||||
`fsdp_wrap_policy: SIZE_BASED_WRAP` 和 `min_num_param` 来启用此功能,将参数设置为所需的大小阈值。
|
||||
|
||||
### 检查点
|
||||
|
||||
应该使用 `fsdp_state_dict_type: SHARDED_STATE_DICT` 来保存中间检查点,
|
||||
因为在排名 0 上保存完整状态字典需要很长时间,通常会导致 `NCCL Timeout` 错误,因为在广播过程中会无限期挂起。
|
||||
您可以使用 [`~accelerate.Accelerator.load_state`] 方法加载分片状态字典以恢复训练。
|
||||
|
||||
```py
|
||||
# 包含检查点的目录
|
||||
accelerator.load_state("ckpt")
|
||||
```
|
||||
|
||||
然而,当训练结束时,您希望保存完整状态字典,因为分片状态字典仅与 FSDP 兼容。
|
||||
|
||||
```py
|
||||
if trainer.is_fsdp_enabled:
|
||||
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
|
||||
|
||||
trainer.save_model(script_args.output_dir)
|
||||
```
|
||||
|
||||
### TPU
|
||||
|
||||
[PyTorch XLA](https://pytorch.org/xla/release/2.1/index.html) 支持用于 TPUs 的 FSDP 训练,
|
||||
可以通过修改由 `accelerate config` 生成的 FSDP 配置文件来启用。除了上面指定的分片策略和包装选项外,
|
||||
您还可以将以下参数添加到文件中。
|
||||
|
||||
```yaml
|
||||
xla: True # 必须设置为 True 以启用 PyTorch/XLA
|
||||
xla_fsdp_settings: # XLA 特定的 FSDP 参数
|
||||
xla_fsdp_grad_ckpt: True # 使用梯度检查点
|
||||
```
|
||||
|
||||
[`xla_fsdp_settings`](https://github.com/pytorch/xla/blob/2e6e183e0724818f137c8135b34ef273dea33318/torch_xla/distributed/fsdp/xla_fully_sharded_data_parallel.py#L128)
|
||||
允许您配置用于 FSDP 的额外 XLA 特定参数。
|
||||
|
||||
## 启动训练
|
||||
|
||||
FSDP 配置文件示例如下所示:
|
||||
|
||||
```yaml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
debug: false
|
||||
distributed_type: FSDP
|
||||
downcast_bf16: "no"
|
||||
fsdp_config:
|
||||
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
|
||||
fsdp_backward_prefetch_policy: BACKWARD_PRE
|
||||
fsdp_cpu_ram_efficient_loading: true
|
||||
fsdp_forward_prefetch: false
|
||||
fsdp_offload_params: true
|
||||
fsdp_sharding_strategy: 1
|
||||
fsdp_state_dict_type: SHARDED_STATE_DICT
|
||||
fsdp_sync_module_states: true
|
||||
fsdp_transformer_layer_cls_to_wrap: BertLayer
|
||||
fsdp_use_orig_params: true
|
||||
machine_rank: 0
|
||||
main_training_function: main
|
||||
mixed_precision: bf16
|
||||
num_machines: 1
|
||||
num_processes: 2
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_env: []
|
||||
tpu_use_cluster: false
|
||||
tpu_use_sudo: false
|
||||
use_cpu: false
|
||||
```
|
||||
|
||||
要启动训练,请运行 [`accelerate launch`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-launch)
|
||||
命令,它将自动使用您之前使用 `accelerate config` 创建的配置文件。
|
||||
|
||||
```bash
|
||||
accelerate launch my-trainer-script.py
|
||||
```
|
||||
|
||||
```bash
|
||||
accelerate launch --fsdp="full shard" --fsdp_config="path/to/fsdp_config/ my-trainer-script.py
|
||||
```
|
||||
|
||||
## 下一步
|
||||
|
||||
FSDP 在大规模模型训练方面是一个强大的工具,您可以使用多个 GPU 或 TPU。
|
||||
通过分片模型参数、优化器和梯度状态,甚至在它们不活动时将其卸载到 CPU 上,
|
||||
FSDP 可以减少大规模训练的高成本。如果您希望了解更多信息,下面的内容可能会有所帮助:
|
||||
|
||||
- 深入参考 Accelerate 指南,了解有关
|
||||
[FSDP](https://huggingface.co/docs/accelerate/usage_guides/fsdp)的更多信息。
|
||||
- 阅读[介绍 PyTorch 完全分片数据并行(FSDP)API](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) 博文。
|
||||
- 阅读[使用 FSDP 在云 TPU 上扩展 PyTorch 模型](https://pytorch.org/blog/scaling-pytorch-models-on-cloud-tpus-with-fsdp/)博文。
|
||||
104
transformers/docs/source/zh/gguf.md
Normal file
104
transformers/docs/source/zh/gguf.md
Normal file
@@ -0,0 +1,104 @@
|
||||
<!--
|
||||
Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# GGUF 和 Transformers 的交互
|
||||
|
||||
GGUF文件格式用于存储模型,以便通过[GGML](https://github.com/ggerganov/ggml)和其他依赖它的库进行推理,例如非常流行的[llama.cpp](https://github.com/ggerganov/llama.cpp)或[whisper.cpp](https://github.com/ggerganov/whisper.cpp)。
|
||||
|
||||
该文件格式[由抱抱脸支持](https://huggingface.co/docs/hub/en/gguf),可用于快速检查文件中张量和元数据。
|
||||
|
||||
该文件格式是一种“单文件格式”,通常单个文件就包含了配置属性、分词器词汇表和其他属性,同时还有模型中要加载的所有张量。这些文件根据文件的量化类型有不同的格式。我们在[这里](https://huggingface.co/docs/hub/en/gguf#quantization-types)进行了简要介绍。
|
||||
|
||||
## 在 Transformers 中的支持
|
||||
|
||||
我们在 transformers 中添加了加载 gguf 文件的功能,这样可以对 GGUF 模型进行进一步的训练或微调,然后再将模型转换回 GGUF 格式,以便在 ggml 生态系统中使用。加载模型时,我们首先将其反量化为 FP32,然后再加载权重以在 PyTorch 中使用。
|
||||
|
||||
> [!注意]
|
||||
> 目前这个功能还处于探索阶段,欢迎大家贡献力量,以便在不同量化类型和模型架构之间更好地完善这一功能。
|
||||
|
||||
目前,支持的模型架构和量化类型如下:
|
||||
|
||||
### 支持的量化类型
|
||||
|
||||
根据分享在 Hub 上的较为热门的量化文件,初步支持以下量化类型:
|
||||
|
||||
- F32
|
||||
- F16
|
||||
- BF16
|
||||
- Q4_0
|
||||
- Q4_1
|
||||
- Q5_0
|
||||
- Q5_1
|
||||
- Q8_0
|
||||
- Q2_K
|
||||
- Q3_K
|
||||
- Q4_K
|
||||
- Q5_K
|
||||
- Q6_K
|
||||
- IQ1_S
|
||||
- IQ1_M
|
||||
- IQ2_XXS
|
||||
- IQ2_XS
|
||||
- IQ2_S
|
||||
- IQ3_XXS
|
||||
- IQ3_S
|
||||
- IQ4_XS
|
||||
- IQ4_NL
|
||||
|
||||
> [!注意]
|
||||
> 为了支持 gguf 反量化,需要安装 `gguf>=0.10.0`。
|
||||
|
||||
### 支持的模型架构
|
||||
|
||||
目前支持以下在 Hub 上非常热门的模型架构:
|
||||
|
||||
- LLaMa
|
||||
- Mistral
|
||||
- Qwen2
|
||||
- Qwen2Moe
|
||||
- Phi3
|
||||
- Bloom
|
||||
- Falcon
|
||||
- StableLM
|
||||
- GPT2
|
||||
- Starcoder2
|
||||
|
||||
## 使用示例
|
||||
|
||||
为了在`transformers`中加载`gguf`文件,你需要在 `from_pretrained`方法中为分词器和模型指定 `gguf_file`参数。下面是从同一个文件中加载分词器和模型的示例:
|
||||
|
||||
```py
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
|
||||
model_id = "TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF"
|
||||
filename = "tinyllama-1.1b-chat-v1.0.Q6_K.gguf"
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id, gguf_file=filename)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id, gguf_file=filename)
|
||||
```
|
||||
|
||||
现在,你就已经可以结合 PyTorch 生态系统中的一系列其他工具,来使用完整的、未量化的模型了。
|
||||
|
||||
为了将模型转换回`gguf`文件,我们建议使用`llama.cpp`中的[`convert-hf-to-gguf.py`文件](https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py)。
|
||||
|
||||
以下是如何补充上面的脚本,以保存模型并将其导出回 `gguf`的示例:
|
||||
|
||||
```py
|
||||
tokenizer.save_pretrained('directory')
|
||||
model.save_pretrained('directory')
|
||||
|
||||
!python ${path_to_llama_cpp}/convert-hf-to-gguf.py ${directory}
|
||||
```
|
||||
138
transformers/docs/source/zh/hpo_train.md
Normal file
138
transformers/docs/source/zh/hpo_train.md
Normal file
@@ -0,0 +1,138 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 使用Trainer API进行超参数搜索
|
||||
|
||||
🤗 Transformers库提供了一个优化过的[`Trainer`]类,用于训练🤗 Transformers模型,相比于手动编写自己的训练循环,这更容易开始训练。[`Trainer`]提供了超参数搜索的API。本文档展示了如何在示例中启用它。
|
||||
|
||||
|
||||
## 超参数搜索后端
|
||||
|
||||
[`Trainer`] 目前支持四种超参数搜索后端:[optuna](https://optuna.org/),[sigopt](https://sigopt.com/),[raytune](https://docs.ray.io/en/latest/tune/index.html),[wandb](https://wandb.ai/site/sweeps)
|
||||
|
||||
在使用它们之前,您应该先安装它们作为超参数搜索后端。
|
||||
|
||||
```bash
|
||||
pip install optuna/sigopt/wandb/ray[tune]
|
||||
```
|
||||
|
||||
## 如何在示例中启用超参数搜索
|
||||
|
||||
定义超参数搜索空间,不同的后端需要不同的格式。
|
||||
|
||||
对于sigopt,请参阅sigopt [object_parameter](https://docs.sigopt.com/ai-module-api-references/api_reference/objects/object_parameter),它类似于以下内容:
|
||||
|
||||
```py
|
||||
>>> def sigopt_hp_space(trial):
|
||||
... return [
|
||||
... {"bounds": {"min": 1e-6, "max": 1e-4}, "name": "learning_rate", "type": "double"},
|
||||
... {
|
||||
... "categorical_values": ["16", "32", "64", "128"],
|
||||
... "name": "per_device_train_batch_size",
|
||||
... "type": "categorical",
|
||||
... },
|
||||
... ]
|
||||
```
|
||||
|
||||
对于optuna,请参阅optuna [object_parameter](https://optuna.readthedocs.io/en/stable/tutorial/10_key_features/002_configurations.html#sphx-glr-tutorial-10-key-features-002-configurations-py),它类似于以下内容:
|
||||
|
||||
```py
|
||||
>>> def optuna_hp_space(trial):
|
||||
... return {
|
||||
... "learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
|
||||
... "per_device_train_batch_size": trial.suggest_categorical("per_device_train_batch_size", [16, 32, 64, 128]),
|
||||
... }
|
||||
```
|
||||
|
||||
Optuna提供了多目标HPO。您可以在`hyperparameter_search`中传递`direction`参数,并定义自己的`compute_objective`以返回多个目标值。在`hyperparameter_search`中将返回Pareto Front(`list[BestRun]`),您应该参考[test_trainer](https://github.com/huggingface/transformers/blob/main/tests/trainer/test_trainer.py)中的测试用例`TrainerHyperParameterMultiObjectOptunaIntegrationTest`。它类似于以下内容:
|
||||
|
||||
```py
|
||||
>>> best_trials = trainer.hyperparameter_search(
|
||||
... direction=["minimize", "maximize"],
|
||||
... backend="optuna",
|
||||
... hp_space=optuna_hp_space,
|
||||
... n_trials=20,
|
||||
... compute_objective=compute_objective,
|
||||
... )
|
||||
```
|
||||
|
||||
对于raytune,可以参考raytune的[object_parameter](https://docs.ray.io/en/latest/tune/api/search_space.html),它类似于以下内容:
|
||||
|
||||
```py
|
||||
>>> def ray_hp_space(trial):
|
||||
... return {
|
||||
... "learning_rate": tune.loguniform(1e-6, 1e-4),
|
||||
... "per_device_train_batch_size": tune.choice([16, 32, 64, 128]),
|
||||
... }
|
||||
```
|
||||
|
||||
对于wandb,可以参考wandb的[object_parameter](https://docs.wandb.ai/guides/sweeps/configuration),它类似于以下内容:
|
||||
|
||||
```py
|
||||
>>> def wandb_hp_space(trial):
|
||||
... return {
|
||||
... "method": "random",
|
||||
... "metric": {"name": "objective", "goal": "minimize"},
|
||||
... "parameters": {
|
||||
... "learning_rate": {"distribution": "uniform", "min": 1e-6, "max": 1e-4},
|
||||
... "per_device_train_batch_size": {"values": [16, 32, 64, 128]},
|
||||
... },
|
||||
... }
|
||||
```
|
||||
|
||||
定义一个`model_init`函数并将其传递给[Trainer],作为示例:
|
||||
|
||||
```py
|
||||
>>> def model_init(trial):
|
||||
... return AutoModelForSequenceClassification.from_pretrained(
|
||||
... model_args.model_name_or_path,
|
||||
... config=config,
|
||||
... cache_dir=model_args.cache_dir,
|
||||
... revision=model_args.model_revision,
|
||||
... use_auth_token=True if model_args.use_auth_token else None,
|
||||
... )
|
||||
```
|
||||
|
||||
使用你的`model_init`函数、训练参数、训练和测试数据集以及评估函数创建一个[`Trainer`]。
|
||||
|
||||
```py
|
||||
>>> trainer = Trainer(
|
||||
... model=None,
|
||||
... args=training_args,
|
||||
... train_dataset=small_train_dataset,
|
||||
... eval_dataset=small_eval_dataset,
|
||||
... compute_metrics=compute_metrics,
|
||||
... processing_class=tokenizer,
|
||||
... model_init=model_init,
|
||||
... data_collator=data_collator,
|
||||
... )
|
||||
```
|
||||
|
||||
调用超参数搜索,获取最佳试验参数,后端可以是`"optuna"`/`"sigopt"`/`"wandb"`/`"ray"`。方向可以是`"minimize"`或`"maximize"`,表示是否优化更大或更低的目标。
|
||||
|
||||
您可以定义自己的compute_objective函数,如果没有定义,将调用默认的compute_objective,并将评估指标(如f1)之和作为目标值返回。
|
||||
|
||||
```py
|
||||
>>> best_trial = trainer.hyperparameter_search(
|
||||
... direction="maximize",
|
||||
... backend="optuna",
|
||||
... hp_space=optuna_hp_space,
|
||||
... n_trials=20,
|
||||
... compute_objective=compute_objective,
|
||||
... )
|
||||
```
|
||||
|
||||
## 针对DDP微调的超参数搜索
|
||||
目前,Optuna和Sigopt已启用针对DDP的超参数搜索。只有rank-zero进程会进行超参数搜索并将参数传递给其他进程。
|
||||
50
transformers/docs/source/zh/index.md
Normal file
50
transformers/docs/source/zh/index.md
Normal file
@@ -0,0 +1,50 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 🤗 Transformers简介
|
||||
|
||||
为 [PyTorch](https://pytorch.org/) 打造的先进的机器学习工具.
|
||||
|
||||
🤗 Transformers 提供了可以轻松地下载并且训练先进的预训练模型的 API 和工具。使用预训练模型可以减少计算消耗和碳排放,并且节省从头训练所需要的时间和资源。这些模型支持不同模态中的常见任务,比如:
|
||||
|
||||
📝 **自然语言处理**:文本分类、命名实体识别、问答、语言建模、摘要、翻译、多项选择和文本生成。<br>
|
||||
🖼️ **机器视觉**:图像分类、目标检测和语义分割。<br>
|
||||
🗣️ **音频**:自动语音识别和音频分类。<br>
|
||||
🐙 **多模态**:表格问答、光学字符识别、从扫描文档提取信息、视频分类和视觉问答。
|
||||
|
||||
🤗 Transformers 模型可以被导出为 ONNX 和 TorchScript 格式,用于在生产环境中部署。
|
||||
|
||||
马上加入在 [Hub](https://huggingface.co/models)、[论坛](https://discuss.huggingface.co/) 或者 [Discord](https://discord.com/invite/JfAtkvEtRb) 上正在快速发展的社区吧!
|
||||
|
||||
## 如果你需要来自 Hugging Face 团队的个性化支持
|
||||
|
||||
<a target="_blank" href="https://huggingface.co/support">
|
||||
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
|
||||
</a>
|
||||
|
||||
## 目录
|
||||
|
||||
这篇文档由以下 5 个章节组成:
|
||||
|
||||
- **开始使用** 包含了库的快速上手和安装说明,便于配置和运行。
|
||||
- **教程** 是一个初学者开始的好地方。本章节将帮助你获得你会用到的使用这个库的基本技能。
|
||||
- **操作指南** 向你展示如何实现一个特定目标,比如为语言建模微调一个预训练模型或者如何创造并分享个性化模型。
|
||||
- **概念指南** 对 🤗 Transformers 的模型,任务和设计理念背后的基本概念和思想做了更多的讨论和解释。
|
||||
- **API 介绍** 描述了所有的类和函数:
|
||||
|
||||
- **主要类别** 详述了配置(configuration)、模型(model)、分词器(tokenizer)和流水线(pipeline)这几个最重要的类。
|
||||
- **模型** 详述了在这个库中和每个模型实现有关的类和函数。
|
||||
- **内部帮助** 详述了内部使用的工具类和函数。
|
||||
230
transformers/docs/source/zh/installation.md
Normal file
230
transformers/docs/source/zh/installation.md
Normal file
@@ -0,0 +1,230 @@
|
||||
<!---
|
||||
Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 安装
|
||||
|
||||
为你正在使用的深度学习框架安装 🤗 Transformers、设置缓存,并选择性配置 🤗 Transformers 以离线运行。
|
||||
|
||||
🤗 Transformers 已在 Python 3.9+ 以及 PyTorch 2.2.0+ 上进行测试。针对你使用的深度学习框架,请参照以下安装说明进行安装:
|
||||
|
||||
* [PyTorch](https://pytorch.org/get-started/locally/) 安装说明。
|
||||
|
||||
## 使用 pip 安装
|
||||
|
||||
你应该使用 [虚拟环境](https://docs.python.org/3/library/venv.html) 安装 🤗 Transformers。如果你不熟悉 Python 虚拟环境,请查看此 [教程](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)。使用虚拟环境,你可以轻松管理不同项目,避免不同依赖项之间的兼容性问题。
|
||||
|
||||
首先,在项目目录中创建虚拟环境:
|
||||
|
||||
```bash
|
||||
python -m venv .env
|
||||
```
|
||||
|
||||
在 Linux 和 MacOs 系统中激活虚拟环境:
|
||||
|
||||
```bash
|
||||
source .env/bin/activate
|
||||
```
|
||||
在 Windows 系统中激活虚拟环境:
|
||||
|
||||
```bash
|
||||
.env/Scripts/activate
|
||||
```
|
||||
|
||||
现在你可以使用以下命令安装 🤗 Transformers:
|
||||
|
||||
```bash
|
||||
pip install transformers
|
||||
```
|
||||
|
||||
若仅需 CPU 支持,可以使用单行命令方便地安装 🤗 Transformers 和深度学习库。例如,使用以下命令安装 🤗 Transformers 和 PyTorch:
|
||||
|
||||
```bash
|
||||
pip install 'transformers[torch]'
|
||||
```
|
||||
|
||||
最后,运行以下命令以检查 🤗 Transformers 是否已被正确安装。该命令将下载一个预训练模型:
|
||||
|
||||
```bash
|
||||
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
|
||||
```
|
||||
|
||||
然后打印标签以及分数:
|
||||
|
||||
```bash
|
||||
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
|
||||
```
|
||||
|
||||
## 源码安装
|
||||
|
||||
使用以下命令从源码安装 🤗 Transformers:
|
||||
|
||||
```bash
|
||||
pip install git+https://github.com/huggingface/transformers
|
||||
```
|
||||
|
||||
此命令下载的是最新的前沿 `main` 版本而不是最新的 `stable` 版本。`main` 版本适用于跟最新开发保持一致。例如,上次正式版发布带来的 bug 被修复了,但新版本尚未被推出。但是,这也说明 `main` 版本并不一定总是稳定的。我们努力保持 `main` 版本的可操作性,大多数问题通常在几个小时或一天以内就能被解决。如果你遇到问题,请提个 [Issue](https://github.com/huggingface/transformers/issues) 以便我们能更快修复。
|
||||
|
||||
运行以下命令以检查 🤗 Transformers 是否已被正确安装:
|
||||
|
||||
```bash
|
||||
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
|
||||
```
|
||||
|
||||
## 可编辑安装
|
||||
|
||||
如果你有下列需求,需要进行可编辑安装:
|
||||
|
||||
* 使用源码的 `main` 版本。
|
||||
* 为 🤗 Transformers 贡献代码,需要测试代码中的更改。
|
||||
|
||||
使用以下命令克隆仓库并安装 🤗 Transformers:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/transformers.git
|
||||
cd transformers
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
这些命令将会链接你克隆的仓库以及你的 Python 库路径。现在,Python 不仅会在正常的库路径中搜索库,也会在你克隆到的文件夹中进行查找。例如,如果你的 Python 包通常本应安装在 `~/anaconda3/envs/main/lib/python3.7/site-packages/` 目录中,在这种情况下 Python 也会搜索你克隆到的文件夹:`~/transformers/`。
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
如果你想继续使用这个库,必须保留 `transformers` 文件夹。
|
||||
|
||||
</Tip>
|
||||
|
||||
现在,你可以使用以下命令,将你克隆的 🤗 Transformers 库轻松更新至最新版本:
|
||||
|
||||
```bash
|
||||
cd ~/transformers/
|
||||
git pull
|
||||
```
|
||||
|
||||
你的 Python 环境将在下次运行时找到 `main` 版本的 🤗 Transformers。
|
||||
|
||||
## 使用 conda 安装
|
||||
|
||||
从 conda 的 `conda-forge` 频道安装:
|
||||
|
||||
```bash
|
||||
conda install conda-forge::transformers
|
||||
```
|
||||
|
||||
## 缓存设置
|
||||
|
||||
预训练模型会被下载并本地缓存到 `~/.cache/huggingface/hub`。这是由环境变量 `TRANSFORMERS_CACHE` 指定的默认目录。在 Windows 上,默认目录为 `C:\Users\username\.cache\huggingface\hub`。你可以按照不同优先级改变下述环境变量,以指定不同的缓存目录。
|
||||
|
||||
1. 环境变量(默认): `HF_HUB_CACHE` 或 `TRANSFORMERS_CACHE`。
|
||||
2. 环境变量 `HF_HOME`。
|
||||
3. 环境变量 `XDG_CACHE_HOME` + `/huggingface`。
|
||||
|
||||
<Tip>
|
||||
|
||||
除非你明确指定了环境变量 `TRANSFORMERS_CACHE`,🤗 Transformers 将可能会使用较早版本设置的环境变量 `PYTORCH_TRANSFORMERS_CACHE` 或 `PYTORCH_PRETRAINED_BERT_CACHE`。
|
||||
|
||||
</Tip>
|
||||
|
||||
## 离线模式
|
||||
|
||||
🤗 Transformers 可以仅使用本地文件在防火墙或离线环境中运行。设置环境变量 `HF_HUB_OFFLINE=1` 以启用该行为。
|
||||
|
||||
<Tip>
|
||||
|
||||
通过设置环境变量 `HF_DATASETS_OFFLINE=1` 将 [🤗 Datasets](https://huggingface.co/docs/datasets/) 添加至你的离线训练工作流程中。
|
||||
|
||||
</Tip>
|
||||
|
||||
例如,你通常会使用以下命令对外部实例进行防火墙保护的的普通网络上运行程序:
|
||||
|
||||
```bash
|
||||
python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en ...
|
||||
```
|
||||
|
||||
在离线环境中运行相同的程序:
|
||||
|
||||
```bash
|
||||
HF_DATASETS_OFFLINE=1 HF_HUB_OFFLINE=1 \
|
||||
python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en ...
|
||||
```
|
||||
|
||||
现在脚本可以应该正常运行,而无需挂起或等待超时,因为它知道只应查找本地文件。
|
||||
|
||||
### 获取离线时使用的模型和分词器
|
||||
|
||||
另一种离线时使用 🤗 Transformers 的方法是预先下载好文件,然后在需要离线使用时指向它们的离线路径。有三种实现的方法:
|
||||
|
||||
* 单击 [Model Hub](https://huggingface.co/models) 用户界面上的 ↓ 图标下载文件。
|
||||
|
||||

|
||||
|
||||
* 使用 [`PreTrainedModel.from_pretrained`] 和 [`PreTrainedModel.save_pretrained`] 工作流程:
|
||||
|
||||
1. 预先使用 [`PreTrainedModel.from_pretrained`] 下载文件:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
|
||||
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
|
||||
```
|
||||
|
||||
2. 使用 [`PreTrainedModel.save_pretrained`] 将文件保存至指定目录:
|
||||
|
||||
```py
|
||||
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
|
||||
>>> model.save_pretrained("./your/path/bigscience_t0")
|
||||
```
|
||||
|
||||
3. 现在,你可以在离线时从指定目录使用 [`PreTrainedModel.from_pretrained`] 重新加载你的文件:
|
||||
|
||||
```py
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
|
||||
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
|
||||
```
|
||||
|
||||
* 使用代码用 [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) 库下载文件:
|
||||
|
||||
1. 在你的虚拟环境中安装 `huggingface_hub` 库:
|
||||
|
||||
```bash
|
||||
python -m pip install huggingface_hub
|
||||
```
|
||||
|
||||
2. 使用 [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) 函数将文件下载到指定路径。例如,以下命令将 `config.json` 文件从 [T0](https://huggingface.co/bigscience/T0_3B) 模型下载至你想要的路径:
|
||||
|
||||
```py
|
||||
>>> from huggingface_hub import hf_hub_download
|
||||
|
||||
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
|
||||
```
|
||||
|
||||
下载完文件并在本地缓存后,指定其本地路径以加载和使用该模型:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoConfig
|
||||
|
||||
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
请参阅 [如何从 Hub 下载文件](https://huggingface.co/docs/hub/how-to-downstream) 部分,获取有关下载存储在 Hub 上文件的更多详细信息。
|
||||
|
||||
</Tip>
|
||||
40
transformers/docs/source/zh/internal/audio_utils.md
Normal file
40
transformers/docs/source/zh/internal/audio_utils.md
Normal file
@@ -0,0 +1,40 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# `FeatureExtractors`的工具
|
||||
|
||||
此页面列出了音频 [`FeatureExtractor`] 可以使用的所有实用函数,以便使用常见的算法(如 *Short Time Fourier Transform* 或 *log mel spectrogram*)从原始音频中计算特殊特征。
|
||||
|
||||
其中大多数仅在您研究库中音频processors的代码时有用。
|
||||
|
||||
|
||||
## 音频转换
|
||||
|
||||
[[autodoc]] audio_utils.hertz_to_mel
|
||||
|
||||
[[autodoc]] audio_utils.mel_to_hertz
|
||||
|
||||
[[autodoc]] audio_utils.mel_filter_bank
|
||||
|
||||
[[autodoc]] audio_utils.optimal_fft_length
|
||||
|
||||
[[autodoc]] audio_utils.window_function
|
||||
|
||||
[[autodoc]] audio_utils.spectrogram
|
||||
|
||||
[[autodoc]] audio_utils.power_to_db
|
||||
|
||||
[[autodoc]] audio_utils.amplitude_to_db
|
||||
45
transformers/docs/source/zh/internal/file_utils.md
Normal file
45
transformers/docs/source/zh/internal/file_utils.md
Normal file
@@ -0,0 +1,45 @@
|
||||
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 通用工具
|
||||
|
||||
此页面列出了在`utils.py`文件中找到的所有Transformers通用实用函数。
|
||||
|
||||
其中大多数仅在您研究库中的通用代码时才有用。
|
||||
|
||||
## Enums和namedtuples(命名元组)
|
||||
|
||||
[[autodoc]] utils.ExplicitEnum
|
||||
|
||||
[[autodoc]] utils.PaddingStrategy
|
||||
|
||||
[[autodoc]] utils.TensorType
|
||||
|
||||
## 特殊的装饰函数
|
||||
|
||||
[[autodoc]] utils.add_start_docstrings
|
||||
|
||||
[[autodoc]] utils.add_start_docstrings_to_model_forward
|
||||
|
||||
[[autodoc]] utils.add_end_docstrings
|
||||
|
||||
[[autodoc]] utils.add_code_sample_docstrings
|
||||
|
||||
[[autodoc]] utils.replace_return_docstrings
|
||||
|
||||
## 其他实用程序
|
||||
|
||||
[[autodoc]] utils._LazyModule
|
||||
184
transformers/docs/source/zh/internal/generation_utils.md
Normal file
184
transformers/docs/source/zh/internal/generation_utils.md
Normal file
@@ -0,0 +1,184 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 用于生成的工具
|
||||
|
||||
此页面列出了所有由 [`~generation.GenerationMixin.generate`]。
|
||||
|
||||
## 生成输出
|
||||
|
||||
[`~generation.GenerationMixin.generate`] 的输出是 [`~utils.ModelOutput`] 的一个子类的实例。这个输出是一种包含 [`~generation.GenerationMixin.generate`] 返回的所有信息数据结构,但也可以作为元组或字典使用。
|
||||
这里是一个例子:
|
||||
|
||||
|
||||
```python
|
||||
from transformers import GPT2Tokenizer, GPT2LMHeadModel
|
||||
|
||||
tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
|
||||
model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2")
|
||||
|
||||
inputs = tokenizer("Hello, my dog is cute and ", return_tensors="pt")
|
||||
generation_output = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
|
||||
```
|
||||
|
||||
`generation_output` 的对象是 [`~generation.GenerateDecoderOnlyOutput`] 的一个实例,从该类的文档中我们可以看到,这意味着它具有以下属性:
|
||||
|
||||
- `sequences`: 生成的tokens序列
|
||||
- `scores`(可选): 每个生成步骤的语言建模头的预测分数
|
||||
- `hidden_states`(可选): 每个生成步骤模型的hidden states
|
||||
- `attentions`(可选): 每个生成步骤模型的注意力权重
|
||||
|
||||
在这里,由于我们传递了 `output_scores=True`,我们具有 `scores` 属性。但我们没有 `hidden_states` 和 `attentions`,因为没有传递 `output_hidden_states=True` 或 `output_attentions=True`。
|
||||
|
||||
您可以像通常一样访问每个属性,如果该属性未被模型返回,则将获得 `None`。例如,在这里 `generation_output.scores` 是语言建模头的所有生成预测分数,而 `generation_output.attentions` 为 `None`。
|
||||
|
||||
当我们将 `generation_output` 对象用作元组时,它只保留非 `None` 值的属性。例如,在这里它有两个元素,`loss` 然后是 `logits`,所以
|
||||
|
||||
|
||||
```python
|
||||
generation_output[:2]
|
||||
```
|
||||
|
||||
将返回元组`(generation_output.sequences, generation_output.scores)`。
|
||||
|
||||
当我们将`generation_output`对象用作字典时,它只保留非`None`的属性。例如,它有两个键,分别是`sequences`和`scores`。
|
||||
|
||||
我们在此记录所有输出类型。
|
||||
|
||||
|
||||
### PyTorch
|
||||
|
||||
[[autodoc]] generation.GenerateDecoderOnlyOutput
|
||||
|
||||
[[autodoc]] generation.GenerateEncoderDecoderOutput
|
||||
|
||||
[[autodoc]] generation.GenerateBeamDecoderOnlyOutput
|
||||
|
||||
[[autodoc]] generation.GenerateBeamEncoderDecoderOutput
|
||||
|
||||
## LogitsProcessor
|
||||
|
||||
[`LogitsProcessor`] 可以用于修改语言模型头的预测分数以进行生成
|
||||
|
||||
|
||||
### PyTorch
|
||||
|
||||
[[autodoc]] AlternatingCodebooksLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] ClassifierFreeGuidanceLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] EncoderNoRepeatNGramLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] EncoderRepetitionPenaltyLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] EpsilonLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] EtaLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] ExponentialDecayLengthPenalty
|
||||
- __call__
|
||||
|
||||
[[autodoc]] ForcedBOSTokenLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] ForcedEOSTokenLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] InfNanRemoveLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] LogitNormalization
|
||||
- __call__
|
||||
|
||||
[[autodoc]] LogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] LogitsProcessorList
|
||||
- __call__
|
||||
|
||||
[[autodoc]] MinLengthLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] MinNewTokensLengthLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] NoBadWordsLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] NoRepeatNGramLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] PrefixConstrainedLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] RepetitionPenaltyLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] SequenceBiasLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] SuppressTokensAtBeginLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] SuppressTokensLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TemperatureLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TopKLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TopPLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] TypicalLogitsWarper
|
||||
- __call__
|
||||
|
||||
[[autodoc]] UnbatchedClassifierFreeGuidanceLogitsProcessor
|
||||
- __call__
|
||||
|
||||
[[autodoc]] WhisperTimeStampLogitsProcessor
|
||||
- __call__
|
||||
|
||||
## StoppingCriteria
|
||||
|
||||
可以使用[`StoppingCriteria`]来更改停止生成的时间(除了EOS token以外的方法)。请注意,这仅适用于我们的PyTorch实现。
|
||||
|
||||
|
||||
[[autodoc]] StoppingCriteria
|
||||
- __call__
|
||||
|
||||
[[autodoc]] StoppingCriteriaList
|
||||
- __call__
|
||||
|
||||
[[autodoc]] MaxLengthCriteria
|
||||
- __call__
|
||||
|
||||
[[autodoc]] MaxTimeCriteria
|
||||
- __call__
|
||||
|
||||
## Streamers
|
||||
|
||||
[[autodoc]] TextStreamer
|
||||
|
||||
[[autodoc]] TextIteratorStreamer
|
||||
@@ -0,0 +1,48 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Image Processors的工具
|
||||
|
||||
此页面列出了image processors使用的所有实用函数功能,主要是用于处理图像的功能变换。
|
||||
|
||||
其中大多数仅在您研究库中image processors的代码时有用。
|
||||
|
||||
|
||||
## 图像转换
|
||||
|
||||
[[autodoc]] image_transforms.center_crop
|
||||
|
||||
[[autodoc]] image_transforms.center_to_corners_format
|
||||
|
||||
[[autodoc]] image_transforms.corners_to_center_format
|
||||
|
||||
[[autodoc]] image_transforms.id_to_rgb
|
||||
|
||||
[[autodoc]] image_transforms.normalize
|
||||
|
||||
[[autodoc]] image_transforms.pad
|
||||
|
||||
[[autodoc]] image_transforms.rgb_to_id
|
||||
|
||||
[[autodoc]] image_transforms.rescale
|
||||
|
||||
[[autodoc]] image_transforms.resize
|
||||
|
||||
[[autodoc]] image_transforms.to_pil_image
|
||||
|
||||
## ImageProcessingMixin
|
||||
|
||||
[[autodoc]] image_processing_utils.ImageProcessingMixin
|
||||
39
transformers/docs/source/zh/internal/modeling_utils.md
Normal file
39
transformers/docs/source/zh/internal/modeling_utils.md
Normal file
@@ -0,0 +1,39 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 自定义层和工具
|
||||
|
||||
此页面列出了库使用的所有自定义层,以及它为模型提供的实用函数。
|
||||
|
||||
其中大多数只有在您研究库中模型的代码时才有用。
|
||||
|
||||
|
||||
## Pytorch自定义模块
|
||||
|
||||
[[autodoc]] pytorch_utils.Conv1D
|
||||
|
||||
## PyTorch帮助函数
|
||||
|
||||
[[autodoc]] pytorch_utils.apply_chunking_to_forward
|
||||
|
||||
[[autodoc]] pytorch_utils.find_pruneable_heads_and_indices
|
||||
|
||||
[[autodoc]] pytorch_utils.prune_layer
|
||||
|
||||
[[autodoc]] pytorch_utils.prune_conv1d_layer
|
||||
|
||||
[[autodoc]] pytorch_utils.prune_linear_layer
|
||||
|
||||
45
transformers/docs/source/zh/internal/pipelines_utils.md
Normal file
45
transformers/docs/source/zh/internal/pipelines_utils.md
Normal file
@@ -0,0 +1,45 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# pipelines的工具
|
||||
|
||||
|
||||
此页面列出了库为pipelines提供的所有实用程序功能。
|
||||
|
||||
其中大多数只有在您研究库中模型的代码时才有用。
|
||||
|
||||
|
||||
## 参数处理
|
||||
|
||||
[[autodoc]] pipelines.ArgumentHandler
|
||||
|
||||
[[autodoc]] pipelines.ZeroShotClassificationArgumentHandler
|
||||
|
||||
[[autodoc]] pipelines.QuestionAnsweringArgumentHandler
|
||||
|
||||
## 数据格式
|
||||
|
||||
[[autodoc]] pipelines.PipelineDataFormat
|
||||
|
||||
[[autodoc]] pipelines.CsvPipelineDataFormat
|
||||
|
||||
[[autodoc]] pipelines.JsonPipelineDataFormat
|
||||
|
||||
[[autodoc]] pipelines.PipedPipelineDataFormat
|
||||
|
||||
## 实用函数
|
||||
|
||||
[[autodoc]] pipelines.PipelineException
|
||||
31
transformers/docs/source/zh/internal/time_series_utils.md
Normal file
31
transformers/docs/source/zh/internal/time_series_utils.md
Normal file
@@ -0,0 +1,31 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 时间序列工具
|
||||
|
||||
|
||||
此页面列出了可用于时间序列类模型的所有实用函数和类。
|
||||
|
||||
其中大多数仅在您研究时间序列模型的代码,或希望添加到分布输出类集合时有用。
|
||||
|
||||
|
||||
## 输出分布
|
||||
|
||||
[[autodoc]] time_series_utils.NormalOutput
|
||||
|
||||
[[autodoc]] time_series_utils.StudentTOutput
|
||||
|
||||
[[autodoc]] time_series_utils.NegativeBinomialOutput
|
||||
43
transformers/docs/source/zh/internal/tokenization_utils.md
Normal file
43
transformers/docs/source/zh/internal/tokenization_utils.md
Normal file
@@ -0,0 +1,43 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Tokenizers的工具
|
||||
|
||||
并保留格式:此页面列出了tokenizers使用的所有实用函数,主要是类
|
||||
[`~tokenization_utils_base.PreTrained TokenizerBase`] 实现了常用方法之间的
|
||||
[`PreTrained Tokenizer`] 和 [`PreTrained TokenizerFast`] 以及混合类
|
||||
[`~tokenization_utils_base.SpecialTokens Mixin`]。
|
||||
|
||||
其中大多数只有在您研究库中tokenizers的代码时才有用。
|
||||
|
||||
|
||||
## PreTrainedTokenizerBase
|
||||
|
||||
[[autodoc]] tokenization_utils_base.PreTrainedTokenizerBase
|
||||
- __call__
|
||||
- all
|
||||
|
||||
## SpecialTokensMixin
|
||||
|
||||
[[autodoc]] tokenization_utils_base.SpecialTokensMixin
|
||||
|
||||
## Enums和namedtuples(命名元组)
|
||||
|
||||
[[autodoc]] tokenization_utils_base.TruncationStrategy
|
||||
|
||||
[[autodoc]] tokenization_utils_base.CharSpan
|
||||
|
||||
[[autodoc]] tokenization_utils_base.TokenSpan
|
||||
50
transformers/docs/source/zh/internal/trainer_utils.md
Normal file
50
transformers/docs/source/zh/internal/trainer_utils.md
Normal file
@@ -0,0 +1,50 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Trainer的工具
|
||||
|
||||
此页面列出了 [`Trainer`] 使用的所有实用函数。
|
||||
|
||||
其中大多数仅在您研究库中Trainer的代码时有用。
|
||||
|
||||
|
||||
## 工具
|
||||
|
||||
[[autodoc]] EvalPrediction
|
||||
|
||||
[[autodoc]] IntervalStrategy
|
||||
|
||||
[[autodoc]] enable_full_determinism
|
||||
|
||||
[[autodoc]] set_seed
|
||||
|
||||
[[autodoc]] torch_distributed_zero_first
|
||||
|
||||
## Callbacks内部机制
|
||||
|
||||
[[autodoc]] trainer_callback.CallbackHandler
|
||||
|
||||
## 分布式评估
|
||||
|
||||
[[autodoc]] trainer_pt_utils.DistributedTensorGatherer
|
||||
|
||||
## Trainer参数解析
|
||||
|
||||
[[autodoc]] HfArgumentParser
|
||||
|
||||
## Debug工具
|
||||
|
||||
[[autodoc]] debug_utils.DebugUnderflowOverflow
|
||||
269
transformers/docs/source/zh/llm_tutorial.md
Normal file
269
transformers/docs/source/zh/llm_tutorial.md
Normal file
@@ -0,0 +1,269 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
|
||||
## 使用LLMs进行生成
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
LLMs,即大语言模型,是文本生成背后的关键组成部分。简单来说,它们包含经过大规模预训练的transformer模型,用于根据给定的输入文本预测下一个词(或更准确地说,下一个`token`)。由于它们一次只预测一个`token`,因此除了调用模型之外,您需要执行更复杂的操作来生成新的句子——您需要进行自回归生成。
|
||||
|
||||
自回归生成是在给定一些初始输入,通过迭代调用模型及其自身的生成输出来生成文本的推理过程。在🤗 Transformers中,这由[`~generation.GenerationMixin.generate`]方法处理,所有具有生成能力的模型都可以使用该方法。
|
||||
|
||||
本教程将向您展示如何:
|
||||
|
||||
* 使用LLM生成文本
|
||||
* 避免常见的陷阱
|
||||
* 帮助您充分利用LLM下一步指导
|
||||
|
||||
在开始之前,请确保已安装所有必要的库:
|
||||
|
||||
|
||||
```bash
|
||||
pip install transformers bitsandbytes>=0.39.0 -q
|
||||
```
|
||||
|
||||
|
||||
## 生成文本
|
||||
|
||||
一个用于[因果语言建模](tasks/language_modeling)训练的语言模型,将文本`tokens`序列作为输入,并返回下一个`token`的概率分布。
|
||||
|
||||
|
||||
<!-- [GIF 1 -- FWD PASS] -->
|
||||
<figure class="image table text-center m-0 w-full">
|
||||
<video
|
||||
style="max-width: 90%; margin: auto;"
|
||||
autoplay loop muted playsinline
|
||||
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_1_1080p.mov"
|
||||
></video>
|
||||
<figcaption>"LLM的前向传递"</figcaption>
|
||||
</figure>
|
||||
|
||||
使用LLM进行自回归生成的一个关键方面是如何从这个概率分布中选择下一个`token`。这个步骤可以随意进行,只要最终得到下一个迭代的`token`。这意味着可以简单的从概率分布中选择最可能的`token`,也可以复杂的在对结果分布进行采样之前应用多种变换,这取决于你的需求。
|
||||
|
||||
<!-- [GIF 2 -- TEXT GENERATION] -->
|
||||
<figure class="image table text-center m-0 w-full">
|
||||
<video
|
||||
style="max-width: 90%; margin: auto;"
|
||||
autoplay loop muted playsinline
|
||||
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_2_1080p.mov"
|
||||
></video>
|
||||
<figcaption>"自回归生成迭代地从概率分布中选择下一个token以生成文本"</figcaption>
|
||||
</figure>
|
||||
|
||||
上述过程是迭代重复的,直到达到某个停止条件。理想情况下,停止条件由模型决定,该模型应学会在何时输出一个结束序列(`EOS`)标记。如果不是这种情况,生成将在达到某个预定义的最大长度时停止。
|
||||
|
||||
正确设置`token`选择步骤和停止条件对于让你的模型按照预期的方式执行任务至关重要。这就是为什么我们为每个模型都有一个[~generation.GenerationConfig]文件,它包含一个效果不错的默认生成参数配置,并与您模型一起加载。
|
||||
|
||||
让我们谈谈代码!
|
||||
|
||||
<Tip>
|
||||
|
||||
如果您对基本的LLM使用感兴趣,我们高级的[`Pipeline`](pipeline_tutorial)接口是一个很好的起点。然而,LLMs通常需要像`quantization`和`token选择步骤的精细控制`等高级功能,这最好通过[`~generation.GenerationMixin.generate`]来完成。使用LLM进行自回归生成也是资源密集型的操作,应该在GPU上执行以获得足够的吞吐量。
|
||||
|
||||
</Tip>
|
||||
|
||||
首先,您需要加载模型。
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForCausalLM
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(
|
||||
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
|
||||
... )
|
||||
```
|
||||
|
||||
您将会注意到在`from_pretrained`调用中的两个标志:
|
||||
|
||||
- `device_map`确保模型被移动到您的GPU(s)上
|
||||
- `load_in_4bit`应用[4位动态量化](main_classes/quantization)来极大地减少资源需求
|
||||
|
||||
还有其他方式来初始化一个模型,但这是一个开始使用LLM很好的起点。
|
||||
|
||||
接下来,你需要使用一个[tokenizer](tokenizer_summary)来预处理你的文本输入。
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
|
||||
>>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to(model.device)
|
||||
```
|
||||
|
||||
`model_inputs`变量保存着分词后的文本输入以及注意力掩码。尽管[`~generation.GenerationMixin.generate`]在未传递注意力掩码时会尽其所能推断出注意力掩码,但建议尽可能传递它以获得最佳结果。
|
||||
|
||||
在对输入进行分词后,可以调用[`~generation.GenerationMixin.generate`]方法来返回生成的`tokens`。生成的`tokens`应该在打印之前转换为文本。
|
||||
|
||||
```py
|
||||
>>> generated_ids = model.generate(**model_inputs)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
'A list of colors: red, blue, green, yellow, orange, purple, pink,'
|
||||
```
|
||||
|
||||
最后,您不需要一次处理一个序列!您可以批量输入,这将在小延迟和低内存成本下显著提高吞吐量。您只需要确保正确地填充您的输入(详见下文)。
|
||||
|
||||
```py
|
||||
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
|
||||
>>> model_inputs = tokenizer(
|
||||
... ["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True
|
||||
... ).to(model.device)
|
||||
>>> generated_ids = model.generate(**model_inputs)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
|
||||
['A list of colors: red, blue, green, yellow, orange, purple, pink,',
|
||||
'Portugal is a country in southwestern Europe, on the Iber']
|
||||
```
|
||||
|
||||
就是这样!在几行代码中,您就可以利用LLM的强大功能。
|
||||
|
||||
|
||||
## 常见陷阱
|
||||
|
||||
有许多[生成策略](generation_strategies),有时默认值可能不适合您的用例。如果您的输出与您期望的结果不匹配,我们已经创建了一个最常见的陷阱列表以及如何避免它们。
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
|
||||
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(
|
||||
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
|
||||
... )
|
||||
```
|
||||
|
||||
### 生成的输出太短/太长
|
||||
|
||||
如果在[`~generation.GenerationConfig`]文件中没有指定,`generate`默认返回20个tokens。我们强烈建议在您的`generate`调用中手动设置`max_new_tokens`以控制它可以返回的最大新tokens数量。请注意,LLMs(更准确地说,仅[解码器模型](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt))也将输入提示作为输出的一部分返回。
|
||||
|
||||
```py
|
||||
>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to(model.device)
|
||||
|
||||
>>> # By default, the output will contain up to 20 tokens
|
||||
>>> generated_ids = model.generate(**model_inputs)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
'A sequence of numbers: 1, 2, 3, 4, 5'
|
||||
|
||||
>>> # Setting `max_new_tokens` allows you to control the maximum length
|
||||
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=50)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
|
||||
```
|
||||
|
||||
### 错误的生成模式
|
||||
|
||||
默认情况下,除非在[`~generation.GenerationConfig`]文件中指定,否则`generate`会在每个迭代中选择最可能的token(贪婪解码)。对于您的任务,这可能是不理想的;像聊天机器人或写作文章这样的创造性任务受益于采样。另一方面,像音频转录或翻译这样的基于输入的任务受益于贪婪解码。通过将`do_sample=True`启用采样,您可以在这篇[博客文章](https://huggingface.co/blog/how-to-generate)中了解更多关于这个话题的信息。
|
||||
|
||||
```py
|
||||
>>> # Set seed or reproducibility -- you don't need this unless you want full reproducibility
|
||||
>>> from transformers import set_seed
|
||||
>>> set_seed(42)
|
||||
|
||||
>>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to(model.device)
|
||||
|
||||
>>> # LLM + greedy decoding = repetitive, boring output
|
||||
>>> generated_ids = model.generate(**model_inputs)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
'I am a cat. I am a cat. I am a cat. I am a cat'
|
||||
|
||||
>>> # With sampling, the output becomes more creative!
|
||||
>>> generated_ids = model.generate(**model_inputs, do_sample=True)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
'I am a cat. Specifically, I am an indoor-only cat. I'
|
||||
```
|
||||
|
||||
### 错误的填充位置
|
||||
|
||||
LLMs是[仅解码器](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt)架构,意味着它们会持续迭代您的输入提示。如果您的输入长度不相同,则需要对它们进行填充。由于LLMs没有接受过从`pad tokens`继续训练,因此您的输入需要左填充。确保在生成时不要忘记传递注意力掩码!
|
||||
|
||||
```py
|
||||
>>> # The tokenizer initialized above has right-padding active by default: the 1st sequence,
|
||||
>>> # which is shorter, has padding on the right side. Generation fails to capture the logic.
|
||||
>>> model_inputs = tokenizer(
|
||||
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
|
||||
... ).to(model.device)
|
||||
>>> generated_ids = model.generate(**model_inputs)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
'1, 2, 33333333333'
|
||||
|
||||
>>> # With left-padding, it works as expected!
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
|
||||
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
|
||||
>>> model_inputs = tokenizer(
|
||||
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
|
||||
... ).to(model.device)
|
||||
>>> generated_ids = model.generate(**model_inputs)
|
||||
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
'1, 2, 3, 4, 5, 6,'
|
||||
```
|
||||
|
||||
### 错误的提示
|
||||
|
||||
一些模型和任务期望某种输入提示格式才能正常工作。当未应用此格式时,您将获得悄然的性能下降:模型能工作,但不如预期提示那样好。有关提示的更多信息,包括哪些模型和任务需要小心,可在[指南](tasks/prompting)中找到。让我们看一个使用[聊天模板](chat_templating)的聊天LLM示例:
|
||||
|
||||
```python
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(
|
||||
... "HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True
|
||||
... )
|
||||
>>> set_seed(0)
|
||||
>>> prompt = """How many helicopters can a human eat in one sitting? Reply as a thug."""
|
||||
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(model.device)
|
||||
>>> input_length = model_inputs.input_ids.shape[1]
|
||||
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=20)
|
||||
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
|
||||
"I'm not a thug, but i can tell you that a human cannot eat"
|
||||
>>> # Oh no, it did not follow our instruction to reply as a thug! Let's see what happens when we write
|
||||
>>> # a better prompt and use the right template for this model (through `tokenizer.apply_chat_template`)
|
||||
|
||||
>>> set_seed(0)
|
||||
>>> messages = [
|
||||
... {
|
||||
... "role": "system",
|
||||
... "content": "You are a friendly chatbot who always responds in the style of a thug",
|
||||
... },
|
||||
... {"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
|
||||
... ]
|
||||
>>> model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
|
||||
>>> input_length = model_inputs.shape[1]
|
||||
>>> generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=20)
|
||||
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
|
||||
'None, you thug. How bout you try to focus on more useful questions?'
|
||||
>>> # As we can see, it followed a proper thug style 😎
|
||||
```
|
||||
|
||||
## 更多资源
|
||||
|
||||
虽然自回归生成过程相对简单,但要充分利用LLM可能是一个具有挑战性的任务,因为很多组件复杂且密切关联。以下是帮助您深入了解LLM使用和理解的下一步:
|
||||
|
||||
### 高级生成用法
|
||||
|
||||
1. [指南](generation_strategies),介绍如何控制不同的生成方法、如何设置生成配置文件以及如何进行输出流式传输;
|
||||
2. [指南](chat_templating),介绍聊天LLMs的提示模板;
|
||||
3. [指南](tasks/prompting),介绍如何充分利用提示设计;
|
||||
4. API参考文档,包括[`~generation.GenerationConfig`]、[`~generation.GenerationMixin.generate`]和[与生成相关的类](internal/generation_utils)。
|
||||
|
||||
### LLM排行榜
|
||||
|
||||
1. [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), 侧重于开源模型的质量;
|
||||
2. [Open LLM-Perf Leaderboard](https://huggingface.co/spaces/optimum/llm-perf-leaderboard), 侧重于LLM的吞吐量.
|
||||
|
||||
### 延迟、吞吐量和内存利用率
|
||||
|
||||
1. [指南](llm_tutorial_optimization),如何优化LLMs以提高速度和内存利用;
|
||||
2. [指南](main_classes/quantization), 关于`quantization`,如bitsandbytes和autogptq的指南,教您如何大幅降低内存需求。
|
||||
|
||||
### 相关库
|
||||
|
||||
1. [`text-generation-inference`](https://github.com/huggingface/text-generation-inference), 一个面向生产的LLM服务器;
|
||||
2. [`optimum`](https://github.com/huggingface/optimum), 一个🤗 Transformers的扩展,优化特定硬件设备的性能
|
||||
129
transformers/docs/source/zh/main_classes/callback.md
Normal file
129
transformers/docs/source/zh/main_classes/callback.md
Normal file
@@ -0,0 +1,129 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Callbacks
|
||||
|
||||
|
||||
Callbacks可以用来自定义PyTorch [Trainer]中训练循环行为的对象(此功能尚未在TensorFlow中实现),该对象可以检查训练循环状态(用于进度报告、在TensorBoard或其他ML平台上记录日志等),并做出决策(例如提前停止)。
|
||||
|
||||
Callbacks是“只读”的代码片段,除了它们返回的[TrainerControl]对象外,它们不能更改训练循环中的任何内容。对于需要更改训练循环的自定义,您应该继承[Trainer]并重载您需要的方法(有关示例,请参见[trainer](trainer))。
|
||||
|
||||
默认情况下,`TrainingArguments.report_to` 设置为"all",然后[Trainer]将使用以下callbacks。
|
||||
|
||||
|
||||
- [`DefaultFlowCallback`],它处理默认的日志记录、保存和评估行为
|
||||
- [`PrinterCallback`] 或 [`ProgressCallback`],用于显示进度和打印日志(如果通过[`TrainingArguments`]停用tqdm,则使用第一个函数;否则使用第二个)。
|
||||
- [`~integrations.TensorBoardCallback`],如果TensorBoard可访问(通过PyTorch版本 >= 1.4 或者 tensorboardX)。
|
||||
- [`~integrations.WandbCallback`],如果安装了[wandb](https://www.wandb.com/)。
|
||||
- [`~integrations.CometCallback`],如果安装了[comet_ml](https://www.comet.com/site/)。
|
||||
- [`~integrations.MLflowCallback`],如果安装了[mlflow](https://www.mlflow.org/)。
|
||||
- [`~integrations.NeptuneCallback`],如果安装了[neptune](https://neptune.ai/)。
|
||||
- [`~integrations.AzureMLCallback`],如果安装了[azureml-sdk](https://pypi.org/project/azureml-sdk/)。
|
||||
- [`~integrations.CodeCarbonCallback`],如果安装了[codecarbon](https://pypi.org/project/codecarbon/)。
|
||||
- [`~integrations.ClearMLCallback`],如果安装了[clearml](https://github.com/allegroai/clearml)。
|
||||
- [`~integrations.DagsHubCallback`],如果安装了[dagshub](https://dagshub.com/)。
|
||||
- [`~integrations.FlyteCallback`],如果安装了[flyte](https://flyte.org/)。
|
||||
- [`~integrations.DVCLiveCallback`],如果安装了[dvclive](https://dvc.org/doc/dvclive)。
|
||||
- [`~integrations.SwanLabCallback`],如果安装了[swanlab](http://swanlab.cn/)。
|
||||
|
||||
如果安装了一个软件包,但您不希望使用相关的集成,您可以将 `TrainingArguments.report_to` 更改为仅包含您想要使用的集成的列表(例如 `["azure_ml", "wandb"]`)。
|
||||
|
||||
实现callbacks的主要类是[`TrainerCallback`]。它获取用于实例化[`Trainer`]的[`TrainingArguments`],可以通过[`TrainerState`]访问该Trainer的内部状态,并可以通过[`TrainerControl`]对训练循环执行一些操作。
|
||||
|
||||
|
||||
## 可用的Callbacks
|
||||
|
||||
这里是库里可用[`TrainerCallback`]的列表:
|
||||
|
||||
[[autodoc]] integrations.CometCallback
|
||||
- setup
|
||||
|
||||
[[autodoc]] DefaultFlowCallback
|
||||
|
||||
[[autodoc]] PrinterCallback
|
||||
|
||||
[[autodoc]] ProgressCallback
|
||||
|
||||
[[autodoc]] EarlyStoppingCallback
|
||||
|
||||
[[autodoc]] integrations.TensorBoardCallback
|
||||
|
||||
[[autodoc]] integrations.WandbCallback
|
||||
- setup
|
||||
|
||||
[[autodoc]] integrations.MLflowCallback
|
||||
- setup
|
||||
|
||||
[[autodoc]] integrations.AzureMLCallback
|
||||
|
||||
[[autodoc]] integrations.CodeCarbonCallback
|
||||
|
||||
[[autodoc]] integrations.NeptuneCallback
|
||||
|
||||
[[autodoc]] integrations.ClearMLCallback
|
||||
|
||||
[[autodoc]] integrations.DagsHubCallback
|
||||
|
||||
[[autodoc]] integrations.FlyteCallback
|
||||
|
||||
[[autodoc]] integrations.DVCLiveCallback
|
||||
- setup
|
||||
|
||||
[[autodoc]] integrations.SwanLabCallback
|
||||
- setup
|
||||
|
||||
## TrainerCallback
|
||||
|
||||
[[autodoc]] TrainerCallback
|
||||
|
||||
以下是如何使用PyTorch注册自定义callback的示例:
|
||||
|
||||
[`Trainer`]:
|
||||
|
||||
```python
|
||||
class MyCallback(TrainerCallback):
|
||||
"A callback that prints a message at the beginning of training"
|
||||
|
||||
def on_train_begin(self, args, state, control, **kwargs):
|
||||
print("Starting training")
|
||||
|
||||
|
||||
trainer = Trainer(
|
||||
model,
|
||||
args,
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
callbacks=[MyCallback], # We can either pass the callback class this way or an instance of it (MyCallback())
|
||||
)
|
||||
```
|
||||
|
||||
注册callback的另一种方式是调用 `trainer.add_callback()`,如下所示:
|
||||
|
||||
|
||||
```python
|
||||
trainer = Trainer(...)
|
||||
trainer.add_callback(MyCallback)
|
||||
# Alternatively, we can pass an instance of the callback class
|
||||
trainer.add_callback(MyCallback())
|
||||
```
|
||||
|
||||
## TrainerState
|
||||
|
||||
[[autodoc]] TrainerState
|
||||
|
||||
## TrainerControl
|
||||
|
||||
[[autodoc]] TrainerControl
|
||||
28
transformers/docs/source/zh/main_classes/configuration.md
Normal file
28
transformers/docs/source/zh/main_classes/configuration.md
Normal file
@@ -0,0 +1,28 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Configuration
|
||||
|
||||
基类[`PretrainedConfig`]实现了从本地文件或目录加载/保存配置的常见方法,或下载库提供的预训练模型配置(从HuggingFace的AWS S3库中下载)。
|
||||
|
||||
每个派生的配置类都实现了特定于模型的属性。所有配置类中共同存在的属性有:`hidden_size`、`num_attention_heads` 和 `num_hidden_layers`。文本模型进一步添加了 `vocab_size`。
|
||||
|
||||
|
||||
## PretrainedConfig
|
||||
|
||||
[[autodoc]] PretrainedConfig
|
||||
- push_to_hub
|
||||
- all
|
||||
62
transformers/docs/source/zh/main_classes/data_collator.md
Normal file
62
transformers/docs/source/zh/main_classes/data_collator.md
Normal file
@@ -0,0 +1,62 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Data Collator
|
||||
|
||||
Data collators是一个对象,通过使用数据集元素列表作为输入来形成一个批次。这些元素与 `train_dataset` 或 `eval_dataset` 的元素类型相同。
|
||||
|
||||
为了能够构建批次,Data collators可能会应用一些预处理(比如填充)。其中一些(比如[`DataCollatorForLanguageModeling`])还会在形成的批次上应用一些随机数据增强(比如随机掩码)。
|
||||
|
||||
在[示例脚本](../examples)或[示例notebooks](../notebooks)中可以找到使用的示例。
|
||||
|
||||
|
||||
## Default data collator
|
||||
|
||||
[[autodoc]] data.data_collator.default_data_collator
|
||||
|
||||
## DefaultDataCollator
|
||||
|
||||
[[autodoc]] data.data_collator.DefaultDataCollator
|
||||
|
||||
## DataCollatorWithPadding
|
||||
|
||||
[[autodoc]] data.data_collator.DataCollatorWithPadding
|
||||
|
||||
## DataCollatorForTokenClassification
|
||||
|
||||
[[autodoc]] data.data_collator.DataCollatorForTokenClassification
|
||||
|
||||
## DataCollatorForSeq2Seq
|
||||
|
||||
[[autodoc]] data.data_collator.DataCollatorForSeq2Seq
|
||||
|
||||
## DataCollatorForLanguageModeling
|
||||
|
||||
[[autodoc]] data.data_collator.DataCollatorForLanguageModeling
|
||||
- numpy_mask_tokens
|
||||
- torch_mask_tokens
|
||||
|
||||
## DataCollatorForWholeWordMask
|
||||
|
||||
[[autodoc]] data.data_collator.DataCollatorForWholeWordMask
|
||||
- numpy_mask_tokens
|
||||
- torch_mask_tokens
|
||||
|
||||
## DataCollatorForPermutationLanguageModeling
|
||||
|
||||
[[autodoc]] data.data_collator.DataCollatorForPermutationLanguageModeling
|
||||
- numpy_mask_tokens
|
||||
- torch_mask_tokens
|
||||
2100
transformers/docs/source/zh/main_classes/deepspeed.md
Normal file
2100
transformers/docs/source/zh/main_classes/deepspeed.md
Normal file
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,39 @@
|
||||
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Feature Extractor
|
||||
|
||||
Feature Extractor负责为音频或视觉模型准备输入特征。这包括从序列中提取特征,例如,对音频文件进行预处理以生成Log-Mel频谱特征,以及从图像中提取特征,例如,裁剪图像文件,同时还包括填充、归一化和转换为NumPy、PyTorch和TensorFlow张量。
|
||||
|
||||
|
||||
## FeatureExtractionMixin
|
||||
|
||||
[[autodoc]] feature_extraction_utils.FeatureExtractionMixin
|
||||
- from_pretrained
|
||||
- save_pretrained
|
||||
|
||||
## SequenceFeatureExtractor
|
||||
|
||||
[[autodoc]] SequenceFeatureExtractor
|
||||
- pad
|
||||
|
||||
## BatchFeature
|
||||
|
||||
[[autodoc]] BatchFeature
|
||||
|
||||
## ImageFeatureExtractionMixin
|
||||
|
||||
[[autodoc]] image_utils.ImageFeatureExtractionMixin
|
||||
34
transformers/docs/source/zh/main_classes/image_processor.md
Normal file
34
transformers/docs/source/zh/main_classes/image_processor.md
Normal file
@@ -0,0 +1,34 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Image Processor
|
||||
|
||||
Image processor负责为视觉模型准备输入特征并后期处理处理它们的输出。这包括诸如调整大小、归一化和转换为PyTorch和NumPy张量等转换。它还可能包括特定于模型的后期处理,例如将logits转换为分割掩码。
|
||||
|
||||
|
||||
## ImageProcessingMixin
|
||||
|
||||
[[autodoc]] image_processing_utils.ImageProcessingMixin
|
||||
- from_pretrained
|
||||
- save_pretrained
|
||||
|
||||
## BatchFeature
|
||||
|
||||
[[autodoc]] BatchFeature
|
||||
|
||||
## BaseImageProcessor
|
||||
|
||||
[[autodoc]] image_processing_utils.BaseImageProcessor
|
||||
107
transformers/docs/source/zh/main_classes/logging.md
Normal file
107
transformers/docs/source/zh/main_classes/logging.md
Normal file
@@ -0,0 +1,107 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Logging
|
||||
|
||||
🤗 Transformers拥有一个集中式的日志系统,因此您可以轻松设置库输出的日志详细程度。
|
||||
|
||||
当前库的默认日志详细程度为`WARNING`。
|
||||
|
||||
要更改日志详细程度,只需使用其中一个直接的setter。例如,以下是如何将日志详细程度更改为INFO级别的方法:
|
||||
|
||||
```python
|
||||
import transformers
|
||||
|
||||
transformers.logging.set_verbosity_info()
|
||||
```
|
||||
|
||||
您还可以使用环境变量`TRANSFORMERS_VERBOSITY`来覆盖默认的日志详细程度。您可以将其设置为以下级别之一:`debug`、`info`、`warning`、`error`、`critical`。例如:
|
||||
|
||||
```bash
|
||||
TRANSFORMERS_VERBOSITY=error ./myprogram.py
|
||||
```
|
||||
|
||||
此外,通过将环境变量`TRANSFORMERS_NO_ADVISORY_WARNINGS`设置为`true`(如*1*),可以禁用一些`warnings`。这将禁用[`logger.warning_advice`]记录的任何警告。例如:
|
||||
|
||||
```bash
|
||||
TRANSFORMERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
|
||||
```
|
||||
|
||||
以下是如何在您自己的模块或脚本中使用与库相同的logger的示例:
|
||||
|
||||
```python
|
||||
from transformers.utils import logging
|
||||
|
||||
logging.set_verbosity_info()
|
||||
logger = logging.get_logger("transformers")
|
||||
logger.info("INFO")
|
||||
logger.warning("WARN")
|
||||
```
|
||||
|
||||
|
||||
此日志模块的所有方法都在下面进行了记录,主要的方法包括 [`logging.get_verbosity`] 用于获取logger当前输出日志详细程度的级别和 [`logging.set_verbosity`] 用于将详细程度设置为您选择的级别。按照顺序(从最不详细到最详细),这些级别(及其相应的整数值)为:
|
||||
|
||||
- `transformers.logging.CRITICAL` 或 `transformers.logging.FATAL`(整数值,50):仅报告最关键的errors。
|
||||
- `transformers.logging.ERROR`(整数值,40):仅报告errors。
|
||||
- `transformers.logging.WARNING` 或 `transformers.logging.WARN`(整数值,30):仅报告error和warnings。这是库使用的默认级别。
|
||||
- `transformers.logging.INFO`(整数值,20):报告error、warnings和基本信息。
|
||||
- `transformers.logging.DEBUG`(整数值,10):报告所有信息。
|
||||
|
||||
默认情况下,将在模型下载期间显示`tqdm`进度条。[`logging.disable_progress_bar`] 和 [`logging.enable_progress_bar`] 可用于禁止或启用此行为。
|
||||
|
||||
## `logging` vs `warnings`
|
||||
|
||||
Python有两个经常一起使用的日志系统:如上所述的`logging`,和对特定buckets中的警告进行进一步分类的`warnings`,例如,`FutureWarning`用于输出已经被弃用的功能或路径,`DeprecationWarning`用于指示即将被弃用的内容。
|
||||
|
||||
我们在`transformers`库中同时使用这两个系统。我们利用并调整了`logging`的`captureWarning`方法,以便通过上面的详细程度setters来管理这些警告消息。
|
||||
|
||||
对于库的开发人员,这意味着什么呢?我们应该遵循以下启发法则:
|
||||
- 库的开发人员和依赖于`transformers`的库应优先使用`warnings`
|
||||
- `logging`应该用于在日常项目中经常使用它的用户
|
||||
|
||||
以下是`captureWarnings`方法的参考。
|
||||
|
||||
[[autodoc]] logging.captureWarnings
|
||||
|
||||
## Base setters
|
||||
|
||||
[[autodoc]] logging.set_verbosity_error
|
||||
|
||||
[[autodoc]] logging.set_verbosity_warning
|
||||
|
||||
[[autodoc]] logging.set_verbosity_info
|
||||
|
||||
[[autodoc]] logging.set_verbosity_debug
|
||||
|
||||
## Other functions
|
||||
|
||||
[[autodoc]] logging.get_verbosity
|
||||
|
||||
[[autodoc]] logging.set_verbosity
|
||||
|
||||
[[autodoc]] logging.get_logger
|
||||
|
||||
[[autodoc]] logging.enable_default_handler
|
||||
|
||||
[[autodoc]] logging.disable_default_handler
|
||||
|
||||
[[autodoc]] logging.enable_explicit_format
|
||||
|
||||
[[autodoc]] logging.reset_format
|
||||
|
||||
[[autodoc]] logging.enable_progress_bar
|
||||
|
||||
[[autodoc]] logging.disable_progress_bar
|
||||
114
transformers/docs/source/zh/main_classes/model.md
Normal file
114
transformers/docs/source/zh/main_classes/model.md
Normal file
@@ -0,0 +1,114 @@
|
||||
<!--版权所有 2020 年 HuggingFace 团队。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版本许可,除非符合许可证的规定,否则您不得使用此文件。您可以在以下网址获取许可证的副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,否则依照许可证分发的软件是基于“原样”提供的,不附带任何明示或暗示的担保或条件。有关特定语言下权限的限制和限制,请参阅许可证。-->
|
||||
|
||||
# 模型
|
||||
|
||||
基类 [`PreTrainedModel`] 实现了从本地文件或目录加载/保存模型的常用方法,或者从库上提供的预训练模型配置(从 HuggingFace 的 AWS S3 存储库下载)加载模型。
|
||||
|
||||
[`PreTrainedModel`] 和 [`TFPreTrainedModel`] 还实现了一些所有模型共有的方法:
|
||||
|
||||
- 在向量词嵌入增加新词汇时调整输入标记(token)的大小
|
||||
- 对模型的注意力头进行修剪。
|
||||
|
||||
其他的通用方法在 [`~modeling_utils.ModuleUtilsMixin`](用于 PyTorch 模型)中定义;文本生成方面的方法则定义在 [`~generation.GenerationMixin`](用于 PyTorch 模型)中。
|
||||
|
||||
## PreTrainedModel
|
||||
|
||||
[[autodoc]] PreTrainedModel
|
||||
- push_to_hub
|
||||
- all
|
||||
|
||||
<a id='from_pretrained-torch-dtype'></a>
|
||||
|
||||
### 大模型加载
|
||||
|
||||
在 Transformers 4.20.0 中,[`~PreTrainedModel.from_pretrained`] 方法已重新设计,以适应使用 [Accelerate](https://huggingface.co/docs/accelerate/big_modeling) 加载大型模型的场景。这需要您使用的 Accelerate 和 PyTorch 版本满足: Accelerate >= 0.9.0, PyTorch >= 1.9.0。除了创建完整模型,然后在其中加载预训练权重(这会占用两倍于模型大小的内存空间,一个用于随机初始化模型,一个用于预训练权重),我们提供了一种选项,将模型创建为空壳,然后只有在加载预训练权重时才实例化其参数。
|
||||
|
||||
此外,如果内存不足以放下加载整个模型(目前仅适用于推理),您可以直接将模型放置在不同的设备上。使用 `device_map="auto"`,Accelerate 将确定将每一层放置在哪个设备上,以最大化使用最快的设备(GPU),并将其余部分卸载到 CPU,甚至硬盘上(如果您没有足够的 GPU 内存 或 CPU 内存)。即使模型分布在几个设备上,它也将像您通常期望的那样运行。
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForSeq2SeqLM
|
||||
|
||||
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", device_map="auto")
|
||||
```
|
||||
|
||||
您可以通过 `hf_device_map` 属性来查看模型是如何在设备上分割的:
|
||||
|
||||
```python
|
||||
t0pp.hf_device_map
|
||||
{'shared': 0,
|
||||
'decoder.embed_tokens': 0,
|
||||
'encoder': 0,
|
||||
'decoder.block.0': 0,
|
||||
'decoder.block.1': 1,
|
||||
'decoder.block.2': 1,
|
||||
'decoder.block.3': 1,
|
||||
'decoder.block.4': 1,
|
||||
'decoder.block.5': 1,
|
||||
'decoder.block.6': 1,
|
||||
'decoder.block.7': 1,
|
||||
'decoder.block.8': 1,
|
||||
'decoder.block.9': 1,
|
||||
'decoder.block.10': 1,
|
||||
'decoder.block.11': 1,
|
||||
'decoder.block.12': 1,
|
||||
'decoder.block.13': 1,
|
||||
'decoder.block.14': 1,
|
||||
'decoder.block.15': 1,
|
||||
'decoder.block.16': 1,
|
||||
'decoder.block.17': 1,
|
||||
'decoder.block.18': 1,
|
||||
'decoder.block.19': 1,
|
||||
'decoder.block.20': 1,
|
||||
'decoder.block.21': 1,
|
||||
'decoder.block.22': 'cpu',
|
||||
'decoder.block.23': 'cpu',
|
||||
'decoder.final_layer_norm': 'cpu',
|
||||
'decoder.dropout': 'cpu',
|
||||
'lm_head': 'cpu'}
|
||||
```
|
||||
|
||||
您还可以按照相同的格式(一个层名称到设备的映射关系的字典)编写自己的设备映射规则。它应该将模型的所有参数映射到给定的设备上,如果该层的所有子模块都在同一设备上,您不必详细说明其中所有子模块的位置。例如,以下设备映射对于 T0pp 将正常工作(只要您有 GPU 内存):
|
||||
|
||||
```python
|
||||
device_map = {"shared": 0, "encoder": 0, "decoder": 1, "lm_head": 1}
|
||||
```
|
||||
|
||||
另一种减少模型内存影响的方法是以较低精度的 dtype(例如 `torch.float16`)实例化它,或者使用下面介绍的直接量化技术。
|
||||
|
||||
### 模型实例化 dtype
|
||||
|
||||
在 PyTorch 下,模型通常以 `torch.float32` 格式实例化。如果尝试加载权重为 fp16 的模型,这可能会导致问题,因为它将需要两倍的内存。为了克服此限制,您可以使用 `dtype` 参数显式传递所需的 `dtype`:
|
||||
|
||||
```python
|
||||
model = T5ForConditionalGeneration.from_pretrained("t5", dtype=torch.float16)
|
||||
```
|
||||
或者,如果您希望模型始终以最优的内存模式加载,则可以使用特殊值 `"auto"`,然后 `dtype` 将自动从模型的权重中推导出:
|
||||
```python
|
||||
model = T5ForConditionalGeneration.from_pretrained("t5", dtype="auto")
|
||||
```
|
||||
|
||||
也可以通过以下方式告知从头开始实例化的模型要使用哪种 `dtype`:
|
||||
|
||||
```python
|
||||
config = T5Config.from_pretrained("t5")
|
||||
model = AutoModel.from_config(config)
|
||||
```
|
||||
|
||||
由于 PyTorch 的设计,此功能仅适用于浮点类型。
|
||||
|
||||
|
||||
## ModuleUtilsMixin
|
||||
|
||||
[[autodoc]] modeling_utils.ModuleUtilsMixin
|
||||
|
||||
## 推送到 Hub
|
||||
[[autodoc]] utils.PushToHubMixin
|
||||
|
||||
## 分片检查点
|
||||
[[autodoc]] modeling_utils.load_sharded_checkpoint
|
||||
50
transformers/docs/source/zh/main_classes/onnx.md
Normal file
50
transformers/docs/source/zh/main_classes/onnx.md
Normal file
@@ -0,0 +1,50 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 导出 🤗 Transformers 模型到 ONNX
|
||||
|
||||
🤗 Transformers提供了一个`transformers.onnx`包,通过利用配置对象,您可以将模型checkpoints转换为ONNX图。
|
||||
|
||||
有关更多详细信息,请参阅导出 🤗 Transformers 模型的[指南](../serialization)。
|
||||
|
||||
## ONNX Configurations
|
||||
|
||||
我们提供了三个抽象类,取决于您希望导出的模型架构类型:
|
||||
|
||||
* 基于编码器的模型继承 [`~onnx.config.OnnxConfig`]
|
||||
* 基于解码器的模型继承 [`~onnx.config.OnnxConfigWithPast`]
|
||||
* 编码器-解码器模型继承 [`~onnx.config.OnnxSeq2SeqConfigWithPast`]
|
||||
|
||||
### OnnxConfig
|
||||
|
||||
[[autodoc]] onnx.config.OnnxConfig
|
||||
|
||||
### OnnxConfigWithPast
|
||||
|
||||
[[autodoc]] onnx.config.OnnxConfigWithPast
|
||||
|
||||
### OnnxSeq2SeqConfigWithPast
|
||||
|
||||
[[autodoc]] onnx.config.OnnxSeq2SeqConfigWithPast
|
||||
|
||||
## ONNX Features
|
||||
|
||||
每个ONNX配置与一组 _特性_ 相关联,使您能够为不同类型的拓扑结构或任务导出模型。
|
||||
|
||||
### FeaturesManager
|
||||
|
||||
[[autodoc]] onnx.features.FeaturesManager
|
||||
|
||||
@@ -0,0 +1,57 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Optimization
|
||||
|
||||
`.optimization` 模块提供了:
|
||||
|
||||
- 一个带有固定权重衰减的优化器,可用于微调模型
|
||||
- 继承自 `_LRSchedule` 多个调度器:
|
||||
- 一个梯度累积类,用于累积多个批次的梯度
|
||||
|
||||
## AdaFactor (PyTorch)
|
||||
|
||||
[[autodoc]] Adafactor
|
||||
|
||||
## Schedules
|
||||
|
||||
### Learning Rate Schedules (Pytorch)
|
||||
|
||||
[[autodoc]] SchedulerType
|
||||
|
||||
[[autodoc]] get_scheduler
|
||||
|
||||
[[autodoc]] get_constant_schedule
|
||||
|
||||
[[autodoc]] get_constant_schedule_with_warmup
|
||||
|
||||
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_constant_schedule.png"/>
|
||||
|
||||
[[autodoc]] get_cosine_schedule_with_warmup
|
||||
|
||||
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_schedule.png"/>
|
||||
|
||||
[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
|
||||
|
||||
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_hard_restarts_schedule.png"/>
|
||||
|
||||
[[autodoc]] get_linear_schedule_with_warmup
|
||||
|
||||
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_linear_schedule.png"/>
|
||||
|
||||
[[autodoc]] get_polynomial_decay_schedule_with_warmup
|
||||
|
||||
[[autodoc]] get_inverse_sqrt_schedule
|
||||
177
transformers/docs/source/zh/main_classes/output.md
Normal file
177
transformers/docs/source/zh/main_classes/output.md
Normal file
@@ -0,0 +1,177 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 模型输出
|
||||
|
||||
所有模型的输出都是 [`~utils.ModelOutput`] 的子类的实例。这些是包含模型返回的所有信息的数据结构,但也可以用作元组或字典。
|
||||
|
||||
让我们看一个例子:
|
||||
|
||||
```python
|
||||
from transformers import BertTokenizer, BertForSequenceClassification
|
||||
import torch
|
||||
|
||||
tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
|
||||
model = BertForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
|
||||
|
||||
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
|
||||
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
|
||||
outputs = model(**inputs, labels=labels)
|
||||
```
|
||||
|
||||
`outputs` 对象是 [`~modeling_outputs.SequenceClassifierOutput`],如下面该类的文档中所示,它表示它有一个可选的 `loss`,一个 `logits`,一个可选的 `hidden_states` 和一个可选的 `attentions` 属性。在这里,我们有 `loss`,因为我们传递了 `labels`,但我们没有 `hidden_states` 和 `attentions`,因为我们没有传递 `output_hidden_states=True` 或 `output_attentions=True`。
|
||||
|
||||
<Tip>
|
||||
|
||||
当传递 `output_hidden_states=True` 时,您可能希望 `outputs.hidden_states[-1]` 与 `outputs.last_hidden_states` 完全匹配。然而,这并不总是成立。一些模型在返回最后的 hidden state时对其应用归一化或其他后续处理。
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
您可以像往常一样访问每个属性,如果模型未返回该属性,您将得到 `None`。在这里,例如,`outputs.loss` 是模型计算的损失,而 `outputs.attentions` 是 `None`。
|
||||
|
||||
当将我们的 `outputs` 对象视为元组时,它仅考虑那些没有 `None` 值的属性。例如这里它有两个元素,`loss` 和 `logits`,所以
|
||||
|
||||
```python
|
||||
outputs[:2]
|
||||
```
|
||||
|
||||
将返回元组 `(outputs.loss, outputs.logits)`。
|
||||
|
||||
将我们的 `outputs` 对象视为字典时,它仅考虑那些没有 `None` 值的属性。例如在这里它有两个键,分别是 `loss` 和 `logits`。
|
||||
|
||||
我们在这里记录了被多个类型模型使用的通用模型输出。特定输出类型在其相应的模型页面上有文档。
|
||||
|
||||
## ModelOutput
|
||||
|
||||
[[autodoc]] utils.ModelOutput
|
||||
- to_tuple
|
||||
|
||||
## BaseModelOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.BaseModelOutput
|
||||
|
||||
## BaseModelOutputWithPooling
|
||||
|
||||
[[autodoc]] modeling_outputs.BaseModelOutputWithPooling
|
||||
|
||||
## BaseModelOutputWithCrossAttentions
|
||||
|
||||
[[autodoc]] modeling_outputs.BaseModelOutputWithCrossAttentions
|
||||
|
||||
## BaseModelOutputWithPoolingAndCrossAttentions
|
||||
|
||||
[[autodoc]] modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
|
||||
|
||||
## BaseModelOutputWithPast
|
||||
|
||||
[[autodoc]] modeling_outputs.BaseModelOutputWithPast
|
||||
|
||||
## BaseModelOutputWithPastAndCrossAttentions
|
||||
|
||||
[[autodoc]] modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
|
||||
|
||||
## Seq2SeqModelOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.Seq2SeqModelOutput
|
||||
|
||||
## CausalLMOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.CausalLMOutput
|
||||
|
||||
## CausalLMOutputWithCrossAttentions
|
||||
|
||||
[[autodoc]] modeling_outputs.CausalLMOutputWithCrossAttentions
|
||||
|
||||
## CausalLMOutputWithPast
|
||||
|
||||
[[autodoc]] modeling_outputs.CausalLMOutputWithPast
|
||||
|
||||
## MaskedLMOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.MaskedLMOutput
|
||||
|
||||
## Seq2SeqLMOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.Seq2SeqLMOutput
|
||||
|
||||
## NextSentencePredictorOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.NextSentencePredictorOutput
|
||||
|
||||
## SequenceClassifierOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.SequenceClassifierOutput
|
||||
|
||||
## Seq2SeqSequenceClassifierOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.Seq2SeqSequenceClassifierOutput
|
||||
|
||||
## MultipleChoiceModelOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.MultipleChoiceModelOutput
|
||||
|
||||
## TokenClassifierOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.TokenClassifierOutput
|
||||
|
||||
## QuestionAnsweringModelOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.QuestionAnsweringModelOutput
|
||||
|
||||
## Seq2SeqQuestionAnsweringModelOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
|
||||
|
||||
## Seq2SeqSpectrogramOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.Seq2SeqSpectrogramOutput
|
||||
|
||||
## SemanticSegmenterOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.SemanticSegmenterOutput
|
||||
|
||||
## ImageClassifierOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.ImageClassifierOutput
|
||||
|
||||
## ImageClassifierOutputWithNoAttention
|
||||
|
||||
[[autodoc]] modeling_outputs.ImageClassifierOutputWithNoAttention
|
||||
|
||||
## DepthEstimatorOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.DepthEstimatorOutput
|
||||
|
||||
## Wav2Vec2BaseModelOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.Wav2Vec2BaseModelOutput
|
||||
|
||||
## XVectorOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.XVectorOutput
|
||||
|
||||
## Seq2SeqTSModelOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.Seq2SeqTSModelOutput
|
||||
|
||||
## Seq2SeqTSPredictionOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.Seq2SeqTSPredictionOutput
|
||||
|
||||
## SampleTSPredictionOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.SampleTSPredictionOutput
|
||||
478
transformers/docs/source/zh/main_classes/pipelines.md
Normal file
478
transformers/docs/source/zh/main_classes/pipelines.md
Normal file
@@ -0,0 +1,478 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Pipelines
|
||||
|
||||
pipelines是使用模型进行推理的一种简单方法。这些pipelines是抽象了库中大部分复杂代码的对象,提供了一个专用于多个任务的简单API,包括专名识别、掩码语言建模、情感分析、特征提取和问答等。请参阅[任务摘要](../task_summary)以获取使用示例。
|
||||
|
||||
有两种pipelines抽象类需要注意:
|
||||
|
||||
- [`pipeline`],它是封装所有其他pipelines的最强大的对象。
|
||||
- 针对特定任务pipelines,适用于[音频](#audio)、[计算机视觉](#computer-vision)、[自然语言处理](#natural-language-processing)和[多模态](#multimodal)任务。
|
||||
|
||||
## pipeline抽象类
|
||||
|
||||
*pipeline*抽象类是对所有其他可用pipeline的封装。它可以像任何其他pipeline一样实例化,但进一步提供额外的便利性。
|
||||
|
||||
简单调用一个项目:
|
||||
|
||||
|
||||
```python
|
||||
>>> pipe = pipeline("text-classification")
|
||||
>>> pipe("This restaurant is awesome")
|
||||
[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
|
||||
```
|
||||
|
||||
如果您想使用 [hub](https://huggingface.co) 上的特定模型,可以忽略任务,如果hub上的模型已经定义了该任务:
|
||||
|
||||
```python
|
||||
>>> pipe = pipeline(model="FacebookAI/roberta-large-mnli")
|
||||
>>> pipe("This restaurant is awesome")
|
||||
[{'label': 'NEUTRAL', 'score': 0.7313136458396912}]
|
||||
```
|
||||
|
||||
要在多个项目上调用pipeline,可以使用*列表*调用它。
|
||||
|
||||
```python
|
||||
>>> pipe = pipeline("text-classification")
|
||||
>>> pipe(["This restaurant is awesome", "This restaurant is awful"])
|
||||
[{'label': 'POSITIVE', 'score': 0.9998743534088135},
|
||||
{'label': 'NEGATIVE', 'score': 0.9996669292449951}]
|
||||
```
|
||||
|
||||
为了遍历整个数据集,建议直接使用 `dataset`。这意味着您不需要一次性分配整个数据集,也不需要自己进行批处理。这应该与GPU上的自定义循环一样快。如果不是,请随时提出issue。
|
||||
|
||||
```python
|
||||
import datasets
|
||||
from transformers import pipeline
|
||||
from transformers.pipelines.pt_utils import KeyDataset
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", device=0)
|
||||
dataset = datasets.load_dataset("superb", name="asr", split="test")
|
||||
|
||||
# KeyDataset (only *pt*) will simply return the item in the dict returned by the dataset item
|
||||
# as we're not interested in the *target* part of the dataset. For sentence pair use KeyPairDataset
|
||||
for out in tqdm(pipe(KeyDataset(dataset, "file"))):
|
||||
print(out)
|
||||
# {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
|
||||
# {"text": ....}
|
||||
# ....
|
||||
```
|
||||
|
||||
为了方便使用,也可以使用生成器:
|
||||
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
pipe = pipeline("text-classification")
|
||||
|
||||
|
||||
def data():
|
||||
while True:
|
||||
# This could come from a dataset, a database, a queue or HTTP request
|
||||
# in a server
|
||||
# Caveat: because this is iterative, you cannot use `num_workers > 1` variable
|
||||
# to use multiple threads to preprocess data. You can still have 1 thread that
|
||||
# does the preprocessing while the main runs the big inference
|
||||
yield "This is a test"
|
||||
|
||||
|
||||
for out in pipe(data()):
|
||||
print(out)
|
||||
# {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
|
||||
# {"text": ....}
|
||||
# ....
|
||||
```
|
||||
|
||||
[[autodoc]] pipeline
|
||||
|
||||
## Pipeline batching
|
||||
|
||||
所有pipeline都可以使用批处理。这将在pipeline使用其流处理功能时起作用(即传递列表或 `Dataset` 或 `generator` 时)。
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
from transformers.pipelines.pt_utils import KeyDataset
|
||||
import datasets
|
||||
|
||||
dataset = datasets.load_dataset("imdb", name="plain_text", split="unsupervised")
|
||||
pipe = pipeline("text-classification", device=0)
|
||||
for out in pipe(KeyDataset(dataset, "text"), batch_size=8, truncation="only_first"):
|
||||
print(out)
|
||||
# [{'label': 'POSITIVE', 'score': 0.9998743534088135}]
|
||||
# Exactly the same output as before, but the content are passed
|
||||
# as batches to the model
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
然而,这并不自动意味着性能提升。它可能是一个10倍的加速或5倍的减速,具体取决于硬件、数据和实际使用的模型。
|
||||
|
||||
主要是加速的示例:
|
||||
|
||||
</Tip>
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
from torch.utils.data import Dataset
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
pipe = pipeline("text-classification", device=0)
|
||||
|
||||
|
||||
class MyDataset(Dataset):
|
||||
def __len__(self):
|
||||
return 5000
|
||||
|
||||
def __getitem__(self, i):
|
||||
return "This is a test"
|
||||
|
||||
|
||||
dataset = MyDataset()
|
||||
|
||||
for batch_size in [1, 8, 64, 256]:
|
||||
print("-" * 30)
|
||||
print(f"Streaming batch_size={batch_size}")
|
||||
for out in tqdm(pipe(dataset, batch_size=batch_size), total=len(dataset)):
|
||||
pass
|
||||
```
|
||||
|
||||
```
|
||||
# On GTX 970
|
||||
------------------------------
|
||||
Streaming no batching
|
||||
100%|██████████████████████████████████████████████████████████████████████| 5000/5000 [00:26<00:00, 187.52it/s]
|
||||
------------------------------
|
||||
Streaming batch_size=8
|
||||
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:04<00:00, 1205.95it/s]
|
||||
------------------------------
|
||||
Streaming batch_size=64
|
||||
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:02<00:00, 2478.24it/s]
|
||||
------------------------------
|
||||
Streaming batch_size=256
|
||||
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:01<00:00, 2554.43it/s]
|
||||
(diminishing returns, saturated the GPU)
|
||||
```
|
||||
|
||||
主要是减速的示例:
|
||||
|
||||
```python
|
||||
class MyDataset(Dataset):
|
||||
def __len__(self):
|
||||
return 5000
|
||||
|
||||
def __getitem__(self, i):
|
||||
if i % 64 == 0:
|
||||
n = 100
|
||||
else:
|
||||
n = 1
|
||||
return "This is a test" * n
|
||||
```
|
||||
|
||||
与其他句子相比,这是一个非常长的句子。在这种情况下,**整个**批次将需要400个tokens的长度,因此整个批次将是 [64, 400] 而不是 [64, 4],从而导致较大的减速。更糟糕的是,在更大的批次上,程序会崩溃。
|
||||
|
||||
```
|
||||
------------------------------
|
||||
Streaming no batching
|
||||
100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 183.69it/s]
|
||||
------------------------------
|
||||
Streaming batch_size=8
|
||||
100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:03<00:00, 265.74it/s]
|
||||
------------------------------
|
||||
Streaming batch_size=64
|
||||
100%|██████████████████████████████████████████████████████████████████████| 1000/1000 [00:26<00:00, 37.80it/s]
|
||||
------------------------------
|
||||
Streaming batch_size=256
|
||||
0%| | 0/1000 [00:00<?, ?it/s]
|
||||
Traceback (most recent call last):
|
||||
File "/home/nicolas/src/transformers/test.py", line 42, in <module>
|
||||
for out in tqdm(pipe(dataset, batch_size=256), total=len(dataset)):
|
||||
....
|
||||
q = q / math.sqrt(dim_per_head) # (bs, n_heads, q_length, dim_per_head)
|
||||
RuntimeError: CUDA out of memory. Tried to allocate 376.00 MiB (GPU 0; 3.95 GiB total capacity; 1.72 GiB already allocated; 354.88 MiB free; 2.46 GiB reserved in total by PyTorch)
|
||||
```
|
||||
|
||||
对于这个问题,没有好的(通用)解决方案,效果可能因您的用例而异。经验法则如下:
|
||||
|
||||
对于用户,一个经验法则是:
|
||||
|
||||
- **使用硬件测量负载性能。测量、测量、再测量。真实的数字是唯一的方法。**
|
||||
- 如果受到延迟的限制(进行推理的实时产品),不要进行批处理。
|
||||
- 如果使用CPU,不要进行批处理。
|
||||
- 如果您在GPU上处理的是吞吐量(您希望在大量静态数据上运行模型),则:
|
||||
- 如果对序列长度的大小没有概念("自然"数据),默认情况下不要进行批处理,进行测试并尝试逐渐添加,添加OOM检查以在失败时恢复(如果您不能控制序列长度,它将在某些时候失败)。
|
||||
- 如果您的序列长度非常规律,那么批处理更有可能非常有趣,进行测试并推动它,直到出现OOM。
|
||||
- GPU越大,批处理越有可能变得更有趣
|
||||
- 一旦启用批处理,确保能够很好地处理OOM。
|
||||
|
||||
## Pipeline chunk batching
|
||||
|
||||
`zero-shot-classification` 和 `question-answering` 在某种意义上稍微特殊,因为单个输入可能会导致模型的多次前向传递。在正常情况下,这将导致 `batch_size` 参数的问题。
|
||||
|
||||
为了规避这个问题,这两个pipeline都有点特殊,它们是 `ChunkPipeline` 而不是常规的 `Pipeline`。简而言之:
|
||||
|
||||
|
||||
```python
|
||||
preprocessed = pipe.preprocess(inputs)
|
||||
model_outputs = pipe.forward(preprocessed)
|
||||
outputs = pipe.postprocess(model_outputs)
|
||||
```
|
||||
|
||||
现在变成:
|
||||
|
||||
|
||||
```python
|
||||
all_model_outputs = []
|
||||
for preprocessed in pipe.preprocess(inputs):
|
||||
model_outputs = pipe.forward(preprocessed)
|
||||
all_model_outputs.append(model_outputs)
|
||||
outputs = pipe.postprocess(all_model_outputs)
|
||||
```
|
||||
|
||||
这对您的代码应该是非常直观的,因为pipeline的使用方式是相同的。
|
||||
|
||||
这是一个简化的视图,因为Pipeline可以自动处理批次!这意味着您不必担心您的输入实际上会触发多少次前向传递,您可以独立于输入优化 `batch_size`。前面部分的注意事项仍然适用。
|
||||
|
||||
## Pipeline自定义
|
||||
|
||||
如果您想要重载特定的pipeline。
|
||||
|
||||
请随时为您手头的任务创建一个issue,Pipeline的目标是易于使用并支持大多数情况,因此 `transformers` 可能支持您的用例。
|
||||
|
||||
如果您想简单地尝试一下,可以:
|
||||
|
||||
- 继承您选择的pipeline
|
||||
|
||||
```python
|
||||
class MyPipeline(TextClassificationPipeline):
|
||||
def postprocess():
|
||||
# Your code goes here
|
||||
scores = scores * 100
|
||||
# And here
|
||||
|
||||
|
||||
my_pipeline = MyPipeline(model=model, tokenizer=tokenizer, ...)
|
||||
# or if you use *pipeline* function, then:
|
||||
my_pipeline = pipeline(model="xxxx", pipeline_class=MyPipeline)
|
||||
```
|
||||
|
||||
这样就可以让您编写所有想要的自定义代码。
|
||||
|
||||
|
||||
## 实现一个pipeline
|
||||
|
||||
[实现一个新的pipeline](../add_new_pipeline)
|
||||
|
||||
## 音频
|
||||
|
||||
可用于音频任务的pipeline包括以下几种。
|
||||
|
||||
### AudioClassificationPipeline
|
||||
|
||||
[[autodoc]] AudioClassificationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### AutomaticSpeechRecognitionPipeline
|
||||
|
||||
[[autodoc]] AutomaticSpeechRecognitionPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### TextToAudioPipeline
|
||||
|
||||
[[autodoc]] TextToAudioPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
|
||||
### ZeroShotAudioClassificationPipeline
|
||||
|
||||
[[autodoc]] ZeroShotAudioClassificationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
## 计算机视觉
|
||||
|
||||
可用于计算机视觉任务的pipeline包括以下几种。
|
||||
|
||||
### DepthEstimationPipeline
|
||||
[[autodoc]] DepthEstimationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### ImageClassificationPipeline
|
||||
|
||||
[[autodoc]] ImageClassificationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### ImageSegmentationPipeline
|
||||
|
||||
[[autodoc]] ImageSegmentationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### ImageToImagePipeline
|
||||
|
||||
[[autodoc]] ImageToImagePipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### ObjectDetectionPipeline
|
||||
|
||||
[[autodoc]] ObjectDetectionPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### VideoClassificationPipeline
|
||||
|
||||
[[autodoc]] VideoClassificationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### ZeroShotImageClassificationPipeline
|
||||
|
||||
[[autodoc]] ZeroShotImageClassificationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### ZeroShotObjectDetectionPipeline
|
||||
|
||||
[[autodoc]] ZeroShotObjectDetectionPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
## 自然语言处理
|
||||
|
||||
可用于自然语言处理任务的pipeline包括以下几种。
|
||||
|
||||
### FillMaskPipeline
|
||||
|
||||
[[autodoc]] FillMaskPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### NerPipeline
|
||||
|
||||
[[autodoc]] NerPipeline
|
||||
|
||||
See [`TokenClassificationPipeline`] for all details.
|
||||
|
||||
### QuestionAnsweringPipeline
|
||||
|
||||
[[autodoc]] QuestionAnsweringPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### SummarizationPipeline
|
||||
|
||||
[[autodoc]] SummarizationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### TableQuestionAnsweringPipeline
|
||||
|
||||
[[autodoc]] TableQuestionAnsweringPipeline
|
||||
- __call__
|
||||
|
||||
### TextClassificationPipeline
|
||||
|
||||
[[autodoc]] TextClassificationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### TextGenerationPipeline
|
||||
|
||||
[[autodoc]] TextGenerationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### Text2TextGenerationPipeline
|
||||
|
||||
[[autodoc]] Text2TextGenerationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### TokenClassificationPipeline
|
||||
|
||||
[[autodoc]] TokenClassificationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### TranslationPipeline
|
||||
|
||||
[[autodoc]] TranslationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### ZeroShotClassificationPipeline
|
||||
|
||||
[[autodoc]] ZeroShotClassificationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
## 多模态
|
||||
|
||||
可用于多模态任务的pipeline包括以下几种。
|
||||
|
||||
### DocumentQuestionAnsweringPipeline
|
||||
|
||||
[[autodoc]] DocumentQuestionAnsweringPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### FeatureExtractionPipeline
|
||||
|
||||
[[autodoc]] FeatureExtractionPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### ImageFeatureExtractionPipeline
|
||||
|
||||
[[autodoc]] ImageFeatureExtractionPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### ImageToTextPipeline
|
||||
|
||||
[[autodoc]] ImageToTextPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### ImageTextToTextPipeline
|
||||
|
||||
[[autodoc]] ImageTextToTextPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### MaskGenerationPipeline
|
||||
|
||||
[[autodoc]] MaskGenerationPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
### VisualQuestionAnsweringPipeline
|
||||
|
||||
[[autodoc]] VisualQuestionAnsweringPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
## Parent class: `Pipeline`
|
||||
|
||||
[[autodoc]] Pipeline
|
||||
146
transformers/docs/source/zh/main_classes/processors.md
Normal file
146
transformers/docs/source/zh/main_classes/processors.md
Normal file
@@ -0,0 +1,146 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Processors
|
||||
|
||||
在 Transformers 库中,processors可以有两种不同的含义:
|
||||
- 为多模态模型,例如[Wav2Vec2](../model_doc/wav2vec2)(语音和文本)或[CLIP](../model_doc/clip)(文本和视觉)预处理输入的对象
|
||||
- 在库的旧版本中用于预处理GLUE或SQUAD数据的已弃用对象。
|
||||
|
||||
## 多模态processors
|
||||
|
||||
任何多模态模型都需要一个对象来编码或解码将多个模态(包括文本、视觉和音频)组合在一起的数据。这由称为processors的对象处理,这些processors将两个或多个处理对象组合在一起,例如tokenizers(用于文本模态),image processors(用于视觉)和feature extractors(用于音频)。
|
||||
|
||||
这些processors继承自以下实现保存和加载功能的基类:
|
||||
|
||||
|
||||
[[autodoc]] ProcessorMixin
|
||||
|
||||
## 已弃用的processors
|
||||
|
||||
所有processor都遵循与 [`~data.processors.utils.DataProcessor`] 相同的架构。processor返回一个 [`~data.processors.utils.InputExample`] 列表。这些 [`~data.processors.utils.InputExample`] 可以转换为 [`~data.processors.utils.InputFeatures`] 以供输送到模型。
|
||||
|
||||
[[autodoc]] data.processors.utils.DataProcessor
|
||||
|
||||
[[autodoc]] data.processors.utils.InputExample
|
||||
|
||||
[[autodoc]] data.processors.utils.InputFeatures
|
||||
|
||||
## GLUE
|
||||
|
||||
[General Language Understanding Evaluation (GLUE)](https://gluebenchmark.com/) 是一个基准测试,评估模型在各种现有的自然语言理解任务上的性能。它与论文 [GLUE: A multi-task benchmark and analysis platform for natural language understanding](https://openreview.net/pdf?id=rJ4km2R5t7) 一同发布。
|
||||
|
||||
该库为以下任务提供了总共10个processor:MRPC、MNLI、MNLI(mismatched)、CoLA、SST2、STSB、QQP、QNLI、RTE 和 WNLI。
|
||||
|
||||
这些processor是:
|
||||
|
||||
- [`~data.processors.utils.MrpcProcessor`]
|
||||
- [`~data.processors.utils.MnliProcessor`]
|
||||
- [`~data.processors.utils.MnliMismatchedProcessor`]
|
||||
- [`~data.processors.utils.Sst2Processor`]
|
||||
- [`~data.processors.utils.StsbProcessor`]
|
||||
- [`~data.processors.utils.QqpProcessor`]
|
||||
- [`~data.processors.utils.QnliProcessor`]
|
||||
- [`~data.processors.utils.RteProcessor`]
|
||||
- [`~data.processors.utils.WnliProcessor`]
|
||||
|
||||
此外,还可以使用以下方法从数据文件加载值并将其转换为 [`~data.processors.utils.InputExample`] 列表。
|
||||
|
||||
[[autodoc]] data.processors.glue.glue_convert_examples_to_features
|
||||
|
||||
|
||||
## XNLI
|
||||
|
||||
[跨语言NLI语料库(XNLI)](https://www.nyu.edu/projects/bowman/xnli/) 是一个评估跨语言文本表示质量的基准测试。XNLI是一个基于[*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/)的众包数据集:”文本对“被标记为包含15种不同语言(包括英语等高资源语言和斯瓦希里语等低资源语言)的文本蕴涵注释。
|
||||
|
||||
它与论文 [XNLI: Evaluating Cross-lingual Sentence Representations](https://huggingface.co/papers/1809.05053) 一同发布。
|
||||
|
||||
该库提供了加载XNLI数据的processor:
|
||||
|
||||
- [`~data.processors.utils.XnliProcessor`]
|
||||
|
||||
请注意,由于测试集上有“gold”标签,因此评估是在测试集上进行的。
|
||||
|
||||
使用这些processor的示例在 [run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) 脚本中提供。
|
||||
|
||||
|
||||
## SQuAD
|
||||
|
||||
[斯坦福问答数据集(SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) 是一个评估模型在问答上性能的基准测试。有两个版本,v1.1 和 v2.0。第一个版本(v1.1)与论文 [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://huggingface.co/papers/1606.05250) 一同发布。第二个版本(v2.0)与论文 [Know What You Don't Know: Unanswerable Questions for SQuAD](https://huggingface.co/papers/1806.03822) 一同发布。
|
||||
|
||||
该库为两个版本各自提供了一个processor:
|
||||
|
||||
### Processors
|
||||
|
||||
这两个processor是:
|
||||
|
||||
- [`~data.processors.utils.SquadV1Processor`]
|
||||
- [`~data.processors.utils.SquadV2Processor`]
|
||||
|
||||
它们都继承自抽象类 [`~data.processors.utils.SquadProcessor`]。
|
||||
|
||||
[[autodoc]] data.processors.squad.SquadProcessor
|
||||
- all
|
||||
|
||||
此外,可以使用以下方法将 SQuAD 示例转换为可用作模型输入的 [`~data.processors.utils.SquadFeatures`]。
|
||||
|
||||
[[autodoc]] data.processors.squad.squad_convert_examples_to_features
|
||||
|
||||
|
||||
这些processor以及前面提到的方法可以与包含数据的文件以及tensorflow_datasets包一起使用。下面给出了示例。
|
||||
|
||||
|
||||
### Example使用
|
||||
|
||||
以下是使用processor以及使用数据文件的转换方法的示例:
|
||||
|
||||
```python
|
||||
# Loading a V2 processor
|
||||
processor = SquadV2Processor()
|
||||
examples = processor.get_dev_examples(squad_v2_data_dir)
|
||||
|
||||
# Loading a V1 processor
|
||||
processor = SquadV1Processor()
|
||||
examples = processor.get_dev_examples(squad_v1_data_dir)
|
||||
|
||||
features = squad_convert_examples_to_features(
|
||||
examples=examples,
|
||||
tokenizer=tokenizer,
|
||||
max_seq_length=max_seq_length,
|
||||
doc_stride=args.doc_stride,
|
||||
max_query_length=max_query_length,
|
||||
is_training=not evaluate,
|
||||
)
|
||||
```
|
||||
|
||||
使用 *tensorflow_datasets* 就像使用数据文件一样简单:
|
||||
|
||||
```python
|
||||
# tensorflow_datasets only handle Squad V1.
|
||||
tfds_examples = tfds.load("squad")
|
||||
examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
|
||||
|
||||
features = squad_convert_examples_to_features(
|
||||
examples=examples,
|
||||
tokenizer=tokenizer,
|
||||
max_seq_length=max_seq_length,
|
||||
doc_stride=args.doc_stride,
|
||||
max_query_length=max_query_length,
|
||||
is_training=not evaluate,
|
||||
)
|
||||
```
|
||||
|
||||
另一个使用这些processor的示例在 [run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) 脚本中提供。
|
||||
572
transformers/docs/source/zh/main_classes/quantization.md
Normal file
572
transformers/docs/source/zh/main_classes/quantization.md
Normal file
@@ -0,0 +1,572 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 量化 🤗 Transformers 模型
|
||||
|
||||
## AWQ集成
|
||||
|
||||
AWQ方法已经在[*AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration*论文](https://huggingface.co/papers/2306.00978)中引入。通过AWQ,您可以以4位精度运行模型,同时保留其原始性能(即没有性能降级),并具有比下面介绍的其他量化方法更出色的吞吐量 - 达到与纯`float16`推理相似的吞吐量。
|
||||
|
||||
我们现在支持使用任何AWQ模型进行推理,这意味着任何人都可以加载和使用在Hub上推送或本地保存的AWQ权重。请注意,使用AWQ需要访问NVIDIA GPU。目前不支持CPU推理。
|
||||
|
||||
|
||||
### 量化一个模型
|
||||
|
||||
我们建议用户查看生态系统中不同的现有工具,以使用AWQ算法对其模型进行量化,例如:
|
||||
|
||||
- [`llm-awq`](https://github.com/mit-han-lab/llm-awq),来自MIT Han Lab
|
||||
- [`autoawq`](https://github.com/casper-hansen/AutoAWQ),来自[`casper-hansen`](https://github.com/casper-hansen)
|
||||
- Intel neural compressor,来自Intel - 通过[`optimum-intel`](https://huggingface.co/docs/optimum/main/en/intel/optimization_inc)使用
|
||||
|
||||
生态系统中可能存在许多其他工具,请随时提出PR将它们添加到列表中。
|
||||
目前与🤗 Transformers的集成仅适用于使用`autoawq`和`llm-awq`量化后的模型。大多数使用`auto-awq`量化的模型可以在🤗 Hub的[`TheBloke`](https://huggingface.co/TheBloke)命名空间下找到,要使用`llm-awq`对模型进行量化,请参阅[`llm-awq`](https://github.com/mit-han-lab/llm-awq/)的示例文件夹中的[`convert_to_hf.py`](https://github.com/mit-han-lab/llm-awq/blob/main/examples/convert_to_hf.py)脚本。
|
||||
|
||||
|
||||
### 加载一个量化的模型
|
||||
|
||||
您可以使用`from_pretrained`方法从Hub加载一个量化模型。通过检查模型配置文件(`configuration.json`)中是否存在`quantization_config`属性,来进行确认推送的权重是量化的。您可以通过检查字段`quantization_config.quant_method`来确认模型是否以AWQ格式进行量化,该字段应该设置为`"awq"`。请注意,为了性能原因,默认情况下加载模型将设置其他权重为`float16`。如果您想更改这种设置,可以通过将`dtype`参数设置为`torch.float32`或`torch.bfloat16`。在下面的部分中,您可以找到一些示例片段和notebook。
|
||||
|
||||
|
||||
## 示例使用
|
||||
|
||||
首先,您需要安装[`autoawq`](https://github.com/casper-hansen/AutoAWQ)库
|
||||
|
||||
```bash
|
||||
pip install autoawq
|
||||
```
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
model_id = "TheBloke/zephyr-7B-alpha-AWQ"
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0")
|
||||
```
|
||||
|
||||
如果您首先将模型加载到CPU上,请确保在使用之前将其移动到GPU设备上。
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
model_id = "TheBloke/zephyr-7B-alpha-AWQ"
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id).to("cuda:0")
|
||||
```
|
||||
|
||||
### 结合 AWQ 和 Flash Attention
|
||||
|
||||
您可以将AWQ量化与Flash Attention结合起来,得到一个既被量化又更快速的模型。只需使用`from_pretrained`加载模型,并传递`attn_implementation="flash_attention_2"`参数。
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", attn_implementation="flash_attention_2", device_map="cuda:0")
|
||||
```
|
||||
|
||||
### 基准测试
|
||||
|
||||
我们使用[`optimum-benchmark`](https://github.com/huggingface/optimum-benchmark)库进行了一些速度、吞吐量和延迟基准测试。
|
||||
|
||||
请注意,在编写本文档部分时,可用的量化方法包括:`awq`、`gptq`和`bitsandbytes`。
|
||||
|
||||
基准测试在一台NVIDIA-A100实例上运行,使用[`TheBloke/Mistral-7B-v0.1-AWQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-AWQ)作为AWQ模型,[`TheBloke/Mistral-7B-v0.1-GPTQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ)作为GPTQ模型。我们还将其与`bitsandbytes`量化模型和`float16`模型进行了对比。以下是一些结果示例:
|
||||
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quantization/forward_memory_plot.png">
|
||||
</div>
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quantization/generate_memory_plot.png">
|
||||
</div>
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quantization/generate_throughput_plot.png">
|
||||
</div>
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quantization/forward_latency_plot.png">
|
||||
</div>
|
||||
|
||||
你可以在[此链接](https://github.com/huggingface/optimum-benchmark/tree/main/examples/running-mistrals)中找到完整的结果以及包版本。
|
||||
|
||||
从结果来看,AWQ量化方法是推理、文本生成中最快的量化方法,并且在文本生成的峰值内存方面属于最低。然而,对于每批数据,AWQ似乎有最大的前向延迟。
|
||||
|
||||
|
||||
### Google colab 演示
|
||||
|
||||
查看如何在[Google Colab演示](https://colab.research.google.com/drive/1HzZH89yAXJaZgwJDhQj9LqSBux932BvY)中使用此集成!
|
||||
|
||||
|
||||
### AwqConfig
|
||||
|
||||
[[autodoc]] AwqConfig
|
||||
|
||||
## `AutoGPTQ` 集成
|
||||
|
||||
🤗 Transformers已经整合了`optimum` API,用于对语言模型执行GPTQ量化。您可以以8、4、3甚至2位加载和量化您的模型,而性能无明显下降,并且推理速度更快!这受到大多数GPU硬件的支持。
|
||||
|
||||
要了解更多关于量化模型的信息,请查看:
|
||||
- [GPTQ](https://huggingface.co/papers/2210.17323)论文
|
||||
- `optimum`关于GPTQ量化的[指南](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization)
|
||||
- 用作后端的[`AutoGPTQ`](https://github.com/PanQiWei/AutoGPTQ)库
|
||||
|
||||
|
||||
### 要求
|
||||
|
||||
为了运行下面的代码,您需要安装:
|
||||
|
||||
- 安装最新版本的 `AutoGPTQ` 库
|
||||
`pip install auto-gptq`
|
||||
|
||||
- 从源代码安装最新版本的`optimum`
|
||||
`pip install git+https://github.com/huggingface/optimum.git`
|
||||
|
||||
- 从源代码安装最新版本的`transformers`
|
||||
`pip install git+https://github.com/huggingface/transformers.git`
|
||||
|
||||
- 安装最新版本的`accelerate`库:
|
||||
`pip install --upgrade accelerate`
|
||||
|
||||
请注意,目前GPTQ集成仅支持文本模型,对于视觉、语音或多模态模型可能会遇到预期以外结果。
|
||||
|
||||
### 加载和量化模型
|
||||
|
||||
GPTQ是一种在使用量化模型之前需要进行权重校准的量化方法。如果您想从头开始对transformers模型进行量化,生成量化模型可能需要一些时间(在Google Colab上对`facebook/opt-350m`模型量化约为5分钟)。
|
||||
|
||||
因此,有两种不同的情况下您可能想使用GPTQ量化模型。第一种情况是加载已经由其他用户在Hub上量化的模型,第二种情况是从头开始对您的模型进行量化并保存或推送到Hub,以便其他用户也可以使用它。
|
||||
|
||||
|
||||
#### GPTQ 配置
|
||||
|
||||
为了加载和量化一个模型,您需要创建一个[`GPTQConfig`]。您需要传递`bits`的数量,一个用于校准量化的`dataset`,以及模型的`tokenizer`以准备数据集。
|
||||
|
||||
```python
|
||||
model_id = "facebook/opt-125m"
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
gptq_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
|
||||
```
|
||||
|
||||
请注意,您可以将自己的数据集以字符串列表形式传递到模型。然而,强烈建议您使用GPTQ论文中提供的数据集。
|
||||
|
||||
|
||||
```python
|
||||
dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]
|
||||
quantization = GPTQConfig(bits=4, dataset = dataset, tokenizer=tokenizer)
|
||||
```
|
||||
|
||||
#### 量化
|
||||
|
||||
您可以通过使用`from_pretrained`并设置`quantization_config`来对模型进行量化。
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=gptq_config)
|
||||
|
||||
```
|
||||
|
||||
请注意,您需要一个GPU来量化模型。我们将模型放在cpu中,并将模块来回移动到gpu中,以便对其进行量化。
|
||||
|
||||
如果您想在使用 CPU 卸载的同时最大化 GPU 使用率,您可以设置 `device_map = "auto"`。
|
||||
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=gptq_config)
|
||||
```
|
||||
|
||||
请注意,不支持磁盘卸载。此外,如果由于数据集而内存不足,您可能需要在`from_pretrained`中设置`max_memory`。查看这个[指南](https://huggingface.co/docs/accelerate/usage_guides/big_modeling#designing-a-device-map)以了解有关`device_map`和`max_memory`的更多信息。
|
||||
|
||||
|
||||
<Tip warning={true}>
|
||||
目前,GPTQ量化仅适用于文本模型。此外,量化过程可能会花费很多时间,具体取决于硬件性能(175B模型在NVIDIA A100上需要4小时)。请在Hub上检查是否有模型的GPTQ量化版本。如果没有,您可以在GitHub上提交需求。
|
||||
</Tip>
|
||||
|
||||
### 推送量化模型到 🤗 Hub
|
||||
|
||||
您可以使用`push_to_hub`将量化模型像任何模型一样推送到Hub。量化配置将与模型一起保存和推送。
|
||||
|
||||
```python
|
||||
quantized_model.push_to_hub("opt-125m-gptq")
|
||||
tokenizer.push_to_hub("opt-125m-gptq")
|
||||
```
|
||||
|
||||
如果您想在本地计算机上保存量化模型,您也可以使用`save_pretrained`来完成:
|
||||
|
||||
```python
|
||||
quantized_model.save_pretrained("opt-125m-gptq")
|
||||
tokenizer.save_pretrained("opt-125m-gptq")
|
||||
```
|
||||
|
||||
请注意,如果您量化模型时想使用`device_map`,请确保在保存之前将整个模型移动到您的GPU或CPU之一。
|
||||
|
||||
```python
|
||||
quantized_model.to("cpu")
|
||||
quantized_model.save_pretrained("opt-125m-gptq")
|
||||
```
|
||||
|
||||
### 从 🤗 Hub 加载一个量化模型
|
||||
|
||||
您可以使用`from_pretrained`从Hub加载量化模型。
|
||||
请确保推送权重是量化的,检查模型配置对象中是否存在`quantization_config`属性。
|
||||
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq")
|
||||
```
|
||||
|
||||
如果您想更快地加载模型,并且不需要分配比实际需要内存更多的内存,量化模型也使用`device_map`参数。确保您已安装`accelerate`库。
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto")
|
||||
```
|
||||
|
||||
### Exllama内核加快推理速度
|
||||
|
||||
保留格式:对于 4 位模型,您可以使用 exllama 内核来提高推理速度。默认情况下,它处于启用状态。您可以通过在 [`GPTQConfig`] 中传递 `use_exllama` 来更改此配置。这将覆盖存储在配置中的量化配置。请注意,您只能覆盖与内核相关的属性。此外,如果您想使用 exllama 内核,整个模型需要全部部署在 gpus 上。此外,您可以使用 版本 > 0.4.2 的 Auto-GPTQ 并传递 `device_map` = "cpu" 来执行 CPU 推理。对于 CPU 推理,您必须在 `GPTQConfig` 中传递 `use_exllama = False`。
|
||||
|
||||
```py
|
||||
import torch
|
||||
gptq_config = GPTQConfig(bits=4)
|
||||
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config=gptq_config)
|
||||
```
|
||||
|
||||
随着 exllamav2 内核的发布,与 exllama 内核相比,您可以获得更快的推理速度。您只需在 [`GPTQConfig`] 中传递 `exllama_config={"version": 2}`:
|
||||
|
||||
```py
|
||||
import torch
|
||||
gptq_config = GPTQConfig(bits=4, exllama_config={"version":2})
|
||||
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config = gptq_config)
|
||||
```
|
||||
|
||||
请注意,目前仅支持 4 位模型。此外,如果您正在使用 peft 对量化模型进行微调,建议禁用 exllama 内核。
|
||||
|
||||
您可以在此找到这些内核的基准测试 [这里](https://github.com/huggingface/optimum/tree/main/tests/benchmark#gptq-benchmark)
|
||||
|
||||
|
||||
#### 微调一个量化模型
|
||||
|
||||
在Hugging Face生态系统的官方支持下,您可以使用GPTQ进行量化后的模型进行微调。
|
||||
请查看`peft`库了解更多详情。
|
||||
|
||||
### 示例演示
|
||||
|
||||
请查看 Google Colab [notebook](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94ilkUFu6ZX4ceb?usp=sharing),了解如何使用GPTQ量化您的模型以及如何使用peft微调量化模型。
|
||||
|
||||
### GPTQConfig
|
||||
|
||||
[[autodoc]] GPTQConfig
|
||||
|
||||
|
||||
## `bitsandbytes` 集成
|
||||
|
||||
🤗 Transformers 与 `bitsandbytes` 上最常用的模块紧密集成。您可以使用几行代码以 8 位精度加载您的模型。
|
||||
自bitsandbytes的0.37.0版本发布以来,大多数GPU硬件都支持这一点。
|
||||
|
||||
在[LLM.int8()](https://huggingface.co/papers/2208.07339)论文中了解更多关于量化方法的信息,或者在[博客文章](https://huggingface.co/blog/hf-bitsandbytes-integration)中了解关于合作的更多信息。
|
||||
|
||||
自其“0.39.0”版本发布以来,您可以使用FP4数据类型,通过4位量化加载任何支持“device_map”的模型。
|
||||
|
||||
如果您想量化自己的 pytorch 模型,请查看 🤗 Accelerate 的[文档](https://huggingface.co/docs/accelerate/main/en/usage_guides/quantization)。
|
||||
|
||||
以下是您可以使用“bitsandbytes”集成完成的事情
|
||||
|
||||
### 通用用法
|
||||
|
||||
只要您的模型支持使用 🤗 Accelerate 进行加载并包含 `torch.nn.Linear` 层,您可以在调用 [`~PreTrainedModel.from_pretrained`] 方法时使用 `load_in_8bit` 或 `load_in_4bit` 参数来量化模型。这也应该适用于任何模态。
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True)
|
||||
model_4bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_4bit=True)
|
||||
```
|
||||
|
||||
默认情况下,所有其他模块(例如 `torch.nn.LayerNorm`)将被转换为 `torch.float16` 类型。但如果您想更改它们的 `dtype`,可以重载 `dtype` 参数:
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoModelForCausalLM
|
||||
|
||||
>>> model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True, dtype=torch.float32)
|
||||
>>> model_8bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
|
||||
torch.float32
|
||||
```
|
||||
|
||||
|
||||
### FP4 量化
|
||||
|
||||
#### 要求
|
||||
|
||||
确保在运行以下代码段之前已完成以下要求:
|
||||
|
||||
- 最新版本 `bitsandbytes` 库
|
||||
`pip install bitsandbytes>=0.39.0`
|
||||
|
||||
- 安装最新版本 `accelerate`
|
||||
`pip install --upgrade accelerate`
|
||||
|
||||
- 安装最新版本 `transformers`
|
||||
`pip install --upgrade transformers`
|
||||
|
||||
#### 提示和最佳实践
|
||||
|
||||
|
||||
- **高级用法:** 请参考 [此 Google Colab notebook](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf) 以获取 4 位量化高级用法和所有可选选项。
|
||||
|
||||
- **使用 `batch_size=1` 实现更快的推理:** 自 `bitsandbytes` 的 `0.40.0` 版本以来,设置 `batch_size=1`,您可以从快速推理中受益。请查看 [这些发布说明](https://github.com/TimDettmers/bitsandbytes/releases/tag/0.40.0) ,并确保使用大于 `0.40.0` 的版本以直接利用此功能。
|
||||
|
||||
- **训练:** 根据 [QLoRA 论文](https://huggingface.co/papers/2305.14314),对于4位基模型训练(使用 LoRA 适配器),应使用 `bnb_4bit_quant_type='nf4'`。
|
||||
|
||||
- **推理:** 对于推理,`bnb_4bit_quant_type` 对性能影响不大。但是为了与模型的权重保持一致,请确保使用相同的 `bnb_4bit_compute_dtype` 和 `dtype` 参数。
|
||||
|
||||
#### 加载 4 位量化的大模型
|
||||
|
||||
在调用 `.from_pretrained` 方法时使用 `load_in_4bit=True`,可以将您的内存使用量减少到大约原来的 1/4。
|
||||
|
||||
```python
|
||||
# pip install transformers accelerate bitsandbytes
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
model_id = "bigscience/bloom-1b7"
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", load_in_4bit=True)
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
需要注意的是,一旦模型以 4 位量化方式加载,就无法将量化后的权重推送到 Hub 上。此外,您不能训练 4 位量化权重,因为目前尚不支持此功能。但是,您可以使用 4 位量化模型来训练额外参数,这将在下一部分中介绍。
|
||||
|
||||
</Tip>
|
||||
|
||||
### 加载 8 位量化的大模型
|
||||
|
||||
您可以通过在调用 `.from_pretrained` 方法时使用 `load_in_8bit=True` 参数,将内存需求大致减半来加载模型
|
||||
|
||||
|
||||
```python
|
||||
# pip install transformers accelerate bitsandbytes
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
|
||||
model_id = "bigscience/bloom-1b7"
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
|
||||
```
|
||||
|
||||
然后,像通常使用 `PreTrainedModel` 一样使用您的模型。
|
||||
|
||||
您可以使用 `get_memory_footprint` 方法检查模型的内存占用。
|
||||
|
||||
|
||||
```python
|
||||
print(model.get_memory_footprint())
|
||||
```
|
||||
|
||||
通过这种集成,我们能够在较小的设备上加载大模型并运行它们而没有任何问题。
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
需要注意的是,一旦模型以 8 位量化方式加载,除了使用最新的 `transformers` 和 `bitsandbytes` 之外,目前尚无法将量化后的权重推送到 Hub 上。此外,您不能训练 8 位量化权重,因为目前尚不支持此功能。但是,您可以使用 8 位量化模型来训练额外参数,这将在下一部分中介绍。
|
||||
|
||||
注意,`device_map` 是可选的,但设置 `device_map = 'auto'` 更适合用于推理,因为它将更有效地调度可用资源上的模型。
|
||||
|
||||
|
||||
</Tip>
|
||||
|
||||
#### 高级用例
|
||||
|
||||
在这里,我们将介绍使用 FP4 量化的一些高级用例。
|
||||
|
||||
##### 更改计算数据类型
|
||||
|
||||
计算数据类型用于改变在进行计算时使用的数据类型。例如,hidden states可以是 `float32`,但为了加速,计算时可以被设置为 `bf16`。默认情况下,计算数据类型被设置为 `float32`。
|
||||
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import BitsAndBytesConfig
|
||||
|
||||
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16)
|
||||
```
|
||||
|
||||
#### 使用 NF4(普通浮点数 4)数据类型
|
||||
|
||||
您还可以使用 NF4 数据类型,这是一种针对使用正态分布初始化的权重而适应的新型 4 位数据类型。要运行:
|
||||
|
||||
```python
|
||||
from transformers import BitsAndBytesConfig
|
||||
|
||||
nf4_config = BitsAndBytesConfig(
|
||||
load_in_4bit=True,
|
||||
bnb_4bit_quant_type="nf4",
|
||||
)
|
||||
|
||||
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
|
||||
```
|
||||
|
||||
#### 使用嵌套量化进行更高效的内存推理
|
||||
|
||||
我们还建议用户使用嵌套量化技术。从我们的经验观察来看,这种方法在不增加额外性能的情况下节省更多内存。这使得 llama-13b 模型能够在具有 1024 个序列长度、1 个批次大小和 4 个梯度累积步骤的 NVIDIA-T4 16GB 上进行 fine-tuning。
|
||||
|
||||
```python
|
||||
from transformers import BitsAndBytesConfig
|
||||
|
||||
double_quant_config = BitsAndBytesConfig(
|
||||
load_in_4bit=True,
|
||||
bnb_4bit_use_double_quant=True,
|
||||
)
|
||||
|
||||
model_double_quant = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=double_quant_config)
|
||||
```
|
||||
|
||||
### 将量化模型推送到🤗 Hub
|
||||
|
||||
您可以使用 `push_to_hub` 方法将量化模型推送到 Hub 上。这将首先推送量化配置文件,然后推送量化模型权重。
|
||||
请确保使用 `bitsandbytes>0.37.2`(在撰写本文时,我们使用的是 `bitsandbytes==0.38.0.post1`)才能使用此功能。
|
||||
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom-560m", quantization_config=BitsAndBytesConfig(load_in_8bit=True))
|
||||
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
|
||||
|
||||
model.push_to_hub("bloom-560m-8bit")
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
对大模型,强烈鼓励将 8 位量化模型推送到 Hub 上,以便让社区能够从内存占用减少和加载中受益,例如在 Google Colab 上加载大模型。
|
||||
|
||||
</Tip>
|
||||
|
||||
### 从🤗 Hub加载量化模型
|
||||
|
||||
您可以使用 `from_pretrained` 方法从 Hub 加载量化模型。请确保推送的权重是量化的,检查模型配置对象中是否存在 `quantization_config` 属性。
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("{your_username}/bloom-560m-8bit", device_map="auto")
|
||||
```
|
||||
|
||||
请注意,在这种情况下,您不需要指定 `load_in_8bit=True` 参数,但需要确保 `bitsandbytes` 和 `accelerate` 已安装。
|
||||
情注意,`device_map` 是可选的,但设置 `device_map = 'auto'` 更适合用于推理,因为它将更有效地调度可用资源上的模型。
|
||||
|
||||
### 高级用例
|
||||
|
||||
本节面向希望探索除了加载和运行 8 位模型之外还能做什么的进阶用户。
|
||||
|
||||
#### 在 `cpu` 和 `gpu` 之间卸载
|
||||
|
||||
此高级用例之一是能够加载模型并将权重分派到 `CPU` 和 `GPU` 之间。请注意,将在 CPU 上分派的权重 **不会** 转换为 8 位,因此会保留为 `float32`。此功能适用于想要适应非常大的模型并将模型分派到 GPU 和 CPU 之间的用户。
|
||||
|
||||
首先,从 `transformers` 中加载一个 [`BitsAndBytesConfig`],并将属性 `llm_int8_enable_fp32_cpu_offload` 设置为 `True`:
|
||||
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
|
||||
quantization_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True)
|
||||
```
|
||||
|
||||
假设您想加载 `bigscience/bloom-1b7` 模型,您的 GPU显存仅足够容纳除了`lm_head`外的整个模型。因此,您可以按照以下方式编写自定义的 device_map:
|
||||
|
||||
```python
|
||||
device_map = {
|
||||
"transformer.word_embeddings": 0,
|
||||
"transformer.word_embeddings_layernorm": 0,
|
||||
"lm_head": "cpu",
|
||||
"transformer.h": 0,
|
||||
"transformer.ln_f": 0,
|
||||
}
|
||||
```
|
||||
|
||||
然后如下加载模型:
|
||||
|
||||
```python
|
||||
model_8bit = AutoModelForCausalLM.from_pretrained(
|
||||
"bigscience/bloom-1b7",
|
||||
device_map=device_map,
|
||||
quantization_config=quantization_config,
|
||||
)
|
||||
```
|
||||
|
||||
这就是全部内容!享受您的模型吧!
|
||||
|
||||
#### 使用`llm_int8_threshold`
|
||||
|
||||
您可以使用 `llm_int8_threshold` 参数来更改异常值的阈值。“异常值”是一个大于特定阈值的`hidden state`值。
|
||||
这对应于`LLM.int8()`论文中描述的异常检测的异常阈值。任何高于此阈值的`hidden state`值都将被视为异常值,对这些值的操作将在 fp16 中完成。值通常是正态分布的,也就是说,大多数值在 [-3.5, 3.5] 范围内,但有一些额外的系统异常值,对于大模型来说,它们的分布非常不同。这些异常值通常在区间 [-60, -6] 或 [6, 60] 内。Int8 量化对于幅度为 ~5 的值效果很好,但超出这个范围,性能就会明显下降。一个好的默认阈值是 6,但对于更不稳定的模型(小模型、微调)可能需要更低的阈值。
|
||||
这个参数会影响模型的推理速度。我们建议尝试这个参数,以找到最适合您的用例的参数。
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
|
||||
model_id = "bigscience/bloom-1b7"
|
||||
|
||||
quantization_config = BitsAndBytesConfig(
|
||||
llm_int8_threshold=10,
|
||||
)
|
||||
|
||||
model_8bit = AutoModelForCausalLM.from_pretrained(
|
||||
model_id,
|
||||
device_map=device_map,
|
||||
quantization_config=quantization_config,
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
```
|
||||
|
||||
#### 跳过某些模块的转换
|
||||
|
||||
一些模型有几个需要保持未转换状态以确保稳定性的模块。例如,Jukebox 模型有几个 `lm_head` 模块需要跳过。使用 `llm_int8_skip_modules` 参数进行相应操作。
|
||||
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
|
||||
model_id = "bigscience/bloom-1b7"
|
||||
|
||||
quantization_config = BitsAndBytesConfig(
|
||||
llm_int8_skip_modules=["lm_head"],
|
||||
)
|
||||
|
||||
model_8bit = AutoModelForCausalLM.from_pretrained(
|
||||
model_id,
|
||||
device_map=device_map,
|
||||
quantization_config=quantization_config,
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
```
|
||||
|
||||
#### 微调已加载为8位精度的模型
|
||||
|
||||
借助Hugging Face生态系统中适配器(adapters)的官方支持,您可以在8位精度下微调模型。这使得可以在单个Google Colab中微调大模型,例如`flan-t5-large`或`facebook/opt-6.7b`。请查看[`peft`](https://github.com/huggingface/peft)库了解更多详情。
|
||||
|
||||
注意,加载模型进行训练时无需传递`device_map`。它将自动将您的模型加载到GPU上。如果需要,您可以将设备映射为特定设备(例如`cuda:0`、`0`、`torch.device('cuda:0')`)。请注意,`device_map=auto`仅应用于推理。
|
||||
|
||||
|
||||
### BitsAndBytesConfig
|
||||
|
||||
[[autodoc]] BitsAndBytesConfig
|
||||
|
||||
|
||||
## 使用 🤗 `optimum` 进行量化
|
||||
|
||||
请查看[Optimum 文档](https://huggingface.co/docs/optimum/index)以了解更多关于`optimum`支持的量化方法,并查看这些方法是否适用于您的用例。
|
||||
|
||||
38
transformers/docs/source/zh/main_classes/text_generation.md
Normal file
38
transformers/docs/source/zh/main_classes/text_generation.md
Normal file
@@ -0,0 +1,38 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Generation
|
||||
|
||||
每个框架都在它们各自的 `GenerationMixin` 类中实现了文本生成的 `generate` 方法:
|
||||
|
||||
- PyTorch [`~generation.GenerationMixin.generate`] 在 [`~generation.GenerationMixin`] 中实现。
|
||||
|
||||
无论您选择哪个框架,都可以使用 [`~generation.GenerationConfig`] 类实例对 generate 方法进行参数化。有关生成方法的控制参数的完整列表,请参阅此类。
|
||||
|
||||
要了解如何检查模型的生成配置、默认值是什么、如何临时更改参数以及如何创建和保存自定义生成配置,请参阅 [文本生成策略指南](../generation_strategies)。该指南还解释了如何使用相关功能,如token流。
|
||||
|
||||
## GenerationConfig
|
||||
|
||||
[[autodoc]] generation.GenerationConfig
|
||||
- from_pretrained
|
||||
- from_model_config
|
||||
- save_pretrained
|
||||
|
||||
## GenerationMixin
|
||||
|
||||
[[autodoc]] generation.GenerationMixin
|
||||
- generate
|
||||
- compute_transition_scores
|
||||
65
transformers/docs/source/zh/main_classes/tokenizer.md
Normal file
65
transformers/docs/source/zh/main_classes/tokenizer.md
Normal file
@@ -0,0 +1,65 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Tokenizer
|
||||
|
||||
tokenizer负责准备输入以供模型使用。该库包含所有模型的tokenizer。大多数tokenizer都有两种版本:一个是完全的 Python 实现,另一个是基于 Rust 库 [🤗 Tokenizers](https://github.com/huggingface/tokenizers) 的“Fast”实现。"Fast" 实现允许:
|
||||
|
||||
1. 在批量分词时显著提速
|
||||
2. 在原始字符串(字符和单词)和token空间之间进行映射的其他方法(例如,获取包含给定字符的token的索引或与给定token对应的字符范围)。
|
||||
|
||||
基类 [PreTrainedTokenizer] 和 [PreTrained TokenizerFast] 实现了在模型输入中编码字符串输入的常用方法(见下文),并从本地文件或目录或从库提供的预训练的 tokenizer(从 HuggingFace 的 AWS S3 存储库下载)实例化/保存 python 和“Fast” tokenizer。它们都依赖于包含常用方法的 [`~tokenization_utils_base.PreTrainedTokenizerBase`]和[`~tokenization_utils_base.SpecialTokensMixin`]。
|
||||
|
||||
因此,[`PreTrainedTokenizer`] 和 [`PreTrainedTokenizerFast`] 实现了使用所有tokenizers的主要方法:
|
||||
|
||||
- 分词(将字符串拆分为子词标记字符串),将tokens字符串转换为id并转换回来,以及编码/解码(即标记化并转换为整数)。
|
||||
- 以独立于底层结构(BPE、SentencePiece……)的方式向词汇表中添加新tokens。
|
||||
- 管理特殊tokens(如mask、句首等):添加它们,将它们分配给tokenizer中的属性以便于访问,并确保它们在标记过程中不会被分割。
|
||||
|
||||
[`BatchEncoding`] 包含 [`~tokenization_utils_base.PreTrainedTokenizerBase`] 的编码方法(`__call__`、`encode_plus` 和 `batch_encode_plus`)的输出,并且是从 Python 字典派生的。当tokenizer是纯 Python tokenizer时,此类的行为就像标准的 Python 字典一样,并保存这些方法计算的各种模型输入(`input_ids`、`attention_mask` 等)。当分词器是“Fast”分词器时(即由 HuggingFace 的 [tokenizers 库](https://github.com/huggingface/tokenizers) 支持),此类还提供了几种高级对齐方法,可用于在原始字符串(字符和单词)与token空间之间进行映射(例如,获取包含给定字符的token的索引或与给定token对应的字符范围)。
|
||||
|
||||
|
||||
## PreTrainedTokenizer
|
||||
|
||||
[[autodoc]] PreTrainedTokenizer
|
||||
- __call__
|
||||
- add_tokens
|
||||
- add_special_tokens
|
||||
- apply_chat_template
|
||||
- batch_decode
|
||||
- decode
|
||||
- encode
|
||||
- push_to_hub
|
||||
- all
|
||||
|
||||
## PreTrainedTokenizerFast
|
||||
|
||||
[`PreTrainedTokenizerFast`] 依赖于 [tokenizers](https://huggingface.co/docs/tokenizers) 库。可以非常简单地将从 🤗 tokenizers 库获取的tokenizers加载到 🤗 transformers 中。查看 [使用 🤗 tokenizers 的分词器](../fast_tokenizers) 页面以了解如何执行此操作。
|
||||
|
||||
[[autodoc]] PreTrainedTokenizerFast
|
||||
- __call__
|
||||
- add_tokens
|
||||
- add_special_tokens
|
||||
- apply_chat_template
|
||||
- batch_decode
|
||||
- decode
|
||||
- encode
|
||||
- push_to_hub
|
||||
- all
|
||||
|
||||
## BatchEncoding
|
||||
|
||||
[[autodoc]] BatchEncoding
|
||||
665
transformers/docs/source/zh/main_classes/trainer.md
Normal file
665
transformers/docs/source/zh/main_classes/trainer.md
Normal file
@@ -0,0 +1,665 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Trainer
|
||||
|
||||
[`Trainer`] 类提供了一个 PyTorch 的 API,用于处理大多数标准用例的全功能训练。它在大多数[示例脚本](https://github.com/huggingface/transformers/tree/main/examples)中被使用。
|
||||
|
||||
<Tip>
|
||||
|
||||
如果你想要使用自回归技术在文本数据集上微调像 Llama-2 或 Mistral 这样的语言模型,考虑使用 [`trl`](https://github.com/huggingface/trl) 的 [`~trl.SFTTrainer`]。[`~trl.SFTTrainer`] 封装了 [`Trainer`],专门针对这个特定任务进行了优化,并支持序列打包、LoRA、量化和 DeepSpeed,以有效扩展到任何模型大小。另一方面,[`Trainer`] 是一个更通用的选项,适用于更广泛的任务。
|
||||
|
||||
</Tip>
|
||||
|
||||
在实例化你的 [`Trainer`] 之前,创建一个 [`TrainingArguments`],以便在训练期间访问所有定制点。
|
||||
|
||||
这个 API 支持在多个 GPU/TPU 上进行分布式训练,支持 [NVIDIA Apex](https://github.com/NVIDIA/apex) 的混合精度和 PyTorch 的原生 AMP。
|
||||
|
||||
[`Trainer`] 包含基本的训练循环,支持上述功能。如果需要自定义训练,你可以继承 `Trainer` 并覆盖以下方法:
|
||||
|
||||
- **get_train_dataloader** -- 创建训练 DataLoader。
|
||||
- **get_eval_dataloader** -- 创建评估 DataLoader。
|
||||
- **get_test_dataloader** -- 创建测试 DataLoader。
|
||||
- **log** -- 记录观察训练的各种对象的信息。
|
||||
- **create_optimizer_and_scheduler** -- 如果它们没有在初始化时传递,请设置优化器和学习率调度器。请注意,你还可以单独继承或覆盖 `create_optimizer` 和 `create_scheduler` 方法。
|
||||
- **create_optimizer** -- 如果在初始化时没有传递,则设置优化器。
|
||||
- **create_scheduler** -- 如果在初始化时没有传递,则设置学习率调度器。
|
||||
- **compute_loss** - 计算单批训练输入的损失。
|
||||
- **training_step** -- 执行一步训练。
|
||||
- **prediction_step** -- 执行一步评估/测试。
|
||||
- **evaluate** -- 运行评估循环并返回指标。
|
||||
- **predict** -- 返回在测试集上的预测(如果有标签,则包括指标)。
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
[`Trainer`] 类被优化用于 🤗 Transformers 模型,并在你在其他模型上使用时可能会有一些令人惊讶的结果。当在你自己的模型上使用时,请确保:
|
||||
|
||||
- 你的模型始终返回元组或 [`~utils.ModelOutput`] 的子类。
|
||||
- 如果提供了 `labels` 参数,你的模型可以计算损失,并且损失作为元组的第一个元素返回(如果你的模型返回元组)。
|
||||
- 你的模型可以接受多个标签参数(在 [`TrainingArguments`] 中使用 `label_names` 将它们的名称指示给 [`Trainer`]),但它们中没有一个应该被命名为 `"label"`。
|
||||
|
||||
</Tip>
|
||||
|
||||
以下是如何自定义 [`Trainer`] 以使用加权损失的示例(在训练集不平衡时很有用):
|
||||
|
||||
```python
|
||||
from torch import nn
|
||||
from transformers import Trainer
|
||||
|
||||
|
||||
class CustomTrainer(Trainer):
|
||||
def compute_loss(self, model, inputs, return_outputs=False):
|
||||
labels = inputs.pop("labels")
|
||||
# forward pass
|
||||
outputs = model(**inputs)
|
||||
logits = outputs.get("logits")
|
||||
# compute custom loss (suppose one has 3 labels with different weights)
|
||||
loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0], device=model.device))
|
||||
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
|
||||
return (loss, outputs) if return_outputs else loss
|
||||
```
|
||||
|
||||
在 PyTorch [`Trainer`] 中自定义训练循环行为的另一种方法是使用 [callbacks](callback),这些回调可以检查训练循环状态(用于进度报告、在 TensorBoard 或其他 ML 平台上记录日志等)并做出决策(比如提前停止)。
|
||||
|
||||
|
||||
## Trainer
|
||||
|
||||
[[autodoc]] Trainer - all
|
||||
|
||||
## Seq2SeqTrainer
|
||||
|
||||
[[autodoc]] Seq2SeqTrainer - evaluate - predict
|
||||
|
||||
## TrainingArguments
|
||||
|
||||
[[autodoc]] TrainingArguments - all
|
||||
|
||||
## Seq2SeqTrainingArguments
|
||||
|
||||
[[autodoc]] Seq2SeqTrainingArguments - all
|
||||
|
||||
## Checkpoints
|
||||
|
||||
默认情况下,[`Trainer`] 会将所有checkpoints保存在你使用的 [`TrainingArguments`] 中设置的 `output_dir` 中。这些checkpoints将位于名为 `checkpoint-xxx` 的子文件夹中,xxx 是训练的步骤。
|
||||
|
||||
从checkpoints恢复训练可以通过调用 [`Trainer.train`] 时使用以下任一方式进行:
|
||||
|
||||
- `resume_from_checkpoint=True`,这将从最新的checkpoint恢复训练。
|
||||
- `resume_from_checkpoint=checkpoint_dir`,这将从指定目录中的特定checkpoint恢复训练。
|
||||
|
||||
此外,当使用 `push_to_hub=True` 时,你可以轻松将checkpoints保存在 Model Hub 中。默认情况下,保存在训练中间过程的checkpoints中的所有模型都保存在不同的提交中,但不包括优化器状态。你可以根据需要调整 [`TrainingArguments`] 的 `hub-strategy` 值:
|
||||
|
||||
- `"checkpoint"`: 最新的checkpoint也被推送到一个名为 last-checkpoint 的子文件夹中,让你可以通过 `trainer.train(resume_from_checkpoint="output_dir/last-checkpoint")` 轻松恢复训练。
|
||||
- `"all_checkpoints"`: 所有checkpoints都像它们出现在输出文件夹中一样被推送(因此你将在最终存储库中的每个文件夹中获得一个checkpoint文件夹)。
|
||||
|
||||
## Logging
|
||||
|
||||
默认情况下,[`Trainer`] 将对主进程使用 `logging.INFO`,对副本(如果有的话)使用 `logging.WARNING`。
|
||||
|
||||
可以通过 [`TrainingArguments`] 的参数覆盖这些默认设置,使用其中的 5 个 `logging` 级别:
|
||||
|
||||
- `log_level` - 用于主进程
|
||||
- `log_level_replica` - 用于副本
|
||||
|
||||
此外,如果 [`TrainingArguments`] 的 `log_on_each_node` 设置为 `False`,则只有主节点将使用其主进程的日志级别设置,所有其他节点将使用副本的日志级别设置。
|
||||
|
||||
请注意,[`Trainer`] 将在其 [`Trainer.__init__`] 中分别为每个节点设置 `transformers` 的日志级别。因此,如果在创建 [`Trainer`] 对象之前要调用其他 `transformers` 功能,可能需要更早地设置这一点(请参见下面的示例)。
|
||||
|
||||
以下是如何在应用程序中使用的示例:
|
||||
|
||||
```python
|
||||
[...]
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Setup logging
|
||||
logging.basicConfig(
|
||||
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
||||
datefmt="%m/%d/%Y %H:%M:%S",
|
||||
handlers=[logging.StreamHandler(sys.stdout)],
|
||||
)
|
||||
|
||||
# set the main code and the modules it uses to the same log-level according to the node
|
||||
log_level = training_args.get_process_log_level()
|
||||
logger.setLevel(log_level)
|
||||
datasets.utils.logging.set_verbosity(log_level)
|
||||
transformers.utils.logging.set_verbosity(log_level)
|
||||
|
||||
trainer = Trainer(...)
|
||||
```
|
||||
|
||||
然后,如果你只想在主节点上看到警告,并且所有其他节点不打印任何可能重复的警告,可以这样运行:
|
||||
|
||||
```bash
|
||||
my_app.py ... --log_level warning --log_level_replica error
|
||||
```
|
||||
|
||||
在多节点环境中,如果你也不希望每个节点的主进程的日志重复输出,你需要将上面的代码更改为:
|
||||
|
||||
```bash
|
||||
my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
|
||||
```
|
||||
|
||||
然后,只有第一个节点的主进程将以 "warning" 级别记录日志,主节点上的所有其他进程和其他节点上的所有进程将以 "error" 级别记录日志。
|
||||
|
||||
如果你希望应用程序尽可能”安静“,可以执行以下操作:
|
||||
|
||||
|
||||
```bash
|
||||
my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
|
||||
```
|
||||
|
||||
(如果在多节点环境,添加 `--log_on_each_node 0`)
|
||||
|
||||
|
||||
## 随机性
|
||||
|
||||
当从 [`Trainer`] 生成的checkpoint恢复训练时,程序会尽一切努力将 _python_、_numpy_ 和 _pytorch_ 的 RNG(随机数生成器)状态恢复为保存检查点时的状态,这样可以使“停止和恢复”式训练尽可能接近“非停止式”训练。
|
||||
|
||||
然而,由于各种默认的非确定性 PyTorch 设置,这可能无法完全实现。如果你想要完全确定性,请参阅[控制随机源](https://pytorch.org/docs/stable/notes/randomness)。正如文档中所解释的那样,使事物变得确定的一些设置(例如 `torch.backends.cudnn.deterministic`)可能会减慢速度,因此不能默认执行,但如果需要,你可以自行启用这些设置。
|
||||
|
||||
|
||||
## 特定GPU选择
|
||||
|
||||
让我们讨论一下如何告诉你的程序应该使用哪些 GPU 以及使用的顺序。
|
||||
|
||||
当使用 [`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) 且仅使用部分 GPU 时,你只需指定要使用的 GPU 数量。例如,如果你有 4 个 GPU,但只想使用前 2 个,可以执行以下操作:
|
||||
|
||||
|
||||
```bash
|
||||
python -m torch.distributed.launch --nproc_per_node=2 trainer-program.py ...
|
||||
```
|
||||
|
||||
如果你安装了 [`accelerate`](https://github.com/huggingface/accelerate) 或 [`deepspeed`](https://github.com/deepspeedai/DeepSpeed),你还可以通过以下任一方法实现相同的效果:
|
||||
|
||||
|
||||
```bash
|
||||
accelerate launch --num_processes 2 trainer-program.py ...
|
||||
```
|
||||
|
||||
```bash
|
||||
deepspeed --num_gpus 2 trainer-program.py ...
|
||||
```
|
||||
|
||||
你不需要使用 Accelerate 或 [Deepspeed 集成](Deepspeed) 功能来使用这些启动器。
|
||||
|
||||
到目前为止,你已经能够告诉程序要使用多少个 GPU。现在让我们讨论如何选择特定的 GPU 并控制它们的顺序。
|
||||
|
||||
以下环境变量可帮助你控制使用哪些 GPU 以及它们的顺序。
|
||||
|
||||
|
||||
**`CUDA_VISIBLE_DEVICES`**
|
||||
|
||||
如果你有多个 GPU,想要仅使用其中的一个或几个 GPU,请将环境变量 `CUDA_VISIBLE_DEVICES` 设置为要使用的 GPU 列表。
|
||||
|
||||
例如,假设你有 4 个 GPU:0、1、2 和 3。要仅在物理 GPU 0 和 2 上运行,你可以执行以下操作:
|
||||
|
||||
|
||||
```bash
|
||||
CUDA_VISIBLE_DEVICES=0,2 python -m torch.distributed.launch trainer-program.py ...
|
||||
```
|
||||
|
||||
现在,PyTorch 将只看到 2 个 GPU,其中你的物理 GPU 0 和 2 分别映射到 `cuda:0` 和 `cuda:1`。
|
||||
|
||||
你甚至可以改变它们的顺序:
|
||||
|
||||
|
||||
```bash
|
||||
CUDA_VISIBLE_DEVICES=2,0 python -m torch.distributed.launch trainer-program.py ...
|
||||
```
|
||||
|
||||
这里,你的物理 GPU 0 和 2 分别映射到 `cuda:1` 和 `cuda:0`。
|
||||
|
||||
上面的例子都是针对 `DistributedDataParallel` 使用模式的,但同样的方法也适用于 [`DataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html):
|
||||
|
||||
|
||||
```bash
|
||||
CUDA_VISIBLE_DEVICES=2,0 python trainer-program.py ...
|
||||
```
|
||||
|
||||
为了模拟没有 GPU 的环境,只需将此环境变量设置为空值,如下所示:
|
||||
|
||||
```bash
|
||||
CUDA_VISIBLE_DEVICES= python trainer-program.py ...
|
||||
```
|
||||
|
||||
与任何环境变量一样,你当然可以将其export到环境变量而不是将其添加到命令行,如下所示:
|
||||
|
||||
|
||||
```bash
|
||||
export CUDA_VISIBLE_DEVICES=0,2
|
||||
python -m torch.distributed.launch trainer-program.py ...
|
||||
```
|
||||
|
||||
这种方法可能会令人困惑,因为你可能会忘记之前设置了环境变量,进而不明白为什么会使用错误的 GPU。因此,在同一命令行中仅为特定运行设置环境变量是一种常见做法,正如本节大多数示例所示。
|
||||
|
||||
|
||||
**`CUDA_DEVICE_ORDER`**
|
||||
|
||||
还有一个额外的环境变量 `CUDA_DEVICE_ORDER`,用于控制物理设备的排序方式。有两个选择:
|
||||
|
||||
1. 按 PCIe 总线 ID 排序(与 nvidia-smi 的顺序相匹配)- 这是默认选项。
|
||||
|
||||
|
||||
```bash
|
||||
export CUDA_DEVICE_ORDER=PCI_BUS_ID
|
||||
```
|
||||
|
||||
2. 按 GPU 计算能力排序。
|
||||
|
||||
```bash
|
||||
export CUDA_DEVICE_ORDER=FASTEST_FIRST
|
||||
```
|
||||
|
||||
大多数情况下,你不需要关心这个环境变量,但如果你的设置不均匀,那么这将非常有用,例如,您的旧 GPU 和新 GPU 物理上安装在一起,但让速度较慢的旧卡排在运行的第一位。解决这个问题的一种方法是交换卡的位置。但如果不能交换卡(例如,如果设备的散热受到影响),那么设置 `CUDA_DEVICE_ORDER=FASTEST_FIRST` 将始终将较新、更快的卡放在第一位。但这可能会有点混乱,因为 `nvidia-smi` 仍然会按照 PCIe 顺序报告它们。
|
||||
|
||||
交换卡的顺序的另一种方法是使用:
|
||||
|
||||
|
||||
```bash
|
||||
export CUDA_VISIBLE_DEVICES=1,0
|
||||
```
|
||||
|
||||
在此示例中,我们只使用了 2 个 GPU,但是当然,对于计算机上有的任何数量的 GPU,都适用相同的方法。
|
||||
|
||||
此外,如果你设置了这个环境变量,最好将其设置在 `~/.bashrc` 文件或其他启动配置文件中,然后就可以忘记它了。
|
||||
|
||||
|
||||
## Trainer集成
|
||||
|
||||
[`Trainer`] 已经被扩展,以支持可能显著提高训练时间并适应更大模型的库。
|
||||
|
||||
目前,它支持第三方解决方案 [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) 和 [PyTorch FSDP](https://pytorch.org/docs/stable/fsdp.html),它们实现了论文 [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, by Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He](https://huggingface.co/papers/1910.02054) 的部分内容。
|
||||
|
||||
截至撰写本文,此提供的支持是新的且实验性的。尽管我们欢迎围绕 DeepSpeed 和 PyTorch FSDP 的issues,但我们不再支持 FairScale 集成,因为它已经集成到了 PyTorch 主线(参见 [PyTorch FSDP 集成](#pytorch-fully-sharded-data-parallel))。
|
||||
|
||||
|
||||
<a id='zero-install-notes'></a>
|
||||
|
||||
### CUDA拓展安装注意事项
|
||||
|
||||
|
||||
撰写时,Deepspeed 需要在使用之前编译 CUDA C++ 代码。
|
||||
|
||||
虽然所有安装问题都应通过 [Deepspeed](https://github.com/deepspeedai/DeepSpeed/issues) 的 GitHub Issues处理,但在构建依赖CUDA 扩展的任何 PyTorch 扩展时,可能会遇到一些常见问题。
|
||||
|
||||
因此,如果在执行以下操作时遇到与 CUDA 相关的构建问题:
|
||||
|
||||
|
||||
```bash
|
||||
pip install deepspeed
|
||||
```
|
||||
|
||||
请首先阅读以下说明。
|
||||
|
||||
在这些说明中,我们提供了在 `pytorch` 使用 CUDA `10.2` 构建时应采取的操作示例。如果你的情况有所不同,请记得将版本号调整为您所需的版本。
|
||||
|
||||
|
||||
#### 可能的问题 #1
|
||||
|
||||
尽管 PyTorch 自带了其自己的 CUDA 工具包,但要构建这两个项目,你必须在整个系统上安装相同版本的 CUDA。
|
||||
|
||||
例如,如果你在 Python 环境中使用 `cudatoolkit==10.2` 安装了 `pytorch`,你还需要在整个系统上安装 CUDA `10.2`。
|
||||
|
||||
确切的位置可能因系统而异,但在许多 Unix 系统上,`/usr/local/cuda-10.2` 是最常见的位置。当 CUDA 正确设置并添加到 `PATH` 环境变量时,可以通过执行以下命令找到安装位置:
|
||||
|
||||
|
||||
```bash
|
||||
which nvcc
|
||||
```
|
||||
|
||||
如果你尚未在整个系统上安装 CUDA,请首先安装。你可以使用你喜欢的搜索引擎查找说明。例如,如果你使用的是 Ubuntu,你可能想搜索:[ubuntu cuda 10.2 install](https://www.google.com/search?q=ubuntu+cuda+10.2+install)。
|
||||
|
||||
|
||||
#### 可能的问题 #2
|
||||
|
||||
另一个可能的常见问题是你可能在整个系统上安装了多个 CUDA 工具包。例如,你可能有:
|
||||
|
||||
|
||||
```bash
|
||||
/usr/local/cuda-10.2
|
||||
/usr/local/cuda-11.0
|
||||
```
|
||||
|
||||
在这种情况下,你需要确保 `PATH` 和 `LD_LIBRARY_PATH` 环境变量包含所需 CUDA 版本的正确路径。通常,软件包安装程序将设置这些变量以包含最新安装的版本。如果遇到构建失败的问题,且是因为在整个系统安装但软件仍找不到正确的 CUDA 版本,这意味着你需要调整这两个环境变量。
|
||||
|
||||
首先,你以查看它们的内容:
|
||||
|
||||
|
||||
```bash
|
||||
echo $PATH
|
||||
echo $LD_LIBRARY_PATH
|
||||
```
|
||||
|
||||
因此,您可以了解其中的内容。
|
||||
|
||||
`LD_LIBRARY_PATH` 可能是空的。
|
||||
|
||||
`PATH` 列出了可以找到可执行文件的位置,而 `LD_LIBRARY_PATH` 用于查找共享库。在这两种情况下,较早的条目优先于较后的条目。 `:` 用于分隔多个条目。
|
||||
|
||||
现在,为了告诉构建程序在哪里找到特定的 CUDA 工具包,请插入所需的路径,让其首先列出:
|
||||
|
||||
|
||||
```bash
|
||||
export PATH=/usr/local/cuda-10.2/bin:$PATH
|
||||
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
|
||||
```
|
||||
|
||||
请注意,我们没有覆盖现有值,而是在前面添加新的值。
|
||||
|
||||
当然,根据需要调整版本号和完整路径。检查你分配的目录是否实际存在。`lib64` 子目录是各种 CUDA `.so` 对象(如 `libcudart.so`)的位置,这个名字可能在你的系统中是不同的,如果是,请调整以反映实际情况。
|
||||
|
||||
|
||||
#### 可能的问题 #3
|
||||
|
||||
一些较旧的 CUDA 版本可能会拒绝使用更新的编译器。例如,你可能有 `gcc-9`,但 CUDA 可能需要 `gcc-7`。
|
||||
|
||||
有各种方法可以解决这个问题。
|
||||
|
||||
如果你可以安装最新的 CUDA 工具包,通常它应该支持更新的编译器。
|
||||
|
||||
或者,你可以在已经拥有的编译器版本之外安装较低版本,或者你可能已经安装了它但它不是默认的编译器,因此构建系统无法找到它。如果你已经安装了 `gcc-7` 但构建系统找不到它,以下操作可能会解决问题:
|
||||
|
||||
|
||||
```bash
|
||||
sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.2/bin/gcc
|
||||
sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.2/bin/g++
|
||||
```
|
||||
|
||||
这里,我们正在从 `/usr/local/cuda-10.2/bin/gcc` 创建到 `gcc-7` 的软链接,由于 `/usr/local/cuda-10.2/bin/` 应该在 `PATH` 环境变量中(参见前一个问题的解决方案),它应该能够找到 `gcc-7`(和 `g++7`),然后构建将成功。
|
||||
|
||||
与往常一样,请确保编辑示例中的路径以匹配你的情况。
|
||||
|
||||
|
||||
|
||||
### PyTorch完全分片数据并行(FSDP)
|
||||
|
||||
为了加速在更大批次大小上训练庞大模型,我们可以使用完全分片的数据并行模型。这种数据并行范例通过对优化器状态、梯度和参数进行分片,实现了在更多数据和更大模型上的训练。要了解更多信息以及其优势,请查看[完全分片的数据并行博客](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/)。我们已经集成了最新的PyTorch完全分片的数据并行(FSDP)训练功能。您只需通过配置启用它。
|
||||
|
||||
**FSDP支持所需的PyTorch版本**: PyTorch Nightly(或者如果你在发布后阅读这个,使用1.12.0版本,因为带有激活的FSDP的模型保存仅在最近的修复中可用。
|
||||
|
||||
|
||||
**用法**:
|
||||
|
||||
- 如果你尚未使用过分布式启动器,确保你已经添加了它 `-m torch.distributed.launch --nproc_per_node=NUMBER_OF_GPUS_YOU_HAVE`。
|
||||
|
||||
- **分片策略**:
|
||||
- FULL_SHARD:在数据并行线程/GPU之间,对优化器状态、梯度和模型参数进行分片。
|
||||
为此,请在命令行参数中添加 `--fsdp full_shard`。
|
||||
- SHARD_GRAD_OP:在数据并行线程/GPU之间对优化器状态和梯度进行分片。
|
||||
为此,请在命令行参数中添加 `--fsdp shard_grad_op`。
|
||||
- NO_SHARD:不进行分片。为此,请在命令行参数中添加 `--fsdp no_shard`。
|
||||
- 要将参数和梯度卸载到CPU,添加 `--fsdp "full_shard offload"` 或 `--fsdp "shard_grad_op offload"` 到命令行参数中。
|
||||
- 要使用 `default_auto_wrap_policy` 自动递归地用FSDP包装层,请添加 `--fsdp "full_shard auto_wrap"` 或 `--fsdp "shard_grad_op auto_wrap"` 到命令行参数中。
|
||||
- 要同时启用CPU卸载和自动包装层工具,请添加 `--fsdp "full_shard offload auto_wrap"` 或 `--fsdp "shard_grad_op offload auto_wrap"` 到命令行参数中。
|
||||
- 其余的FSDP配置通过 `--fsdp_config <path_to_fsdp_config.json>` 传递。它可以是FSDP json配置文件的位置(例如,`fsdp_config.json`)或已加载的json文件作为 `dict`。
|
||||
- 如果启用了自动包装,您可以使用基于transformer的自动包装策略或基于大小的自动包装策略。
|
||||
- 对于基于transformer的自动包装策略,建议在配置文件中指定 `fsdp_transformer_layer_cls_to_wrap`。如果未指定,则默认值为 `model._no_split_modules`(如果可用)。这将指定要包装的transformer层类名(区分大小写),例如 [`BertLayer`]、[`GPTJBlock`]、[`T5Block`] 等。这很重要,因为共享权重的子模块(例如,embedding层)不应最终出现在不同的FSDP包装单元中。使用此策略,每个包装的块将包含多头注意力和后面的几个MLP层。剩余的层,包括共享的embedding层,都将被方便地包装在同一个最外层的FSDP单元中。因此,对于基于transformer的模型,请使用这个方法。
|
||||
- 对于基于大小的自动包装策略,请在配置文件中添加 `fsdp_min_num_params`。它指定了FSDP进行自动包装的最小参数数量。
|
||||
- 可以在配置文件中指定 `fsdp_backward_prefetch`。它控制何时预取下一组参数。`backward_pre` 和 `backward_pos` 是可用的选项。有关更多信息,请参阅 `torch.distributed.fsdp.fully_sharded_data_parallel.BackwardPrefetch`
|
||||
- 可以在配置文件中指定 `fsdp_forward_prefetch`。它控制何时预取下一组参数。如果是`"True"`,在执行前向传递时,FSDP明确地预取下一次即将发生的全局聚集。
|
||||
- 可以在配置文件中指定 `limit_all_gathers`。如果是`"True"`,FSDP明确地同步CPU线程,以防止太多的进行中的全局聚集。
|
||||
- 可以在配置文件中指定 `activation_checkpointing`。如果是`"True"`,FSDP activation checkpoint是一种通过清除某些层的激活值并在反向传递期间重新计算它们来减少内存使用的技术。实际上,这以更多的计算时间为代价减少了内存使用。
|
||||
|
||||
|
||||
**需要注意几个注意事项**
|
||||
- 它与 `generate` 不兼容,因此与所有seq2seq/clm脚本(翻译/摘要/clm等)中的 `--predict_with_generate` 不兼容。请参阅issue[#21667](https://github.com/huggingface/transformers/issues/21667)。
|
||||
|
||||
|
||||
### PyTorch/XLA 完全分片数据并行
|
||||
|
||||
对于所有TPU用户,有个好消息!PyTorch/XLA现在支持FSDP。所有最新的完全分片数据并行(FSDP)训练都受支持。有关更多信息,请参阅[在云端TPU上使用FSDP扩展PyTorch模型](https://pytorch.org/blog/scaling-pytorch-models-on-cloud-tpus-with-fsdp/)和[PyTorch/XLA FSDP的实现](https://github.com/pytorch/xla/tree/master/torch_xla/distributed/fsdp)。使用它只需通过配置启用。
|
||||
|
||||
**需要的 PyTorch/XLA 版本以支持 FSDP**:>=2.0
|
||||
|
||||
**用法**:
|
||||
|
||||
传递 `--fsdp "full shard"`,同时对 `--fsdp_config <path_to_fsdp_config.json>` 进行以下更改:
|
||||
- `xla` 应设置为 `True` 以启用 PyTorch/XLA FSDP。
|
||||
- `xla_fsdp_settings` 的值是一个字典,存储 XLA FSDP 封装参数。完整的选项列表,请参见[此处](https://github.com/pytorch/xla/blob/master/torch_xla/distributed/fsdp/xla_fully_sharded_data_parallel.py)。
|
||||
- `xla_fsdp_grad_ckpt`。当 `True` 时,在每个嵌套的 XLA FSDP 封装层上使用梯度checkpoint。该设置只能在将 xla 标志设置为 true,并通过 `fsdp_min_num_params` 或 `fsdp_transformer_layer_cls_to_wrap` 指定自动包装策略时使用。
|
||||
- 您可以使用基于transformer的自动包装策略或基于大小的自动包装策略。
|
||||
- 对于基于transformer的自动包装策略,建议在配置文件中指定 `fsdp_transformer_layer_cls_to_wrap`。如果未指定,默认值为 `model._no_split_modules`(如果可用)。这指定了要包装的transformer层类名列表(区分大小写),例如 [`BertLayer`]、[`GPTJBlock`]、[`T5Block`] 等。这很重要,因为共享权重的子模块(例如,embedding层)不应最终出现在不同的FSDP包装单元中。使用此策略,每个包装的块将包含多头注意力和后面的几个MLP层。剩余的层,包括共享的embedding层,都将被方便地包装在同一个最外层的FSDP单元中。因此,对于基于transformer的模型,请使用这个方法。
|
||||
- 对于基于大小的自动包装策略,请在配置文件中添加 `fsdp_min_num_params`。它指定了自动包装的 FSDP 的最小参数数量。
|
||||
|
||||
|
||||
### 在 Mac 上使用 Trainer 进行加速的 PyTorch 训练
|
||||
|
||||
随着 PyTorch v1.12 版本的发布,开发人员和研究人员可以利用 Apple Silicon GPU 进行显著更快的模型训练。这使得可以在 Mac 上本地执行原型设计和微调等机器学习工作流程。Apple 的 Metal Performance Shaders(MPS)作为 PyTorch 的后端实现了这一点,并且可以通过新的 `"mps"` 设备来使用。
|
||||
这将在 MPS 图形框架上映射计算图和神经图元,并使用 MPS 提供的优化内核。更多信息,请参阅官方文档 [Introducing Accelerated PyTorch Training on Mac](https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/) 和 [MPS BACKEND](https://pytorch.org/docs/stable/notes/mps.html)。
|
||||
|
||||
|
||||
<Tip warning={false}>
|
||||
|
||||
我们强烈建议在你的 MacOS 机器上安装 PyTorch >= 1.13(在撰写本文时为最新版本)。对于基于 transformer 的模型, 它提供与模型正确性和性能改进相关的重大修复。有关更多详细信息,请参阅[pytorch/pytorch#82707](https://github.com/pytorch/pytorch/issues/82707)。
|
||||
|
||||
</Tip>
|
||||
|
||||
**使用 Apple Silicon 芯片进行训练和推理的好处**
|
||||
|
||||
1. 使用户能够在本地训练更大的网络或批量数据。
|
||||
2. 由于统一内存架构,减少数据检索延迟,并为 GPU 提供对完整内存存储的直接访问。从而提高端到端性能。
|
||||
3. 降低与基于云的开发或需要额外本地 GPU 的成本。
|
||||
|
||||
**先决条件**:要安装带有 mps 支持的 torch,请按照这篇精彩的 Medium 文章操作 [GPU-Acceleration Comes to PyTorch on M1 Macs](https://medium.com/towards-data-science/gpu-acceleration-comes-to-pytorch-on-m1-macs-195c399efcc1)。
|
||||
|
||||
**用法**:
|
||||
如果可用,`mps` 设备将默认使用,类似于使用 `cuda` 设备的方式。因此,用户无需采取任何操作。例如,您可以使用以下命令在 Apple Silicon GPU 上运行官方的 Glue 文本分类任务(从根文件夹运行):
|
||||
|
||||
```bash
|
||||
export TASK_NAME=mrpc
|
||||
|
||||
python examples/pytorch/text-classification/run_glue.py \
|
||||
--model_name_or_path google-bert/bert-base-cased \
|
||||
--task_name $TASK_NAME \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--max_seq_length 128 \
|
||||
--per_device_train_batch_size 32 \
|
||||
--learning_rate 2e-5 \
|
||||
--num_train_epochs 3 \
|
||||
--output_dir /tmp/$TASK_NAME/ \
|
||||
--overwrite_output_dir
|
||||
```
|
||||
|
||||
**需要注意的一些注意事项**
|
||||
|
||||
1. 一些 PyTorch 操作尚未在 mps 中实现,将引发错误。解决此问题的一种方法是设置环境变量 `PYTORCH_ENABLE_MPS_FALLBACK=1`,它将把这些操作回退到 CPU 进行。然而,它仍然会抛出 UserWarning 信息。
|
||||
2. 分布式设置 `gloo` 和 `nccl` 在 `mps` 设备上不起作用。这意味着当前只能使用 `mps` 设备类型的单个 GPU。
|
||||
|
||||
最后,请记住,🤗 `Trainer` 仅集成了 MPS 后端,因此如果你在使用 MPS 后端时遇到任何问题或有疑问,请在 [PyTorch GitHub](https://github.com/pytorch/pytorch/issues) 上提交问题。
|
||||
|
||||
|
||||
## 通过 Accelerate Launcher 使用 Trainer
|
||||
|
||||
Accelerate 现在支持 Trainer。用户可以期待以下内容:
|
||||
- 他们可以继续使用 Trainer 的迭代,如 FSDP、DeepSpeed 等,而无需做任何更改。
|
||||
- 现在可以在 Trainer 中使用 Accelerate Launcher(建议使用)。
|
||||
|
||||
通过 Accelerate Launcher 使用 Trainer 的步骤:
|
||||
1. 确保已安装 🤗 Accelerate,无论如何,如果没有它,你无法使用 `Trainer`。如果没有,请执行 `pip install accelerate`。你可能还需要更新 Accelerate 的版本:`pip install accelerate --upgrade`。
|
||||
2. 运行 `accelerate config` 并填写问题。以下是一些加速配置的示例:
|
||||
|
||||
a. DDP 多节点多 GPU 配置:
|
||||
|
||||
```yaml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
distributed_type: MULTI_GPU
|
||||
downcast_bf16: 'no'
|
||||
gpu_ids: all
|
||||
machine_rank: 0 #change rank as per the node
|
||||
main_process_ip: 192.168.20.1
|
||||
main_process_port: 9898
|
||||
main_training_function: main
|
||||
mixed_precision: fp16
|
||||
num_machines: 2
|
||||
num_processes: 8
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_env: []
|
||||
tpu_use_cluster: false
|
||||
tpu_use_sudo: false
|
||||
use_cpu: false
|
||||
```
|
||||
|
||||
b. FSDP 配置:
|
||||
|
||||
```yaml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
distributed_type: FSDP
|
||||
downcast_bf16: 'no'
|
||||
fsdp_config:
|
||||
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
|
||||
fsdp_backward_prefetch_policy: BACKWARD_PRE
|
||||
fsdp_forward_prefetch: true
|
||||
fsdp_offload_params: false
|
||||
fsdp_sharding_strategy: 1
|
||||
fsdp_state_dict_type: FULL_STATE_DICT
|
||||
fsdp_sync_module_states: true
|
||||
fsdp_transformer_layer_cls_to_wrap: BertLayer
|
||||
fsdp_use_orig_params: true
|
||||
machine_rank: 0
|
||||
main_training_function: main
|
||||
mixed_precision: bf16
|
||||
num_machines: 1
|
||||
num_processes: 2
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_env: []
|
||||
tpu_use_cluster: false
|
||||
tpu_use_sudo: false
|
||||
use_cpu: false
|
||||
```
|
||||
|
||||
c. 指向文件的 DeepSpeed 配置:
|
||||
|
||||
```yaml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
deepspeed_config:
|
||||
deepspeed_config_file: /home/user/configs/ds_zero3_config.json
|
||||
zero3_init_flag: true
|
||||
distributed_type: DEEPSPEED
|
||||
downcast_bf16: 'no'
|
||||
machine_rank: 0
|
||||
main_training_function: main
|
||||
num_machines: 1
|
||||
num_processes: 4
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_env: []
|
||||
tpu_use_cluster: false
|
||||
tpu_use_sudo: false
|
||||
use_cpu: false
|
||||
```
|
||||
|
||||
d. 使用 accelerate 插件的 DeepSpeed 配置:
|
||||
|
||||
```yaml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
deepspeed_config:
|
||||
gradient_accumulation_steps: 1
|
||||
gradient_clipping: 0.7
|
||||
offload_optimizer_device: cpu
|
||||
offload_param_device: cpu
|
||||
zero3_init_flag: true
|
||||
zero_stage: 2
|
||||
distributed_type: DEEPSPEED
|
||||
downcast_bf16: 'no'
|
||||
machine_rank: 0
|
||||
main_training_function: main
|
||||
mixed_precision: bf16
|
||||
num_machines: 1
|
||||
num_processes: 4
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_env: []
|
||||
tpu_use_cluster: false
|
||||
tpu_use_sudo: false
|
||||
use_cpu: false
|
||||
```
|
||||
|
||||
3. 使用accelerate配置文件参数或启动器参数以外的参数运行Trainer脚本。以下是一个使用上述FSDP配置从accelerate启动器运行`run_glue.py`的示例。
|
||||
|
||||
```bash
|
||||
cd transformers
|
||||
|
||||
accelerate launch \
|
||||
./examples/pytorch/text-classification/run_glue.py \
|
||||
--model_name_or_path google-bert/bert-base-cased \
|
||||
--task_name $TASK_NAME \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--max_seq_length 128 \
|
||||
--per_device_train_batch_size 16 \
|
||||
--learning_rate 5e-5 \
|
||||
--num_train_epochs 3 \
|
||||
--output_dir /tmp/$TASK_NAME/ \
|
||||
--overwrite_output_dir
|
||||
```
|
||||
|
||||
4. 你也可以直接使用`accelerate launch`的cmd参数。上面的示例将映射到:
|
||||
|
||||
```bash
|
||||
cd transformers
|
||||
|
||||
accelerate launch --num_processes=2 \
|
||||
--use_fsdp \
|
||||
--mixed_precision=bf16 \
|
||||
--fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
|
||||
--fsdp_transformer_layer_cls_to_wrap="BertLayer" \
|
||||
--fsdp_sharding_strategy=1 \
|
||||
--fsdp_state_dict_type=FULL_STATE_DICT \
|
||||
./examples/pytorch/text-classification/run_glue.py
|
||||
--model_name_or_path google-bert/bert-base-cased \
|
||||
--task_name $TASK_NAME \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--max_seq_length 128 \
|
||||
--per_device_train_batch_size 16 \
|
||||
--learning_rate 5e-5 \
|
||||
--num_train_epochs 3 \
|
||||
--output_dir /tmp/$TASK_NAME/ \
|
||||
--overwrite_output_dir
|
||||
```
|
||||
|
||||
有关更多信息,请参阅 🤗 Accelerate CLI 指南:[启动您的 🤗 Accelerate 脚本](https://huggingface.co/docs/accelerate/basic_tutorials/launch)。
|
||||
|
||||
已移动的部分:
|
||||
|
||||
[ <a href="./deepspeed#deepspeed-trainer-integration">DeepSpeed</a><a id="deepspeed"></a> | <a href="./deepspeed#deepspeed-installation">Installation</a><a id="installation"></a> | <a href="./deepspeed#deepspeed-multi-gpu">Deployment with multiple GPUs</a><a id="deployment-with-multiple-gpus"></a> | <a href="./deepspeed#deepspeed-one-gpu">Deployment with one GPU</a><a id="deployment-with-one-gpu"></a> | <a href="./deepspeed#deepspeed-notebook">Deployment in Notebooks</a><a id="deployment-in-notebooks"></a> | <a href="./deepspeed#deepspeed-config">Configuration</a><a id="configuration"></a> | <a href="./deepspeed#deepspeed-config-passing">Passing Configuration</a><a id="passing-configuration"></a> | <a href="./deepspeed#deepspeed-config-shared">Shared Configuration</a><a id="shared-configuration"></a> | <a href="./deepspeed#deepspeed-zero">ZeRO</a><a id="zero"></a> | <a href="./deepspeed#deepspeed-zero2-config">ZeRO-2 Config</a><a id="zero-2-config"></a> | <a href="./deepspeed#deepspeed-zero3-config">ZeRO-3 Config</a><a id="zero-3-config"></a> | <a href="./deepspeed#deepspeed-nvme">NVMe Support</a><a id="nvme-support"></a> | <a href="./deepspeed#deepspeed-zero2-zero3-performance">ZeRO-2 vs ZeRO-3 Performance</a><a id="zero-2-vs-zero-3-performance"></a> | <a href="./deepspeed#deepspeed-zero2-example">ZeRO-2 Example</a><a id="zero-2-example"></a> | <a href="./deepspeed#deepspeed-zero3-example">ZeRO-3 Example</a><a id="zero-3-example"></a> | <a href="./deepspeed#deepspeed-optimizer">Optimizer</a><a id="optimizer"></a> | <a href="./deepspeed#deepspeed-scheduler">Scheduler</a><a id="scheduler"></a> | <a href="./deepspeed#deepspeed-fp32">fp32 Precision</a><a id="fp32-precision"></a> | <a href="./deepspeed#deepspeed-amp">Automatic Mixed Precision</a><a id="automatic-mixed-precision"></a> | <a href="./deepspeed#deepspeed-bs">Batch Size</a><a id="batch-size"></a> | <a href="./deepspeed#deepspeed-grad-acc">Gradient Accumulation</a><a id="gradient-accumulation"></a> | <a href="./deepspeed#deepspeed-grad-clip">Gradient Clipping</a><a id="gradient-clipping"></a> | <a href="./deepspeed#deepspeed-weight-extraction">Getting The Model Weights Out</a><a id="getting-the-model-weights-out"></a>]
|
||||
|
||||
|
||||
## 通过 NEFTune 提升微调性能
|
||||
|
||||
NEFTune 是一种提升聊天模型性能的技术,由 Jain 等人在论文“NEFTune: Noisy Embeddings Improve Instruction Finetuning” 中引入。该技术在训练过程中向embedding向量添加噪音。根据论文摘要:
|
||||
|
||||
> 使用 Alpaca 对 LLaMA-2-7B 进行标准微调,可以在 AlpacaEval 上达到 29.79%,而使用带有噪音embedding的情况下,性能提高至 64.69%。NEFTune 还在modern instruction数据集上大大优于基线。Evol-Instruct 训练的模型表现提高了 10%,ShareGPT 提高了 8%,OpenPlatypus 提高了 8%。即使像 LLaMA-2-Chat 这样通过 RLHF 进一步细化的强大模型,通过 NEFTune 的额外训练也能受益。
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/neft-screenshot.png">
|
||||
</div>
|
||||
|
||||
要在 `Trainer` 中使用它,只需在创建 `TrainingArguments` 实例时传递 `neftune_noise_alpha`。请注意,为了避免任何意外行为,NEFTune在训练后被禁止,以此恢复原始的embedding层。
|
||||
|
||||
```python
|
||||
from transformers import Trainer, TrainingArguments
|
||||
|
||||
args = TrainingArguments(..., neftune_noise_alpha=0.1)
|
||||
trainer = Trainer(..., args=args)
|
||||
|
||||
...
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
160
transformers/docs/source/zh/model_doc/bert.md
Normal file
160
transformers/docs/source/zh/model_doc/bert.md
Normal file
@@ -0,0 +1,160 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
<div style="float: right;">
|
||||
<div class="flex flex-wrap space-x-1">
|
||||
<img alt="PyTorch" src="https://img.shields.io/badge/PyTorch-DE3412?style=flat&logo=pytorch&logoColor=white">
|
||||
<img alt="TensorFlow" src="https://img.shields.io/badge/TensorFlow-FF6F00?style=flat&logo=tensorflow&logoColor=white">
|
||||
<img alt="Flax" src="https://img.shields.io/badge/Flax-29a79b.svg?style=flat&logo=data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAC0AAAAtCAMAAAANxBKoAAAC7lBMVEUAAADg5vYHPVgAoJH+/v76+v39/f9JbLP///9+AIgAnY3///+mcqzt8fXy9fgkXa3Ax9709fr+///9/f8qXq49qp5AaLGMwrv8/P0eW60VWawxYq8yqJzG2dytt9Wyu9elzci519Lf3O3S2efY3OrY0+Xp7PT///////+dqNCexMc6Z7AGpJeGvbenstPZ5ejQ1OfJzOLa7ejh4+/r8fT29vpccbklWK8PVa0AS6ghW63O498vYa+lsdKz1NDRt9Kw1c672tbD3tnAxt7R6OHp5vDe7OrDyuDn6vLl6/EAQKak0MgATakkppo3ZK/Bz9y8w9yzu9jey97axdvHzeG21NHH4trTwthKZrVGZLSUSpuPQJiGAI+GAI8SWKydycLL4d7f2OTi1+S9xNzL0ePT6OLGzeEAo5U0qJw/aLEAo5JFa7JBabEAp5Y4qZ2QxLyKmsm3kL2xoMOehrRNb7RIbbOZgrGre68AUqwAqZqNN5aKJ5N/lMq+qsd8kMa4pcWzh7muhLMEV69juq2kbKqgUaOTR5uMMZWLLZSGAI5VAIdEAH+ovNDHuNCnxcy3qcaYx8K8msGplrx+wLahjbYdXrV6vbMvYK9DrZ8QrZ8tqJuFms+Sos6sw8ecy8RffsNVeMCvmb43aLltv7Q4Y7EZWK4QWa1gt6meZKUdr6GOAZVeA4xPAISyveLUwtivxtKTpNJ2jcqfvcltiMiwwcfAoMVxhL+Kx7xjdrqTe60tsaNQs6KaRKACrJ6UTZwkqpqTL5pkHY4AloSgsd2ptNXPvNOOncuxxsqFl8lmg8apt8FJcr9EbryGxLqlkrkrY7dRa7ZGZLQ5t6iXUZ6PPpgVpZeJCJFKAIGareTa0+KJod3H0deY2M+esM25usmYu8d2zsJOdcBVvrCLbqcAOaaHaKQAMaScWqKBXqCXMJ2RHpiLF5NmJZAdAHN2kta11dKu1M+DkcZLdb+Mcql3TppyRJdzQ5ZtNZNlIY+DF4+voCOQAAAAZ3RSTlMABAT+MEEJ/RH+/TP+Zlv+pUo6Ifz8+fco/fz6+evr39S9nJmOilQaF/7+/f38+smmoYp6b1T+/v7++vj189zU0tDJxsGzsrKSfv34+Pf27dDOysG9t6+n/vv6+vr59uzr1tG+tZ6Qg9Ym3QAABR5JREFUSMeNlVVUG1EQhpcuxEspXqS0SKEtxQp1d3d332STTRpIQhIISQgJhODu7lAoDoUCpe7u7u7+1puGpqnCPOyZvffbOXPm/PsP9JfQgyCC+tmTABTOcbxDz/heENS7/1F+9nhvkHePG0wNDLbGWwdXL+rbLWvpmZHXD8+gMfBjTh+aSe6Gnn7lwQIOTR0c8wfX3PWgv7avbdKwf/ZoBp1Gp/PvuvXW3vw5ib7emnTW4OR+3D4jB9vjNJ/7gNvfWWeH/TO/JyYrsiKCRjVEZA3UB+96kON+DxOQ/NLE8PE5iUYgIXjFnCOlxEQMaSGVxjg4gxOnEycGz8bptuNjVx08LscIgrzH3umcn+KKtiBIyvzOO2O99aAdR8cF19oZalnCtvREUw79tCd5sow1g1UKM6kXqUx4T8wsi3sTjJ3yzDmmhenLXLpo8u45eG5y4Vvbk6kkC4LLtJMowkSQxmk4ggVJEG+7c6QpHT8vvW9X7/o7+3ELmiJi2mEzZJiz8cT6TBlanBk70cB5GGIGC1gRDdZ00yADLW1FL6gqhtvNXNG5S9gdSrk4M1qu7JAsmYshzDS4peoMrU/gT7qQdqYGZaYhxZmVbGJAm/CS/HloWyhRUlknQ9KYcExTwS80d3VNOxUZJpITYyspl0LbhArhpZCD9cRWEQuhYkNGMHToQ/2Cs6swJlb39CsllxdXX6IUKh/H5jbnSsPKjgmoaFQ1f8wRLR0UnGE/RcDEjj2jXG1WVTwUs8+zxfcrVO+vSsuOpVKxCfYZiQ0/aPKuxQbQ8lIz+DClxC8u+snlcJ7Yr1z1JPqUH0V+GDXbOwAib931Y4Imaq0NTIXPXY+N5L18GJ37SVWu+hwXff8l72Ds9XuwYIBaXPq6Shm4l+Vl/5QiOlV+uTk6YR9PxKsI9xNJny31ygK1e+nIRC1N97EGkFPI+jCpiHe5PCEy7oWqWSwRrpOvhFzcbTWMbm3ZJAOn1rUKpYIt/lDhW/5RHHteeWFN60qo98YJuoq1nK3uW5AabyspC1BcIEpOhft+SZAShYoLSvnmSfnYADUERP5jJn2h5XtsgCRuhYQqAvwTwn33+YWEKUI72HX5AtfSAZDe8F2DtPPm77afhl0EkthzuCQU0BWApgQIH9+KB0JhopMM7bJrdTRoleM2JAVNMyPF+wdoaz+XJpGoVAQ7WXUkcV7gT3oUZyi/ISIJAVKhgNp+4b4veCFhYVJw4locdSjZCp9cPUhLF9EZ3KKzURepMEtCDPP3VcWFx4UIiZIklIpFNfHpdEafIF2aRmOcrUmjohbT2WUllbmRvgfbythbQO3222fpDJoufaQPncYYuqoGtUEsCJZL6/3PR5b4syeSjZMQG/T2maGANlXT2v8S4AULWaUkCxfLyW8iW4kdka+nEMjxpL2NCwsYNBp+Q61PF43zyDg9Bm9+3NNySn78jMZUUkumqE4Gp7JmFOdP1vc8PpRrzj9+wPinCy8K1PiJ4aYbnTYpCCbDkBSbzhu2QJ1Gd82t8jI8TH51+OzvXoWbnXUOBkNW+0mWFwGcGOUVpU81/n3TOHb5oMt2FgYGjzau0Nif0Ss7Q3XB33hjjQHjHA5E5aOyIQc8CBrLdQSs3j92VG+3nNEjbkbdbBr9zm04ruvw37vh0QKOdeGIkckc80fX3KH/h7PT4BOjgCty8VZ5ux1MoO5Cf5naca2LAsEgehI+drX8o/0Nu+W0m6K/I9gGPd/dfx/EN/wN62AhsBWuAAAAAElFTkSuQmCC
|
||||
">
|
||||
<img alt="SDPA" src="https://img.shields.io/badge/SDPA-DE3412?style=flat&logo=pytorch&logoColor=white">
|
||||
</div>
|
||||
</div>
|
||||
|
||||
# BERT
|
||||
|
||||
[BERT](https://huggingface.co/papers/1810.04805) 是一个在无标签的文本数据上预训练的双向 transformer,用于预测句子中被掩码的(masked) token,以及预测一个句子是否跟随在另一个句子之后。其主要思想是,在预训练过程中,通过随机掩码一些 token,让模型利用左右上下文的信息预测它们,从而获得更全面深入的理解。此外,BERT 具有很强的通用性,其学习到的语言表示可以通过额外的层或头进行微调,从而适配其他下游 NLP 任务。
|
||||
|
||||
你可以在 [BERT](https://huggingface.co/collections/google/bert-release-64ff5e7a4be99045d1896dbc) 集合下找到 BERT 的所有原始 checkpoint。
|
||||
|
||||
> [!TIP]
|
||||
> 点击右侧边栏中的 BERT 模型,以查看将 BERT 应用于不同语言任务的更多示例。
|
||||
|
||||
下面的示例演示了如何使用 [`Pipeline`], [`AutoModel`] 和命令行预测 `[MASK]` token。
|
||||
|
||||
<hfoptions id="usage">
|
||||
<hfoption id="Pipeline">
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import pipeline
|
||||
|
||||
pipeline = pipeline(
|
||||
task="fill-mask",
|
||||
model="google-bert/bert-base-uncased",
|
||||
dtype=torch.float16,
|
||||
device=0
|
||||
)
|
||||
pipeline("Plants create [MASK] through a process known as photosynthesis.")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="AutoModel">
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import AutoModelForMaskedLM, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
"google-bert/bert-base-uncased",
|
||||
)
|
||||
model = AutoModelForMaskedLM.from_pretrained(
|
||||
"google-bert/bert-base-uncased",
|
||||
dtype=torch.float16,
|
||||
device_map="auto",
|
||||
attn_implementation="sdpa"
|
||||
)
|
||||
inputs = tokenizer("Plants create [MASK] through a process known as photosynthesis.", return_tensors="pt").to("cuda")
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = model(**inputs)
|
||||
predictions = outputs.logits
|
||||
|
||||
masked_index = torch.where(inputs['input_ids'] == tokenizer.mask_token_id)[1]
|
||||
predicted_token_id = predictions[0, masked_index].argmax(dim=-1)
|
||||
predicted_token = tokenizer.decode(predicted_token_id)
|
||||
|
||||
print(f"The predicted token is: {predicted_token}")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="transformers">
|
||||
|
||||
```bash
|
||||
echo -e "Plants create [MASK] through a process known as photosynthesis." | transformers run --task fill-mask --model google-bert/bert-base-uncased --device 0
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## 注意
|
||||
|
||||
- 输入内容应在右侧进行填充,因为 BERT 使用绝对位置嵌入。
|
||||
## BertConfig
|
||||
|
||||
[[autodoc]] BertConfig
|
||||
- all
|
||||
|
||||
## BertTokenizer
|
||||
|
||||
[[autodoc]] BertTokenizer
|
||||
- build_inputs_with_special_tokens
|
||||
- get_special_tokens_mask
|
||||
- create_token_type_ids_from_sequences
|
||||
- save_vocabulary
|
||||
|
||||
## BertTokenizerFast
|
||||
|
||||
[[autodoc]] BertTokenizerFast
|
||||
|
||||
## BertModel
|
||||
|
||||
[[autodoc]] BertModel
|
||||
- forward
|
||||
|
||||
## BertForPreTraining
|
||||
|
||||
[[autodoc]] BertForPreTraining
|
||||
- forward
|
||||
|
||||
## BertLMHeadModel
|
||||
|
||||
[[autodoc]] BertLMHeadModel
|
||||
- forward
|
||||
|
||||
## BertForMaskedLM
|
||||
|
||||
[[autodoc]] BertForMaskedLM
|
||||
- forward
|
||||
|
||||
## BertForNextSentencePrediction
|
||||
|
||||
[[autodoc]] BertForNextSentencePrediction
|
||||
- forward
|
||||
|
||||
## BertForSequenceClassification
|
||||
|
||||
[[autodoc]] BertForSequenceClassification
|
||||
- forward
|
||||
|
||||
## BertForMultipleChoice
|
||||
|
||||
[[autodoc]] BertForMultipleChoice
|
||||
- forward
|
||||
|
||||
## BertForTokenClassification
|
||||
|
||||
[[autodoc]] BertForTokenClassification
|
||||
- forward
|
||||
|
||||
## BertForQuestionAnswering
|
||||
|
||||
[[autodoc]] BertForQuestionAnswering
|
||||
- forward
|
||||
|
||||
## Bert specific outputs
|
||||
|
||||
[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
|
||||
164
transformers/docs/source/zh/model_sharing.md
Normal file
164
transformers/docs/source/zh/model_sharing.md
Normal file
@@ -0,0 +1,164 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 分享模型
|
||||
|
||||
最后两个教程展示了如何使用PyTorch、Keras和 🤗 Accelerate进行分布式设置来微调模型。下一步是将您的模型与社区分享!在Hugging Face,我们相信公开分享知识和资源,能实现人工智能的普及化,让每个人都能受益。我们鼓励您将您的模型与社区分享,以帮助他人节省时间和精力。
|
||||
|
||||
在本教程中,您将学习两种在[Model Hub](https://huggingface.co/models)上共享训练好的或微调的模型的方法:
|
||||
|
||||
- 通过编程将文件推送到Hub。
|
||||
- 使用Web界面将文件拖放到Hub。
|
||||
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/XvSGPZFEjDY" title="YouTube video player"
|
||||
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
|
||||
picture-in-picture" allowfullscreen></iframe>
|
||||
|
||||
<Tip>
|
||||
|
||||
要与社区共享模型,您需要在[huggingface.co](https://huggingface.co/join)上拥有一个帐户。您还可以加入现有的组织或创建一个新的组织。
|
||||
|
||||
</Tip>
|
||||
|
||||
## 仓库功能
|
||||
|
||||
Model Hub上的每个仓库都像是一个典型的GitHub仓库。我们的仓库提供版本控制、提交历史记录以及可视化差异的能力。
|
||||
|
||||
Model Hub的内置版本控制基于git和[git-lfs](https://git-lfs.github.com/)。换句话说,您可以将一个模型视为一个仓库,从而实现更好的访问控制和可扩展性。版本控制允许使用*修订*方法来固定特定版本的模型,可以使用提交哈希值、标签或分支来标记。
|
||||
|
||||
因此,您可以通过`revision`参数加载特定的模型版本:
|
||||
|
||||
```py
|
||||
>>> model = AutoModel.from_pretrained(
|
||||
... "julien-c/EsperBERTo-small", revision="4c77982" # tag name, or branch name, or commit hash
|
||||
... )
|
||||
```
|
||||
|
||||
文件也可以轻松地在仓库中编辑,您可以查看提交历史记录以及差异:
|
||||

|
||||
|
||||
## 设置
|
||||
|
||||
在将模型共享到Hub之前,您需要拥有Hugging Face的凭证。如果您有访问终端的权限,请在安装🤗 Transformers的虚拟环境中运行以下命令。这将在您的Hugging Face缓存文件夹(默认为`~/.cache/`)中存储您的`access token`:
|
||||
|
||||
|
||||
```bash
|
||||
hf auth login
|
||||
```
|
||||
|
||||
如果您正在使用像Jupyter或Colaboratory这样的`notebook`,请确保您已安装了[`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library)库。该库允许您以编程方式与Hub进行交互。
|
||||
|
||||
```bash
|
||||
pip install huggingface_hub
|
||||
```
|
||||
然后使用`notebook_login`登录到Hub,并按照[这里](https://huggingface.co/settings/token)的链接生成一个token进行登录:
|
||||
|
||||
|
||||
```py
|
||||
>>> from huggingface_hub import notebook_login
|
||||
|
||||
>>> notebook_login()
|
||||
```
|
||||
|
||||
## 在训练过程中推送模型
|
||||
|
||||
<Youtube id="Z1-XMy-GNLQ"/>
|
||||
|
||||
将模型分享到Hub就像添加一个额外的参数或回调函数一样简单。请记住,在[微调教程](training)中,`TrainingArguments`类是您指定超参数和附加训练选项的地方。其中一项训练选项包括直接将模型推送到Hub的能力。在您的`TrainingArguments`中设置`push_to_hub=True`:
|
||||
|
||||
|
||||
```py
|
||||
>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)
|
||||
```
|
||||
|
||||
像往常一样将您的训练参数传递给[`Trainer`]:
|
||||
|
||||
```py
|
||||
>>> trainer = Trainer(
|
||||
... model=model,
|
||||
... args=training_args,
|
||||
... train_dataset=small_train_dataset,
|
||||
... eval_dataset=small_eval_dataset,
|
||||
... compute_metrics=compute_metrics,
|
||||
... )
|
||||
```
|
||||
|
||||
在您微调完模型后,在[`Trainer`]上调用[`~transformers.Trainer.push_to_hub`]将训练好的模型推送到Hub。🤗 Transformers甚至会自动将训练超参数、训练结果和框架版本添加到你的模型卡片中!
|
||||
|
||||
```py
|
||||
>>> trainer.push_to_hub()
|
||||
```
|
||||
|
||||
## 使用`push_to_hub`功能
|
||||
|
||||
您可以直接在您的模型上调用`push_to_hub`来将其上传到Hub。
|
||||
|
||||
在`push_to_hub`中指定你的模型名称:
|
||||
|
||||
```py
|
||||
>>> pt_model.push_to_hub("my-awesome-model")
|
||||
```
|
||||
|
||||
这会在您的用户名下创建一个名为`my-awesome-model`的仓库。用户现在可以使用`from_pretrained`函数加载您的模型:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModel
|
||||
|
||||
>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
|
||||
```
|
||||
|
||||
如果您属于一个组织,并希望将您的模型推送到组织名称下,只需将其添加到`repo_id`中:
|
||||
|
||||
```py
|
||||
>>> pt_model.push_to_hub("my-awesome-org/my-awesome-model")
|
||||
```
|
||||
|
||||
`push_to_hub`函数还可以用于向模型仓库添加其他文件。例如,向模型仓库中添加一个`tokenizer`:
|
||||
|
||||
```py
|
||||
>>> tokenizer.push_to_hub("my-awesome-model")
|
||||
```
|
||||
|
||||
现在,当您导航到您的Hugging Face个人资料时,您应该看到您新创建的模型仓库。点击**文件**选项卡将显示您已上传到仓库的所有文件。
|
||||
|
||||
有关如何创建和上传文件到仓库的更多详细信息,请参考Hub文档[这里](https://huggingface.co/docs/hub/how-to-upstream)。
|
||||
|
||||
|
||||
## 使用Web界面上传
|
||||
|
||||
喜欢无代码方法的用户可以通过Hugging Face的Web界面上传模型。访问[huggingface.co/new](https://huggingface.co/new)创建一个新的仓库:
|
||||
|
||||

|
||||
|
||||
从这里开始,添加一些关于您的模型的信息:
|
||||
|
||||
- 选择仓库的**所有者**。这可以是您本人或者您所属的任何组织。
|
||||
- 为您的项目选择一个名称,该名称也将成为仓库的名称。
|
||||
- 选择您的模型是公开还是私有。
|
||||
- 指定您的模型的许可证使用情况。
|
||||
|
||||
现在点击**文件**选项卡,然后点击**添加文件**按钮将一个新文件上传到你的仓库。接着拖放一个文件进行上传,并添加提交信息。
|
||||
|
||||

|
||||
|
||||
## 添加模型卡片
|
||||
|
||||
为了确保用户了解您的模型的能力、限制、潜在偏差和伦理考虑,请在仓库中添加一个模型卡片。模型卡片在`README.md`文件中定义。你可以通过以下方式添加模型卡片:
|
||||
|
||||
* 手动创建并上传一个`README.md`文件。
|
||||
* 在你的模型仓库中点击**编辑模型卡片**按钮。
|
||||
|
||||
可以参考DistilBert的[模型卡片](https://huggingface.co/distilbert/distilbert-base-uncased)来了解模型卡片应该包含的信息类型。有关您可以在`README.md`文件中控制的更多选项的细节,例如模型的碳足迹或小部件示例,请参考文档[这里](https://huggingface.co/docs/hub/models-cards)。
|
||||
178
transformers/docs/source/zh/multilingual.md
Normal file
178
transformers/docs/source/zh/multilingual.md
Normal file
@@ -0,0 +1,178 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 用于推理的多语言模型
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
🤗 Transformers 中有多种多语言模型,它们的推理用法与单语言模型不同。但是,并非*所有*的多语言模型用法都不同。一些模型,例如 [google-bert/bert-base-multilingual-uncased](https://huggingface.co/google-bert/bert-base-multilingual-uncased) 就可以像单语言模型一样使用。本指南将向您展示如何使用不同用途的多语言模型进行推理。
|
||||
|
||||
## XLM
|
||||
|
||||
XLM 有十个不同的检查点,其中只有一个是单语言的。剩下的九个检查点可以归为两类:使用语言嵌入的检查点和不使用语言嵌入的检查点。
|
||||
|
||||
### 带有语言嵌入的 XLM
|
||||
|
||||
以下 XLM 模型使用语言嵌入来指定推理中使用的语言:
|
||||
|
||||
- `FacebookAI/xlm-mlm-ende-1024` (掩码语言建模,英语-德语)
|
||||
- `FacebookAI/xlm-mlm-enfr-1024` (掩码语言建模,英语-法语)
|
||||
- `FacebookAI/xlm-mlm-enro-1024` (掩码语言建模,英语-罗马尼亚语)
|
||||
- `FacebookAI/xlm-mlm-xnli15-1024` (掩码语言建模,XNLI 数据集语言)
|
||||
- `FacebookAI/xlm-mlm-tlm-xnli15-1024` (掩码语言建模+翻译,XNLI 数据集语言)
|
||||
- `FacebookAI/xlm-clm-enfr-1024` (因果语言建模,英语-法语)
|
||||
- `FacebookAI/xlm-clm-ende-1024` (因果语言建模,英语-德语)
|
||||
|
||||
语言嵌入被表示一个张量,其形状与传递给模型的 `input_ids` 相同。这些张量中的值取决于所使用的语言,并由分词器的 `lang2id` 和 `id2lang` 属性识别。
|
||||
|
||||
在此示例中,加载 `FacebookAI/xlm-clm-enfr-1024` 检查点(因果语言建模,英语-法语):
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
|
||||
|
||||
>>> tokenizer = XLMTokenizer.from_pretrained("FacebookAI/xlm-clm-enfr-1024")
|
||||
>>> model = XLMWithLMHeadModel.from_pretrained("FacebookAI/xlm-clm-enfr-1024")
|
||||
```
|
||||
|
||||
分词器的 `lang2id` 属性显示了该模型的语言及其对应的id:
|
||||
|
||||
```py
|
||||
>>> print(tokenizer.lang2id)
|
||||
{'en': 0, 'fr': 1}
|
||||
```
|
||||
|
||||
接下来,创建一个示例输入:
|
||||
|
||||
```py
|
||||
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size 为 1
|
||||
```
|
||||
|
||||
将语言 id 设置为 `"en"` 并用其定义语言嵌入。语言嵌入是一个用 `0` 填充的张量,这个张量应该与 `input_ids` 大小相同。
|
||||
|
||||
```py
|
||||
>>> language_id = tokenizer.lang2id["en"] # 0
|
||||
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
|
||||
|
||||
>>> # 我们将其 reshape 为 (batch_size, sequence_length) 大小
|
||||
>>> langs = langs.view(1, -1) # 现在的形状是 [1, sequence_length] (我们的 batch size 为 1)
|
||||
```
|
||||
|
||||
现在,你可以将 `input_ids` 和语言嵌入传递给模型:
|
||||
|
||||
```py
|
||||
>>> outputs = model(input_ids, langs=langs)
|
||||
```
|
||||
|
||||
[run_generation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation/run_generation.py) 脚本可以使用 `xlm-clm` 检查点生成带有语言嵌入的文本。
|
||||
|
||||
### 不带语言嵌入的 XLM
|
||||
|
||||
以下 XLM 模型在推理时不需要语言嵌入:
|
||||
|
||||
- `FacebookAI/xlm-mlm-17-1280` (掩码语言建模,支持 17 种语言)
|
||||
- `FacebookAI/xlm-mlm-100-1280` (掩码语言建模,支持 100 种语言)
|
||||
|
||||
与之前的 XLM 检查点不同,这些模型用于通用句子表示。
|
||||
|
||||
## BERT
|
||||
|
||||
以下 BERT 模型可用于多语言任务:
|
||||
|
||||
- `google-bert/bert-base-multilingual-uncased` (掩码语言建模 + 下一句预测,支持 102 种语言)
|
||||
- `google-bert/bert-base-multilingual-cased` (掩码语言建模 + 下一句预测,支持 104 种语言)
|
||||
|
||||
这些模型在推理时不需要语言嵌入。它们应该能够从上下文中识别语言并进行相应的推理。
|
||||
|
||||
## XLM-RoBERTa
|
||||
|
||||
以下 XLM-RoBERTa 模型可用于多语言任务:
|
||||
|
||||
- `FacebookAI/xlm-roberta-base` (掩码语言建模,支持 100 种语言)
|
||||
- `FacebookAI/xlm-roberta-large` (掩码语言建模,支持 100 种语言)
|
||||
|
||||
XLM-RoBERTa 使用 100 种语言的 2.5TB 新创建和清理的 CommonCrawl 数据进行了训练。与之前发布的 mBERT 或 XLM 等多语言模型相比,它在分类、序列标记和问答等下游任务上提供了更强大的优势。
|
||||
|
||||
## M2M100
|
||||
|
||||
以下 M2M100 模型可用于多语言翻译:
|
||||
|
||||
- `facebook/m2m100_418M` (翻译)
|
||||
- `facebook/m2m100_1.2B` (翻译)
|
||||
|
||||
在此示例中,加载 `facebook/m2m100_418M` 检查点以将中文翻译为英文。你可以在分词器中设置源语言:
|
||||
|
||||
```py
|
||||
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
|
||||
|
||||
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
|
||||
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
|
||||
|
||||
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
|
||||
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
|
||||
```
|
||||
|
||||
对文本进行分词:
|
||||
|
||||
```py
|
||||
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
|
||||
```
|
||||
|
||||
M2M100 强制将目标语言 id 作为第一个生成的标记,以进行到目标语言的翻译。在 `generate` 方法中将 `forced_bos_token_id` 设置为 `en` 以翻译成英语:
|
||||
|
||||
```py
|
||||
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
|
||||
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
|
||||
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
|
||||
```
|
||||
|
||||
## MBart
|
||||
|
||||
以下 MBart 模型可用于多语言翻译:
|
||||
|
||||
- `facebook/mbart-large-50-one-to-many-mmt` (一对多多语言机器翻译,支持 50 种语言)
|
||||
- `facebook/mbart-large-50-many-to-many-mmt` (多对多多语言机器翻译,支持 50 种语言)
|
||||
- `facebook/mbart-large-50-many-to-one-mmt` (多对一多语言机器翻译,支持 50 种语言)
|
||||
- `facebook/mbart-large-50` (多语言翻译,支持 50 种语言)
|
||||
- `facebook/mbart-large-cc25`
|
||||
|
||||
在此示例中,加载 `facebook/mbart-large-50-many-to-many-mmt` 检查点以将芬兰语翻译为英语。 你可以在分词器中设置源语言:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
||||
|
||||
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
|
||||
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
|
||||
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
|
||||
```
|
||||
|
||||
对文本进行分词:
|
||||
|
||||
```py
|
||||
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
|
||||
```
|
||||
|
||||
MBart 强制将目标语言 id 作为第一个生成的标记,以进行到目标语言的翻译。在 `generate` 方法中将 `forced_bos_token_id` 设置为 `en` 以翻译成英语:
|
||||
|
||||
```py
|
||||
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
|
||||
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
|
||||
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
|
||||
```
|
||||
|
||||
如果你使用的是 `facebook/mbart-large-50-many-to-one-mmt` 检查点,则无需强制目标语言 id 作为第一个生成的令牌,否则用法是相同的。
|
||||
215
transformers/docs/source/zh/peft.md
Normal file
215
transformers/docs/source/zh/peft.md
Normal file
@@ -0,0 +1,215 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# 使用 🤗 PEFT 加载adapters
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
[参数高效微调(PEFT)方法](https://huggingface.co/blog/peft)在微调过程中冻结预训练模型的参数,并在其顶部添加少量可训练参数(adapters)。adapters被训练以学习特定任务的信息。这种方法已被证明非常节省内存,同时具有较低的计算使用量,同时产生与完全微调模型相当的结果。
|
||||
|
||||
使用PEFT训练的adapters通常比完整模型小一个数量级,使其方便共享、存储和加载。
|
||||
|
||||
<div class="flex flex-col justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/PEFT-hub-screenshot.png"/>
|
||||
<figcaption class="text-center">与完整尺寸的模型权重(约为700MB)相比,存储在Hub上的OPTForCausalLM模型的adapter权重仅为~6MB。</figcaption>
|
||||
</div>
|
||||
|
||||
如果您对学习更多关于🤗 PEFT库感兴趣,请查看[文档](https://huggingface.co/docs/peft/index)。
|
||||
|
||||
|
||||
## 设置
|
||||
|
||||
首先安装 🤗 PEFT:
|
||||
|
||||
```bash
|
||||
pip install peft
|
||||
```
|
||||
|
||||
如果你想尝试全新的特性,你可能会有兴趣从源代码安装这个库:
|
||||
|
||||
```bash
|
||||
pip install git+https://github.com/huggingface/peft.git
|
||||
```
|
||||
## 支持的 PEFT 模型
|
||||
|
||||
Transformers原生支持一些PEFT方法,这意味着你可以加载本地存储或在Hub上的adapter权重,并使用几行代码轻松运行或训练它们。以下是受支持的方法:
|
||||
|
||||
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
|
||||
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
|
||||
- [AdaLoRA](https://huggingface.co/papers/2303.10512)
|
||||
|
||||
如果你想使用其他PEFT方法,例如提示学习或提示微调,或者关于通用的 🤗 PEFT库,请参阅[文档](https://huggingface.co/docs/peft/index)。
|
||||
|
||||
## 加载 PEFT adapter
|
||||
|
||||
要从huggingface的Transformers库中加载并使用PEFTadapter模型,请确保Hub仓库或本地目录包含一个`adapter_config.json`文件和adapter权重,如上例所示。然后,您可以使用`AutoModelFor`类加载PEFT adapter模型。例如,要为因果语言建模加载一个PEFT adapter模型:
|
||||
|
||||
1. 指定PEFT模型id
|
||||
2. 将其传递给[`AutoModelForCausalLM`]类
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
peft_model_id = "ybelkada/opt-350m-lora"
|
||||
model = AutoModelForCausalLM.from_pretrained(peft_model_id)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
你可以使用`AutoModelFor`类或基础模型类(如`OPTForCausalLM`或`LlamaForCausalLM`)来加载一个PEFT adapter。
|
||||
|
||||
|
||||
</Tip>
|
||||
|
||||
您也可以通过`load_adapter`方法来加载 PEFT adapter。
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
model_id = "facebook/opt-350m"
|
||||
peft_model_id = "ybelkada/opt-350m-lora"
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id)
|
||||
model.load_adapter(peft_model_id)
|
||||
```
|
||||
|
||||
## 基于8bit或4bit进行加载
|
||||
|
||||
`bitsandbytes`集成支持8bit和4bit精度数据类型,这对于加载大模型非常有用,因为它可以节省内存(请参阅`bitsandbytes`[指南](./quantization#bitsandbytes-integration)以了解更多信息)。要有效地将模型分配到您的硬件,请在[`~PreTrainedModel.from_pretrained`]中添加`load_in_8bit`或`load_in_4bit`参数,并将`device_map="auto"`设置为:
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
|
||||
peft_model_id = "ybelkada/opt-350m-lora"
|
||||
model = AutoModelForCausalLM.from_pretrained(peft_model_id, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
|
||||
```
|
||||
|
||||
## 添加新的adapter
|
||||
|
||||
你可以使用[`~peft.PeftModel.add_adapter`]方法为一个已有adapter的模型添加一个新的adapter,只要新adapter的类型与当前adapter相同即可。例如,如果你有一个附加到模型上的LoRA adapter:
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
|
||||
from peft import PeftConfig
|
||||
|
||||
model_id = "facebook/opt-350m"
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id)
|
||||
|
||||
lora_config = LoraConfig(
|
||||
target_modules=["q_proj", "k_proj"],
|
||||
init_lora_weights=False
|
||||
)
|
||||
|
||||
model.add_adapter(lora_config, adapter_name="adapter_1")
|
||||
```
|
||||
|
||||
|
||||
添加一个新的adapter:
|
||||
|
||||
```py
|
||||
# attach new adapter with same config
|
||||
model.add_adapter(lora_config, adapter_name="adapter_2")
|
||||
```
|
||||
现在您可以使用[`~peft.PeftModel.set_adapter`]来设置要使用的adapter。
|
||||
|
||||
```py
|
||||
# use adapter_1
|
||||
model.set_adapter("adapter_1")
|
||||
output = model.generate(**inputs)
|
||||
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
|
||||
|
||||
# use adapter_2
|
||||
model.set_adapter("adapter_2")
|
||||
output_enabled = model.generate(**inputs)
|
||||
print(tokenizer.decode(output_enabled[0], skip_special_tokens=True))
|
||||
```
|
||||
|
||||
## 启用和禁用adapters
|
||||
一旦您将adapter添加到模型中,您可以启用或禁用adapter模块。要启用adapter模块:
|
||||
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
|
||||
from peft import PeftConfig
|
||||
|
||||
model_id = "facebook/opt-350m"
|
||||
adapter_model_id = "ybelkada/opt-350m-lora"
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
text = "Hello"
|
||||
inputs = tokenizer(text, return_tensors="pt")
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id)
|
||||
peft_config = PeftConfig.from_pretrained(adapter_model_id)
|
||||
|
||||
# to initiate with random weights
|
||||
peft_config.init_lora_weights = False
|
||||
|
||||
model.add_adapter(peft_config)
|
||||
model.enable_adapters()
|
||||
output = model.generate(**inputs)
|
||||
```
|
||||
要禁用adapter模块:
|
||||
|
||||
```py
|
||||
model.disable_adapters()
|
||||
output = model.generate(**inputs)
|
||||
```
|
||||
## 训练一个 PEFT adapter
|
||||
|
||||
PEFT适配器受[`Trainer`]类支持,因此您可以为您的特定用例训练适配器。它只需要添加几行代码即可。例如,要训练一个LoRA adapter:
|
||||
|
||||
|
||||
<Tip>
|
||||
|
||||
如果你不熟悉如何使用[`Trainer`]微调模型,请查看[微调预训练模型](training)教程。
|
||||
|
||||
</Tip>
|
||||
|
||||
1. 使用任务类型和超参数定义adapter配置(参见[`~peft.LoraConfig`]以了解超参数的详细信息)。
|
||||
|
||||
```py
|
||||
from peft import LoraConfig
|
||||
|
||||
peft_config = LoraConfig(
|
||||
lora_alpha=16,
|
||||
lora_dropout=0.1,
|
||||
r=64,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
```
|
||||
|
||||
2. 将adapter添加到模型中。
|
||||
|
||||
```py
|
||||
model.add_adapter(peft_config)
|
||||
```
|
||||
|
||||
3. 现在可以将模型传递给[`Trainer`]了!
|
||||
|
||||
```py
|
||||
trainer = Trainer(model=model, ...)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
要保存训练好的adapter并重新加载它:
|
||||
|
||||
```py
|
||||
model.save_pretrained(save_dir)
|
||||
model = AutoModelForCausalLM.from_pretrained(save_dir)
|
||||
```
|
||||
|
||||
<!--
|
||||
TODO: (@younesbelkada @stevhliu)
|
||||
- Link to PEFT docs for further details
|
||||
- Trainer
|
||||
- 8-bit / 4-bit examples ?
|
||||
-->
|
||||
156
transformers/docs/source/zh/perf_hardware.md
Normal file
156
transformers/docs/source/zh/perf_hardware.md
Normal file
@@ -0,0 +1,156 @@
|
||||
<!---
|
||||
Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
|
||||
# 训练用的定制硬件
|
||||
|
||||
您用来运行模型训练和推断的硬件可能会对性能产生重大影响。要深入了解 GPU,务必查看 Tim Dettmer 出色的[博文](https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/)。
|
||||
|
||||
让我们来看一些关于 GPU 配置的实用建议。
|
||||
|
||||
## GPU
|
||||
当你训练更大的模型时,基本上有三种选择:
|
||||
|
||||
- 更大的 GPU
|
||||
- 更多的 GPU
|
||||
- 更多的 CPU 和 NVMe(通过[DeepSpeed-Infinity](main_classes/deepspeed#nvme-support)实现)
|
||||
|
||||
让我们从只有一块GPU的情况开始。
|
||||
|
||||
### 供电和散热
|
||||
|
||||
如果您购买了昂贵的高端GPU,请确保为其提供正确的供电和足够的散热。
|
||||
|
||||
**供电**:
|
||||
|
||||
一些高端消费者级GPU卡具有2个,有时甚至3个PCI-E-8针电源插口。请确保将与插口数量相同的独立12V PCI-E-8针线缆插入卡中。不要使用同一根线缆两端的2个分叉(也称为pigtail cable)。也就是说,如果您的GPU上有2个插口,您需要使用2条PCI-E-8针线缆连接电源和卡,而不是使用一条末端有2个PCI-E-8针连接器的线缆!否则,您无法充分发挥卡的性能。
|
||||
|
||||
每个PCI-E-8针电源线缆需要插入电源侧的12V轨上,并且可以提供最多150W的功率。
|
||||
|
||||
其他一些卡可能使用PCI-E-12针连接器,这些连接器可以提供最多500-600W的功率。
|
||||
|
||||
低端卡可能使用6针连接器,这些连接器可提供最多75W的功率。
|
||||
|
||||
此外,您需要选择具有稳定电压的高端电源。一些质量较低的电源可能无法为卡提供所需的稳定电压以发挥其最大性能。
|
||||
|
||||
当然,电源还需要有足够的未使用的瓦数来为卡供电。
|
||||
|
||||
**散热**:
|
||||
|
||||
当GPU过热时,它将开始降频,不会提供完整的性能。如果温度过高,可能会缩短GPU的使用寿命。
|
||||
|
||||
当GPU负载很重时,很难确定最佳温度是多少,但任何低于+80度的温度都是好的,越低越好,也许在70-75度之间是一个非常好的范围。降频可能从大约84-90度开始。但是除了降频外,持续的高温可能会缩短GPU的使用寿命。
|
||||
|
||||
接下来让我们看一下拥有多个GPU时最重要的方面之一:连接。
|
||||
|
||||
### 多GPU连接
|
||||
|
||||
如果您使用多个GPU,则卡之间的互连方式可能会对总训练时间产生巨大影响。如果GPU位于同一物理节点上,您可以运行以下代码:
|
||||
|
||||
```bash
|
||||
nvidia-smi topo -m
|
||||
```
|
||||
|
||||
它将告诉您GPU如何互连。在具有双GPU并通过NVLink连接的机器上,您最有可能看到类似以下内容:
|
||||
|
||||
```
|
||||
GPU0 GPU1 CPU Affinity NUMA Affinity
|
||||
GPU0 X NV2 0-23 N/A
|
||||
GPU1 NV2 X 0-23 N/A
|
||||
```
|
||||
|
||||
在不同的机器上,如果没有NVLink,我们可能会看到:
|
||||
```
|
||||
GPU0 GPU1 CPU Affinity NUMA Affinity
|
||||
GPU0 X PHB 0-11 N/A
|
||||
GPU1 PHB X 0-11 N/A
|
||||
```
|
||||
|
||||
这个报告包括了这个输出:
|
||||
|
||||
```
|
||||
X = Self
|
||||
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
|
||||
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
|
||||
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
|
||||
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
|
||||
PIX = Connection traversing at most a single PCIe bridge
|
||||
NV# = Connection traversing a bonded set of # NVLinks
|
||||
```
|
||||
|
||||
因此,第一个报告`NV2`告诉我们GPU通过2个NVLink互连,而第二个报告`PHB`展示了典型的消费者级PCIe+Bridge设置。
|
||||
|
||||
检查你的设置中具有哪种连接类型。其中一些会使卡之间的通信更快(例如NVLink),而其他则较慢(例如PHB)。
|
||||
|
||||
根据使用的扩展解决方案的类型,连接速度可能会产生重大或较小的影响。如果GPU很少需要同步,就像在DDP中一样,那么较慢的连接的影响将不那么显著。如果GPU经常需要相互发送消息,就像在ZeRO-DP中一样,那么更快的连接对于实现更快的训练变得非常重要。
|
||||
|
||||
|
||||
#### NVlink
|
||||
|
||||
[NVLink](https://en.wikipedia.org/wiki/NVLink)是由Nvidia开发的一种基于线缆的串行多通道近程通信链接。
|
||||
|
||||
每个新一代提供更快的带宽,例如在[Nvidia Ampere GA102 GPU架构](https://www.nvidia.com/content/dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf)中有这样的引述:
|
||||
|
||||
> Third-Generation NVLink®
|
||||
> GA102 GPUs utilize NVIDIA’s third-generation NVLink interface, which includes four x4 links,
|
||||
> with each link providing 14.0625 GB/sec bandwidth in each direction between two GPUs. Four
|
||||
> links provide 56.25 GB/sec bandwidth in each direction, and 112.5 GB/sec total bandwidth
|
||||
> between two GPUs. Two RTX 3090 GPUs can be connected together for SLI using NVLink.
|
||||
> (Note that 3-Way and 4-Way SLI configurations are not supported.)
|
||||
|
||||
所以,在`nvidia-smi topo -m`输出的`NVX`报告中获取到的更高的`X`值意味着更好的性能。生成的结果将取决于您的GPU架构。
|
||||
|
||||
让我们比较在小样本wikitext上训练gpt2语言模型的执行结果。
|
||||
|
||||
结果是:
|
||||
|
||||
|
||||
| NVlink | Time |
|
||||
| ----- | ---: |
|
||||
| Y | 101s |
|
||||
| N | 131s |
|
||||
|
||||
|
||||
可以看到,NVLink使训练速度提高了约23%。在第二个基准测试中,我们使用`NCCL_P2P_DISABLE=1`告诉GPU不要使用NVLink。
|
||||
|
||||
这里是完整的基准测试代码和输出:
|
||||
|
||||
```bash
|
||||
# DDP w/ NVLink
|
||||
|
||||
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
|
||||
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path openai-community/gpt2 \
|
||||
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
|
||||
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
|
||||
|
||||
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
|
||||
|
||||
# DDP w/o NVLink
|
||||
|
||||
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
|
||||
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path openai-community/gpt2 \
|
||||
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
|
||||
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
|
||||
|
||||
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
|
||||
```
|
||||
|
||||
硬件: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`)
|
||||
软件: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
|
||||
69
transformers/docs/source/zh/perf_infer_gpu_multi.md
Normal file
69
transformers/docs/source/zh/perf_infer_gpu_multi.md
Normal file
@@ -0,0 +1,69 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 多GPU推理
|
||||
|
||||
某些模型现已支持内置的**张量并行**(Tensor Parallelism, TP),并通过 PyTorch 实现。张量并行技术将模型切分到多个 GPU 上,从而支持更大的模型尺寸,并对诸如矩阵乘法等计算任务进行并行化。
|
||||
|
||||
要启用张量并行,只需在调用 [`~AutoModelForCausalLM.from_pretrained`] 时传递参数 `tp_plan="auto"`:
|
||||
|
||||
```python
|
||||
import os
|
||||
import torch
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
|
||||
|
||||
# 初始化分布式环境
|
||||
rank = int(os.environ["RANK"])
|
||||
device = torch.device(f"cuda:{rank}")
|
||||
torch.cuda.set_device(device)
|
||||
torch.distributed.init_process_group("nccl", device_id=device)
|
||||
|
||||
# 获取支持张量并行的模型
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model_id,
|
||||
tp_plan="auto",
|
||||
)
|
||||
|
||||
# 准备输入tokens
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
prompt = "Can I help"
|
||||
inputs = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
|
||||
|
||||
# 分布式运行
|
||||
outputs = model(inputs)
|
||||
```
|
||||
|
||||
您可以使用 `torchrun` 命令启动上述脚本,多进程模式会自动将每个进程映射到一张 GPU:
|
||||
|
||||
```
|
||||
torchrun --nproc-per-node 4 demo.py
|
||||
```
|
||||
|
||||
目前,PyTorch 张量并行支持以下模型:
|
||||
* [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel)
|
||||
|
||||
如果您希望对其他模型添加张量并行支持,可以通过提交 GitHub Issue 或 Pull Request 来提出请求。
|
||||
|
||||
### 预期性能提升
|
||||
|
||||
对于推理场景(尤其是处理大批量或长序列的输入),张量并行可以显著提升计算速度。
|
||||
|
||||
以下是 [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel) 模型在序列长度为 512 且不同批量大小情况下的单次前向推理的预期加速效果:
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/Meta-Llama-3-8B-Instruct%2C%20seqlen%20%3D%20512%2C%20python%2C%20w_%20compile.png">
|
||||
</div>
|
||||
362
transformers/docs/source/zh/perf_torch_compile.md
Normal file
362
transformers/docs/source/zh/perf_torch_compile.md
Normal file
@@ -0,0 +1,362 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 使用 torch.compile() 优化推理
|
||||
|
||||
本指南旨在为使用[`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html)在[🤗 Transformers中的计算机视觉模型](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending)中引入的推理速度提升提供一个基准。
|
||||
|
||||
|
||||
## torch.compile 的优势
|
||||
|
||||
根据模型和GPU的不同,`torch.compile()`在推理过程中可以提高多达30%的速度。要使用`torch.compile()`,只需安装2.0及以上版本的`torch`即可。
|
||||
|
||||
编译模型需要时间,因此如果您只需要编译一次模型而不是每次推理都编译,那么它非常有用。
|
||||
要编译您选择的任何计算机视觉模型,请按照以下方式调用`torch.compile()`:
|
||||
|
||||
|
||||
```diff
|
||||
from transformers import AutoModelForImageClassification
|
||||
|
||||
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
|
||||
+ model = torch.compile(model)
|
||||
```
|
||||
|
||||
`compile()` 提供了多种编译模式,它们在编译时间和推理开销上有所不同。`max-autotune` 比 `reduce-overhead` 需要更长的时间,但会得到更快的推理速度。默认模式在编译时最快,但在推理时间上与 `reduce-overhead` 相比效率较低。在本指南中,我们使用了默认模式。您可以在[这里](https://pytorch.org/get-started/pytorch-2.0/#user-experience)了解更多信息。
|
||||
|
||||
我们在 PyTorch 2.0.1 版本上使用不同的计算机视觉模型、任务、硬件类型和数据批量大小对 `torch.compile` 进行了基准测试。
|
||||
|
||||
## 基准测试代码
|
||||
|
||||
以下是每个任务的基准测试代码。我们在推理之前”预热“GPU,并取300次推理的平均值,每次使用相同的图像。
|
||||
|
||||
### 使用 ViT 进行图像分类
|
||||
|
||||
```python
|
||||
import torch
|
||||
from PIL import Image
|
||||
import requests
|
||||
import numpy as np
|
||||
from transformers import AutoImageProcessor, AutoModelForImageClassification
|
||||
|
||||
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
|
||||
image = Image.open(requests.get(url, stream=True).raw)
|
||||
|
||||
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
|
||||
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
|
||||
model = torch.compile(model)
|
||||
|
||||
processed_input = processor(image, return_tensors='pt').to(device="cuda")
|
||||
|
||||
with torch.no_grad():
|
||||
_ = model(**processed_input)
|
||||
|
||||
```
|
||||
|
||||
#### 使用 DETR 进行目标检测
|
||||
|
||||
```python
|
||||
from transformers import AutoImageProcessor, AutoModelForObjectDetection
|
||||
|
||||
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
|
||||
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to("cuda")
|
||||
model = torch.compile(model)
|
||||
|
||||
texts = ["a photo of a cat", "a photo of a dog"]
|
||||
inputs = processor(text=texts, images=image, return_tensors="pt").to("cuda")
|
||||
|
||||
with torch.no_grad():
|
||||
_ = model(**inputs)
|
||||
```
|
||||
|
||||
#### 使用 Segformer 进行图像分割
|
||||
|
||||
```python
|
||||
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
|
||||
|
||||
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
|
||||
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to("cuda")
|
||||
model = torch.compile(model)
|
||||
seg_inputs = processor(images=image, return_tensors="pt").to("cuda")
|
||||
|
||||
with torch.no_grad():
|
||||
_ = model(**seg_inputs)
|
||||
```
|
||||
|
||||
以下是我们进行基准测试的模型列表。
|
||||
|
||||
**图像分类**
|
||||
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
|
||||
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
|
||||
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
|
||||
- [microsoft/resnet-50](https://huggingface.co/)
|
||||
|
||||
**图像分割**
|
||||
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
|
||||
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
|
||||
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
|
||||
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
|
||||
|
||||
**目标检测**
|
||||
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
|
||||
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
|
||||
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
|
||||
|
||||
下面是使用和不使用`torch.compile()`的推理持续时间可视化,以及每个模型在不同硬件和数据批量大小下的改进百分比。
|
||||
|
||||
|
||||
<div class="flex">
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
|
||||
</div>
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
|
||||
</div>
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div class="flex">
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
|
||||
</div>
|
||||
<div>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
|
||||
</div>
|
||||
</div>
|
||||
|
||||
|
||||
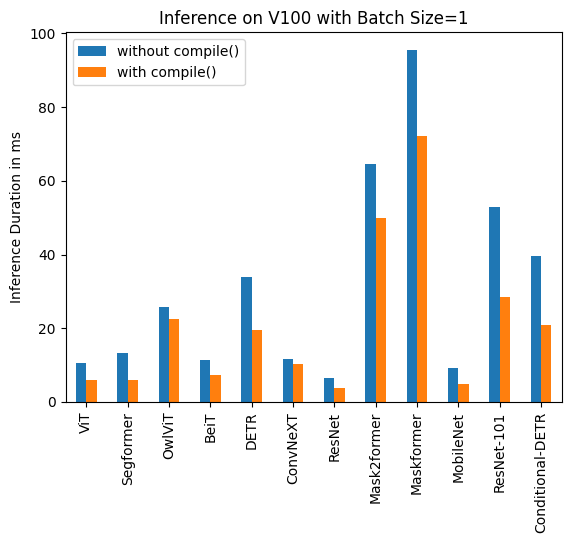
|
||||
|
||||
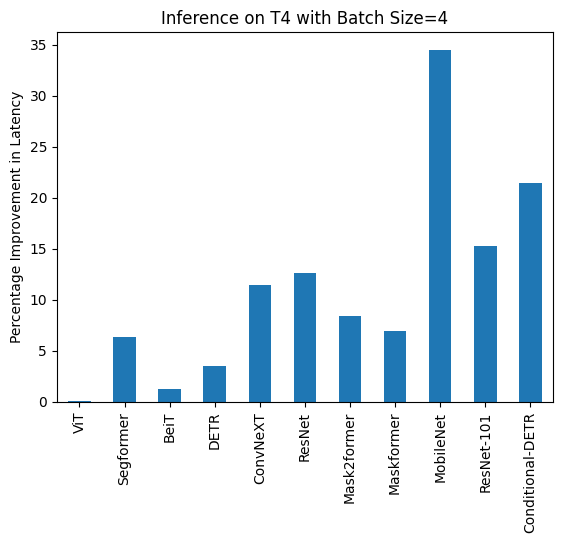
|
||||
|
||||
下面可以找到每个模型使用和不使用`compile()`的推理时间(毫秒)。请注意,OwlViT在大批量大小下会导致内存溢出。
|
||||
|
||||
### A100 (batch size: 1)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 9.325 | 7.584 |
|
||||
| Image Segmentation/Segformer | 11.759 | 10.500 |
|
||||
| Object Detection/OwlViT | 24.978 | 18.420 |
|
||||
| Image Classification/BeiT | 11.282 | 8.448 |
|
||||
| Object Detection/DETR | 34.619 | 19.040 |
|
||||
| Image Classification/ConvNeXT | 10.410 | 10.208 |
|
||||
| Image Classification/ResNet | 6.531 | 4.124 |
|
||||
| Image Segmentation/Mask2former | 60.188 | 49.117 |
|
||||
| Image Segmentation/Maskformer | 75.764 | 59.487 |
|
||||
| Image Segmentation/MobileNet | 8.583 | 3.974 |
|
||||
| Object Detection/Resnet-101 | 36.276 | 18.197 |
|
||||
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
|
||||
|
||||
|
||||
### A100 (batch size: 4)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 14.832 | 14.499 |
|
||||
| Image Segmentation/Segformer | 18.838 | 16.476 |
|
||||
| Image Classification/BeiT | 13.205 | 13.048 |
|
||||
| Object Detection/DETR | 48.657 | 32.418|
|
||||
| Image Classification/ConvNeXT | 22.940 | 21.631 |
|
||||
| Image Classification/ResNet | 6.657 | 4.268 |
|
||||
| Image Segmentation/Mask2former | 74.277 | 61.781 |
|
||||
| Image Segmentation/Maskformer | 180.700 | 159.116 |
|
||||
| Image Segmentation/MobileNet | 14.174 | 8.515 |
|
||||
| Object Detection/Resnet-101 | 68.101 | 44.998 |
|
||||
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
|
||||
|
||||
### A100 (batch size: 16)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 40.944 | 40.010 |
|
||||
| Image Segmentation/Segformer | 37.005 | 31.144 |
|
||||
| Image Classification/BeiT | 41.854 | 41.048 |
|
||||
| Object Detection/DETR | 164.382 | 161.902 |
|
||||
| Image Classification/ConvNeXT | 82.258 | 75.561 |
|
||||
| Image Classification/ResNet | 7.018 | 5.024 |
|
||||
| Image Segmentation/Mask2former | 178.945 | 154.814 |
|
||||
| Image Segmentation/Maskformer | 638.570 | 579.826 |
|
||||
| Image Segmentation/MobileNet | 51.693 | 30.310 |
|
||||
| Object Detection/Resnet-101 | 232.887 | 155.021 |
|
||||
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
|
||||
|
||||
### V100 (batch size: 1)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 10.495 | 6.00 |
|
||||
| Image Segmentation/Segformer | 13.321 | 5.862 |
|
||||
| Object Detection/OwlViT | 25.769 | 22.395 |
|
||||
| Image Classification/BeiT | 11.347 | 7.234 |
|
||||
| Object Detection/DETR | 33.951 | 19.388 |
|
||||
| Image Classification/ConvNeXT | 11.623 | 10.412 |
|
||||
| Image Classification/ResNet | 6.484 | 3.820 |
|
||||
| Image Segmentation/Mask2former | 64.640 | 49.873 |
|
||||
| Image Segmentation/Maskformer | 95.532 | 72.207 |
|
||||
| Image Segmentation/MobileNet | 9.217 | 4.753 |
|
||||
| Object Detection/Resnet-101 | 52.818 | 28.367 |
|
||||
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
|
||||
|
||||
### V100 (batch size: 4)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 15.181 | 14.501 |
|
||||
| Image Segmentation/Segformer | 16.787 | 16.188 |
|
||||
| Image Classification/BeiT | 15.171 | 14.753 |
|
||||
| Object Detection/DETR | 88.529 | 64.195 |
|
||||
| Image Classification/ConvNeXT | 29.574 | 27.085 |
|
||||
| Image Classification/ResNet | 6.109 | 4.731 |
|
||||
| Image Segmentation/Mask2former | 90.402 | 76.926 |
|
||||
| Image Segmentation/Maskformer | 234.261 | 205.456 |
|
||||
| Image Segmentation/MobileNet | 24.623 | 14.816 |
|
||||
| Object Detection/Resnet-101 | 134.672 | 101.304 |
|
||||
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
|
||||
|
||||
### V100 (batch size: 16)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 52.209 | 51.633 |
|
||||
| Image Segmentation/Segformer | 61.013 | 55.499 |
|
||||
| Image Classification/BeiT | 53.938 | 53.581 |
|
||||
| Object Detection/DETR | OOM | OOM |
|
||||
| Image Classification/ConvNeXT | 109.682 | 100.771 |
|
||||
| Image Classification/ResNet | 14.857 | 12.089 |
|
||||
| Image Segmentation/Mask2former | 249.605 | 222.801 |
|
||||
| Image Segmentation/Maskformer | 831.142 | 743.645 |
|
||||
| Image Segmentation/MobileNet | 93.129 | 55.365 |
|
||||
| Object Detection/Resnet-101 | 482.425 | 361.843 |
|
||||
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
|
||||
|
||||
### T4 (batch size: 1)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 16.520 | 15.786 |
|
||||
| Image Segmentation/Segformer | 16.116 | 14.205 |
|
||||
| Object Detection/OwlViT | 53.634 | 51.105 |
|
||||
| Image Classification/BeiT | 16.464 | 15.710 |
|
||||
| Object Detection/DETR | 73.100 | 53.99 |
|
||||
| Image Classification/ConvNeXT | 32.932 | 30.845 |
|
||||
| Image Classification/ResNet | 6.031 | 4.321 |
|
||||
| Image Segmentation/Mask2former | 79.192 | 66.815 |
|
||||
| Image Segmentation/Maskformer | 200.026 | 188.268 |
|
||||
| Image Segmentation/MobileNet | 18.908 | 11.997 |
|
||||
| Object Detection/Resnet-101 | 106.622 | 82.566 |
|
||||
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
|
||||
|
||||
### T4 (batch size: 4)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 43.653 | 43.626 |
|
||||
| Image Segmentation/Segformer | 45.327 | 42.445 |
|
||||
| Image Classification/BeiT | 52.007 | 51.354 |
|
||||
| Object Detection/DETR | 277.850 | 268.003 |
|
||||
| Image Classification/ConvNeXT | 119.259 | 105.580 |
|
||||
| Image Classification/ResNet | 13.039 | 11.388 |
|
||||
| Image Segmentation/Mask2former | 201.540 | 184.670 |
|
||||
| Image Segmentation/Maskformer | 764.052 | 711.280 |
|
||||
| Image Segmentation/MobileNet | 74.289 | 48.677 |
|
||||
| Object Detection/Resnet-101 | 421.859 | 357.614 |
|
||||
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
|
||||
|
||||
### T4 (batch size: 16)
|
||||
|
||||
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|
|
||||
| Image Classification/ViT | 163.914 | 160.907 |
|
||||
| Image Segmentation/Segformer | 192.412 | 163.620 |
|
||||
| Image Classification/BeiT | 188.978 | 187.976 |
|
||||
| Object Detection/DETR | OOM | OOM |
|
||||
| Image Classification/ConvNeXT | 422.886 | 388.078 |
|
||||
| Image Classification/ResNet | 44.114 | 37.604 |
|
||||
| Image Segmentation/Mask2former | 756.337 | 695.291 |
|
||||
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
|
||||
| Image Segmentation/MobileNet | 299.003 | 201.942 |
|
||||
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
|
||||
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
|
||||
|
||||
## PyTorch Nightly
|
||||
我们还在 PyTorch Nightly 版本(2.1.0dev)上进行了基准测试,可以在[这里](https://download.pytorch.org/whl/nightly/cu118)找到 Nightly 版本的安装包,并观察到了未编译和编译模型的延迟性能改善。
|
||||
|
||||
### A100
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
|
||||
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
|
||||
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
|
||||
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
|
||||
| Object Detection/DETR | 4 | 46.816 | 30.942 |
|
||||
| Object Detection/DETR | 16 | 163.749 | 163.706 |
|
||||
|
||||
### T4
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
|
||||
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
|
||||
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
|
||||
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
|
||||
| Object Detection/DETR | 4 | 269.615 | 204.785 |
|
||||
| Object Detection/DETR | 16 | OOM | OOM |
|
||||
|
||||
### V100
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
|
||||
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
|
||||
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
|
||||
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
|
||||
| Object Detection/DETR | 4 | 88.402 | 62.949|
|
||||
| Object Detection/DETR | 16 | OOM | OOM |
|
||||
|
||||
|
||||
## 降低开销
|
||||
我们在 PyTorch Nightly 版本中为 A100 和 T4 进行了 `reduce-overhead` 编译模式的性能基准测试。
|
||||
|
||||
### A100
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
|
||||
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
|
||||
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
|
||||
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
|
||||
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
|
||||
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
|
||||
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
|
||||
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
|
||||
|
||||
|
||||
### T4
|
||||
|
||||
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
|
||||
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
|
||||
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
|
||||
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
|
||||
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
|
||||
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
|
||||
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
|
||||
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
|
||||
|
||||
|
||||
85
transformers/docs/source/zh/perf_train_cpu.md
Normal file
85
transformers/docs/source/zh/perf_train_cpu.md
Normal file
@@ -0,0 +1,85 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 在CPU上进行高效训练
|
||||
|
||||
本指南将重点介绍如何在CPU上高效训练大型模型。
|
||||
|
||||
## 使用IPEX进行混合精度训练
|
||||
混合精度训练在模型中可以同时使用单精度(fp32)和半精度(bf16/fp16)的数据类型来加速训练或推理过程,并且仍然能保留大部分单精度的准确性。现代的CPU,例如第三代、第四代和第五代Intel® Xeon® Scalable处理器,原生支持bf16,而第六代Intel® Xeon® Scalable处理器原生支持bf16和fp16。您在训练时启用bf16或fp16的混合精度训练可以直接提高处理性能。
|
||||
|
||||
为了进一步最大化训练性能,您可以使用Intel® PyTorch扩展(IPEX)。IPEX是一个基于PyTorch构建的库,增加了额外的CPU指令集架构(ISA)级别的支持,比如Intel®高级向量扩展512(Intel® AVX512-VNNI)和Intel®高级矩阵扩展(Intel® AMX)。这为Intel CPU提供额外的性能提升。然而,仅支持AVX2的CPU(例如AMD或较旧的Intel CPU)在使用IPEX时并不保证能提高性能。
|
||||
|
||||
从PyTorch 1.10版本起,CPU后端已经启用了自动混合精度(AMP)。IPEX还支持bf16/fp16的AMP和bf16/fp16算子优化,并且部分功能已经上游到PyTorch主分支。通过IPEX AMP,您可以获得更好的性能和用户体验。
|
||||
|
||||
点击[这里](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/amp.html)查看**自动混合精度**的更多详细信息。
|
||||
|
||||
|
||||
### IPEX 安装:
|
||||
|
||||
IPEX 的发布与 PyTorch 一致,您可以通过 pip 安装:
|
||||
|
||||
| PyTorch Version | IPEX version |
|
||||
| :---------------: | :----------: |
|
||||
| 2.5.0 | 2.5.0+cpu |
|
||||
| 2.4.0 | 2.4.0+cpu |
|
||||
| 2.3.0 | 2.3.0+cpu |
|
||||
| 2.2.0 | 2.2.0+cpu |
|
||||
|
||||
请运行 `pip list | grep torch` 以获取您的 `pytorch_version`,然后根据该版本安装相应的 `IPEX version_name`。
|
||||
```bash
|
||||
pip install intel_extension_for_pytorch==<version_name> -f https://developer.intel.com/ipex-whl-stable-cpu
|
||||
```
|
||||
|
||||
如果需要的话,您可以在 [ipex-whl-stable-cpu](https://developer.intel.com/ipex-whl-stable-cpu) 查看最新版本。
|
||||
|
||||
查看更多 [安装IPEX](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/installation.html) 的方法。
|
||||
|
||||
|
||||
### 在 Trainer 中使用 IPEX
|
||||
在 Trainer 中使用 IPEX 时,您应在训练命令参数中添加 `use_ipex`、`bf16` 或 `fp16` 以及 `no_cuda` 来启用自动混合精度。
|
||||
|
||||
以 [Transformers 问答任务](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)为例:
|
||||
|
||||
- 在 CPU 上使用 BF16 自动混合精度训练 IPEX 的示例如下:
|
||||
<pre> python examples/pytorch/question-answering/run_qa.py \
|
||||
--model_name_or_path google-bert/bert-base-uncased \
|
||||
--dataset_name squad \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--per_device_train_batch_size 12 \
|
||||
--learning_rate 3e-5 \
|
||||
--num_train_epochs 2 \
|
||||
--max_seq_length 384 \
|
||||
--doc_stride 128 \
|
||||
--output_dir /tmp/debug_squad/ \
|
||||
<b>--use_ipex</b> \
|
||||
<b>--bf16</b> \
|
||||
<b>--use_cpu</b></pre>
|
||||
|
||||
如果您想在脚本中启用 `use_ipex` 和 `bf16`,请像下面这样将这些参数添加到 `TrainingArguments` 中:
|
||||
```diff
|
||||
training_args = TrainingArguments(
|
||||
output_dir=args.output_path,
|
||||
+ bf16=True,
|
||||
+ use_ipex=True,
|
||||
+ use_cpu=True,
|
||||
**kwargs
|
||||
)
|
||||
```
|
||||
|
||||
### 实践示例
|
||||
|
||||
博客: [使用 Intel Sapphire Rapids 加速 PyTorch Transformers](https://huggingface.co/blog/intel-sapphire-rapids)
|
||||
58
transformers/docs/source/zh/perf_train_special.md
Normal file
58
transformers/docs/source/zh/perf_train_special.md
Normal file
@@ -0,0 +1,58 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# 在 Apple Silicon 芯片上进行 PyTorch 训练
|
||||
|
||||
之前,在 Mac 上训练模型仅限于使用 CPU 训练。不过随着PyTorch v1.12的发布,您可以通过在 Apple Silicon 芯片的 GPU 上训练模型来显著提高性能和训练速度。这是通过将 Apple 的 Metal 性能着色器 (Metal Performance Shaders, MPS) 作为后端集成到PyTorch中实现的。[MPS后端](https://pytorch.org/docs/stable/notes/mps.html) 将 PyTorch 操作视为自定义的 Metal 着色器来实现,并将对应模块部署到`mps`设备上。
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
某些 PyTorch 操作目前还未在 MPS 上实现,可能会抛出错误提示。可以通过设置环境变量`PYTORCH_ENABLE_MPS_FALLBACK=1`来使用CPU内核以避免这种情况发生(您仍然会看到一个`UserWarning`)。
|
||||
|
||||
<br>
|
||||
|
||||
如果您遇到任何其他错误,请在[PyTorch库](https://github.com/pytorch/pytorch/issues)中创建一个 issue,因为[`Trainer`]类中只集成了 MPS 后端.
|
||||
|
||||
</Tip>
|
||||
|
||||
配置好`mps`设备后,您可以:
|
||||
|
||||
* 在本地训练更大的网络或更大的批量大小
|
||||
* 降低数据获取延迟,因为 GPU 的统一内存架构允许直接访问整个内存存储
|
||||
* 降低成本,因为您不需要再在云端 GPU 上训练或增加额外的本地 GPU
|
||||
|
||||
在确保已安装PyTorch后就可以开始使用了。 MPS 加速支持macOS 12.3及以上版本。
|
||||
|
||||
```bash
|
||||
pip install torch torchvision torchaudio
|
||||
```
|
||||
|
||||
[`TrainingArguments`]类默认使用`mps`设备(如果可用)因此无需显式设置设备。例如,您可以直接运行[run_glue.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-classification/run_glue.py)脚本,在无需进行任何修改的情况下自动启用 MPS 后端。
|
||||
|
||||
```diff
|
||||
export TASK_NAME=mrpc
|
||||
|
||||
python examples/pytorch/text-classification/run_glue.py \
|
||||
--model_name_or_path google-bert/bert-base-cased \
|
||||
--task_name $TASK_NAME \
|
||||
- --use_mps_device \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--max_seq_length 128 \
|
||||
--per_device_train_batch_size 32 \
|
||||
--learning_rate 2e-5 \
|
||||
--num_train_epochs 3 \
|
||||
--output_dir /tmp/$TASK_NAME/ \
|
||||
--overwrite_output_dir
|
||||
```
|
||||
|
||||
用于[分布式设置](https://pytorch.org/docs/stable/distributed.html#backends)的后端(如`gloo`和`nccl`)不支持`mps`设备,这也意味着使用 MPS 后端时只能在单个 GPU 上进行训练。
|
||||
|
||||
您可以在[Introducing Accelerated PyTorch Training on Mac](https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/)博客文章中了解有关 MPS 后端的更多信息。
|
||||
63
transformers/docs/source/zh/performance.md
Normal file
63
transformers/docs/source/zh/performance.md
Normal file
@@ -0,0 +1,63 @@
|
||||
<!---
|
||||
Copyright 2021 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 性能与可扩展性
|
||||
|
||||
训练大型transformer模型并将其部署到生产环境会面临各种挑战。
|
||||
在训练过程中,模型可能需要比可用的GPU内存更多的资源,或者表现出较慢的训练速度。在部署阶段,模型可能在生产环境中难以处理所需的吞吐量。
|
||||
|
||||
本文档旨在帮助您克服这些挑战,并找到适合您使用场景的最佳设置。教程分为训练和推理部分,因为每个部分都有不同的挑战和解决方案。在每个部分中,您将找到针对不同硬件配置的单独指南,例如单GPU与多GPU用于训练或CPU与GPU用于推理。
|
||||
|
||||
将此文档作为您的起点,进一步导航到与您的情况匹配的方法。
|
||||
|
||||
## 训练
|
||||
|
||||
高效训练大型transformer模型需要使用加速器硬件,如GPU或TPU。最常见的情况是您只有一个GPU。您应用于单个GPU上提高训练效率的方法可以扩展到其他设置,如多个GPU。然而,也有一些特定于多GPU或CPU训练的技术。我们在单独的部分中介绍它们。
|
||||
|
||||
* [在单个GPU上进行高效训练的方法和工具](perf_train_gpu_one):从这里开始学习常见的方法,可以帮助优化GPU内存利用率、加快训练速度或两者兼备。
|
||||
* [多GPU训练部分](perf_train_gpu_many):探索此部分以了解适用于多GPU设置的进一步优化方法,例如数据并行、张量并行和流水线并行。
|
||||
* [CPU训练部分](perf_train_cpu):了解在CPU上的混合精度训练。
|
||||
* [在多个CPU上进行高效训练](perf_train_cpu_many):了解分布式CPU训练。
|
||||
* [使用TensorFlow在TPU上进行训练](perf_train_tpu_tf):如果您对TPU还不熟悉,请参考此部分,了解有关在TPU上进行训练和使用XLA的建议性介绍。
|
||||
* [自定义硬件进行训练](perf_hardware):在构建自己的深度学习机器时查找技巧和窍门。
|
||||
* [使用Trainer API进行超参数搜索](hpo_train)
|
||||
|
||||
|
||||
## 推理
|
||||
|
||||
在生产环境中对大型模型进行高效推理可能与训练它们一样具有挑战性。在接下来的部分中,我们将详细介绍如何在CPU和单/多GPU设置上进行推理的步骤。
|
||||
|
||||
* [在单个CPU上进行推理](perf_infer_cpu)
|
||||
* [在单个GPU上进行推理](perf_infer_gpu_one)
|
||||
* [多GPU推理](perf_infer_gpu_one)
|
||||
* [TensorFlow模型的XLA集成](tf_xla)
|
||||
|
||||
## 训练和推理
|
||||
|
||||
在这里,您将找到适用于训练模型或使用它进行推理的技巧、窍门和技巧。
|
||||
|
||||
* [实例化大型模型](big_models)
|
||||
* [解决性能问题](debugging)
|
||||
|
||||
## 贡献
|
||||
|
||||
这份文档还远远没有完成,还有很多需要添加的内容,所以如果你有补充或更正的内容,请毫不犹豫地提交一个PR(Pull Request),或者如果你不确定,可以创建一个Issue,我们可以在那里讨论细节。
|
||||
|
||||
在做出贡献时,如果A比B更好,请尽量包含可重复的基准测试和(或)该信息来源的链接(除非它直接来自您)。
|
||||
65
transformers/docs/source/zh/philosophy.md
Normal file
65
transformers/docs/source/zh/philosophy.md
Normal file
@@ -0,0 +1,65 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
|
||||
|
||||
# Transformers 的设计理念
|
||||
|
||||
🤗 Transformers 是一个专为以下用户群体构建的库:
|
||||
|
||||
- 寻求使用、研究或扩展大规模 Transformers 模型的机器学习研究人员和教育者。
|
||||
- 希望微调这些模型或在生产环境中使用它们(或两者兼而有之)的实际操作者。
|
||||
- 只想下载预训练模型并将其用于解决给定机器学习任务的工程师。
|
||||
|
||||
Transformers 设计时有两个主要目标:
|
||||
|
||||
1. 尽可能简单快速地使用:
|
||||
|
||||
- 我们尽可能地限制用户能接触的抽象层,实际上几乎没有抽象。用户只需学习三个标准类即可使用每个模型:[configuration](main_classes/configuration)、[models](main_classes/model) 和一个预处理类(用于 NLP 的 [tokenizer](main_classes/tokenizer),用于视觉的 [image processor](main_classes/image_processor),用于音频的 [feature extractor](main_classes/feature_extractor),以及用于多模态输入的 [processor](main_classes/processors))。
|
||||
- 所有这些类都可以通过一个通用的 `from_pretrained()` 方法从预训练实例中简单统一地初始化,该方法会从提供在 [Hugging Face Hub](https://huggingface.co/models) 上的预训练检查点(如果需要的话)下载、缓存和加载相关类实例及相关数据(配置的超参数、分词器的词汇表和模型的权重)。
|
||||
- 在这三个基本类之上,该库提供了两种 API:[`pipeline`] 用于快速在给定任务上使用模型进行推断,以及 [`Trainer`] 用于快速训练或微调 PyTorch 模型。
|
||||
- 因此,Transformers 不是神经网络的模块化工具箱。如果要基于 Transformers 扩展或搭建新项目,请使用常规的 Python 或者 PyTorch 模块,并从 Transformers 的基类继承以重用模型加载和保存等功能。如果想了解更多有关我们的模型代码的设计理念,请查看我们的[重复自己](https://huggingface.co/blog/transformers-design-philosophy)博文。
|
||||
|
||||
2. 提供与原始模型性能尽可能接近的最新模型:
|
||||
|
||||
- 我们为每种架构提供至少一个示例,复现了该架构官方作者提供的结果。
|
||||
- 代码通常尽可能接近原始代码库,这意味着某些 PyTorch 代码可能不够*pytorchic*,因为它可能是从其它的深度学习框架转换过来的代码。
|
||||
|
||||
其他几个目标:
|
||||
|
||||
- 尽可能一致地公开模型的内部:
|
||||
|
||||
- 我们使用单一 API 提供对完整隐藏状态和注意力权重的访问。
|
||||
- 预处理类和基本模型 API 标准化,便于在不同模型之间轻松切换。
|
||||
|
||||
- 结合主观选择的有前途的工具进行模型微调和调查:
|
||||
|
||||
- 简单一致的方法来向词汇表和嵌入中添加新标记以进行微调。
|
||||
- 简单的方法来屏蔽和修剪 Transformer 头部。
|
||||
|
||||
## 主要概念
|
||||
|
||||
该库围绕每个模型的三类类构建:
|
||||
|
||||
- **模型类** 是 PyTorch 模型([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)),这些模型可以使用库中提供的预训练权重。
|
||||
- **配置类** 存储构建模型所需的超参数(如层数和隐藏大小)。通常情况下,如果您使用不进行任何修改的预训练模型,则创建模型将自动处理配置的实例化(配置是模型的一部分)。
|
||||
- **预处理类** 将原始数据转换为模型可接受的格式。一个 [tokenizer](main_classes/tokenizer) 存储每个模型的词汇表,并提供编码和解码字符串为要馈送到模型的令牌嵌入索引列表的方法。[Image processors](main_classes/image_processor) 预处理视觉输入,[feature extractors](main_classes/feature_extractor) 预处理音频输入,而 [processor](main_classes/processors) 则处理多模态输入。
|
||||
|
||||
所有这些类都可以从预训练实例中实例化、本地保存,并通过以下三种方法与 Hub 共享:
|
||||
|
||||
- `from_pretrained()` 允许您从库自身提供的预训练版本(支持的模型可在 [Model Hub](https://huggingface.co/models) 上找到)或用户本地(或服务器上)存储的版本实例化模型、配置和预处理类。
|
||||
- `save_pretrained()` 允许您本地保存模型、配置和预处理类,以便可以使用 `from_pretrained()` 重新加载。
|
||||
- `push_to_hub()` 允许您将模型、配置和预处理类共享到 Hub,以便所有人都可以轻松访问。
|
||||
310
transformers/docs/source/zh/pipeline_tutorial.md
Normal file
310
transformers/docs/source/zh/pipeline_tutorial.md
Normal file
@@ -0,0 +1,310 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 推理pipeline
|
||||
|
||||
[`pipeline`] 让使用[Hub](https://huggingface.co/models)上的任何模型进行任何语言、计算机视觉、语音以及多模态任务的推理变得非常简单。即使您对特定的模态没有经验,或者不熟悉模型的源码,您仍然可以使用[`pipeline`]进行推理!本教程将教您:
|
||||
|
||||
- 如何使用[`pipeline`] 进行推理。
|
||||
- 如何使用特定的`tokenizer`(分词器)或模型。
|
||||
- 如何使用[`pipeline`] 进行音频、视觉和多模态任务的推理。
|
||||
|
||||
<Tip>
|
||||
|
||||
请查看[`pipeline`]文档以获取已支持的任务和可用参数的完整列表。
|
||||
|
||||
</Tip>
|
||||
|
||||
## Pipeline使用
|
||||
|
||||
虽然每个任务都有一个关联的[`pipeline`],但使用通用的抽象的[`pipeline`]更加简单,其中包含所有特定任务的`pipelines`。[`pipeline`]会自动加载一个默认模型和一个能够进行任务推理的预处理类。让我们以使用[`pipeline`]进行自动语音识别(ASR)或语音转文本为例。
|
||||
|
||||
1. 首先,创建一个[`pipeline`]并指定推理任务:
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> transcriber = pipeline(task="automatic-speech-recognition")
|
||||
```
|
||||
|
||||
2. 将您的输入传递给[`pipeline`]。对于语音识别,这通常是一个音频输入文件:
|
||||
|
||||
|
||||
```py
|
||||
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
|
||||
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}
|
||||
```
|
||||
|
||||
您没有得到您期望的结果?可以在Hub上查看一些[最受欢迎的自动语音识别模型](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=trending)
|
||||
,看看是否可以获得更好的转录。
|
||||
|
||||
让我们尝试来自 OpenAI 的[Whisper large-v2](https://huggingface.co/openai/whisper-large) 模型。Whisperb比Wav2Vec2晚2年发布,使用接近10倍的数据进行了训练。因此,它在大多数下游基准测试上击败了Wav2Vec2。
|
||||
它还具有预测标点和大小写的附加优势,而Wav2Vec2则无法实现这些功能。
|
||||
|
||||
让我们在这里尝试一下,看看它的表现如何:
|
||||
|
||||
|
||||
```py
|
||||
>>> transcriber = pipeline(model="openai/whisper-large-v2")
|
||||
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
|
||||
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
|
||||
```
|
||||
|
||||
现在这个结果看起来更准确了!要进行深入的Wav2Vec2与Whisper比较,请参阅[音频变换器课程](https://huggingface.co/learn/audio-course/chapter5/asr_models)。
|
||||
我们鼓励您在 Hub 上查看不同语言的模型,以及专业领域的模型等。您可以在Hub上直接查看并比较模型的结果,以确定是否适合或处理边缘情况是否比其他模型更好。如果您没有找到适用于您的用例的模型,您始终可以[训练](training)自己的模型!
|
||||
|
||||
如果您有多个输入,您可以将输入作为列表传递:
|
||||
|
||||
|
||||
```py
|
||||
transcriber(
|
||||
[
|
||||
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
|
||||
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
|
||||
]
|
||||
)
|
||||
```
|
||||
|
||||
`Pipelines`非常适合用于测试,因为从一个模型切换到另一个模型非常琐碎;但是,还有一些方法可以将它们优化后用于大型工作负载而不仅仅是测试。请查看以下指南,深入探讨如何迭代整个数据集或在Web服务器中使用`Pipelines`:
|
||||
* [在数据集上使用流水线](#using-pipelines-on-a-dataset)
|
||||
* [在Web服务器中使用流水线](./pipeline_webserver)
|
||||
|
||||
|
||||
## 参数
|
||||
|
||||
[`pipeline`] 支持许多参数;有些是适用于特定任务的,而有些适用于所有`pipeline`。通常情况下,您可以在任何地方指定对应参数:
|
||||
|
||||
|
||||
```py
|
||||
transcriber = pipeline(model="openai/whisper-large-v2", my_parameter=1)
|
||||
|
||||
out = transcriber(...) # This will use `my_parameter=1`.
|
||||
out = transcriber(..., my_parameter=2) # This will override and use `my_parameter=2`.
|
||||
out = transcriber(...) # This will go back to using `my_parameter=1`.
|
||||
```
|
||||
|
||||
让我们查看其中的三个重要参数:
|
||||
|
||||
|
||||
### 设备
|
||||
|
||||
如果您使用 `device=n`,`pipeline`会自动将模型放在指定的设备上。无论您使用PyTorch还是Tensorflow,这都可以工作。
|
||||
|
||||
|
||||
```py
|
||||
transcriber = pipeline(model="openai/whisper-large-v2", device=0)
|
||||
```
|
||||
|
||||
如果模型对于单个GPU来说过于庞大,并且您正在使用PyTorch,您可以设置 `device_map="auto"` 以自动确定如何加载和存储模型权重。使用 `device_map` 参数需要安装🤗 [Accelerate](https://huggingface.co/docs/accelerate) 软件包:
|
||||
|
||||
|
||||
```bash
|
||||
pip install --upgrade accelerate
|
||||
```
|
||||
|
||||
以下代码会自动在各个设备上加载和存储模型权重:
|
||||
|
||||
|
||||
```py
|
||||
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")
|
||||
```
|
||||
|
||||
请注意,如果传递了 `device_map="auto"`,在实例化您的 `pipeline` 时不需要添加 `device=device` 参数,否则可能会遇到一些意外的状况!
|
||||
|
||||
### 批量大小
|
||||
|
||||
默认情况下,`pipelines`不会进行批量推理,原因在[这里](https://huggingface.co/docs/transformers/main_classes/pipelines#pipeline-batching)详细解释。因为批处理不一定更快,实际上在某些情况下可能会更慢。
|
||||
|
||||
但如果在您的用例中起作用,您可以使用:
|
||||
|
||||
|
||||
```py
|
||||
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
|
||||
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
|
||||
texts = transcriber(audio_filenames)
|
||||
```
|
||||
|
||||
以上代码会在提供的4个音频文件上运行`pipeline`,它会将它们以2个一组的批次传递给模型(模型在GPU上,此时批处理更有可能有所帮助),而您无需编写额外的代码。输出应始终与没有批处理时收到的结果相一致。它只是一种帮助您更快地使用`pipeline`的方式。
|
||||
|
||||
`pipeline`也可以减轻一些批处理的复杂性,因为对于某些`pipeline`,需要将单个项目(如长音频文件)分成多个部分以供模型处理。`pipeline`为您执行这种[*chunk batching*](./main_classes/pipelines#pipeline-chunk-batching)。
|
||||
|
||||
### 任务特定参数
|
||||
|
||||
所有任务都提供了特定于任务的参数,这些参数提供额外的灵活性和选择,以帮助您完成工作。
|
||||
例如,[`transformers.AutomaticSpeechRecognitionPipeline.__call__`] 方法具有一个 `return_timestamps` 参数,对于字幕视频似乎很有帮助:
|
||||
|
||||
```py
|
||||
>>> transcriber = pipeline(model="openai/whisper-large-v2", return_timestamps=True)
|
||||
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
|
||||
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}
|
||||
```
|
||||
|
||||
正如您所看到的,模型推断出了文本,还输出了各个句子发音的**时间**。
|
||||
|
||||
每个任务都有许多可用的参数,因此请查看每个任务的API参考,以了解您可以进行哪些调整!例如,[`~transformers.AutomaticSpeechRecognitionPipeline`] 具有 `chunk_length_s` 参数,对于处理非常长的音频文件(例如,为整部电影或长达一小时的视频配字幕)非常有帮助,这通常是模型无法单独处理的:
|
||||
|
||||
```python
|
||||
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30, return_timestamps=True)
|
||||
>>> transcriber("https://huggingface.co/datasets/sanchit-gandhi/librispeech_long/resolve/main/audio.wav")
|
||||
{'text': " Chapter 16. I might have told you of the beginning of this liaison in a few lines, but I wanted you to see every step by which we came. I, too, agree to whatever Marguerite wished, Marguerite to be unable to live apart from me. It was the day after the evening...
|
||||
```
|
||||
|
||||
如果您找不到一个真正有帮助的参数,欢迎[提出请求](https://github.com/huggingface/transformers/issues/new?assignees=&labels=feature&template=feature-request.yml)!
|
||||
|
||||
## 在数据集上使用pipelines
|
||||
|
||||
`pipelines`也可以对大型数据集进行推理。我们建议使用迭代器来完成这一任务,这是最简单的方法:
|
||||
|
||||
|
||||
```py
|
||||
def data():
|
||||
for i in range(1000):
|
||||
yield f"My example {i}"
|
||||
|
||||
|
||||
pipe = pipeline(model="openai-community/gpt2", device=0)
|
||||
generated_characters = 0
|
||||
for out in pipe(data()):
|
||||
generated_characters += len(out[0]["generated_text"])
|
||||
```
|
||||
|
||||
迭代器 `data()` 会产生每个结果,`pipelines`会自动识别输入为可迭代对象,并在GPU上处理数据的同时开始获取数据(在底层使用[DataLoader](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader))。这一点非常重要,因为您不必为整个数据集分配内存,可以尽可能快地将数据传送到GPU。
|
||||
|
||||
由于批处理可以加速处理,因此在这里尝试调整 `batch_size` 参数可能会很有用。
|
||||
|
||||
迭代数据集的最简单方法就是从🤗 [Datasets](https://github.com/huggingface/datasets/) 中加载数据集:
|
||||
|
||||
|
||||
```py
|
||||
# KeyDataset is a util that will just output the item we're interested in.
|
||||
from transformers.pipelines.pt_utils import KeyDataset
|
||||
from datasets import load_dataset
|
||||
|
||||
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
|
||||
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
|
||||
|
||||
for out in pipe(KeyDataset(dataset, "audio")):
|
||||
print(out)
|
||||
```
|
||||
|
||||
|
||||
## 在Web服务器上使用pipelines
|
||||
|
||||
<Tip>
|
||||
创建推理引擎是一个复杂的主题,值得有自己的页面。
|
||||
</Tip>
|
||||
|
||||
[链接](./pipeline_webserver)
|
||||
|
||||
## 视觉流水线
|
||||
|
||||
对于视觉任务,使用[`pipeline`] 几乎是相同的。
|
||||
|
||||
指定您的任务并将图像传递给分类器。图像可以是链接、本地路径或base64编码的图像。例如,下面显示的是哪种品种的猫?
|
||||
|
||||

|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
|
||||
>>> preds = vision_classifier(
|
||||
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
|
||||
... )
|
||||
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
|
||||
>>> preds
|
||||
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
|
||||
```
|
||||
|
||||
## 文本流水线
|
||||
|
||||
对于NLP任务,使用[`pipeline`] 几乎是相同的。
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> # This model is a `zero-shot-classification` model.
|
||||
>>> # It will classify text, except you are free to choose any label you might imagine
|
||||
>>> classifier = pipeline(model="facebook/bart-large-mnli")
|
||||
>>> classifier(
|
||||
... "I have a problem with my iphone that needs to be resolved asap!!",
|
||||
... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
|
||||
... )
|
||||
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}
|
||||
```
|
||||
|
||||
## 多模态流水线
|
||||
|
||||
[`pipeline`] 支持多个模态。例如,视觉问题回答(VQA)任务结合了文本和图像。请随意使用您喜欢的任何图像链接和您想要问关于该图像的问题。图像可以是URL或图像的本地路径。
|
||||
|
||||
例如,如果您使用这个[invoice image](https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png):
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> vqa = pipeline(model="impira/layoutlm-document-qa")
|
||||
>>> output = vqa(
|
||||
... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
|
||||
... question="What is the invoice number?",
|
||||
... )
|
||||
>>> output[0]["score"] = round(output[0]["score"], 3)
|
||||
>>> output
|
||||
[{'score': 0.425, 'answer': 'us-001', 'start': 16, 'end': 16}]
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
要运行上面的示例,除了🤗 Transformers之外,您需要安装[`pytesseract`](https://pypi.org/project/pytesseract/)。
|
||||
|
||||
|
||||
```bash
|
||||
sudo apt install -y tesseract-ocr
|
||||
pip install pytesseract
|
||||
```
|
||||
|
||||
</Tip>
|
||||
|
||||
## 在大模型上使用🤗 `accelerate`和`pipeline`:
|
||||
|
||||
您可以轻松地使用🤗 `accelerate`在大模型上运行 `pipeline`!首先确保您已经使用 `pip install accelerate` 安装了 `accelerate`。
|
||||
|
||||
首先使用 `device_map="auto"` 加载您的模型!我们将在示例中使用 `facebook/opt-1.3b`。
|
||||
|
||||
|
||||
```py
|
||||
# pip install accelerate
|
||||
import torch
|
||||
from transformers import pipeline
|
||||
|
||||
pipe = pipeline(model="facebook/opt-1.3b", dtype=torch.bfloat16, device_map="auto")
|
||||
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
|
||||
```
|
||||
|
||||
如果安装 `bitsandbytes` 并添加参数 `load_in_8bit=True`,您还可以传递8位加载的模型。
|
||||
|
||||
|
||||
```py
|
||||
# pip install accelerate bitsandbytes
|
||||
import torch
|
||||
from transformers import pipeline
|
||||
|
||||
pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
|
||||
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
|
||||
```
|
||||
|
||||
请注意,您可以将`checkpoint`替换为任何支持大模型加载的Hugging Face模型,比如BLOOM!
|
||||
|
||||
512
transformers/docs/source/zh/preprocessing.md
Normal file
512
transformers/docs/source/zh/preprocessing.md
Normal file
@@ -0,0 +1,512 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 预处理
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
在您可以在数据集上训练模型之前,数据需要被预处理为期望的模型输入格式。无论您的数据是文本、图像还是音频,它们都需要被转换并组合成批量的张量。🤗 Transformers 提供了一组预处理类来帮助准备数据以供模型使用。在本教程中,您将了解以下内容:
|
||||
|
||||
* 对于文本,使用[分词器](./main_classes/tokenizer)(`Tokenizer`)将文本转换为一系列标记(`tokens`),并创建`tokens`的数字表示,将它们组合成张量。
|
||||
* 对于语音和音频,使用[特征提取器](./main_classes/feature_extractor)(`Feature extractor`)从音频波形中提取顺序特征并将其转换为张量。
|
||||
* 图像输入使用[图像处理器](./main_classes/image)(`ImageProcessor`)将图像转换为张量。
|
||||
* 多模态输入,使用[处理器](./main_classes/processors)(`Processor`)结合了`Tokenizer`和`ImageProcessor`或`Processor`。
|
||||
|
||||
<Tip>
|
||||
|
||||
`AutoProcessor` **始终**有效的自动选择适用于您使用的模型的正确`class`,无论您使用的是`Tokenizer`、`ImageProcessor`、`Feature extractor`还是`Processor`。
|
||||
|
||||
</Tip>
|
||||
|
||||
在开始之前,请安装🤗 Datasets,以便您可以加载一些数据集来进行实验:
|
||||
|
||||
|
||||
```bash
|
||||
pip install datasets
|
||||
```
|
||||
|
||||
## 自然语言处理
|
||||
|
||||
<Youtube id="Yffk5aydLzg"/>
|
||||
|
||||
处理文本数据的主要工具是[Tokenizer](main_classes/tokenizer)。`Tokenizer`根据一组规则将文本拆分为`tokens`。然后将这些`tokens`转换为数字,然后转换为张量,成为模型的输入。模型所需的任何附加输入都由`Tokenizer`添加。
|
||||
|
||||
<Tip>
|
||||
|
||||
如果您计划使用预训练模型,重要的是使用与之关联的预训练`Tokenizer`。这确保文本的拆分方式与预训练语料库相同,并在预训练期间使用相同的标记-索引的对应关系(通常称为*词汇表*-`vocab`)。
|
||||
|
||||
</Tip>
|
||||
|
||||
开始使用[`AutoTokenizer.from_pretrained`]方法加载一个预训练`tokenizer`。这将下载模型预训练的`vocab`:
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
|
||||
```
|
||||
|
||||
然后将您的文本传递给`tokenizer`:
|
||||
|
||||
|
||||
```py
|
||||
>>> encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
|
||||
>>> print(encoded_input)
|
||||
{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
|
||||
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
|
||||
```
|
||||
|
||||
`tokenizer`返回一个包含三个重要对象的字典:
|
||||
|
||||
* [input_ids](glossary#input-ids) 是与句子中每个`token`对应的索引。
|
||||
* [attention_mask](glossary#attention-mask) 指示是否应该关注一个`token`。
|
||||
* [token_type_ids](glossary#token-type-ids) 在存在多个序列时标识一个`token`属于哪个序列。
|
||||
|
||||
通过解码 `input_ids` 来返回您的输入:
|
||||
|
||||
|
||||
```py
|
||||
>>> tokenizer.decode(encoded_input["input_ids"])
|
||||
'[CLS] Do not meddle in the affairs of wizards, for they are subtle and quick to anger. [SEP]'
|
||||
```
|
||||
|
||||
如您所见,`tokenizer`向句子中添加了两个特殊`token` - `CLS` 和 `SEP`(分类器和分隔符)。并非所有模型都需要特殊`token`,但如果需要,`tokenizer`会自动为您添加。
|
||||
|
||||
如果有多个句子需要预处理,将它们作为列表传递给`tokenizer`:
|
||||
|
||||
|
||||
```py
|
||||
>>> batch_sentences = [
|
||||
... "But what about second breakfast?",
|
||||
... "Don't think he knows about second breakfast, Pip.",
|
||||
... "What about elevensies?",
|
||||
... ]
|
||||
>>> encoded_inputs = tokenizer(batch_sentences)
|
||||
>>> print(encoded_inputs)
|
||||
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
|
||||
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
|
||||
[101, 1327, 1164, 5450, 23434, 136, 102]],
|
||||
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0]],
|
||||
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
|
||||
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
|
||||
[1, 1, 1, 1, 1, 1, 1]]}
|
||||
```
|
||||
|
||||
### 填充
|
||||
|
||||
句子的长度并不总是相同,这可能会成为一个问题,因为模型输入的张量需要具有统一的形状。填充是一种策略,通过在较短的句子中添加一个特殊的`padding token`,以确保张量是矩形的。
|
||||
|
||||
将 `padding` 参数设置为 `True`,以使批次中较短的序列填充到与最长序列相匹配的长度:
|
||||
|
||||
```py
|
||||
>>> batch_sentences = [
|
||||
... "But what about second breakfast?",
|
||||
... "Don't think he knows about second breakfast, Pip.",
|
||||
... "What about elevensies?",
|
||||
... ]
|
||||
>>> encoded_input = tokenizer(batch_sentences, padding=True)
|
||||
>>> print(encoded_input)
|
||||
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
|
||||
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
|
||||
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
|
||||
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
|
||||
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
|
||||
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
|
||||
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
|
||||
```
|
||||
|
||||
第一句和第三句因为较短,通过`0`进行填充,。
|
||||
|
||||
### 截断
|
||||
|
||||
另一方面,有时候一个序列可能对模型来说太长了。在这种情况下,您需要将序列截断为更短的长度。
|
||||
|
||||
将 `truncation` 参数设置为 `True`,以将序列截断为模型接受的最大长度:
|
||||
|
||||
|
||||
```py
|
||||
>>> batch_sentences = [
|
||||
... "But what about second breakfast?",
|
||||
... "Don't think he knows about second breakfast, Pip.",
|
||||
... "What about elevensies?",
|
||||
... ]
|
||||
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
|
||||
>>> print(encoded_input)
|
||||
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
|
||||
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
|
||||
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
|
||||
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
|
||||
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
|
||||
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
|
||||
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
查看[填充和截断](./pad_truncation)概念指南,了解更多有关填充和截断参数的信息。
|
||||
|
||||
</Tip>
|
||||
|
||||
### 构建张量
|
||||
|
||||
最后,`tokenizer`可以返回实际输入到模型的张量。
|
||||
|
||||
将 `return_tensors` 参数设置为 `pt`(对于PyTorch)或 `tf`(对于TensorFlow):
|
||||
|
||||
|
||||
|
||||
```py
|
||||
>>> batch_sentences = [
|
||||
... "But what about second breakfast?",
|
||||
... "Don't think he knows about second breakfast, Pip.",
|
||||
... "What about elevensies?",
|
||||
... ]
|
||||
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
|
||||
>>> print(encoded_input)
|
||||
{'input_ids': tensor([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
|
||||
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
|
||||
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]]),
|
||||
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
|
||||
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
|
||||
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
|
||||
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
|
||||
```
|
||||
|
||||
## 音频
|
||||
|
||||
对于音频任务,您需要[feature extractor](main_classes/feature_extractor)来准备您的数据集以供模型使用。`feature extractor`旨在从原始音频数据中提取特征,并将它们转换为张量。
|
||||
|
||||
加载[MInDS-14](https://huggingface.co/datasets/PolyAI/minds14)数据集(有关如何加载数据集的更多详细信息,请参阅🤗 [Datasets教程](https://huggingface.co/docs/datasets/load_hub))以了解如何在音频数据集中使用`feature extractor`:
|
||||
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset, Audio
|
||||
|
||||
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
|
||||
```
|
||||
|
||||
访问 `audio` 列的第一个元素以查看输入。调用 `audio` 列会自动加载和重新采样音频文件:
|
||||
|
||||
```py
|
||||
>>> dataset[0]["audio"]
|
||||
{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
|
||||
0. , 0. ], dtype=float32),
|
||||
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
|
||||
'sampling_rate': 8000}
|
||||
```
|
||||
|
||||
这会返回三个对象:
|
||||
|
||||
* `array` 是加载的语音信号 - 并在必要时重新采为`1D array`。
|
||||
* `path` 指向音频文件的位置。
|
||||
* `sampling_rate` 是每秒测量的语音信号数据点数量。
|
||||
|
||||
对于本教程,您将使用[Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base)模型。查看模型卡片,您将了解到Wav2Vec2是在16kHz采样的语音音频数据上预训练的。重要的是,您的音频数据的采样率要与用于预训练模型的数据集的采样率匹配。如果您的数据的采样率不同,那么您需要对数据进行重新采样。
|
||||
|
||||
1. 使用🤗 Datasets的[`~datasets.Dataset.cast_column`]方法将采样率提升到16kHz:
|
||||
|
||||
```py
|
||||
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
|
||||
```
|
||||
|
||||
2. 再次调用 `audio` 列以重新采样音频文件:
|
||||
|
||||
|
||||
```py
|
||||
>>> dataset[0]["audio"]
|
||||
{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ...,
|
||||
3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
|
||||
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
|
||||
'sampling_rate': 16000}
|
||||
```
|
||||
|
||||
接下来,加载一个`feature extractor`以对输入进行标准化和填充。当填充文本数据时,会为较短的序列添加 `0`。相同的理念适用于音频数据。`feature extractor`添加 `0` - 被解释为静音 - 到`array` 。
|
||||
|
||||
使用 [`AutoFeatureExtractor.from_pretrained`] 加载`feature extractor`:
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoFeatureExtractor
|
||||
|
||||
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
|
||||
```
|
||||
|
||||
将音频 `array` 传递给`feature extractor`。我们还建议在`feature extractor`中添加 `sampling_rate` 参数,以更好地调试可能发生的静音错误:
|
||||
|
||||
|
||||
```py
|
||||
>>> audio_input = [dataset[0]["audio"]["array"]]
|
||||
>>> feature_extractor(audio_input, sampling_rate=16000)
|
||||
{'input_values': [array([ 3.8106556e-04, 2.7506407e-03, 2.8015103e-03, ...,
|
||||
5.6335266e-04, 4.6588284e-06, -1.7142107e-04], dtype=float32)]}
|
||||
```
|
||||
|
||||
就像`tokenizer`一样,您可以应用填充或截断来处理批次中的可变序列。请查看这两个音频样本的序列长度:
|
||||
|
||||
|
||||
```py
|
||||
>>> dataset[0]["audio"]["array"].shape
|
||||
(173398,)
|
||||
|
||||
>>> dataset[1]["audio"]["array"].shape
|
||||
(106496,)
|
||||
```
|
||||
|
||||
创建一个函数来预处理数据集,以使音频样本具有相同的长度。通过指定最大样本长度,`feature extractor`将填充或截断序列以使其匹配:
|
||||
|
||||
|
||||
```py
|
||||
>>> def preprocess_function(examples):
|
||||
... audio_arrays = [x["array"] for x in examples["audio"]]
|
||||
... inputs = feature_extractor(
|
||||
... audio_arrays,
|
||||
... sampling_rate=16000,
|
||||
... padding=True,
|
||||
... max_length=100000,
|
||||
... truncation=True,
|
||||
... )
|
||||
... return inputs
|
||||
```
|
||||
|
||||
将`preprocess_function`应用于数据集中的前几个示例:
|
||||
|
||||
|
||||
```py
|
||||
>>> processed_dataset = preprocess_function(dataset[:5])
|
||||
```
|
||||
|
||||
现在样本长度是相同的,并且与指定的最大长度匹配。您现在可以将经过处理的数据集传递给模型了!
|
||||
|
||||
|
||||
```py
|
||||
>>> processed_dataset["input_values"][0].shape
|
||||
(100000,)
|
||||
|
||||
>>> processed_dataset["input_values"][1].shape
|
||||
(100000,)
|
||||
```
|
||||
|
||||
## 计算机视觉
|
||||
|
||||
对于计算机视觉任务,您需要一个[ image processor](main_classes/image_processor)来准备数据集以供模型使用。图像预处理包括多个步骤将图像转换为模型期望输入的格式。这些步骤包括但不限于调整大小、标准化、颜色通道校正以及将图像转换为张量。
|
||||
|
||||
<Tip>
|
||||
|
||||
图像预处理通常遵循某种形式的图像增强。图像预处理和图像增强都会改变图像数据,但它们有不同的目的:
|
||||
|
||||
* 图像增强可以帮助防止过拟合并增加模型的鲁棒性。您可以在数据增强方面充分发挥创造性 - 调整亮度和颜色、裁剪、旋转、调整大小、缩放等。但要注意不要改变图像的含义。
|
||||
* 图像预处理确保图像与模型预期的输入格式匹配。在微调计算机视觉模型时,必须对图像进行与模型训练时相同的预处理。
|
||||
|
||||
您可以使用任何您喜欢的图像增强库。对于图像预处理,请使用与模型相关联的`ImageProcessor`。
|
||||
|
||||
</Tip>
|
||||
|
||||
加载[food101](https://huggingface.co/datasets/food101)数据集(有关如何加载数据集的更多详细信息,请参阅🤗 [Datasets教程](https://huggingface.co/docs/datasets/load_hub))以了解如何在计算机视觉数据集中使用图像处理器:
|
||||
|
||||
<Tip>
|
||||
|
||||
因为数据集相当大,请使用🤗 Datasets的`split`参数加载训练集中的少量样本!
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset
|
||||
|
||||
>>> dataset = load_dataset("food101", split="train[:100]")
|
||||
```
|
||||
|
||||
接下来,使用🤗 Datasets的[`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image)功能查看图像:
|
||||
|
||||
|
||||
```py
|
||||
>>> dataset[0]["image"]
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/vision-preprocess-tutorial.png"/>
|
||||
</div>
|
||||
|
||||
使用 [`AutoImageProcessor.from_pretrained`] 加载`image processor`:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoImageProcessor
|
||||
|
||||
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
|
||||
```
|
||||
|
||||
首先,让我们进行图像增强。您可以使用任何您喜欢的库,但在本教程中,我们将使用torchvision的[`transforms`](https://pytorch.org/vision/stable/transforms.html)模块。如果您有兴趣使用其他数据增强库,请参阅[Albumentations](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb)或[Kornia notebooks](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb)中的示例。
|
||||
|
||||
1. 在这里,我们使用[`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html)将[`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html)和 [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html)变换连接在一起。请注意,对于调整大小,我们可以从`image_processor`中获取图像尺寸要求。对于一些模型,精确的高度和宽度需要被定义,对于其他模型只需定义`shortest_edge`。
|
||||
|
||||
|
||||
```py
|
||||
>>> from torchvision.transforms import RandomResizedCrop, ColorJitter, Compose
|
||||
|
||||
>>> size = (
|
||||
... image_processor.size["shortest_edge"]
|
||||
... if "shortest_edge" in image_processor.size
|
||||
... else (image_processor.size["height"], image_processor.size["width"])
|
||||
... )
|
||||
|
||||
>>> _transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5)])
|
||||
```
|
||||
|
||||
2. 模型接受 [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values) 作为输入。`ImageProcessor` 可以进行图像的标准化,并生成适当的张量。创建一个函数,将图像增强和图像预处理步骤组合起来处理批量图像,并生成 `pixel_values`:
|
||||
|
||||
|
||||
```py
|
||||
>>> def transforms(examples):
|
||||
... images = [_transforms(img.convert("RGB")) for img in examples["image"]]
|
||||
... examples["pixel_values"] = image_processor(images, do_resize=False, return_tensors="pt")["pixel_values"]
|
||||
... return examples
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
在上面的示例中,我们设置`do_resize=False`,因为我们已经在图像增强转换中调整了图像的大小,并利用了适当的`image_processor`的`size`属性。如果您在图像增强期间不调整图像的大小,请将此参数排除在外。默认情况下`ImageProcessor`将处理调整大小。
|
||||
|
||||
如果希望将图像标准化步骤为图像增强的一部分,请使用`image_processor.image_mean`和`image_processor.image_std`。
|
||||
|
||||
</Tip>
|
||||
|
||||
3. 然后使用🤗 Datasets的[`set_transform`](https://huggingface.co/docs/datasets/process#format-transform)在运行时应用这些变换:
|
||||
|
||||
|
||||
```py
|
||||
>>> dataset.set_transform(transforms)
|
||||
```
|
||||
|
||||
4. 现在,当您访问图像时,您将注意到`image processor`已添加了 `pixel_values`。您现在可以将经过处理的数据集传递给模型了!
|
||||
|
||||
|
||||
```py
|
||||
>>> dataset[0].keys()
|
||||
```
|
||||
|
||||
这是在应用变换后的图像样子。图像已被随机裁剪,并其颜色属性发生了变化。
|
||||
|
||||
|
||||
```py
|
||||
>>> import numpy as np
|
||||
>>> import matplotlib.pyplot as plt
|
||||
|
||||
>>> img = dataset[0]["pixel_values"]
|
||||
>>> plt.imshow(img.permute(1, 2, 0))
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/preprocessed_image.png"/>
|
||||
</div>
|
||||
|
||||
<Tip>
|
||||
|
||||
对于诸如目标检测、语义分割、实例分割和全景分割等任务,`ImageProcessor`提供了训练后处理方法。这些方法将模型的原始输出转换为有意义的预测,如边界框或分割地图。
|
||||
|
||||
</Tip>
|
||||
|
||||
### 填充
|
||||
|
||||
在某些情况下,例如,在微调[DETR](./model_doc/detr)时,模型在训练时应用了尺度增强。这可能导致批处理中的图像大小不同。您可以使用[`DetrImageProcessor.pad`]来指定自定义的`collate_fn`将图像批处理在一起。
|
||||
|
||||
```py
|
||||
>>> def collate_fn(batch):
|
||||
... pixel_values = [item["pixel_values"] for item in batch]
|
||||
... encoding = image_processor.pad(pixel_values, return_tensors="pt")
|
||||
... labels = [item["labels"] for item in batch]
|
||||
... batch = {}
|
||||
... batch["pixel_values"] = encoding["pixel_values"]
|
||||
... batch["pixel_mask"] = encoding["pixel_mask"]
|
||||
... batch["labels"] = labels
|
||||
... return batch
|
||||
```
|
||||
|
||||
## 多模态
|
||||
|
||||
对于涉及多模态输入的任务,您需要[processor](main_classes/processors)来为模型准备数据集。`processor`将两个处理对象-例如`tokenizer`和`feature extractor`-组合在一起。
|
||||
|
||||
加载[LJ Speech](https://huggingface.co/datasets/lj_speech)数据集(有关如何加载数据集的更多详细信息,请参阅🤗 [Datasets 教程](https://huggingface.co/docs/datasets/load_hub))以了解如何使用`processor`进行自动语音识别(ASR):
|
||||
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset
|
||||
|
||||
>>> lj_speech = load_dataset("lj_speech", split="train")
|
||||
```
|
||||
|
||||
对于ASR(自动语音识别),主要关注`audio`和`text`,因此可以删除其他列:
|
||||
|
||||
|
||||
```py
|
||||
>>> lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
|
||||
```
|
||||
|
||||
现在查看`audio`和`text`列:
|
||||
|
||||
```py
|
||||
>>> lj_speech[0]["audio"]
|
||||
{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
|
||||
7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
|
||||
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
|
||||
'sampling_rate': 22050}
|
||||
|
||||
>>> lj_speech[0]["text"]
|
||||
'Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition'
|
||||
```
|
||||
|
||||
请记住,您应始终[重新采样](preprocessing#audio)音频数据集的采样率,以匹配用于预训练模型数据集的采样率!
|
||||
|
||||
|
||||
```py
|
||||
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
|
||||
```
|
||||
|
||||
使用[`AutoProcessor.from_pretrained`]加载一个`processor`:
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoProcessor
|
||||
|
||||
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
|
||||
```
|
||||
|
||||
1. 创建一个函数,用于将包含在 `array` 中的音频数据处理为 `input_values`,并将 `text` 标记为 `labels`。这些将是输入模型的数据:
|
||||
|
||||
```py
|
||||
>>> def prepare_dataset(example):
|
||||
... audio = example["audio"]
|
||||
|
||||
... example.update(processor(audio=audio["array"], text=example["text"], sampling_rate=16000))
|
||||
|
||||
... return example
|
||||
```
|
||||
|
||||
2. 将 `prepare_dataset` 函数应用于一个示例:
|
||||
|
||||
```py
|
||||
>>> prepare_dataset(lj_speech[0])
|
||||
```
|
||||
|
||||
`processor`现在已经添加了 `input_values` 和 `labels`,并且采样率也正确降低为为16kHz。现在可以将处理后的数据集传递给模型!
|
||||
417
transformers/docs/source/zh/quicktour.md
Normal file
417
transformers/docs/source/zh/quicktour.md
Normal file
@@ -0,0 +1,417 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 快速上手
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
快来使用 🤗 Transformers 吧!无论你是开发人员还是日常用户,这篇快速上手教程都将帮助你入门并且向你展示如何使用 [`pipeline`] 进行推理,使用 [AutoClass](./model_doc/auto) 加载一个预训练模型和预处理器,以及使用 PyTorch 或 TensorFlow 快速训练一个模型。如果你是一个初学者,我们建议你接下来查看我们的教程或者[课程](https://huggingface.co/course/chapter1/1),来更深入地了解在这里介绍到的概念。
|
||||
|
||||
在开始之前,确保你已经安装了所有必要的库:
|
||||
|
||||
```bash
|
||||
!pip install transformers datasets evaluate accelerate
|
||||
```
|
||||
|
||||
你还需要安装喜欢的机器学习框架:
|
||||
|
||||
|
||||
```bash
|
||||
pip install torch
|
||||
```
|
||||
|
||||
## Pipeline
|
||||
|
||||
<Youtube id="tiZFewofSLM"/>
|
||||
|
||||
使用 [`pipeline`] 是利用预训练模型进行推理的最简单的方式。你能够将 [`pipeline`] 开箱即用地用于跨不同模态的多种任务。来看看它支持的任务列表:
|
||||
|
||||
| **任务** | **描述** | **模态** | **Pipeline** |
|
||||
|------------------------------|-----------------------------------|-----------------|-----------------------------------------------|
|
||||
| 文本分类 | 为给定的文本序列分配一个标签 | NLP | pipeline(task="sentiment-analysis") |
|
||||
| 文本生成 | 根据给定的提示生成文本 | NLP | pipeline(task="text-generation") |
|
||||
| 命名实体识别 | 为序列里的每个 token 分配一个标签(人, 组织, 地址等等) | NLP | pipeline(task="ner") |
|
||||
| 问答系统 | 通过给定的上下文和问题, 在文本中提取答案 | NLP | pipeline(task="question-answering") |
|
||||
| 掩盖填充 | 预测出正确的在序列中被掩盖的token | NLP | pipeline(task="fill-mask") |
|
||||
| 文本摘要 | 为文本序列或文档生成总结 | NLP | pipeline(task="summarization") |
|
||||
| 文本翻译 | 将文本从一种语言翻译为另一种语言 | NLP | pipeline(task="translation") |
|
||||
| 图像分类 | 为图像分配一个标签 | Computer vision | pipeline(task="image-classification") |
|
||||
| 图像分割 | 为图像中每个独立的像素分配标签(支持语义、全景和实例分割) | Computer vision | pipeline(task="image-segmentation") |
|
||||
| 目标检测 | 预测图像中目标对象的边界框和类别 | Computer vision | pipeline(task="object-detection") |
|
||||
| 音频分类 | 给音频文件分配一个标签 | Audio | pipeline(task="audio-classification") |
|
||||
| 自动语音识别 | 将音频文件中的语音提取为文本 | Audio | pipeline(task="automatic-speech-recognition") |
|
||||
| 视觉问答 | 给定一个图像和一个问题,正确地回答有关图像的问题 | Multimodal | pipeline(task="vqa") |
|
||||
|
||||
创建一个 [`pipeline`] 实例并且指定你想要将它用于的任务,就可以开始了。你可以将 [`pipeline`] 用于任何一个上面提到的任务,如果想知道支持的任务的完整列表,可以查阅 [pipeline API 参考](./main_classes/pipelines)。不过, 在这篇教程中,你将把 [`pipeline`] 用在一个情感分析示例上:
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> classifier = pipeline("sentiment-analysis")
|
||||
```
|
||||
|
||||
[`pipeline`] 会下载并缓存一个用于情感分析的默认的[预训练模型](https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english)和分词器。现在你可以在目标文本上使用 `classifier` 了:
|
||||
|
||||
```py
|
||||
>>> classifier("We are very happy to show you the 🤗 Transformers library.")
|
||||
[{'label': 'POSITIVE', 'score': 0.9998}]
|
||||
```
|
||||
|
||||
如果你有不止一个输入,可以把所有输入放入一个列表然后传给[`pipeline`],它将会返回一个字典列表:
|
||||
|
||||
```py
|
||||
>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
|
||||
>>> for result in results:
|
||||
... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
|
||||
label: POSITIVE, with score: 0.9998
|
||||
label: NEGATIVE, with score: 0.5309
|
||||
```
|
||||
|
||||
[`pipeline`] 也可以为任何你喜欢的任务遍历整个数据集。在下面这个示例中,让我们选择自动语音识别作为我们的任务:
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
|
||||
```
|
||||
|
||||
加载一个你想遍历的音频数据集(查阅 🤗 Datasets [快速开始](https://huggingface.co/docs/datasets/quickstart#audio) 获得更多信息)。比如,加载 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 数据集:
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset, Audio
|
||||
|
||||
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
|
||||
```
|
||||
|
||||
你需要确保数据集中的音频的采样率与 [`facebook/wav2vec2-base-960h`](https://huggingface.co/facebook/wav2vec2-base-960h) 训练用到的音频的采样率一致:
|
||||
|
||||
```py
|
||||
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
|
||||
```
|
||||
|
||||
当调用 `"audio"` 列时, 音频文件将会自动加载并重采样。
|
||||
从前四个样本中提取原始波形数组,将它作为列表传给 pipeline:
|
||||
|
||||
```py
|
||||
>>> result = speech_recognizer(dataset[:4]["audio"])
|
||||
>>> print([d["text"] for d in result])
|
||||
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FODING HOW I'D SET UP A JOIN TO HET WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE AP SO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AND I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I THURN A JOIN A COUNT']
|
||||
```
|
||||
|
||||
对于输入非常庞大的大型数据集(比如语音或视觉),你会想到使用一个生成器,而不是一个将所有输入都加载进内存的列表。查阅 [pipeline API 参考](./main_classes/pipelines) 来获取更多信息。
|
||||
|
||||
### 在 pipeline 中使用另一个模型和分词器
|
||||
|
||||
[`pipeline`] 可以容纳 [Hub](https://huggingface.co/models) 中的任何模型,这让 [`pipeline`] 更容易适用于其他用例。比如,你想要一个能够处理法语文本的模型,就可以使用 Hub 上的标记来筛选出合适的模型。靠前的筛选结果会返回一个为情感分析微调的多语言的 [BERT 模型](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment),你可以将它用于法语文本:
|
||||
|
||||
```py
|
||||
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
|
||||
```
|
||||
|
||||
使用 [`AutoModelForSequenceClassification`] 和 [`AutoTokenizer`] 来加载预训练模型和它关联的分词器(更多信息可以参考下一节的 `AutoClass`):
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
||||
|
||||
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
|
||||
```
|
||||
|
||||
在 [`pipeline`] 中指定模型和分词器,现在你就可以在法语文本上使用 `classifier` 了:
|
||||
|
||||
```py
|
||||
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
|
||||
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
|
||||
[{'label': '5 stars', 'score': 0.7273}]
|
||||
```
|
||||
|
||||
如果你没有找到适合你的模型,就需要在你的数据上微调一个预训练模型了。查看 [微调教程](./training) 来学习怎样进行微调。最后,微调完模型后,考虑一下在 Hub 上与社区 [分享](./model_sharing) 这个模型,把机器学习普及到每一个人! 🤗
|
||||
|
||||
## AutoClass
|
||||
|
||||
<Youtube id="AhChOFRegn4"/>
|
||||
|
||||
在幕后,是由 [`AutoModelForSequenceClassification`] 和 [`AutoTokenizer`] 一起支持你在上面用到的 [`pipeline`]。[AutoClass](./model_doc/auto) 是一个能够通过预训练模型的名称或路径自动查找其架构的快捷方式。你只需要为你的任务选择合适的 `AutoClass` 和它关联的预处理类。
|
||||
|
||||
让我们回过头来看上一节的示例,看看怎样使用 `AutoClass` 来重现使用 [`pipeline`] 的结果。
|
||||
|
||||
### AutoTokenizer
|
||||
|
||||
分词器负责预处理文本,将文本转换为用于输入模型的数字数组。有多个用来管理分词过程的规则,包括如何拆分单词和在什么样的级别上拆分单词(在 [分词器总结](./tokenizer_summary) 学习更多关于分词的信息)。要记住最重要的是你需要实例化的分词器要与模型的名称相同, 来确保和模型训练时使用相同的分词规则。
|
||||
|
||||
使用 [`AutoTokenizer`] 加载一个分词器:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer
|
||||
|
||||
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
|
||||
```
|
||||
|
||||
将文本传入分词器:
|
||||
|
||||
```py
|
||||
>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
|
||||
>>> print(encoding)
|
||||
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
|
||||
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
|
||||
```
|
||||
|
||||
分词器返回了含有如下内容的字典:
|
||||
|
||||
* [input_ids](./glossary#input-ids):用数字表示的 token。
|
||||
* [attention_mask](.glossary#attention-mask):应该关注哪些 token 的指示。
|
||||
|
||||
分词器也可以接受列表作为输入,并填充和截断文本,返回具有统一长度的批次:
|
||||
|
||||
|
||||
```py
|
||||
>>> pt_batch = tokenizer(
|
||||
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
|
||||
... padding=True,
|
||||
... truncation=True,
|
||||
... max_length=512,
|
||||
... return_tensors="pt",
|
||||
... )
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
查阅[预处理](./preprocessing)教程来获得有关分词的更详细的信息,以及如何使用 [`AutoFeatureExtractor`] 和 [`AutoProcessor`] 来处理图像,音频,还有多模式输入。
|
||||
|
||||
</Tip>
|
||||
|
||||
### AutoModel
|
||||
|
||||
🤗 Transformers 提供了一种简单统一的方式来加载预训练的实例. 这表示你可以像加载 [`AutoTokenizer`] 一样加载 [`AutoModel`]。唯一不同的地方是为你的任务选择正确的[`AutoModel`]。对于文本(或序列)分类,你应该加载[`AutoModelForSequenceClassification`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForSequenceClassification
|
||||
|
||||
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
|
||||
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
通过 [任务摘要](./task_summary) 查找 [`AutoModel`] 支持的任务.
|
||||
|
||||
</Tip>
|
||||
|
||||
现在可以把预处理好的输入批次直接送进模型。你只需要通过 `**` 来解包字典:
|
||||
|
||||
```py
|
||||
>>> pt_outputs = pt_model(**pt_batch)
|
||||
```
|
||||
|
||||
模型在 `logits` 属性输出最终的激活结果. 在 `logits` 上应用 softmax 函数来查询概率:
|
||||
|
||||
```py
|
||||
>>> from torch import nn
|
||||
|
||||
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
|
||||
>>> print(pt_predictions)
|
||||
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
|
||||
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
所有 🤗 Transformers 模型(PyTorch 或 TensorFlow)在最终的激活函数(比如 softmax)*之前* 输出张量,
|
||||
因为最终的激活函数常常与 loss 融合。模型的输出是特殊的数据类,所以它们的属性可以在 IDE 中被自动补全。模型的输出就像一个元组或字典(你可以通过整数、切片或字符串来索引它),在这种情况下,为 None 的属性会被忽略。
|
||||
|
||||
</Tip>
|
||||
|
||||
### 保存模型
|
||||
|
||||
当你的模型微调完成,你就可以使用 [`PreTrainedModel.save_pretrained`] 把它和它的分词器保存下来:
|
||||
|
||||
```py
|
||||
>>> pt_save_directory = "./pt_save_pretrained"
|
||||
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
|
||||
>>> pt_model.save_pretrained(pt_save_directory)
|
||||
```
|
||||
|
||||
当你准备再次使用这个模型时,就可以使用 [`PreTrainedModel.from_pretrained`] 加载它了:
|
||||
|
||||
```py
|
||||
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
|
||||
```
|
||||
|
||||
## 自定义模型构建
|
||||
|
||||
你可以修改模型的配置类来改变模型的构建方式。配置指明了模型的属性,比如隐藏层或者注意力头的数量。当你从自定义的配置类初始化模型时,你就开始自定义模型构建了。模型属性是随机初始化的,你需要先训练模型,然后才能得到有意义的结果。
|
||||
|
||||
通过导入 [`AutoConfig`] 来开始,之后加载你想修改的预训练模型。在 [`AutoConfig.from_pretrained`] 中,你能够指定想要修改的属性,比如注意力头的数量:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoConfig
|
||||
|
||||
>>> my_config = AutoConfig.from_pretrained("distilbert/distilbert-base-uncased", n_heads=12)
|
||||
```
|
||||
|
||||
使用 [`AutoModel.from_config`] 根据你的自定义配置创建一个模型:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModel
|
||||
|
||||
>>> my_model = AutoModel.from_config(my_config)
|
||||
```
|
||||
|
||||
查阅 [创建一个自定义结构](./create_a_model) 指南获取更多关于构建自定义配置的信息。
|
||||
|
||||
## Trainer - PyTorch 优化训练循环
|
||||
|
||||
所有的模型都是标准的 [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module),所以你可以在任何典型的训练模型中使用它们。当你编写自己的训练循环时,🤗 Transformers 为 PyTorch 提供了一个 [`Trainer`] 类,它包含了基础的训练循环并且为诸如分布式训练,混合精度等特性增加了额外的功能。
|
||||
|
||||
取决于你的任务, 你通常可以传递以下的参数给 [`Trainer`]:
|
||||
|
||||
1. [`PreTrainedModel`] 或者 [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module):
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForSequenceClassification
|
||||
|
||||
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
|
||||
```
|
||||
|
||||
2. [`TrainingArguments`] 含有你可以修改的模型超参数,比如学习率,批次大小和训练时的迭代次数。如果你没有指定训练参数,那么它会使用默认值:
|
||||
|
||||
```py
|
||||
>>> from transformers import TrainingArguments
|
||||
|
||||
>>> training_args = TrainingArguments(
|
||||
... output_dir="path/to/save/folder/",
|
||||
... learning_rate=2e-5,
|
||||
... per_device_train_batch_size=8,
|
||||
... per_device_eval_batch_size=8,
|
||||
... num_train_epochs=2,
|
||||
... )
|
||||
```
|
||||
|
||||
3. 一个预处理类,比如分词器,特征提取器或者处理器:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
|
||||
```
|
||||
|
||||
4. 加载一个数据集:
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset
|
||||
|
||||
>>> dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
|
||||
```
|
||||
|
||||
5. 创建一个给数据集分词的函数,并且使用 [`~datasets.Dataset.map`] 应用到整个数据集:
|
||||
|
||||
```py
|
||||
>>> def tokenize_dataset(dataset):
|
||||
... return tokenizer(dataset["text"])
|
||||
|
||||
>>> dataset = dataset.map(tokenize_dataset, batched=True)
|
||||
```
|
||||
|
||||
6. 用来从数据集中创建批次的 [`DataCollatorWithPadding`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import DataCollatorWithPadding
|
||||
|
||||
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
|
||||
```
|
||||
|
||||
现在把所有的类传给 [`Trainer`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import Trainer
|
||||
|
||||
>>> trainer = Trainer(
|
||||
... model=model,
|
||||
... args=training_args,
|
||||
... train_dataset=dataset["train"],
|
||||
... eval_dataset=dataset["test"],
|
||||
... processing_class=tokenizer,
|
||||
... data_collator=data_collator,
|
||||
... ) # doctest: +SKIP
|
||||
```
|
||||
|
||||
一切准备就绪后,调用 [`~Trainer.train`] 进行训练:
|
||||
|
||||
```py
|
||||
>>> trainer.train() # doctest: +SKIP
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
对于像翻译或摘要这些使用序列到序列模型的任务,用 [`Seq2SeqTrainer`] 和 [`Seq2SeqTrainingArguments`] 来替代。
|
||||
|
||||
</Tip>
|
||||
|
||||
你可以通过子类化 [`Trainer`] 中的方法来自定义训练循环。这样你就可以自定义像损失函数,优化器和调度器这样的特性。查阅 [`Trainer`] 参考手册了解哪些方法能够被子类化。
|
||||
|
||||
另一个自定义训练循环的方式是通过[回调](./main_classes/callback)。你可以使用回调来与其他库集成,查看训练循环来报告进度或提前结束训练。回调不会修改训练循环。如果想自定义损失函数等,就需要子类化 [`Trainer`] 了。
|
||||
|
||||
## 使用 Tensorflow 训练
|
||||
|
||||
所有模型都是标准的 [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model),所以你可以通过 [Keras](https://keras.io/) API 实现在 Tensorflow 中训练。🤗 Transformers 提供了 [`~TFPreTrainedModel.prepare_tf_dataset`] 方法来轻松地将数据集加载为 `tf.data.Dataset`,这样你就可以使用 Keras 的 [`compile`](https://keras.io/api/models/model_training_apis/#compile-method) 和 [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) 方法马上开始训练。
|
||||
|
||||
1. 使用 [`TFPreTrainedModel`] 或者 [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) 来开始:
|
||||
|
||||
```py
|
||||
>>> from transformers import TFAutoModelForSequenceClassification
|
||||
|
||||
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
|
||||
```
|
||||
|
||||
2. 一个预处理类,比如分词器,特征提取器或者处理器:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
|
||||
```
|
||||
|
||||
3. 创建一个给数据集分词的函数
|
||||
|
||||
```py
|
||||
>>> def tokenize_dataset(dataset):
|
||||
... return tokenizer(dataset["text"]) # doctest: +SKIP
|
||||
```
|
||||
|
||||
4. 使用 [`~datasets.Dataset.map`] 将分词器应用到整个数据集,之后将数据集和分词器传给 [`~TFPreTrainedModel.prepare_tf_dataset`]。如果你需要的话,也可以在这里改变批次大小和是否打乱数据集:
|
||||
|
||||
```py
|
||||
>>> dataset = dataset.map(tokenize_dataset) # doctest: +SKIP
|
||||
>>> tf_dataset = model.prepare_tf_dataset(
|
||||
... dataset, batch_size=16, shuffle=True, tokenizer=tokenizer
|
||||
... ) # doctest: +SKIP
|
||||
```
|
||||
|
||||
5. 一切准备就绪后,调用 `compile` 和 `fit` 开始训练:
|
||||
|
||||
```py
|
||||
>>> from tensorflow.keras.optimizers import Adam
|
||||
|
||||
>>> model.compile(optimizer=Adam(3e-5))
|
||||
>>> model.fit(dataset) # doctest: +SKIP
|
||||
```
|
||||
|
||||
## 接下来做什么?
|
||||
|
||||
现在你已经完成了 🤗 Transformers 的快速上手教程,来看看我们的指南并且学习如何做一些更具体的事情,比如写一个自定义模型,为某个任务微调一个模型以及如何使用脚本来训练模型。如果你有兴趣了解更多 🤗 Transformers 的核心章节,那就喝杯咖啡然后来看看我们的概念指南吧!
|
||||
314
transformers/docs/source/zh/run_scripts.md
Normal file
314
transformers/docs/source/zh/run_scripts.md
Normal file
@@ -0,0 +1,314 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 使用脚本进行训练
|
||||
|
||||
除了 🤗 Transformers [notebooks](./notebooks),还有示例脚本演示了如何使用[PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch)训练模型以解决特定任务。
|
||||
|
||||
您还可以在这些示例中找到我们在[研究项目](https://github.com/huggingface/transformers-research-projects/)和[遗留示例](https://github.com/huggingface/transformers/tree/main/examples/legacy)中使用过的脚本,这些脚本主要是由社区贡献的。这些脚本已不再被积极维护,需要使用特定版本的🤗 Transformers, 可能与库的最新版本不兼容。
|
||||
|
||||
示例脚本可能无法在初始配置下直接解决每个问题,您可能需要根据要解决的问题调整脚本。为了帮助您,大多数脚本都完全暴露了数据预处理的方式,允许您根据需要对其进行编辑。
|
||||
|
||||
如果您想在示例脚本中实现任何功能,请在[论坛](https://discuss.huggingface.co/)或[issue](https://github.com/huggingface/transformers/issues)上讨论,然后再提交Pull Request。虽然我们欢迎修复错误,但不太可能合并添加更多功能的Pull Request,因为这会降低可读性。
|
||||
|
||||
本指南将向您展示如何在[PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization)中运行示例摘要训练脚本。
|
||||
|
||||
## 设置
|
||||
|
||||
要成功运行示例脚本的最新版本,您必须在新虚拟环境中**从源代码安装 🤗 Transformers**:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/transformers
|
||||
cd transformers
|
||||
pip install .
|
||||
```
|
||||
|
||||
对于旧版本的示例脚本,请点击下面的切换按钮:
|
||||
|
||||
<details>
|
||||
<summary>老版本🤗 Transformers示例 </summary>
|
||||
<ul>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
|
||||
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
|
||||
</ul>
|
||||
</details>
|
||||
|
||||
然后切换您clone的 🤗 Transformers 仓到特定的版本,例如v3.5.1:
|
||||
|
||||
```bash
|
||||
git checkout tags/v3.5.1
|
||||
```
|
||||
|
||||
在安装了正确的库版本后,进入您选择的版本的`example`文件夹并安装例子要求的环境:
|
||||
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
## 运行脚本
|
||||
|
||||
|
||||
示例脚本从🤗 [Datasets](https://huggingface.co/docs/datasets/)库下载并预处理数据集。然后,脚本通过[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer)使用支持摘要任务的架构对数据集进行微调。以下示例展示了如何在[CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail)数据集上微调[T5-small](https://huggingface.co/google-t5/t5-small)。由于T5模型的训练方式,它需要一个额外的`source_prefix`参数。这个提示让T5知道这是一个摘要任务。
|
||||
|
||||
```bash
|
||||
python examples/pytorch/summarization/run_summarization.py \
|
||||
--model_name_or_path google-t5/t5-small \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--dataset_name cnn_dailymail \
|
||||
--dataset_config "3.0.0" \
|
||||
--source_prefix "summarize: " \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
## 分布式训练和混合精度
|
||||
|
||||
[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) 支持分布式训练和混合精度,这意味着你也可以在脚本中使用它。要启用这两个功能,可以做如下设置:
|
||||
|
||||
- 添加 `fp16` 参数以启用混合精度。
|
||||
- 使用 `nproc_per_node` 参数设置使用的GPU数量。
|
||||
|
||||
|
||||
```bash
|
||||
torchrun \
|
||||
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
|
||||
--fp16 \
|
||||
--model_name_or_path google-t5/t5-small \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--dataset_name cnn_dailymail \
|
||||
--dataset_config "3.0.0" \
|
||||
--source_prefix "summarize: " \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
## 在TPU上运行脚本
|
||||
|
||||
|
||||
张量处理单元(TPUs)是专门设计用于加速性能的。PyTorch使用 [PyTorch/XLA](https://github.com/pytorch/xla/blob/master/README.md) 支持TPU。要使用TPU,请启动`xla_spawn.py`脚本并使用`num_cores`参数设置要使用的TPU核心数量。
|
||||
|
||||
```bash
|
||||
python xla_spawn.py --num_cores 8 \
|
||||
summarization/run_summarization.py \
|
||||
--model_name_or_path google-t5/t5-small \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--dataset_name cnn_dailymail \
|
||||
--dataset_config "3.0.0" \
|
||||
--source_prefix "summarize: " \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
## 基于🤗 Accelerate运行脚本
|
||||
|
||||
🤗 [Accelerate](https://huggingface.co/docs/accelerate) 是一个仅支持 PyTorch 的库,它提供了一种统一的方法来在不同类型的设置(仅 CPU、多个 GPU、多个TPU)上训练模型,同时保持对 PyTorch 训练循环的完全可见性。如果你还没有安装 🤗 Accelerate,请确保你已经安装了它:
|
||||
|
||||
> 注意:由于 Accelerate 正在快速发展,因此必须安装 git 版本的 accelerate 来运行脚本。
|
||||
|
||||
```bash
|
||||
pip install git+https://github.com/huggingface/accelerate
|
||||
```
|
||||
|
||||
你需要使用`run_summarization_no_trainer.py`脚本,而不是`run_summarization.py`脚本。🤗 Accelerate支持的脚本需要在文件夹中有一个`task_no_trainer.py`文件。首先运行以下命令以创建并保存配置文件:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
检测您的设置以确保配置正确:
|
||||
|
||||
```bash
|
||||
accelerate test
|
||||
```
|
||||
|
||||
现在您可以开始训练模型了:
|
||||
|
||||
```bash
|
||||
accelerate launch run_summarization_no_trainer.py \
|
||||
--model_name_or_path google-t5/t5-small \
|
||||
--dataset_name cnn_dailymail \
|
||||
--dataset_config "3.0.0" \
|
||||
--source_prefix "summarize: " \
|
||||
--output_dir ~/tmp/tst-summarization
|
||||
```
|
||||
|
||||
## 使用自定义数据集
|
||||
|
||||
摘要脚本支持自定义数据集,只要它们是CSV或JSON Line文件。当你使用自己的数据集时,需要指定一些额外的参数:
|
||||
- `train_file` 和 `validation_file` 分别指定您的训练和验证文件的路径。
|
||||
- `text_column` 是输入要进行摘要的文本。
|
||||
- `summary_column` 是目标输出的文本。
|
||||
|
||||
使用自定义数据集的摘要脚本看起来是这样的:
|
||||
|
||||
|
||||
```bash
|
||||
python examples/pytorch/summarization/run_summarization.py \
|
||||
--model_name_or_path google-t5/t5-small \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--train_file path_to_csv_or_jsonlines_file \
|
||||
--validation_file path_to_csv_or_jsonlines_file \
|
||||
--text_column text_column_name \
|
||||
--summary_column summary_column_name \
|
||||
--source_prefix "summarize: " \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--overwrite_output_dir \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
## 测试脚本
|
||||
|
||||
通常,在提交整个数据集之前,最好先在较少的数据集示例上运行脚本,以确保一切按预期工作,因为完整数据集的处理可能需要花费几个小时的时间。使用以下参数将数据集截断为最大样本数:
|
||||
|
||||
- `max_train_samples`
|
||||
- `max_eval_samples`
|
||||
- `max_predict_samples`
|
||||
|
||||
|
||||
```bash
|
||||
python examples/pytorch/summarization/run_summarization.py \
|
||||
--model_name_or_path google-t5/t5-small \
|
||||
--max_train_samples 50 \
|
||||
--max_eval_samples 50 \
|
||||
--max_predict_samples 50 \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--dataset_name cnn_dailymail \
|
||||
--dataset_config "3.0.0" \
|
||||
--source_prefix "summarize: " \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
并非所有示例脚本都支持`max_predict_samples`参数。如果您不确定您的脚本是否支持此参数,请添加`-h`参数进行检查:
|
||||
|
||||
```bash
|
||||
examples/pytorch/summarization/run_summarization.py -h
|
||||
```
|
||||
|
||||
## 从checkpoint恢复训练
|
||||
|
||||
另一个有用的选项是从之前的checkpoint恢复训练。这将确保在训练中断时,您可以从之前停止的地方继续进行,而无需重新开始。有两种方法可以从checkpoint恢复训练。
|
||||
|
||||
第一种方法使用`output_dir previous_output_dir`参数从存储在`output_dir`中的最新的checkpoint恢复训练。在这种情况下,您应该删除`overwrite_output_dir`:
|
||||
|
||||
```bash
|
||||
python examples/pytorch/summarization/run_summarization.py
|
||||
--model_name_or_path google-t5/t5-small \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--dataset_name cnn_dailymail \
|
||||
--dataset_config "3.0.0" \
|
||||
--source_prefix "summarize: " \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--output_dir previous_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
第二种方法使用`resume_from_checkpoint path_to_specific_checkpoint`参数从特定的checkpoint文件夹恢复训练。
|
||||
|
||||
|
||||
```bash
|
||||
python examples/pytorch/summarization/run_summarization.py
|
||||
--model_name_or_path google-t5/t5-small \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--dataset_name cnn_dailymail \
|
||||
--dataset_config "3.0.0" \
|
||||
--source_prefix "summarize: " \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--resume_from_checkpoint path_to_specific_checkpoint \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
## 分享模型
|
||||
|
||||
所有脚本都可以将您的最终模型上传到[Model Hub](https://huggingface.co/models)。在开始之前,请确保您已登录Hugging Face:
|
||||
|
||||
```bash
|
||||
hf auth login
|
||||
```
|
||||
|
||||
然后,在脚本中添加`push_to_hub`参数。这个参数会创建一个带有您Hugging Face用户名和`output_dir`中指定的文件夹名称的仓库。
|
||||
|
||||
为了给您的仓库指定一个特定的名称,使用`push_to_hub_model_id`参数来添加它。该仓库将自动列出在您的命名空间下。
|
||||
|
||||
以下示例展示了如何上传具有特定仓库名称的模型:
|
||||
|
||||
|
||||
```bash
|
||||
python examples/pytorch/summarization/run_summarization.py
|
||||
--model_name_or_path google-t5/t5-small \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--dataset_name cnn_dailymail \
|
||||
--dataset_config "3.0.0" \
|
||||
--source_prefix "summarize: " \
|
||||
--push_to_hub \
|
||||
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
169
transformers/docs/source/zh/serialization.md
Normal file
169
transformers/docs/source/zh/serialization.md
Normal file
@@ -0,0 +1,169 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 导出为 ONNX
|
||||
|
||||
在生产环境中部署 🤗 Transformers 模型通常需要或者能够受益于,将模型导出为可在专门的运行时和硬件上加载和执行的序列化格式。
|
||||
|
||||
🤗 Optimum 是 Transformers 的扩展,可以通过其 `exporters` 模块将模型从 PyTorch 或 TensorFlow 导出为 ONNX 及 TFLite 等序列化格式。🤗 Optimum 还提供了一套性能优化工具,可以在目标硬件上以最高效率训练和运行模型。
|
||||
|
||||
本指南演示了如何使用 🤗 Optimum 将 🤗 Transformers 模型导出为 ONNX。有关将模型导出为 TFLite 的指南,请参考 [导出为 TFLite 页面](tflite)。
|
||||
|
||||
## 导出为 ONNX
|
||||
|
||||
[ONNX (Open Neural Network eXchange 开放神经网络交换)](http://onnx.ai) 是一个开放的标准,它定义了一组通用的运算符和一种通用的文件格式,用于表示包括 PyTorch 和 TensorFlow 在内的各种框架中的深度学习模型。当一个模型被导出为 ONNX时,这些运算符被用于构建计算图(通常被称为*中间表示*),该图表示数据在神经网络中的流动。
|
||||
|
||||
通过公开具有标准化运算符和数据类型的图,ONNX使得模型能够轻松在不同深度学习框架间切换。例如,在 PyTorch 中训练的模型可以被导出为 ONNX,然后再导入到 TensorFlow(反之亦然)。
|
||||
|
||||
导出为 ONNX 后,模型可以:
|
||||
- 通过 [图优化(graph optimization)](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization) 和 [量化(quantization)](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/quantization) 等技术进行推理优化。
|
||||
- 通过 [`ORTModelForXXX` 类](https://huggingface.co/docs/optimum/onnxruntime/package_reference/modeling_ort) 使用 ONNX Runtime 运行,它同样遵循你熟悉的 Transformers 中的 `AutoModel` API。
|
||||
- 使用 [优化推理流水线(pipeline)](https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/pipelines) 运行,其 API 与 🤗 Transformers 中的 [`pipeline`] 函数相同。
|
||||
|
||||
🤗 Optimum 通过利用配置对象提供对 ONNX 导出的支持。多种模型架构已经有现成的配置对象,并且配置对象也被设计得易于扩展以适用于其他架构。
|
||||
|
||||
现有的配置列表请参考 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/exporters/onnx/overview)。
|
||||
|
||||
有两种方式可以将 🤗 Transformers 模型导出为 ONNX,这里我们展示这两种方法:
|
||||
|
||||
- 使用 🤗 Optimum 的 CLI(命令行)导出。
|
||||
- 使用 🤗 Optimum 的 `optimum.onnxruntime` 模块导出。
|
||||
|
||||
### 使用 CLI 将 🤗 Transformers 模型导出为 ONNX
|
||||
|
||||
要将 🤗 Transformers 模型导出为 ONNX,首先需要安装额外的依赖项:
|
||||
|
||||
```bash
|
||||
pip install optimum[exporters]
|
||||
```
|
||||
|
||||
请参阅 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli) 以查看所有可用参数,或者在命令行中查看帮助:
|
||||
|
||||
```bash
|
||||
optimum-cli export onnx --help
|
||||
```
|
||||
|
||||
运行以下命令,以从 🤗 Hub 导出模型的检查点(checkpoint),以 `distilbert/distilbert-base-uncased-distilled-squad` 为例:
|
||||
|
||||
```bash
|
||||
optimum-cli export onnx --model distilbert/distilbert-base-uncased-distilled-squad distilbert_base_uncased_squad_onnx/
|
||||
```
|
||||
|
||||
你应该能在日志中看到导出进度以及生成的 `model.onnx` 文件的保存位置,如下所示:
|
||||
|
||||
```bash
|
||||
Validating ONNX model distilbert_base_uncased_squad_onnx/model.onnx...
|
||||
-[✓] ONNX model output names match reference model (start_logits, end_logits)
|
||||
- Validating ONNX Model output "start_logits":
|
||||
-[✓] (2, 16) matches (2, 16)
|
||||
-[✓] all values close (atol: 0.0001)
|
||||
- Validating ONNX Model output "end_logits":
|
||||
-[✓] (2, 16) matches (2, 16)
|
||||
-[✓] all values close (atol: 0.0001)
|
||||
The ONNX export succeeded and the exported model was saved at: distilbert_base_uncased_squad_onnx
|
||||
```
|
||||
|
||||
上面的示例说明了从 🤗 Hub 导出检查点的过程。导出本地模型时,首先需要确保将模型的权重和分词器文件保存在同一目录(`local_path`)中。在使用 CLI 时,将 `local_path` 传递给 `model` 参数,而不是 🤗 Hub 上的检查点名称,并提供 `--task` 参数。你可以在 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/exporters/task_manager)中查看支持的任务列表。如果未提供 `task` 参数,将默认导出不带特定任务头的模型架构。
|
||||
|
||||
```bash
|
||||
optimum-cli export onnx --model local_path --task question-answering distilbert_base_uncased_squad_onnx/
|
||||
```
|
||||
|
||||
生成的 `model.onnx` 文件可以在支持 ONNX 标准的 [许多加速引擎(accelerators)](https://onnx.ai/supported-tools.html#deployModel) 之一上运行。例如,我们可以使用 [ONNX Runtime](https://onnxruntime.ai/) 加载和运行模型,如下所示:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer
|
||||
>>> from optimum.onnxruntime import ORTModelForQuestionAnswering
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert_base_uncased_squad_onnx")
|
||||
>>> model = ORTModelForQuestionAnswering.from_pretrained("distilbert_base_uncased_squad_onnx")
|
||||
>>> inputs = tokenizer("What am I using?", "Using DistilBERT with ONNX Runtime!", return_tensors="pt")
|
||||
>>> outputs = model(**inputs)
|
||||
```
|
||||
|
||||
### 使用 `optimum.onnxruntime` 将 🤗 Transformers 模型导出为 ONNX
|
||||
|
||||
除了 CLI 之外,你还可以使用代码将 🤗 Transformers 模型导出为 ONNX,如下所示:
|
||||
|
||||
```python
|
||||
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
|
||||
>>> from transformers import AutoTokenizer
|
||||
|
||||
>>> model_checkpoint = "distilbert_base_uncased_squad"
|
||||
>>> save_directory = "onnx/"
|
||||
|
||||
>>> # 从 transformers 加载模型并将其导出为 ONNX
|
||||
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(model_checkpoint, export=True)
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
|
||||
|
||||
>>> # 保存 onnx 模型以及分词器
|
||||
>>> ort_model.save_pretrained(save_directory)
|
||||
>>> tokenizer.save_pretrained(save_directory)
|
||||
```
|
||||
|
||||
### 导出尚未支持的架构的模型
|
||||
|
||||
如果你想要为当前无法导出的模型添加支持,请先检查 [`optimum.exporters.onnx`](https://huggingface.co/docs/optimum/exporters/onnx/overview) 是否支持该模型,如果不支持,你可以 [直接为 🤗 Optimum 贡献代码](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/contribute)。
|
||||
|
||||
### 使用 `transformers.onnx` 导出模型
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
`transformers.onnx` 不再进行维护,请如上所述,使用 🤗 Optimum 导出模型。这部分内容将在未来版本中删除。
|
||||
|
||||
</Tip>
|
||||
|
||||
要使用 `transformers.onnx` 将 🤗 Transformers 模型导出为 ONNX,请安装额外的依赖项:
|
||||
|
||||
```bash
|
||||
pip install transformers[onnx]
|
||||
```
|
||||
|
||||
将 `transformers.onnx` 包作为 Python 模块使用,以使用现成的配置导出检查点:
|
||||
|
||||
```bash
|
||||
python -m transformers.onnx --model=distilbert/distilbert-base-uncased onnx/
|
||||
```
|
||||
|
||||
以上代码将导出由 `--model` 参数定义的检查点的 ONNX 图。传入任何 🤗 Hub 上或者存储与本地的检查点。生成的 `model.onnx` 文件可以在支持 ONNX 标准的众多加速引擎上运行。例如,使用 ONNX Runtime 加载并运行模型,如下所示:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer
|
||||
>>> from onnxruntime import InferenceSession
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
|
||||
>>> session = InferenceSession("onnx/model.onnx")
|
||||
>>> # ONNX Runtime expects NumPy arrays as input
|
||||
>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
|
||||
>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
|
||||
```
|
||||
|
||||
可以通过查看每个模型的 ONNX 配置来获取所需的输出名(例如 `["last_hidden_state"]`)。例如,对于 DistilBERT,可以用以下代码获取输出名称:
|
||||
|
||||
```python
|
||||
>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
|
||||
|
||||
>>> config = DistilBertConfig()
|
||||
>>> onnx_config = DistilBertOnnxConfig(config)
|
||||
>>> print(list(onnx_config.outputs.keys()))
|
||||
["last_hidden_state"]
|
||||
```
|
||||
|
||||
要导出本地存储的模型,请将模型的权重和分词器文件保存在同一目录中(例如 `local-pt-checkpoint`),然后通过将 `transformers.onnx` 包的 `--model` 参数指向该目录,将其导出为 ONNX:
|
||||
|
||||
```bash
|
||||
python -m transformers.onnx --model=local-pt-checkpoint onnx/
|
||||
```
|
||||
345
transformers/docs/source/zh/task_summary.md
Normal file
345
transformers/docs/source/zh/task_summary.md
Normal file
@@ -0,0 +1,345 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 🤗 Transformers 能做什么
|
||||
|
||||
🤗 Transformers是一个用于自然语言处理(NLP)、计算机视觉和音频和语音处理任务的预训练模型库。该库不仅包含Transformer模型,还包括用于计算机视觉任务的现代卷积网络等非Transformer模型。如果您看看今天最受欢迎的一些消费产品,比如智能手机、应用程序和电视,很可能背后都有某种深度学习技术的支持。想要从您智能手机拍摄的照片中删除背景对象吗?这里是一个全景分割任务的例子(如果您还不了解这是什么意思,我们将在以下部分进行描述!)。
|
||||
|
||||
本页面提供了使用🤗 Transformers库仅用三行代码解决不同的语音和音频、计算机视觉和NLP任务的概述!
|
||||
|
||||
|
||||
## 音频
|
||||
音频和语音处理任务与其他模态略有不同,主要是因为音频作为输入是一个连续的信号。与文本不同,原始音频波形不能像句子可以被划分为单词那样被整齐地分割成离散的块。为了解决这个问题,通常在固定的时间间隔内对原始音频信号进行采样。如果在每个时间间隔内采样更多样本,采样率就会更高,音频更接近原始音频源。
|
||||
|
||||
以前的方法是预处理音频以从中提取有用的特征。现在更常见的做法是直接将原始音频波形输入到特征编码器中,以提取音频表示。这样可以简化预处理步骤,并允许模型学习最重要的特征。
|
||||
|
||||
### 音频分类
|
||||
|
||||
音频分类是一项将音频数据从预定义的类别集合中进行标记的任务。这是一个广泛的类别,具有许多具体的应用,其中一些包括:
|
||||
|
||||
* 声学场景分类:使用场景标签("办公室"、"海滩"、"体育场")对音频进行标记。
|
||||
* 声学事件检测:使用声音事件标签("汽车喇叭声"、"鲸鱼叫声"、"玻璃破碎声")对音频进行标记。
|
||||
* 标记:对包含多种声音的音频进行标记(鸟鸣、会议中的说话人识别)。
|
||||
* 音乐分类:使用流派标签("金属"、"嘻哈"、"乡村")对音乐进行标记。
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> classifier = pipeline(task="audio-classification", model="superb/hubert-base-superb-er")
|
||||
>>> preds = classifier("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
|
||||
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
|
||||
>>> preds
|
||||
[{'score': 0.4532, 'label': 'hap'},
|
||||
{'score': 0.3622, 'label': 'sad'},
|
||||
{'score': 0.0943, 'label': 'neu'},
|
||||
{'score': 0.0903, 'label': 'ang'}]
|
||||
```
|
||||
|
||||
### 自动语音识别
|
||||
|
||||
自动语音识别(ASR)将语音转录为文本。这是最常见的音频任务之一,部分原因是因为语音是人类交流的自然形式。如今,ASR系统嵌入在智能技术产品中,如扬声器、电话和汽车。我们可以要求虚拟助手播放音乐、设置提醒和告诉我们天气。
|
||||
|
||||
但是,Transformer架构帮助解决的一个关键挑战是低资源语言。通过在大量语音数据上进行预训练,仅在一个低资源语言的一小时标记语音数据上进行微调,仍然可以产生与以前在100倍更多标记数据上训练的ASR系统相比高质量的结果。
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-small")
|
||||
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
|
||||
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
|
||||
```
|
||||
|
||||
## 计算机视觉
|
||||
|
||||
计算机视觉任务中最早成功之一是使用卷积神经网络([CNN](glossary#convolution))识别邮政编码数字图像。图像由像素组成,每个像素都有一个数值。这使得将图像表示为像素值矩阵变得容易。每个像素值组合描述了图像的颜色。
|
||||
|
||||
计算机视觉任务可以通过以下两种通用方式解决:
|
||||
|
||||
1. 使用卷积来学习图像的层次特征,从低级特征到高级抽象特征。
|
||||
2. 将图像分成块,并使用Transformer逐步学习每个图像块如何相互关联以形成图像。与CNN偏好的自底向上方法不同,这种方法有点像从一个模糊的图像开始,然后逐渐将其聚焦清晰。
|
||||
|
||||
### 图像分类
|
||||
|
||||
图像分类将整个图像从预定义的类别集合中进行标记。像大多数分类任务一样,图像分类有许多实际用例,其中一些包括:
|
||||
|
||||
* 医疗保健:标记医学图像以检测疾病或监测患者健康状况
|
||||
* 环境:标记卫星图像以监测森林砍伐、提供野外管理信息或检测野火
|
||||
* 农业:标记农作物图像以监测植物健康或用于土地使用监测的卫星图像
|
||||
* 生态学:标记动物或植物物种的图像以监测野生动物种群或跟踪濒危物种
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> classifier = pipeline(task="image-classification")
|
||||
>>> preds = classifier(
|
||||
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
|
||||
... )
|
||||
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
|
||||
>>> print(*preds, sep="\n")
|
||||
{'score': 0.4335, 'label': 'lynx, catamount'}
|
||||
{'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}
|
||||
{'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}
|
||||
{'score': 0.0239, 'label': 'Egyptian cat'}
|
||||
{'score': 0.0229, 'label': 'tiger cat'}
|
||||
```
|
||||
|
||||
### 目标检测
|
||||
|
||||
与图像分类不同,目标检测在图像中识别多个对象以及这些对象在图像中的位置(由边界框定义)。目标检测的一些示例应用包括:
|
||||
|
||||
* 自动驾驶车辆:检测日常交通对象,如其他车辆、行人和红绿灯
|
||||
* 遥感:灾害监测、城市规划和天气预报
|
||||
* 缺陷检测:检测建筑物中的裂缝或结构损坏,以及制造业产品缺陷
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> detector = pipeline(task="object-detection")
|
||||
>>> preds = detector(
|
||||
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
|
||||
... )
|
||||
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"], "box": pred["box"]} for pred in preds]
|
||||
>>> preds
|
||||
[{'score': 0.9865,
|
||||
'label': 'cat',
|
||||
'box': {'xmin': 178, 'ymin': 154, 'xmax': 882, 'ymax': 598}}]
|
||||
```
|
||||
|
||||
### 图像分割
|
||||
|
||||
图像分割是一项像素级任务,将图像中的每个像素分配给一个类别。它与使用边界框标记和预测图像中的对象的目标检测不同,因为分割更加精细。分割可以在像素级别检测对象。有几种类型的图像分割:
|
||||
|
||||
* 实例分割:除了标记对象的类别外,还标记每个对象的不同实例(“dog-1”,“dog-2”)
|
||||
* 全景分割:语义分割和实例分割的组合; 它使用语义类为每个像素标记并标记每个对象的不同实例
|
||||
|
||||
分割任务对于自动驾驶车辆很有帮助,可以创建周围世界的像素级地图,以便它们可以在行人和其他车辆周围安全导航。它还适用于医学成像,其中任务的更精细粒度可以帮助识别异常细胞或器官特征。图像分割也可以用于电子商务,通过您的相机在现实世界中覆盖物体来虚拟试穿衣服或创建增强现实体验。
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> segmenter = pipeline(task="image-segmentation")
|
||||
>>> preds = segmenter(
|
||||
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
|
||||
... )
|
||||
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
|
||||
>>> print(*preds, sep="\n")
|
||||
{'score': 0.9879, 'label': 'LABEL_184'}
|
||||
{'score': 0.9973, 'label': 'snow'}
|
||||
{'score': 0.9972, 'label': 'cat'}
|
||||
```
|
||||
|
||||
### 深度估计
|
||||
|
||||
深度估计预测图像中每个像素到相机的距离。这个计算机视觉任务对于场景理解和重建尤为重要。例如,在自动驾驶汽车中,车辆需要了解行人、交通标志和其他车辆等物体的距离,以避免障碍物和碰撞。深度信息还有助于从2D图像构建3D表示,并可用于创建生物结构或建筑物的高质量3D表示。
|
||||
|
||||
有两种方法可以进行深度估计:
|
||||
|
||||
* stereo(立体):通过比较同一图像的两个略微不同角度的图像来估计深度
|
||||
* monocular(单目):从单个图像中估计深度
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> depth_estimator = pipeline(task="depth-estimation")
|
||||
>>> preds = depth_estimator(
|
||||
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
|
||||
... )
|
||||
```
|
||||
|
||||
## 自然语言处理
|
||||
|
||||
NLP任务是最常见的类型之一,因为文本是我们进行交流的自然方式。为了让文本变成模型识别的格式,需要对其进行分词。这意味着将一段文本分成单独的单词或子词(`tokens`),然后将这些`tokens`转换为数字。因此,可以将一段文本表示为一系列数字,一旦有了一系列的数字,就可以将其输入到模型中以解决各种NLP任务!
|
||||
|
||||
### 文本分类
|
||||
|
||||
像任何模态的分类任务一样,文本分类将一段文本(可以是句子级别、段落或文档)从预定义的类别集合中进行标记。文本分类有许多实际应用,其中一些包括:
|
||||
|
||||
* 情感分析:根据某些极性(如`积极`或`消极`)对文本进行标记,可以支持政治、金融和营销等领域的决策制定
|
||||
* 内容分类:根据某些主题对文本进行标记,有助于组织和过滤新闻和社交媒体提要中的信息(`天气`、`体育`、`金融`等)
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> classifier = pipeline(task="sentiment-analysis")
|
||||
>>> preds = classifier("Hugging Face is the best thing since sliced bread!")
|
||||
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
|
||||
>>> preds
|
||||
[{'score': 0.9991, 'label': 'POSITIVE'}]
|
||||
```
|
||||
|
||||
### Token分类
|
||||
|
||||
在任何NLP任务中,文本都经过预处理,将文本序列分成单个单词或子词。这些被称为[tokens](/glossary#token)。Token分类将每个`token`分配一个来自预定义类别集的标签。
|
||||
|
||||
两种常见的Token分类是:
|
||||
|
||||
* 命名实体识别(NER):根据实体类别(如组织、人员、位置或日期)对`token`进行标记。NER在生物医学设置中特别受欢迎,可以标记基因、蛋白质和药物名称。
|
||||
* 词性标注(POS):根据其词性(如名词、动词或形容词)对标记进行标记。POS对于帮助翻译系统了解两个相同的单词如何在语法上不同很有用(作为名词的银行与作为动词的银行)。
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> classifier = pipeline(task="ner")
|
||||
>>> preds = classifier("Hugging Face is a French company based in New York City.")
|
||||
>>> preds = [
|
||||
... {
|
||||
... "entity": pred["entity"],
|
||||
... "score": round(pred["score"], 4),
|
||||
... "index": pred["index"],
|
||||
... "word": pred["word"],
|
||||
... "start": pred["start"],
|
||||
... "end": pred["end"],
|
||||
... }
|
||||
... for pred in preds
|
||||
... ]
|
||||
>>> print(*preds, sep="\n")
|
||||
{'entity': 'I-ORG', 'score': 0.9968, 'index': 1, 'word': 'Hu', 'start': 0, 'end': 2}
|
||||
{'entity': 'I-ORG', 'score': 0.9293, 'index': 2, 'word': '##gging', 'start': 2, 'end': 7}
|
||||
{'entity': 'I-ORG', 'score': 0.9763, 'index': 3, 'word': 'Face', 'start': 8, 'end': 12}
|
||||
{'entity': 'I-MISC', 'score': 0.9983, 'index': 6, 'word': 'French', 'start': 18, 'end': 24}
|
||||
{'entity': 'I-LOC', 'score': 0.999, 'index': 10, 'word': 'New', 'start': 42, 'end': 45}
|
||||
{'entity': 'I-LOC', 'score': 0.9987, 'index': 11, 'word': 'York', 'start': 46, 'end': 50}
|
||||
{'entity': 'I-LOC', 'score': 0.9992, 'index': 12, 'word': 'City', 'start': 51, 'end': 55}
|
||||
```
|
||||
|
||||
### 问答
|
||||
|
||||
问答是另一个`token-level`的任务,返回一个问题的答案,有时带有上下文(开放领域),有时不带上下文(封闭领域)。每当我们向虚拟助手提出问题时,例如询问一家餐厅是否营业,就会发生这种情况。它还可以提供客户或技术支持,并帮助搜索引擎检索您要求的相关信息。
|
||||
|
||||
有两种常见的问答类型:
|
||||
|
||||
* 提取式:给定一个问题和一些上下文,答案是从模型必须提取的上下文中的一段文本跨度。
|
||||
* 抽象式:给定一个问题和一些上下文,答案从上下文中生成;这种方法由[`Text2TextGenerationPipeline`]处理,而不是下面显示的[`QuestionAnsweringPipeline`]。
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> question_answerer = pipeline(task="question-answering")
|
||||
>>> preds = question_answerer(
|
||||
... question="What is the name of the repository?",
|
||||
... context="The name of the repository is huggingface/transformers",
|
||||
... )
|
||||
>>> print(
|
||||
... f"score: {round(preds['score'], 4)}, start: {preds['start']}, end: {preds['end']}, answer: {preds['answer']}"
|
||||
... )
|
||||
score: 0.9327, start: 30, end: 54, answer: huggingface/transformers
|
||||
```
|
||||
|
||||
### 摘要
|
||||
|
||||
摘要从较长的文本中创建一个较短的版本,同时尽可能保留原始文档的大部分含义。摘要是一个序列到序列的任务;它输出比输入更短的文本序列。有许多长篇文档可以进行摘要,以帮助读者快速了解主要要点。法案、法律和财务文件、专利和科学论文等文档可以摘要,以节省读者的时间并作为阅读辅助工具。
|
||||
|
||||
像问答一样,摘要有两种类型:
|
||||
|
||||
* 提取式:从原始文本中识别和提取最重要的句子
|
||||
* 抽象式:从原始文本生成目标摘要(可能包括不在输入文档中的新单词);[`SummarizationPipeline`]使用抽象方法。
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> summarizer = pipeline(task="summarization")
|
||||
>>> summarizer(
|
||||
... "In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention. For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles."
|
||||
... )
|
||||
[{'summary_text': ' The Transformer is the first sequence transduction model based entirely on attention . It replaces the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention . For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers .'}]
|
||||
```
|
||||
|
||||
### 翻译
|
||||
|
||||
翻译将一种语言的文本序列转换为另一种语言。它对于帮助来自不同背景的人们相互交流、帮助翻译内容以吸引更广泛的受众,甚至成为学习工具以帮助人们学习一门新语言都非常重要。除了摘要之外,翻译也是一个序列到序列的任务,意味着模型接收输入序列并返回目标输出序列。
|
||||
|
||||
在早期,翻译模型大多是单语的,但最近,越来越多的人对可以在多种语言之间进行翻译的多语言模型感兴趣。
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> text = "translate English to French: Hugging Face is a community-based open-source platform for machine learning."
|
||||
>>> translator = pipeline(task="translation", model="google-t5/t5-small")
|
||||
>>> translator(text)
|
||||
[{'translation_text': "Hugging Face est une tribune communautaire de l'apprentissage des machines."}]
|
||||
```
|
||||
|
||||
### 语言模型
|
||||
|
||||
语言模型是一种预测文本序列中单词的任务。它已成为一种非常流行的NLP任务,因为预训练的语言模型可以微调用于许多其他下游任务。最近,人们对大型语言模型(LLMs)表现出了极大的兴趣,这些模型展示了`zero learning`或`few-shot learning`的能力。这意味着模型可以解决它未被明确训练过的任务!语言模型可用于生成流畅和令人信服的文本,但需要小心,因为文本可能并不总是准确的。
|
||||
|
||||
有两种类型的话语模型:
|
||||
|
||||
* causal:模型的目标是预测序列中的下一个`token`,而未来的`tokens`被遮盖。
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> prompt = "Hugging Face is a community-based open-source platform for machine learning."
|
||||
>>> generator = pipeline(task="text-generation")
|
||||
>>> generator(prompt) # doctest: +SKIP
|
||||
```
|
||||
|
||||
* masked:模型的目标是预测序列中被遮蔽的`token`,同时具有对序列中所有`tokens`的完全访问权限。
|
||||
|
||||
```py
|
||||
>>> text = "Hugging Face is a community-based open-source <mask> for machine learning."
|
||||
>>> fill_mask = pipeline(task="fill-mask")
|
||||
>>> preds = fill_mask(text, top_k=1)
|
||||
>>> preds = [
|
||||
... {
|
||||
... "score": round(pred["score"], 4),
|
||||
... "token": pred["token"],
|
||||
... "token_str": pred["token_str"],
|
||||
... "sequence": pred["sequence"],
|
||||
... }
|
||||
... for pred in preds
|
||||
... ]
|
||||
>>> preds
|
||||
[{'score': 0.2236,
|
||||
'token': 1761,
|
||||
'token_str': ' platform',
|
||||
'sequence': 'Hugging Face is a community-based open-source platform for machine learning.'}]
|
||||
```
|
||||
|
||||
## 多模态
|
||||
|
||||
多模态任务要求模型处理多种数据模态(文本、图像、音频、视频)以解决特定问题。图像描述是一个多模态任务的例子,其中模型将图像作为输入并输出描述图像或图像某些属性的文本序列。
|
||||
|
||||
虽然多模态模型处理不同的数据类型或模态,但内部预处理步骤帮助模型将所有数据类型转换为`embeddings`(向量或数字列表,包含有关数据的有意义信息)。对于像图像描述这样的任务,模型学习图像嵌入和文本嵌入之间的关系。
|
||||
|
||||
### 文档问答
|
||||
|
||||
文档问答是从文档中回答自然语言问题的任务。与`token-level`问答任务不同,文档问答将包含问题的文档的图像作为输入,并返回答案。文档问答可用于解析结构化文档并从中提取关键信息。在下面的例子中,可以从收据中提取总金额和找零金额。
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
>>> from PIL import Image
|
||||
>>> import requests
|
||||
|
||||
>>> url = "https://huggingface.co/datasets/hf-internal-testing/example-documents/resolve/main/jpeg_images/2.jpg"
|
||||
>>> image = Image.open(requests.get(url, stream=True).raw)
|
||||
|
||||
>>> doc_question_answerer = pipeline("document-question-answering", model="magorshunov/layoutlm-invoices")
|
||||
>>> preds = doc_question_answerer(
|
||||
... question="What is the total amount?",
|
||||
... image=image,
|
||||
... )
|
||||
>>> preds
|
||||
[{'score': 0.8531, 'answer': '17,000', 'start': 4, 'end': 4}]
|
||||
```
|
||||
|
||||
希望这个页面为您提供了一些有关每种模态中所有类型任务的背景信息以及每个任务的实际重要性。在[下一节](tasks_explained)中,您将了解Transformers如何解决这些任务。
|
||||
384
transformers/docs/source/zh/tasks/asr.md
Normal file
384
transformers/docs/source/zh/tasks/asr.md
Normal file
@@ -0,0 +1,384 @@
|
||||
<!--
|
||||
Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# 自动语音识别
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
<Youtube id="TksaY_FDgnk"/>
|
||||
|
||||
自动语音识别(ASR)将语音信号转换为文本,将一系列音频输入映射到文本输出。
|
||||
Siri 和 Alexa 这类虚拟助手使用 ASR 模型来帮助用户日常生活,还有许多其他面向用户的有用应用,如会议实时字幕和会议纪要。
|
||||
|
||||
本指南将向您展示如何:
|
||||
|
||||
1. 在 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 数据集上对
|
||||
[Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) 进行微调,以将音频转录为文本。
|
||||
2. 使用微调后的模型进行推断。
|
||||
|
||||
<Tip>
|
||||
|
||||
如果您想查看所有与本任务兼容的架构和检查点,最好查看[任务页](https://huggingface.co/tasks/automatic-speech-recognition)。
|
||||
|
||||
</Tip>
|
||||
|
||||
在开始之前,请确保您已安装所有必要的库:
|
||||
|
||||
```bash
|
||||
pip install transformers datasets evaluate jiwer
|
||||
```
|
||||
|
||||
我们鼓励您登录自己的 Hugging Face 账户,这样您就可以上传并与社区分享您的模型。
|
||||
出现提示时,输入您的令牌登录:
|
||||
|
||||
```py
|
||||
>>> from huggingface_hub import notebook_login
|
||||
|
||||
>>> notebook_login()
|
||||
```
|
||||
|
||||
## 加载 MInDS-14 数据集
|
||||
|
||||
首先从🤗 Datasets 库中加载 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14)
|
||||
数据集的一个较小子集。这将让您有机会先进行实验,确保一切正常,然后再花更多时间在完整数据集上进行训练。
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset, Audio
|
||||
|
||||
>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train[:100]")
|
||||
```
|
||||
|
||||
使用 [`~Dataset.train_test_split`] 方法将数据集的 `train` 拆分为训练集和测试集:
|
||||
|
||||
```py
|
||||
>>> minds = minds.train_test_split(test_size=0.2)
|
||||
```
|
||||
|
||||
然后看看数据集:
|
||||
|
||||
```py
|
||||
>>> minds
|
||||
DatasetDict({
|
||||
train: Dataset({
|
||||
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
|
||||
num_rows: 16
|
||||
})
|
||||
test: Dataset({
|
||||
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
|
||||
num_rows: 4
|
||||
})
|
||||
})
|
||||
```
|
||||
|
||||
虽然数据集包含 `lang_id` 和 `english_transcription` 等许多有用的信息,但在本指南中,
|
||||
您将专注于 `audio` 和 `transcription`。使用 [`~datasets.Dataset.remove_columns`] 方法删除其他列:
|
||||
|
||||
```py
|
||||
>>> minds = minds.remove_columns(["english_transcription", "intent_class", "lang_id"])
|
||||
```
|
||||
|
||||
再看看示例:
|
||||
|
||||
```py
|
||||
>>> minds["train"][0]
|
||||
{'audio': {'array': array([-0.00024414, 0. , 0. , ..., 0.00024414,
|
||||
0.00024414, 0.00024414], dtype=float32),
|
||||
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
|
||||
'sampling_rate': 8000},
|
||||
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
|
||||
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
|
||||
```
|
||||
|
||||
有 2 个字段:
|
||||
|
||||
- `audio`:由语音信号形成的一维 `array`,用于加载和重新采样音频文件。
|
||||
- `transcription`:目标文本。
|
||||
|
||||
## 预处理
|
||||
|
||||
下一步是加载一个 Wav2Vec2 处理器来处理音频信号:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoProcessor
|
||||
|
||||
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base")
|
||||
```
|
||||
|
||||
MInDS-14 数据集的采样率为 8000kHz(您可以在其[数据集卡片](https://huggingface.co/datasets/PolyAI/minds14)中找到此信息),
|
||||
这意味着您需要将数据集重新采样为 16000kHz 以使用预训练的 Wav2Vec2 模型:
|
||||
|
||||
```py
|
||||
>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
|
||||
>>> minds["train"][0]
|
||||
{'audio': {'array': array([-2.38064706e-04, -1.58618059e-04, -5.43987835e-06, ...,
|
||||
2.78103951e-04, 2.38446111e-04, 1.18740834e-04], dtype=float32),
|
||||
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
|
||||
'sampling_rate': 16000},
|
||||
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
|
||||
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
|
||||
```
|
||||
|
||||
如您在上面的 `transcription` 中所看到的,文本包含大小写字符的混合。
|
||||
Wav2Vec2 分词器仅训练了大写字符,因此您需要确保文本与分词器的词汇表匹配:
|
||||
|
||||
```py
|
||||
>>> def uppercase(example):
|
||||
... return {"transcription": example["transcription"].upper()}
|
||||
|
||||
|
||||
>>> minds = minds.map(uppercase)
|
||||
```
|
||||
|
||||
现在创建一个预处理函数,该函数应该:
|
||||
|
||||
1. 调用 `audio` 列以加载和重新采样音频文件。
|
||||
2. 从音频文件中提取 `input_values` 并使用处理器对 `transcription` 列执行 tokenizer 操作。
|
||||
|
||||
```py
|
||||
>>> def prepare_dataset(batch):
|
||||
... audio = batch["audio"]
|
||||
... batch = processor(audio["array"], sampling_rate=audio["sampling_rate"], text=batch["transcription"])
|
||||
... batch["input_length"] = len(batch["input_values"][0])
|
||||
... return batch
|
||||
```
|
||||
|
||||
要在整个数据集上应用预处理函数,可以使用🤗 Datasets 的 [`~datasets.Dataset.map`] 函数。
|
||||
您可以通过增加 `num_proc` 参数来加速 `map` 的处理进程数量。
|
||||
使用 [`~datasets.Dataset.remove_columns`] 方法删除不需要的列:
|
||||
|
||||
```py
|
||||
>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
|
||||
```
|
||||
|
||||
🤗 Transformers 没有用于 ASR 的数据整理器,因此您需要调整 [`DataCollatorWithPadding`] 来创建一个示例批次。
|
||||
它还会动态地将您的文本和标签填充到其批次中最长元素的长度(而不是整个数据集),以使它们具有统一的长度。
|
||||
虽然可以通过在 `tokenizer` 函数中设置 `padding=True` 来填充文本,但动态填充更有效。
|
||||
|
||||
与其他数据整理器不同,这个特定的数据整理器需要对 `input_values` 和 `labels` 应用不同的填充方法:
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
|
||||
>>> from dataclasses import dataclass, field
|
||||
>>> from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
|
||||
>>> @dataclass
|
||||
... class DataCollatorCTCWithPadding:
|
||||
... processor: AutoProcessor
|
||||
... padding: Union[bool, str] = "longest"
|
||||
|
||||
... def __call__(self, features: list[dict[str, Union[list[int], torch.Tensor]]]) -> dict[str, torch.Tensor]:
|
||||
... # split inputs and labels since they have to be of different lengths and need
|
||||
... # different padding methods
|
||||
... input_features = [{"input_values": feature["input_values"][0]} for feature in features]
|
||||
... label_features = [{"input_ids": feature["labels"]} for feature in features]
|
||||
|
||||
... batch = self.processor.pad(input_features, padding=self.padding, return_tensors="pt")
|
||||
|
||||
... labels_batch = self.processor.pad(labels=label_features, padding=self.padding, return_tensors="pt")
|
||||
|
||||
... # replace padding with -100 to ignore loss correctly
|
||||
... labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
|
||||
|
||||
... batch["labels"] = labels
|
||||
|
||||
... return batch
|
||||
```
|
||||
|
||||
现在实例化您的 `DataCollatorForCTCWithPadding`:
|
||||
|
||||
```py
|
||||
>>> data_collator = DataCollatorCTCWithPadding(processor=processor, padding="longest")
|
||||
```
|
||||
|
||||
## 评估
|
||||
|
||||
在训练过程中包含一个指标通常有助于评估模型的性能。
|
||||
您可以通过🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 库快速加载一个评估方法。
|
||||
对于这个任务,加载 [word error rate](https://huggingface.co/spaces/evaluate-metric/wer)(WER)指标
|
||||
(请参阅🤗 Evaluate [快速上手](https://huggingface.co/docs/evaluate/a_quick_tour)以了解如何加载和计算指标):
|
||||
|
||||
```py
|
||||
>>> import evaluate
|
||||
|
||||
>>> wer = evaluate.load("wer")
|
||||
```
|
||||
|
||||
然后创建一个函数,将您的预测和标签传递给 [`~evaluate.EvaluationModule.compute`] 来计算 WER:
|
||||
|
||||
```py
|
||||
>>> import numpy as np
|
||||
|
||||
|
||||
>>> def compute_metrics(pred):
|
||||
... pred_logits = pred.predictions
|
||||
... pred_ids = np.argmax(pred_logits, axis=-1)
|
||||
|
||||
... pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
|
||||
|
||||
... pred_str = processor.batch_decode(pred_ids)
|
||||
... label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
|
||||
|
||||
... wer = wer.compute(predictions=pred_str, references=label_str)
|
||||
|
||||
... return {"wer": wer}
|
||||
```
|
||||
|
||||
您的 `compute_metrics` 函数现在已经准备就绪,当您设置好训练时将返回给此函数。
|
||||
|
||||
## 训练
|
||||
|
||||
<Tip>
|
||||
|
||||
如果您不熟悉使用[`Trainer`]微调模型,请查看这里的基本教程[here](../training#train-with-pytorch-trainer)!
|
||||
|
||||
</Tip>
|
||||
|
||||
现在您已经准备好开始训练您的模型了!使用 [`AutoModelForCTC`] 加载 Wav2Vec2。
|
||||
使用 `ctc_loss_reduction` 参数指定要应用的减少方式。通常最好使用平均值而不是默认的求和:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForCTC, TrainingArguments, Trainer
|
||||
|
||||
>>> model = AutoModelForCTC.from_pretrained(
|
||||
... "facebook/wav2vec2-base",
|
||||
... ctc_loss_reduction="mean",
|
||||
... pad_token_id=processor.tokenizer.pad_token_id,
|
||||
)
|
||||
```
|
||||
|
||||
此时,只剩下 3 个步骤:
|
||||
|
||||
1. 在 [`TrainingArguments`] 中定义您的训练参数。唯一必需的参数是 `output_dir`,用于指定保存模型的位置。
|
||||
您可以通过设置 `push_to_hub=True` 将此模型推送到 Hub(您需要登录到 Hugging Face 才能上传您的模型)。
|
||||
在每个 epoch 结束时,[`Trainer`] 将评估 WER 并保存训练检查点。
|
||||
2. 将训练参数与模型、数据集、分词器、数据整理器和 `compute_metrics` 函数一起传递给 [`Trainer`]。
|
||||
3. 调用 [`~Trainer.train`] 来微调您的模型。
|
||||
|
||||
```py
|
||||
>>> training_args = TrainingArguments(
|
||||
... output_dir="my_awesome_asr_mind_model",
|
||||
... per_device_train_batch_size=8,
|
||||
... gradient_accumulation_steps=2,
|
||||
... learning_rate=1e-5,
|
||||
... warmup_steps=500,
|
||||
... max_steps=2000,
|
||||
... gradient_checkpointing=True,
|
||||
... fp16=True,
|
||||
... group_by_length=True,
|
||||
... eval_strategy="steps",
|
||||
... per_device_eval_batch_size=8,
|
||||
... save_steps=1000,
|
||||
... eval_steps=1000,
|
||||
... logging_steps=25,
|
||||
... load_best_model_at_end=True,
|
||||
... metric_for_best_model="wer",
|
||||
... greater_is_better=False,
|
||||
... push_to_hub=True,
|
||||
... )
|
||||
|
||||
>>> trainer = Trainer(
|
||||
... model=model,
|
||||
... args=training_args,
|
||||
... train_dataset=encoded_minds["train"],
|
||||
... eval_dataset=encoded_minds["test"],
|
||||
... processing_class=processor,
|
||||
... data_collator=data_collator,
|
||||
... compute_metrics=compute_metrics,
|
||||
... )
|
||||
|
||||
>>> trainer.train()
|
||||
```
|
||||
|
||||
训练完成后,使用 [`~transformers.Trainer.push_to_hub`] 方法将您的模型分享到 Hub,方便大家使用您的模型:
|
||||
|
||||
```py
|
||||
>>> trainer.push_to_hub()
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
要深入了解如何微调模型进行自动语音识别,
|
||||
请查看这篇博客[文章](https://huggingface.co/blog/fine-tune-wav2vec2-english)以了解英语 ASR,
|
||||
还可以参阅[这篇文章](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2)以了解多语言 ASR。
|
||||
|
||||
</Tip>
|
||||
|
||||
## 推断
|
||||
|
||||
很好,现在您已经微调了一个模型,您可以用它进行推断了!
|
||||
|
||||
加载您想要运行推断的音频文件。请记住,如果需要,将音频文件的采样率重新采样为与模型匹配的采样率!
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset, Audio
|
||||
|
||||
>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
|
||||
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
|
||||
>>> sampling_rate = dataset.features["audio"].sampling_rate
|
||||
>>> audio_file = dataset[0]["audio"]["path"]
|
||||
```
|
||||
|
||||
尝试使用微调后的模型进行推断的最简单方法是使用 [`pipeline`]。
|
||||
使用您的模型实例化一个用于自动语音识别的 `pipeline`,并将您的音频文件传递给它:
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> transcriber = pipeline("automatic-speech-recognition", model="stevhliu/my_awesome_asr_minds_model")
|
||||
>>> transcriber(audio_file)
|
||||
{'text': 'I WOUD LIKE O SET UP JOINT ACOUNT WTH Y PARTNER'}
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
转录结果还不错,但可以更好!尝试用更多示例微调您的模型,以获得更好的结果!
|
||||
|
||||
</Tip>
|
||||
|
||||
如果您愿意,您也可以手动复制 `pipeline` 的结果:
|
||||
|
||||
|
||||
加载一个处理器来预处理音频文件和转录,并将 `input` 返回为 PyTorch 张量:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoProcessor
|
||||
|
||||
>>> processor = AutoProcessor.from_pretrained("stevhliu/my_awesome_asr_mind_model")
|
||||
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
|
||||
```
|
||||
|
||||
将您的输入传递给模型并返回 logits:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForCTC
|
||||
|
||||
>>> model = AutoModelForCTC.from_pretrained("stevhliu/my_awesome_asr_mind_model")
|
||||
>>> with torch.no_grad():
|
||||
... logits = model(**inputs).logits
|
||||
```
|
||||
|
||||
获取具有最高概率的预测 `input_ids`,并使用处理器将预测的 `input_ids` 解码回文本:
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
|
||||
>>> predicted_ids = torch.argmax(logits, dim=-1)
|
||||
>>> transcription = processor.batch_decode(predicted_ids)
|
||||
>>> transcription
|
||||
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
|
||||
```
|
||||
55
transformers/docs/source/zh/tiktoken.md
Normal file
55
transformers/docs/source/zh/tiktoken.md
Normal file
@@ -0,0 +1,55 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
``
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Transformers与Tiktonken的互操作性
|
||||
|
||||
在🤗 transformers中,当使用`from_pretrained`方法从Hub加载模型时,如果模型包含tiktoken格式的`tokenizer.model`文件,框架可以无缝支持tiktoken模型文件,并自动将其转换为我们的[快速词符化器](https://huggingface.co/docs/transformers/main/en/main_classes/tokenizer#transformers.PreTrainedTokenizerFast)。
|
||||
|
||||
### 已知包含`tiktoken.model`文件发布的模型:
|
||||
- gpt2
|
||||
- llama3
|
||||
|
||||
## 使用示例
|
||||
|
||||
为了在transformers中正确加载`tiktoken`文件,请确保`tiktoken.model`文件是tiktoken格式的,并且会在加载`from_pretrained`时自动加载。以下展示如何从同一个文件中加载词符化器(tokenizer)和模型:
|
||||
|
||||
```py
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id, subfolder="original")
|
||||
```
|
||||
## 创建tiktoken词符化器(tokenizer)
|
||||
|
||||
`tokenizer.model`文件中不包含任何额外的词符(token)或模式字符串(pattern strings)的信息。如果这些信息很重要,需要将词符化器(tokenizer)转换为适用于[`PreTrainedTokenizerFast`]类的`tokenizer.json`格式。
|
||||
|
||||
使用[tiktoken.get_encoding](https://github.com/openai/tiktoken/blob/63527649963def8c759b0f91f2eb69a40934e468/tiktoken/registry.py#L63)生成`tokenizer.model`文件,再使用[`convert_tiktoken_to_fast`]函数将其转换为`tokenizer.json`文件。
|
||||
|
||||
```py
|
||||
|
||||
from transformers.integrations.tiktoken import convert_tiktoken_to_fast
|
||||
from tiktoken import get_encoding
|
||||
|
||||
# You can load your custom encoding or the one provided by OpenAI
|
||||
encoding = get_encoding("gpt2")
|
||||
convert_tiktoken_to_fast(encoding, "config/save/dir")
|
||||
```
|
||||
|
||||
生成的`tokenizer.json`文件将被保存到指定的目录,并且可以通过[`PreTrainedTokenizerFast`]类来加载。
|
||||
|
||||
```py
|
||||
tokenizer = PreTrainedTokenizerFast.from_pretrained("config/save/dir")
|
||||
```
|
||||
234
transformers/docs/source/zh/tokenizer_summary.md
Normal file
234
transformers/docs/source/zh/tokenizer_summary.md
Normal file
@@ -0,0 +1,234 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 分词器的摘要
|
||||
[[open-in-colab]]
|
||||
|
||||
在这个页面,我们来仔细研究分词的知识。
|
||||
<Youtube id="VFp38yj8h3A"/>
|
||||
|
||||
正如我们在[the preprocessing tutorial](preprocessing)所看到的那样,对文本进行分词就是将一段文本分割成很多单词或者子单词,
|
||||
这些单词或者子单词然后会通过一个查询表格被转换到id,将单词或者子单词转换到id是很直截了当的,也就是一个简单的映射,
|
||||
所以这么来看,我们主要关注将一段文本分割成很多单词或者很多子单词(像:对一段文本进行分词),更加准确的来说,我们将关注
|
||||
在🤗 Transformers内用到的三种主要类型的分词器:[Byte-Pair Encoding (BPE)](#byte-pair-encoding), [WordPiece](#wordpiece),
|
||||
and [SentencePiece](#sentencepiece),并且给出了示例,哪个模型用到了哪种类型的分词器。
|
||||
|
||||
注意到在每个模型的主页,你可以查看文档上相关的分词器,就可以知道预训练模型使用了哪种类型的分词器。
|
||||
举个例子,如果我们查看[`BertTokenizer`],我们就能看到模型使用了[WordPiece](#wordpiece)。
|
||||
|
||||
## 介绍
|
||||
将一段文本分词到小块是一个比它看起来更加困难的任务,并且有很多方式来实现分词,举个例子,让我们看看这个句子
|
||||
`"Don't you love 🤗 Transformers? We sure do."`
|
||||
|
||||
<Youtube id="nhJxYji1aho"/>
|
||||
|
||||
对这段文本分词的一个简单方式,就是使用空格来分词,得到的结果是:
|
||||
|
||||
```
|
||||
["Don't", "you", "love", "🤗", "Transformers?", "We", "sure", "do."]
|
||||
```
|
||||
|
||||
上面的分词是一个明智的开始,但是如果我们查看token `"Transformers?"` 和 `"do."`,我们可以观察到标点符号附在单词`"Transformer"`
|
||||
和 `"do"`的后面,这并不是最理想的情况。我们应该将标点符号考虑进来,这样一个模型就没必要学习一个单词和每个可能跟在后面的
|
||||
标点符号的不同的组合,这么组合的话,模型需要学习的组合的数量会急剧上升。将标点符号也考虑进来,对范例文本进行分词的结果就是:
|
||||
|
||||
```
|
||||
["Don", "'", "t", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
|
||||
```
|
||||
|
||||
分词的结果更好了,然而,这么做也是不好的,分词怎么处理单词`"Don't"`,`"Don't"`的含义是`"do not"`,所以这么分词`["Do", "n't"]`
|
||||
会更好。现在开始事情就开始变得复杂起来了,部分的原因是每个模型都有它自己的分词类型。依赖于我们应用在文本分词上的规则,
|
||||
相同的文本会产生不同的分词输出。用在训练数据上的分词规则,被用来对输入做分词操作,一个预训练模型才会正确的执行。
|
||||
|
||||
[spaCy](https://spacy.io/) and [Moses](http://www.statmt.org/moses/?n=Development.GetStarted) 是两个受欢迎的基于规则的
|
||||
分词器。将这两个分词器应用在示例文本上,*spaCy* 和 *Moses*会输出类似下面的结果:
|
||||
|
||||
```
|
||||
["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
|
||||
```
|
||||
|
||||
可见上面的分词使用到了空格和标点符号的分词方式,以及基于规则的分词方式。空格和标点符号分词以及基于规则的分词都是单词分词的例子。
|
||||
不那么严格的来说,单词分词的定义就是将句子分割到很多单词。然而将文本分割到更小的块是符合直觉的,当处理大型文本语料库时,上面的
|
||||
分词方法会导致很多问题。在这种情况下,空格和标点符号分词通常会产生一个非常大的词典(使用到的所有不重复的单词和tokens的集合)。
|
||||
像:[Transformer XL](model_doc/transformerxl)使用空格和标点符号分词,结果会产生一个大小是267,735的词典!
|
||||
|
||||
这么大的一个词典容量,迫使模型有着一个巨大的embedding矩阵,以及巨大的输入和输出层,这会增加内存使用量,也会提高时间复杂度。通常
|
||||
情况下,transformers模型几乎没有词典容量大于50,000的,特别是只在一种语言上预训练的模型。
|
||||
|
||||
所以如果简单的空格和标点符号分词让人不满意,为什么不简单的对字符分词?
|
||||
|
||||
<Youtube id="ssLq_EK2jLE"/>
|
||||
|
||||
尽管字符分词是非常简单的,并且能极大的减少内存使用,降低时间复杂度,但是这样做会让模型很难学到有意义的输入表达。像:
|
||||
比起学到单词`"today"`的一个有意义的上下文独立的表达,学到字母`"t"`的一个有意义的上下文独立的表达是相当困难的。因此,
|
||||
字符分词经常会伴随着性能的下降。所以为了获得最好的结果,transformers模型在单词级别分词和字符级别分词之间使用了一个折中的方案
|
||||
被称作**子词**分词。
|
||||
|
||||
## 子词分词
|
||||
|
||||
<Youtube id="zHvTiHr506c"/>
|
||||
|
||||
子词分词算法依赖这样的原则:频繁使用的单词不应该被分割成更小的子词,但是很少使用的单词应该被分解到有意义的子词。举个例子:
|
||||
`"annoyingly"`能被看作一个很少使用的单词,能被分解成`"annoying"`和`"ly"`。`"annoying"`和`"ly"`作为独立地子词,出现
|
||||
的次数都很频繁,而且与此同时单词`"annoyingly"`的含义可以通过组合`"annoying"`和`"ly"`的含义来获得。在粘合和胶水语言上,
|
||||
像Turkish语言,这么做是相当有用的,在这样的语言里,通过线性组合子词,大多数情况下你能形成任意长的复杂的单词。
|
||||
|
||||
子词分词允许模型有一个合理的词典大小,而且能学到有意义的上下文独立地表达。除此以外,子词分词可以让模型处理以前从来没见过的单词,
|
||||
方式是通过分解这些单词到已知的子词,举个例子:[`~transformers.BertTokenizer`]对句子`"I have a new GPU!"`分词的结果如下:
|
||||
|
||||
```py
|
||||
>>> from transformers import BertTokenizer
|
||||
|
||||
>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
|
||||
>>> tokenizer.tokenize("I have a new GPU!")
|
||||
["i", "have", "a", "new", "gp", "##u", "!"]
|
||||
```
|
||||
|
||||
因为我们正在考虑不区分大小写的模型,句子首先被转换成小写字母形式。我们可以见到单词`["i", "have", "a", "new"]`在分词器
|
||||
的词典内,但是这个单词`"gpu"`不在词典内。所以,分词器将`"gpu"`分割成已知的子词`["gp" and "##u"]`。`"##"`意味着剩下的
|
||||
token应该附着在前面那个token的后面,不带空格的附着(分词的解码或者反向)。
|
||||
|
||||
另外一个例子,[`~transformers.XLNetTokenizer`]对前面的文本例子分词结果如下:
|
||||
|
||||
```py
|
||||
>>> from transformers import XLNetTokenizer
|
||||
|
||||
>>> tokenizer = XLNetTokenizer.from_pretrained("xlnet/xlnet-base-cased")
|
||||
>>> tokenizer.tokenize("Don't you love 🤗 Transformers? We sure do.")
|
||||
["▁Don", "'", "t", "▁you", "▁love", "▁", "🤗", "▁", "Transform", "ers", "?", "▁We", "▁sure", "▁do", "."]
|
||||
```
|
||||
|
||||
当我们查看[SentencePiece](#sentencepiece)时会回过头来解释这些`"▁"`符号的含义。正如你能见到的,很少使用的单词
|
||||
`"Transformers"`能被分割到更加频繁使用的子词`"Transform"`和`"ers"`。
|
||||
|
||||
现在让我们来看看不同的子词分割算法是怎么工作的,注意到所有的这些分词算法依赖于某些训练的方式,这些训练通常在语料库上完成,
|
||||
相应的模型也是在这个语料库上训练的。
|
||||
|
||||
<a id='byte-pair-encoding'></a>
|
||||
|
||||
### Byte-Pair Encoding (BPE)
|
||||
|
||||
Byte-Pair Encoding (BPE)来自于[Neural Machine Translation of Rare Words with Subword Units (Sennrich et
|
||||
al., 2015)](https://huggingface.co/papers/1508.07909)。BPE依赖于一个预分词器,这个预分词器会将训练数据分割成单词。预分词可以是简单的
|
||||
空格分词,像::[GPT-2](model_doc/gpt2),[RoBERTa](model_doc/roberta)。更加先进的预分词方式包括了基于规则的分词,像: [XLM](model_doc/xlm),[FlauBERT](model_doc/flaubert),FlauBERT在大多数语言使用了Moses,或者[GPT](model_doc/gpt),GPT
|
||||
使用了Spacy和ftfy,统计了训练语料库中每个单词的频次。
|
||||
|
||||
在预分词以后,生成了单词的集合,也确定了训练数据中每个单词出现的频次。下一步,BPE产生了一个基础词典,包含了集合中所有的符号,
|
||||
BPE学习融合的规则-组合基础词典中的两个符号来形成一个新的符号。BPE会一直学习直到词典的大小满足了期望的词典大小的要求。注意到
|
||||
期望的词典大小是一个超参数,在训练这个分词器以前就需要人为指定。
|
||||
|
||||
举个例子,让我们假设在预分词以后,下面的单词集合以及他们的频次都已经确定好了:
|
||||
|
||||
```
|
||||
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
|
||||
```
|
||||
|
||||
所以,基础的词典是`["b", "g", "h", "n", "p", "s", "u"]`。将所有单词分割成基础词典内的符号,就可以获得:
|
||||
|
||||
```
|
||||
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
|
||||
```
|
||||
BPE接着会统计每个可能的符号对的频次,然后挑出出现最频繁的的符号对,在上面的例子中,`"h"`跟了`"u"`出现了10 + 5 = 15次
|
||||
(10次是出现了10次`"hug"`,5次是出现了5次`"hugs"`)。然而,最频繁的符号对是`"u"`后面跟了个`"g"`,总共出现了10 + 5 + 5
|
||||
= 20次。因此,分词器学到的第一个融合规则是组合所有的`"u"`后面跟了个`"g"`符号。下一步,`"ug"`被加入到了词典内。单词的集合
|
||||
就变成了:
|
||||
|
||||
```
|
||||
("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
|
||||
```
|
||||
|
||||
BPE接着会统计出下一个最普遍的出现频次最大的符号对。也就是`"u"`后面跟了个`"n"`,出现了16次。`"u"`,`"n"`被融合成了`"un"`。
|
||||
也被加入到了词典中,再下一个出现频次最大的符号对是`"h"`后面跟了个`"ug"`,出现了15次。又一次这个符号对被融合成了`"hug"`,
|
||||
也被加入到了词典中。
|
||||
|
||||
在当前这步,词典是`["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]`,我们的单词集合则是:
|
||||
|
||||
```
|
||||
("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
|
||||
```
|
||||
|
||||
假设,the Byte-Pair Encoding在这个时候停止训练,学到的融合规则并应用到其他新的单词上(只要这些新单词不包括不在基础词典内的符号
|
||||
就行)。举个例子,单词`"bug"`会被分词到`["b", "ug"]`,但是`"mug"`会被分词到`["<unk>", "ug"]`,因为符号`"m"`不在基础词典内。
|
||||
通常来看的话,单个字母像`"m"`不会被`"<unk>"`符号替换掉,因为训练数据通常包括了每个字母,每个字母至少出现了一次,但是在特殊的符号
|
||||
中也可能发生像emojis。
|
||||
|
||||
就像之前提到的那样,词典的大小,举个例子,基础词典的大小 + 融合的数量,是一个需要配置的超参数。举个例子:[GPT](model_doc/gpt)
|
||||
的词典大小是40,478,因为GPT有着478个基础词典内的字符,在40,000次融合以后选择了停止训练。
|
||||
|
||||
#### Byte-level BPE
|
||||
|
||||
一个包含了所有可能的基础字符的基础字典可能会非常大,如果考虑将所有的unicode字符作为基础字符。为了拥有一个更好的基础词典,[GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)使用了字节
|
||||
作为基础词典,这是一个非常聪明的技巧,迫使基础词典是256大小,而且确保了所有基础字符包含在这个词典内。使用了其他的规则
|
||||
来处理标点符号,这个GPT2的分词器能对每个文本进行分词,不需要使用到<unk>符号。[GPT-2](model_doc/gpt)有一个大小是50,257
|
||||
的词典,对应到256字节的基础tokens,一个特殊的文本结束token,这些符号经过了50,000次融合学习。
|
||||
|
||||
<a id='wordpiece'></a>
|
||||
|
||||
### WordPiece
|
||||
|
||||
WordPiece是子词分词算法,被用在[BERT](model_doc/bert),[DistilBERT](model_doc/distilbert),和[Electra](model_doc/electra)。
|
||||
这个算法发布在[Japanese and Korean
|
||||
Voice Search (Schuster et al., 2012)](https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/37842.pdf)
|
||||
和BPE非常相似。WordPiece首先初始化一个词典,这个词典包含了出现在训练数据中的每个字符,然后递进的学习一个给定数量的融合规则。和BPE相比较,
|
||||
WordPiece不会选择出现频次最大的符号对,而是选择了加入到字典以后能最大化训练数据似然值的符号对。
|
||||
|
||||
所以这到底意味着什么?参考前面的例子,最大化训练数据的似然值,等价于找到一个符号对,它们的概率除以这个符号对中第一个符号的概率,
|
||||
接着除以第二个符号的概率,在所有的符号对中商最大。像:如果`"ug"`的概率除以`"u"`除以`"g"`的概率的商,比其他任何符号对更大,
|
||||
这个时候才能融合`"u"`和`"g"`。直觉上,WordPiece,和BPE有点点不同,WordPiece是评估融合两个符号会失去的量,来确保这么做是值得的。
|
||||
|
||||
<a id='unigram'></a>
|
||||
|
||||
### Unigram
|
||||
|
||||
Unigram是一个子词分词器算法,介绍见[Subword Regularization: Improving Neural Network Translation
|
||||
Models with Multiple Subword Candidates (Kudo, 2018)](https://huggingface.co/papers/1804.10959)。和BPE或者WordPiece相比较
|
||||
,Unigram使用大量的符号来初始化它的基础字典,然后逐渐的精简每个符号来获得一个更小的词典。举例来看基础词典能够对应所有的预分词
|
||||
的单词以及最常见的子字符串。Unigram没有直接用在任何transformers的任何模型中,但是和[SentencePiece](#sentencepiece)一起联合使用。
|
||||
|
||||
在每个训练的步骤,Unigram算法在当前词典的训练数据上定义了一个损失函数(经常定义为log似然函数的),还定义了一个unigram语言模型。
|
||||
然后,对词典内的每个符号,算法会计算如果这个符号从词典内移除,总的损失会升高多少。Unigram然后会移除百分之p的符号,这些符号的loss
|
||||
升高是最低的(p通常是10%或者20%),像:这些在训练数据上对总的损失影响最小的符号。重复这个过程,直到词典已经达到了期望的大小。
|
||||
为了任何单词都能被分词,Unigram算法总是保留基础的字符。
|
||||
|
||||
因为Unigram不是基于融合规则(和BPE以及WordPiece相比较),在训练以后算法有几种方式来分词,如果一个训练好的Unigram分词器
|
||||
的词典是这个:
|
||||
|
||||
```
|
||||
["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"],
|
||||
```
|
||||
`"hugs"`可以被分词成`["hug", "s"]`, `["h", "ug", "s"]`或者`["h", "u", "g", "s"]`。所以选择哪一个呢?Unigram在保存
|
||||
词典的时候还会保存训练语料库内每个token的概率,所以在训练以后可以计算每个可能的分词结果的概率。实际上算法简单的选择概率
|
||||
最大的那个分词结果,但是也会提供概率来根据分词结果的概率来采样一个可能的分词结果。
|
||||
|
||||
分词器在损失函数上训练,这些损失函数定义了这些概率。假设训练数据包含了这些单词 $x_{1}$, $\dots$, $x_{N}$,一个单词$x_{i}$
|
||||
的所有可能的分词结果的集合定义为$S(x_{i})$,然后总的损失就可以定义为:
|
||||
|
||||
$$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )$$
|
||||
|
||||
<a id='sentencepiece'></a>
|
||||
|
||||
### SentencePiece
|
||||
目前为止描述的所有分词算法都有相同的问题:它们都假设输入的文本使用空格来分开单词。然而,不是所有的语言都使用空格来分开单词。
|
||||
一个可能的解决方案是使用某种语言特定的预分词器。像:[XLM](model_doc/xlm)使用了一个特定的中文、日语和Thai的预分词器。
|
||||
为了更加广泛的解决这个问题,[SentencePiece: A simple and language independent subword tokenizer and
|
||||
detokenizer for Neural Text Processing (Kudo et al., 2018)](https://huggingface.co/papers/1808.06226)
|
||||
将输入文本看作一个原始的输入流,因此使用的符合集合中也包括了空格。SentencePiece然后会使用BPE或者unigram算法来产生合适的
|
||||
词典。
|
||||
|
||||
举例来说,[`XLNetTokenizer`]使用了SentencePiece,这也是为什么上面的例子中`"▁"`符号包含在词典内。SentencePiece解码是非常容易的,因为所有的tokens能被concatenate起来,然后将`"▁"`替换成空格。
|
||||
|
||||
库内所有使用了SentencePiece的transformers模型,会和unigram组合起来使用,像:使用了SentencePiece的模型是[ALBERT](model_doc/albert),
|
||||
[XLNet](model_doc/xlnet),[Marian](model_doc/marian),和[T5](model_doc/t5)。
|
||||
197
transformers/docs/source/zh/torchscript.md
Normal file
197
transformers/docs/source/zh/torchscript.md
Normal file
@@ -0,0 +1,197 @@
|
||||
<!--
|
||||
Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# 导出为 TorchScript
|
||||
|
||||
<Tip>
|
||||
|
||||
这是开始使用 TorchScript 进行实验的起点,我们仍在探索其在变量输入大小模型中的能力。
|
||||
这是我们关注的焦点,我们将在即将发布的版本中深入分析,提供更多的代码示例、更灵活的实现以及比较
|
||||
Python 代码与编译 TorchScript 的性能基准。
|
||||
|
||||
</Tip>
|
||||
|
||||
根据 [TorchScript 文档](https://pytorch.org/docs/stable/jit.html):
|
||||
|
||||
> TorchScript 是从 PyTorch 代码创建可序列化和可优化的模型的一种方式。
|
||||
|
||||
有两个 PyTorch 模块:[JIT 和 TRACE](https://pytorch.org/docs/stable/jit.html)。
|
||||
这两个模块允许开发人员将其模型导出到其他程序中重用,比如面向效率的 C++ 程序。
|
||||
|
||||
我们提供了一个接口,允许您将 🤗 Transformers 模型导出为 TorchScript,
|
||||
以便在与基于 PyTorch 的 Python 程序不同的环境中重用。
|
||||
本文解释如何使用 TorchScript 导出并使用我们的模型。
|
||||
|
||||
导出模型需要两个步骤:
|
||||
|
||||
- 使用 `torchscript` 参数实例化模型
|
||||
- 使用虚拟输入进行前向传递
|
||||
|
||||
这些必要条件意味着开发人员应该注意以下详细信息。
|
||||
|
||||
## TorchScript 参数和绑定权重
|
||||
|
||||
`torchscript` 参数是必需的,因为大多数 🤗 Transformers 语言模型的 `Embedding` 层和
|
||||
`Decoding` 层之间有绑定权重。TorchScript 不允许导出具有绑定权重的模型,因此必须事先解绑和克隆权重。
|
||||
|
||||
使用 `torchscript` 参数实例化的模型将其 `Embedding` 层和 `Decoding` 层分开,
|
||||
这意味着它们不应该在后续进行训练。训练将导致这两层不同步,产生意外结果。
|
||||
|
||||
对于没有语言模型头部的模型,情况不同,因为这些模型没有绑定权重。
|
||||
这些模型可以安全地导出而无需 `torchscript` 参数。
|
||||
|
||||
## 虚拟输入和标准长度
|
||||
|
||||
虚拟输入用于模型的前向传递。当输入的值传播到各层时,PyTorch 会跟踪在每个张量上执行的不同操作。
|
||||
然后使用记录的操作来创建模型的 *trace* 。
|
||||
|
||||
跟踪是相对于输入的维度创建的。因此,它受到虚拟输入的维度限制,对于任何其他序列长度或批量大小都不起作用。
|
||||
当尝试使用不同大小时,会引发以下错误:
|
||||
|
||||
```text
|
||||
`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
|
||||
```
|
||||
|
||||
我们建议使用至少与推断期间将馈送到模型的最大输入一样大的虚拟输入大小进行跟踪。
|
||||
填充可以帮助填补缺失的值。然而,由于模型是使用更大的输入大小进行跟踪的,矩阵的维度也会很大,导致更多的计算。
|
||||
|
||||
在每个输入上执行的操作总数要仔细考虑,并在导出不同序列长度模型时密切关注性能。
|
||||
|
||||
## 在 Python 中使用 TorchScript
|
||||
|
||||
本节演示了如何保存和加载模型以及如何使用 trace 进行推断。
|
||||
|
||||
### 保存模型
|
||||
|
||||
要使用 TorchScript 导出 `BertModel`,请从 `BertConfig` 类实例化 `BertModel`,
|
||||
然后将其保存到名为 `traced_bert.pt` 的磁盘文件中:
|
||||
|
||||
```python
|
||||
from transformers import BertModel, BertTokenizer, BertConfig
|
||||
import torch
|
||||
|
||||
enc = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
|
||||
|
||||
# 对输入文本分词
|
||||
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
|
||||
tokenized_text = enc.tokenize(text)
|
||||
|
||||
# 屏蔽一个输入 token
|
||||
masked_index = 8
|
||||
tokenized_text[masked_index] = "[MASK]"
|
||||
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
|
||||
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
|
||||
|
||||
# 创建虚拟输入
|
||||
tokens_tensor = torch.tensor([indexed_tokens])
|
||||
segments_tensors = torch.tensor([segments_ids])
|
||||
dummy_input = [tokens_tensor, segments_tensors]
|
||||
|
||||
# 使用 torchscript 参数初始化模型
|
||||
# 即使此模型没有 LM Head,也将参数设置为 True。
|
||||
config = BertConfig(
|
||||
vocab_size_or_config_json_file=32000,
|
||||
hidden_size=768,
|
||||
num_hidden_layers=12,
|
||||
num_attention_heads=12,
|
||||
intermediate_size=3072,
|
||||
torchscript=True,
|
||||
)
|
||||
|
||||
# 实例化模型
|
||||
model = BertModel(config)
|
||||
|
||||
# 模型需要处于评估模式
|
||||
model.eval()
|
||||
|
||||
# 如果您使用 *from_pretrained* 实例化模型,还可以轻松设置 TorchScript 参数
|
||||
model = BertModel.from_pretrained("google-bert/bert-base-uncased", torchscript=True)
|
||||
|
||||
# 创建 trace
|
||||
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
|
||||
torch.jit.save(traced_model, "traced_bert.pt")
|
||||
```
|
||||
|
||||
### 加载模型
|
||||
|
||||
现在,您可以从磁盘加载先前保存的 `BertModel`、`traced_bert.pt`,并在先前初始化的 `dummy_input` 上使用:
|
||||
|
||||
```python
|
||||
loaded_model = torch.jit.load("traced_bert.pt")
|
||||
loaded_model.eval()
|
||||
|
||||
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
|
||||
```
|
||||
|
||||
### 使用 trace 模型进行推断
|
||||
|
||||
通过使用其 `__call__` dunder 方法使用 trace 模型进行推断:
|
||||
|
||||
```python
|
||||
traced_model(tokens_tensor, segments_tensors)
|
||||
```
|
||||
|
||||
## 使用 Neuron SDK 将 Hugging Face TorchScript 模型部署到 AWS
|
||||
|
||||
AWS 引入了用于云端低成本、高性能机器学习推理的
|
||||
[Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/) 实例系列。
|
||||
Inf1 实例由 AWS Inferentia 芯片提供支持,这是一款专为深度学习推理工作负载而构建的定制硬件加速器。
|
||||
[AWS Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#) 是
|
||||
Inferentia 的 SDK,支持对 transformers 模型进行跟踪和优化,以便在 Inf1 上部署。Neuron SDK 提供:
|
||||
|
||||
1. 简单易用的 API,只需更改一行代码即可为云端推理跟踪和优化 TorchScript 模型。
|
||||
2. 针对[改进的性能成本](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/)的即插即用性能优化。
|
||||
3. 支持使用 [PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html)
|
||||
或 [TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html)
|
||||
构建的 Hugging Face transformers 模型。
|
||||
|
||||
### 影响
|
||||
|
||||
基于 [BERT(来自 Transformers 的双向编码器表示)](https://huggingface.co/docs/transformers/main/model_doc/bert)架构的
|
||||
transformers 模型,或其变体,如 [distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert)
|
||||
和 [roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta) 在 Inf1 上运行最佳,
|
||||
可用于生成抽取式问答、序列分类和标记分类等任务。然而,文本生成任务仍可以适应在 Inf1 上运行,
|
||||
如这篇 [AWS Neuron MarianMT 教程](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html)所述。
|
||||
有关可以直接在 Inferentia 上转换的模型的更多信息,请参阅 Neuron 文档的[模型架构适配](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia)章节。
|
||||
|
||||
### 依赖关系
|
||||
|
||||
使用 AWS Neuron 将模型转换为模型需要一个
|
||||
[Neuron SDK 环境](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide),
|
||||
它已经预先配置在 [AWS 深度学习 AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html)上。
|
||||
|
||||
### 将模型转换为 AWS Neuron
|
||||
|
||||
使用与 [Python 中使用 TorchScript](torchscript#using-torchscript-in-python) 相同的代码来跟踪
|
||||
`BertModel` 以将模型转换为 AWS NEURON。导入 `torch.neuron` 框架扩展以通过 Python API 访问 Neuron SDK 的组件:
|
||||
|
||||
```python
|
||||
from transformers import BertModel, BertTokenizer, BertConfig
|
||||
import torch
|
||||
import torch.neuron
|
||||
```
|
||||
|
||||
您只需要修改下面这一行:
|
||||
|
||||
```diff
|
||||
- torch.jit.trace(model, [tokens_tensor, segments_tensors])
|
||||
+ torch.neuron.trace(model, [token_tensor, segments_tensors])
|
||||
```
|
||||
|
||||
这样就能使 Neuron SDK 跟踪模型并对其进行优化,以在 Inf1 实例上运行。
|
||||
|
||||
要了解有关 AWS Neuron SDK 功能、工具、示例教程和最新更新的更多信息,
|
||||
请参阅 [AWS NeuronSDK 文档](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html)。
|
||||
309
transformers/docs/source/zh/training.md
Normal file
309
transformers/docs/source/zh/training.md
Normal file
@@ -0,0 +1,309 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# 微调预训练模型
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
使用预训练模型有许多显著的好处。它降低了计算成本,减少了碳排放,同时允许您使用最先进的模型,而无需从头开始训练一个。🤗 Transformers 提供了涉及各种任务的成千上万的预训练模型。当您使用预训练模型时,您需要在与任务相关的数据集上训练该模型。这种操作被称为微调,是一种非常强大的训练技术。在本教程中,您将使用您选择的深度学习框架来微调一个预训练模型:
|
||||
|
||||
* 使用 🤗 Transformers 的 [`Trainer`] 来微调预训练模型。
|
||||
* 在 TensorFlow 中使用 Keras 来微调预训练模型。
|
||||
* 在原生 PyTorch 中微调预训练模型。
|
||||
|
||||
<a id='data-processing'></a>
|
||||
|
||||
## 准备数据集
|
||||
|
||||
<Youtube id="_BZearw7f0w"/>
|
||||
|
||||
在您进行预训练模型微调之前,需要下载一个数据集并为训练做好准备。之前的教程向您展示了如何处理训练数据,现在您有机会将这些技能付诸实践!
|
||||
|
||||
首先,加载[Yelp评论](https://huggingface.co/datasets/yelp_review_full)数据集:
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset
|
||||
|
||||
>>> dataset = load_dataset("yelp_review_full")
|
||||
>>> dataset["train"][100]
|
||||
{'label': 0,
|
||||
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
|
||||
```
|
||||
|
||||
正如您现在所知,您需要一个`tokenizer`来处理文本,包括填充和截断操作以处理可变的序列长度。如果要一次性处理您的数据集,可以使用 🤗 Datasets 的 [`map`](https://huggingface.co/docs/datasets/process#map) 方法,将预处理函数应用于整个数据集:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
|
||||
|
||||
|
||||
>>> def tokenize_function(examples):
|
||||
... return tokenizer(examples["text"], padding="max_length", truncation=True)
|
||||
|
||||
|
||||
>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
|
||||
```
|
||||
如果愿意的话,您可以从完整数据集提取一个较小子集来进行微调,以减少训练所需的时间:
|
||||
|
||||
```py
|
||||
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
|
||||
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
|
||||
```
|
||||
|
||||
<a id='trainer'></a>
|
||||
|
||||
## 训练
|
||||
|
||||
此时,您应该根据您训练所用的框架来选择对应的教程章节。您可以使用右侧的链接跳转到您想要的章节 - 如果您想隐藏某个框架对应的所有教程内容,只需使用右上角的按钮!
|
||||
|
||||
|
||||
<Youtube id="nvBXf7s7vTI"/>
|
||||
|
||||
## 使用 PyTorch Trainer 进行训练
|
||||
|
||||
🤗 Transformers 提供了一个专为训练 🤗 Transformers 模型而优化的 [`Trainer`] 类,使您无需手动编写自己的训练循环步骤而更轻松地开始训练模型。[`Trainer`] API 支持各种训练选项和功能,如日志记录、梯度累积和混合精度。
|
||||
|
||||
首先加载您的模型并指定期望的标签数量。根据 Yelp Review [数据集卡片](https://huggingface.co/datasets/yelp_review_full#data-fields),您知道有五个标签:
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForSequenceClassification
|
||||
|
||||
>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=5)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
您将会看到一个警告,提到一些预训练权重未被使用,以及一些权重被随机初始化。不用担心,这是完全正常的!BERT 模型的预训练`head`被丢弃,并替换为一个随机初始化的分类`head`。您将在您的序列分类任务上微调这个新模型`head`,将预训练模型的知识转移给它。
|
||||
|
||||
</Tip>
|
||||
|
||||
### 训练超参数
|
||||
|
||||
接下来,创建一个 [`TrainingArguments`] 类,其中包含您可以调整的所有超参数以及用于激活不同训练选项的标志。对于本教程,您可以从默认的训练[超参数](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments)开始,但随时可以尝试不同的设置以找到最佳设置。
|
||||
|
||||
指定保存训练检查点的位置:
|
||||
|
||||
```py
|
||||
>>> from transformers import TrainingArguments
|
||||
|
||||
>>> training_args = TrainingArguments(output_dir="test_trainer")
|
||||
```
|
||||
|
||||
### 评估
|
||||
|
||||
[`Trainer`] 在训练过程中不会自动评估模型性能。您需要向 [`Trainer`] 传递一个函数来计算和展示指标。[🤗 Evaluate](https://huggingface.co/docs/evaluate/index) 库提供了一个简单的 [`accuracy`](https://huggingface.co/spaces/evaluate-metric/accuracy) 函数,您可以使用 [`evaluate.load`] 函数加载它(有关更多信息,请参阅此[快速入门](https://huggingface.co/docs/evaluate/a_quick_tour)):
|
||||
|
||||
```py
|
||||
>>> import numpy as np
|
||||
>>> import evaluate
|
||||
|
||||
>>> metric = evaluate.load("accuracy")
|
||||
```
|
||||
在 `metric` 上调用 [`~evaluate.compute`] 来计算您的预测的准确性。在将预测传递给 `compute` 之前,您需要将预测转换为`logits`(请记住,所有 🤗 Transformers 模型都返回对`logits`):
|
||||
|
||||
```py
|
||||
>>> def compute_metrics(eval_pred):
|
||||
... logits, labels = eval_pred
|
||||
... predictions = np.argmax(logits, axis=-1)
|
||||
... return metric.compute(predictions=predictions, references=labels)
|
||||
```
|
||||
|
||||
如果您希望在微调过程中监视评估指标,请在您的训练参数中指定 `eval_strategy` 参数,以在每个`epoch`结束时展示评估指标:
|
||||
|
||||
```py
|
||||
>>> from transformers import TrainingArguments, Trainer
|
||||
|
||||
>>> training_args = TrainingArguments(output_dir="test_trainer", eval_strategy="epoch")
|
||||
```
|
||||
|
||||
### 训练器
|
||||
|
||||
创建一个包含您的模型、训练参数、训练和测试数据集以及评估函数的 [`Trainer`] 对象:
|
||||
|
||||
|
||||
```py
|
||||
>>> trainer = Trainer(
|
||||
... model=model,
|
||||
... args=training_args,
|
||||
... train_dataset=small_train_dataset,
|
||||
... eval_dataset=small_eval_dataset,
|
||||
... compute_metrics=compute_metrics,
|
||||
... )
|
||||
```
|
||||
然后调用[`~transformers.Trainer.train`]以微调模型:
|
||||
|
||||
```py
|
||||
>>> trainer.train()
|
||||
```
|
||||
|
||||
<a id='pytorch_native'></a>
|
||||
|
||||
## 在原生 PyTorch 中训练
|
||||
|
||||
<Youtube id="Dh9CL8fyG80"/>
|
||||
|
||||
[`Trainer`] 负责训练循环,允许您在一行代码中微调模型。对于喜欢编写自己训练循环的用户,您也可以在原生 PyTorch 中微调 🤗 Transformers 模型。
|
||||
|
||||
现在,您可能需要重新启动您的`notebook`,或执行以下代码以释放一些内存:
|
||||
|
||||
```py
|
||||
del model
|
||||
del trainer
|
||||
torch.cuda.empty_cache()
|
||||
```
|
||||
|
||||
接下来,手动处理 `tokenized_dataset` 以准备进行训练。
|
||||
|
||||
1. 移除 text 列,因为模型不接受原始文本作为输入:
|
||||
|
||||
```py
|
||||
>>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
|
||||
```
|
||||
|
||||
2. 将 label 列重命名为 labels,因为模型期望参数的名称为 labels:
|
||||
|
||||
```py
|
||||
>>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
|
||||
```
|
||||
|
||||
3. 设置数据集的格式以返回 PyTorch 张量而不是`lists`:
|
||||
|
||||
```py
|
||||
>>> tokenized_datasets.set_format("torch")
|
||||
```
|
||||
|
||||
接着,创建一个先前展示的数据集的较小子集,以加速微调过程
|
||||
|
||||
```py
|
||||
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
|
||||
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
|
||||
```
|
||||
|
||||
### DataLoader
|
||||
|
||||
您的训练和测试数据集创建一个`DataLoader`类,以便可以迭代处理数据批次
|
||||
|
||||
```py
|
||||
>>> from torch.utils.data import DataLoader
|
||||
|
||||
>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
|
||||
>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
|
||||
```
|
||||
|
||||
加载您的模型,并指定期望的标签数量:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForSequenceClassification
|
||||
|
||||
>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=5)
|
||||
```
|
||||
|
||||
### Optimizer and learning rate scheduler
|
||||
|
||||
创建一个`optimizer`和`learning rate scheduler`以进行模型微调。让我们使用 PyTorch 中的 [AdamW](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html) 优化器:
|
||||
|
||||
```py
|
||||
>>> from torch.optim import AdamW
|
||||
|
||||
>>> optimizer = AdamW(model.parameters(), lr=5e-5)
|
||||
```
|
||||
|
||||
创建来自 [`Trainer`] 的默认`learning rate scheduler`:
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import get_scheduler
|
||||
|
||||
>>> num_epochs = 3
|
||||
>>> num_training_steps = num_epochs * len(train_dataloader)
|
||||
>>> lr_scheduler = get_scheduler(
|
||||
... name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
|
||||
... )
|
||||
```
|
||||
|
||||
最后,指定 `device` 以使用 GPU(如果有的话)。否则,使用 CPU 进行训练可能需要几个小时,而不是几分钟。
|
||||
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
|
||||
>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
|
||||
>>> model.to(device)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
如果没有 GPU,可以通过notebook平台如 [Colaboratory](https://colab.research.google.com/) 或 [SageMaker StudioLab](https://studiolab.sagemaker.aws/) 来免费获得云端GPU使用。
|
||||
|
||||
</Tip>
|
||||
|
||||
现在您已经准备好训练了!🥳
|
||||
|
||||
### 训练循环
|
||||
|
||||
为了跟踪训练进度,使用 [tqdm](https://tqdm.github.io/) 库来添加一个进度条,显示训练步数的进展:
|
||||
|
||||
```py
|
||||
>>> from tqdm.auto import tqdm
|
||||
|
||||
>>> progress_bar = tqdm(range(num_training_steps))
|
||||
|
||||
>>> model.train()
|
||||
>>> for epoch in range(num_epochs):
|
||||
... for batch in train_dataloader:
|
||||
... batch = {k: v.to(device) for k, v in batch.items()}
|
||||
... outputs = model(**batch)
|
||||
... loss = outputs.loss
|
||||
... loss.backward()
|
||||
|
||||
... optimizer.step()
|
||||
... lr_scheduler.step()
|
||||
... optimizer.zero_grad()
|
||||
... progress_bar.update(1)
|
||||
```
|
||||
|
||||
### 评估
|
||||
|
||||
就像您在 [`Trainer`] 中添加了一个评估函数一样,当您编写自己的训练循环时,您需要做同样的事情。但与在每个`epoch`结束时计算和展示指标不同,这一次您将使用 [`~evaluate.add_batch`] 累积所有批次,并在最后计算指标。
|
||||
|
||||
```py
|
||||
>>> import evaluate
|
||||
|
||||
>>> metric = evaluate.load("accuracy")
|
||||
>>> model.eval()
|
||||
>>> for batch in eval_dataloader:
|
||||
... batch = {k: v.to(device) for k, v in batch.items()}
|
||||
... with torch.no_grad():
|
||||
... outputs = model(**batch)
|
||||
|
||||
... logits = outputs.logits
|
||||
... predictions = torch.argmax(logits, dim=-1)
|
||||
... metric.add_batch(predictions=predictions, references=batch["labels"])
|
||||
|
||||
>>> metric.compute()
|
||||
```
|
||||
|
||||
<a id='additional-resources'></a>
|
||||
|
||||
## 附加资源
|
||||
|
||||
更多微调例子可参考如下链接:
|
||||
|
||||
- [🤗 Transformers 示例](https://github.com/huggingface/transformers/tree/main/examples) 包含用于在 PyTorch 和 TensorFlow 中训练常见自然语言处理任务的脚本。
|
||||
|
||||
- [🤗 Transformers 笔记](notebooks) 包含针对特定任务在 PyTorch 和 TensorFlow 中微调模型的各种`notebook`。
|
||||
Reference in New Issue
Block a user