初始化项目,由ModelHub XC社区提供模型
Model: BAAI/RoboBrain Source: Original Platform
This commit is contained in:
52
.gitattributes
vendored
Normal file
52
.gitattributes
vendored
Normal file
@@ -0,0 +1,52 @@
|
|||||||
|
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.bin.* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.model filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||||
|
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.zstandard filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.db* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ark* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
**/*ckpt*data* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
**/*ckpt*.meta filter=lfs diff=lfs merge=lfs -text
|
||||||
|
**/*ckpt*.index filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.gguf* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.ggml filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.llamafile* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pt2 filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.tar filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||||
|
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||||
|
model-00001-of-00004.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||||
|
model-00002-of-00004.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||||
|
model-00003-of-00004.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||||
|
model-00004-of-00004.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||||
|
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
||||||
356
README.md
Normal file
356
README.md
Normal file
@@ -0,0 +1,356 @@
|
|||||||
|
---
|
||||||
|
extra_gated_prompt: "You agree to not use the model to conduct experiments that cause harm to human subjects."
|
||||||
|
extra_gated_fields:
|
||||||
|
Company/Organization: text
|
||||||
|
Country: country
|
||||||
|
|
||||||
|
license: apache-2.0
|
||||||
|
datasets:
|
||||||
|
- BAAI/ShareRobot
|
||||||
|
- lmms-lab/LLaVA-OneVision-Data
|
||||||
|
language:
|
||||||
|
- en
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img src="https://github.com/FlagOpen/RoboBrain/raw/main/assets/logo.jpg" width="400"/>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
# [CVPR 25] RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete.
|
||||||
|
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
</a>  ⭐️ <a href="https://superrobobrain.github.io/">Project</a></a>   |   🤗 <a href="https://huggingface.co/BAAI/RoboBrain/">Hugging Face</a>   |   🤖 <a href="https://www.modelscope.cn/models/BAAI/RoboBrain/files/">ModelScope</a>   |   🌎 <a href="https://github.com/FlagOpen/ShareRobot">Dataset</a>   |   📑 <a href="http://arxiv.org/abs/2502.21257">Paper</a>   |   💬 <a href="./assets/wechat.png">WeChat</a>
|
||||||
|
</p>
|
||||||
|
<p align="center">
|
||||||
|
</a>  🎯 <a href="https://arxiv.org/pdf/2505.03673">RoboOS</a>: An Efficient Open-Source Multi-Robot Coordination System for RoboBrain.
|
||||||
|
</p>
|
||||||
|
<p align="center">
|
||||||
|
</a>  🎯 <a href="https://tanhuajie.github.io/ReasonRFT/">Reason-RFT</a>: Exploring a New RFT Paradigm to Enhance RoboBrain's Visual Reasoning Capabilities.
|
||||||
|
</p>
|
||||||
|
|
||||||
|
## 🔥 Overview
|
||||||
|
Recent advancements in Multimodal Large Language Models (MLLMs) have shown remarkable capabilities across various multimodal contexts. However, their application in robotic scenarios, particularly for long-horizon manipulation tasks, reveals significant limitations. These limitations arise from the current MLLMs lacking three essential robotic brain capabilities: **(1) Planning Capability**, which involves decomposing complex manipulation instructions into manageable sub-tasks; **(2) Affordance Perception**, the ability to recognize and interpret the affordances of interactive objects; and **(3) Trajectory Prediction**, the foresight to anticipate the complete manipulation trajectory necessary for successful execution. To enhance the robotic brain's core capabilities from abstract to concrete, we introduce ShareRobot, a high-quality heterogeneous dataset that labels multi-dimensional information such as task planning, object affordance, and end-effector trajectory. ShareRobot's diversity and accuracy have been meticulously refined by three human annotators. Building on this dataset, we developed RoboBrain, an MLLM-based model that combines robotic and general multi-modal data, utilizes a multi-stage training strategy, and incorporates long videos and high-resolution images to improve its robotic manipulation capabilities. Extensive experiments demonstrate that RoboBrain achieves state-of-the-art performance across various robotic tasks, highlighting its potential to advance robotic brain capabilities.
|
||||||
|
|
||||||
|
|
||||||
|
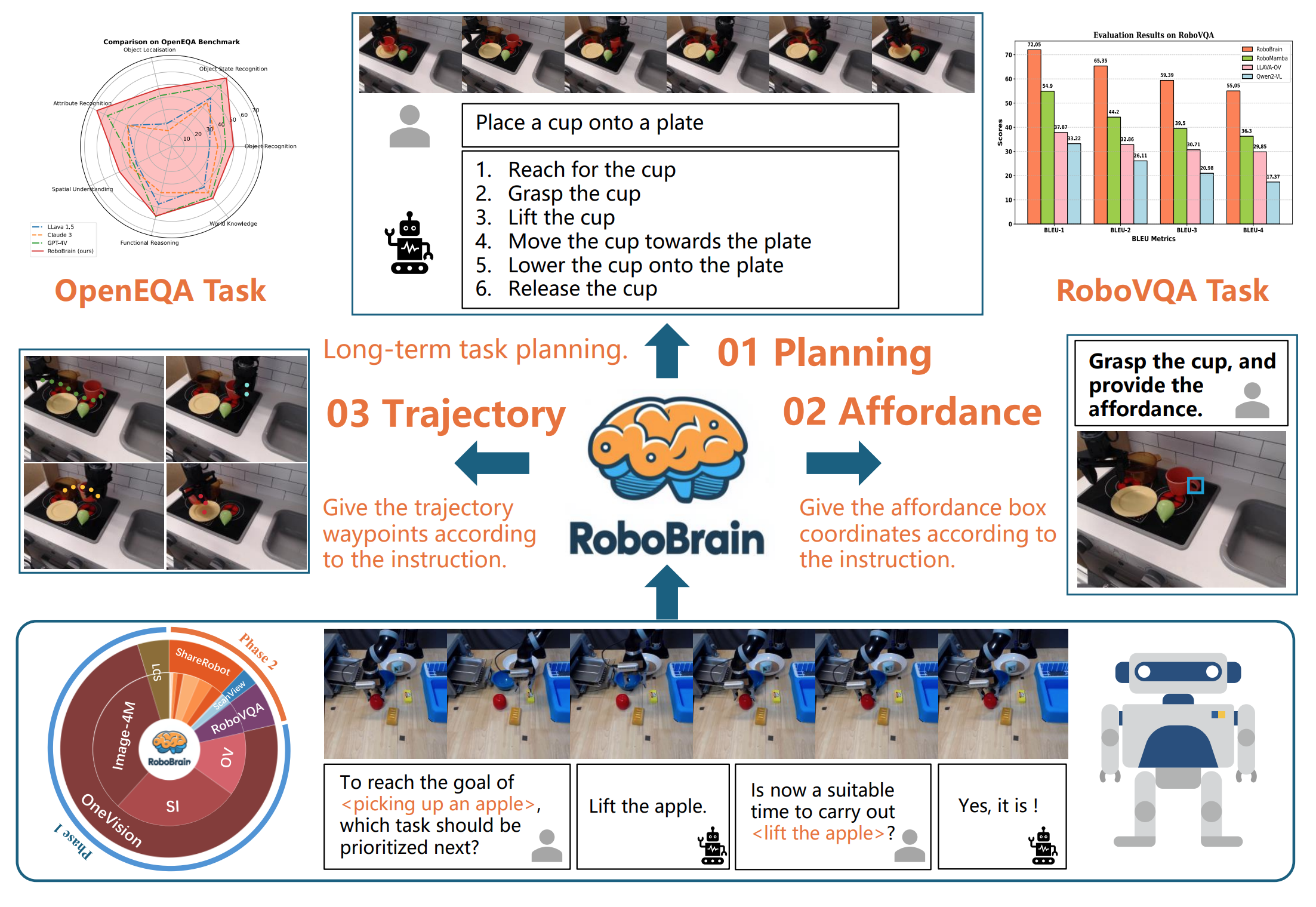
|
||||||
|
|
||||||
|
|
||||||
|
## 🚀 Features
|
||||||
|
This repository supports:
|
||||||
|
- **`Data Preparation`**: Please refer to [Dataset Preparation](https://github.com/FlagOpen/ShareRobot) for how to prepare the dataset.
|
||||||
|
- **`Training for RoboBrain`**: Please refer to [Training Section](#Training) for the usage of training scripts.
|
||||||
|
- **`Support HF/VLLM Inference`**: Please see [Inference Section](#Inference), now we support inference with [VLLM](https://github.com/vllm-project/vllm).
|
||||||
|
- **`Evaluation for RoboBrain`**: Please refer to [Evaluation Section](#Evaluation) for how to prepare the benchmarks.
|
||||||
|
- **`ShareRobot Generation`**: Please refer to [ShareRobot](https://github.com/FlagOpen/ShareRobot) for details.
|
||||||
|
|
||||||
|
|
||||||
|
## 🗞️ News
|
||||||
|
|
||||||
|
- **`2025-04-04`**: 🤗 We have released [Trajectory Checkpoint](https://huggingface.co/BAAI/RoboBrain-LoRA-Trajectory/) in Huggingface.
|
||||||
|
- **`2025-03-29`**: 🤗 We have released [Affordance Checkpoint](https://huggingface.co/BAAI/RoboBrain-LoRA-Affordance/) in Huggingface.
|
||||||
|
- **`2025-03-27`**: 🤗 We have released [Planning Checkpoint](https://huggingface.co/BAAI/RoboBrain/) in Huggingface.
|
||||||
|
- **`2025-03-26`**: 🔥 We have released the [RoboBrain](https://github.com/FlagOpen/RoboBrain/) repository.
|
||||||
|
- **`2025-02-27`**: 🌍 Our [RoboBrain](http://arxiv.org/abs/2502.21257/) was accepted to CVPR2025.
|
||||||
|
|
||||||
|
|
||||||
|
## 📆 Todo
|
||||||
|
- [x] Release scripts for model training and inference.
|
||||||
|
- [x] Release Planning checkpoint.
|
||||||
|
- [x] Release Affordance checkpoint.
|
||||||
|
- [x] Release ShareRobot dataset.
|
||||||
|
- [x] Release Trajectory checkpoint.
|
||||||
|
- [x] Training more powerful **Robobrain-v2**.
|
||||||
|
|
||||||
|
|
||||||
|
## 🤗 Models
|
||||||
|
|
||||||
|
- **[`Base Planning Model`](https://huggingface.co/BAAI/RoboBrain/)**: The model was trained on general datasets in Stages 1–2 and on the Robotic Planning dataset in Stage 3, which is designed for Planning prediction.
|
||||||
|
- **[`A-LoRA for Affordance`](https://huggingface.co/BAAI/RoboBrain-LoRA-Affordance/)**: Based on the Base Planning Model, Stage 4 involves LoRA-based training with our Affordance dataset to predict affordance.
|
||||||
|
- **[`T-LoRA for Trajectory`](https://huggingface.co/BAAI/RoboBrain-LoRA-Trajectory/)**: Based on the Base Planning Model, Stage 4 involves LoRA-based training with our Trajectory dataset to predict trajectory.
|
||||||
|
|
||||||
|
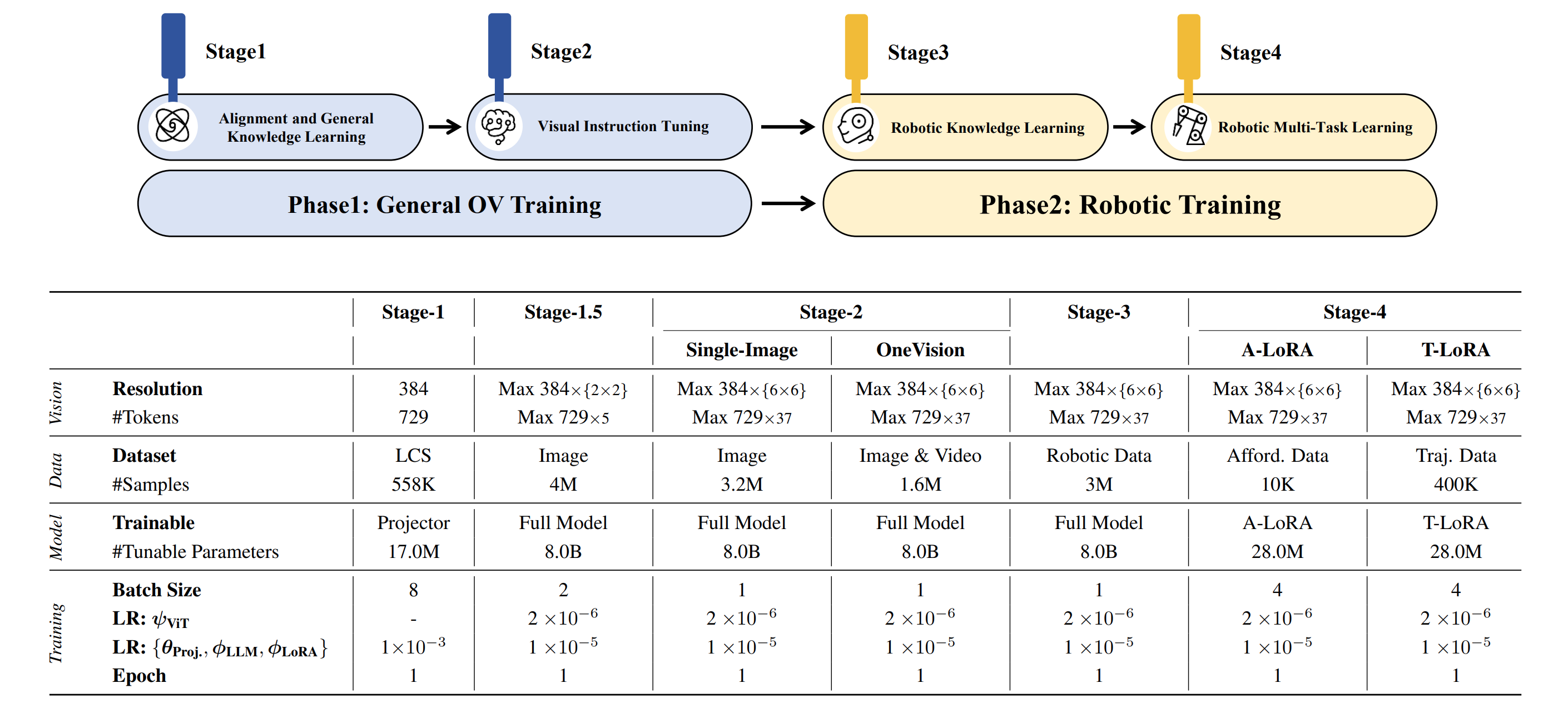
|
||||||
|
|
||||||
|
|
||||||
|
| Models | Checkpoint | Description |
|
||||||
|
|----------------------|----------------------------------------------------------------|------------------------------------------------------------|
|
||||||
|
| Planning Model | [🤗 Planning CKPTs](https://huggingface.co/BAAI/RoboBrain/) | Used for Planning prediction in our paper |
|
||||||
|
| Affordance (A-LoRA) | [🤗 Affordance CKPTs](https://huggingface.co/BAAI/RoboBrain-LoRA-Affordance/) | Used for Affordance prediction in our paper |
|
||||||
|
| Trajectory (T-LoRA) | [🤗 Trajectory CKPTs](https://huggingface.co/BAAI/RoboBrain-LoRA-Trajectory/) | Used for Trajectory prediction in our paper |
|
||||||
|
|
||||||
|
|
||||||
|
## 🛠️ Setup
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# clone repo.
|
||||||
|
git clone https://github.com/FlagOpen/RoboBrain.git
|
||||||
|
cd RoboBrain
|
||||||
|
|
||||||
|
# build conda env.
|
||||||
|
conda create -n robobrain python=3.10
|
||||||
|
conda activate robobrain
|
||||||
|
pip install -r requirements.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
## <a id="Training"> 🤖 Training</a>
|
||||||
|
|
||||||
|
### 1. Data Preparation
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Modify datasets for Stage 1, please refer to:
|
||||||
|
- yaml_path: scripts/train/yaml/stage_1_0.yaml
|
||||||
|
|
||||||
|
# Modify datasets for Stage 1.5, please refer to:
|
||||||
|
- yaml_path: scripts/train/yaml/stage_1_5.yaml
|
||||||
|
|
||||||
|
# Modify datasets for Stage 2_si, please refer to:
|
||||||
|
- yaml_path: scripts/train/yaml/stage_2_si.yaml
|
||||||
|
|
||||||
|
# Modify datasets for Stage 2_ov, please refer to:
|
||||||
|
- yaml_path: scripts/train/yaml/stage_2_ov.yaml
|
||||||
|
|
||||||
|
# Modify datasets for Stage 3_plan, please refer to:
|
||||||
|
- yaml_path: scripts/train/yaml/stage_3_planning.yaml
|
||||||
|
|
||||||
|
# Modify datasets for Stage 4_aff, please refer to:
|
||||||
|
- yaml_path: scripts/train/yaml/stage_4_affordance.yaml
|
||||||
|
|
||||||
|
# Modify datasets for Stage 4_traj, please refer to:
|
||||||
|
- yaml_path: scripts/train/yaml/stage_4_trajectory.yaml
|
||||||
|
```
|
||||||
|
**Note:** The sample format in each json file should be like:
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"id": "xxxx",
|
||||||
|
"image": [
|
||||||
|
"image1.png",
|
||||||
|
"image2.png",
|
||||||
|
],
|
||||||
|
"conversations": [
|
||||||
|
{
|
||||||
|
"from": "human",
|
||||||
|
"value": "<image>\n<image>\nAre there numerous dials near the bottom left of the tv?"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"from": "gpt",
|
||||||
|
"value": "Yes. The sun casts shadows ... a serene, clear sky."
|
||||||
|
}
|
||||||
|
]
|
||||||
|
},
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2. Training
|
||||||
|
```bash
|
||||||
|
# Training on Stage 1:
|
||||||
|
bash scripts/train/stage_1_0_pretrain.sh
|
||||||
|
|
||||||
|
# Training on Stage 1.5:
|
||||||
|
bash scripts/train/stage_1_5_direct_finetune.sh
|
||||||
|
|
||||||
|
# Training on Stage 2_si:
|
||||||
|
bash scripts/train/stage_2_0_resume_finetune_si.sh
|
||||||
|
|
||||||
|
# Training on Stage 2_ov:
|
||||||
|
bash scripts/train/stage_2_0_resume_finetune_ov.sh
|
||||||
|
|
||||||
|
# Training on Stage 3_plan:
|
||||||
|
bash scripts/train/stage_3_0_resume_finetune_robo.sh
|
||||||
|
|
||||||
|
# Training on Stage 4_aff:
|
||||||
|
bash scripts/train/stage_4_0_resume_finetune_lora_a.sh
|
||||||
|
|
||||||
|
# Training on Stage 4_traj:
|
||||||
|
bash scripts/train/stage_4_0_resume_finetune_lora_t.sh
|
||||||
|
```
|
||||||
|
**Note:** Please change the environment variables (e.g. *DATA_PATH*, *IMAGE_FOLDER*, *PREV_STAGE_CHECKPOINT*) in the script to your own.
|
||||||
|
|
||||||
|
### 3. Convert original weights to HF weights
|
||||||
|
```bash
|
||||||
|
# Planning Model
|
||||||
|
python model/llava_utils/convert_robobrain_to_hf.py --model_dir /path/to/original/checkpoint/ --dump_path /path/to/output/
|
||||||
|
|
||||||
|
# A-LoRA & T-RoRA
|
||||||
|
python model/llava_utils/convert_lora_weights_to_hf.py --model_dir /path/to/original/checkpoint/ --dump_path /path/to/output/
|
||||||
|
```
|
||||||
|
|
||||||
|
## <a id="Inference">⭐️ Inference</a>
|
||||||
|
|
||||||
|
### 1. Usage for Planning Prediction
|
||||||
|
|
||||||
|
#### Option 1: HF inference
|
||||||
|
|
||||||
|
```python
|
||||||
|
from inference import SimpleInference
|
||||||
|
|
||||||
|
model_id = "BAAI/RoboBrain"
|
||||||
|
model = SimpleInference(model_id)
|
||||||
|
|
||||||
|
prompt = "Given the obiects in the image, if you are required to complete the task \"Put the apple in the basket\", what is your detailed plan? Write your plan and explain it in detail, using the following format: Step_1: xxx\nStep_2: xxx\n ...\nStep_n: xxx\n"
|
||||||
|
|
||||||
|
image = "./assets/demo/planning.png"
|
||||||
|
|
||||||
|
pred = model.inference(prompt, image, do_sample=True)
|
||||||
|
print(f"Prediction: {pred}")
|
||||||
|
|
||||||
|
'''
|
||||||
|
Prediction: (as an example)
|
||||||
|
Step_1: Move to the apple. Move towards the apple on the table.
|
||||||
|
Step_2: Pick up the apple. Grab the apple and lift it off the table.
|
||||||
|
Step_3: Move towards the basket. Move the apple towards the basket without dropping it.
|
||||||
|
Step_4: Put the apple in the basket. Place the apple inside the basket, ensuring it is in a stable position.
|
||||||
|
'''
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Option 2: VLLM inference
|
||||||
|
Install and launch VLLM
|
||||||
|
```bash
|
||||||
|
# Install vllm package
|
||||||
|
pip install vllm==0.6.6.post1
|
||||||
|
|
||||||
|
# Launch Robobrain with vllm
|
||||||
|
python -m vllm.entrypoints.openai.api_server --model BAAI/RoboBrain --served-model-name robobrain --max_model_len 16384 --limit_mm_per_prompt image=8
|
||||||
|
```
|
||||||
|
|
||||||
|
Run python script as example:
|
||||||
|
```python
|
||||||
|
from openai import OpenAI
|
||||||
|
import base64
|
||||||
|
|
||||||
|
openai_api_key = "robobrain-123123"
|
||||||
|
openai_api_base = "http://127.0.0.1:8000/v1"
|
||||||
|
|
||||||
|
client = OpenAI(
|
||||||
|
api_key=openai_api_key,
|
||||||
|
base_url=openai_api_base,
|
||||||
|
)
|
||||||
|
|
||||||
|
prompt = "Given the obiects in the image, if you are required to complete the task \"Put the apple in the basket\", what is your detailed plan? Write your plan and explain it in detail, using the following format: Step_1: xxx\nStep_2: xxx\n ...\nStep_n: xxx\n"
|
||||||
|
|
||||||
|
image = "./assets/demo/planning.png"
|
||||||
|
|
||||||
|
with open(image, "rb") as f:
|
||||||
|
encoded_image = base64.b64encode(f.read())
|
||||||
|
encoded_image = encoded_image.decode("utf-8")
|
||||||
|
base64_img = f"data:image;base64,{encoded_image}"
|
||||||
|
|
||||||
|
response = client.chat.completions.create(
|
||||||
|
model="robobrain",
|
||||||
|
messages=[
|
||||||
|
{
|
||||||
|
"role": "user",
|
||||||
|
"content": [
|
||||||
|
{"type": "image_url", "image_url": {"url": base64_img}},
|
||||||
|
{"type": "text", "text": prompt},
|
||||||
|
],
|
||||||
|
},
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
content = response.choices[0].message.content
|
||||||
|
print(content)
|
||||||
|
|
||||||
|
'''
|
||||||
|
Prediction: (as an example)
|
||||||
|
Step_1: Move to the apple. Move towards the apple on the table.
|
||||||
|
Step_2: Pick up the apple. Grab the apple and lift it off the table.
|
||||||
|
Step_3: Move towards the basket. Move the apple towards the basket without dropping it.
|
||||||
|
Step_4: Put the apple in the basket. Place the apple inside the basket, ensuring it is in a stable position.
|
||||||
|
'''
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2. Usage for Affordance Prediction
|
||||||
|
```python
|
||||||
|
from inference import SimpleInference
|
||||||
|
|
||||||
|
model_id = "BAAI/RoboBrain"
|
||||||
|
lora_id = "BAAI/RoboBrain-LoRA-Affordance"
|
||||||
|
model = SimpleInference(model_id, lora_id)
|
||||||
|
|
||||||
|
# Example 1:
|
||||||
|
prompt = "You are a robot using the joint control. The task is \"pick_up the suitcase\". Please predict a possible affordance area of the end effector?"
|
||||||
|
|
||||||
|
image = "./assets/demo/affordance_1.jpg"
|
||||||
|
|
||||||
|
pred = model.inference(prompt, image, do_sample=False)
|
||||||
|
print(f"Prediction: {pred}")
|
||||||
|
|
||||||
|
'''
|
||||||
|
Prediction: [0.733, 0.158, 0.845, 0.263]
|
||||||
|
'''
|
||||||
|
|
||||||
|
# Example 2:
|
||||||
|
prompt = "You are a robot using the joint control. The task is \"push the bicycle\". Please predict a possible affordance area of the end effector?"
|
||||||
|
|
||||||
|
image = "./assets/demo/affordance_2.jpg"
|
||||||
|
|
||||||
|
pred = model.inference(prompt, image, do_sample=False)
|
||||||
|
print(f"Prediction: {pred}")
|
||||||
|
|
||||||
|
'''
|
||||||
|
Prediction: [0.600, 0.127, 0.692, 0.227]
|
||||||
|
'''
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
### 3. Usage for Trajectory Prediction
|
||||||
|
```python
|
||||||
|
# please refer to https://github.com/FlagOpen/RoboBrain
|
||||||
|
from inference import SimpleInference
|
||||||
|
model_id = "BAAI/RoboBrain"
|
||||||
|
lora_id = "BAAI/RoboBrain-LoRA-Affordance"
|
||||||
|
model = SimpleInference(model_id, lora_id)
|
||||||
|
# Example 1:
|
||||||
|
prompt = "You are a robot using the joint control. The task is \"reach for the cloth\". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. [[x1, y1], [x2, y2], ...], where each tuple contains the x and y coordinates of a point."
|
||||||
|
image = "./assets/demo/trajectory_1.jpg"
|
||||||
|
pred = model.inference(prompt, image, do_sample=False)
|
||||||
|
print(f"Prediction: {pred}")
|
||||||
|
'''
|
||||||
|
Prediction: [[0.781, 0.305], [0.688, 0.344], [0.570, 0.344], [0.492, 0.312]]
|
||||||
|
'''
|
||||||
|
# Example 2:
|
||||||
|
prompt = "You are a robot using the joint control. The task is \"reach for the grapes\". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. [[x1, y1], [x2, y2], ...], where each tuple contains the x and y coordinates of a point."
|
||||||
|
image = "./assets/demo/trajectory_2.jpg"
|
||||||
|
pred = model.inference(prompt, image, do_sample=False)
|
||||||
|
print(f"Prediction: {pred}")
|
||||||
|
'''
|
||||||
|
Prediction: [[0.898, 0.352], [0.766, 0.344], [0.625, 0.273], [0.500, 0.195]]
|
||||||
|
'''
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## <a id="Evaluation">🤖 Evaluation</a>
|
||||||
|
*Coming Soon ...*
|
||||||
|
|
||||||
|
|
||||||
|
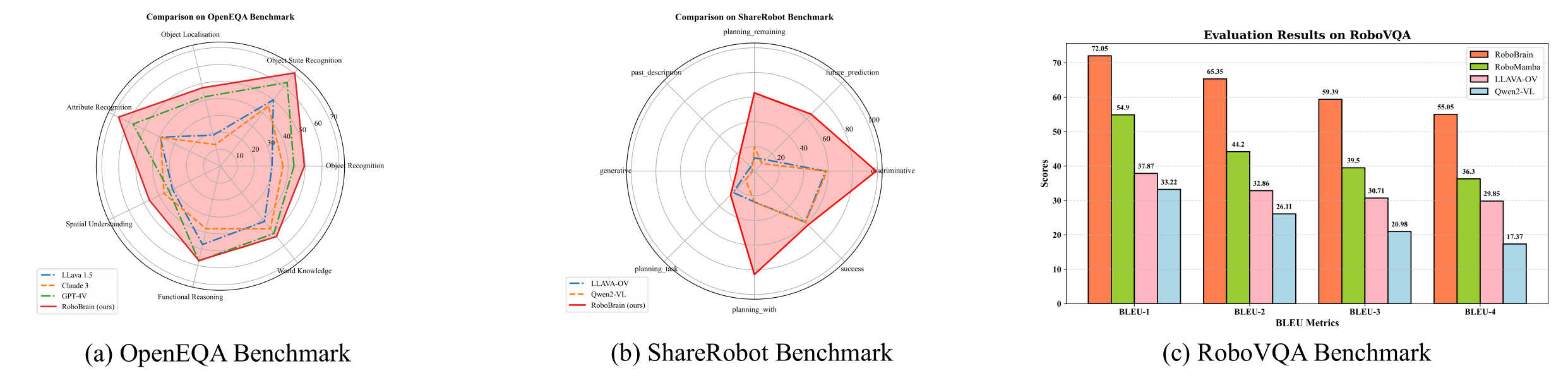
|
||||||
|
|
||||||
|
<!-- <div align="center">
|
||||||
|
<img src="https://github.com/FlagOpen/RoboBrain/blob/main/assets/result.png" />
|
||||||
|
</div> -->
|
||||||
|
|
||||||
|
## 😊 Acknowledgement
|
||||||
|
|
||||||
|
We would like to express our sincere gratitude to the developers and contributors of the following projects:
|
||||||
|
1. [LLaVA-NeXT](https://github.com/LLaVA-VL/LLaVA-NeXT): The comprehensive codebase for training Vision-Language Models (VLMs).
|
||||||
|
2. [lmms-eval](https://github.com/EvolvingLMMs-Lab/lmms-eval): A powerful evaluation tool for Vision-Language Models (VLMs).
|
||||||
|
3. [vllm](https://github.com/vllm-project/vllm): A high-throughput and memory-efficient LLMs/VLMs inference engine.
|
||||||
|
4. [OpenEQA](https://github.com/facebookresearch/open-eqa): A wonderful benchmark for Embodied Question Answering.
|
||||||
|
5. [RoboVQA](https://github.com/google-deepmind/robovqa): Provide high-level reasoning models and datasets for robotics applications.
|
||||||
|
|
||||||
|
Their outstanding contributions have played a pivotal role in advancing our research and development initiatives.
|
||||||
|
|
||||||
|
## 📑 Citation
|
||||||
|
If you find this project useful, welcome to cite us.
|
||||||
|
```bib
|
||||||
|
@article{ji2025robobrain,
|
||||||
|
title={RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete},
|
||||||
|
author={Ji, Yuheng and Tan, Huajie and Shi, Jiayu and Hao, Xiaoshuai and Zhang, Yuan and Zhang, Hengyuan and Wang, Pengwei and Zhao, Mengdi and Mu, Yao and An, Pengju and others},
|
||||||
|
journal={arXiv preprint arXiv:2502.21257},
|
||||||
|
year={2025}
|
||||||
|
}
|
||||||
|
```
|
||||||
26
added_tokens.json
Normal file
26
added_tokens.json
Normal file
@@ -0,0 +1,26 @@
|
|||||||
|
{
|
||||||
|
"</tool_call>": 151658,
|
||||||
|
"<image>": 151665,
|
||||||
|
"<tool_call>": 151657,
|
||||||
|
"<video>": 151666,
|
||||||
|
"<|box_end|>": 151649,
|
||||||
|
"<|box_start|>": 151648,
|
||||||
|
"<|endoftext|>": 151643,
|
||||||
|
"<|file_sep|>": 151664,
|
||||||
|
"<|fim_middle|>": 151660,
|
||||||
|
"<|fim_pad|>": 151662,
|
||||||
|
"<|fim_prefix|>": 151659,
|
||||||
|
"<|fim_suffix|>": 151661,
|
||||||
|
"<|im_end|>": 151645,
|
||||||
|
"<|im_start|>": 151644,
|
||||||
|
"<|image_pad|>": 151655,
|
||||||
|
"<|object_ref_end|>": 151647,
|
||||||
|
"<|object_ref_start|>": 151646,
|
||||||
|
"<|quad_end|>": 151651,
|
||||||
|
"<|quad_start|>": 151650,
|
||||||
|
"<|repo_name|>": 151663,
|
||||||
|
"<|video_pad|>": 151656,
|
||||||
|
"<|vision_end|>": 151653,
|
||||||
|
"<|vision_pad|>": 151654,
|
||||||
|
"<|vision_start|>": 151652
|
||||||
|
}
|
||||||
3
chat_template.json
Normal file
3
chat_template.json
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
{
|
||||||
|
"chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n'}}{# Render all images first #}{% for content in message['content'] | selectattr('type', 'equalto', 'image') %}{{ '<image>\n' }}{% endfor %}{# Render all video then #}{% for content in message['content'] | selectattr('type', 'equalto', 'video') %}{{ '<video>\n' }}{% endfor %}{# Render all text next #}{% if message['role'] != 'assistant' %}{% for content in message['content'] | selectattr('type', 'equalto', 'text') %}{{ content['text'] }}{% endfor %}{% else %}{% for content in message['content'] | selectattr('type', 'equalto', 'text') %}{% generation %}{{ content['text'] }}{% endgeneration %}{% endfor %}{% endif %}{{'<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
|
||||||
|
}
|
||||||
189
config.json
Normal file
189
config.json
Normal file
@@ -0,0 +1,189 @@
|
|||||||
|
{
|
||||||
|
"architectures": [
|
||||||
|
"LlavaOnevisionForConditionalGeneration"
|
||||||
|
],
|
||||||
|
"image_grid_pinpoints": [
|
||||||
|
[
|
||||||
|
384,
|
||||||
|
384
|
||||||
|
],
|
||||||
|
[
|
||||||
|
384,
|
||||||
|
768
|
||||||
|
],
|
||||||
|
[
|
||||||
|
384,
|
||||||
|
1152
|
||||||
|
],
|
||||||
|
[
|
||||||
|
384,
|
||||||
|
1536
|
||||||
|
],
|
||||||
|
[
|
||||||
|
384,
|
||||||
|
1920
|
||||||
|
],
|
||||||
|
[
|
||||||
|
384,
|
||||||
|
2304
|
||||||
|
],
|
||||||
|
[
|
||||||
|
768,
|
||||||
|
384
|
||||||
|
],
|
||||||
|
[
|
||||||
|
768,
|
||||||
|
768
|
||||||
|
],
|
||||||
|
[
|
||||||
|
768,
|
||||||
|
1152
|
||||||
|
],
|
||||||
|
[
|
||||||
|
768,
|
||||||
|
1536
|
||||||
|
],
|
||||||
|
[
|
||||||
|
768,
|
||||||
|
1920
|
||||||
|
],
|
||||||
|
[
|
||||||
|
768,
|
||||||
|
2304
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1152,
|
||||||
|
384
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1152,
|
||||||
|
768
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1152,
|
||||||
|
1152
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1152,
|
||||||
|
1536
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1152,
|
||||||
|
1920
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1152,
|
||||||
|
2304
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1536,
|
||||||
|
384
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1536,
|
||||||
|
768
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1536,
|
||||||
|
1152
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1536,
|
||||||
|
1536
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1536,
|
||||||
|
1920
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1536,
|
||||||
|
2304
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1920,
|
||||||
|
384
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1920,
|
||||||
|
768
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1920,
|
||||||
|
1152
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1920,
|
||||||
|
1536
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1920,
|
||||||
|
1920
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1920,
|
||||||
|
2304
|
||||||
|
],
|
||||||
|
[
|
||||||
|
2304,
|
||||||
|
384
|
||||||
|
],
|
||||||
|
[
|
||||||
|
2304,
|
||||||
|
768
|
||||||
|
],
|
||||||
|
[
|
||||||
|
2304,
|
||||||
|
1152
|
||||||
|
],
|
||||||
|
[
|
||||||
|
2304,
|
||||||
|
1536
|
||||||
|
],
|
||||||
|
[
|
||||||
|
2304,
|
||||||
|
1920
|
||||||
|
],
|
||||||
|
[
|
||||||
|
2304,
|
||||||
|
2304
|
||||||
|
]
|
||||||
|
],
|
||||||
|
"image_token_index": 151665,
|
||||||
|
"model_type": "llava_onevision",
|
||||||
|
"projector_hidden_act": "gelu",
|
||||||
|
"text_config": {
|
||||||
|
"_name_or_path": "/home/vlm/pretrain_model/Qwen2.5-7B-Instruct",
|
||||||
|
"architectures": [
|
||||||
|
"Qwen2ForCausalLM"
|
||||||
|
],
|
||||||
|
"bos_token_id": 151643,
|
||||||
|
"eos_token_id": 151645,
|
||||||
|
"hidden_size": 3584,
|
||||||
|
"intermediate_size": 18944,
|
||||||
|
"model_type": "qwen2",
|
||||||
|
"num_attention_heads": 28,
|
||||||
|
"num_hidden_layers": 28,
|
||||||
|
"num_key_value_heads": 4,
|
||||||
|
"rope_theta": 1000000.0,
|
||||||
|
"torch_dtype": "bfloat16",
|
||||||
|
"vocab_size": 152128
|
||||||
|
},
|
||||||
|
"tie_word_embeddings": false,
|
||||||
|
"torch_dtype": "float16",
|
||||||
|
"transformers_version": "4.46.1",
|
||||||
|
"use_image_newline_parameter": true,
|
||||||
|
"video_token_index": 151666,
|
||||||
|
"vision_aspect_ratio": "anyres_max_9",
|
||||||
|
"vision_config": {
|
||||||
|
"hidden_size": 1152,
|
||||||
|
"image_size": 384,
|
||||||
|
"intermediate_size": 4304,
|
||||||
|
"model_type": "siglip_vision_model",
|
||||||
|
"num_attention_heads": 16,
|
||||||
|
"num_hidden_layers": 26,
|
||||||
|
"patch_size": 14,
|
||||||
|
"vision_use_head": false
|
||||||
|
},
|
||||||
|
"vision_feature_layer": -1,
|
||||||
|
"vision_feature_select_strategy": "full"
|
||||||
|
}
|
||||||
1
configuration.json
Normal file
1
configuration.json
Normal file
@@ -0,0 +1 @@
|
|||||||
|
{"framework": "pytorch", "task": "others", "allow_remote": true}
|
||||||
6
generation_config.json
Normal file
6
generation_config.json
Normal file
@@ -0,0 +1,6 @@
|
|||||||
|
{
|
||||||
|
"_from_model_config": true,
|
||||||
|
"bos_token_id": 151643,
|
||||||
|
"eos_token_id": 151645,
|
||||||
|
"transformers_version": "4.46.1"
|
||||||
|
}
|
||||||
151388
merges.txt
Normal file
151388
merges.txt
Normal file
File diff suppressed because it is too large
Load Diff
3
model-00001-of-00004.safetensors
Normal file
3
model-00001-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:3908588ffd931433d302418994859097973f60f99f1f786d97d5b17e01c028a1
|
||||||
|
size 4911200360
|
||||||
3
model-00002-of-00004.safetensors
Normal file
3
model-00002-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:91e9ac472fa3e93e7773fe7d56842f0b8826d8c9d8f7c70a12d0346ad6cf983a
|
||||||
|
size 4991497664
|
||||||
3
model-00003-of-00004.safetensors
Normal file
3
model-00003-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:dc35575def86d1b304f7fcb15836bf7d59ef4c8a92fdf24e0ab627224cb3e9d3
|
||||||
|
size 4932752752
|
||||||
3
model-00004-of-00004.safetensors
Normal file
3
model-00004-of-00004.safetensors
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:29ec2e1399dc515adce87ee6f958efd23941f255beb8623973986d91d98c721e
|
||||||
|
size 1226266240
|
||||||
772
model.safetensors.index.json
Normal file
772
model.safetensors.index.json
Normal file
@@ -0,0 +1,772 @@
|
|||||||
|
{
|
||||||
|
"metadata": {
|
||||||
|
"total_size": 16061615168
|
||||||
|
},
|
||||||
|
"weight_map": {
|
||||||
|
"image_newline": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.lm_head.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"language_model.model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.0.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.0.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.0.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.1.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.1.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.1.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.10.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.10.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.10.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.10.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.10.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.10.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.10.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.10.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.10.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.11.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.11.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.11.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.12.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.12.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.12.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.13.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.13.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.13.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.14.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.14.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.14.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.14.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.14.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.15.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.15.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.15.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.15.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.15.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.15.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.15.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.15.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.15.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.15.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.15.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.15.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.16.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.16.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.16.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.16.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.16.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.16.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.16.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.16.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.16.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.16.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.16.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.16.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.17.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.17.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.17.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.17.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.17.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.17.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.17.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.17.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.17.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.17.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.17.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.17.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.18.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.18.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.18.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.18.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.18.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.18.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.18.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.18.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.18.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.18.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.18.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.18.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.19.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.19.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.19.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.19.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.19.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.19.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.19.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.19.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.19.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.19.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.19.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.19.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.2.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.2.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.2.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.20.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.20.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.20.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.20.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.20.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.20.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.20.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.20.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.20.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.20.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.20.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.20.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.21.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.21.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.21.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.21.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.21.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.21.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.21.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.21.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.21.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.21.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.21.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.21.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.22.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.22.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.22.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.22.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.22.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.22.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.22.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.22.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.22.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.22.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.23.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.23.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.23.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.23.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.23.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.23.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.23.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.23.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.23.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.24.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.24.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.24.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.24.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.24.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.24.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.24.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.24.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.24.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.24.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.24.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.24.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.25.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.25.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.25.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.25.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.25.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.25.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.25.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.25.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.25.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.25.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.25.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.25.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.26.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.26.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.26.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.26.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.26.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.26.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.26.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.26.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.26.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.26.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.26.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.26.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.27.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.27.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.27.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.27.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.27.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.27.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.27.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.27.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.27.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.27.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.27.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.27.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.3.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.3.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.3.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.4.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.4.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.4.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.5.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.5.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.5.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.5.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.5.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.6.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.6.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.6.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.6.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.6.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.6.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.6.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.6.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.6.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.7.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.7.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.7.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.7.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.7.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.7.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.7.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.7.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.7.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.7.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.7.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.7.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.8.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.8.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.8.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.8.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.8.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.8.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.8.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.8.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.8.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.8.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.8.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.8.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.9.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.9.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.9.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.9.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.9.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.9.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.9.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.9.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.9.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.9.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.9.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.layers.9.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"language_model.model.norm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"multi_modal_projector.linear_1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"multi_modal_projector.linear_1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"multi_modal_projector.linear_2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"multi_modal_projector.linear_2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.embeddings.patch_embedding.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.embeddings.patch_embedding.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.embeddings.position_embedding.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.10.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.11.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.12.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.13.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.14.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.15.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.16.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.17.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.18.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.19.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.20.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.21.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.22.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.23.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.24.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.25.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.7.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.8.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.encoder.layers.9.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.post_layernorm.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"vision_tower.vision_model.post_layernorm.weight": "model-00001-of-00004.safetensors"
|
||||||
|
}
|
||||||
|
}
|
||||||
171
preprocessor_config.json
Normal file
171
preprocessor_config.json
Normal file
@@ -0,0 +1,171 @@
|
|||||||
|
{
|
||||||
|
"do_convert_rgb": true,
|
||||||
|
"do_normalize": true,
|
||||||
|
"do_pad": true,
|
||||||
|
"do_rescale": true,
|
||||||
|
"do_resize": true,
|
||||||
|
"image_grid_pinpoints": [
|
||||||
|
[
|
||||||
|
384,
|
||||||
|
384
|
||||||
|
],
|
||||||
|
[
|
||||||
|
384,
|
||||||
|
768
|
||||||
|
],
|
||||||
|
[
|
||||||
|
384,
|
||||||
|
1152
|
||||||
|
],
|
||||||
|
[
|
||||||
|
384,
|
||||||
|
1536
|
||||||
|
],
|
||||||
|
[
|
||||||
|
384,
|
||||||
|
1920
|
||||||
|
],
|
||||||
|
[
|
||||||
|
384,
|
||||||
|
2304
|
||||||
|
],
|
||||||
|
[
|
||||||
|
768,
|
||||||
|
384
|
||||||
|
],
|
||||||
|
[
|
||||||
|
768,
|
||||||
|
768
|
||||||
|
],
|
||||||
|
[
|
||||||
|
768,
|
||||||
|
1152
|
||||||
|
],
|
||||||
|
[
|
||||||
|
768,
|
||||||
|
1536
|
||||||
|
],
|
||||||
|
[
|
||||||
|
768,
|
||||||
|
1920
|
||||||
|
],
|
||||||
|
[
|
||||||
|
768,
|
||||||
|
2304
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1152,
|
||||||
|
384
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1152,
|
||||||
|
768
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1152,
|
||||||
|
1152
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1152,
|
||||||
|
1536
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1152,
|
||||||
|
1920
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1152,
|
||||||
|
2304
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1536,
|
||||||
|
384
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1536,
|
||||||
|
768
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1536,
|
||||||
|
1152
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1536,
|
||||||
|
1536
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1536,
|
||||||
|
1920
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1536,
|
||||||
|
2304
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1920,
|
||||||
|
384
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1920,
|
||||||
|
768
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1920,
|
||||||
|
1152
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1920,
|
||||||
|
1536
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1920,
|
||||||
|
1920
|
||||||
|
],
|
||||||
|
[
|
||||||
|
1920,
|
||||||
|
2304
|
||||||
|
],
|
||||||
|
[
|
||||||
|
2304,
|
||||||
|
384
|
||||||
|
],
|
||||||
|
[
|
||||||
|
2304,
|
||||||
|
768
|
||||||
|
],
|
||||||
|
[
|
||||||
|
2304,
|
||||||
|
1152
|
||||||
|
],
|
||||||
|
[
|
||||||
|
2304,
|
||||||
|
1536
|
||||||
|
],
|
||||||
|
[
|
||||||
|
2304,
|
||||||
|
1920
|
||||||
|
],
|
||||||
|
[
|
||||||
|
2304,
|
||||||
|
2304
|
||||||
|
]
|
||||||
|
],
|
||||||
|
"image_mean": [
|
||||||
|
0.5,
|
||||||
|
0.5,
|
||||||
|
0.5
|
||||||
|
],
|
||||||
|
"image_processor_type": "LlavaOnevisionImageProcessor",
|
||||||
|
"image_std": [
|
||||||
|
0.5,
|
||||||
|
0.5,
|
||||||
|
0.5
|
||||||
|
],
|
||||||
|
"processor_class": "LlavaOnevisionProcessor",
|
||||||
|
"resample": 3,
|
||||||
|
"rescale_factor": 0.00392156862745098,
|
||||||
|
"size": {
|
||||||
|
"height": 384,
|
||||||
|
"width": 384
|
||||||
|
}
|
||||||
|
}
|
||||||
7
processor_config.json
Normal file
7
processor_config.json
Normal file
@@ -0,0 +1,7 @@
|
|||||||
|
{
|
||||||
|
"image_token": "<image>",
|
||||||
|
"num_image_tokens": 729,
|
||||||
|
"processor_class": "LlavaOnevisionProcessor",
|
||||||
|
"video_token": "<video>",
|
||||||
|
"vision_feature_select_strategy": "full"
|
||||||
|
}
|
||||||
31
special_tokens_map.json
Normal file
31
special_tokens_map.json
Normal file
@@ -0,0 +1,31 @@
|
|||||||
|
{
|
||||||
|
"additional_special_tokens": [
|
||||||
|
"<|im_start|>",
|
||||||
|
"<|im_end|>",
|
||||||
|
"<|object_ref_start|>",
|
||||||
|
"<|object_ref_end|>",
|
||||||
|
"<|box_start|>",
|
||||||
|
"<|box_end|>",
|
||||||
|
"<|quad_start|>",
|
||||||
|
"<|quad_end|>",
|
||||||
|
"<|vision_start|>",
|
||||||
|
"<|vision_end|>",
|
||||||
|
"<|vision_pad|>",
|
||||||
|
"<|image_pad|>",
|
||||||
|
"<|video_pad|>"
|
||||||
|
],
|
||||||
|
"eos_token": {
|
||||||
|
"content": "<|im_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false
|
||||||
|
},
|
||||||
|
"pad_token": {
|
||||||
|
"content": "<|endoftext|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false
|
||||||
|
}
|
||||||
|
}
|
||||||
3
tokenizer.json
Normal file
3
tokenizer.json
Normal file
@@ -0,0 +1,3 @@
|
|||||||
|
version https://git-lfs.github.com/spec/v1
|
||||||
|
oid sha256:f1771948f18963fb6a0cfe4e4442a8cd402936c5e23d8293ca997ded597e29d5
|
||||||
|
size 11422264
|
||||||
224
tokenizer_config.json
Normal file
224
tokenizer_config.json
Normal file
@@ -0,0 +1,224 @@
|
|||||||
|
{
|
||||||
|
"add_bos_token": false,
|
||||||
|
"add_prefix_space": false,
|
||||||
|
"added_tokens_decoder": {
|
||||||
|
"151643": {
|
||||||
|
"content": "<|endoftext|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151644": {
|
||||||
|
"content": "<|im_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151645": {
|
||||||
|
"content": "<|im_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151646": {
|
||||||
|
"content": "<|object_ref_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151647": {
|
||||||
|
"content": "<|object_ref_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151648": {
|
||||||
|
"content": "<|box_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151649": {
|
||||||
|
"content": "<|box_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151650": {
|
||||||
|
"content": "<|quad_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151651": {
|
||||||
|
"content": "<|quad_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151652": {
|
||||||
|
"content": "<|vision_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151653": {
|
||||||
|
"content": "<|vision_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151654": {
|
||||||
|
"content": "<|vision_pad|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151655": {
|
||||||
|
"content": "<|image_pad|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151656": {
|
||||||
|
"content": "<|video_pad|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151657": {
|
||||||
|
"content": "<tool_call>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151658": {
|
||||||
|
"content": "</tool_call>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151659": {
|
||||||
|
"content": "<|fim_prefix|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151660": {
|
||||||
|
"content": "<|fim_middle|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151661": {
|
||||||
|
"content": "<|fim_suffix|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151662": {
|
||||||
|
"content": "<|fim_pad|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151663": {
|
||||||
|
"content": "<|repo_name|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151664": {
|
||||||
|
"content": "<|file_sep|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": false
|
||||||
|
},
|
||||||
|
"151665": {
|
||||||
|
"content": "<image>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151666": {
|
||||||
|
"content": "<video>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"additional_special_tokens": [
|
||||||
|
"<|im_start|>",
|
||||||
|
"<|im_end|>",
|
||||||
|
"<|object_ref_start|>",
|
||||||
|
"<|object_ref_end|>",
|
||||||
|
"<|box_start|>",
|
||||||
|
"<|box_end|>",
|
||||||
|
"<|quad_start|>",
|
||||||
|
"<|quad_end|>",
|
||||||
|
"<|vision_start|>",
|
||||||
|
"<|vision_end|>",
|
||||||
|
"<|vision_pad|>",
|
||||||
|
"<|image_pad|>",
|
||||||
|
"<|video_pad|>"
|
||||||
|
],
|
||||||
|
"bos_token": null,
|
||||||
|
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
|
||||||
|
"clean_up_tokenization_spaces": false,
|
||||||
|
"eos_token": "<|im_end|>",
|
||||||
|
"errors": "replace",
|
||||||
|
"model_max_length": 131072,
|
||||||
|
"pad_token": "<|endoftext|>",
|
||||||
|
"processor_class": "LlavaOnevisionProcessor",
|
||||||
|
"split_special_tokens": false,
|
||||||
|
"tokenizer_class": "Qwen2Tokenizer",
|
||||||
|
"unk_token": null
|
||||||
|
}
|
||||||
1
vocab.json
Normal file
1
vocab.json
Normal file
File diff suppressed because one or more lines are too long
Reference in New Issue
Block a user